

Meta Network for Flow-Based Image Style Transfer


Abstract
1. Introduction
2. Related Works
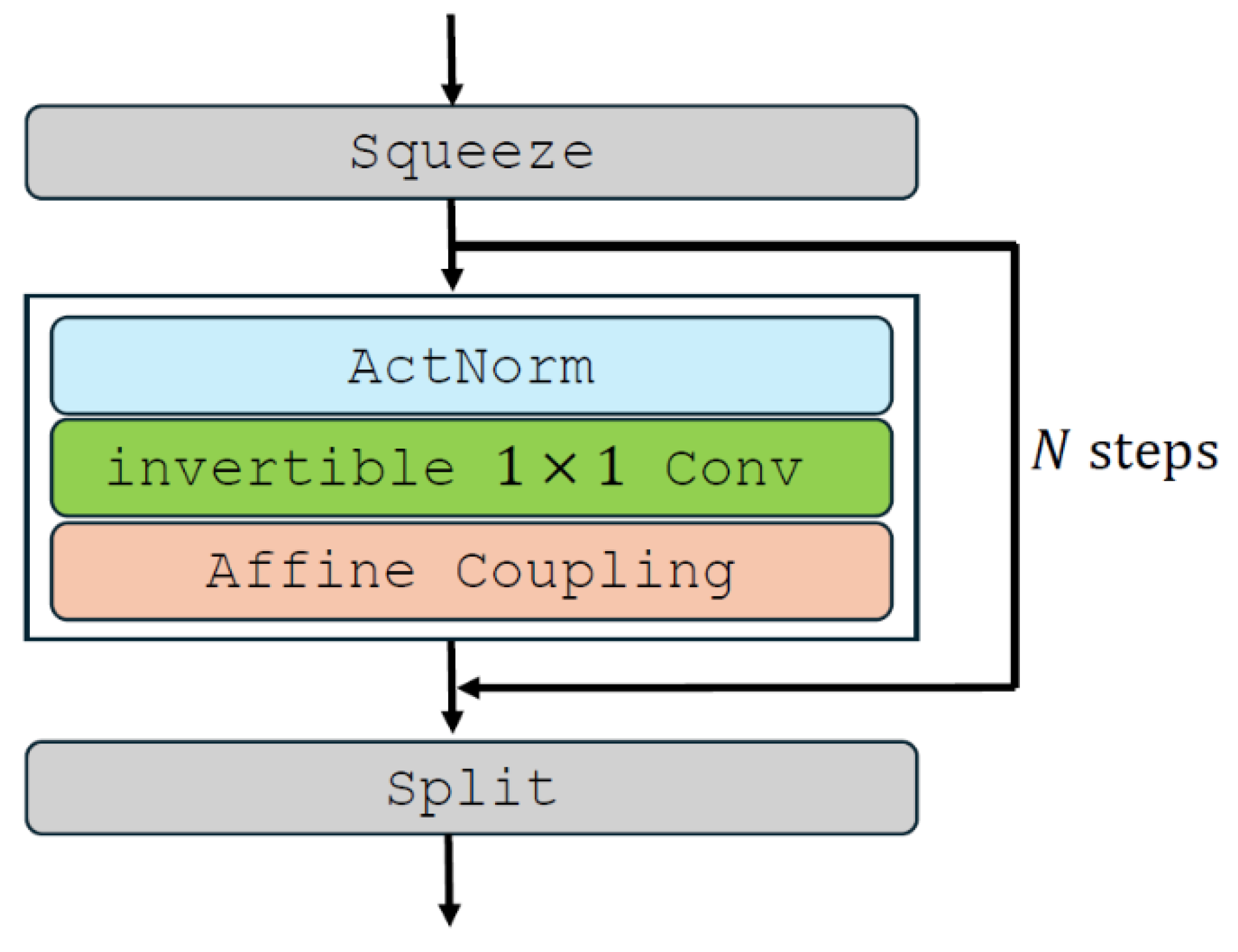
2.1. Flow-Based Style Transfer Models
2.2. Meta Learning for Style Transfer
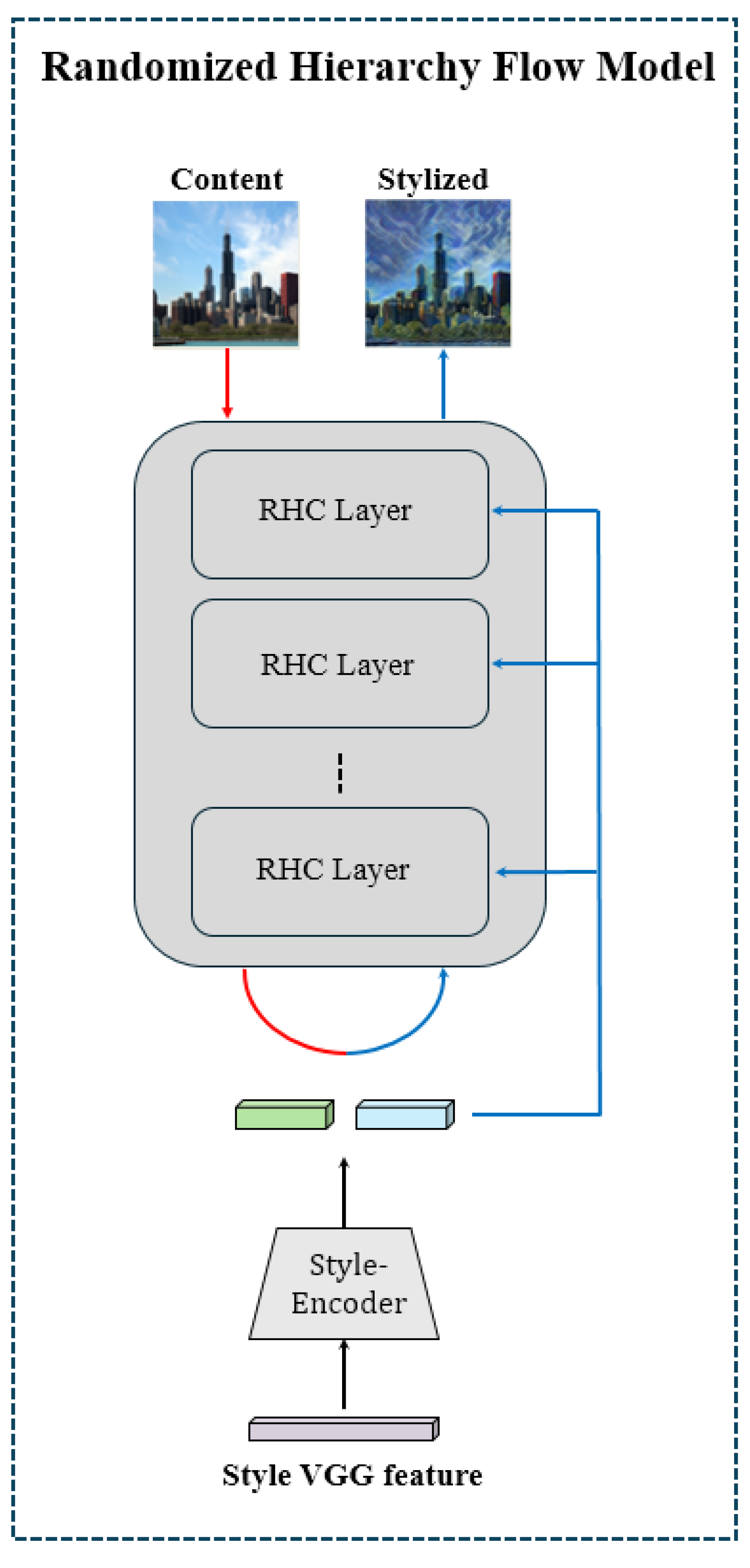
3. Meta Model for Flow-Based Image Style Transfer
3.1. Randomized Hierarchical Flow Model
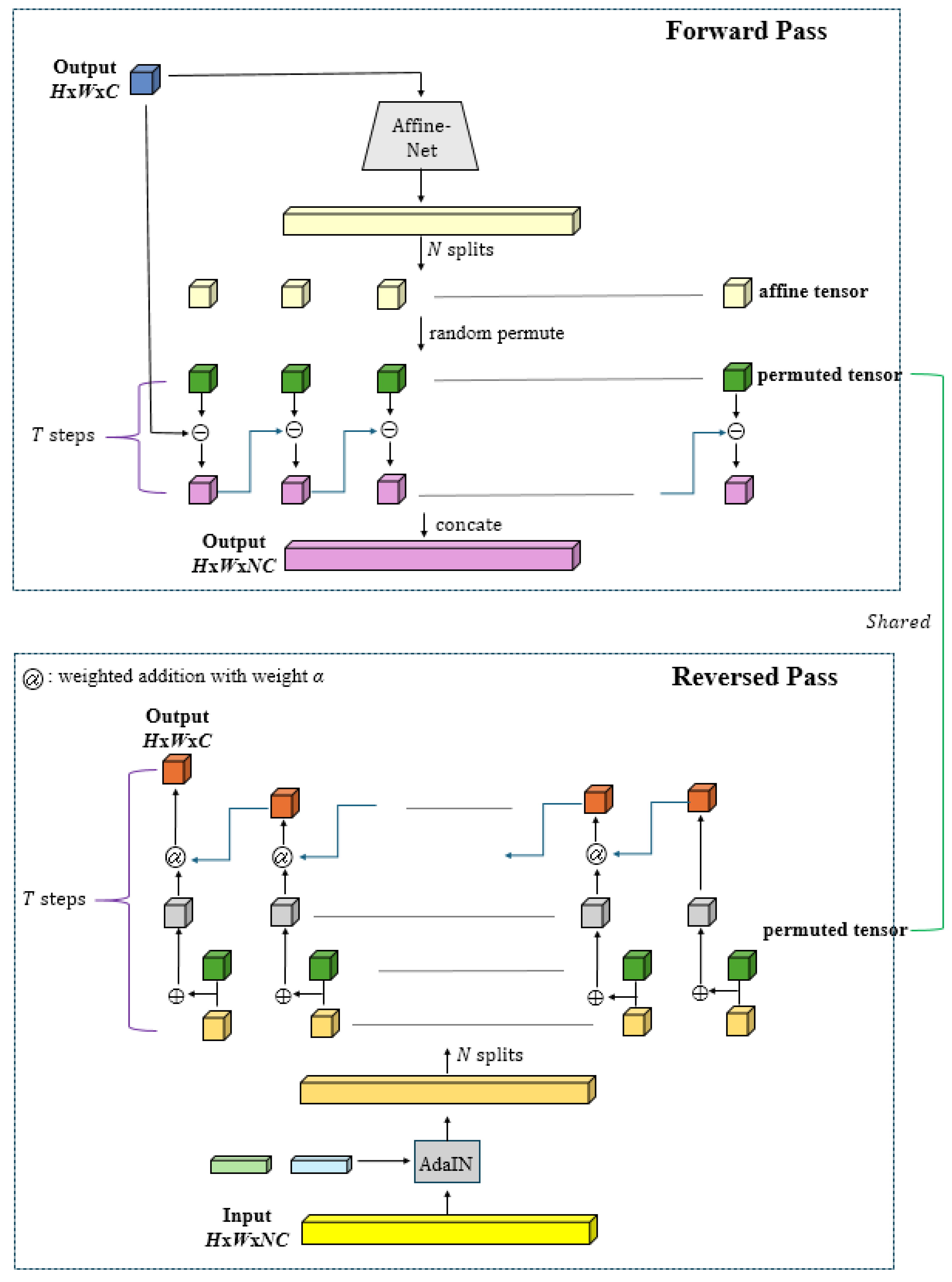
- Randomized Hierarchical Coupling Layers
- Forward Pass
| Algorithm 1. Forward Pass |
| FORWARD() Affine-Net() split random permute for to do concat return |
- Reverse Pass
| Algorithm 2. Reversed Pass |
| REVERSED( ) AdaIN() split() for downto 1 do return |
- RH Flow
| Algorithm 3. Randomized Hierarchy Flow |
| RH_FLOW() Style-Encoder() for to do FORWARD() REVERSED( ) return |
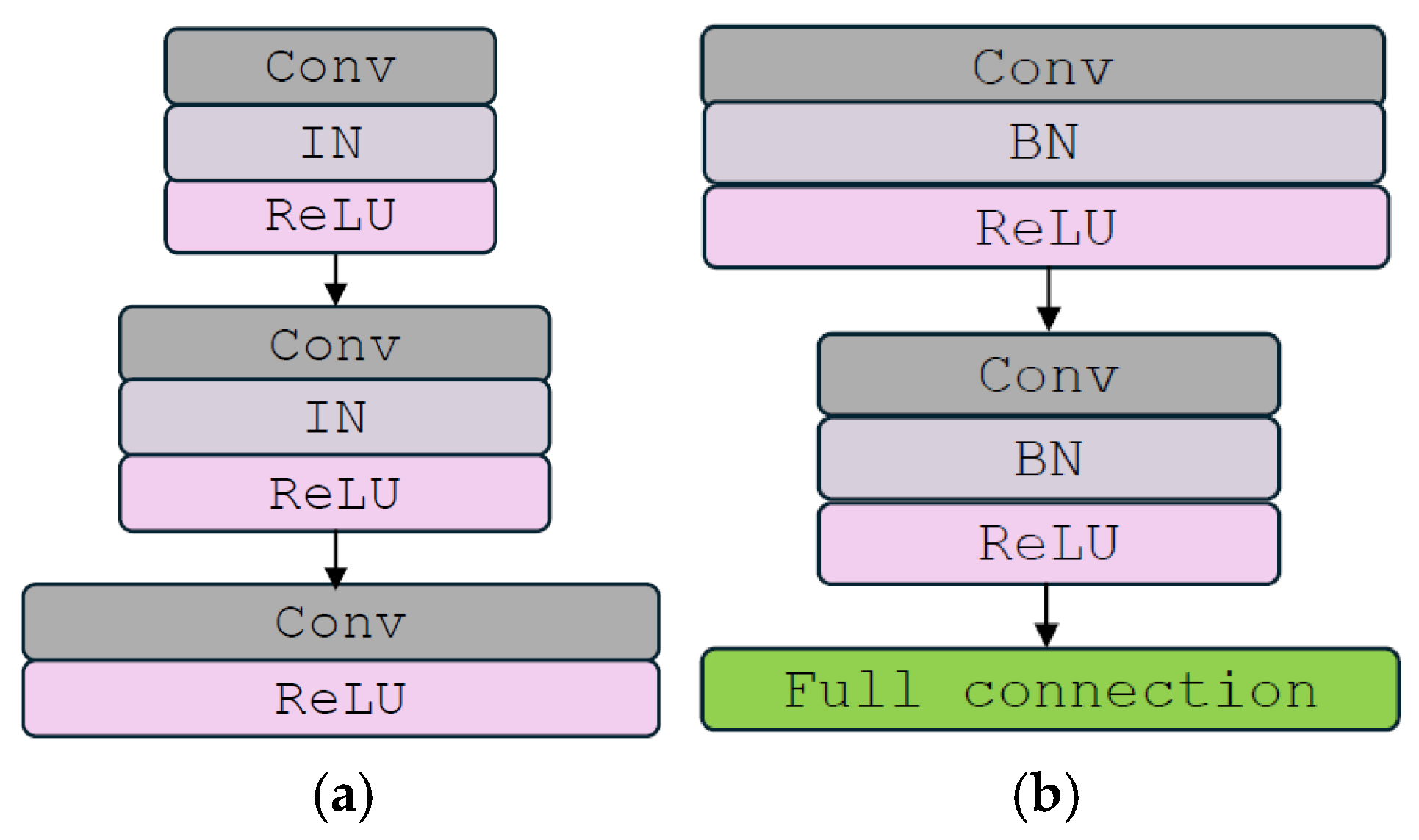
- Affine-Net and Style Encoder
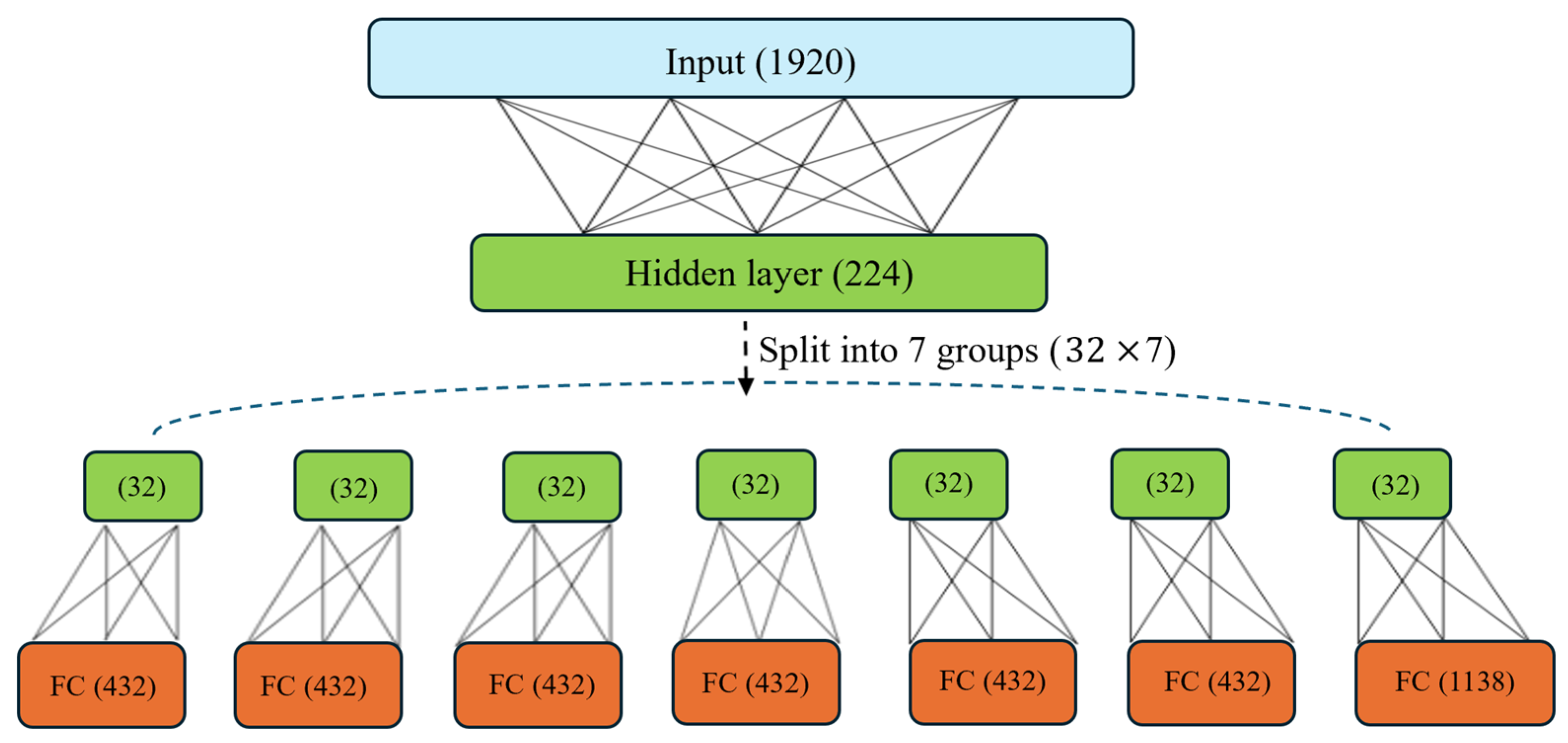
3.2. MFIST Architecture
- Architecture of the Meta Network
3.3. Training the Meta Network
| Algorithm 4. Meta Net Training |
| META() Meta Net() RH_FLOW() |
4. Experimental Results
5. Conclusions and Discussion
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Wang, T.C.; Liu, M.Y.; Zhu, J.Y.; Tao, A.; Kautz, J.; Catanzaro, B. High-Resolution Image Synthesis and Semantic Manipulation with Conditional GANs. arXiv 2018, arXiv:1711.11585. [Google Scholar]
- Miyato, T.; Koyama, M. CGANs with Projection Discriminator. arXiv 2018, arXiv:1802.05637. [Google Scholar]
- Zhu, J.Y.; Zhang, R.; Pathak, D.; Darrell, T.; Efros, A.A.; Wang, O.; Shechtman, E. Toward Multimodal Image-to-Image Translation. arXiv 2018, arXiv:1711.11586. [Google Scholar]
- Zhu, J.Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. arXiv 2018, arXiv:1703.10593. [Google Scholar]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-Image Translation with Conditional Adversarial Networks. arXiv 2018, arXiv:1611.07004. [Google Scholar]
- Park, T.; Liu, M.Y.; Wang, T.C.; Zhu, J.Y. Semantic Image Synthesis with Spatially-Adaptive Normalization. arXiv 2019, arXiv:1903.07291. [Google Scholar]
- Kotovenko, D.; Sanakoyeu, A.; Ma, P.; Lang, S.; Ommer, B. A Content Transformation Block for Image Style Transfer. arXiv 2020, arXiv:2003.08407. [Google Scholar]
- Wei, Y. Artistic Image Style Transfer Based on CycleGAN Network Model. Int. J. Image Graph. 2024, 24, 2450049. [Google Scholar] [CrossRef]
- Liu, J.; Liu, H.; He, Y.; Tong, S. An Improved Detail-Enhancement CycleGAN Using AdaLIN for Facial Style Transfer. Appl. Sci. 2024, 14, 6311. [Google Scholar] [CrossRef]
- Gatys, L.A.; Ecker, A.S.; Bethge, M. A Neural Algorithm of Artistic Style. arXiv 2015, arXiv:1508.06576v2. [Google Scholar] [CrossRef]
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual Losses for Real-Time Style Transfer and Super-Resolution. arXiv 2016, arXiv:1603.08155v1. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary Style Transfer in Real-Time with Adaptive Instance Normalization. arXiv 2017, arXiv:1703.06868v2. [Google Scholar]
- Dumoulin, V.; Shlens, J.; Kudlur, M. A Learned Representation for Artistic Style. arXiv 2017, arXiv:1610.07629v5. [Google Scholar]
- Li, Y.; Fang, C.; Yang, J.; Wang, Z.; Lu, X.; Yang, M.-H. Universal Style Transfer via Feature Transforms. arXiv 2017, arXiv:1705.08086v2. [Google Scholar]
- Chen, D.; Yuan, L.; Liao, J.; Yu, N.; Hua, G. StyleBank: An Explicit Representation for Neural Image Style Transfer. arXiv 2017, arXiv:1703.09210v2. [Google Scholar]
- Sheng, L.; Lin, Z.; Shao, J.; Wang, X. Avatar-Net: Multi-scale Zero-shot Style Transfer by Feature Decoration. arXiv 2018, arXiv:1805.03857v2. [Google Scholar]
- Li, X.; Liu, S.; Kautz, J.; Yang, M.-H. Learning Linear Transformations for Fast Arbitrary Style Transfer. arXiv 2018, arXiv:1808.04537v1. [Google Scholar]
- Liu, B.; Wang, C.; Cao, T.; Jia, K.; Huang, J. Towards Understanding Cross and Self-Attention in Stable Diffusion for Text-Guided Image Editing. arXiv 2024, arXiv:2403.03431v1. [Google Scholar]
- Zhou, X.; Yin, M.; Chen, X.; Sun, L.; Gao, C.; Li, Q. Cross Attention Based Style Distribution for Controllable Person Image Synthesis. In Computer Vision—ECCV 2022; Avidan, S., Brostow, G., Cissé, M., Farinella, G.M., Hassner, T., Eds.; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2022; Volume 13675. [Google Scholar]
- Pan, X.; Zhang, M.; Ding, D.; Yang, M. A Geometrical Perspective on Image Style Transfer with Adversarial Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 44, 63–75. [Google Scholar] [CrossRef]
- An, J.; Huang, S.; Song, Y.; Dou, D.; Liu, W.; Luo, J. ArtFlow: Unbiased Image Style Transfer via Reversible Neural Flows. arXiv 2021, arXiv:2103.16877v2. [Google Scholar]
- Fan, W.; Chen, J.; Liu, Z. Hierarchy Flow for High-Fidelity Image-to-Image Translation. arXiv 2023, arXiv:2308.06909v1. [Google Scholar]
- Kingma, D.P.; Dhariwal, P. Glow: Generative Flow with Invertible 1 × 1 Convolutions. arXiv 2018, arXiv:1807.03039v2. [Google Scholar]
- Yao, F. A learning theory of meta learning. Natl. Sci. Rev. 2024, 11, nwae133. [Google Scholar] [CrossRef] [PubMed]
- Gao, W.; Shao, M.; Shu, J.; Zhuang, X. Meta-BN Net for Few-Shot Learning. Front. Comput. Sci. 2023, 17, 171302. [Google Scholar] [CrossRef]
- Shen, F.; Yan, S.; Zeng, G. Meta Networks for Neural Style Transfer. arXiv 2017, arXiv:1709.04111v1. [Google Scholar]
- Schmidhuber, J. Evolutionary Principles in Self-Referential Learning. Master’s Thesis, Technische Universität München, München, Germany, 1987. [Google Scholar]
- Thrun, S.; Pratt, L. Learning to Learn; Springer Science & Business Media: Berlin/Heidelberg, Germany, 2012. [Google Scholar]
- Bechtle, S.; Molchanov, A.; Chebotar, Y.; Grefenstette, E.; Righetti, L.; Sukhatme, G.; Meier, F. Meta-learning via learned loss. arXiv 2019, arXiv:1906.05374. [Google Scholar]
- Finn, C.; Abbeel, P.; Levine, S. Model-agnostic meta-learning for fast adaptation of deep networks. In Proceedings of the 34th International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017. [Google Scholar]
- Meier, F.; Kappler, D.; Schaal, S. Online learning of a memory for learning rates. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, Australia, 21–25 May 2018; pp. 2425–2432. [Google Scholar]
- Houthooft, R.; Chen, Y.; Isola, P.; Stadie, B.C.; Wolski, F.; Ho, J.; Abbeel, P. Evolved policy gradients. In Proceedings of the NeurIPS Proceeding, Montréal, QC, Canada, 2–8 December 2018; pp. 5405–5414. [Google Scholar]
- Metz, L.; Maheswaranathan, N.; Cheung, B.; Sohl-Dickstein, J. Learning unsupervised learning rules. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Lin, T.-Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Doll, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the European Conference on Computer Vision, Zurich, Switzerland, 6–12 September 2014; Springer: Cham, Switzerland, 2014; pp. 740–755. [Google Scholar]
- Nichol, K. Painter by Numbers, Wikiart. 2016. Available online: https://www.kaggle.com/c/painter-by-numbers/ (accessed on 1 October 2024).





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | SSIM ↑ | Gram Distance ↓ |
|---|---|---|
| StyleSwap | 0.44 | 0.00482 |
| AdaIN | 0.29 | 0.00127 |
| WCT | 0.27 | 0.00074 |
| LinearWCT | 0.35 | 0.00093 |
| OptimalWCT | 0.21 | 0.00035 |
| Avatar-Net | 0.31 | 0.00099 |
| Artlow+AdaIN | 0.45 | 0.00078 |
| Ours | 0.615 | 0.00050 |
| Method | SSIM ↑ | KID ↓ | Parameters |
|---|---|---|---|
| AdaIN | 0.28 | 41.1/5.1 | 7.01 M |
| WCT | 0.24 | 51.2/6.2 | 34.24 M |
| Artflow+AdaIN | 0.52 | 24.6/3.8 | 6.42 M |
| Artflow+WCT | 0.53 | 33.3/5.3 | 6.42 M |
| CCPL | 0.43 | 39.1/6.8 | 8.67 M |
| Hierarchy Flow | 0.60 | 28.2/4.7 | 1.01 M |
| Ours | 0.615 | 29.0/5.0 | 0.55 M |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tsai, Y.; Lin, H.-W.; Chen, C.-J.; Lin, H.-J.; Yu, C.-H. Meta Network for Flow-Based Image Style Transfer. Electronics 2025, 14, 2035. https://doi.org/10.3390/electronics14102035
Tsai Y, Lin H-W, Chen C-J, Lin H-J, Yu C-H. Meta Network for Flow-Based Image Style Transfer. Electronics. 2025; 14(10):2035. https://doi.org/10.3390/electronics14102035
Chicago/Turabian StyleTsai, Yihjia, Hsiau-Wen Lin, Chii-Jen Chen, Hwei-Jen Lin, and Chen-Hsiang Yu. 2025. "Meta Network for Flow-Based Image Style Transfer" Electronics 14, no. 10: 2035. https://doi.org/10.3390/electronics14102035
APA StyleTsai, Y., Lin, H.-W., Chen, C.-J., Lin, H.-J., & Yu, C.-H. (2025). Meta Network for Flow-Based Image Style Transfer. Electronics, 14(10), 2035. https://doi.org/10.3390/electronics14102035