1. Introduction
Elevators, which are integral to daily life, have a profound impact on public safety, making their reliable operation crucial [
1]. Modern elevator systems commonly employ light curtain technology to detect obstacles in the path of the elevator doors, relying on the emission and reception of light beams for object detection. However, due to optical limitations, light curtains can struggle to detect certain types of objects. For instance, objects with surfaces that do not efficiently reflect infrared light or those smaller than the beam diameter or detection area may not be accurately detected [
2,
3]. As shown in
Figure 1, there are two typical abnormal obstacles in elevators: one is a slender and flexible object, such as various types of pet rope, and the other is a transparent glass object. To address these challenges, this paper proposes the use of deep learning models to analyze video streams captured by cameras installed in elevators for accurately identifying unusual obstacles and thus reducing the risk of accidents.
Common abnormal events in elevators can be categorized into two groups based on their causes: passenger-related abnormal behaviors and anomalous objects. The former includes incidents such as falling, fighting, fainting, door kicking, jumping, and crowding, which primarily stem from passengers’ physical or behavioral abnormalities. The latter encompasses situations like battery-operated vehicles entering elevators, the emergence of open flames or smoke, and glass or pet rope being jammed in the door area, which are typically not supposed to be present in elevators or their door zones. Currently, research on passenger abnormal behaviors has been relatively comprehensive [
1,
4], and the detection of anomalous objects has been largely addressed for broad categories and objects with distinct features [
5,
6]. However, the identification of complex objects still requires further investigation.
Researchers have explored various methods for detecting transparent and slender objects. While these approaches have shown some success, their validation has been primarily limited to binary classification segmentation datasets [
7,
8,
9], with little evaluation on datasets that reflect real-world application scenarios involving multiple object classes. Detecting transparent and slender objects in elevator environments presents the following challenges: concerns regarding passenger privacy and data confidentiality often hinder the acquisition of relevant data, making it difficult to create large-scale datasets for network training; the reflective properties of the elevator surroundings frequently cause the cabin walls to mirror the objects intended for identification, and since these objects typically occupy a small area within the image, the complexity of the background impacts network training. Given the slender and transparent nature of ropes and glass, deep learning networks must be capable of accurately capturing fine features and distinguishing reflections from actual objects by integrating global contextual and edge localization information. Therefore, this study primarily focuses on glass and pet rope detection.
This study aims to address the aforementioned challenges. First, we have developed the first large-scale dataset specifically designed for detecting transparent and elongated objects in elevator environments. Secondly, we observed that most monitoring applications feature inherently static backgrounds, with primary focus on dynamically changing foreground objects. Inspired by this observation, we propose a novel module named BDE (Background Difference Information Extraction). The BDE module recalibrates differential features across both channel and spatial dimensions, employing them as attention mechanisms applied to dynamic image features. This approach enhances the network’s ability to focus on newly appearing objects while mitigating the background’s influence on network learning. Slender and transparent objects in elevators, as moving anomalous entities, are highly susceptible to motion blur. This can result in the loss of edge information in changing areas during the downsampling of difference feature maps and may even lead to the neglect of certain dynamic regions. We introduce EFGU (Edge Feature Gating Unit) to further enhance the extraction of complex edge features and filter out unnecessary feature information to solve the problem. We propose PKNet based on these two key prior pieces of knowledge. Finally, to further investigate the impact of high-quality and diverse datasets on supervised anomaly segmentation, we propose a synthetic data generation workflow specifically designed for slender objects called ES-Aug (Elevator Slender Object Data Augmentation). By utilizing synthetic data to provide key semantic features for pet rope segmentation, ES-Aug effectively enhances the model’s generalization and reliability.
The main contributions of this work can be summarized as follows:
We created the first large-scale dataset for transparent and slender object segmentation in elevator scenarios (ETAE-D).
Based on the prior knowledge utilized by the BDE and EFGU modules, we propose PKNet, which enables the network model to focus its attention on the features of newly emerging dynamic foreground objects while mitigating the loss of edge information caused by motion blur.
We propose a synthetic data generation workflow for slender objects, called ES-Aug, and evaluate its effectiveness and robustness in practical applications.
2. Related Work
2.1. Image Segmentation
Understanding pixel-level semantic segmentation has long been a significant challenge in the field of computer vision. FCN [
10] was the first end-to-end fully convolutional network designed for pixel-level semantic segmentation. DeepLab [
11] employs dilated convolutions for semantic segmentation and suggests using multiple scales to enhance segmentation results. Unlike convolution-based models, Transformer architectures can model long-range dependencies through self-attention mechanisms, thereby better capturing global contextual information. Swin Transformer [
12] introduces a hierarchical window attention mechanism to overcome the high computational complexity of traditional Transformers with high-resolution inputs, while ensuring efficient integration of global and local information. Mask2Former [
13,
14] further enhances segmentation accuracy and efficiency by optimizing the attention relationships between different tokens.
Recent studies have aimed to unify all visual tasks into a single framework that includes segmentation, developing a general model capable of handling a wide range of segmentation tasks [
15,
16,
17]. However, in practical applications, such general models often struggle to meet the precise requirements of specific tasks. Although a unified model can provide solutions for a broad range of tasks through a single architecture and benefit from diverse data corpora, it lacks the necessary precision and specificity when addressing fine-grained tasks, making it difficult to fully replace models tailored for specific tasks.
2.2. Transparent Object Segmentation
Due to the similarity between transparent objects and their surrounding environments, segmenting transparent objects has long been considered a challenging task in computer vision. For RGB image glass segmentation, Mei [
7] introduced the first dataset for glass surface segmentation, and Lin [
8] further provided a more challenging glass surface dataset. Han [
18] presents a smartphone screen glass dataset and explores the performance of different detection models on this dataset. As research has progressed, efforts have been made to improve glass segmentation accuracy by integrating information from other sensors, including refractive distortion information captured by light field cameras [
19], high-contrast edge information obtained from polarized images [
20], depth information extracted from depth images [
21], and thermal images captured by thermal infrared cameras [
22]. Existing methods for enhancing transparent object segmentation explore various technical approaches, which can be broadly categorized as follows:
Feature Fusion Methods: Yu [
23] proposed integrating features at different levels to obtain more comprehensive high-level and low-level information. Mei [
7] explored rich contextual features from large receptive fields. Guan [
24] utilized semantic associations between mirrors and their surrounding objects.
Boundary Information Methods: He [
25] suggested using boundary information provided by reference objects (such as window frames, door frames, and stickers) to locate glass, rather than relying on the reflections of the glass itself. Mei [
26] improved prediction results by incorporating boundary cues from the glass itself.
Additional Sensor Methods: Lin [
8] proposed aggregating contextual information by using glass reflection images during training. Huo [
22] introduced improvements in segmentation results by using both RGB and thermal images during training.
Although these transparent segmentation methods have achieved some results, additional sensors cannot be added to the elevator scene due to cost constraints, and they also ignore possible interference from other objects in the scene that have reflective properties (e.g., elevator car baffles).
2.3. Slender Object Segmentation
Research on slender object segmentation is widespread across various fields, including medical image segmentation and wall crack segmentation. The technical approaches in this research can be broadly categorized as follows:
Enhancing Ability to Capture Fine-Grained Features: DUNet [
27] integrates deformable convolutions into a U-shaped architecture, adaptively adjusting the receptive field based on the scale and shape of vessels. PointScatter [
28] represents tubular structures using point sets and introduces a tree-structured convolutional gating recurrent unit to explicitly model the topology of coronary arteries. Dynamic serpentine convolution [
29] considers the serpentine morphology of tubular structures and supplements the free learning process of deformable convolutions with continuous constraints. HRNet [
30] effectively reduces the loss of spatial resolution during the transition from high to low to high resolution by removing downsampling operations in the initial stages and reducing the number of high-resolution representation layers.
Addressing Highly Imbalanced Class Issues: Zhang et al. [
31] proposed a supervised generative adversarial learning method for end-to-end training, which addresses the network’s tendency to treat all pixels as background by continuously generating realistic annotated images (GT) of cracks. Additionally, some researchers use Dice [
32], Combo [
33], and Weighted Cross-Entropy [
9,
34] loss functions to tackle class imbalance issues.
Current research on slender object segmentation methods is primarily based on simple binary classification datasets and focuses mainly on static, easily identifiable slender objects, lacking validation in complex scenarios involving dynamic foreground object segmentation.
2.4. Generation Methods for Dataset Construction
The diffusion model [
35] has gained attention for its effectiveness in image synthesis with low computational costs. Li et al. [
36] proposed a method that integrates both text labels and image captions to form text prompts for SD (Stable Diffusion), generating diverse images that improve model performance in classification tasks. Fang et al. [
37] proposed a data augmentation method based on diffusion models and visual priors for object detection, demonstrating the effectiveness of diffusion-generated data in improving the accuracy of downstream object detection models, particularly under few-shot settings. Zhang et al. [
38] proposed RealNet, which models the distribution of normal samples using diffusion models to synthesize defect samples, enhancing the accuracy and generalizability of defect detection models.
Despite these advances, there are still many challenges in applying large models in real-world engineering that deserve further exploration by researchers [
39]. The field of security surveillance usually relies on cheap cameras to acquire image data, which is significantly different from well-designed high-quality datasets in the generative field. The images captured by these cameras are usually characterized by the following features: the subject is not prominent in the foreground part, the image texture favors realism over cinematic texture, and the scene often contains multiple complex features, which makes it more difficult to generate the whole image directly. To address the aforementioned challenges and further explore the potential of large models in engineering applications, we propose ES-Aug, a specialized data augmentation framework tailored for pet rope generation in elevator monitoring scenarios. By integrating advanced SD technology into traditional modeling approaches, ES-Aug enables the controlled replacement of anomalous pet rope in the scene while ensuring that the generated images adhere to realistic physical constraints.
3. Method
Figure 2 shows the overall structure of the proposed our paper, consisting of two main parts:
(1) Dataset construction: We first obtain static background images and dynamic anomalous object foreground images from multi-class real elevators as input images for PKNet. Subsequently, we built a set of controllable elevator pet rope image generation workflows based on the FLUX generative big model to further explore the influence of the diversity of samples on the segmentation performance of PKNet.
(2) PKNet: We propose a segmentation model PKNet based on prior knowledge, aiming to enhance the model’s ability to effectively detect foreground objects. Given two input images, the first image (where d denotes the dynamic foreground image) is taken from the ETAE-D dataset, and the second image (where s denotes the static background image) is the corresponding static background image. We first extract visual features from each layer using a shared encoder, denoted as , (where i denotes the output of the i-th layer in the backbone network). When extracting features from the static images, the network’s gradients are frozen to prevent overfitting caused by the high similarity of the static images. The differential features are then extracted using the BDE module and applied back to the original image features to enhance the network’s focus on newly emerging objects. Next, the feature (where denotes the foreground features refined by differential feature) is sent to the EFGU, which refines the edge features and selectively channels information to enhance the effectiveness and flexibility of feature extraction. Finally, these refined edge features are combined with the semantic visual features and passed to the decoder to predict the dynamic foreground objects and anomalous object masks for each frame.
Figure 2.
Overall architecture of our method. We constructed our dataset in two steps. First, we constructed a dataset consisting entirely of real elevator images to evaluate the performance of PKNet. Second, we generated virtual synthetic images using the real elevator dataset to assess the impact of synthetic data on the performance of PKNet. In PKNet, dynamic foreground and static background images are processed. The BDE module extracts differential features, which are then applied to the original image to enhance dynamic foreground object features. These enhanced features, along with refined edge features from the EFGU module, are integrated to generate the final prediction. In this framework, BDE represents Background Difference Information Extraction, EFGU represents Edge Feature Gathering Unit, and FP represents Feature Pyramid.
Figure 2.
Overall architecture of our method. We constructed our dataset in two steps. First, we constructed a dataset consisting entirely of real elevator images to evaluate the performance of PKNet. Second, we generated virtual synthetic images using the real elevator dataset to assess the impact of synthetic data on the performance of PKNet. In PKNet, dynamic foreground and static background images are processed. The BDE module extracts differential features, which are then applied to the original image to enhance dynamic foreground object features. These enhanced features, along with refined edge features from the EFGU module, are integrated to generate the final prediction. In this framework, BDE represents Background Difference Information Extraction, EFGU represents Edge Feature Gathering Unit, and FP represents Feature Pyramid.
3.1. Background Difference Information Extraction
In a static background, most objects remain stationary and thus provide little useful information for segmentation tasks. Therefore, the key challenge is mitigating background interference to improve foreground object focus. Traditional visual algorithms that use background subtraction are very sensitive to changes in ambient lighting. Even in the constant lighting environment of an indoor elevator, it is difficult to accurately extract foreground objects directly. In some studies [
40], background subtraction methods only focus on the changes themselves, without further using this change information for recognition. Therefore, we explored the use of a background subtraction module that utilizes prior knowledge of the static background. The basic idea of BDE is to map the differential features to another feature space, simulating the interdependencies between channels by adaptively recalibrating the channel feature responses and feeding this recalibrated response back into the original image features.
Figure 3 shows the background differential attention module. This module utilizes spatial squeeze-and-channel and channel squeeze-and-space methods to adjust differential features and enhance the original image features. First, the absolute difference between the feature representations
and
is calculated to obtain the difference between the input images, and 3x3 convolution is used to extract feature information:
,
,
represent the static background features, dynamic background features, and differential features at the spatial scale i. Subsequently, parallel Channel Squeeze Activation (CSA) and Spatial Squeeze Activation (SSA) modules are employed to enhance the channel and spatial recalibration capabilities of the differential feature representations. The CSA module aggregates the C × H × W feature map into a C × 1 × 1 one-dimensional feature vector through global average pooling, compressing the spatial information of different features into channel descriptors. This one-dimensional feature vector is then sequentially passed through two fully connected layers to reweight the importance of channels, thereby dynamically adjusting the differential features in each channel. SSA module compresses the C × H × W feature map into 1 × H × W using 1 × 1 convolution, reducing channel information into spatial descriptors to capture spatial dependencies across channels. This module enhances the network’s focus on key spatial locations in differential features by adjusting spatial attention across channels. Through the integration of these two modules, the differential features can be adaptively adjusted to compensate for slight fluctuations in the static background between two images caused by temporal changes. The adjusted difference features and the original dynamic background features are element-wise multiplied along both the channel and spatial dimensions, and the feature maps obtained through the CSA and SSA methods are fused to generate the weighted dynamic foreground features. Mathematically, this process can be represented as follows:
represents the output from the i-th BDE module. This differential feature extraction and dynamic enhancement of foreground object features continues until the output of the backbone feature network at the third layer, i.e., i=3, resulting in the final feature representation
. Finally, the final feature representation is processed through a change classifier to obtain the final change probability map
. The Binary Cross-Entropy (CE) loss is employed to compute the discrepancy between the predicted change map
and the ground truth change map
, thereby defining the region-of-interest loss
, as expressed in the following formula:
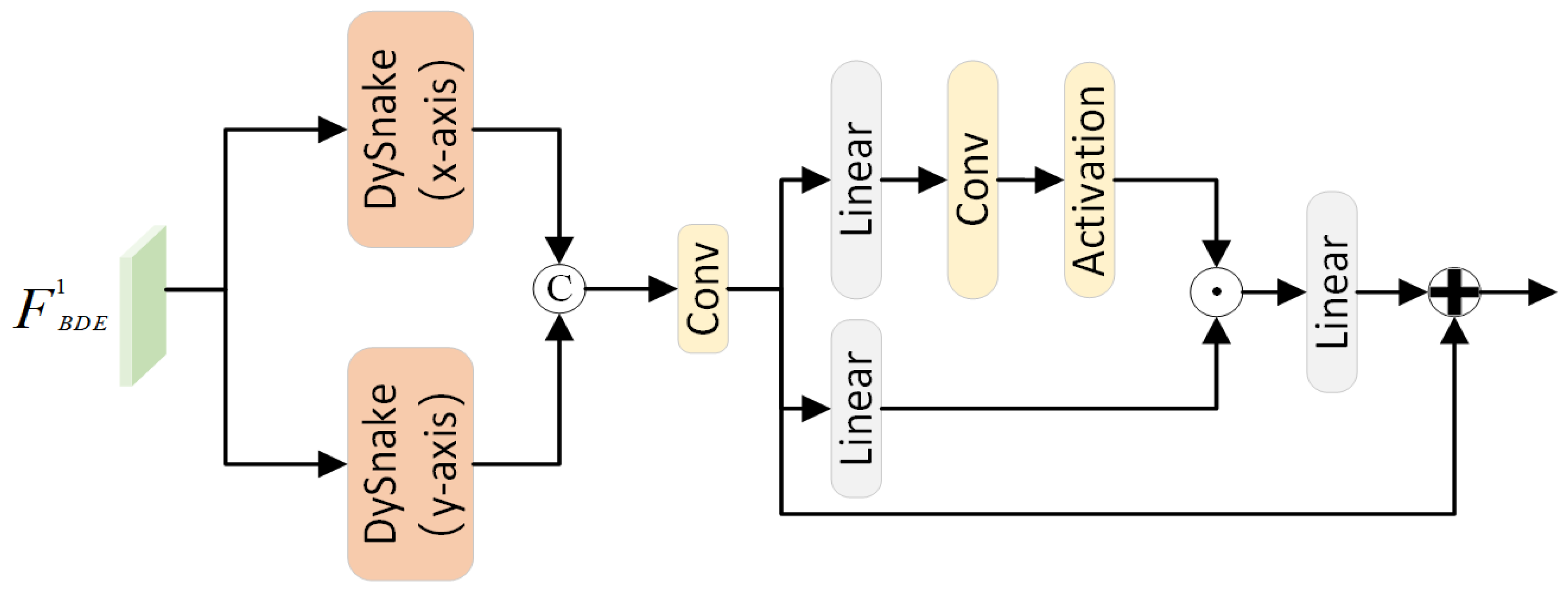
3.2. Edge Feature Gating Unit
In the feature encoding stage, deep features contain rich semantic information, while spatial information is lost in the process of layer-by-layer convolution. Conversely, shallow features retain abundant spatial information essential for localization but lack comprehensive semantic richness. Although the BDE module effectively extracts reliable dynamic foreground object features by incorporating static background prior knowledge, it still relies on edge features of flexible ropes and transparent glass to further refine the final segmentation results. Moreover, since elevator walls are typically made of highly reflective materials such as stainless steel or aluminum alloy, objects entering the elevator often produce slight reflections on the walls, making it necessary to utilize edge features to distinguish blurred features on the walls. Inspired by methods of thin strip image segmentation and gating mechanisms, we propose the Edge Feature Gating Unit module (EFGU). This module utilizes a variant of deformable convolution, dynamic snake convolution [
29], to refine and continuously extract edge features. Finally, it employs convolutional gating units for adaptive filtering of low-dimensional features to alleviate the problem of feature inconsistency between low-dimensional and high-dimensional features.
Figure 3.
BDE structure diagram. Given static background features and dynamic foreground features, BDE can extract differential features along spatial (top side) and channel (bottom side) dimensions, then apply them back to foreground features.
Figure 3.
BDE structure diagram. Given static background features and dynamic foreground features, BDE can extract differential features along spatial (top side) and channel (bottom side) dimensions, then apply them back to foreground features.
As shown in
Figure 4, the feature map
is first independently fed into the dynamic snake convolution (DSConv) to extract edge features along the x- and y-axes, respectively. Compared to traditional convolution, deformable convolution aims to adjust the shape of the convolutional kernel dynamically by learning the offsets of sampling points in the 2D space. Building upon this, DSConv introduces a linear morphological constraint and adopts an iterative strategy to ensure that the calculation of each convolutional value is related to the previous one, thereby maintaining continuity in attention. Taking the x-axis as an example, the core mathematical formula for computing the convolution sampling points is as follows:
where
represents the specific position of each convolutional grid, where c = 0,1,2,3,4 denotes the horizontal distance from the center grid, and
is the cumulative offset. The edge features are then concatenated and passed through a gated selection unit, which filters out redundant edge features. Specifically, we employ a Convolutional Gated Linear Unit (GLU) consisting of two linear projections, element-wise multiplied, where one projection is activated by a gating function. Our approach generates the gating signal from the feature itself, allowing for the selection of edge features that are most beneficial for segmenting glass and pet rope. Finally, the edge features are combined with global features, utilizing a feature pyramid to extract multi-scale features. The output is a classification probability map generated by a class classifier. The predicted class map
is compared with the ground truth map
using a binary cross-entropy loss function, as shown in the following equation:
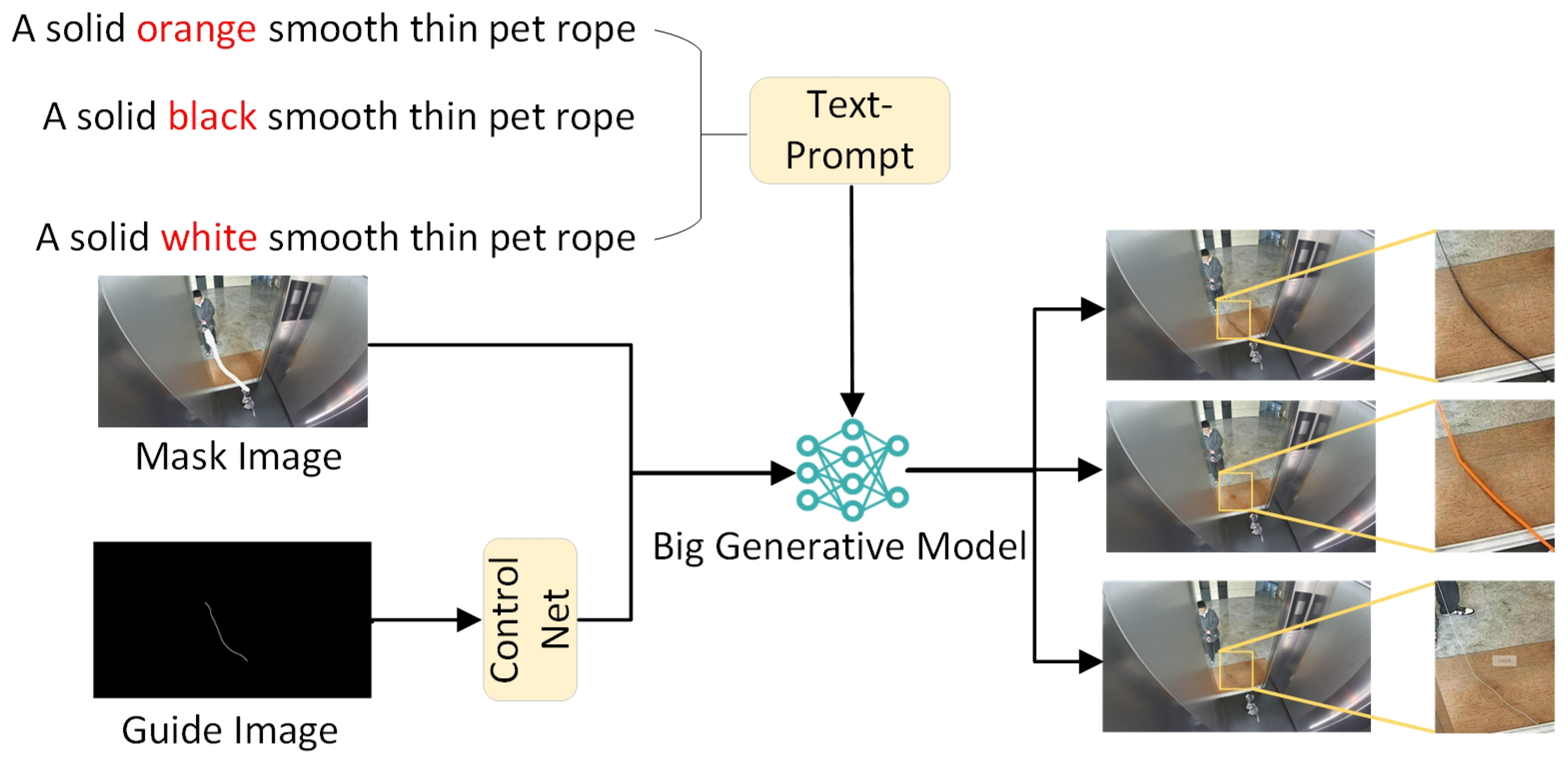
3.3. ES-Aug Pipeline
Big text-to-image models have strong generative capabilities, but when deploying them for specific downstream tasks, they usually have domain gaps that do not match the real image, exhibiting excessive over-smoothing and some artificial textures. Therefore, instead of generating the images directly, we use local redrawing to enhance the generation effect by finely controlling local regions of the image. Specifically, as shown in
Figure 5, ES-Aug selects FLUX [
41], a generative macromodel with 12 billion parameters, as the base model, describes the color and material of the object through textual cues, the mask image provides a rough spatial localization of the object, and the bootstrap image introduces fine morphological constraints for model generation.
When using generative models with ControlNet [
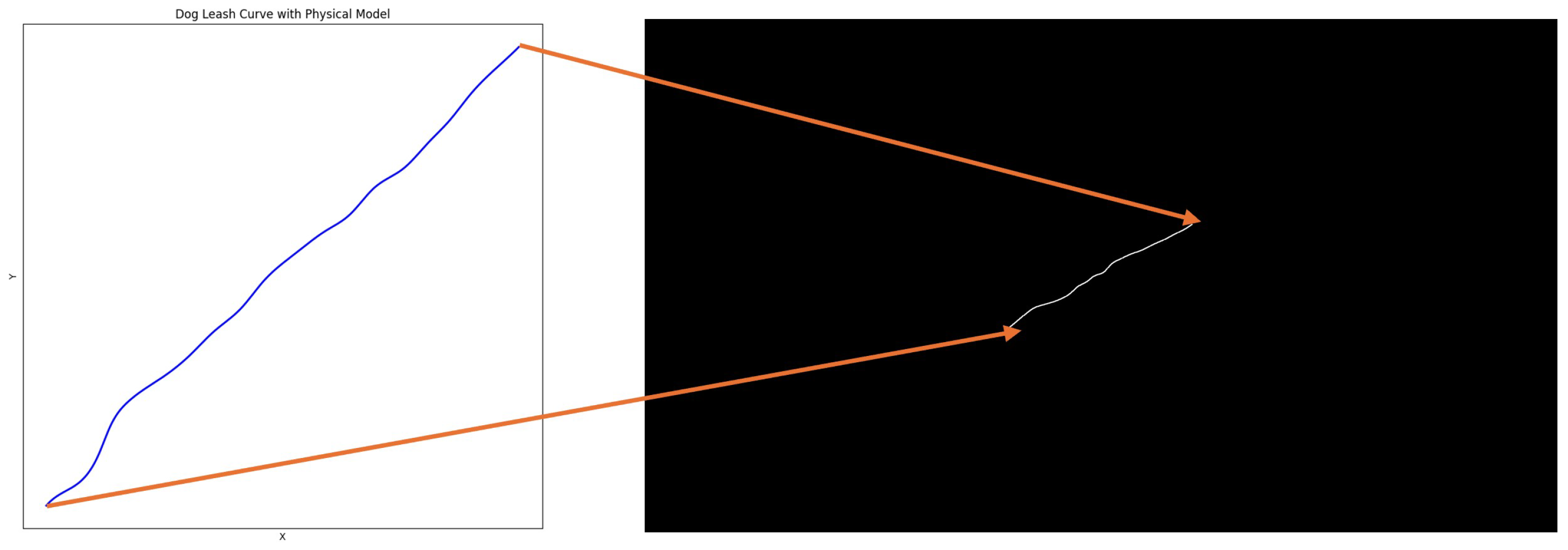
42] to create pet rope that aligns with real-world scenarios, manually drawn curves struggle to accurately simulate the natural bending and swinging of a pet rope under real-world forces, while also lacking the diversity needed to meet the requirements of different scenes. In order to solve this problem, a physical strength-based method of analogical simulation of the power of a mass was used [
43]. During the simulation, position/velocity are adjusted via spring, random, and damping forces, a random power and a damping force to create a natural trajectory of the pet rope. A certain number of randomly selected mass positions are chosen in a predefined mask area, and the mass positions are updated at each moment in time by means of the physics equations, as shown in the following equation:
where
i represents the corresponding particle,
v is the velocity of the point in the x and y directions of the image coordinate system,
t is the time state,
represents the natural frequency of the physical model,
is the elastic force,
is the random disturbance force,
is the damping force, and the clip represents the position of the selected point within the mask region. After reaching the predetermined time state, all point sets are fitted to the pet rope curve through interpolation an algorithm, and the average sampling points located between the two ends of the mask area are taken to obtain the pet rope guidance map. The final result is shown in
Figure 6.
4. Experiment
4.1. Dataset Construction
We collected data using real elevator cameras and established the first large-scale dataset for detecting transparent and elongated objects in elevator scenes. This dataset consists of 4797 image frames, featuring accurately annotated masks of transparent and elongated objects extracted from multiple viewpoints of 10 types of elevators (such as freight elevators, passenger elevators, and home elevators). Example images from the dataset are shown in
Figure 7. The test set (740 images) is composed of two types of elevator images that did not appear in the training set, along with randomly selected samples from the remaining eight types of elevator images that were present in the training set. The training set (4057 images) is made up of the remaining image frames.
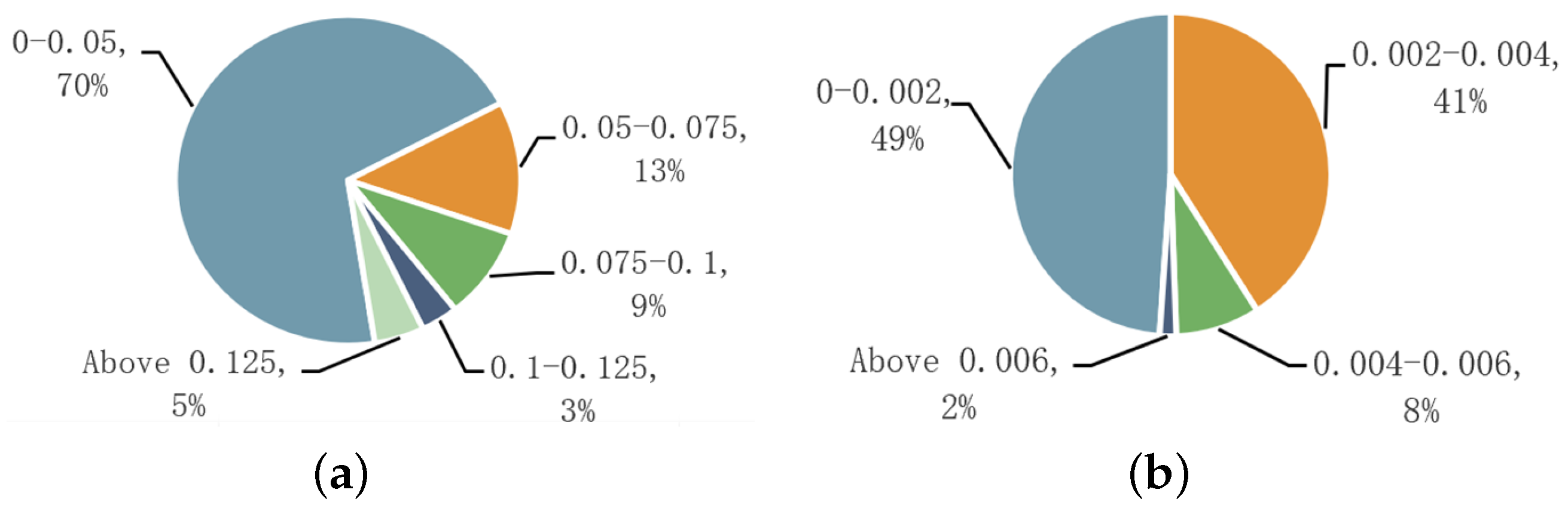
Figure 8 shows the ratio of the area occupied by glass and pet rope to the total area of the image. From the data distribution, it can be observed that most anomalous objects occupy a relatively low pixel proportion in the image. The area of the glass region is mainly concentrated at below 10% of the total image area, while the area of the pet rope region is even smaller, primarily concentrated at below 0.5% of the total image area. This leads to the following issues: the large proportion of background in the image makes it a challenge to eliminate background interference during the network training process; the significant disparity in pixel proportions between glass and pet rope poses a considerable challenge in balancing the network’s ability to fit these two complex object categories.
We also evaluated the data generated by ES-Aug, focusing on the quality of the generated images and the segmentation performance in the downstream task, the latter of which is described in the experimental details in
Section 4.5.
Figure 9 shows some of the images generated using ES-Aug.
4.2. Implementation Details and Evaluation Metrics
We implemented our method using the PyTorch2.4.1 framework and conducted all experiments on an NVIDIA GeForce RTX 3090 with 24 GB of memory. The SGD optimizer was employed with a weight decay of and a initial learning rate of . A linear learning rate scheduler with a warm-up period was used to adjust the learning rate. The batch size and number of training epochs were set to 10 and 100, respectively. In the data preprocessing stage, the size of the input image is only resized to 512 × 512, and no other operations are performed. We utilized a pre-trained ResNet-50 on ImageNet as the encoder. The performance of model was evaluated using the widely adopted dense prediction metric: Intersection over Union (IoU).
4.3. Result and Analysis
We systematically evaluated the effectiveness of the proposed method by comparing it with 11 state-of-the-art methods from three related tasks: glass/mirror segmentation (GDNet, GlassNet, MirroNet, EBLNet), crack segmentation (CrackFormer, CSBSR), and semantic segmentation (IDRNet, Deeplab, Segformer, MCIBI++, Mask2former). It is important to note that some methods are designed for single-class segmentation and are not capable of performing multi-class segmentation. To address this, we trained separate models for each class of data, and the results are summarized in
Table 1. To ensure fair comparison, for all experiments, we selected an encoder provided by the original author with a similar number of parameters as ResNet50 for backbone feature extraction.
Quantitative Comparison:
Table 1 presents the IoU and mIoU values for different methods on various classes within the ETAE-D dataset. It is evident that our method achieved the best performance in both the pet rope and glass categories. Specifically, our approach outperformed the glass segmentation method EBLNet, which focuses on single RGB images, by 4.36%, and surpassed the crack segmentation method CSBSR, which specializes in slender wall crack segmentation, by 5.26%. Furthermore, our method significantly outperformed the semantic segmentation approaches as well.
Visual Comparison: A visual comparison between our model and other methods is shown in
Figure 10. Due to the reflection from the elevator walls, other methods may misclassify objects reflected in the background glass as the target objects to be segmented. Additionally, since foreground objects are often in dynamic motion, static frames captured by the camera exhibit blurring at the edges between the glass and the pet rope, which existing methods fail to effectively handle, resulting in discontinuous segmentation. We have labeled the above questions using red boxes in the second and sixth rows, respectively, in
Figure 10. In contrast, our proposed method not only effectively filters out noisy background information but also ensures the integrity of the segmentation for both the pet rope and the glass.
We conducted experiments comparing the inference time of the proposed network with existing methods for related tasks, and the results are shown in
Table 2. The experiments show that our method meets the real-time requirement in terms of inference speed, and although there is a slight gap compared to some networks, it outperforms these methods in terms of accuracy and achieves a balance between efficiency and performance.
4.4. Ablation Study
To evaluate the effectiveness of our proposed model, we conducted a series of ablation studies on the ETAS-D. These experiments aim to evaluate the performance of our integrated BDE and EFGU. We use the architecture of deeplabv3 (ResNet50 encoder, ASPP multiscale feature aggregation layer, and segmentation header) to construct the baseline model. We then progressively incorporated our modules to perform the ablation studies. The results of these experiments are presented in
Table 3,
Table 4 and
Table 5.
We compared the effect of adding BDE modules after different stages of the backbone network on the segmentation results, and the experimental results are shown in
Table 3. The results show that the best segmentation results are obtained when the BDE modules are added at Stage1, Stage2, and Stage3 positions, with the number of parameters of the network increasing by 4.68%, the pet rope accuracy increasing by 26.85%, and the glass accuracy increasing by 37.43%. When the BDE module is added at the Stage4 position, the reason for the decrease in accuracy is that the deep features already contain global semantic information, and at this time, when the static background and dynamic foreground object feature differencing is performed, it is easy to cause the loss of global semantic information, which leads to the weakening of the model’s ability to perceive contextual information. Additionally, although we need to perform feature extraction of two images in the training phase of the model, we can store the features output from the static background image at different stages in the inference phase of the model, thus further reducing the computational complexity of the model.
We integrate feature information from different stages into high-dimensional features using the short-connections of the EFGU module. The final segmentation results are obtained through a feature aggregation layer and the segmentation head. As demonstrated in
Table 4, the edge features from Stage 1 are selectively filtered via the EFGU, which enhances the segmentation performance by focusing on the most relevant features. As a result, the model’s parameter count increased by 6.14%. Notably, the pet rope accuracy improved by 9.04%, while the glass accuracy increased by 20.48%. These findings indicate that the introduction of the EFGU module effectively leverages shallow-layer spatial details to guide deeper feature representations, leading to more accurate segmentation of the boundary and corner information of anomalous objects, thereby improving the overall segmentation performance.
After determining the optimal placement of the BDE and EFGU modules, we investigated the effect of whether or not to add dynamic foreground object supervision on the segmentation results. As shown in
Table 5, the accuracy of the Pet rope is improved by 3.67% and the accuracy of the glass is improved by 3.66% compared to not introducing dynamic foreground object supervision, and the results show that the
loss is crucial, which further ensures that the network pays attention to the foreground objects, allowing the model to have more explicit information to avoid wrong attention, and thus improving the segmentation accuracy.
4.5. Performance of Synthetic Data
The scarcity of abnormal events is a prevalent issue in the real world, typically due to the rarity of abnormal events. In this experiment, we validated the impact of dataset diversity on PKNet. First, the baseline training set consisted of four types of elevator images (440 images); the test set included two types of elevator images that did not appear in the training set and four types of elevator images that had appeared in the training set (120 images). Subsequently, we constructed three control training sets around these images, supplemented with 50, 190, and 440 synthetic data samples, which accounted for 10%, 30%, 50% of the total training set, respectively. The results of this experiment, presented in
Table 6, indicate that ES-Aug effectively addresses the challenge of data sparsity in monitoring environments. Incorporating synthetic data compensates for the lack of real samples.
5. Conclusions
This paper addresses the problem of abnormal object segmentation in elevators. First, we establish a large-scale dataset for detecting transparent and elongated objects in elevator scenes. Second, we propose PKNet for abnormal object segmentation in elevators, which includes two novel modules: BDE and EFGU. The former utilizes prior static background information to further enhance the model’s focus on dynamic foreground objects at the feature level, while the latter filters and enhances edge feature information. Experimental results demonstrate that our method outperforms state-of-the-art approaches in relevant tasks. Finally, we further explore the performance of AIGC technology in pet rope segmentation, finding that it compensates for the lack of sufficient datasets in real-world applications, thereby improving segmentation accuracy. However, there are still limitations in directly synthesizing real images under surveillance and repainting complex objects (e.g., glass), which presents an area worth further exploration by researchers.
Author Contributions
Conceptualization, Z.L., G.X. and J.W.; data curation, Z.L., W.O. and M.N.; methodology, Z.L., W.O. and J.W.; writing—original draft, Z.L., G.X. and W.O.; writing—review and editing, G.X., M.N. and J.W. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Ningbo Key Technology Breakthrough Project of “Science and Innovation Yongjiang 2035” (2024Z265) and the Major Application Demonstration Plan of “Science and Technology Innovation Yongjiang 2035” (2024Z016).
Data Availability Statement
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Lei, J.; Sun, W.; Fang, Y.; Ye, N.; Yang, S.; Wu, J. A Model for Detecting Abnormal Elevator Passenger Behavior Based on Video Classification. Electronics 2024, 13, 2472. [Google Scholar] [CrossRef]
- Lan, S.; Gao, Y.; Jiang, S. Computer vision for system protection of elevators. J. Phys. Conf. Ser. 2021, 1848, 012156. [Google Scholar] [CrossRef]
- Prahlow, J.A.; Ashraf, Z.; Plaza, N.; Rogers, C.; Ferreira, P.; Fowler, D.R.; Blessing, M.M.; Wolf, D.A.; Graham, M.A.; Sandberg, K.; et al. Elevator-related deaths. J. Forensic Sci. 2020, 65, 823–832. [Google Scholar] [CrossRef]
- Meng, L.; Zhang, L.; Ban, G.; Luo, S.; Liu, J. Power Grid Violation Action Recognition via Few-Shot Adaptive Network. Electronics 2025, 14, 112. [Google Scholar] [CrossRef]
- Liu, C.; Wu, F.; Shi, L. FasterGDSF-DETR: A Faster End-to-End Real-Time Fire Detection Model via the Gather-and-Distribute Mechanism. Electronics 2025, 14, 1472. [Google Scholar] [CrossRef]
- Wang, K.; Zhang, W.; Song, X. A Fire Detection Method for Aircraft Cargo Compartments Utilizing Radio Frequency Identification Technology and an Improved YOLO Model. Electronics 2025, 14, 106. [Google Scholar] [CrossRef]
- Mei, H.; Yang, X.; Wang, Y.; Liu, Y.; He, S. Don’t Hit Me! Glass Detection in Real-World Scenes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 3687–3696. [Google Scholar]
- Lin, J.; He, Z.; Lau, R.W. Rich Context Aggregation with Reflection Prior for Glass Surface Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 13415–13424. [Google Scholar]
- Liu, Y.; Yao, J.; Lu, X.; Xie, R.; Li, L. DeepCrack: A Deep Hierarchical Feature Learning Architecture for Crack Segmentation. Neurocomputing 2019, 338, 139–153. [Google Scholar] [CrossRef]
- Long, J.; Shelhamer, E.; Darrell, T. Fully Convolutional Networks for Semantic Segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3431–3440. [Google Scholar]
- Chen, L.C.; Zhu, Y.; Papandreou, G.; Schroff, F.; Adam, H. Encoder-Decoder with Atrous Separable Convolution for Semantic Image Segmentation. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 801–818. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z. Swin Transformer: Hierarchical Vision Transformer Using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; IEEE/CVF: Piscataway, NJ, USA, 2021; pp. 10012–10022. [Google Scholar]
- Cheng, B.; Schwing, A.; Kirillov, A. Per-Pixel Classification Is Not All You Need for Semantic Segmentation. Adv. Neural Inf. Process. Syst. 2021, 34, 17864–17875. [Google Scholar]
- Cheng, B.; Misra, I.; Schwing, A.G.; Kirillov, A.; Girdhar, R. Masked-Attention Mask Transformer for Universal Image Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE/CVF: Piscataway, NJ, USA, 2022; pp. 1290–1299. [Google Scholar]
- Athar, A.; Hermans, A.; Luiten, J.; Ramanan, D.; Leibe, B. Tarvis: A Unified Architecture for Target-Based Video Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 17–24 June 2023; IEEE/CVF: Piscataway, NJ, USA, 2023; Volume 2, p. 6. [Google Scholar]
- Wang, X.; Zhang, X.; Cao, Y.; Wang, W.; Shen, C.; Huang, T. SegGPT: Segmenting Everything in Context. arXiv 2023, arXiv:2304.03284. [Google Scholar]
- Yan, B.; Jiang, Y.; Wu, J.; Wang, D.; Luo, P.; Yuan, Z.; Lu, H. Universal Instance Perception as Object Discovery and Retrieval. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023; IEEE/CVF: Piscataway, NJ, USA, 2023; pp. 15325–15336. [Google Scholar]
- Han, H.; Yang, R.; Li, S.; Hu, R.; Li, X. SSGD: A Smartphone Screen Glass Dataset for Defect Detection. In Proceedings of the ICASSP 2023—IEEE International Conference on Acoustics, Speech and Signal Processing, Rhodes Island, Greece, 4–10 June 2023; IEEE: Piscataway, NJ, USA, 2023. [Google Scholar]
- Xu, Y.; Nagahara, H.; Shimada, A.; Taniguchi, R.I. TransCut: Transparent Object Segmentation from a Light-Field Image. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 3442–3450. [Google Scholar]
- Mei, H.; Dong, B.; Dong, W.; Yang, J.; Baek, S.H.; Heide, F.; Yang, X. Glass Segmentation Using Intensity and Spectral Polarization Cues. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; IEEE/CVF: Piscataway, NJ, USA, 2022; pp. 12622–12631. [Google Scholar]
- Mei, H.; Dong, B.; Dong, W.; Peers, P.; Yang, X.; Zhang, Q.; Wei, X. Depth-Aware Mirror Segmentation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; IEEE/CVF: Piscataway, NJ, USA, 2021; pp. 3044–3053. [Google Scholar]
- Huo, D.; Wang, J.; Qian, Y.; Yang, Y.H. Glass Segmentation with RGB-Thermal Image Pairs. IEEE Trans. Image Process. 2023, 32, 1911–1926. [Google Scholar] [CrossRef]
- Yu, L.; Mei, H.; Dong, W.; Wei, Z.; Zhu, L.; Wang, Y.; Yang, X. Progressive glass segmentation. IEEE Trans. Image Process. 2022, 31, 2920–2933. [Google Scholar] [CrossRef] [PubMed]
- Guan, H.; Lin, J.; Lau, R.W.H. Learning semantic associations for mirror detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition 2022, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- He, H.; Li, X.; Cheng, G.; Shi, J.; Tong, Y.; Meng, G.; Prinet, V.; Weng, L. Enhanced boundary learning for glass-like object segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2021, Montreal, QC, Canada, 10–17 October 2021; pp. 15859–15868. [Google Scholar]
- Mei, H.; Yang, X.; Yu, L.; Zhang, Q.; Wei, X.; Lau, R.W. Large-field contextual feature learning for glass detection. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 3329–3346. [Google Scholar] [CrossRef] [PubMed]
- Jin, Q.; Meng, Z.; Pham, T.D.; Chen, Q.; Wei, L.; Su, R. DUNet: A Deformable Network for Retinal Vessel Segmentation. Knowl.-Based Syst. 2019, 178, 149–162. [Google Scholar] [CrossRef]
- Wang, D.; Zhang, Z.; Zhao, Z.; Liu, Y.; Chen, Y.; Wang, L. PointScatter: Point Set Representation for Tubular Structure Extraction. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Cham, Switzerland, 2022; pp. 366–383. [Google Scholar]
- Qi, Y.; He, Y.; Qi, X.; Zhang, Y.; Yang, G. Dynamic Snake Convolution Based on Topological Geometric Constraints for Tubular Structure Segmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Paris, France, 1–6 October 2023; pp. 6070–6079. [Google Scholar]
- Yuan, Y.; Chen, X.; Wang, J. Object-Contextual Representations for Semantic Segmentation. In Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VI 16; Springer International Publishing: Cham, Switzerland, 2020; pp. 173–190. [Google Scholar]
- Zhang, K.; Zhang, Y.; Cheng, H.D. CrackGAN: Pavement Crack Detection Using Partially Accurate Ground Truths Based on Generative Adversarial Learning. IEEE Trans. Intell. Transp. Syst. 2020, 22, 1306–1319. [Google Scholar] [CrossRef]
- Rezaie, A.; Achanta, R.; Godio, M.; Beyer, K. Comparison of Crack Segmentation Using Digital Image Correlation Measurements and Deep Learning. Constr. Build. Mater. 2020, 261, 120474. [Google Scholar] [CrossRef]
- Chen, H.; Su, Y.; He, W. Automatic Crack Segmentation Using Deep High-Resolution Representation Learning. Appl. Opt. 2021, 60, 6080–6090. [Google Scholar] [CrossRef]
- Liu, H.; Miao, X.; Mertz, C.; Xu, C.; Kong, H. Crackformer: Transformer Network for Fine-Grained Crack Detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 3783–3792. [Google Scholar]
- Rombach, R.; Blattmann, A.; Lorenz, D.; Esser, P.; Ommer, B. High-Resolution Image Synthesis with Latent Diffusion Models. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 10684–10695. [Google Scholar]
- Li, B.; Xu, X.; Wang, X.; Hou, Y.; Feng, Y.; Wang, F.; Che, W. Semantic-Guided Generative Image Augmentation Method with Diffusion Models for Image Classification. Proc. AAAI Conf. Artif. Intell. 2024, 38, 3018–3027. [Google Scholar] [CrossRef]
- Fang, H.; Han, B.; Zhang, S.; Zhou, S.; Hu, C.; Ye, W.M. Data Augmentation for Object Detection via Controllable Diffusion Models. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 3–8 January 2024; pp. 1257–1266. [Google Scholar]
- Zhang, X.; Xu, M.; Zhou, X. RealNet: A Feature Selection Network with Realistic Synthetic Anomaly for Anomaly Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 16–22 June 2024; pp. 16699–16708. [Google Scholar]
- Huang, L.; Yu, W.; Ma, W.; Zhong, W.; Feng, Z.; Wang, H. A Survey on Hallucination in Large Language Models: Principles, Taxonomy, Challenges, and Open Questions. ACM Trans. Inf. Syst. 2025, 43, 1–55. [Google Scholar] [CrossRef]
- Fang, S.; Li, K.; Li, Z. Changer: Feature Interaction Is What You Need for Change Detection. IEEE Trans. Geosci. Remote Sens. 2023, 61, 1–11. [Google Scholar] [CrossRef]
- Black Forest Labs. FLUX. 2024. Available online: https://github.com/black-forest-labs/flux (accessed on 1 August 2024).
- Zhang, L.; Rao, A.; Agrawala, M. Adding conditional control to text-to-image diffusion models. In Proceedings of the IEEE/CVF International Conference on Computer Vision 2023, Paris, France, 1–6 October 2023; pp. 3836–3847. [Google Scholar]
- Wang, W.; Zhou, C.; Yang, Y.; Wang, X.; Qu, J. Flexible rope simulation based on improved mass-spring mode. J. Comput.-Aided Des. Comput. Graph. 2015, 27, 2230–2236. [Google Scholar]
- Jin, Z.; Zhang, Y.; Li, X.; Chen, W.; Wang, H.; Liu, J. IDRNet: Intervention-driven relation network for semantic segmentation. Adv. Neural Inf. Process. Syst. 2023, 36, 51606–51620. [Google Scholar]
- Xie, E.; Wang, W.; Yu, Z.; Li, X.; Zhang, Y.; Liu, J. SegFormer: Simple and efficient design for semantic segmentation with transformers. Adv. Neural Inf. Process. Syst. 2021, 34, 12077–12090. [Google Scholar]
- Jin, Z.; Zhang, Y.; Li, X.; Chen, W.; Wang, H.; Liu, J. MCIBI++: Soft mining contextual information beyond image for semantic segmentation. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 5988–6005. [Google Scholar] [CrossRef] [PubMed]
- Pang, Y.; Zhang, X.; Li, Z.; Wang, L.; Liu, J. Multi-scale interactive network for salient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 9413–9422. [Google Scholar]
- Yang, X.; Zhang, L.; Wang, Y.; Liu, H.; Chen, Z. Where is my mirror? In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8808–8817. [Google Scholar]
- Liu, H.; Yang, J.; Miao, X.; Mertz, C.; Kong, H. CrackFormer network for pavement crack segmentation. IEEE Trans. Intell. Transp. Syst. 2023, 24, 9240–9252. [Google Scholar] [CrossRef]
- Kondo, Y.; Ukita, N. Joint learning of blind super-resolution and crack segmentation for realistic degraded images. IEEE Trans. Instrum. Meas. 2024, 73, 3374293. [Google Scholar] [CrossRef]
Figure 1.
Pet rope (left), glass (right), enlarged abnormal area (center).
Figure 1.
Pet rope (left), glass (right), enlarged abnormal area (center).
Figure 4.
EFGU structure diagram. Use dynamic snake convolution and gating mechanism to refine edge features.
Figure 4.
EFGU structure diagram. Use dynamic snake convolution and gating mechanism to refine edge features.
Figure 5.
Schematic overview of the ES-Aug pipeline. Use text-prompt and guiding image to control the generation process.
Figure 5.
Schematic overview of the ES-Aug pipeline. Use text-prompt and guiding image to control the generation process.
Figure 6.
Pet rope guidance diagram. The original rope guidance map generated by the physical model (left), and the rope guidance map pasted back into the original image space (right).
Figure 6.
Pet rope guidance diagram. The original rope guidance map generated by the physical model (left), and the rope guidance map pasted back into the original image space (right).
Figure 7.
Visual display (left: frames; right: masks) of several examples of proposed ETAS-D dataset.
Figure 7.
Visual display (left: frames; right: masks) of several examples of proposed ETAS-D dataset.
Figure 8.
Statistics of the constructed ETAE-D dataset. (a) The proportion of glass of different sizes in the total dataset, (b) the proportion of pet rope of different sizes in the total dataset. The first row of data labeled beside the pie chart represents the area proportion of such pixels in a single image, while the second row of data indicates the distribution ratio of such images within the entire image dataset.
Figure 8.
Statistics of the constructed ETAE-D dataset. (a) The proportion of glass of different sizes in the total dataset, (b) the proportion of pet rope of different sizes in the total dataset. The first row of data labeled beside the pie chart represents the area proportion of such pixels in a single image, while the second row of data indicates the distribution ratio of such images within the entire image dataset.
Figure 9.
Visual display of data generated by ES-Aug. (a) Color, thickness, and texture variations performed on the pet rope, (b) swinging pattern, deformation state on the pet rope.
Figure 9.
Visual display of data generated by ES-Aug. (a) Color, thickness, and texture variations performed on the pet rope, (b) swinging pattern, deformation state on the pet rope.
Figure 10.
Qualitative visualization of experimental results (the label values in VOC format are transformed, e.g., from (1,1,1) to (0,0,128)).
Figure 10.
Qualitative visualization of experimental results (the label values in VOC format are transformed, e.g., from (1,1,1) to (0,0,128)).
Table 1.
Quantitative comparisons of 11 various methods. Best results are shown in bold.
Table 1.
Quantitative comparisons of 11 various methods. Best results are shown in bold.
| Methods | Task | Class IoU | MIoU |
|---|
|
Pet Rope
|
Glass
|
Human
|
Pet
|
|---|
| IDRNet [44] | SS | 0.289 | 0.538 | 0.890 | 0.867 | 0.646 |
| Deeplab [11] | 0.365 | 0.537 | 0.879 | 0.867 | 0.662 |
| Segformer [45] | 0.322 | 0.695 | 0.896 | 0.871 | 0.696 |
| MCBI++ [46] | 0.332 | 0.532 | 0.886 | 0.863 | 0.653 |
| Mask2former [14] | 0.393 | 0.718 | 0.899 | 0.889 | 0.725 |
| GDNet [7] | GSD/MD | 0.349 | 0.652 | 0.892 | 0.862 | 0.689 |
| GlassNet [47] | 0.375 | 0.707 | 0.884 | 0.854 | 0.705 |
| MirroNet [48] | 0.368 | 0.713 | 0.882 | 0.873 | 0.709 |
| EBLNet [25] | 0.389 | 0.733 | 0.876 | 0.883 | 0.720 |
| CrackFormer [49] | CS | 0.428 | 0.565 | 0.875 | 0.875 | 0.686 |
| CSBSR [50] | 0.456 | 0.595 | 0.873 | 0.847 | 0.693 |
| Ours | | 0.480 | 0.765 | 0.910 | 0.893 | 0.762 |
Table 2.
Comparison results with related methods. The speeds are tested with 512 × 512 inputs. All the inference times are tested with one NVIDIA GeForce RTX 3090.
Table 2.
Comparison results with related methods. The speeds are tested with 512 × 512 inputs. All the inference times are tested with one NVIDIA GeForce RTX 3090.
| Method | Deeplabv3 | Mask2former | Mcibi++ | EBLNet | MirroNet | CrackFormer | Ours |
|---|
| FPS | 51 | 18 | 32 | 45 | 32 | 26 | 41 |
Table 3.
Ablation experiments on the BDE module. Best results are shown in bold.
Table 3.
Ablation experiments on the BDE module. Best results are shown in bold.
| Baseline | BDE Placement | Class IoU | MIoU | Parameter
Size (M) |
|---|
|
1
|
2
|
3
|
4
|
Pet Rope
|
Glass
|
Human
|
Pet
|
|---|
| ✓ | | | | | 0.365 | 0.537 | 0.879 | 0.867 | 0.662 | 42.29 |
| ✓ | ✓ | | | | 0.427 | 0.722 | 0.892 | 0.867 | 0.727 | 42.56 |
| ✓ | ✓ | ✓ | | | 0.455 | 0.736 | 0.886 | 0.882 | 0.740 | 42.85 |
| ✓ | ✓ | ✓ | ✓ | | 0.463 | 0.738 | 0.903 | 0.881 | 0.746 | 44.27 |
| ✓ | ✓ | ✓ | ✓ | ✓ | 0.459 | 0.745 | 0.902 | 0.875 | 0.740 | 48.97 |
Table 4.
Ablation experiments on the EFGU module. Best results are shown in bold.
Table 4.
Ablation experiments on the EFGU module. Best results are shown in bold.
| Baseline | EFGU Placement | Class IoU | MIoU | Parameter Size (M) |
|---|
|
1
|
2
|
3
|
Pet Rope
|
Glass
|
Human
|
Pet
|
|---|
| ✓ | | | | 0.365 | 0.537 | 0.879 | 0.867 | 0.662 | 42.29 |
| ✓ | ✓ | | | 0.398 | 0.647 | 0.878 | 0.876 | 0.700 | 44.89 |
| ✓ | | ✓ | | 0.375 | 0.583 | 0.865 | 0.869 | 0.673 | 46.36 |
| ✓ | | | ✓ | 0.388 | 0.578 | 0.881 | 0.879 | 0.682 | 49.47 |
Table 5.
Ablation experiments on the loss function. Best results are shown in bold.
Table 5.
Ablation experiments on the loss function. Best results are shown in bold.
| Baseline | | | Class IoU | MIoU |
|---|
|
Pet Rope
|
Glass
|
Human
|
Pet
|
|---|
| ✓ | ✓ | | 0.463 | 0.738 | 0.903 | 0.881 | 0.746 |
| ✓ | ✓ | ✓ | 0.480 | 0.765 | 0.910 | 0.893 | 0.762 |
Table 6.
Performance of synthetic samples on the PKNet. The mixing ratio refers to the proportion of synthesized sample training data relative to the total number of training samples. Best results are shown in bold.
Table 6.
Performance of synthetic samples on the PKNet. The mixing ratio refers to the proportion of synthesized sample training data relative to the total number of training samples. Best results are shown in bold.
| Model | Mixing Ratio | Class IoU | MIoU |
|---|
|
Pet Rope
|
Human
|
Pet
|
|---|
| PKNet | 0% | 0.476 | 0.903 | 0.878 | 0.752 |
| 10% | 0.479 | 0.905 | 0.882 | 0.755 |
| 30% | 0.485 | 0.917 | 0.889 | 0.764 |
| 50% | 0.498 | 0.915 | 0.891 | 0.768 |
| Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}