

Fuzzy Rules for Explaining Deep Neural Network Decisions (FuzRED)


Abstract
1. Introduction
2. Related Work
2.1. AI Explainability
2.2. Fuzzy Association Rule Mining (FARM)
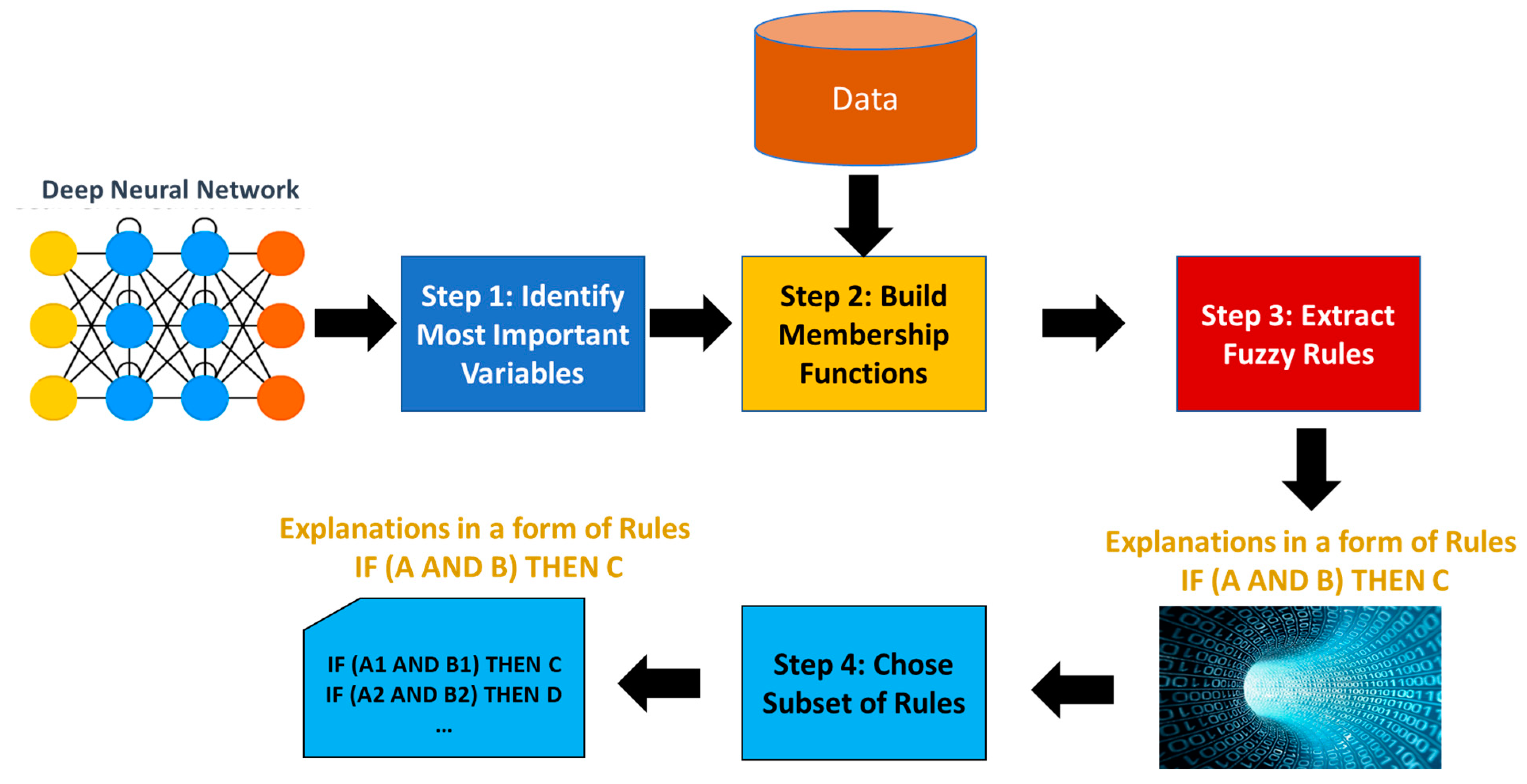
3. Materials and Methods
3.1. Determination of the Most Important Features
3.2. Building FMFs
3.3. Extracting Fuzzy Association Rules
- IF (Temperature IS Strong Fever) AND (Skin IS Yellowish) AND (Loss of appetite IS Profound) THEN (Hepatitis is Acute)
- The rule states that a patient exhibiting a strong fever, yellowish skin, and a profound loss of appetite is likely suffering from acute hepatitis. “Strong Fever”, “Yellowish”, “Profound”, and “Acute” are membership functions of the variables Temperature, Skin, Loss of appetite, and Hepatitis, respectively. To illustrate this, consider the FMFs for the variable Temperature given in Figure 2. According to the definition in that figure, a person with a body temperature of 100 °F has a “Normal” temperature with a membership value of 0.2 and, simultaneously, has a “Fever” with a membership value of 0.78. These FMFs provide a nuanced way to interpret data, reflecting the complexity of real-world situations. More information on fuzzy logic and fuzzy membership functions can be found in [11].
3.4. Choosing a Subset of Rules
4. Results
4.1. Spam Email Identification
4.1.1. FuzRED Results
- IF (word_freq_george IS High) THEN No-Spam, sup = 0.0263, conf = 1
- IF (word_freq_hp IS Medium) THEN No-Spam, sup = 0.0753, conf = 1
- The above rule says that if the frequency of the word hp (Hewlett Packard) is medium (see Figure 10), then the email is no-spam. The support of the rule is 7.53% and the rule is always true. The creators of the dataset were all HP employees, and many no-spam emails provided included their business emails, so this rule also makes perfect sense. A similar rule is shown below:
- IF (word_freq_hp IS High) THEN No-Spam, sup = 0.0145, conf = 1
- Some no-spam rules are related to the frequency of the words meeting, 1999, or lab:
- IF (word_freq_meeting IS Medium) THEN No-Spam, sup = 0.0217, conf = 1
- IF (word_freq_meeting IS High) THEN No-Spam, sup = 0.0046, conf = 1
- IF (word_freq_george IS Medium AND word_freq_1999 IS Medium) THEN No-Spam, sup = 0.0014, conf = 1
- IF (char_freq_$ IS High) THEN Spam, sup = 0.0033, conf = 1
- IF (char_freq_$ IS Medium AND char_freq_! IS Medium) THEN Spam, sup = 0.0028, conf = 1
- IF (capital_run_length_average IS Medium) THEN Spam, sup = 0.0026, conf = 1
- The above rule says that if the average length of uninterrupted sequences of capital letters is Medium, then the email is always spam.
- IF (char_freq_$ IS Medium AND capital_run_length_total IS High) THEN Spam, sup = 0.0020, conf = 1
- The above rule says that if the total number of capital letters in the email is high, then the email is always spam. Historically, spam emails use a lot of capital letters, so this rule is logical.
4.1.2. Anchors Results
- IF (char_freq_$ <= 0.05 AND word_freq_free <= 0.00 AND word_freq_money <= 0.00) THEN No-Spam, coverage = 0.5872, precision = 0.8543
- This rule says that if the frequency of $ is less than or equal to 0.05, and the frequencies of free and money are less than or equal to 0, then the email is No-Spam in 85.43% of the cases. Of course, frequency cannot be a negative number, and frequency is an integer; therefore, being less than or equal to 0.05, is the same as being zero. Therefore, the rule actually says that if the frequency of $, free, and money is zero, then the email is No-Spam in 85.43% of the cases. The 0.05 threshold in the rule is arbitrary. The rule has a large coverage (58.72%) and is true in 85.43% cases.
- IF (word_freq_hp > 0.00 AND char_freq_! <= 0.00 AND word_freq_remove <= 0.00) THEN No-Spam, coverage = 0.1672, precision = 1
- This rule says that if the frequency of hp is greater than 0 and the frequencies of ! and remove are less than or equal to 0, then the email is always No-Spam. Of course, frequency cannot be a negative number, so the rule actually says that if the frequency of hp is greater than 0 and the frequencies of ! and remove are 0, then the email is always No-Spam. This rule covers 16.72% of the data.
- IF (word_freq_remove > 0.00 AND char_freq_$ > 0.05 AND capital_run_length_longest > 43.00) THEN Spam, coverage = 0.0671, precision = 1
- IF (word_freq_remove > 0.00 AND char_freq_$ > 0.05 AND capital_run_length_average > 3.71) THEN Spam, coverage = 0.0579, precision = 1
- IF (word_freq_3d > 0.00 AND capital_run_length_average > 3.71 AND word_freq_you > 2.63) THEN Spam, coverage = 0.0007, precision = 1
4.2. Phishing Link Detection
4.2.1. FuzRED Results
- IF (nb_dots IS High) THEN Phishing, sup = 0.0039, conf = 1This rule says that if the nb_dots (number of dots in the URL) is high, then the URL is always predicted to be a phishing domain by the model. An example of such a URL is below (13 dots in the domain name):
- http://https.email.office.nhc8fso9liwz2e1rk12vhqaxgeq4g.hgbtmd8eshlu1rkesgz11.tk0mqbhgkkuvsf3u821.1sytn1idkv8s2qm4ehh7jja7d.mne8jnxrh8klahtqu.0fll4ryeb76852jeplwk9ckd6zqof.2wvxm5n6uamkxq7wxhpbxaq1a4.cxdtens.duckdns.org/365NewOfficeG15/jsmith@imaphost.com/paul/
- IF (nb_www IS High AND length_words_raw IS High) THEN Phishing, sup = 0.0023522, conf = 1.0
- Length_words_raw is an integer that refers to how many words there are in a URL. The rule says that if the nb_www and length_words_raw are high, then the URL is a phishing one. In the phishing URL below, nb_www is 2, and length_words_raw is 16:
- http://timetravel.mementoweb.org/reconstruct/20141123205914mp_/https:/www.paypal.com/signin?returnuri=https:/www.paypal.com/cgi-bin/webscr?cmd=_account
- IF (page_rank IS High AND nb_hyperlinks IS High) THEN No-Phishing, sup = 0.0141772, conf = 0.9991)
4.2.2. Anchors Results
- IF (nb_star > 0.00) THEN Phishing, coverage = 0.0011, precision = 1
- Nb_star refers to the number of stars (*) in a URL. The above rule is always true and describes 0.11% of the dataset.
- IF (page_rank <= 1.00 AND google_index > 0.00 AND longest_words_raw > 16.00) THEN Phishing, coverage = 0.1021, precision = 1
- Google_index is a binary variable describing whether a given domain is indexed by Google or not (1 means indexed, and 0 means not indexed); web pages not indexed by Google have a higher probability of phishing. The above rule says that if page_rank <= 1.00, the google_index > 0.00 (in reality google_index = 1, meaning indexed by google), and the longest_words_raw > 16.00, the web page is always phishing. It is unclear why URLs indexed by Google would be related to phishing; as such, this rule appears contradictory.
- IF (google_index <= 0.00 AND ratio_extErrors > 0.00 AND domain_registration_length > 446.75) THEN No-Phishing, coverage = 0.0684, precision = 0.9961
- The above rule is very difficult to comprehend: when google_index is 0, the page is not indexed by Google, so why would this be related to No-Phishing? In the dataset, ratio_extErrors is always > 0; therefore, this part of the rule does nothing. Finally, the domain_registration_length has a difficult-to-understand threshold value. The rule is true in 99.61% of cases.
- IF (google_index > 0.00 AND nb_hyperlinks <= 9.00 AND avg_words_raw > 8.00) THEN Phishing, coverage = 0.0551, precision = 0.9952
4.3. Robotic Navigation
4.3.1. FuzRED Results
- IF target_red_box IS true AND red_box_detected IS false THEN turn_left, sup = 0.104, conf = 1
- IF target_blue_box IS true AND blue_box_detected IS false THEN turn_left, sup = 0.115, conf = 1
- IF target_yellow_box IS true AND yellow_box_detected IS false THEN turn_right, sup = 0.116, conf = 1
- IF target_blue_box IS true AND red_box_detected IS true THEN turn_left, sup = 0.041, conf = 1
- IF target_blue_box IS true AND blue_box_detected IS true THEN move_forwardsup-0.240, conf = 1
- The above rule shows that the agent always moves forward when the blue box is the target and it is in the field of view.
- IF target_yellow_box IS true AND yellow_box_detected IS true THEN move_forward, sup = 0.223, conf = 0.996
- The rule above shows that the agent almost always moves forward when the yellow box is the target and it is in the field of view.
- IF target_red_box IS true AND red_box_position_x IS middle AND yellow_box_detected IS false THEN move_forward, sup = 0.031, conf = 1
- IF target_red_box IS true AND red_box_width IS wide AND blue_box_detected IS false THEN move_forward, sup = 0.015, conf = 0.999
- IF target_red_box IS true AND red_box_height IS tall AND yellow_box_detected IS false THEN move_forward, sup = 0.071, conf = 0.987
- The above rules show examples of some of the other conditions that need to be in place for the agent to move forward toward the red box, namely that it needs to be in the middle of the field of view or taking up a large portion of the field of view in height or width and the other boxes are not in the way.
4.3.2. Anchors Results
- IF (target_red_box <= 0.00 AND blue_box_height > 0.16) THEN move_forward, coverage = 0.1898, precision = 1
- Target_red_box is a binary variable, meaning that this rule really says that if the target_red_box = 0 (this means the red box is not the target) and blue_box_height > 0.16, move_forward. The meaning of blue_box_height > 0.16 is unknown.
- IF (0.00 < blue_box_position_x <= 0.06) THEN move_forward, coverage = 0.0819, precision = 0.9712
- It is difficult to understand what the threshold values of blue_box_position_x mean in this rule.
- IF (blue_box_detected <= 0.00 AND target_blue_box > 0.00) THEN turn_left, coverage = 0.115, precision = 1
- Blue_box_detected and target_blue_box are binary features. As such, the rule really says that if blue_box_detected = 0.00 and target_blue_box = 1.0, then always turn_left. In other words, it says that if the blue_box is not detected and the target is the blue_box, then turn_left. This rule is the same as one of the FuzRED rules described in 4.3.1.2. The only difference is that the FuzRED rule was easy to understand:
- IF target_blue_box IS true AND blue_box_detected IS false THEN turn_left
- Here are some examples of rules with three antecedents (note that most of the Anchors rules have three antecedents):
- IF (blue_box_position_x <= 0.06 AND red_box_height > 0.14 AND target_red_box > 0.00) THEN move_forward, coverage = 0.1228, precision = 0.9744
- Taking into account that some of the features are binary, this rule says that if target_red_box = 1 (so the target is the red_box), blue_box_position_x <= 0.06, and red_box_height > 0.14, then most of the time move_forward. The thresholds 0.06 and 0.14 are difficult to understand.
- IF (target_red_box > 0.00 AND blue_box_height > 0.16 AND red_box_detected <= 0.00) THEN turn_left, coverage = 0.0244, precision = 1
- Taking into account that some of the features are binary, this rule says that if target_red_box = 1 (meaning that the red_box is the target), red_box_detected = 0 (red_box not detected), and blue_box_height > 0.16, then always move_right. The threshold 0.16 is difficult to understand.
5. Discussion
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| AI | Artificial intelligence |
| ARM | Association rule mining |
| DRL | Deep reinforcement learning |
| FARM | Fuzzy association rule mining |
| FMF | Fuzzy membership function |
| FuzRED | Fuzzy rules for explaining deep neural network decisions |
| GMM | Gaussian mixture model |
| HRL | Hierarchical reinforcement learning |
| LIME | Local interpretable model-agnostic explanations |
| MD | Matching degree |
| MMD | Maximum matching degree |
| ReLU | Rectified linear unit |
| SHAP | Shapley additive explanations |
| SME | Subject matter expert |
| UCI | University of California Irvine |
| XAI | Explainable artificial intelligence |
| YOLO | You look only once |
Appendix A
Appendix A.1. Additional Results for the Spam Email Identifiction Dataset



- IF (word_freq_remove IS High) THEN Spam, sup = 0.0119, conf = 1
- Many spam emails play on people’s fear, claiming their account will be deleted unless they take immediate action, in emails like: “Urgent: Verify your account or we will need to remove it from our system. Click here to verify.”
- IF (word_freq_000 IS High AND word_freq_1999 IS Low) THEN Spam, sup = 0.0085, conf = 1
- The above rule says that if the frequency of 000 is high (spam emails often mention $ and a lot of zeros) and the frequency of 1999 (many no-spam emails were from 1999) is low, then the email is always spam.
- IF (word_freq_re IS High) THEN No-Spam, sup = 0.0020, conf = 1
- If someone is replying to someone else’s email (or chain of email replies), this is not spam.
- IF (word_freq_hpl IS High) THEN No-Spam, sup = 0.0198, conf = 1
- Hpl is the acronym for Hewlett Packard Labs, and the rule states that if its frequency is high, the email is always no-spam.
- IF (word_freq_remove > 0.00 AND word_freq_hp <= 0.00 AND word_freq_will > 0.00) THEN Spam, coverage = 0.1192, precision = 1
- IF (word_freq_george > 0.00 AND word_freq_labs > 0.00) THEN No-Spam, coverage = 0.0533, precision = 1

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Antecedent 1 | Antecedent 2 | Antecedent 3 | Consequent | Support | Confidence |
|---|---|---|---|---|---|
| word_freq_hp; Medium | No-Spam | 0.0753 | 1 | ||
| word_freq_hpl; Medium | No-Spam | 0.0598 | 1 | ||
| word_freq_george; High | No-Spam | 0.0263 | 1 | ||
| capital_run_length_longest; Medium | Spam | 0.0237 | 1 | ||
| word_freq_meeting; Medium | No-Spam | 0.0217 | 1 | ||
| word_freq_hpl; High | No-Spam | 0.0198 | 1 | ||
| word_freq_hp; High | No-Spam | 0.0145 | 1 | ||
| word_freq_1999; Low | word_freq_telnet; Medium | word_freq_technology; Medium | No-Spam | 0.0142 | 1 |
| word_freq_cs; Medium | No-Spam | 0.0126 | 1 | ||
| word_freq_direct; High | No-Spam | 0.0112 | 1 | ||
| word_freq_lab; Low | word_freq_telnet; Medium | word_freq_technology; Medium | No-Spam | 0.0107 | 1 |
| word_freq_telnet; High | No-Spam | 0.0099 | 1 | ||
| word_freq_1999; Medium | word_freq_edu; Medium | No-Spam | 0.0097 | 1 | |
| word_freq_lab; Medium | word_freq_technology; Medium | No-Spam | 0.0089 | 1 | |
| word_freq_project; Medium | No-Spam | 0.0079 | 1 | ||
| word_freq_1999; Medium | word_freq_technology; Medium | No-Spam | 0.0055 | 1 | |
| word_freq_1999; Medium | char_freq_; Medium | No-Spam | 0.0054 | 1 | |
| word_freq_edu; High | No-Spam | 0.0053 | 1 | ||
| char_freq_$; Medium | word_freq_direct; Medium | Spam | 0.0047 | 1 | |
| word_freq_meeting; High | No-Spam | 0.0046 | 1 | ||
| word_freq_email; Medium | char_freq_$; Medium | Spam | 0.0043 | 1 | |
| char_freq_; High | No-Spam | 0.0039 | 1 | ||
| char_freq_$; High | Spam | 0.0033 | 1 | ||
| char_freq_$; Medium | char_freq_; Medium | Spam | 0.0030 | 1 | |
| word_freq_email; High | word_freq_re; Low | word_freq_all; Low | Spam | 0.0029 | 1 |
| word_freq_cs; High | No-Spam | 0.0026 | 1 | ||
| word_freq_email; Medium | word_freq_all; High | No-Spam | 0.0026 | 1 | |
| word_freq_re; High | No-Spam | 0.0020 | 1 | ||
| word_freq_edu; Medium | word_freq_all; Medium | No-Spam | 0.0020 | 1 | |
| word_freq_edu; Low | word_freq_edu; Medium | No-Spam | 0.0014 | 1 | |
| word_freq_george; Medium | word_freq_1999; Medium | No-Spam | 0.0014 | 1 | |
| word_freq_george; Medium | word_freq_1999; High | No-Spam | 0.0013 | 1 | |
| word_freq_george; Medium | char_freq_; Medium | No-Spam | 0.0013 | 1 | |
| word_freq_1999; High | word_freq_all; Medium | No-Spam | 0.0012 | 1 | |
| word_freq_hp; Low | char_freq_$; Medium | word_freq_all; Medium | Spam | 0.0065 | 1 |
| word_freq_857; Medium | No-Spam | 0.0217 | 0.9999 | ||
| word_freq_email; Medium | word_freq_direct; Low | word_freq_direct; Medium | Spam | 0.0011 | 0.9996 |
| word_freq_re; Medium | No-Spam | 0.0258 | 0.9940 | ||
| word_freq_lab; High | No-Spam | 0.0099 | 0.9930 | ||
| word_freq_telnet; Medium | No-Spam | 0.0261 | 0.9901 | ||
| word_freq_technology; Low | word_freq_technology; Medium | No-Spam | 0.0023 | 0.9788 | |
| word_freq_email; Low | word_freq_email; Medium | word_freq_telnet; Low | Spam | 0.0044 | 0.9763 |
| word_freq_george; Medium | No-Spam | 0.0155 | 0.9747 | ||
| word_freq_lab; Medium | No-Spam | 0.0158 | 0.9641 | ||
| word_freq_hp; Low | char_freq_$; Medium | word_freq_meeting; Low | Spam | 0.0306 | 0.9630 |
| word_freq_edu; Medium | No-Spam | 0.0329 | 0.9615 | ||
| word_freq_hp; Low | word_freq_email; Medium | word_freq_direct; Medium | Spam | 0.0083 | 0.9283 |
| word_freq_email; Medium | word_freq_all; Low | word_freq_all; Medium | Spam | 0.0047 | 0.9233 |
| word_freq_1999; Medium | No-Spam | 0.0576 | 0.9109 | ||
| word_freq_table; Medium | word_freq_all; Medium | No-Spam | 0.0014 | 0.8914 | |
| capital_run_length_longest; Low | word_freq_all; High | No-Spam | 0.0148 | 0.8817 | |
| word_freq_technology; Medium | word_freq_all; Medium | No-Spam | 0.0049 | 0.8816 | |
| word_freq_email; Medium | word_freq_telnet; Low | word_freq_all; Medium | Spam | 0.0218 | 0.8791 |
| word_freq_email; Medium | char_freq_$; Low | word_freq_direct; Medium | No-Spam | 0.0229 | 0.8453 |
| word_freq_technology; Medium | No-Spam | 0.0387 | 0.8429 | ||
| word_freq_direct; Low | word_freq_direct; Medium | word_freq_technology; Low | Spam | 0.0020 | 0.8257 |
| word_freq_hp; Low | word_freq_direct; Medium | word_freq_857; Low | Spam | 0.0158 | 0.7933 |
| word_freq_hp; Low | word_freq_email; Medium | word_freq_telnet; Low | Spam | 0.0598 | 0.7865 |
| char_freq_$; Low | char_freq_; Medium | capital_run_length_longest; Low | No-Spam | 0.0123 | 0.7714 |
| word_freq_1999; High | No-Spam | 0.0038 | 0.7435 | ||
| word_freq_hpl; Low | word_freq_technology; Low | word_freq_all_; Medium | Spam | 0.0991 | 0.7326 |
| word_freq_telnet; Low | word_freq_hpl; Low | word_freq_all; Medium | Spam | 0.0998 | 0.7298 |
| word_freq_email; Low | char_freq_$; Low | word_freq_all; Low | No-Spam | 0.5013 | 0.6670 |
| word_freq_email; Low | word_freq_all; Low | No-Spam | 0.5031 | 0.6476 | |
| char_freq_$; Low | word_freq_all; Low | No-Spam | 0.5194 | 0.6431 | |
| word_freq_email; Low | char_freq_$; Low | No-Spam | 0.5526 | 0.6292 | |
| char_freq_$; Low | capital_run_length_longest; Low | No-Spam | 0.5801 | 0.6155 |
Appendix A.2. Additional Results for Phishing Link Detection

- IF (nb_dollar > 0.00 AND nb_dots > 3.00) THEN Phishing, coverage = 0.0005, precision = 1
- IF (google_index > 0.00 AND nb_www <= 0.00 AND domain_age <= 978.50) THEN Phishing coverage = 0.1169, precision = 0.9615

| Antecedent 1 | Antecedent 2 | Antecedent 3 | Consequent | Support | Confidence |
|---|---|---|---|---|---|
| nb_at; High | Phishing | 0.0236 | 1 | ||
| nb_space; Low | nb_colon; High | Phishing | 0.0069 | 1 | |
| nb_semicolumn; High | Phishing | 0.0045 | 1 | ||
| longest_words_raw; High | Phishing | 0.0045 | 1 | ||
| phish_hints; High | ratio_digits_host; High | Phishing | 0.0045 | 1 | |
| brand_in_subdomain; High | Phishing | 0.0040 | 1 | ||
| nb_dots_; High | Phishing | 0.0039 | 1 | ||
| nb_hyperlinks; High | ratio_extRedirection; High | No-Phishing | 0.0035 | 1 | |
| domain_registration_length; High | nb_hyperlinks; High | No-Phishing | 0.0028 | 1 | |
| nb_www; High | length_words_raw; High | Phishing | 0.0024 | 1 | |
| domain_registration_length; High | ratio_digits_host; High | Phishing | 0.0011 | 1 | |
| phish_hints; High | ratio_extRedirection; High | Phishing | 0.0095 | 0.9999 | |
| ratio_extRedirection; High | ratio_digits_host; High | Phishing | 0.0037 | 0.9993 | |
| page_rank; High | nb_hyperlinks; High | No-Phishing | 0.0142 | 0.9991 | |
| phish_hints; High | page_rank; Low | Phishing | 0.0711 | 0.9945 | |
| nb_space; High | domain_registration_length; High | No-Phishing | 0.0011 | 0.9931 | |
| nb_www; Low | ratio_digits_host; High | Phishing | 0.0325 | 0.9902 | |
| nb_space; High | page_rank; High | nb_www; High | No-Phishing | 0.0016 | 0.9837 |
| domain_registration_length; Low | phish_hints; High | Phishing | 0.0784 | 0.9832 | |
| phish_hints; High | nb_www; Low | Phishing | 0.0596 | 0.9825 | |
| page_rank; High | ratio_extRedirection; High | nb_www; High | No-Phishing | 0.0273 | 0.9803 |
| nb_hyphens; High | page_rank; High | ratio_extRedirection; High | No-Phishing | 0.0035 | 0.9770 |
| nb_hyphens; High | page_rank; High | length_words_raw; Low | No-Phishing | 0.0314 | 0.9758 |
| ratio_digits_host; High | Phishing | 0.0350 | 0.9755 | ||
| nb_hyperlinks; High | nb_www; Low | No-Phishing | 0.0098 | 0.9721 | |
| phish_hints; Low | nb_hyperlinks; High | No-Phishing | 0.0179 | 0.9702 | |
| nb_hyphens; High | page_rank; High | No-Phishing | 0.0320 | 0.9610 | |
| page_rank; High | nb_www; High | No-Phishing | 0.2250 | 0.9565 | |
| nb_hyphens; Low | nb_hyphens; High | nb_www; High | No-Phishing | 0.0029 | 0.9546 |
| domain_registration_length; High | ratio_extRedirection; High | nb_www; High | No-Phishing | 0.0040 | 0.9534 |
| page_rank; High | ratio_extRedirection; Low | ratio_extRedirection; High | No-Phishing | 0.0112 | 0.9530 |
| domain_registration_length; Low | domain_registration_length; High | page_rank; High | No-Phishing | 0.0038 | 0.9527 |
| domain_registration_length; High | nb_www; High | length_words_raw; Low | No-Phishing | 0.0435 | 0.9462 |
| nb_dots; Low | nb_www; Low | length_words_raw; High | No-Phishing | 0.0015 | 0.9422 |
| nb_hyphens; High | ratio_extRedirection; Low | nb_www; High | No-Phishing | 0.0227 | 0.9403 |
| longest_words_raw; Low | domain_registration_length; High | ratio_extRedirection; High | No-Phishing | 0.0072 | 0.9375 |
| nb_space; High | phish_hints; Low | nb_www; High | No-Phishing | 0.0032 | 0.9230 |
| ratio_extRedirection; Low | ratio_extRedirection; High | nb_www; High | No-Phishing | 0.0070 | 0.9084 |
| nb_underscore; High | page_rank; High | nb_colon; Low | No-Phishing | 0.0092 | 0.9045 |
| phish_hints; Low | ratio_extRedirection; High | nb_www; High | No-Phishing | 0.0418 | 0.8770 |
| page_rank; Low | ratio_extRedirection; Low | nb_www; Low | Phishing | 0.2589 | 0.8661 |
| phish_hints; Low | ratio_extRedirection; Low | ratio_extRedirection; High | No-Phishing | 0.0126 | 0.8583 |
| page_rank; Low | nb_www; Low | Phishing | 0.2845 | 0.8524 | |
| nb_hyphens; High | nb_at; Low | phish_hints; Low | No-Phishing | 0.0383 | 0.8489 |
| nb_space; High | page_rank; Low | page_rank; High | No-Phishing | 0.0011 | 0.8375 |
| page_rank; Low | page_rank; High | ratio_extRedirection; High | No-Phishing | 0.0139 | 0.8301 |
| domain_registration_length; High | phish_hints; Low | page_rank; High | No-Phishing | 0.0489 | 0.8230 |
| phish_hints; Low | nb_www; High | No-Phishing | 0.3468 | 0.8155 |
Appendix A.3. Additional Results for Robotic Navigation

- IF (yellow_box_detected <= 1.00 AND blue_box_height > 0.16 AND yellow_box_position_y <= 0.77 AND blue_box_position_y <= 0.78) THEN move_forward, coverage =0.0591, precision = 0.96
- IF (blue_box_detected <= 1.00 AND red_box_height > 0.14 AND target_red_box > 0.00 AND yellow_box_detected <= 0.00) THEN move_forward, coverage = 0.1268, precision = 0.9689
| Antecedent 1 | Antecedent 2 | Antecedent 3 | Consequent | Support | Confidence |
|---|---|---|---|---|---|
| blue_box_detected; True | target_blue_box; True | move_forward | 0.24 | 1 | |
| yellow_box_height; Tall | target_yellow_box; True | move_forward | 0.118 | 1 | |
| yellow_box_detected; False | target_yellow_box; True | turn_right | 0.116 | 1 | |
| blue_box_detected; False | target_blue_box; True | turn_left | 0.115 | 1 | |
| red_box_detected; False | target_red_box; True | turn_left | 0.104 | 1 | |
| yellow_box_width; Narrow | target_yellow_box; True | move_forward | 0.046 | 1 | |
| red_box_width; Medium | yellow_box_position_x; Right | yellow_box_height; Tall | move_forward | 0.046 | 1 |
| blue_box_width; Medium | yellow_box_position_x; Middle | move_forward | 0.033 | 1 | |
| red_box_position_x; Middle | yellow_box_detected; False | target_red_box; True | move_forward | 0.031 | 1 |
| red_box_position_x; Left | blue_box_height; Tall | move_forward | 0.024 | 1 | |
| red_box_width; Medium | red_box_height; Medium | yellow_box_height; Tall | move_forward | 0.023 | 1 |
| red_box_position_x; Middle | red_box_width; Medium | yellow_box_width; Medium | move_forward | 0.022 | 1 |
| red_box_position_x; Right | yellow_box_position_x; Right | move_forward | 0.02 | 1 | |
| yellow_box_width; Wide | target_yellow_box; True | move_forward | 0.016 | 1 | |
| red_box_position_x; Right | target_red_box; True | move_forward | 0.013 | 1 | |
| red_box_position_y; Middle | yellow_box_width; Medium | move_forward | 0.013 | 1 | |
| yellow_box_height; Short | target_yellow_box; True | move_forward | 0.013 | 1 | |
| red_box_width; Narrow | yellow_box_width; Medium | blue_box_detected; False | move_forward | 0.013 | 1 |
| red_box_height; Medium | yellow_box_position_x; Left | yellow_box_position_y; Bottom | move_forward | 0.012 | 1 |
| red_box_width; Narrow | blue_box_width; Medium | move_forward | 0.011 | 1 | |
| red_box_width; Medium | blue_box_width; Medium | yellow_box_detected; False | move_forward | 0.011 | 1 |
| red_box_height; Tall | yellow_box_width; Narrow | move_forward | 0.01 | 1 | |
| red_box_width; Wide | blue_box_detected; False | target_red_box; True | move_forward | 0.015 | 0.999 |
| red_box_width; Narrow | blue_box_detected; False | target_red_box; True | move_forward | 0.017 | 0.997 |
| yellow_box_detected; True | target_yellow_box; True | move_forward | 0.223 | 0.996 | |
| blue_box_width; Medium | yellow_box_position_y; Middle | move_forward | 0.02 | 0.995 | |
| red_box_width; Medium | blue_box_position_x; Middle | blue_box_position_y; Bottom | move_forward | 0.015 | 0.995 |
| blue_box_position_y; Middle | blue_box_width; Medium | yellow_box_height; Medium | move_forward | 0.015 | 0.991 |
References
- Towards trustable machine learning. Nat. Biomed. Eng. 2018, 2, 709–710. [CrossRef] [PubMed]
- Sayler, K. Artificial Intelligence and National Security; U.S. Congressional Research Service: Washington, DC, USA, 2019. [Google Scholar]
- Fjeld, J.; Hilligoss, H.; Achten, N.; Daniel, M.L.; Feldman, J.; Kagay, S. Principled Artificial Intelligence; Berkman Klein Center: Harvard, MA, USA, 2019; Available online: https://ai-hr.cyber.harvard.edu/primp-viz.html (accessed on 1 February 2025).
- Doshi-Velez, F.; Kortz, M. Accountability of AI Under the law: The Role of Explanation. arXiv 2017. Available online: https://arxiv.org/abs/1711.01134 (accessed on 1 February 2025). [CrossRef]
- Wagner, J. GDPR and Explainable AI. 2019. Available online: https://www.jwtechwriter.com/project-146.php (accessed on 1 February 2025).
- Guidotti, R.; Monreale, A.; Ruggieri, S.; Turini, F.; Giannotti, F.; Pedreschi, D. A survey of methods for explaining black box models. ACM Comput. Surv. 2018, 51, 93. [Google Scholar] [CrossRef]
- Lipton, Z.C. The mythos of model interpretability. arXiv 2017. Available online: https://arxiv.org/abs/1606.03490 (accessed on 1 February 2025).
- Molnar, C. Interpretable Machine Learning: A Guide for Making Black Box Models Explainable, 2nd ed. 2022. Available online: https://christophm.github.io/interpretable-ml-book/ (accessed on 1 February 2025).
- Pedrycz, W.; Gomide, F. Fuzzy Systems Engineering: Toward Human-Centric Computing; Wiley-IEEE Press: Hoboken, NJ, USA, 2007. [Google Scholar]
- Lundberg, S.M.; Lee, S. A unified approach to interpreting model predictions. In Proceedings of the Advances in Neural Information Processing Systems 30 (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Zadeh, L.A. Fuzzy sets. Inf. Control 1965, 8, 338–353. [Google Scholar] [CrossRef]
- Das, A.; Rad, P. Opportunities and challenges in explainable artificial intelligence (XAI): A survey. arXiv 2020. Available online: https://arxiv.org/abs/2006.11371 (accessed on 1 February 2025).
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2019, 128, 336–359. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?”: Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; ACM: New York, NY, USA, 2016; pp. 1135–1144. [Google Scholar]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. Anchors: High-precision model-agnostic explanations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar] [CrossRef]
- Stepin, I.; Alonso, J.M.; Catalá, A.; Pereira-Fariña, M. A Survey of Contrastive and Counterfactual Explanation Generation Methods for Explainable Artificial Intelligence. IEEE Access 2021, 9, 11974–12001. [Google Scholar] [CrossRef]
- Mazzine Barbosa, R.; Martens, D. A Framework and Benchmarking Study for Counterfactual Generating Methods on Tabular Data. Appl. Sci. 2021, 11, 7274. [Google Scholar] [CrossRef]
- Wachter, S.; Mittelstadt, B.; Russell, C. Counterfactual explanations without opening the black box: Automated decisions and the GDPR. Harv. J. Law Technol. 2017, 31, 841–887. [Google Scholar] [CrossRef]
- Verma, S.; Dickerson, J.; Hines, K. Counterfactual explanations for machine learning: A review. arXiv 2020. Available online: https://arxiv.org/abs/2010.10596 (accessed on 1 February 2025).
- Kim, B.; Wattenberg, M.; Gilmer, J.; Cai, C.; Wexler, J.; Viegas, F.; Sayres, R. Interpretability Beyond Feature Attribution: Quantitative Testing with Concept Activation Vectors (TCAV). In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018. [Google Scholar]
- Agrawal, R.; Srikant, R. Fast algorithms for mining association rules. In Proceedings of the 20th International Conference on Very Large Data Bases, Santiago, Chile, 12–15 September 1994; pp. 487–499. [Google Scholar]
- Agrawal, R.; Imielinski, T.; Swami, A. Mining association rules between sets of items in large databases. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Washington, DC, USA, 26–28 May 1993; ACM: New York, NY, USA, 1993; pp. 207–216. [Google Scholar]
- Kuok, C.M.; Fu, A.; Wong, M.H. Mining fuzzy association rules in databases. ACM Sigmod Rec. 1998, 27, 41–46. [Google Scholar] [CrossRef]
- Liu, B.; Hsu, W.; Ma, Y. Integrating classification and association rule mining. In Proceedings of the 4th International Conference on Knowledge Discovery and Data Mining (KDD), New York, NY, USA, 27–31 August 1998; AAAI Press: Washington, DC, USA, 1998. [Google Scholar]
- Reynolds, D. Gaussian mixture models. In Encyclopedia of Biometrics; Li, S.Z., Jain, A., Eds.; Springer: Berlin/Heidelberg, Germany, 2009. [Google Scholar] [CrossRef]
- Dua, D.; Graff, C. UCI Machine Learning Repository; University of California, School of Information and Computer Science: Irvine, CA, USA, 2019; Available online: http://archive.ics.uci.edu/ml (accessed on 1 February 2025).
- scikit-learn. (n.d.). StandardScaler. Available online: https://scikit-learn.org/stable/modules/generated/sklearn.preprocessing.StandardScaler.html (accessed on 1 February 2025).
- Lundberg, S.M. (n.d.). SHAP Documentation. Available online: https://shap.readthedocs.io/en/latest/ (accessed on 1 February 2025).
- Hannousse, A.; Yahiouche, S. Towards benchmark datasets for machine learning based website phishing detection: An experimental study. arXiv 2020. Available online: https://arxiv.org/abs/2010.12847 (accessed on 1 February 2025). [CrossRef]
- Chevalier-Boisvert, M.; Dai, B.; Towers, M.; de Lazcano, R.; Willems, L.; Lahlou, S.; Pal, S.; Castro, P.S.; Terry, J. Minigrid & Miniworld: Modular & customizable reinforcement learning environments for goal-oriented tasks. arXiv 2023. Available online: https://arxiv.org/abs/2306.13831 (accessed on 1 February 2025).
- Raffin, A.; Hill, A.; Gleave, A.; Kanervisto, A.; Ernestus, M.; Dormann, N. Stable-baselines3: Reliable reinforcement learning implementations. J. Mach. Learn. Res. 2021, 22, 1–8. [Google Scholar]
- Jocher, G.; Chaurasia, A.; Qiu, J. Ultralytics YOLOv8 (Version 8.0.0). 2023. Available online: https://github.com/ultralytics/ultralytics (accessed on 1 February 2025).





















| Row Number | Min Rule Confidence | Method | Number of Rules | Number of Rules After Pruning | Total Coverage |
|---|---|---|---|---|---|
| 1 | 0.6 | Maximum contribution | 609 | 139 | 0.9717 |
| 2 | 0.6 | Mean magnitude | 545 | 128 | 0.9671 |
| 3 | 0.6 | Frequency | 578 | 133 | 0.9671 |
| 4 | 0.7 | Mean magnitude | 387 | 126 | 0.9414 |
| 5 | 0.7 | Frequency | 384 | 131 | 0.9414 |
| 6 | 0.7 | Maximum contribution | 353 | 135 | 0.9309 |
| 7 | 0.6 | Mean contribution | 406 | 109 | 0.9289 |
| 8 | 0.6 | Maximum magnitude | 342 | 96 | 0.9243 |
| 9 | 0.7 | Mean contribution | 230 | 106 | 0.9019 |
| 10 | 0.7 | Maximum magnitude | 238 | 90 | 0.8907 |
| 11 | 0.6 | Minimum contribution | 195 | 67 | 0.7966 |
| 12 | 0.8 | Mean magnitude | 253 | 114 | 0.6458 |
| 13 | 0.8 | Frequency | 250 | 118 | 0.6248 |
| 14 | 0.8 | Mean contribution | 182 | 102 | 0.6004 |
| 15 | 0.9 | Mean magnitude | 204 | 102 | 0.5747 |
| 16 | 0.9 | Frequency | 209 | 107 | 0.5583 |
| 17 | 0.95 | Mean magnitude | 158 | 94 | 0.5332 |
| 18 | 0.7 | Minimum contribution | 179 | 62 | 0.5346 |
| 19 | 0.95 | Frequency | 161 | 99 | 0.5168 |
| 20 | 0.96 | Mean magnitude | 149 | 91 | 0.5122 |
| 21 | 0.9 | Mean contribution | 144 | 92 | 0.5089 |
| 22 | 0.97 | Mean magnitude | 139 | 87 | 0.5010 |
| 23 | 0.96 | Frequency | 154 | 96 | 0.4924 |
| 24 | 0.8 | Maximum magnitude | 157 | 81 | 0.4852 |
| 25 | 0.98 | Mean magnitude | 138 | 85 | 0.4918 |
| 26 | 0.97 | Frequency | 146 | 91 | 0.4852 |
| 27 | 0.95 | Mean contribution | 125 | 87 | 0.4885 |
| 28 | 0.98 | Frequency | 144 | 89 | 0.4760 |
| 29 | 0.96 | Mean contribution | 116 | 83 | 0.4635 |
| 30 | 0.99 | Mean magnitude | 121 | 76 | 0.4602 |
| 31 | 0.99 | Frequency | 126 | 80 | 0.4523 |
| 32 | 0.97 | Mean contribution | 113 | 80 | 0.4523 |
| 33 | 0.98 | Mean contribution | 111 | 77 | 0.4457 |
| 34 | 0.9 | Maximum magnitude | 120 | 71 | 0.4332 |
| 35 | 0.99 | Mean contribution | 100 | 70 | 0.4134 |
| 36 | 0.8 | Maximum contribution | 212 | 120 | 0.3568 |
| 37 | 0.95 | Maximum magnitude | 99 | 66 | 0.4009 |
| 38 | 0.8 | Minimum contribution | 104 | 56 | 0.4075 |
| 39 | 0.96 | Maximum magnitude | 93 | 63 | 0.3726 |
| 40 | 0.97 | Maximum magnitude | 87 | 60 | 0.3568 |
| 41 | 0.98 | Maximum magnitude | 88 | 59 | 0.3562 |
| 42 | 0.9 | Minimum contribution | 86 | 49 | 0.3805 |
| 43 | 0.99 | Maximum magnitude | 82 | 56 | 0.3430 |
| 44 | 0.9 | Maximum contribution | 183 | 108 | 0.2877 |
| 45 | 1 | Mean magnitude | 72 | 48 | 0.3364 |
| 46 | 0.95 | Minimum contribution | 71 | 46 | 0.3476 |
| 47 | 0.96 | Minimum contribution | 68 | 46 | 0.3476 |
| 48 | 1 | Frequency | 73 | 47 | 0.3246 |
| 49 | 0.95 | Maximum contribution | 161 | 101 | 0.2646 |
| 50 | 1 | Mean contribution | 64 | 46 | 0.3160 |
| 51 | 0.96 | Maximum contribution | 158 | 99 | 0.2600 |
| 52 | 0.97 | Maximum contribution | 151 | 94 | 0.2535 |
| 53 | 0.98 | Maximum contribution | 148 | 91 | 0.2508 |
| 54 | 0.97 | Minimum contribution | 64 | 43 | 0.3226 |
| 55 | 0.99 | Maximum contribution | 136 | 87 | 0.2357 |
| 56 | 0.99 | Minimum contribution | 60 | 40 | 0.3061 |
| 57 | 0.98 | Minimum contribution | 60 | 40 | 0.3061 |
| 58 | 1 | Maximum magnitude | 54 | 35 | 0.2791 |
| 59 | 1 | Minimum contribution | 60 | 36 | 0.2791 |
| 60 | 1 | Maximum contribution | 77 | 49 | 0.1554 |
| Row Number | Min Rule Confidence | Method | Number of Rules | Num of Rules After Pruning | Total Coverage |
|---|---|---|---|---|---|
| 1 | 0.6 | Frequency | 912 | 163 | 1 |
| 2 | 0.6 | Mean magnitude | 939 | 164 | 1 |
| 3 | 0.7 | Mean magnitude | 773 | 164 | 1 |
| 4 | 0.8 | Mean magnitude | 582 | 164 | 1 |
| 5 | 0.7 | Frequency | 765 | 162 | 0.9992 |
| 6 | 0.8 | Frequency | 588 | 159 | 0.9984 |
| 7 | 0.6 | Minimum contribution | 299 | 100 | 0.9981 |
| 8 | 0.6 | Maximum contribution | 113 | 56 | 0.9966 |
| 9 | 0.7 | Minimum contribution | 257 | 95 | 0.9960 |
| 10 | 0.6 | Mean contribution | 366 | 124 | 0.9952 |
| 11 | 0.9 | Frequency | 413 | 141 | 0.9862 |
| 12 | 0.7 | Maximum contribution | 100 | 53 | 0.9841 |
| 13 | 0.7 | Mean contribution | 294 | 115 | 0.9838 |
| 14 | 0.9 | Mean magnitude | 380 | 142 | 0.9825 |
| 15 | 0.6 | Maximum magnitude | 220 | 58 | 0.9793 |
| 16 | 0.8 | Maximum contribution | 69 | 52 | 0.9722 |
| 17 | 0.7 | Maximum magnitude | 187 | 56 | 0.9700 |
| 18 | 0.8 | Minimum contribution | 181 | 87 | 0.9669 |
| 19 | 0.95 | Frequency | 252 | 119 | 0.9517 |
| 20 | 0.95 | Mean magnitude | 238 | 118 | 0.9459 |
| 21 | 0.9 | Minimum contribution | 121 | 73 | 0.9427 |
| 22 | 0.96 | Frequency | 225 | 108 | 0.9337 |
| 23 | 0.96 | Mean magnitude | 210 | 106 | 0.9266 |
| 24 | 0.9 | Maximum contribution | 55 | 43 | 0.8834 |
| 25 | 0.95 | Minimum contribution | 95 | 61 | 0.7961 |
| 26 | 0.8 | Mean contribution | 195 | 89 | 0.7908 |
| 27 | 0.8 | Maximum magnitude | 116 | 48 | 0.7704 |
| 28 | 0.96 | Minimum contribution | 88 | 58 | 0.7216 |
| 29 | 0.97 | Frequency | 185 | 94 | 0.7235 |
| 30 | 0.97 | Mean magnitude | 175 | 91 | 0.6779 |
| 31 | 0.98 | Frequency | 139 | 75 | 0.6694 |
| 32 | 0.95 | Maximum contribution | 44 | 34 | 0.6622 |
| 33 | 0.96 | Maximum contribution | 49 | 32 | 0.6516 |
| 34 | 0.98 | Mean magnitude | 132 | 71 | 0.6259 |
| 35 | 0.99 | Frequency | 91 | 53 | 0.5623 |
| 36 | 0.99 | Mean magnitude | 90 | 54 | 0.5411 |
| 37 | 0.9 | Mean contribution | 103 | 58 | 0.5427 |
| 38 | 0.97 | Minimum contribution | 76 | 52 | 0.5005 |
| 39 | 0.9 | Maximum magnitude | 66 | 39 | 0.4907 |
| 40 | 0.95 | Maximum magnitude | 44 | 32 | 0.4801 |
| 41 | 0.96 | Maximum magnitude | 38 | 28 | 0.4629 |
| 42 | 0.98 | Minimum contribution | 65 | 47 | 0.4449 |
| 43 | 0.99 | Minimum contribution | 52 | 39 | 0.3624 |
| 44 | 0.97 | Maximum contribution | 33 | 25 | 0.2654 |
| 45 | 0.95 | Mean contribution | 62 | 40 | 0.2569 |
| 46 | 0.97 | Maximum magnitude | 38 | 26 | 0.2450 |
| 47 | 0.96 | Mean contribution | 58 | 38 | 0.2169 |
| 48 | 0.97 | Mean contribution | 54 | 38 | 0.2155 |
| 49 | 0.98 | Maximum contribution | 32 | 23 | 0.2121 |
| 50 | 0.98 | Maximum magnitude | 29 | 22 | 0.2092 |
| 51 | 0.99 | Maximum contribution | 22 | 16 | 0.1893 |
| 52 | 0.98 | Mean contribution | 45 | 35 | 0.1853 |
| 53 | 0.99 | Mean contribution | 29 | 27 | 0.1665 |
| 54 | 0.99 | Maximum magnitude | 23 | 17 | 0.1575 |
| 55 | 1 | Frequency | 23 | 16 | 0.0793 |
| 56 | 1 | Mean magnitude | 17 | 13 | 0.0745 |
| 57 | 1 | Minimum contribution | 20 | 15 | 0.0567 |
| 58 | 1 | Maximum magnitude | 15 | 10 | 0.0536 |
| 59 | 1 | Mean contribution | 11 | 9 | 0.0488 |
| 60 | 1 | Maximum contribution | 8 | 8 | 0.0424 |
| Hyperparameter | Value |
|---|---|
| Discount factor (γ) | 0.99 |
| Entropy coefficient | 0.05 |
| Learning rate | 0.0005 |
| Batch size | 1024 |
| Number of layers | 2 |
| Layer size | 128 |
| Number of environments | 16 |
| Number of steps per update | 2048 |
| Feature Name | Description |
|---|---|
| red_box_position_x | The x coordinate of the center of the YOLO bounding box around the red box. |
| red_box_position_y | The y coordinate of the center of the YOLO bounding box around the red box. |
| red_box_width | The width of the YOLO bounding box around the red box. |
| red_box_height | The height of the YOLO bounding box around the red box. |
| blue_box_position_x | The x coordinate of the center of the YOLO bounding box around the blue box. |
| blue_box_position_y | The y coordinate of the center of the YOLO bounding box around the blue box. |
| blue_box_width | The width of the YOLO bounding box around the blue box. |
| blue_box_height | The height of the YOLO bounding box around the blue box. |
| yellow_box_position_x | The x coordinate of the center of the YOLO bounding box around the yellow box. |
| yellow_box_position_y | The y coordinate of the center of the YOLO bounding box around the yellow box. |
| yellow_box_width | The width of the YOLO bounding box around the yellow box. |
| yellow_box_height | The height of the YOLO bounding box around the yellow box. |
| red_box_detected | Binary feature that indicates if YOLO has detected the red box (0 = false, 1 = true). |
| blue_box_detected | Binary feature that indicates if YOLO has detected the blue box (0 = false, 1 = true). |
| yellow_box_detected | Binary feature that indicates if YOLO has detected the yellow box (0 = false, 1 = true). |
| target_red_box | Binary feature that indicates if the red box is the current target (0 = false, 1 = true). |
| target_blue_box | Binary feature that indicates if the blue box is the current target (0 = false, 1 = true). |
| target_yellow_box | Binary feature that indicates if the yellow box is the current target (0 = false, 1 = true). |
| Row Number | Minimum Rule Confidence | Total Number of Rules | Total Number of Rules After Pruning | Total Coverage |
|---|---|---|---|---|
| 1 | 0.6 | 1250 | 42 | 0.9984 |
| 2 | 0.7 | 1189 | 38 | 0.9921 |
| 3 | 0.8 | 1131 | 37 | 0.9913 |
| 4 | 0.9 | 1007 | 36 | 0.9874 |
| 5 | 0.95 | 824 | 36 | 0.9874 |
| 6 | 0.96 | 749 | 36 | 0.9874 |
| 7 | 0.97 | 697 | 35 | 0.9819 |
| 8 | 0.98 | 647 | 31 | 0.9740 |
| 9 | 0.99 | 560 | 28 | 0.9213 |
| 10 | 1 | 189 | 22 | 0.8606 |
| Criteria | FuzRED | SHAP | LIME | Anchors |
|---|---|---|---|---|
| Interpretability | High; intuitive fuzzy IF–THEN rules | Medium; feature importance values | Medium; local surrogate models (linear rules) | Medium-high; IF–THEN rules, but thresholds can be difficult to understand |
| Computation time | Low (seconds/minutes) | Medium (minutes/hours, depending on model size) | Medium (minutes/hours) | High (hours/days, especially with large datasets) |
| Explanation scope | Global and local (integrates both scopes) | Primarily local, aggregated for global insights | Primarily local; global insight limited | Local; separate rules per instance |
| Scalability to large models | Medium; potential complexity with very large feature sets | Medium; computationally intensive for large datasets/models | Medium; relies on sampling, complexity rises with dataset/model size | Low; challenging for large models/datasets |
| Ease of use for non-experts | Medium-high; intuitive linguistic rules in plain language, only requires basic understanding of features in data | Low-medium; numeric values less intuitive without visualization | Medium; explanations clear but rely on numeric thresholds and linear approximations | Medium; rules straightforward but numeric thresholds less intuitive |
| Strengths | Interpretable rules, computational efficiency, combined local/global insights | Rigorous theoretical foundations, strong global feature analysis | Intuitive local approximations, straightforward interpretation | Precise local explanations, high precision |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Buczak, A.L.; Baugher, B.D.; Zaback, K. Fuzzy Rules for Explaining Deep Neural Network Decisions (FuzRED). Electronics 2025, 14, 1965. https://doi.org/10.3390/electronics14101965
Buczak AL, Baugher BD, Zaback K. Fuzzy Rules for Explaining Deep Neural Network Decisions (FuzRED). Electronics. 2025; 14(10):1965. https://doi.org/10.3390/electronics14101965
Chicago/Turabian StyleBuczak, Anna L., Benjamin D. Baugher, and Katie Zaback. 2025. "Fuzzy Rules for Explaining Deep Neural Network Decisions (FuzRED)" Electronics 14, no. 10: 1965. https://doi.org/10.3390/electronics14101965
APA StyleBuczak, A. L., Baugher, B. D., & Zaback, K. (2025). Fuzzy Rules for Explaining Deep Neural Network Decisions (FuzRED). Electronics, 14(10), 1965. https://doi.org/10.3390/electronics14101965