
A Tetris-Based Task Allocation Strategy for Real-Time Operating Systems


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
Abstract
1. Introduction
- We innovatively abstract the task scheduling process into a Tetris game and propose a reliable task scheduling algorithm that can comprehensively consider multiple-heuristic parameters, by extending El Tetris, a classic Tetris playing algorithm, and combining it with task scheduling. Most existing algorithms are only able to consider a single-heuristic parameter.
- We not only conduct WCRT analysis on the results of the scheduling algorithm, but also conduct actual real-time task tests on Ubuntu 22.04 with real-time patch on AMD Ryzen 7 4800U.
2. Related Work
3. System Model
3.1. Task Execution Model
- is not included in the directed edges set of .
- At least one directed path in connects and .
3.2. RTA Analysis Strategy
3.2.1. High-Priority Interference
3.2.2. Self-Interference
- and are executed on the same processor.
- and are in an NDT relationship.
4. Tetris-Based Allocation Model
- Landing height: The height where the piece is placed, which equals the height of the column plus half the height of the piece.
- Rows eliminated: The number of rows eliminated after the last piece is placed.
- Row transitions: The total number of row transitions. A row transition occurs when an empty cell is adjacent to a filled cell on the same row and vice versa.
- Column transitions: The total number of column transitions. A column transition occurs when an empty cell is adjacent to a filled cell on the same column and vice versa.
- Number of holes: A hole is an empty cell that has at least one filled cell above it in the same column.
- Well sums: A well is a succession of empty cells such that their left cells and right cells are both filled.
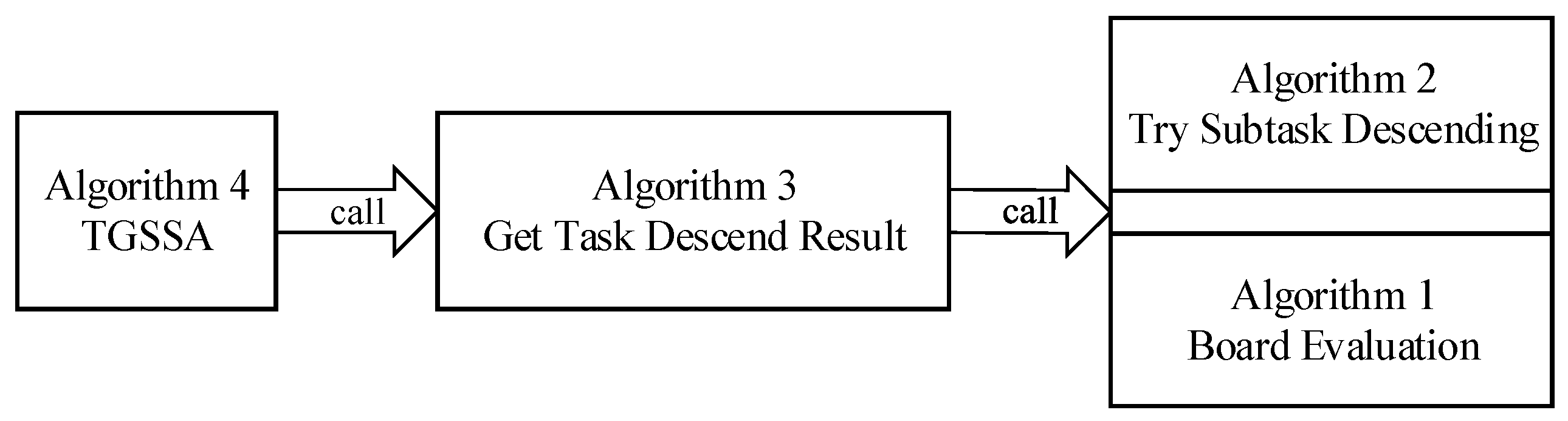
5. Scoring Method and Allocation Strategy
| Algorithm 1 Board evaluation |
| Input: , , , ; Output: ;
|
| Algorithm 2 Try Subtask Descending |
| Input: , , , , m; Output: , ;
|
| Algorithm 3 Get Task Descend Result |
| Input: , , , m; Output: , ;
|
| Algorithm 4 TGSSA |
| Input: , , , m; Output: P
|
5.1. Tetris Board Evaluation
- (line 1): represents the height of the center of gravity of the most recently placed piece, multiplied by the coefficient . In the context of task scheduling, where pieces are strips, the center of gravity corresponds to the row index of the piece’s midpoint. Intuitively, we aim to place pieces as low as possible in Tetris. Therefore, is a negative value.
- (line 2): denotes the number of rows cleared as a result of placing the most recent piece, weighted by the coefficient . Naturally, more clear rows is desirable. Thus, is positive.
- (line 3): represents the number of row transitions in the remaining Tetris board after the recently placed piece has landed and all completed rows have been cleared, weighted by . A row transition occurs when a filled cell is adjacent to an empty cell or vice versa within a single row. The total number of row transitions is computed by summing this value of all rows. It is important to note that the calculation of row transitions in the task scheduling context differs from that in the standard Tetris game. In Tetris, the board is bounded by “walls” on both sides, which are typically modeled as columns of filled cells in the original El-Tetris algorithm. In the task scheduling scenario, however, each column represents a distinct processor (or core) and all processors access the same shared memory. Therefore, the leftmost and rightmost columns are treated as adjacent, forming a “cylindrical” structure. Since fewer row transitions are preferable, is a negative value.
- (line 4): measures the number of column transitions in the remaining Tetris board after the most recent piece placement and clearing completed rows, multiplied by . A column transition occurs when a filled cell is adjacent to an empty cell or vice versa within a single column. Summing these transitions across all columns yields the total column transitions for the board. Similarly to row transitions, fewer column transitions are desirable, making a negative value.
- (line 5): represents the number of “holes” in the remaining Tetris board after the recent placement and removal of the completed rows. A “hole” in a column is defined as an empty cell that has at least one filled cell above it in the same column. The total number of holes is obtained by summing the holes in each column. Fewer holes are preferred, so is a negative value.
- (line 6): is the sum of “wells” in the remaining Tetris board after the most recent piece placement and row clear, weighted by . A “well” is defined as an empty cell that lies over a column’s filled cells and is flanked by filled cells on both sides. The total number of wells is calculated as the number of such empty cells in the board. Similar to holes, fewer wells are desirable; therefore, is negative.
5.2. Try Subtask Descending
- Board expansion (line 1 to 3): If the number of rows in is less than , extend the board by adding rows until its number of rows equals .
- Filling cells (line 4 to 6): In the extended , mark the empty cells in the n specified , spanning form row to , as filled cells.
- Row count recording (line 7): The number of completed rows in at this stage is recorded and denoted as .
- Row removal (line 8): Completed rows are removed from .
5.3. Get Task Descend Result
- Initialization (lines 4 to 5): The maximum score for the subtask is set to be , and the current state of is stored in .
- Processor assignment (lines 6 to 13): Through using Algorithm 2 , subtask is attempted to be assigned to each processor. For each attempt, a new temporary board is generated. The state of the resulting board can be evaluated through Algorithm 1 to obtain a score for the assignment.
- Score update (lines 14 to 18): If the score for the current processor assignment exceeds the current maximum score , should be updated to the new score. The corresponding processor assignment should be recorded in , and should be updated to the state of .
- Board update (line 20): After attempting to assign to all processors and determining the processor corresponding to the highest score, should be updated to . This reflects the updated state of board after assigning based on the highest scoring placement.
5.4. General Progress
5.5. Discussion
6. Experiments
6.1. Tested DAG Sets Generation
- U: The utilization of the DAG task set .
- N: The number of DAG tasks in .
- : The number of subtasks in
- p: The probability of creating edges.
- m: The number of processors.
- U: 1.0, 1.2, 1.4, 1.6, 1.8, 2.0, 2.2.
- N: 20, 25, 30, 35, 40, 45, 50.
- : 10, 14, 18, 22, 26, 30.
- p: 5%, 10%, 15%, 20%, 25%, 30%.
- m: 2, 4, 8, 16.
6.2. Actual Platform Settings
- In General setup -> Preemption Model, select Fully Preemptible Kernel (RT).
- Uncheck Device Drivers -> Staging drivers.
- In General setup -> Timer subsystem, enable High Resolution Timer Support.
- In processor type and features -> Timer frequency, set the frequency to 1000 Hz.
6.3. Experiment Results
7. Conclusions and Future Work
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
Abbreviations
| RTOS | Real-time operating system |
| IoT | Internet of Things |
| WCRT | Worst-case response time |
| RMS | Rate monotonic scheduling |
| EDF | Earliest deadline first |
| DMS | Deadline monotonic scheduling |
| DAG | Directed acyclic graph |
| STPA | Schedulability testing priority assignment |
| WCET | Worst-case execution time |
| TGSSA | Tetris game scoring scheduling algorithm |
| RTA | Response time algorithm |
| ERU | Equilibrium remaining utilization |
References
- Hiroyuki, C. RT-Seed: Real-Time Middleware for Semi-Fixed-Priority Scheduling. In Proceedings of the 2016 IEEE 19th International Symposium on Real-Time Distributed Computing (ISORC), York, UK, 17–20 May 2016; pp. 124–133. [Google Scholar]
- Ranvijay; Yadav, R.S.; Smriti, A. Efficient energy constrained scheduling approach for dynamic real time system. In Proceedings of the 2010 First International Conference On Parallel, Distributed and Grid Computing (PDGC 2010), Solan, India, 28–30 October 2010; pp. 284–289. [Google Scholar]
- Biao, H.; Cao, Z.C.; Zhou, M.C. Scheduling Real-Time Parallel Applications in Cloud to Minimize Energy Consumption. IEEE Trans. Cloud Comput. 2022, 10, 662–674. [Google Scholar]
- Hu, M.L.; Bharadwaj, V. Dynamic Scheduling of Hybrid Real-Time Tasks on Clusters. IEEE Trans. Comput. 2014, 63, 2988–2997. [Google Scholar] [CrossRef]
- Dong, W.; Chen, C.; Liu, X.; Zheng, K.G.; Chu, R.; Bu, J.J. FIT: A Flexible, Lightweight, and Real-Time Scheduling System for Wireless Sensor Platforms. IEEE Trans. Parallel Distrib. Syst. 2010, 21, 126–138. [Google Scholar] [CrossRef]
- Zhu, Q.; Zeng, H.B.; Zheng, W.; Marco Di, N.; Alberto, S.V. Optimization of task allocation and priority assignment in hard real-time distributed systems. ACM Trans. Embed. Comput. Syst. (TECS) 2012, 11, 85–96. [Google Scholar] [CrossRef]
- Alessandro, B.; Giorgio, B. Engine control: Task modeling and analysis. In Proceedings of the 2015 Design, Automation & Test in Europe Conference & Exhibition (DATE), Grenoble, France, 9–13 March 2015; pp. 525–530. [Google Scholar]
- Nong, G.; Hamdi, M. On the provision of quality-of-service guarantees for input queued switches. IEEE Commun. Mag. 2000, 38, 62–69. [Google Scholar]
- Biondi, A.; Di Natale, M.; Buttazzo, G. Response-Time Analysis of Engine Control Applications Under Fixed-Priority Scheduling. IEEE Trans. Comput. 2018, 67, 687–703. [Google Scholar] [CrossRef]
- Alessandro, B.; Alessandra, M.; Mauro, M.; Marco, D.N.; Giorgio, B. Exact Interference of Adaptive Variable-Rate Tasks under Fixed-Priority Scheduling. In Proceedings of the 2014 26th Euromicro Conference on Real-Time Systems, Madrid, Spain, 8–11 July 2014; pp. 165–174. [Google Scholar]
- Chen, Y.M.; Liu, S.L.; Chen, Y.J.; Ling, X. A scheduling algorithm for heterogeneous computing systems by edge cover queue. Knowl.-Based Syst. 2023, 265, 110369. [Google Scholar] [CrossRef]
- Wu, Y.L.; Zhang, W.Z.; Guan, N.; Ma, Y.H. TDTA: Topology-Based Real-Time DAG Task Allocation on Identical Multiprocessor Platforms. IEEE Trans. Parallel Distrib. Syst. 2023, 34, 2895–2909. [Google Scholar] [CrossRef]
- Wu, Y.L.; Zhang, W.Z.; Guan, N.; Tang, Y. Improving Interference Analysis for Real-Time DAG Tasks Under Partitioned Scheduling. IEEE Trans. Comput. 2022, 71, 1495–1506. [Google Scholar] [CrossRef]
- Abusayeed, S.; Kunal, A.; Lu, C.Y.; Christopher, G. Multicore Real-Time Scheduling for Generalized Parallel Task Models. In Proceedings of the 2011 IEEE 32nd Real-Time Systems Symposium, Washington, DC, USA, 29 November–2 December 2011; Volume 10, pp. 217–226. [Google Scholar]
- Marko, B.; Sanjoy, B. Limited Preemption EDF Scheduling of Sporadic Task Systems. IEEE Trans. Ind. Inform. 2010, 6, 579–591. [Google Scholar]
- Shinpei, K.; Yutaka, I. Gang EDF Scheduling of Parallel Task Systems. In Proceedings of the 2009 30th IEEE Real-Time Systems Symposium, Washington, DC, USA, 1–4 December 2009; pp. 459–468. [Google Scholar]
- Karthik, L.; Shinpei, K.; Ragunathan, R. Scheduling Parallel Real-Time Tasks on multicore Processors. In Proceedings of the 2010 31st IEEE Real-Time Systems Symposium, San Diego, CA, USA, 30 November–3 December 2010; pp. 259–268. [Google Scholar]
- Daniel, C.; Alessandro, B.; Geoffrey, N.; Giorgio, B. Partitioned Fixed-Priority Scheduling of Parallel Tasks Without Preemptions. In Proceedings of the 2018 IEEE Real-Time Systems Symposium (RTSS), Nashville, TN, USA, 11–14 December 2018; pp. 421–433. [Google Scholar]
- Özkaya, M.Y.; Benoit, A.; Uçar, B.; Herrmann, J.; Çatalyürek, Ü.V. A Scalable Clustering-Based Task Scheduler for Homogeneous Processors Using DAG Partitioning. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019; pp. 155–165. [Google Scholar]
- El-Tetris: An Improvement on Pierre Dellacheries Algorithm. Available online: https://imake.ninja/el-tetris-an-improvement-on-pierre-dellacheries-algorithm/ (accessed on 26 December 2024).
- Abusayeed, S.; David, F.; Li, J.; Kunal, A.; Lu, C.Y.; Christopher, D.G. Parallel Real-Time Scheduling of DAGs. IEEE Trans. Parallel Distrib. Syst. 2014, 25, 3242–3252. [Google Scholar]
- Shamit, B.; Zhao, Y.C.; Zeng, H.B.; Yang, K.H. Optimal Implementation of Simulink Models on Multicore Architectures with Partitioned Fixed Priority Scheduling. In Proceedings of the 2018 IEEE Real-Time Systems Symposium (RTSS), Nashville, TN, USA, 11–14 December 2018; Volume 10, pp. 242–253. [Google Scholar]
- Jose, F.; Geoffrey, N.; Vincent, N.; Luís Miguel, P. Response time analysis of sporadic DAG tasks under partitioned scheduling. In Proceedings of the 2016 11th IEEE Symposium on Industrial Embedded Systems (SIES), Krakow, Poland, 23–25 May 2016; pp. 1–10. [Google Scholar]
- Erdős, P.; Alfréd, R. On Random Graphs I. Publ. Math. 1959, 4, 3286–3291. [Google Scholar] [CrossRef]
- Davis, R.I.; Burns, A. Response Time Upper Bounds for Fixed Priority Real-Time Systems. In Proceedings of the 2008 Real-Time Systems Symposium, Washington, DC, USA, 30 November–3 December 2008; pp. 407–418. [Google Scholar]
- Guan, N.; Martin, S.; Yi, W.; Yu, G. New Response Time Bounds for Fixed Priority Multiprocessor Scheduling. In Proceedings of the 2009 30th IEEE Real-Time Systems Symposium, Washington, DC, USA, 1–4 December 2009; pp. 387–397. [Google Scholar]
- RT-Linux System. Available online: https://en.wikipedia.org/wiki/RTLinux (accessed on 26 December 2024).
- Anderson, G.G. Application of Standard Optimization Methods to Operating System Scheduler Tuning. In Operating System Scheduling Optimization; University of Johannesburg: Johannesburg, South Africa, 2013; pp. 56–69. [Google Scholar]
- Wiseman, Y.; Feitelson, D.G. Paired gang scheduling. IEEE Trans. Parallel Distrib. Syst. 2003, 14, 581–592. [Google Scholar] [CrossRef]




Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, Y.; Liu, S.; He, Z.; Ling, X. A Tetris-Based Task Allocation Strategy for Real-Time Operating Systems. Electronics 2025, 14, 98. https://doi.org/10.3390/electronics14010098
Chen Y, Liu S, He Z, Ling X. A Tetris-Based Task Allocation Strategy for Real-Time Operating Systems. Electronics. 2025; 14(1):98. https://doi.org/10.3390/electronics14010098
Chicago/Turabian StyleChen, Yumeng, Songlin Liu, Zongmiao He, and Xiang Ling. 2025. "A Tetris-Based Task Allocation Strategy for Real-Time Operating Systems" Electronics 14, no. 1: 98. https://doi.org/10.3390/electronics14010098
APA StyleChen, Y., Liu, S., He, Z., & Ling, X. (2025). A Tetris-Based Task Allocation Strategy for Real-Time Operating Systems. Electronics, 14(1), 98. https://doi.org/10.3390/electronics14010098