1. Introduction
High-altitude balloons are becoming increasingly important in various areas such as volcanic plumes [
1], atmospheric analysis [
2], and other applications [
3,
4]. Consequently, assessing the feasibility of high-altitude balloons’ path planning in the stratosphere is crucial to addressing the diverse mission requirements. Balloons do not possess a horizontal propulsion system: they ascend or descend solely by inflating and deflating to change their buoyancy, allowing vertical navigation through diverse wind layers to determine horizontal direction. This method of control results in minimal energy consumption and facilitates prolonged flights in the stratosphere [
5,
6]. Selecting the appropriate altitude in a three-dimensional wind field presents considerable path planning challenges. Furthermore, the partial observability increases the complexity of the problem [
7], which is common even when the state-of-the-art real-time wind prediction technology has large deviations [
8]. Given the discrepancies in wind field predictions and the intricate nonlinear dynamics between balloon controls and their guided navigation towards set goals, it is difficult for conventional techniques to design a direct and efficient control policy [
9,
10].
In recent years, various path planning methods have been extensively utilized across multiple fields and applications. Examples include target tracking [
11], valet parking [
12], autonomous mobile robot navigation [
13], collision avoidance [
14], and trajectory planning [
15]. Traditional algorithms, such as graph search algorithms [
16,
17] and rapidly exploring random tree [
18], are structurally simple but suffer from inefficiency in large-scale searches and lack robust global optimization capabilities. In contrast, intelligent heuristic algorithms, including particle swarm optimization [
19], genetic algorithm [
20], ant colony optimization [
21], and neural network-based algorithms [
22], typically offer superior performance in solving complex problems. However, these heuristic methods exhibit sensitivity issues when applied to complex environments, such as dynamic wind fields, and are prone to becoming stuck in local optima or failing to reach the goal. Deep reinforcement learning can handle cases with high uncertainty and high dimensionality at the same time, which is ideal for learning complex solutions and unobvious connections [
23]. This capability offers new opportunities for path planning in the stratosphere [
24]. To date, research on path planning for stratospheric aerostats has primarily focused on airships. Yang et al. [
25] proposed an adaptive horizontal trajectory control method for stratospheric airships in uncertain wind fields using the Q-learning algorithm, where the action strategy is determined based on wind direction. Zheng et al. [
26] employed a dual-depth recurrent Q-network for an airship path planning model. Compared to heuristic algorithms, this method achieves higher energy efficiency and success rates under identical conditions. Considering the impact of high-altitude cold clouds on airship motion, Wang et al. [
27] introduced a trajectory planning algorithm for stratospheric airships based on the Soft Actor–Critic (SAC) reinforcement learning algorithm. This algorithm effectively plans trajectories to any area while avoiding cold clouds. The aforementioned studies on airship path planning are based on 2D wind fields, assuming that airships operate on a fixed horizontal plane. While maintaining a constant altitude is feasible for airship path planning, this approach is possible because airships are powered vehicles capable of controlling direction and speed via their propulsion system, rather than relying solely on the wind field. In contrast, balloons lack a propulsion system and can only adjust their altitude to find favorable winds for the mission. As a result, balloons have fewer control options and must navigate in a 3D wind field, which significantly increases the complexity of their path planning.
The research within the domain of balloon control via deep reinforcement learning is not extensive, predominantly focused on station-keeping, that is, controlling the balloon as much as possible so that it stays within 50 km of the base station and can comfortably communicate with a ground device [
28]. The most outstanding work is by Google’s Loon. Bellmare et al. [
29] designed a deep reinforcement learning approach that significantly improved performance compared to their previous manual algorithm on station-keeping. Subsequently, Google launched Loon balloons at altitudes of 15–20 km in diverse global regions, a notable case being a 39-day controlled expedition in the Pacific Ocean. Jeger et al. [
30] focused on flying the balloon to a predefined target position at low altitudes (up to 3 km above mean sea level) because low-altitude winds vary over smaller length scales and timescales, allowing more reachable locations compared to high-altitude operation. They used a fully autonomous custom-designed outdoor prototype and implemented the DQN method in real-world conditions. Over six flights, the prototype navigated to predefined positions, with an averaging target distance error of 360 m after traveling approximately 10 km within a volume of 22 × 22 × 3.2 km.
Path planning for stratospheric aerostats plays a crucial role in various applications [
31], particularly in high-altitude communication [
29], environmental monitoring [
32,
33], and scientific research [
34]. However, existing research on balloon control has primarily focused on station-keeping tasks [
35,
36,
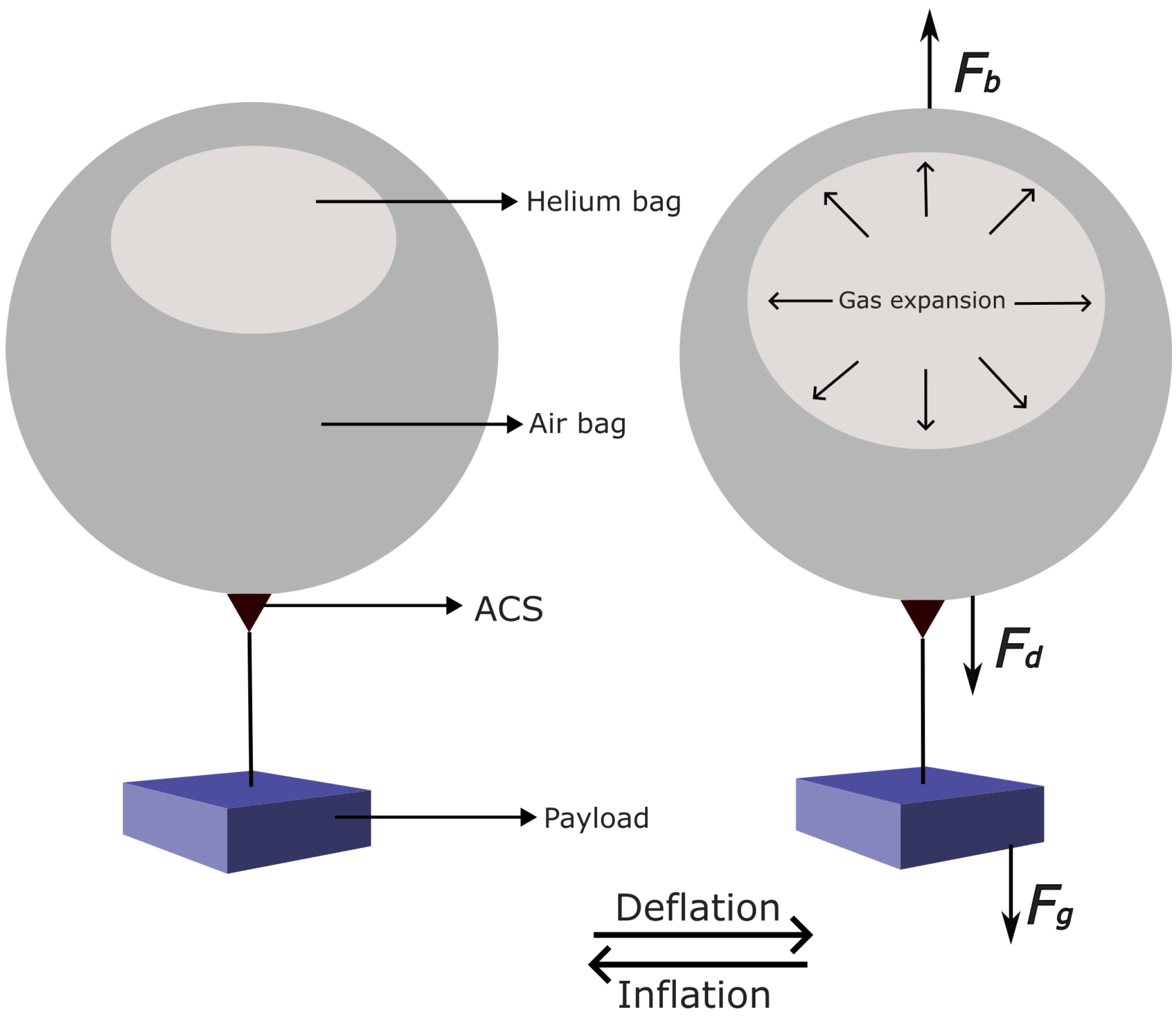
37], while studies on stratospheric aerostat path planning largely concentrate on powered airships navigating in 2D wind fields. The critical challenges of path planning for stratospheric balloons remain unexplored in the current literature. Therefore, this study employs a reinforcement learning-based approach to address the challenges of path planning for stratospheric balloons. In this study, we define the scenario shown in
Figure 1, assuming the balloon is in station-keeping mode, when upon switching to path planning mode, the balloon must locate and follow favorable wind currents through ascending and descending to reach a small target area as quickly as possible. This presents a challenging path planning problem, as the wind field may lack favorable wind currents, and the time-optimal path to the target may require spatial detours. Our aim is to control the balloon to reach a target range as fast as possible. This paper proposes a path planning method for stratospheric balloon navigation based on deep reinforcement learning. The main contributions of this work are as follows:
We develop a reinforcement learning agent for an superpressure balloon that can reach a randomly selected target within a stratospheric 3D wind field, using one-dimensional actions while operating under limited temporal and spatial constraints. It provides an efficient solution to the previously unexplored problem of navigating a stratospheric balloon to a small target area.
By analyzing the characteristics of balloon flight and wind fields, we design an effective state space and reward function that enhances the practicality and reliability of the controller. Additionally, we establish a baseline controller for comparison to evaluate the feasibility and effectiveness of the reinforcement learning-based path planning for stratospheric balloons.
The experimental results indicate that reinforcement learning can effectively learn a control policy that achieves fast navigation with a higher success rate, surpassing baseline methods. This task was trained in Google’s Balloon Learning Environment, which allows researchers to conveniently train reinforcement learning controllers with balloon agents [
38] that, in theory, could smoothly switch between different controllers to handle different situations and tasks. This work aims to advance balloon control technology by addressing previously underexplored mission scenarios.
3. Experiment
3.1. Training
For the training phase, each episode lasts for a maximum of 960 steps and consists of one flight. The controller receives inputs and emits commands at three-minute intervals. To prevent the balloon from crossing the edge of the target range without being detected in a three-minute interval, the balloon’s ambient variables are updated every 10 s. After receiving a command from the controller, the Altitude Control System (ACS) adjusts the balloon’s altitude by either pumping in or venting out air, thus selecting an optimal wind direction for controlling its horizontal path. However, in actual flight, various factors such as buoyancy, gravity, and air resistance significantly influence the balloon’s dynamics. A realistic simulation environment is crucial for bridging the gap between simulations and real-world conditions. The US Standard Atmosphere Model 1976 is used to simulate environmental changes, including variations in atmospheric temperature, density, and pressure with altitude. This simulation environment takes full account of atmospheric temperature, pressure, and density variations at different altitudes, as well as the heat exchange between the balloon and its surroundings. The real flight path significantly increases computational load, consequently slowing down the simulation. The controller was trained for 30 days (wall-clock time) on an RTX 3070 GPU across 100,000 episodes.
At the beginning of each episode, the station’s location, the balloon’s altitude, and date, time, and wind noise are determined by a random seed. The target position is a uniform distribution within a 50 km station-keeping range. During real-world deployment of Project Loon, the balloon remains within the station-keeping range approximately 79% of the time in the Pacific Ocean experiment. To match the real-world scenario, the initial latitude and longitude of the balloon fall within the station-keeping range and the distance followed a similar distribution to that observed in the Pacific Ocean experiment of Project Loon. This distribution follows a beta distribution with parameters (a = 4 and b = 2). An episode concludes when the balloon reaches target range, goes out of bounds, or exceeds the time limit.
To thoroughly investigate the outcomes of various decisions, we adopt an exploratory strategy to explore a wider range of possibilities. The majority of training trials are dedicated to exploration. During these trials, the reinforcement learning controller and the exploration policy were alternated at intervals of 4 h and 2 h. Exploration strategies that take too long tend to produce substantial data, which are useless for replacement buffering. Data are logged as a series of state, action, and reward transitions. When a trial concludes, these transitions are appended to a randomly chosen replay buffer for subsequent training.
3.2. Baseline Controller
The station-keeping controller proposed in previous studies provides insight into how to design a manual algorithm [
29]. When the balloon is out of station-keeping range, the balloon will preferentially look for wind at a small bearing to the site location. The baseline controller receives same wind variables in state space as input with 181 different pressure levels. In order for the balloon to reach the target as soon as possible, the wind speed is also taken into account. The score of each wind layer is calculated based on the wind speed and wind angle to let the balloon move to the wind layer with higher score, and the formula is as follows, where a wind score
is computed for each pressure level
l on the basis of the wind magnitude
and bearing
:
The term
defines a penalty for the angle of the wind relative to the target, and
is a constant.
The term
represents the relative weight assigned to the distance D between the balloon and the target. The coefficient
has the most significant impact on
. The farther the distance, the smaller the
.
The term is the uncertainty at pressure level l, and and are constants. The last term is the hysteresis term, meaning the extra cost of time for moving. Depending on the wind layer with the highest score , the balloon chooses to ascend, descend, or stay in its current position.
3.3. Performance Evaluation
The primary performance evaluation metrics for the task include success rate and average success time. Success rate serves as a core indicator of the balloon’s ability to reach the target area. It is calculated as the ratio of successful attempts to the total number of tasks, reflecting the controller’s capability to complete the assigned mission. Average success time measures the average time required for the balloon to navigate from the starting point to the target area. This metric highlights the navigation efficiency, particularly in scenarios where the task is time-constrained.
Every 20,000 training episodes, the controller undergoes an evaluation with 1000 flights. During this evaluation, factors influencing the balloon’s flight path like starting position, altitude, target position and station location, date, time, and wind conditions are set by a random number seed. Using a consistent seed ensures that the flight path is determined solely by the neural network parameters of the RL controller, enhancing time efficiency by minimizing randomness and reducing the need for simulating numerous flights to obtain a fair assessment. Each flight records the number of random seeds, whether the balloon reached the target range, and the accumulated reward value, and the key performance metrics for the controller are the success rate and average time to successfully reach the target range.
4. Simulation Results and Discussion
4.1. Baseline Controller Performance
The baseline controller, which requires no training, is also assessed with the same seed over 1000 flights. We evaluated the performance of the baseline controller when the target radii are 5 km and 10 km. The results are shown in
Table 3, where SR (%) is the success rate and AST (h) is the average success time.
4.2. RL Controller Performance
Multi-step decision tasks require the agent to take a sequence of actions to achieve a goal, with each decision influencing both future states and the eventual outcome. A key challenge in such tasks is balancing the final reward and the rewards received at each step. Excessive reliance on stepwise rewards may lead the agent to focus on optimizing short-term goals, neglecting the long-term global objective. Conversely, over-dependence on endgame rewards can cause training instability, especially in the early stages, when the agent may struggle to accurately evaluate the value of individual actions. Therefore, designing and adjusting the reward structure, especially the balance between the final goal and stepwise rewards, is crucial for solving complex tasks. In this study, we train the reinforcement learning (RL) controller with target ranges of 5 km and 10 km, respectively, to adjust the balance between the final reward
and stepwise rewards. Each was trained over 100,000 episodes and evaluated at intervals of 20,000 episodes. The results are presented in
Figure 4 and
Figure 5. Experimental data indicate that as the target radius increases, the balloon’s success rate in reaching the target area also increases, concurrently reducing the average success time. When
, the success rate fluctuates for target ranges of 5 km and 10 km, with slower and more unstable convergence compared to when
. In contrast, with
, the controller achieves a high success rate as early as 40,000 episodes, with gradual improvement as training progresses. The experimental results show that setting
to 50 results in more stable and effective controller training compared to a setting of
at 100.
Additionally, the average success time cannot serve as the sole metric for performance evaluation; rather, it should be assessed alongside the average success rate. When the balloon operates without any control, its mission success rate is low, despite the short average time to reach the target. This suggests a higher probability of the balloon reaching the target when in close proximity rather than an improvement in time efficiency resulting from passive flight.
As shown in
Figure 6, the moving average of episodic rewards and the average success rate, calculated with a window size of 200, is used to illustrate reward trends for a target radius of 5 km and
of 100. Initially, due to a lack of experience samples, the agent employs an exploration strategy, resulting in relatively low reward values. However, as training progresses, the agent interacts with the environment and accumulates a substantial number of experience samples. Consequently, the algorithm’s reward values and the average success rate gradually increase overall.
4.3. Performance Analysis
Figure 7 and
Figure 8 illustrates the best performance of the baseline controller and RL controller, and we also tested the random selection controller and the passive drift controller. By comparing the success rates of different controllers, the RL controller outperforms the baseline controller. The RL controller achieves a 60.6% success rate and the baseline controller achieves a 54.4% success rate when the target radius is 10 km, achieving success rates of 57.6% and 43.1%, respectively, when the target radius is 5 km.
By comparing the average success time of different controllers, at a higher success rate, the RL controller achieved a target range arrival time that is 3.77 h quicker than the baseline controller on average with a target radius of 5 km and 1.68 h quicker for a 10 km target radius.
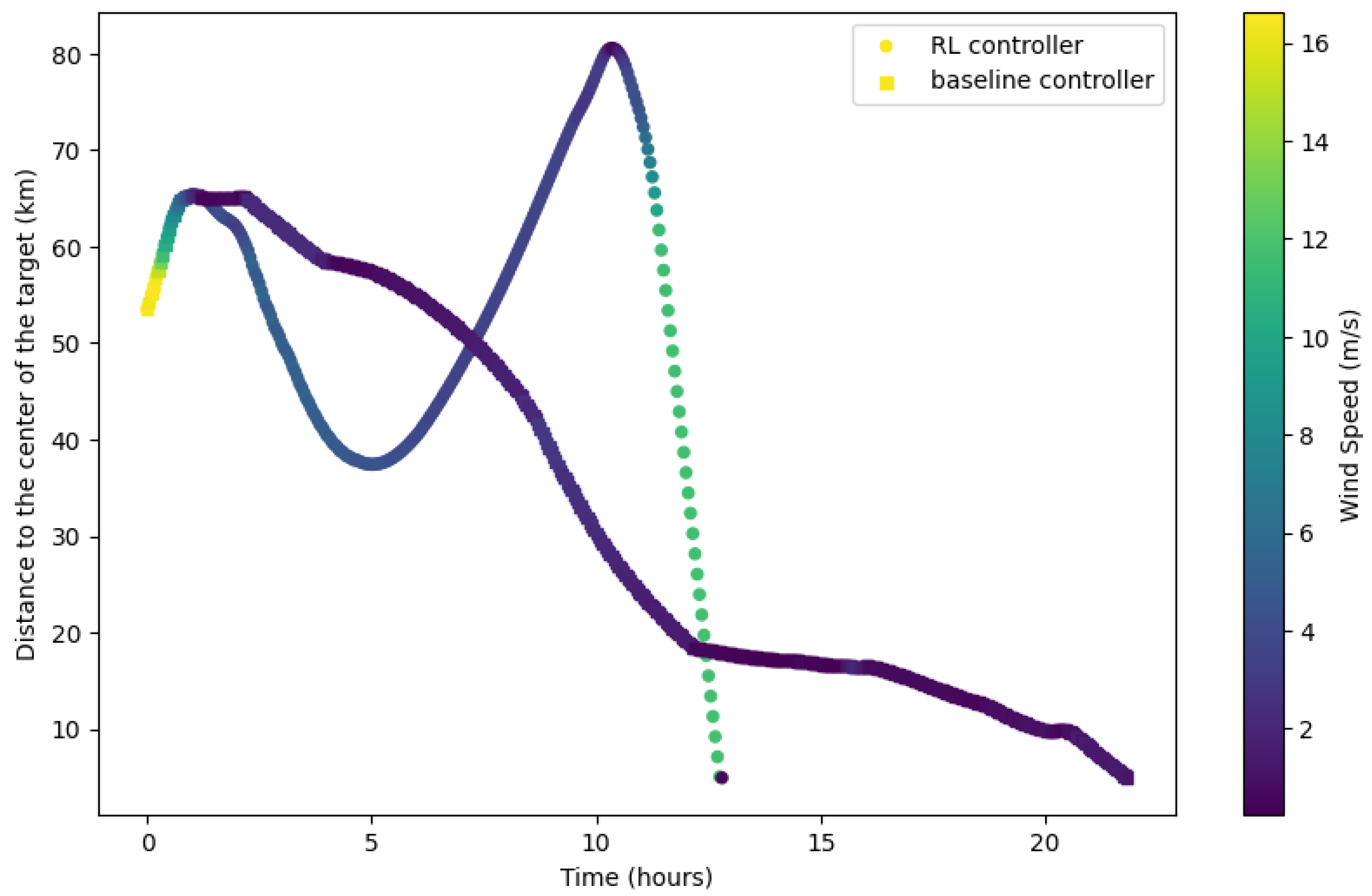
Figure 9 and
Figure 10 illustrate the superior performance of the RL controller over the baseline controller. Using the same random seed during evaluation ensures identical conditions for the target area, the balloon’s starting position, and wind conditions. The balloon’s position was recorded every three minutes using the same random seed for both controllers.
Figure 9 illustrates one episode of the task, where both controllers reached the target range starting from the same position and under identical wind field conditions.
Figure 10 presents the variation in the balloon’s distance from the target’s center and wind speed over time. The baseline controller completed the flight in 21.9 h, while the reinforcement learning controller required only 12.9 h. The baseline controller, using a manual algorithm, preferentially selected wind flows with a relatively small angle to the target. In contrast, the reinforcement learning controller began to diverge from the target point around five hours, at one point exceeding 80 km, but eventually reached the target quickly by utilizing high-speed wind currents from approximately 11 h onward, following a more circuitous route to find a faster path. Reinforcement learning-based controllers have demonstrated superior capabilities in navigating complex wind fields and making decisions from a global perspective. Compared to traditional methods, reinforcement learning controllers can incorporate long-term dynamics and optimize them to the overall task objective, enabling better adaptation to changing conditions and more effective alignment with the task’s global goals.
We recorded the electrical energy of the balloon, irrespective of controller type, value, or target radius, and following RL controller training over 20,000 episodes, the balloon’s average residual power is approximately 75%, regardless of whether the target range is reached or not. Implementing a constraint on excessive inflating in the reward function or manual algorithm could theoretically conserve power; however, it also curtails the balloon’s exploratory potential. Given the practical considerations, where path planning tasks require relatively shorter execution times compared to station-keeping tasks and simulation experiments reveal high residual balloon power, the design strategy prioritizes optimal performance without imposing constraints.
4.4. Robustness Analysis of Balloon Initial Position
To evaluate the robustness of the controllers to the initial positions of the balloons, we selected five different initial test points (0 km, 12.5 km, 25 km, 37.5 km, and 50 km). Within a fixed 5 km target range, each distance was evaluated over 1000 episodes to analyze the impact of the initial position distance on task success rates and average success times. Based on the experimental data, the following conclusions can be drawn:
Figure 11 shows the success rates of the RL and baseline controllers at different initial distances from the station center. As the initial position distance from the station center increases, the average expected distance of the balloon to a random target point becomes larger, and the success rate gradually decreases. The reinforcement learning (RL) controller demonstrated stronger robustness under different initial conditions, while the baseline controller showed relatively weaker performance. In evaluations with random initial positions, the success rate of the RL controller was 54.4%, significantly outperforming the baseline controller’s 43.1%. When the initial position was fixed at the station center (0 km), the success rates of the RL and baseline controllers increased by 8.4% and 7.1%, respectively. Conversely, when the initial position was fixed 50 km from the station, the success rates decreased by 1.2% and 6.6%, respectively.
Figure 12 shows the average success times of the RL and baseline controllers at different initial distances from the station center. Further analysis of average success time reveals that the RL controller not only excelled in terms of success rate but also demonstrated significantly better navigation efficiency. Under random initial position conditions, the RL controller’s average success time was 11.38 h, compared to 15.2 h for the baseline controller. In tests with fixed initial positions, the RL controller’s average success time increased from 8.6 h (at 0 km distance) to 13.67 h (at 50 km distance), while the baseline controller’s average success time increased from 10.14 h to 17.8 h.
In summary, the experimental results indicate that the RL controller exhibits significantly greater robustness to variations in the balloon’s initial position compared to the baseline controller. This robustness enables the RL controller to complete tasks effectively under a broader range of initial conditions and achieve higher task efficiency in complex navigation scenarios. These findings provide important insights for optimizing navigation strategies in practical applications and further validate the advantages of reinforcement learning in path planning tasks.
5. Conclusions and Discussion
In this paper, we propose for the first time the task of superpressure balloon path planning in the stratosphere, and employ deep reinforcement learning methods to build a controller for an autonomous balloon. Utilizing surrounding wind variables and ambient variables, the balloon as an agent obtains the optimal action strategy through the optimization network, trying to reach the target range as soon as possible. Using success rate and average success time as evaluation metrics, the results demonstrate that the RL controller outperforms the baseline controller, reaching the target range more frequently and with a shorter average success time. Although we ultimately developed a controller capable of efficiently solving this novel problem, it may not be optimal in terms of training time and final performance. Due to the large computational overhead, training 100,000 episodes requires a computational time of 30 days, limiting our search for an optimal hyperparameter. It is believed that configurations exist that could enhance performance, such as improved reward function designs, hyperparameter selection, and varying neural network sizes. Theoretically, determining a broad range for all settings and parameters, sampling within this range, training controllers, and recording both training time and final performance could achieve the Monte Carlo theoretical optimum. However, the large dataset size and the high precision required for path calculations impose significant time constraints, preventing us from conducting such an exhaustive exploration. Despite these limitations, the successful application of our method to this problem establishes it as a reliable starting point for further research. The success of the reinforcement learning method in stratospheric wind field tasks proves that reinforcement learning can solve the nonlinear relationship between complex wind fields and balloon control, and its exploration characteristics can find more efficient flight paths than manual algorithms.
The ability of balloons to achieve precise navigation to small targets in the stratosphere represents the core outcome of this research. This capability has the potential to bring significant benefits to fields such as meteorology, communication networks, and environmental/ecological monitoring. For instance, in emergency communication scenarios or when providing connectivity to remote areas, balloons can precisely navigate to target locations, delivering stable communication signal coverage to ground users. By navigating to specific target regions, balloons can efficiently perform localized environmental monitoring tasks, such as air quality assessments or greenhouse gas emission evaluations. In atmospheric science and climate change research, balloons can accurately collect high-resolution data, which is particularly valuable given that the current highest resolution of stratospheric wind field data is only 23 km. This capability significantly contributes to global climate change monitoring and prediction. Additionally, in the aftermath of natural disasters, balloons can rapidly move to affected areas, providing critical support for rescue operations and data collection.
The deployment of balloons for precise navigation to small targets raises ethical and safety concerns that must be addressed responsibly. High-resolution sensors, such as cameras or radar, may inadvertently infringe on privacy by monitoring ground activities or sensitive areas. To mitigate this, data collection should be restricted to mission-specific, low-resolution data, avoiding private regions, with transparency ensured through communication with stakeholders and necessary permissions obtained. Additionally, risks such as hardware failures or debris impacting sensitive ecosystems can be reduced by using biodegradable materials and avoiding protected ecological areas, ensuring both ethical and environmental considerations are met.














{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}