
Fusing Essential Text for Question Answering over Incomplete Knowledge Base


Abstract
1. Introduction
2. Related Work
2.1. KBQA Methods Based on Semantic Parsing
2.2. KBQA Methods Based on Information Retrieval
2.3. Incomplete KBQA
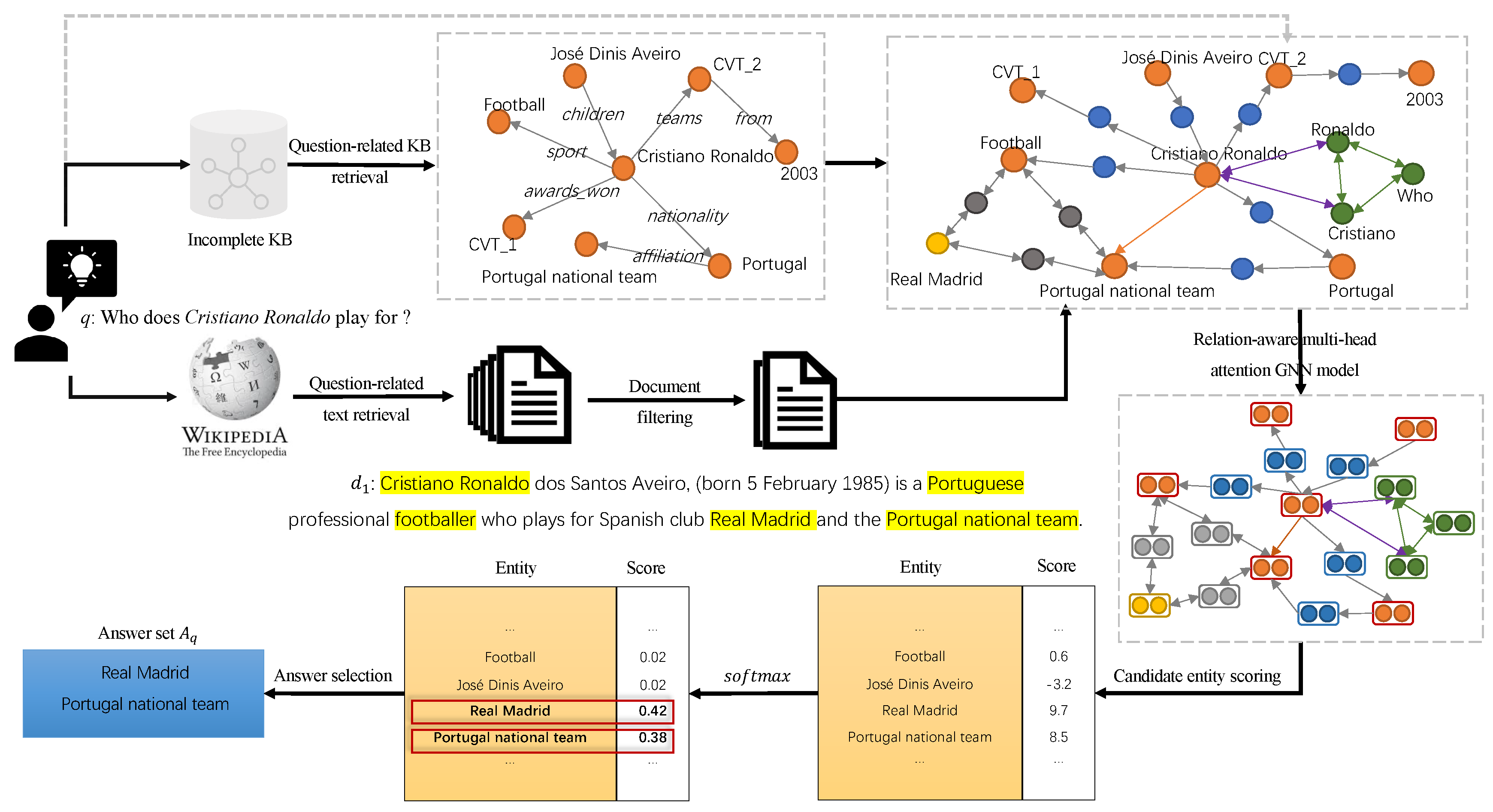
3. Proposed Approach
3.1. Preliminaries
3.2. Framework
3.3. Question-Related KB and Text Retrieval
3.3.1. Question-Related KB Retrieval
3.3.2. Question-Related Text Retrieval and Filtering
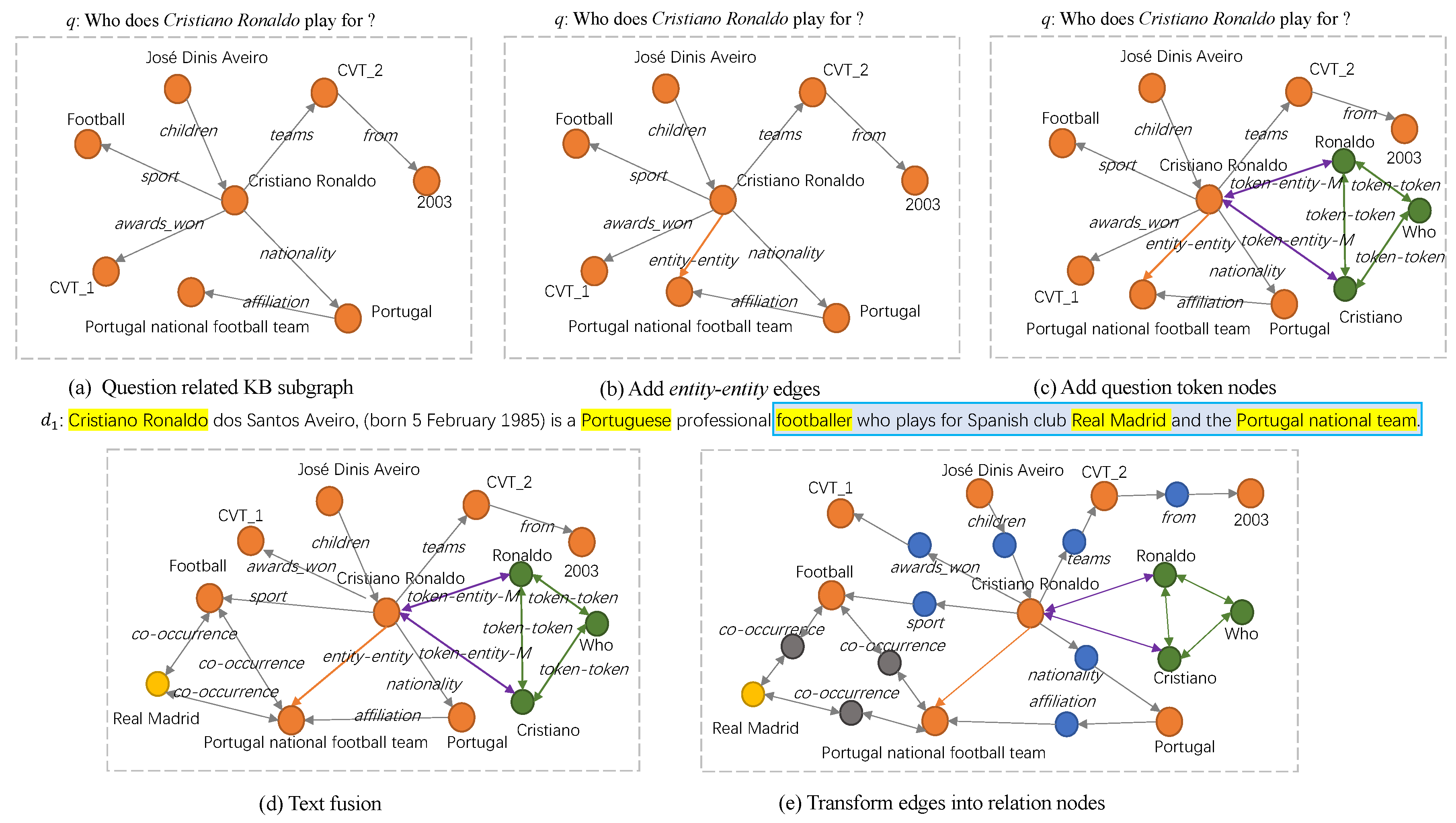
3.4. Question-Related Subgraph Construction
3.5. Relation-Aware Multi-Head Attention GNN Model
4. Experiments
4.1. Experimental Settings
4.1.1. Datasets
4.1.2. Parameter Setting
4.1.3. Baselines
4.2. Experimental Results and Analysis
4.2.1. Overall Performance
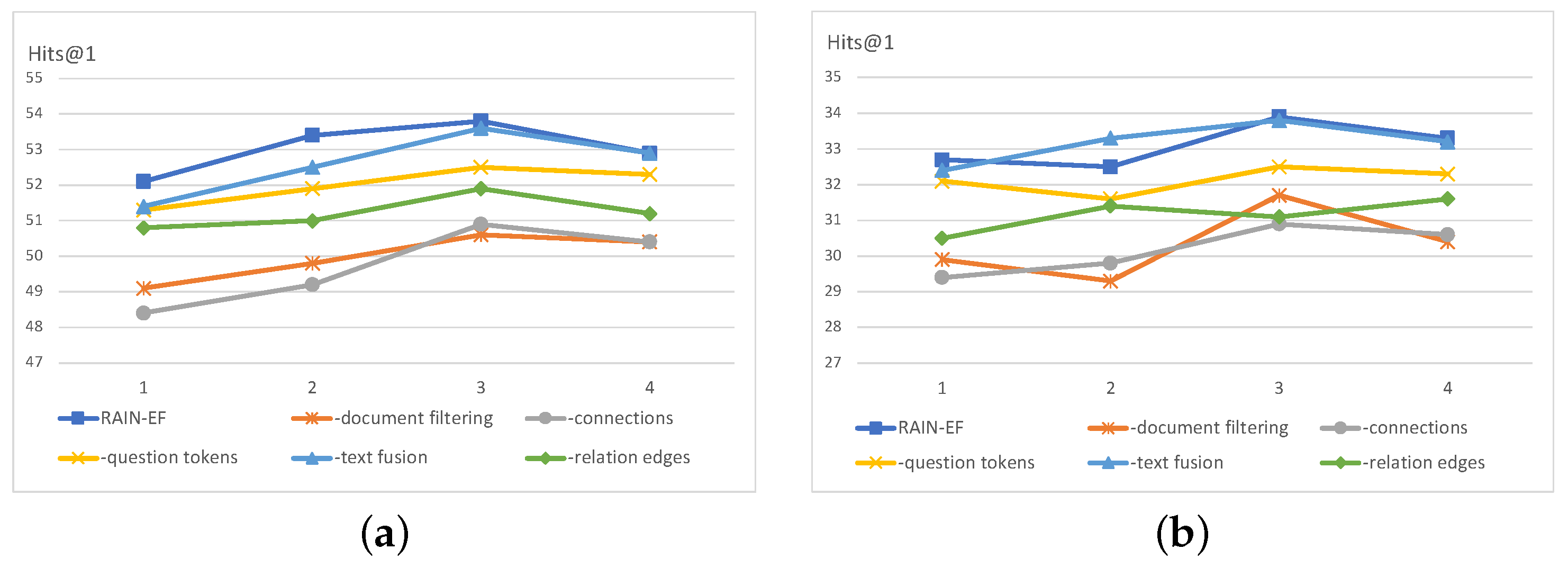
4.2.2. Ablation Experiments
4.2.3. Performance on Different Question Complexity
4.2.4. Impact of Hyper-Parameter Settings
5. Conclusions
6. Limitations
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Bollacker, K.; Evans, C.; Paritosh, P.; Sturge, T.; Taylor, J. Freebase: A collaboratively created graph database for structuring human knowledge. In Proceedings of the ACM SIGMOD International Conference on Management of Data, Amsterdam, The Netherlands, 30 June–5 July 2008; pp. 1247–1249. [Google Scholar]
- Lehmann, J.; Isele, R.; Jakob, M.; Jentzsch, A.; Kontokostas, D.; Mendes, P.N.; Hellmann, S.; Morsey, M.; Van Kleef, P.; Auer, S.; et al. DBpedia-a large-scale, multilingual knowledge base extracted from wikipedia. Semant. Web 2015, 6, 167–195. [Google Scholar] [CrossRef]
- Tanon, T.P.; Vrandečić, D.; Schaffert, S.; Steiner, T.; Pintscher, L. From freebase to wikidata: The great migration. In Proceedings of the 25th International World Wide Web Conference, Montreal, QC, Canada, 11–15 April 2016; pp. 1419–1428. [Google Scholar]
- Suchanek, F.M.; Kasneci, G.; Weikum, G. Yago: A core of semantic knowledge. In Proceedings of the 16th International World Wide Web Conference, Banff, AB, Canada, 8–12 May 2007; pp. 697–706. [Google Scholar]
- Diefenbach, D.; Lopez, V.; Singh, K.; Maret, P. Core techniques of question answering systems over knowledge bases: A survey. Knowl. Inf. Syst. 2018, 55, 529–569. [Google Scholar] [CrossRef]
- Lan, Y.; He, G.; Jiang, J.; Zhao, W.X.; Wen, J.R. Complex knowledge base question answering: A survey. arXiv 2022, arXiv:2108.06688v5. [Google Scholar] [CrossRef]
- Min, B.; Grishman, R.; Wan, L.; Wang, C.; Gondek, D. Distant supervision for relation extraction with an incomplete knowledge base. In Proceedings of the 2013 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Atlanta, Georgia, 9–14 June 2013; pp. 777–782. [Google Scholar]
- Saxena, A.; Tripathi, A.; Talukdar, P.P. Improving multi-hop question answering over knowledge graphs using knowledge base embeddings. In Proceedings of the Association for Computational Linguistics, Online, 5–10 July 2020; pp. 4498–4507. [Google Scholar]
- Guo, Q.; Wang, X.; Zhu, Z.; Liu, P.; Xu, L. A knowledge inference model for question answering on an incomplete knowledge graph. Appl. Intell. 2023, 53, 7634–7646. [Google Scholar] [CrossRef]
- Ye, X.; Xiao, L.; Zhang, C.; Yamasaki, T. E-ReaRev: Adaptive Reasoning for Question Answering over Incomplete Knowledge Graphs by Edge and Meaning Extensions. In Proceedings of the International Conference on Applications of Natural Language to Information Systems, Turin, Italy, 25–27 June 2024; pp. 85–95. [Google Scholar]
- Sun, H.; Dhingra, B.; Zaheer, M.; Mazaitis, K.; Salakhutdinov, R.; Cohen, W.W. Open domain question answering using early fusion of knowledge bases and text. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 4231–4242. [Google Scholar]
- Xiong, W.; Yu, M.; Chang, S.; Guo, X.; Wang, W.Y. Improving question answering over incomplete KBs with knowledge-aware reader. arXiv 2019, arXiv:1905.07098. [Google Scholar]
- Han, J.; Cheng, B.; Wang, X. Open domain question answering based on text enhanced knowledge graph with hyperedge infusion. In Proceedings of the Findings of the Association for Computational Linguistics Findings of ACL, Toronto, ON, Canada, 9–14 July 2020; pp. 1475–1481. [Google Scholar]
- Yih, S.W.; Chang, M.W.; He, X.; Gao, J. Semantic parsing via staged query graph generation: Question answering with knowledge base. In Proceedings of the Joint Conference of the 53rd Annual Meeting of the ACL and the 7th International Joint Conference on Natural Language Processing of the AFNLP, Beijing, China, 26–31 July 2015; pp. 1321–1331. [Google Scholar]
- Zheng, W.; Yu, J.X.; Zou, L.; Cheng, H. Question answering over knowledge graphs: Question understanding via template decomposition. Proc. VLDB Endow. 2018, 11, 1373–1386. [Google Scholar] [CrossRef]
- Maheshwari, G.; Trivedi, P.; Lukovnikov, D.; Chakraborty, N.; Fischer, A.; Lehmann, J. Learning to rank query graphs for complex question answering over knowledge graphs. In Proceedings of the 18th International Semantic Web Conference, Auckland, New Zealand, 26–30 October 2019; pp. 487–504. [Google Scholar]
- Sun, Y.; Zhang, L.; Cheng, G.; Qu, Y. SPARQA: Skeleton-based semantic parsing for complex questions over knowledge bases. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; pp. 8952–8959. [Google Scholar]
- Zhang, J.; Zhang, L.; Hui, B.; Tian, L. Improving complex knowledge base question answering via structural information learning. Knowl.-Based Syst. 2022, 242, 108252. [Google Scholar] [CrossRef]
- Dong, L.; Wei, F.; Zhou, M.; Xu, K. Question answering over freebase with multi-column convolutional neural networks. In Proceedings of the 53rd Annual Meeting of the Association for Computational Linguistics and the 7th International Joint Conference on Natural Language Processing, Beijing, China, 26–31 July 2015; pp. 260–269. [Google Scholar]
- Xu, K.; Lai, Y.; Feng, Y.; Wang, Z. Enhancing key-value memory neural networks for knowledge based question answering. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 16–21 June 2019; pp. 2937–2947. [Google Scholar]
- Qiu, Y.; Wang, Y.; Jin, X.; Zhang, K. Stepwise reasoning for multi-relation question answering over knowledge graph with weak supervision. In Proceedings of the 13th International Conference on Web Search and Data Mining, Houston, Texas, USA, 3–7 February 2020; pp. 474–482. [Google Scholar]
- He, G.; Lan, Y.; Jiang, J.; Zhao, W.X.; Wen, J.R. Improving multi-hop knowledge base question answering by learning intermediate supervision signals. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Online, 8–12 March 2021; pp. 553–561. [Google Scholar]
- Zhang, J.; Zhang, X.; Yu, J.; Tang, J.; Tang, J.; Li, C.; Chen, H. Subgraph retrieval enhanced model for multi-hop knowledge base question answering. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Dublin, Ireland, 22–27 May 2022; pp. 5773–5784. [Google Scholar]
- Das, R.; Zaheer, M.; Reddy, S.; McCallum, A. Question answering on knowledge bases and text using universal schema and memory networks. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 358–365. [Google Scholar]
- Sun, H.; Bedrax-Weiss, T.; Cohen, W.W. PullNet: Open domain question answering with iterative retrieval on knowledge bases and text. In Proceedings of the Conference on Empirical Methods in Natural Language Processing and 9th International Joint Conference on Natural Language Processing, Hong Kong, China, 3–7 November 2019; pp. 2380–2390. [Google Scholar]
- Ding, Y.; Rao, Y.; Yang, F.P. Graph-based KB and text fusion interaction network for open domain question answering. In Proceedings of the 2021 International Joint Conference on Neural Networks, Virtual, 18–22 July 2021; pp. 1–8. [Google Scholar]
- Sun, H.; Arnold, A.; Bedrax Weiss, T.; Pereira, F.; Cohen, W. Faithful embeddings for knowledge base queries. Adv. Neural Inf. Process. Syst. 2020, 33, 22505–22516. [Google Scholar]
- Ren, H.; Dai, H.; Dai, B.; Chen, X.; Yasunaga, M.; Sun, H.; Schuurmans, D.; Leskovec, J.; Zhou, D. Lego: Latent execution-guided reasoning for multi-hop question answering on knowledge graphs. In Proceedings of the 38th International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 8959–8970. [Google Scholar]
- Saxena, A.; Kochsiek, A.; Gemulla, R. Sequence-to-sequence knowledge graph completion and question answering. In Proceedings of the Annual Meeting of the Association for Computational Linguistics, Bangkok, Thailand, 11–16 August 2022; pp. 2814–2828. [Google Scholar]
- Haveliwala, T.H. Topic-sensitive pagerank. In Proceedings of the 11th international conference on World Wide Web, Honolulu, Hawaii, 7 May 2002; pp. 517–526. [Google Scholar]
- Chen, D.; Fisch, A.; Weston, J.; Bordes, A. Reading wikipedia to answer open-domain questions. In Proceedings of the 55th Annual Meeting of the Association for Computational Linguistics, Vancouver, BC, Canada, 30 July–4 August 2017; pp. 1870–1879. [Google Scholar]
- Yih, W.; Richardson, M.; Meek, C.; Chang, M.W.; Suh, J. The value of semantic parse labeling for knowledge base question answering. In Proceedings of the 54th Annual Meeting of the Association for Computational Linguistics, Berlin, Germany, 7–12 August 2016; pp. 201–206. [Google Scholar]
- Talmor, A.; Berant, J. The web as a knowledge-base for answering complex questions. In Proceedings of the Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Mexico City, Mexico, 16–21 June 2018; pp. 641–651. [Google Scholar]
- Miller, A.; Fisch, A.; Dodge, J.; Karimi, A.H.; Bordes, A.; Weston, J. Key-value memory networks for directly reading documents. In Proceedings of the Conference on Empirical Methods in Natural Language Processing, Austin, TX, USA, 1–5 November 2016; pp. 1400–1409. [Google Scholar]
- Chen, Y.; Li, H.; Qi, G.; Wu, T.; Wang, T. Outlining and filling: Hierarchical query graph generation for answering complex questions over knowledge graphs. IEEE Trans. Knowl. Data Eng. 2022, 35, 8343–8357. [Google Scholar] [CrossRef]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Train | Dev | Test | Doc |
|---|---|---|---|---|
| WQSP | 2848 | 250 | 1639 | 235,567 |
| CWQ | 27,639 | 3519 | 3531 | 802,573 |
| WikiMovies-10K | 10,000 | 10,000 | 10,000 | 79,728 |
| Model | 10%KB | 30%KB | 50%KB | |||
|---|---|---|---|---|---|---|
| Hits@1 | F1 | Hits@1 | F1 | Hits@1 | F1 | |
| KVMem | 12.5 | 4.3 | 25.8 | 13.8 | 33.3 | 21.3 |
| GN-KB | 15.5 | 6.5 | 34.9 | 20.4 | 47.7 | 34.3 |
| PullNet | - | - | - | - | 50.3 | - |
| SG-KA | 17.1 | 7.0 | 35.9 | 20.2 | 49.2 | 33.5 |
| HGCN | 18.3 | 7.9 | 35.2 | 21.0 | 49.3 | 34.3 |
| GTFIN | 19.1 | 8.30 | 36.4 | 21.3 | 51.1 | 37.4 |
| EmbedKGQA | - | - | 31.4 | - | 42.5 | - |
| LEGO | - | - | 38.0 | - | 48.5 | - |
| KGT5 | - | - | - | - | 50.5 | - |
| RAIN-KB (ours) | 19.3 | 8.4 | 35.8 | 21.4 | 51.4 | 37.1 |
| KVMem | 24.6 | 14.4 | 27.0 | 17.7 | 32.5 | 23.6 |
| GN-LF | 29.8 | 17.0 | 39.1 | 25.9 | 46.2 | 35.6 |
| GN-EF | 31.5 | 17.7 | 40.7 | 25.2 | 49.9 | 34.7 |
| GN-EF+LF | 33.3 | 19.3 | 42.5 | 26.7 | 52.3 | 37.4 |
| PullNet | - | - | - | - | 51.9 | - |
| SG-KA | 33.6 | 18.9 | 42.6 | 27.1 | 52.7 | 36.1 |
| HGCN | 33.7 | 19.9 | 42.8 | 27.5 | 52.8 | 37.1 |
| GTFIN | 35.5 | 21.9 | 44.2 | 28.2 | 53.6 | 39.8 |
| RAIN-TF (ours) | 36.7 | 23.1 | 45.1 | 28.9 | 53.8 | 38.5 |
| Model | 50%KB | Model | 50%KB |
|---|---|---|---|
| KVMem * | 14.8 | KVMem * | 15.2 |
| GN-KB * | 26.1 | GN-EF * | 26.9 |
| PullNet | 31.5 | PullNet | 33.7 |
| LEGO | 29.4 | - | - |
| RAIN-KB (ours) | 31.9 | RAIN-TF(ours) | 33.9 |
| Model | 10%KB | 30%KB | 50%KB | |||
|---|---|---|---|---|---|---|
| Hits@1 | F1 | Hits@1 | F1 | Hits@1 | F1 | |
| KVMem | 15.8 | 9.8 | 44.7 | 30.4 | 63.8 | 46.4 |
| GN-KB | 19.7 | 17.3 | 48.4 | 37.1 | 67.7 | 53.4 |
| RAIN-KB (ours) | 41.2 | 32.1 | 57.5 | 48.3 | 73.4 | 62.5 |
| KVMem | 53.6 | 44.0 | 60.6 | 48.1 | 75.3 | 59.1 |
| GN-LF | 74.5 | 65.4 | 78.7 | 68.5 | 83.3 | 74.2 |
| GN-EF | 75.4 | 66.3 | 82.6 | 71.3 | 87.6 | 76.2 |
| GN-EF+LF | 79.0 | 66.7 | 84.6 | 74.2 | 88.4 | 78.6 |
| RAIN-TF(ours) | 81.2 | 68.0 | 86.3 | 75.7 | 90.4 | 79.5 |
| Model | WQSP | CWQ | Wikimovies-10K |
|---|---|---|---|
| RAIN-TF | 53.8 | 33.9 | 90.4 |
| -document filtering | 50.6 (−3.2) | 31.7 (−2.2) | 87.5 (−2.9) |
| -connections between the topic entity and other entities | 50.9 (−2.9) | 30.9 (−3.0) | 88.7 (−1.7) |
| -question token nodes | 52.5 (−1.3) | 32.5 (−1.4) | 89.2 (−1.2) |
| -text fusion | 53.6 (−0.2) | 33.8 (−0.1) | 90.3 (−0.1) |
| -relation edge transformation | 51.9 (−1.9) | 31.6 (−2.3) | 88.2 (−2.2) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2025 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Li, H.; Feng, Y.; Liu, L. Fusing Essential Text for Question Answering over Incomplete Knowledge Base. Electronics 2025, 14, 161. https://doi.org/10.3390/electronics14010161
Li H, Feng Y, Liu L. Fusing Essential Text for Question Answering over Incomplete Knowledge Base. Electronics. 2025; 14(1):161. https://doi.org/10.3390/electronics14010161
Chicago/Turabian StyleLi, Huiying, Yuxi Feng, and Liheng Liu. 2025. "Fusing Essential Text for Question Answering over Incomplete Knowledge Base" Electronics 14, no. 1: 161. https://doi.org/10.3390/electronics14010161
APA StyleLi, H., Feng, Y., & Liu, L. (2025). Fusing Essential Text for Question Answering over Incomplete Knowledge Base. Electronics, 14(1), 161. https://doi.org/10.3390/electronics14010161