
Zero-FVeinNet: Optimizing Finger Vein Recognition with Shallow CNNs and Zero-Shuffle Attention for Low-Computational Devices

 ,
,  , ,
, ,  and
and
Abstract
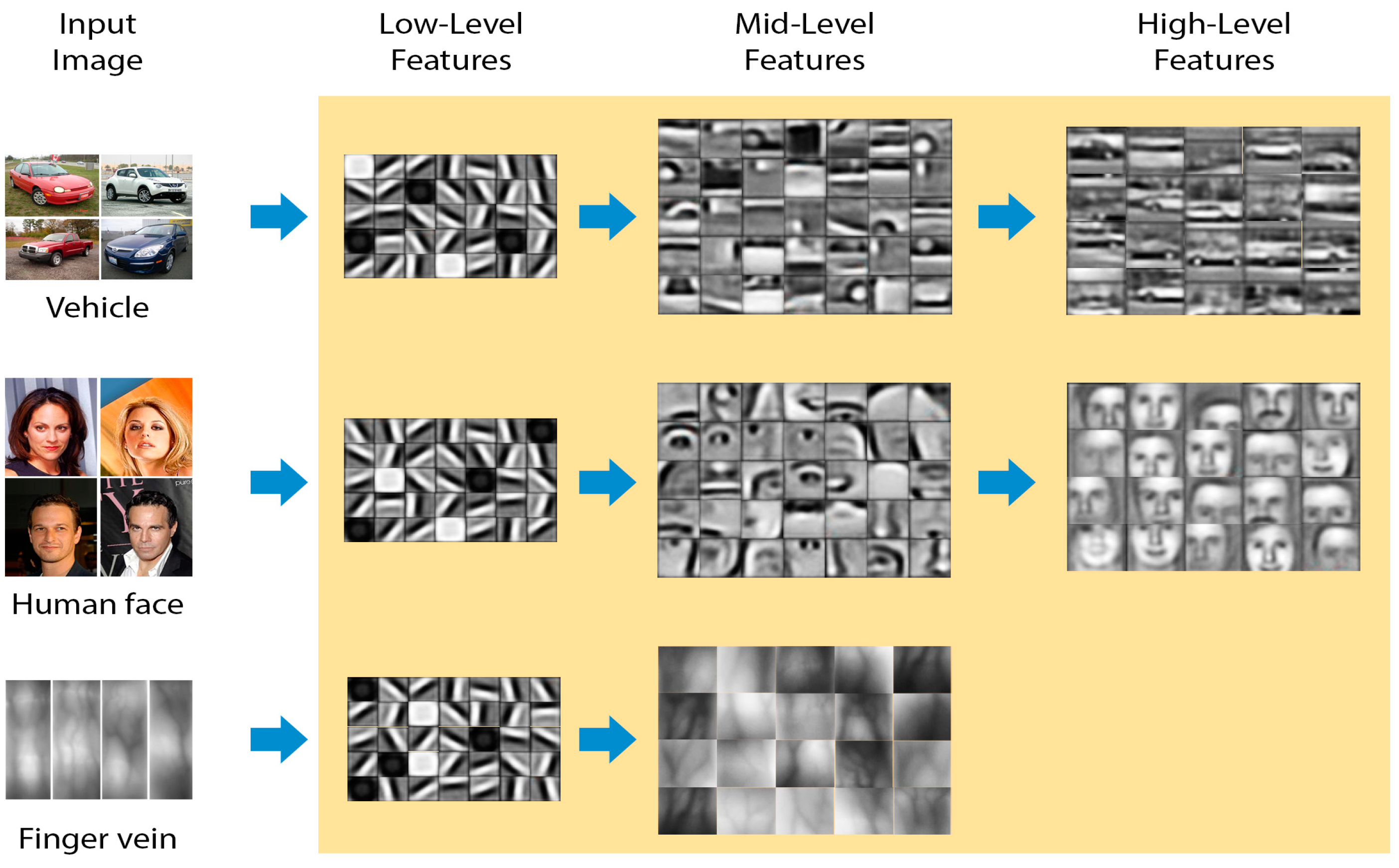
1. Introduction
- Shallow CNN network combined with a re-parameterization mechanism: by adjusting the number of layers to a minimal yet sufficient level and re-parameterizing the system, this approach not only reduces the amount of redundancy in parameter usage but also retains the model’s learning capability, which is crucial for achieving a high accuracy.
- Integrating a blur pool layer into a lightweight model: this modification maintains feature extraction consistency across translated images, thereby stabilizing recognition accuracy.
- Zero parameter channel shuffle coordinate attention block (ZSCA): this attention mechanism helps to reduce the computational costs associated with traditional attention models and maintains the ability to learn important features. It is particularly effective in extracting subtle vein characteristics.
2. Literature Review
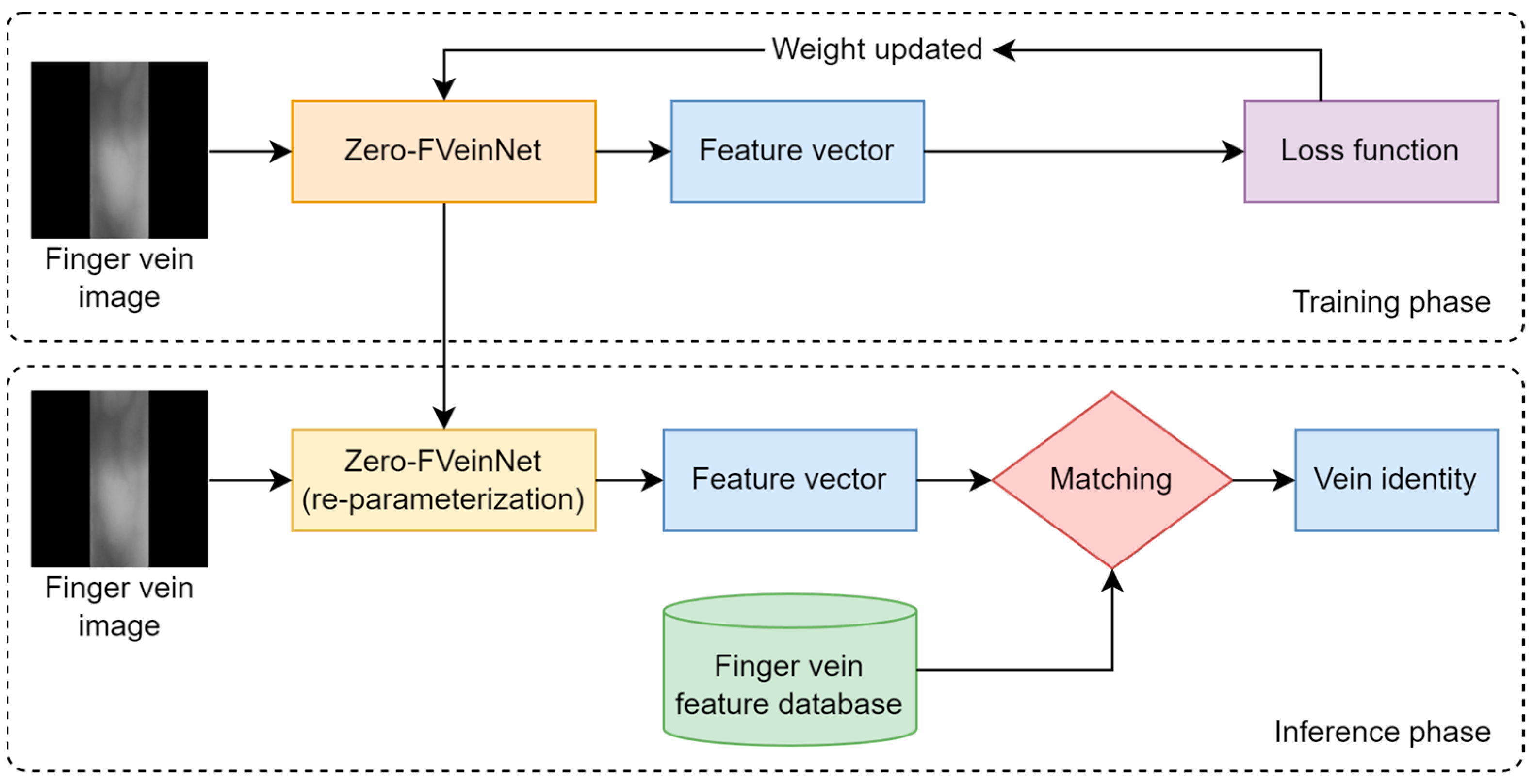
3. Methodology
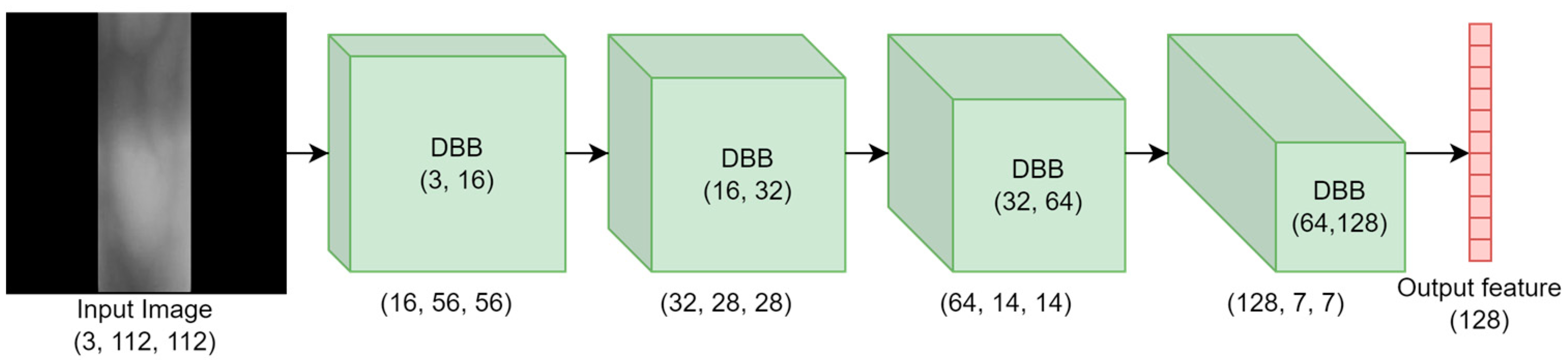
3.1. Shallow CNN Network with a Re-Parameterization Mechanism
3.2. ZeroBlur-DBB Module: Diverse Branch Block with Blur Pool and Zero Shuffle Coordinate Attention
3.2.1. Blur Pool Layer
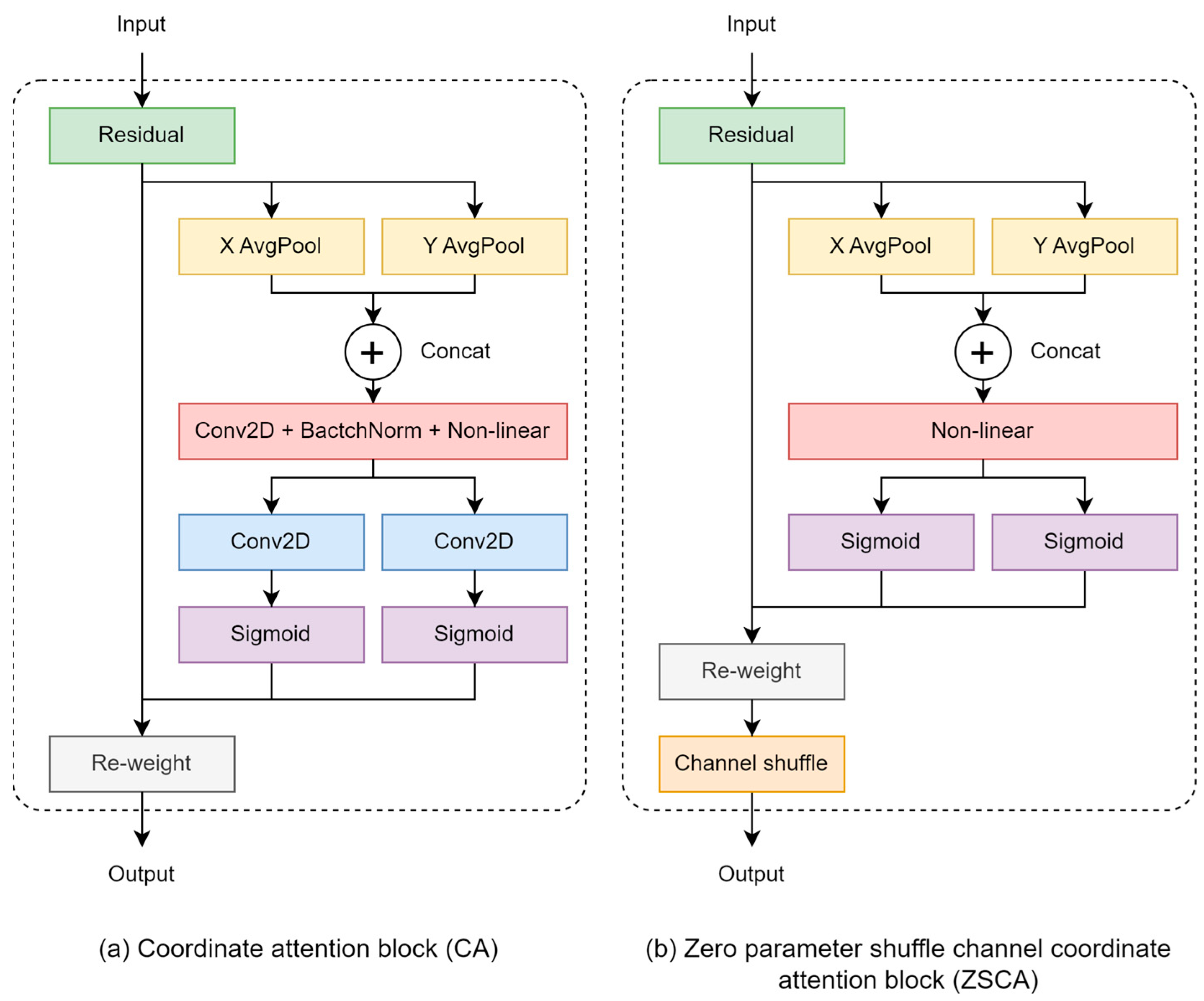
3.2.2. Zero Parameter Channel Shuffle Coordinate Attention (ZSCA)
3.3. Evaluation Metrics and Loss Function
3.3.1. Evaluation Metrics
- Model Complexity: We calculate the model size by counting the number of parameters. We measure the model’s speed in terms of inference time (millisecond), and we assess computational costs (FLOPs) associated with the model’s multiply operations.
- Model Performance: We utilize the Correct Identity Rate (CIR) as the evaluation metric. The CIR measures the model’s security efficacy; a higher CIR value signifies greater security and improved recognition performance, making it ideal for one-to-many finger vein recognition tasks. The method for calculating the CIR is detailed in Equation (3).
3.3.2. Loss Function
4. Experiments
4.1. Finger-Vein Public Datasets
- The SDUMLA-FV dataset [10]: This dataset has been compiled by Shandong University and includes data from 106 participants. Each participant provided images of their index, middle, and ring fingers from both hands, constituting 636 unique finger classes in total. In a single collection session, each finger was imaged six times, summing up to 3816 images. The original images have a resolution of 320 × 240 pixels. For our study, we implemented basic image processing techniques, including edge detection combined with image contrast enhancement, to extract Regions of Interest (ROI) from finger vein images with dimensions of 300 × 150 pixels, as the dataset does not originally include ROI images.
- The FV-USM dataset [11]: Developed by the University Sains Malaysia, this dataset involves images from 123 individuals, capturing the index and middle fingers of both left and right hands. The cohort includes 83 males and 40 females, aged 20 to 52 years. Each finger was photographed six times across two sessions, and the dataset provides pre-extracted ROI images with a resolution of 100 × 300 pixels that are suitable for finger vein recognition.
- The SCUT-FVD dataset [12]: Introduced by the South China University of Technology (SCUT), this dataset is designed for both finger vein recognition and spoof detection tasks. It comprises over 7000 images, evenly split between genuine and spoof images. For the purposes of this research, only the genuine images were utilized, involving 101 subjects each with six distinct finger vein identities. Each identity was documented in six separate data samples, resulting in a total of 3636 genuine samples.
- The THU-FVFDT dataset [13]: The THUFV2 dataset, released by Tsinghua University in 2014, includes ROIs of finger veins and dorsal textures. It features 610 subjects, with each providing one image of each type, captured in two sessions. The ROIs have been standardized to a resolution of 200 × 100 pixels. The participants were predominantly students and staff from the Tsinghua University’s Graduate School at Shenzhen.
4.2. Experimental Configuration
4.3. Experimental Results
4.4. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Krizhevsky, A.; Sutskever, I.; Hinton, G.E. ImageNet classification with deep convolutional neural networks. In Proceedings of the International Conference on Neural Information Processing Systems, Lake Tahoe, NV, USA, 3–6 December 2012; pp. 1097–1105. [Google Scholar]
- Szegedy, C.; Liu, W.; Jia, Y.; Sermanet, P.; Reed, S.; Anguelov, D.; Erhan, D.; Vanhoucke, V.; Rabinovich, A. Going deeper with convolutions. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1–9. [Google Scholar]
- Dahl, G.E.; Yu, D.; Deng, L.; Acero, A. Context-dependent pre-trained deep neural networks for large-vocabulary speech recognition. IEEE Trans. Audio Speech Lang. Process. 2011, 20, 30–42. [Google Scholar] [CrossRef]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. In Proceedings of the Conference on International Conference on Neural Information Processing Systems, Montreal, QB, Canada, 7–12 December 2015; pp. 91–99. [Google Scholar]
- Long, J.; Shelhamer, E.; Darrell, T. Fully convolutional networks for semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 3431–3440. [Google Scholar]
- Mikolov, T.; Karafiát, M.; Burget, L.; Cernocký, J.; Khudanpur, S. Recurrent neural network based language model. In Proceedings of the Conference of the International Speech Communication Association, Makuhari, Japan, 26–30 September 2010; pp. 1045–1048. [Google Scholar]
- Chen, Y.-Y.; Hsia, C.-H.; Chen, P.-H. Contactless multispectral palm-vein recognition with lightweight convolutional neural network. IEEE Access 2021, 9, 149796–149806. [Google Scholar] [CrossRef]
- Algarni, M. An Extra Security Measurement for Android Mobile Applications Using the Fingerprint Authentication Methodology. J. Inf. Secur. Cybercrimes Res. 2023, 6, 139–149. [Google Scholar] [CrossRef]
- Syazana-Itqan, K.; Syafeeza, A.; Saad, N.; Hamid, N.A.; Saad, W. A review of finger-vein biometrics identification approaches. Indian J. Sci. Technol. 2016, 9, 1–9. [Google Scholar] [CrossRef]
- Yin, Y.; Liu, L.; Sun, X. SDUMLAHMT: A multimodal biometric database. In Chinese Conference on Biometric Recognition; Springer: Berlin/Heidelberg, Germany, 2011; pp. 260–268. [Google Scholar]
- Asaari, M.S.M.; Suandi, S.A.; Rosdi, B.A. Fusion of band limited phase only correlation and width centroid contour distance for finger based biometrics. Expert Syst. Appl. 2014, 41, 3367–3382. [Google Scholar] [CrossRef]
- Qiu, X.; Kang, W.; Tian, S.; Jia, W.; Huang, Z. Finger vein presentation attack detection using total variation decomposition. IEEE Trans. Inf. Forensics Secur. 2017, 13, 465–477. [Google Scholar] [CrossRef]
- Yang, W.; Qin, C.; Liao, Q. A database with ROI extraction for studying fusion of finger vein and finger dorsal texture. In Chinese Conference on Biometric Recognition; Springer: Berlin/Heidelberg, Germany, 2014; pp. 266–270. [Google Scholar]
- Miura, N.; Nagasaka, A.; Miyatake, T. Feature extraction of finger-vein patterns based on repeated line tracking and its application to personal identification. Mach. Vis. Appl. 2004, 15, 194–203. [Google Scholar] [CrossRef]
- Miura, N.; Nagasaka, A.; Miyatake, T. Extraction of finger vein patterns using maximum curvature points in image profiles. IEICE TRANSACTIONS Inf. Syst. 2007, 90, 1185–1194. [Google Scholar] [CrossRef]
- Huang, B.; Dai, Y.; Li, R.; Tang, D.; Li, W. Finger vein authentication based on wide line detector and pattern normalization. In Proceedings of the 2010 20th International Conference on Pattern Recognition, Istanbul, Turkey, 23–26 August 2010; IEEE: Piscataway, NJ, USA, 2010; pp. 1269–1272. [Google Scholar]
- Ma, H.; Hu, N.; Fang, C. The biometric recognition system based on near-infrared finger vein image. Infrared Phys. Technol. 2021, 116, 103734. [Google Scholar] [CrossRef]
- Zhang, W.; Wang, Y. Core based structure matching algorithm of Finger Vein verification. In Object Recognition Supported by User Interaction for Service Robots; IEEE: Piscataway, NJ, USA, 2002; Volume 1, pp. 70–74. [Google Scholar]
- Nagao, M. Methods of Image Pattern Recognition; Corona: San Antonio, TX, USA, 1983. [Google Scholar]
- Meng, X.; Zheng, J.; Xi, X.; Zhang, Q.; Yin, Y. Finger vein recognition based on zone-based minutia matching. Neurocomputing 2021, 423, 110–123. [Google Scholar] [CrossRef]
- Minaee, S.; Abdolrashidi, A.; Su, H.; Bennamoun, M.; Zhang, D. Biometrics recognition using deep learning: A survey. arXiv 2019, arXiv:1912.00271. [Google Scholar] [CrossRef]
- Hong, H.G.; Lee, M.B.; Park, K.R. Convolutional neural network based finger vein recognition using nir image sensors. Sensors 2017, 17, 1297. [Google Scholar] [CrossRef] [PubMed]
- Zeng, J.; Wang, F.; Deng, J.; Qin, C.; Zhai, Y.; Gan, J.; Piuri, V. Finger vein verification algorithm based on fully convolutional neural network and conditional random field. IEEE Access 2020, 8, 65402–65419. [Google Scholar] [CrossRef]
- Kuzu, R.S.; Maioranay, E.; Campisi, P. Vein-based biometric verification using transfer learning. In Proceedings of the 2020 43rd International Conference on Telecommunications and Signal Processing (TSP), Milan, Italy, 7–9 July 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 403–409. [Google Scholar]
- Yang, W.; Hui, C.; Chen, Z.; Xue, J.; Liao, Q. FV-GAN: Finger vein representation using generative adversarial networks. IEEE Trans. Inf. Forensics Secur. 2019, 14, 2512–2524. [Google Scholar] [CrossRef]
- Hou, B.; Yan, R. Triplet-classier gan for finger-vein verification. IEEE Trans. Instrum. Meas. 2022, 71, 212–223. [Google Scholar] [CrossRef]
- Yang, W.; Shi, D.; Zhou, W. Convolutional neural network approach based on multimodal biometric system with fusion of face and finger vein features. Sensors 2022, 22, 6039. [Google Scholar] [CrossRef] [PubMed]
- Lin, H.Y. Embedded Artificial Intelligence: Intelligence on Devices. Computer 2023, 56, 90–93. [Google Scholar] [CrossRef]
- Zhao, D.; Ma, H.; Yang, Z.; Li, J.; Tian, W. Finger vein recognition based on lightweight CNN combining center loss and dynamic regularization. Infrared Phys. Technol. 2020, 105, 103221. [Google Scholar] [CrossRef]
- Hsia, C.H.; Ke, L.Y.; Chen, S.T. Improved Lightweight Convolutional Neural Network for Finger Vein Recognition System. Bioengineering 2023, 10, 919. [Google Scholar] [CrossRef]
- Ding, X.; Zhang, X.; Han, J.; Ding, G. Diverse branch block: Building a convolution as an inception-like unit. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Chaman, A.; Dokmanic, I. Truly shift-invariant convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Noh, K.J.; Choi, J.; Hong, J.S.; Park, K.R. Finger-Vein Recognition Based on Densely Connected Convolutional Network Using Score-Level Fusion with Shape and Texture Images. IEEE Access 2020, 8, 96748–96766. [Google Scholar] [CrossRef]
- Zhang, X.; Zhou, X.; Lin, M.; Sun, J. Shufflenet: An extremely efficient convolutional neural network for mobile devices. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018. [Google Scholar]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Searching for mobilenetv3. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019. [Google Scholar]
- Mehta, S.; Rastegari, M. Mobilevit: Light-weight, general-purpose, and mobile-friendly vision transformer. arXiv 2021, arXiv:2110.02178. [Google Scholar]
- Wu, D.; Wang, Y.; Xia, S.T.; Bailey, J.; Ma, X. Skip connections matter: On the transferability of adversarial examples generated with resnets. arXiv 2020, arXiv:2002.05990. [Google Scholar]
- Zhu, X.; Bain, M. B-CNN: Branch convolutional neural network for hierarchical classification. arXiv 2017, arXiv:1709.09890. [Google Scholar]
- Zhang, R. Making convolutional networks shift-invariant again. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.-Y.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision, Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Zhang, Q.-L.; Yang, Y.-B. Sa-net: Shuffle attention for deep convolutional neural networks. In Proceedings of the ICASSP 2021-2021 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Toronto, ON, Canada, 6–11 June 2021; IEEE: Piscataway, NJ, USA, 2021. [Google Scholar]
- Boutros, F.; Damer, N.; Kirchbuchner, F.; Kuijper, A. ElasticFace: Elastic margin loss for deep face recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, New Orleans, LA, USA, 18–24 June 2022; pp. 1578–1587. [Google Scholar]
- Lu, H.; Wang, Y.; Gao, R.; Zhao, C.; Li, Y. A novel roi extraction method based on the characteristics of the original finger vein image. Sensors 2021, 21, 4402. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019. [Google Scholar]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Database | # of Classes | # of Samples per Class | Total Samples |
|---|---|---|---|
| SDUMLA-FV | 636 | 6 | 3816 |
| FV-USM | 492 | 12 | 5904 |
| SCUT-FVD | 606 | 6 | 3636 |
| THU-FVFDT | 610 | 2 | 1220 |
| Model | CIR (%) | Params (M) | Inference Time (ms) | FLOPs (G) | |||
|---|---|---|---|---|---|---|---|
| FV-USM | SCUT-FVD | SDUMLA-FV | THU-FVFDT | ||||
| resnet50 [47] | 99.70 | 97.17 | 95.44 | 70.10 | 24.81 | 1.13 | 2.18 |
| inception_v3 [2] | 99.59 | 96.67 | 95.75 | 60.33 | 22.8 | 1.03 | 1.082 |
| mobilenetv2_035 [36] | 99.09 | 82.17 | 84.28 | 31.80 | 1.21 | 0.77 | 0.035 |
| mobilenetv3_small_050 [37] | 99.19 | 90.17 | 84.91 | 60.57 | 1.07 | 0.69 | 0.024 |
| mobilevit_xxs [38] | 99.29 | 89.33 | 84.28 | 50.98 | 1.16 | 0.92 | 0.115 |
| mobilevitv2_050 [38] | 99.39 | 83.17 | 82.08 | 28.20 | 1.24 | 0.83 | 0.196 |
| efficientnet_b0 [48] | 99.24 | 93.83 | 88.52 | 46.56 | 4.64 | 0.82 | 0.218 |
| ILCNN [30] | 99.80 | 95.50 | 97.48 | 51.31 | 1.23 | 0.88 | 0.198 |
| Proposed | 99.90 | 97.83 | 97.80 | 68.69 | 0.365 | 0.49 | 0.149 |
| Model | CIR (%) | Params (M) | Inference Time (ms) | FLOPs (G) | |||
|---|---|---|---|---|---|---|---|
| FV-USM | SCUT-FVD | SDUMLA-FV | THU-FVFDT | ||||
| (1) Proposed (ZSCA + Blur) | 99.9 | 97.83 | 97.8 | 68.69 | 0.365 | 0.498 | 74.58 |
| (2) Proposed (ZSCA) | 99.8 | 96.67 | 97.43 | 60.33 | 0.365 | 0.498 | 74.58 |
| (3) Proposed (Blur) | 99.9 | 97.17 | 97.64 | 57.05 | 0.371 | 0.512 | 74.73 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tran, N.C.; Pham, B.-T.; Chu, V.C.-M.; Li, K.-C.; Le, P.T.; Chen, S.-L.; Frisky, A.Z.K.; Li, Y.-H.; Wang, J.-C. Zero-FVeinNet: Optimizing Finger Vein Recognition with Shallow CNNs and Zero-Shuffle Attention for Low-Computational Devices. Electronics 2024, 13, 1751. https://doi.org/10.3390/electronics13091751
Tran NC, Pham B-T, Chu VC-M, Li K-C, Le PT, Chen S-L, Frisky AZK, Li Y-H, Wang J-C. Zero-FVeinNet: Optimizing Finger Vein Recognition with Shallow CNNs and Zero-Shuffle Attention for Low-Computational Devices. Electronics. 2024; 13(9):1751. https://doi.org/10.3390/electronics13091751
Chicago/Turabian StyleTran, Nghi C., Bach-Tung Pham, Vivian Ching-Mei Chu, Kuo-Chen Li, Phuong Thi Le, Shih-Lun Chen, Aufaclav Zatu Kusuma Frisky, Yung-Hui Li, and Jia-Ching Wang. 2024. "Zero-FVeinNet: Optimizing Finger Vein Recognition with Shallow CNNs and Zero-Shuffle Attention for Low-Computational Devices" Electronics 13, no. 9: 1751. https://doi.org/10.3390/electronics13091751
APA StyleTran, N. C., Pham, B.-T., Chu, V. C.-M., Li, K.-C., Le, P. T., Chen, S.-L., Frisky, A. Z. K., Li, Y.-H., & Wang, J.-C. (2024). Zero-FVeinNet: Optimizing Finger Vein Recognition with Shallow CNNs and Zero-Shuffle Attention for Low-Computational Devices. Electronics, 13(9), 1751. https://doi.org/10.3390/electronics13091751