
Byzantine Fault-Tolerant Federated Learning Based on Trustworthy Data and Historical Information


Abstract
1. Introduction
- We introduce FLTH, which provides Byzantine fault tolerance by assessing client nodes from a historical perspective based on trustworthy data.
- We show that FLTH has a low time complexity, which does not compromise the training efficiency, and establish its convergence result under mild assumptions.
- We conduct extensive simulations to evaluate the performance of FLTH. The simulation results show that FLTH achieves higher model accuracy compared to state-of-the-art methods under typical kinds of attack.
2. Related Work
2.1. Attacks on Federated Learning
2.2. Fault-Tolerant Algorithms
3. Problem Formulation
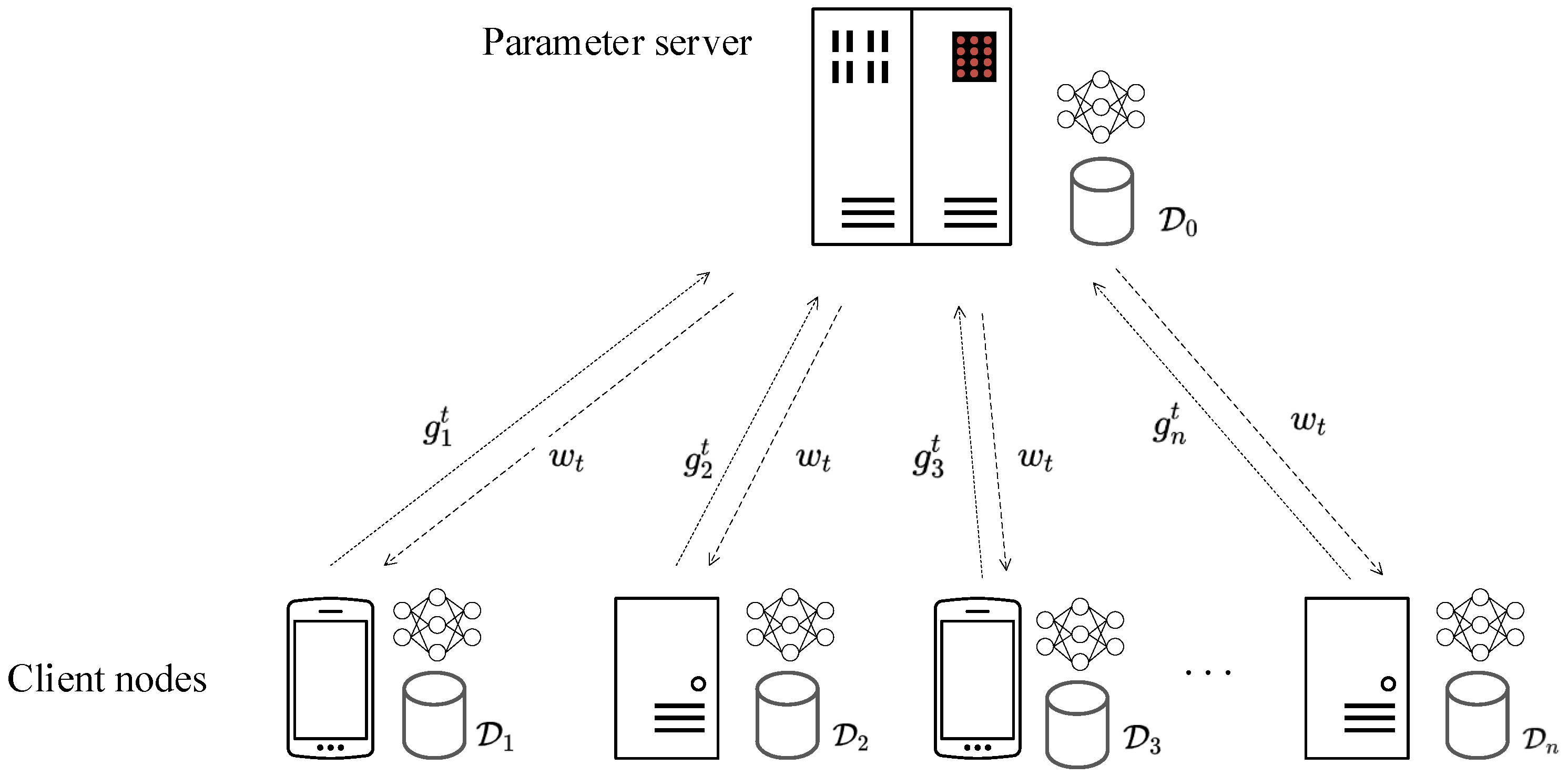
3.1. Federated Learning Framework
- First, the parameter server broadcasts the current global model to every client node.
- If a client node is honest, it then computes its local model gradient and sends to the parameter server. If otherwise, it sends an arbitrary vector instead.
- After collecting every , , the parameter server finally employs an aggregation algorithm to obtain an aggregated gradient update , and subsequently utilizes the learning rate to achieve a new global model as follows:
3.2. Attack Model
3.3. Defender’s Ability
4. Federated Learning with Trustworthy Data and Historical Information
4.1. Algorithm Description
| Algorithm 1 FLTH Algorithm |
| Input: |
| client nodes number n, initial model , learning rate |
| momentum parameter , filter parameter k |
| training round T, fault tolerance parameter p |
| Initialize: |
| client nodes global credibility value |
| Output: |
| Global model |
| for to T do |
| parameter server send model to all client nodes |
| Client node: |
| for to n do |
| client node i calculates |
| send to parameter server |
| end for |
| Parameter Server: |
| parameter server calculates |
| let |
| for to n do |
| if then |
| calculate client node i’s credibility value |
| else |
| client node i’s credibility value |
| end if |
| end for |
| for to n do |
| client node credibility value normalization |
| end for |
| for to n do |
| calculate client node i’s global credibility value |
| end for |
| calculate sum of global credibility value |
| |
| end for |
| return |
4.2. Convergence Result
5. Performance Evaluation
5.1. Experiment Setup
5.2. Attacks
- Sign-Flipping attack: where each parameter of the gradient sent to the parameter server by a Byzantine node is set to be the opposite value of the training gradient.
- Label-Flipping attack: For Label-Flipping, since both the MNIST and CIFAR-10 datasets have only the labels ‘0’ to ‘9’, we will modify their labels to range from ‘9’ to ‘0’, respectively.
- ALIE attack [21]: ALIE is a targeted attack method. It allows all colluding client nodes to send the same value, causing errors in the final result. In this paper, we adopt the default settings in [21] as our chosen attack strategy, where all the Byzantine nodes send . Here, is the set of honest client nodes, is standard deviation function, and , where denotes cumulative standard normal function, and f denotes the number of Byzantine nodes.
5.3. Fault Tolerance Algorithms for Comparison
5.4. Experimental Results
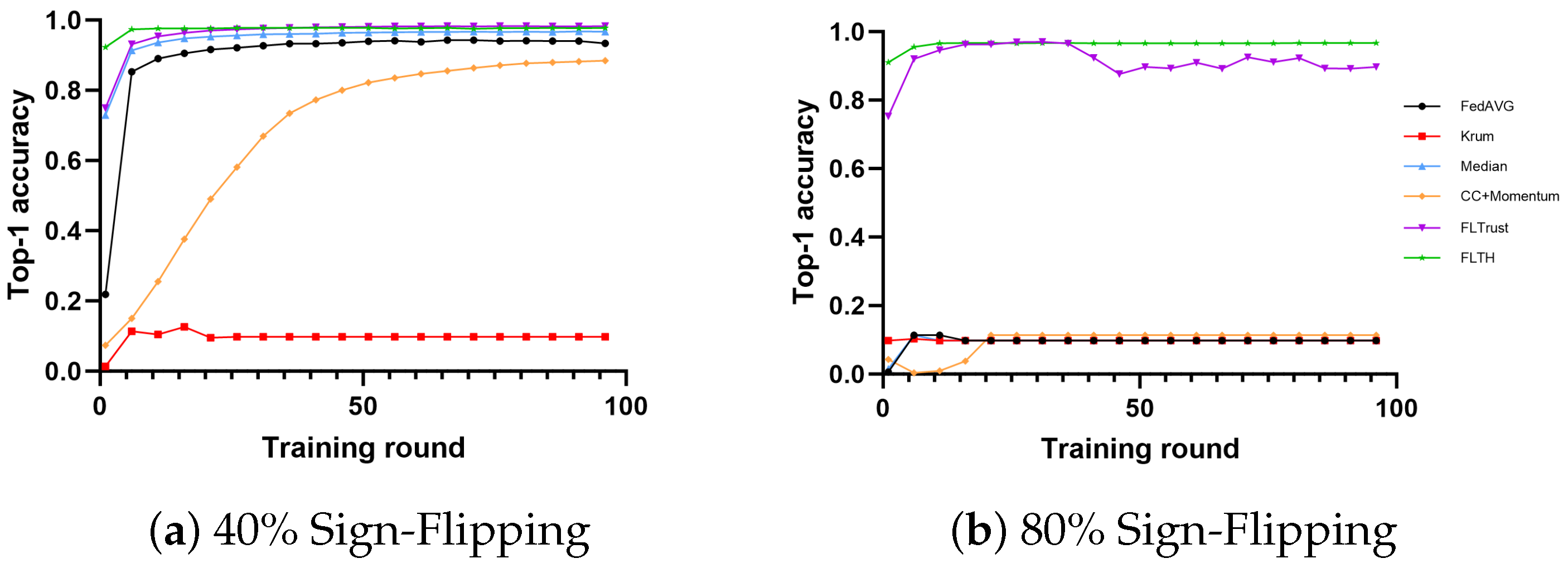
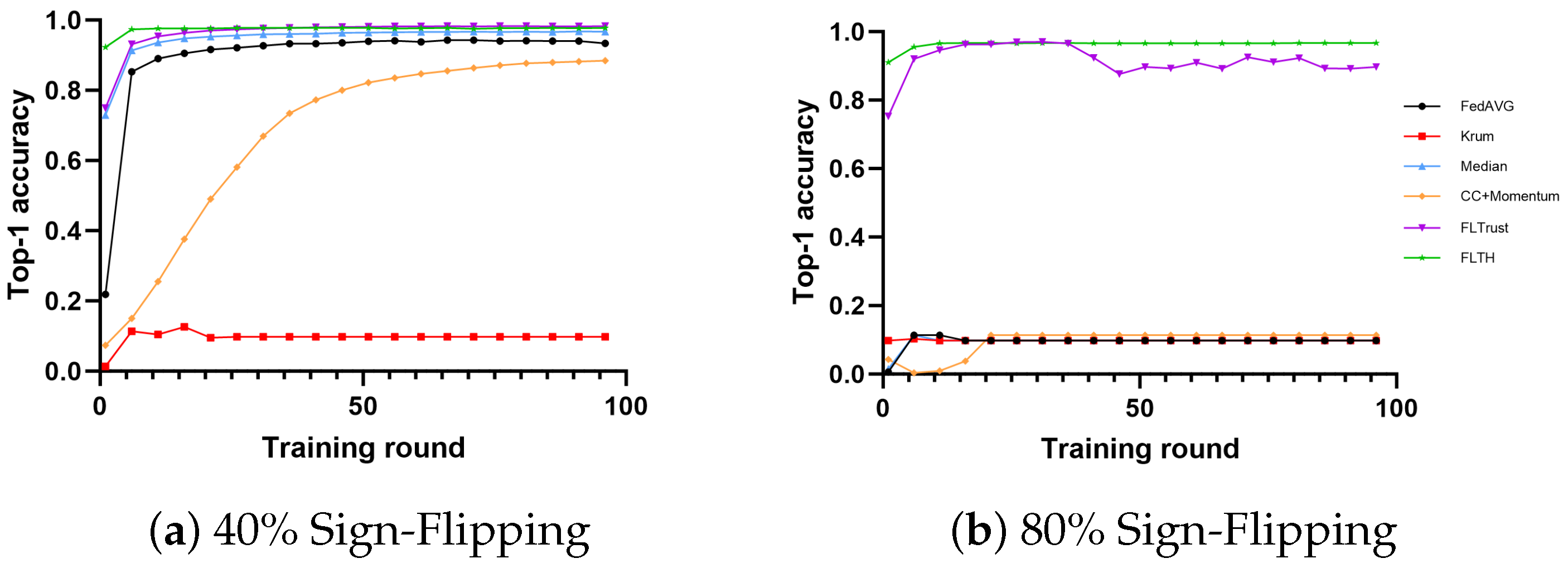
- In the MNIST dataset, under the condition of 40% Byzantine nodes, except for Krum, all algorithms exhibit high accuracy. Among them, FLTH, FLTrust, and Median perform well. Additionally, FedAvg also demonstrates fault tolerance capabilities. We believe this is because Byzantine nodes only send gradients opposite to the original gradients, allowing a large proportion of honest client nodes to partially offset the influence of these Byzantine nodes. Although CC + Momentum is fault-tolerant, it lags behind most methods to some extent. Under the condition of 80% Byzantine nodes, only FLTH and FLTrust demonstrate fault tolerance capabilities, with FLTH being approximately 6% higher in accuracy compared to FLTrust.
- In the CIFAR-10 dataset, under the condition of 40% Byzantine nodes, only FLTH and FLTrust perform well, while Median and Krum are significantly disrupted by Byzantine nodes. Under the condition of 80% Byzantine nodes, only FLTH and FLTrust demonstrate fault tolerance capabilities, with FLTH being approximately 2.5% higher in accuracy compared to FLTrust.
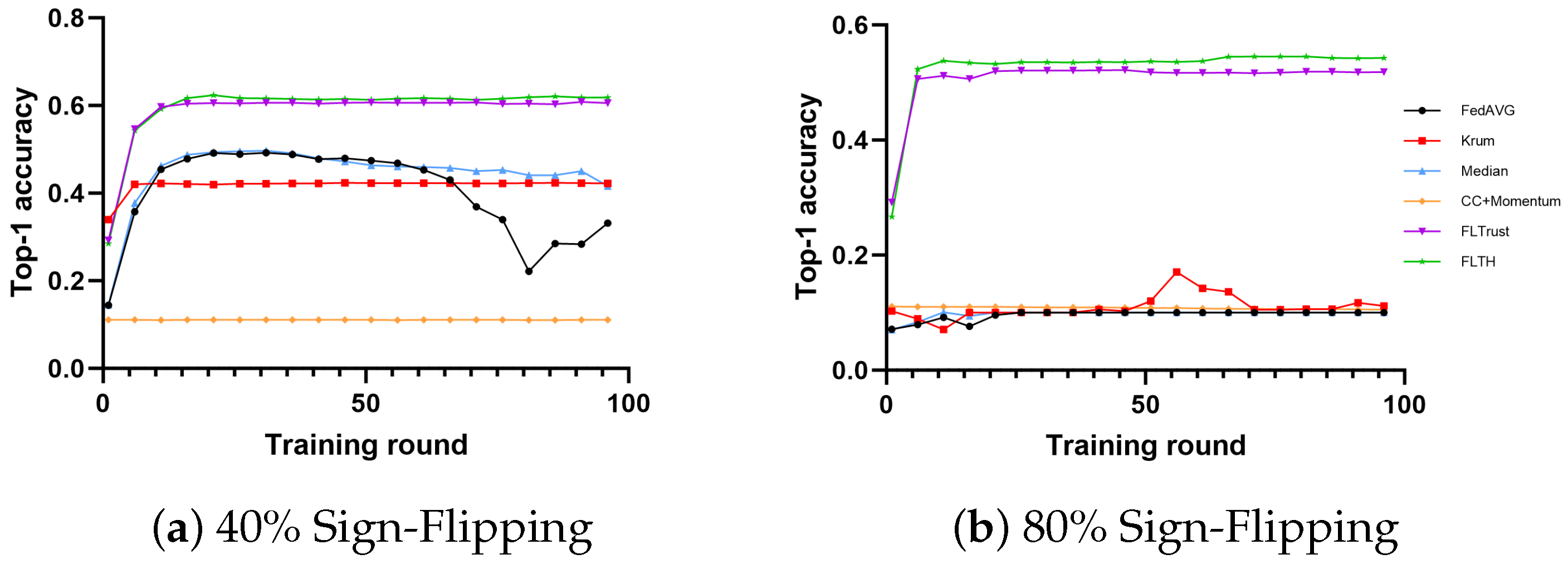
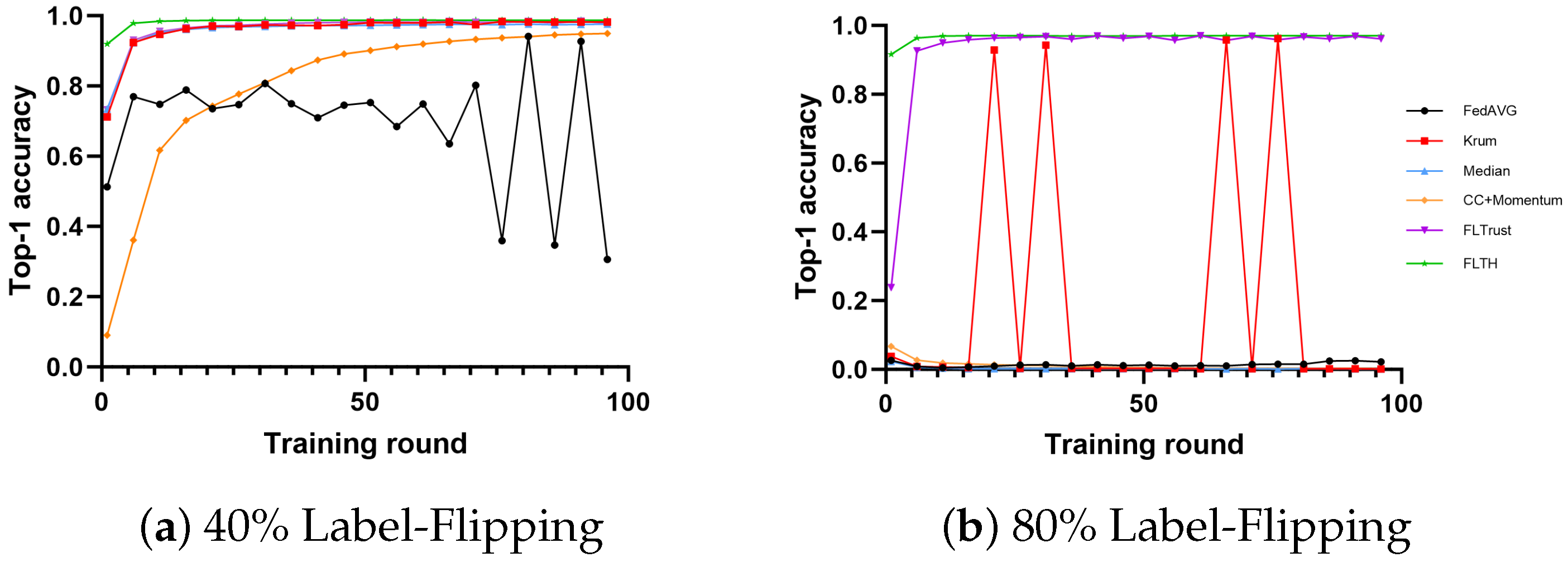
- In the MNIST dataset, all methods except FedAvg exhibit fault tolerance with 40% Byzantine nodes, showing little difference in performance. The reason for this is that the gradients of the Byzantine nodes differ significantly from those of honest client nodes’ gradients. Under the condition of 80% Byzantine nodes, only FLTH and FLTrust demonstrate fault tolerance capabilities, with no significant difference in accuracy performance.
- In the CIFAR-10 dataset, under the condition of 40% Byzantine nodes, FLTH and Median perform well, while other fault-tolerant methods are affected on different levels. Under the condition of 80% Byzantine nodes, only FLTH achieves fault tolerance.
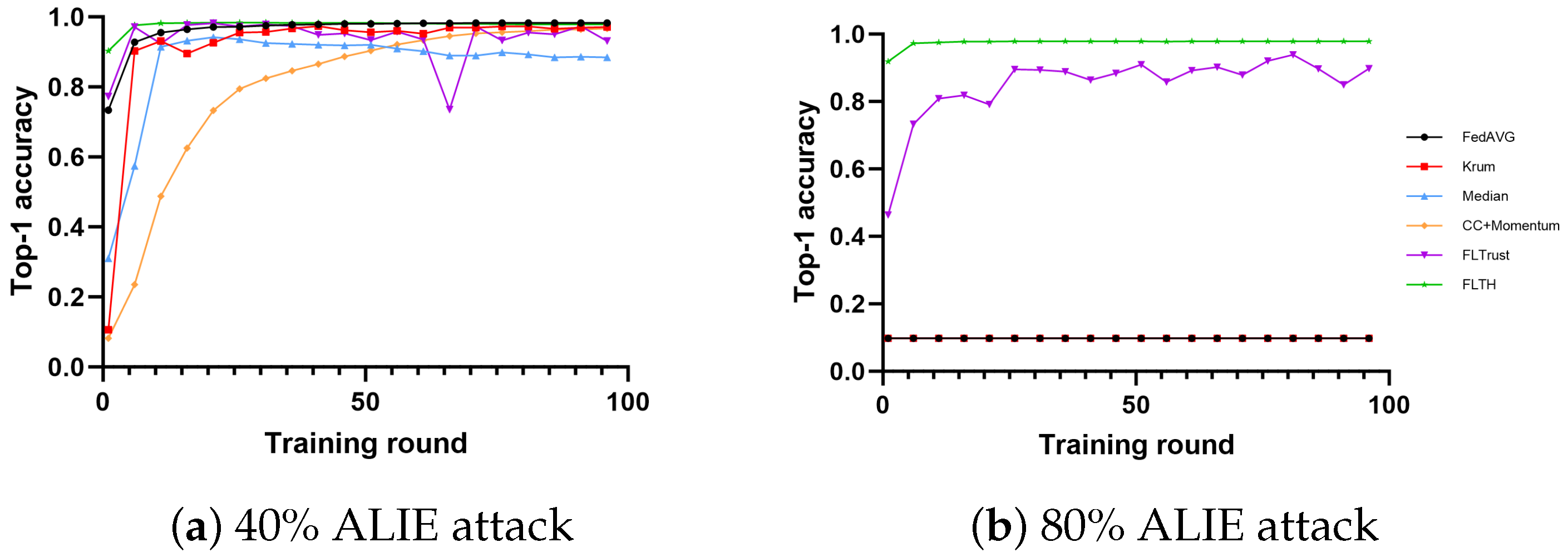
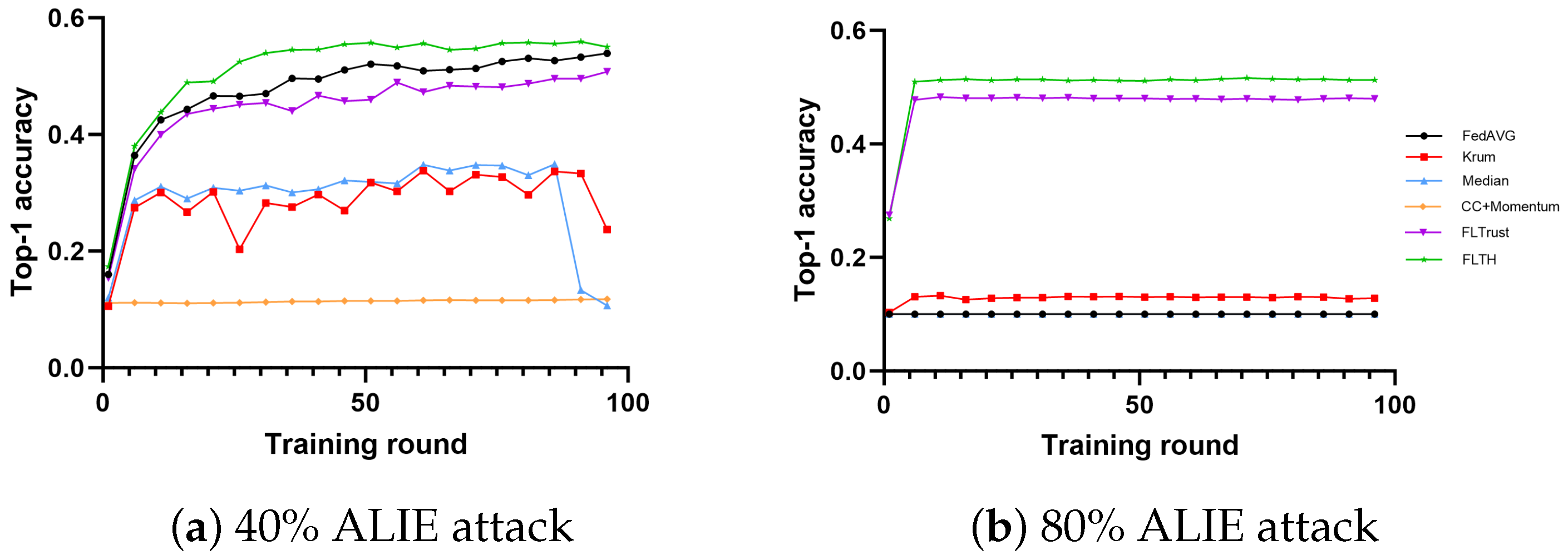
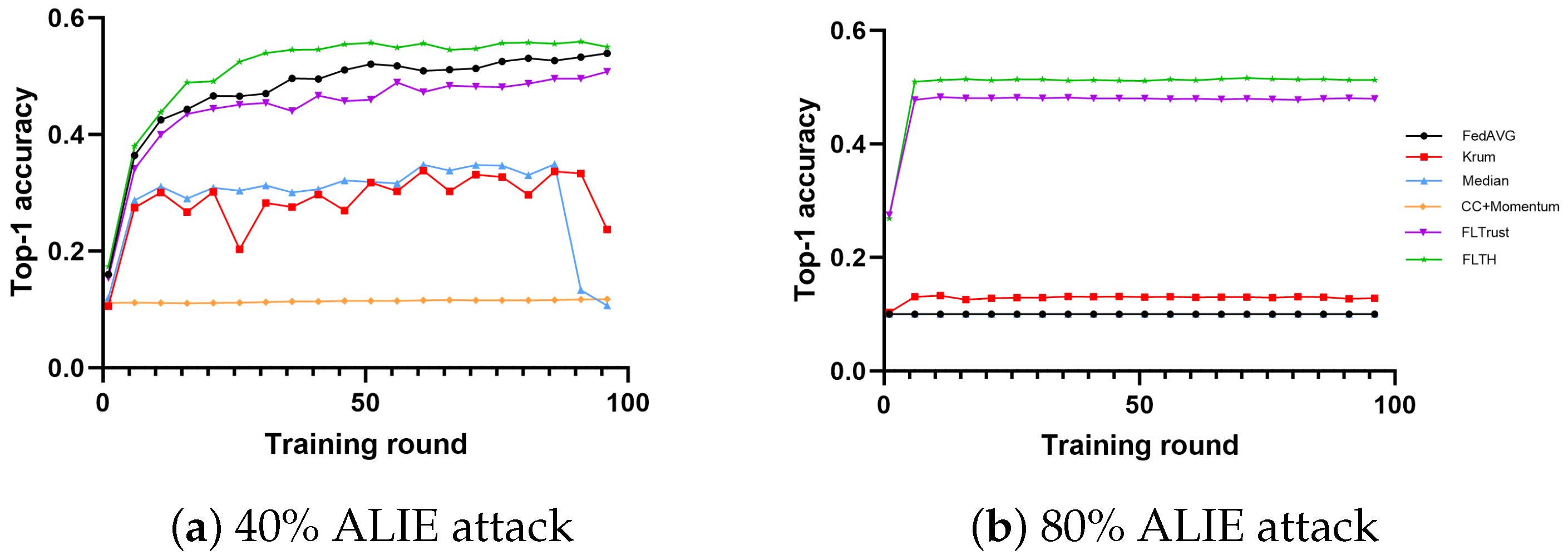
- In the MNIST dataset, under the condition of 40% Byzantine nodes, all methods are minimally affected in terms of accuracy, with Median being the most affected. We attribute this to the ALIE attack, which causes smaller but more definite gradient shifts. Under the condition of 80% Byzantine nodes, FLTH and FLTrust demonstrate fault tolerance, with FLTH achieving approximately 8% higher accuracy compared to FLTrust. We believe FLTrust is impacted significantly because it evaluates nodes in each round of aggregation independently.
- In the CIFAR-10 dataset, under the condition of 40% Byzantine nodes, FLTH, FedAvg, and FLTrust perform well, while other methods are significantly impacted. Under the condition of 80% Byzantine nodes, only FLTH and FLTrust exhibit fault tolerance, with FLTH achieving approximately 3% higher accuracy compared to FLTrust.
- For the MNIST dataset, FLTH with performs slightly better than that with and in all circumstances.
- For the CIFAR-10 dataset, FLTH with performs slightly better than that with and in most cases. One exception is that FLTH with achieves a low accuracy when there are 80% Byzantine nodes performing the Label-Flipping attack, where cannot provide sufficient fault tolerance capability.
6. Concluding Remarks
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- McMahan, B.; Moore, E.; Ramage, D.; Hampson, S.; Arcas, B.A. Communication-efficient learning of deep networks from decentralized data. In Proceedings of the Artificial Intelligence and Statistics, Fort Lauderdale, FL, USA, 20–22 April 2017; pp. 1273–1282. [Google Scholar]
- Sheller, M.J.; Edwards, B.; Reina, G.A.; Martin, J.; Pati, S.; Kotrotsou, A.; Milchenko, M.; Xu, W.; Marcus, D.; Colen, R.R.; et al. Federated learning in medicine: Facilitating multi-institutional collaborations without sharing patient data. Sci. Rep. 2020, 10, 12598. [Google Scholar] [CrossRef] [PubMed]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated learning for mobile keyboard prediction. arXiv 2018, arXiv:1811.03604. [Google Scholar]
- Chen, M.; Yang, Z.; Saad, W.; Yin, C.; Poor, H.V.; Cui, S. A joint learning and communications framework for federated learning over wireless networks. IEEE Trans. Wirel. Commun. 2020, 20, 269–283. [Google Scholar] [CrossRef]
- Blanchard, P.; El Mhamdi, E.M.; Guerraoui, R.; Stainer, J. Machine learning with adversaries: Byzantine tolerant gradient descent. In Proceedings of the Advances in Neural Information Processing Systems 30 (NeurIPS 2017), Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Guerraoui, R.; Rouault, S. The hidden vulnerability of distributed learning in byzantium. In Proceedings of the International Conference on Machine Learning, Honolulu, HI, USA, 23–29 July 2018; pp. 3521–3530. [Google Scholar]
- Pillutla, K.; Kakade, S.M.; Harchaoui, Z. Robust aggregation for federated learning. IEEE Trans. Signal Process. 2022, 70, 1142–1154. [Google Scholar] [CrossRef]
- Nguyen, T.D.; Rieger, P.; De Viti, R.; Chen, H.; Brandenburg, B.B.; Yalame, H.; Möllering, H.; Fereidooni, H.; Marchal, S.; Miettinen, M.; et al. FLAME: Taming backdoors in federated learning. In Proceedings of the 31st USENIX Security Symposium, Boston, MA, USA, 10–12 August 2022; pp. 1415–1432. [Google Scholar]
- Yin, D.; Chen, Y.; Kannan, R.; Bartlett, P. Byzantine-robust distributed learning: Towards optimal statistical rates. In Proceedings of the International Conference on Machine Learning, Stockholm, Sweden, 10–15 July 2018; pp. 5650–5659. [Google Scholar]
- Chen, Y.; Su, L.; Xu, J. Distributed statistical machine learning in adversarial settings: Byzantine gradient descent. Proc. ACM Meas. Anal. Comput. Syst. 2017, 1, 1–25. [Google Scholar] [CrossRef]
- Karimireddy, S.P.; He, L.; Jaggi, M. Learning from history for byzantine robust optimization. In Proceedings of the International Conference on Machine Learning, Virtual, 18–24 July 2021; pp. 5311–5319. [Google Scholar]
- Farhadkhani, S.; Guerraoui, R.; Gupta, N.; Pinot, R.; Stephan, J. Byzantine machine learning made easy by resilient averaging of momentums. In Proceedings of the International Conference on Machine Learning, Baltimore, MD, USA, 17–23 July 2022; pp. 6246–6283. [Google Scholar]
- Fu, S.; Xie, C.; Li, B.; Chen, Q. Attack-resistant federated learning with residual-based reweighting. arXiv 2019, arXiv:1912.11464. [Google Scholar]
- Alistarh, D.; Allen-Zhu, Z.; Li, J. Byzantine stochastic gradient descent. In Proceedings of the Advances in Neural Information Processing Systems 31 (NeurIPS 2018), Montréal, QC, Canada, 3–8 December 2018. [Google Scholar]
- Li, Z.; Liu, L.; Zhang, J.; Liu, J. Byzantine-robust federated learning through spatial-temporal analysis of local model updates. In Proceedings of the 2021 IEEE 27th International Conference on Parallel and Distributed Systems, Beijing, China, 14–16 December 2021; pp. 372–379. [Google Scholar]
- Xie, C.; Koyejo, S.; Gupta, I. Zeno: Distributed stochastic gradient descent with suspicion-based fault-tolerance. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 6893–6901. [Google Scholar]
- Cao, X.; Lai, L. Distributed gradient descent algorithm robust to an arbitrary number of byzantine attackers. IEEE Trans. Signal Process. 2019, 67, 5850–5864. [Google Scholar] [CrossRef]
- Cao, X.; Fang, M.; Liu, J.; Gong, N. FLTrust: Byzantine-robust Federated Learning via Trust Bootstrapping. In Proceedings of the Network and Distributed System Security Symposium, Virtual, 21–25 February 2021. [Google Scholar]
- Guo, H.; Wang, H.; Song, T.; Hua, Y.; Lv, Z.; Jin, X.; Xue, Z.; Ma, R.; Guan, H. Siren: Byzantine-robust federated learning via proactive alarming. In Proceedings of the ACM Symposium on Cloud Computing, Seattle, WA, USA, 1–4 November 2021; pp. 47–60. [Google Scholar]
- Bhagoji, A.N.; Chakraborty, S.; Mittal, P.; Calo, S. Analyzing federated learning through an adversarial lens. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; pp. 634–643. [Google Scholar]
- Baruch, G.; Baruch, M.; Goldberg, Y. A little is enough: Circumventing defenses for distributed learning. In Proceedings of the Advances in Neural Information Processing Systems 32 (NeurIPS 2019), Vancouver, BC, Canada, 8–14 December 2019. [Google Scholar]
- Xie, C.; Koyejo, O.; Gupta, I. Fall of empires: Breaking byzantine-tolerant sgd by inner product manipulation. In Proceedings of the Uncertainty in Artificial Intelligence, Online, 3–6 August 2020; pp. 261–270. [Google Scholar]
- Fang, M.; Cao, X.; Jia, J.; Gong, N. Local model poisoning attacks to Byzantine-Robust federated learning. In Proceedings of the 29th USENIX Security Symposium, Boston, MA, USA, 12–14 August 2020; pp. 1605–1622. [Google Scholar]
- Xie, C.; Huang, K.; Chen, P.Y.; Li, B. Dba: Distributed backdoor attacks against federated learning. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Shepard, D. A two-dimensional interpolation function for irregularly-spaced data. In Proceedings of the 23rd ACM National Conference, New York, NY, USA, 27–29 August 1968; pp. 517–524. [Google Scholar]
- LeCun, Y.; Bottou, L.; Bengio, Y.; Haffner, P. Gradient-based learning applied to document recognition. Proc. IEEE 1998, 86, 2278–2324. [Google Scholar] [CrossRef]
- Krizhevsky, A.; Hinton, G. Learning Multiple Layers of Features from Tiny Images. Technical Report. 2009. Available online: www.cs.utoronto.ca/~kriz/learning-features-2009-TR.pdf (accessed on 8 January 2024).
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| FedAvg | Krum | Median | CC+ Momentum | FLTrust | FLTH | |||
|---|---|---|---|---|---|---|---|---|
| 40% Byzantine nodes | MNIST | Sign-Flipping | 0.9077 | 0.0980 | 0.9665 | 0.8880 | 0.9824 | 0.9775 |
| Label-Flipping | 0.2963 | 0.9830 | 0.9757 | 0.9505 | 0.9800 | 0.9870 | ||
| ALIE | 0.9841 | 0.9735 | 0.8771 | 0.9688 | 0.9279 | 0.9779 | ||
| CIFAR-10 | Sign-Flipping | 0.2791 | 0.4228 | 0.4319 | 0.1108 | 0.6046 | 0.6170 | |
| Label-Flipping | 0.6070 | 0.4296 | 0.6159 | 0.1178 | 0.6113 | 0.6558 | ||
| ALIE | 0.5423 | 0.2515 | 0.1000 | 0.1180 | 0.5045 | 0.5652 | ||
| 80% Byzantine nodes | MNIST | Sign-Flipping | 0.0980 | 0.0980 | 0.0980 | 0.1135 | 0.8956 | 0.9669 |
| Label-Flipping | 0.0182 | 0.0032 | 0.0014 | 0.0023 | 0.9602 | 0.9704 | ||
| ALIE | 0.0980 | 0.0980 | 0.0980 | 0.0980 | 0.9029 | 0.9787 | ||
| CIFAR-10 | Sign-Flipping | 0.1000 | 0.1092 | 0.1000 | 0.1049 | 0.5187 | 0.5428 | |
| Label-Flipping | 0.1623 | 0.0773 | 0.0619 | 0.1167 | 0.1293 | 0.6485 | ||
| ALIE | 0.1000 | 0.1283 | 0.1000 | 0.1000 | 0.4804 | 0.5132 |
| 40% Byzantine nodes | MNIST | Sign-Flipping | 0.9702 | 0.9775 | 0.9705 |
| Label-Flipping | 0.9696 | 0.9870 | 0.9706 | ||
| ALIE | 0.9709 | 0.9779 | 0.9699 | ||
| CIFAR-10 | Sign-Flipping | 0.6230 | 0.6170 | 0.6174 | |
| Label-Flipping | 0.5291 | 0.6558 | 0.6205 | ||
| ALIE | 0.5477 | 0.5652 | 0.5936 | ||
| 80% Byzantine nodes | MNIST | Sign-Flipping | 0.9632 | 0.9669 | 0.9643 |
| Label-Flipping | 0.9701 | 0.9704 | 0.9704 | ||
| ALIE | 0.9700 | 0.9787 | 0.9698 | ||
| CIFAR-10 | Sign-Flipping | 0.5443 | 0.5428 | 0.5303 | |
| Label-Flipping | 0.2058 | 0.6485 | 0.5927 | ||
| ALIE | 0.5131 | 0.5132 | 0.5142 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Luo, X.; Tang, B. Byzantine Fault-Tolerant Federated Learning Based on Trustworthy Data and Historical Information. Electronics 2024, 13, 1540. https://doi.org/10.3390/electronics13081540
Luo X, Tang B. Byzantine Fault-Tolerant Federated Learning Based on Trustworthy Data and Historical Information. Electronics. 2024; 13(8):1540. https://doi.org/10.3390/electronics13081540
Chicago/Turabian StyleLuo, Xujiang, and Bin Tang. 2024. "Byzantine Fault-Tolerant Federated Learning Based on Trustworthy Data and Historical Information" Electronics 13, no. 8: 1540. https://doi.org/10.3390/electronics13081540
APA StyleLuo, X., & Tang, B. (2024). Byzantine Fault-Tolerant Federated Learning Based on Trustworthy Data and Historical Information. Electronics, 13(8), 1540. https://doi.org/10.3390/electronics13081540