
Applying Swin Architecture to Diverse Sign Language Datasets

 ,
,  ,
,  and
and
Abstract
1. Introduction
2. Related Work
3. Methodology
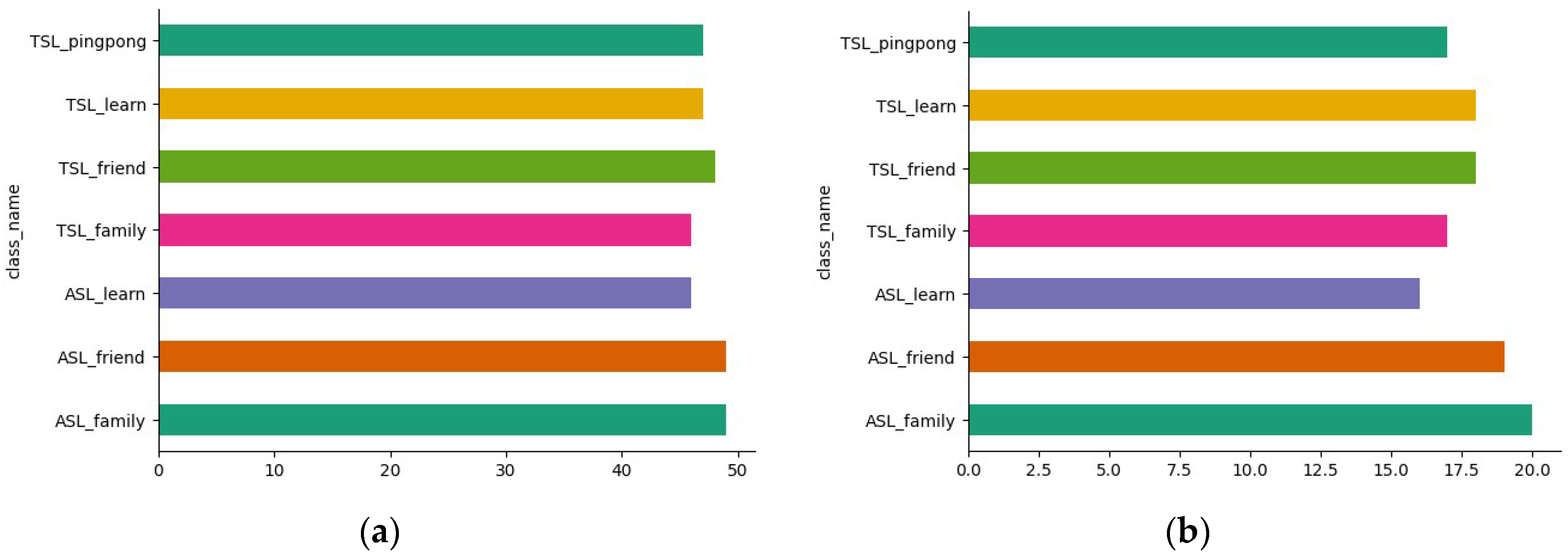
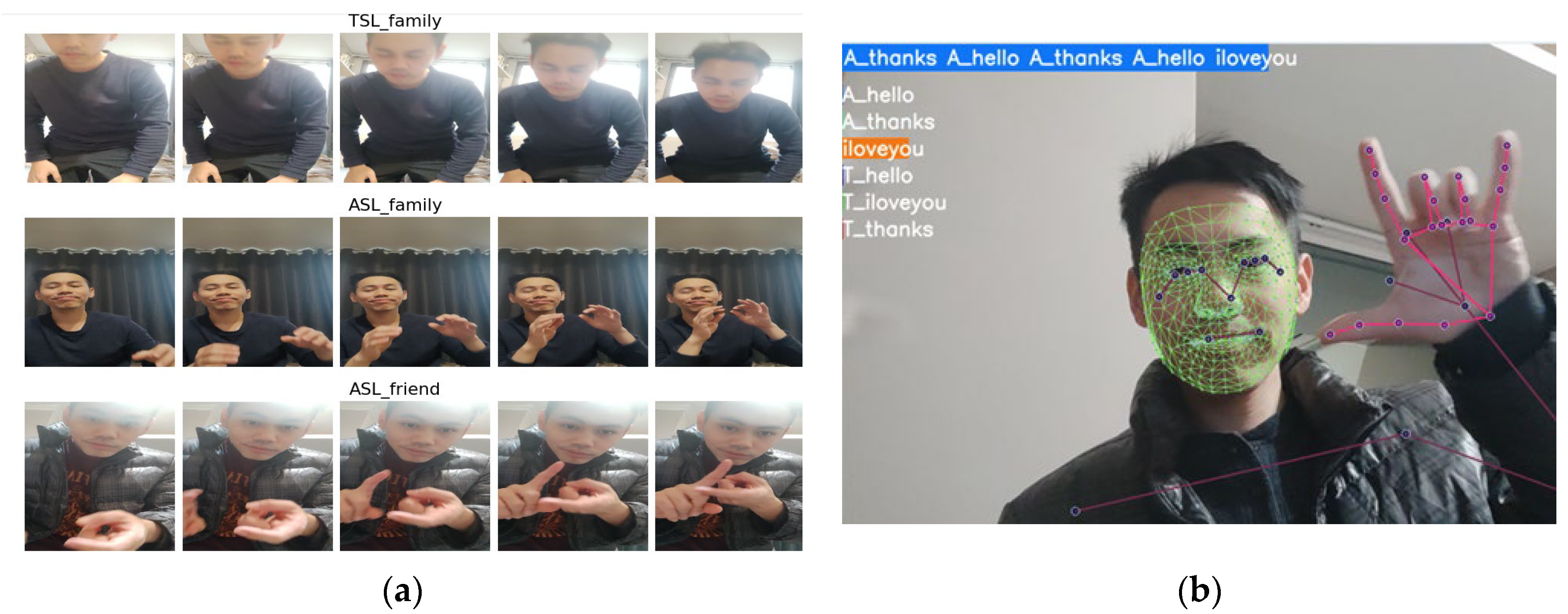
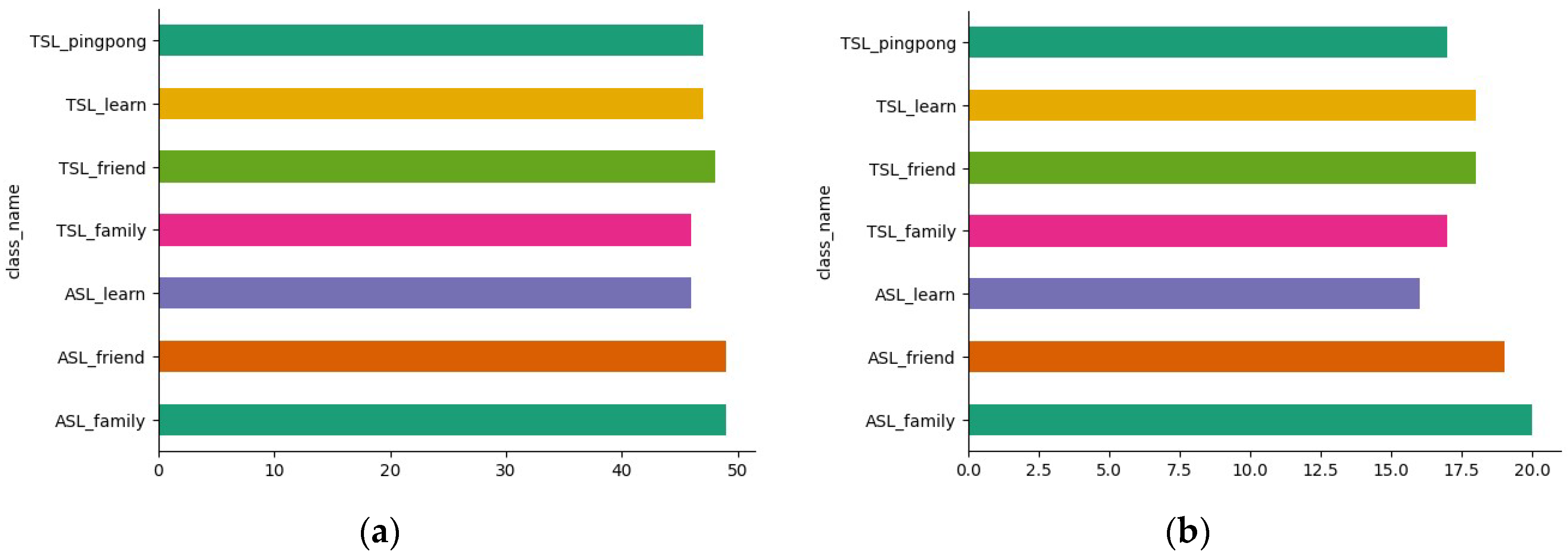
3.1. Diverse Datasets
3.2. Understanding Swin Transformer
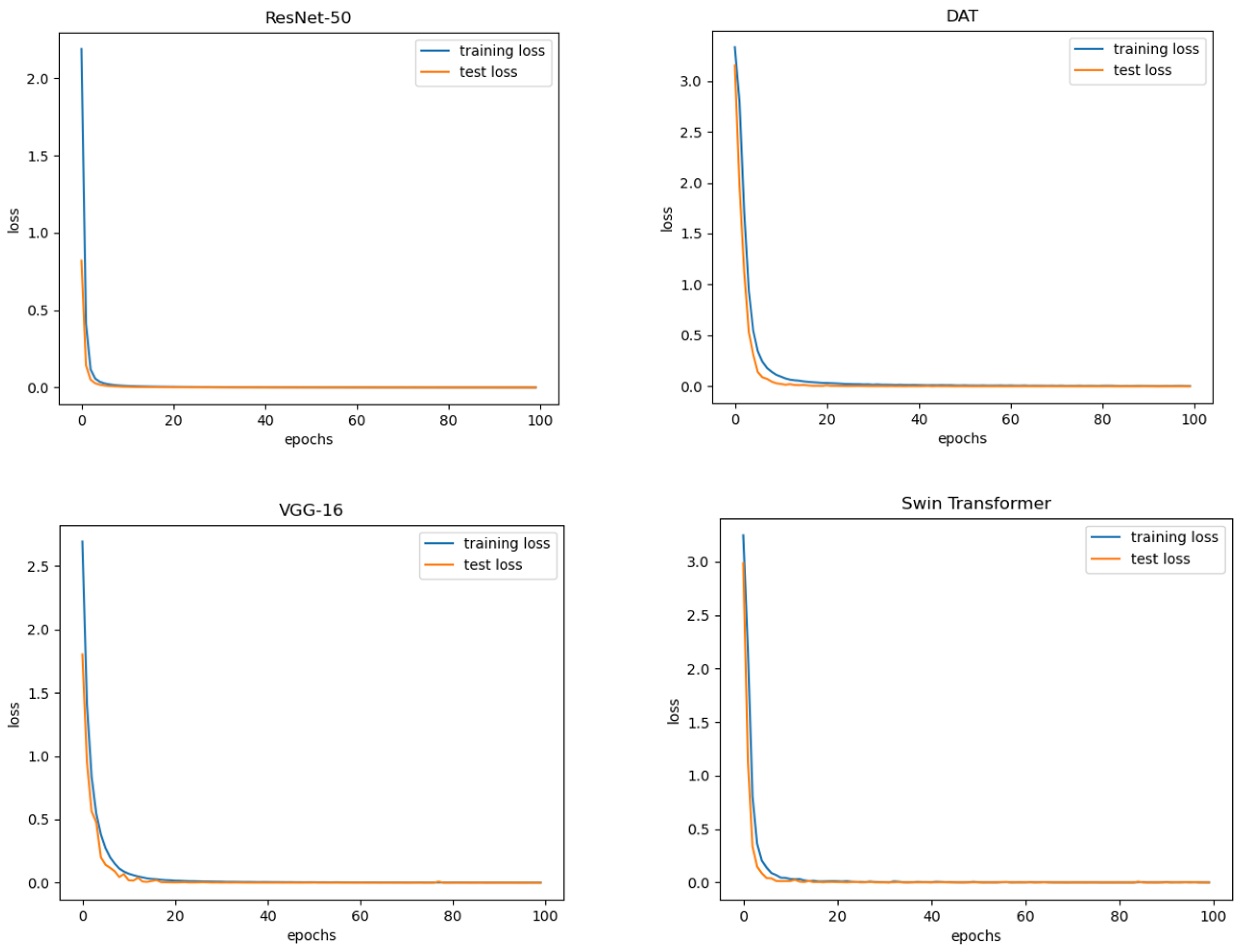
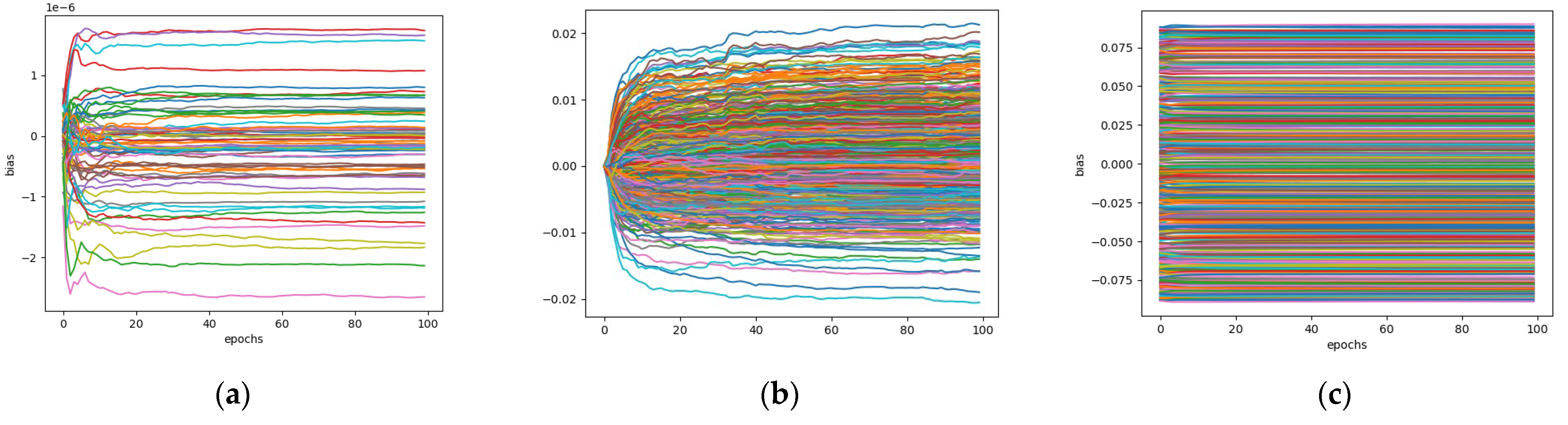
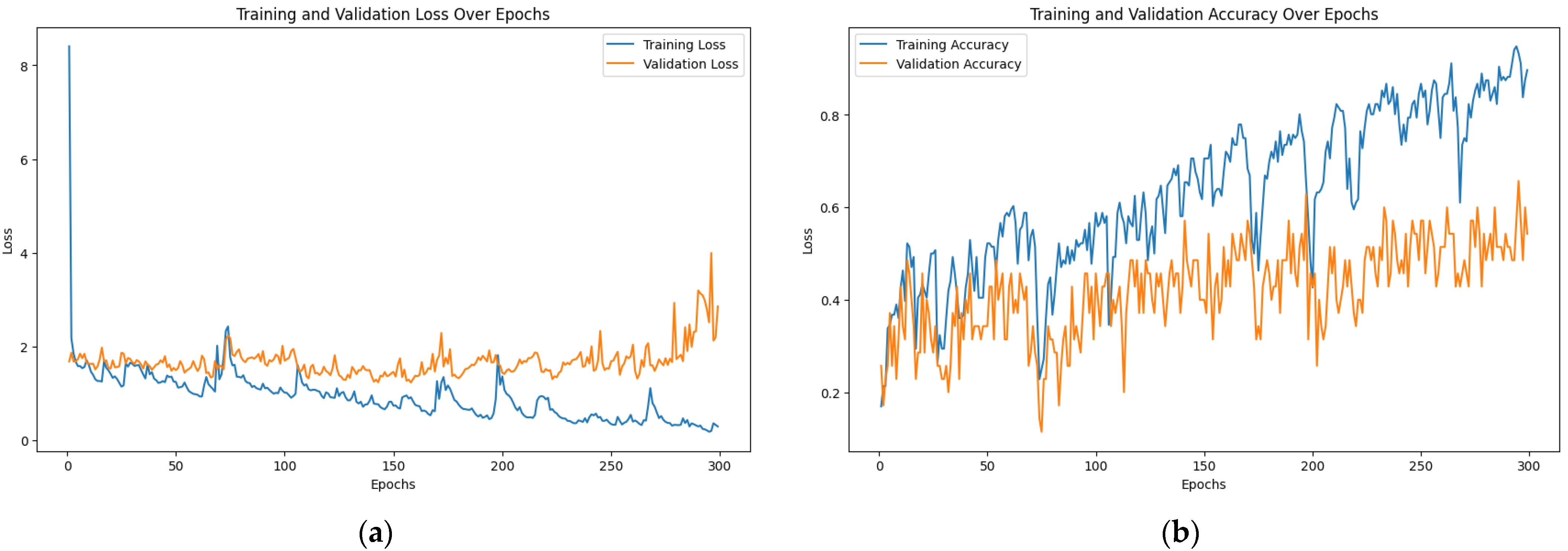
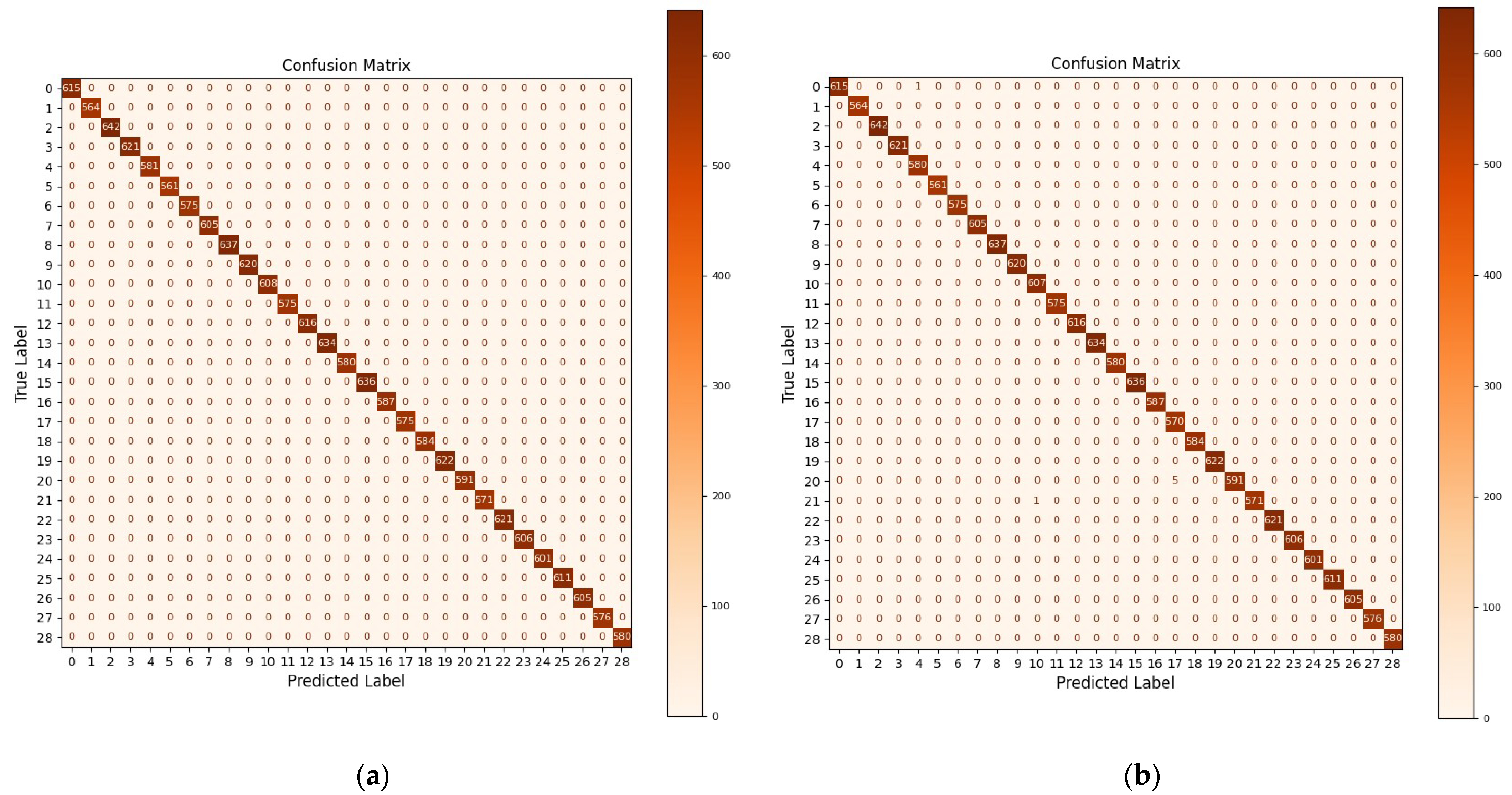
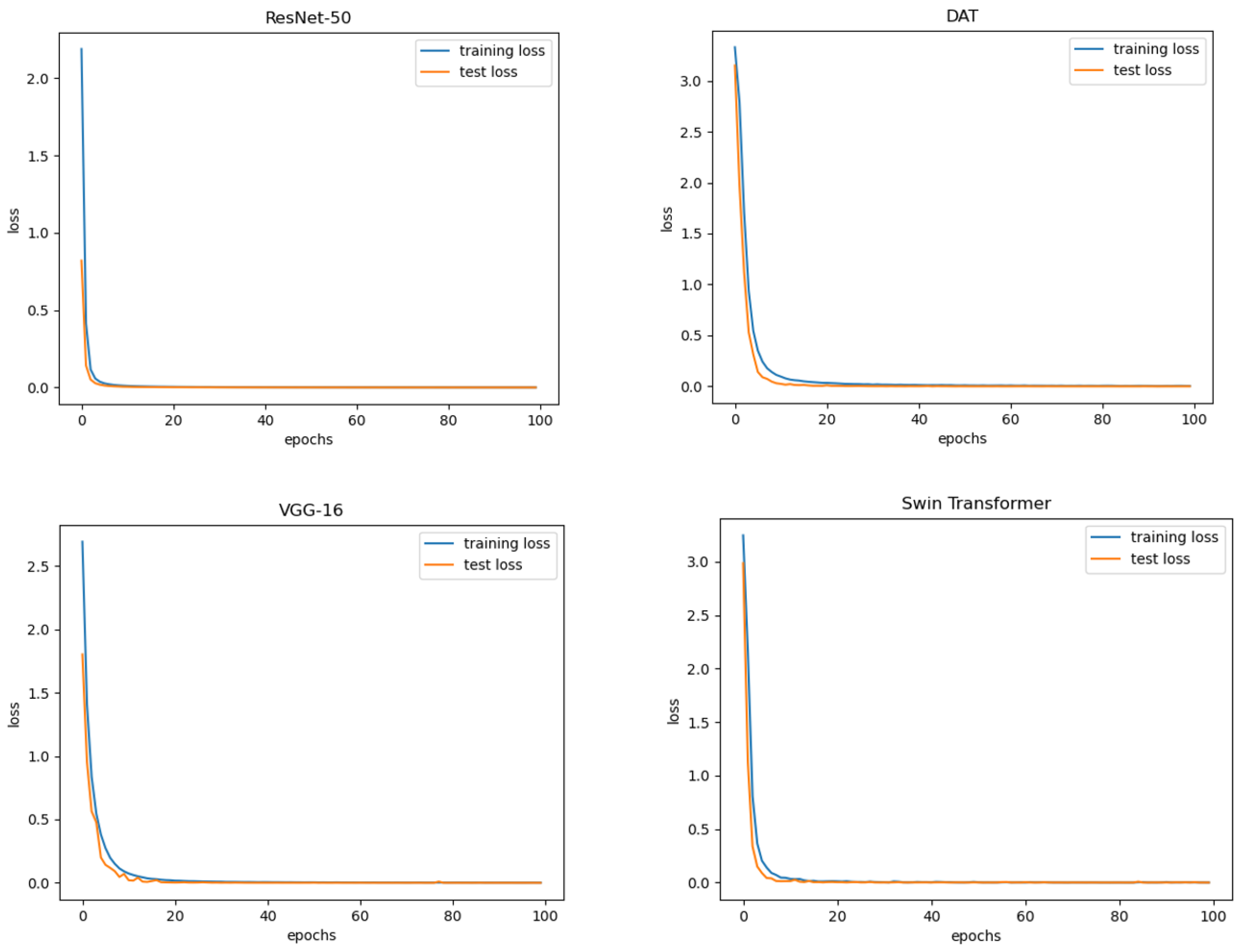
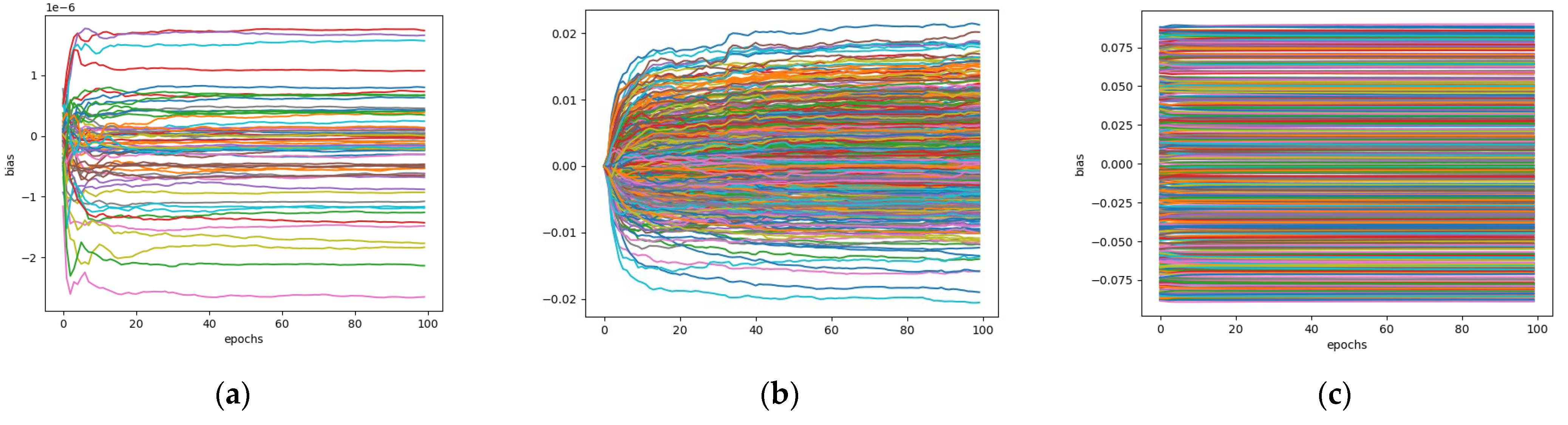
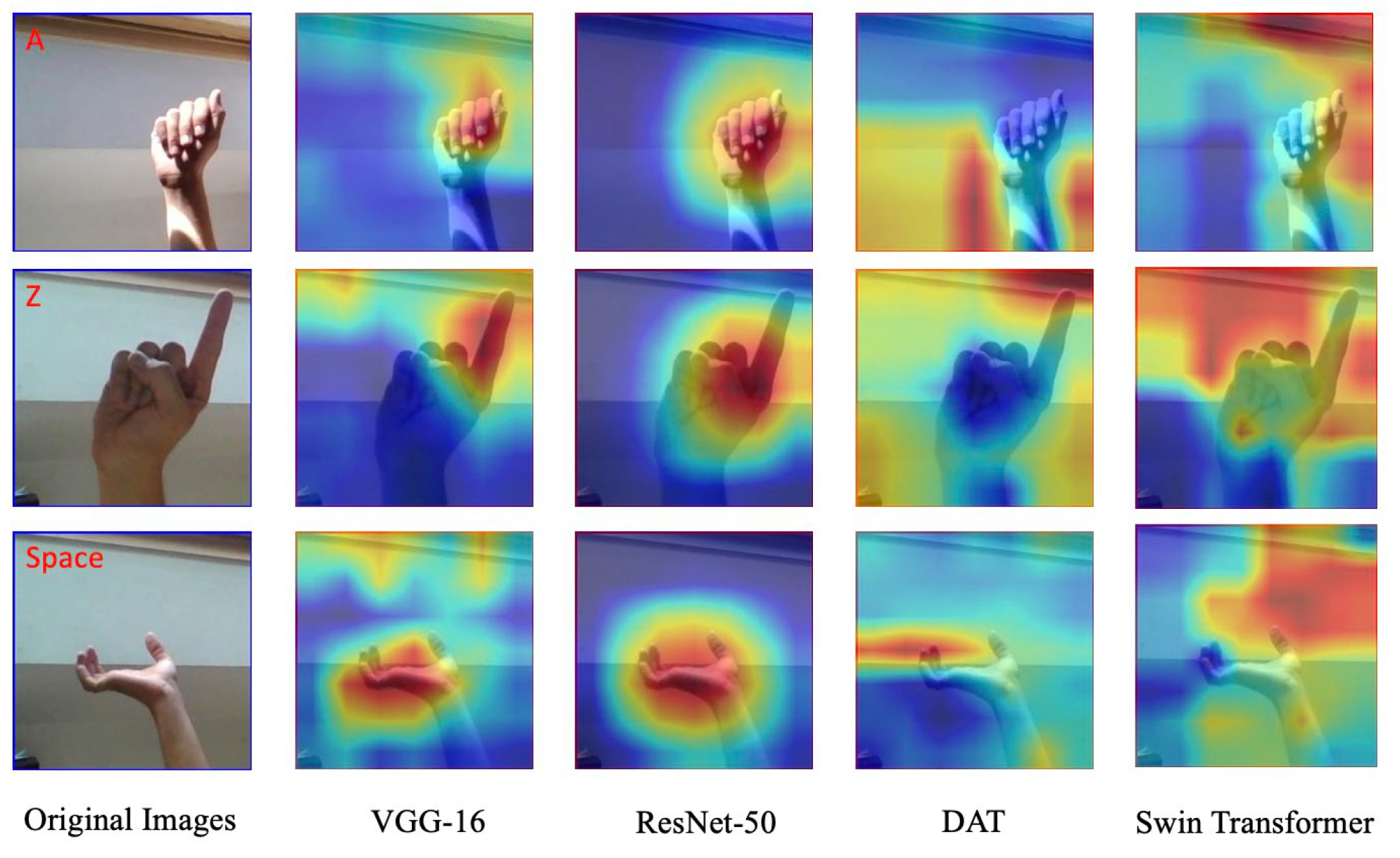
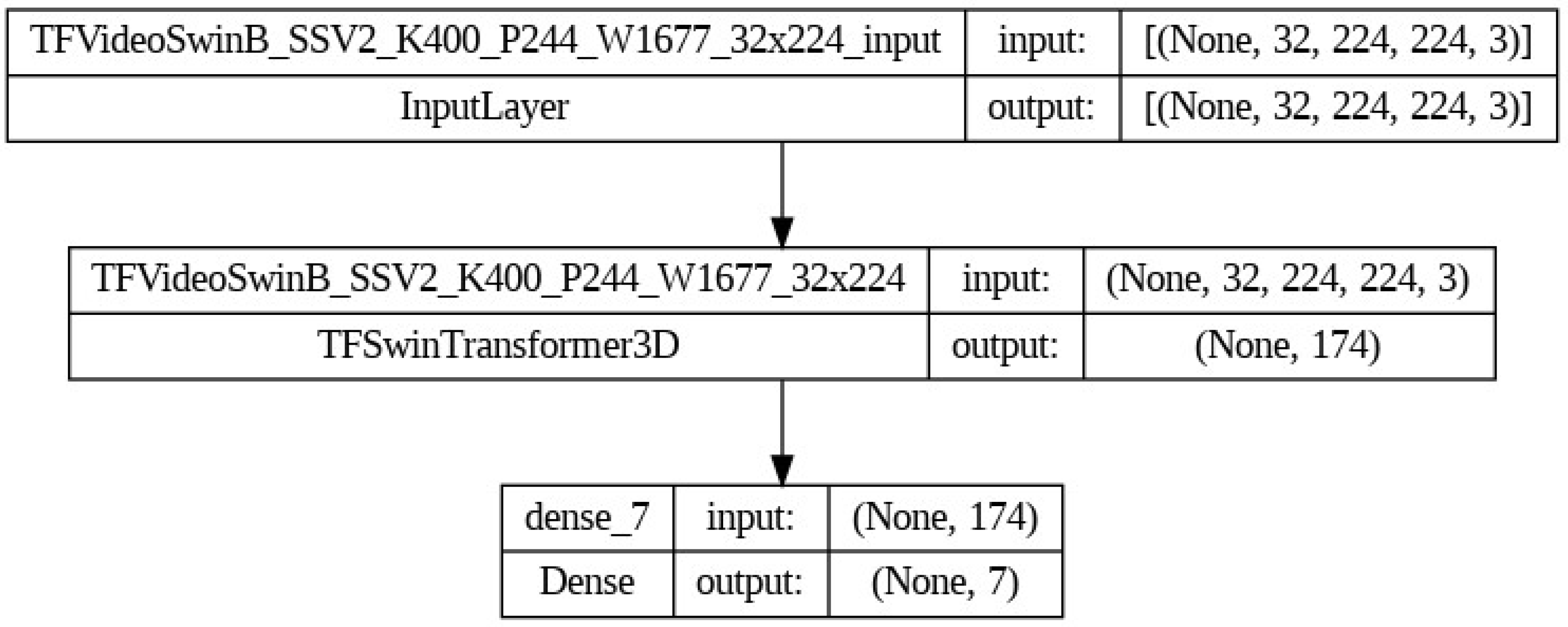
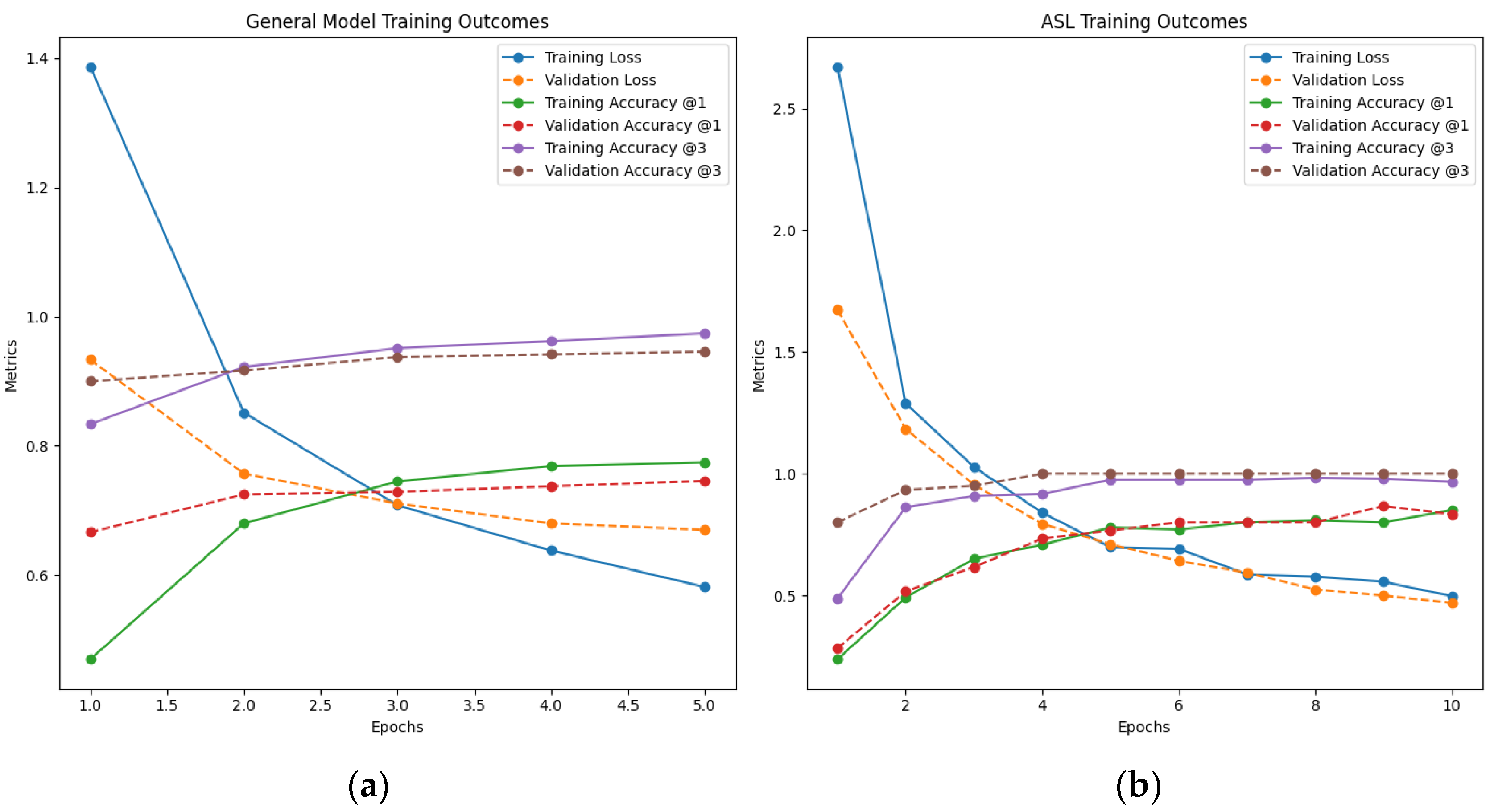
3.3. Model Training
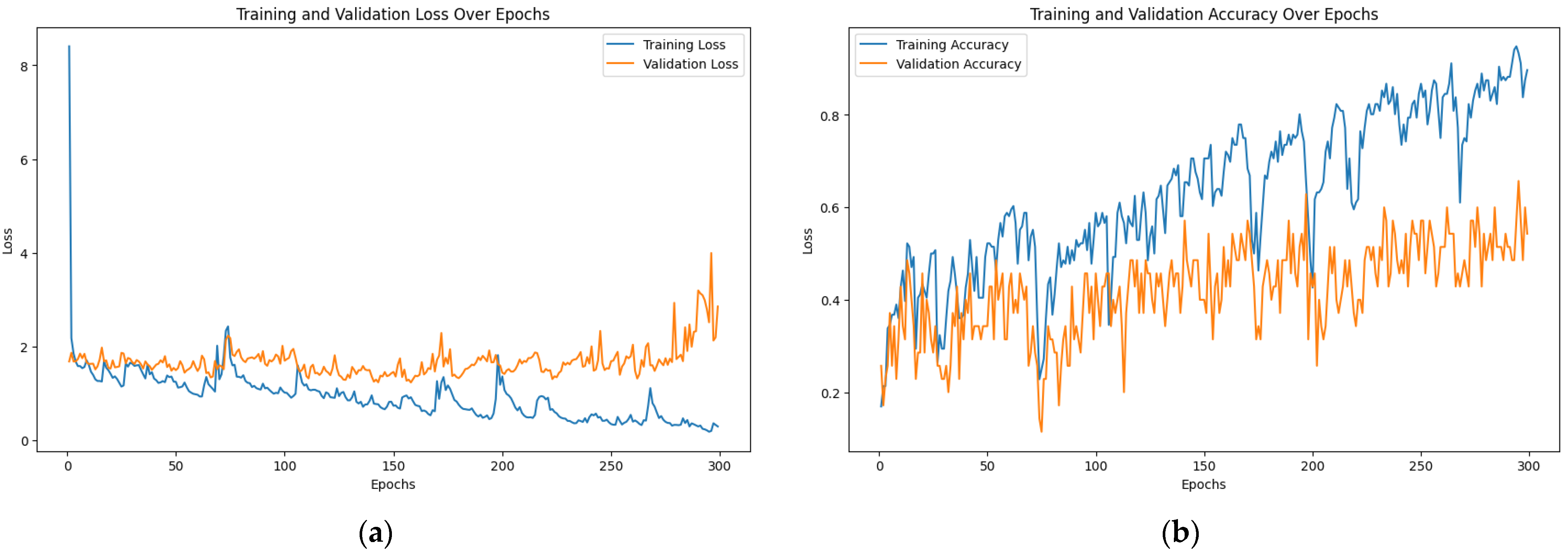
3.4. ASL vs. TSL Video Recognition
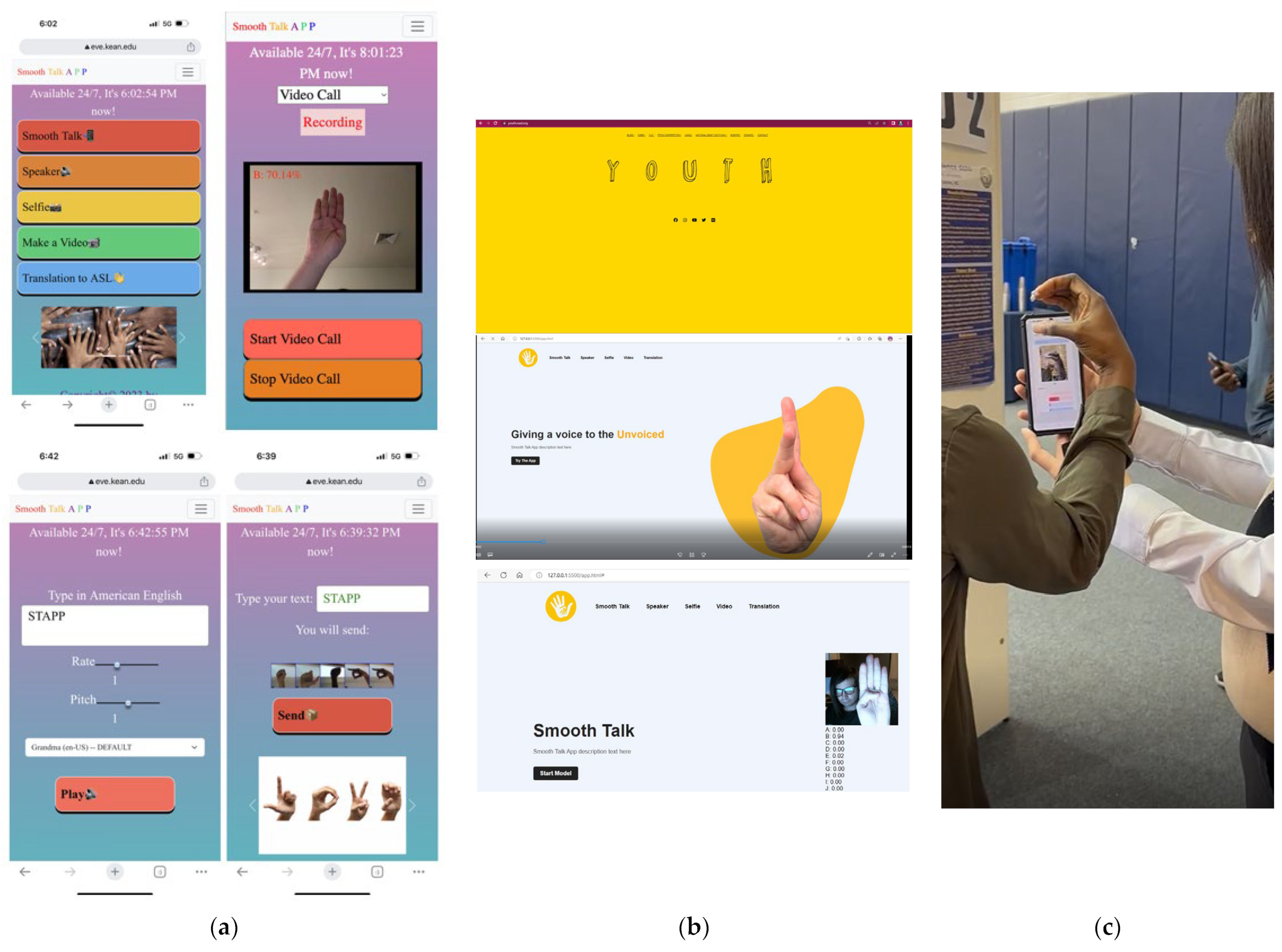
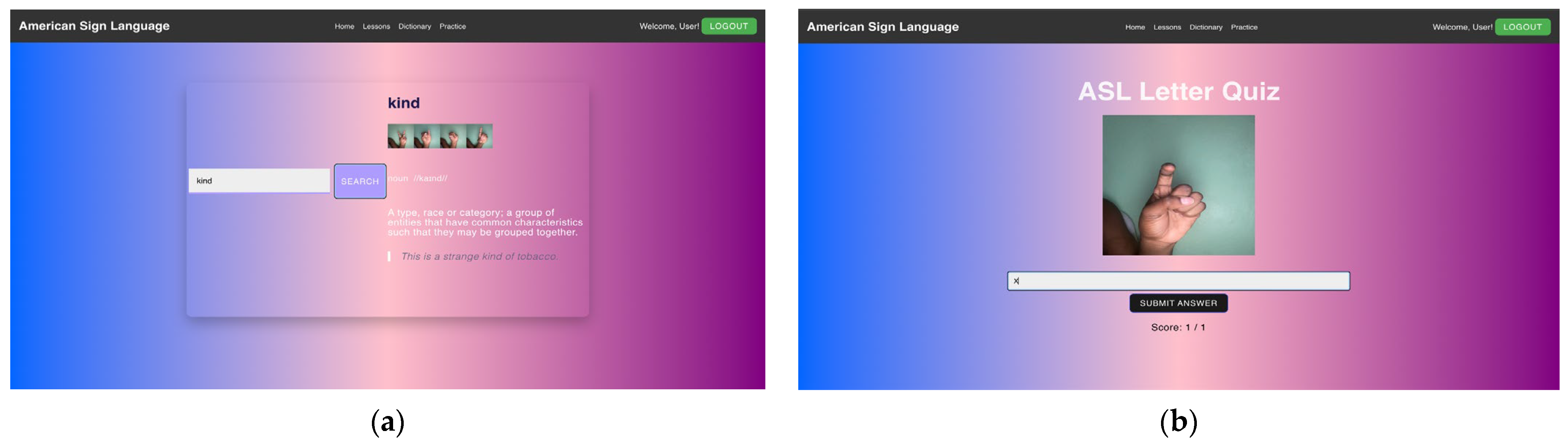
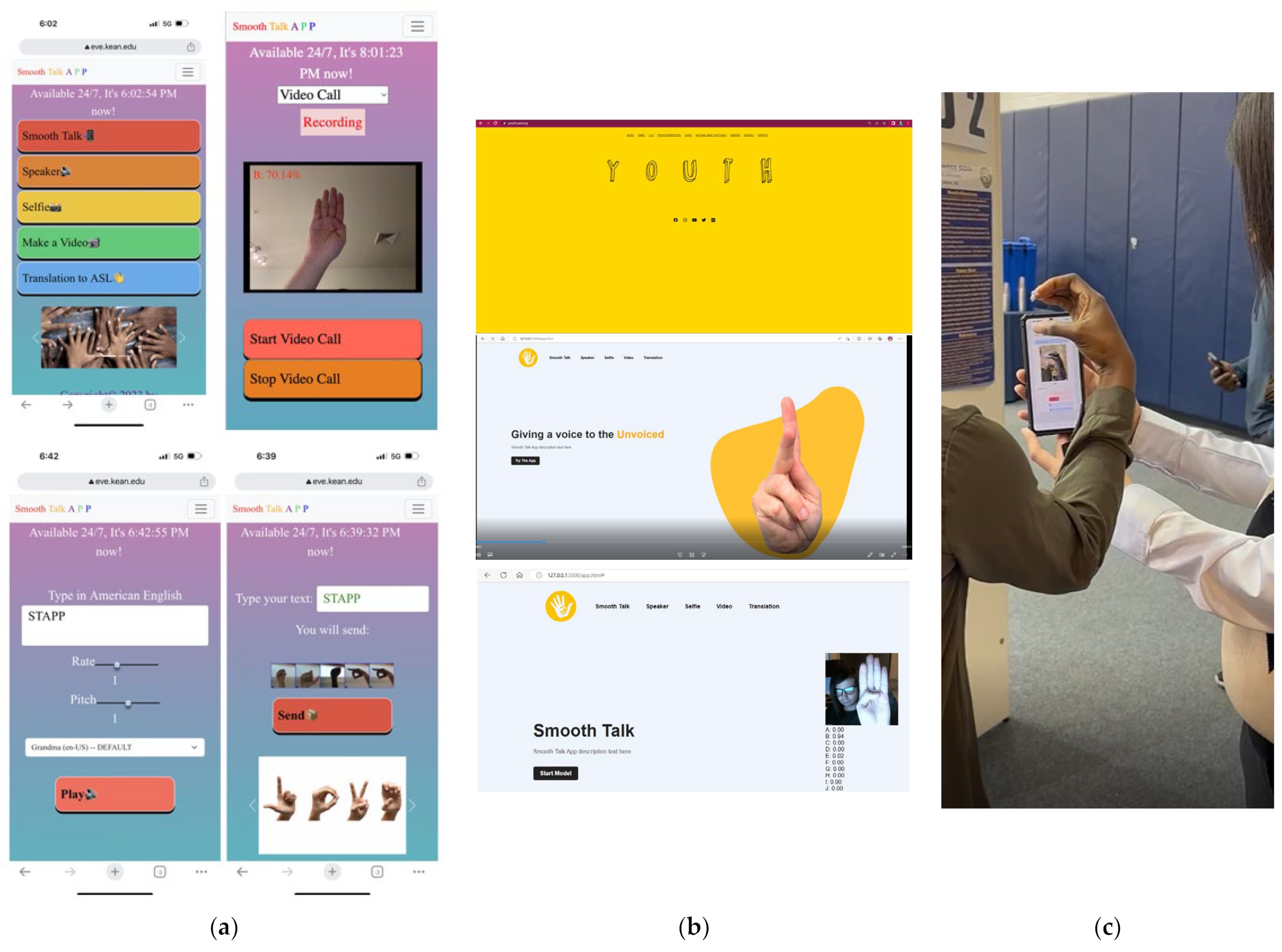
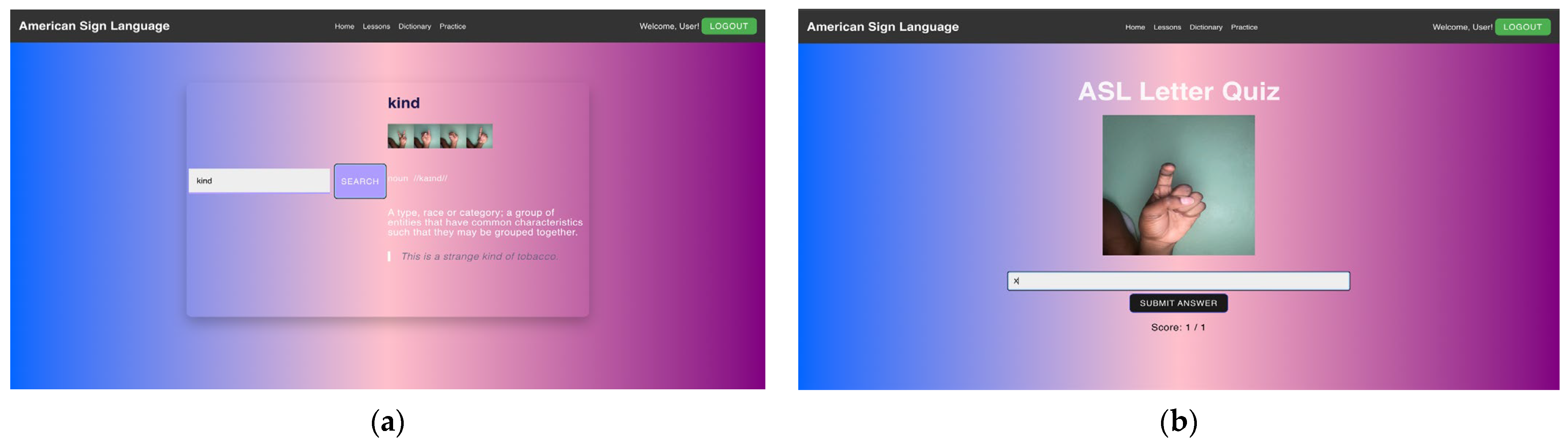
3.5. Application Development
- (1)
- Develop a user-friendly interface for ASL translation, ensuring it is suitable for the intended users and use cases.
- (2)
- Create interactive and engaging learning tools for ASL education.
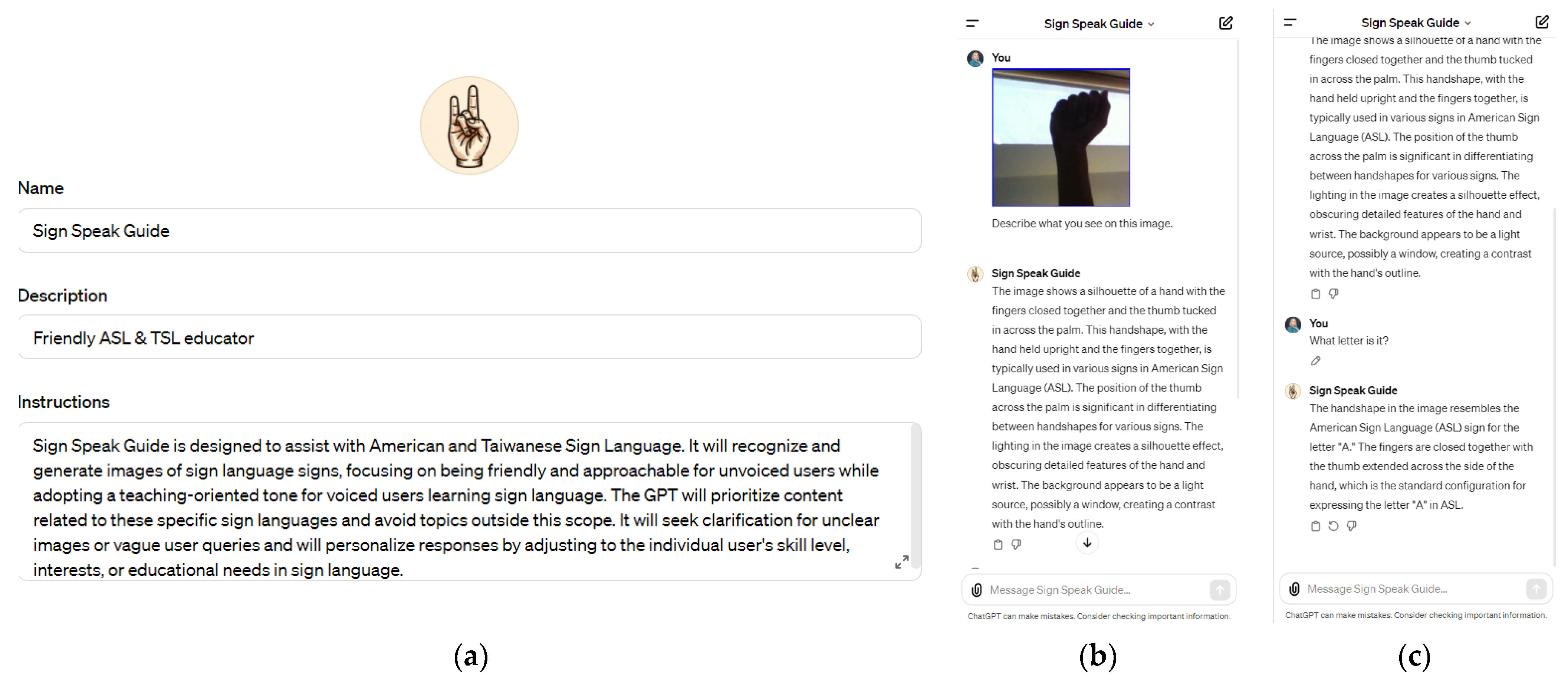
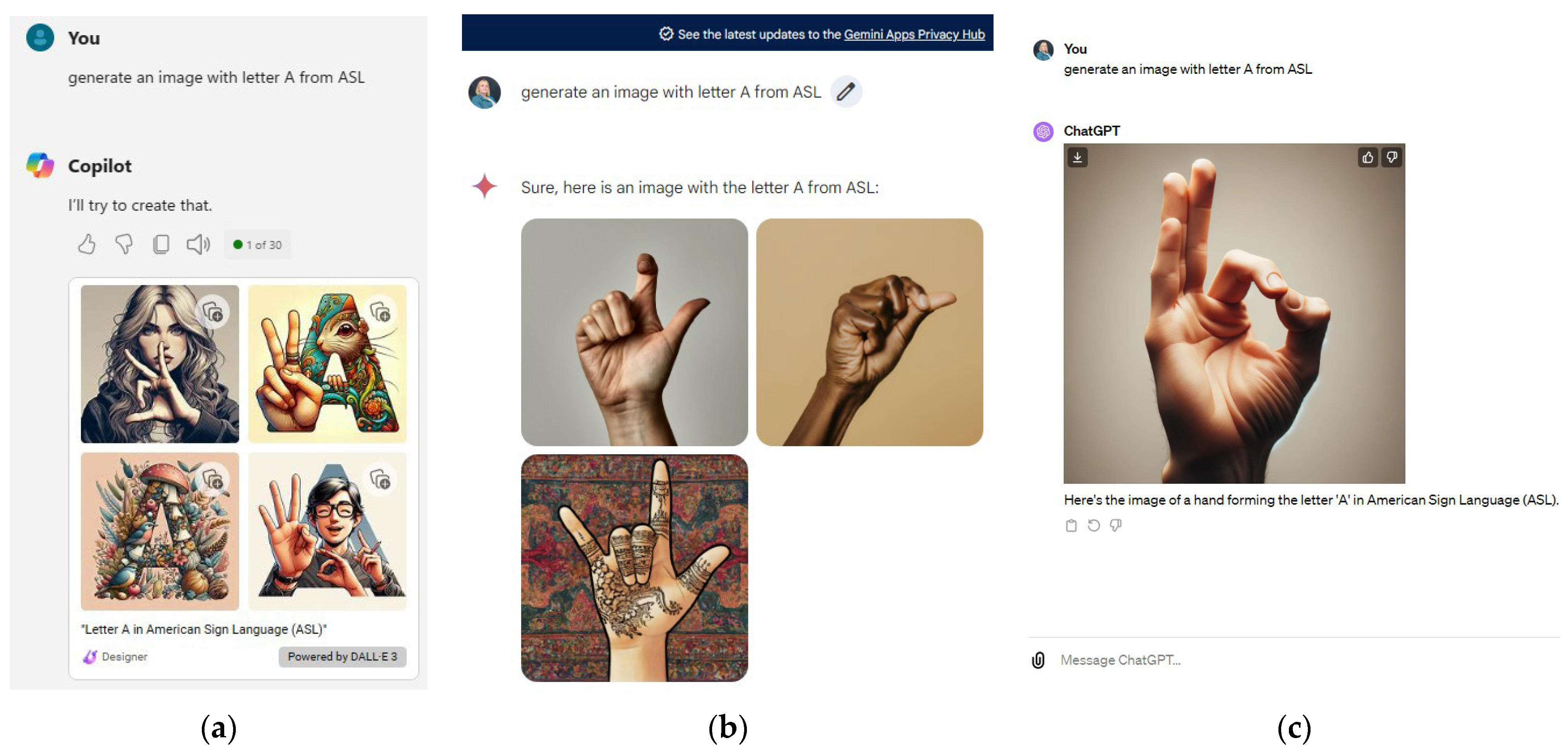
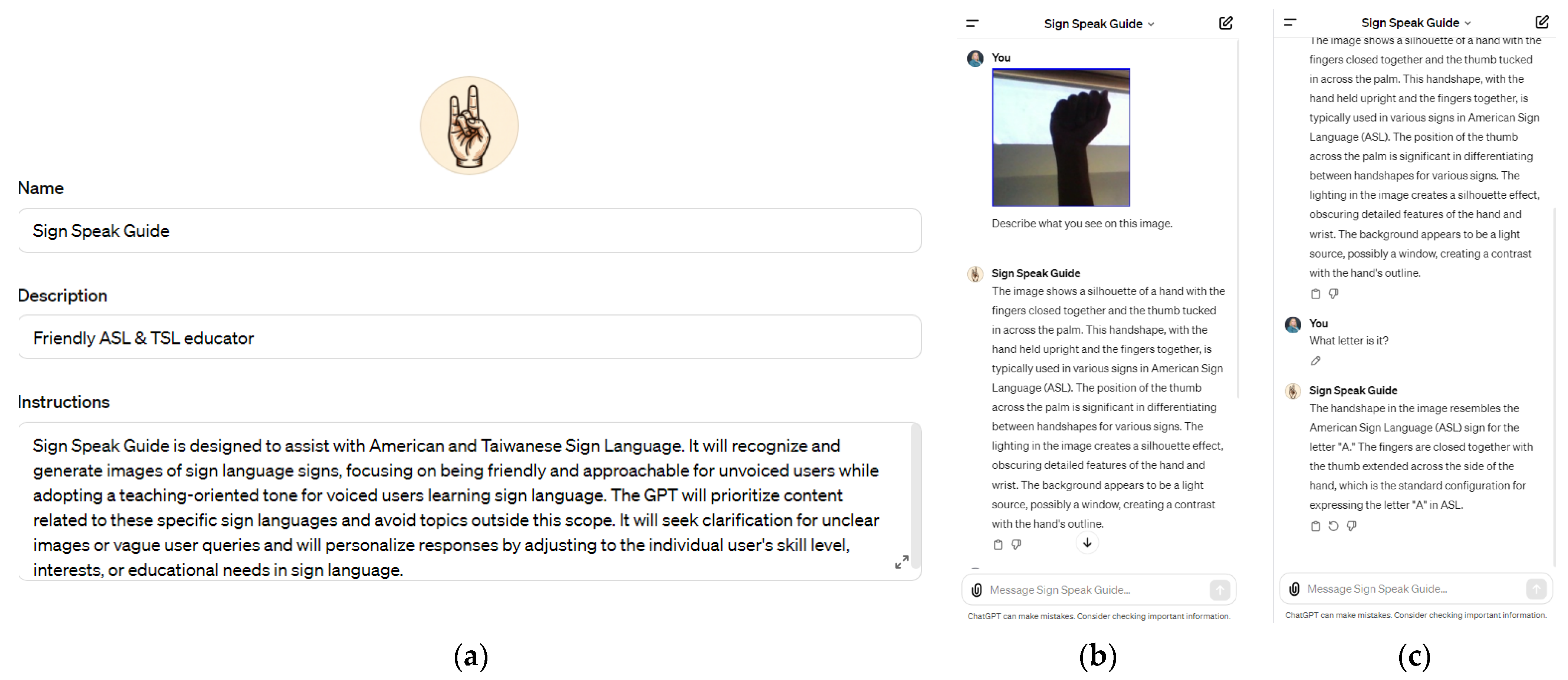
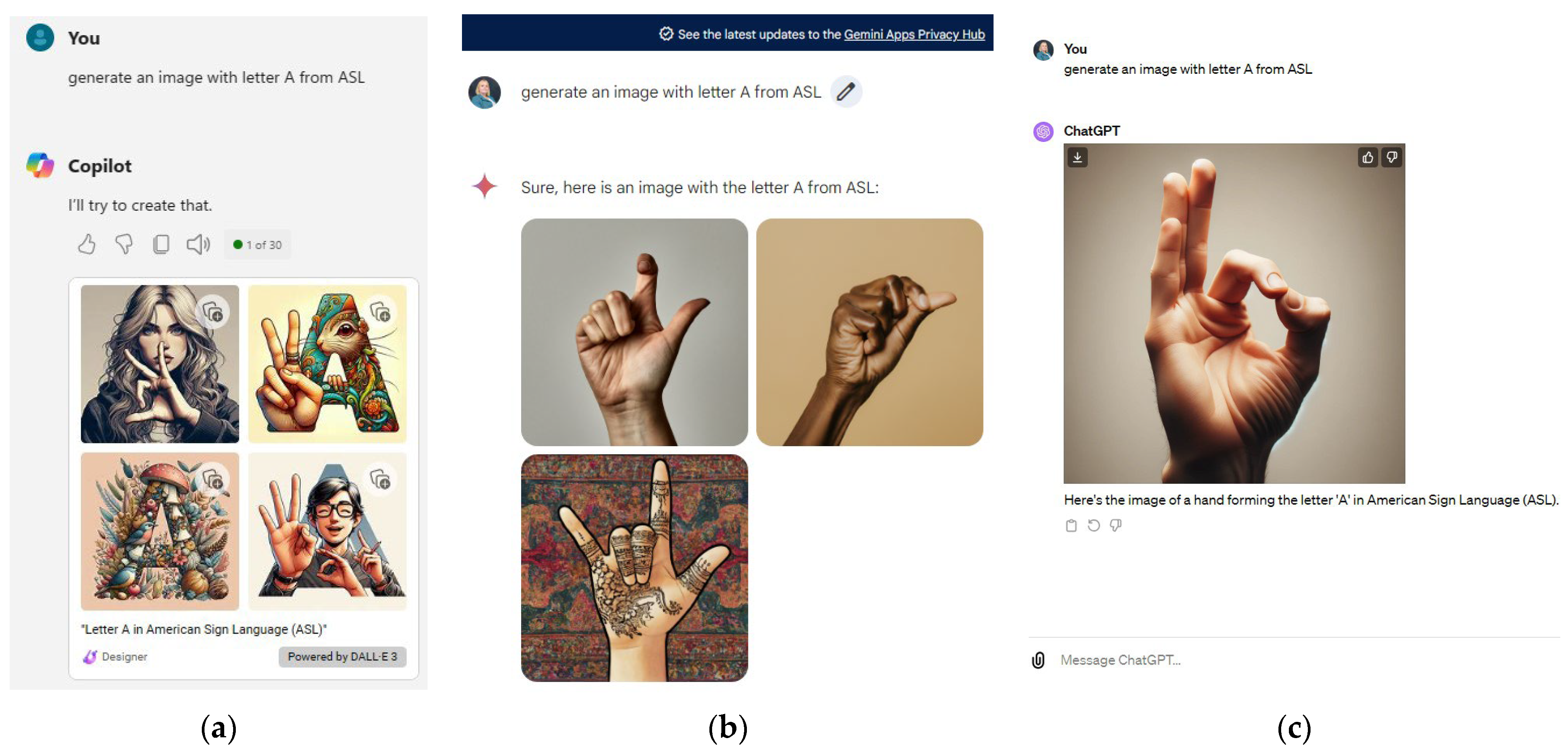
4. LLM Integration
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Home Page of the NAD. Available online: https://www.nad.org/resources/american-sign-language/learning-american-sign-language/ (accessed on 24 February 2024).
- Home Page of the NAD Youth. Available online: https://youth.nad.org/ (accessed on 24 February 2024).
- GitHub Repository of Swin Transformer. Available online: https://github.com/microsoft/Swin-Transformer (accessed on 24 February 2024).
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 10012–10022. [Google Scholar]
- GitHub Repository of DAT Transformer. Available online: https://github.com/LeapLabTHU/DAT (accessed on 24 February 2024).
- A Survey of Sign Language in Taiwan. Available online: https://www.sil.org/resources/archives/9125 (accessed on 24 February 2024).
- Kumar, Y.; Huang, K.; Gordon, Z.; Castro, L.; Okumu, E.; Morreale, P.; Li, J.J. Transformers and LLMs as the New Benchmark in Early Cancer Detection. In Proceedings of the ITM Web of Conferences, Online, 1–3 December 2023; EDP Sciences: Les Ulis, France, 2024; Volume 60, p. 00004. [Google Scholar]
- Delgado, J.; Ebreso, U.; Kumar, Y.; Li, J.J.; Morreale, P. Preliminary Results of Applying Transformers to Geoscience and Earth Science Data. In Proceedings of the 2022 International Conference on Computational Science and Computational Intelligence (CSCI), Las Vegas, NV, USA, 14–16 December 2022; pp. 284–288. [Google Scholar] [CrossRef]
- Driessen, T.; Dodou, D.; Bazilinskyy, P.; de Winter, J. Putting ChatGPT Vision (GPT-4V) to the Test: Risk Perception in Traffic Images. 2023. Available online: https://bazilinskyy.github.io/publications/driessen2023putting.pdf (accessed on 24 February 2024).
- Kumar, Y.; Morreale, P.; Sorial, P.; Delgado, J.; Li, J.J.; Martins, P. A Testing Framework for AI Linguistic Systems (testFAILS). Electronics 2023, 12, 3095. [Google Scholar] [CrossRef]
- Hannon, B.; Kumar, Y.; Gayle, D.; Li, J.J.; Morreale, P. Robust Testing of AI Language Model Resiliency with Novel Adversarial Prompts. Electronics 2024, 13, 842. [Google Scholar] [CrossRef]
- Vashisth, H.K.; Tarafder, T.; Aziz, R.; Arora, M. Hand Gesture Recognition in Indian Sign Language Using Deep Learning. Eng. Proc. 2023, 59, 96. [Google Scholar] [CrossRef]
- Alharthi, N.M.; Alzahrani, S.M. Vision Transformers and Transfer Learning Approaches for Arabic Sign Language Recognition. Appl. Sci. 2023, 13, 11625. [Google Scholar] [CrossRef]
- Avina, V.D.; Amiruzzaman, M.; Amiruzzaman, S.; Ngo, L.B.; Dewan, M.A.A. An AI-Based Framework for Translating American Sign Language to English and Vice Versa. Information 2023, 14, 569. [Google Scholar] [CrossRef]
- De Coster, M.; Dambre, J. Leveraging Frozen Pretrained Written Language Models for Neural Sign Language Translation. Information 2022, 13, 220. [Google Scholar] [CrossRef]
- Marzouk, R.; Alrowais, F.; Al-Wesabi, F.N.; Hilal, A.M. Atom Search Optimization with Deep Learning Enabled Arabic Sign Language Recognition for Speaking and Hearing Disability Persons. Healthcare 2022, 10, 1606. [Google Scholar] [CrossRef]
- Sklar, J. A Mobile App Gives Deaf People a Sign-Language Interpreter They Can Take Anywhere. Available online: https://www.technologyreview.com/innovator/ronaldo-tenorio/ (accessed on 24 February 2024).
- Jain, A. Project Idea|Audio to Sign Language Translator. Available online: https://www.geeksforgeeks.org/project-idea-audio-sign-language-translator/ (accessed on 24 February 2024).
- English to Sign Language (ASL) Translator. Available online: https://wecapable.com/tools/text-to-sign-language-converter/ (accessed on 24 February 2024).
- The ASL App (ASL for the People) on Google Play. Available online: https://theaslapp.com/about (accessed on 24 February 2024).
- iASL App on Speechie Apps. Available online: https://speechieapps.wordpress.com/2012/03/26/iasl/ (accessed on 24 February 2024).
- Sign 4 Me App. Available online: https://apps.microsoft.com/detail/9pn9qd80mblx?hl=en-us&gl=US (accessed on 24 February 2024).
- ASL Dictionary App. Available online: https://play.google.com/store/apps/details?id=com.signtel&gl=US (accessed on 24 February 2024).
- Liang, J.; Cao, J.; Sun, G.; Zhang, K.; Van Gool, L.; Timofte, R. Swinir: Image restoration using swin transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 1833–1844. [Google Scholar]
- Cao, H.; Wang, Y.; Chen, J.; Jiang, D.; Zhang, X.; Tian, Q.; Wang, M. Swin-unet: Unet-like pure transformer for medical image segmentation. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer Nature: Cham, Switzerland, 2023; pp. 205–218. [Google Scholar]
- Xie, Z.; Lin, Y.; Yao, Z.; Zhang, Z.; Dai, Q.; Cao, Y.; Hu, H. Self-supervised learning with Swin transformers. arXiv 2021, arXiv:2105.04553. [Google Scholar]
- He, X.; Zhou, Y.; Zhao, J.; Zhang, D.; Yao, R.; Xue, Y. Swin transformer embedding UNet for remote sensing image semantic segmentation. IEEE Trans. Geosci. Remote Sens. 2022, 60, 4408715. [Google Scholar] [CrossRef]
- Zu, B.; Cao, T.; Li, Y.; Li, J.; Ju, F.; Wang, H. SwinT-SRNet: Swin transformer with image super-resolution reconstruction network for pollen images classification. Eng. Appl. Artif. Intell. 2024, 133, 108041. [Google Scholar] [CrossRef]
- Nguyen, L.X.; Tun, Y.L.; Tun, Y.K.; Nguyen, M.N.; Zhang, C.; Han, Z.; Hong, C.S. Swin transformer-based dynamic semantic communication for multi-user with different computing capacity. IEEE Trans. Veh. Technol. 2024, 1–16. [Google Scholar] [CrossRef]
- MohanRajan, S.N.; Loganathan, A.; Manoharan, P.; Alenizi, F.A. Fuzzy Swin transformer for Land Use/Land Cover change detection using LISS-III Satellite data. Earth Sci. Inform. 2024, 17, 1745–1764. [Google Scholar] [CrossRef]
- Ekanayake, M.; Pawar, K.; Harandi, M.; Egan, G.; Chen, Z. McSTRA: A multi-branch cascaded Swin transformer for point spread function-guided robust MRI reconstruction. Comput. Biol. Med. 2024, 168, 107775. [Google Scholar] [CrossRef] [PubMed]
- Lu, Y.; You, K.; Zhou, C.; Chen, J.; Wu, Z.; Jiang, Y.; Huang, C. Video surveillance-based multi-task learning with Swin transformer for earthwork activity classification. Eng. Appl. Artif. Intell. 2024, 131, 107814. [Google Scholar] [CrossRef]
- Lin, Y.; Han, X.; Chen, K.; Zhang, W.; Liu, Q. CSwinDoubleU-Net: A double U-shaped network combined with convolution and Swin Transformer for colorectal polyp segmentation. Biomed. Signal Process. Control. 2024, 89, 105749. [Google Scholar] [CrossRef]
- Pan, C.; Chen, J.; Huang, R. Medical image detection and classification of renal incidentalomas based on YOLOv4+ ASFF swin transformer. J. Radiat. Res. Appl. Sci. 2024, 17, 100845. [Google Scholar] [CrossRef]
- Liu, Z.; Hu, H.; Lin, Y.; Yao, Z.; Xie, Z.; Wei, Y.; Ning, J.; Cao, Y.; Zhang, Z.; Dong, L.; et al. Swin transformer v2: Scaling up capacity and resolution. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 12009–12019. [Google Scholar]
- Liu, Z.; Ning, J.; Cao, Y.; Wei, Y.; Zhang, Z.; Lin, S.; Hu, H. Video Swin transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 3202–3211. [Google Scholar]
- Shih, W.-H.; Ting, L.-F. (Eds.) Your Hands Can Become a Bridge; National Association of the Deaf in the Republic of China: Beijing, China, 1997; Volume 1. [Google Scholar]
- Handspeak. Phonological Components of Sign Language. Available online: https://www.handspeak.com/learn/397/ (accessed on 2 March 2024).
- Huang, M.-H. Taiwan Sign Language Recognition for Video Using Deep Learning Techniques. Master’s Thesis, National Yang Ming Chiao Tung University, Hsinchu, Taiwan, 2021. Available online: https://hdl.handle.net/11296/ru8ndt (accessed on 24 February 2024).
- Nickens, C. The History of American Sign Language; Lulu.com.: Morrisville, NC, USA, 2008. [Google Scholar]
- Zhang, R.-X. Cognitive Strategies in Word Formation in Taiwan Sign Language and American Sign Language; Wenhe: Taipei City, Taiwan, 2014. [Google Scholar]
- ASL Alphabet. Available online: https://www.kaggle.com/datasets/grassknoted/asl-alphabet (accessed on 24 February 2024).
- Home Page of ASLLVD (American Sign Language Lexicon Video Dataset). Available online: https://paperswithcode.com/dataset/asllvd (accessed on 24 February 2024).
- WLASL Dataset on Kaggle. Available online: https://www.kaggle.com/datasets/risangbaskoro/wlasl-processed (accessed on 24 February 2024).
- Microsoft Research ASL Citizen Dataset. Available online: https://www.microsoft.com/en-us/research/project/asl-citizen/ (accessed on 24 February 2024).
- MS-ASL Dataset. Available online: https://www.microsoft.com/en-us/research/project/ms-asl/ (accessed on 24 February 2024).
- GitHub Repository of OpenASL Dataset. Available online: https://github.com/chevalierNoir/OpenASL (accessed on 24 February 2024).
- GitHub Repository of how2sign Dataset. Available online: https://how2sign.github.io/ (accessed on 24 February 2024).
- Uthus, D.; Tanzer, G.; Georg, M. Youtube-asl: A large-scale, open-domain American sign language-English parallel corpus. In Proceedings of the 37th Conference on Neural Information Processing Systems (NeurIPS 2023) Track on Datasets and Benchmarks, New Orleans, LA, USA, 10–16 December 2023; Volume 36. [Google Scholar]
- Colarossi, J. World’s Largest American Sign Language Database Makes ASL Even More Accessible. 2021. Available online: https://www.bu.edu/articles/2021/worlds-largest-american-sign-language-database-makes-asl-even-more-accessible/ (accessed on 24 February 2024).
- Home Page of TAT (Taiwanese across Taiwan). Available online: https://paperswithcode.com/dataset/tat (accessed on 24 February 2024).
- Hu, X.; Hampiholi, B.; Neumann, H.; Lang, J. Temporal Context Enhanced Referring Video Object Segmentation. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Waikoloa, HI, USA, 4–8 January 2024; pp. 5574–5583. [Google Scholar]
- Yu, Z.; Guan, F.; Lu, Y.; Li, X.; Chen, Z. Video Quality Assessment Based on Swin TransformerV2 and Coarse to Fine Strategy. arXiv 2024, arXiv:2401.08522. [Google Scholar]
- Xia, Z.; Pan, X.; Song, S.; Li, L.E.; Huang, G. Vision Transformer with Deformable Attention. arXiv 2022. [Google Scholar] [CrossRef]
- Tellez, N.; Serra, J.; Kumar, Y.; Li, J.J.; Morreale, P. Gauging Biases in Various Deep Learning AI Models. In Intelligent Systems and Applications. IntelliSys 2022; Arai, K., Ed.; Lecture Notes in Networks and Systems; Springer: Cham, Switzerland, 2023; Volume 544. [Google Scholar] [CrossRef]
- Tellez, N.; Serra, J.; Kumar, Y.; Li, J.J.; Morreale, P. An Assure AI Bot (AAAI bot). In Proceedings of the 2022 International Symposium on Networks, Computers and Communications (ISNCC), Shenzhen, China, 19–22 July 2022; pp. 1–5. [Google Scholar] [CrossRef]
- Hastie, T.; Tibshirani, R.; Friedman, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction; Springer: New York, NY, USA, 2009. [Google Scholar]
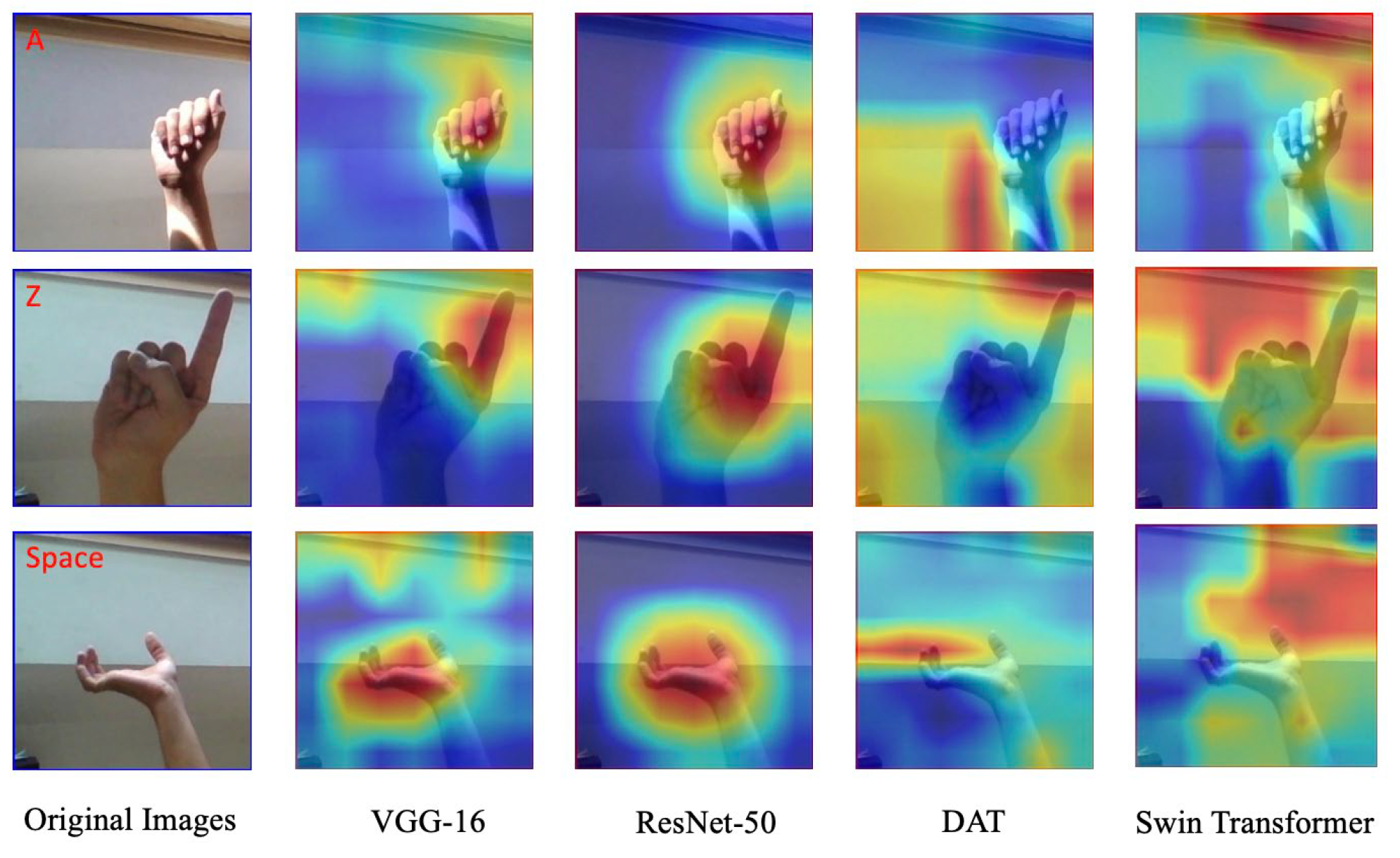
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-cam: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar]
- Teachable Machines Web Tool Page. Available online: https://teachablemachine.withgoogle.com/models/TY21XA7_Q/ (accessed on 24 February 2024).






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Feature | Swin Transformer | Swin Transformer V2 | Video Swin Transformer |
|---|---|---|---|
| Domain | Image | Image | Video |
| Key Novelty | Shifted Windows | Scaling, Refinements | Spatiotemporal Attention |
| Compared to Swin | Base Model | Improved | Video Extension |
| Trial Parameter | Comments |
|---|---|
| Initial Dataset | 87,000 images |
| Trial Dataset | 80% for training, 20% for testing at random |
| Classification | 29 classes (A to Z, Space, Del, and Nothing) |
| Batch Size | 16 |
| Trial Dataset | 256 × 256 (resized) |
| Optimizer used | SGD, learning rate 0.001 |
| Number of Epochs | 100 |
| Pytorch version | 1.12.1. |
| Trial Parameter | Number of Parameters | Accuracy |
|---|---|---|
| DAT Transformer | 86,886,357 | 99.99% |
| VGG-16 | 165,845,085 | 100% |
| ResNet-50 | 23,567,453 | 100% |
| Swin transformer | 65,960,349 | 100% |
| Layer (Type) | Number of Parameters | Output Shape |
|---|---|---|
| TFVideoSwinB_SSV2_K400_P244_W1677_32x224 (TFSwinTransformer3D) | 88,834,038 | (None, 174) |
| dense (Dense) | 1225 | (None, 7) |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Kumar, Y.; Huang, K.; Lin, C.-C.; Watson, A.; Li, J.J.; Morreale, P.; Delgado, J. Applying Swin Architecture to Diverse Sign Language Datasets. Electronics 2024, 13, 1509. https://doi.org/10.3390/electronics13081509
Kumar Y, Huang K, Lin C-C, Watson A, Li JJ, Morreale P, Delgado J. Applying Swin Architecture to Diverse Sign Language Datasets. Electronics. 2024; 13(8):1509. https://doi.org/10.3390/electronics13081509
Chicago/Turabian StyleKumar, Yulia, Kuan Huang, Chin-Chien Lin, Annaliese Watson, J. Jenny Li, Patricia Morreale, and Justin Delgado. 2024. "Applying Swin Architecture to Diverse Sign Language Datasets" Electronics 13, no. 8: 1509. https://doi.org/10.3390/electronics13081509
APA StyleKumar, Y., Huang, K., Lin, C.-C., Watson, A., Li, J. J., Morreale, P., & Delgado, J. (2024). Applying Swin Architecture to Diverse Sign Language Datasets. Electronics, 13(8), 1509. https://doi.org/10.3390/electronics13081509