2.1. Design
In broad terms, an ES is a computer program designed to mimic the decision-making abilities of a human expert in a particular field [
51]. It employs AI and knowledge engineering techniques to replicate the expertise and reasoning of a skilled professional. Expert systems are utilized across multiple domains to address complex problems, make or support decisions, and provide valuable insights [
52].
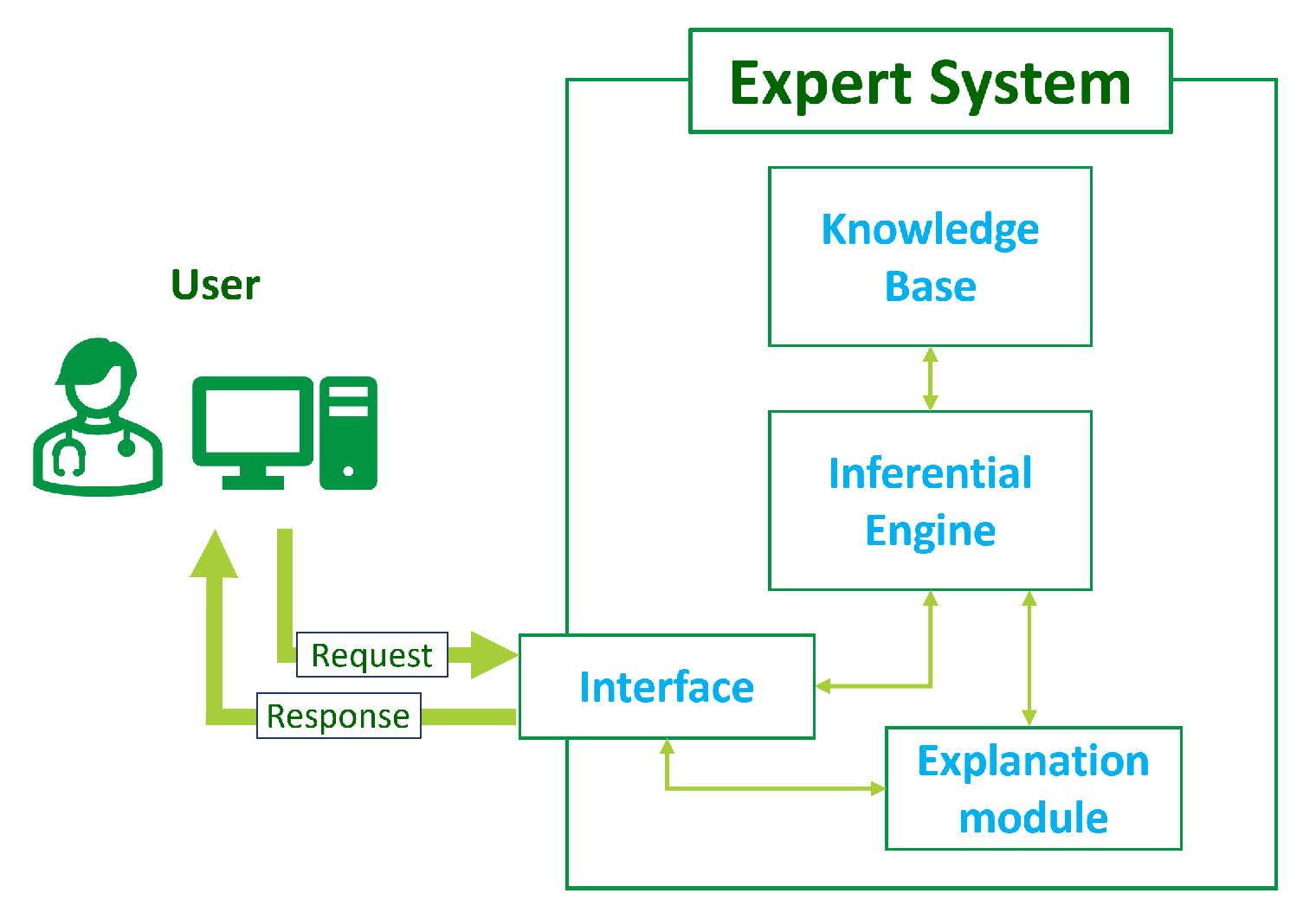
The general architecture of an ES consists of several modules (
Figure 1):
Knowledge base: This central component stores information, facts, rules, and heuristics related to the specific domain of expertise. It encapsulates the knowledge of the human experts and is used for problem-solving.
Inferential engine: This is the reasoning component that processes information from the knowledge base using logical rules and inference mechanisms. It interprets incoming data, derives conclusions, and makes decisions based on the available knowledge.
Interface: This module allows for interacting with the ES to input data, ask questions, and receive recommendations or decisions. It can take various forms, including a graphical user interface, a command-line interface, or application programming interface (API) to enable machine-to-machine communication.
Explanation module: Such a module is often included to provide transparent insights into the reasoning process of the expert system. It helps users to understand the system’s decision-making logic and is crucial for building trust and confidence in the system’s decisions.
The design of an ES involves several steps, from knowledge acquisition to testing and validation. The first one consists of gathering knowledge from human experts in the targeted domain. This may involve interviews, documentation review, and observations to capture tacit knowledge (i.e., information that is not explicitly articulated or documented but is embedded in the experiences, intuitions, and practices of human experts). In the case of the proposed ES, the expert panel was a multidisciplinary medical team composed of general practitioners and specialized professionals proficient in managing and treating COVID-19 patients.
Then, the acquired knowledge needs to be modeled into a format suitable for computer processing. This often includes structuring information and defining relationships in a way that the inferential engine can use. Subsequently, the design of the inference mechanism takes place: it involves defining the logical processes and algorithms that the system will use to perform reasoning based on the information stored in the knowledge base; it focuses on creating the rules and procedures that guide the system’s inferential capabilities. Finally, before the testing and validation phases, the ES is provided with an interaction interface, which allows for effective bidirectional communication with the system.
The primary objective of the ES is to recommend the most suitable monitoring intensity for the patient at any given moment. This results in the proposal of more intensive monitoring for individuals considered to be at higher risk of deterioration and, conversely, milder monitoring in patients at lower risk. Therefore, the ES first assesses the patient’s risk level, then matches the risk with a monitoring plan whose intensity allows for enhancing the early detection of signs of aggravation. In this process, risk definition is based on a comprehensive patient characterization, which includes both pre-existing medical conditions and newly acquired IoT data coming from telemonitoring systems. In particular, the expert team identified nine relevant data categories that are representative of the knowledge to be analyzed for decision making:
Sex and potential menopausal status for females;
Anthropometric profile;
Age;
Working conditions;
Presence of problematic health conditions among the patient’s family members (e.g., arterial hypertension, diabetes, cardiomyopathy, and heart failure);
Habits related to smoking, alcohol, and substance use;
Underlying comorbidities the patient may have;
Antibody titer status for SARS-CoV-2 resulting from vaccinations and/or previous infections;
Vital parameters and symptoms.
To account for the significant amount of data that the ES uses, which may not always be completely available, the experts identified the most relevant factors for observing disease progression and made them strictly required for the input. This guarantees that the minimum dataset required to make a decision is always present, still leaving the possibility of improving the outcome personalization by providing the rest of the optional data.
Overall, the input data categories were modeled into 61 variables, as reported in
Table 1. The table delineates each variable’s type, data source, optional or mandatory status, whether it belongs to static or dynamic patient knowledge, and its associated reasoning block.
These variables may be the result of some pre-processing, as in the case of data coming from IoT devices, or directly conveying the information already present in the electronic health record (EHR), as for anamnestic variables. In some cases, they are the result of a mixture of sources, as for “fever” (anamnesis and IoT device) or “signs of pneumonia” (anamnesis and EHR clinical registrations). A data source also reflects data variability: in fact, anamnestic data are expected to vary rarely or much slower than the disease progression, whereas information gathered from IoT devices changes at any time. For these reasons, the former are defined as “static” data and the latter as “dynamic”.
As far as the data type is concerned, a variable can be of type numerical, Boolean, select, or multiselect. In the case of a numerical variable, the rules compare its value against threshold to classify the patient into a category; in the other cases, the decision is based on equality checks over the assumed value. In the case of data coming from anamnesis, evaluation is done directly on the data as it is; in contrast, data from IoT devices are subjected to a more complex pre-processing, which is required to transform multiple sources of timestamped data into a single variable. In fact, IoT data comprise vital parameters obtained from biomedical sensors and responses from surveys conveyed through telemonitoring systems. Since the objective is to monitor the progression of the disease through the collection of clinical symptoms and the analysis of trends and variations, the processing of this data must consider the collection timestamp. In addition, the establishment of a health condition baseline is crucial, which is done using the initial anamnesis. Then, the contribution of surveys is dual: in some cases, they report symptoms that cannot be measured using sensors (e.g., cough); in others, they contribute to reported episodes that may have occurred but have not been measured. For instance, fever pre-processing is aimed at identifying its presence and determining its duration, particularly if it is has persisted beyond 72 h. Hence, the anamnesis is used to find out how many days the patient has been feverish at the time of enrollment, whereas the incoming temperature measurements and surveys are used to reconstruct the trend over time, especially over the past 72 h.
Table 2 reports the subset of input variables that are the result of the pre-processing of multiple data sources and details the associated vital parameter, whether surveys contribute to the evaluation, and what is the contribution of the anamnesis.
As already mentioned, IoT data (i.e., temperature, heart rate, respiratory acts, pulse oximetry, and survey) constitute the “dynamic” part of the input data, and its role is crucial in determining the evolution of COVID-19. Indeed, while static data provide the necessary clinical context for the patient, it is the IoT data that mainly enable timely and accurate updates to the monitoring intensity, giving dynamism and responsiveness to the whole system. This ultimately allows for enhancing the precision of the telemonitoring, with the aiming to improve the detection of potential rapid deteriorations of the clinical status.
The last column of
Table 1 shows the variables’ reasoning block pertinence within the overall system. In fact, as the reasoning done by experts consists of several sub-decisions that collectively contribute to the final evaluation, to mimic this behavior, the knowledge base was organized into hierarchical blocks.
In general, a block is composed of a set of rules that together concur to give a value for a specific intermediate variable, which is provided as the output of the block. Intermediate variables from the decisions made at previous steps are maintained and propagated to subsequent levels of the hierarchy; hence, they also represent inputs to other blocks. In contrast, each block of the first layer uses a subset of the variables of
Table 1 as the input, whereas the output of the last block represents the final output of the ES.
Table 3 further details the intermediate variables indicating the represented knowledge (the decision), the position in the reasoning hierarchy, and the values they can assume. It is worth noticing that these values are labels representing a category in which the patient can be framed; hence, their meaning is not immediately intelligible without additional support. On the whole, however, the explainability of the decision process is guaranteed, as explained in
Section 2.2.
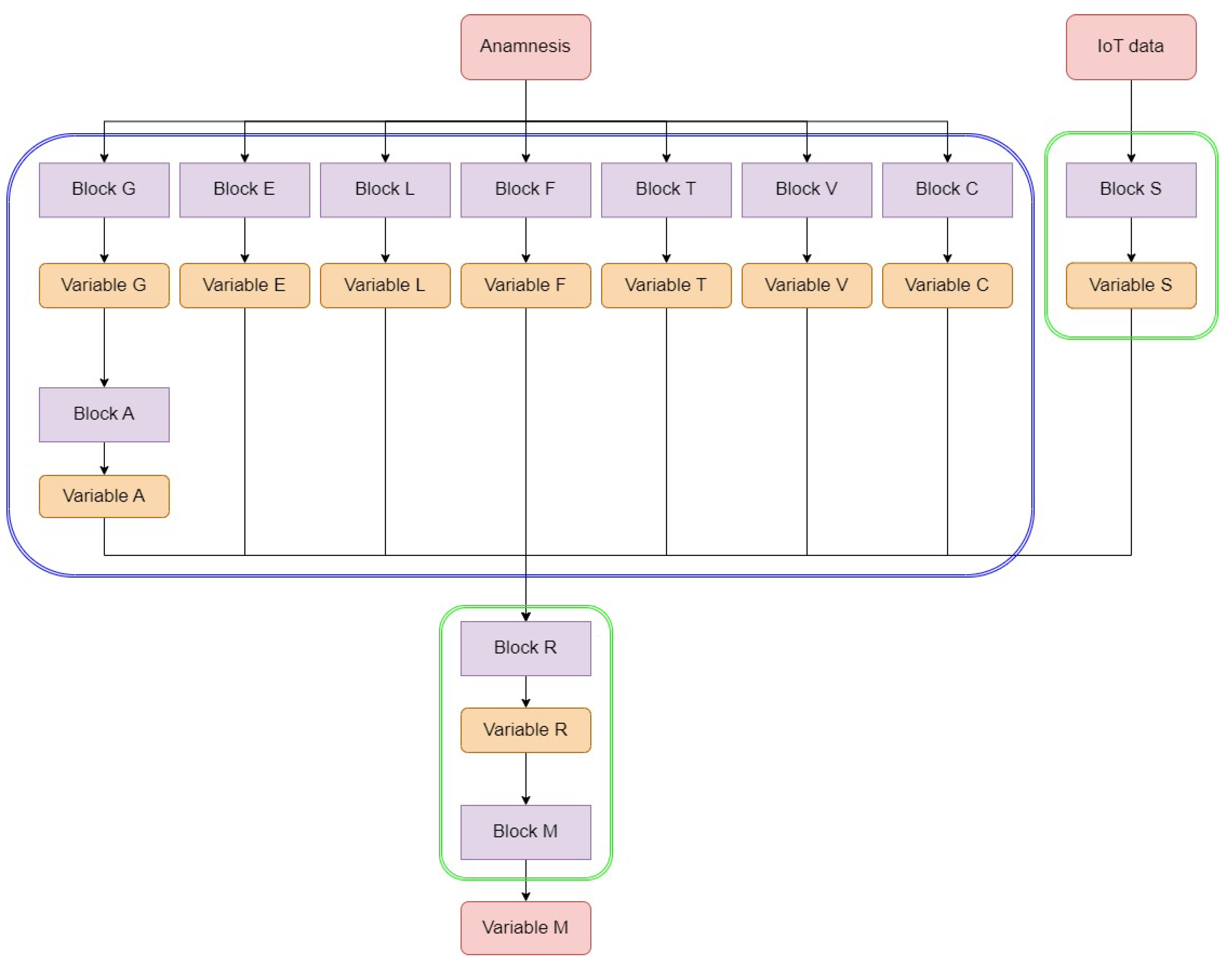
Figure 2 shows the block diagram of the proposed ES. Rounded red squares represent inputs and outputs of the ES, purple squares represent rule-based reasoning blocks, and the rounded orange squares are the intermediate variables. The ES is composed of a total of 11 blocks, whose evaluation proceeds from top to bottom: first, it takes partial decisions on ES input data that together provide a risk estimation (block R); then, it categorizes the risk into a specific monitoring intensity that can be low (LM), medium (MM), or high (HM).
Each block has a well-defined input, output, and decision role in the chain. More in detail:
Block S determines the value of the S variable, which is related to the stage of the disease (i.e., the level of severity), using the ES input data regarding vital parameters and clinical signs/symptoms present.
Block G provides the variable G, which identifies the sex of the patient and the possible menopausal condition in the case of females.
Block E calculates the variable E, which is aimed at identifying the age group to which the patient belongs. The only mandatory numeric input parameter is the patient’s age.
Block L identifies the working conditions and related risks to which the patient being evaluated is subjected. Output variable L is evaluated from a single optional input variable “Working condition”.
Block F considers the input data regarding the patient’s family history to determine the value of the output variable F, which is related to the specific risk due to the presence of diseases among the patient’s family members. In the presence of multiple familiarities related to different levels of risk, the policy is to consider the one with higher severity as the F output value.
Block T evaluates the patient’s smoking, alcohol, and substance abuse habits. Its output variable T can assume multiple values.
Block C is responsible for calculating the value of the multivalued variable C related to relevant past illnesses present in the patient being evaluated (i.e., comorbidities).
Block V decides the value of variable V, which represents the antibody titer status for SARS-CoV-2, which is derived from vaccinations received and/or the presence of prior infections.
Block A deals with the calculation of anthropometric characterization of the patient being evaluated from the anthropometric input variables shown in
Table 1 and the partial output of block G. Output variable A represents an index of patient risk related to anthropometric factors.
Block R evaluates the overall risk by processing the intermediate results obtained from blocks S, A, E, L, F, T, C, and V. Thus, the output variable R provides an indication of the risk for the patient given the general and specific pictures outlined by the preceding blocks. The R stage does not directly receive any user-supplied input value.
Block M, which is the terminal of the processing chain, is responsible for defining the monitoring intensity for the patient based on the risk class calculated by the preceding R block. The output of the block, which is coincident with that of the whole system, is represented by the variable M.
Table 4 reports, for each block, the number of rules, the number of used inputs, and the name of the output variable. For the exhaustive list of the inputs, refer to
Table 1 for the ES input data (the last column “Block pertinence” indicates the block to which the variable is provided as input) and
Table 3 for the intermediate variables.
The designed block-based structure provides modularity to the system, facilitating the extension of the rule base and adaptation of the ES to various objectives. For instance, it is possible to reuse the static risk evaluation and simply substitute the block for vital parameter-based disease stage evaluation to create a new ES capable of supporting other diseases. Alternatively, by modifying only the M block, a different evaluation outcome for COVID-19 can be pursued.
In its entirety, the knowledge base comprises 140 rules and 72 variables for input, intermediate, and output results. Given the specific decision-oriented nature of the rules and the designed structure of the ES, the distinction made for input data into dynamic and static classes is also reflected in the rules: out of 140 rules, 76 are dedicated to dynamic data processing and 64 to static data processing. The distinction is also visible in
Figure 2: block S receives incoming dynamic inputs, which are then propagated down in the hierarchy through variable S to block R and, ultimately, block M. This allows for considering dynamic health-related IoT data along the entire reasoning chain, improving the ES’s ability to provide suitable monitoring intensity for the patient.
Figure 2 highlights static blocks by encircling them in blue and the dynamic ones in green.
Overall, the extensive rule set allows for intricate reasoning simulations, incorporating multiple pieces of clinical evidence, and delivering a comprehensive patient characterization that surpasses existing state-of-the-art tools.
As illustrated in
Figure 2, the last deductive step consists of associating the monitoring intensity and the corresponding plan (i.e., the ES ultimate output) to the decided risk. A monitoring plan delineates the list of activities and their frequencies that the patient must undertake at home while utilizing a telemonitoring system. These activities encompass not only vital parameter measurements (such as temperature, pressure, and oximetry) but also walking tests and surveys.
The expert team formulated five distinct plans, which are detailed in
Table 5. The three main plans (namely, LM, MM, and HM) exhibit a progressive escalation in the quantity and frequency of activities, which corresponds to an increasing level of patient risk. Additionally, two supplementary plans were introduced to prevent two contrasting scenarios: the complete absence of monitoring and excessive monitoring intensity for a non-severe/asymptomatic patient. The former may happen if the ES is not able to make a decision, for example, in the case of contradictory, imprecise, or incomplete input data. To mitigate the consequences of such a problem and safeguard the safety and health of patients, a precautionary principle is implemented: in case no decision is made, the “Mparachute” plan is given as output, which follows the most complete and intensive plan available. Conversely, to alleviate an unnecessary burden, the “Msurvey” plan is proposed after a patient has followed the LM plan for 7 consecutive days. In this case, the patient is considered at low risk and there have been, for a sufficient amount of time, no notable exacerbations necessitating heightened monitoring, which justifies the easing. This approach offers enhanced patient comfort while leaving minimal monitoring in place, thus allowing for preserving the detection of any changes and a subsequent timely response.
In summary, the designed ES initially establishes the patient’s baseline risk by considering anthropometric, physiological, family, and pharmacological data, along with a clinical-pathological history, comorbidities, and SARS-CoV-2 vaccination status. Subsequently, the stage of COVID-19 is determined through the analysis of measured vital parameters and clinical symptoms. These deductions contribute to define the overall risk classification, which ultimately contributes to the selection or development of a tailored monitoring plan for the current clinical scenario.
2.2. Implementation
The implementation phase involved translating the conceptual framework, rules, and logic defined during the design stage into a working software application. The proposed ES was implemented utilizing the well-known Spring framework (version 5.1.5) for the application development and incorporates the Java library RuleBook (version 0.12), which provides a programmer-friendly way to build and evaluate a custom set of rules.
Specifically, RuleBook provides a Java domain-specific language (DSL) using the given–when–then format to implement rules and an inferential engine to infer knowledge from the input data. RuleBook’s inferential engine is based on forward chaining and implements the “chain of responsibility” (CoR) pattern. The former is a reasoning strategy in which the expert system starts with available data or facts and works forward to infer conclusions or make decisions; it involves applying rules to the existing data and triggering actions based on the conditions specified in those rules. The latter is a behavioral design pattern where a set of handler objects are organized in a chain and each of them has the capability to process a request that may either handle it or pass it along the chain to the next handler. Utilizing the CoR, rules are systematically examined in sequential order, and this adherence to a structured examination is crucial for maintaining alignment with the designed system. Moreover, the flexibility of the CoR allows for the incorporation of thousands of rules, providing ample capability for the ES’s intended purposes.
RuleBook works with rules and facts. Rules are the basic building blocks and the knowledge handlers of the CoR pattern. They evaluate and act on facts, which are the information provided in the form of a name/value pair. The same set of rules can be used in different threads with different facts without conflicts. Furthermore, the generated outcomes are appropriately partitioned on a per-thread basis, and there is provision for thread pooling. Consequently, the execution of an ES with varying facts across multiple threads ensures distinct results, effectively avoiding conflicts and definitively improving the performance. This characteristic makes a RuleBook-defined ES perfectly suited for the Spring framework environment.
Rule specification is achievable either through a Lambda-enabled DSL or by utilizing user-defined plain old Java objects (POJOs) that are properly annotated. Considering the choice of the Spring framework and the fact that RuleBook instances can be injected if created as annotated POJOs, this latter strategy was adopted. A rule is therefore implemented with a dedicated Java class and annotated with the @Rule and @RuleBean specific annotations, which enable proper management and injection within the Spring environment. Such a class must also have two private fields annotated with @Given and @Result, respectively, to map the input and the output of the rule, and it must define two methods, namely, one annotated with @When and the other with @Then. These are the fundamental elements of a rule since the former defines the condition that verifies the rule and “fires” the corresponding action, which is detailed in the latter method.
Considering the aforementioned method, the entire knowledge base was translated into Java classes, one per rule, and the admissible values for input and intermediate variables were mapped on primitive and enumeration Java types.
In addition, two custom classes were defined: one that is used to model the input of the ES and used as an input fact (i.e., the @Given-annotated object), and the other to represent the outcome of the system (i.e., the @Result-annotated field). The input class contains all the variables defined in
Table 1, whereas the output class accommodates both the intermediate and output variables. Although the ES output consists solely of the chosen monitoring plan, for explanation purposes, the ES also provides information about the intermediate decisions taken and the list of rules activated during the facts evaluation. RuleBook supports such information propagation by exploiting the @Given and @Result objects, whose instances are passed through all the rules and their values can be updated as part of the action done when the rule is fired. A simplified class diagram of the input and output classes (CovidESInput and CovidESDecision, respectively) is shown in
Figure 3.
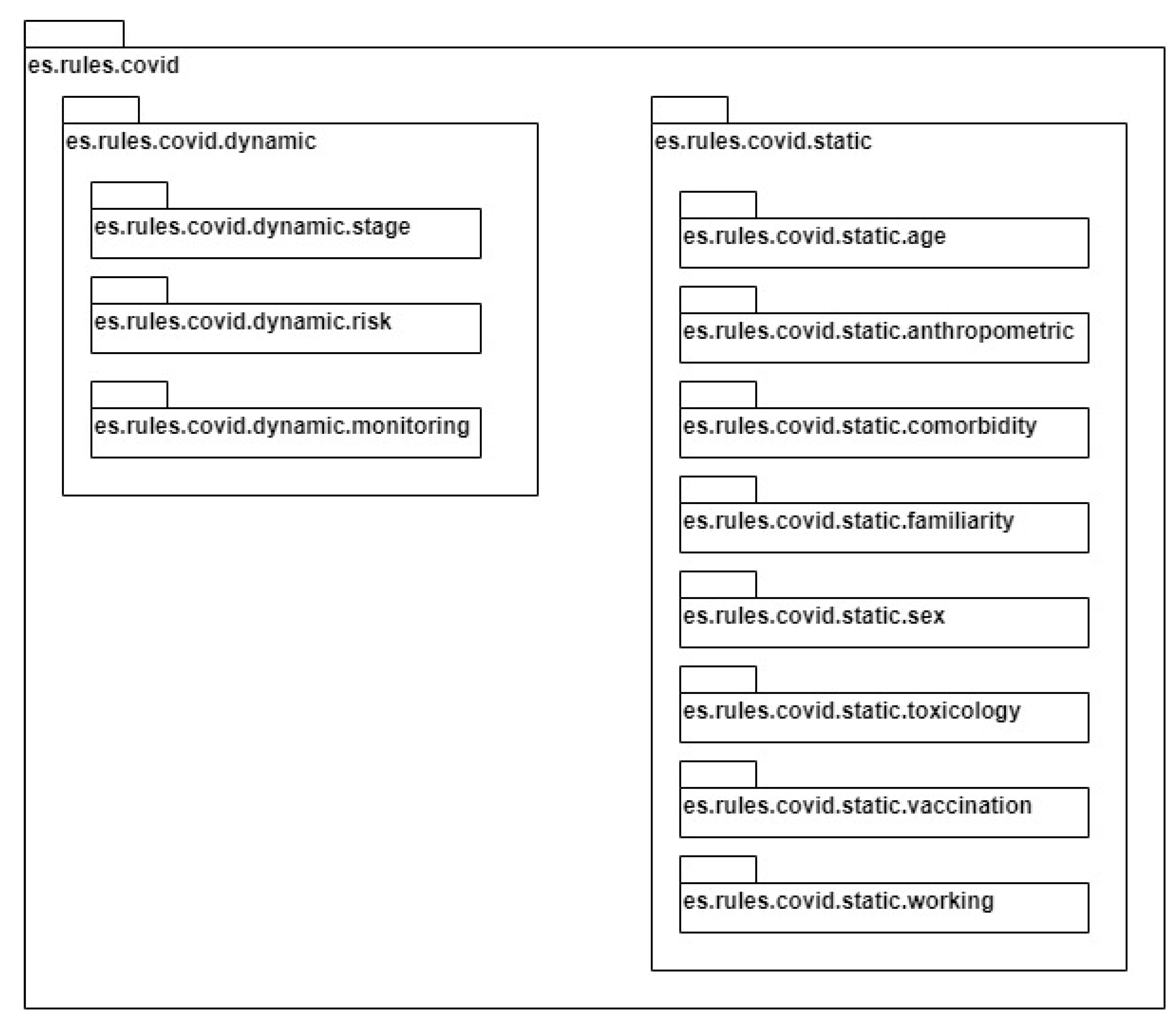
The designed rule hierarchy is reflected in the ES package organization, as shown in
Figure 4: in addition to the top-level package enclosing the whole rule set, each block has a dedicated subpackage containing POJO classes, and the latter are further grouped into two middle-level packages for static and dynamic blocks. This allows for an easier injection of the RuleBook ES instance into the main Spring application through special configuration classes containing references to desired package names.
The implemented package organization also provides modularity to the expert system. Given the configuration policy through the package name, it is possible to make the system use only a subset of the complete rule base. As a result, in the case of the proposed ES, it enables configuring (and injecting into different components) multiple RuleBook objects, with each one taking decisions on a specific data category. It is therefore possible, for example, to store the decision taken on the static data categories (e.g., comorbidities, sex, age) and then re-evaluate only the dynamic portion of the rule set when new IoT data are received. This approach may also result in an overall scalability improvement.
Although the hierarchy is provided at the code level through package organization, the actual rule ordering at the execution time is conveyed by a class-specific order property. In fact, RuleBook’s rules are evaluated randomly unless a specific order level is indicated in the @Rule annotation. Ordering is expressed with an integer value: the lower the value, the higher the priority, and rules presenting the same order are evaluated randomly. Consequently, the designed ordering of
Figure 2 is implemented by assigning values to rules per block, as shown in
Table 6. Even though forcing the desired sorting is sufficient to differentiate the priority values by one unit, it was chosen to maintain a delta between successive blocks of 10 units to allow for possible future extensions to the rule base. In addition, note that the only strictly required ordering is between S, G, E, A, L, F, T, C, and V and R and M (i.e., M must be the last and R the second to last). However, forcing an overall ordering helps to maintain modularity, eases future extensions, and improves the explainability automation.
Explainability is, in fact, a fundamental aspect of an expert system: it involves making the reasoning and decision-making process of the system transparent and interpretable to human users, and this is particularly crucial in domains where the decisions taken have significant consequences, such as in healthcare. As previously stated, the proposed ES addresses explainability mainly through the CovidESDecision output object. In fact, during the execution phase, an instance of this class is sequentially passed from one rule to the next, accumulating intermediate decisions and identifiers of activated rules as the process unfolds. In particular, rule identifiers are kept in the activation order and are useful to allow for the reconstruction of the decision process in a verbose manner by associating a description with each of them. Overall, a domain expert user is able to comprehend the whole reasoning process behind a decision taken by the ES.
In order to deal with the potential absence of optional input data, which manifests as exceptions thrown when running rules, the RuleBook library provides three alternative behaviors: CONTINUE_ON_FAILURE, ERROR_ON_FAILURE, and STOP_ON_FAILURE. The first option allows the engine to skip the rule and proceed to the subsequent in the chain; the second halts the rule chain evaluation and propagates the exception to the uppermost layers; the third one stops the rule chain without propagating the exception. The behavior is configured on a per-rule basis, and all the rules of the proposed system follow the CONTINUE_ON_FAILURE policy. This consistent approach enables the ES to always complete the evaluation process even in the presence of missing data or general execution errors. This, combined with the adoption of the “parachute” monitoring precautionary principle, maximizes the likelihood of formulating a truly personalized monitoring plan and ensures continuous surveillance for the patient.
The implemented ES is an independent software module, and it offers a representational state transfer (REST) application program interface (API) for seamless integration into pre-existing telemedicine systems. This API facilitates a request–response mechanism, enabling the expert system to receive input data and provide the determined monitoring plan along with explainability information. Both requests and responses adhere to a specifically defined schema and can be encoded in either JSON or XML formats. This setup allows any platform to effectively utilize the ES by submitting patient characterization and subsequently taking actions based on the received monitoring plan. More in detail, the ES provides a single REST endpoint that requests a CovidESInput object and returns a CovidESDecision, which are two objects mentioned earlier. In addition, it can be easily extended with a graphical user interface (GUI), allowing the tool to be fully adaptable and integrable into any other health service, whether through machine-to-machine or human-to-machine interaction.






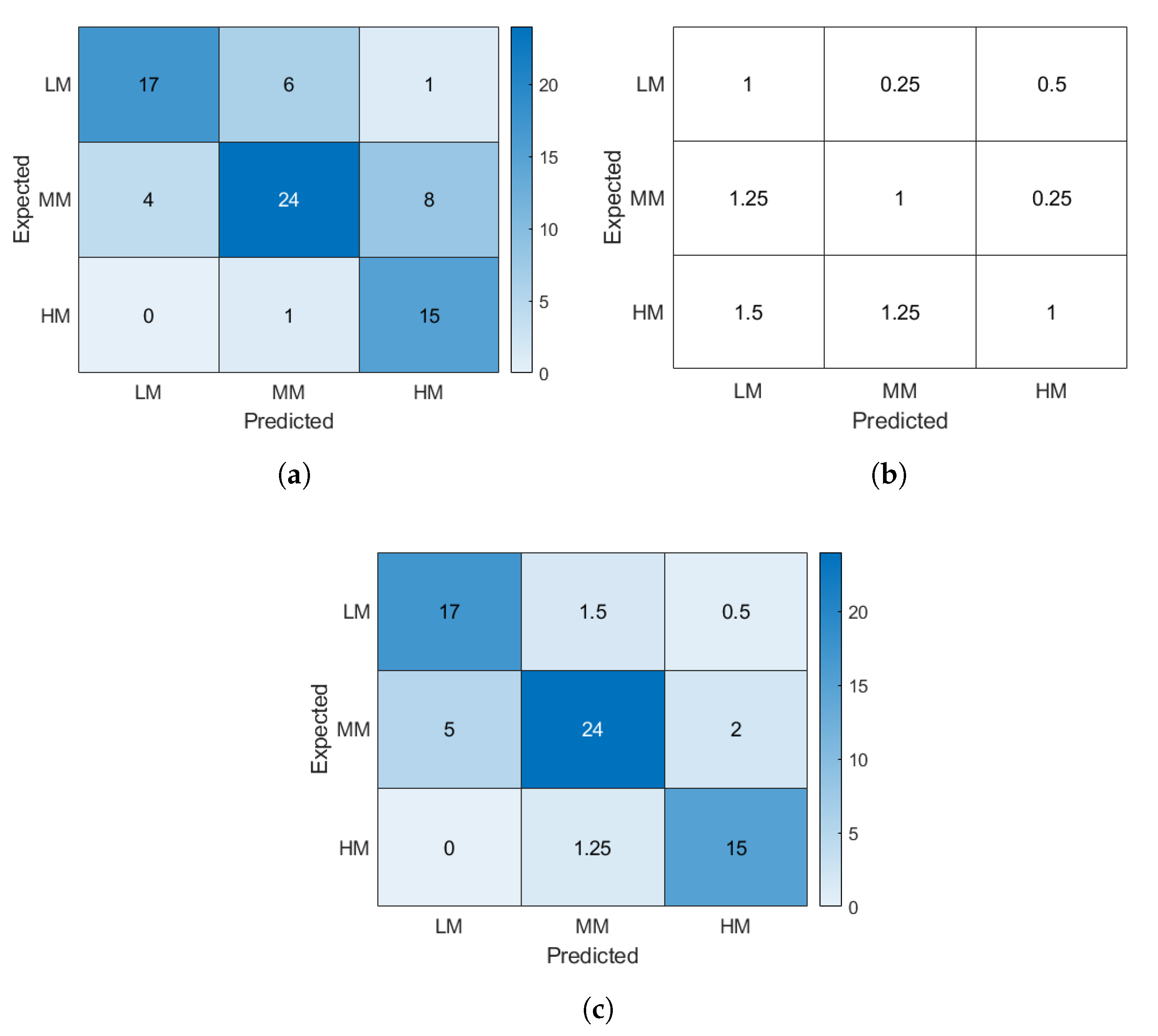
 ,
, 





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}