
WCC-EC 2.0: Enhancing Neural Machine Translation with a 1.6M+ Web-Crawled English-Chinese Parallel Corpus



Abstract
1. Introduction
- Firstly, there was a clear gap in the creation of bilingual English-Chinese corpora for music, a gap not addressed by major projects such as WMT and OPUS [22], even though there were corpora with tens of millions of pairs. Furthermore, lyrics tended to be more conversational, full of spoken phrases, slang, and common expressions that are closer to everyday language. The common use of words with multiple meanings in spoken language gives NMT more context to work with, helping it deal with uncertainties and improve translation accuracy.
- The scaling laws of language modeling suggests that the effectiveness of a model depended on how much data it has. In recent years, increasing the amount of data has been a common way to make language models better. However, the Epoch AI Research team [23] predicted that the stock of high-quality language data would run out by 2026, and even the stock of lower-quality data would start to run out between 2030 and 2050. Therefore, combining a music domain parallel corpus with WCC-EC 1.0 to create a Domain-Specific Parallel Corpus—WCC-EC 2.0 is very important.
- We introduced WCC-EC 2.0, an expanded parallel corpus that combins approximately 1.3 million pairs of lyrics data with existing news data, significantly enhancing the diversity of languages represented and augmenting the corpus’s applicability for NMT research. Additionally, we have filled a notable gap by including texts from the music domain, which are currently scarce. This corpus is freely available for download for non-commercial research purposes, providing a valuable resource for the NMT community.
- We set up a strong human evaluation system that goes well with automatic measures, such as BLEU scores, to give a more detailed look at the quality of translations. This system makes it possible to judge translations based on how natural they sound, how complete they are, and how well they use everyday language, giving a deeper insight into the performance of WCC-EC 2.0.
2. Related Works
2.1. Corpus Construction
2.2. Text Alignment
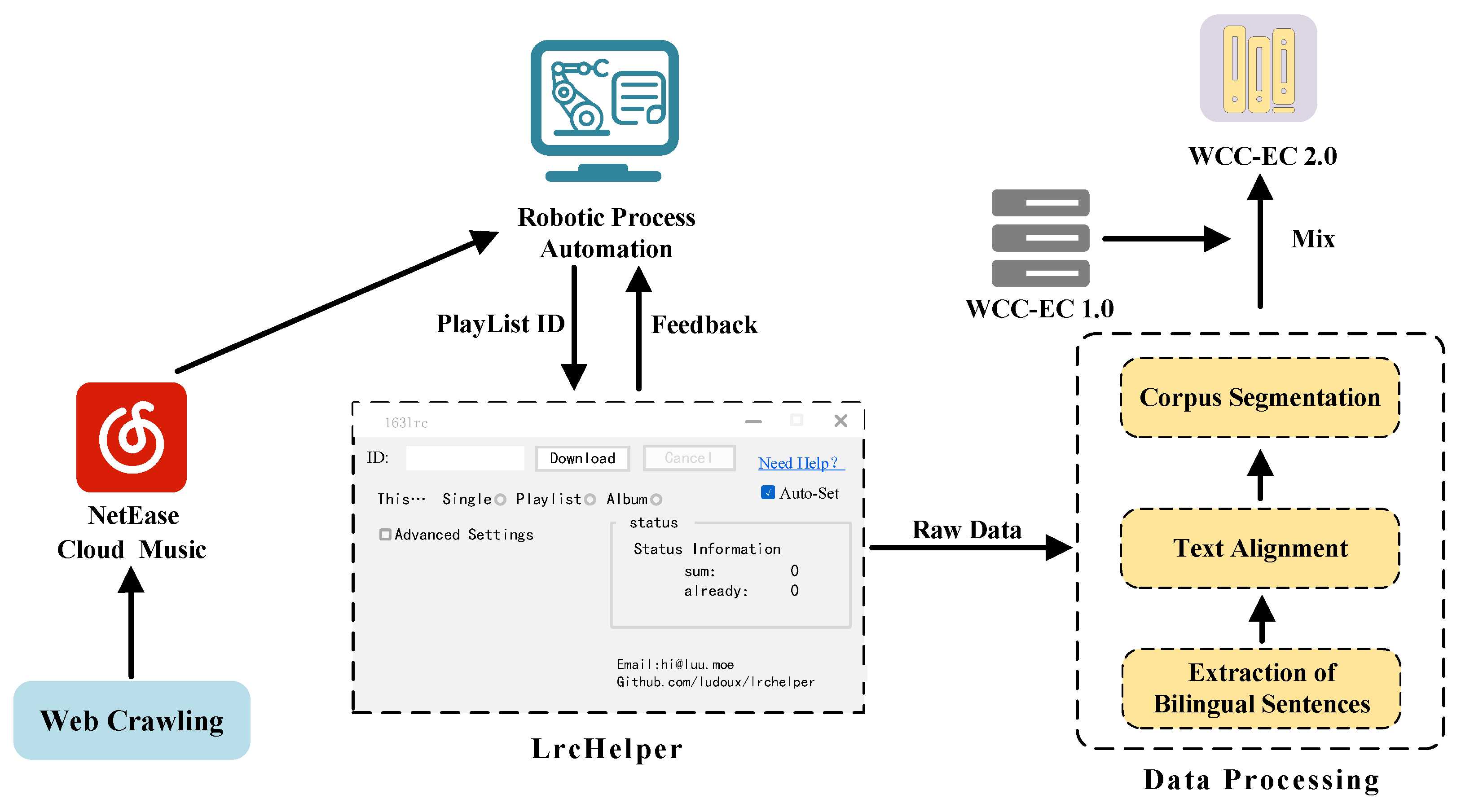
3. Construction of the WCC-EC 2.0
3.1. Web Crawling
3.2. Extraction of Bilingual Sentences
3.3. Text Alignment
3.4. Corpus Segmentation
3.5. Summary of the Corpus Construction
4. Experiment and Evaluation
4.1. Dataset
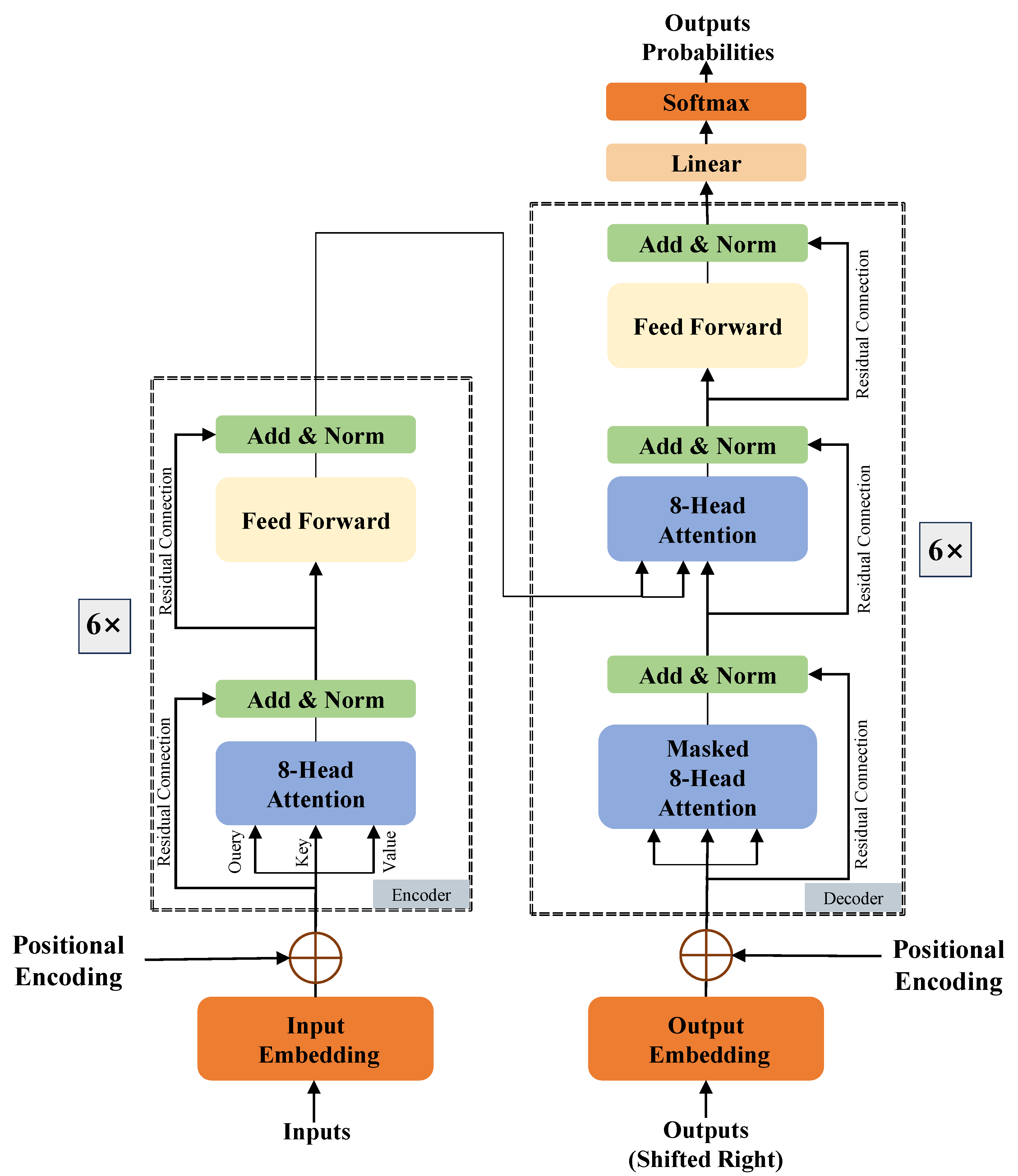
4.2. Setting Up the NMT Framework
- Word segmentation and tokenization: Initially, Jieba was applied to segment Chinese sentences, followed by the use of Moses for tokenizing both Chinese and English sentences. This step transformed the original continuous text into individual words or tokens, allowing the model to better comprehend the structure and semantics of the text.
- BPE: We utilized the subword-nmt tool for encoding the bilingual files with Byte-Pair Encoding. BPE was a method that encoded common word combinations or phrases into single tokens, which helped the model better understand and process low-frequency vocabulary, thus enhancing the accuracy of translation.
- Length limit: The clean-corpus-n.perl tool in Moses was employed to clean the data and eliminate sentences exceeding 256 words. This step could reduce the computational burden on the model and avoid potential interference from overly long sentences during training. This step might have decreased the size of the dataset, but we believe it could improve the training efficiency and translation quality of the model.
- Generate input text: We generated the vocabulary and binaries needed for model training using the “fairseq-preprocess” preprocessing function in fairseq.
4.3. Evaluation
4.3.1. Machine Translation Performance and Analysis
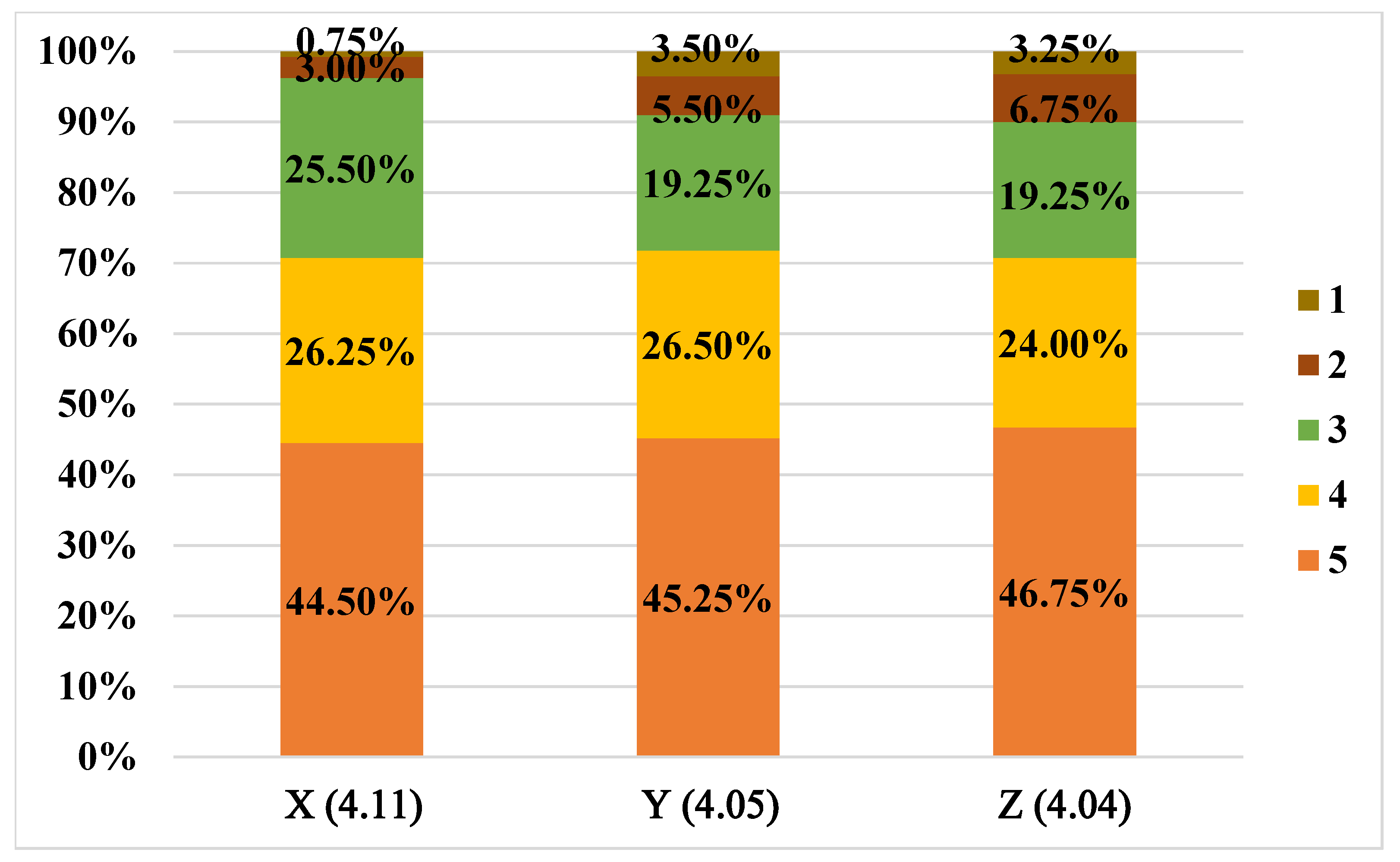
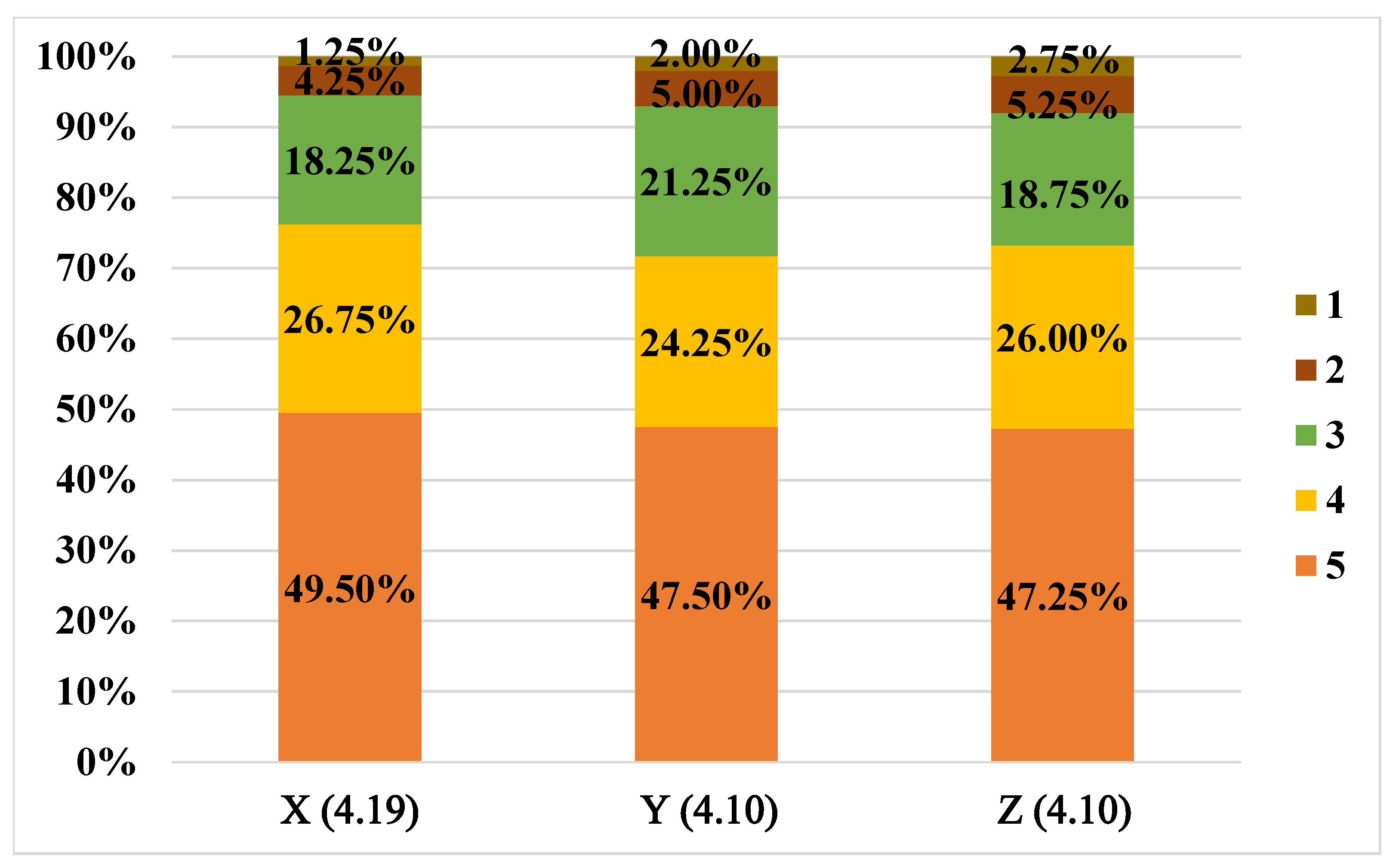
4.3.2. Manual Evaluation Results and Analysis
5. Summary and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sutskever, I.; Vinyals, O.; Le, Q.V. Sequence to Sequence Learning with Neural Networks. In Proceedings of the Advances in Neural Information Processing Systems 27: Annual Conference on Neural Information Processing Systems 2014, Montreal, QC, Canada, 8–13 December 2014; Ghahramani, Z., Welling, M., Cortes, C., Lawrence, N.D., Weinberger, K.Q., Eds.; MIT Press: Cambridge, MA, USA, 2014; pp. 3104–3112. [Google Scholar]
- Luong, M.T.; Pham, H.; Manning, C.D. Effective Approaches to Attention-based Neural Machine Translation. In Proceedings of the 2015 Conference on Empirical Methods in Natural Language Processing, Lisbon, Portugal, 17–21 September 2015; ACL: Lisbon, Portugal, 2015; pp. 1412–1421. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, L.; Polosukhin, I. Attention is All you Need. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017; Guyon, I., von Luxburg, U., Bengio, S., Wallach, H.M., Fergus, R., Vishwanathan, S.V.N., Garnett, R., Eds.; pp. 5998–6008. [Google Scholar]
- Stahlberg, F. Neural Machine Translation: A Review. J. Artif. Intell. Res. 2020, 69, 343–418. [Google Scholar] [CrossRef]
- OpenAI. OpenAI Blog: Introducing ChatGPT, 30 November 2022. Available online: https://openai.com/blog/chatgpt (accessed on 15 February 2024).
- OpenAI. GPT-4 Technical Report. arXiv 2023, arXiv:2303.08774. [Google Scholar]
- Sanz-Valdivieso, L.; López-Arroyo, B. Google Translate vs. ChatGPT: Can non-language professionals trust them for specialized translation? In Proceedings of the International Conference Human-informed Translation and Interpreting Technology, Naples, Italy, 7–9 July 2023. [Google Scholar]
- Zhu, W.; Liu, H.; Dong, Q.; Xu, J.; Kong, L.; Chen, J.; Li, L.; Huang, S. Multilingual Machine Translation with Large Language Models: Empirical Results and Analysis. arXiv 2023, arXiv:2304.04675. [Google Scholar]
- Hendy, A.; Abdelrehim, M.; Sharaf, A.; Raunak, V.; Gabr, M.; Matsushita, H.; Kim, Y.J.; Afify, M.; Awadalla, H.H. How Good Are GPT Models at Machine Translation? A Comprehensive Evaluation. arXiv 2023, arXiv:2302.09210. [Google Scholar]
- Vilar, D.; Freitag, M.; Cherry, C.; Luo, J.; Ratnakar, V.; Foster, G.F. Prompting PaLM for Translation: Assessing Strategies and Performance. In Proceedings of the Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), ACL 2023, Toronto, ON, Canada, 9–14 July 2023; Rogers, A., Boyd-Graber, J.L., Okazaki, N., Eds.; Association for Computational Linguistics: Toronto, ON, Canada; pp. 15406–15427. [Google Scholar] [CrossRef]
- Zhang, B.; Haddow, B.; Birch, A. Prompting Large Language Model for Machine Translation: A Case Study. In Proceedings of the International Conference on Machine Learning, ICML, Honolulu, HI, USA, 23–29 July 2023; Proceedings of Machine Learning Research (PMLR). Krause, A., Brunskill, E., Cho, K., Engelhardt, B., Sabato, S., Scarlett, J., Eds.; Volume 202, pp. 41092–41110. [Google Scholar]
- Jiao, W.; Wang, W.; Huang, J.; Wang, X.; Tu, Z. Is ChatGPT A Good Translator? A Preliminary Study. arXiv 2023, arXiv:2301.08745. [Google Scholar]
- Robinson, N.R.; Ogayo, P.; Mortensen, D.R.; Neubig, G. ChatGPT MT: Competitive for High- (but Not Low-) Resource Languages. In Proceedings of the Eighth Conference on Machine Translation, WMT 2023, Singapore, 6–7 December 2023; Koehn, P., Haddon, B., Kocmi, T., Monz, C., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 392–418. [Google Scholar]
- Karpinska, M.; Iyyer, M. Large Language Models Effectively Leverage Document-level Context for Literary Translation, but Critical Errors Persist. In Proceedings of the Eighth Conference on Machine Translation, WMT 2023, Singapore, 6–7 December 2023; Koehn, P., Haddon, B., Kocmi, T., Monz, C., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 419–451. [Google Scholar]
- Wang, L.; Lyu, C.; Ji, T.; Zhang, Z.; Yu, D.; Shi, S.; Tu, Z. Document-Level Machine Translation with Large Language Models. In Proceedings of the 2023 Conference on Empirical Methods in Natural Language Processing, EMNLP 2023, Singapore, 6–10 December 2023; Bouamor, H., Pino, J., Bali, K., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2023; pp. 16646–16661. [Google Scholar]
- Xu, H.; Kim, Y.J.; Sharaf, A.; Awadalla, H.H. A Paradigm Shift in Machine Translation: Boosting Translation Performance of Large Language Models. arXiv 2023, arXiv:2309.11674. [Google Scholar]
- Yang, W.; Li, C.; Zhang, J.; Zong, C. BigTrans: Augmenting Large Language Models with Multilingual Translation Capability over 100 Languages. arXiv 2023, arXiv:2305.18098. [Google Scholar]
- Bawden, R.; Yvon, F. Investigating the Translation Performance of a Large Multilingual Language Model: The Case of BLOOM. In Proceedings of the 24th Annual Conference of the European Association for Machine Translation, EAMT 2023, Tampere, Finland, 12–15 June 2023; Nurminen, M., Brenner, J., Koponen, M., Latomaa, S., Mikhailov, M., Schierl, F., Ranasinghe, T., Vanmassenhove, E., Vidal, S.A., Aranberri, N., et al., Eds.; European Association for Machine Translation: Sheffield, UK, 2023; pp. 157–170. [Google Scholar]
- Lu, H.; Huang, H.; Zhang, D.; Yang, H.; Lam, W.; Wei, F. Chain-of-Dictionary Prompting Elicits Translation in Large Language Models. arXiv 2023, arXiv:2305.06575. [Google Scholar]
- Ranathunga, S.; Lee, E.A.; Skenduli, M.P.; Shekhar, R.; Alam, M.; Kaur, R. Neural Machine Translation for Low-resource Languages: A Survey. ACM Comput. Surv. 2023, 55, 229:1–229:37. [Google Scholar] [CrossRef]
- Zhang, J.; Guo, C.; Mao, J.; Guo, C.; Matsumoto, T. An Enhanced Method for Neural Machine Translation via Data Augmentation Based on the Self-Constructed English-Chinese Corpus, WCC-EC. IEEE Access 2023, 11, 112123–112132. [Google Scholar] [CrossRef]
- Tiedemann, J. OPUS-parallel corpora for everyone. In Proceedings of the 19th Annual Conference of the European Association for Machine Translation: Projects/Products, EAMT 2016, Riga, Latvia, 30 May–1 June 2016. [Google Scholar]
- Villalobos, P.; Sevilla, J.; Heim, L.; Besiroglu, T.; Hobbhahn, M.; Ho, A. Will we run out of data? An analysis of the limits of scaling datasetdatasets in Machine Learning. arXiv 2022, arXiv:2211.04325. [Google Scholar]
- Mackenzie, J.M.; Benham, R.; Petri, M.; Trippas, J.R.; Culpepper, J.S.; Moffat, A. CC-News-En: A Large English News Corpus. In Proceedings of the CIKM ’20: The 29th ACM International Conference on Information and Knowledge Management, Virtual Event, 19–23 October 2020; d’Aquin, M., Dietze, S., Hauff, C., Curry, E., Cudré-Mauroux, P., Eds.; ACM: New York, NY, USA, 2020; pp. 3077–3084. [Google Scholar] [CrossRef]
- Lefer, M.A. Parallel corpora. In A Practical Handbook of Corpus Linguistics; Springer: Berlin/Heidelberg, Germany, 2021; pp. 257–282. [Google Scholar]
- Bañón, M.; Chen, P.; Haddow, B.; Heafield, K.; Hoang, H.; Esplà-Gomis, M.; Forcada, M.L.; Kamran, A.; Kirefu, F.; Koehn, P.; et al. ParaCrawl: Web-Scale Acquisition of Parallel Corpora. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 4555–4567. [Google Scholar] [CrossRef]
- Ziemski, M.; Junczys-Dowmunt, M.; Pouliquen, B. The United Nations Parallel Corpus v1.0. In Proceedings of the Tenth International Conference on Language Resources and Evaluation LREC 2016, Portorož, Slovenia, 23–28 May 2016; Calzolari, N., Choukri, K., Declerck, T., Goggi, S., Grobelnik, M., Maegaard, B., Mariani, J., Mazo, H., Moreno, A., Odijk, J., et al., Eds.; European Language Resources Association (ELRA): Paris, France, 2016. [Google Scholar]
- Liu, B.; Huang, L. NEJM-enzh: A Parallel Corpus for English-Chinese Translation in the Biomedical Domain. arXiv 2020, arXiv:2005.09133. [Google Scholar]
- Liu, Z.; Wang, H.; Niu, Z.; Wu, H.; Che, W. DuRecDial 2.0: A Bilingual Parallel Corpus for Conversational Recommendation. In Proceedings of the 2021 Conference on Empirical Methods in Natural Language Processing, EMNLP 2021, Virtual Event/Punta Cana, Dominican Republic, 7–11 November, 2021; Moens, M., Huang, X., Specia, L., Yih, S.W., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2021; pp. 4335–4347. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, Y.; Mao, J.; Han, M.; Matsumoto, T. WCC-JC: A web-crawled corpus for Japanese-Chinese neural machine translation. Appl. Sci. 2022, 12, 6002. [Google Scholar] [CrossRef]
- Zhang, J.; Tian, Y.; Mao, J.; Han, M.; Wen, F.; Guo, C.; Gao, Z.; Matsumoto, T. WCC-JC 2.0: A Web-Crawled and Manually Aligned Parallel Corpus for Japanese-Chinese Neural Machine Translation. Electronics 2023, 12, 1140. [Google Scholar] [CrossRef]
- Sugiyama, A.; Yoshinaga, N. Data augmentation using back-translation for context-aware neural machine translation. In Proceedings of the Fourth Workshop on Discourse in Machine Translation, DiscoMT@EMNLP 2019, Hong Kong, China, 3 November 2019; Popescu-Belis, A., Loáiciga, S., Hardmeier, C., Xiong, D., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 35–44. [Google Scholar] [CrossRef]
- Li, X.; Yu, P.; Zhou, C.; Schick, T.; Zettlemoyer, L.; Levy, O.; Weston, J.; Lewis, M. Self-Alignment with Instruction Backtranslation. arXiv 2023, arXiv:2308.06259. [Google Scholar]
- Morita, T.; Akiba, T.; Tsukada, H. Hybrid Sampling for Iterative Back-Translation of Neural Machine Translation. IEICE Trans. Inf. Syst. (Jpn. Ed.) 2023, 106, 298–306. [Google Scholar]
- Zhang, J.; Matsumoto, T. Corpus Augmentation for Neural Machine Translation with Chinese–Japanese Parallel Corpora. Appl. Sci. 2019, 9, 2036. [Google Scholar] [CrossRef]
- Dou, Z.Y.; Neubig, G. Word alignment by fine-tuning embeddings on parallel corpora. arXiv 2021, arXiv:2101.08231. [Google Scholar]
- Church, K.W. Word2Vec. Nat. Lang. Eng. 2017, 23, 155–162. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of tricks for efficient text classification. arXiv 2016, arXiv:1607.01759. [Google Scholar]
- Li, X.; Meng, Y.; Sun, X.; Han, Q.; Yuan, A.; Li, J. Is Word Segmentation Necessary for Deep Learning of Chinese Representations? In Proceedings of the 57th Conference of the Association for Computational Linguistics, ACL 2019, Florence, Italy, 28 July–2 August 2019; Volume 1: Long Papers. Korhonen, A., Traum, D.R., Màrquez, L., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 3242–3252. [Google Scholar] [CrossRef]
- Jiang, C.; Maddela, M.; Lan, W.; Zhong, Y.; Xu, W. Neural CRF Model for Sentence Alignment in Text Simplification. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 7943–7960. [Google Scholar] [CrossRef]
- Zhang, B.; Nagesh, A.; Knight, K. Parallel Corpus Filtering via Pre-trained Language Models. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, ACL 2020, Online, 5–10 July 2020; Jurafsky, D., Chai, J., Schluter, N., Tetreault, J.R., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2020; pp. 8545–8554. [Google Scholar] [CrossRef]
- Cao, S.; Kitaev, N.; Klein, D. Multilingual Alignment of Contextual Word Representations. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Reimers, N.; Gurevych, I. Sentence-BERT: Sentence Embeddings using Siamese BERT-Networks. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing, EMNLP-IJCNLP 2019, Hong Kong, China, 3–7 November 2019; Inui, K., Jiang, J., Ng, V., Wan, X., Eds.; Association for Computational Linguistics: Toronto, ON, Canada, 2019; pp. 3980–3990. [Google Scholar] [CrossRef]
- Papineni, K.; Roukos, S.; Ward, T.; Zhu, W. Bleu: A Method for Automatic Evaluation of Machine Translation. In Proceedings of the 40th Annual Meeting of the Association for Computational Linguistics (ACL), Philadelphia, PA, USA, 6–12 July 2002; pp. 311–318. [Google Scholar] [CrossRef]
- Scao, T.L.; Fan, A.; Akiki, C.; Pavlick, E.; Ilic, S.; Hesslow, D.; Castagné, R.; Luccioni, A.S.; Yvon, F.; Gallé, M.; et al. BLOOM: A 176B-Parameter Open-Access Multilingual Language Model. arXiv 2022, arXiv:2211.05100. [Google Scholar]
- Touvron, H.; Martin, L.; Stone, K.; Albert, P.; Almahairi, A.; Babaei, Y.; Bashlykov, N.; Batra, S.; Bhargava, P.; Bhosale, S.; et al. Llama 2: Open Foundation and Fine-Tuned Chat Models. arXiv 2023, arXiv:2307.09288. [Google Scholar]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Corpus | Quantity | Language Pairs | Source Field | Applications | Manual Evaluation |
|---|---|---|---|---|---|
| ParaCrawl [26] | 223 million | 23 EU languages with EN | General | NMT | No |
| OPUS [22] | 3.2 billion | Over 200 | General | NMT | No |
| UN Corpus [27] | Over 10 million | AR, ZH, EN, FR, RU, ES | News | NMT | No |
| NEJM-enzh [28] | 100,000 | ZH & EN | Biomedical | NMT | No |
| DuRecDial 2.0 [29] | Over 8000 | ZH & EN | Dialogue | Conversation | No |
| WCC-EC 2.0 | Over 1.6 million | ZH & EN | News & Lyrics | NMT | Yes |
| Contents | Number of English and Chinese Bilingual Sentences | |||
|---|---|---|---|---|
| WCC-EC 2.0-Full | WCC-EC 2.0-Lyrics | WCC-EC 2.0-News | V16 Dataset | |
| Training set | 1,662,908 | 1,323,651 | 339,257 | 318,235 |
| Development set | 2000 | 2000 | 2000 | 2000 |
| Test set | 2000 | 2000 | 2000 | 2000 |
| Training Data | Test Data | Average BLEU | |||
|---|---|---|---|---|---|
| V | W | WL | WN | ||
| V16 Dataset | 11.40 | 1.99 | 2.70 | 3.69 | 4.94 |
| WCC-EC 2.0-Full | 15.18 | 19.16 | 12.96 | 12.57 | 14.97 |
| WCC-EC 2.0-Lyrics | 2.11 | 5.04 | 16.46 | 1.87 | 6.37 |
| WCC-EC 2.0-News | 16.68 | 15.73 | 7.52 | 15.14 | 13.77 |
| Training Data | Test Data | Average BLEU | |||
|---|---|---|---|---|---|
| V | W | WL | WN | ||
| V16 Dataset | 12.80 | 1.88 | 1.25 | 1.28 | 4.31 |
| WCC-EC 2.0-Full | 20.77 | 24.72 | 21.85 | 16.89 | 21.06 |
| WCC-EC 2.0-Lyrics | 2.02 | 7.25 | 23.42 | 1.74 | 8.61 |
| WCC-EC 2.0-News | 18.77 | 17.77 | 9.35 | 17.80 | 15.93 |
| Grade | Evaluation Criteria |
|---|---|
| 5 | All important content has been accurately conveyed. (100%) |
| 4 | Most of the key content has been accurately conveyed. (Approximately 80%∼100%) |
| 3 | More than half of the core content is accurately conveyed. (About 50%∼80%) |
| 2 | Some important content has been successfully conveyed. (Roughly 20%∼50%) |
| 1 | The minimum basic content has been transmitted correctly. (Up to about 20%) |
| Attribute | Team X | Team Y | Team Z |
|---|---|---|---|
| Age | 34, 27 | 35, 31 | 30, 35 |
| Gender | Male, Male | Female, Male | Female, Male |
| Occupation | Lab Researcher, PhD Student | Asst. Prof., PhD Student | Media Staff, Asst. Prof. |
| Language | Excellent, Proficient | Excellent, Proficient | Proficient, Excellent |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, J.; Su, K.; Tian, Y.; Matsumoto, T. WCC-EC 2.0: Enhancing Neural Machine Translation with a 1.6M+ Web-Crawled English-Chinese Parallel Corpus. Electronics 2024, 13, 1381. https://doi.org/10.3390/electronics13071381
Zhang J, Su K, Tian Y, Matsumoto T. WCC-EC 2.0: Enhancing Neural Machine Translation with a 1.6M+ Web-Crawled English-Chinese Parallel Corpus. Electronics. 2024; 13(7):1381. https://doi.org/10.3390/electronics13071381
Chicago/Turabian StyleZhang, Jinyi, Ke Su, Ye Tian, and Tadahiro Matsumoto. 2024. "WCC-EC 2.0: Enhancing Neural Machine Translation with a 1.6M+ Web-Crawled English-Chinese Parallel Corpus" Electronics 13, no. 7: 1381. https://doi.org/10.3390/electronics13071381
APA StyleZhang, J., Su, K., Tian, Y., & Matsumoto, T. (2024). WCC-EC 2.0: Enhancing Neural Machine Translation with a 1.6M+ Web-Crawled English-Chinese Parallel Corpus. Electronics, 13(7), 1381. https://doi.org/10.3390/electronics13071381