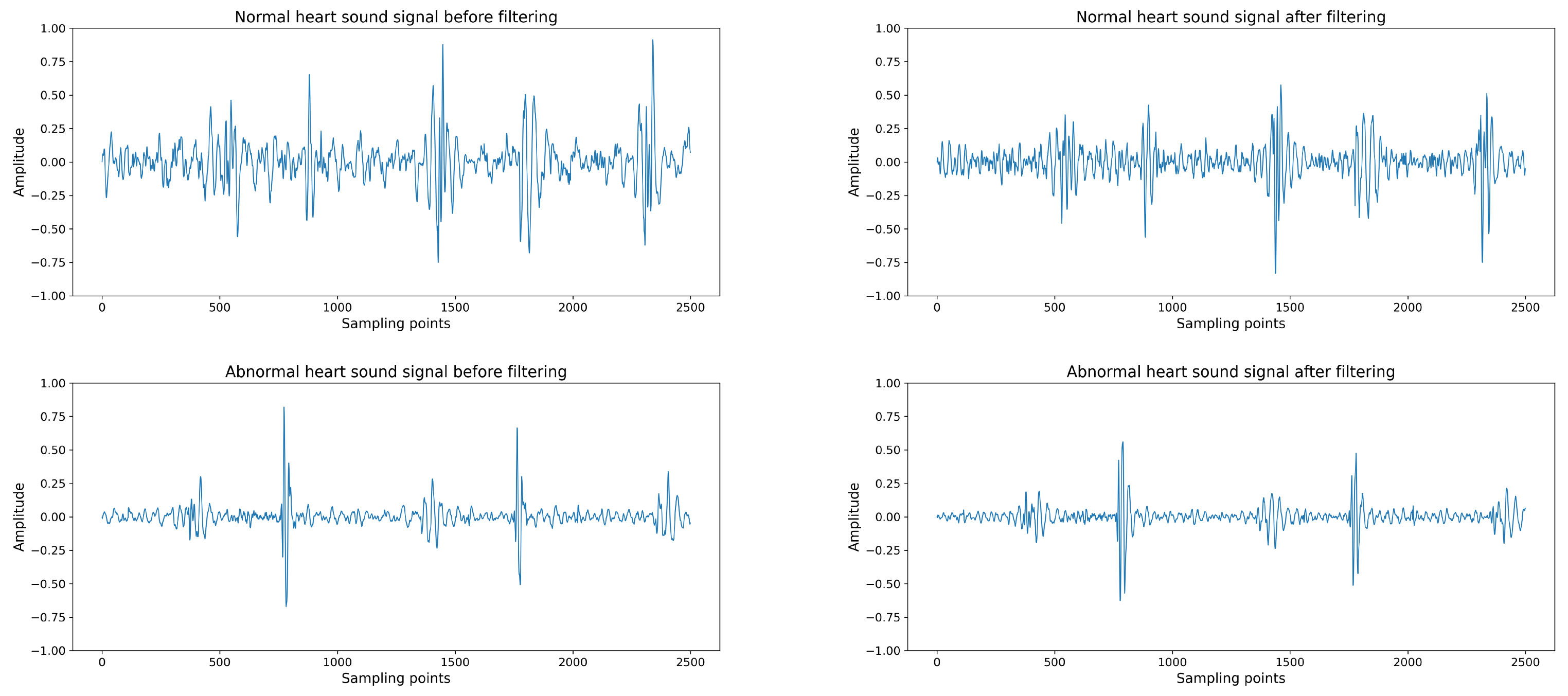
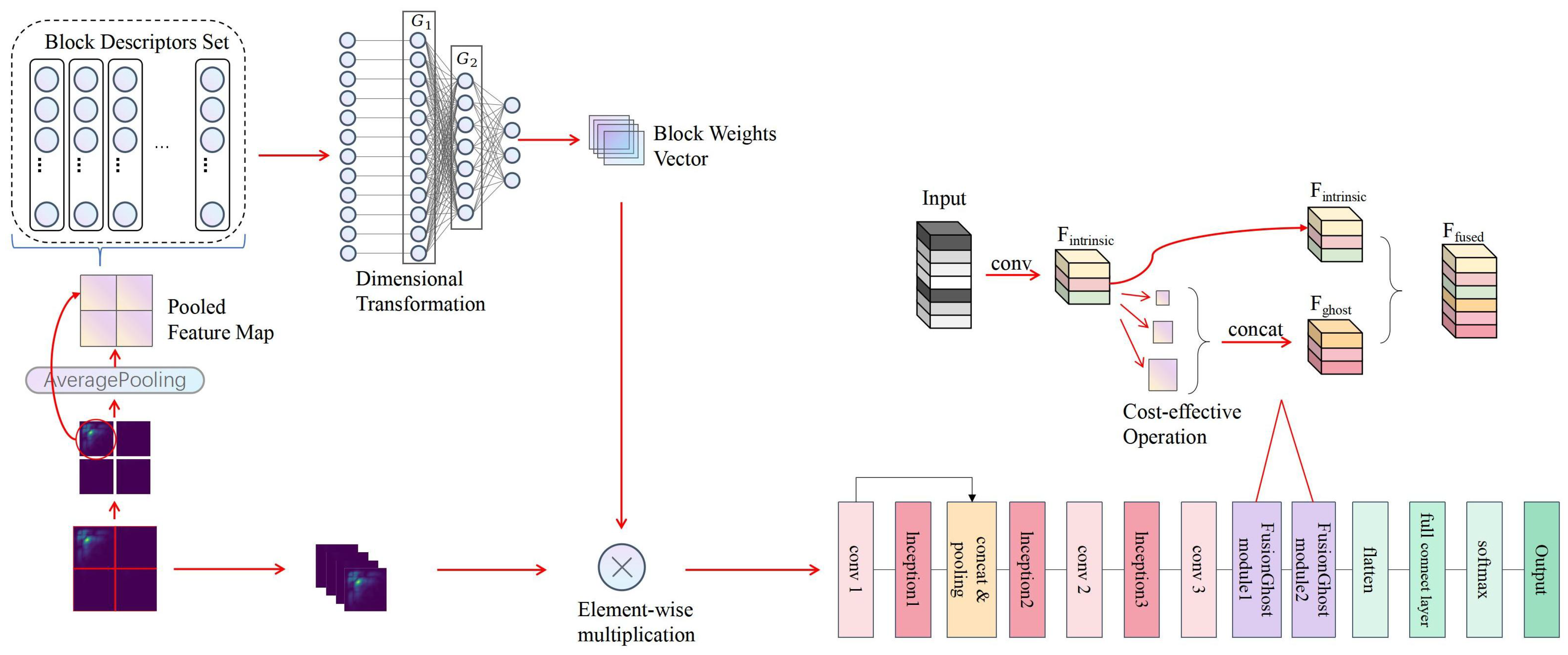
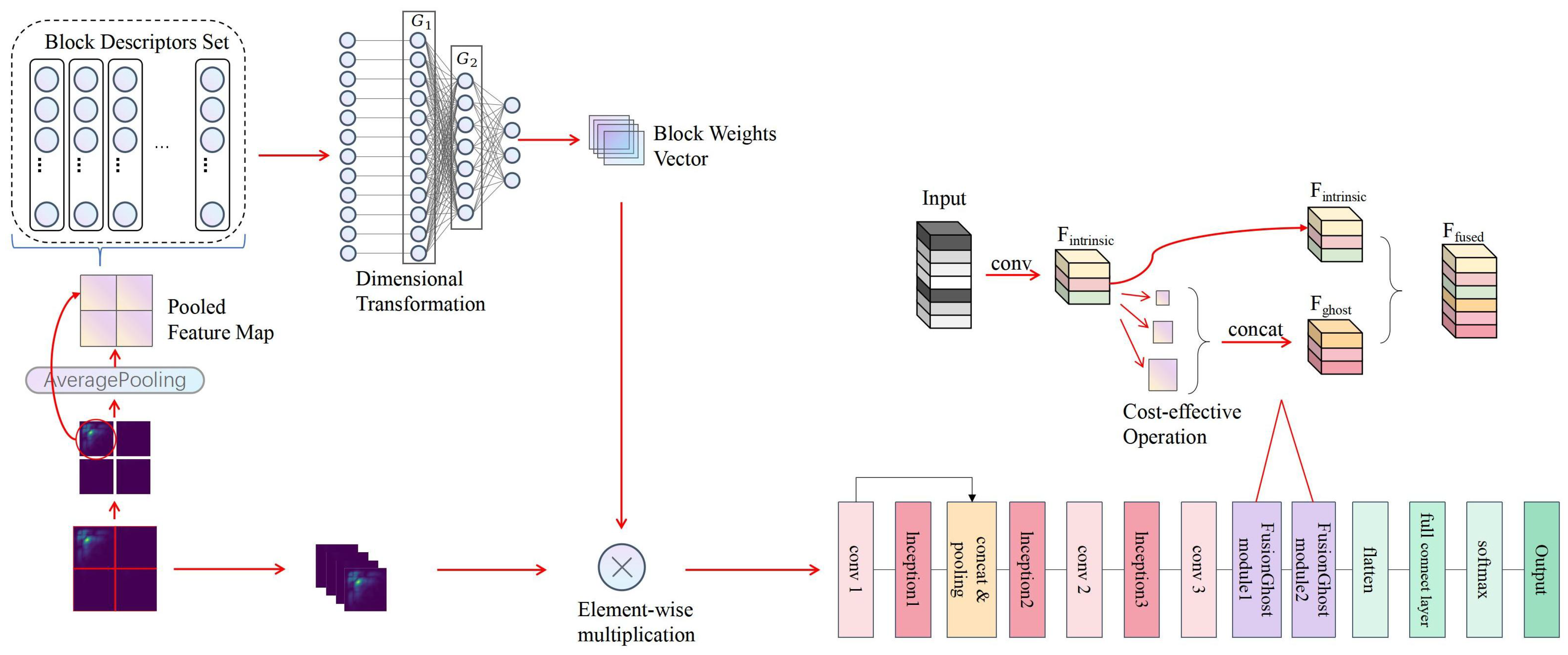
3.4. Partition Attention Module
Our heart sound signal classification framework features the innovative Partition Attention Network (PANet), a key development that significantly elevates the model’s proficiency in isolating and analyzing critical features of heart sound signals. Central to this enhancement is the Partition Attention Module, a sophisticated mechanism designed to meticulously partition the input feature map, thereby facilitating a more granular analysis of the acoustic signals.
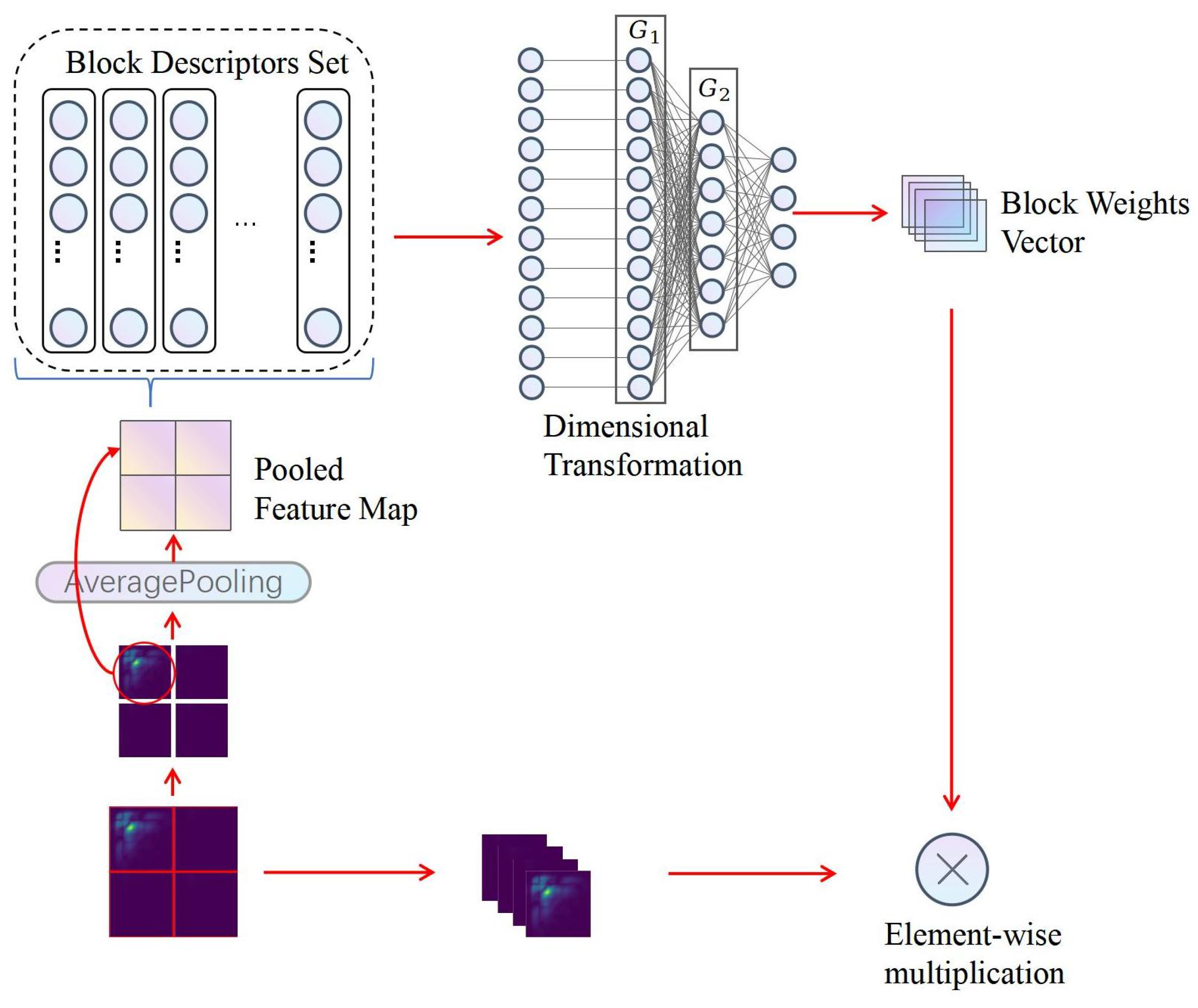
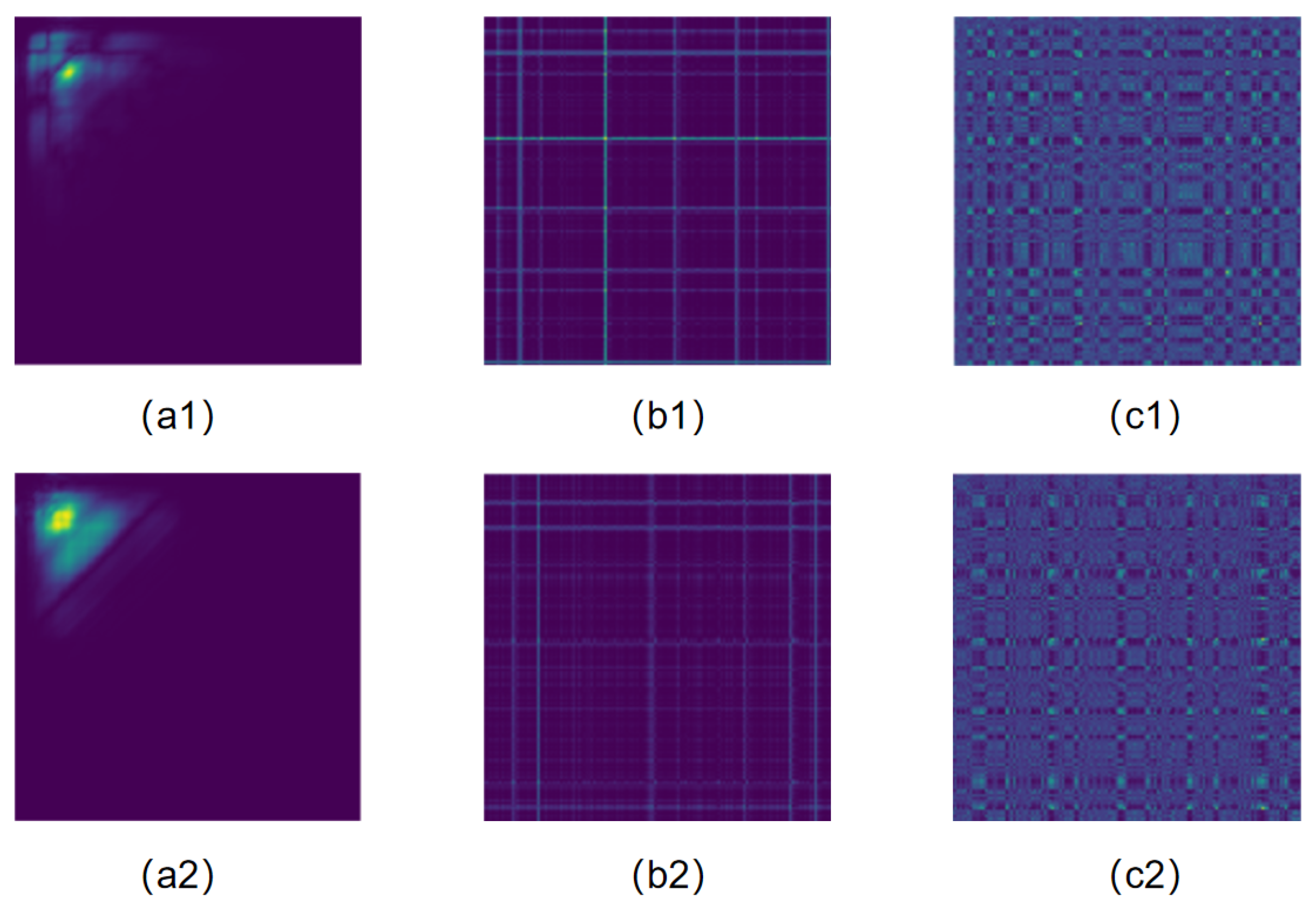
Figure 4 provides a detailed visual representation of the nuanced operations within the Partition Attention Module, beginning with a bispectrum as the initial input. This bispectrum is processed through a Partition Mechanism, segmenting the signal into distinct blocks, which are subsequently streamlined via an Average Pooling layer into a pooled feature map.This streamlined process paves the way for Global Feature Vector Extraction, where a Block Descriptors Set is formulated, encapsulating the essential traits of the signal. The journey of data transformation continues with a Dimensional Transformation, preparing the data for the subsequent stages of processing. A critical phase follows, where a Weight Allocation layer assigns a vector of block weights, ingeniously designed to magnify the significant features within the heart sound signals through an element-wise multiplication with the initial blocks. This methodical enhancement of pivotal features underscores the advanced capability of PANet in accentuating crucial patterns within the heart sound signals, thereby underlining the framework’s enhanced effectiveness in the precise classification of these signals.
Partition Mechanism: The initial step involves uniformly dividing the input two-dimensional feature map (e.g., 256 × 256 × 1) into B equivalent blocks, where serves as a typical example, with each block having dimensions of 128 × 128. This segmentation not only divides the feature map physically but also logically treats each block as an individual channel, enabling detailed local feature extraction.
Average Pooling Layer: Each block is subjected to an average pooling operation to reduce its dimensionality. Average pooling computes the mean of the elements within a specified neighborhood, effectively condensing the information into a more compact representation. For a block of size
, the average pooling operation with a pooling size of
is defined as:
where
is the pooled value,
is the original value at the
th position in the block, and the summation is carried out over the
neighborhood.
Global Feature Vector Extraction: After average pooling, each block is transformed into a global feature vector. This vectorization step converts the pooled
block into a one-dimensional array of length
, capturing the essence of the block’s features. The transformation is represented by:
where
is the global feature vector and
denotes the vectorization of the pooled block
P.
Block Descriptors Set: The global feature vectors from all blocks are concatenated to form the feature vector set , represented as a matrix: , where each is the vectorized representation of block i.
Dimensional Transformation: To process these feature vectors and extract pivotal information for the classification task, two fully connected layers, represented as linear transformation layers, and , are employed. reduces the dimensions of the feature vectors in , aiming to simplify computations and highlight key features. The dimensions of are defined as , where r is the reduction ratio. Subsequently, maps the output of to the final number of blocks B, with dimensions .
Weight Allocation Layer: The linear transformations provided by
and
generate a set of weights
for each block. These weights are computed by passing the feature vector set
through
for dimension reduction, followed by an application of the ReLU function [
37] for non-linear activation, and finally through
for mapping to the weight space corresponding to the number of blocks
B. This process is mathematically represented as:
where the ReLU function introduces non-linearity, aiding the model in learning complex patterns of weight distribution. The weight vector
represents the importance of each block for the classification task, allowing the model to focus more on blocks containing significant information.
These weights are then used to reweight the feature map, producing the output of the PA module. Each block’s original features
are multiplied by their corresponding weights
, yielding reweighted features which emphasize the more informative parts of the input. The operation for obtaining the final weighted feature map is given by:
where
represents the reweighted feature of the
n-th block. This reweighting process ensures that the network prioritizes blocks with essential information, significantly improving the overall performance of the model.
3.6. Computation Analysis
The parameters of the PA module mainly come from the fully connected layer. The number of neurons in G1 is 64 × 64 × 4, in G2 is 128, and in the final output layer is 4. Therefore, the number of parameters can be calculated by 64 × 64 × 4 × 128 + 128 + 128 × 4 + 4, resulting in a total of 2,097,796 parameters for the PA module. The computational load of the PA module primarily originates from the Average Pooling and the fully connected layer. The computational load of Average Pooling is: 128 × 128 × 4, and the fully connected layer is: 64 × 64 × 4 × 128 + (64 × 64 × 4 − 1) × 128 + 128 × 4 + 127 × 4. Thus, the total computational load of the PA module is the sum of these two parts, amounting to 4,195,196.
Conv1’s convolutional kernel size is 1 × 1 × 64, with a stride of 2. Therefore, the number of parameters for Conv1 can be calculated as 1 × 1 × 4 × 64 + 64, and its computational load is 128 × 128 × 64 × (4 + 4 − 1). Thus, Conv1 has 320 parameters and a computational load of 7,340,032.
Inception1 module’s parameters and computational load are derived from four branches: one with a 1 × 1 convolution, one with a 1 × 1 and a 3 × 3 convolution, one with a 1 × 1 and a 5 × 5 convolution, and one with a 3 × 3 max pooling and a 1 × 1 convolution. With input and output sizes both at (128, 128, 64), the total parameter count for Inception1 sums up to 38,912, calculated from the individual branches’ parameters (1024 + 10,240 + 26,624 + 1024), and the total computational load reaches 151,011,944, derived from the computational loads of each branch (2,097,152 + 39,845,888 + 106,954,752 + 2,097,152).
For Concat+Pooling, there are no parameters involved, and the computational load primarily stems from the pooling operation. This operation utilizes average pooling, with an input dimension of (128, 128, 128) and an output dimension of (64, 64, 128), using a pooling size of (2, 2) and a stride of 2. Consequently, the computational load is calculated to be 2,097,152, following the formula 64 × 64 × 128 × 4.
Inception2 module’s parameters and computational load are derived from four branches: one with a 1 × 1 convolution, one with a 1 × 1 and a 3 × 3 convolution, one with a 1 × 1 and a 5 × 5 convolution, and one with a 3 × 3 max pooling and a 1 × 1 convolution. Inception2 operates with an input and output size of (64, 64, 128). The total parameters for Inception2 are derived from the sum of its branches’ parameters, amounting to 51,200. Similarly, the computational load of Inception2 is the sum of its branches’ computational load, totaling 209, 715, 200.
Conv2 processes inputs of size (64, 64, 128) and outputs of (32, 32, 128) using 3 × 3 convolutions with a stride of 2. To enhance the model’s feature extraction capabilities, we employed two instances of Conv2. Each Conv2 has a parameter count of (3 × 3 × 128 + 1) × 128 and a computational load of 32 × 32 × 128 × (3 × 3 × 128). Thus, with two Conv2 layers, the total parameters amount to 295,168, and the combined computational effort is 301,989,888.
Inception3 module’s parameters and computational load are derived from four branches: one with a 1 × 1 convolution, one with a 1 × 1 and a 3 × 3 convolution, one with a 1 × 1 and a 5 × 5 convolution, and one with a 3 × 3 max pooling and a 1 × 1 convolution. Inception3 operates with input and output dimensions of (32, 32, 256). The total parameters for Inception3, aggregated from its individual branches, amount to 205,312, calculated as 16,384 × 4 + 36,864 + 102,400. Likewise, its computational load, summed from the contributions of each branch, totals 244,366,784, with a calculation breakdown of 16,777,216 × 4 × 47,185,920 × 131,072,000.
Conv3 with an input size of (32, 32, 256) and reduces the output to (16, 16, 256) through 3 × 3 convolutions with a stride of 2. The total parameters for Conv3 are calculated as 3 × 3 × 256 + 1) × 256, which equals 590,080. The computational load for Conv3 is determined by the formula 16 × 16 × 256 × 3 × 3 × 256), resulting in 150,994,944 operations.
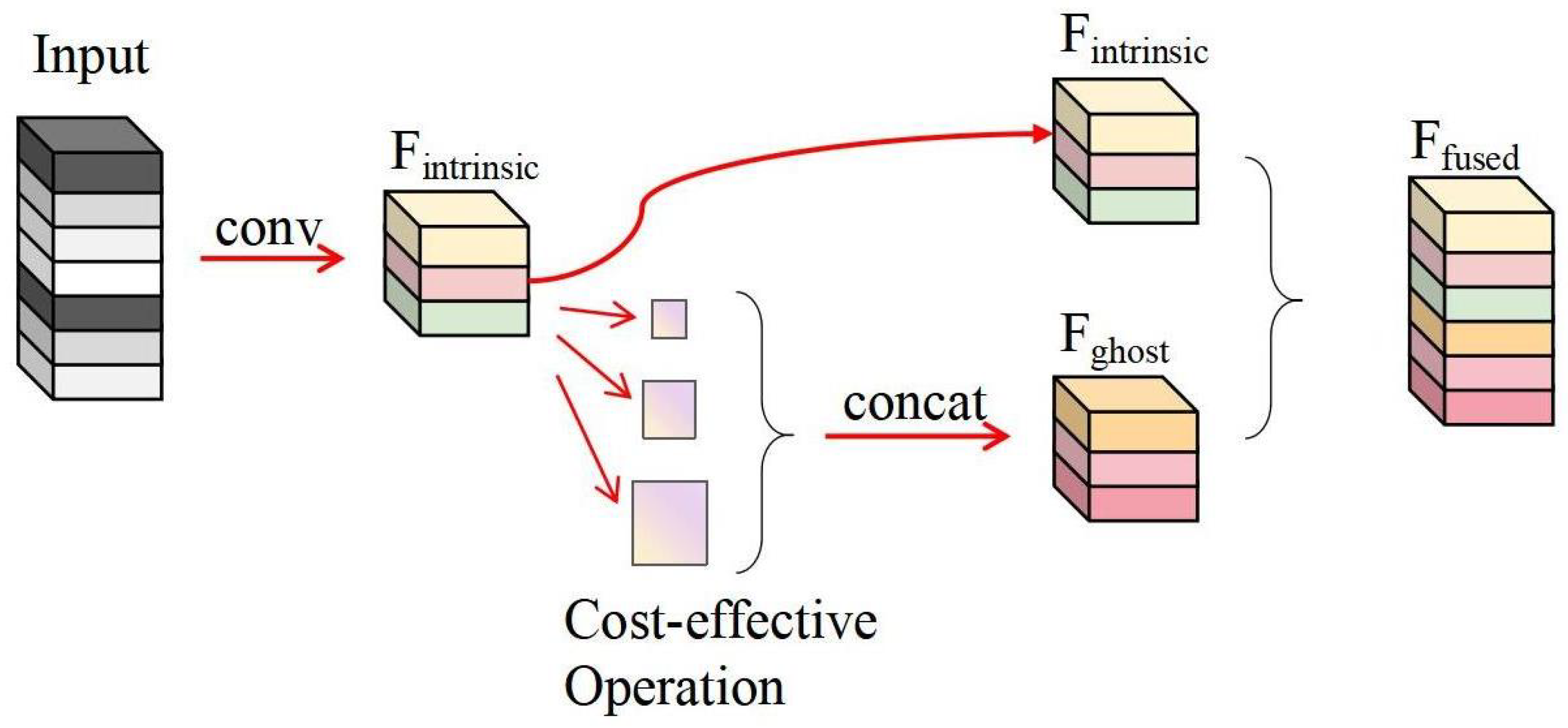
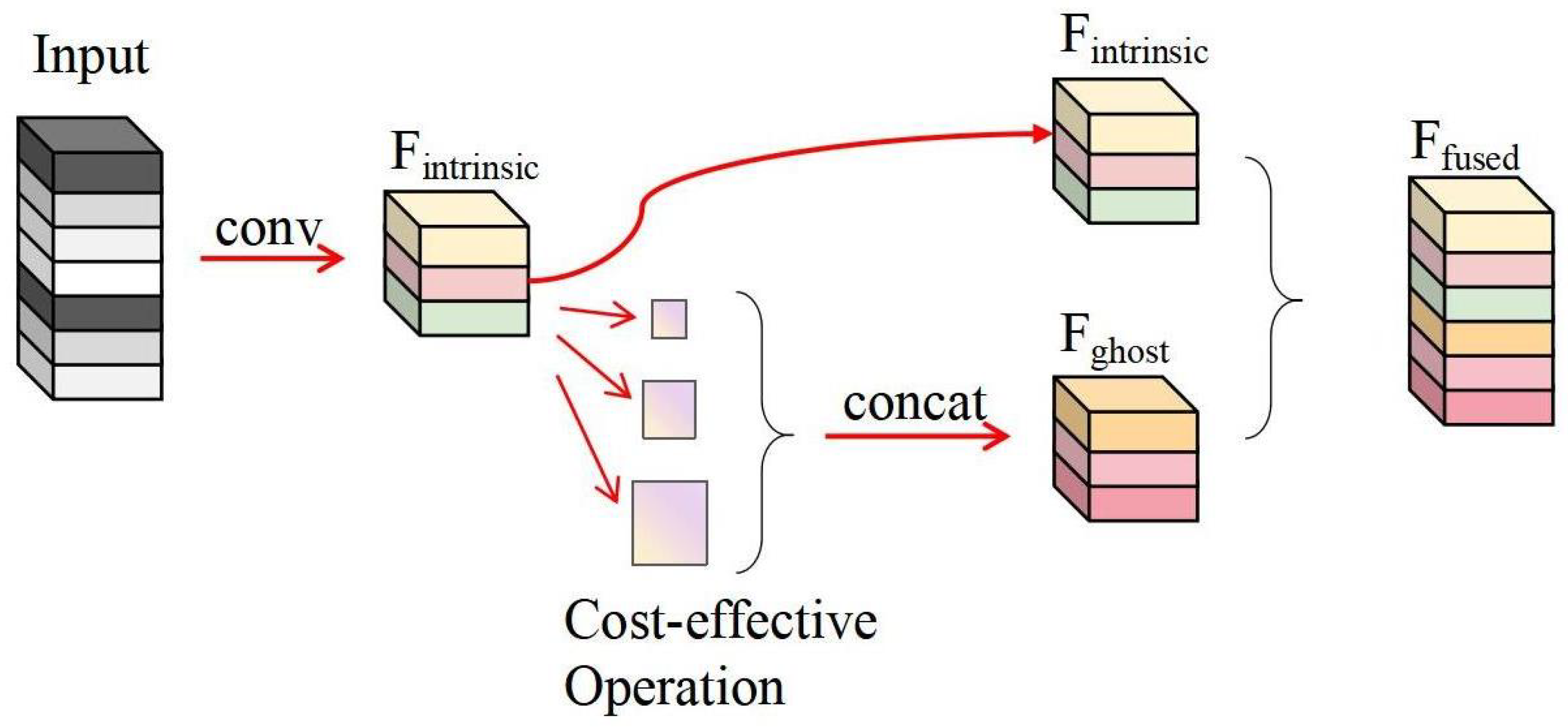
FusionGhost Module1 has an input dimension of (16, 16, 256) and produces an output of (8, 8, 128). It involves 147,456 parameters, calculated from 3 × 3 × 256 × 64, and its computational operations amount to 9,437,184, determined by 3 × 3 × 256 × 8 × 8 × 64.
FusionGhost Module2 takes an input of (8, 8, 128) and yields an output dimension of (4, 4, 64). This module requires 36,864 parameters, computed as 3 × 3 × 128 × 32, and its total computational operations are 589,824, derived from 3 × 3 × 128 × 4 × 4 × 32.
The Classification Layer includes a Flatten operation and a fully connected layer. The input size is (4, 4, 64), and it is flattened into 4 × 4 × 64 neurons, which are then fully connected to 2 neurons. The Classification Layer has a total of 2050 parameters, calculated as 4 × 4 × 64 × 2 + 2, and the computational load is 4094, derived from 2 × (4 × 4 × 64 × 4 × 4 × 64 − 1).
As shown in
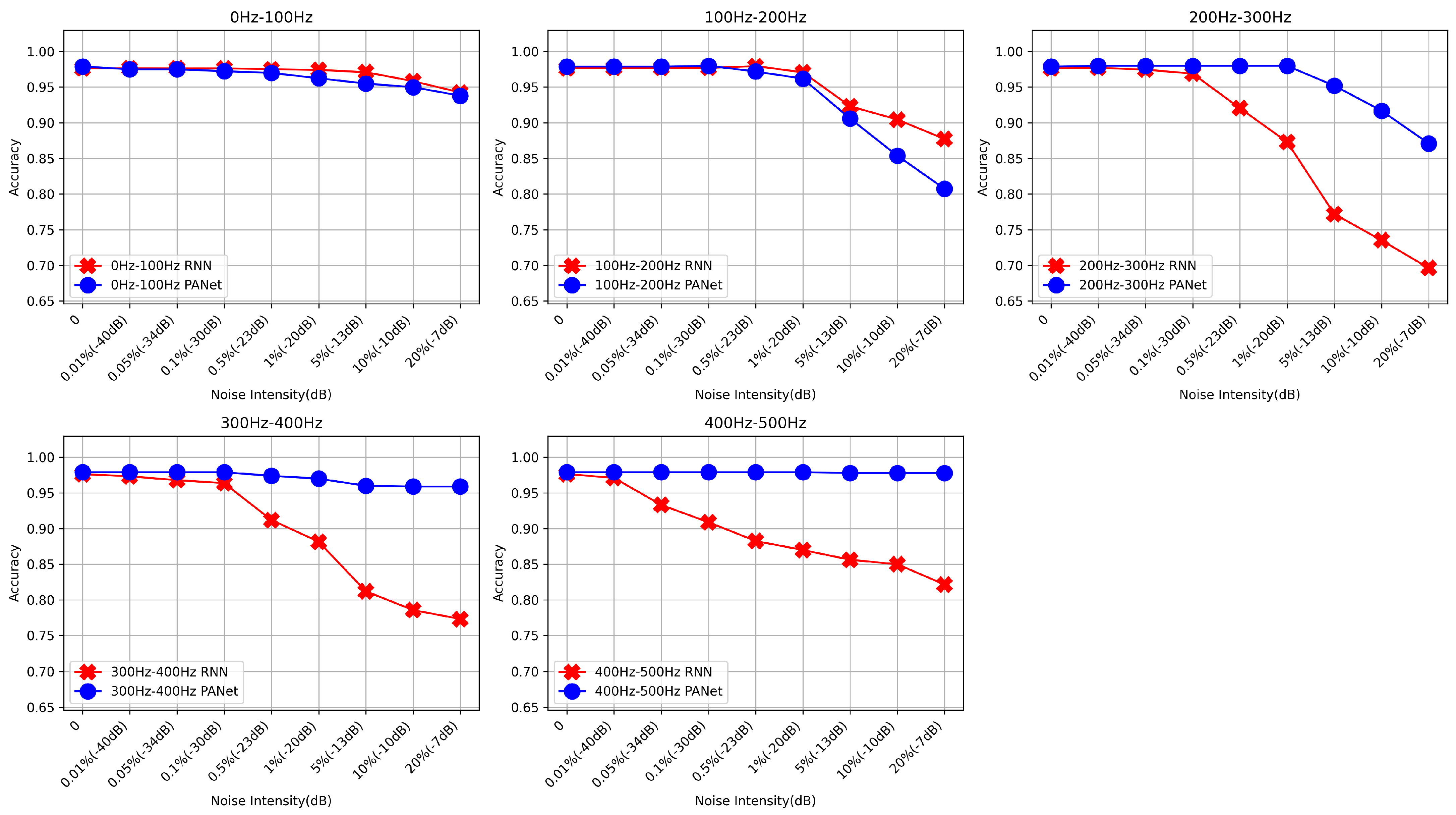
Table 2, which outlines the parameters and computational efforts for each layer, it is found that PANet possesses a total of 3,465,158 (3.46 M) parameters and requires computational efforts amounting to 1,081,742,242 (1081.7 M). Compared to contemporary networks of similar capabilities, PANet demonstrates an advantage in terms of both parameter efficiency and computational load. This reflects the optimization considerations we incorporated during the design phase of PANet, aimed at enhancing network efficiency and practicality.
Through the innovative integration of the PA module and the FusionGhost module, PANet not only achieves high accuracy in heart sound signal classification but also maintains a compact and efficient network architecture. These modules employ a refined attention mechanism and an effective feature fusion strategy, significantly reducing unnecessary computational overhead without compromising performance.
Moreover, the design of PANet takes into account the adaptability to diverse computational settings, including resource-constrained devices, ensuring its practical applicability across a wide range of scenarios [
38]. We believe that these attributes position PANet as a valuable tool in the field of heart sound signal processing, particularly for medical and healthcare applications requiring efficient and accurate heart sound classification.




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}