Fast and Accurate Short-Term Load Forecasting with a Hybrid Model



Abstract
1. Introduction
2. Materials and Methods
2.1. Variational Mode Decomposition (VMD) Process
- 1.
- Application of the Hilbert transform calculates the associated signal of each IMF to derive a unilateral frequency spectrum.
- 2.
- Shifting each spectrum of to the baseband is accomplished by mixing it with an exponential function tuned to the respective computed central frequency.
- 3.
- Determination of the bandwidth of is based on the H1 Gaussian smoothness of the shifted signal.
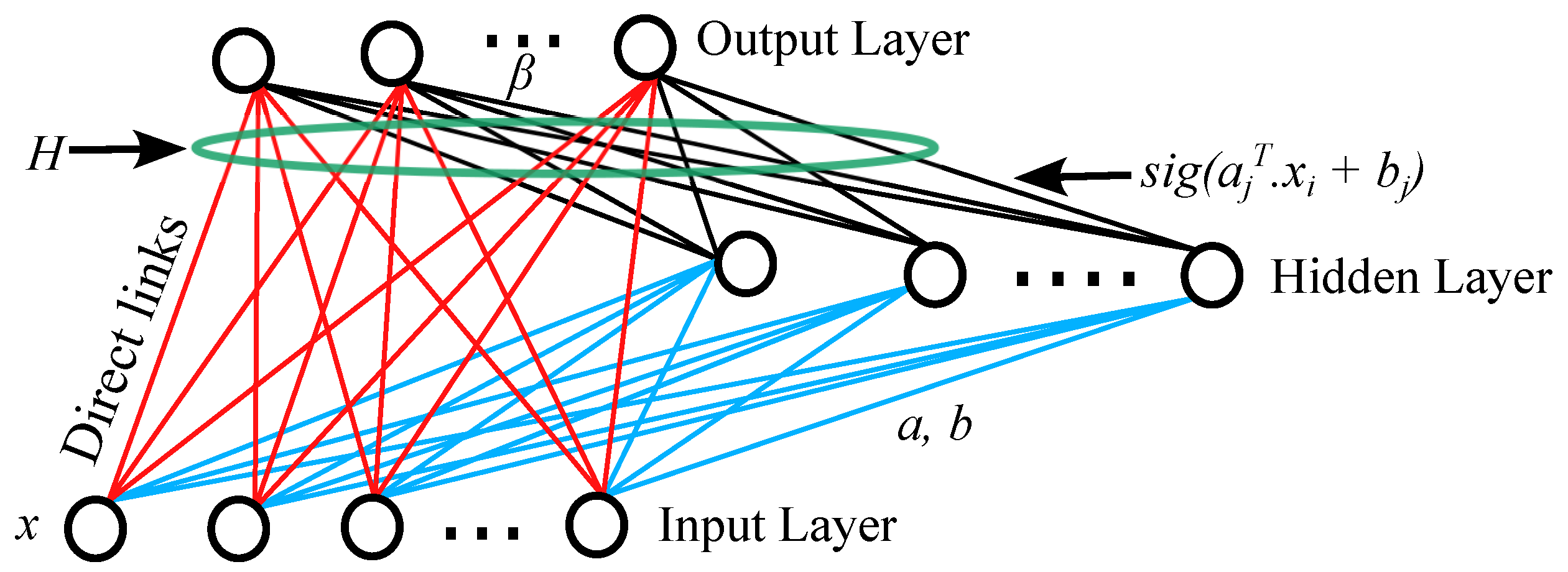
2.2. Random Vector Functional Link (RVFL)
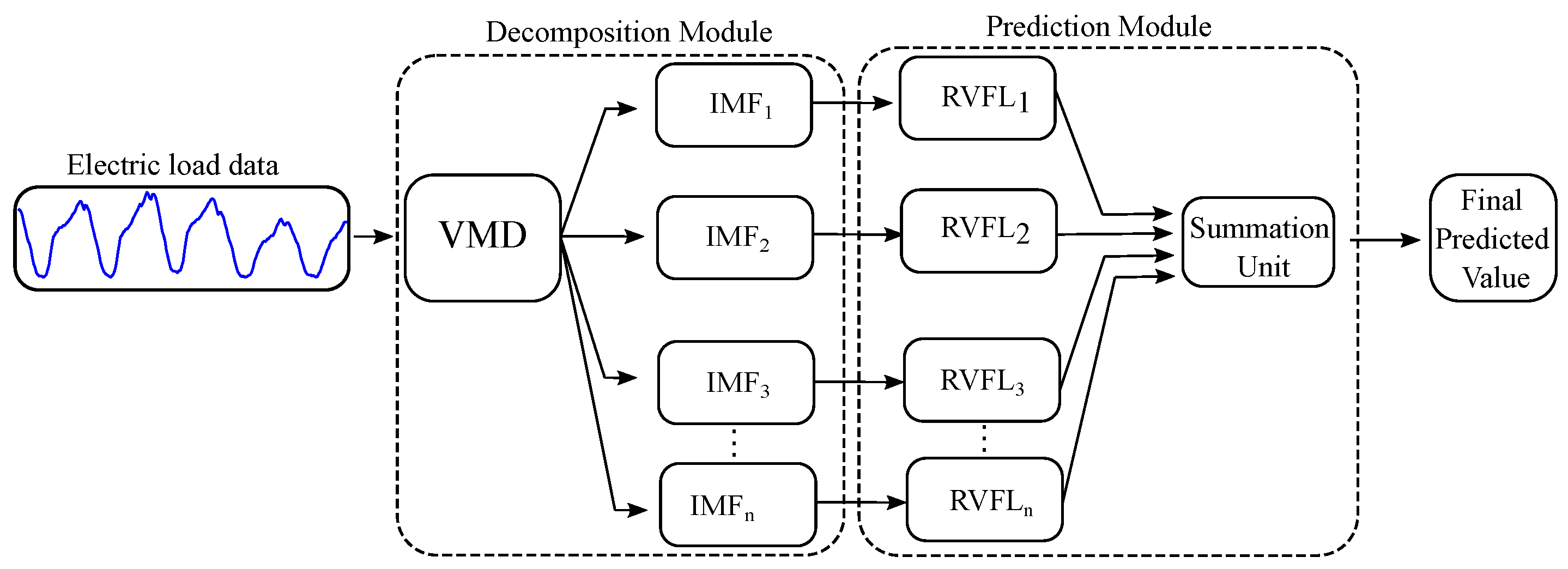
2.3. Electric Load Forecasting with VMD-RVFL
- 1.
- In the initial phase, we employ VMD to break down respiratory motion into IMFs (, , ,…, ) and a residual component (R), as illustrated in the decomposition module of Figure 2. This process focuses on tackling the intra-trace variabilities and irregularities inherent in respiratory motion through decomposition strategies.
- 2.
- Secondly, we construct a training dataset to serve as the input for each RVFL network (, ,…, , ) corresponding to each extracted IMF and residue. is defined as a sequence of inputs: , where represents the magnitude of respiratory motion recorded at time instant t. Predicting respiratory motion for a known horizon can be approached as a classical learning problem, aiming to estimate the relationship between elements in the input space and elements in the target space . The elements in the input space are formulated by considering the recent history of the respiratory motion trace: , with m representing the dimension of the input feature vector. The elements in the target space corresponding to are defined as . Here, denotes the predicted value samples ahead, computed at the tth sample.
- 3.
- Subsequently, input vectors along with their corresponding target vectors, formulated using the training data from , , ,…, are fed into the , , ,…, models. These models learn a non-linear mapping that captures the intrinsic relationship between the input feature space and the target space. This phase is depicted in the prediction module of Figure 2.
- 4.
- During this phase, the non-linear mapping established during the training stages of , , ,…, will be applied to predict unseen data for all , , ,…, .
- 5.
- Lastly, sum up the predicted outputs of all RVFL networks (, , ,…, ) to formulate the predicted output as illustrated in the summation unit of Figure 2.
3. Experimental Setup
3.1. Datasets
3.2. Performance Indices
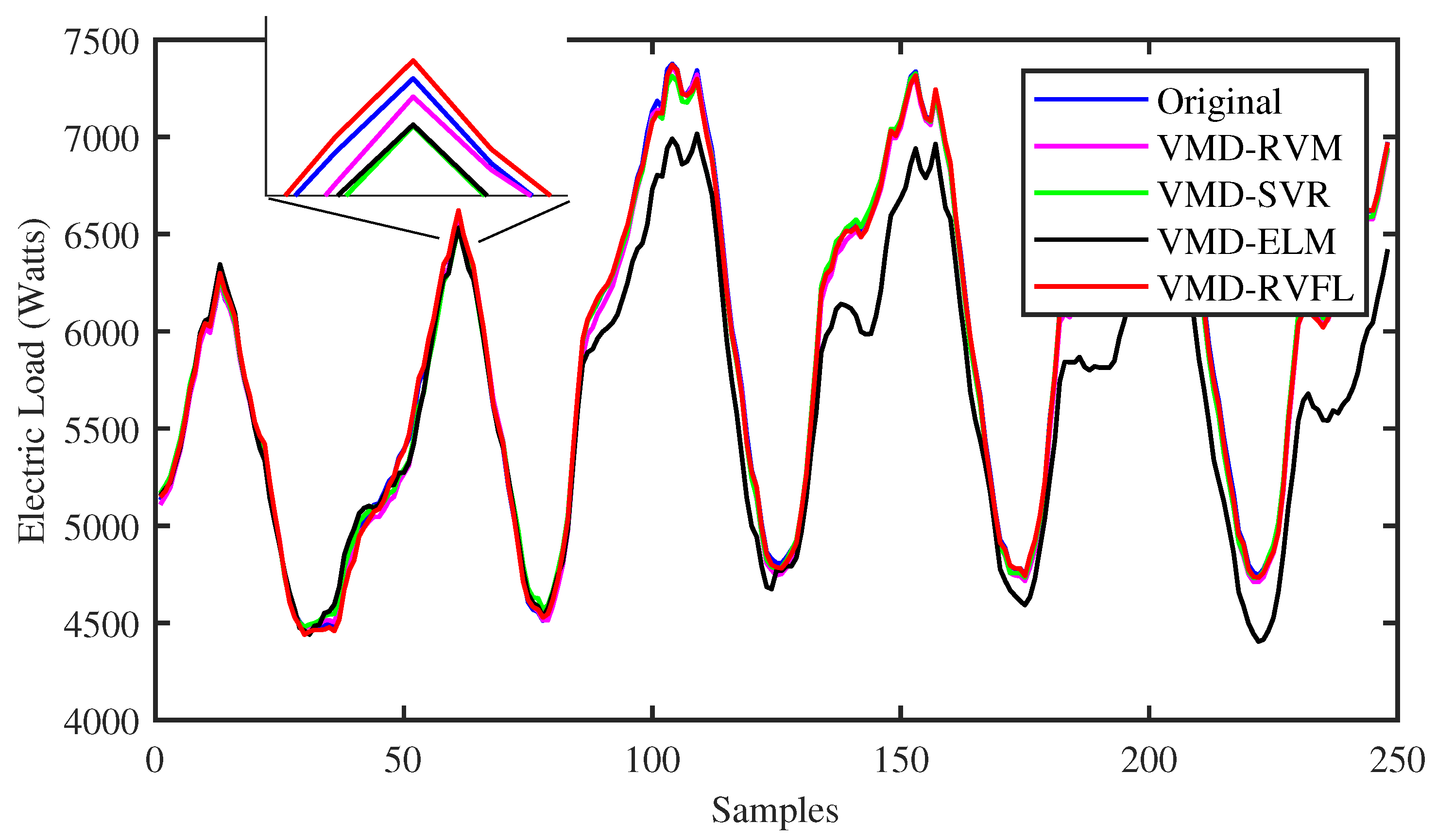
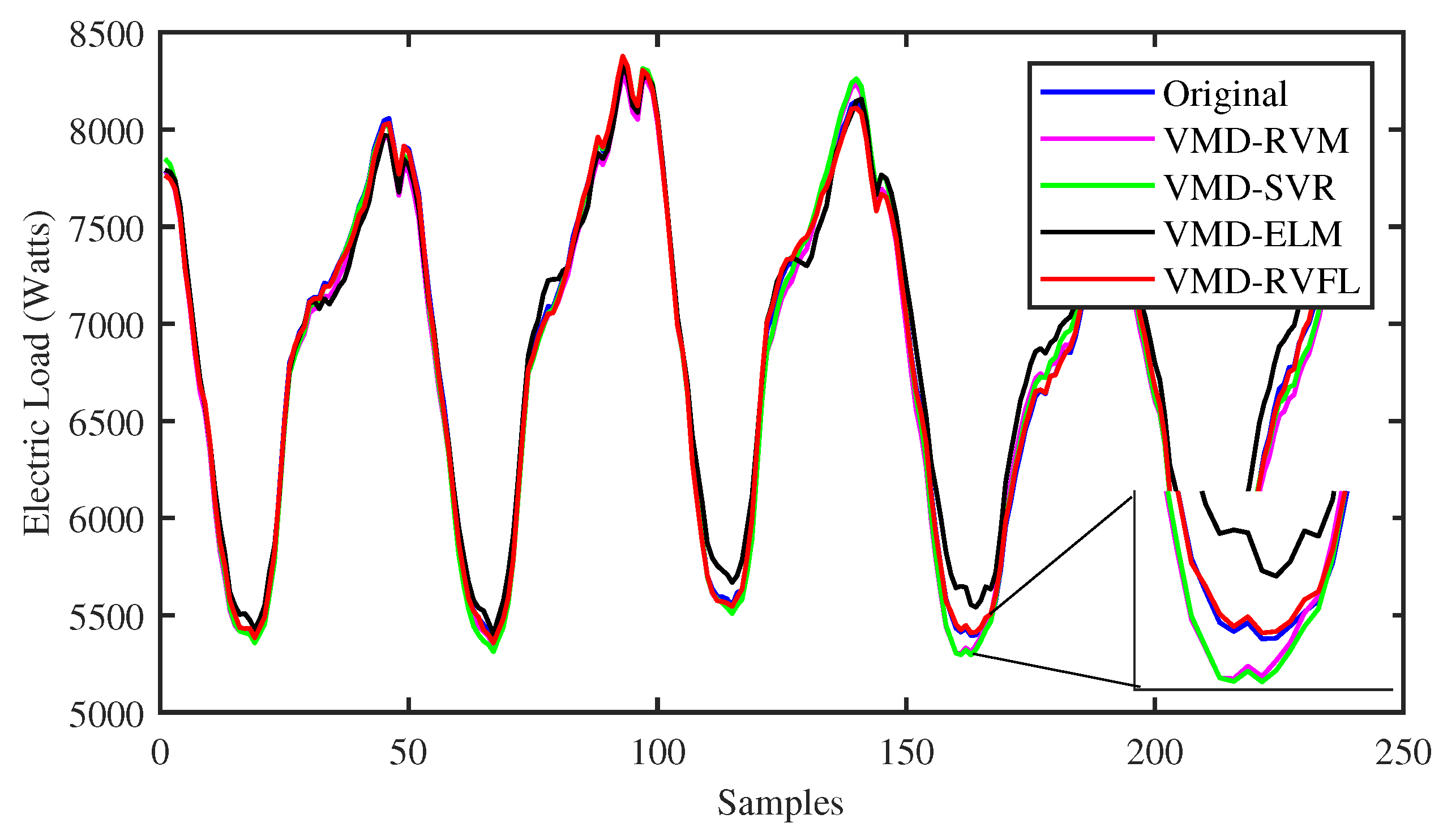
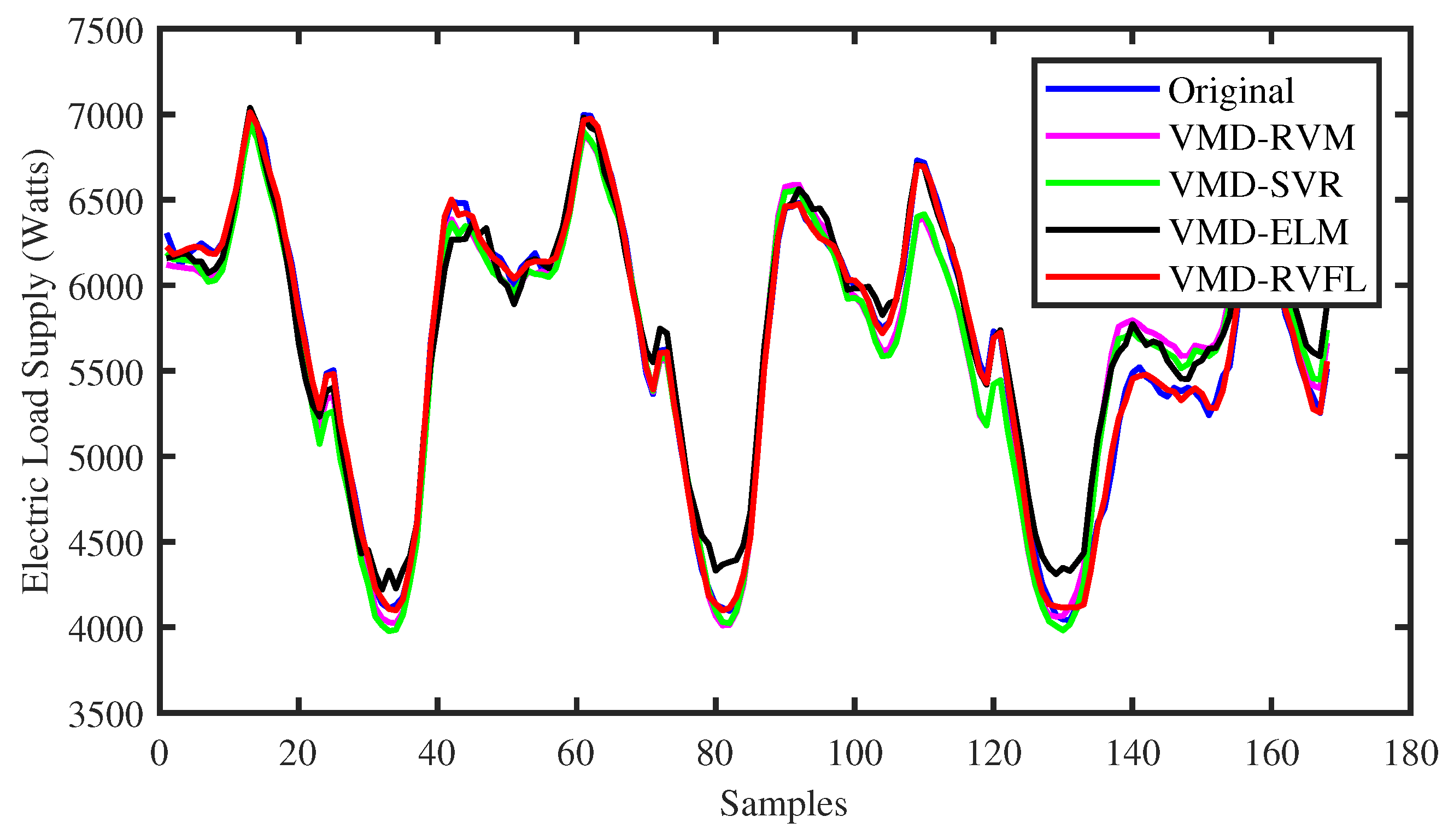
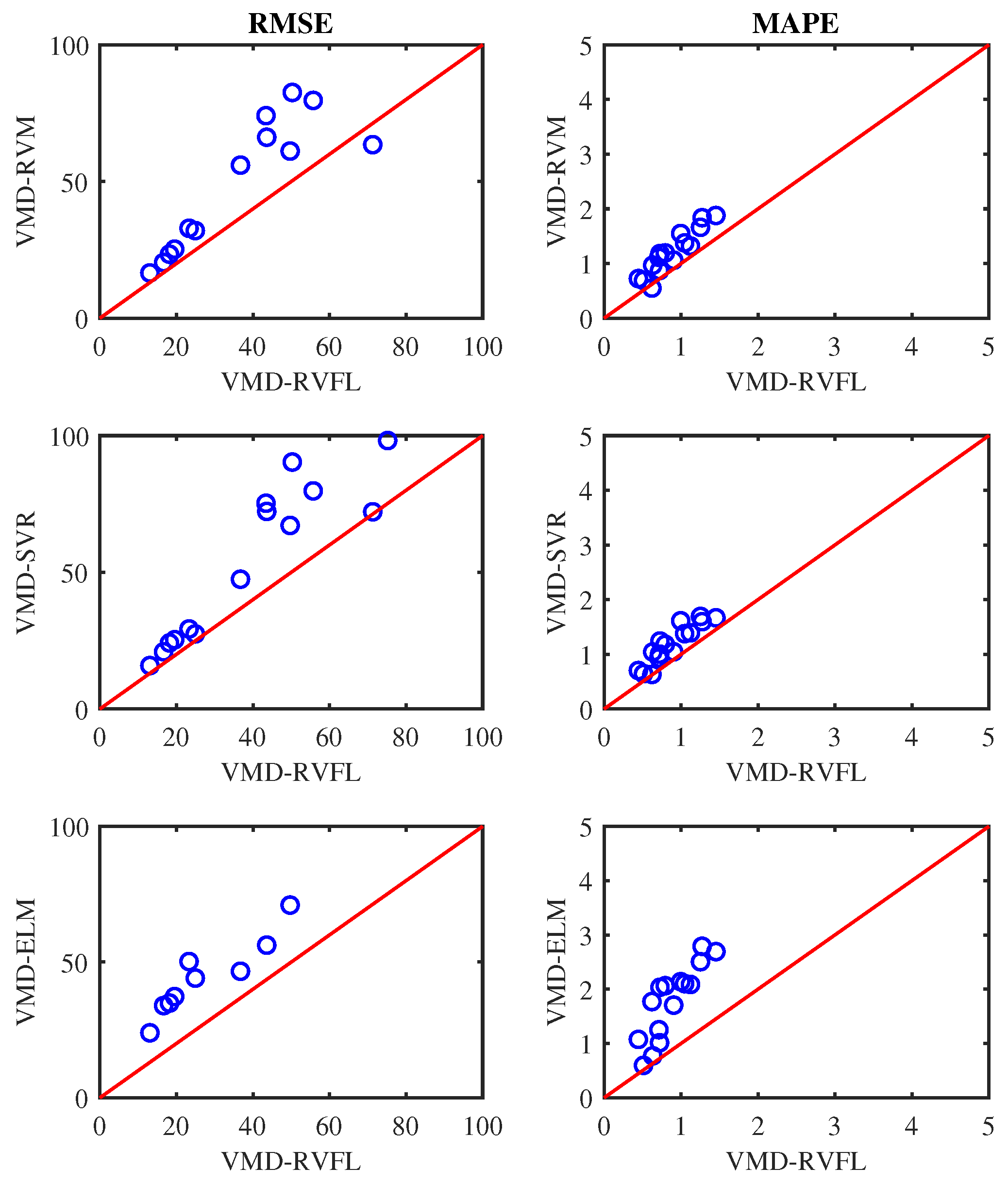
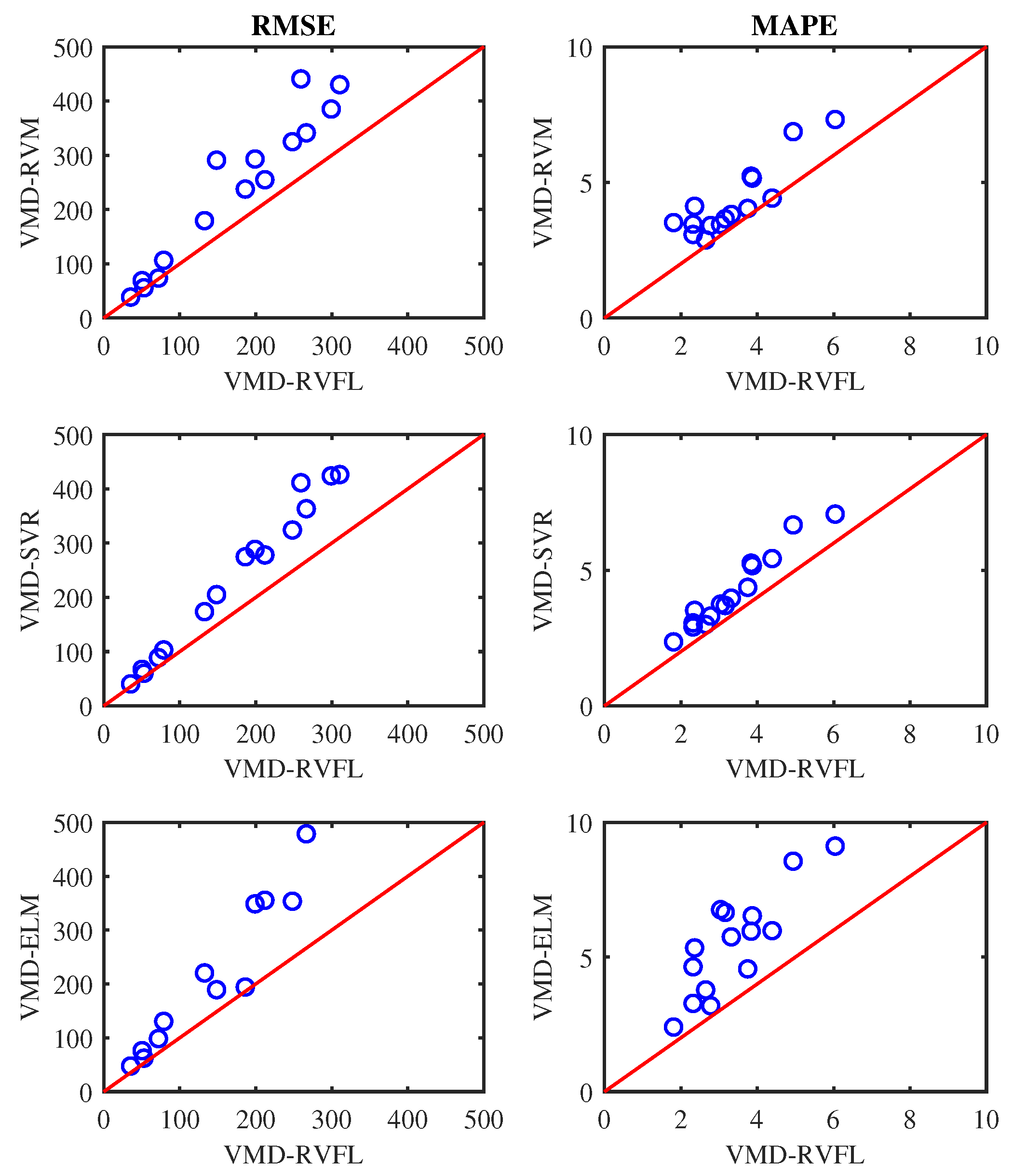
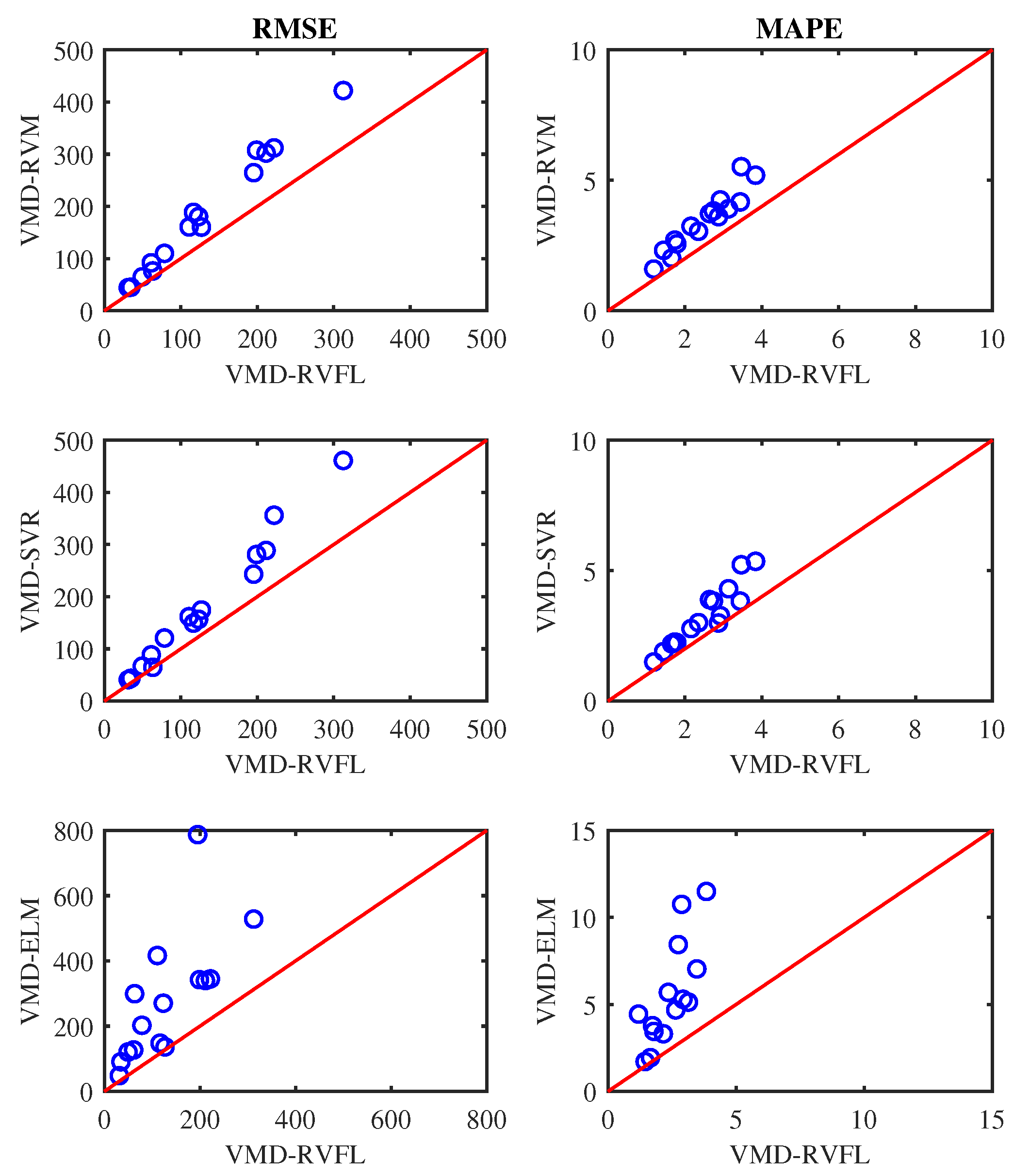
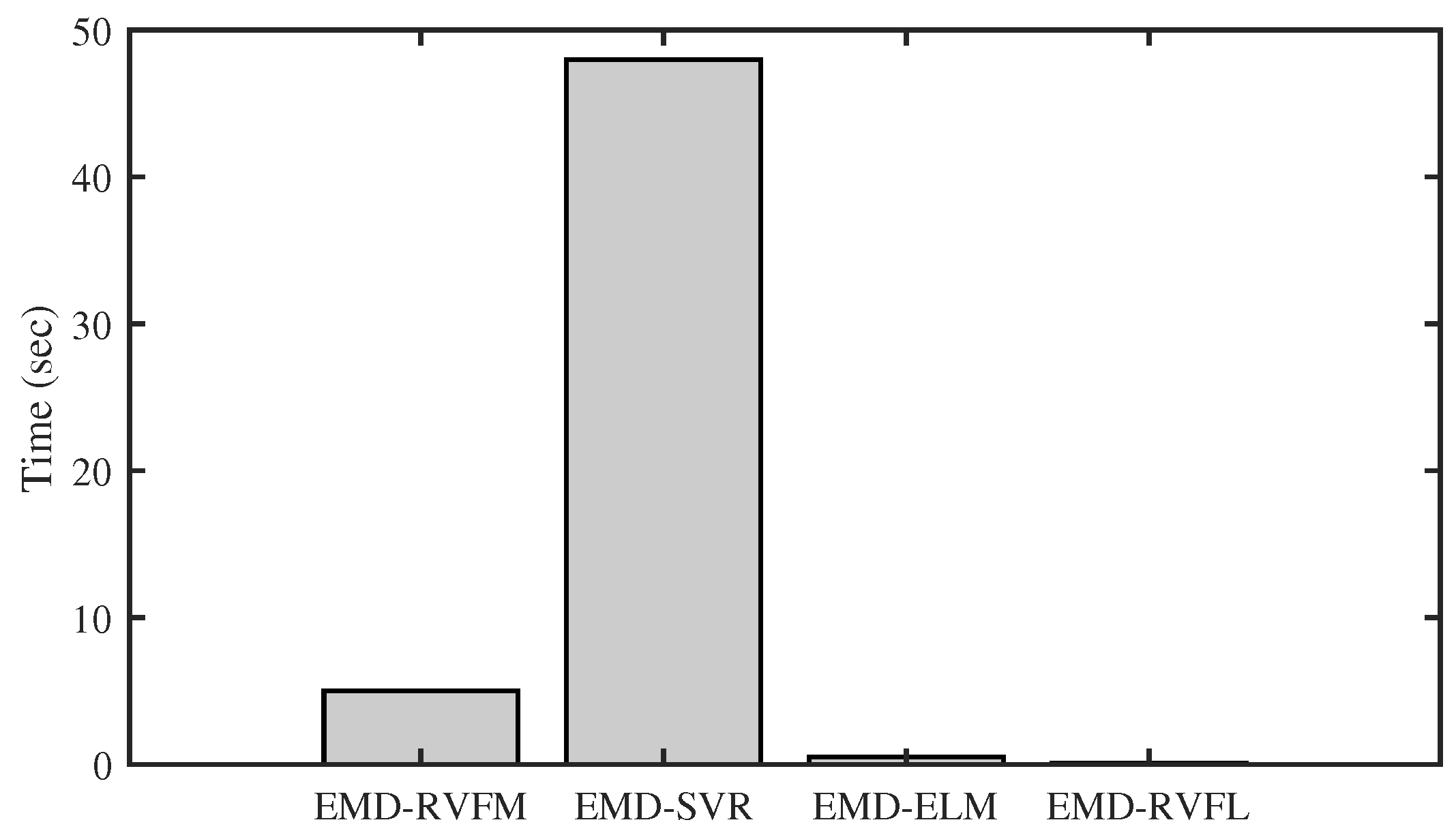
4. Results and Discussion
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Alfares, H.K.; Nazeeruddin, M. Electric load forecasting: Literature survey and classification of methods. Int. J. Syst. Sci. 2002, 33, 23–34. [Google Scholar] [CrossRef]
- Xiao, L.; Shao, W.; Yu, M.; Ma, J.; Jin, C. Research and application of a combined model based on multi-objective optimization for electrical load forecasting. Energy 2017, 119, 1057–1074. [Google Scholar] [CrossRef]
- Lusis, P.; Khalilpour, K.R.; Andrew, L.; Liebman, A. Short-term residential load forecasting: Impact of calendar effects and forecast granularity. Appl. Energy 2017, 205, 654–669. [Google Scholar] [CrossRef]
- Chahkoutahi, F.; Khashei, M. A seasonal direct optimal hybrid model of computational intelligence and soft computing techniques for electricity load forecasting. Energy 2017, 140, 988–1004. [Google Scholar] [CrossRef]
- Qiu, X.; Suganthan, P.N.; Amaratunga, G.A. Ensemble incremental learning random vector functional link network for short-term electric load forecasting. Knowl.-Based Syst. 2018, 145, 182–196. [Google Scholar] [CrossRef]
- Koprinska, I.; Rana, M.; Agelidis, V.G. Correlation and instance based feature selection for electricity load forecasting. Knowl.-Based Syst. 2015, 82, 29–40. [Google Scholar] [CrossRef]
- Zhang, J.; Wei, Y.M.; Li, D.; Tan, Z.; Zhou, J. Short term electricity load forecasting using a hybrid model. Energy 2018, 158, 774–781. [Google Scholar] [CrossRef]
- Zhang, M.G. Short-term load forecasting based on support vector machines regression. In Proceedings of the 2005 International Conference on Machine Learning and Cybernetics, Guangzhou, China, 18–21 August 2005; Volume 7, pp. 4310–4314. [Google Scholar]
- Taylor, J.W. Short-term electricity demand forecasting using double seasonal exponential smoothing. J. Oper. Res. Soc. 2003, 54, 799–805. [Google Scholar] [CrossRef]
- Lee, C.M.; Ko, C.N. Short-term load forecasting using lifting scheme and ARIMA models. Expert Syst. Appl. 2011, 38, 5902–5911. [Google Scholar] [CrossRef]
- Hong, T. Short Term Electric Load Forecasting. Ph.D. Thesis, Faculty of North Carolina State University, Raleigh, NC, USA, 2010. [Google Scholar]
- Goude, Y.; Nedellec, R.; Kong, N. Local short and middle term electricity load forecasting with semi-parametric additive models. IEEE Trans. Smart Grid 2013, 5, 440–446. [Google Scholar] [CrossRef]
- Fan, S.; Hyndman, R.J. Short-term load forecasting based on a semi-parametric additive model. IEEE Trans. Power Syst. 2011, 27, 134–141. [Google Scholar] [CrossRef]
- Leshno, M.; Lin, V.Y.; Pinkus, A.; Schocken, S. Multilayer feedforward networks with a nonpolynomial activation function can approximate any function. Neural Netw. 1993, 6, 861–867. [Google Scholar] [CrossRef]
- Gao, R.; Du, L.; Yuen, K.F.; Suganthan, P.N. Walk-forward empirical wavelet random vector functional link for time series forecasting. Appl. Soft Comput. 2021, 108, 107450. [Google Scholar] [CrossRef]
- Zhang, G.; Patuwo, B.E.; Hu, M.Y. Forecasting with artificial neural networks: The state of the art. Int. J. Forecast. 1998, 14, 35–62. [Google Scholar] [CrossRef]
- Pao, Y.H.; Phillips, S.M.; Sobajic, D.J. Neural-net computing and the intelligent control of systems. Int. J. Control 1992, 56, 263–289. [Google Scholar] [CrossRef]
- Pao, Y.H.; Park, G.H.; Sobajic, D.J. Learning and generalization characteristics of the random vector functional-link net. Neurocomputing 1994, 6, 163–180. [Google Scholar] [CrossRef]
- Ganaie, M.; Tanveer, M.; Malik, A.K.; Suganthan, P. Minimum variance embedded random vector functional link network with privileged information. In Proceedings of the 2022 International Joint Conference on Neural Networks (IJCNN), Padua, Italy, 18–23 July 2022; pp. 1–8. [Google Scholar]
- Malik, A.K.; Ganaie, M.; Tanveer, M.; Suganthan, P.N. Extended features based random vector functional link network for classification problem. IEEE Trans. Comput. Soc. Syst. 2022, 1–10. [Google Scholar] [CrossRef]
- Malik, A.K.; Tanveer, M. Graph embedded ensemble deep randomized network for diagnosis of Alzheimer’s disease. IEEE ACM Trans. Comput. Biol. Bioinform. 2022, 1–13. [Google Scholar] [CrossRef]
- Ganaie, M.; Sajid, M.; Malik, A.; Tanveer, M. Graph Embedded Intuitionistic Fuzzy RVFL for Class Imbalance Learning. arXiv 2023, arXiv:2307.07881. [Google Scholar]
- Sharma, R.; Goel, T.; Tanveer, M.; Suganthan, P.; Razzak, I.; Murugan, R. Conv-ERVFL: Convolutional Neural Network Based Ensemble RVFL Classifier for Alzheimer’s Disease Diagnosis. IEEE J. Biomed. Health Inform. 2022, 27, 4995–5003. [Google Scholar] [CrossRef]
- Suganthan, P.N. On non-iterative learning algorithms with closed-form solution. Appl. Soft Comput. 2018, 70, 1078–1082. [Google Scholar] [CrossRef]
- Malik, A.K.; Gao, R.; Ganaie, M.; Tanveer, M.; Suganthan, P.N. Random vector functional link network: Recent developments, applications, and future directions. Appl. Soft Comput. 2023, 143, 110377. [Google Scholar] [CrossRef]
- Shi, Q.; Katuwal, R.; Suganthan, P.N.; Tanveer, M. Random vector functional link neural network based ensemble deep learning. Pattern Recognit. 2021, 117, 107978. [Google Scholar] [CrossRef]
- Gao, R.; Li, R.; Hu, M.; Suganthan, P.N.; Yuen, K.F. Significant wave height forecasting using hybrid ensemble deep randomized networks with neurons pruning. Eng. Appl. Artif. Intell. 2023, 117, 105535. [Google Scholar] [CrossRef]
- Ahmad, N.; Ganaie, M.A.; Malik, A.K.; Lai, K.T.; Tanveer, M. Minimum variance embedded intuitionistic fuzzy weighted random vector functional link network. In Proceedings of the International Conference on Neural Information Processing, New Delhi, India, 22–26 November 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 600–611. [Google Scholar]
- Schmidt, W.F.; Kraaijveld, M.A.; Duin, R.P. Feed forward neural networks with random weights. In International Conference on Pattern Recognition; IEEE Computer Society Press: Piscataway, NJ, USA, 1992; p. 1. [Google Scholar]
- Zhang, L.; Suganthan, P.N. A comprehensive evaluation of random vector functional link networks. Inf. Sci. 2016, 367, 1094–1105. [Google Scholar] [CrossRef]
- Rasheed, A.; Adebisi, A.; Veluvolu, K.C. Respiratory motion prediction with random vector functional link (RVFL) based neural networks. In Proceedings of the 2020 4th International Conference on Electrical, Automation and Mechanical Engineering, Beijing, China, 21–22 June 2020; IOP Publishing: Bristol, UK, 2020; Volume 1626, p. 012022. [Google Scholar]
- Al-qaness, M.A.; Ewees, A.A.; Fan, H.; Abualigah, L.; Elsheikh, A.H.; Abd Elaziz, M. Wind power prediction using random vector functional link network with capuchin search algorithm. Ain Shams Eng. J. 2023, 14, 102095. [Google Scholar] [CrossRef]
- Rasheed, A.; Veluvolu, K.C. Respiratory motion prediction with empirical mode decomposition-based random vector functional link. Mathematics 2024, 12, 588. [Google Scholar] [CrossRef]
- Dietterich, T.G. Ensemble methods in machine learning. In International Workshop on Multiple Classifier Systems; Springer: Berlin/Heidelberg, Germany, 2000; pp. 1–15. [Google Scholar]
- Ren, Y.; Zhang, L.; Suganthan, P.N. Ensemble classification and regression-recent developments, applications and future directions. IEEE Comput. Intell. Mag. 2016, 11, 41–53. [Google Scholar] [CrossRef]
- Abdoos, A.; Hemmati, M.; Abdoos, A.A. Short term load forecasting using a hybrid intelligent method. Knowl.-Based Syst. 2015, 76, 139–147. [Google Scholar] [CrossRef]
- Huang, N.E.; Shen, Z.; Long, S.R.; Wu, M.C.; Shih, H.H.; Zheng, Q.; Yen, N.C.; Tung, C.C.; Liu, H.H. The empirical mode decomposition and the Hilbert spectrum for nonlinear and non-stationary time series analysis. Proc. R. Soc. Lond. Ser. A Math. Phys. Eng. Sci. 1998, 454, 903–995. [Google Scholar] [CrossRef]
- Dragomiretskiy, K.; Zosso, D. Variational mode decomposition. IEEE Trans. Signal Process. 2013, 62, 531–544. [Google Scholar] [CrossRef]
- Ren, Y.; Suganthan, P.; Srikanth, N. A comparative study of empirical mode decomposition-based short-term wind speed forecasting methods. IEEE Trans. Sustain. Energy 2014, 6, 236–244. [Google Scholar] [CrossRef]
- Qiu, X.; Suganthan, P.N.; Amaratunga, G.A. Electricity load demand time series forecasting with empirical mode decomposition based random vector functional link network. In Proceedings of the 2016 IEEE International Conference on Systems, Man, and Cybernetics (SMC), Budapest, Hungary, 9–12 October 2016; pp. 001394–001399. [Google Scholar]
- Tatinati, S.; Wang, Y.; Khong, A.W. Hybrid method based on random convolution nodes for short-term wind speed forecasting. IEEE Trans. Ind. Inform. 2020, 18, 7019–7029. [Google Scholar] [CrossRef]
- Bisoi, R.; Dash, P.; Mishra, S. Modes decomposition method in fusion with robust random vector functional link network for crude oil price forecasting. Appl. Soft Comput. 2019, 80, 475–493. [Google Scholar] [CrossRef]
- Australian Energy Market Operator. 2016. Available online: http://www.aemo.com.au/ (accessed on 10 December 2023).
- Wang, Z.; Gao, R.; Wang, P.; Chen, H. A new perspective on air quality index time series forecasting: A ternary interval decomposition ensemble learning paradigm. Technol. Forecast. Soc. Change 2023, 191, 122504. [Google Scholar] [CrossRef]
- Su, W.; Lei, Z.; Yang, L.; Hu, Q. Mold-level prediction for continuous casting using VMD–SVR. Metals 2019, 9, 458. [Google Scholar] [CrossRef]
- Abdoos, A.A. A new intelligent method based on combination of VMD and ELM for short term wind power forecasting. Neurocomputing 2016, 203, 111–120. [Google Scholar] [CrossRef]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Year | Length | Min | Median | Mean | Max | Std |
|---|---|---|---|---|---|---|---|
| QLD | 2013 | 17,520 | 4148.7 | 5752.1 | 5703.7 | 8278.4 | 747.0 |
| 2014 | 17,520 | 4073.0 | 5726.0 | 5745.7 | 8445.3 | 794.0 | |
| 2015 | 17,520 | 4281.4 | 6005.6 | 6035.4 | 8808.7 | 777.2 | |
| NSW | 2013 | 17,520 | 5113.0 | 8045.0 | 7981.6 | 13,788 | 1190.9 |
| 2014 | 17,520 | 5138.1 | 7987.4 | 7917.8 | 11,846 | 1170.1 | |
| 2015 | 17,520 | 5337.4 | 7990.4 | 7979.8 | 12,602 | 1232.7 | |
| TAS | 2013 | 17,520 | 659.5 | 1109.0 | 1129.3 | 1650.3 | 142.3 |
| 2014 | 17,520 | 569.1 | 1088.7 | 1109.7 | 1630.1 | 139.0 | |
| 2015 | 17,520 | 479.4 | 1112.3 | 1138.2 | 1667.2 | 145.3 | |
| SA | 2013 | 17,520 | 728.6 | 1389.3 | 1426.6 | 2991.3 | 301.7 |
| 2014 | 17,520 | 682.5 | 1360.8 | 1403.3 | 3245.9 | 312.8 | |
| 2015 | 17,520 | 696.3 | 1352.7 | 1398.5 | 2870.4 | 306.0 | |
| VIC | 2013 | 17,520 | 3551.6 | 5458.1 | 5511.8 | 9587.5 | 895.9 |
| 2014 | 17,520 | 3272.9 | 5307.8 | 5324.4 | 10240 | 921.4 | |
| 2015 | 17,520 | 3369.1 | 5186.5 | 5194.6 | 8579.9 | 864.7 |
| Dataset | Year | Metrics | Persistence | VMD-RVM | VMD-SVR | VMD-ELM | VMD-RVFL |
|---|---|---|---|---|---|---|---|
| QLD | 2013 | RMSE | 292.58 | 61.12 | 67.13 | 70.99 | 49.69 |
| 2014 | RMSE | 270.70 | 66.19 | 72.26 | 56.23 | 43.58 | |
| 2015 | RMSE | 240.04 | 55.98 | 47.47 | 46.61 | 36.72 | |
| NSW | 2013 | RMSE | 470.05 | 115.21 | 98.18 | 137.85 | 75.18 |
| 2014 | RMSE | 348.01 | 74.08 | 75.26 | 108.04 | 43.39 | |
| 2015 | RMSE | 505.88 | 63.45 | 72.11 | 181.14 | 71.24 | |
| TAS | 2013 | RMSE | 60.58 | 20.35 | 20.89 | 33.78 | 16.66 |
| 2014 | RMSE | 32.58 | 25.23 | 25.33 | 37.21 | 19.66 | |
| 2015 | RMSE | 29.80 | 16.53 | 15.87 | 23.98 | 13.02 | |
| SA | 2013 | RMSE | 145.88 | 32.88 | 29.21 | 50.54 | 23.23 |
| 2014 | RMSE | 165.33 | 23.36 | 24.19 | 34.95 | 18.51 | |
| 2015 | RMSE | 128.99 | 32.09 | 27.27 | 44.04 | 24.92 | |
| VIC | 2013 | RMSE | 320.55 | 82.53 | 90.37 | 141.44 | 50.17 |
| 2014 | RMSE | 325.10 | 116.62 | 117.89 | 146.28 | 71.88 | |
| 2015 | RMSE | 320.55 | 79.62 | 79.78 | 148.69 | 55.75 |
| Dataset | Year | Metrics | Persistence | VMD-RVM | VMD-SVR | VMD-ELM | VMD-RVFL |
|---|---|---|---|---|---|---|---|
| QLD | 2013 | MAPE | 3.78 | 0.87 | 1.00 | 1.01 | 0.72 |
| 2014 | MAPE | 3.15 | 0.96 | 1.04 | 0.77 | 0.63 | |
| 2015 | MAPE | 2.8 | 0.69 | 0.64 | 0.59 | 0.51 | |
| NSW | 2013 | MAPE | 3.18 | 0.72 | 0.78 | 1.07 | 0.44 |
| 2014 | MAPE | 3.58 | 1.11 | 0.93 | 1.24 | 0.71 | |
| 2015 | MAPE | 3.98 | 0.55 | 0.63 | 1.77 | 0.62 | |
| TAS | 2013 | MAPE | 2.99 | 1.31 | 1.39 | 2.08 | 1.11 |
| 2014 | MAPE | 3.45 | 1.66 | 1.69 | 2.50 | 1.25 | |
| 2015 | MAPE | 3.5 | 1.04 | 1.04 | 1.70 | 0.90 | |
| SA | 2013 | MAPE | 7.89 | 1.83 | 1.59 | 2.79 | 1.27 |
| 2014 | MAPE | 7.25 | 1.37 | 1.37 | 2.10 | 1.04 | |
| 2015 | MAPE | 8.87 | 1.87 | 1.66 | 2.69 | 1.45 | |
| VIC | 2013 | MAPE | 6.45 | 1.54 | 1.61 | 2.13 | 0.99 |
| 2014 | MAPE | 5.14 | 1.18 | 1.24 | 2.03 | 0.75 | |
| 2015 | MAPE | 5.12 | 1.19 | 1.18 | 2.06 | 0.79 |
| Dataset | Year | Metrics | Persistence | VMD-RVM | VMD-SVR | VMD-ELM | VMD-RVFL |
|---|---|---|---|---|---|---|---|
| QLD | 2013 | RMSE | 492.58 | 291.02 | 205.07 | 189.36 | 148.48 |
| 2014 | RMSE | 588.70 | 341.37 | 363.39 | 478.79 | 266.49 | |
| 2015 | RMSE | 453.07 | 293.16 | 288.50 | 348.78 | 199.02 | |
| NSW | 2013 | RMSE | 901.51 | 325.09 | 324.14 | 353.69 | 248.21 |
| 2014 | RMSE | 878.07 | 385.28 | 423.94 | 662.85 | 299.32 | |
| 2015 | RMSE | 1055.406 | 440.84 | 411.32 | 532.81 | 259.41 | |
| TAS | 2013 | RMSE | 97.85 | 38.67 | 40.46 | 47.69 | 35.37 |
| 2014 | RMSE | 86.86 | 68.94 | 67.35 | 76.12 | 50.49 | |
| 2015 | RMSE | 83.99 | 55.77 | 60.09 | 62.18 | 52.87 | |
| SA | 2013 | RMSE | 288.77 | 179.54 | 173.62 | 220.52 | 132.59 |
| 2014 | RMSE | 242.23 | 73.71 | 88.79 | 98.61 | 71.95 | |
| 2015 | RMSE | 265.14 | 106.40 | 103.15 | 130.51 | 78.89 | |
| VIC | 2013 | RMSE | 781.68 | 430.24 | 426.36 | 523.44 | 310.49 |
| 2014 | RMSE | 719.40 | 237.72 | 274.77 | 194.27 | 186.17 | |
| 2015 | RMSE | 874.69 | 254.98 | 278.19 | 355.49 | 211.98 |
| Dataset | Year | Metrics | Persistence | VMD-RVM | VMD-SVR | VMD-ELM | VMD-RVFL |
|---|---|---|---|---|---|---|---|
| 2013 | MAPE | 6.38 | 3.52 | 2.36 | 2.40 | 1.81 | |
| 2014 | MAPE | 7.14 | 3.66 | 3.70 | 6.66 | 3.16 | |
| 2015 | MAPE | 6.63 | 3.46 | 3.06 | 4.64 | 2.32 | |
| NSW | 2013 | MAPE | 8.65 | 3.08 | 2.91 | 3.28 | 2.33 |
| 2014 | MAPE | 8.51 | 3.45 | 3.75 | 6.76 | 3.04 | |
| 2015 | MAPE | 9.68 | 4.12 | 3.52 | 5.34 | 2.36 | |
| TAS | 2013 | MAPE | 6.87 | 2.88 | 3.00 | 3.78 | 2.65 |
| 2014 | MAPE | 6.51 | 5.23 | 5.26 | 5.96 | 3.84 | |
| 2015 | MAPE | 6.03 | 4.04 | 4.37 | 4.56 | 3.75 | |
| SA | 2013 | MAPE | 16.02 | 7.32 | 7.07 | 9.12 | 6.04 |
| 2014 | MAPE | 14.41 | 4.42 | 5.43 | 5.98 | 4.39 | |
| 2015 | MAPE | 15.39 | 6.87 | 6.67 | 8.56 | 4.94 | |
| VIC | 2013 | MAPE | 10.71 | 5.16 | 5.17 | 6.53 | 3.87 |
| 2014 | MAPE | 11.24 | 3.41 | 3.31 | 3.19 | 2.78 | |
| 2015 | MAPE | 10.86 | 3.82 | 3.97 | 5.75 | 3.32 |
| Month | Metrics | Persistence | VMD-RVM | VMD-SVR | VMD-ELM | VMD-RVFL |
|---|---|---|---|---|---|---|
| Jan | RMSE | 842.732 | 256.151 | 296.022 | 424.44 | 167.135 |
| MAPE | 7.393 | 2.810 | 3.0102 | 4.9952 | 1.766 | |
| Apr | RMSE | 769.606 | 128.519 | 141.163 | 525.474 | 97.955 |
| MAPE | 6.801 | 1.252 | 1.359 | 5.674 | 0.956 | |
| Jul | RMSE | 989.372 | 389.809 | 360.240 | 645.186 | 233.994 |
| MAPE | 9.831 | 3.857 | 3.480 | 6.369 | 2.176 | |
| Oct | RMSE | 1620.508 | 302.301 | 248.087 | 244.602 | 96.339 |
| MAPE | 14.887 | 2.891 | 2.188 | 2.384 | 0.998 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Shin, S.M.; Rasheed, A.; Kil-Heum, P.; Veluvolu, K.C. Fast and Accurate Short-Term Load Forecasting with a Hybrid Model. Electronics 2024, 13, 1079. https://doi.org/10.3390/electronics13061079
Shin SM, Rasheed A, Kil-Heum P, Veluvolu KC. Fast and Accurate Short-Term Load Forecasting with a Hybrid Model. Electronics. 2024; 13(6):1079. https://doi.org/10.3390/electronics13061079
Chicago/Turabian StyleShin, Sang Mun, Asad Rasheed, Park Kil-Heum, and Kalyana C. Veluvolu. 2024. "Fast and Accurate Short-Term Load Forecasting with a Hybrid Model" Electronics 13, no. 6: 1079. https://doi.org/10.3390/electronics13061079
APA StyleShin, S. M., Rasheed, A., Kil-Heum, P., & Veluvolu, K. C. (2024). Fast and Accurate Short-Term Load Forecasting with a Hybrid Model. Electronics, 13(6), 1079. https://doi.org/10.3390/electronics13061079