
Exploration- and Exploitation-Driven Deep Deterministic Policy Gradient for Active SLAM in Unknown Indoor Environments



Abstract
1. Introduction
- The exploration- and exploitation-driven reward function is proposed, which depends on the locations visited by the robot as well as its movement trajectories, allowing the strategy to be quickly learned and generalized to other complex environments without training.
- The DDPG algorithm is proposed for robot path planning based on the exploration- and exploitation-driven reward function. Compared to other methods, the DDPG excels in representing continuous motion and action spaces, enabling the robot to move at higher speeds and with smooth movement.
- The Active SLAM framework is proposed based on the DDPG, which simultaneously focus on robotic exploration and exploitation. In comparison to existing reinforcement learning-based methods, our proposed method enhances the completeness of SLAM maps.
2. Background
2.1. Reinforcement Learning (RL)
2.2. Deep Deterministic Policy Gradient (DDPG)
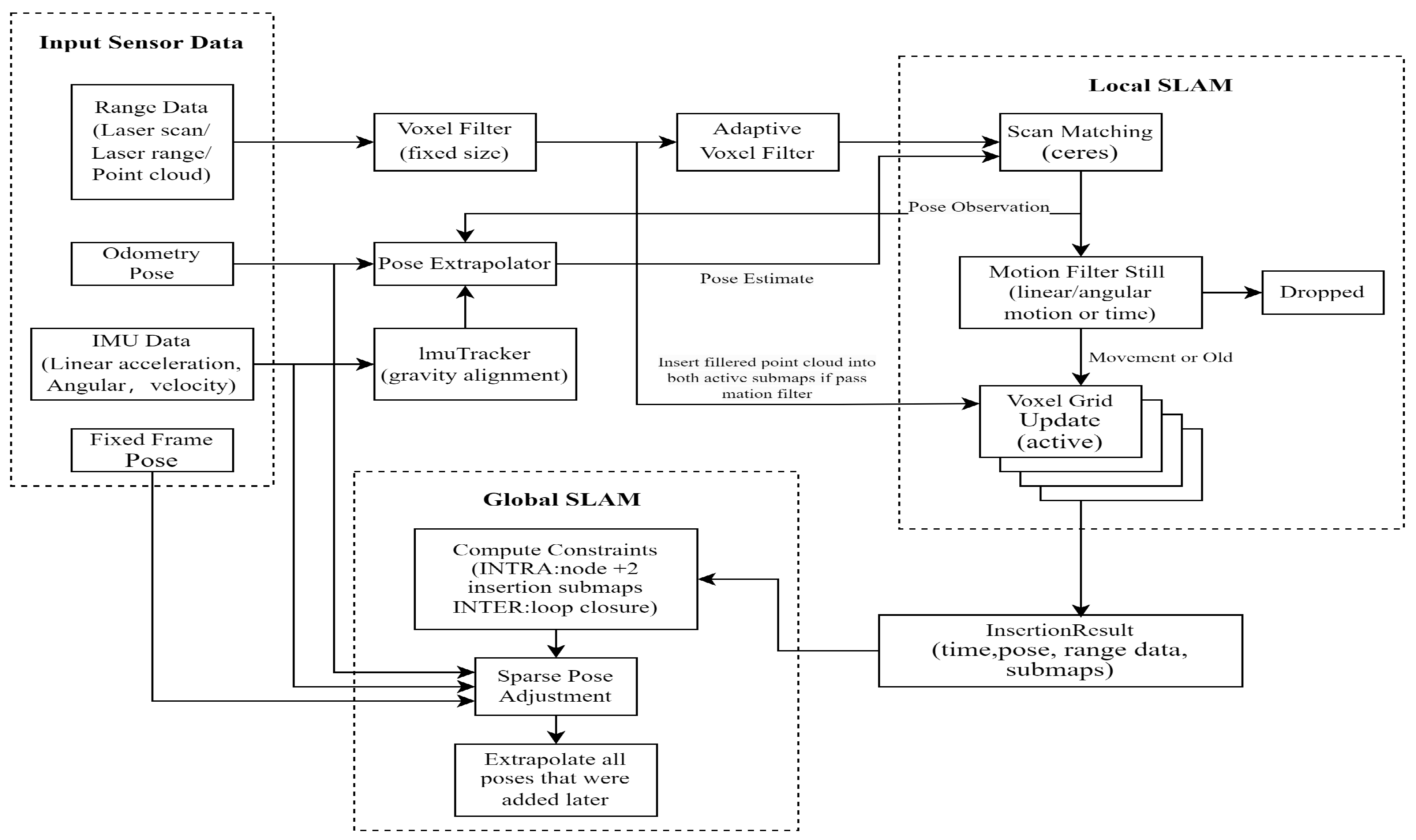
2.3. Cartographer SLAM Method
3. Methodology
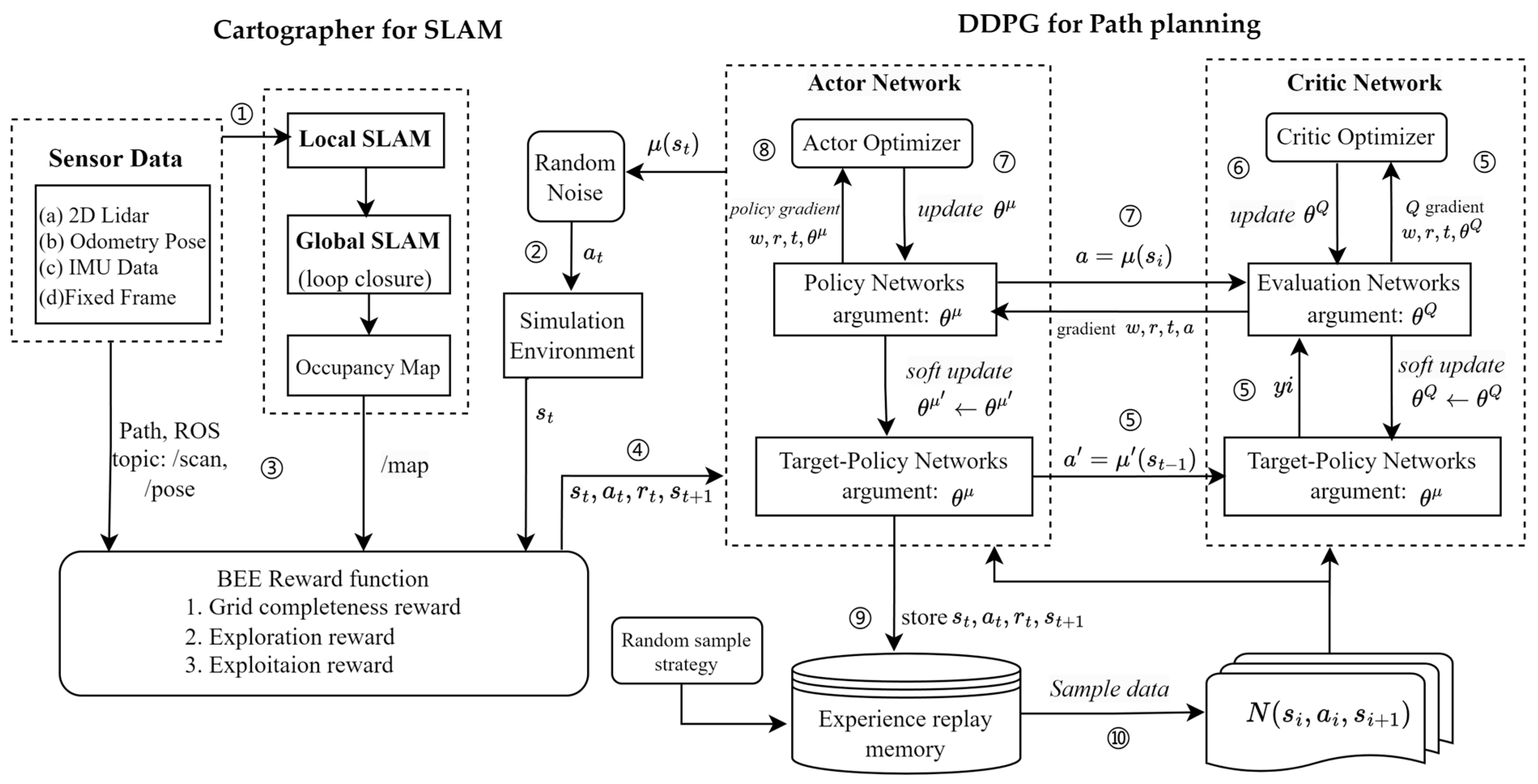
3.1. Proposed Framework for Active SLAM
- The local SLAM module takes input from LiDAR data, IMU data, and robot motion control commands. These inputs construct a map of the robot’s local environment and estimate its trajectory. The global SLAM algorithm is responsible for merging maps from different local SLAM sessions to create a globally consistent map. It considers the correlation between multiple local maps and the transformation of the robot’s pose across different local maps. The loop closure module performs loop closure operations, such as adjusting the robot’s pose or optimizing the entire map, to minimize errors caused by loops and ensure map consistency.
- The neural network’s parameters are initialized. The actor chooses the action based on the behavior policy. Random noise is appended to the action chosen by the policy network. The action is subsequently transmitted to the environment for its execution.
- The proposed BEE reward algorithm utilizes sensor data and map information from the SLAM stage. This valuable information assists the reward function in accurately describing the current state of the agent (robot).
- After the environment has executed the action, return to reward and new state are achieved.
- The actor stores the state transition in the replay memory as the training set of the online network.
- The DDPG creates two copies of neural networks for the policy and the Q networks, respectively: the online and target networks. The update method of the policy network is as follows:The Q network update method is as follows:transition data are randomly sampled from the replay memory as minibatch training data of the online policy network and online network. Single transition data are represented by .
- Critically, the gradient of the online network is calculated. The loss of the Q network is defined as follows:The gradient for and can be obtained: , where the calculation uses the target policy network and target Q network .
- The online Q is updated and is updated by using the Adam optimizer.
- The online policy network is updated and is updated with the Adam optimizer.
- In the actor, the policy gradient of the policy network is calculated as follows:
- The parameters of the target network adopt the method of soft update:
3.2. Proposed Exploration and Exploitation Reward Functions
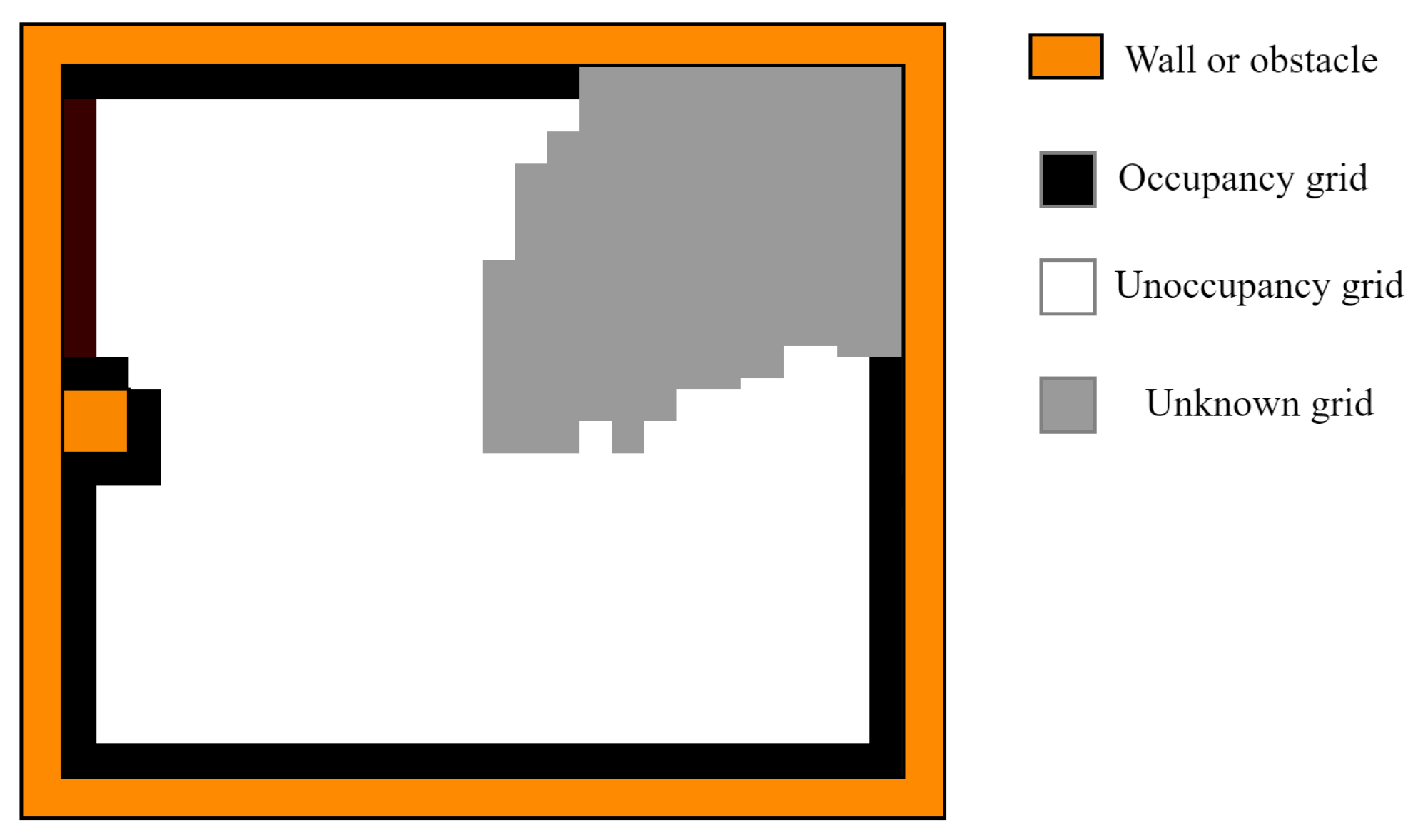
3.2.1. Grid Completeness Reward
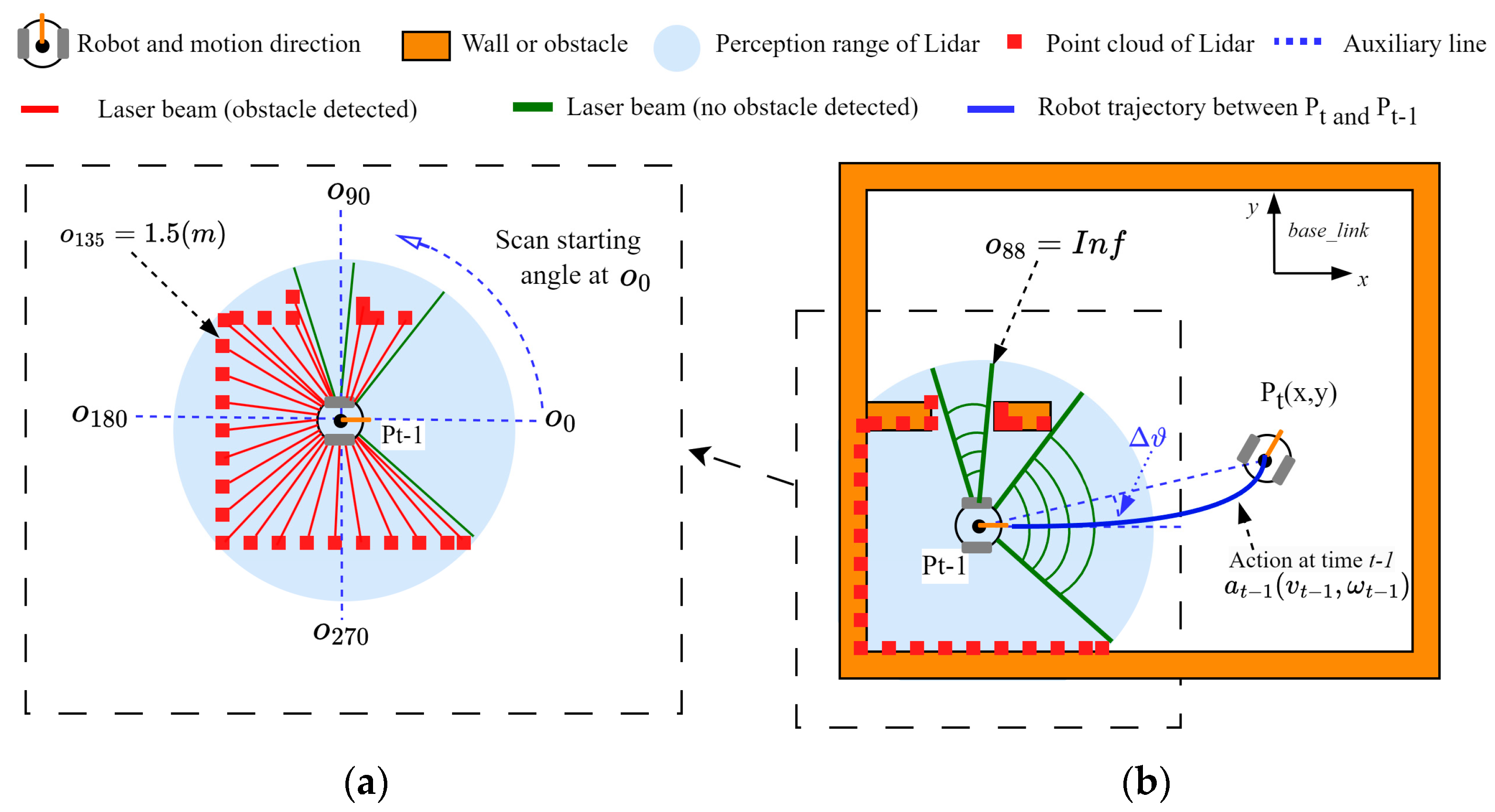
3.2.2. Exploration Reward
| Algorithm 1. The proposed exploration reward. |
| Input: ROS topic: /scan; Action: ; Grid completeness: Output: Reward: |
| /scan ← ROS topic of robot LiDAR information |
| /map ← ROS topic of map information |
| ← The list of laser scan range values (total 360 data) in the /scan at time |
| ← The position of the robot at time |
| ← The position of the robot at the last time |
| ← Changes in the angle of heading angle when robot moved from to |
| ← Linear velocity of the robot |
| ← Angular velocity of the robot |
| ← The agent took action at the last time, ← Discount factor |
| 1. Initialize scan memory |
| 2. Initialize the list: |
| 3. while perform |
| 4. Subscribe the topic /scan |
| 5. Store the LiDAR scan data with : ← , |
| 6. Obtain from according to |
| 7. for ← 0 to 359, perform |
| 8. if , perform |
| 9. ← |
| 10. end |
| 11. end |
| 12. Calculate ← |
| 13. Set robot motion direction angle at to |
| 14. ← |
| 15. if (, perform |
| 16. ← |
| 17. else ← |
| 18. end |
| 19. end |
3.2.3. Exploitation Reward
| Algorithm 2. The proposed exploitation reward. |
| Input: ROS topic: /map, /pose; Action: ; Grid completeness: Output: Reward: |
| /map ← ROS topic of map information |
| /pose ← ROS topic of robot position information |
| ← Loop closure label |
| ← Minimum distance values |
| ← The position of the robot at time |
| ← Linear velocity of the robot |
| ← Angular velocity of the robot |
| ← The agent took action at the last time ← Discount factor |
| 1. Initialize path memory |
| 2. Subscribe the topic: /pose |
| 3. Store the position data: ← |
| 4. while perform |
| 5. for in perform |
| 6. if , perform |
| 7. ← |
| 8. else ← |
| 9. end |
| 10. end |
| 11. end |
3.3. State and Action Spaces
4. Simulation Results
4.1. Simulation Setup
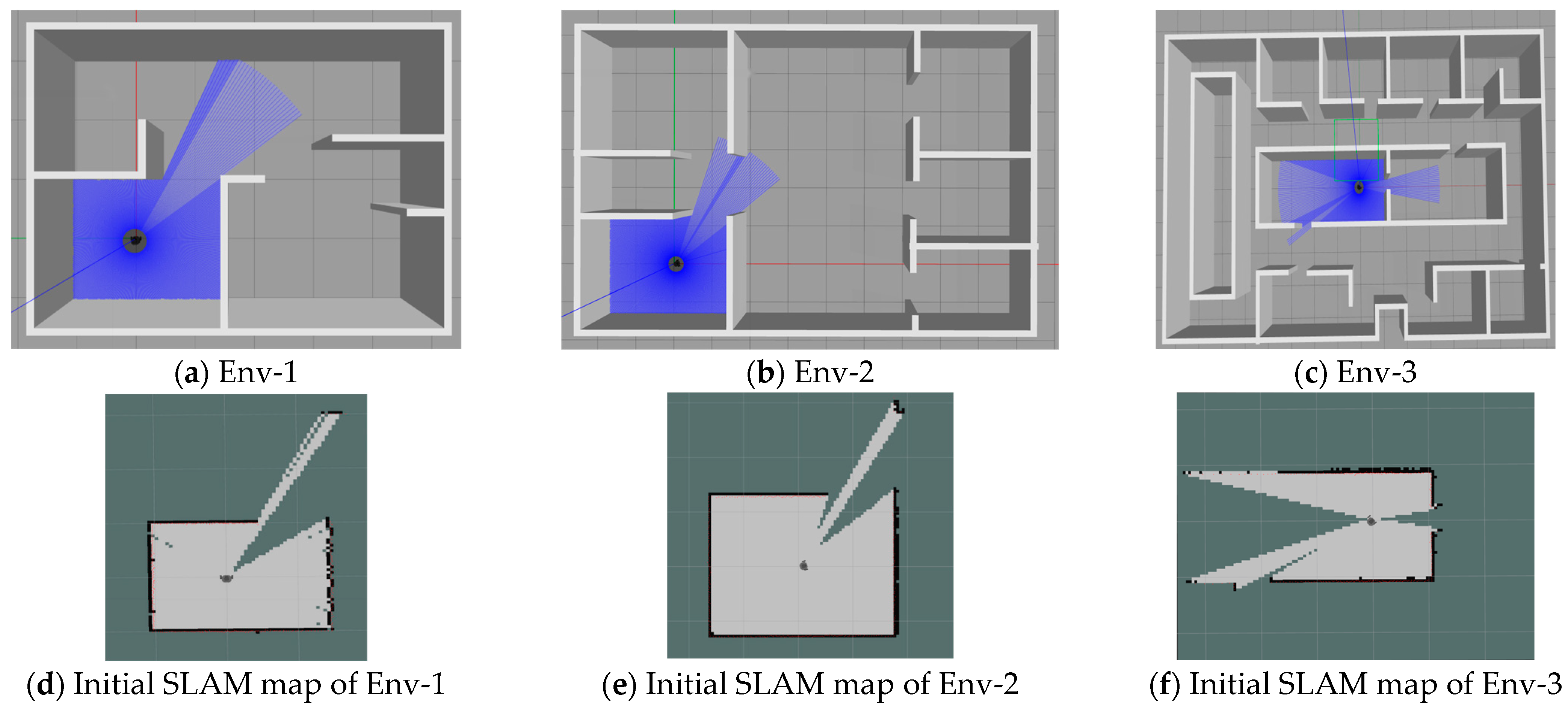
4.1.1. Environment Setup
4.1.2. Decision Making Module
4.2. Evaluation Index
4.3. Evaluation Results
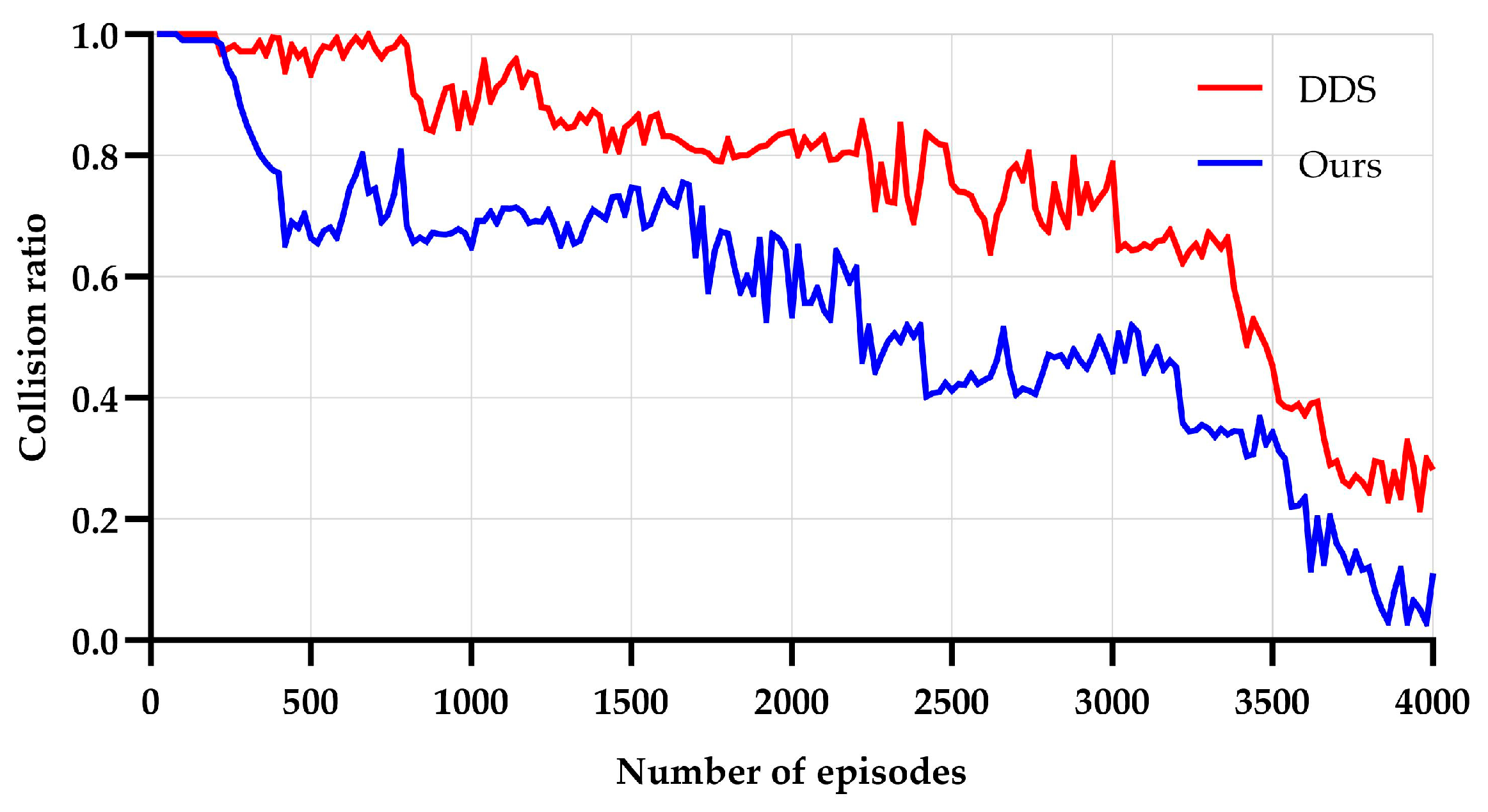
4.3.1. Comparison of Training Results
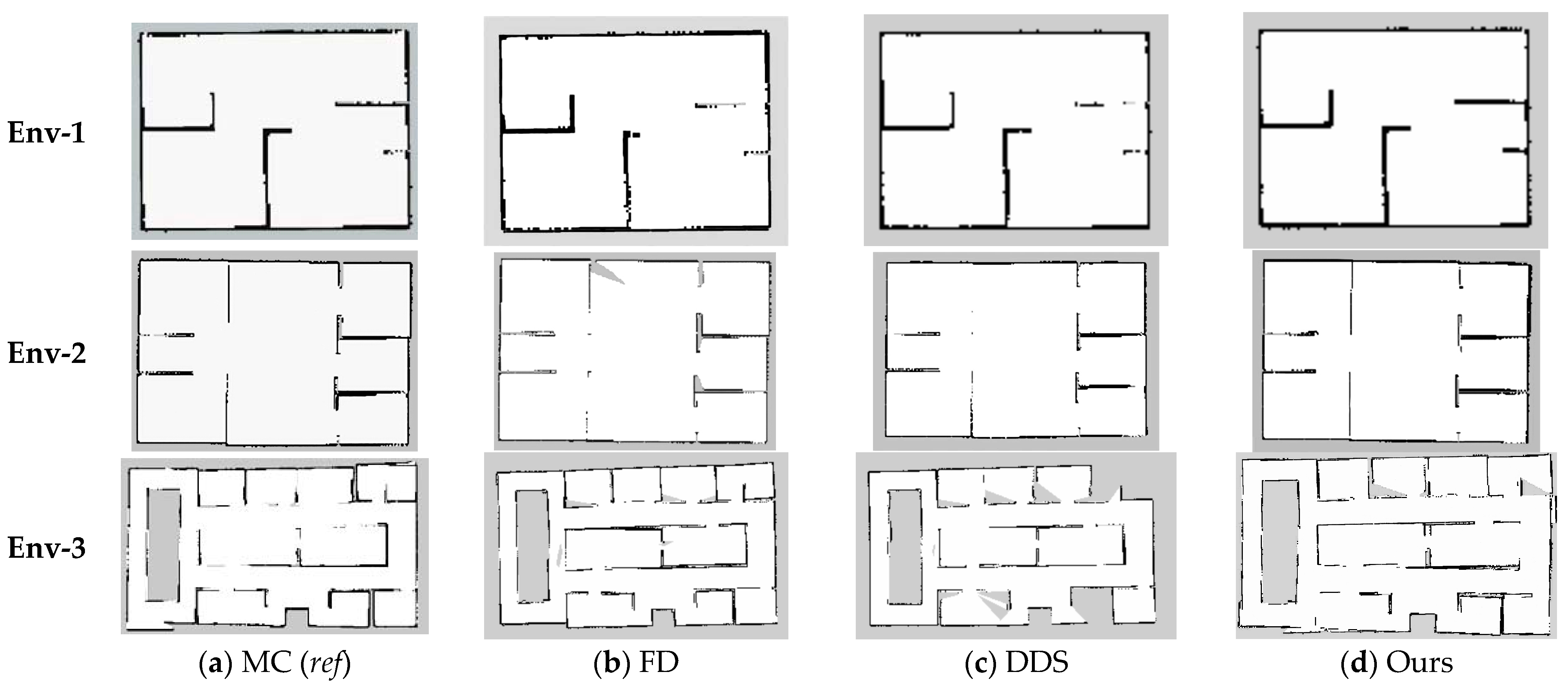
4.3.2. Comparison of SLAM Results
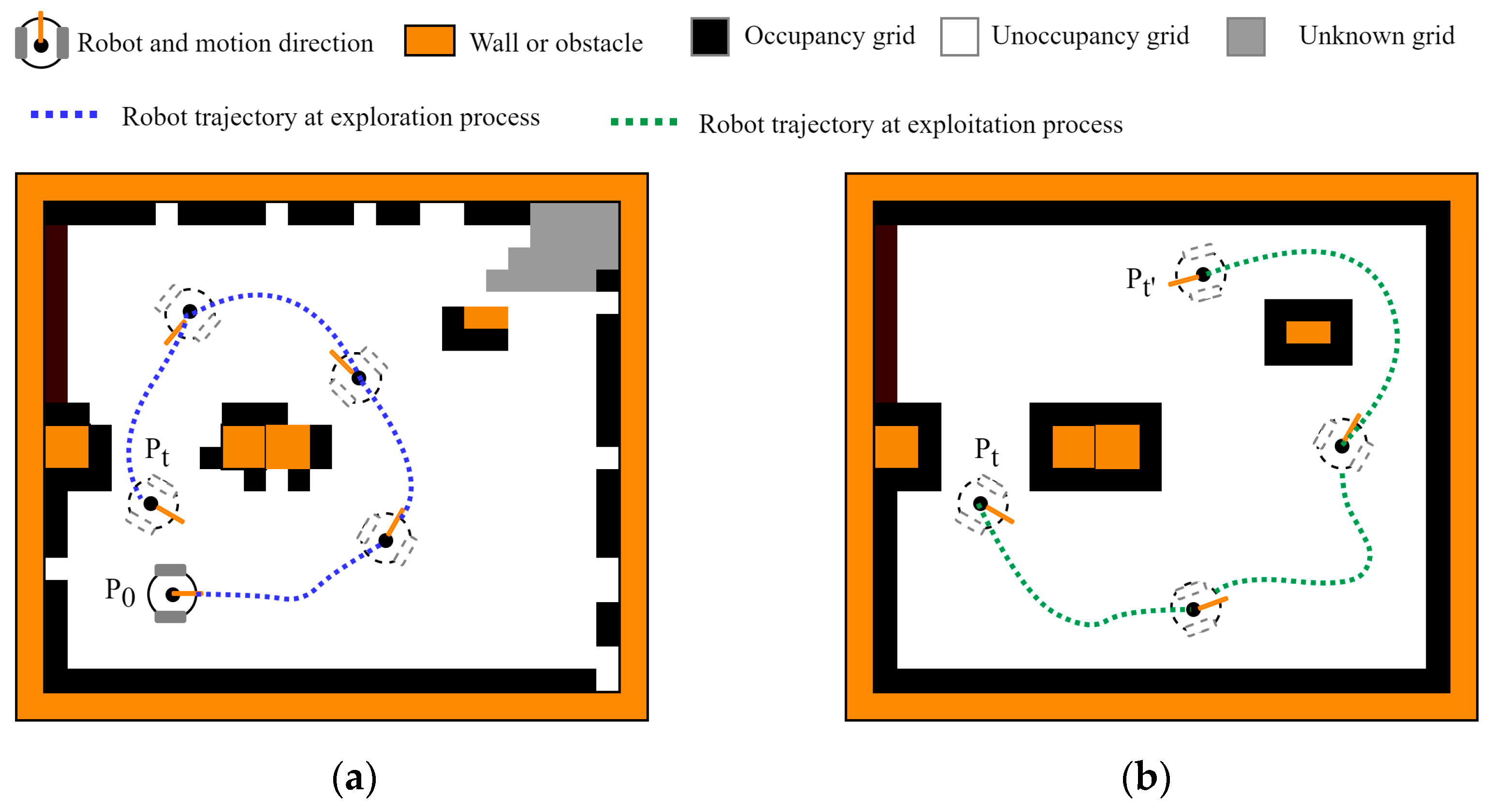
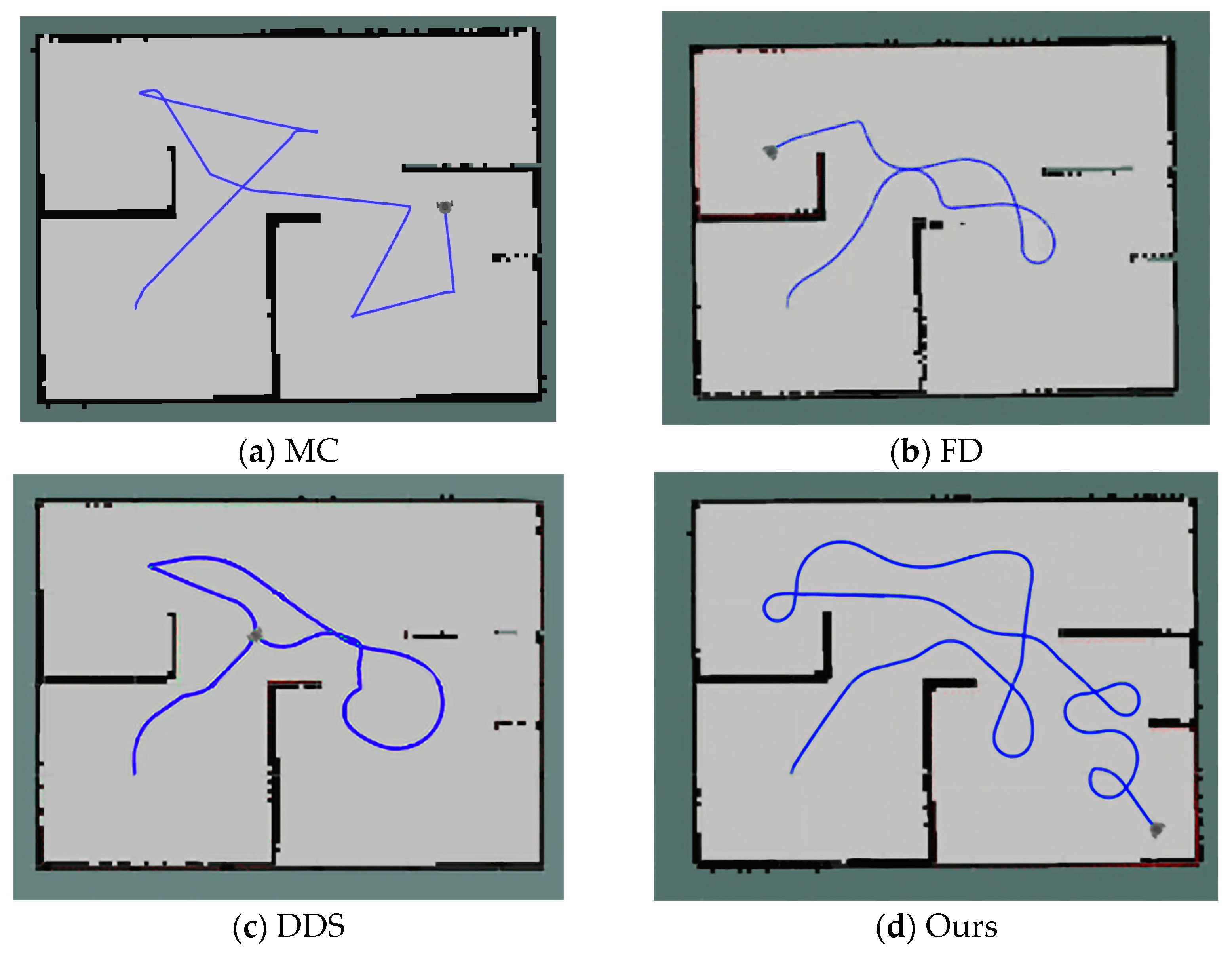
4.3.3. Comparison of Robot Trajectories
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Filip, I.; Pyo, J.; Lee, M.; Joe, H. LiDAR SLAM with a Wheel Encoder in a Featureless Tunnel Environment. Electronics 2023, 12, 1002. [Google Scholar] [CrossRef]
- Zhao, S.; Hwang, S.-H. ROS-Based Autonomous Navigation Robot Platform with Stepping Motor. Sensors 2023, 23, 3648. [Google Scholar] [CrossRef] [PubMed]
- Zhao, S.; Hwang, S.H. Complete coverage path planning scheme for autonomous navigation ROS-based robots. ICT Express 2024, 10, 83–89. [Google Scholar] [CrossRef]
- Guo, F.; Yang, H.; Wu, X.; Dong, H.; Wu, Q.; Li, Z. Model-Based Deep Learning for Low-Cost IMU Dead Reckoning of Wheeled Mobile Robot. IEEE Trans. Ind. Electron. 2023, 1–11. [Google Scholar] [CrossRef]
- Motta, J.M.S.T.; de Carvalho, G.C.; McMaster, R.S. Robot Calibration Using a 3D Vision-Based Measurement System with a Single Camera. Robot. Comput.-Integr. Manuf. 2001, 17, 487–497. [Google Scholar] [CrossRef]
- Bailey, T.; Nieto, J.; Guivant, J.; Stevens, M.; Nebot, E. Consistency of the EKF-SLAM Algorithm. In Proceedings of the 2006 IEEE/RSJ International Conference on Intelligent Robots and Systems, Beijing, China, 9–15 October 2006; pp. 3562–3568. [Google Scholar]
- Nieto, J.; Bailey, T.; Nebot, E. Recursive Scan-Matching SLAM. Robot. Auton. Syst. 2007, 55, 39–49. [Google Scholar] [CrossRef]
- Zhang, Q.; Wang, P.; Chen, Z. An Improved Particle Filter for Mobile Robot Localization Based on Particle Swarm Optimization. Expert Syst. Appl. 2019, 135, 181–193. [Google Scholar] [CrossRef]
- Montemerlo, M.; Thrun, S. Simultaneous Localization and Mapping with Unknown Data Association Using FastSLAM. In Proceedings of the 2003 IEEE International Conference on Robotics and Automation (Cat. No.03CH37422), Taipei, Taiwan, 14–19 September 2003; Volume 2, pp. 1985–1991. [Google Scholar]
- Grisetti, G.; Stachniss, C.; Burgard, W. Improved Techniques for Grid Mapping With Rao-Blackwellized Particle Filters. IEEE Trans. Robot. 2007, 23, 34–46. [Google Scholar] [CrossRef]
- Arshad, S.; Kim, G.-W. Role of Deep Learning in Loop Closure Detection for Visual and Lidar SLAM: A Survey. Sensors 2021, 21, 1243. [Google Scholar] [CrossRef]
- Cartographer ROS Integration—Cartographer ROS Documentation. Available online: https://google-cartographer-ros.readthedocs.io/en/latest/ (accessed on 28 December 2023).
- Ahmed, M.F.; Masood, K.; Fremont, V.; Fantoni, I. Active SLAM: A Review on Last Decade. Sensors 2023, 23, 8097. [Google Scholar] [CrossRef]
- Yamauchi, B. A Frontier-Based Approach for Autonomous Exploration. In Proceedings of the 1997 IEEE International Symposium on Computational Intelligence in Robotics and Automation CIRA’97. “Towards New Computational Principles for Robotics and Automation”, Monterey, CA, USA, 10–11 July 1997; pp. 146–151. [Google Scholar]
- Li, B.; Chen, B. An adaptive rapidly-exploring random tree. IEEE/CAA J. Autom. Sin. 2021, 9, 283–294. [Google Scholar] [CrossRef]
- Placed, J.A.; Castellanos, J.A. A general relationship between optimality criteria and connectivity indices for active graph-SLAM. IEEE Robot. Autom. Lett. 2022, 8, 816–823. [Google Scholar] [CrossRef]
- Gul, F.; Mir, I.; Abualigah, L.; Sumari, P.; Forestiero, A. A Consolidated Review of Path Planning and Optimization Techniques: Technical Perspectives and Future Directions. Electronics 2021, 10, 2250. [Google Scholar] [CrossRef]
- Wang, H.; Yu, Y.; Yuan, Q. Application of Dijkstra Algorithm in Robot Path-Planning. In Proceedings of the 2011 Second International Conference on Mechanic Automation and Control Engineering, Hohhot, China, 15–17 July 2011; pp. 1067–1069. [Google Scholar]
- Carlone, L.; Du, J.; Kaouk Ng, M.; Bona, B.; Indri, M. Active SLAM and Exploration with Particle Filters Using Kullback-Leibler Divergence. J. Intell. Robot. Syst. 2014, 75, 291–311. [Google Scholar] [CrossRef]
- Trivun, D.; Šalaka, E.; Osmanković, D.; Velagić, J.; Osmić, N. Active SLAM-Based Algorithm for Autonomous Exploration with Mobile Robot. In Proceedings of the 2015 IEEE International Conference on Industrial Technology (ICIT), Seville, Spain, 17–19 March 2015; pp. 74–79. [Google Scholar]
- Mihálik, M.; Malobický, B.; Peniak, P.; Vestenický, P. The New Method of Active SLAM for Mapping Using LiDAR. Electronics 2022, 11, 1082. [Google Scholar] [CrossRef]
- Placed, J.A.; Castellanos, J.A. Fast Autonomous Robotic Exploration Using the Underlying Graph Structure. In Proceedings of the 2021 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Prague, Czech Republic, 27 September–1 October 2021; pp. 6672–6679. [Google Scholar]
- Suresh, S.; Sodhi, P.; Mangelson, J.G.; Wettergreen, D.; Kaess, M. Active SLAM Using 3D Submap Saliency for Underwater Volumetric Exploration. In Proceedings of the 2020 IEEE International Conference on Robotics and Automation (ICRA), Paris, France, 31 May–31 August 2020; pp. 3132–3138. [Google Scholar]
- Hester, T.; Vecerik, M.; Pietquin, O.; Lanctot, M.; Schaul, T.; Piot, B.; Horgan, D.; Quan, J.; Sendonaris, A.; Osband, I.; et al. Deep Q-Learning From Demonstrations. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Li, X.; Chen, G.; Wu, G.; Sun, Z.; Chen, G. Research on Multi-Agent D2D Communication Resource Allocation Algorithm Based on A2C. Electronics 2023, 12, 360. [Google Scholar] [CrossRef]
- Cimurs, R.; Lee, J.H.; Suh, I.H. Goal-Oriented Obstacle Avoidance with Deep Reinforcement Learning in Continuous Action Space. Electronics 2020, 9, 411. [Google Scholar] [CrossRef]
- Chen, F.; Martin, J.D.; Huang, Y.; Wang, J.; Englot, B. Autonomous Exploration Under Uncertainty via Deep Reinforcement Learning on Graphs. In Proceedings of the 2020 IEEE/RSJ International Conference on Intelligent Robots and Systems (IROS), Las Vegas, NV, USA, 24 October 2020–24 January 2021; pp. 6140–6147. [Google Scholar]
- Placed, J.A.; Rodríguez, J.J.G.; Tardós, J.D.; Castellanos, J.A. ExplORB-SLAM: Active Visual SLAM Exploiting the Pose-Graph Topology. In Proceedings of the ROBOT2022: Fifth Iberian Robotics Conference; Tardioli, D., Matellán, V., Heredia, G., Silva, M.F., Marques, L., Eds.; Springer International Publishing: Cham, Switzerland, 2023; pp. 199–210. [Google Scholar]
- Placed, J.A.; Castellanos, J.A. A Deep Reinforcement Learning Approach for Active SLAM. Appl. Sci. 2020, 10, 8386. [Google Scholar] [CrossRef]
- Li, S.; Xu, X.; Zuo, L. Dynamic Path Planning of a Mobile Robot with Improved Q-Learning Algorithm. In Proceedings of the 2015 IEEE International Conference on Information and Automation, Lijiang, China, 8–10 August 2015; pp. 409–414. [Google Scholar]
- Vithayathil Varghese, N.; Mahmoud, Q.H. A Survey of Multi-Task Deep Reinforcement Learning. Electronics 2020, 9, 1363. [Google Scholar] [CrossRef]
- Lillicrap, T.P.; Hunt, J.J.; Pritzel, A.; Heess, N.; Erez, T.; Tassa, Y.; Silver, D.; Wierstra, D. Continuous control with deep reinforcement learning. arXiv 2015, arXiv:1509.02971. [Google Scholar]
- Rviz—ROS Wiki. Available online: https://wiki.ros.org/rviz (accessed on 15 January 2024).
- Gazebo. Available online: https://gazebosim.org/home (accessed on 15 January 2024).
- Name, Y. ROBOTIS E-Manual. Available online: https://emanual.robotis.com/docs/en/platform/turtlebot3/overview/ (accessed on 15 January 2024).
- Kingma, D.P.; Ba, J. Adam: A Method for Stochastic Optimization. arXiv 2014, arXiv:1412.6980. [Google Scholar]
- Kümmerle, R.; Steder, B.; Dornhege, C.; Ruhnke, M.; Grisetti, G.; Stachniss, C.; Kleiner, A. On Measuring the Accuracy of SLAM Algorithms. Auton. Robot. 2009, 27, 387–407. [Google Scholar] [CrossRef]
- Cao, L.; Ling, J.; Xiao, X. Study on the Influence of Image Noise on Monocular Feature-Based Visual SLAM Based on FFDNet. Sensors 2020, 20, 4922. [Google Scholar] [CrossRef] [PubMed]
- Sankalprajan, P.; Sharma, T.; Perur, H.D.; Sekhar Pagala, P. Comparative Analysis of ROS Based 2D and 3D SLAM Algorithms for Autonomous Ground Vehicles. In Proceedings of the 2020 International Conference for Emerging Technology (INCET), Belgaum, India, 5–7 June 2020; pp. 1–6. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Reference | Active SLAM | Reward Design | Focus on Exploration | Focus on Exploitation | |
|---|---|---|---|---|---|
| SLAM Method | Path Planning Method | ||||
| Carlone et al. [19] | Particle filter | Frontier-based exploration | - | √ | - |
| Trivun et al. [20] | Fast SLAM | A*, | - | √ | - |
| Michal et al. [21] | EKF SLAM | A* | - | √ | - |
| Placed et al. [22] | Open Karto | Dijkstra | - | √ | - |
| Suresh et al. [23] | Graph SLAM | - | √ | - | |
| Chen et al. [27] | - | , | T-opt | √ | - |
| Juna et al. [28] | Graph SLAM | DQN | D-opt | √ | - |
| Castellanos et al. [29] | Gmapping | D-opt | √ | - | |
| Ours | Cartographer | √ | √ | ||
| Parameter | Description | Value |
|---|---|---|
| Adam optimizer | ADAM | |
| Learning rate for actor network | ||
| Learning rate for critic network | ||
| L2 regularization coefficient | ||
| Discount factor | 0.99 | |
| Target network update | 0.001 | |
| OU random noise | 0.15 | |
| Batch size | 64 | |
| Total time steps | ||
| C | Collision threshold (m) | 1000 |
| Maximum steps per episode | 2000 |
| Scenarios | Methods | MSE | PSNR (dB) | SSIM |
|---|---|---|---|---|
| Env-1 | 0 | Inf | 1 | |
| 0.55 | 25 | 0.63 | ||
| 0.51 | 26 | 0.72 | ||
| Ours | 0.30 | 37 | 0.88 | |
| Env-2 | 0 | Inf | 1 | |
| 0.61 | 20 | 0.59 | ||
| 0.59 | 27 | 0.61 | ||
| Ours | 0.41 | 35 | 0.74 | |
| Env-3 | 0 | Inf | 1 | |
| 0.81 | 25 | 0.43 | ||
| 0.71 | 21 | 0.37 | ||
| Ours | 0.54 | 30 | 0.64 |
| Scenarios | Methods | Path Length (m) | Time (s) | Grid Completeness (%) | Cost Value (J/m2) | ||
|---|---|---|---|---|---|---|---|
| Env-1 | 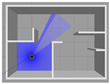 | 25.02 | 230 | 99.2 | 22.2 | ||
| 22.1 | 215 | 97.9 | 20.9 | ||||
| 23.3 | 195 | 97.7 | 19.2 | ||||
| 24.3 | 184 | 98.0 | 18.1 | ||||
| 35.7 | 254 | 98.7 | - | ||||
| Env-2 |  | 36.8 | 378 | 98.7 | 10.9 | ||
| 39.7 | 346 | 95.4 | 10.4 | ||||
| 42.6 | 354 | 95.1 | 10.7 | ||||
| 40.9 | 332 | 96.1 | 9.9 | ||||
| 52.8 | 216 | 98.2 | - | ||||
| Env-3 |  | 97.8 | 1489 | 97.9 | 23.2 | ||
| 123.9 | 1332 | 91.6 | 22.5 | ||||
| 100.5 | 965 | 84.2 | 17.8 | ||||
| 111.8 | 924 | 95.3 | 15.2 | ||||
| 134.6 | 634 | 96.1 | - | ||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhao, S.; Hwang, S.-H. Exploration- and Exploitation-Driven Deep Deterministic Policy Gradient for Active SLAM in Unknown Indoor Environments. Electronics 2024, 13, 999. https://doi.org/10.3390/electronics13050999
Zhao S, Hwang S-H. Exploration- and Exploitation-Driven Deep Deterministic Policy Gradient for Active SLAM in Unknown Indoor Environments. Electronics. 2024; 13(5):999. https://doi.org/10.3390/electronics13050999
Chicago/Turabian StyleZhao, Shengmin, and Seung-Hoon Hwang. 2024. "Exploration- and Exploitation-Driven Deep Deterministic Policy Gradient for Active SLAM in Unknown Indoor Environments" Electronics 13, no. 5: 999. https://doi.org/10.3390/electronics13050999
APA StyleZhao, S., & Hwang, S.-H. (2024). Exploration- and Exploitation-Driven Deep Deterministic Policy Gradient for Active SLAM in Unknown Indoor Environments. Electronics, 13(5), 999. https://doi.org/10.3390/electronics13050999