Abstract
With the rapid development of 6G networks, data transmission speed has significantly increased, making data privacy protection issues even more crucial. The federated learning (FL) is a distributed machine learning framework with privacy protection and secure encryption technology, aimed at enabling dispersed participants to collaborate on model training without disclosing private data to other participants. Nonetheless, recent research indicates that the exchange of shared gradients may lead to information disclosure, and thus FL still needs to address privacy concerns. Additionally, FL relies on a large number of diverse training data to forge efficient models, but in reality, the training data available to clients are limited, and data imbalance issues lead to over fitting in existing federated learning models. To alleviate these issues, we introduce a Novel Federated Learning Framework based on Conditional Generative Adversarial Networks (NFL-CGAN). NFL-CGAN divides the local networks of each client into private and public modules. The private module contains an extractor and a discriminator to protect privacy by retaining them locally. Conversely, the public module is shared with the server to aggregate the shared knowledge of clients, thereby improving the performance of each client local network. Comprehensive experimental analyses demonstrate that NFL-CGAN surpasses traditional FL baseline methods in data classification, showcasing its superior efficacy. Moreover, privacy assessments also verified robust and reliable privacy protection capabilities of NFL-CGAN.
1. Introduction
Deep learning models have marked remarkable success across diverse domains, including computer vision, natural language processing, and recommendation systems [1,2,3]. However, these successes often rely on the availability of large-scale training data. In real-world applications, due to distributed data and considerations of privacy and regulation [4,5], data owners are often reluctant to share their data directly, posing significant challenges for model training.
To deal with the issues of data dispersion and privacy protection, the concept of federated learning (FL) [6] was proposed in 2018. Federated learning allows multiple clients to cooperate to build deep models without sharing private data, and only needs to share updated information of the model. With the rise of 6G networks, more devices are connected to the network and generate a large amount of data, which provides new possibilities for joint training. Federated learning requires the cooperation of multiple clients and has high network requirements, and the emergence of 6G networks has greatly accelerated the speed of federated learning between clients. At the same time, an efficient and privacy-protected federated learning framework is crucial for 6G network applications, and it can significantly improve the user experience on 6G networks.
However, developing robust federated models with constrained data availability on individual devices presents a significant challenge. There is a desire to increase the number of existing data with similar samples, especially those from rare categories, to address data imbalance issues. Recently, various techniques such as Generative Adversarial Networks (GAN) [7] have been successfully applied in the field of machine learning, particularly for generating synthetic data to increase sample numbers and address undersampling issues. Although FL has demonstrated efficacy in discriminative models, the integration of generative networks within FL remains an active area of investigation.
Concurrently, conventional joint averaging methodologies like FedAvg [8] and its derivatives, for instance, FedProx [9], are vulnerable to gradient-based privacy incursions [10], exemplified by Deep Leakage from Gradients (DLG) [11]. Such attacks are capable of reconstructing an original data of client by using publicly shared gradients and parameters. To fortify privacy of FL, various approaches have been employed, with Homomorphic Encryption (HE) [12] and Differential Privacy (DP) [13] being notably prevalent. Although HE offers a high level of security protection, it is impractical for deep learning models, typically involving numerous parameters, due to high computational and communication costs. While DP reduces the complexity of FL, it can lead to decreased model accuracy and remains vulnerable to data recovery attacks [14].
In response to these difficulties, we introduce NFL-CGAN, a novel federated learning paradigm employing Conditional Generative Adversarial Networks (CGAN). This approach not only offers enhanced privacy protection against DLG attacks but also outperforms traditional FL methods in model efficacy.
The principal contributions of this study are fourfold:
- (1)
- Integrating Conditional Generative Adversarial Networks into federated learning, where, through this conditionality, the generator can capture feature distributions of specific labels, thus protecting client data privacy while maintaining good classification performance of the client models.
- (2)
- Introducing private extractors before public classifiers and retaining extractors locally to strengthen privacy measures.
- (3)
- Sharing only the generators with the server for aggregating shared knowledge among clients to improve model performance.
- (4)
- Conducting extensive experiments to validate the performance of NFL-CFAN, demonstrating its superior performance in maintaining privacy compared to FL baseline methods.
The subsequent sections of this study unfold as follows. In Section 2, domain-specific background knowledge and an overview of existing research are provided. Following that, Section 3 comprehensively introduces the core content of the NFL-CGAN framework. Section 4 offers a detailed overview of specific experimental details. Section 5 presents the final experimental results. Finally, in Section 6, the main findings of this paper are summarized, and conclusions are presented.
2. Prepare Knowledge and Related Work
2.1. Federated Learning
In 2018, Hard et al. [6] proposed federated earning, a distributed machine learning approach designed to address privacy protection and data dispersion issues. It allows multiple parties (typically devices or clients) to collaboratively train machine learning models without centralizing the raw datasets. Subsequently, in 2019, Li et al. [8] introduced the Federated Averaging (FedAvg) algorithm, aimed at optimizing federated processes on edge devices. The FedAvg protocol commences with the central server distributing the global model to selected clients (edge devices). These clients then execute Stochastic Gradient Descent (SGD) on their private datasets for local model refinement. The central server, post receipt of these updates from all clients, amalgamates them, updating the global model by averaging these contributions.
Despite the ingenuity of these methods, the necessity for clients to upload model parameters for global amalgamation poses potential risks of client model exposure. To mitigate this, researchers such as Truex et al. [15] have explored diverse secure computation methods to shield data and model parameters in federated learning. For instance, in 2021, Mou et al. [16] proposed an innovative federated learning architecture, combining Secure Multi-party Computation (SMC) and Differential Privacy, aiming to reduce inference leakage during learning processes and outputs. In 2022, Wu et al. [17] advocated the application of Differential Privacy to combat assorted background knowledge assaults. Concurrently, Ma et al. [18] employed Homomorphic Encryption (HE) strategies, facilitating arithmetic operations on ciphertexts sans decryption, thus preserving model parameters. Recently in 2024, Cao et al. [19] introduced a novel, secure and robust federated learning framework (SRFL) predicated on Trusted Execution Environment (TEE), leveraging TEE to safeguard sensitive model elements within the trusted execution milieu.
However, these methods still have drawbacks, such as high communication or computational costs [20,21], or reliance on specific hardware implementations [22]. To prevent data leakage while still enjoying the benefits of FL, Pathak et al. [23] conceptualized FedSplit, an innovative combination of split learning and joint learning. This strategy proposes dividing client networks into private and public sectors, preserving privacy by concealing the private models from the server. However, FedSplit experienced certain performance decreases [24]. Researchers are trying to balance privacy and efficiency by only sharing the public model, dividing neural networks into private and public parts [25].
2.2. Generative Adversarial Network
In 2014, Goodfellow et al. [26] proposed the Generative Adversarial Network, introduced as a novel method for training generative models. It consists of two deep neural networks: a generator model , which captures data distribution, and a discriminator model , estimating if a sample is from the training data or the generator . Both models can utilize nonlinear mapping functions. To learn the generative distribution over data points , the generator constructs a mapping function from a prior noise distribution to the data space. The discriminator outputs a scalar representing the probability that comes from the training data. and are trained simultaneously: we adjust the parameters of generator to minimize and to minimize , engaging them in a two-player game with the value function . The goal of this game is to find equilibrium where the generator can produce realistic data, while the discriminator cannot accurately distinguish between generated and real data. The formula is as follows:
Subsequently, Mirza et al. [27] introduced the Conditional Generative Adversarial Network (CGAN), which allows generating data with specific attributes (“conditions”) on the GAN basis. Practically, the condition y could be the data label. More formally, CGAN training can be represented as optimizing the function , as follows:
2.3. Generative Adversarial Networks in Federated Learning
Recent research in federated learning involving Generative Adversarial Networks mainly focuses on two aspects:
Initially, several researchers [28] have focused on developing high-quality Generative Adversarial Networks (GANs) across decentralized data sources to cope with limitations in privacy, efficiency, or data heterogeneity. For instance, Hardy et al. [29] introduced MD-GAN, a pioneering approach for the concurrent training of GAN models. This method incorporates multiple discriminators alongside a singular generator to curtail computational demands. Significantly, the generator is stationed on the server, while the discriminators reside within local clients. The generator fabricates simulated data, dispatching it to each local client, where discriminators engage in distinguishing between simulated and actual data. A critical aspect of MD-GAN involves each discriminator intermittently exchanging parameters with others, facilitated by a gossip algorithm [30]. Although such parameter interchange can avert overfitting, it concurrently necessitates model retraining. Hence, MD-GAN must judiciously balance the complexity of training against the diversity of data, which might impinge upon the diversity of generated data. Concurrently, there is an acknowledgment in the research community that malevolent clients might exploit shared discriminator models within GANs to train generators, subsequently utilizing these trained generators to replicate the training samples of victim clients [31], potentially leading to breaches in data privacy. In conclusion, the problem of balance, training complexity, and potential data privacy leakage are all drawbacks of the MD-GAN method. When designing joint training GAN models, it is necessary to carefully consider these issues and seek better solutions to improve both model performance and security.
Another noteworthy methodology is FL-GAN [32], which endeavors to train an ensemble of GAN models employing the federated averaging technique. In this setup, each client maintains a standard GAN model, while the global model is developed through the aggregation of local computational updates, iteratively applying federated averaging. While this method yields satisfactory outcomes with Independently and Identically Distributed (IID) training data, its efficacy might be compromised in scenarios involving Non-Independently and Identically Distributed (non-IID) data, potentially detracting from model performance.
On the other hand, some researchers also focus on how to use uploaded GAN model parameters for data recovery attacks. For example, servers might engage in malicious behavior, learning representations of victim client data through deep leakage attacks, then using these representations to train generators, ultimately generating the private data of victims. Existing federated learning solutions focus more on improving model performance and overlook the impact of DLG. Once model parameters are attacked, data of client will be exposed, and data privacy will not be protected. Therefore, a federated learning framework that can maintain good model performance while providing privacy protection is urgently needed.
3. Methods
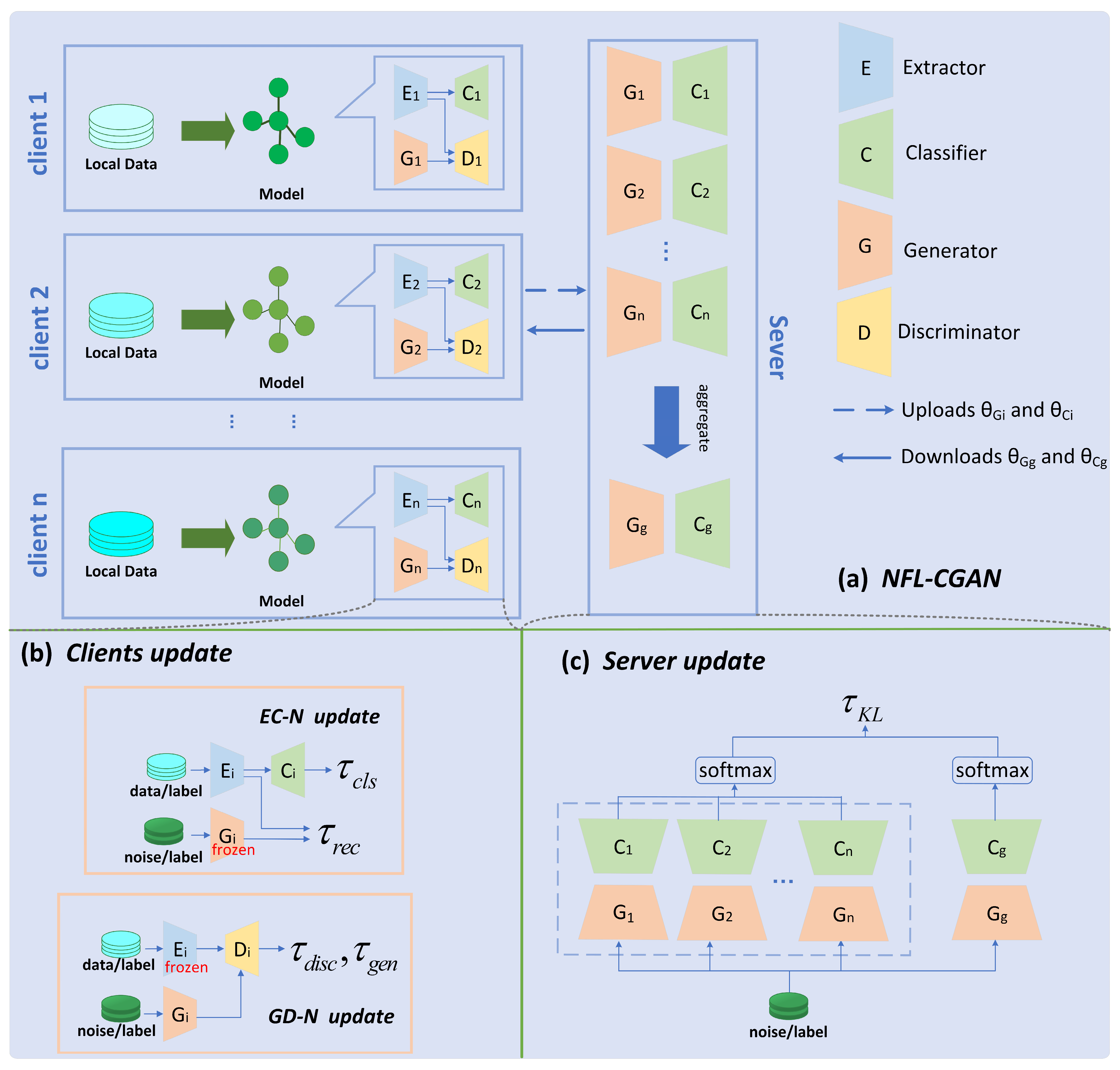
This section introduces the innovative federated learning framework based on Conditional Generative Adversarial Networks, which enhances data privacy protection and model classification performance. In this framework, each client is equipped with an extractor, classifier, generator, and discriminator. Data are first input into the extractor and then into the classifier or discriminator. It is important to note that the model parameters of the extractor are not uploaded to the server to prevent the uploaded model parameters from being vulnerable to DLG, leading to the exposure of the original data. At the same time, the discriminator is also not uploaded to the server because keeping the discriminator locally benefits the generator in generating data that aligns better with local data features, resulting in improved training effectiveness and enhancing privacy protection to some extent while reducing communication overhead. After the local client’s training updates are completed, the client uploads the model parameters of the classifier and generator to the server. The server aggregates all parameters using the federated averaging method and then employs knowledge distillation to train the global model. The generator and discriminator used in this process are based on the CGAN model proposed by Mirza et al. [27]. Detailed overall framework is shown in Figure 1.
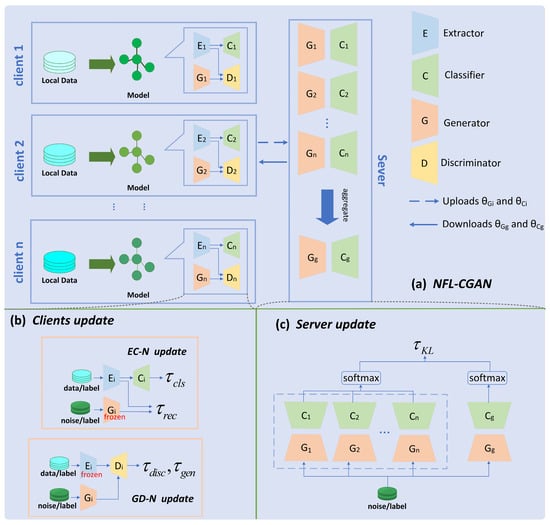
Figure 1.
Overall framework of NFL-CGAN. Overall framework of NFL-CGAN (a) NFL-CGAN (b) Clients update and (c) Server update.
3.1. Overview
NFL-CGAN include a central server and clients. Each of clients owns a private dataset from the distribution of . These private datasets share a common feature space while differing in their respective sample spaces.
Each client is equipped with an Extraction-Classification Network (EC-N) and a Generation-Discrimination Network (GD-N). The EC-N, composed of an extractor and a classifier, aims to prevent direct exposure of the classifier to raw data, thereby effectively safeguarding against gradient leakage attacks and data breaches, maintaining user privacy. Additionally, the extractor assists the classifier in accurately categorizing data by extracting useful information. The classifier is responsible for data classification.
The purpose of the GD-N is to maintain client privacy and sustain high model performance. This network consists of a generator with conditional inputs and a discriminator. The generator produces synthetic data based on conditions and random Gaussian noise. Its output, combined with the output of extractor and associated labels, is fed into the discriminator. The local training goal for the generator is to mimic data similar to the extractor output, enabling the generator to capture feature distributions and generate realistic, effectively classifiable data.
As illustrated in Figure 1a, NFL-CGAN operates as follows. In each FL communication round, after local training, each client uploads its and to the server, while keeping and locally, thereby enhancing privacy protection. Then, the server aggregates the global model parameters through federated averaging and applies Knowledge Distillation [33] to train the global generator and global classifier . After construction, clients download and to replace their local counterparts and start a new training round.
In NFL-CGAN, clients collaboratively train a global generator and classifier with the help of server, while each client uses the global versions to build personalized local extraction networks, which perform well on their local test datasets. The next two subsections provide detailed explanations.
3.2. Collaboration Mechanisms of Clients
The training process of client is divided into two phases: Extraction-Classification Network update and Generation-Discrimination Network update, as shown in
3.2.1. EC-N Update
As shown in EC-N update of Figure 1b, during this stage, real data and labels are sequentially input into the extractor and classifier, while random noise and labels are input into the generator. Each client uses a cross-entropy loss function to update the model parameters of its extractor and classifier .
Here, is the label for image , and is the prediction result after the image x passes through the extractor and classifier.
Client also seeks to integrate the shared knowledge embedded in the global generator from the previous round into its local extractor. To do this, it freezes the global generator and uses the absolute difference loss method to optimize its local extractor , as shown:
Here, is the image output by the extractor after input, and is the image generated by the generator after inputting the same label and random noise as .
The total loss comprises classification loss and reconstruction loss, as follows:
Here, is a non-negative hyperparameter to balance the two loss terms. In our study, increases from 0 to 1 as the feature representation of global generator becomes more accurate, to achieve balance.
3.2.2. GD-N Update
The update steps for the Generative Adversarial Network are shown in GD-N update of Figure 1b. Here, the goal of client is to adjust the local generator to produce data closer to the feature representation of local extractor. The client freezes the extractor and trains the generator through the adversarial game between the discriminator and generator. Specifically, it samples a batch of training data , sends to the extractor for feature representation , generates Gaussian noise of the same batch size, and inputs to the local generator to produce the estimated feature representation . Finally, and are input into the discriminator , calculating discriminator and generator losses and minimizing these to optimize and . The loss formulas are:
Once local training is complete, each client sends its generator and classifier to the server for aggregation.
3.2.3. Server Update
In NFL-CGAN, the server trains model parameters through Knowledge Distillation (KD), using the output of the classifier model in each client to train the global classifier, as depicted in Figure 1c. Compared to other KD methods in FL, a major advantage of NFL-CGAN is its ability to perform distillation without server access to any public data, allowing flexible aggregation of heterogeneous client models with fewer training rounds. Figure 1 shows the server aggregation method. When the server perceives the generators and classifiers uploaded by clients, it uses weighted averaging to initialize the global generator and global classifier .
For the distillation process, the server first generates a small batch of training data , with noise sampled from a Gaussian distribution and labels from a uniform distribution . Then, the server provides to all generators, including clients and the server, and calculates category probability distributions and , where the former comes from the ensemble of client classifiers and the latter from the global classifier. Finally, the server optimizes the global classifier and generator by minimizing the KL divergence between these two distributions . The overall process is illustrated in Figure 1c and the formulas are:
Here, is the number of categories. is the output of the client classifier, and is the output of the global classifier.
Once the server completes aggregation, it distributes the global generator and global classifier to all clients. The clients download and update these, continuing to train their local models.
4. Experiment
4.1. Datasets
Four image datasets are used to evaluate the performance of client model. They are, respectively, FMNIST (Fashion MNIST), CIFAR10, Digit5, and OfficeCaltech10.
For FMNIST and CIFAR10 datasets, an Independent and Identically Distributed (IID) setting is adopted. The FMNIST dataset contains a total of 60,000 images, including 10,000 test images, each with a resolution of pixels. Each image is presented in grayscale format, with pixel values ranging from 0 to 255. Each sample in this dataset is categorized into one of the following ten categories: T-shirt/top, trousers, pullover, dress, coat, sandals, shirt, sneakers, bag, and ankle boots. The CIFAR10 dataset comprises a total of 50,000 pixel RGB images covering ten different categories, including airplane, automobile, bird, cat, deer, dog, frog, horse, ship, and truck. Each category contains 5000 training images and 1000 test images.
Additionally, the Digit5 and OfficeCaltech10 datasets adopted a non-IID setting. The Digit5 dataset encompasses samples from five digital recognition benchmarks, including MNIST, Synthetic Digits, MNIST-M, SVHN, and USPS. The OfficeCaltech10 dataset contains images of 10 types of office supplies from four different domains: Amazon, DSLR, Webcam, and Caltech.
4.2. Experimental Environment
Our experiments are conducted on a computer equipped with an Intel Core i9 processor (3.0 GHz), sourced from Intel Corporation, Santa Clara, United States, 128 GB RAM, and an NVIDIA GeForce RTX 4090 GPU, sourced from NVIDIA Corporation, Santa Clara, United States. The operating system is Windows 10. PyTorch framework (version 3.8.0) is used to develop and train models in our experiments.
4.3. Model Parameters
The extractor and classifier employ two different network architectures: one is Convolutional Neural Network (CNN) and the other is Deep Residual Network architecture. The CNN consists of 2D convolutional layers, 2D average pooling layers, a flattening layer, Sigmoid activation functions, and linear layers, with specific model parameters detailed in Table 1.

Table 1.
Specific parameters of Convolutional Neural Networks.
The Deep Residual Network architecture includes an input layer, four residual blocks, and a fully connected layer. Each residual block comprises two residual units, each containing two convolutional layers. This design uses skip connections to allow direct information passage, addressing the problem of gradient vanishing. Specific model parameters are shown in Table 2.
Table 2.
Specific parameters of Deep Residual Network.
The generator model consists of an Embedding layer, four ConvTranspose2d layers, BatchNorm2d layers, and LeakyReLU and Sigmoid activation functions. The discriminator model includes an Embedding layer, four Spectral_norm layers, BatchNorm2d layers, LeakyReLU, and Sigmoid activation functions. Specific model parameters are presented in Table 3.
Table 3.
Specific parameters of Generative Adversarial Network.
4.4. Experimental Setup
We conduct 100 global communication rounds and 10 local epochs, with a batch size of 8. All experiments used the Adam optimizer with a learning rate of and weight decay of .
For above datasets, we consider the situation of four clients. For the FMNIST and CIFAR10 datasets, we randomly divide the training and testing sets into four parts and assign them to four clients. Then, we extract 20% of the training dataset from each client as the validation dataset. For Digit5 and OfficeCaltech 10 datasets, we treat each domain as data contained in the client, and randomly divide 60% of the data in each domain as the training set, 20% as the validation set, and 20% as the testing set. Before training any GANs, we apply the same normalization preprocessing operation to each image in these datasets.
4.5. Evaluation Metrics
Comparing the model from two aspects, one is the classifier performance in the model, and the other is the privacy protection performance of the model.
Accuracy, precision, recall, F1 score, FPR, and ROC curves are used to assess the performance of classifier of NFL-CGAN model. These metrics depend on four terms: True Positive (TP), True Negative (TN), False Negative (FN), and False Positive (FP), corresponding, respectively, to the number of positive samples correctly classified as positive, negative samples correctly classified as negative, positive samples incorrectly classified as negative, and negative samples incorrectly classified as positive.
Accuracy: This metric represents the ratio of accurately classified samples to the overall sample size within a specified test dataset. The corresponding formula is as follows:
Precision: This metric denotes the fraction of correctly identified samples among all those labeled as positive. The formula is as follows:
Recall: This metric measures the percentage of actual positive samples correctly identified as positive, also termed as the True Positive Rate (TPR). The formula is as follows:
F1 Score: This metric combines precision and recall and reflects a balance between the two. As precision increases, recall tends to decrease and vice versa. The F1 Score was developed to harmonize these metrics, and the formula is as follows:
False Positive Rate (FPR): This measures the ratio of incorrectly identified positive cases to the total number of actual negative instances, also referred to as the False Acceptance Rate (FAR). The formula is as follows:
Receiver Operating Characteristic (ROC) Curve: Also known as the acceptability curve. Points on the curve reflect responses to the same signal stimulus but obtained under several different judgment criteria. The curve is plotted by connecting points with FPR as the X-coordinate and True Positive Rate TPR as the Y-coordinate.
Relative Test Accuracy (RTA): The goal of federated learning is to obtain a model of higher quality than those trained independently locally. Thus, RTA can be used to measure the improvement in model quality. For example, if a model trained independently locally achieves a test classification accuracy of 70%, and the model obtained through federated learning reaches 90% on the same test set, the RTA for the client is approximately 90%/70% ≈ 1.29.
We use Peak Signal-to-Noise Ratio (PSNR) as the assessment metric to assess the privacy protection performance of NFL-CGAN model. The higher the PSNR value, the higher the similarity between the generated and original images. However, in our experiments, our goal is to generate images that can be correctly classified but are as dissimilar as possible from the original data, so we prefer a lower PSNR value. The formula for PSNR is as follows:
here, peakval represents the maximum value in the image data. If using 8-bit unsigned integer data type, then the value of peakval will be 255. The unit of PSNR is usually decibels (dB). Mean Squared Error (MSE) represents the degree of difference between two images.
5. Experimental Results
5.1. Comparative Experiment Introduction
In the following experiments, five different FL models are compared with our NFL-CGAN model, which can be divided into two types. The first type is that clients and the server have identical network structures, including FedAvg [8], FedProx [9], and FedDF [34]. The second type is that clients only share their public classifiers with the server, including FedSplit [23] and FedGen [35].
5.2. Experimental Results of Deep Residual Network
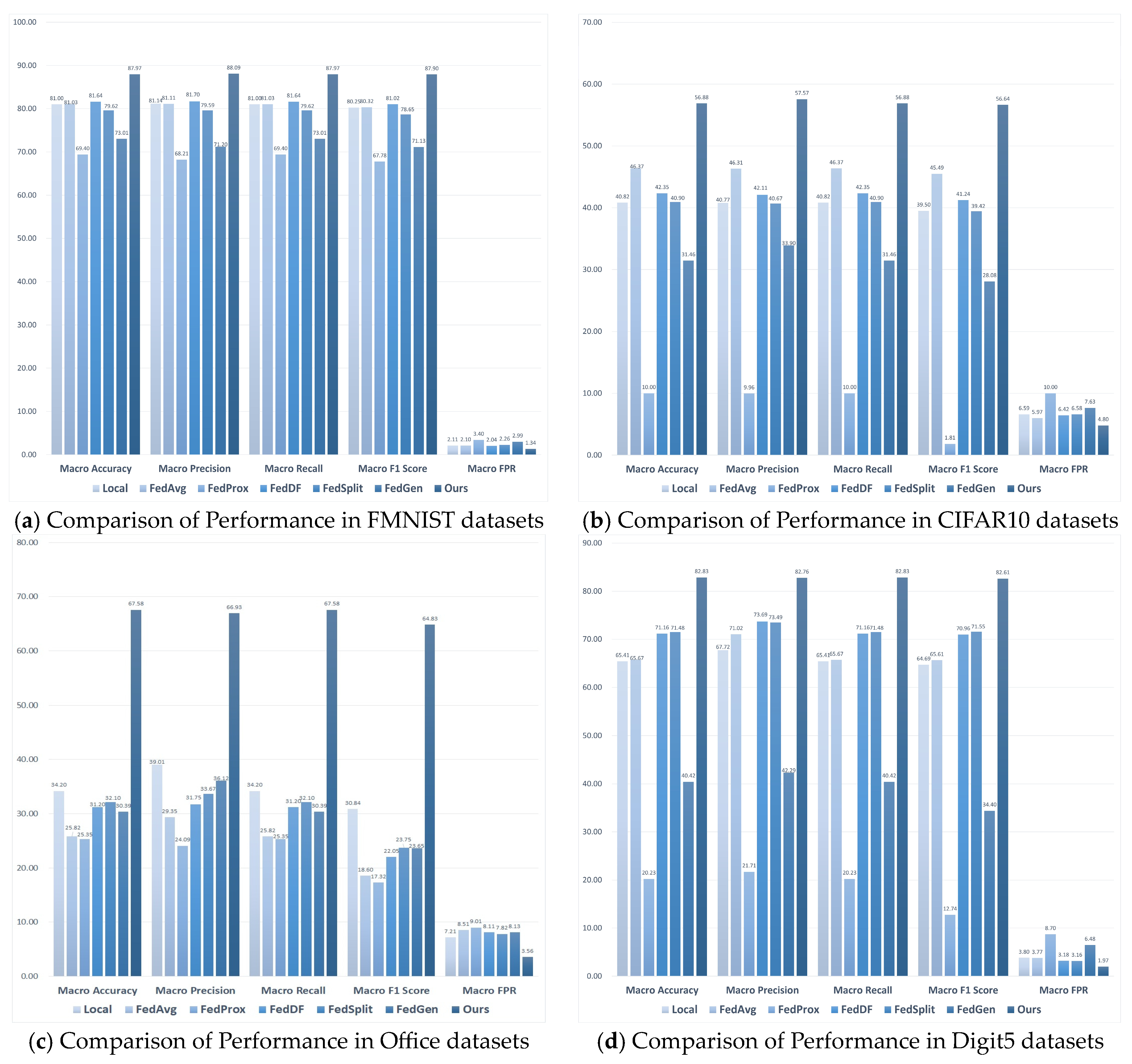
In the experiments, we compare the performance between aforementioned five FL algorithms with NFL-CGAN. Also, our model is also compared with datasets trained independently on the local client. According to the macro average accuracy, precision, F1 scores, recall, and FPR setting on IID and non-IID datasets, we evaluate the performance of NFL-CGAN and other models. The increase in accuracy, precision, recall, and F1 score indicate an improvement in model performance, while the decrease in FAR value also reflects better model performance.
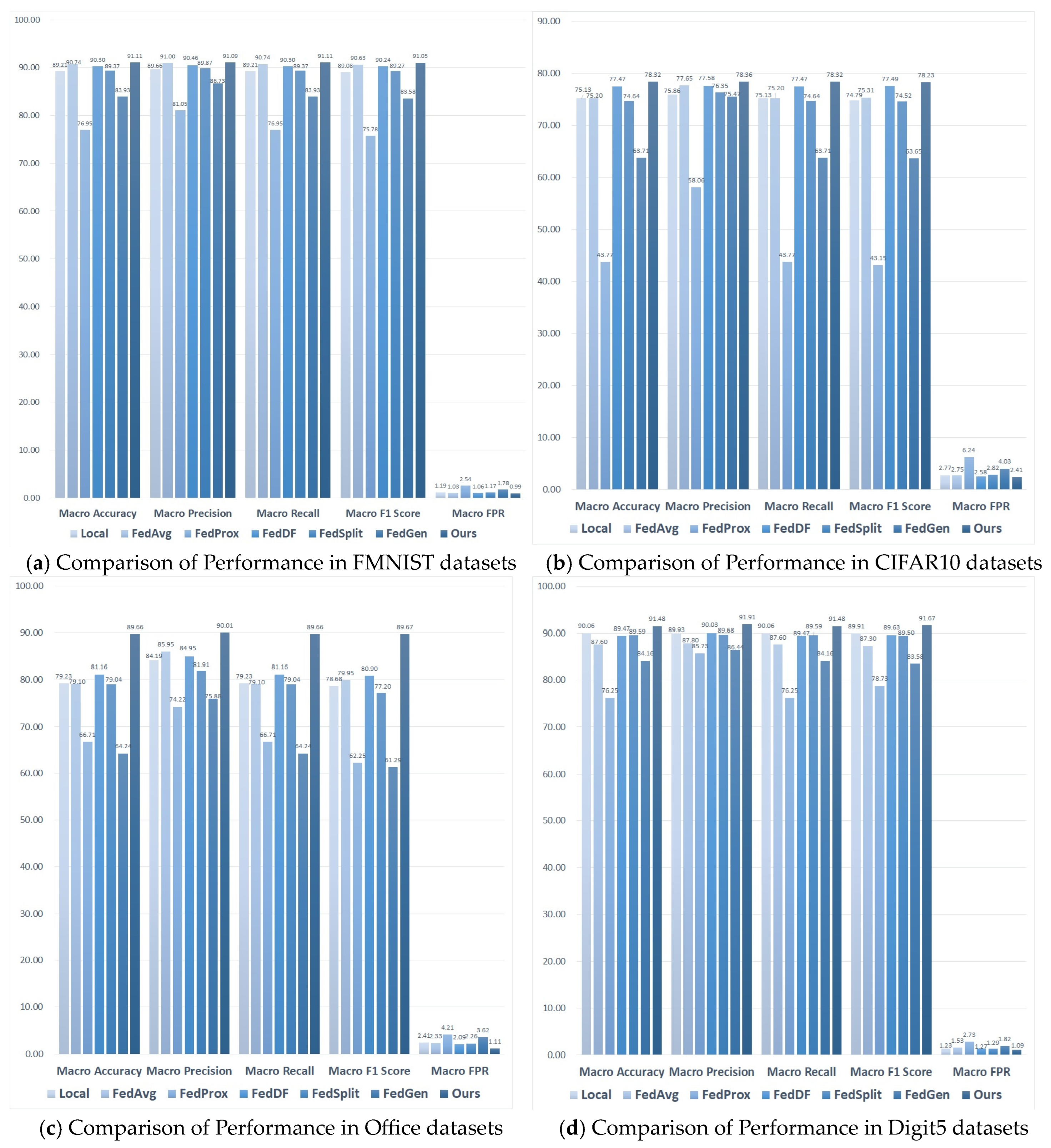
As seen from Figure 2, NFL-CGAN outperforms the six benchmark algorithms across all five mentioned evaluation metrics. For the FMNIST dataset, the accuracy of NFL-CGAN model reaches 91.11%, compared to 89.21%, 90.74%, 76.95%, 90.30%, 89.37%, and 83.93% with the other models. For the CIFAR10 dataset, the accuracy of NFL-CGAN model is 78.32%, about 3% higher than most of the control experiments. For the Digit5 dataset, our accuracy is 91.48%, slightly higher than other experimental results. Notably, for the non-IID Office dataset, the accuracy of the other six benchmark algorithms is only about 70%, while ours significantly increased to 89.66%.
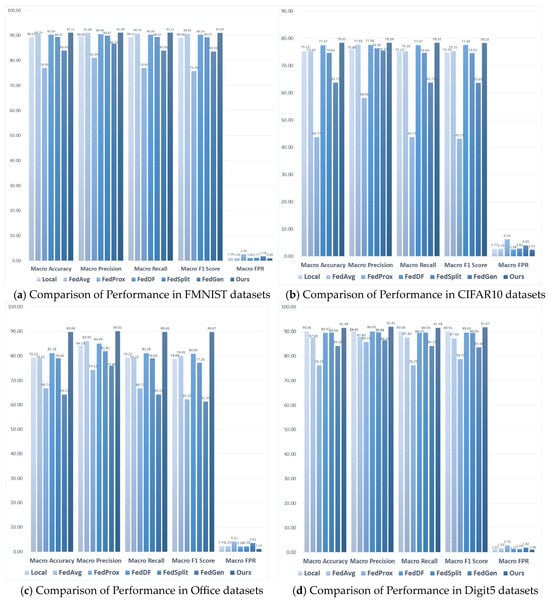
Figure 2.
The test results (%) of Local, FedAvg, FedProx, FedDF, FedSplit, FedGen and Ours on the deep residual network. (a) Comparison of Performance in FMNIST datasets (b) Comparison of Performance in CIFAR10 datasets (c) Comparison of Performance in Office datasets and (d) Comparison of Performance in Digit5 datasets.
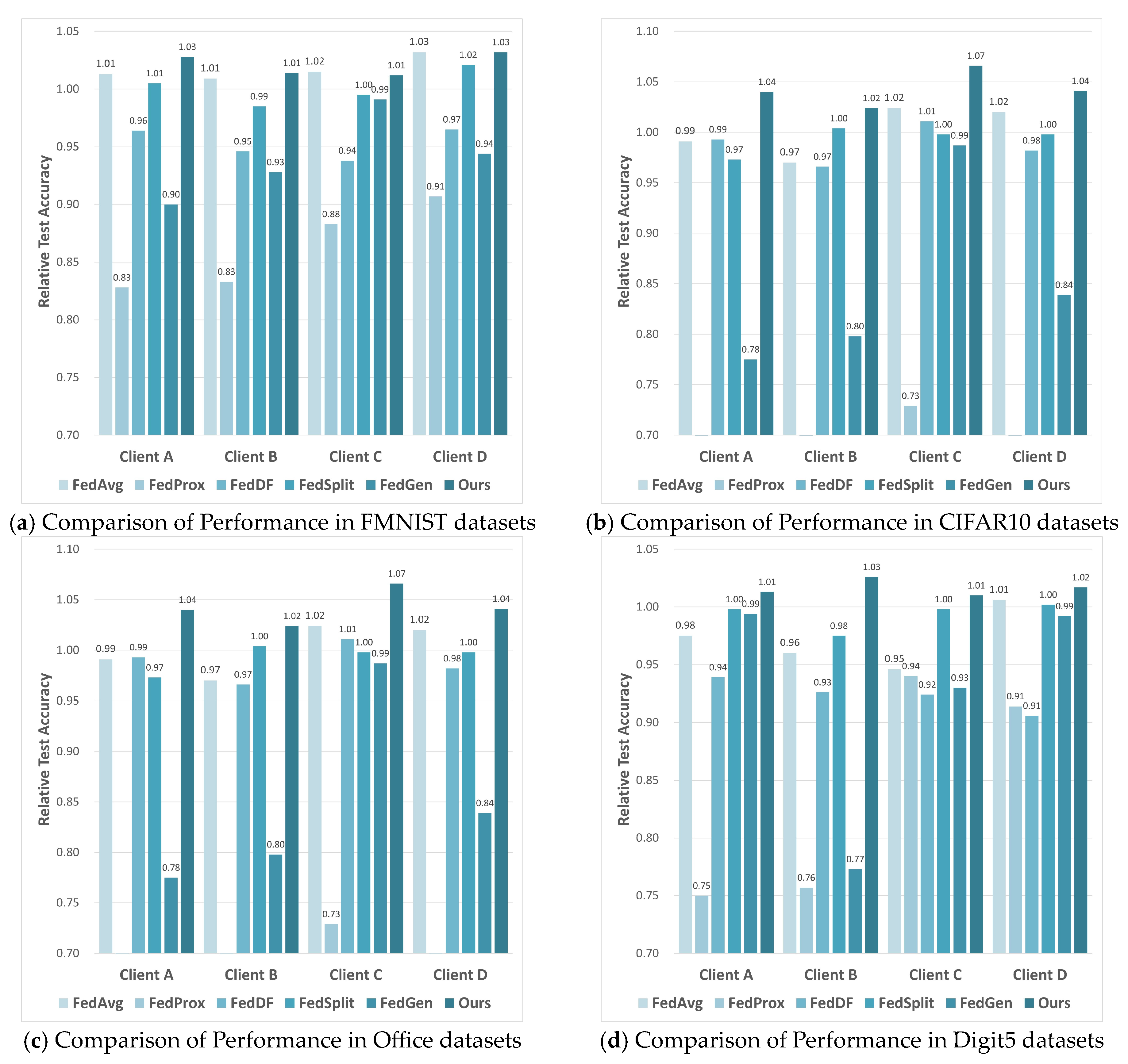
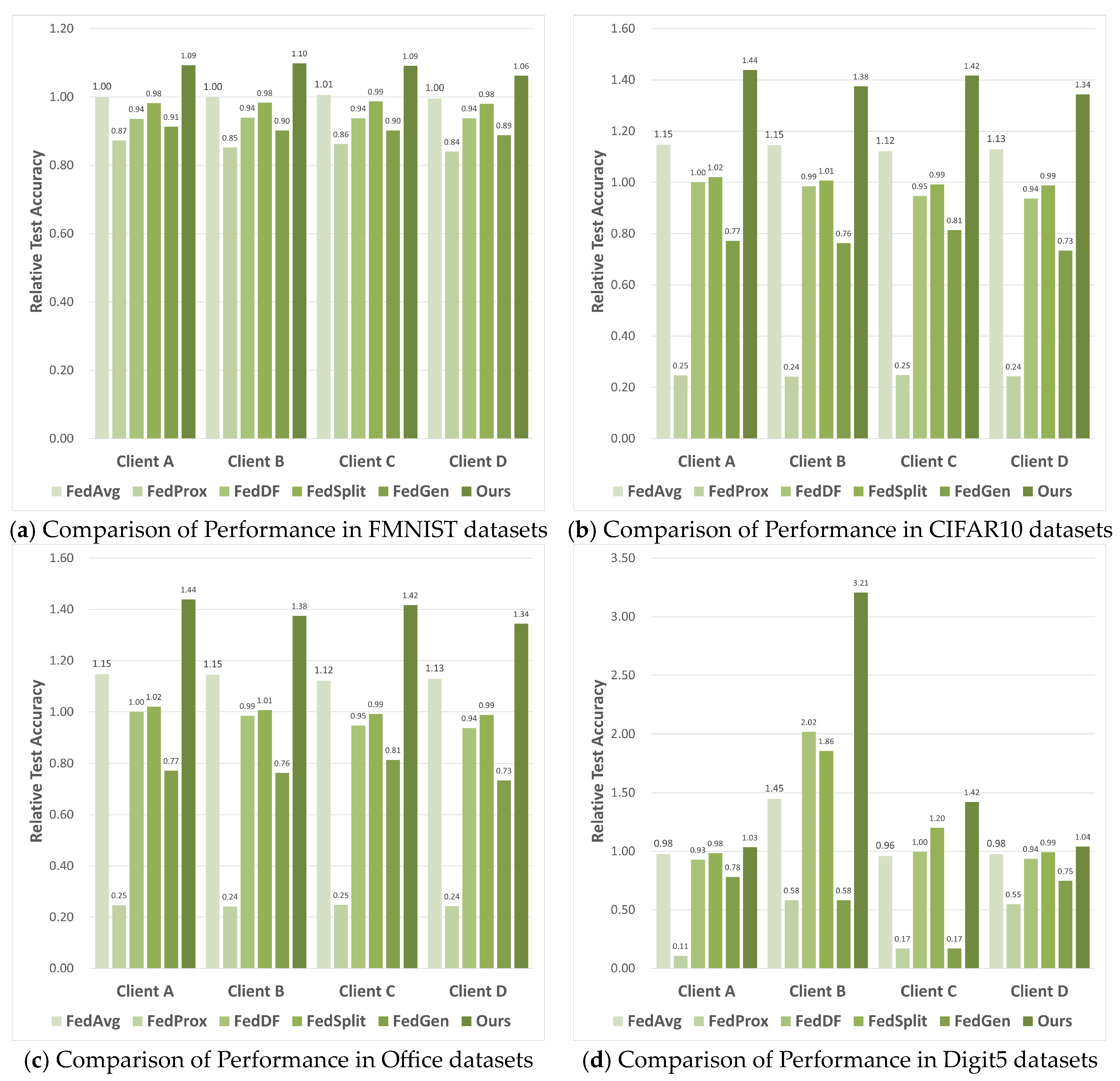
The ultimate goal of NFL-CGAN is to enhance the performance of personalized local network on local test data in each client. So, we further compare the Relative Testing Accuracy (RTA) of NFL-CGAN with five FL baseline methods on local client. The results are illustrated in Figure 3.
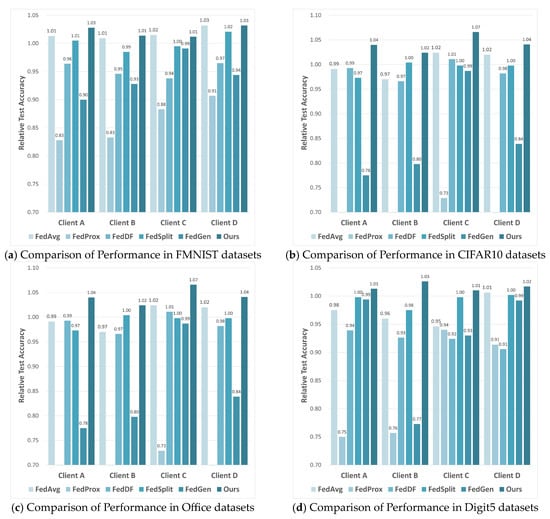
Figure 3.
The RTA results of four clients of FedAvg, FedProx, FedDF, FedSplit, FedGen and Ours on the deep residual network. (a) Comparison of Performance in FMNIST datasets (b) Comparison of Performance in CIFAR10 datasets (c) Comparison of Performance in Office datasets and (d) Comparison of Performance in Digit5 datasets.
Across four different clients, the performance of NFL-CGAN model is outstanding in both IID and non-IID scenarios. Our method outperformed the Local method on all clients. Taking the FMNIST dataset as an example, only FedAvg and our method surpass an RTA of 1 on every client, with our method slightly higher, reaching a maximum RTA of 1.03 and a minimum of 1.01, while the highest RTA of FedAvg is only 1.02. For the CIFAR10 dataset, only the RTA of our method exceed 1, reaching a maximum of 1.07 and a minimum of 1.02, with an average of 1.04. Our RTA is particularly notable on the Office dataset, reaching a maximum of 1.17 and an average of 1.13. For the Digit5 dataset, the average RTA also reaches 1.02. The suboptimal results of other models may be due to the globally averaged model being far from the local optimum of the clients.
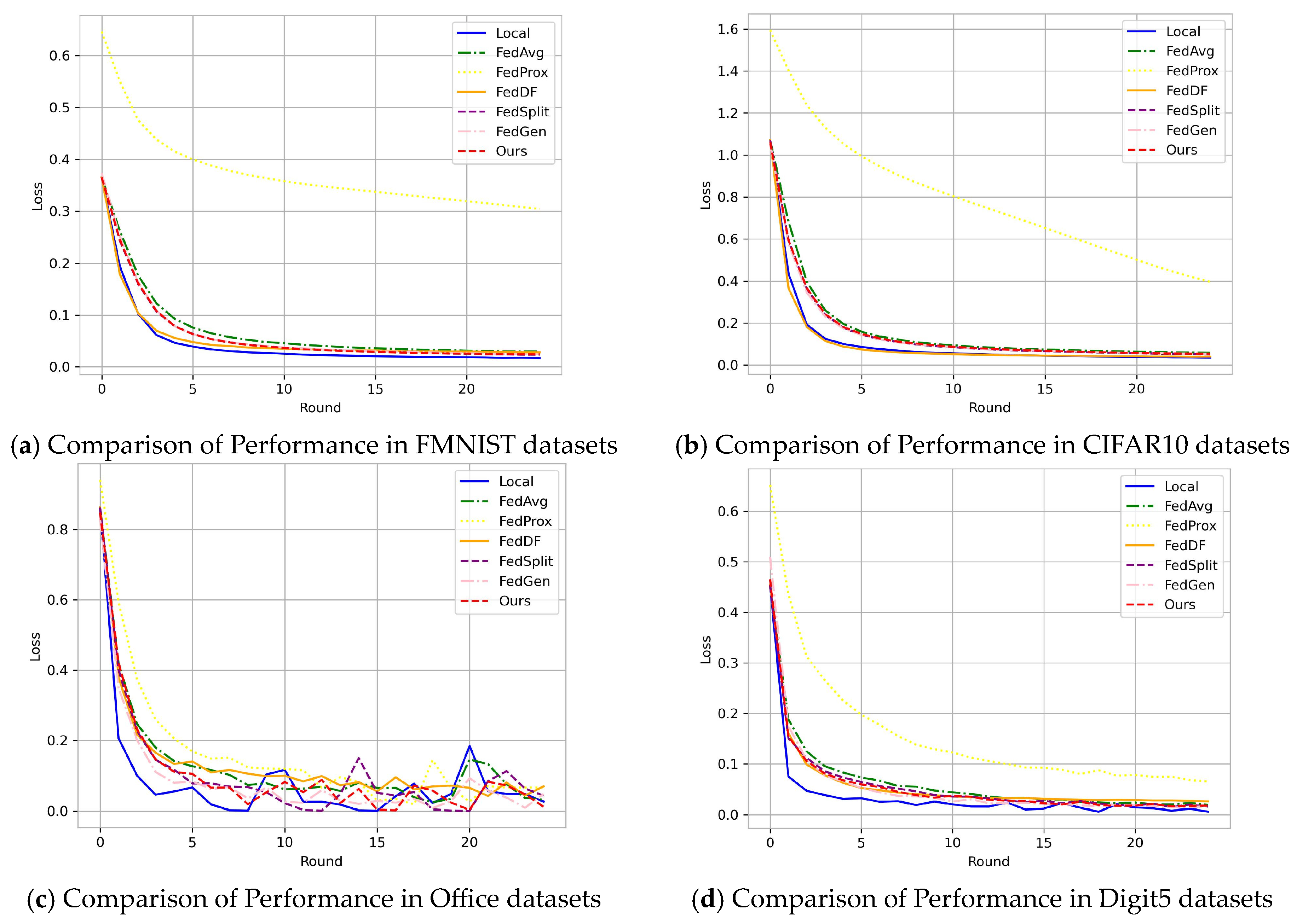
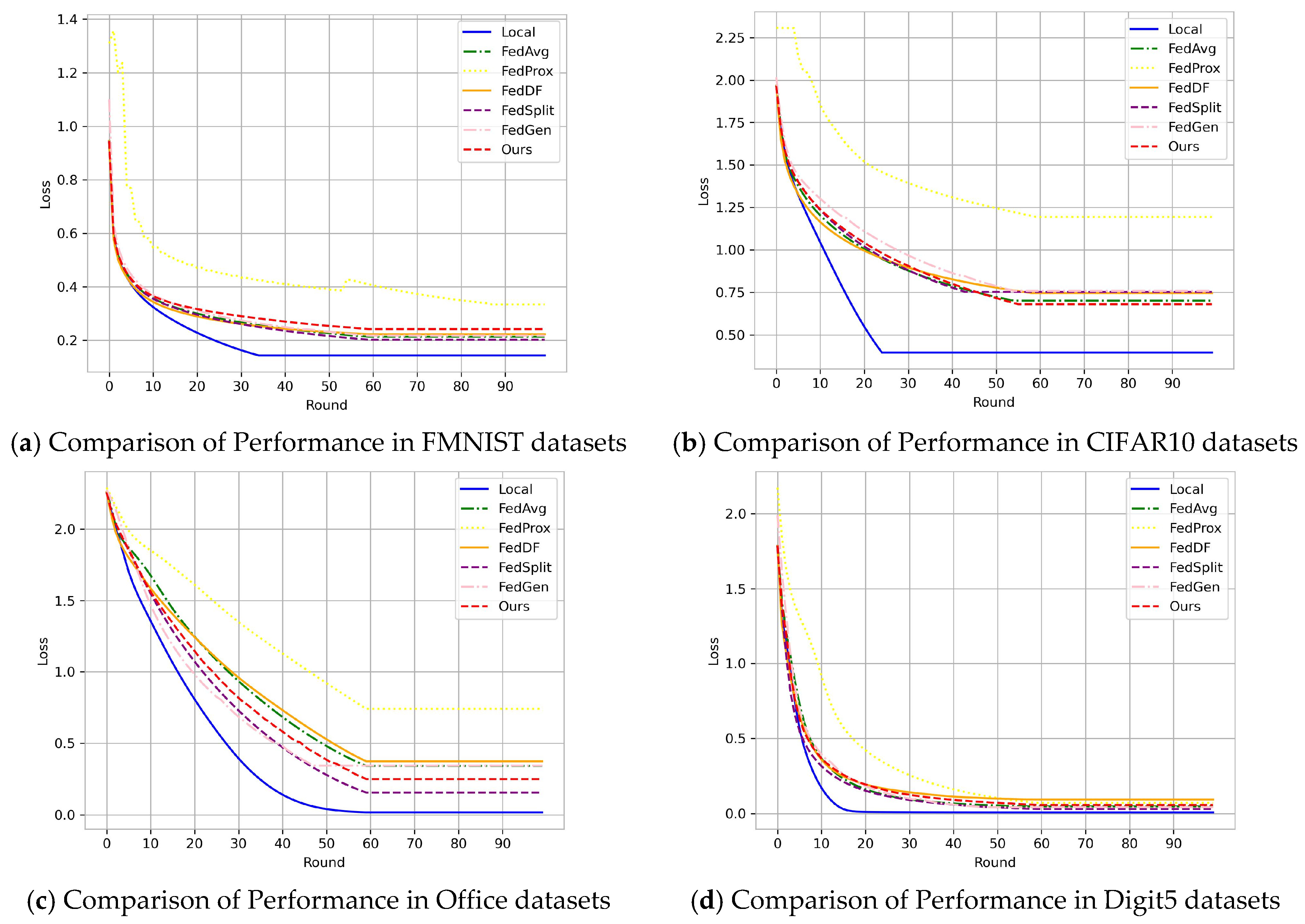
To further demonstrate the performance of the NFL-CGAN model in classification tasks, we provide training loss curves for all experiments across the four datasets. As clearly visible in Figure 4, the loss values decreased rapidly. After the fifth round of communication, our loss already drops below 0.1, reaching 0.025, 0.057, 0.006, and 0.015 on the FMNIST, CIFAR10, Office, and Digit5 datasets, respectively. It can be observed from Figure 4 that after 15 communication rounds, the classifier is stabilized. NFL-CGAN demonstrates rapid convergence and stability in a federated learning environment, which is crucial for enhancing distributed learning scenarios. This implies that in various real-world applications, models can learn from data across multiple locations more quickly, accelerating the decision-making and problem-solving process. Furthermore, reducing the number of communications and costs makes federated learning more suitable for large-scale, efficient data collaboration, expanding its application domains.
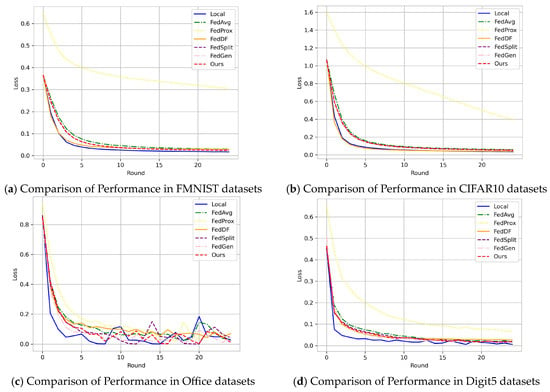
Figure 4.
Loss curves in Local, FedAvg, FedProx, FedDF, FedSplit, FedGen and Ours on the deep residual network. (a) Comparison of Performance in FMNIST datasets (b) Comparison of Performance in CIFAR10 datasets (c) Comparison of Performance in Office datasets and (d) Comparison of Performance in Digit5 datasets.
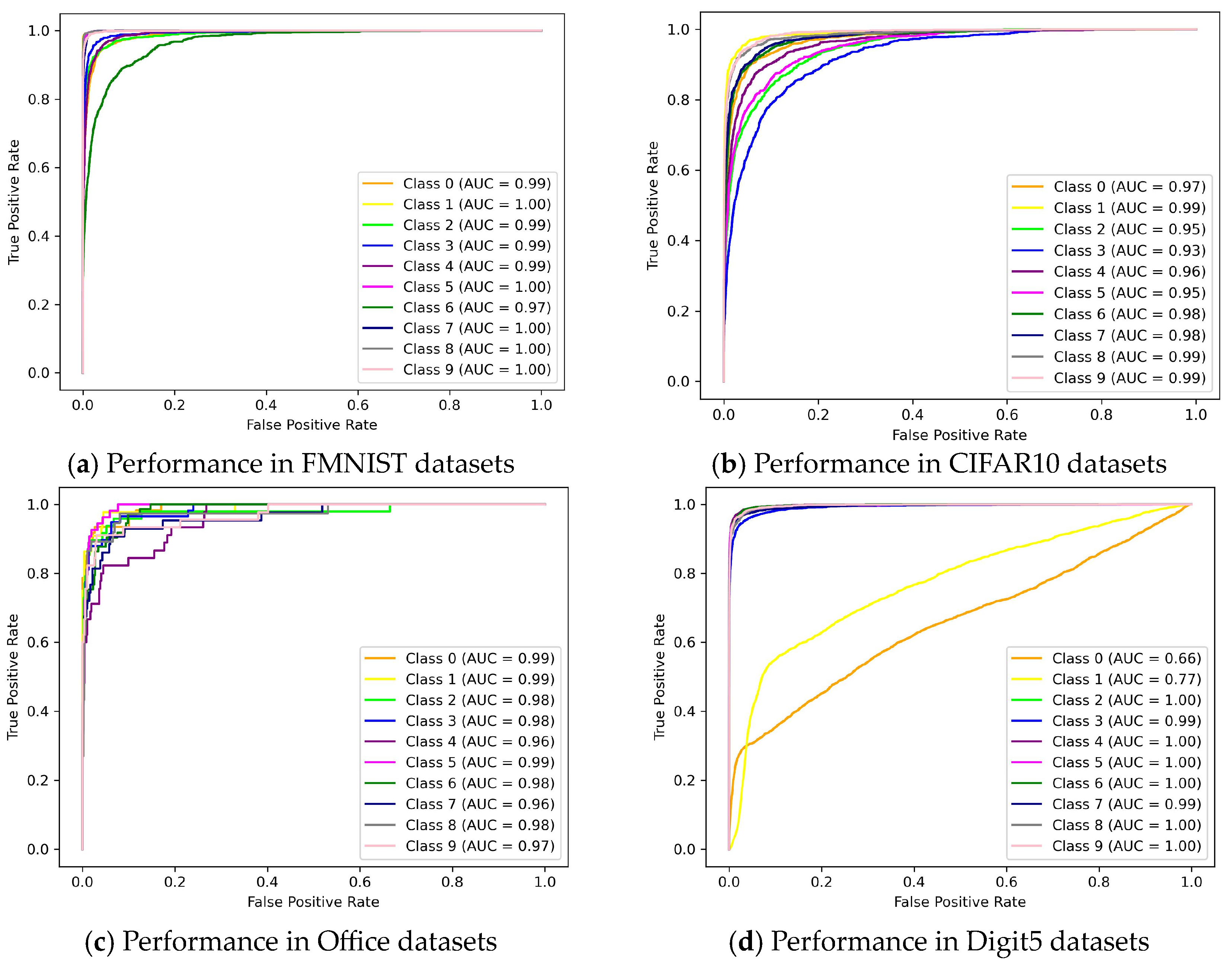
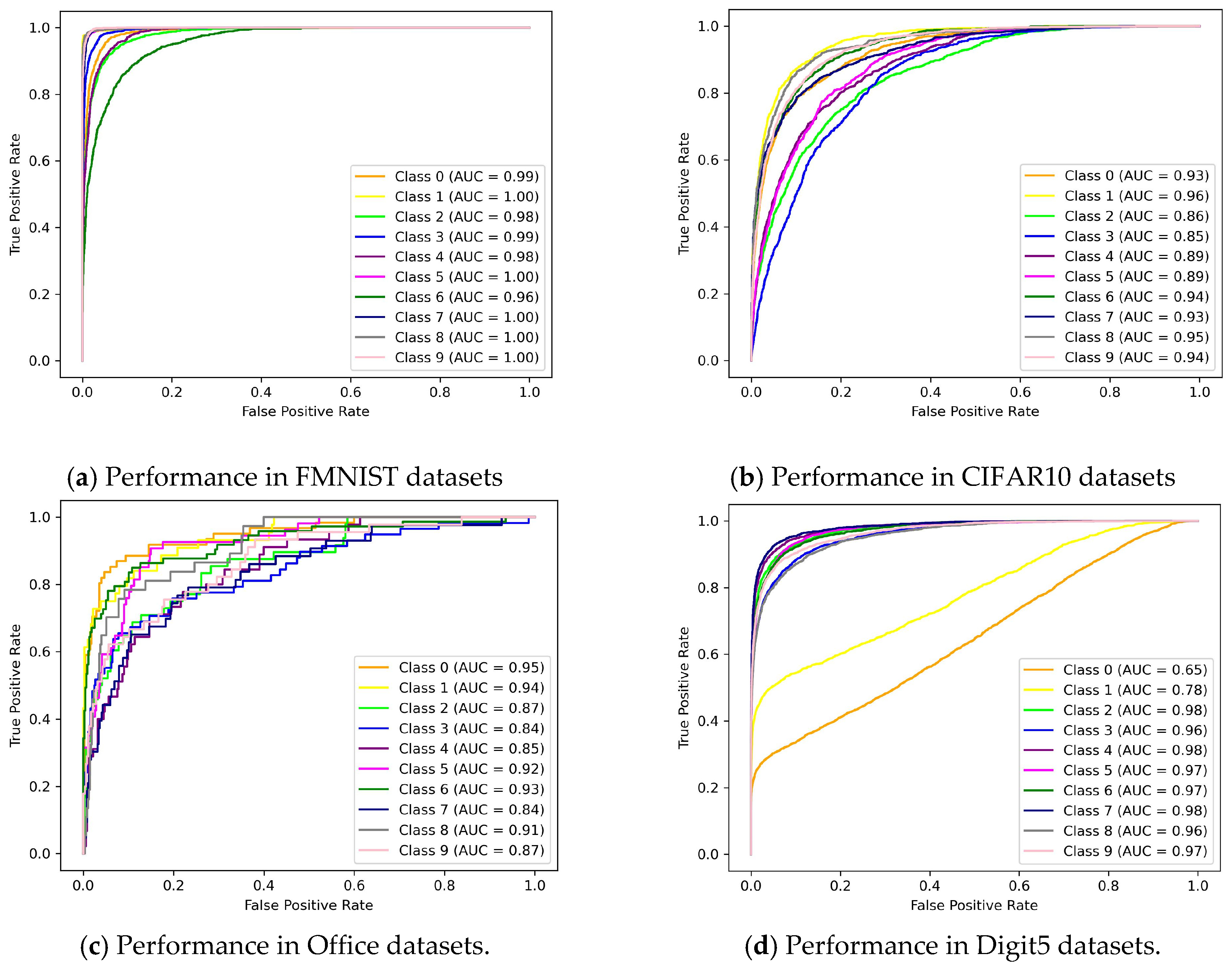
Similarly, ROC curve is depicted of NFL-CGAN model for these four datasets. From Figure 5, it is evident that in most categories across the four datasets, the AUC exceed 0.9. The AUC values for the four datasets are 0.993, 0.969, 0.941, and 0.978, respectively. These results fully demonstrate the excellent performance and robustness of NFL-CGAN model.
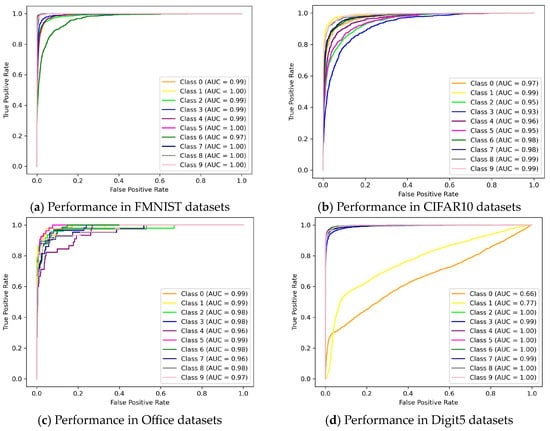
Figure 5.
ROC curves of NFL-CGAN model on the deep residual network. (a) Performance in FMNIST datasets (b) Performance in CIFAR10 datasets (c) Performance in Office datasets and (d) Performance in Digit5 datasets.
Except for FedGen, all other federated learning methods do not adopt privacy protection measures. This means that if subjected to gradient leakage attacks, client data may be entirely exposed, resulting in poor privacy protection effectiveness. We also compare FedGen and NFL-CGAN in terms of Peak Signal-to-Noise Ratio (PSNR) to assess their performance, where a lower PSNR value is better. As shown in Table 4, NFL-CGAN has the lowest PSNR values across all four datasets, generally below 13 dB, indicating superior performance. In comparison, PSNR values of FedGen exceeded 13 dB. For the FMNIST dataset, our PSNR value is 12.6 dB, 0.4 dB lower than FedGen. For CIFAR10, our PSNR is particularly outstanding at 11.2 dB. On Office and Digit5, the PSNR is 12.6 dB and 12.9 dB, respectively, slightly lower than FedGen.
Table 4.
PSNR (dB) of four datasets on the deep residual network.
5.3. Experimental Results of Convolutional Neural Network
To further validate the effectiveness of our framework, we conduct an experiment which replace Deep Residual Networks with Convolutional Neural Networks. The previously mentioned evaluation metrics are also adopted for assessment. The results indicate that even with a change in the network structure of model, our framework still perform better than other frameworks.
Under this network configuration, our framework still demonstrates a clear advantage compared to other frameworks. As shown in Figure 6, we still achieve the best results across all datasets. For the FMNIST dataset, the precision of NFL-CGAN model reaches 88.1%, 6.4% higher than the second-ranked FedDF network. For the CIFAR10 dataset, considering that other control experiments achieve less than 50% precision, our model precision is as high as 57.6%, surpassing the second-ranked FedAvg by 11.3%. Notably, for the Office dataset, the precision of NFL-CGAN model is almost more than double that of other frameworks. The second-ranked Local precision is only 39%, while our model precision reaches 66.9%, 27.9 percentage points higher. For the Digit5 dataset, the precision of NFL-CGAN model is 82.8%, 8.6% higher than the second-ranked FedDF. This fully demonstrates the stronger transferability and universality of our framework, capable of adapting to different network models.
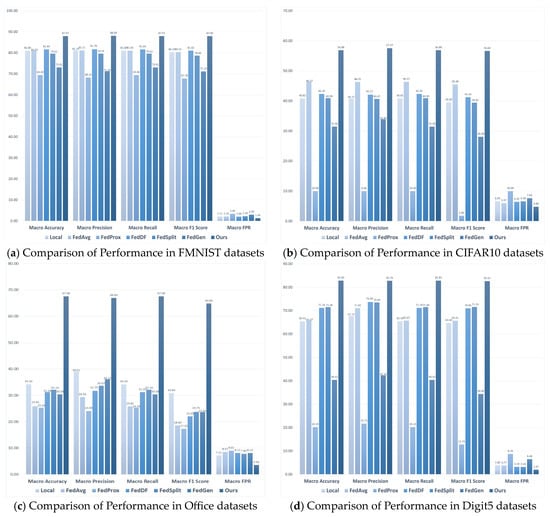
Figure 6.
The test results (%) of Local, FedAvg, FedProx, FedDF, FedSplit, FedGen, and Ours on the convolutional neural network. (a) Comparison of Performance in FMNIST datasets (b) Comparison of Performance in CIFAR10 datasets (c) Comparison of Performance in Office datasets and (d) Comparison of Performance in Digit5 datasets.
We also demonstrate the classification performance of each client in our experiments. As evident from Figure 7, our model performance remains superior across all four datasets. Notably, our performance improvement is relatively modest on IID-type data, but on non-IID data, it significantly outperforms other control experiments. As shown in Figure 7, for the FMNIST dataset, the average RTA is approximately 1.086, while the second-ranked FedAvg only achieves 1.000. None of the other four experiments surpass 1. For the CIFAR10 dataset, the RTA values for all four clients exceed 1.3, with an average of 1.394, which is still the highest. For the Office dataset, the RTA of client B reaches 2.917, which is three times our accuracy when trained locally. Clients A, C, and D have RTA values of 1.435, 2.167, and 1.673, respectively. Our results are similarly outstanding on the Digit5 dataset, with RTA of client B reaching an impressive 3.21, and the remaining three clients also surpassing 1, far superior to other control experiments. These results demonstrate that we have successfully achieved the goal of enhancing the individualized local networks for each client and verified performance on local test data.
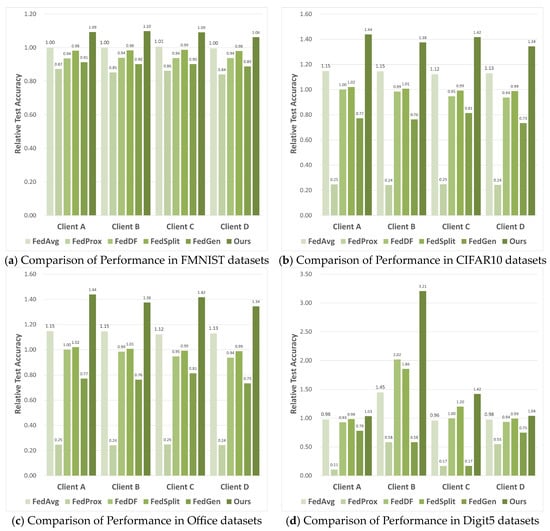
Figure 7.
The RTA of four clients in FedAvg, FedProx, FedDF, FedSplit, FedGen, and Ours on the convolutional neural network. (a) Comparison of Performance in FMNIST datasets (b) Comparison of Performance in CIFAR10 datasets (c) Comparison of Performance in Office datasets and (d) Comparison of Performance in Digit5 datasets.
From the loss curves in Figure 8, it is evident that as the network structure becomes more simplified, the convergence speed of model slows down. In comparison to the Deep Residual Networks architecture mentioned earlier, which achieved convergence around the 15th round, this Convolutional Neural Networks architecture requires approximately 60 rounds to reach the minimum loss value and fully convergence. Specifically, the loss values for the FMNIST dataset ultimately reach 0.28, 0.31 for CIFAR10, 0.27 for Office, and 0.07 for Digit5.
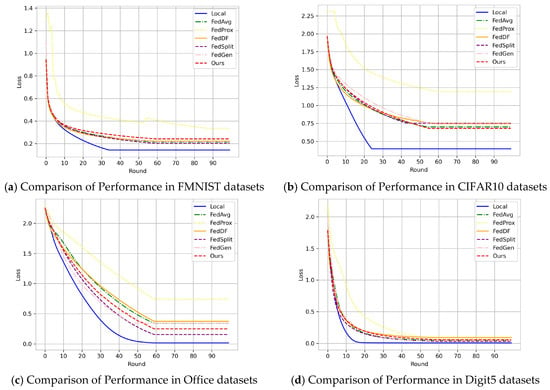
Figure 8.
Loss curves in Local, FedAvg, FedProx, FedDF, FedSplit, FedGen, and Ours on the convolutional neural network. (a) Comparison of Performance in FMNIST datasets (b) Comparison of Performance in CIFAR10 datasets (c) Comparison of Performance in Office datasets and (d) Comparison of Performance in Digit5 datasets.
Lastly, ROC curves are plotted to demonstrate the performance of NFL-CGAN. As shown in Figure 9 below. For the FMNIST dataset, the AUC values are consistently high, averaging 0.990. Similarly, in the CIFAR10, Digit5, and Office datasets, the AUC values are impressive, at 0.914, 0.892, and 0.920, respectively.
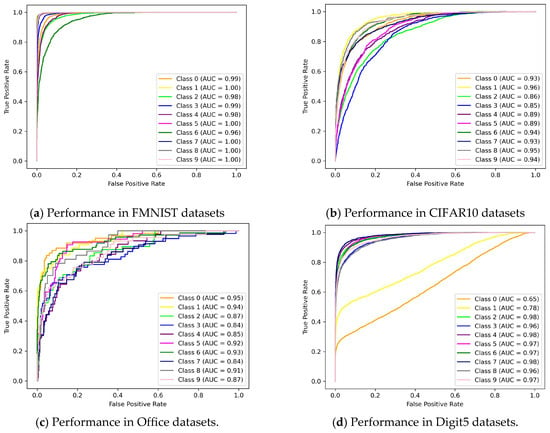
Figure 9.
ROC curves of NFL-CGAN models on the convolutional neural network. (a) Performance in FMNIST datasets (b) Performance in CIFAR10 datasets (c) Performance in Office datasets and (d) Performance in Digit5 datasets.
Regarding privacy assessment, we also compare the performance of FedGen and NFL-CGAN in terms of PSNR, where lower PSNR values indicate better privacy. As seen in Table 5, NFL-CGAN continues to have the lowest PSNR values across all four datasets. On the FMNIST dataset, our PSNR value is 11.6 dB, 1.4 dB lower than FedGen. On CIFAR10, our PSNR value is 8.3 dB. In the Office and Digit5 datasets, the PSNR values are 12.6 dB and 12.9 dB, both lower than FedGen, highlighting the superior privacy protection performance of the NFL-CGAN framework.
Table 5.
PSNR (dB) on four datasets on the convolutional neural network.
6. Conclusions
In this work, we propose a novel federated learning model aimed at preserving data privacy while maintaining excellent performance. To address the issue of poor model training performance caused by local data scarcity and uneven distribution, we introduced locally deployed CGANs to address these challenges. To mitigate the risk of gradient leakage attacks in federated learning, we employ a data extractor to perform feature extraction on the data before passing it to the classifier, avoiding direct contact between raw data and the classifier. To protect data privacy, clients only upload the model parameters of the classifier and generator to the server, thus maintaining a balance between model performance and data privacy while also reducing communication overhead. Furthermore, to enhance the model performance of local clients and protect data privacy, we employ knowledge distillation, which is more beneficial for improving the model performance of local client compared to solely using traditional federated averaging. In the future, our work will focus on addressing data heterogeneity issues to further enhance model performance.
NFL-CGAN, as a federated learning strategy, holds tremendous potential in the real world. It not only enables collaboration among multiple clients to enhance classification performance but also ensures the effective protection of sensitive or private data. This approach can find widespread applications in fields such as healthcare, finance, education, government, and market research. It assists in compliance data analysis, improves services and decision-making, all while complying with data privacy regulations and ethical requirements, providing robust support for data-driven decisions.
However, the challenges in federated learning are multifaceted. In this paper, we primarily focus on addressing issues related to sparse local data, uneven data distribution, and privacy protection, proposing corresponding solutions. Regarding other challenges in federated learning, such as the problem of some clients falling behind and issues related to client trustworthiness, further research and solutions are also needed. We aspire to combine 6G technology with federated learning through collaborative efforts to achieve more efficient and secure distributed machine learning.
Author Contributions
Conceptualization, J.H.; methodology, J.H. and Z.C.; validation, J.H., Z.C. and S.L.; formal analysis, J.H. and Z.C.; investigation, J.H.; resources, H.L.; data curation, J.H.; writing—original draft preparation, J.H.; writing—review and editing, H.L.; visualization, J.H. and S.L.; supervision, H.L.; project administration, H.L.; funding acquisition, H.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the National Natural Science Foundation of China (No. 62262019), the Hainan Provincial Natural Science Foundation of China (No. 823RC488, No. 623RC481, No. 620RC603, No.721QN0890), the Haikou Science and Technology Plan Project of China (No. 2022-016), Hainan Province Graduate Innovation Research Project (No. Qhys2023-408).
Data Availability Statement
In this study, we used several datasets for our analysis. The FMNIST dataset can be accessed via the following link: https://github.com/zalandoresearch/fashion-mnist on 1 January 2023. For the CIFAR-10 datasets, you can find them on the official website: https://www.cs.toronto.edu/~kriz/cifar.html on 1 January 2023. To access the OfficeCaltech10 dataset, please refer to the OfficeCaltech10 paper along with the associated code: Office-Caltech-10 Dataset|Papers With Code. For the Digit5 dataset, you can obtain it from the Digits-Five Datasets, which are also available on Papers with Code: Digits-Five Dataset|Papers With Code.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Voulodimos, A.; Doulamis, N.; Doulamis, A.; Protopapadakis, E. Deep Learning for Computer Vision: A Brief Review. Comput. Intell. Neurosci. 2018, 2018, 7068349. [Google Scholar] [CrossRef] [PubMed]
- Torfi, A.; Shirvani, R.A.; Keneshloo, Y.; Tavaf, N.; Fox, E.A. Natural Language Processing Advancements by Deep Learning: A Survey. arXiv 2021, arXiv:2003.01200. [Google Scholar]
- Cheng, H.-T.; Koc, L.; Harmsen, J.; Shaked, T.; Chandra, T.; Aradhye, H.; Anderson, G.; Corrado, G.; Chai, W.; Ispir, M.; et al. Wide & Deep Learning for Recommender Systems. In Proceedings of the 1st Workshop on Deep Learning for Recommender Systems, Boston, MA, USA, 15 September 2016; ACM: New York, NY, USA, 2016; pp. 7–10. [Google Scholar]
- Asgarinia, H.; Chomczyk Penedo, A.; Esteves, B.; Lewis, D. “Who Should I Trust with My Data?” Ethical and Legal Challenges for Innovation in New Decentralized Data Management Technologies. Information 2023, 14, 351. [Google Scholar] [CrossRef]
- Hoffmann, I.; Jensen, N.; Cristescu, A. Decentralized Governance for Digital Platforms-Architecture Proposal for the Mobility Market to Enhance Data Privacy and Market Diversity. In Proceedings of the 2021 IEEE 18th Annual Consumer Communications & Networking Conference (CCNC), Las Vegas, NV, USA, 9–12 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–6. [Google Scholar]
- Hard, A.; Rao, K.; Mathews, R.; Ramaswamy, S.; Beaufays, F.; Augenstein, S.; Eichner, H.; Kiddon, C.; Ramage, D. Federated Learning for Mobile Keyboard Prediction. arXiv 2019, arXiv:1811.03604. [Google Scholar]
- Aggarwal, A.; Mittal, M.; Battineni, G. Generative Adversarial Network: An Overview of Theory and Applications. Int. J. Inf. Manag. Data Insights 2021, 1, 100004. [Google Scholar] [CrossRef]
- Li, X.; Huang, K.; Yang, W.; Wang, S.; Zhang, Z. On the Convergence of FedAvg on Non-IID Data. arXiv 2020, arXiv:1907.02189. [Google Scholar]
- Yuan, X.; Li, P. On Convergence of FedProx: Local Dissimilarity Invariant Bounds, Non-Smoothness and Beyond. Adv. Neural Inf. Process. Syst. 2022, 35, 10752–10765. [Google Scholar]
- Liu, H.; Li, B.; Xie, P.; Zhao, C. Privacy-Encoded Federated Learning Against Gradient-Based Data Reconstruction Attacks. IEEE Trans. Inf. Forensics Secur. 2023, 18, 5860–5875. [Google Scholar] [CrossRef]
- He, X.; Peng, C.; Tan, W. Fast and Accurate Deep Leakage from Gradients Based on Wasserstein Distance. Int. J. Intell. Syst. 2023, 2023, 5510329. [Google Scholar] [CrossRef]
- Acar, A.; Aksu, H.; Uluagac, A.S.; Conti, M. A Survey on Homomorphic Encryption Schemes: Theory and Implementation. ACM Comput. Surv. 2019, 51, 1–35. [Google Scholar] [CrossRef]
- Dwork, C. Differential Privacy. In Automata, Languages and Programming; Bugliesi, M., Preneel, B., Sassone, V., Wegener, I., Eds.; Springer: Berlin/Heidelberg, Germany, 2006; pp. 1–12. [Google Scholar]
- Ruan, J.; Liang, G.; Zhao, J.; Qiu, J.; Dong, Z.Y. An Inertia-Based Data Recovery Scheme for False Data Injection Attack. IEEE Trans. Ind. Inform. 2022, 18, 7814–7823. [Google Scholar] [CrossRef]
- Truex, S.; Baracaldo, N.; Anwar, A.; Steinke, T.; Ludwig, H.; Zhang, R.; Zhou, Y. A Hybrid Approach to Privacy-Preserving Federated Learning. In Proceedings of the 12th ACM Workshop on Artificial Intelligence and Security, London, UK, 11 November 2019; ACM: New York, NY, USA, 2019; pp. 1–11. [Google Scholar]
- Mou, W.; Fu, C.; Lei, Y.; Hu, C. A Verifiable Federated Learning Scheme Based on Secure Multi-Party Computation. In Wireless Algorithms, Systems, and Applications; Liu, Z., Wu, F., Das, S.K., Eds.; Lecture Notes in Computer Science; Springer International Publishing: Cham, Switzerland, 2021; Volume 12938, pp. 198–209. ISBN 978-3-030-86129-2. [Google Scholar]
- Wu, X.; Zhang, Y.; Shi, M.; Li, P.; Li, R.; Xiong, N.N. An Adaptive Federated Learning Scheme with Differential Privacy Preserving. Future Gener. Comput. Syst. 2022, 127, 362–372. [Google Scholar] [CrossRef]
- Ma, J.; Naas, S.; Sigg, S.; Lyu, X. Privacy-preserving Federated Learning Based on Multi-key Homomorphic Encryption. Int. J. Intell. Syst. 2022, 37, 5880–5901. [Google Scholar] [CrossRef]
- Cao, Y.; Zhang, J.; Zhao, Y.; Su, P.; Huang, H. SRFL: A Secure & Robust Federated Learning Framework for IoT with Trusted Execution Environments. Expert Syst. Appl. 2024, 239, 122410. [Google Scholar]
- Xia, Q.; Ye, W.; Tao, Z.; Wu, J.; Li, Q. A Survey of Federated Learning for Edge Computing: Research Problems and Solutions. High-Confid. Comput. 2021, 1, 100008. [Google Scholar] [CrossRef]
- Yu, R.; Li, P. Toward Resource-Efficient Federated Learning in Mobile Edge Computing. IEEE Netw. 2021, 35, 148–155. [Google Scholar] [CrossRef]
- Khalil, K.; Khan Mamun, M.M.R.; Sherif, A.; Elsersy, M.S.; Imam, A.A.-A.; Mahmoud, M.; Alsabaan, M. A Federated Learning Model Based on Hardware Acceleration for the Early Detection of Alzheimer’s Disease. Sensors 2023, 23, 8272. [Google Scholar] [CrossRef]
- Pathak, R.; Wainwright, M.J. FedSplit: An Algorithmic Framework for Fast Federated Optimization. Adv. Neural Inf. Process. Syst. 2020, 33, 7057–7066. [Google Scholar]
- Malekmohammadi, S.; Shaloudegi, K.; Hu, Z.; Yu, Y. An Operator Splitting View of Federated Learning. arXiv 2021, arXiv:2108.05974. [Google Scholar]
- Ishwarya, T.M.; Durai, K.N. Detection of Face Mask Using Convolutional Neural Network. In Proceedings of the 2022 8th International Conference on Advanced Computing and Communication Systems (ICACCS), Coimbatore, India, 25–26 March 2022; IEEE: Piscataway, NJ, USA, 2022; Volume 1, pp. 2008–2012. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Nets. Adv. Neural Inf. Process. Syst. 2014, 1050, 10. [Google Scholar]
- Mirza, M.; Osindero, S. Conditional Generative Adversarial Nets. arXiv 2014, arXiv:1411.1784. [Google Scholar]
- Zhang, Y.; Qu, H.; Chang, Q.; Liu, H.; Metaxas, D.; Chen, C. Training Federated GANs with Theoretical Guarantees: A Universal Aggregation Approach. arXiv 2021, arXiv:2102.04655. [Google Scholar]
- Hardy, C.; Le Merrer, E.; Sericola, B. Md-Gan: Multi-Discriminator Generative Adversarial Networks for Distributed Datasets. In Proceedings of the 2019 IEEE International Parallel and Distributed Processing Symposium (IPDPS), Rio de Janeiro, Brazil, 20–24 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 866–877. [Google Scholar]
- Gan, S.; Lian, X.; Wang, R.; Chang, J.; Liu, C.; Shi, H.; Zhang, S.; Li, X.; Sun, T.; Jiang, J.; et al. BAGUA: Scaling up Distributed Learning with System Relaxations. arXiv 2021, arXiv:2107.01499. [Google Scholar] [CrossRef]
- Liu, X.; Hsieh, C.-J. Rob-Gan: Generator, Discriminator, and Adversarial Attacker. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11234–11243. [Google Scholar]
- Cao, L.; Li, K.; Du, K.; Guo, Y.; Song, P.; Wang, T.; Fu, C. FL-GAN: Feature Learning Generative Adversarial Network for High-Quality Face Sketch Synthesis. IEICE Trans. Fundam. Electron. Commun. Comput. Sci. 2021, E104.A, 1389–1402. [Google Scholar] [CrossRef]
- Gou, J.; Yu, B.; Maybank, S.J.; Tao, D. Knowledge Distillation: A Survey. Int. J. Comput. Vis. 2021, 129, 1789–1819. [Google Scholar] [CrossRef]
- Lin, T.; Kong, L.; Stich, S.U.; Jaggi, M. Ensemble Distillation for Robust Model Fusion in Federated Learning. Adv. Neural Inf. Process. Syst. 2020, 33, 2351–2363. [Google Scholar]
- Venkateswaran, P.; Isahagian, V.; Muthusamy, V.; Venkatasubramanian, N. FedGen: Generalizable Federated Learning for Se-quential Data. arXiv 2023, arXiv:2211.01914. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).