
Using a Bunch Testing Time Augmentations to Detect Rice Plants Based on Aerial Photography




Abstract
1. Introduction
- We enlarged the scale of CSL-YOLO and incorporated random affine operations during training, empowering Enhanced CSL-YOLO to effectively adapt to dynamic changes in agricultural landscapes.
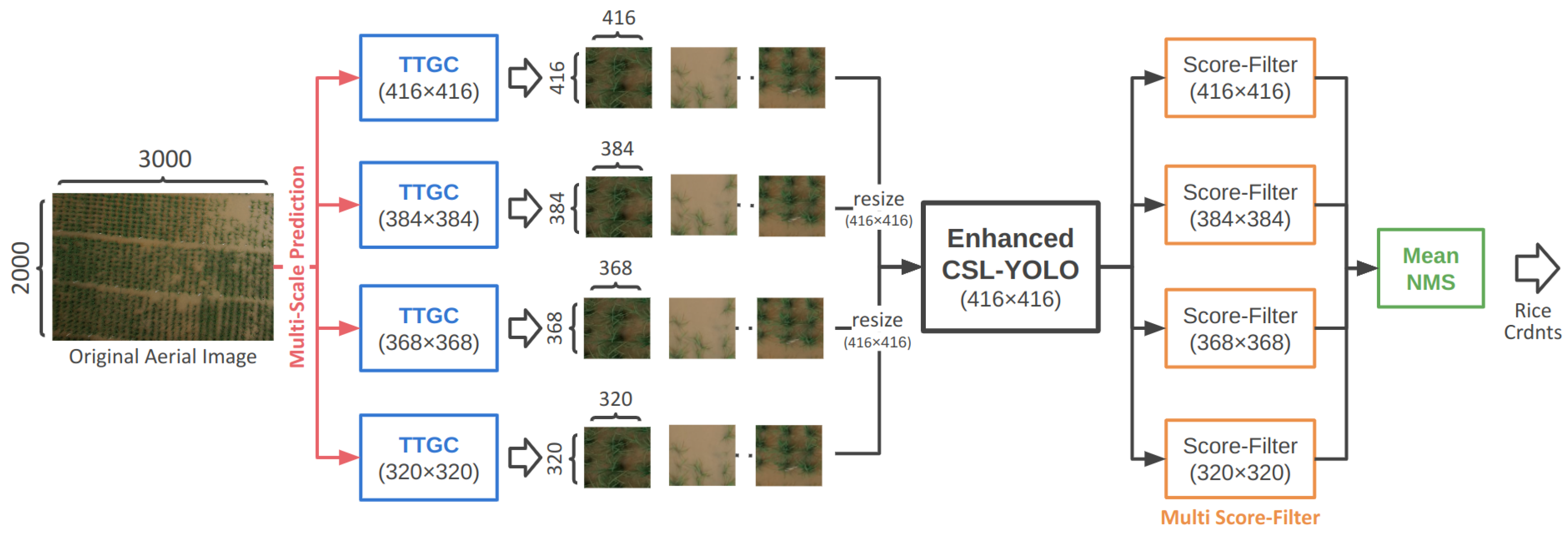
- Confronted with high-resolution aerial images and rice plants exhibiting a substantial size disparity, we introduced a tailored grid cropping method, namely testing time grid cropping (TTGC), which significantly elevated the performance of the detector during the testing phase.
- Beyond TTGC, we integrated additional data augmentation techniques, including multi-scale prediction (MSP), mean-NMS, and multi score-filter (MSF), during the testing phase. These enhancements further bolstered the capability of enhanced CSL-YOLO to detect densely packed small rice plants.
2. Related Work
2.1. Machine Learning in Agricultural Applications
2.2. Two-Stage Object Detection
2.3. One-Stage Object Detection
3. Proposed Approaches
3.1. Training Data Preprocessing
3.1.1. Random Cropping
3.1.2. Semi-Supervised Labeling Bounding Box
3.1.3. Random Affine Operations for Training
3.2. Enhancing CSL-YOLO for Accurate Detection
3.2.1. Bigger Backbone
3.2.2. Bigger FPN
3.2.3. Fully Soft-NMS
3.3. Testing Time Augmentation (TTA)
3.3.1. Testing Time Grid Crop (TTGC)
3.3.2. Multi-Scale Prediction (MSP)
3.3.3. Mean-NMS for Root Coordinate
3.3.4. Multi Score-Filter (MSF)
4. Experiments
4.1. Ablation Studies
4.1.1. Enhanced CSL-YOLO
4.1.2. Testing Time Augmentation (TTA)
4.2. Compared to Other Methods
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| CNN | Convolutional Neural Network |
| FPN | Feature Pyramid Network |
| FLOPs | Floating Point Operations |
| NMS | Non-Maximum Suppression |
| TTA | Testing Time Augumentation |
| TTGC | Testing Time Grid Cropping |
| MSP | Multi-SCale Prediction |
| MSF | Multi Score-Filter |
References
- Bargoti, S.; Underwood, J.P. Image segmentation for fruit detection and yield estimation in apple orchards. J. Field Robot. 2017, 34, 1039–1060. [Google Scholar] [CrossRef]
- Sa, I.; Ge, Z.; Dayoub, F.; Upcroft, B.; Perez, T.; McCool, C. Deepfruits: A fruit detection system using deep neural networks. Sensors 2016, 16, 1222. [Google Scholar] [CrossRef]
- Liu, X.; Chen, S.W.; Liu, C.; Shivakumar, S.S.; Das, J.; Taylor, C.J.; Underwood, J.; Kumar, V. Monocular camera based fruit counting and mapping with semantic data association. IEEE Robot. Autom. Lett. 2019, 4, 2296–2303. [Google Scholar] [CrossRef]
- McCool, C.; Perez, T.; Upcroft, B. Mixtures of lightweight deep convolutional neural networks: Applied to agricultural robotics. IEEE Robot. Autom. Lett. 2017, 2, 1344–1351. [Google Scholar] [CrossRef]
- Mortensen, A.K.; Dyrmann, M.; Karstoft, H.; Jørgensen, R.N.; Gislum, R. Semantic segmentation of mixed crops using deep convolutional neural network. In Proceedings of the CIGR-AgEng Conference, Aarhus, Denmark, 26–29 June 2016; pp. 26–29. [Google Scholar]
- Ribera, J.; Guera, D.; Chen, Y.; Delp, E.J. Locating objects without bounding boxes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6479–6489. [Google Scholar]
- Li, Y.; Zhang, X.; Chen, D. Csrnet: Dilated convolutional neural networks for understanding the highly congested scenes. In Proceedings of the IEEE conference on computer vision and pattern recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 1091–1100. [Google Scholar]
- Haug, S.; Michaels, A.; Biber, P.; Ostermann, J. Plant classification system for crop/weed discrimination without segmentation. In Proceedings of the IEEE Winter Conference on Applications of Computer Vision, Steamboat Springs, CO, USA, 24–26 March 2014; pp. 1142–1149. [Google Scholar]
- Lottes, P.; Hörferlin, M.; Sander, S.; Stachniss, C. Effective vision-based classification for separating sugar beets and weeds for precision farming. J. Field Robot. 2017, 34, 1160–1178. [Google Scholar] [CrossRef]
- Lottes, P.; Hoeferlin, M.; Sander, S.; Müter, M.; Schulze, P.; Stachniss, L.C. An effective classification system for separating sugar beets and weeds for precision farming applications. In Proceedings of the 2016 IEEE International Conference on Robotics and Automation (ICRA), Stockholm, Sweden, 16–21 May 2016; pp. 5157–5163. [Google Scholar]
- Chen, S.W.; Shivakumar, S.S.; Dcunha, S.; Das, J.; Okon, E.; Qu, C.; Taylor, C.J.; Kumar, V. Counting apples and oranges with deep learning: A data-driven approach. IEEE Robot. Autom. Lett. 2017, 2, 781–788. [Google Scholar] [CrossRef]
- Potena, C.; Nardi, D.; Pretto, A. Fast and accurate crop and weed identification with summarized train sets for precision agriculture. In Proceedings of the Intelligent Autonomous Systems 14: Proceedings of the 14th International Conference IAS-14 14, Shanghai, China, 10 February 2017; Springer: Berlin/Heidelberg, Germany, 2017; pp. 105–121. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster r-cnn: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef] [PubMed]
- Zhang, Y.M.; Lee, C.C.; Hsieh, J.W.; Fan, K.C. CSL-YOLO: A Cross-Stage Lightweight Object Detector with Low FLOPs. In Proceedings of the 2022 IEEE International Symposium on Circuits and Systems (ISCAS), Austin, TX, USA, 27 May–1 June 2022; pp. 2730–2734. [Google Scholar]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- He, K.; Gkioxari, G.; Dollár, P.; Girshick, R. Mask r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2961–2969. [Google Scholar]
- Qin, Z.; Li, Z.; Zhang, Z.; Bao, Y.; Yu, G.; Peng, Y.; Sun, J. ThunderNet: Towards real-time generic object detection on mobile devices. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6718–6727. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single shot multibox detector. In Proceedings of the European Conference on Computer Vision, Amsterdam, The Netherlands, 11–14 October 2016; Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Lin, T.Y.; Goyal, P.; Girshick, R.; He, K.; Dollár, P. Focal loss for dense object detection. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2980–2988. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Lin, T.Y.; Maire, M.; Belongie, S.; Hays, J.; Perona, P.; Ramanan, D.; Dollár, P.; Zitnick, C.L. Microsoft coco: Common objects in context. In Proceedings of the Computer Vision–ECCV 2014: 13th European Conference, Zurich, Switzerland, 6–12 September 2014; Springer: Berlin/Heidelberg, Germany, 2014; pp. 740–755. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 1580–1589. [Google Scholar]
- Wang, C.Y.; Liao, H.Y.M.; Wu, Y.H.; Chen, P.Y.; Hsieh, J.W.; Yeh, I.H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops, Seattle, WA, USA, 14–19 June 2020; pp. 390–391. [Google Scholar]
- Wang, K.; Liew, J.H.; Zou, Y.; Zhou, D.; Feng, J. Panet: Few-shot image semantic segmentation with prototype alignment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 9197–9206. [Google Scholar]
- Zhang, Y.M.; Hsieh, J.W.; Lee, C.C.; Fan, K.C. SFPN: Synthetic FPN for object detection. In Proceedings of the 2022 IEEE International Conference on Image Processing (ICIP), Bordeaux, France, 16–19 October 2022; pp. 1316–1320. [Google Scholar]
- Tan, M.; Pang, R.; Le, Q.V. Efficientdet: Scalable and efficient object detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020; pp. 10781–10790. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Singh, A.; Bhambhu, Y.; Buckchash, H.; Gupta, D.K.; Prasad, D.K. Latent Graph Attention for Enhanced Spatial Context. arXiv 2023, arXiv:2307.04149. [Google Scholar]
- Chen, X.; He, K. Exploring simple siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 15750–15758. [Google Scholar]
- Dwibedi, D.; Aytar, Y.; Tompson, J.; Sermanet, P.; Zisserman, A. With a little help from my friends: Nearest-neighbor contrastive learning of visual representations. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 9588–9597. [Google Scholar]
- Biswas, M.; Buckchash, H.; Prasad, D.K. pNNCLR: Stochastic Pseudo Neighborhoods for Contrastive Learning based Unsupervised Representation Learning Problems. arXiv 2023, arXiv:2308.06983. [Google Scholar]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. mixup: Beyond empirical risk minimization. arXiv 2017, arXiv:1710.09412. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning. PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 6105–6114. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Backbone | Filters | R | MFLOPs | F1(%) |
|---|---|---|---|---|
| CSL-Bone | 112 | 3 | 1441 | 79.3 |
| EfficientNet-B1 | 112 | 3 | 2112 | 79.6 |
| EfficientNet-B1 | 128 | 3 | 2250 | 79.8 |
| EfficientNet-B1 | 128 | 4 | 2434 | 80.3 |
| EfficientNet-B1 | 128 | 5 | 2618 | 80.3 |
| EfficientNet-B3 | 144 | 5 | 3986 | 80.1 |
| TTGC | MSP | Mean-NMS | MSF | F1(%) |
|---|---|---|---|---|
| - | - | - | - | 79.3 |
| - | - | - | - | 80.3 |
| ✓ | - | - | - | 90.6 |
| - | ✓ | - | - | 91.4 |
| - | - | ✓ | - | 80.2 |
| ✓ | ✓ | - | - | 92.4 |
| ✓ | - | ✓ | - | 90.6 |
| ✓ | ✓ | ✓ | - | 92.8 |
| ✓ | ✓ | ✓ | ✓ | 93.0 |
| F1(%) | |
|---|---|
| U-Net | 82.0 |
| U-Net w/ EfficientNet-B1 | 83.0 |
| U-Net w/ EfficientNet-B3 | 85.0 |
| U-Net w/ EfficientNet-B7 | 88.2 |
| CSRNet | 89.6 |
| Ensembled CSRNet | 92.0 |
| Enhanced CSL-YOLO | 86.2 |
| Enhanced CSL-YOLO w/ TTA | 94.2 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Zhang, Y.-M.; Chuang, C.-H.; Lee, C.-C.; Fan, K.-C. Using a Bunch Testing Time Augmentations to Detect Rice Plants Based on Aerial Photography. Electronics 2024, 13, 632. https://doi.org/10.3390/electronics13030632
Zhang Y-M, Chuang C-H, Lee C-C, Fan K-C. Using a Bunch Testing Time Augmentations to Detect Rice Plants Based on Aerial Photography. Electronics. 2024; 13(3):632. https://doi.org/10.3390/electronics13030632
Chicago/Turabian StyleZhang, Yu-Ming, Chi-Hung Chuang, Chun-Chieh Lee, and Kuo-Chin Fan. 2024. "Using a Bunch Testing Time Augmentations to Detect Rice Plants Based on Aerial Photography" Electronics 13, no. 3: 632. https://doi.org/10.3390/electronics13030632
APA StyleZhang, Y.-M., Chuang, C.-H., Lee, C.-C., & Fan, K.-C. (2024). Using a Bunch Testing Time Augmentations to Detect Rice Plants Based on Aerial Photography. Electronics, 13(3), 632. https://doi.org/10.3390/electronics13030632