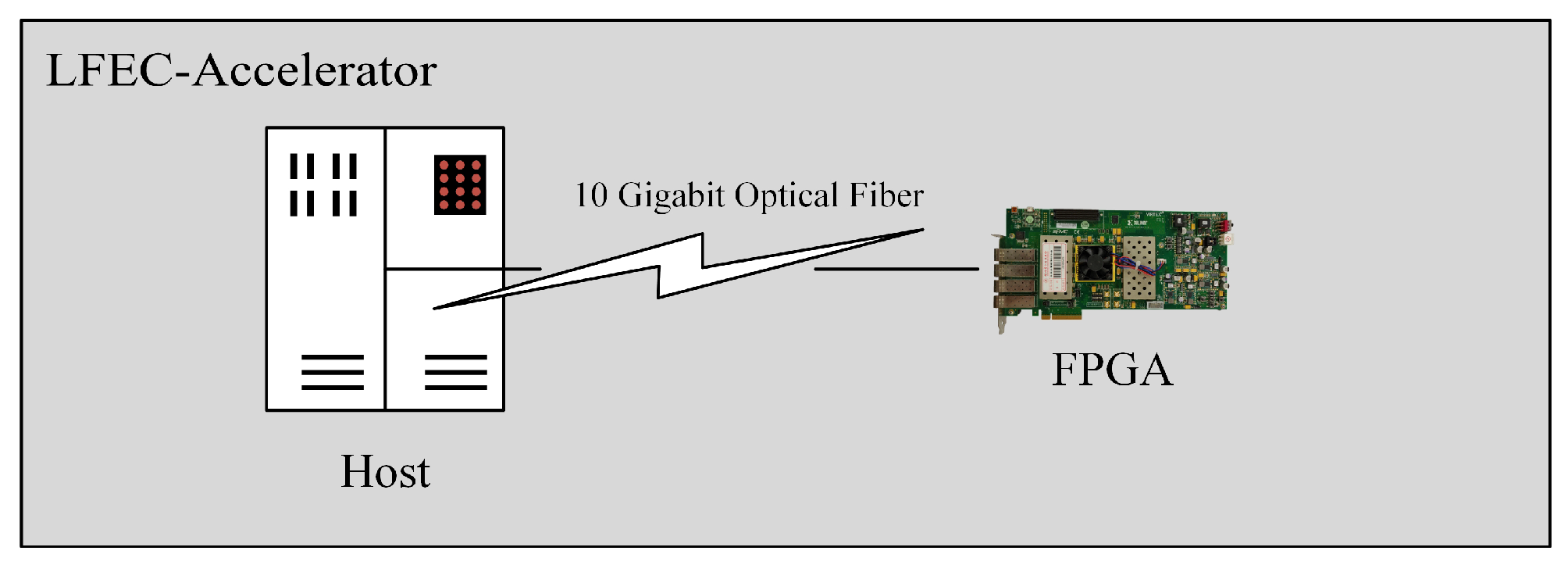
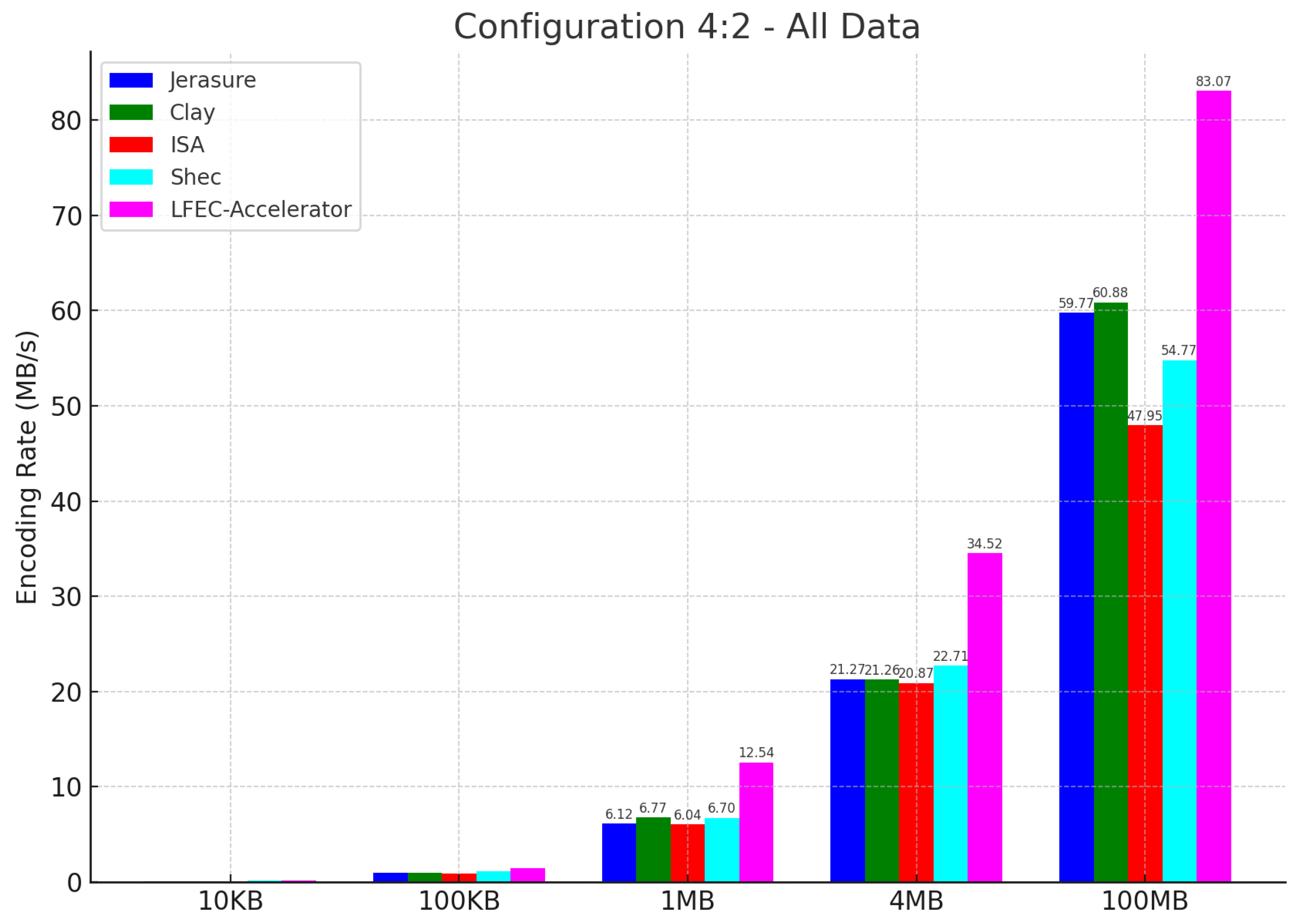
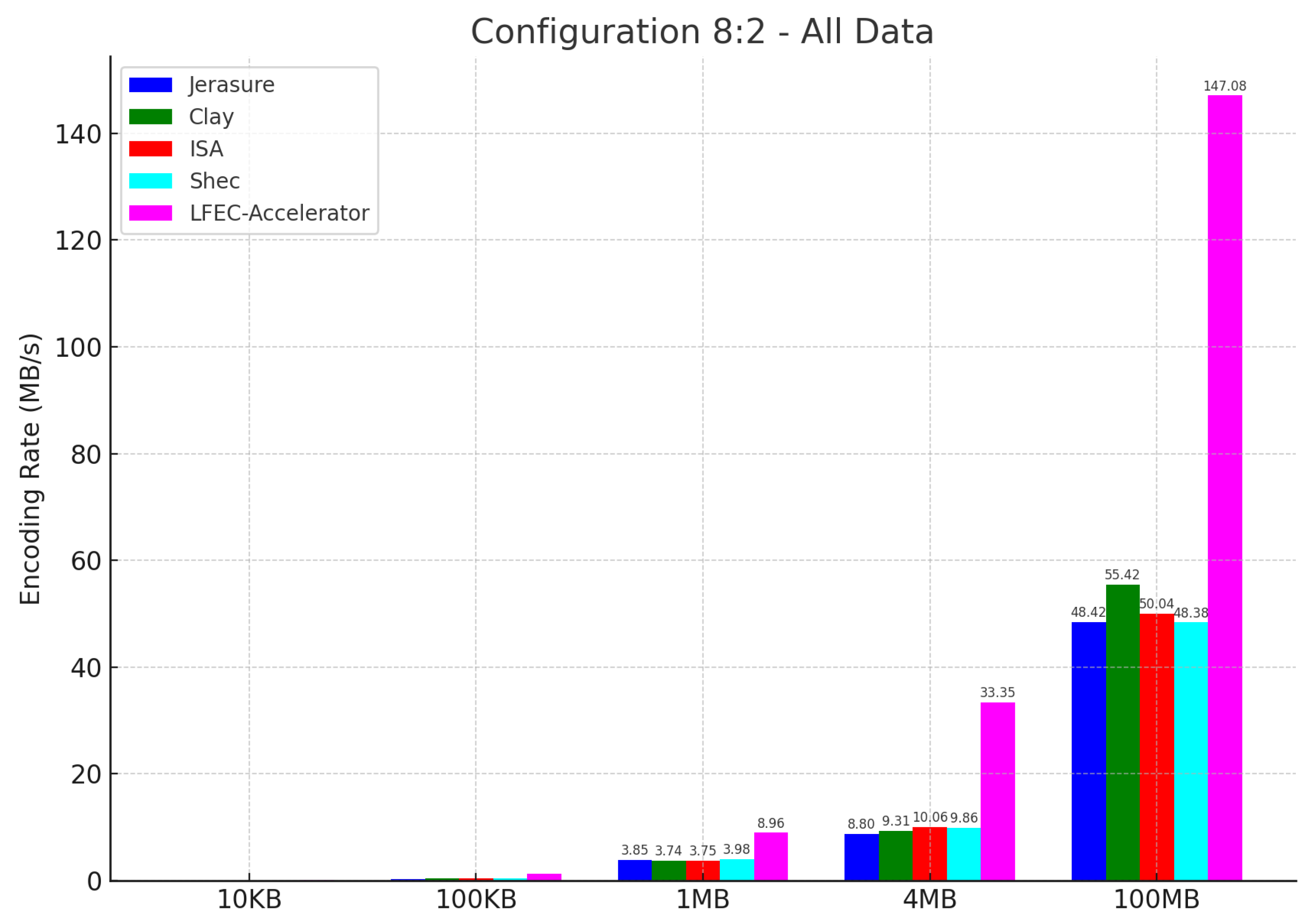
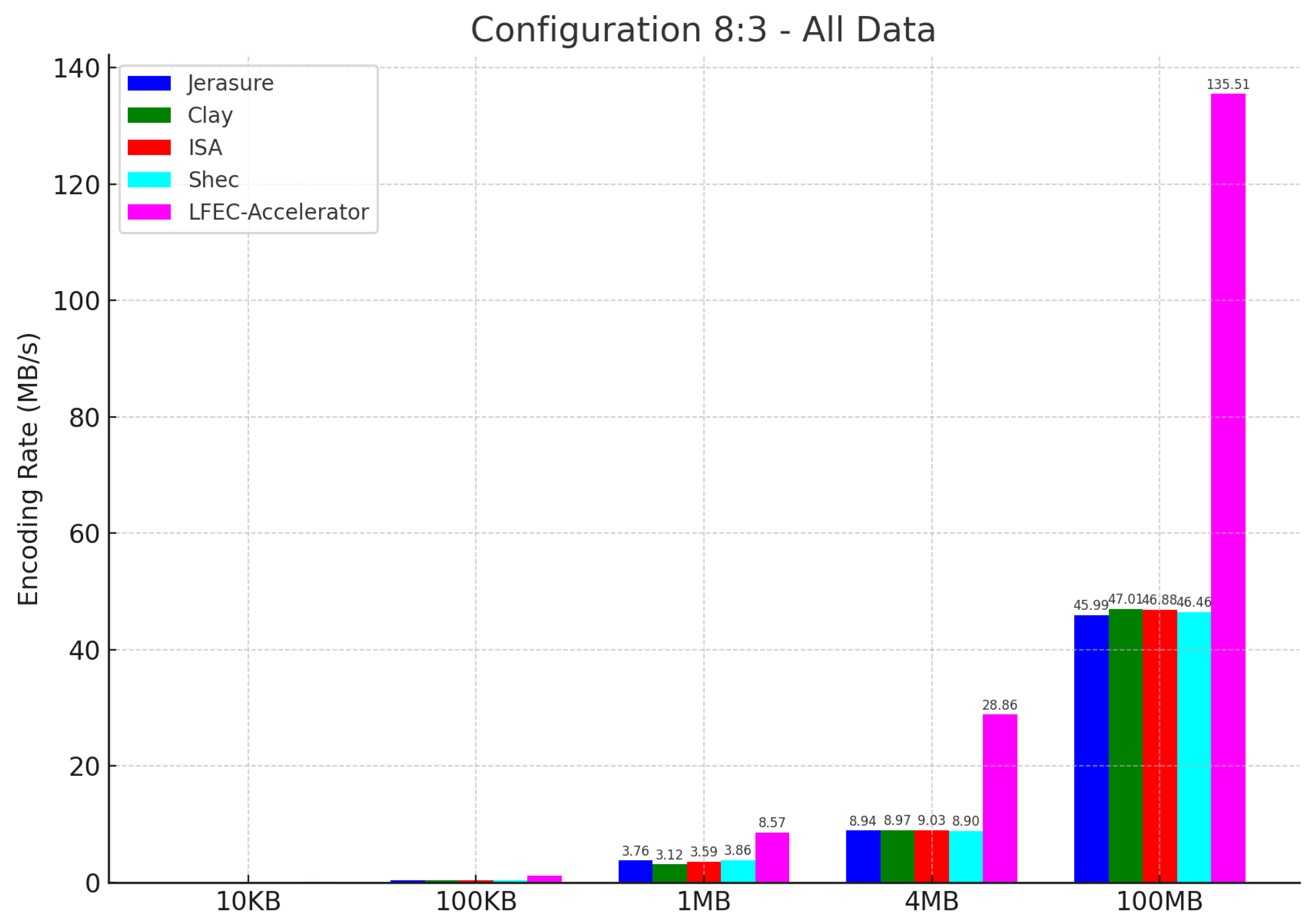
In this section, we delve deep into the hardware acceleration layer. This layer serves as the heart of the FPGA accelerator, encompassing the high-performance data transfer module and the erasure coding accelerator.
3.4.1. Design and Implementation of Data Transfer Module
Modular design plays a pivotal role in achieving high-performance FPGA designs. Such an approach not only enhances design reusability and maintainability but also simplifies the design process, thereby boosting design efficiency. Our work leverages the Ethernet and 10G optical communication modules to establish a high-performance data transfer system.
Figure 5 shows the connection between the XPAK optical module core and the XAUI (10G Attachment Unit Interface) core. In the diagram, the 10G Ethernet MAC core handles the MAC layer of the Ethernet frame, including sending and receiving frames and frame validation. The XAUI core deals with the physical layer interface of the 10G Ethernet, including encoding and decoding of signals and link establishment and maintenance. The XPAK optical module converts electrical signals to optical signals for transmission in fiber-optic networks. Specifically, when the 10G Ethernet MAC core wishes to send an Ethernet frame, it sends the data and control information of the frame to the XAUI core. The XAUI core encodes this information into 10G Ethernet physical layer signals and passes it to the XPAK optical module via the XGMII interface. The XPAK optical module then converts these electrical signals to optical signals and transmits them via the fiber-optic network. On the receiving end, when the XPAK optical module receives optical signals it converts them to electrical signals and sends them to the XAUI core via the XGMII interface. The XAUI core then decodes these signals back to Ethernet frame data and control information and sends them to the 10G Ethernet MAC core. The 10G Ethernet MAC core then processes this information, completing the frame reception. Hence, the 10G Ethernet MAC core, XAUI core and XPAK optical module work together to transmit and receive Ethernet frames and to convert between electrical and optical signals.
In
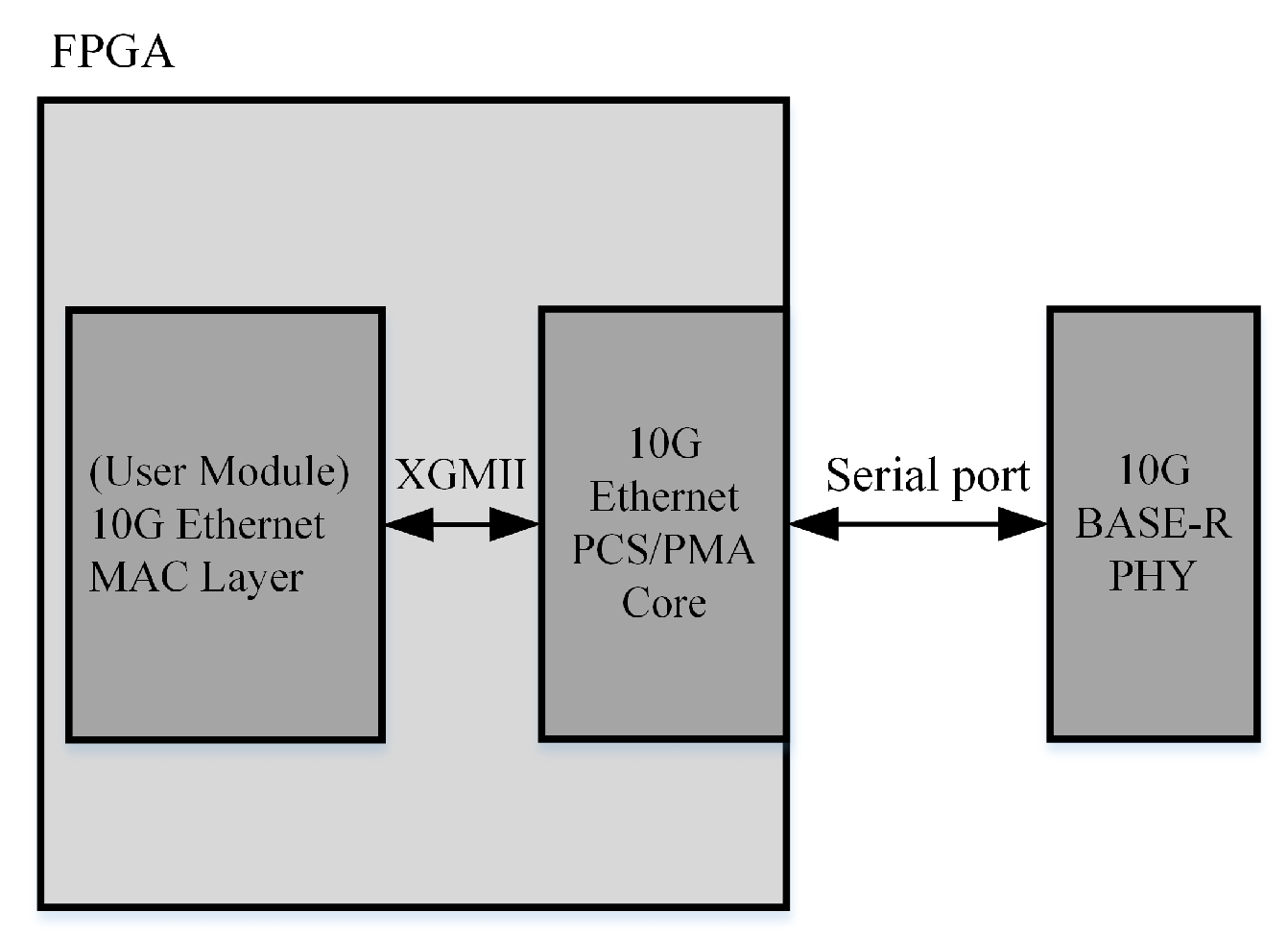
Figure 6, we see the situation when the 10G Ethernet MAC core is connected to the 10G Ethernet PCS/PMA core. In this figure, we observe the FPGA’s user logic and serial interface. The user module is part of the FPGA and can be programmed for specific tasks like data or signal processing. The serial interface is used for communications with external devices, such as network devices or other FPGAs.
In
Figure 6, the connection between the user logic and serial interface is through the 10G Ethernet MAC core. This core is a hardware module designed for 10G Ethernet communication. It handles the transmission and reception of data and other Ethernet-related tasks. The figure also shows a 10G BASE-R PHY (developed for fiber optic medium). This device is responsible for the physical layer communication, converting electrical signals into optical signals for transmission in fiber-optic networks. In this system, the 10G BASE-R PHY connects to the FPGA’s serial interface, converting electrical signals from the FPGA into optical signals and vice versa. These signals are then sent to the user logic through the 10G Ethernet MAC core. Overall,
Figure 6 describes a system using FPGA, a 10G Ethernet MAC core and 10G BASE-R PHY for 10G Ethernet communication, where the 10G Ethernet MAC core is central, communicating with the other components for data transmission and reception. Next, the details of data reception and transmission will be elaborated upon.
Before the FPGA receives data from the Physical Layer (PHY), several configurations and preparations are required. The FPGA needs to configure its hardware interfaces, such as the XGMII (10G Media Independent Interface), to communicate with the PHY. This involves setting the mode, speed and electrical characteristics of the interface. The XGMII interface is used to connect to the physical layer, be it a standalone device or an Ethernet MAC core implemented alongside the FPGA. Depending on design requirements, the PHY interface can be a 32-bit DDR XGMII or a 32/64-bit SDR interface, depending on the core customization. The ports of the 32-bit XGMII interface are described in
Table 2.
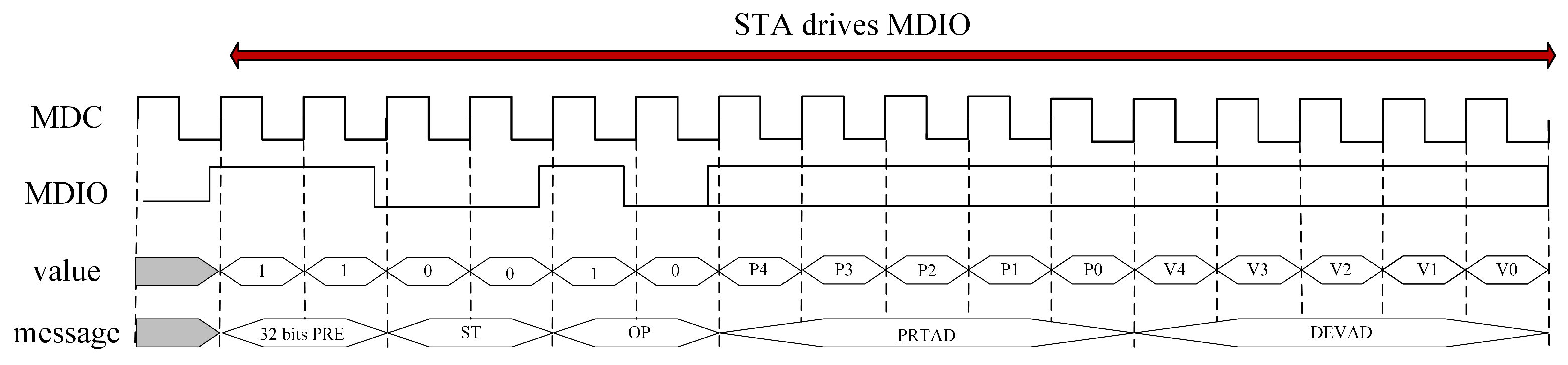
Next, the FPGA needs to set the address of the register to be read. This is typically achieved by sending a specific address read request to the MD (Management Data Input/Output) IO interface. The read request usually contains an opcode (e.g., OP = 10 for a specific address read request), a port address (PRTAD) and a device address (DEVAD). The port and device addresses specify the location of the register in the PHY device to be read. As shown in
Figure 7.
After setting the register address, the FPGA needs to send a read command to start reading the data. The read command typically contains an opcode (e.g., OP = 11 for the read command) and a Transfer Access (TA) signal. The TA signal indicates that the control of the MDIO line has shifted from the FPGA to the PHY device, which starts returning the register data.
When data are input to the FPGA, a typical read process can refer to
Figure 8. First, the start signal (STA) drives the Management Data Input/Output (MDIO) line, initiating the read transaction. This operation is defined by the opcode OP = 11, indicating a read transaction. Then, the port address (PRTAD) and device address (DEVAD) fields specify the location of the register to be read in the PHY device. The values of these two fields are usually set by the higher-level application or hardware logic to locate the correct data source. Following this, the Transfer Access (TA) phase begins, indicating that the control of the MDIO line has shifted from the start signal (STA) to the Media Dependent Interface (MMD). This is the phase where the data are actually read. The PHY device returns a 16-bit word from the specified register location. Finally, when the data reading is complete, the MDIO line enters the IDLE state, indicating that the current read transaction has ended and the MDIO line is free for the next transaction.
During the data transmission process, the sending device (e.g., processor or DMA controller) can send data streams to the receiving device (e.g., peripheral or memory) through the AXI4-Stream interface. AXI4-Stream (Advanced eXtensible Interface 4-Stream) is an interface protocol defined by ARM, part of the AXI4 interface specification, specifically designed for data stream communications. It supports high-performance, high-bandwidth data stream transfers and allows for continuous, non-blocking transmissions, making it suitable for applications handling large amounts of data. In the data transmission system designed in this paper, the AXI4-Stream interface is used to connect the MAC core and FIFO interface to implement data transmission. When the MAC core needs to send data, it sends the data to the FIFO interface through the AXI4-Stream interface, which then transmits the data to the physical layer.
During the data transmission process, the first thing to understand is that the data transmission interface tx_axis_tdata is logically divided into multiple channels. For a 32-bit interface, there are channels 0 to 3 and for a 64-bit interface, there are channels 0 to 7. Each channel corresponds to a tx_axis_tkeep bit which indicates whether the data on tx_axis_tdata are valid.
During the data frame transmission, the tx_axis_tvalid signal must first be set to valid, indicating that data need to be sent. At the same time, the content of the data frame should be placed on the tx_axis_tdata interface. Specifically, for a 32-bit interface, the data frame content will be divided into four parts, each 8 bits, placed on four channels. For a 64-bit interface, the content will be divided into eight parts, each 8 bits, placed on eight channels.
During the data frame transmission, the tx_axis_tlast signal will be set to valid when the last byte of each data frame is sent, indicating that the current data frame has been completely transmitted. At the same time, the tx_axis_tready signal will be set to valid once the data frame has been successfully transmitted, indicating that the interface is ready to send the next data frame.
During the data frame transmission, the
tx_axis_tuser signal can also be used to indicate whether an underflow error has occurred. If the
tx_axis_tuser signal is set to 0, it indicates an underflow error, and the data frame needs to be resent. If the
tx_axis_tuser signal is set to 1, it indicates that the data frame has been successfully sent.
Figure 9 describes the transmission process for a 32-bit frame.
3.4.2. Design and Implementation of the Reed–Solomon Encoder
Reed–Solomon encoding, as a crucial error-correcting code in digital communication and storage systems, aims to ensure the integrity and accuracy of data. The process involves taking
k information symbols and producing
m parity symbols, forming a complete codeword of
symbols. These symbols can be viewed as coefficients of a polynomial. If the entire codeword cannot be evenly divided by a certain generating polynomial, it indicates the presence of errors in the codeword. This principle is further detailed in Equation (
12). The figure below presents a standard Reed–Solomon codeword format, which includes both the arrangement of information and parity symbols and the verification process using the generating polynomial.
An essential step in designing a Reed–Solomon encoder is the selection of an appropriate generating polynomial. This article provides recommended default generating polynomials for various symbol widths. For example, for a 4-bit symbol width, the suggested polynomial is
. These recommended polynomials, along with their details, are tabulated in
Table 3, showcasing the default generating polynomials for different symbol widths and their decimal representation.
Having chosen the generating polynomial, the next step is to determine the lengths of information and parity symbols and configure the encoder’s input and output interfaces. The setting of these interfaces requires a clear definition of key parameters such as data and control signal bit widths, clock frequency and others. The figure below gives a schematic representation of the core interfaces and signals of the encoder, as well as their interactions.
In
Figure 10, the primary input and output ports of the encoder can be observed, illustrating how they interact with external devices.
s_axis_input: This serves as the primary data input interface for the encoder, accepting raw data to be encoded.
s_axis_ctrl: This is a control interface responsible for transmitting control signals related to the encoding process.
m_axis_output: This is the encoder’s primary data output interface, where encoded data are outputted.
m_axis_stat: This is a status output interface conveying status information about the encoding process. Error detection and calculation: this section denotes the core functionality of the encoder, specifically error detection and the calculation of check symbols.
Moreover, signals related to the AXI-Stream interface, such as tvalid and tready, are depicted in the figure. These signals are utilized for synchronizing data transfer and flow control. Upon data input to the Reed–Solomon encoder, the encoder first receives it via the s_axis_input interface. These data are treated as information symbols and are directed to the core section of the encoder for processing. Here, check symbols are generated based on the principles of Reed–Solomon encoding. These check symbols, combined with the original information symbols, formulate a complete Reed–Solomon codeword. Once encoding is complete, the full codeword is outputted via the m_axis_output interface. Throughout the encoding process, the encoder also detects any potential errors in the input data. If errors are detected, related status information is transmitted via the m_axis_stat interface.
To ensure efficient encoding, the encoder’s design supports multi-channel operations, allowing the encoder to process multiple data streams in parallel, significantly enhancing data processing throughput. The specific implementation of this parallel operation can be found in
Figure 11. This figure provides a detailed description of the workflow in multi-channel operations, showing how data are processed in parallel across multiple channels and the direction and processing method of the data flow on each channel.
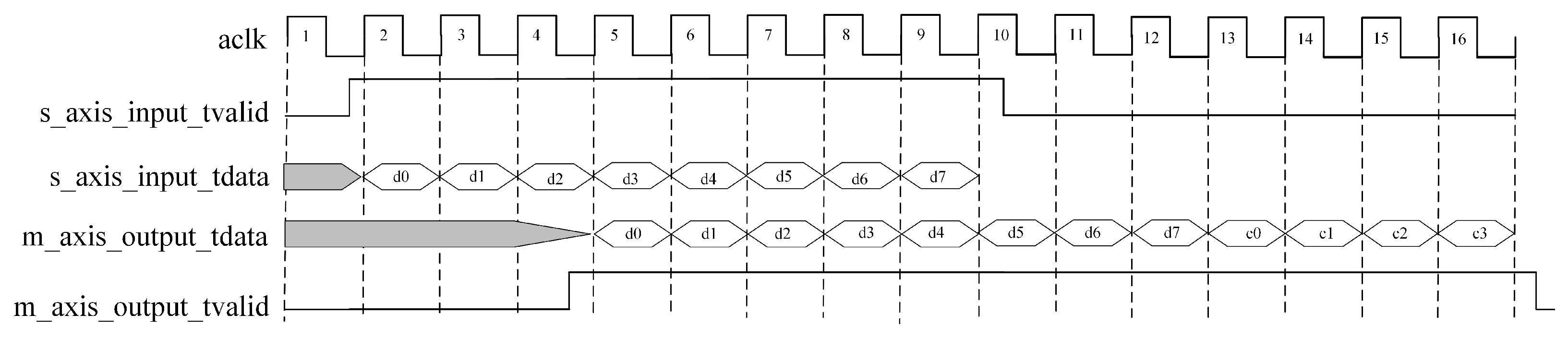
Figure 11 illustrates the multi-channel operation mode of the Reed–Solomon encoder. From the figure, it is evident how the encoder processes data from different channels in various clock cycles, realizing multi-channel parallel operations. Firstly,
aclk serves as the clock signal in the figure, providing a synchronization reference for the entire operation.
s_axis_input_tvalid is a validity signal; when high, it indicates that the data in
s_axis_input_tdata are valid. Meanwhile,
s_axis_input_tdata is the input data signal. In the figure, data blocks
d0–d7 are input during clock cycles 2–9. On the output side,
m_axis_output_tdata is the output data signal, and data blocks
d0–d7 along with check blocks
c0–c3 are input during clock cycles 5–16. Simultaneously,
m_axis_output_tvalid serves as the validity signal for the output data; when high, it indicates that the data in
m_axis_output_tdata have been correctly encoded and are ready for output.
Regarding data transmission, this article opts for the AXI4-Stream channel as the primary data transfer protocol. This protocol ensures data continuity and enhances data transfer efficiency. The specific data transmission process and the working method of this channel are detailed in
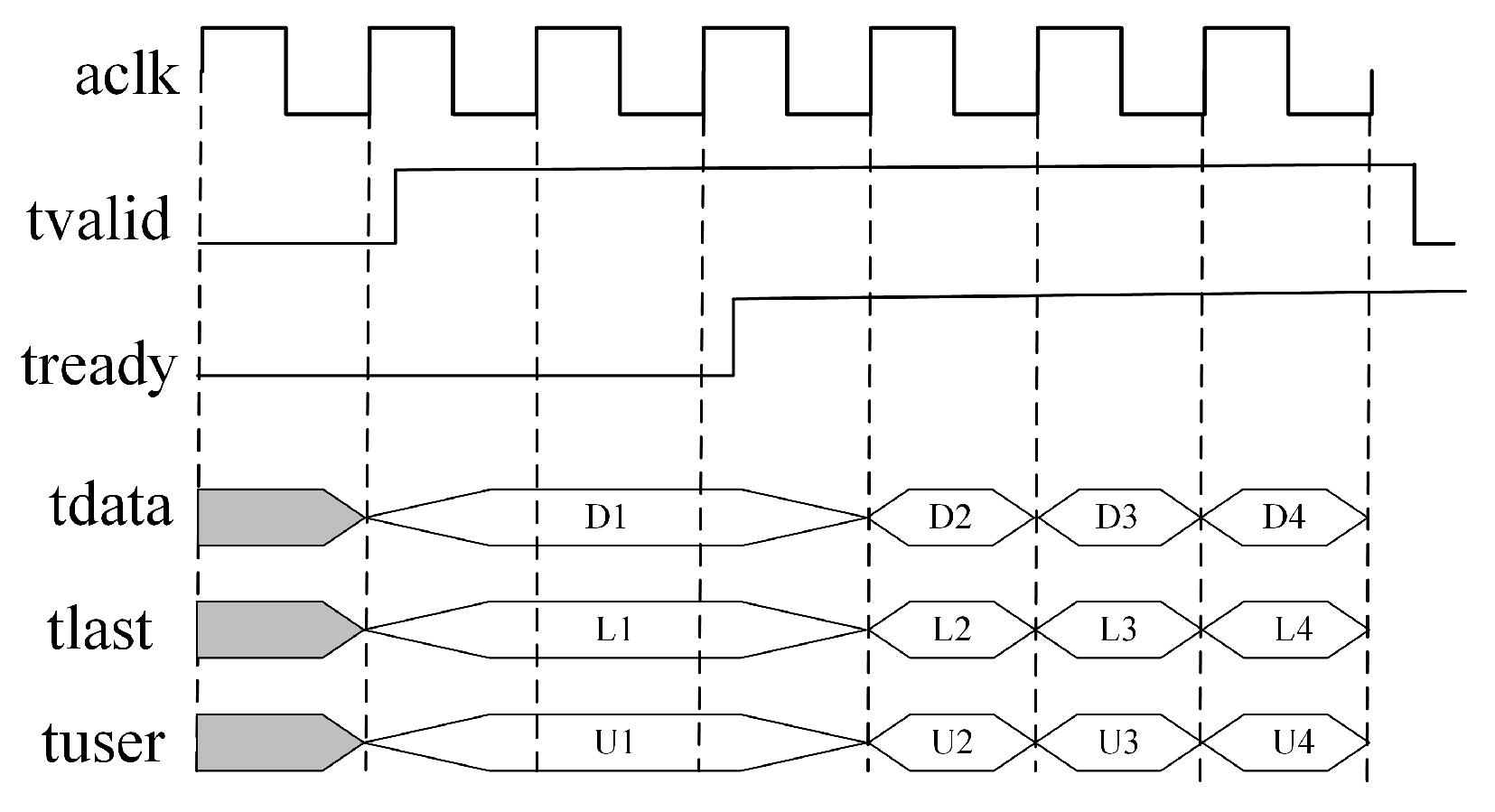
Figure 12, which presents the data transmission flow in the AXI4-Stream channel, encompassing data input, processing and output procedures, along with related control signals.
Figure 12 illustrates the data transfer process within the AXI4-Stream channel involving multiple crucial signals. First is
aclk, a clock signal used for synchronizing data transfer.
tvalid is driven by the source (master device), indicating the values within the payload fields (
tdata,
tuser and
tlast) are valid. In contrast
tready, driven by the receiver (slave device), signals that the slave device is prepared to receive data.
tdata is the data signal transmitting the data. In the figure, it is divided into four parts representing D1, D2, D3 and D4.
tlast marks the last byte of a data frame, indicating the completion of the current data frame transmission.
tuser can be used to indicate specific control information or states, such as U1, U2, U3 and U4. In the AXI4-Stream channel’s data transfer process, the coordinated operation of
tvalid and
tready signals facilitates self-adjusting flow control. Data transfer occurs when both
tvalid and
tready are true. If the downstream data path is not prepared to handle the data, data loss is prevented through the back-pressure mechanism via
tready. Moreover, the article also references two input channels:
S_AXIS_INPUT and
S_AXIS_CTRL. If block parameters configurable at runtime, such as block length, are selected, these channels are utilized. Through these signals and control mechanisms, the AXI4-Stream channel ensures data continuity and efficiency, offering a flexible data transfer solution for hardware design.















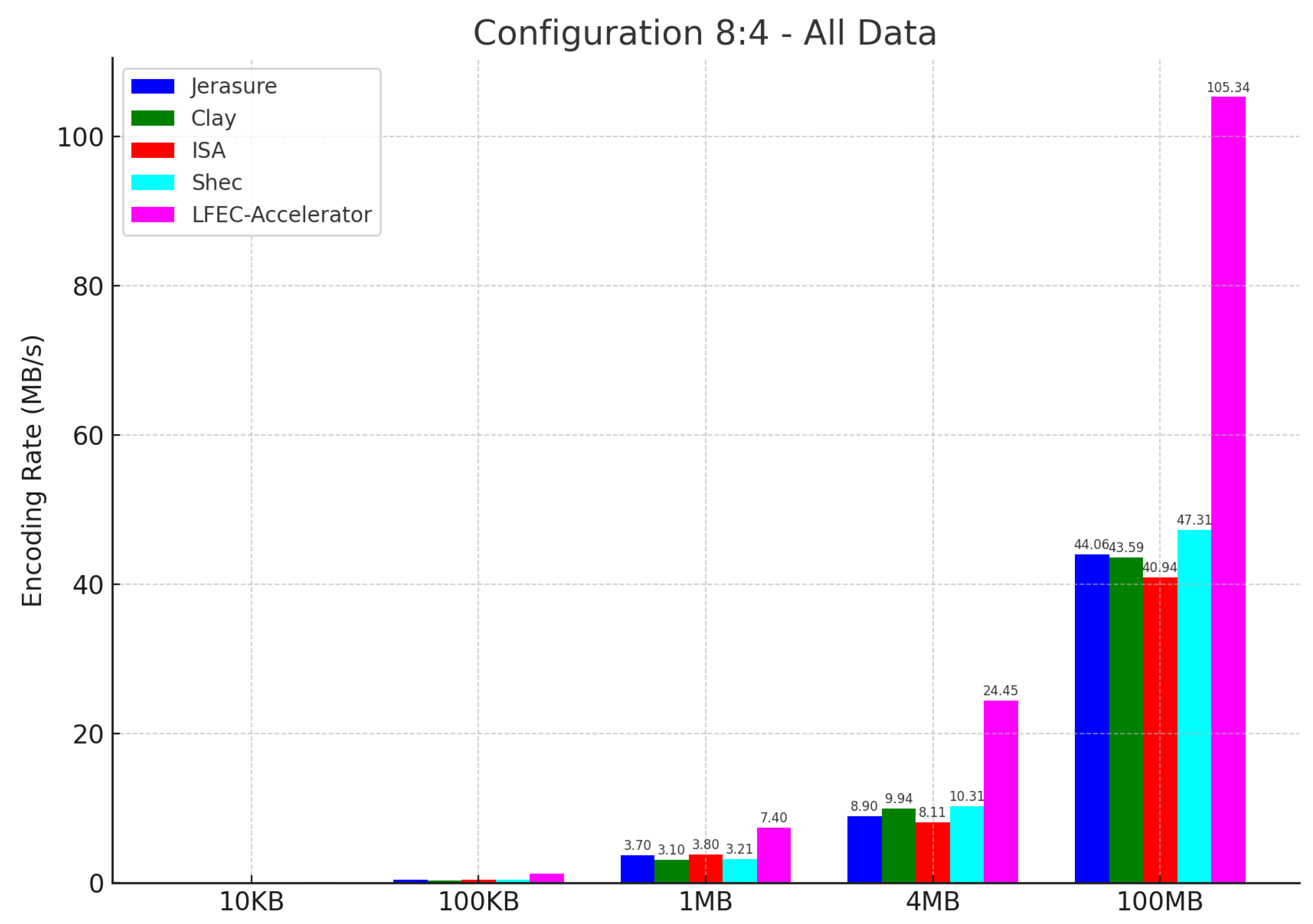
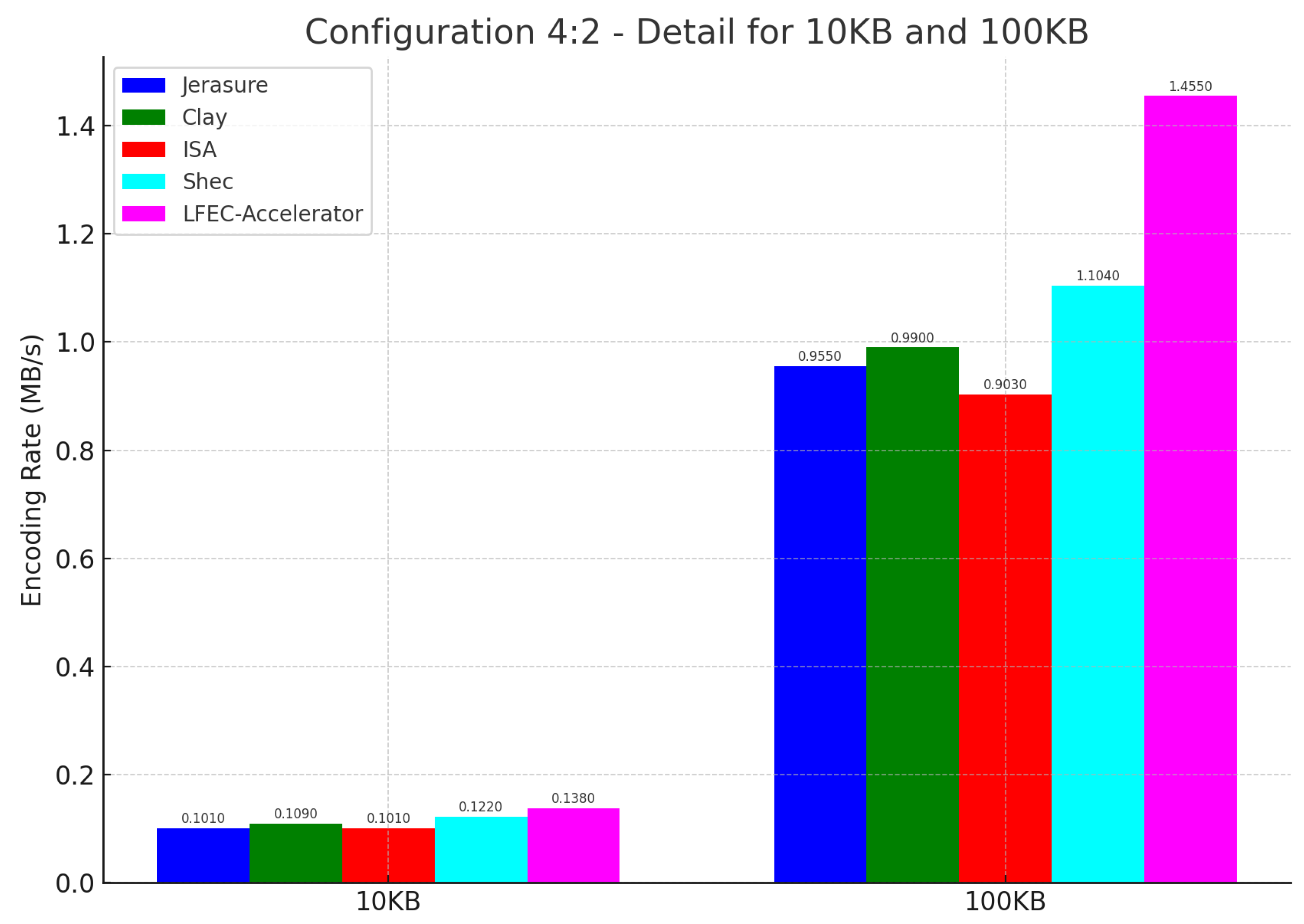
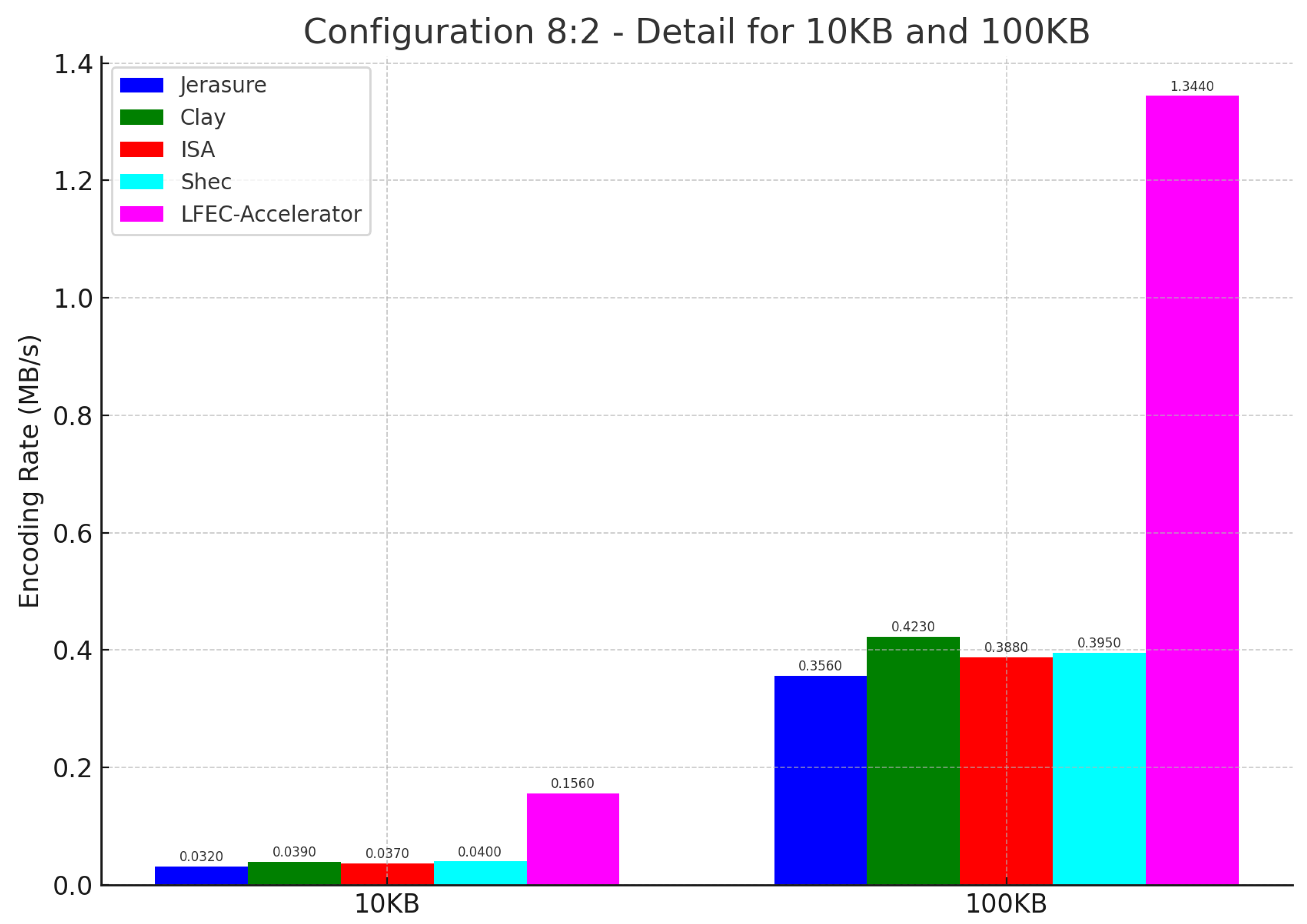



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}