
YOLO-Rlepose: Improved YOLO Based on Swin Transformer and Rle-Oks Loss for Multi-Person Pose Estimation


Abstract
1. Introduction
- This study adds the Swin Transformer to the C3 module and proposes C3STR, enabling the network to better capture global information.
- This study introduces the Rle-Oks loss and applies it to human pose estimation, enabling the model to have keypoint weights when calculating the error between predicted and ground-truth keypoint values.
- On the COCO dataset, the proposed YOLO-Rlepose achieved 65.01 (AP), outperforming YOLO-Pose (previous SOTA method) by 2.11%.
2. Related Work
2.1. Multi-Person 2D Pose Estimation
2.1.1. Top-Down Methods
2.1.2. Bottom-Up Methods
2.1.3. Single-Stage Human Pose Estimation
2.2. Transformer in Vision
2.3. Heatmap-Based Pose Estimation and Regression-Based Pose Estimation
2.3.1. Heatmap-Based Pose Estimation
2.3.2. Regression-Based Pose Estimation
3. Proposed Method
3.1. YOLO-Pose
3.2. C3 Module with Swin Transformer
3.3. Rle-Oks Loss
4. Experiments
4.1. Implementation Details
4.2. Results on COCO Test Set
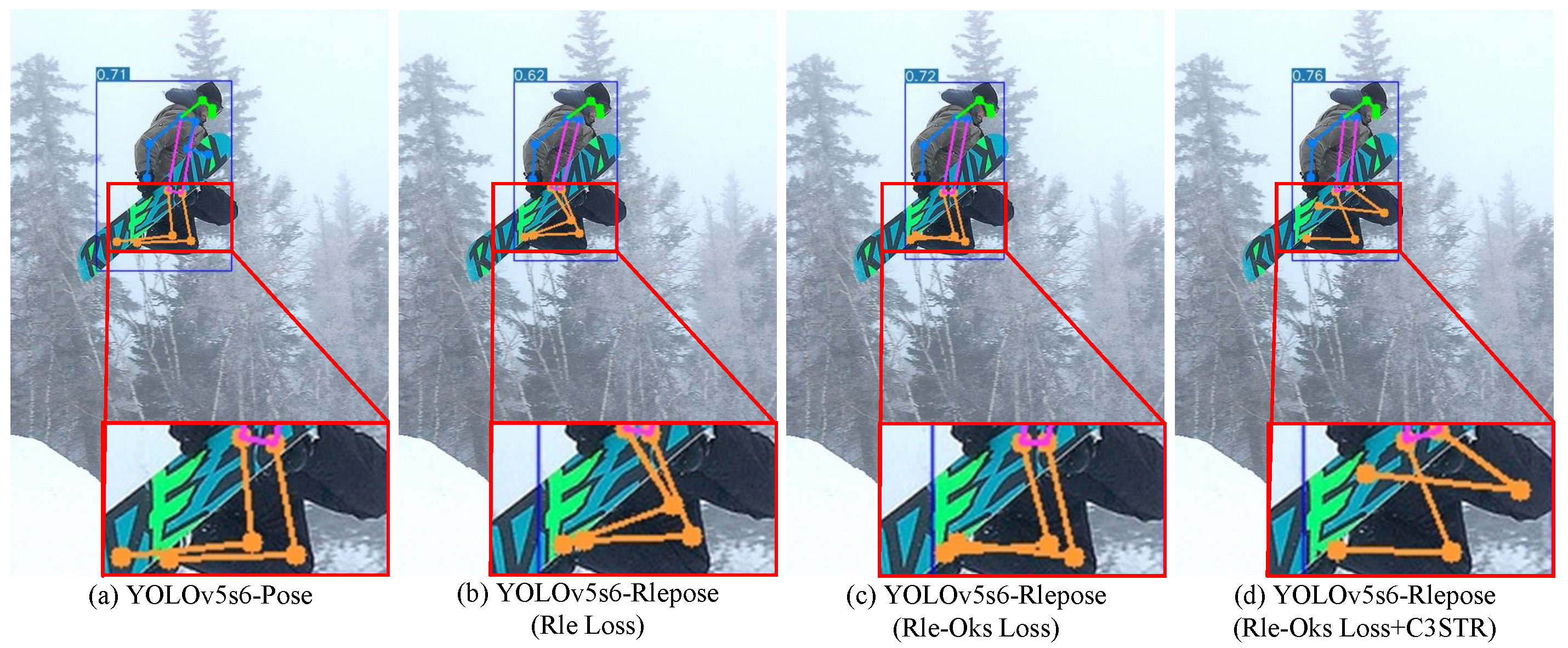
4.3. Comparison of Rle-Oks Loss with Rle Loss and OKS Loss
4.4. Ablation Experiments
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Du, Y.; Wang, W.; Wang, L. Hierarchical recurrent neural network for skeleton based action recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 8–10 June 2015; pp. 1110–1118. [Google Scholar]
- Jain, H.P.; Subramanian, A.; Das, S.; Mittal, A. Real-time upper-body human pose estimation using a depth camera. In Proceedings of the Computer Vision/Computer Graphics Collaboration Techniques: 5th International Conference, MIRAGE 2011, Rocquencourt, France, 10–11 October 2011; Proceedings 5. Springer: Berlin/Heidelberg, Germany, 2011; pp. 227–238. [Google Scholar]
- Andriluka, M.; Iqbal, U.; Insafutdinov, E.; Pishchulin, L.; Milan, A.; Gall, J.; Schiele, B. Posetrack: A benchmark for human pose estimation and tracking. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 19–21 June 2018; pp. 5167–5176. [Google Scholar]
- Liu, J.; Ni, B.; Yan, Y.; Zhou, P.; Cheng, S.; Hu, J. Pose transferrable person re-identification. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 19–21 June 2018; pp. 4099–4108. [Google Scholar]
- Mao, W.; Tian, Z.; Wang, X.; Shen, C. Fcpose: Fully convolutional multi-person pose estimation with dynamic instance-aware convolutions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 9034–9043. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 19–21 June 2018; pp. 8759–8768. [Google Scholar]
- Newell, A.; Yang, K.; Deng, J. Stacked hourglass networks for human pose estimation. In Proceedings of the Computer Vision—ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part VIII 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 483–499. [Google Scholar]
- Chen, Y.; Wang, Z.; Peng, Y.; Zhang, Z.; Yu, G.; Sun, J. Cascaded pyramid network for multi-person pose estimation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake, UT, USA, 19–21 June 2018; pp. 7103–7112. [Google Scholar]
- Cao, Z.; Simon, T.; Wei, S.E.; Sheikh, Y. Realtime multi-person 2D pose estimation using part affinity fields. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7291–7299. [Google Scholar]
- Cheng, B.; Xiao, B.; Wang, J.; Shi, H.; Huang, T.S.; Zhang, L. Higherhrnet: Scale-aware representation learning for bottom-up human pose estimation. In Proceedings of the IEEE/CVF Conference on computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 5386–5395. [Google Scholar]
- Nie, X.; Feng, J.; Zhang, J.; Yan, S. Single-stage multi-person pose machines. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 6951–6960. [Google Scholar]
- Shi, D.; Wei, X.; Yu, X.; Tan, W.; Ren, Y.; Pu, S. Inspose: Instance-aware networks for single-stage multi-person pose estimation. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 3079–3087. [Google Scholar]
- Tian, Z.; Chen, H.; Shen, C. Directpose: Direct end-to-end multi-person pose estimation. arXiv 2019, arXiv:1911.07451. [Google Scholar]
- Wei, F.; Sun, X.; Li, H.; Wang, J.; Lin, S. Point-set anchors for object detection, instance segmentation and pose estimation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part X 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 527–544. [Google Scholar]
- Maji, D.; Nagori, S.; Mathew, M.; Poddar, D. Yolo-pose: Enhancing yolo for multi person pose estimation using object keypoint similarity loss. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 19–20 June 2022; pp. 2637–2646. [Google Scholar]
- Yang, S.; Quan, Z.; Nie, M.; Yang, W. Transpose: Keypoint localization via transformer. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11802–11812. [Google Scholar]
- Li, Y.; Zhang, S.; Wang, Z.; Yang, S.; Yang, W.; Xia, S.T.; Zhou, E. Tokenpose: Learning keypoint tokens for human pose estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11313–11322. [Google Scholar]
- Mao, W.; Ge, Y.; Shen, C.; Tian, Z.; Wang, X.; Wang, Z.; den Hengel, A.v. Poseur: Direct human pose regression with transformers. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; Springer: Berlin/Heidelberg, Germany, 2022; pp. 72–88. [Google Scholar]
- Xu, Y.; Zhang, J.; Zhang, Q.; Tao, D. Vitpose: Simple vision transformer baselines for human pose estimation. Adv. Neural Inf. Process. Syst. 2022, 35, 38571–38584. [Google Scholar]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin transformer: Hierarchical vision transformer using shifted windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 10012–10022. [Google Scholar]
- Tompson, J.J.; Jain, A.; LeCun, Y.; Bregler, C. Joint training of a convolutional network and a graphical model for human pose estimation. In Advances in Neural Information Processing Systems, Proceedings of the NIPS 2014, Montreal, QC, Canada, 8–13 December 2014; Neural Information Processing Systems Foundation, Inc. (NeurIPS): San Diego, CA, USA, 2014; Volume 27. [Google Scholar]
- Cai, Y.; Wang, Z.; Luo, Z.; Yin, B.; Du, A.; Wang, H.; Zhang, X.; Zhou, X.; Zhou, E.; Sun, J. Learning delicate local representations for multi-person pose estimation. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part III 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 455–472. [Google Scholar]
- Sun, K.; Xiao, B.; Liu, D.; Wang, J. Deep high-resolution representation learning for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 5693–5703. [Google Scholar]
- Sun, X.; Shang, J.; Liang, S.; Wei, Y. Compositional human pose regression. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2602–2611. [Google Scholar]
- Zhang, F.; Zhu, X.; Dai, H.; Ye, M.; Zhu, C. Distribution-aware coordinate representation for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 7093–7102. [Google Scholar]
- Carreira, J.; Agrawal, P.; Fragkiadaki, K.; Malik, J. Human pose estimation with iterative error feedback. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 4733–4742. [Google Scholar]
- Li, J.; Bian, S.; Zeng, A.; Wang, C.; Pang, B.; Liu, W.; Lu, C. Human pose regression with residual log-likelihood estimation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 11025–11034. [Google Scholar]
- Rogez, G.; Weinzaepfel, P.; Schmid, C. Lcr-net: Localization-classification-regression for human pose. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 3433–3441. [Google Scholar]
- Pavllo, D.; Feichtenhofer, C.; Grangier, D.; Auli, M. 3D human pose estimation in video with temporal convolutions and semi-supervised training. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 7753–7762. [Google Scholar]
- Wang, L.; Chen, Y.; Guo, Z.; Qian, K.; Lin, M.; Li, H.; Ren, J.S. Generalizing monocular 3D human pose estimation in the wild. In Proceedings of the IEEE/CVF International Conference on Computer Vision Workshops, Seoul, Republic of Korea, 27–28 October 2019; pp. 4024–4033. [Google Scholar]
- Zeng, A.; Sun, X.; Huang, F.; Liu, M.; Xu, Q.; Lin, S. Srnet: Improving generalization in 3D human pose estimation with a split-and-recombine approach. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part XIV 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 507–523. [Google Scholar]
- Choi, H.; Moon, G.; Lee, K.M. Pose2mesh: Graph convolutional network for 3D human pose and mesh recovery from a 2D human pose. In Proceedings of the Computer Vision—ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; Proceedings, Part VII 16. Springer: Berlin/Heidelberg, Germany, 2020; pp. 769–787. [Google Scholar]
- Fang, H.S.; Xu, Y.; Wang, W.; Liu, X.; Zhu, S.C. Learning pose grammar to encode human body configuration for 3D pose estimation. In Proceedings of the AAAI Conference on Artificial Intelligence, New Orleans, LA, USA, 2–7 February 2018; Volume 32. [Google Scholar]
- Rezende, D.; Mohamed, S. Variational inference with normalizing flows. In Proceedings of the International Conference on Machine Learning, Lille, France, 6–11 July 2015; PMLR. pp. 1530–1538. [Google Scholar]
- Papandreou, G.; Zhu, T.; Chen, L.C.; Gidaris, S.; Tompson, J.; Murphy, K. Personlab: Person pose estimation and instance segmentation with a bottom-up, part-based, geometric embedding model. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 269–286. [Google Scholar]
- Kreiss, S.; Bertoni, L.; Alahi, A. Pifpaf: Composite fields for human pose estimation. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 11977–11986. [Google Scholar]
- Neff, C.; Sheth, A.; Furgurson, S.; Tabkhi, H. Efficienthrnet: Efficient scaling for lightweight high-resolution multi-person pose estimation. arXiv 2020, arXiv:2007.08090. [Google Scholar]
- Tan, M.; Le, Q. Efficientnet: Rethinking model scaling for convolutional neural networks. In Proceedings of the International Conference on Machine Learning, Long Beach, CA, USA, 9–15 June 2019; PMLR; pp. 6105–6114. [Google Scholar]
- Geng, Z.; Sun, K.; Xiao, B.; Zhang, Z.; Wang, J. Bottom-up human pose estimation via disentangled keypoint regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 14676–14686. [Google Scholar]







{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Backbone | Size | AP | AP50 | AP75 | APL | AR |
|---|---|---|---|---|---|---|---|
| Openpose [10] | − | − | 61.8 | 84.9 | 67.5 | 68.2 | 66.5 |
| Hourglass [8] | Hourglass | 512 | 56.6 | 81.8 | 61.8 | 67.0 | − |
| PersonLab [36] | ResNet-152 | 1401 | 66.5 | 88.0 | 72.6 | 72.3 | 71.0 |
| PiPaf [37] | − | − | 66.7 | − | − | 72.9 | − |
| HRHet [24] | HRNet-W32 | 512 | 64.1 | 86.3 | 70.4 | 73.9 | − |
| EfficientHRNet-H0 [38] | EfficientNetB0 [39] | 512 | 64.0 | − | − | − | − |
| EfficientHRNet-H0 † [38] | EfficientNetB0 [39] | 512 | 67.1 | − | − | − | − |
| HigherHRNet [11] | HRNet-W32 | 512 | 66.4 | 87.5 | 72.8 | 74.2 | − |
| HigherHRNet [11] | HRNet-W48 | 640 | 68.4 | 88.2 | 75.1 | 74.2 | − |
| HigherHRNet † [11] | HRNet-W48 | 640 | 70.5 | 89.3 | 77.2 | 75.8 | − |
| DEKR [40] | HRNet-W32 | 512 | 67.3 | 87.9 | 74.1 | 76.1 | 72.4 |
| DEKR [40] | HRNet-W48 | 640 | 70.0 | 89.4 | 77.3 | 76.9 | 75.4 |
| YOLOv5s6-Pose [16] | Darknet-csp-d53-s | 960 | 62.9 | 87.7 | 69.4 | 71.8 | 69.8 |
| YOLOv5m6-Pose [16] | Darknet-csp-d53-m | 960 | 66.6 | 89.8 | 73.8 | 75.2 | 73.4 |
| YOLOv5l6-Pose [16] | Darknet-csp-d53-l | 960 | 68.5 | 90.3 | 74.8 | 76.5 | 75.0 |
| YOLOv5s6-Rlepose | Darknet-csp-d53-s | 960 | 65.0 | 87.8 | 71.2 | 71.7 | 71.5 |
| YOLOv5m6-Rlepose | Darknet-csp-d53-m | 960 | 67.6 | 89.2 | 74.5 | 73.8 | 74.0 |
| Method | Loss | Size | AP | AP50 | AP75 |
|---|---|---|---|---|---|
| YOLOv5s6-Rlepose | OKS | 960 | 62.9 | 87.7 | 69.4 |
| YOLOv5s6-Rlepose | Rle Loss | 960 | 55.24 | 83.26 | 60.93 |
| YOLOv5s6-Rlepose | Rle-Oks Loss | 960 | 64.02 | 87.47 | 70.96 |
| Method | AP | AP50 | AP75 | AR |
|---|---|---|---|---|
| YOLOv5s6-Pose | 62.9 | 87.7 | 69.4 | 71.8 |
| YOLOv5s6-Rlepose (Rle Loss) | 60.66 | 85.61 | 66.68 | 67.27 |
| YOLOv5s6-Rlepose (Rle-Oks Loss) | 64.02 | 87.47 | 70.96 | 70.40 |
| YOLOv5s6-Rlepose (Rle-Oks Loss+C3STR) | 65.01 | 87.84 | 71.20 | 71.54 |
| Method | #Param.(M) | GFLOPs |
|---|---|---|
| YOLOv5s6-Pose | 15.09 | 20.2 |
| YOLOv5s6-Rlepose (Rle Loss) | 15.09 | 20.2 |
| YOLOv5s6-Rlepose (Rle-Oks Loss) | 15.09 | 20.2 |
| YOLOv5s6-Rlepose (Rle-Oks Loss+C3STR) | 16.0 | 23.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Jiang, Y.; Yang, K.; Zhu, J.; Qin, L. YOLO-Rlepose: Improved YOLO Based on Swin Transformer and Rle-Oks Loss for Multi-Person Pose Estimation. Electronics 2024, 13, 563. https://doi.org/10.3390/electronics13030563
Jiang Y, Yang K, Zhu J, Qin L. YOLO-Rlepose: Improved YOLO Based on Swin Transformer and Rle-Oks Loss for Multi-Person Pose Estimation. Electronics. 2024; 13(3):563. https://doi.org/10.3390/electronics13030563
Chicago/Turabian StyleJiang, Yi, Kexin Yang, Jinlin Zhu, and Li Qin. 2024. "YOLO-Rlepose: Improved YOLO Based on Swin Transformer and Rle-Oks Loss for Multi-Person Pose Estimation" Electronics 13, no. 3: 563. https://doi.org/10.3390/electronics13030563
APA StyleJiang, Y., Yang, K., Zhu, J., & Qin, L. (2024). YOLO-Rlepose: Improved YOLO Based on Swin Transformer and Rle-Oks Loss for Multi-Person Pose Estimation. Electronics, 13(3), 563. https://doi.org/10.3390/electronics13030563