
Ontological Modeling and Clustering Techniques for Service Allocation on the Edge: A Comprehensive Framework


Abstract
1. Introduction
2. Related Works
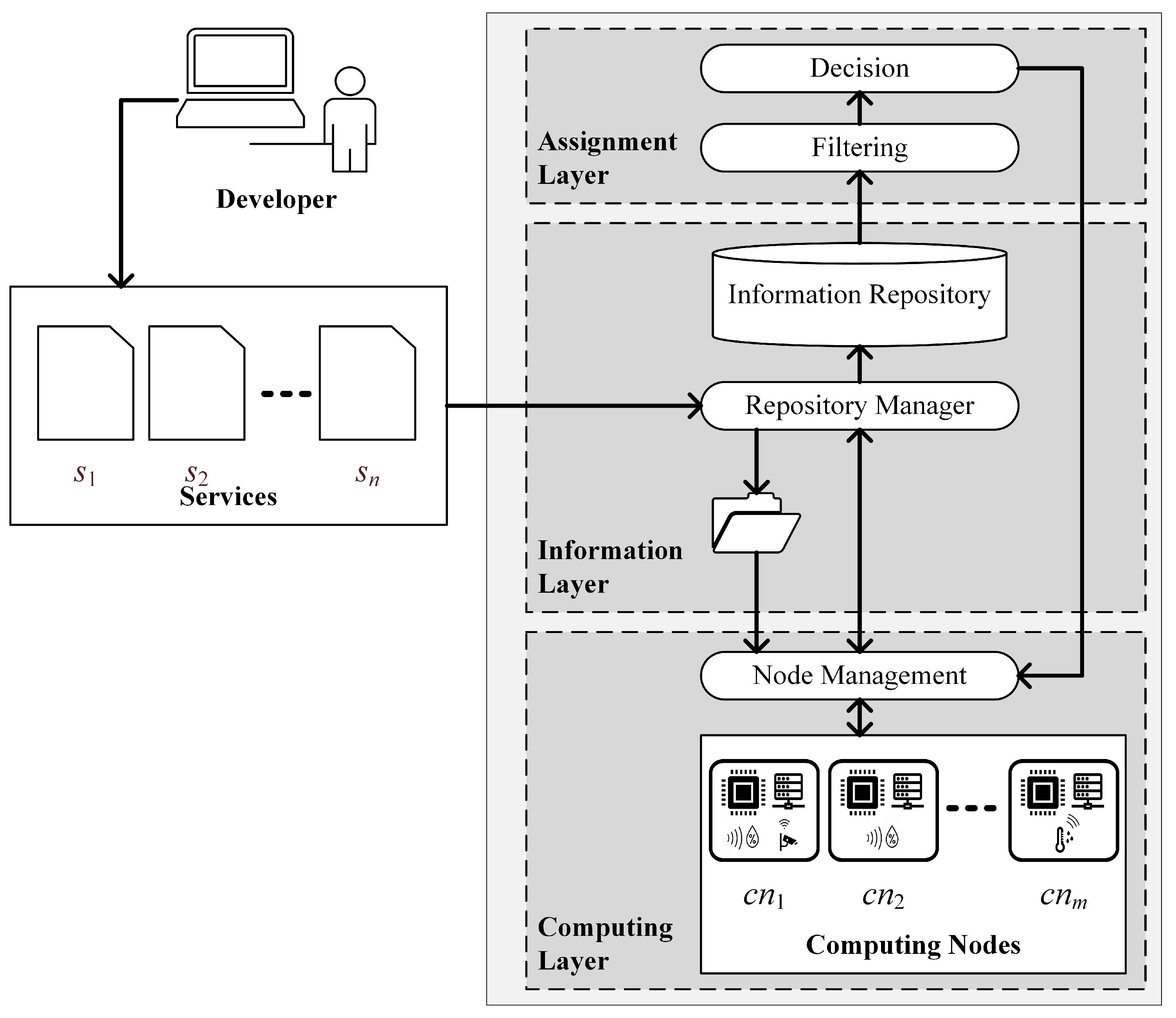
3. Proposed Framework
3.1. Computing Layer
3.2. Information Layer
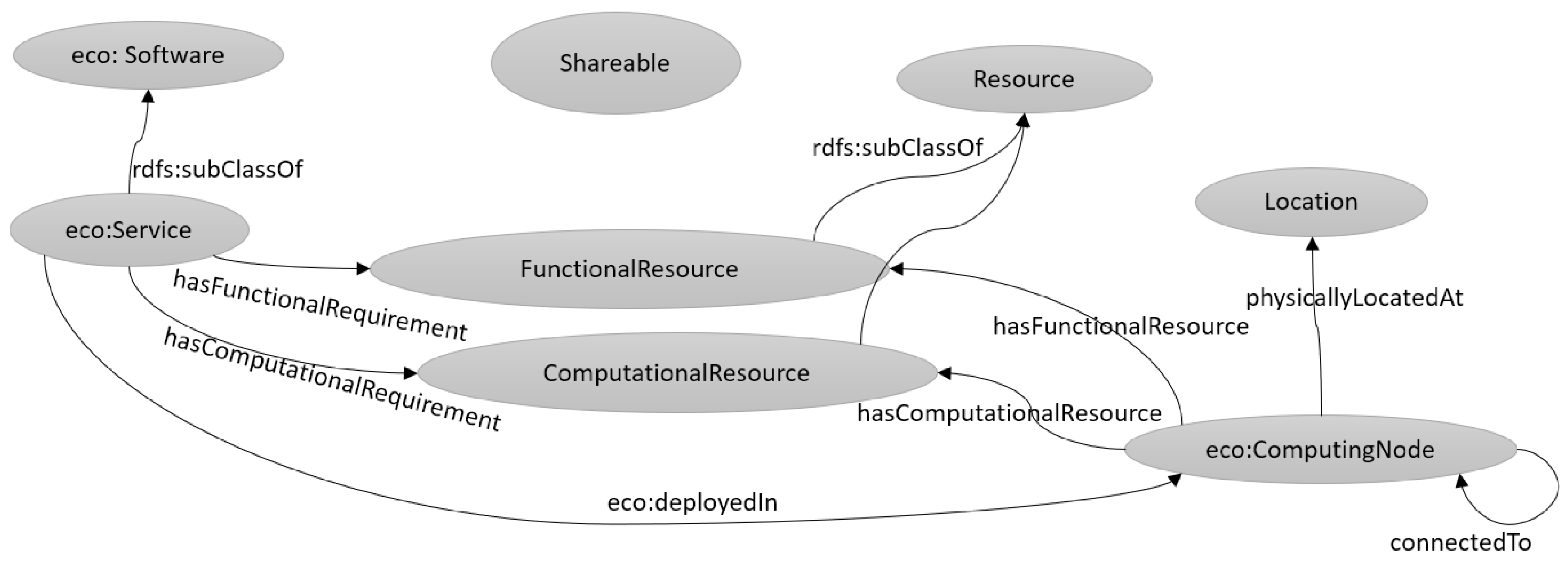
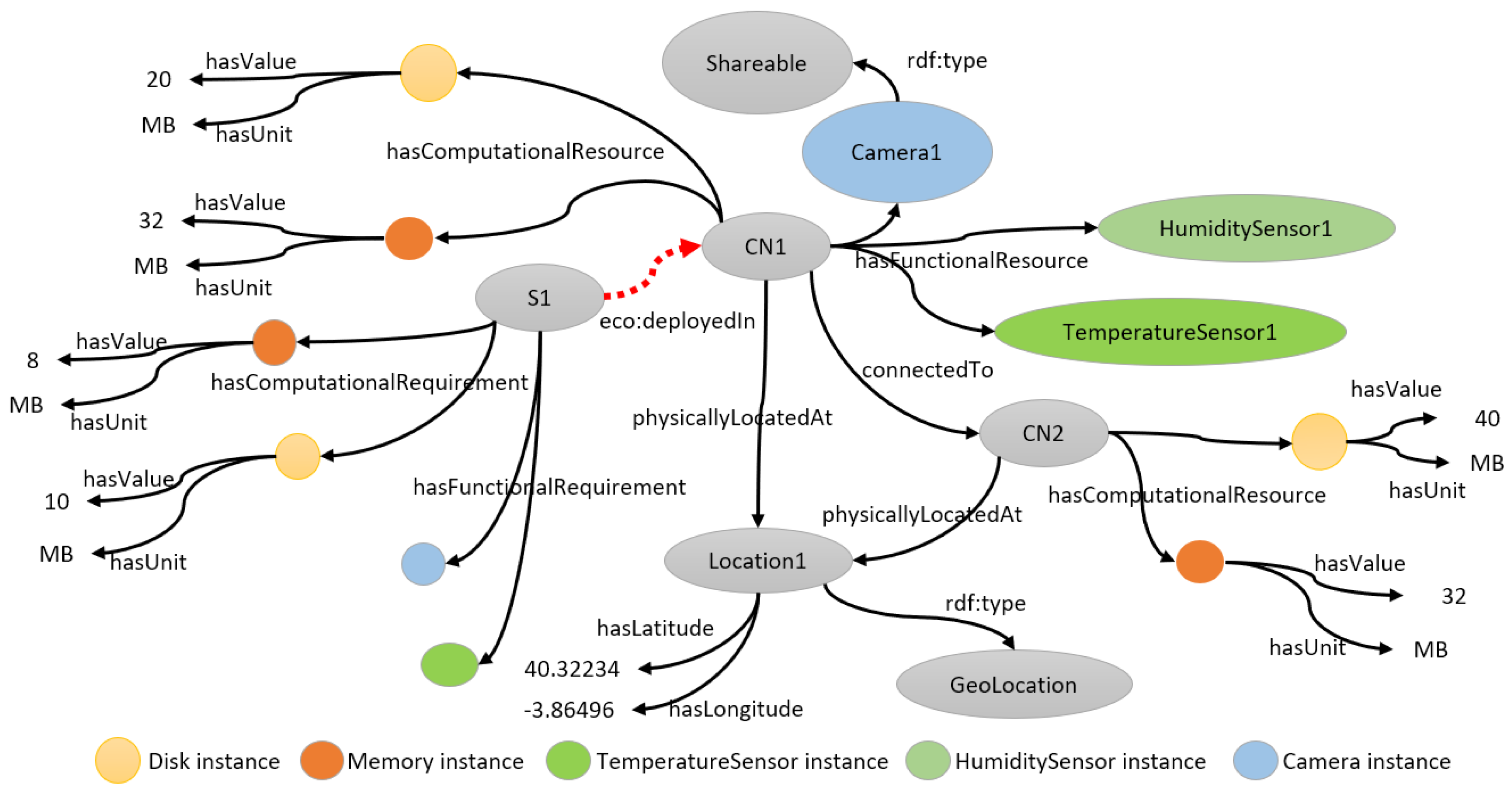
3.2.1. Knowledge Representation
3.2.2. Inferencing and Querying the Model
| Listing 1: Example of query for obtaining pairs of services and computing nodes with enough availability of RAM and HDD for some computational requirements. |
| 1 PREFIX owl : <http://www.w3.org/2002/07/owl#> |
| 2 PREFIX rdf: <http://www.w3.org/1999/02/22-rdf-syntax-ns#> |
| 3 PREFIX rdfs: <http://www.w3.org/2000/01/rdf-schema#> |
| 4 PREFIX on: <https://www.ia.urjc.es/ontologies/networkOntology/> |
| 5 SELECT DISTINCT ?serv ?cn |
| 6 WHERE { |
| 7 ?serv rdf:type on:Service; |
| 8 on:hasComputationalRequirement ?hddS; |
| 9 on:hasComputationalRequirement ?memS. |
| 10 ?hddS rdf:type on:Disk; |
| 11 on:hasValue ?valHDDS. |
| 12 ?memS rdf:type on:Memory; |
| 13 on:hasValue ?valMemS. |
| 14 |
| 15 ?cn rdf:type on:ComputingNode; |
| 16 on:hasComputationalResource ?hddCN; |
| 17 on:hasComputationalResource ?memCN. |
| 18 ?hddCN rdf:type on:Disk; |
| 19 on:hasValue ?valHDDCN. |
| 20 ?memCN rdf:type on:Memory; |
| 21 on:hasValue ?valMemCN. |
| 22 |
| 23 FILTER(?valHDDS <= ?valHDDCN) |
| 24 FILTER(?valMemS <= ?valMemCN) |
| 25 } |
| Listing 2: SPARQL statement to obtain a list of nodes with available resources. |
| 1 SELECT DISTINCT ?computingNode ?res |
| 2 WHERE { |
| 3 ?computingNode rdf:type on:ComputingNode. |
| 4 { |
| 5 ?computingNode on:hasResource ?res . |
| 6 } |
| 7 UNION |
| 8 { |
| 9 ?location rdf:type on:Location. |
| 10 ?computingNode on:physicallyLocatedAt ?location. |
| 11 ?computingNode on:connectedTo ?computingNode2. |
| 12 ?computingNode2 on:physicallyLocatedAt ?location. |
| 13 FILTER (?computingNode != ?computingNode2) |
| 14 ?computingNode2 on:hasResource ?res . |
| 15 ?res rdf:type on:Shareable. |
| 16 } |
| 17 } |
| 18 ORDER BY ?computingNode |
3.2.3. Formal Representation
3.3. Assignment Layer
3.3.1. Filtering
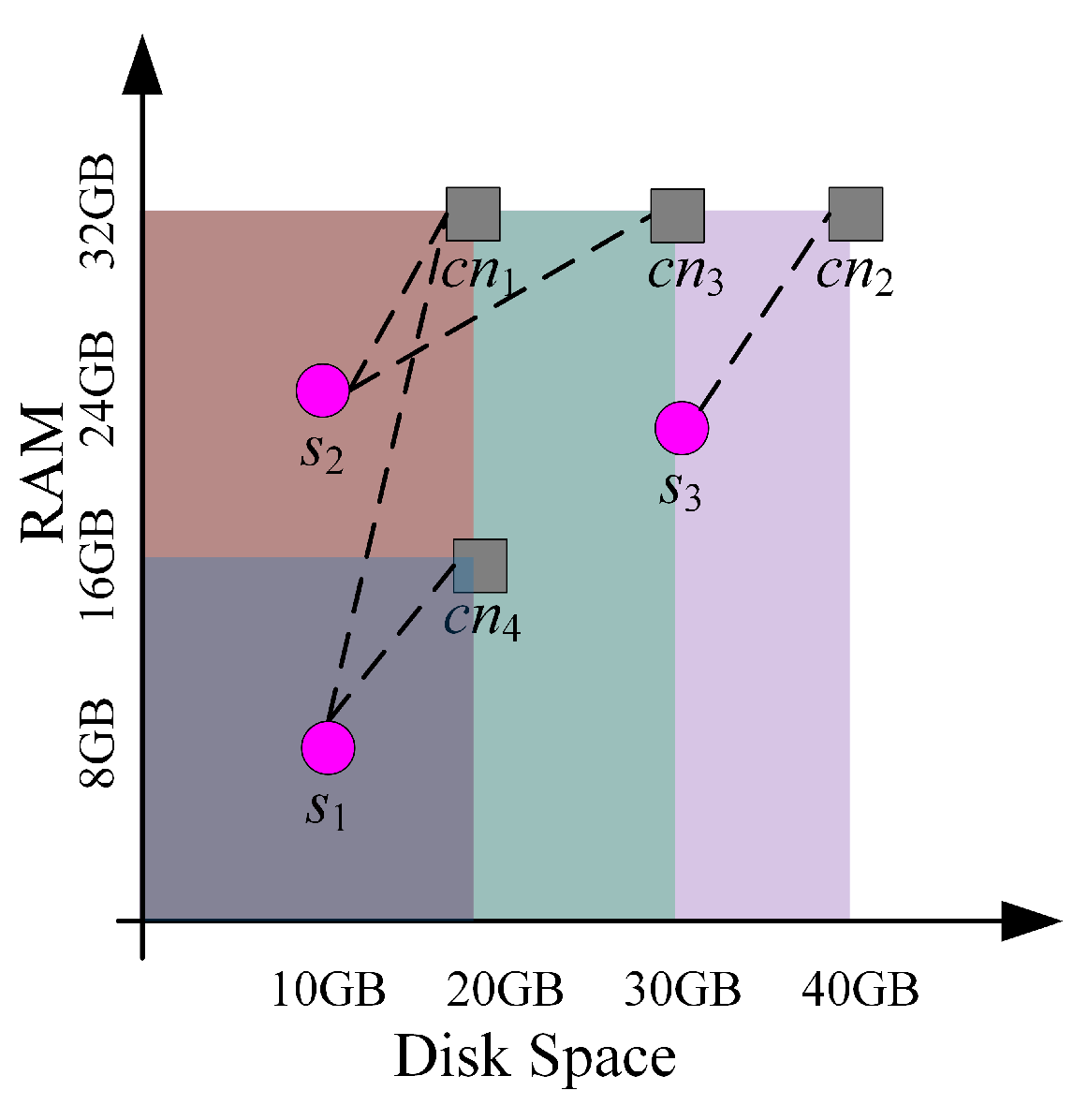
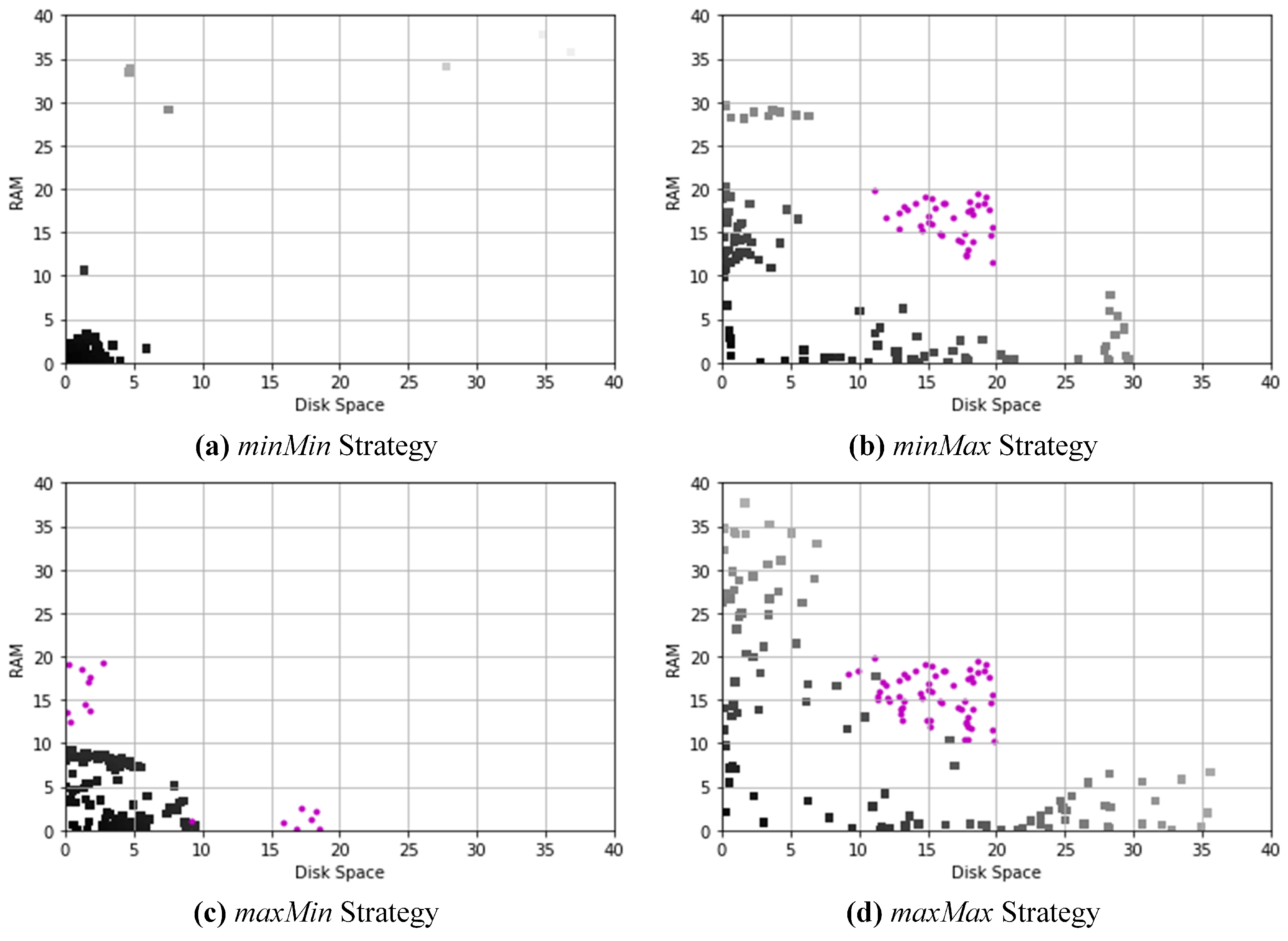
3.3.2. Decision
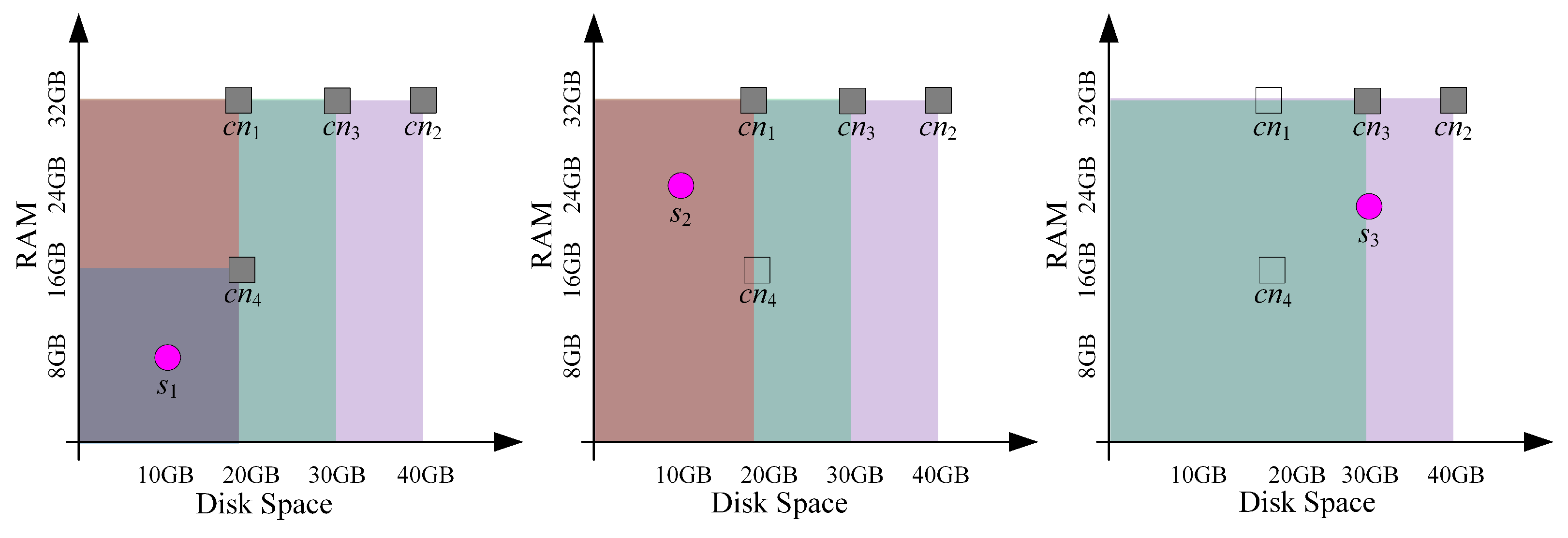
- (a)
- . The minimum of the shortest distance of each . This strategy selects the pair (, ) from where the amounts of resources required by the service and offered by the computing node are as similar as possible.
- (b)
- . The maximum of the shortest distance of each . This strategy selects the pair (, ) from where the amounts of resources required and offered are similar. That is, it selects the whose minimum distance to services is the highest among the computing nodes. It can be seen as a relaxation of minMin, where it still prefers small distances but by selecting the maximum of the distance it leaves the rest of the resources of available for another possible allocation.
- (c)
- . The minimum of the greatest distance of each . This strategy selects the pair (, ) from where the amounts of resources required and offered are quite different. This strategy promotes the allocation of services that require few resources in computing nodes with a low availability of such resources.
- (d)
- . The maximum of the greatest distance of each . This strategy selects the pair (, ) from where the amounts of resources required and offered are very different. This strategy promotes the allocation of services that require few resources in computing nodes with a high availability of said resources.
| Algorithm 1: Clustering-based allocation |
 |
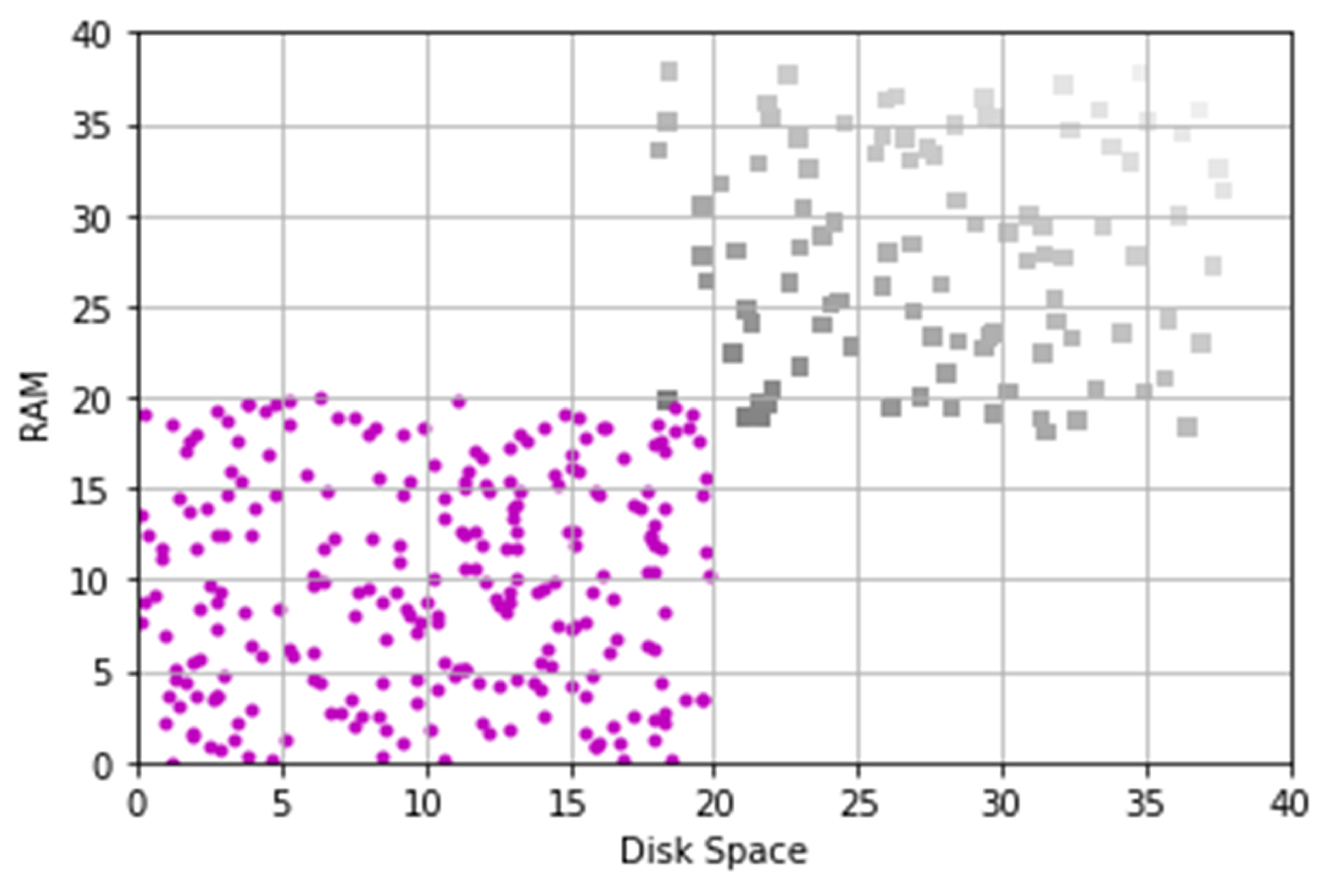
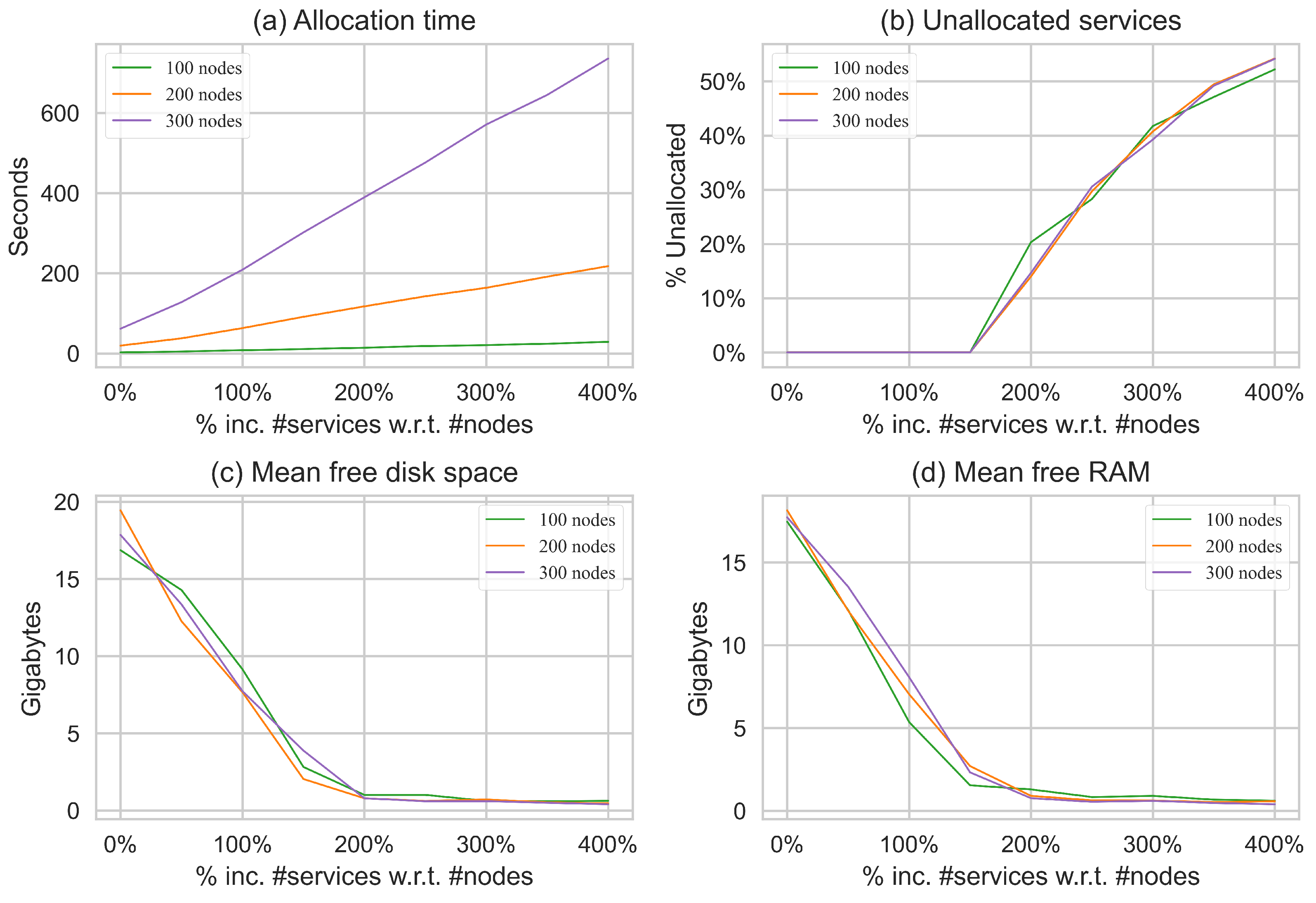
4. Allocation Experiments
5. Discussion
5.1. Dynamic Adaptation of the Allocation Process
5.2. Relation to Other Allocation Approaches
5.3. Quantifying Distances between Computational Resources
6. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yousefpour, A.; Fung, C.; Nguyen, T.; Kadiyala, K.; Jalali, F.; Niakanlahiji, A.; Kong, J.; Jue, J.P. All one needs to know about fog computing and related edge computing paradigms: A complete survey. J. Syst. Archit. 2019, 98, 289–330. [Google Scholar] [CrossRef]
- Ullah, A.; Dagdeviren, H.; Ariyattu, R.C.; DesLauriers, J.; Kiss, T.; Bowden, J. Micado-edge: Towards an application-level orchestrator for the cloud-to-edge computing continuum. J. Grid Comput. 2021, 19, 47. [Google Scholar] [CrossRef]
- Kimovski, D.; Matha, R.; Hammer, J.; Mehran, N.; Hellwagner, H.; Prodan, R. Cloud, Fog, or Edge: Where to Compute? IEEE Internet Comput. 2021, 25, 30–36. [Google Scholar] [CrossRef]
- Karanik, M.; Bernabé-Sánchez, I.; Fernández, A. Edge Service Allocation Based on Clustering Techniques. In Proceedings of the Trends in Sustainable Smart Cities and Territories; Castillo Ossa, L.F., Isaza, G., Cardona, Ó., Castrillón, O.D., Corchado Rodriguez, J.M., De la Prieta Pintado, F., Eds.; Springer: Cham, Switzerland, 2023; pp. 429–441. [Google Scholar]
- Miyamoto, S. Theory of Agglomerative Hierarchical Clustering; Springer: Singapore, 2022; Volume 15. [Google Scholar] [CrossRef]
- Murtagh, F.; Contreras, P. Algorithms for hierarchical clustering: An overview. WIREs Data Min. Knowl. Discov. 2012, 2, 86–97. [Google Scholar] [CrossRef]
- Cao, K.; Liu, Y.; Meng, G.; Sun, Q. An overview on edge computing research. IEEE Access 2020, 8, 85714–85728. [Google Scholar] [CrossRef]
- Araldo, A.; Stefano, A.D.; Stefano, A.D. Resource allocation for edge computing with multiple tenant configurations. In Proceedings of the 35th Annual ACM Symposium on Applied Computing, Virtual, 30 March–3 April 2020; pp. 1190–1199. [Google Scholar]
- Goudarzi, M.; Wu, H.; Palaniswami, M.; Buyya, R. An Application Placement Technique for Concurrent IoT Applications in Edge and Fog Computing Environments. IEEE Trans. Mob. Comput. 2021, 20, 1298–1311. [Google Scholar] [CrossRef]
- Ning, Z.; Hu, X.; Chen, Z.; Zhou, M.; Hu, B.; Cheng, J.; Obaidat, M.S. A cooperative quality-aware service access system for social Internet of vehicles. IEEE Internet Things J. 2017, 5, 2506–2517. [Google Scholar] [CrossRef]
- Zhang, Y.; Zhao, L.; Liang, K.; Zheng, G.; Chen, K.C. Energy Efficiency and Delay Optimization of Virtual Slicing of Fog Radio Access Network. IEEE Internet Things J. 2023, 10, 2297–2313. [Google Scholar] [CrossRef]
- Pan, M.; Li, Z. Multi-user Computation Offloading Algorithm for Mobile Edge Computing. In Proceedings of the 2021 2nd International Conference on Electronics, Communications and Information Technology (CECIT), Sanya, China, 27–29 December 2021; pp. 771–776. [Google Scholar] [CrossRef]
- Deepika, T.; Rao, A.N. Active resource provision in cloud computing through virtualization. In Proceedings of the 2014 IEEE International Conference on Computational Intelligence and Computing Research, Coimbatore, India, 18–20 December 2014; pp. 1–4. [Google Scholar]
- Usman, M.J.; Samad, A.; Chizari, H.; Aliyu, A. Energy-Efficient virtual machine allocation technique using interior search algorithm for cloud datacenter. In Proceedings of the 2017 6th ICT International Student Project Conference (ICT-ISPC), Johor, Malaysia, 23–24 May 2017; pp. 1–4. [Google Scholar]
- Wang, C.F.; Hung, W.Y.; Yang, C.S. A prediction based energy conserving resources allocation scheme for cloud computing. In Proceedings of the 2014 IEEE International Conference on Granular Computing (GrC), Noboribetsu, Japan, 22–24 October 2014; pp. 320–324. [Google Scholar]
- Liu, X.; Yu, J.; Wang, J.; Gao, Y. Resource allocation with edge computing in IoT networks via machine learning. IEEE Internet Things J. 2020, 7, 3415–3426. [Google Scholar] [CrossRef]
- Ullah, I.; Youn, H.Y. Task classification and scheduling based on K-means clustering for edge computing. Wirel. Pers. Commun. 2020, 113, 2611–2624. [Google Scholar] [CrossRef]
- Adhikari, M.; Nandy, S.; Amgoth, T. Meta heuristic-based task deployment mechanism for load balancing in IaaS cloud. J. Netw. Comput. Appl. 2019, 128, 64–77. [Google Scholar] [CrossRef]
- Somasundaram, T.S.; Govindarajan, K. CLOUDRB: A framework for scheduling and managing High-Performance Computing (HPC) applications in science cloud. Future Gener. Comput. Syst. 2014, 34, 47–65. [Google Scholar] [CrossRef]
- Behera, I.; Sobhanayak, S. Task scheduling optimization in heterogeneous cloud computing environments: A hybrid GA-GWO approach. J. Parallel Distrib. Comput. 2024, 183, 104766. [Google Scholar] [CrossRef]
- Hogan, A.; Blomqvist, E.; Cochez, M.; d’Amato, C.; Melo, G.D.; Gutierrez, C.; Kirrane, S.; Gayo, J.E.L.; Navigli, R.; Neumaier, S.; et al. Knowledge graphs. ACM Comput. Surv. 2021, 54, 1–37. [Google Scholar] [CrossRef]
- Imam, F.T. Application of ontologies in cloud computing: The state-of-the-art. arXiv 2016, arXiv:1610.02333. [Google Scholar]
- Moscato, F.; Aversa, R.; Di Martino, B.; Fortiş, T.F.; Munteanu, V. An analysis of mosaic ontology for cloud resources annotation. In Proceedings of the 2011 Federated Conference on Computer Science and Information Systems (FedCSIS), Szczecin, Poland, 18–21 September 2011; pp. 973–980. [Google Scholar]
- Guha, R.V.; Brickley, D.; Macbeth, S. Schema. org: Evolution of structured data on the web. Commun. ACM 2016, 59, 44–51. [Google Scholar] [CrossRef]
- Daniele, L.; den Hartog, F.; Roes, J. Created in close interaction with the industry: The smart appliances reference (SAREF) ontology. In Proceedings of the Formal Ontologies Meet Industry: 7th International Workshop, FOMI 2015, Berlin, Germany, 5 August 2015; pp. 100–112. [Google Scholar]
- Liquori, L.; Scarrone, E.; Peraldi-Frati, M.A.; Jeong, S.M.; Cimmino, A.; Castro, R.G.; Koss, J.; Khan, A.Q.; Kumar, S.; El Khatab, S. ETSI SmartM2M Technical Report 103715; Study for oneM2M; Discovery and Query Solutions Analysis & Selection; Technical Report; European Telecommunications Standard Institute: Sophia Antípolis, France, 2021. [Google Scholar]
- Bernabé-Sánchez, I.; Fernández, A.; Billhardt, H.; Ossowski, S. Problem Detection in the Edge of IoT Applications. Int. J. Interact. Multimed. Artif. Intell. 2023, 8, 85–97. [Google Scholar] [CrossRef]
- Ghomi, E.J.; Rahmani, A.M.; Qader, N.N. Load-balancing algorithms in cloud computing: A survey. J. Netw. Comput. Appl. 2017, 88, 50–71. [Google Scholar] [CrossRef]
- Bhoi, U.; Ramanuj, P.N. Enhanced max-min task scheduling algorithm in cloud computing. Int. J. Appl. Innov. Eng. Manag. (IJAIEM) 2013, 2, 259–264. [Google Scholar]
- Chen, H.; Wang, F.; Helian, N.; Akanmu, G. User-priority guided Min-Min scheduling algorithm for load balancing in cloud computing. In Proceedings of the 2013 National Conference on Parallel Computing Technologies (PARCOMPTECH), Karnataka, India, 21–23 February 2013; pp. 1–8. [Google Scholar]
- Rjoub, G.; Bentahar, J.; Abdel Wahab, O.; Saleh Bataineh, A. Deep and reinforcement learning for automated task scheduling in large-scale cloud computing systems. Concurr. Comput. Pract. Exp. 2021, 33, e5919. [Google Scholar] [CrossRef]
- Taneja, M.; Davy, A. Resource aware placement of IoT application modules in Fog-Cloud Computing Paradigm. In Proceedings of the 2017 IFIP/IEEE Symposium on Integrated Network and Service Management (IM), Lisbon, Portugal, 8–12 May 2017; pp. 1222–1228. [Google Scholar]
- Wang, S.; Urgaonkar, R.; He, T.; Chan, K.; Zafer, M.; Leung, K.K. Dynamic service placement for mobile micro-clouds with predicted future costs. IEEE Trans. Parallel Distrib. Syst. 2016, 28, 1002–1016. [Google Scholar] [CrossRef]
- Ni, L.; Zhang, J.; Jiang, C.; Yan, C.; Yu, K. Resource allocation strategy in fog computing based on priced timed petri nets. IEEE Internet Things J. 2017, 4, 1216–1228. [Google Scholar] [CrossRef]
- Abbasi, M.; Mohammadi Pasand, E.; Khosravi, M.R. Workload allocation in iot-fog-cloud architecture using a multi-objective genetic algorithm. J. Grid Comput. 2020, 18, 43–56. [Google Scholar] [CrossRef]
- Xu, X.; Fu, S.; Cai, Q.; Tian, W.; Liu, W.; Dou, W.; Sun, X.; Liu, A.X. Dynamic resource allocation for load balancing in fog environment. Wirel. Commun. Mob. Comput. 2018, 2018, 6421607. [Google Scholar] [CrossRef]
- Fawwaz, D.Z.; Chung, S.H.; Lee, H. Dynamic IoT-Fog Task Allocation using Many-to-One Shortest Path Algorithm. In Proceedings of the 2019 IEEE International Conference on Internet of Things and Intelligence System (IoTaIS), Bali, Indonesia, 5–7 November 2019; pp. 244–247. [Google Scholar]










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| ObjectProperty | Domain | Range |
|---|---|---|
| hasRequirement | Software | Resource |
| hasComputationalRequirement | Software | ComputationalResource |
| hasFunctionalRequirement | Software | FunctionalResource |
| hasResource | ComputingNode | Resource |
| hasComputationalResource | ComputingNode | ComputationalResource |
| hasFunctionalResource | ComputingNode | FucntionalResource |
| installedOn | Software | ComputingNode |
| connectedTo (Symm) | ComputingNode | ComputingNode |
| physicallyLocatedAt (Trans) | ComputingNode or Resource | Location |
| ObjectProperty | Domain | Range |
|---|---|---|
| hasLatitude | GeoLocation | xsd:double |
| hasLongitude | GeoLocation | xsd:double |
| hasUnit | ComputationalResource | xsd:string |
| hasValue | ComputationalResource | - |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Karanik, M.; Bernabé-Sánchez, I.; Fernández, A. Ontological Modeling and Clustering Techniques for Service Allocation on the Edge: A Comprehensive Framework. Electronics 2024, 13, 477. https://doi.org/10.3390/electronics13030477
Karanik M, Bernabé-Sánchez I, Fernández A. Ontological Modeling and Clustering Techniques for Service Allocation on the Edge: A Comprehensive Framework. Electronics. 2024; 13(3):477. https://doi.org/10.3390/electronics13030477
Chicago/Turabian StyleKaranik, Marcelo, Iván Bernabé-Sánchez, and Alberto Fernández. 2024. "Ontological Modeling and Clustering Techniques for Service Allocation on the Edge: A Comprehensive Framework" Electronics 13, no. 3: 477. https://doi.org/10.3390/electronics13030477
APA StyleKaranik, M., Bernabé-Sánchez, I., & Fernández, A. (2024). Ontological Modeling and Clustering Techniques for Service Allocation on the Edge: A Comprehensive Framework. Electronics, 13(3), 477. https://doi.org/10.3390/electronics13030477