4.1.1. Heterogeneous Hypergraph Embedding
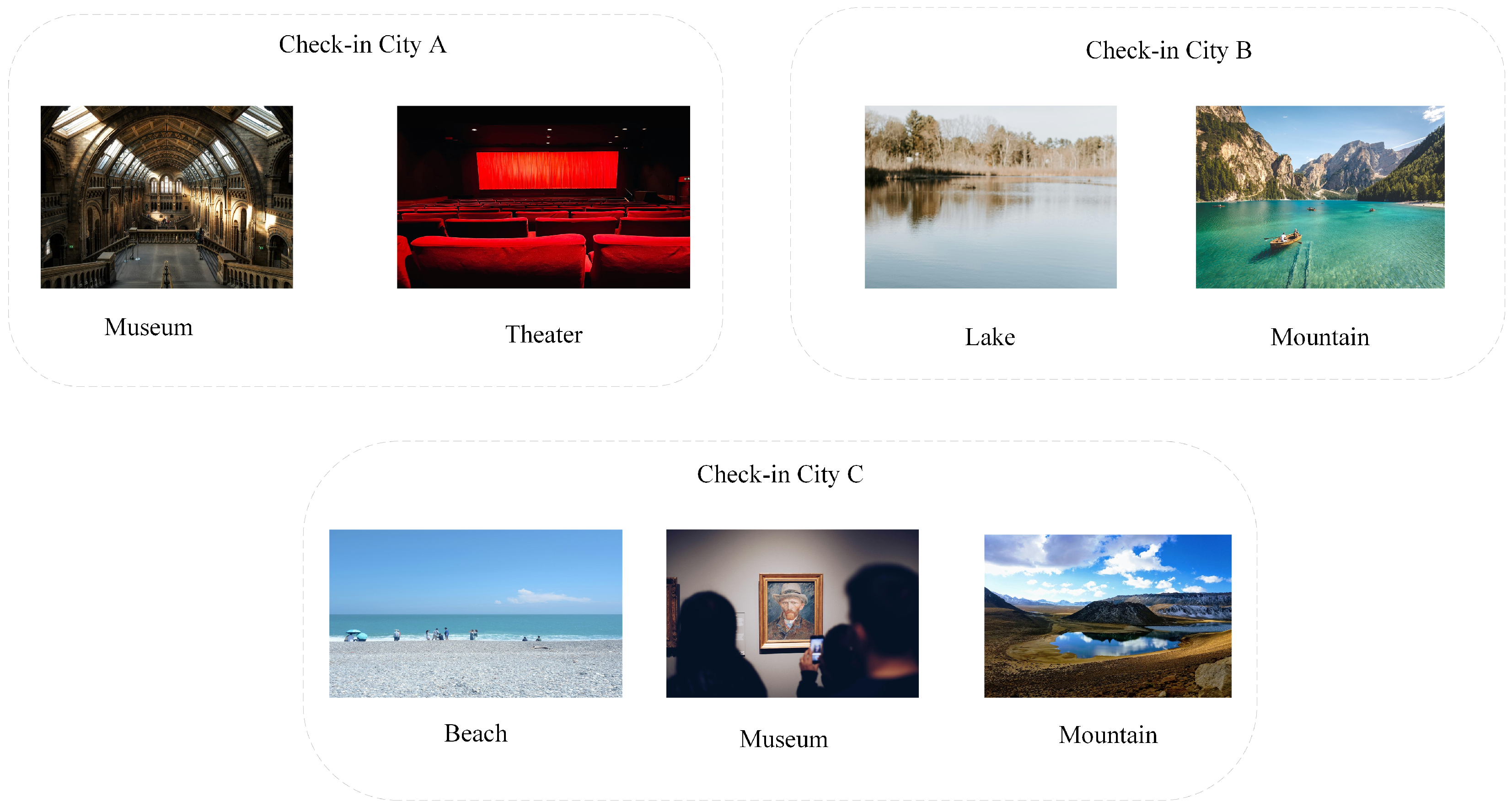
Before users arrive at their target city, they not only check in at the source city but may also check in at other cities along the way. Previous studies typically address these check-ins by either deleting the check-ins made in other cities or treating them as check-ins at the source city. Such methods result in information loss and distort data, leading to biases in the extraction of user preferences.
Table 1 summarizes the assumption methods used in past research for handling user check-ins.
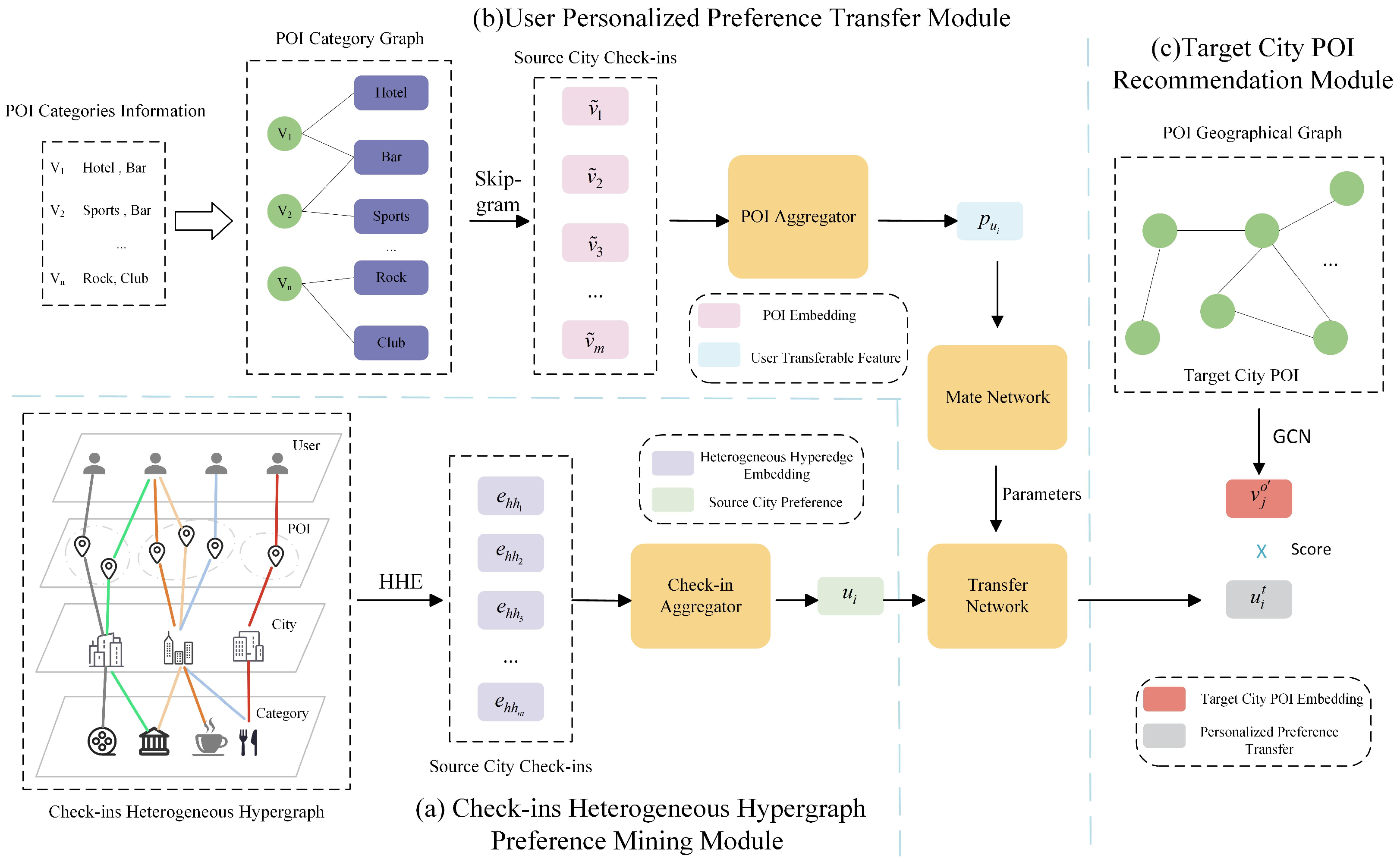
In cross-city recommendation scenarios, multiple types of relationships exist between users, POI, and geographical locations. For instance, there is a check-in relationship between users and POI, a geographical distance relationship between POI, and a category affiliation relationship between POI and their respective categories. However, traditional graph models are often inadequate for handling such diverse relationships simultaneously. In contrast, heterogeneous hypergraphs can accommodate various nodes and relationship types within a single framework, offering a more comprehensive representation of the data. To address these challenges, this paper proposes constructing a heterogeneous hypergraph for modeling user check-ins.
For a user, check-ins may occur in multiple cities. To better categorize a user’s multiple check-ins, it is essential to recognize that POI within the same city exhibit spatial similarity, adhering to the First Law of Geography. Similarly, POI in different cities may be interconnected due to their similar category information or because they have been checked into by the same user.
The check-in heterogeneous hypergraph comprises four distinct types of nodes . Each hyperedge includes four nodes, each belonging to a different type. This configuration distinguishes the POI checked into by the same user in different cities through city nodes. Additionally, POI from different cities are connected via user and category nodes.
The heterogeneous hyperedges in the check-in heterogeneous hypergraph are constructed based on users’ check-in records, reflecting the interactive relationships among different objects within the hyper-edges. Four distinct types of nodes are included in this heterogeneous hypergraph. Unlike homogeneous hypergraphs, there are two critical aspects of heterogeneous hypergraphs that must not be overlooked:
- (1)
Indecomposability: In a heterogeneous hypergraph, hyperedges are typically indecomposable, meaning that the nodes within a hyperedge exhibit strong relationships, whereas the subset of nodes may not. For instance, in the “user, region, POI, category” cross-city POI recommendation model, the relationship between “user” and “category” is generally weak. Consequently, traditional hypergraph learning methods that decompose hyperedges cannot be employed;
- (2)
Structural Preservation: Network embedding typically preserves local structures through observable relationships. However, due to network sparsity, many existing relationships are unobservable, and preserving the entire hypergraph structure solely through local structures is insufficient. Global structures, such as neighborhood structures, are also affected by data sparsity.
To address this, this paper proposes HHE, as shown in
Figure 3.
For the check-in heterogeneous hypergraph, according to the theory presented in [
22], it must satisfy both first-order and second-order similarities. Specifically, first-order similarity refers to the relationships between vertices within a hyperedge. For
m nodes, if these
m nodes
simultaneously exist within the same hyperedge and the subsets of these nodes do not form hyperedges, then these
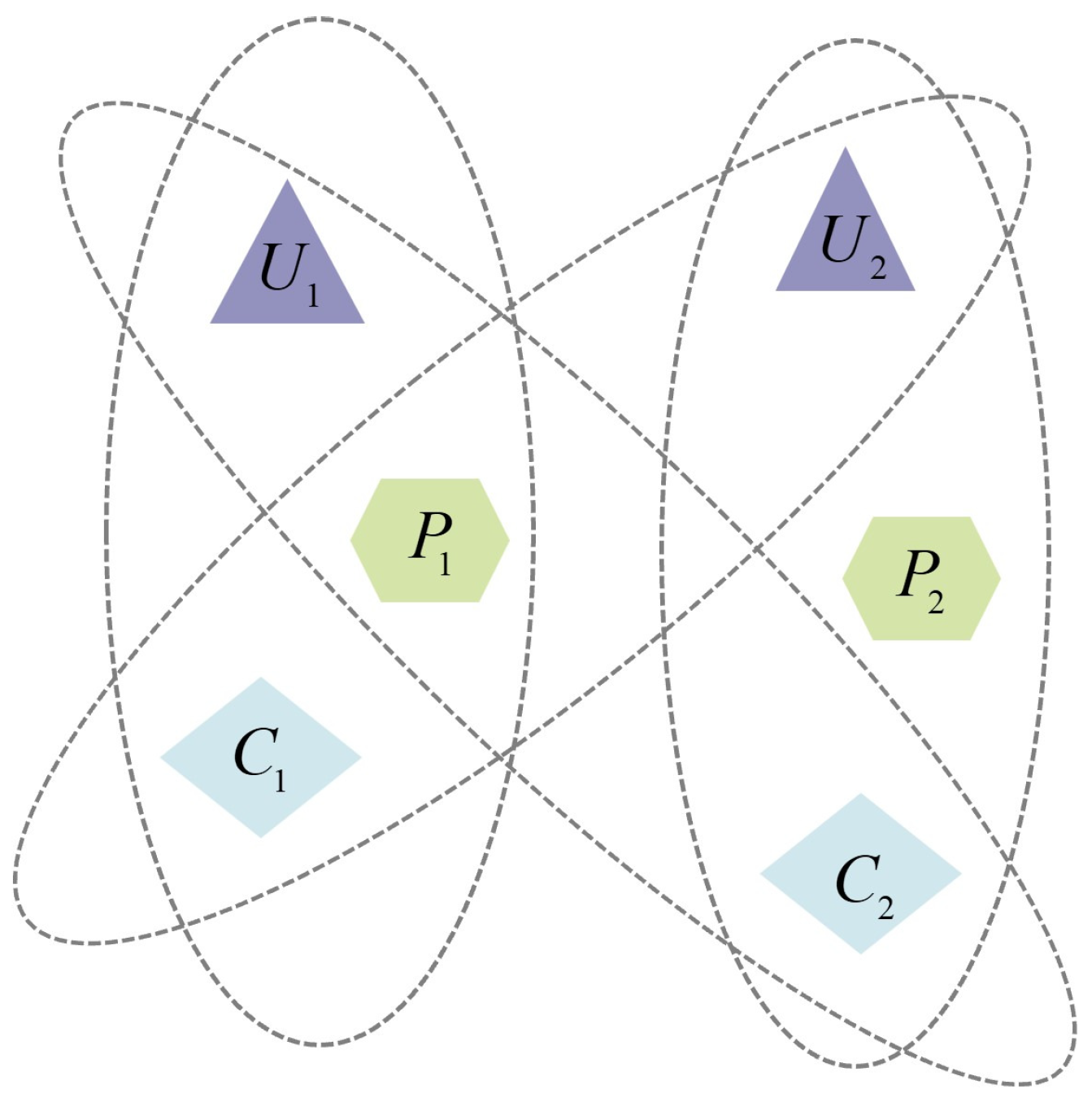
m nodes satisfy first-order similarity, which is defined as 1. Second-order similarity measures the similarity between the neighborhoods of nodes. To better illustrate second-order similarity, as shown in
Figure 4, a dashed ellipse represents a heterogeneous hyperedge. In this example, the neighborhood nodes of
include
, and the neighborhood nodes of
include
. Since both
and
share the node
, both
and
satisfy second-order similarity.
Since, in cross-city POI recommendations, users may check in at the same point multiple times, a weight is assigned to each hyperedge in the heterogeneous hypergraph . A hyperedge weight matrix of size is defined, where represents the number of times that a user has checked in at a POI within the hyperedge , and .
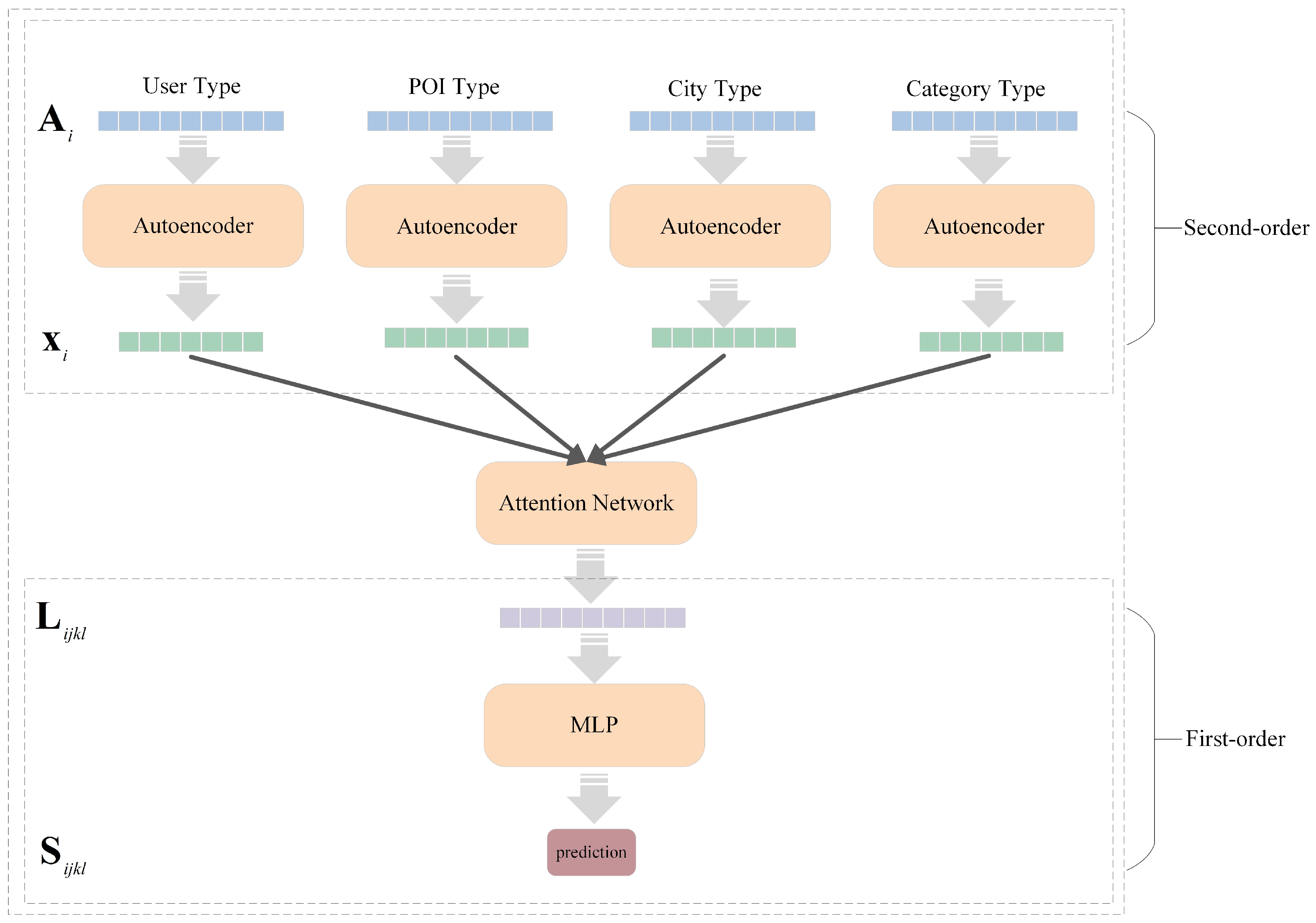
To obtain the adjacency matrix of the heterogeneous hypergraph, it is necessary to define the incidence matrix and the degree matrix separately. The degree matrix is derived from the hyperedge weight matrix and the incidence matrix . The incidence matrix has a size of , where , and indicates ; otherwise, it equals 0. is a diagonal matrix, with diagonal elements representing the degree of the corresponding vertices. The vertex degree is obtained by , where represents the weight corresponding to hyperedge in matrix .
The adjacency matrix
, where the superscript
T denotes the transpose of a matrix. The values in the adjacency matrix represent the co-occurrence frequency between two nodes. Each row of the adjacency matrix represents the neighborhood information of the current node. To better preserve the neighborhood information of the nodes, the nodes in the adjacency matrix are reencoded using an autoencoder [
23], with the adjacency matrix as the input. The encoder and decoder are described by the following formulas:
Here, is the i-th row of the adjacency matrix, and are weight matrices, and are bias vectors, and represents the Sigmoid function. ; here, is the embedding matrix of the nodes in the heterogeneous hypergraph.
The autoencoder has the capability to extract features and reconstruct encoding by minimizing the error between the input and output. This reconstruction process preserves the neighborhood information of nodes, thereby maintaining the second-order similarity between nodes. Since the adjacency matrix of the heterogeneous hypergraph is highly sparse, to accelerate the training speed of the model, only the non-zero elements of the adjacency matrix are reconstructed. The reconstruction error is shown as follows:
Here, ⊙ represents element-wise multiplication, and is the sign function.
Furthermore, the vertices in the heterogeneous hyperedges have different types. Considering that nodes of different types may have distinct embedding representations, each type of node has its own autoencoder. The reconstruction loss is shown as follows:
Here, t is the number of node types.
By employing an attention network, the embeddings of four nodes
are used as inputs to obtain a joint embedding representation, as shown below:
Here, represents the joint embedding, is the Sigmoid function, and and are the weight matrix and bias vector, respectively.
After obtaining
, it is mapped to a probability space through a non-linear layer to obtain the similarity:
Here
is the Sigmoid function,
and
are the weight matrix and the bias vector, and the loss function is shown in the following equation:
Define to be 1 if there is a hyperedge between ; otherwise, it is 0. If equals 1, the similarity should be larger; otherwise, the similarity is smaller. In other words, first-order similarity is preserved.
Finally, to simultaneously preserve first-order and second-order proximities, Equations (4) and (7) are combined to derive the final loss function:
Here,
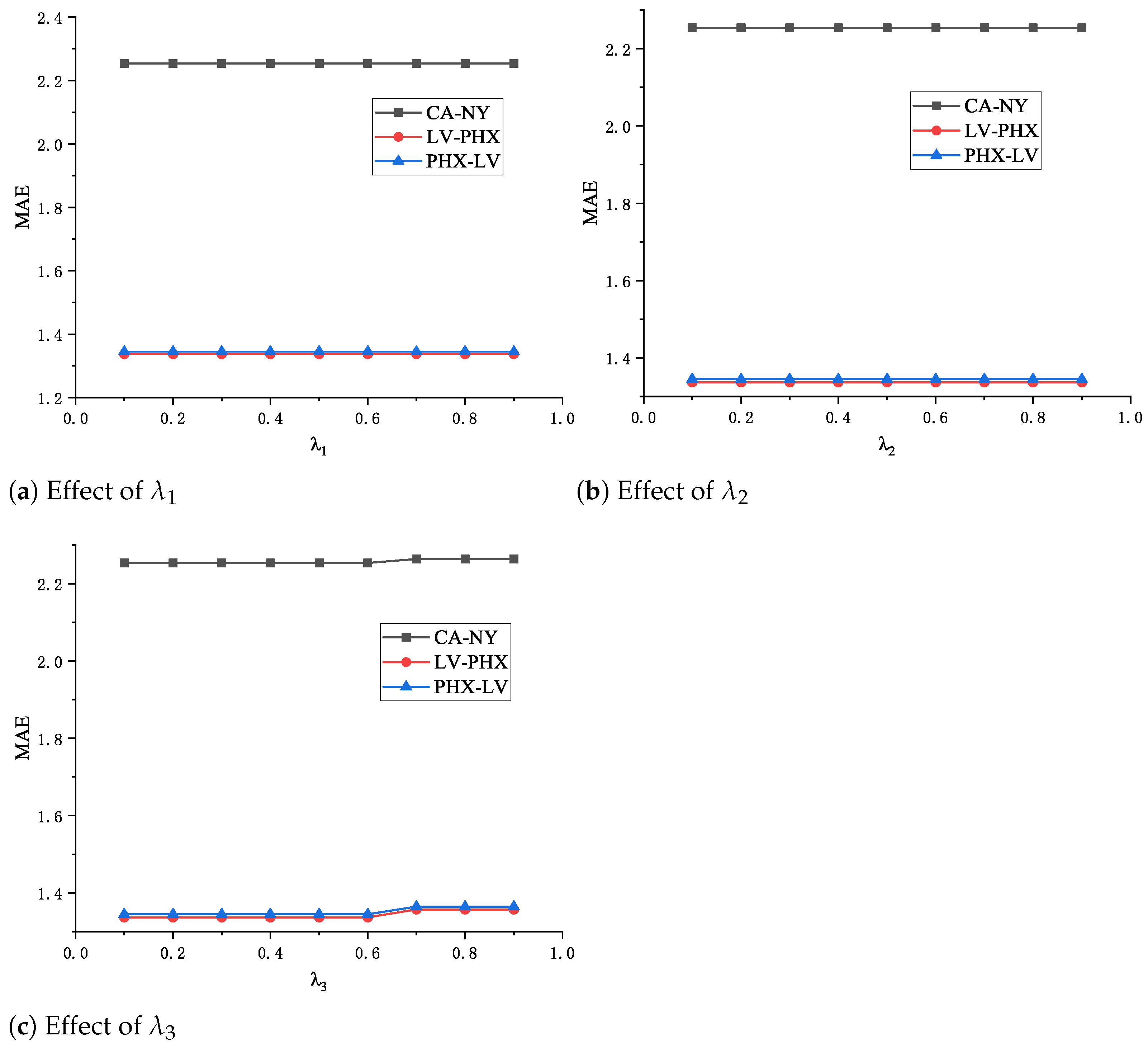
is a hyperparameter used to regulate the effect of
on total losses. The whole algorithm is shown in Algorithm 1.
| Algorithm 1: Heterogeneous Hypergraph Embedding (HHE) |
- Input:
Check-in heterogeneous hypergraph , Incidence matrix , Degree matrix , Adjacency matrix - Output:
Node embedding matrix - 1:
Initialize the weight parameters - 2:
while not converge do - 3:
Encode the nodes of different types according to Equation ( 1) - 4:
Decode according to Equation ( 2) - 5:
Calculate the reconstruction loss according to Equation ( 4) - 6:
Obtain the joint embedding of the four different types of nodes according to Equation (5) - 7:
Calculate the similarity according to Equation ( 6) - 8:
Compute the loss according to Equation ( 7) - 9:
Calculate the joint loss function according to Equation ( 8) and update the parameters - 10:
end while - 11:
return the node embedding matrix
|





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}