4.2.3. Comparison Experiments of Benchmark Models
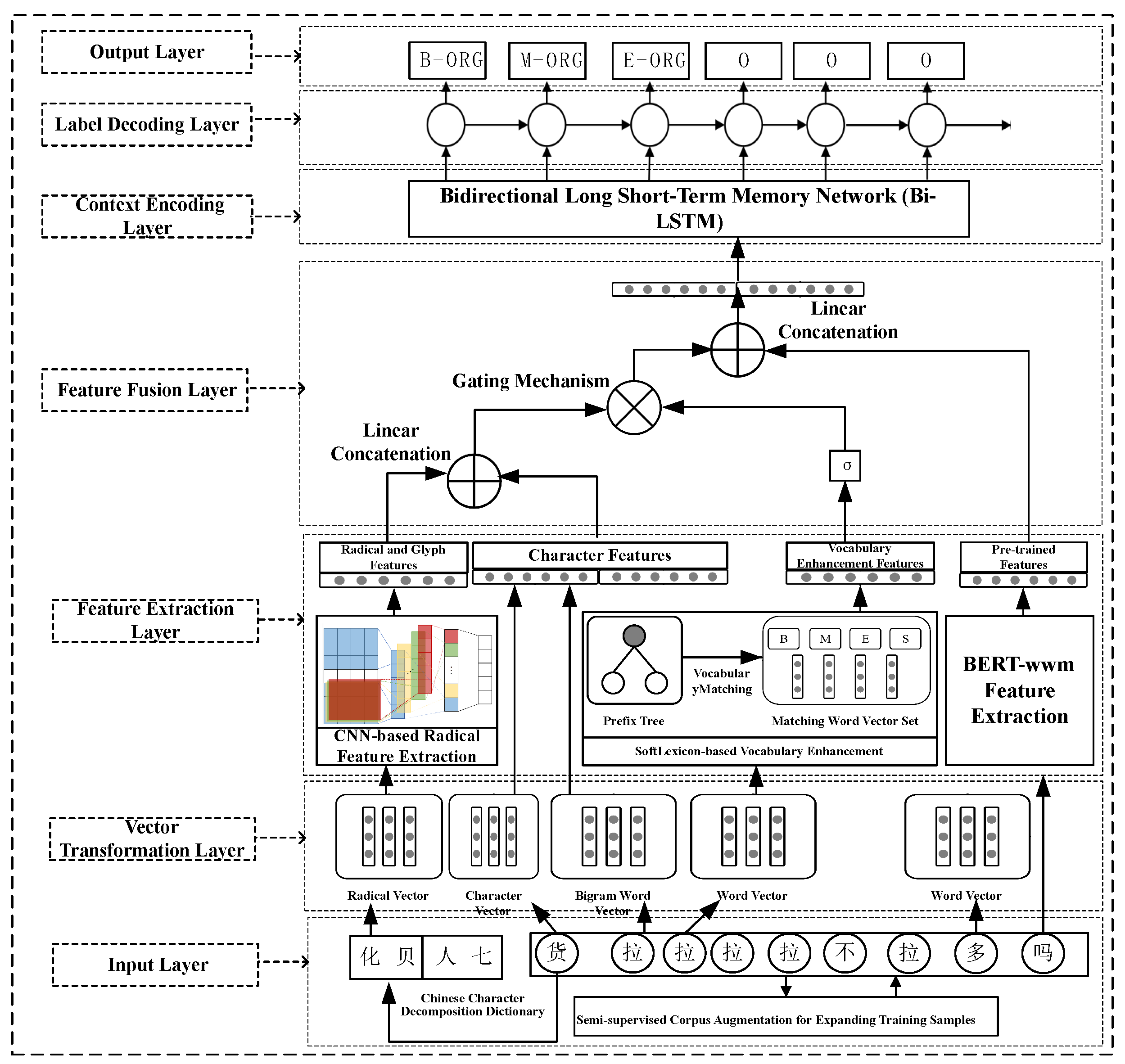
This subsection aims to verify the effectiveness of the features proposed in this paper for optimizing the performance of Chinese named entity recognition. It first conducts self-comparative experiments to evaluate the impact of radical and glyph feature extraction, lexical enhancement, pre-training modules, and their combinations on entity recognition performance. Then, the proposed multi-feature entity recognition model is compared with other classical Chinese named entity recognition methods that enhance lexical information to validate its effectiveness.
The specific self-comparative experiments include the following:
Radical: Only the radical and glyph features are used to enhance character features, followed by entity recognition using the LSTM-CRF network. Lexicon: Only the lexical enhancement strategy is used to enhance character features. Radical+Lexicon: Combines radical and glyph features with character features, followed by lexical enhancement. Radical+Lexicon+BERT-wwm: Combines radical and glyph features, lexical enhancement features, and BERT pre-training features. Comparative experiments with other methods include the following:
Lattice-LSTM [
14]: Introduced lexical enhancement into CER but had processing issues. WC-LSTM [
19]: Proposed a lexical encoding strategy for parallel computation and portability but suffered from information loss. LR-CNN (2019) [
34]: Used attention mechanisms to handle lexical conflicts but was computationally complex.
SoftLexicon (2020) [
20]: Adaptive lexical enhancement, fully utilizing all lexical information, with strong model independence. FLAT (2020) [
18]: Introduced position encoding and self-attention mechanisms, solving issues of lexical loss and long-distance dependencies. The FLAT model does not report Precision (P) and Recall (R) due to its focus on other evaluation metrics like F1-score and structural accuracy, which better capture the model’s performance in handling complex sequence labeling tasks. FLAT is typically evaluated using F1-score, which balances both precision and recall, providing a more comprehensive view of performance, especially in multi-label or multi-class problems where the balance between false positives and false negatives is crucial. MECT (2021) [
35]: Improved on FLAT by integrating a dual-stream attention mechanism with radical and glyph information to enhance accuracy. Additionally, the paper compares models such as Word-LSTM-CRF (direct segmentation), Char-LSTM-CRF (no segmentation), and BERT-LSTM-CRF (inputting characters into a pre-trained BERT model).
The models were run on four Chinese named entity recognition public datasets: Resume, Weibo, MSRA, and OntoNotes4, with the following results:
- (1)
Resume dataset [
14] comparative experiment results.
It can be seen from
Table 4 that, in the Resume dataset, due to the high quality of the text and dense entity information, all models showed high accuracy. Models based on the Radical and Lexicon strategies outperformed the Char-LSTM-CRF model in terms of accuracy, recall rate, and F1 score, demonstrating the effectiveness of root and glyph features and lexical enhancement features. The Lexicon model performed better than the Radical model, indicating a greater contribution of lexical enhancement to performance improvement.
The Radical+Lexicon model surpassed models using Radical or Lexicon strategies alone, matching the performance of the latest MECT lexical enhancement strategy, proving the effectiveness of the multi-feature fusion strategy based on gating mechanisms. The Radical+Lexicon+BERT-wwm strategy showed the best performance, with the highest accuracy, recall rate, and F1 score, reaching 96.44%. Compared to the traditional BERT-LSTM-CRF model, the root and glyph features and lexical enhancement strategy also improved the BERT pre-trained model, although the increase was limited due to the well-annotated Resume dataset.
As shown in
Figure 7, the Radical+Lexicon+BERT-wwm multi-feature fusion model has the fastest decline in loss function and ultimately the smallest loss, indicating the effectiveness of the proposed multi-feature fusion model and its advantage in training speed.
In summary, the entity recognition strategy based on multi-feature fusion proposed in this paper is the best, achieving the highest F1 score. Next is the Radical+Lexicon multi-feature fusion strategy without pre-training features, followed by the Lexicon lexical enhancement strategy alone, then the Radical root and glyph feature strategy alone, and finally, the simple Char-LSTM-CRF and Word-LSTM-CRF models.
- (2)
Weibo dataset [
14] comparative experiment results.
It can be seen from
Table 5 that, in the comparative experiments on the Weibo dataset, due to the diversity of text entity categories and issues like irregular and colloquial text, the accuracy of various models was generally low. The F1 score of the Word-LSTM-CRF model was 5.44 percentage points lower than that of the Char-LSTM-CRF model, indicating that, in irregular texts, incorrect segmentation affects entity boundary recognition and thus reduces performance. The Char-LSTM-CRF model, based on character input, performed better than the Word-LSTM-CRF model, based on word segmentation.
Models based on Radical and Lexicon strategies had higher accuracy, recall rate, and F1 score than Char-LSTM-CRF, demonstrating that root and glyph features and lexical enhancement can improve model performance. The Lexicon strategy significantly enhanced performance for irregular texts like Weibo, increasing by 9.95 percentage points. The Radical+Lexicon model outperformed models using only Radical or Lexicon strategies and exceeded the latest MECT strategy, making it suitable for scenarios with small training sets and irregular annotations.
The Radical+Lexicon+BERT-wwm strategy achieved the highest F1 score of 69.40%, an increase of 4.99 percentage points compared to the Radical+Lexicon model, indicating that, for irregular texts like Weibo, BERT features, with their large-scale unsupervised corpus knowledge, significantly impact performance improvement. Compared to the traditional BERT model, the Radical+Lexicon+BERT-wwm model improved by 2 percentage points, demonstrating that the multi-feature fusion strategy is still applicable on BERT models, further enhancing the performance of BERT entity recognition models.
This demonstrates that the entity recognition strategy based on multi-feature fusion proposed in this paper is the best, achieving the highest F1 score. Next is the Radical+Lexicon multi-feature fusion strategy without pre-training features, followed by the Lexicon lexical enhancement strategy alone, then the Radical root and glyph feature strategy alone, and finally, the simple Char-LSTM-CRF and Word-LSTM-CRF models.
- (3)
MSRA dataset [
14] comparative experiment results.
It can be seen from
Table 6 that, in the MSRA dataset, due to its large scale and fewer categories, all models show high accuracy. The F1 score of the Word-LSTM-CRF model is 2 percentage points lower than that of the Char-LSTM-CRF model, indicating that models based on character input perform better than those based on word segmentation.
Models based on Radical and Lexicon strategies have higher F1 scores than the Char-LSTM-CRF model that uses only character sequences, proving the effectiveness of root and glyph features and lexical enhancement features. The Radical+Lexicon model outperforms models using either Radical or Lexicon alone and is slightly better than the latest MECT strategy by 0.25 percentage points, validating the effectiveness of the multi-feature fusion strategy.
The Radical+Lexicon+BERT-wwm multi-feature fusion model achieves the highest F1 score in all experiments, reaching 95.40%, while the Radical+Lexicon model also achieves 95.08%. However, the improvement from BERT features is not significant, suggesting that, for large-scale corpora like MSRA, traditional models already perform well, and BERT features offer limited performance enhancement. Compared to the traditional BERT model, the Radical+Lexicon+BERT-wwm model shows a slight increase of 0.4 percentage points in F1 score.
- (4)
OntoNotes4 dataset [
14] comparative experiment results.
From
Table 7, it is observed that the F1 score of the Word-LSTM-CRF model is 1.33 percentage points higher than that of the Char-LSTM-CRF model, indicating that character-based recognition models are not always superior to word segmentation-based models.
Models based on Radical and Lexicon strategies significantly outperform the Char-LSTM-CRF model, which only uses character sequences. This demonstrates the effectiveness of root feature enhancement and lexical feature enhancement, with lexical enhancement proving to be more effective than root and glyph feature enhancement. The Radical+Lexicon model surpasses models using either Radical or Lexicon strategies alone and is 2.2 percentage points higher than the newly proposed MECT strategy, validating the effectiveness of the multi-feature fusion strategy based on gating mechanisms. The Radical+Lexicon+BERT-wwm model proposed in this paper achieves the highest F1 score of 81.89% among all algorithms, proving the effectiveness of the multi-feature fusion model. However, the improvement in the F1 score of the BERT-LSTM-CRF model to 81.82% is not very significant.
4.2.4. Optimization Effect Verification Experiment
- (1)
Experiment to Verify the Optimization Effect of the Adaptive DSC Loss Function
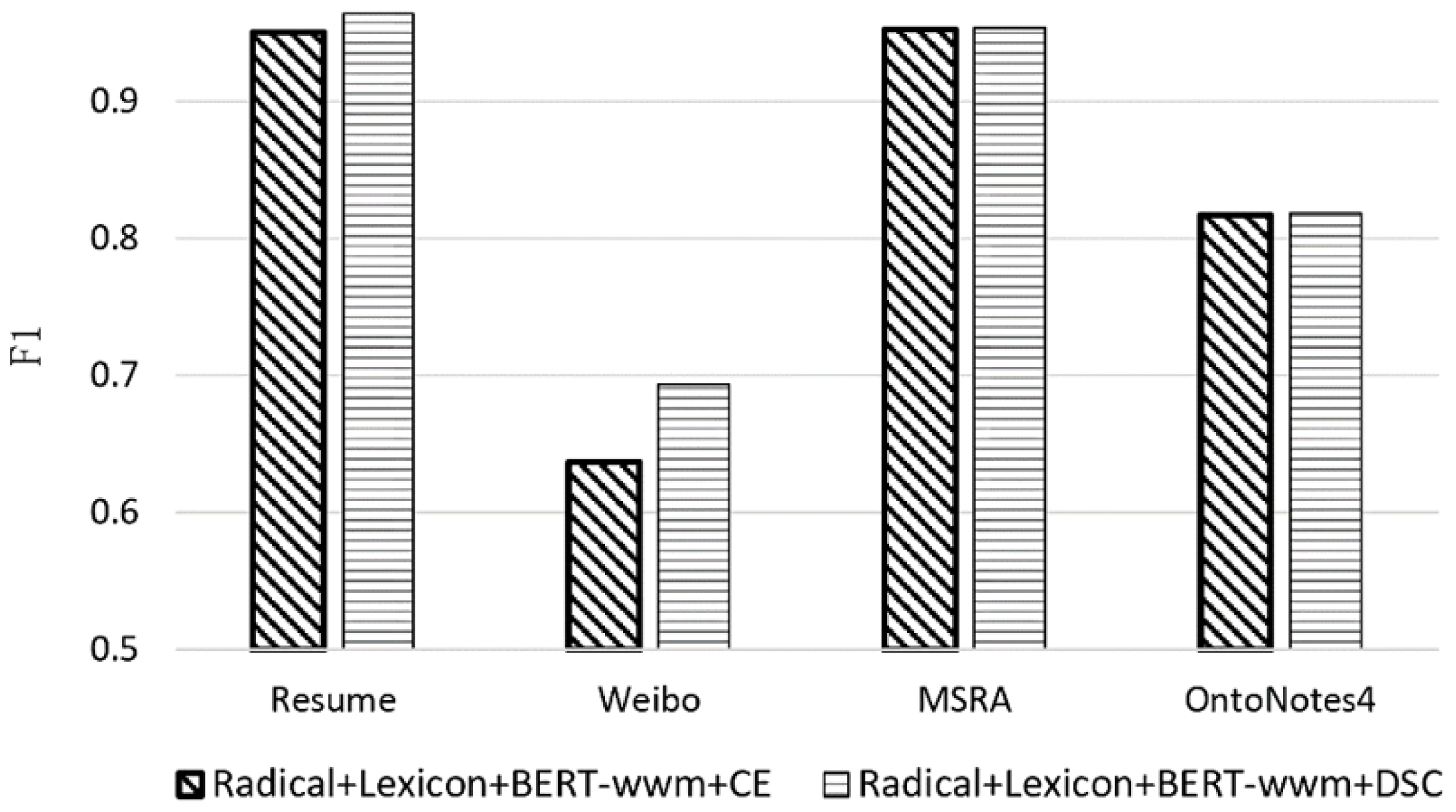
The purpose of this experiment is to verify the effect of the adaptive DSC loss function optimization on the performance of the multi-feature semantic enhancement entity recognition model. The model used in this experiment is the Radical+Lexicon+BERT-wwm model, and the main variable is the loss function used by the model, i.e., the traditional Cross-Entropy (CE) loss function or the adaptive DSC loss function. The F1 value is still used as the evaluation metric, with a higher F1 value indicating better entity recognition performance by the model. The experimental results are shown in
Table 8 and
Figure 8.
From
Table 8, it is evident that the multi-feature fusion models using the adaptive DSC loss function have higher F1 scores on all four CER datasets compared to when using the cross-entropy (CE) loss function.
The improvement was more pronounced in the less standard Weibo and Resume datasets, where there are many entity categories with significant category bias. In contrast, the MSRA and OntoNotes4 datasets, with fewer entity categories, more balanced data, and more annotated samples, showed less improvement with the DSC loss function.
Taking the Resume dataset as an example, the accuracy of the Radical+Lexicon+BERT-wwm+DSC model was 96.61%, and the recall rate was 96.26%, with a small deviation between accuracy and recall. Meanwhile, the Radical+Lexicon+BERT-wwm+CE model had an accuracy of 97.61% and a recall rate of 92.26%, with a larger deviation between the two.
This suggests that the adaptive DSC loss function balances Precision and Recall, bringing them closer together, thereby improving the F1 score.
The results in
Table 8 show that models using the adaptive loss function achieved higher F1 values. Therefore, the adaptive DSC loss function can optimize the entity recognition performance of models, especially in smaller datasets and those with sample category bias.
- (2)
Experiment to Verify the Effectiveness of Data Augmentation Optimization
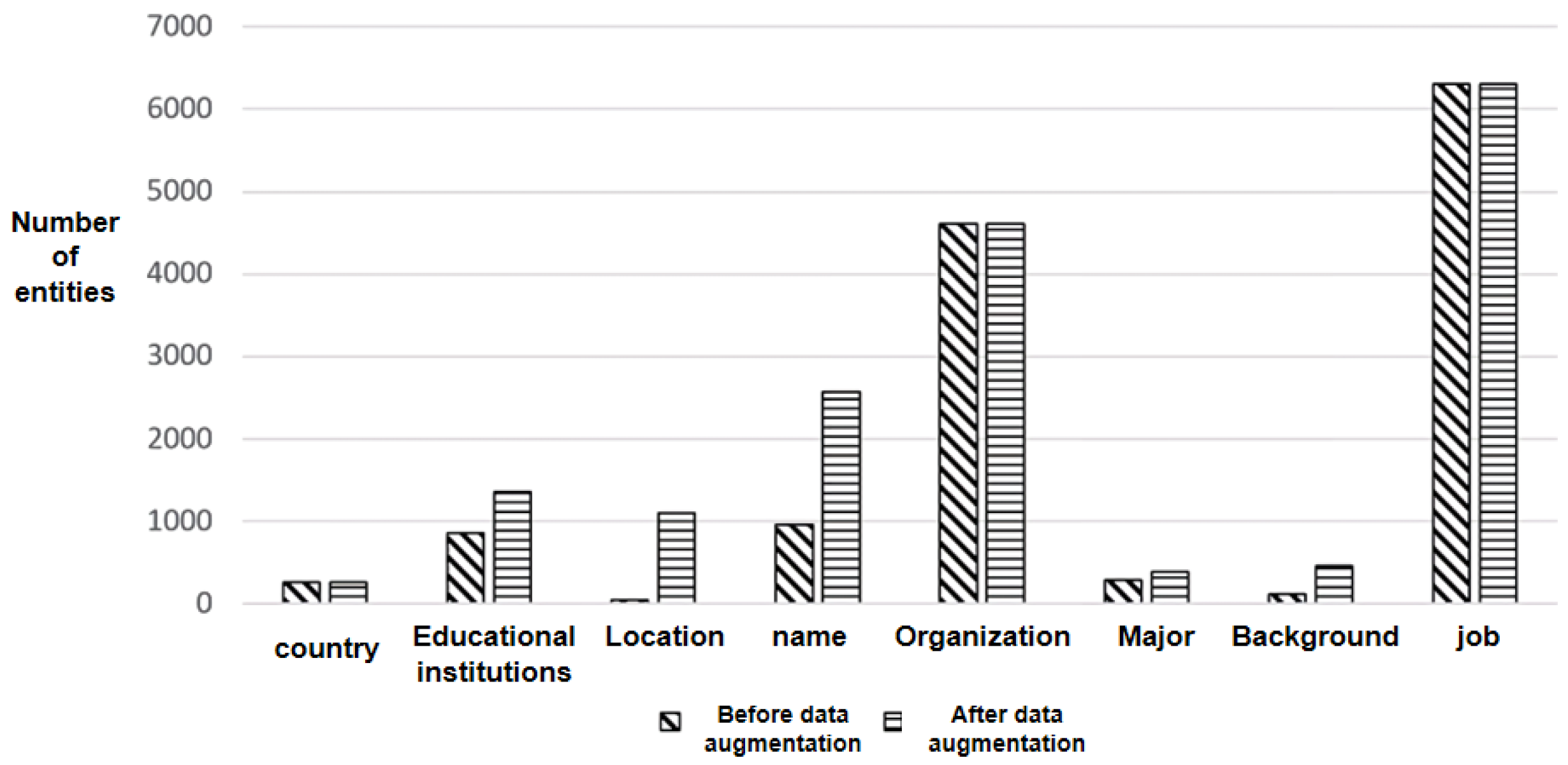
This experiment aims to verify the impact of data augmentation optimization on the performance of the multi-feature semantic enhancement entity recognition model. Data augmentation methods under BERT-like pre-trained models show no significant effect and might even degrade performance due to the introduction of noise. It is also challenging to distinguish whether the improvement in model performance is due to data augmentation strategies or BERT features. Therefore, this experiment does not use BERT pre-trained features. Experiment 1 utilizes the Radical+Lexicon feature fusion model, while Experiment 2 applies data augmentation to the training set under the Radical+Lexicon feature fusion strategy. The comparison before and after data augmentation for the Resume dataset is shown in
Figure 9.
Before data augmentation, the data distribution in the Resume dataset was very imbalanced. After augmenting samples with fewer quantities, data augmentation significantly increased the presence of underrepresented entity categories like names and locations, reducing the impact of uneven entity distribution.
In this experiment, the F1 value is used as the evaluation metric, with higher F1 values indicating better entity recognition performance. It can be seen from
Table 9, the Radical+Lexicon model, after data augmentation, achieved higher recall rates, accuracy, and F1 values on all four CER datasets compared to the model without data augmentation. Particularly on the Weibo dataset, there was an increase of 1.05 percentage points. This suggests that data augmentation significantly improves performance in scenarios with many category labels, irregular annotations, and small sample sizes, while in situations with fewer category labels and more training data, like the MSRA dataset, the improvement is less pronounced. These results indicate that data augmentation for datasets with imbalanced category labels can effectively enhance overall performance in CER.
4.2.5. Ablation Control Experiment
- (1)
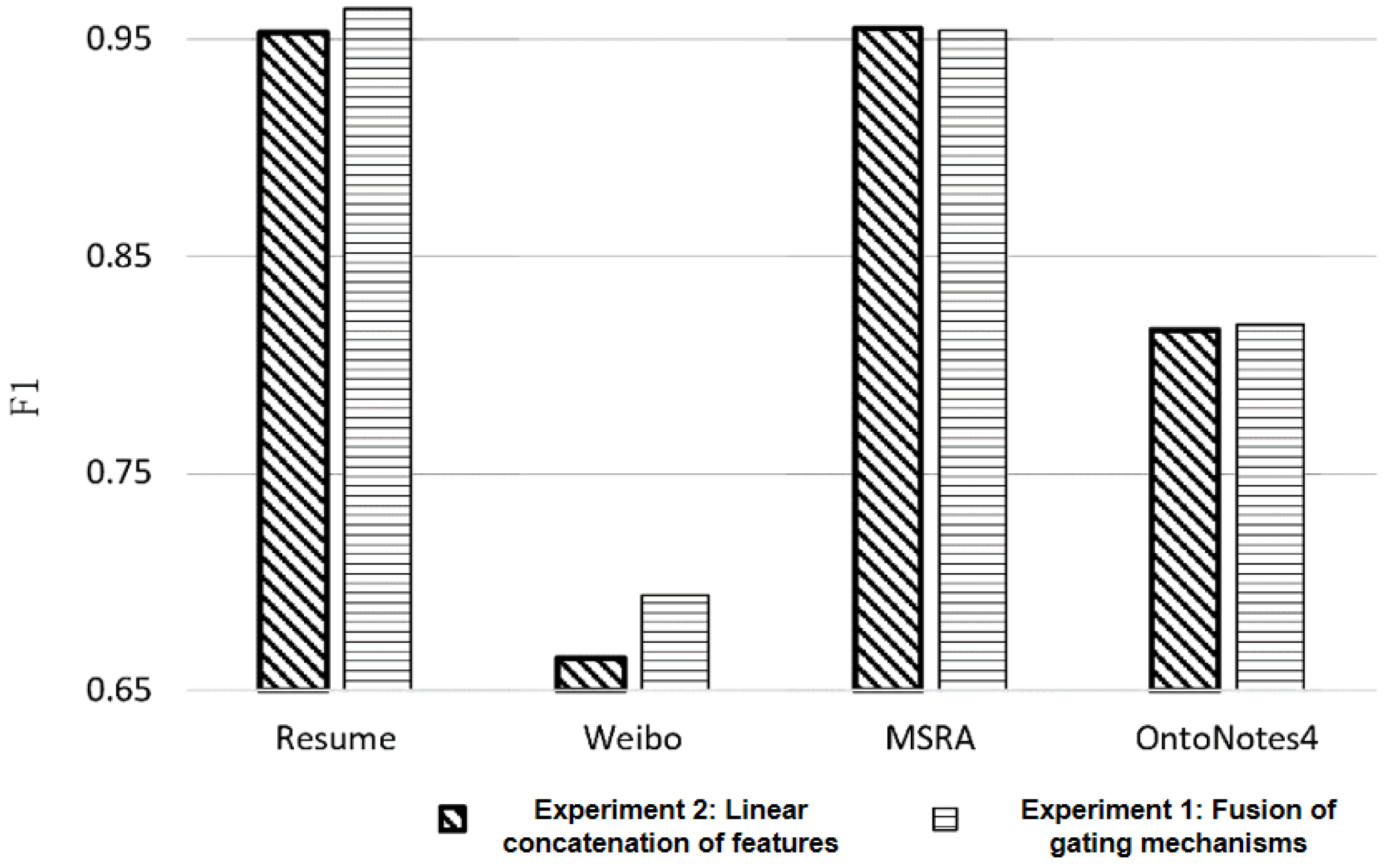
Control experiment of ablation with feature fusion mode
The purpose of this experiment is to verify the impact of the multi-feature fusion based on the gating mechanisms proposed in this paper on the performance of entity recognition models. The experiment was conducted on four Chinese open-source entity recognition datasets: Resume, Weibo, MSRA, and OntoNotes4. Experiment 1 is based on the Radical+Lexicon+BERT-wwm+DSC model and employs the feature fusion strategy based on the gating mechanisms proposed in this paper. Experiment 2, under the same conditions as Experiment 1, directly uses linear concatenation for the fusion of the extracted four features.
Table 10 and
Figure 10 show that the multi-feature fusion based on gating mechanisms significantly improves entity recognition performance in small-scale datasets, such as the Weibo and Resume datasets, with F1 scores increasing by 1.12 and 2.89 percentage points, respectively. This validates the effectiveness of the proposed multi-feature fusion method.
However, on large-scale and well-annotated datasets like OntoNotes4, the performance improvement with the gating mechanism-based multi-feature fusion is not significant, showing only a 0.26 percentage point increase. On the MSRA dataset, the F1 score of the linear concatenation strategy even surpasses the gating mechanism-based feature fusion model by 0.11 percentage points. This may be because the models on large-scale datasets with standardized annotations are already performing at a high level and are difficult to further improve. On the other hand, linear concatenation, by increasing the number of parameters in the fully connected layer, fits better in datasets with more training data. Therefore, future work could consider introducing more complex fusion strategies, such as multi-layer attention mechanisms or more intricate gating network models, to utilize more parameters for better model fitting.
- (2)
Control experiments of ablation with different dictionaries
This experiment aims to verify the impact of different dictionaries on the performance of multi-feature fusion entity recognition models, using datasets including the Resume and Weibo datasets. Experiment 1 utilizes the Radical+Lexicon+YJ dictionary model, while Experiment 2, under the same conditions, employs the Radical+Lexicon+LS dictionary for lexical feature fusion.
As seen in
Table 11, the effectiveness of vocabulary enhancement varies with different dictionaries. On the Resume dataset, the F1 score using the YJ dictionary is 0.76 percentage points higher than with the LS dictionary. Conversely, on the Weibo dataset, the Radical+Lexicon model based on the LS dictionary outperforms the YJ-based one by 0.75 percentage points. This indicates that integrating specific domain dictionaries is significant for improving domain entity recognition performance. The LS dictionary, sourced from Zhihu and Weibo, adapts better to the Weibo dataset but is less effective than the YJ dictionary in the more formal language context of the Resume dataset.
In summary, the multi-feature fusion entity recognition model proposed in this paper effectively utilizes lexical features, radical and glyph features, and pre-training features to uncover hidden semantic information, thereby enhancing context semantic analysis and improving entity recognition accuracy. The proposed multi-feature fusion strategy performs best across all four datasets, followed by the Radical+Lexicon strategy without pre-training features, then the Lexicon vocabulary enhancement strategy alone, the Radical root and glyph feature strategy alone, and finally, the Char-LSTM-CRF and Word-LSTM-CRF models. Additionally, the data augmentation and adaptive DSC loss function optimization proposed in this paper can improve sequence entity recognition performance to varying degrees.











{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}