
Applied Research on Face Image Beautification Based on a Generative Adversarial Network

Abstract
1. Introduction
- (1)
- A face image beautification network that can generate images with different beautification styles through adjusting the beautification intensity for the target features of an image is constructed.
- (2)
- A beautification style intensity loss function is designed to preserve the similarity of the generated image to the original image during the process of beautification in order to avoid the generated image being biased toward the original or style image.
- (3)
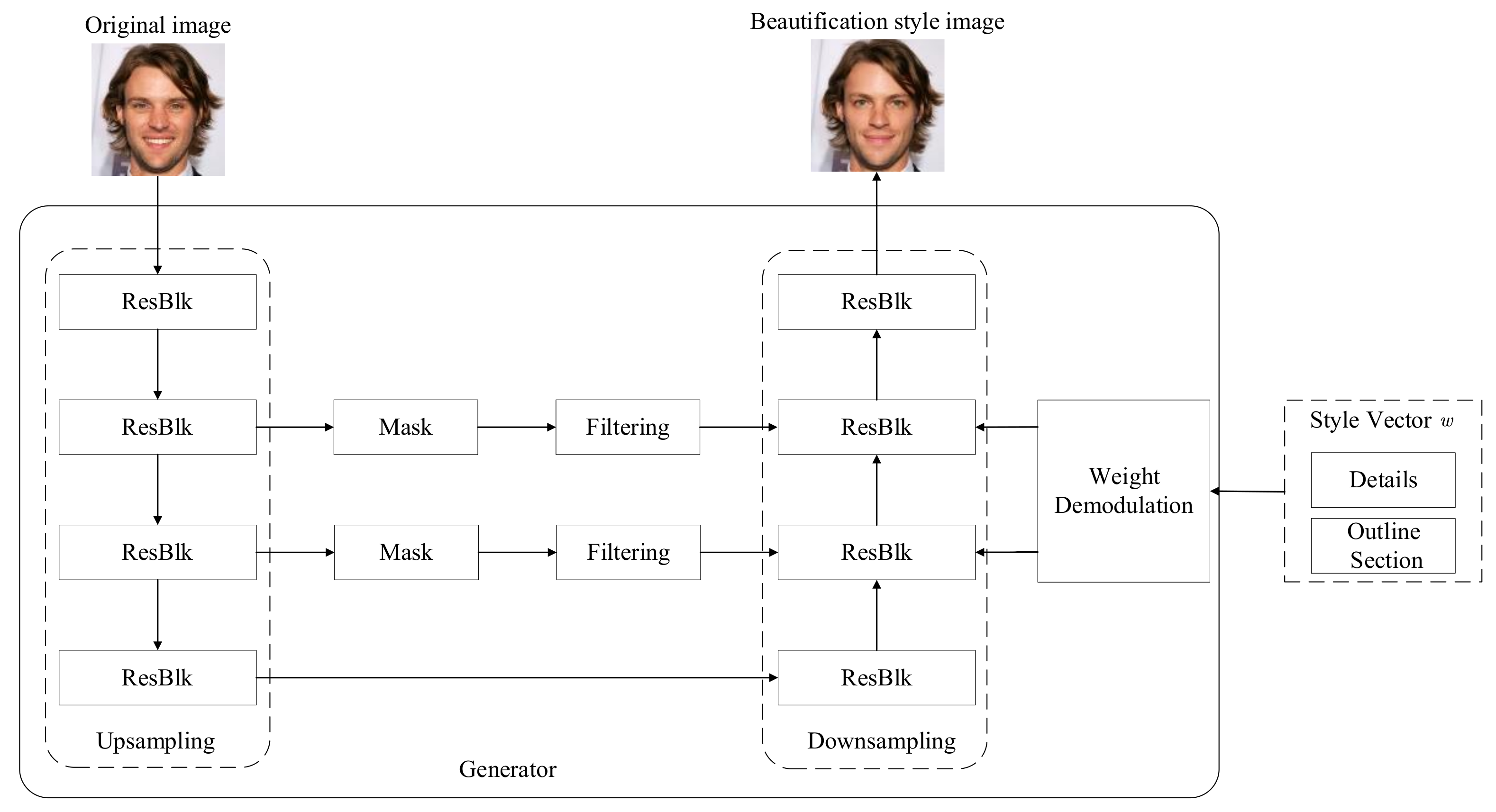
- A weight demodulation method is proposed, and the generator is re-designed to effectively reduce feature artifacts in the generated images and to avoid distortions during style transmission.
2. Related Work
2.1. Generative Adversarial Networks
2.2. AdaIN in Image Beautification Styles
2.3. Encoder
- (1)
- Face image beautification generative adversarial network methods with no pre-encoder. These are networks that only improve on an existing GAN, such as CycleGAN [22] (cycle-consistent generative adversarial network), StyleGAN [23] (style generative adversarial network), or other similar models. GANs without pre-encoders have obvious advantages, such as the simpler network structure, reduced computational cost, and higher training speed. As no additional encoders are required for the extraction of features, the network is more lightweight and the training and reasoning process is more efficient. However, this simplification sometimes prevents the network from sufficiently extracting the features of the input data, affecting the quality and diversity of the generated images. In addition, some GANs without pre-encoders face the problem of training instability, thus requiring the use of additional methods. While this approach performs well in some cases, its feature extraction, training stability, and data requirements remain to be addressed.
- (2)
- Face image beautification adversarial network methods with a pre-encoder. When an encoder is added to the start of a GAN, the network structure becomes more complex, but more realistic results can be obtained. StarGAN [24] (star generative adversarial network) is an example of such a network. GANs with pre-encoders make better use of the characteristics of the input data, thereby improving the quality and variety of the generated images. Through using pre-trained encoders to extract high-level features from the input data, the network is able to more accurately understand and learn the distribution of the data, which, in turn, allows for the production of more diverse images. In addition, GANs with pre-encoders generally have better training stability as they are able to learn the representation of the data more efficiently, reducing the instability during training. However, this approach increases the complexity and computational cost of the network, requiring additional encoders to extract features, thus resulting in increased time and resource consumption for training and inference processes.
- (1)
- It takes a lot of computing resources and time to train GANs. For complex tasks or high-resolution images, the computational cost is higher, which results in higher requirements for the hardware equipment and training time.
- (2)
- At present, while face image beautification style learning networks can be converted between different styles, the conversion results are not always natural and distortions may be observed.
- (3)
- Although GANs without pre-encoders simplify the structure and reduce the computing cost, they cannot fully extract the input data features, thus affecting the diversity of the generated images; furthermore, extensive normalization operations—as in the case of AdaIN—can lead to the loss of detail information. On the other hand, although GANs with pre-encoders improve the diversity, their complex network structures and pre-encoders increase the computing cost and, therefore, the training time. In order to solve the above problems, FIBGAN is proposed in this paper.
3. Methods
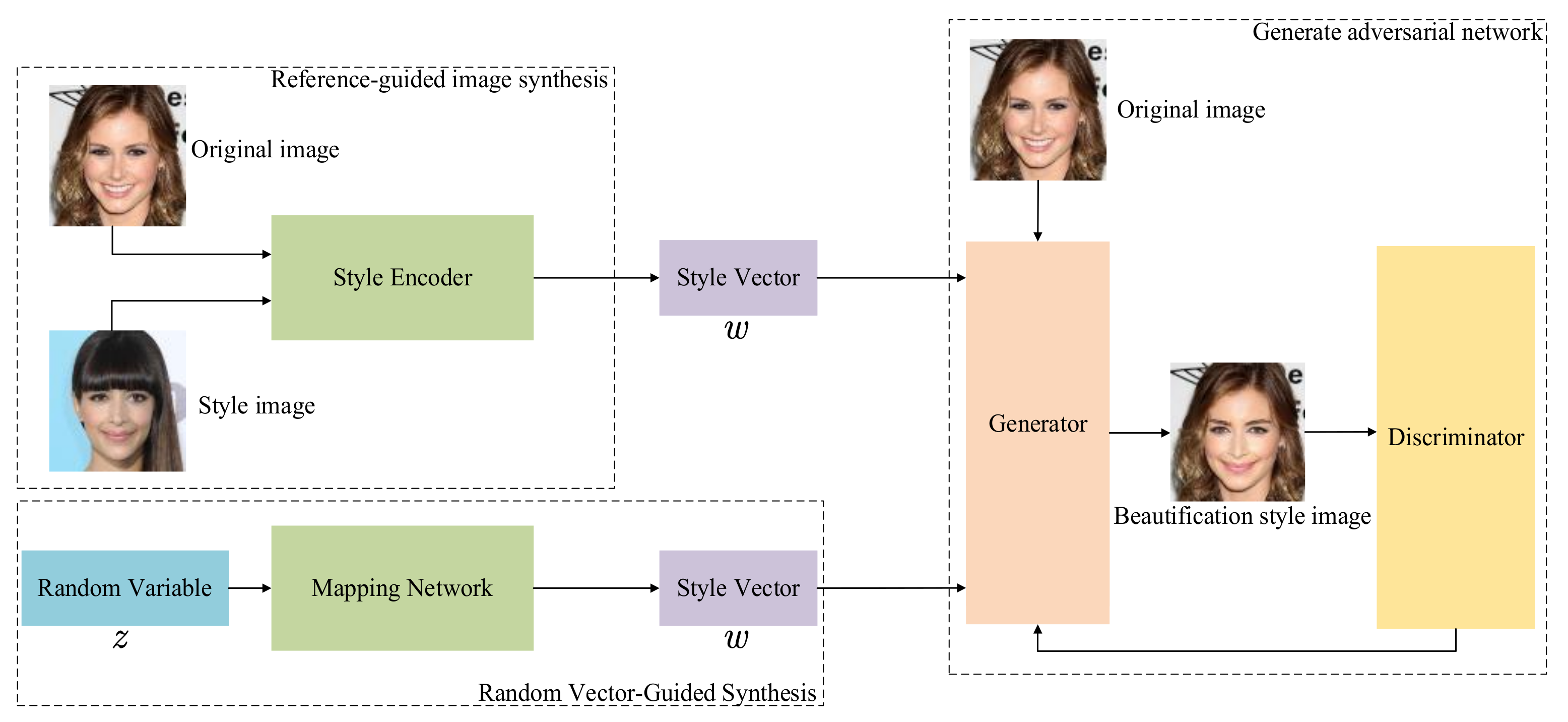
3.1. Network Model
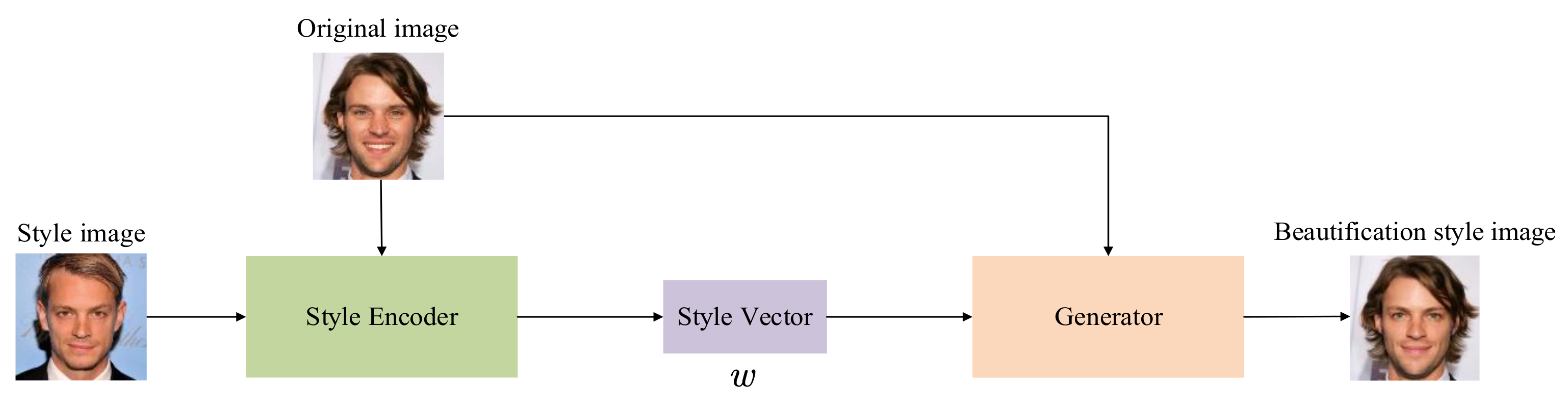
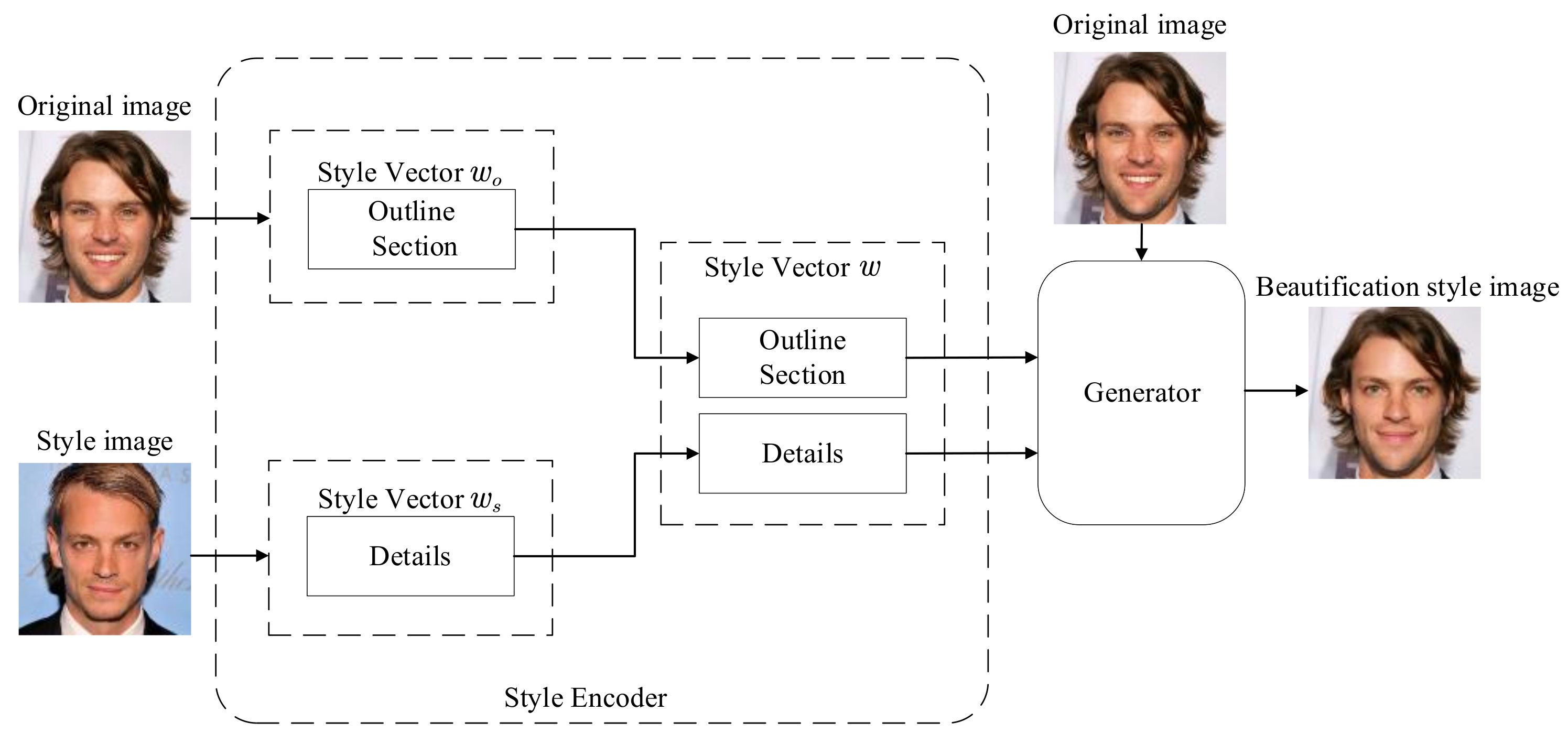
3.2. Reference-Guided Image Synthesis
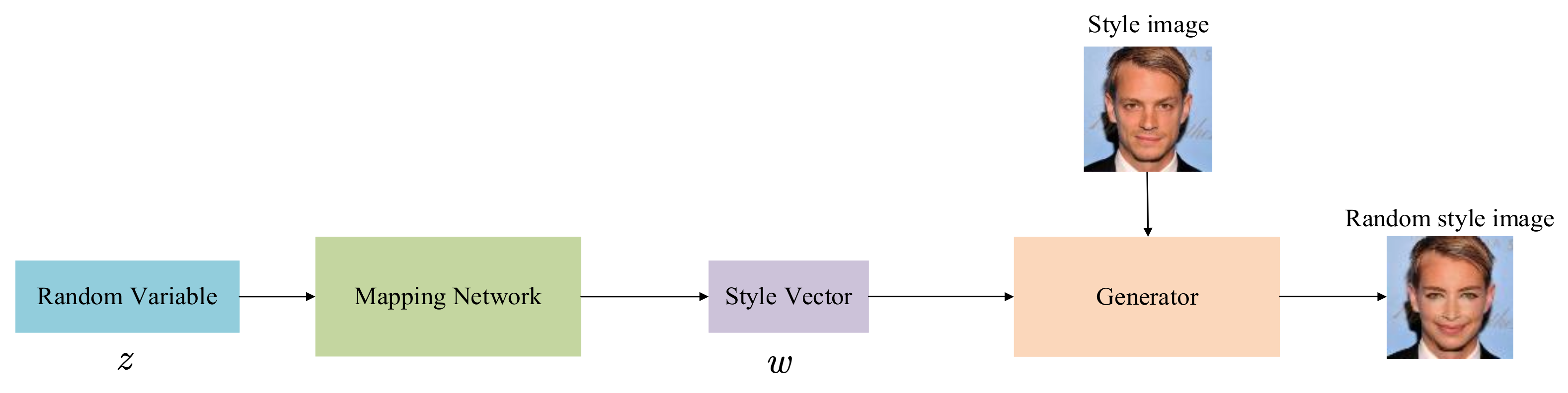
3.3. Random Vector-Guided Synthesis
3.4. The Adversarial Network Structure
3.4.1. Generator
3.4.2. Discriminator
3.5. Loss Function
4. Experimental Results and Analysis
4.1. Experiment
4.1.1. Experimental Environment
4.1.2. Experimental Data Set
4.2. Experimental Results of Reference-Guided Image Synthesis
4.3. Results of the Random Vector-Guided Synthesis Experiment
4.4. Experimental Results of the Beautification Style Intensity Experiment
4.5. Ablation Results
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Yadav, N.; Singh, S.K.; Dubey, S.R. Isa-gan: Inception-based self attentive encoder–decoder network for face synthesis using delin eated facial images. The Vis. Comput. 2024, 40, 8205–8225. [Google Scholar] [CrossRef]
- Hu, K.; Liu, Y.; Liu, R.; Lu, W.; Yu, G.; Fu, B. Enhancing quality of pose-varied face restoration with local weak feature sensing and gan prior. Neural Comput. Appl. 2024, 36, 399–412. [Google Scholar] [CrossRef]
- Hatakeyama, T.; Furuta, R.; Sato, Y. Simultaneous control of head pose and expressions in 3D facial keypoint-based GAN. Multimed. Tools Appl. 2024, 83, 79861–79878. [Google Scholar] [CrossRef]
- Chen, H.; Li, W.; Gao, X.; Xiao, B. AEP-GAN: Aesthetic Enhanced Perception Generative Adversarial Network for Asian facial beauty synthesis. Appl. Intell. 2023, 53, 20441–20468. [Google Scholar] [CrossRef]
- Wang, J.; Zhou, Z. De-Beauty GAN: Restore the original beauty of the face. In Proceedings of the 2023 International Conference on Image Processing, Computer Vision and Machine Learning (ICICML), Chengdu, China, 3–5 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 527–531. [Google Scholar]
- Chen, H.; Li, W.; Gao, X.; Xiao, B.; Li, F.; Huang, Y. Facial Aesthetic Enhancement Network for Asian Faces Based on Differential Facial Aesthetic Activations. In Proceedings of the ICASSP 2024—2024 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Seoul, Republic of Korea, 14–19 April 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 3785–3789. [Google Scholar]
- Fang, S.; Duan, M.; Li, K.; Li, K. Facial makeup transfer with GAN for different aging faces. J. Vis. Commun. Image Represent. 2022, 85, 103464. [Google Scholar] [CrossRef]
- Li, S.; Liu, L.; Liu, J.; Song, W.; Hao, A.; Qin, H. SC-GAN: Subspace clustering based GAN for automatic expression manipulation. Pattern Recognit. 2023, 134, 109072. [Google Scholar] [CrossRef]
- Chandaliya, P.K.; Nain, N. PlasticGAN: Holistic generative adversarial network on face plastic and aesthetic surgery. Multimed. Tools Appl. 2022, 81, 32139–32160. [Google Scholar] [CrossRef] [PubMed]
- Liu, Z.; Li, M.; Zhang, Y.; Wang, C.; Zhang, Q.; Wang, J.; Nie, Y. Fine-grained face swapping via regional gan inversion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 17–24 June 2023. [Google Scholar]
- Xiang, J.; Chen, J.; Liu, W.; Hou, X.; Shen, L. RamGAN: Region attentive morphing GAN for region-level makeup transfer. In European Conference on Computer Vision; Springer: Cham, Switzerland, 2022. [Google Scholar]
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Warde-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative adversarial nets. In Proceedings of the Advances in Neural Information Processing Systems, Montreal, QC, Canada, 8–13 December 2014; Volume 27. Available online: https://papers.nips.cc/paper_files/paper/2014/hash/5ca3e9b122f61f8f06494c97b1afccf3-Abstract.html (accessed on 1 October 2024).
- Ghani, M.A.N.U.; She, K.; Rauf, M.A.; Alajmi, M.; Ghadi, Y.Y.; Algarni, A. Securing synthetic faces: A GAN-blockchain approach to privacy-enhanced facial recognition. J. King Saud Univ.-Comput. Inf. Sci. 2024, 36, 102036. [Google Scholar] [CrossRef]
- Luo, S.; Huang, F. MaGAT: Mask-Guided Adversarial Training for Defending Face Editing GAN Models From Proactive Defense. IEEE Signal Process. Lett. 2024, 31, 969–973. [Google Scholar] [CrossRef]
- Wei, J.; Wang, W. Facial attribute editing method combined with parallel GAN for attribute separation. J. Vis. Commun. Image Represent. 2024, 98, 104031. [Google Scholar] [CrossRef]
- Tian, Y.; Wang, S.; Chen, B.; Kwong, S. Causal Representation Learning for GAN-Generated Face Image Quality Assessment. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 7589–7600. [Google Scholar] [CrossRef]
- Peng, T.; Li, M.; Chen, F.; Xu, Y.; Xie, Y.; Sun, Y.; Zhang, D. ISFB-GAN: Interpretable semantic face beautification with generative adversarial network. Expert Syst. Appl. 2024, 236, 121131. [Google Scholar] [CrossRef]
- Akram, A.; Khan, N. US-GAN: On the importance of ultimate skip connection for facial expression synthesis. Multimed. Tools Appl. 2024, 83, 7231–7247. [Google Scholar] [CrossRef]
- Dubey, S.R.; Singh, S.K. Transformer-based generative adversarial networks in computer vision: A comprehensive survey. IEEE Trans. Artif. Intell. 2024, 5, 4851–4867. [Google Scholar] [CrossRef]
- Yauri-Lozano, E.; Castillo-Cara, M.; Orozco-Barbosa, L.; García-Castro, R. Generative Adversarial Networks for text-to-face synthesis & generation: A quantitative–qualitative analysis of Natural Language Processing encoders for Spanish. Inf. Process. Manag. 2024, 61, 103667. [Google Scholar]
- Huang, X.; Belongie, S. Arbitrary style transfer in real-time with adaptive instance normalization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 1501–1510. [Google Scholar]
- Zhu, J.-Y.; Park, T.; Isola, P.; Efros, A.A. Unpaired image-to-image translation using cycle-consistent adversarial networks. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 2223–2232. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Choi, Y.; Choi, M.; Kim, M.; Ha, J.W.; Kim, S.; Choo, J. Stargan: Unified generative adversarial networks for multi-domain image-to-image translation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8789–8797. [Google Scholar]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Heusel, M.; Ramsauer, H.; Unterthiner, T.; Nessler, B.; Hochreiter, S. Gans trained by a two time-scale update rule converge to a local nash equilibrium. In Proceedings of the Advances in Neural Information Processing Systems, Long Beach, CA, USA, 4–9 December 2017; Volume 30. Available online: https://papers.nips.cc/paper_files/paper/2017/hash/8a1d694707eb0fefe65871369074926d-Abstract.html (accessed on 1 October 2024).
- Johnson, J.; Alahi, A.; Li, F.-F. Perceptual losses for real-time style transfer and super-resolution. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part II 14. Springer International Publishing: Berlin/Heidelberg, Germany, 2016; pp. 694–711. [Google Scholar]
- Salimans, T.; Goodfellow, I.; Zaremba, W.; Cheung, V.; Radford, A.; Chen, X. Improved techniques for training gans. In Proceedings of the Advances in Neural Information Processing Systems, Barcelona, Spain, 5–10 December 2016; Volume 29. Available online: https://arxiv.org/abs/1606.03498 (accessed on 1 October 2024).
- Wang, Z.; Bovik, A.C.; Sheikh, H.R.; Simoncelli, E.P. Image quality assessment: From error visibility to structural similarity. IEEE Trans. Image Process. 2004, 13, 600–612. [Google Scholar] [CrossRef] [PubMed]
- Isola, P.; Zhu, J.Y.; Zhou, T.; Efros, A.A. Image-to-image translation with conditional adversarial networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 1125–1134. [Google Scholar]
- Choi, Y.; Uh, Y.; Yoo, J.; Ha, J.W. Stargan v2: Diverse image synthesis for multiple domains. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 8188–8197. [Google Scholar]
- Gao, F.; Yang, Y.; Wang, J.; Sun, J.; Yang, E.; Zhou, H. A deep convolutional generative adversarial networks (DCGANs)-based semi-supervised method for object recognition in synthetic aperture radar (SAR) images. Remote Sens. 2018, 10, 846. [Google Scholar] [CrossRef]
- Arjovsky, M.; Chintala, S.; Bottou, L. Wasserstein generative adversarial networks. In Proceedings of the International Conference on Machine Learning, Sydney, Australia, 6–11 August 2017; pp. 214–223. [Google Scholar]





{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Model | FID | IS | SSIM | LPIPS |
|---|---|---|---|---|
| StyleGAN [23] | 69.3 | 20.6 | 0.536 | 0.312 |
| pix2pix [30] | 136.5 | 15.3 | 0.458 | 0.135 |
| CycleGAN [22] | 70.3 | 19.8 | 0.589 | 0.277 |
| StarGAN v2 [31] | 25.5 | 22.6 | 0.653 | 0.381 |
| FIBGAN | 20.5 | 25.3 | 0.695 | 0.396 |
| Model | FID | IS | SSIM | LPIPS |
|---|---|---|---|---|
| StyleGAN [23] | 13.8 | 17.8 | 0.510 | 0.420 |
| DCGAN [32] | 32.5 | 13.5 | 0.416 | 0.395 |
| WGAN [33] | 15.3 | 18.6 | 0.543 | 0.258 |
| StarGAN v2 [31] | 14.1 | 24.3 | 0.653 | 0.450 |
| FIBGAN | 12.5 | 26.5 | 0.711 | 0.553 |
| Model | k = 1 | k = 2 | k = 3 | k = 4 |
|---|---|---|---|---|
| StarGAN v2 [31] | 14.3 | 13.9 | 13.1 | 12.6 |
| FIBGAN | 13.6 | 12.5 | 11.3 | 10.5 |
| Model | FID | IS | SSIM | LPIPS |
|---|---|---|---|---|
| StarGAN v2 [31] | 14.1 | 24.3 | 0.653 | 0.450 |
| StarGAN v2 [31] + FPN [25] | 13.9 | 24.6 | 0.668 | 0.498 |
| StarGAN v2 [31] + FPN [25] + Weight demodulation | 13.3 | 25.1 | 0.673 | 0.505 |
| StarGAN v2 [31] + FPN [25] + Weight demodulation + Lsty | 12.8 | 25.3 | 0.689 | 0.526 |
| FIBGAN | 12.5 | 26.5 | 0.711 | 0.553 |
| Number of FPN Layers | FID | IS | SSIM | LPIPS |
|---|---|---|---|---|
| 1 × 512 | 12.800 | 25.300 | 0.689 | 0.526 |
| 3 × 512 | 12.734 | 25.987 | 0.698 | 0.539 |
| 6 × 512 | 12.500 | 26.500 | 0.711 | 0.553 |
| 8 × 512 | 12.701 | 26.234 | 0.705 | 0.547 |
| 10 × 512 | 12.605 | 26.472 | 0.718 | 0.550 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the author. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gan, J.; Liu, J. Applied Research on Face Image Beautification Based on a Generative Adversarial Network. Electronics 2024, 13, 4780. https://doi.org/10.3390/electronics13234780
Gan J, Liu J. Applied Research on Face Image Beautification Based on a Generative Adversarial Network. Electronics. 2024; 13(23):4780. https://doi.org/10.3390/electronics13234780
Chicago/Turabian StyleGan, Junying, and Jianqiang Liu. 2024. "Applied Research on Face Image Beautification Based on a Generative Adversarial Network" Electronics 13, no. 23: 4780. https://doi.org/10.3390/electronics13234780
APA StyleGan, J., & Liu, J. (2024). Applied Research on Face Image Beautification Based on a Generative Adversarial Network. Electronics, 13(23), 4780. https://doi.org/10.3390/electronics13234780