
Applications of Machine Learning in Cancer Imaging: A Review of Diagnostic Methods for Six Major Cancer Types



Abstract
1. Introduction
1.1. Paper Structure
1.2. Motivation and Contribution
- ▪
- Analyzes and highlights the most important aspects of the aforementioned six cancer types.
- ▪
- Analyzes various ML methods based on benchmark datasets and several performance evaluation metrics.
- ▪
- Identifies the majority of datasets utilized in the reviewed papers.
- ▪
- Outlined various research challenges, potential solutions, and opportunities for cancer analysis and care suggested for future researchers.
1.3. Summary
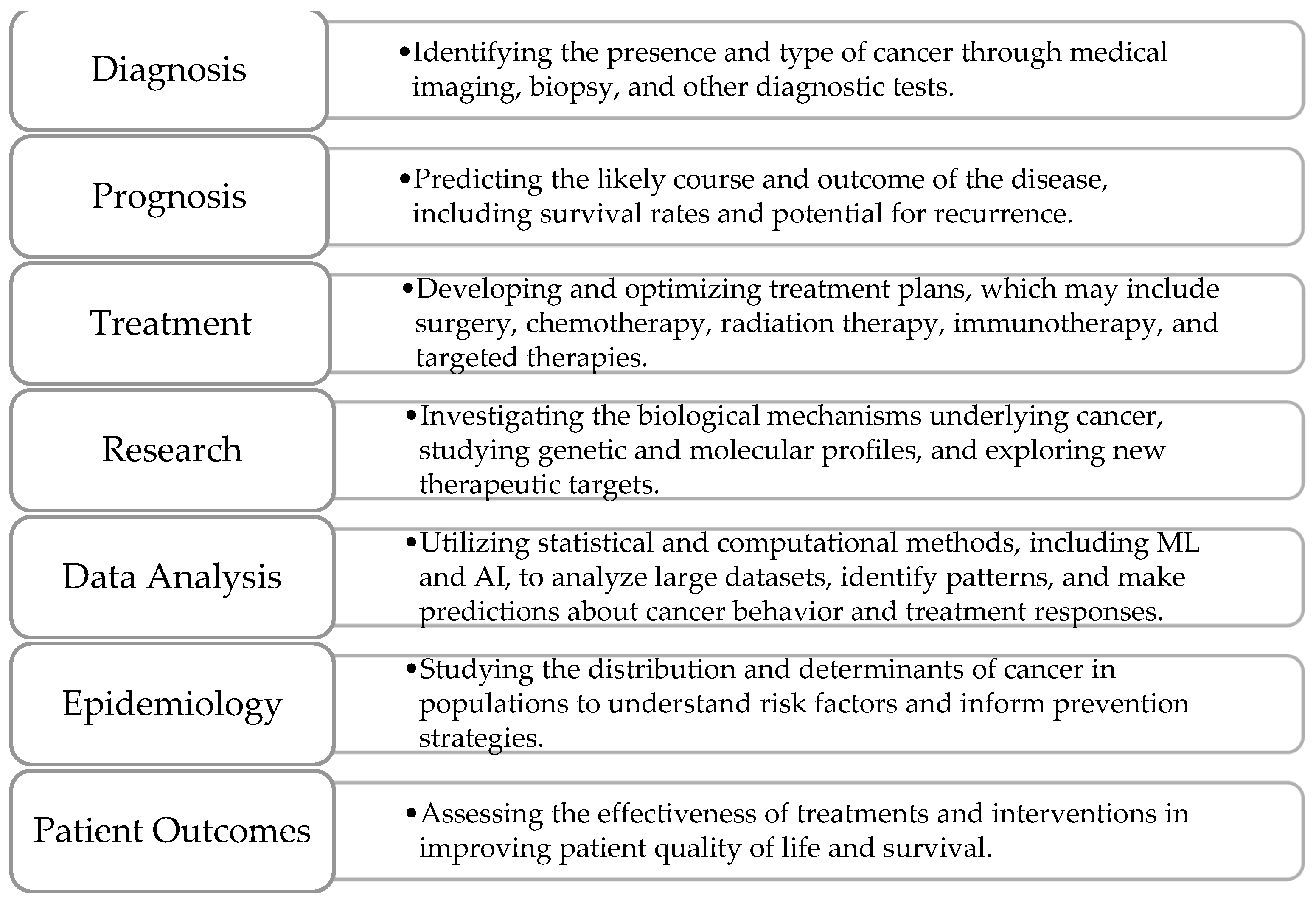
- ▪
- Lung cancer originates in the tissues of the lungs, usually in the cells lining the air passages. It is strongly associated with smoking, but can also occur in non-smokers due to other risk factors like exposure to secondhand smoke, radon, or certain chemicals. Lung cancer is one of the leading causes of cancer-related deaths worldwide, emphasizing the importance of early detection and smoking cessation efforts. It is detected primarily through chest X-rays, CT scans, and PET scans. CT scans offer high-resolution images and are particularly useful for detecting small lung nodules, while PET scans help assess the metabolic activity of suspected tumors, aiding in staging and treatment planning.
- ▪
- Breast cancer develops in the cells of the breasts, most commonly in the ducts or lobules. It predominantly affects women, but men can also develop it, although it is much less common. This cancer is often diagnosed using mammography, ultrasound, and MRI modalities. Mammography remains the gold standard for screening, while ultrasound and MRI are utilized for further evaluation of suspicious findings, particularly in dense breast tissue.
- ▪
- Brain cancer refers to tumors that develop within the brain or its surrounding tissues. These tumors can be benign or malignant. It is diagnosed using imaging modalities like MRI, CT scans, PET scans, and sometimes biopsy for histological confirmation. MRI is the preferred imaging modality for evaluating brain tumors due to its superior soft tissue contrast, allowing for precise localization and characterization of lesions.
- ▪
- Cervical cancer starts in the cells lining the cervix, which is the lower part of the uterus that connects to the vagina. It is primarily caused by certain strains of human papillomavirus (HPV). Regular screening tests such as Pap smear tests, HPV DNA tests, colposcopy, and biopsy can help detect cervical cancer early, when it is most treatable.
- ▪
- Colorectal cancer develops in the colon or rectum, typically starting as polyps on the inner lining of the colon or rectum. These polyps can become cancerous over time if not removed. Screening tests rely on various imaging modalities, including colonoscopy, sigmoidoscopy, fecal occult blood tests, and CT colonography (virtual colonoscopy). Colonoscopy is considered the gold standard for detecting colorectal polyps and cancers, allowing for both visualization and tissue biopsy during the procedure.
- ▪
- Liver cancer arises from the cells of the liver and can either start within the liver itself (primary liver cancer) or spread to the liver from other parts of the body (secondary liver cancer). Chronic liver diseases such as hepatitis B or C infection, cirrhosis, and excessive alcohol consumption are major risk factors for primary liver cancer. Its diagnosis relies on imaging modalities such as ultrasound, CT scans, MRI, and PET scans, along with blood tests for tumor markers such as alpha-fetoprotein (AFP). These imaging techniques enable the detection of liver lesions, nodules, or masses, aiding in the diagnosis, staging, and treatment planning for liver cancer patients.
1.4. Methods
2. Medical Imaging and Diagnostic Techniques: An Overview of Key Modalities
2.1. X-Rays
2.2. Mammography
2.3. Ultrasound
2.4. Computed Tomography
2.5. Positron Emission Tomography
2.6. Magnetic Resonance Imaging
2.7. Endoscopic Biopsy
2.7.1. Colonoscopy
2.7.2. Bronchoscopy
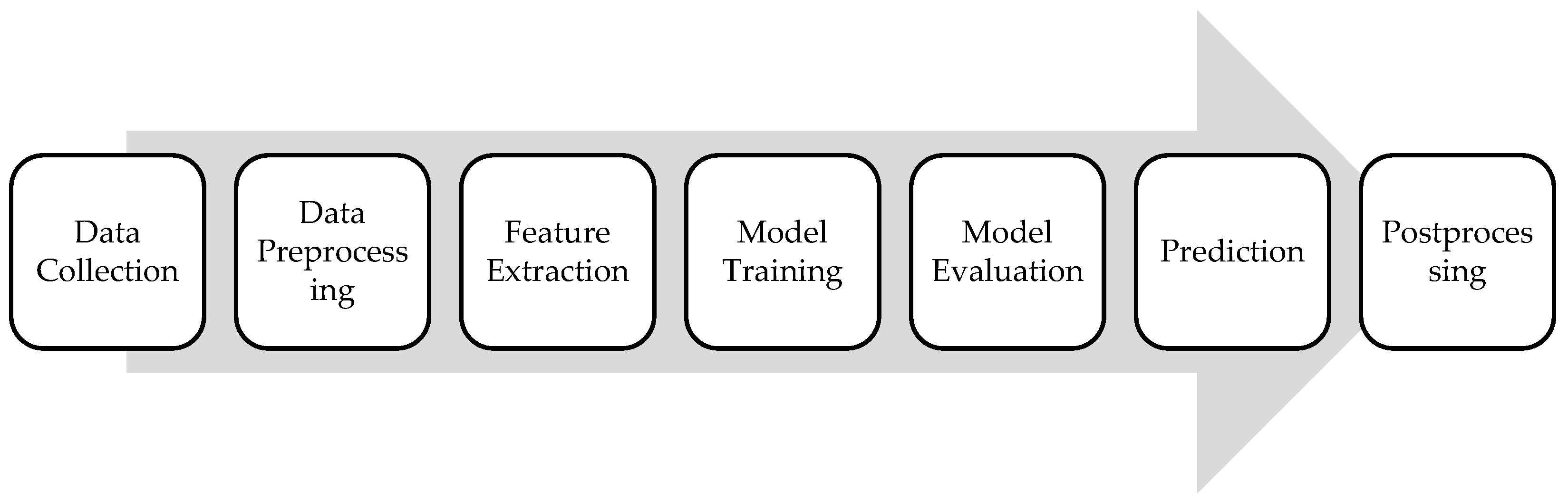
3. Machine Learning Framework
3.1. Data Collection
3.2. Data Preprocessing
3.3. Feature Extraction
3.4. Model Training
3.5. Model Evaluation
3.5.1. Classification
- ▪
- True Positives (TP): Instances that are correctly predicted as belonging to the positive class.
- ▪
- False Positives (FP): Instances that are incorrectly predicted as belonging to the positive class when they actually belong to the negative class.
- ▪
- True Negatives (TN): Instances that are correctly predicted as belonging to the negative class.
- ▪
- False Negatives (FN): Instances that are incorrectly predicted as belonging to the negative class when they actually belong to the positive class.
- ▪
- Accuracy measures the proportion of correctly classified instances out of the total instances and is calculated as the number of true positives and true negatives divided by the total number of instances:
- ▪
- Precision measures the proportion of true positive predictions among all positive predictions made by the classifier and is calculated as the number of true positives divided by the total number of instances predicted as positive:
- ▪
- Recall or sensitivity measures the proportion of true positives that are correctly identified by the classifier and is calculated as the number of true positives divided by the total number of actual positive instances:
- ▪
- Specificity measures the proportion of true negatives that are correctly identified by the classifier and is calculated as the number of true negatives divided by the total number of actual negative instances:
- ▪
- F1 score is the harmonic mean of precision and recall, providing a balance between the two metrics and is calculated as the harmonic mean of precision and recall:
- ▪
- Precision–recall (PR) curves plot the precision against the recall for different threshold values used by the classifier to make predictions. Each point on the curve corresponds to a different threshold setting used by the classifier, where a higher threshold leads to higher precision but lower recall, and vice versa.
- ▪
- Area under the PR (AUC-PR) curves summarize the performance of the classifier across all possible threshold values, with a higher AUC-PR indicating better overall performance in terms of both precision and recall.
- ▪
- Receiver operating characteristic (ROC) curves plot the recall against the false-positive rate (FPR, which measures the proportion of false-positive predictions among all actual negative instances) for various threshold values used by the classifier to make predictions. Each point on the curve corresponds to a different threshold setting used by the classifier, where a higher threshold leads to higher specificity but lower recall, and vice versa.
- ▪
- Area under the ROC curve (AUC-ROC or simply AUC) summarizes the performance of the classifier across all possible threshold values, with a higher AUC indicating better overall performance in terms of both recall and specificity.
3.5.2. Segmentation
- ▪
- Intersection over union (IOU) measures the overlap between the predicted and ground-truth masks by calculating the ratio of the intersection to the union of the two masks:
- ▪
- Dice similarity coefficient (DSC) measures the spatial overlap between the predicted segmentation mask and the ground-truth mask and is calculated as twice the intersection of the predicted and ground-truth masks divided by the sum of their volumes:
- ▪
- Mean intersection over union (mIoU) measures the average IoU across all classes or segments in the image:
- ▪
- Pixel accuracy measures the proportion of correctly classified pixels in the segmentation mask and is calculated as the number of pixels correctly classified divided by the total number of pixels in the image:
- ▪
- Mean average precision (mAP) summarizes the precision–recall (PR) curve across multiple classes or categories and is calculated in three steps:
- For each class or category in the dataset, the PR curve is computed based on the model’s predictions and ground-truth annotations.
- The AUC-AP curve is computed for each class.
- The mAP is calculated by taking the mean of the average precision values across all classes in the dataset.
- ▪
- Hausdorff distance (HD) measures the similarity between two sets of points in a metric space. It quantifies the maximum distance from a point in one set to the closest point in the other set, and vice versa.
3.6. Prediction
3.7. Postprocessing
- ▪
- Shapley additive explanation (SHAP) [28] values explain individual predictions by attributing the contribution of each feature (e.g., patient characteristics or image pixels) to the final outcome. SHAP helps clinicians understand which variables had the most significant influence on the prediction.
- ▪
- Local interpretable model-agnostic explanations (LIME) [29] approximate complex models by perturbing input data slightly and analyzing the effect on predictions. It provides local explanations for individual instances, making it particularly useful in understanding predictions made by complex, black-box models.
- ▪
- Gradient-weighted class activation mapping (Grad-CAM) [30] generates visual explanations of model decisions by highlighting the regions of an image that were most influential in the model’s decision-making process. This is particularly important in cancer imaging, where clinicians need to verify that the model is focusing on relevant areas when diagnosing or classifying cancer.
- ▪
- Score-weighted class activation mapping (Score-CAM) [31] provides visual explanations for the decisions made by CNNs, particularly in image classification and object detection tasks. It extends the concept of Grad-CAM by using the activation maps directly from the network to generate class-specific attention maps, but without relying on the gradients.
4. Literature Review
4.1. Lung Cancer
4.2. Breast Cancer
4.3. Brain Cancer
4.4. Cervical Cancer
4.5. Colorectal Cancer
4.6. Liver Cancer
5. Challenges and Limitations
5.1. Computing Infrastructure and Scalability
5.2. Data Quality and Availability
5.3. Limited Data for Rare Cancer Types
5.4. Model Overfitting, Robustness, and Adaptability
5.5. Model Validation and Generalizability
5.6. Model Interpretability and Explainability
5.7. Clinical Adoption and Usability
5.8. Integration with Clinical Workflows
5.9. Ethical Considerations in Data Usage
5.10. Regulatory and Legal Frameworks
6. Discussion and Future Directions
7. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
Abbreviations
| Abbreviation | Definition |
| ABC | area-boundary constraint |
| AI | artificial intelligence |
| ALTS | ASCUS/LSIL Triage Study |
| ANN | artificial neural network |
| ASCUS | atypical squamous cells of undetermined significance |
| AUC | area under curve |
| BES | bald eagle search |
| BPNN | backpropagation neural network |
| BUSI | breast ultrasound image |
| CARTs | classification and regression trees |
| CBIS | curated breast imaging subset |
| CLAHE | contrast limited adaptive histogram equalization |
| CNN | convolutional neural network |
| CRC | colorectal cancer |
| CS | cuckoo search |
| CT | computed tomography |
| DDSM | Digital Database for Screening Mammography |
| DICOM | Digital Imaging and Communications in Medicine |
| DL | deep learning |
| DLCN | deep learning capsule network |
| DNN | deep neural network |
| DOBES | dynamic opposite bald eagle search |
| DOL | dynamic opposition learning |
| DSC | dice similarity coefficient |
| EHR | electronic health record |
| EL | ensemble learning |
| FFN | feedforward network |
| FN | false negative |
| FP | false positive |
| GBM | gradient boosting machines |
| GDPR | general data protection regulation |
| GMMs | Gaussian mixture models |
| Grad-CAM | gradient-weighted class activation mapping |
| HCC | hepatocellular carcinoma |
| HD | Hausdorff distance |
| HHO | Harris hawks optimization |
| HTL | hybrid transfer learning |
| LBC | liquid-based cytology |
| LIME | local interpretable model-agnostic explanations |
| LNM | lymph node metastases |
| LSIL | low-grade squamous intraepithelial lesion |
| MA | multi-scale attention |
| MIAS | Mammographic Image Analysis Society |
| ML | machine learning |
| MR | magnetic resonance |
| MRI | magnetic resonance imaging |
| NHS | natural history study |
| OKMT | optimal Kapur’s multilevel thresholding |
| OMLTS | optimal multi-level thresholding-based segmentation |
| OS | overall survival |
| PCA | principal component analysis |
| PET | positron emission tomography |
| PPV | positive predictive values |
| PR | precision–recall |
| RBF | radial basis function |
| RCNN | region-based CNN |
| ROC | receiver operating characteristic |
| ROI | region of interest |
| Score-CAM | score-weighted class activation mapping |
| SE | squeeze and excitation |
| SEER | Surveillance, Epidemiology, and End Results |
| SGO | shell game optimization |
| SHAP | Shapley additive explanation |
| SKMs | selective kernel modules |
| SL | supervised learning |
| SMOTE | synthetic minority over-sampling technique |
| SNR | suspected nodule regions |
| SSL | semi-supervised learning |
| SVM | support vector machine |
| TCGA | The Cancer Genome Atlas |
| TL | transfer learning |
| TN | true negative |
| TP | true positive |
| TS | tactile sensor |
| UL | unsupervised learning |
| US | ultrasound |
| VGG | visual geometry group |
| VS | vision-based surface |
| WHO | World Health Organization |
| WSIs | whole-slide images |
References
- Bray, F.; Laversanne, M.; Sung, H.; Ferlay, J.; Siegel, R.L.; Soerjomataram, I.; Jemal, A. Global cancer statistics 2022: GLOBOCAN estimates of incidence and mortality worldwide for 36 cancers in 185 countries. CA Cancer J. Clin. 2024, 74, 229–263. [Google Scholar] [CrossRef] [PubMed]
- Siegel, R.L.; Giaquinto, A.N.; Jemal, A. Cancer statistics, 2024. CA Cancer J. Clin. 2024, 74, 12–49. [Google Scholar] [CrossRef] [PubMed]
- Manhas, J.; Gupta, R.K.; Roy, P.P. A Review on Automated Cancer Detection in Medical Images using Machine Learning and Deep Learning based Computational Techniques: Challenges and Opportunities. Arch. Comput. Methods Eng. 2022, 29, 2893–2933. [Google Scholar] [CrossRef]
- Panayides, A.S.; Amini, A.; Filipovic, N.D.; Sharma, A.; Tsaftaris, S.A.; Young, A.; Foran, D.; Do, N.; Golemati, S.; Kurç, T.; et al. AI in medical imaging informatics: Current challenges and future directions. IEEE J. Biomed. Health Inform. 2020, 24, 1837–1857. [Google Scholar] [CrossRef]
- Tian, Y.; Fu, S. A descriptive framework for the field of deep learning applications in medical images. Knowl.-Based Syst. 2020, 210, 106445. [Google Scholar] [CrossRef]
- Suckling, J. Medical image processing. In Webb’s Physics of Medical Imaging 2016, 2nd ed.; CRC Press: Boca Raton, FL, USA, 2016; pp. 713–738. [Google Scholar] [CrossRef]
- Debongnie, J.C.; Pauls, C.; Fievez, M.; Wibin, E. Prospective evaluation of the diagnostic accuracy of liver ultrasonography. Gut 1981, 22, 130–135. [Google Scholar] [CrossRef]
- Wan, Y.; Wang, D.; Li, H.; Xu, Y. The imaging techniques and diagnostic performance of ultrasound, CT, and MRI in detecting liver steatosis and fat quantification: A systematic review. J. Radiat. Res. Appl. Sci. 2023, 16, 100658. [Google Scholar] [CrossRef]
- Kim, H.S.; Lee, K.S.; Ohno, Y.; Van Beek, E.J.R.; Biederer, J. PET/CT versus MRI for diagnosis, staging, and follow-up of lung cancer. J. Magn. Reson. Imaging 2015, 42, 247–260. [Google Scholar] [CrossRef]
- de Savornin Lohman, E.A.J.; de Bitter, T.J.J.; van Laarhoven, C.J.H.M.; Hermans, J.J.; de Haas, R.J.; de Reuver, P.R. The diagnostic accuracy of CT and MRI for the detection of lymph node metastases in gallbladder cancer: A systematic review and meta-analysis. Eur. J. Radiol. 2019, 110, 156–162. [Google Scholar] [CrossRef]
- Fiocca, R.; Ceppa, P. Endoscopic biopsies. J. Clin. Pathol. 2003, 56, 321–322. [Google Scholar] [CrossRef]
- Ahn, J.H. An update on the role of bronchoscopy in the diagnosis of pulmonary disease. Yeungnam Univ. J. Med. 2020, 37, 253–261. [Google Scholar] [CrossRef] [PubMed]
- Stauffer, C.M.; Pfeifer, C. Colonoscopy. StatPearls [Internet]. 2024. Available online: https://www.ncbi.nlm.nih.gov/books/NBK559274 (accessed on 20 January 2024).
- Mahmoud, N.; Vashisht, R.; Sanghavi, D.K.; Kalanjeri, S.; Bronchoscopy. StatPearls [Internet]. 2024. Available online: https://www.ncbi.nlm.nih.gov/books/NBK448152 (accessed on 20 January 2024).
- Gillies, R.J.; Kinahan, P.E.; Hricak, H. Radiomics: Images are more than pictures, they are data. Radiology 2016, 278, 563–577. [Google Scholar] [CrossRef] [PubMed]
- Sharma, A.; Saurabh, S. Medical image preprocessing: A literature review. Int. J. Comput. Intell. Res. 2020, 16, 5–20. [Google Scholar]
- Litjens, G.; Kooi, T.; Bejnordi, B.E.; Setio, A.A.A.; Ciompi, F.; Ghafoorian, M.; van Ginneken, B. A survey on deep learning in medical image analysis. Med. Image Anal. 2017, 42, 60–88. [Google Scholar] [CrossRef]
- Franklin, J. The Elements of Statistical Learning: Data Mining, Inference, and Prediction. Math. Intell. 2005, 27, 83–85. [Google Scholar] [CrossRef]
- Chen, T.; Guestrin, C. XGBoost: A scalable tree boosting system. In Proceedings of the ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar] [CrossRef]
- Goodfellow, I.; Bengio, Y.; Courville, A. Deep Learning; MIT Press: Cambridge, MA, USA, 2016; Available online: http://www.deeplearningbook.org (accessed on 20 January 2024).
- Simonyan, K.; Zisserman, A. Very deep convolutional networks for large-scale image recognition. In Proceedings of the 3rd International Conference on Learning Representations, ICLR 2015—Conference Track Proceedings, San Diego, CA, USA, 7–9 May 2015; pp. 1–14. [Google Scholar] [CrossRef]
- Ronneberger, O.; Fischer, P.; Brox, T. U-Net: Convolutional networks for biomedical image segmentation. arXiv 2015. [Google Scholar] [CrossRef]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Computer Society Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar] [CrossRef]
- Naser, M.Z.; Alavi, A.H. Error metrics and performance fitness indicators for artificial intelligence and machine learning in engineering and sciences. Archit. Struct. Constr. 2023, 3, 499–517. [Google Scholar] [CrossRef]
- Maurya, S.; Tiwari, S.; Mothukuri, M.C.; Tangeda, C.M.; Nandigam, R.N.S.; Addagiri, D.C. A review on recent developments in cancer detection using machine learning and deep learning models. Biomed. Signal Process. Control 2023, 80, 104398. [Google Scholar] [CrossRef]
- Faghani, S.; Khosravi, B.; Zhang, K.; Moassefi, M.; Jagtap, J.M.; Nugen, F.; Vahdati, S.; Kuanar, S.P.; Rassoulinejad-Mousavi, S.M.; Singh, Y.; et al. Mitigating bias in radiology machine learning: 3. Performance metrics. Radiol. Artif. Intell. 2022, 4, e220061. [Google Scholar] [CrossRef]
- Erickson, B.J.; Kitamura, F. Magician’s corner: 9. Performance metrics for machine learning models. Radiol. Artif. Intell. 2021, 3, e200126. [Google Scholar] [CrossRef]
- Lundberg, S.M.; Lee, S.-I. A unified approach to interpreting model predictions. arXiv 2017. [Google Scholar] [CrossRef]
- Ribeiro, M.T.; Singh, S.; Guestrin, C. “Why should I trust you?” Explaining the predictions of any classifier. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 1135–1144. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual explanations from deep networks via gradient-based localization. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 618–626. [Google Scholar] [CrossRef]
- Wang, H.; Wang, Z.; Du, M.; Yang, F.; Zhang, Z.; Ding, S.; Mardziel, P. Score-CAM: Score-weighted Visual Explanations for Convolutional Neural Networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020; Available online: https://arxiv.org/abs/1910.01279 (accessed on 20 January 2024).
- American Cancer Society. Key Statistics for Lung Cancer. 2017. Available online: https://www.cancer.org/cancer/non-small-cell-lung-cancer/about/key-statistics.html (accessed on 14 February 2024).
- American Cancer Society. Cancer Facts and Figures 2017. 2017. Available online: https://www.cancer.org/content/dam/cancer-org/research/cancer-facts-and-statistics/annualcancer-facts-and-figures/2017/cancer-facts-and-figures-2017.pdf (accessed on 14 February 2024).
- Jassim, O.A.; Abed, M.J.; Saied, Z.H. Deep learning techniques in the cancer-related medical domain: A transfer deep learning ensemble model for lung cancer prediction. Baghdad Sci. J. 2024, 21, 1101–1118. [Google Scholar] [CrossRef]
- Hany, M. Chest CT-Scan Images Dataset. Kaggle. 2020. Available online: https://www.kaggle.com/datasets/mohamedhanyyy/chest-ctscan-images (accessed on 14 February 2024).
- Muhtasim, N.; Hany, U.; Islam, T.; Nawreen, N.; Al Mamun, A. Artificial intelligence for detection of lung cancer using transfer learning and morphological features. J. Supercomput. 2024, 80, 13576–13606. [Google Scholar] [CrossRef]
- Al-Yasriy, H.F.; Al-Husieny, M.S.; Mohsen, F.Y.; Khalil, E.A.; Hassan, Z.S. Diagnosis of lung cancer based on CT scans using CNN. IOP Conf. Ser. Mater. Sci. Eng. 2020, 928, 022035. [Google Scholar] [CrossRef]
- Luo, S. Lung cancer classification using reinforcement learning-based ensemble learning. Int. J. Adv. Comput. Sci. Appl. 2023, 14, 1112–1122. [Google Scholar] [CrossRef]
- Armato, I.; Samuel, G.; McLennan, G.; Bidaut, L.; McNitt-Gray, M.F.; Meyer, C.R.; Reeves, A.P.; Clarke, L.P. Data from LIDC-IDRI [Data Set]; The Cancer Imaging Archive: Palo Alto, CA, USA, 2015. [Google Scholar] [CrossRef]
- Mamun, M.; Farjana, A.; Al Mamun, M.; Ahammed, M.S. Lung cancer prediction model using ensemble learning techniques and a systematic review analysis. In Proceedings of the 2022 IEEE World AI IoT Congress (AIIoT 2022), Seattle, WA, USA, 6–9 June 2022; pp. 187–193. [Google Scholar] [CrossRef]
- Das, S. Lung Cancer Dataset—Does Smoking Cause Lung Cancer. Kaggle. 2022. Available online: https://www.kaggle.com/datasets/shuvojitdas/lung-cancer-dataset (accessed on 14 February 2024).
- Venkatesh, S.P.; Raamesh, L. Predicting lung cancer survivability: A machine learning ensemble method on SEER data. Int. J. Cancer Res. Ther. 2023, 8, 148–154. [Google Scholar] [CrossRef]
- Altekruse, S.F.; Rosenfeld, G.E.; Carrick, D.M.; Pressman, E.J.; Schully, S.D.; Mechanic, L.E.; Cronin, K.A.; Hernandez, B.Y.; Lynch, C.F.; Cozen, W.; et al. SEER cancer registry biospecimen research: Yesterday and tomorrow. Cancer Epidemiol. Biomark. Prev. 2014, 23, 2681–2687. [Google Scholar] [CrossRef]
- Said, Y.; Alsheikhy, A.A.; Shawly, T.; Lahza, H. Medical images segmentation for lung cancer diagnosis based on deep learning architectures. Diagnostics 2023, 13, 546. [Google Scholar] [CrossRef]
- Antonelli, M.; Reinke, A.; Bakas, S.; Farahani, K.; Kopp-Schneider, A.; Landman, B.A.; Litjens, G.; Menze, B.; Ronneberger, O.; Summers, R.M.; et al. The medical segmentation decathlon. Nat. Commun. 2022, 13, 4128. [Google Scholar] [CrossRef]
- Siegel, R.L.; Miller, K.D.; Jemal, A. Cancer statistics, 2019. CA Cancer J. Clin. 2019, 69, 7–34. [Google Scholar] [CrossRef]
- World Health Organization. Global Cancer Burden Growing, Amidst Mounting Need for Services. 2024. Available online: https://www.who.int/news/item/01-02-2024-global-cancer-burden-growing--amidst-mounting-need-for-services (accessed on 6 March 2024).
- Oeffinger, K.C.; Fontham, E.T.; Etzioni, R.; Herzig, A.; Michaelson, J.S.; Shih, Y.C.T.; Walter, L.C.; Church, T.R.; Flowers, C.R.; LaMonte, S.J.; et al. Breast cancer screening for women at average risk: 2015 guideline update from the American Cancer Society. JAMA 2015, 314, 1599–1614. [Google Scholar] [CrossRef] [PubMed]
- Stower, H. AI for breast-cancer screening. Nat. Med. 2020, 26, 163. [Google Scholar] [CrossRef]
- Interlenghi, M.; Salvatore, C.; Magni, V.; Caldara, G.; Schiavon, E.; Cozzi, A.; Schiaffino, S.; Carbonaro, L.A.; Castiglioni, I.; Sardanelli, F. A Machine Learning Ensemble Based on Radiomics to Predict BI-RADS Category and Reduce the Biopsy Rate of Ultrasound-Detected Suspicious Breast Masses. Diagnostics 2022, 12, 187. [Google Scholar] [CrossRef]
- Kavitha, T.; Mathai, P.P.; Karthikeyan, C.; Ashok, M.; Kohar, R.; Avanija, J.; Neelakandan, S. Deep learning based capsule neural network model for breast cancer diagnosis using mammogram images. Interdiscip. Sci. Comput. Life Sci. 2022, 14, 113–129. [Google Scholar] [CrossRef] [PubMed]
- Ionkina, K.; Svistunov, A.; Galin, I.; Onykiy, B.; Pronicheva, L. MIAS database semantic structure. Procedia Comput. Sci. 2018, 145, 254–259. [Google Scholar] [CrossRef]
- Sawyer-Lee, R.; Gimenez, F.; Hoogi, A.; Rubin, D. Curated Breast Imaging Subset of Digital Database for Screening Mammography (CBIS-DDSM) [Data Set]; The Cancer Imaging Archive: Palo Alto, CA, USA, 2016. [Google Scholar] [CrossRef]
- Chen, G.; Liu, Y.; Qian, J.; Zhang, J.; Yin, X.; Cui, L.; Dai, Y. DSEU-net: A novel deep supervision SEU-net for medical ultrasound image segmentation. Expert Syst. Appl. 2023, 223, 119939. [Google Scholar] [CrossRef]
- Al-Dhabyani, W.; Gomaa, M.; Khaled, H.; Fahmy, A. Dataset of breast ultrasound images. Data Brief 2020, 28, 104863. [Google Scholar] [CrossRef]
- Dogiwal, S.R. Breast cancer prediction using supervised machine learning techniques. J. Inf. Optim. Sci. 2023, 44, 383–392. [Google Scholar]
- Wolberg, W.; Mangasarian, O.; Street, N.; Street, W. Breast Cancer Wisconsin (Diagnostic); UCI Machine Learning Repository: Irvine, CA, USA, 1995. [Google Scholar] [CrossRef]
- Al-Azzam, N.; Shatnawi, I. Comparing supervised and semi-supervised machine learning models on diagnosing breast cancer. Ann. Med. Surg. 2021, 62, 53–64. [Google Scholar] [CrossRef]
- Ayana, G.; Park, J.; Jeong, J.W.; Choe, S.W. A novel multistage transfer learning for ultrasound breast cancer image classification. Diagnostics 2022, 12, 135. [Google Scholar] [CrossRef]
- Rodrigues, P.S. Breast Ultrasound Image. Mendeley Data 2017, V1. Available online: https://data.mendeley.com/datasets/wmy84gzngw/1 (accessed on 24 November 2024).
- Umer, M.; Naveed, M.; Alrowais, F.; Ishaq, A.; Hejaili, A.A.; Alsubai, S.; Eshmawi, A.A.; Mohamed, A.; Ashraf, I. Breast Cancer Detection Using Convoluted Features and Ensemble Machine Learning Algorithm. Cancers 2022, 14, 6015. [Google Scholar] [CrossRef]
- Hekal, A.A.; Moustafa, H.E.D.; Elnakib, A. Ensemble deep learning system for early breast cancer detection. Evol. Intell. 2023, 16, 1045–1054. [Google Scholar] [CrossRef]
- Deb, S.D.; Jha, R.K. Segmentation of mammogram images using deep learning for breast cancer detection. In Proceedings of the 2022 2nd International Conference on Image Processing and Robotics (ICIPRob), Colombo, Sri Lanka, 12–13 March 2022; pp. 1–6. [Google Scholar] [CrossRef]
- Moreira, I.C.; Amaral, I.; Domingues, I.; Cardoso, A.; Cardoso, M.J.; Cardoso, J.S. INBreast: Toward a full-field digital mammographic database. Acad. Radiol. 2012, 19, 236–248. [Google Scholar] [CrossRef]
- Haris, U.; Kabeer, V.; Afsal, K. Breast cancer segmentation using hybrid HHO-CS SVM optimization techniques. Multimed. Tools Appl. 2024, 83, 69145–69167. [Google Scholar] [CrossRef]
- Walker, D.; Hamilton, W.; Walter, F.M.; Watts, C. Strategies to accelerate diagnosis of primary brain tumors at the primary-secondary care interface in children and adults. CNS Oncol. 2013, 2, 447–462. [Google Scholar] [CrossRef]
- Hanif, F.; Muzaffar, K.; Perveen, K.; Malhi, S.M.; Simjee, S.U. Glioblastoma multiforme: A review of its epidemiology and pathogenesis through clinical presentation and treatment. Asian Pac. J. Cancer Prev. 2017, 18, 3–9. [Google Scholar] [CrossRef]
- Khan, M.; Shah, S.A.; Ali, T.; Quratulain; Khan, A.; Choi, G.S. Brain tumor detection and segmentation using RCNN. Comput. Mater. Contin. 2022, 71, 5005–5020. [Google Scholar] [CrossRef]
- Menze, B.H.; Jakab, A.; Bauer, S.; Kalpathy-Cramer, J.; Farahani, K.; Kirby, J.; Burren, Y.; Porz, N.; Slotboom, J.; Wiest, R.; et al. The multimodal brain tumor image segmentation benchmark (BRATS). IEEE Trans. Med. Imaging 2015, 34, 1993–2024. [Google Scholar] [CrossRef]
- Bakas, S.; Akbari, H.; Sotiras, A.; Bilello, M.; Rozycki, M.; Kirby, J.S.; Freymann, J.B.; Farahani, K.; Davatzikos, C. Advancing The Cancer Genome Atlas glioma MRI collections with expert segmentation labels and radiomic features. Nat. Sci. Data 2017, 4, 170117. [Google Scholar] [CrossRef]
- Bakas, S.; Reyes, M.; Jakab, A.; Bauer, S.; Rempfler, M.; Crimi, A.; Shinohara, R.T.; Berger, C.; Ha, S.M.; Rozycki, M.; et al. Identifying the Best Machine Learning Algorithms for Brain Tumor Segmentation, Progression Assessment, and Overall Survival Prediction in the BRATS Challenge; Apollo—University of Cambridge Repository: Cambridge, UK, 2018. [Google Scholar] [CrossRef]
- Sharma, S.R.; Alshathri, S.; Singh, B.; Kaur, M.; Mostafa, R.R.; El-Shafai, W. Hybrid multilevel thresholding image segmentation approach for brain MRI. Diagnostics 2023, 13, 925. [Google Scholar] [CrossRef]
- Brima, Y.; Hossain, M.; Tushar, K.; Kabir, U.; Islam, T. Brain MRI Dataset [Data Set]; Figshare: London, UK, 2021. [Google Scholar] [CrossRef]
- Ngo, D.K.; Tran, M.T.; Kim, S.H.; Yang, H.J.; Lee, G.S. Multi-task learning for small brain tumor segmentation from MRI. Appl. Sci. 2020, 10, 7790. [Google Scholar] [CrossRef]
- Ullah, F.; Nadeem, M.; Abrar, M.; Amin, F.; Salam, A.; Alabrah, A.; AlSalman, H. Evolutionary Model for Brain Cancer-Grading and Classification. IEEE Access 2023, 11, 126182–126194. [Google Scholar] [CrossRef]
- Saha, P.; Das, R.; Das, S.K. BCM-VEMT: Classification of brain cancer from MRI images using deep learning and ensemble of machine learning techniques. Multimed. Tools Appl. 2023, 82, 44479–44506. [Google Scholar] [CrossRef]
- Cheng, J. Brain Tumor Dataset [Data Set]. Figshare. 2017. Available online: https://figshare.com/articles/dataset/brain_tumor_dataset/1512427 (accessed on 25 March 2024).
- Chakrabarty, N. Brain MRI Images for Brain Tumor Detection [Data Set]. Kaggle. 2019. Available online: https://www.kaggle.com/datasets/navoneel/brain-mri-images-for-brain-tumor-detection (accessed on 25 March 2024).
- Bhuvaji, S.; Kadam, A.; Bhumkar, P.; Dedge, S.; Kanchan, S. Brain Tumor Classification (MRI) [Data Set]; Kaggle: San Francisco, CA, USA, 2020. [Google Scholar] [CrossRef]
- Kessler, T.A. Cervical cancer: Prevention and early detection. Semin. Oncol. Nurs. 2017, 33, 172–183. [Google Scholar] [CrossRef]
- Zhang, L.; Lu, L.; Nogues, I.; Summers, R.M.; Liu, S.; Yao, J. DeepPap: Deep convolutional networks for cervical cell classification. IEEE J. Biomed. Health Inform. 2017, 21, 1633–1643. [Google Scholar] [CrossRef]
- Albuquerque, T.; Cruz, R.; Cardoso, J.S. Ordinal losses for classification of cervical cancer risk. PeerJ Comput. Sci. 2021, 7, 1–21. [Google Scholar] [CrossRef]
- Hussain, E.; Mahanta, L.B.; Borah, H.; Das, C.R. Liquid based-cytology Pap smear dataset for automated multi-class diagnosis of pre-cancerous and cervical cancer lesions. Data Brief 2020, 30, 105589. [Google Scholar] [CrossRef]
- Guo, P.; Xue, Z.; Angara, S.; Antani, S.K. Unsupervised deep learning registration of uterine cervix sequence images. Cancers 2022, 14, 2401. [Google Scholar] [CrossRef]
- Herrero, R.; Hildesheim, A.; Rodríguez, A.C.; Wacholder, S.; Bratti, C.; Solomon, D.; González, P.; Porras, C.; Jiménez, S.; Guillen, D.; et al. Rationale and design of a community-based double-blind randomized clinical trial of an HPV 16 and 18 vaccine in Guanacaste, Costa Rica. Vaccine 2008, 26, 4795–4808. [Google Scholar] [CrossRef]
- Herrero, R.; Wacholder, S.; Rodríguez, A.C.; Solomon, D.; González, P.; Kreimer, A.R.; Porras, C.; Schussler, J.; Jiménez, S.; Sherman, M.E.; et al. Prevention of persistent human papillomavirus infection by an HPV16/18 vaccine: A community-based randomized clinical trial in Guanacaste, Costa Rica. Cancer Discov. 2011, 1, 408–419. [Google Scholar] [CrossRef]
- The Atypical Squamous Cells of Undetermined Significance/Low-Grade Squamous Intraepithelial Lesions Triage Study (ALTS) Group. Human papillomavirus testing for triage of women with cytologic evidence of low-grade squamous intraepithelial lesions: Baseline data from a randomized trial. J. Natl. Cancer Inst. 2000, 92, 397–402. [Google Scholar] [CrossRef]
- Intel & MobileODT Cervical Cancer Screening Competition. (2017, March). Kaggle. Available online: https://www.kaggle.com/c/intel-mobileodt-cervical-cancer-screening (accessed on 15 May 2024).
- Angara, S.; Guo, P.; Xue, Z.; Antani, S. Semi-supervised learning for cervical precancer detection. In Proceedings of the 2021 IEEE 34th International Symposium on Computer-Based Medical Systems (CBMS), Aveiro, Portugal, 7–9 June 2021; pp. 202–206. [Google Scholar] [CrossRef]
- Kudva, V.; Prasad, K.; Guruvare, S. Transfer learning for classification of uterine cervix images for cervical cancer screening. Lect. Notes Electr. Eng. 2020, 614, 299–312. [Google Scholar] [CrossRef]
- Ahishakiye, E.; Wario, R.; Mwangi, W.; Taremwa, D. Prediction of cervical cancer basing on risk factors using ensemble learning. In Proceedings of the 2020 IST-Africa Conference (IST-Africa 2020), Kampala, Uganda, 18–22 May 2020. [Google Scholar]
- Hodneland, E.; Kaliyugarasan, S.; Wagner-Larsen, K.S.; Lura, N.; Andersen, E.; Bartsch, H.; Smit, N.; Halle, M.K.; Krakstad, C.; Lundervold, A.S.; et al. Fully Automatic Whole-Volume Tumor Segmentation in Cervical Cancer. Cancers 2022, 14, 2372. [Google Scholar] [CrossRef]
- World Health Organization. Cancer. 2022. Available online: https://www.who.int/news-room/fact-sheets/detail/cancer (accessed on 15 May 2024).
- Guo, J.; Cao, W.; Nie, B.; Qin, Q. Unsupervised learning composite network to reduce training cost of deep learning model for colorectal cancer diagnosis. IEEE J. Transl. Eng. Health Med. 2023, 11, 54–59. [Google Scholar] [CrossRef] [PubMed]
- Zhou, C.; Jin, Y.; Chen, Y.; Huang, S.; Huang, R.; Wang, Y.; Zhao, Y.; Chen, Y.; Guo, L.; Liao, J. Histopathology classification and localization of colorectal cancer using global labels by weakly supervised deep learning. Comput. Med. Imaging Graph. 2021, 88, 101861. [Google Scholar] [CrossRef]
- Venkatayogi, N.; Kara, O.C.; Bonyun, J.; Ikoma, N.; Alambeigi, F. Classification of colorectal cancer polyps via transfer learning and vision-based tactile sensing. In Proceedings of the 2022 IEEE Sensors, Dallas, TX, USA, 8 December 2022; pp. 1–4. [Google Scholar] [CrossRef]
- Tamang, L.D.; Kim, M.T.; Kim, S.J.; Kim, B.W. Tumor-stroma classification in colorectal cancer patients with transfer learning based binary classifier. In Proceedings of the 2021 International Conference on Information and Communication Technology Convergence (ICTC), Jeju Island, Republic of Korea, 20–22 October 2021; pp. 1645–1648. [Google Scholar] [CrossRef]
- Kather, J.N.; Weis, C.A.; Bianconi, F.; Melchers, S.M.; Schad, L.R.; Gaiser, T.; Marx, A.; Zöllner, F.G. Multi-class texture analysis in colorectal cancer histology. Sci. Rep. 2016, 6, 27988. [Google Scholar] [CrossRef]
- Liu, Y.; Wang, J.; Wu, C.; Liu, L.; Zhang, Z.; Yu, H. Fovea-UNet: Detection and segmentation of lymph node metastases in colorectal cancer with deep learning. Biomed. Eng. Online 2023, 22, 74. [Google Scholar] [CrossRef]
- Fang, Y.; Zhu, D.; Yao, J.; Yuan, Y.; Tong, K.Y. ABC-Net: Area-boundary constraint network with dynamical feature selection for colorectal polyp segmentation. IEEE Sens. J. 2021, 21, 11799–11809. [Google Scholar] [CrossRef]
- Vázquez, D.; Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; López, A.M.; Romero, A.; Drozdzal, M.; Courville, A. A benchmark for endoluminal scene segmentation of colonoscopy images. J. Healthc. Eng. 2017, 2017, 4037190. [Google Scholar] [CrossRef]
- Jha, D.; Smedsrud, P.H.; Riegler, M.A.; Halvorsen, P.; Lange, T.D.; Johansen, D.; Johansen, H.D. Kvasir-SEG: A segmented polyp dataset. In Proceedings of the 26th International Conference on Multimedia Modeling, Daejeon, Republic of Korea, 5–8 January 2020; pp. 451–462. [Google Scholar] [CrossRef]
- Silva, J.S.; Histace, A.; Romain, O.; Dray, X.; Granado, B. Toward embedded detection of polyps in WCE images for early diagnosis of colorectal cancer. Int. J. Comput. Assist. Radiol. Surg. 2014, 9, 283–293. [Google Scholar] [CrossRef]
- Elkarazle, K.; Raman, V.; Then, P.; Chua, C. Improved colorectal polyp segmentation using enhanced MA-NET and modified Mix-ViT transformer. IEEE Access 2023, 11, 69295–69309. [Google Scholar] [CrossRef]
- Bernal, J.; Sánchez, F.J.; Fernández-Esparrach, G.; Gil, D.; Rodríguez, C.; Vilariño, F. WM-DOVA maps for accurate polyp highlighting in colonoscopy: Validation vs. saliency maps from physicians. Comput. Med. Imaging Graph. 2015, 43, 99–111. [Google Scholar] [CrossRef]
- Bernal, J.; Sánchez, J.; Vilariño, F. Towards automatic polyp detection with a polyp appearance model. Pattern Recognit. 2012, 45, 3166–3182. [Google Scholar] [CrossRef]
- Arnold, M.; Abnet, C.C.; Neale, R.E.; Vignat, J.; Giovannucci, E.L.; McGlynn, K.A.; Bray, F. Global burden of 5 major types of gastrointestinal cancer. Gastroenterology 2020, 159, 335–349. [Google Scholar] [CrossRef]
- Masuzaki, R. Liver cancer: Improving standard diagnosis and therapy. Cancers 2023, 15, 4602. [Google Scholar] [CrossRef]
- Napte, K.; Mahajan, A.; Urooj, S. ESP-UNet: Encoder-decoder convolutional neural network with edge-enhanced features for liver segmentation. Trait. Du Signal 2023, 40, 2275–2281. [Google Scholar] [CrossRef]
- Bilic, P.; Christ, P.; Li, H.B.; Vorontsov, E.; Ben-Cohen, A.; Kaissis, G.; Szeskin, A.; Jacobs, C.; Mamani, G.E.H.; Chartrand, G.; et al. The liver tumor segmentation benchmark (LiTS). Med. Image Anal. 2023, 84, 102680. [Google Scholar] [CrossRef]
- Suganeshwari, G.; Appadurai, J.P.; Kavin, B.P.; Kavitha, C.; Lai, W.C. En–DeNet based segmentation and gradational modular network classification for liver cancer diagnosis. Biomedicines 2023, 11, 1309. [Google Scholar] [CrossRef]
- Soler, L.; Hostettler, A.; Agnus, V.; Charnoz, A.; Fasquel, J.; Moreau, J.; Osswald, A.; Bouhadjar, M.; Marescaux, J. 3D Image Reconstruction for Comparison of Algorithm Database: A Patient Specific Anatomical and Medical Image Database. IRCAD. 2010. Available online: https://www.ircad.fr/research/data-sets/liver-segmentation-3d-ircadb-01 (accessed on 24 November 2024).
- Araújo, J.D.L.; da Cruz, L.B.; Diniz, J.O.B.; Ferreira, J.L.; Silva, A.C.; de Paiva, A.C.; Gattass, M. Liver segmentation from computed tomography images using cascade deep learning. Comput. Biol. Med. 2022, 140, 105095. [Google Scholar] [CrossRef] [PubMed]
- Badawy, S.M.; Mohamed, A.E.-N.A.; Hefnawy, A.A.; Zidan, H.E.; GadAllah, M.T.; El-Banby, G.M. Automatic semantic segmentation of breast tumors in ultrasound images based on combining fuzzy logic and deep learning—A feasibility study. PLoS ONE 2021, 16, e0251899. [Google Scholar] [CrossRef] [PubMed]
- United States Government Accountability Office. Artificial Intelligence in Health Care: Benefits and Challenges of Machine Learning Technologies for Medical Diagnostics; United States Government Accountability Office: Washington, DC, USA, 2022; pp. 3–30. Available online: https://www.gao.gov/assets/gao-22-104629.pdf (accessed on 24 November 2024).
- Sebastian, A.M.; Peter, D. Artificial intelligence in cancer research: Trends, challenges and future directions. Life 2022, 12, 1991. [Google Scholar] [CrossRef] [PubMed]
- Ellis, R.J.; Sander, R.M.; Limon, A. Twelve key challenges in medical machine learning and solutions. Intell. Med. 2022, 6, 100068. [Google Scholar] [CrossRef]
- Maleki, F.; Muthukrishnan, N.; Ovens, K.; Reinhold, C.; Forghani, R. Machine learning algorithm validation: From essentials to advanced applications and implications for regulatory certification and deployment. Neuroimaging Clin. N. Am. 2020, 30, 433–445. [Google Scholar] [CrossRef] [PubMed]
- Shreve, J.T.; Khanani, S.A.; Haddad, T.C. Artificial intelligence in oncology: Current capabilities, future opportunities, and ethical considerations. ASCO Educ. Book 2022, 42, 842–851. [Google Scholar] [CrossRef]
- Carter, S.M.; Rogers, W.; Win, K.T.; Frazer, H.; Richards, B.; Houssami, N. The ethical, legal and social implications of using artificial intelligence systems in breast cancer care. Breast 2020, 49, 25–32. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
| Algorithm | Description | Strengths | Weaknesses | Applications |
|---|---|---|---|---|
| SVM [18] | Finds the hyperplane that best separates the data points of different classes. |
|
|
|
| k-NN [18] | Classifies data based on the majority class of the k-nearest neighbors in the dataset. |
|
|
|
| Decision Tree [18] | A tree-like model of decisions and their possible consequences. |
|
|
|
| Random Forest [18] | An EL method that builds multiple decision trees and combines them for a more accurate prediction. |
|
|
|
| Extra Trees [18] | Similar to random forest, but selects splits at random rather than calculating the best possible split, leading to faster training times. |
|
|
|
| Logistic Regression [18] | Estimates the probability that a given input belongs to a particular class. |
|
|
|
| GBM [19] | An EL method that builds models sequentially, minimizing the loss at each stage to improve accuracy. |
|
|
|
| XGBoost [19] | A fast and efficient implementation of GBM designed for large-scale datasets. |
|
|
|
| Bagging [18] | An ensemble method that trains multiple models on different subsets of the data and combines their predictions to reduce variance. |
|
|
|
| AdaBoost [18] | A boosting algorithm that combines weak learners into a strong learner by adjusting weights to focus on harder-to-classify examples. |
|
|
|
| Gaussian Naïve Bayes [18] | A probabilistic classifier that assumes features are normally distributed and independent of each other. |
|
|
|
| CNN [20] | A DL algorithm primarily used for image recognition. |
|
|
|
| VGG-16 [21] | A CNN architecture with 16 layers known for using small convolutional filters (3 × 3) and deep layers. |
|
|
|
| U-Net [22] | A type of CNN tailored for biomedical image segmentation that uses an encoder–decoder structure. |
|
|
|
| ResNet [23] | A DNN that introduces “residual connections” to solve the vanishing gradient problem, allowing the training of much deeper networks. |
|
|
|
| Author | Model | Data Type | Dataset | Preprocessing | |
|---|---|---|---|---|---|
| Size | Classes | ||||
| Jassim et al. [34] | Transfer DL Ensemble | CT | 1000 | Normal Adenocarcinoma Large cell Squamous cell | Conversion to RGB Resizing Data augmentation |
| Muhtasim et al. [36] | Ensemble CNN + VGG16 TL | CT | 1190 | Normal Benign Malignant | Resizing Normalization Smoothing Enhancement Morphological segmentation |
| Luo [38] | LLC-QE | CT | 1018 | Non-nodule > or =3 mm Nodule > or =3 mm Nodule < 3 mm | - |
| Mamun et al. [40] | XGBoost LightGBM AdaBoost Bagging | 16 attributes | 309 | Normal Cancer | Feature extraction Data cleaning Missing value handling Categorical variables transformation SMOTE |
| Venkatesh & Raamesh [42] | Bagging AdaBoost Integrated | 24 attributes | 1000 | Normal Cancer | Interpolation Normalization |
| Said et al. [44] | UNETR | CT | 96 | Benign Malignant | Segmentation |
| Author | Model | Data Type | Dataset | Preprocessing | |
|---|---|---|---|---|---|
| Size | Classes | ||||
| Interlenghi et al. [50] | Radiomics-based ML | US | 821 | Benign Malignant | Image balancing Histogram equalization |
| Kavitha et al. [51] | OMLTS-DLCN | Mammogram | 322 + 13,128 | Normal Benign Malignant | Noise reduction Thresholding Segmentation |
| Chen et al. [54] | DSEU-Net | US | 780 | Normal Benign Malignant | - |
| Dogiwal [56] | Random Forest Logistic Regression SVM | 32 attributes | 699 | Benign Malignant | Feature extraction Feature selection |
| Al-Azzam & Shatnawi [58] | SL Semi-SL | 32 features | 569 | Benign Malignant | Exploratory Data Analysis Correlation analysis |
| Ayana et al. [59] | ResNet50 | US | 200 + 400 | Benign Malignant | Adaptive thresholding Noise reduction Data augmentation |
| Umer et al. [61] | Voting CNN | 32 features | - | Benign Malignant | Feature extraction Label encoder |
| Hekal et al. [62] | Ensemble DL SVM | Mammogram | 3549 | Benign Malignant | ROI extraction Smoothing Otsu thresholding |
| Deb et al. [63] | BCDU-Net | Mammogram | 410 | Masses Calcifications Asymmetries Distortions | ROI extraction Otsu thresholding Resizing |
| Haris et al. [65] | HHO-CS SVM | Mammogram | 2620 | Normal Benign Malignant | Histogram equalization Contrast stretching Adaptive equalization |
| Author | Model | Data Type | Dataset | Preprocessing | |
|---|---|---|---|---|---|
| Size | Classes | ||||
| Khan et al. [68] | RCNN | MRI | 663 | Glioma | Denoising |
| Sharma et al. [72] | DOBES | MRI | 3064 | Meningioma Glioma Pituitary | Multilevel thresholding Kapur’s method DOBES algorithm Morphological operations based postprocessing |
| Ngo et al. [74] | U-Net | MRI | 351 | Glioma | Cropping Normalization Data augmentation |
| Ullah et al. [75] | Lightweight XGBoost Ensemble | MRI | 285 | Glioma grade II Glioma grade III Glioma grade IV | Image registration Skull stripping Intensity Resizing |
| Saha et al. [76] | BCM-VEMT | MRI | 3787 | Normal Glioma Meningioma Pituitary | Resizing Cropping Normalization Data augmentation |
| Author | Model | Data Type | Dataset | Preprocessing | Interpretability | |
|---|---|---|---|---|---|---|
| Size | Classes | |||||
| Zhang et al. [81] | DeepPap | Pap smear Pap staining | 917 + 1978 | Abnormal Normal | Patch extraction Data augmentation | - |
| Guo et al. [84] | DeTr | Colposcopic | 3398 + 939 + 1950 + 5100 | Normal Cancer | Resizing | - |
| Angara et al. [89] | ResNeSt50 | Cytology HPV Testing Cervicography | 3384 + 26,000 | Normal Cancer | Resizing Cropping Data augmentation PCA noise Normalizing | Score-CAM |
| Kudva et al. [90] | HTL | Pap smear | 2198 | Benign Malignant | Data augmentation | - |
| Ahishakiye et al. [91] | Voting EL | 36 attributes | 858 | Normal Cancer | Normalization Standardization | - |
| Hodneland et al. [92] | ResU-Net | MRI | 131 | Cancer | Resampling Interpolation Z-normalization Resizing Data augmentation | - |
| Author | Model | Data Type | Dataset | Preprocessing | |
|---|---|---|---|---|---|
| Size | Classes | ||||
| Guo et al. [94] | RK-net | Histopathology | 360 | Cancer Normal | Normalization Resizing |
| Zhou et al. [95] | CNN | Histopathology | 1346 | Cancer Normal | Feature combination |
| Venkatayogi et al. [96] | ResNet1 ResNet2 | Fabricated | 48 | IIa IIc Ip LST | Cropping Resizing Data augmentation |
| Tamang et al. [97] | EfficientNetB1 InceptionResNetV2 | Histopathology | 625 | Tumor Stroma | Data augmentation |
| Liu et al. [99] | Fovea-UNet | CT | 624 | Metastatic regions | Resizing |
| Fang et al. [100] | ABC-Net | Colonoscopy | 912 + 1000 + 196 | Polyps Non-polyps | Resizing Data augmentation |
| Elkarazle et al. [104] | MA-NET Mix-ViT | Colonoscopy | 1000 + 612 + 196 | Polyps Non-polyps | Resizing Normalization CIEL*A*B* color space conversion CLAHE |
| Author | Model | Data Type | Dataset | Preprocessing | |
|---|---|---|---|---|---|
| Size | Classes | ||||
| Napte et al. [109] | ESP-UNet | CT | 131 | Normal Cancer | Kirsch’s filter Segmentation |
| Suganeshwari et al. [111] | En-DeNet | CT | 2346 | Normal Cancer | Data augmentation Resizing Normalization |
| Araújo et al. [113] | U-Net | CT | 131 | Normal Cancer | Windowing Voxel rescaling False-positive reduction Hole filling |
| Cancer Type | Author | ML Model | Type | Dataset | Accuracy |
|---|---|---|---|---|---|
| Lung Cancer | Jassim et al. [34] | Transfer DL Ensemble | Multi-class | Chest CT-Scan images [35] | 99.44% |
| Muhtasim et al. [36] | Ensemble CNN+VGG16 TL | Multi-class | IQ-OTHNCCD [37] | 99.55% | |
| Luo [38] | LLC-QE | Multi-class | LIDC-IDRI [39] | 92.90% | |
| Mamun et al. [40] | XGBoost | Binary | Lung Cancer Dataset [41] | 94.42% | |
| LightGBM | 92.55% | ||||
| AdaBoost | 90.70% | ||||
| Bagging | 89.76% | ||||
| Venkatesh & Raamesh [42] | Bagging | Binary | SEER [43] | 93.90% | |
| AdaBoost | 95.46% | ||||
| Integrated | 98.30% | ||||
| Said et al. [44] | UNETR | Binary | Decathlon [45] | 98.77% | |
| Breast Cancer | Interlenghi et al. [50] | Radiomics-based ML | Binary | - | 92.70% |
| Kavitha et al. [51] | OMLTS-DLCN | Multi-class | Mini-MIAS [52] | 98.50% | |
| CBIS-DDSM [53] | 97.56% | ||||
| Dogiwal [56] | Random Forest | Binary | Breast Cancer Wisconsin (Diagnostic) [57] | 98.60% | |
| Logistic Regression | 94.41% | ||||
| SVM | 93.71% | ||||
| Al-Azzam & Shatnawi [58] | SL | Binary | Breast Cancer Wisconsin (Diagnostic) [57] | 97.00% | |
| Semi-SL | 98.00% | ||||
| Ayana et al. [59] | ResNet50 | Binary | Mendeley [60] | 99.00% | |
| MT-Small-Dataset [55,114] | 98.70% | ||||
| Umer et al. [61] | Voting CNN | Binary | Breast Cancer Wisconsin (Diagnostic) [57] | 99.89% | |
| Hekal et al. [62] | Ensemble DL SVM | Binary | CBIS-DDSM [53]—case | 94.00% | |
| CBIS-DDSM [53]—mass | 95.00% | ||||
| Brain Cancer | Ullah et al. [75] | Lightweight XGBoost Ensemble | Multi-class | BraTS 2020 [69,70,71] | 93.00% |
| Saha et al. [76] | BCM-VEMT | Multi-class | Figshare [64], Kaggle [78,79] | 98.42% | |
| Cervical Cancer | Zhang et al. [81] | DeepPap | Binary | Herlev [82], HEMLBC [83] | 98.30% |
| Angara et al. [89] | ResNeSt50 | Binary | ALTS [87], NHS | 82.02% | |
| Kudva et al. [90] | HTL | Binary | Kasturba Medical College, National Cancer Institute | 91.46% | |
| Ahishakiye et al. [91] | Voting EL | Binary | UCI ML Repository | 87.21% | |
| Colorectal Cancer | Guo et al. [94] | RK-net | Binary | - | 95.00% |
| Zhou et al. [95] | CNN | Multi-class | TCGA | 94.60% | |
| Venkatayogi et al. [96] | ResNet1 | Multi-class | - | 54.95% | |
| ResNet2 | 91.93% | ||||
| Tamang et al. [97] | VGG19 | Binary | ImageNet, Kather et al. [98] | 96.40% | |
| EfficientNetB1 | 96.87% | ||||
| InceptionResNetV2 | 97.65% | ||||
| Liver Cancer | Suganeshwari et al. [101] | En-DeNet | Binary | 3DIRCADb01 [112] | 97.22% |
| LiTS [110] | 88.08% |
| Cancer Type | Author | ML Model | Dataset | DSC | IOU |
|---|---|---|---|---|---|
| Lung Cancer | Muhtasim et al. [36] | Ensemble CNN+VGG16 TL | IQ-OTHNCCD [37] | - | - |
| Said et al. [44] | UNETR | Decathlon [45] | 0.9642 | 0.9309 | |
| Breast Cancer | Kavitha et al. [51] | OMLTS-DLCN | Mini-MIAS [52] | - | - |
| CBIS-DDSM [53] | - | - | |||
| Chen et al. [54] | DSEU-Net | BUSI [55] | 0.7851 | 0.7036 | |
| Deb et al. [63] | U-Net | INBreast [64] | 0.8781 | 0.7827 | |
| BCDU-Net | 0.8949 | 0.8098 | |||
| Haris et al. [65] | HHO+CS SVM | CBIS-DDSM [53] | 0.9877 | 0.9768 | |
| Brain Cancer | Khan et al. [68] | RCNN | BraTS 2020 [69,70,71] | 0.9200 | 0.8519 |
| Sharma et al. [72] | DOBES | Figshare [73] | - | - | |
| Ngo et al. [74] | U-Net | BraTS 2018 [69,70,71] | 0.4499 | 0.2902 | |
| Cervical Cancer | Guo et al. [84] | DeTr | CVT [85,86], ALTS [87], Kaggle [88], DYSIS | 0.9380 | 0.8850 |
| Hodneland et al. [92] | ResU-Net | - | 0.7800 | 0.6393 | |
| Colorectal Cancer | Liu et al. [99] | Fovea-UNet | LMN [99] | 0.8851 | 0.7938 |
| Fang et al. [100] | ABC-Net | EndoScene [101] | 0.8570 | 0.7620 | |
| Kvasir-SEG [102] | 0.9140 | 0.8480 | |||
| ETIS-LaribDB [103] | 0.8640 | 0.7700 | |||
| Elkarazle et al. [104] | MA-NET Mix-ViT | CVC-ColonDB [106] | 0.9830 | 0.9730 | |
| ETIS-LaribDB [103] | 0.9890 | 0.9850 | |||
| Liver Cancer | Napte et al. [109] | ESP-UNet | LiTS [110] | 0.9590 | 0.9210 |
| Suganeshwari et al. [111] | En-DeNet | 3DIRCADb01 [112] | 0.8481 | 0.7363 | |
| LiTS [110] | 0.8594 | 0.7535 | |||
| Araújo et al. [113] | U-Net | LiTS [110] | 0.9564 | 0.9164 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Dumachi, A.I.; Buiu, C. Applications of Machine Learning in Cancer Imaging: A Review of Diagnostic Methods for Six Major Cancer Types. Electronics 2024, 13, 4697. https://doi.org/10.3390/electronics13234697
Dumachi AI, Buiu C. Applications of Machine Learning in Cancer Imaging: A Review of Diagnostic Methods for Six Major Cancer Types. Electronics. 2024; 13(23):4697. https://doi.org/10.3390/electronics13234697
Chicago/Turabian StyleDumachi, Andreea Ionela, and Cătălin Buiu. 2024. "Applications of Machine Learning in Cancer Imaging: A Review of Diagnostic Methods for Six Major Cancer Types" Electronics 13, no. 23: 4697. https://doi.org/10.3390/electronics13234697
APA StyleDumachi, A. I., & Buiu, C. (2024). Applications of Machine Learning in Cancer Imaging: A Review of Diagnostic Methods for Six Major Cancer Types. Electronics, 13(23), 4697. https://doi.org/10.3390/electronics13234697