
ENSG: Enhancing Negative Sampling in Graph Convolutional Networks for Recommendation Systems

Abstract
1. Introduction
- (1)
- In the field of recommendation, existing negative sampling techniques often struggle to mine hard negative samples, which can lead to models overemphasizing simple samples during training and neglecting the truly challenging hard negative samples. This, in turn, affects the model’s recommendation accuracy.
- (2)
- Research has found that hard negative samples have a significant impact on the recommendation accuracy of models. In existing studies, after obtaining hard negative samples, there has not been consideration of how to further improve their quality based on these hard negative samples, thereby enhancing the recommendation model’s ability to distinguish between positive and negative samples.
- (1)
- A new negative sampling strategy is proposed; firstly, the original negative samples are randomly selected; secondly, the positive sample embedding information is randomly introduced into the original negative samples using the interpolated multivariate technique; and then the final difficult negative samples are synthesized by using the inner-product method selection strategy in the process of aggregation in the graph convolutional network to lay the foundation for the subsequent model training.
- (2)
- Introducing the contrast learning method, by mining more feature information in the positive samples and the difficult negative samples, the difficult negative samples are made closer to the positive samples in the feature space, which further improves the model’s ability to recognize the boundary of the positive and negative samples.
- (3)
- In order to validate the overall performance of the collaborative filtering recommendation algorithm based on multivariate sampling for graphical convolutional networks, the experimental results comparing it with a variety of state-of-the-art algorithms on three publicly available datasets, Yelp2018, Alibaba, and Gowalla, are conducted, significantly demonstrating that the proposed model has a significant performance enhancement with respect to the baseline model. This improvement not only validates the effectiveness of the multivariate negative sampling module but also confirms the positive role of the contrast learning module in the model.
2. Related Work
2.1. Recommendation Model Based on GCN
2.2. Negative Sampling Strategy
2.3. Contrast Learning
3. Algorithm Design
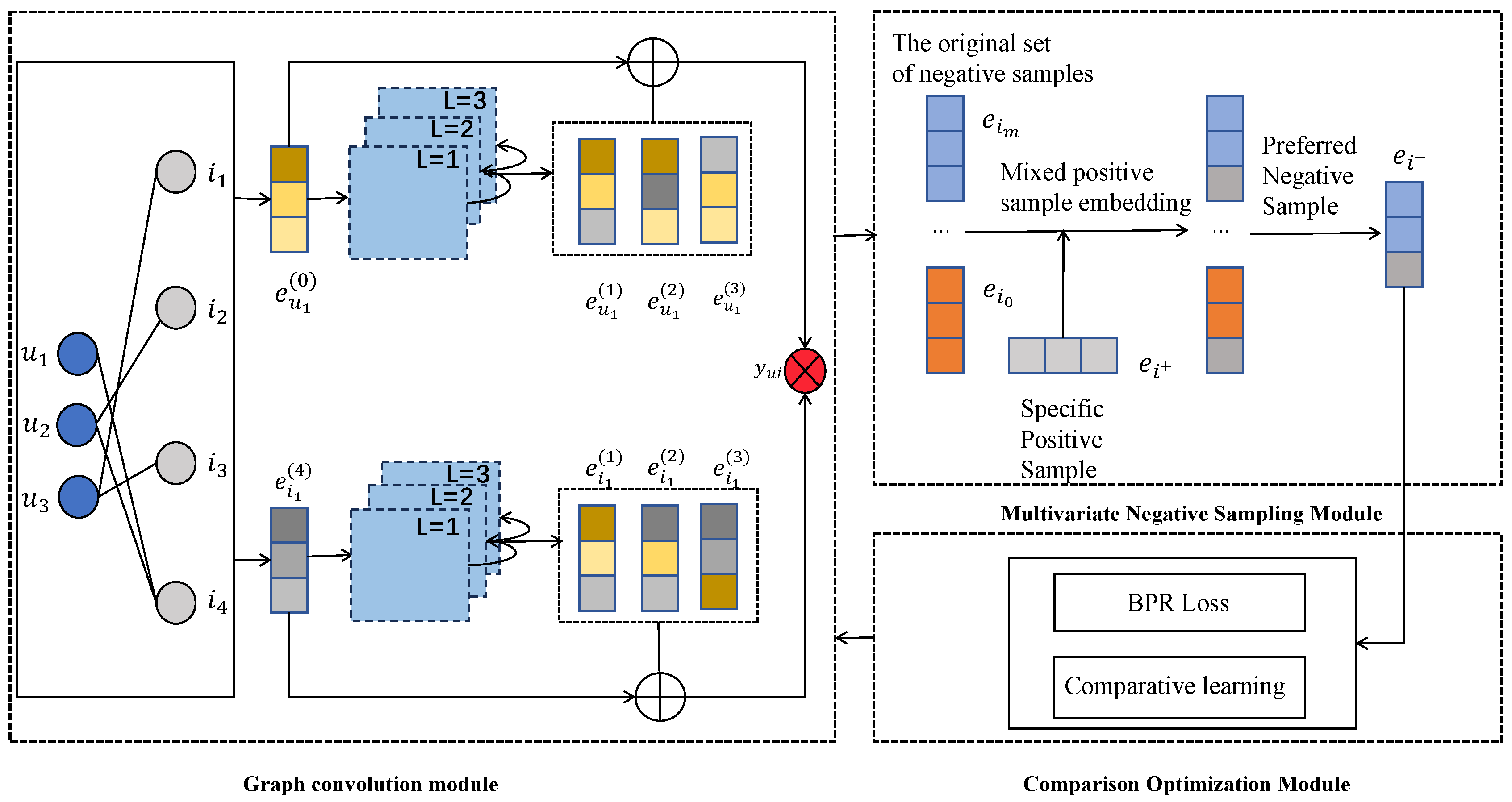
3.1. Overall Framework
- (1)
- Multivariate negative sampling module: the primary recommendation task employs a multivariate negative sampling strategy during the negative sampling phase, generating challenging negative samples by integrating information across different nodes.
- (2)
- Graph convolutional network module: the multivariate negative sampling module provides the difficult negative sample data required for model training, and the graph convolutional network module performs feature extraction based on the graph structure and the sample data obtained from sampling.
- (3)
- Optimization module: the positive samples and the obtained difficult negative samples are compared and learned as sample pairs so as to narrow the distance between the difficult negative samples and the positive samples in the semantic feature space, and the model parameters are optimized by minimizing the BPR loss function.
3.2. Multivariate Negative Sampling
3.2.1. Generate an Augmented Negative Sample Candidate Set
3.2.2. Sample Optimization and Aggregation
3.3. Graph Convolutional Network
3.4. Contrastive Learning
3.5. Optimize Model Parameters
| Algorithm 1: Enhancing Negative Sampling in Graph Convolutional Networks for Recommendation Systems (ENSG) |
| Input: user set , item set, user–item interaction set . Output: Each returns a list of recommended items. (1) Construct an interaction view, . (2) For , do. (3) Based on Equations (4)–(6), calculate the user representation and the positive sample representation . (4) Based on Equations (1) and (2), generate the embedding representations of hard negative samples in the continuous space for set . (5) Optimize the quality of hard negative samples according to Equation (8). (6) Calculate the predicted scores for users on items based on Equation (7) for set . (7) Calculate the BPR loss according to Equation (9) and optimize the parameters. (8) End for. (9) Return a list of recommended items for each user. |
4. Experiments and Analysis of Results
4.1. Datasets and Evaluation Indicators
4.2. Benchmarking Model
- (1)
- BPRMF [27]: a classic collaborative filtering algorithm optimized using matrix factorization.
- (2)
- NGCF [14]: graph convolutional neural network is applied to the collaborative filtering recommendation task by constructing a bipartite graph of user–item interactions in order to capture high-dimensional interactions between users and items.
- (3)
- LightGCN [15]: discarded the traditional complete graph convolution process and removed the feature transformation and nonlinear activation steps. Reduces the computational complexity of the model.
- (4)
- RNS [17]: a negative sampling module is added to the traditional network to select un-interacted items as negative examples to enrich the training data and improve the model performance.
- (5)
- PinSage [19]: the core idea is to learn the embedded representations of the nodes in the graph through efficient random wandering and graph convolution operations to capture high-dimensional interactions between users and items.
- (6)
- SGL [20] adding an auxiliary self-supervised task to the classical supervised recommendation task to enhance node representation learning through self-recognition.
- (7)
- SimGCL [22]: a simple contrastive learning strategy has been proposed, forgoing complex graph enhancement techniques and instead introducing uniform noise into the embedding space to create comparative views.
4.2.1. Experimental Environment and Parameter Settings
4.2.2. Analysis of Experimental Results
- (1)
- Recommendation algorithms that employ graph convolutional networks, such as NGCF, demonstrate significant advantages compared with traditional algorithms like BPRMF that do not utilize this technology. This finding strongly supports the exceptional performance of graph convolutional networks in enhancing the effectiveness of recommendation systems.
- (2)
- Recommendation models based on graph contrastive learning, such as SimGCL, SGL, and ENSG, outperform NGCF and LightGCN in terms of performance, which confirms the effectiveness of contrastive learning in recommendation tasks.
- (3)
- The proposed model demonstrates significant advantages in all performance indicators, especially in the key indicator of Recall@20. Compared with the best baseline model, the proposed model achieves 8.43%, 16.27%, and 7.0% performance improvement on the three datasets, respectively. This significant performance improvement fully verifies the validity and superiority of the proposed model in this paper, which is mainly due to the following aspects:
- (a)
- ENSG adopts a multivariate sampling method, which can generate hard negative samples with higher quality and lay a good foundation for subsequent improvement.
- (b)
- ENSG employs the idea of contrastive learning to further explore the hidden features of samples based on obtaining higher-quality hard negative samples. It brings the hard negative samples closer to the positive samples in the feature space, thereby enhancing the quality of the hard negative samples and further improving the model’s ability to recognize them.
4.2.3. Ablation Experiment
4.2.4. Hyperparametric Analysis
5. Conclusions
Supplementary Materials
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Chai, W.; Zhang, Z. A recommendation system based on graph attention convolutional neural networks. Comput. Appl. Softw. 2023, 8, 201–206. [Google Scholar] [CrossRef]
- Lee, D.; Kang, S.; Ju, H.; Park, C.; Yu, H. Bootstrapping user and item representations for one-class collaborative filtering. In Proceeding soft the 44th International ACM SIGlR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; ACM: New York, NY, USA, 2021; pp. 317–326. [Google Scholar] [CrossRef]
- Hemaraju, S.; Kaloor, P.M.; Arasu, K. Your care: A diet and fitness recommendation system using machine learning algorithms. AIP Conf. Proc. 2023, 6, 35–39. [Google Scholar] [CrossRef]
- Wu, B.; Liang, X.; Zhang, S.; Xu, R. Frontier Progress and Applications of Graph Neural Networks. Chin. J. Comput. 2022, 45, 35–68. [Google Scholar] [CrossRef]
- Wang, C. Research on Recommendation Algorithm Based on Graph Neural Network and Its Privacy Protection. Master’s Thesis, Southeast University, Nanjing, China, 2024. [Google Scholar]
- Laroussi, C.; Ayachi, R. A deep meta-level spatio-categorical POI recommender system. Int. J. Data Sci. Anal. 2023, 16, 285–299. [Google Scholar] [CrossRef]
- Chen, L.; Bi, X.; Fan, G.; Sun, H. A multitask recommendation algorithm based on DeepFM and Graph Convolutional Network. Concurr. Comput. Pract. Exp. 2023, 7, 30–37. [Google Scholar] [CrossRef]
- Tong, G.; Li, D.; Liu, X. An improved model combining knowledge graph and GCN for PLM knowledge recommendation. Soft Comput. Fusion Found. Methodol. Appl. 2024, 28, 5557–5575. [Google Scholar] [CrossRef]
- Qian, L.; Zhao, W. A Text Classification Method Based on Contrastive Learning and Attention Mechanism. Comput. Eng. 2024, 50, 104–111. [Google Scholar] [CrossRef]
- Boughareb, R.; Seridi, H.; Beldjoudi, S. Explainable Recommendation Based on Weighted Knowledge Graphs and Graph Convolutional Networks. J. Inf. Knowl. Manag. 2023, 7, 83–87. [Google Scholar] [CrossRef]
- Patel, R.; Thakkar, P.; Ukani, V. CNN Rec: Convolutional Neural Network based recommender systems—A survey. Eng. Appl. Artif. Intell. 2024, 3, 133. [Google Scholar] [CrossRef]
- Wang, Z. Research on Sports Marketing and Personalized Recommendation Algorithms for Precise Targeting and Promotion Strategies for Target Groups. Appl. Math. Nonlinear Sci. 2024, 9, 50–58. [Google Scholar] [CrossRef]
- Chen, L.; Wu, L.; Hong, R.; Zhang, K.; Wang, M. Revisiting graph based collaborative filtering: A linear residual graph convolutional network approach. Proc. AAAl Conf. Artif. Intell. 2020, 34, 27–34. [Google Scholar] [CrossRef]
- Wang, X.; He, X.; Wang, M. Neural Graph Collaborative Filtering. In Proceedings of the 42nd International ACM SIGIR Conference on Research and Development in Information Retrieval, Paris, France, 21–25 July 2019; ACM: New York, NY, USA, 2019. [Google Scholar] [CrossRef]
- He, X.; Deng, K.; Wang, X. LightGCN: Simplifying and Powering Graph Convolution Network for Recommendation. In Proceedings of the 43rd International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 25–30 July 2020; ACM: New York, NY, USA, 2020; Volume 7, pp. 65–69. [Google Scholar] [CrossRef]
- Huang, Y.; Mu, C.; Fang, Y. Graph Convolutional Neural Network Recommendation Algorithm with Graph Negative Sampling. J. Xidian Univ. 2024, 51, 86–99. [Google Scholar] [CrossRef]
- Pan, R.; Zhou, Y.; Cao, B.; Liu, N.N.; Lukose, R.; Scholz, M.; Yang, Q. One-Class Collaborative Filtering. In Proceedings of the Eighth IEEE International Conference on Data Mining, Pisa, Italy, 15–19 December 2008; IEEE: Piscataway, NJ, USA, 2008. [Google Scholar] [CrossRef]
- Perozzi, B.; Rou, R.; Skiena, S. DeepWalk: Online Learning of Social Representations. In Proceedings of the 20th ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, New York, NY, USA, 24–27 August 2014; ACM: New York, NY, USA, 2014. [Google Scholar] [CrossRef]
- Yang, Z.; Ding, M.; Zhou, C. Understanding Negative Sampling in Graph Representation Learning. In Proceedings of the 26th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, Virtual, 6–10 July 2020; Volume 8, pp. 1666–1676. [Google Scholar] [CrossRef]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; ACM: New York, NY, USA, 2018; Volume 6, pp. 201–211. [Google Scholar] [CrossRef]
- Ma, Y.; Wang, S.; Aggarwal, C.; Yin, D.; Tang, J. Multi-dimensional graph convolutional networks. In Proceedings of the 2019 SIAM International Conference on Data Mining, Calgary, AB, Canada, 2–4 May 2019; Society for Industrial and Applied Mathematics: Philadelphia, PA, USA, 2019; pp. 657–665. [Google Scholar]
- Wu, J.; Wang, X.; Feng, F.; He, X.; Chen, L.; Lian, J.; Xie, X. Self-supervised graph learning for recommendation. In Proceedings of the 44th International ACM SIGIR Conference on Research and Development in Information Retrieval, Virtual, 11–15 July 2021; ACM: New York, NY, USA, 2021; pp. 726–735. [Google Scholar]
- Cheng, L.; Chen, H.Y.; Ning, G. SimGCL: Graph Contrastive Learning by Finding Homophily in Heterophily. Knowl. Inf. Syst. 2024, 3, 66–73. [Google Scholar] [CrossRef]
- Chuang, C.Y.; Hjelm, R.D.; Wang, X.; Vineet, V.; Joshi, N.; Torralba, A.; Jegelka, S.; Song, Y. Robust Contrastive Learning against Noisy Views. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 16670–16681. [Google Scholar] [CrossRef]
- Zhang, H.; Cisse, M.; Dauphin, Y.N.; Lopez-Paz, D. Mixup: Beyond empirical riskminimization. arXiv 2017. [Google Scholar] [CrossRef]
- Kalantidis, Y.; Sariyildiz, M.B.; Pion, N. Hard negative mixing for contrastive learning. In Proceedings of the 2020 Advances in Neural Information Processing Systems, Online, 6–12 December 2020; Curran Associates, Inc.: Vancouver, BC, Canada, 2020; pp. 21798–21809. [Google Scholar] [CrossRef]
- Rendle, S.; Freudenthaler, C.; Gantner, Z. BPR:Bayesian personalized ranking from implicit feedback. In Proceedings of the 25th Conference on Uncertainty in Artificial Intelligence, Montreal, QC, Canada, 18–21 June 2009; AUAI Press: Arington, VA, USA, 2009; pp. 452–461. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
| Dataset Name | Number of Users | Number of Products | Number of Interactions | Data Density |
|---|---|---|---|---|
| Yelp2018 | 31,668 | 38,048 | 1,561,406 | 0.00130 |
| Alibaba | 106,042 | 53,591 | 907,407 | 0.00130 |
| Gowalla | 29,858 | 40,981 | 1,027,370 | 0.00084 |
| Dataset Name Model Name | Yelp2018 | Alibaba | Gowalla | |||
|---|---|---|---|---|---|---|
| Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | Recall@20 | NDCG@20 | |
| BPRMF | 0.0433 | 0.0332 | 0.0351 | 0.0112 | 0.1389 | 0.0921 |
| NGCF | 0.0543 | 0.0443 | 0.0426 | 0.0197 | 0.1573 | 0.1332 |
| LightGCN | 0.0637 | 0.0531 | 0.0585 | 0.0275 | 0.1822 | 0.1543 |
| PinSage | 0.0470 | 0.0392 | 0.0411 | 0.0232 | 0.1380 | 0.1195 |
| RNS | 0.0625 | 0.0516 | 0.0506 | 0.0332 | 0.1532 | 0.1319 |
| SGL | 0.0675 | 0.0553 | 0.0688 | 0.0338 | 0.1611 | 0.1398 |
| SimGCL | 0.0676 | 0.0555 | 0.0450 | 0.0336 | 0.1871 | 0.1589 |
| ENSG | 0.0733 | 0.0603 | 0.080 | 0.0381 | 0.2002 | 0.1696 |
| Improve/% | 8.43% | 8.64% | 16.27% | 12.72% | 7.0% | 6.73% |
| q/l | 1 | 2 | 3 |
|---|---|---|---|
| 0.1 | 0.0706 | 0.0710 | 0.0716 |
| 0.2 | 0.0709 | 0.0712 | 0.0720 |
| 0.3 | 0.0710 | 0.0715 | 0.0723 |
| 0.4 | 0.0712 | 0.0716 | 0.0727 |
| 0.5 | 0.0713 | 0.0718 | 0.0733 |
| q/l | 1 | 2 | 3 |
|---|---|---|---|
| 0.1 | 0.0581 | 0.0583 | 0.0596 |
| 0.2 | 0.0582 | 0.0585 | 0.0598 |
| 0.3 | 0.0585 | 0.0586 | 0.0600 |
| 0.4 | 0.0587 | 0.0588 | 0.0602 |
| 0.5 | 0.0588 | 0.0589 | 0.0603 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Hai, Y.; Zheng, J.; Liu, Z.; Wang, D.; Ding, C. ENSG: Enhancing Negative Sampling in Graph Convolutional Networks for Recommendation Systems. Electronics 2024, 13, 4696. https://doi.org/10.3390/electronics13234696
Hai Y, Zheng J, Liu Z, Wang D, Ding C. ENSG: Enhancing Negative Sampling in Graph Convolutional Networks for Recommendation Systems. Electronics. 2024; 13(23):4696. https://doi.org/10.3390/electronics13234696
Chicago/Turabian StyleHai, Yan, Jitao Zheng, Zhizhong Liu, Dongyang Wang, and Chengrui Ding. 2024. "ENSG: Enhancing Negative Sampling in Graph Convolutional Networks for Recommendation Systems" Electronics 13, no. 23: 4696. https://doi.org/10.3390/electronics13234696
APA StyleHai, Y., Zheng, J., Liu, Z., Wang, D., & Ding, C. (2024). ENSG: Enhancing Negative Sampling in Graph Convolutional Networks for Recommendation Systems. Electronics, 13(23), 4696. https://doi.org/10.3390/electronics13234696