Abstract
Commonsense question answering (CSQA) is a challenging task in the field of knowledge graph question answering. It combines the context of the question with the relevant knowledge in the knowledge graph to reason and give an answer to the question. Existing CSQA models combine pretrained language models and graph neural networks to process question context and knowledge graph information, respectively, and obtain each other’s information during the reasoning process to improve the accuracy of reasoning. However, the existing models do not fully utilize the textual representation and graph representation after reasoning to reason about the answer, and they do not give enough semantic representation to the edges during the reasoning process of the knowledge graph. Therefore, we propose a novel parallel fusion framework for text and knowledge graphs, using the fused global graph information to enhance the semantic information of reasoning answers. In addition, we enhance the relationship embedding by enriching the initial semantics and adjusting the initial weight distribution, thereby improving the reasoning ability of the graph neural network. We conducted experiments on two public datasets, CommonsenseQA and OpenBookQA, and found that our model is competitive when compared with other baseline models. Additionally, we validated the generalizability of our model on the MedQA-USMLE dataset.
1. Introduction
Commonsense question answering (CSQA) is a challenging task. To solve commonsense questions, people usually extract the knowledge contained in the question text as a constraint in the reasoning process [1]. Therefore, pretrained language models, as popular methods for obtaining text representations in recent years, have been introduced for CSQA tasks [2,3]. Although pretrained language models possess strong text comprehension capabilities and naturally contain a certain level of commonsense knowledge through training data, they struggle when faced with the vast amount of commonsense and structured data in the real world. Knowledge graphs, as structured knowledge representation methods, not only provide a large amount of commonsense knowledge but also support complex logical reasoning [4]. In order to use the relevant knowledge in a knowledge graph to solve commonsense problems, researchers have introduced graph neural networks [5,6,7] to embed and reason about the structured knowledge in a knowledge graph. Therefore, in recent studies, graph neural networks have been introduced into question-answering systems and combined with pretrained language models, which has developed into a trend for solving commonsense question-answering problems [8,9,10].
Many studies focusing on deriving answers based on question text and knowledge graphs have followed a similar methodology. Initially, the question text serves as a basis for subgraph retrieval, where relevant candidate answer paths are selected from the extensive knowledge graph and processed to form a knowledge subgraph. This approach enhances the efficiency of answer retrieval. Secondly, the retrieved subgraph is modeled through a graph neural network. The graph neural network implements multihop reasoning based on its own message passing mechanism, thereby inferring the answer to the question [11,12,13].
The problem with this approach is that there is isolation between the text representations obtained by the pretrained language models and the graph representations generated by the graph neural networks, lacking an effective integration mechanism. Consequently, recent research has focused on building a bridge between the two to enhance the synergy in the reasoning capabilities between text and graph representations [14,15,16,17]. On the other hand, in an attempt to make the subgraphs retrieved from the KG contain as much relevant information as possible related to the question, the retrieved subgraphs often encompass numerous entities and relationships unrelated to the answer. These noncritical details can interfere with the accuracy of the model’s reasoning. Therefore, reducing the impact of these noise nodes on the reasoning process is also a current research direction. Although existing methods that combine LM and KG for CSQA have made considerable progress, they still face the following three issues: (1) The interaction between the two representation modalities is not sufficient, and the accuracy of removing noise nodes needs to be improved to avoid removing relevant nodes. (2) When predicting answers, only a single semantic representation is used, lacking the integration of whole-graph information to guide the choice of answers. (3) In previous models, relationship types were represented by one-hot vectors, which inherently lack semantic information, thereby limiting the model’s reasoning capabilities. Based on the above considerations, inspired by the Mobile-Former [18] model in the field of computer vision, we propose a novel bidirectional interactive model, PRS-QA (Parallel Fusion, Relation Embedding Optimization, Semantic Enhancement, and Question Answering), which is based on self-attention and multihead cross-attention, to improve the information transfer ability between question representation and graph representation, and we use the multihead attention score as the basis for the graph pooling layer to delete irrelevant nodes. Simultaneously, we aggregate global graph information to boost the semantic representation of question text, thereby improving the predictive layer’s reasoning capabilities for answers. Inspired by TransE [19], we enhance the semantic representation of the edge by utilizing the representation difference between the tail node and the head node, and we determine the final representation of the edge based on the relevance of the edge to the question.
The main contributions of this paper can be summarized as follows:
- We propose the PRS-QA model, a parallel fusion model based on self-attention and multihead cross-attention, enabling the question context to aid in the reasoning of the graph neural network layers.
- We design a semantic enhancement module that utilizes self-attention to highlight the key nodes in the graph, and we employed additive attention and pooling layers to obtain a vector representation that integrates graph structural information and textual semantic information.
- We concatenate the difference in the representation between the tail node and the head node with the previous relationship representation to form a new edge vector. The final edge vector is determined based on the relevance of the new edge vector to the question context.
2. Related Work
The challenge in CSQA is that the required commonsense knowledge is difficult to find in the context of question and answer choices. Even utilizing pretrained language models, the inherent commonsense knowledge is often insufficient to support accurate answers. Consequently, the “LM+KG” approach has been proposed to address CSQA tasks. Lin et al. [11] introduced a knowledge-aware network model that combines graph convolutional networks and LSTM, employing a hierarchical path attention mechanism to enhance the model’s transparency and interpretability. Feng et al. [12] combined the advantages of path-based models and graph neural networks by incorporating a structured relational attention mechanism, achieving efficient and transparent multihop reasoning path modeling. Yasunaga et al. [13] proposed an end-to-end “LM+KG model” that puts the question representation as a graph node into a graph neural network for joint reasoning, which alleviates the problem that graphs and texts are two independent modalities that do not update each other.
However, the above methods still have room for improvement in the interaction between graph and text representations. Specifically, the representations of graphs and texts are only fused once at the prediction stage, and this shallow fusion limits the possibility of their interaction and joint reasoning during the reasoning process. Subsequently, researchers focusing on CSQA models began to emphasize the integration and updating of information between LM and KG. Zhang et al. [14] proposed a word-level bidirectional fusion model called GreaseLM, which allows the two modalities to fuse information by defining a modality interaction layer. Zhang et al. [16] introduced meta-paths to overcome the difference between the two representations to achieve better multihop graph reasoning. Zheng et al. [17] calculated the correlations among neighborhood nodes to obtain a dynamic neighborhood matrix, thereby enhancing the ability to capture reasoning paths. Zhang et al. [20] introduced a CSQA model named DRLK, which achieves dynamic layered reasoning from both interlayer and intralayer perspectives. Zhang et al. [21] introduced a multiple-choice question-answering model named MKSQA, which combines local and global knowledge subgraphs to explore multiple reasoning chains, making full use of the elimination norm to select the correct answer. Sha et al. [22] proposed a model named RAKG, which utilizes a density matrix to extract enhanced subgraphs to remove irrelevant nodes and uses graph convolutional networks (GCNs) to integrate the representations of the question and graph entities. Zheng et al. [23] developed a method for fine tuning causal graphs to retain the knowledge in pretrained language models, thereby enhancing the performance of the KG+LLM method.
Sun et al. [15] proposed JointLK, which captures the fine-grained features between KG and LM through a trilinear attention module. Additionally, they utilized graph pooling layers [24] to recursively remove some noise nodes, thereby improving the efficiency of reasoning multihead attention mechanisms so they can concurrently focus on different parts of the input sequence, capturing richer information. Therefore, we used a multihead attention mechanism to interact the information between KG and LM, and we considered the attention scores from multiple heads when using the graph pooling layer to prevent the deletion of relevant nodes that could affect the reasoning of answers. Simultaneously, we found that the fine-grained text representation integrated with graph representation has not been well applied. Therefore, we designed a semantic enhancement module to use the fused graph and text data to improve the reasoning ability of the model.
3. Preliminaries
3.1. Knowledge Graph
In this paper, a knowledge graph is defined as , where is a set of entities, and is a set of relations. A triplet in the knowledge graph is defined as , , which, respectively, represent the head and tail nodes in the triplet. indicates the type of relationship between them. In this work, we used ConceptNet as the knowledge graph.
3.2. Graph Pooling Layer
Self-attention graph pooling (SagPooling) involves obtaining self-attention scores for each node through graph convolution. Subsequently, it retains the top k highest-scoring nodes based on their scores to form a mask:
where is a function that returns the indices of the nodes to be preserved; is a hyperparameter representing the proportion of retained node sets V. Finally, the features and topological information of the specified nodes in node set X are preserved according to :
Inspired by SagPooling, we use the average scores from multihead attention as the score for each node.
3.3. Graph Attention Networks
The graph neural network used in this paper is a variant of the graph attention network (GAT). GAT updates the target node by aggregating information from neighboring nodes through a message-passing mechanism. Given a graph , nodes , and edges , The process of updating node representations in the GAT layer is as follows:
where represents trainable parameters, is the representation of the target node in layer k, represents the neighboring nodes, represents the edge representation between two nodes, denotes the set of neighbors of node i, ‖ represents the combination of H heads, and is the representation of the next-layer nodes after aggregating the neighboring nodes.
3.4. Task Definition
In this paper, CSQA is presented in the form of multiple-choice questions. Given a natural language question q and n candidate answers , the task is to select the correct option from the candidate answers based on the question. As shown in Figure 1, the correct answer is .
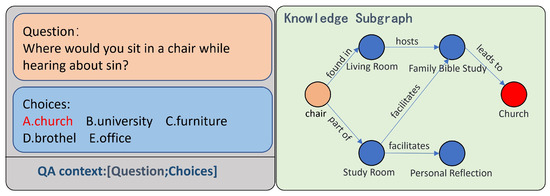
Figure 1.
An example of CSQA and the reasoning process derived from the CommonsenseQA dataset.
The knowledge graph provides external knowledge to assist in deducing the correct answer. Following the approach of Yasunaga et al. [13], a relevant subgraph is retrieved from the knowledge graph concerning the question, which can improve the efficiency of reasoning the answer.
4. Methodology
4.1. Overview
As shown in Figure 2, our method consists of four modules: Question Context Embedding, Parallel Fusion Reasoning, Semantic Enhancement, and Answer Prediction. We first concatenate the question text and option text into the question context, and we input it into the pretrained language model to obtain the [CLS] token representation of the question text and the hidden state of each word. We use the word representation and the graph representation after the knowledge graph subgraph is embedded for parallel fusion, so that the graph neural network can focus on different parts of the question during the reasoning process, and we optimize edge embedding to alleviate the over-smoothing problem caused by the stacking of the graph neural network layers. We compute additive attention using the last layer’s word representations and graph representations to acquire a vector representation that aggregates global graph information. This vector is then used to enhance the accuracy of answer selection.
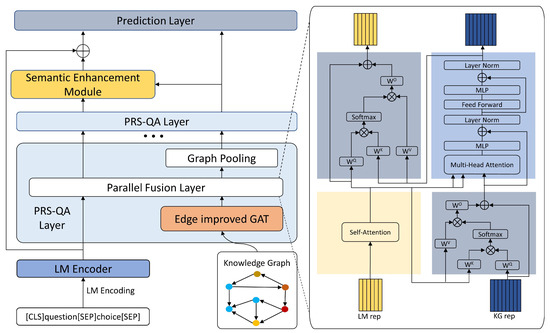
Figure 2.
Overview of the PRS-QA architecture. In the main framework of the figure, the dark blue module represents the question context embedding module (Section 4.2). The light blue module (Section 4.3) includes the relation embedding optimization module (Section 4.3.1) and the parallel fusion module (Section 4.3.2). The yellow module represents the semantic enhancement module (Section 4.4). The green module represents the answer prediction module (Section 4.5).
4.2. Question Context Embedding Module
We use a pretrained language model to encode the question context (comprising both the question and options) to obtain the representation of each word in the question, where L represents the length of the sentence. We utilize the first hidden state corresponding to the “[CLS]” token as the semantic representation of the context, which generally contains the global semantic information of the question. To align the representation space of the text with the entity representation space in the knowledge graph, we feed each word representation into a nonlinear layer:
where , are the linear transformations used for adjusting dimension sizes, represents the dimension of the hidden layers of the language model, is the dimension of the target entity representations, is the activation function , and is the word-level question context embedding. This embedding is passed into the parallel fusion module for interaction with the graph node representations produced by the graph neural network layers.
4.3. Relation Embedding Optimization and Parallel Fusion Module
In a parallel fusion reasoning layer, a graph attention network after optimizing relation embedding is included, with a bidirectional interaction module between graph representation and word-level text representation, as well as a graph pooling layer for filtering irrelevant nodes.
4.3.1. Optimizing Relation Embedding Module
In previous work, relation embedding was performed using the one-hot vector representing the relation type. Without proper relation embedding, the responsibility of learning meaningful relation embedding falls on the model layer. Therefore, we use the feature difference between the tail node and the head node as the new relation feature according to the mechanism of the TransE model, and we obtain representations of the same relation type through an average pooling layer. These representations are then fused with the original features, and the distribution of edge features is adjusted according to the correlation between the relation representation and the question representation. The specific implementation process is as follows:
where and , respectively, represent the representations of the tail node and the head node from the previous layer; C denotes the set of relationship types in the subgraph; n indicates the number of the same type of relationships within the subgraph; is the previous relationship representation; stands for the activation function; is a trainable matrix; and is a bias term. Then, is reduced in dimensions through a nonlinear layer to obtain , which is then expanded into the question context semantic matrix :
where is the question semantic matrix composed of N instances of . Finally, a customized dot product attention is used to calculate the correlation scores between the question context semantic representation and the relationship representation, and the final edge features are determined based on the correlation scores:
where is the edge feature matrix composed of N instances of , and represents the learnable weight matrix.
4.3.2. Parallel Fusion Module
We use the word-level question representation and the graph representation output by the graph neural network to interact. By applying a layer of self-attention to the question representation , we can capture the long-range dependencies in the sequence, so that the model can dynamically decide which parts are more important when processing the sequence:
and are first interacted through multihead cross attention to obtain the graph representation . Queries Q, keys K, and values V are then obtained by applying projection . Finally, attention is calculated using the standard attention function ; the output representation is calculated as follows:
where represents the attention function, and its formula is . , which represents the concatenation operation of h head, and converts the concatenated embedding dimension to the original embedding dimension. We obtain the final graph representation from the second interaction between and using a parallel fusion layer. Specifically, we modify a standard Transformer block [25] by adding a component after both the multihead cross-attention and the feedforward neural network to enhance the model’s learning capacity and adaptability. The final graph representation for each layer is calculated as follows:
Residual connections and layer normalization are added to the module to prevent the issue of gradient explosion. Then, symmetric cross-attention is used to interact and to obtain the final fine-grained text representation in the parallel fusion layer:
The graph pooling module decides which entities to retain for the next layer of computation based on the attention scores between the question and entity nodes. We select the attention scores generated when and are involved in the attention calculations. To improve the accuracy of the attention scores, we take into account the decision influences from multiple heads and use the average attention score for the pooling operations. For brevity, we formalize the process as follows:
4.4. Semantic Enhancement Module
Previous research has found that integrating graph information can significantly enhance the accuracy of question-answering systems. We use the outputs from the last layer of parallel fusion reasoning, and . First, is passed through a self-attention layer to more accurately capture the interdependencies and importance among nodes:
Then, using as the query vector and as the key vector, additive attention is employed together with textual features to emphasize important parts within the text. After the attention layer processes these features, they are passed through an average pooling layer to obtain a feature vector that includes information from the graph. Finally, a multilayer perceptron is used to produce a vector H that is aligned with the dimension of the question’s semantic features, facilitating its integration with the contextual semantic representation of the question in the answer prediction layer. The output vector H is calculated as follows:
where is a learnable weight matrix, and b is a bias term. The specific module structure is shown in Figure 3.
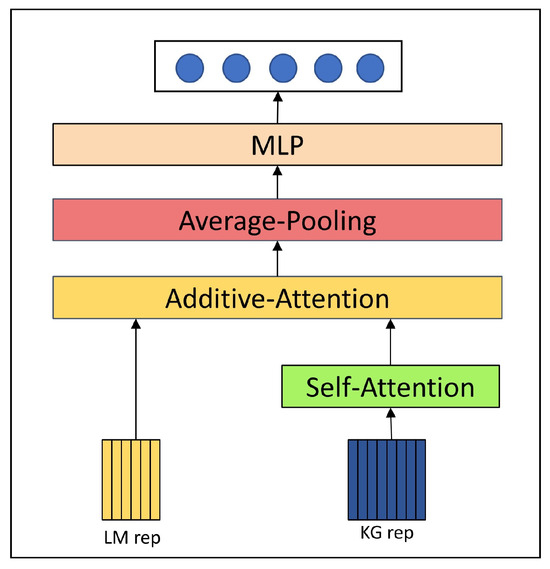
Figure 3.
Semantic Enhancement Module.
4.5. Answer Prediction Module
After executing multiple PRS-QA layers, we obtain the final graph representation . The vector H fusing the global graph features and the original semantic vector is added element-by-element to obtain , and multihead attention pooling is used to obtain the final subgraph embedding :
Then, the subgraph embedding and the question semantic representation after aggregating the global graph information are sent to to obtain the candidate answer score:
where represents the merging operation.
In fact, during the reasoning process, we construct a subgraph for each option in the question. Ultimately, each subgraph receives an answer probability score, and we select the option corresponding to the subgraph with the highest score as the answer to the question.
5. Experimental Setup
5.1. Datasets
In this study, we selected two typical commonsense question-answering datasets, CommonsenseQA (Talmor et al., 2019) [26] and OpenBookQA (Mihaylov et al., 2018) [27], to evaluate the performance of our model, and we used a medical dataset, MedQA-USMLE [28], to assess the generalizability of the model. The statistics for these datasets are shown in Table 1.

Table 1.
Experimental dataset statistics.
CommonsenseQA is a dataset consisting of 12,102 five-option questions, designed to assess the commonsense reasoning capabilities of models. Each question is derived from a concept extracted from ConceptNet and includes two distractors to suppress simplistic machine inference. We followed the approach of Lin et al. [11] and conducted experiments on an in-house data split.
OpenBook is a four-option question-answering dataset containing 5957 questions that require answers based on scientific facts or commonsense knowledge. We adhered to established research methods and utilized the official data split provided.
MedQA-USMLE is a medical text question-answering dataset in a multiple-choice format, with questions sourced from the United States Medical Licensing Examination. USMLE refers to the English version of the MEDQA dataset.
5.2. Implementation Details
Our research is based on QA-GNN, using the commonsense knowledge graph ConceptNet [4] as the external knowledge source, the cross-entropy loss as the loss function, RAdam [29] as the optimizer, and an early stopping mechanism. We followed the experimental settings of JointLK, and the ratio of graph pooling nodes retained on the CommonsenseQA dataset was 0.92. On the OpenBookQA dataset, our experiments determined that the optimal node retention ratio in the graph pooling layer was 0.94. We used separate learning rates for the language model encoder and the graph encoder, and each encoder was trained using a separate GPU. The specific model and experimental hyperparameters are shown in Table 2.
Table 2.
Model and experimental hyperparameter settings.
5.3. Comparison Methods
Our research focused on optimizing the collaborative reasoning between knowledge graphs and language models, so most of the comparison methods we chose are based on the design idea of “LM+KG”. We used the RoBERTa-Large model as the language model encoder for the CommonsenseQA dataset and the OpenBookQA dataset, and we used the AristoRoBERTa [30] model as the comparison model for the OpenBookQA dataset to show the generalization ability when facing different LMs.
For the LM+KG approach, we compared our methods with RGCN [6], GconAttn [31], MHGRN [12], QAGNN [13], GreaseLM [14], JointLK [15], MKSQA [21], RAKG [22], and CET+SAFE [23]. Additionally, we compared PRS-QA with path enhancement models such as KagNet [11], MRGNN [16], and DRGN [17]. Different from the LM+KG method, the path enhancement method mainly uses the path information in the knowledge graph to improve the reasoning process and can gradually build a path from question to answer. Therefore, this method has strong interpretability.
6. Results and Analysis
6.1. Main Results
PRS-QA was compared with other models on the CommonsenseQA dataset, as shown in Table 3. Compared to the baseline models, our model obtained significantly improved test performance on the CommonsenseQA dataset. Equipped with RoBERTa-Large, PRS-QA achieved the highest accuracy of 74.68%, which was 1.27% higher than that of QA-GNN. This indicates that our model has made significant progress in handling cross-modal information interaction and answer reasoning. Compared to the module interaction mechanism in GreaseLM, PRS-QA employs multihead cross-attention. This design not only facilitates information interaction but also focuses on important parts of the sequence, thereby improving accuracy on the test set by 0.48%. The JointLK model compared to the QA-GNN model, removed an important feature in the GNN, the node relevance score. To compensate for this, we used a combination of question and relation embeddings enhances the relevance constraints between nodes. Therefore, under the premise of ensuring accuracy, the standard deviation calculated through multiple experiments was smaller than that of previous models, indicating the stability of model performance.
Table 3.
Performance comparison on CommonsenseQA in-house split. We followed the data division method of Lin et al. [11] and report the in-house Dev (IHdev) and Test (IHtest) accuracy (mean and standard deviation of four runs).
Table 4 presents the results of the experiments on the official split of the OpenBook dataset. Using different language models, the performance improvement over the original model was 5.5% and 5%. PRS-QA equipped with RoBERTa-Large achieved the highest accuracy of 70.3%, which was 2.56% higher than QA-GNN and 0.26% higher than DRGN. PRS-QA with AristoRoBERTa outperformed most of the other baseline models.
Table 4.
Comparison of test accuracy on OpenBookQA.
Further analysis showed that both MKSQA and RAKG models integrated the representations of questions and graph entities using their respective strategies, affirming the value of the “LM+KG” approach. Additionally, the computational overhead of the PRS-QA model primarily concentrates in the parallel fusion layer, and Table 5 shows the computational overhead of our model compared to that of the baseline model. In summary, although the PRS-QA model requires more time than previous models, it has higher accuracy in question answering.
Table 5.
The computational complexity of L-hop reasoning models on a dense or sparse graph G = (V,E) with question length N, relation set R, and number of attention heads H.
6.2. Ablation Studies
In this section, we demonstrate the effectiveness of the components of RPS-QA through ablation experiments, with the results presented in Table 6. The experimental settings were as follows:
Table 6.
Ablation study results for PRS-QA on the CommonsenseQA dataset.
- With Parallel Fusion Module: This setting explored the model’s performance using only the parallel fusion strategy and compared the accuracy improvement over the baseline model QA-GNN.
- With Parallel Fusion Module and Optimizing Relation Embedding Module: This variant added the optimizing relation embedding module on top of the fusion module to evaluate the changes in accuracy and standard deviation.
- With Parallel Fusion Module and Semantic Enhancement Module: This variant added the semantic enhancement module to the fusion module to assess the impact of fine-grained semantics on answer accuracy.
The experimental results indicated that the performance of the three variants declined compared to that of the full PRS-QA model. When the Parallel Fusion Module was introduced into the baseline QA-GNN model, the accuracy of predicting answers significantly increased. This suggests that the graph entities at each layer of the graph neural network can flexibly focus on different parts of the question text to selectively obtain relevant information. Furthermore, we analyzed the time complexity of the multihead attention in the parallel fusion layer; the results in Table 5 show that this method effectively improves the model’s performance while maintaining reasonable resource consumption. After adding the Optimized Relation Embedding Module to the Fusion Module, we observed a noticeable improvement in model stability compared to using the Fusion Module alone, where the results ranged between [77.64, 78.78]. The variant showed results of (78.21, 78.05, 78.30, 78.13) across four experiments, with a standard deviation of ±0.11. We believe that this module plays a more significant role in enhancing model stability than node relevance scores. It can guide the model to always focus on the question during the reasoning process and prevent it from deviating from the correct answer path. Furthermore, the slight increase in accuracy indicated that the semantic information introduced for optimizing relation embeddings indeed served its purpose. When we added the Semantic Enhancement Module to the Fusion Module, it was found that the fine-grained semantic representation, integrating the entire graph structure information, significantly improved the model’s prediction accuracy, with results in the range of [77.81, 78.87], also supporting the findings from the previous variant.
These variants support our conclusion that the Parallel Fusion Module and the Semantic Enhancement Module significantly enhance the model’s reasoning ability, where the Parallel Fusion Module has a greater impact on improving model performance, while the Optimized Relation Embedding Module primarily enhances model stability.
6.3. Impact of the Number of PRS-QA Layers
To investigate the impact of the number of layers in the graph neural networks on model performance, we conducted comparative experiments using PRS-QA models with various layers on the validation set of the CommonsenseQA dataset, with the results shown in Figure 4. The results show that the accuracy on IHdev was 77.84% with a three-layer model; it increased to 78.30% with four layers and peaked at 78.52% with five layers. However, further increasing the number of layers caused a decline in accuracy. This indicates that while adding more layers can enhance the model’s learning capacity, excessively stacking layers may lead to overfitting or other adverse effects.
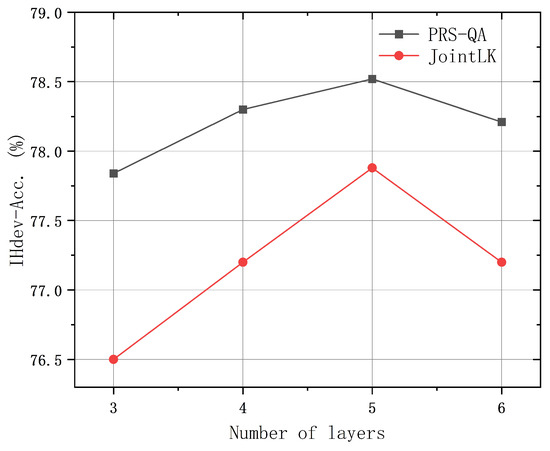
Figure 4.
Comparison of the accuracy of different PRS-QA layers on CommonsenseQA.
Additionally, in Figure 4, we compare the accuracy of PRS-QA with JointLK across different layers. Although we used the same pruning strategy as JointLK to remove noise nodes, our work focused on improving the accuracy of node selection, preventing nodes from being mistakenly identified as noise and removed, thus allowing them to participate in the subsequent computations.
6.4. Impact of the Number of Attention Heads Involved in Graph Pooling
The JointLK model uses a dynamic pruning module to remove irrelevant nodes in the subgraph to improve inference efficiency. However, this method may lead to the deletion of valid nodes. To enhance the accuracy of the pruning process, we employ multihead attention to calculate attention scores from multiple perspectives. We observed that increasing the number of attention heads generally enhanced the model’s performance. However, as the number of heads increased, the model became more complex, which not only increased the training cost but could also cause the model to overfit or learn noise information, thereby reducing the performance of the model. Therefore, we need to find a balance between the complexity and performance of the model to ensure the generalization ability and effectiveness of the model. Referring to the experimental results (as shown in Figure 5), we set the number of attention heads involved in the graph pooling calculation to eight.
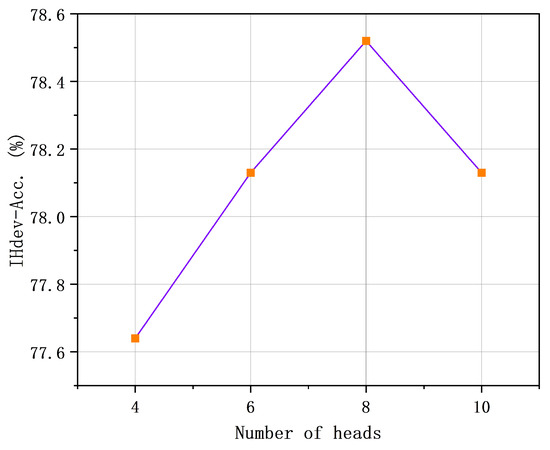
Figure 5.
Impact of the number of attention heads on the CommonsenseQA IHdev set.
6.5. Analysis of Model Generalizability
The previous section highlighted the model’s performance on general commonsense question-answering datasets. In this section, we explore whether PRS-QA can be applied to other question-answering domains by evaluating it on the MedQA-USMLE dataset. We used BioBERTa-Large [32], SapBERT-Base [33], QAGNN [13], GREASELM [14], and DRLK [20] as comparison models. The experimental results in Table 7 show that our approach improves upon previous classic methods. This indicates that the PRS-QA model has generalizability in other question-answering domains, and it can serve as a reference for developing question-answering systems in other specialized fields.
Table 7.
Performance on MedQA-USMLE.
6.6. Model Interpretability Analysis
We conducted an interpretability analysis of the reasoning process of PRS-QA and visually demonstrate the attention shifts within the knowledge subgraph. We selected an example from the baseline model’s incorrect predictions to analyze the path through which PRS-QA infers the correct answer. In this case, the answer to the question was “Florida”, but the baseline model chose “California”. Figure 6 shows the changes in model attention during GNN message passing, where the nodes on the solid path represent high-weight attention, while the dashed path indicates low-weight areas. As the GNN weights change, we remove irrelevant nodes with lower weights. In Figure 6, the key aspect of the question is the coast. Although both reasoning paths “” and “” are reasonable, the former is more closely related to the semantics of the question. Therefore, the model selects “Florida” as the correct answer. This demonstrates that maintaining a semantic orientation during the answer reasoning process is the right approach.
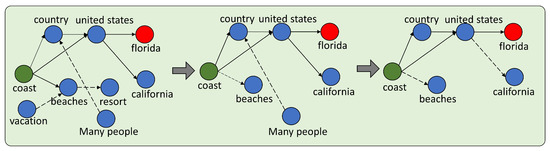
Figure 6.
Model interpretability case study. The question and answer for the case were “The peninsula and panhandle make for a long coast, this is why many people like to vacation or retire where? A. United States B. Florida C. Country D. Where it is hot E. California”. Green nodes represent the question concept, and red nodes represent the correct answer.
6.7. Error Analysis
Missing Evidence. The main knowledge sources used to infer answers are KGs. However, the knowledge graphs themselves are not complete, resulting in the lack of key nodes in the reasoning path. For example, James’s parents felt that he was wasting his money, but they still let him put a coin in the wishing well every weekend. The correct answer in the options is “wishing well”, but this knowledge is not covered in ConceptNet.
Indistinguishable Answers. When the subgraph contains significant noise, the model can filter out clearly irrelevant entities based on attention weights. However, for nodes that are hard to distinguish, we may not be able to differentiate them through weight scores, which can lead to incorrect answers. For example, for the question, “Where could you see an advertisement while reading news?”, our model eliminated the clearly noisy options of “bus” and “email” and chose “TV”, but the correct answer was “webpage”. However, this choice is reasonable from both a semantic perspective and common life knowledge. Therefore, in the GNN reasoning process, distinguishing between noise with similar attention weights remains a challenge.
Difficult Questions. Through case analysis, we found that our model shows improved accuracy compared to the baseline model for long questions and those involving complex scenarios. For example, in the question, “If someone is aloof and self-important, what is their experience when meeting people?”, the baseline model did not take into account the context of “aloof and self-important”, leading it to choose “make friends”. In contrast, we used semantic enhancement to select “being bored”. However, when facing such complex questions, our model cannot achieve complete accuracy. Our analysis indicates that semantic enhancement based on embeddings cannot fully address the diversity and ambiguity of natural language, resulting in understanding biases when the model encounters unseen expressions.
Missing Relationships. In the subgraphs retrieved from ConceptNet, some nodes have implicit relationships. The absence of these implicit relationships can prevent the model from fully capturing the potential connections between the nodes. After each graph pooling operation, the original graph structure is altered, which can break the existing relational paths, making it impossible to infer the correct answers.
7. Conclusions
In this paper, we proposed a knowledge graph question-answering method called PRS-QA. First, we built a novel graph-text interaction framework based on self-attention and bidirectional cross-attention, allowing the two modalities to learn effectively from each other during training. Secondly, we optimized the embedding of relationships in graph neural networks, enhancing the representation of relationships with richer information and alleviating the over-smoothing problem caused by the stacking of graph neural network layers. Finally, we leveraged the global graph’s information to enhance semantic representations, thereby boosting the model’s reasoning capabilities. The effectiveness of our proposed method was validated through experiments conducted on two public datasets.
Author Contributions
Conceptualization, Z.L.; methodology, Z.L. and J.Z.; software, J.Z.; validation, T.C. and J.Z.; formal analysis, J.Z. and Y.Z.; investigation, J.Z.; data curation, J.Z. and Z.L.; writing—original draft preparation, J.Z.; writing—review and editing, Y.Z. and L.Z.; visualization, J.Z.; supervision, T.C. and L.Z.; funding acquisition, Z.L. All authors have read and agreed to the published version of the manuscript.
Funding
This research was funded by the Improvement of Innovation Ability of Small and Medium Sci-tech Enterprises Program grant number 2023TSGC0182; the Taishan Industry Leading Talent Project grant number tscx202211111; Central Government Funds for Guiding Local Science and Technology Development Projects grant number YDZX2023050.
Data Availability Statement
The CommonsenseQA dataset is available at: https://www.tau-nlp.org/commonsenseqa; The OpenBookQA dataset is available at: http://data.allenai.org/OpenBookQA; The MedQA-USMLE dataset is available at: https://github.com/jind11/MedQA (accessed on 20 November 2024).
Conflicts of Interest
Author Yiming Zhan is employed by the company Evay Info. The remaining authors declare that the research was conducted in the absence of any commercial or financial relationships that could be construed as a potential conflict of interest.
References
- Khashabi, D.; Min, S.; Khot, T.; Sabharwal, A.; Tafjord, O.; Clark, P.; Hajishirzi, H. UNIFIEDQA: Crossing Format Boundaries with a Single QA System. In Proceedings of the Findings of the Association for Computational Linguistics: EMNLP 2020, Online Event, 16–20 November 2020; pp. 1896–1907. [Google Scholar]
- Liu, Y. Roberta: A robustly optimized bert pretraining approach. arXiv 2019, arXiv:1907.11692. [Google Scholar]
- Raffel, C.; Shazeer, N.; Roberts, A.; Lee, K.; Narang, S.; Matena, M.; Zhou, Y.; Li, W.; Liu, P.J. Exploring the limits of transfer learning with a unified text-to-text transformer. J. Mach. Learn. Res. 2020, 21, 1–67. [Google Scholar]
- Speer, R.; Chin, J.; Havasi, C. Conceptnet 5.5: An open multilingual graph of general knowledge. In Proceedings of the AAAI Conference on Artificial Intelligence, San Francisco, CA, USA, 4–9 February 2017; Volume 31. [Google Scholar]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016, arXiv:1609.02907. [Google Scholar]
- Schlichtkrull, M.; Kipf, T.N.; Bloem, P.; Van Den Berg, R.; Titov, I.; Welling, M. Modeling relational data with graph convolutional networks. In Proceedings of the The Semantic Web: 15th International Conference, ESWC 2018, Heraklion, Crete, Greece, 3–7 June 2018; proceedings 15. Springer: Berlin/Heidelberg, Germany, 2018; pp. 593–607. [Google Scholar]
- Velickovic, P.; Cucurull, G.; Casanova, A.; Romero, A.; Lio, P.; Bengio, Y. Graph attention networks. Stat 2017, 1050, 10–48550. [Google Scholar]
- Wang, Y.; Zhang, H.; Liang, J.; Li, R. Dynamic heterogeneous-graph reasoning with language models and knowledge representation learning for commonsense question answering. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 14048–14063. [Google Scholar]
- Ye, Q.; Cao, B.; Chen, N.; Xu, W.; Zou, Y. Fits: Fine-grained two-stage training for knowledge-aware question answering. In Proceedings of the AAAI Conference on Artificial Intelligence, Washington, DC, USA, 7–14 February 2023; Volume 37, pp. 13914–13922. [Google Scholar]
- Yang, Z.; Zhang, Y.; Cao, P.; Liu, C.; Chen, J.; Zhao, J.; Liu, K. Information bottleneck based knowledge selection for commonsense reasoning. Inf. Sci. 2024, 660, 120134. [Google Scholar] [CrossRef]
- Lin, B.Y.; Chen, X.; Chen, J.; Ren, X. Kagnet: Knowledge-aware graph networks for commonsense reasoning. arXiv 2019, arXiv:1909.02151. [Google Scholar]
- Feng, Y.; Chen, X.; Lin, B.Y.; Wang, P.; Yan, J.; Ren, X. Scalable multi-hop relational reasoning for knowledge-aware question answering. arXiv 2020, arXiv:2005.00646. [Google Scholar]
- Yasunaga, M.; Ren, H.; Bosselut, A.; Liang, P.; Leskovec, J. QA-GNN: Reasoning with language models and knowledge graphs for question answering. arXiv 2021, arXiv:2104.06378. [Google Scholar]
- Zhang, X.; Bosselut, A.; Yasunaga, M.; Ren, H.; Liang, P.; Manning, C.D.; Leskovec, J. Greaselm: Graph reasoning enhanced language models for question answering. arXiv 2022, arXiv:2201.08860. [Google Scholar]
- Sun, Y.; Shi, Q.; Qi, L.; Zhang, Y. JointLK: Joint Reasoning with Language Models and Knowledge Graphs for Commonsense Question Answering. In Proceedings of the 2022 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Seattle, WA, USA, 10–15 July 2022; pp. 5049–5060. [Google Scholar]
- Zhang, M.; He, T.; Dong, M. Meta-path reasoning of knowledge graph for commonsense question answering. Front. Comput. Sci. 2024, 18, 181303. [Google Scholar] [CrossRef]
- Zheng, C.; Kordjamshidi, P. Dynamic Relevance Graph Network for Knowledge-Aware Question Answering. In Proceedings of the 29th International Conference on Computational Linguistics, Gyeongju, Republic of Korea, 12–17 October 2022. [Google Scholar]
- Chen, Y.; Dai, X.; Chen, D.; Liu, M.; Dong, X.; Yuan, L.; Liu, Z. Mobile-former: Bridging mobilenet and transformer. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022; pp. 5270–5279. [Google Scholar]
- Bordes, A.; Usunier, N.; Garcia-Duran, A.; Weston, J.; Yakhnenko, O. Translating embeddings for modeling multi-relational data. Adv. Neural Inf. Process. Syst. 2013, 26, 2787–2795. [Google Scholar]
- Zhang, M.; Dai, R.; Dong, M.; He, T. Drlk: Dynamic hierarchical reasoning with language model and knowledge graph for question answering. In Proceedings of the 2022 Conference on Empirical Methods in Natural Language Processing, Abu Dhabi, United Arab Emirates, 7–11 December 2022; pp. 5123–5133. [Google Scholar]
- Zhang, Q.; Chen, S.; Fang, M.; Chen, X. Joint reasoning with knowledge subgraphs for Multiple Choice Question Answering. Inf. Process. Manag. 2023, 60, 103297. [Google Scholar] [CrossRef]
- Sha, Y.; Feng, Y.; He, M.; Liu, S.; Ji, Y. Retrieval-Augmented Knowledge Graph Reasoning for Commonsense Question Answering. Mathematics 2023, 11, 3269. [Google Scholar] [CrossRef]
- Zheng, J.; Ma, Q.; Qiu, S.; Wu, Y.; Ma, P.; Liu, J.; Feng, H.; Shang, X.; Chen, H. Preserving Commonsense Knowledge from Pre-trained Language Models via Causal Inference. In Proceedings of the 61st Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Toronto, ON, Canada, 9–14 July 2023; pp. 9155–9173. [Google Scholar]
- Lee, J.; Lee, I.; Kang, J. Self-attention graph pooling. In Proceedings of the International Conference on Machine Learning, PMLR, Long Beach, CA, USA, 9–15 June 2019; pp. 3734–3743. [Google Scholar]
- Ashish, V. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017, 30, I. [Google Scholar]
- Talmor, A.; Herzig, J.; Lourie, N.; Berant, J. CommonsenseQA: A Question Answering Challenge Targeting Commonsense Knowledge. In Proceedings of the 2019 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Volume 1 (Long and Short Papers), Minneapolis, MN, USA, 2–7 June 2019; pp. 4149–4158. [Google Scholar]
- Mihaylov, T.; Clark, P.; Khot, T.; Sabharwal, A. Can a Suit of Armor Conduct Electricity? A New Dataset for Open Book Question Answering. In Proceedings of the 2018 Conference on Empirical Methods in Natural Language Processing, Brussels, Belgium, 31 October–4 November 2018; pp. 2381–2391. [Google Scholar]
- Jin, D.; Pan, E.; Oufattole, N.; Weng, W.H.; Fang, H.; Szolovits, P. What disease does this patient have? a large-scale open domain question answering dataset from medical exams. Appl. Sci. 2021, 11, 6421. [Google Scholar] [CrossRef]
- Liu, L.; Jiang, H.; He, P.; Chen, W.; Liu, X.; Gao, J.; Han, J. On the variance of the adaptive learning rate and beyond. In Proceedings of the 8th International Conference on Learning Representations, ICLR 2020, Addis Ababa, Ethiopia, 26–30 April 2020. [Google Scholar]
- Clark, P.; Etzioni, O.; Khot, T.; Khashabi, D.; Mishra, B.; Richardson, K.; Sabharwal, A.; Schoenick, C.; Tafjord, O.; Tandon, N.; et al. From ‘F’to ‘A’on the NY regents science exams: An overview of the aristo project. Ai Mag. 2020, 41, 39–53. [Google Scholar]
- Wang, X.; Kapanipathi, P.; Musa, R.; Yu, M.; Talamadupula, K.; Abdelaziz, I.; Chang, M.; Fokoue, A.; Makni, B.; Mattei, N.; et al. Improving natural language inference using external knowledge in the science questions domain. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February 2019; Volume 33, pp. 7208–7215. [Google Scholar]
- Lee, J.; Yoon, W.; Kim, S.; Kim, D.; Kim, S.; So, C.H.; Kang, J. BioBERT: A pre-trained biomedical language representation model for biomedical text mining. Bioinformatics 2020, 36, 1234–1240. [Google Scholar] [CrossRef] [PubMed]
- Liu, F.; Shareghi, E.; Meng, Z.; Basaldella, M.; Collier, N. Self-Alignment Pretraining for Biomedical Entity Representations. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4228–4238. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).