1. Introduction
Dry bulk ports and terminals are critical components of the global economy, facilitating approximately 50% of the world’s seaborne trade [
1]. These facilities, either dedicated or multipurpose, handle a variety of dry bulk commodities, including bulk minerals, agricultural products, fertilizers, and biomass, and serve as essential nodes in the logistics supply chain. In China, coal plays a dominant role in the national energy structure. Due to geographical imbalances between coal supply and demand, large-scale coal transportation from the west to the east and north to the south is essential. Ports, as vital hubs in this network, ensure the efficient operation of the coal transport system. With increasing demand for coal transport, enhancing the dispatching capacity and scheduling efficiency of dry bulk coal terminals has become a pressing need.
The coal loading process at export terminals is highly specialized. It involves reclaimers positioned along reclaimer lines to retrieve coal from stockpiles, transporting it via conveyors to the shiploading line, and completing the loading onto the vessel by a shiploader. Terminal productivity and efficiency are directly influenced by infrastructure, handling equipment, and operational practices. Given the discrepancy between vessel demands and stockpile arrangements, a single vessel often requires coal from multiple stockpiles. To meet blending requirements, terminals typically configure “dual reclaimers on a single line”, wherein two reclaimers retrieve coal from different stockpiles in specified proportions, blending them before loading. Additionally, mobile shiploaders, when feasible, load coal to adjacent berths, either individually or cooperatively.
Effective planning is crucial for improving the efficiency of reclaiming and loading operations. In the context of shiploading operations at container terminals, Ref. [
2] provides a comprehensive literature review on the shiploading problem, emphasizing the integration of stowage planning with loading sequencing and scheduling to enhance ship handling efficiency. Iris et al. [
3] further advance this integration by combining operational stowage planning with transport vehicle assignment and scheduling, and propose a GRASP heuristic based on greedy randomized adaptive search to obtain efficient, near-optimal solutions for complex terminal operations. To address the integrated berth allocation and quay crane assignment problem in container terminals, Iris et al. [
4] propose novel set partitioning models and variable reduction techniques, while Iris et al. [
5] introduce an Adaptive Large Neighborhood Search (ALNS) heuristic that improves known bounds and outperforms state-of-the-art heuristics on larger benchmarks. Although research related to container terminals provides valuable insights for optimizing shiploading [
2], transportation operations [
6], and storage yard management [
7], bulk cargo terminals present unique characteristics. These include variable stockpile sizes, the limitation of bucket-wheel reclaimers to linear tracks, and greater flexibility in the movement of container carriers [
8]. For bulk cargo terminals, the production department must devise appropriate loading schemes based on the vessel demand schedule and the stockpile distribution within the yard. Ships require varying coal types for different cabins, with products stored across multiple stockpile locations. This increases the number of potential loading schemes and could result in operational conflicts between reclaimers or shiploaders, leading to interruptions and delays. Such disruptions not only extend loading times but also negatively affect subsequent vessel schedules.
The complexity of bulk cargo port operations and the critical need for efficient scheduling have attracted substantial research interest. To address the comprehensive scheduling challenges in dry bulk ports, several methods have been proposed, including meta-heuristic algorithms [
9,
10], mixed-integer programming (MIP) with rule-based heuristics [
11], MIP with Benders decomposition [
12], MIP with meta-heuristics [
13], as well as constraint programming enhanced by meta-heuristics [
14]. De Paula et al. [
9] introduced an integrated scheduling strategy for the Hunter Valley coal export system, utilizing a parallel genetic algorithm to concurrently schedule train and vessel arrivals, stockpile buildup, and reclaim periods across three coal export terminals. To tackle the integrated problem of planning, scheduling, yard allocation, and berth assignment in dry bulk terminals, De Andrade et al. [
13] proposed a solution based on column generation, which accounted for conflicts in equipment usage. In the context of dry bulk terminals handling fertilizers, Cheimanoff et al. [
11] developed a mixed-integer linear programming model incorporating production scheduling, berth allocation, and yard storage. This model was solved using a multi-start GRASP-ILS meta-heuristic algorithm. Lu et al. [
14] focused on coal blending operations and proposed an integrated scheduling solution for coal port inbound and outbound operations. This solution employed a two-stage method that combined constraint programming with adaptive local search. Unsal et al. [
12] addressed berth allocation, reclaimer scheduling, and stockyard allocation at export dry bulk terminals by proposing a logic-driven Benders decomposition algorithm. Improving energy efficiency and reducing carbon emissions in ports have become critical focus areas for the port industry. Ref. [
15] conducts a systematic literature review to analyze operational strategies, technology usage, renewable energy, alternative fuels, and more, aimed at enhancing the energy efficiency of ports and terminals. To minimize total scheduling time, maximize berth allocation efficiency, and reduce carbon emissions, Jiang et al. [
10] developed a multi-objective optimization model integrating channel vessel scheduling, berth loading, and yard unloading, solved using the NSGA-II-DPGR algorithm.
Recently, integrated challenges within dry bulk terminals and coal export supply chains have attracted significant research attention [
16,
17,
18,
19]. However, several of these studies simplify key aspects of reclaimer operations by assuming, for instance, that each rail track is served by a single reclaimer [
16,
17]. In practice, most dry bulk terminals enable more flexible configurations where shiploaders can move to adjacent berths for collaborative loading, and two reclaimers operating on the same track can perform parallel reclaiming or blending operations simultaneously. Collaborative loading [
20] and parallel reclaiming [
8] significantly enhance operational efficiency and reduce vessel berthing wait times. To address the scheduling of collaborative shiploader operations, an optimization problem was formulated in [
20] to minimize both the energy consumption of operational lines and the berthing times of vessels at coal export terminals, utilizing a mixed-integer programming (MIP) model and a simulation-based decoding scheme. Additionally, Wang et al. [
8] demonstrated that deploying two reclaimers for simultaneous material reclaiming from the same stockpile notably boosts efficiency, although this introduces potential collision risks between reclaimers.
In practice, while multiple reclaimers might operate on the same rail track, they cannot pass each other. Avoiding equipment conflicts during collaborative loading and parallel reclaiming thus becomes a critical research issue. Recognizing the presence of multiple reclaimers on a single track, recent studies [
10,
12,
21] have incorporated reclaimer cross-operational conflict constraints into the scheduling optimization problem at dry bulk terminals. However, these studies assume that each vessel only loads a single type of bulk material, overlooking the complexity of reclaiming from multiple stockpiles and the potential for parallel reclaiming to further enhance efficiency. Burdett et al. [
17] addressed reclaimer conflicts by adapting a collision detection strategy from the train scheduling domain, dividing each reclaiming line into smaller regions and applying a penalty to the objective function when conflicts were detected. Lu et al. [
14] accounted for reclaimer conflicts in blending operations to meet ship demands. While Li et al. [
22] introduced stockyard scheduling into the reclaiming–loading process, they restricted operations to single-machine modes for both reclaimers and shiploaders, significantly reducing operational efficiency.
The reclaiming–loading scheduling (RLS) problems in dry bulk ports are unequivocally classified as NP-hard problems since they contain multiple subproblems, including task sequencing, reclaimer selection, and shiploader selection [
23]. Due to the exponential growth in the number of variables and constraints of the proposed mathematical models, the model-based exact algorithms are unable to yield optimal solutions within an acceptable time. When attempting to address this issue within a reasonable duration, traditional heuristics often fail to produce satisfactory scheduling solutions. In this context, the memetic algorithm (MA), a robust optimization technique that integrates evolutionary mechanisms with problem-specific local intensification, holds promise for effectively solving complex scheduling problems.
Inspired by Darwinian principles of natural evolution and Dawkins’ concept of the meme, the algorithm incorporates both evolutionary search and local refinements, constituting what is termed a memetic algorithm [
24,
25]. As a versatile optimization framework, MAs have been successfully applied for various problem domains, including the traveling salesman problem and the shop scheduling problem [
25], as well as the graph bipartition problem [
26]. A review of the literature on MAs applied to scheduling problems reveals that the specially designed problem-specific algorithms in the memetic computing framework can solve complex problems effectively. Specifically, the analysis of problem characteristics, the extraction and application of knowledge, and the adoption of a reasonable cooperative approach are fundamental to successfully addressing intricate scheduling challenges. Consequently, it is anticipated that a superior performance can be achieved by merging knowledge-driven mechanisms with problem-specific operators within the memetic computing framework.
This paper addresses the RLS problem within real-world coal port operations using a memetic algorithm framework that incorporates factors such as parallel reclaiming, collaborative loading, and equipment conflicts. To minimize the total operational time across all loading tasks, we developed a calculation model that accounts for key operational constraints, including task sequencing, reclaimer selection, and shiploader selection. Based on this model, we propose an innovative knowledge-driven memetic algorithm (KDMA), which integrates domain-specific knowledge with problem-specific operators within a memetic computing framework. A comprehensive series of multi-scale and multi-parameter experimental analyses demonstrates the effectiveness of the KDMA in solving the RLS problem. Comparisons with a genetic algorithm and a non-parallel operation strategy reveal the distinct advantages of the KDMA, underscoring the potential of knowledge-driven memetic algorithms to enhance scheduling efficiency in coal port operations.
The remainder of this paper is organized as follows.
Section 2 analyzes the characteristics of scheduling in dry bulk ports.
Section 3 formulates the reclaiming–loading scheduling problem. The design of the knowledge-driven memetic algorithm is detailed in
Section 4.
Section 5 presents and analyzes the results of multi-scale experimental studies. Finally,
Section 6 concludes the paper with a summary of key findings.
4. Knowledge-Driven Memetic Algorithm
In this section, a knowledge-driven memetic algorithm is proposed, featuring components such as encoding and decoding, population initialization, a knowledge-driven evolutionary mechanism, and local intensification.
4.1. Encoding and Initialization
Effective encoding and decoding methods can directly influence the search space and search efficiency. For the operation scheduling in a dry bulk port, the task sequence of each vessel, stockpile selection, reclaimer selection, and shiploader selection for each task should be determined together. Thus, a four-layer string is used to represent an encoded solution. The length of each of the four strings is the number of the tasks . The first string with task sequence is used to represent the task sequence of each vessel, where represents the task sequence belonging to vessel s, . The second string is represented by , where denotes the assigned stockpiles for task . The third string is represented by , where denotes the assigned reclaimer for task . The fourth string is represented by , where denotes the assigned shiploader/shiploading lines for task . Considering the task constraints, each task occurs once and only once in the and each task must belong to the corresponding vessel. Meanwhile, due to the constraints of different operation lines, the stockpiles should be selected in the available set of each task . Furthermore, the reclaimer and shiploader should be selected in the available set, considering accessibility. Therefore, the solution can be ensured to be feasible according the the above rules.
To obtain high-quality schedules based on the encoded solutions, the decoding method is designed considering parallel reclaiming, collaborative operation between adjacent loaders, and conflicts between reclaimers and loaders. To improve reclaiming efficiency, if there is more than one reclaimer on the assigned reclaiming lines and multiple available stockpiles, parallel reclaiming can be performed. To ensure the parallel reclaiming can reduce the task operation time, the available time of the parallel reclaimers should also be taken into account. If the completion time of parallel reclaimers is more than that of one reclaimer, parallel reclaiming will not be executed. To speed up the operation time, collaborative operation between adjacent loaders is also incorporated into the decoding process. If the adjacent loader is idle, the task assigned to it can be operated simultaneously. In addition, the conflicts between reclaimers and loaders are also considered during the decoding process to satisfying the constraints developed in the calculation model.
In the initialization phase, the population with solutions is generated randomly, considering the various constraints and decoded to the schedules. During the search process, the best solution is retained.
4.2. Knowledge-Driven Evolutionary Mechanism
To improve search efficiency, a knowledge-driven evolutionary mechanism is designed to enable inferior solutions to learn from elite solutions. First, two solutions in the population are selected randomly. Second, the inferior solution learns from elite solution based on their performance. Specifically, the difference in operation time for each vessel between solutions and is calculated, and the vessel with largest time difference is selected due to the huge space improvement. Third, the task schedule of the selected vessel of solution is transplanted to the corresponding vessel of solution . Thus, solution can be improved by learning from the better solution.
To enhance the population diversity, a mutation operator is developed for the improved solution with a mutation probability . The mutation operator is implemented by randomly selecting a vessel and regenerating its task sequence, stockpile, reclaimer, and shiploader. Consequently, the KDMA can improve convergence while mitigating the risk of local optima.
4.3. Local Intensification
To enhance the exploitation capability, a knowledge-driven local intensification is designed to further refine promising solutions. To reduce the total loading time for all vessels, three local search operators with prior knowledge are designed for adjusting the task sequence, reclaimer selection, and loader selection, including critical task swap (TS), task insertion (TI), reclaimer selection (CS), and loader selection (LS). Suppose the vessel s is selected to adjust the three subproblems:
TS: For the tasks belonging to the vessel s, select two tasks randomly and then swap them.
TI: For the tasks belonging to the vessel s, select two tasks randomly and then insert one task before another one.
CS: For all tasks belonging to the vessel s, select two stockpiles with two available reclaimers. If there are no stockpiles satisfying the condition, then randomly select one stockpile and reclaimer.
LS: For all tasks belonging to the vessel s, select a different available and adjacent loader from the loaders of previous task to improve the possibility of collaborative operation.
The procedure of local intensification is shown as Algorithm 1, where
denotes the depth of local intensification.
| Algorithm 1 Local Intensification |
- 1:
Designate an elite solution among the top 10% solutions; - 2:
flag = true, . - 3:
while do - 4:
if flag == true then - 5:
Select the vessel s with largest operation time. - 6:
else - 7:
Select the vessel s randomly. - 8:
end if - 9:
Randomly perform TS() or TI() to get . - 10:
Perform CS() and LS() to get . - 11:
if is better than then - 12:
= . - 13:
else - 14:
flag = !flag. - 15:
end if - 16:
; - 17:
end while
|
4.4. Algorithm Framework
The pseudo-code of the knowledge-driven memetic algorithm (KDMA) is delineated in Algorithm 2, including the population initialization, knowledge-driven evolutionary mechanism, and local intensification scheme. Through the several problem-specific designs, it is expected to achieve a superior performance via a balance of exploration and exploitation.
| Algorithm 2 Knowledge-driven Memetic Algorithm |
- 1:
Initialize the population size , local search depth and maximum iterations , generations . - 2:
Initialize the population. - 3:
while do - 4:
for do - 5:
Select two solutions and randomly. - 6:
Perform learning operator for solutions and to obtain new solution . - 7:
if rand > 0.5 %rand denotes a random number in (0,1); then - 8:
Perform mutation operator for solution . - 9:
end if - 10:
Sort all the solutions and select the best solutions as new population. - 11:
Perform local intensification. - 12:
Update the best solution. - 13:
end for - 14:
end while
|
5. Experimental Results and Analysis
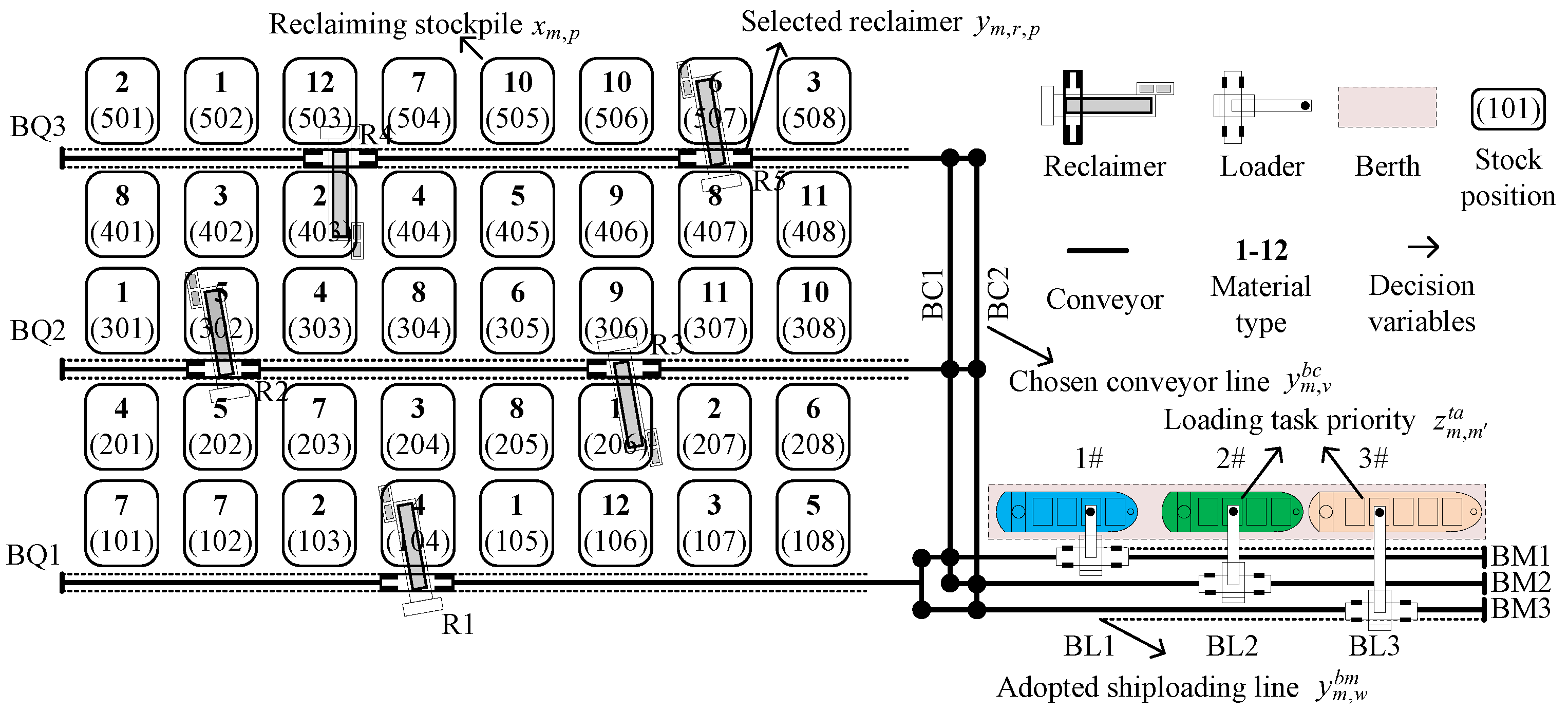
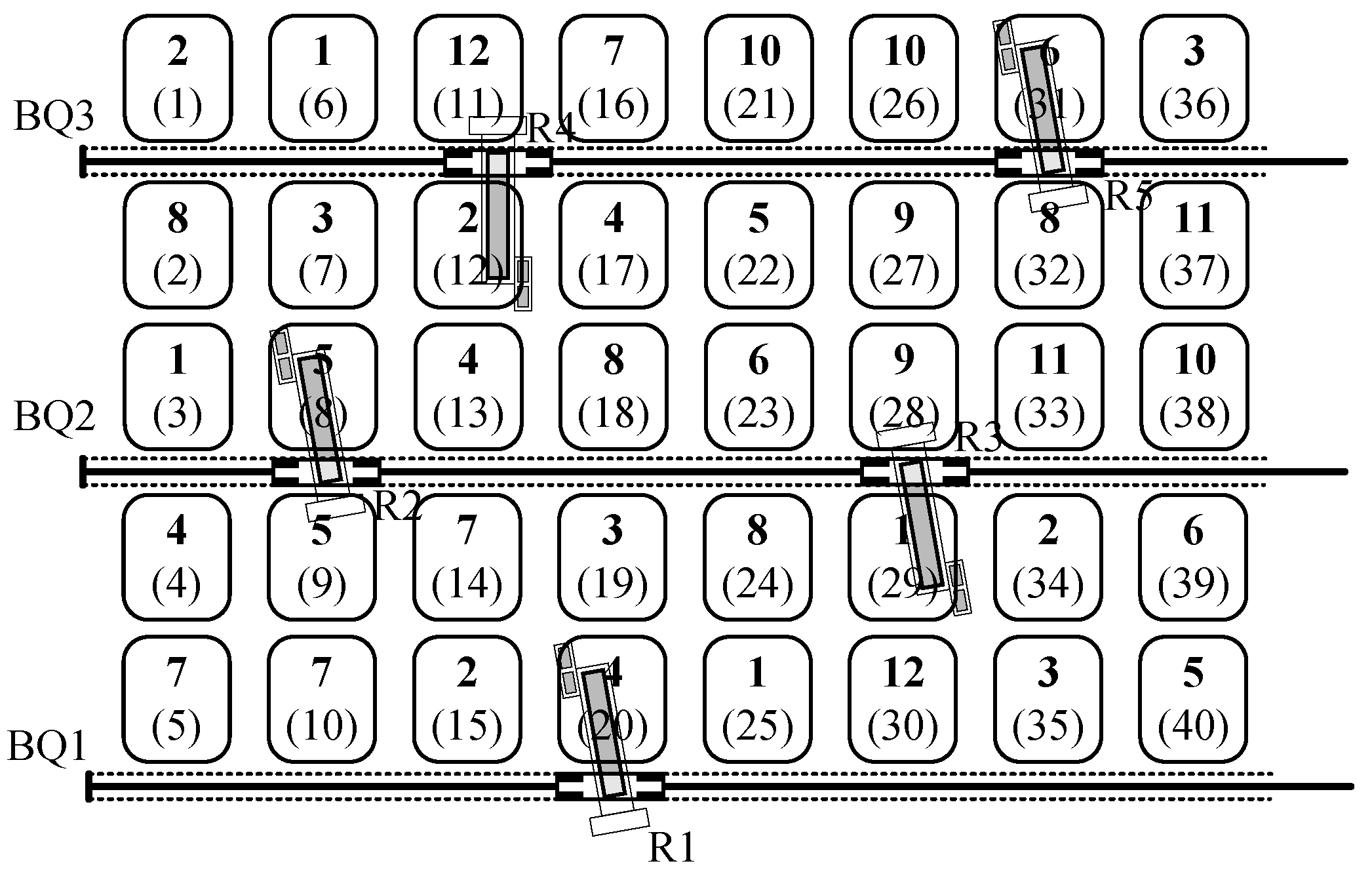
As a case study, this paper compares and analyzes the scheduling plan derived from the proposed optimization problem with the results obtained from genetic algorithm optimization at a coal export terminal in China, thereby validating the effectiveness of the proposed optimization algorithm. The layout of the entire shiploading operation is illustrated in
Figure 1. Without considering the collaborative operation of shiploaders, the accessibility between the designated berth and the three conveyor lines—the reclaiming line, horizontal line, and shiploading line—is detailed in
Table 2. Additionally, the reclaiming speeds of reclaimers R1 to R5 are 6000, 6000, 3000, 6000, and 3000 t per hour, respectively. The distances from berths 1# to 3# to the stockyard are 450, 750, and 1000 m, respectively.
This experiment considers the optimization of the shiploading tasks for 60 vessels during the planning period.
Table 3 provides detailed information on vessel arrival times, dock assignments, and the types and quantities of bulk cargo required.
For the scheduling optimization of 30 vessels and their corresponding 185 tasks over a 15-day period,
Figure 5 and
Figure 6 present the results obtained using the KDMA proposed in this paper. Due to space constraints, only the optimization results for the first six days are shown, with each subplot displaying results for two days or 48 h.
Figure 5 illustrates the outcomes under a conventional single reclaimer operation, while
Figure 6 demonstrates the performance of the proposed parallel reclaiming operation, where two reclaimers can simultaneously handle the same type of bulk cargo from different stockpiles. For each loading task,
Table 4 details the utilization of the stockpiles, reclaimers, and the three operational lines under both conditions: with and without the reclaimer parallel strategy.
Taking vessel S1 as an example, we illustrate the scheduling result adopting the traditional approach of using a single reclaimer for a loading task, as shown in
Figure 5. The vertical lines on either side of the unfilled rectangular box represent the vessel’s docking and departure times. The vessel S1 docks at berth 2# at 01:15 on day 1. After completing the turnaround operations, it sequentially performs its six loading tasks (T5, T2, T6, T1, T3, T4) during the following time intervals: T5 from 02:30 to 04:01, T2 from 02:30 to 03:58, T6 from 04:01 to 06:54, T1 from 03:58 to 06:52, T3 from 06:52 to 08:21, and T4 from 06:54 to 09:41. Once the final task, T4, and the auxiliary operations are completed, the vessel departs at 10:04. It is important to note that due to the collaborative loading mechanism, shiploader BL1 executes the loading tasks (T2, T1, T3), while shiploader BL2 executes the tasks (T5, T6, T4) simultaneously.
Using the parallel reclaiming strategy, as shown in
Table 4 and
Figure 6, vessel S1 performs its six reclaiming tasks as follows: Task T3 is reclaimed from stockpile 2 by reclaimer R4 and from stockpile 32 by reclaimer R5 in parallel between 02:30 and 03:31. Task T5 is reclaimed from stockpile 18 by reclaimer R2 and from stockpile 24 by reclaimer R3 in parallel between 02:30 and 03:31. Tasks T6, T4, T2, and T1 are reclaimed in a similar manner, either in parallel or individually. Finally, Task T1 is reclaimed from stockpile 2 by reclaimer R4 and from stockpile 32 by reclaimer R5 in parallel between 05:01 and 06:08. After completing the final task T1, vessel S1 is unfastened and departs at 06:31.
Due to the implementation of the parallel reclaiming operation mechanism, the docking duration of vessel S1 was reduced by 40.36%, from 8.824 h to 5.263 h. As a result of the expedited completion of tasks for vessel S1, the waiting time for vessel S2 decreased by 60.03%, from 3.959 h to 1.581 h. This improvement is clearly illustrated on day 4 to day 6 in
Figure 5, where inefficient completion of earlier shiploading tasks caused delays and accumulations for subsequent vessels S10 to S15—at least six consecutive ships. However, by adopting the parallel strategy, as shown in
Figure 6, only the loading tasks for vessels S10 and S11 were affected, while operations for S12 and those following were restored to normal. Overall, for all 30 vessels, the total loading time
F was reduced by 33.3%, from 329.64 h to 219.66 h, significantly enhancing the efficiency of port loading operations. Meanwhile, ship-based emissions—particularly during port stay time—constitute a significant portion of the total energy consumption in container and dry bulk terminals [
15,
27]. By converting energy consumption into monetary terms, the analysis shows that the unit port stay cost is RMB 1416 per hour, as reported by Tian [
27]. Following optimization, the port stay cost for 30 vessels decreased from RMB 466,770 to RMB 311,038, achieving a savings of RMB 155,731.
On the other hand,
Table 4 illustrates that, when employing the parallel reclaiming strategy, the number orders of the adopted reclaimers and the stockpiles are consistent, indicating that the proposed algorithm can effectively avoid conflicts in parallel reclaiming operations. Meanwhile, as shown in
Figure 6, on the third day, shiploader BL3 is assigned to perform the T28 loading task for the vessel S5 docked at berth 3#, while shiploader BL2 is assigned to perform the T30 loading task for the vessel S6 docked at berth 1#. The consistency in the number order of the selected shiploaders and the berths indicates that the proposed scheme can effectively avoid conflicts of shiploaders in the collaborative loading operations.
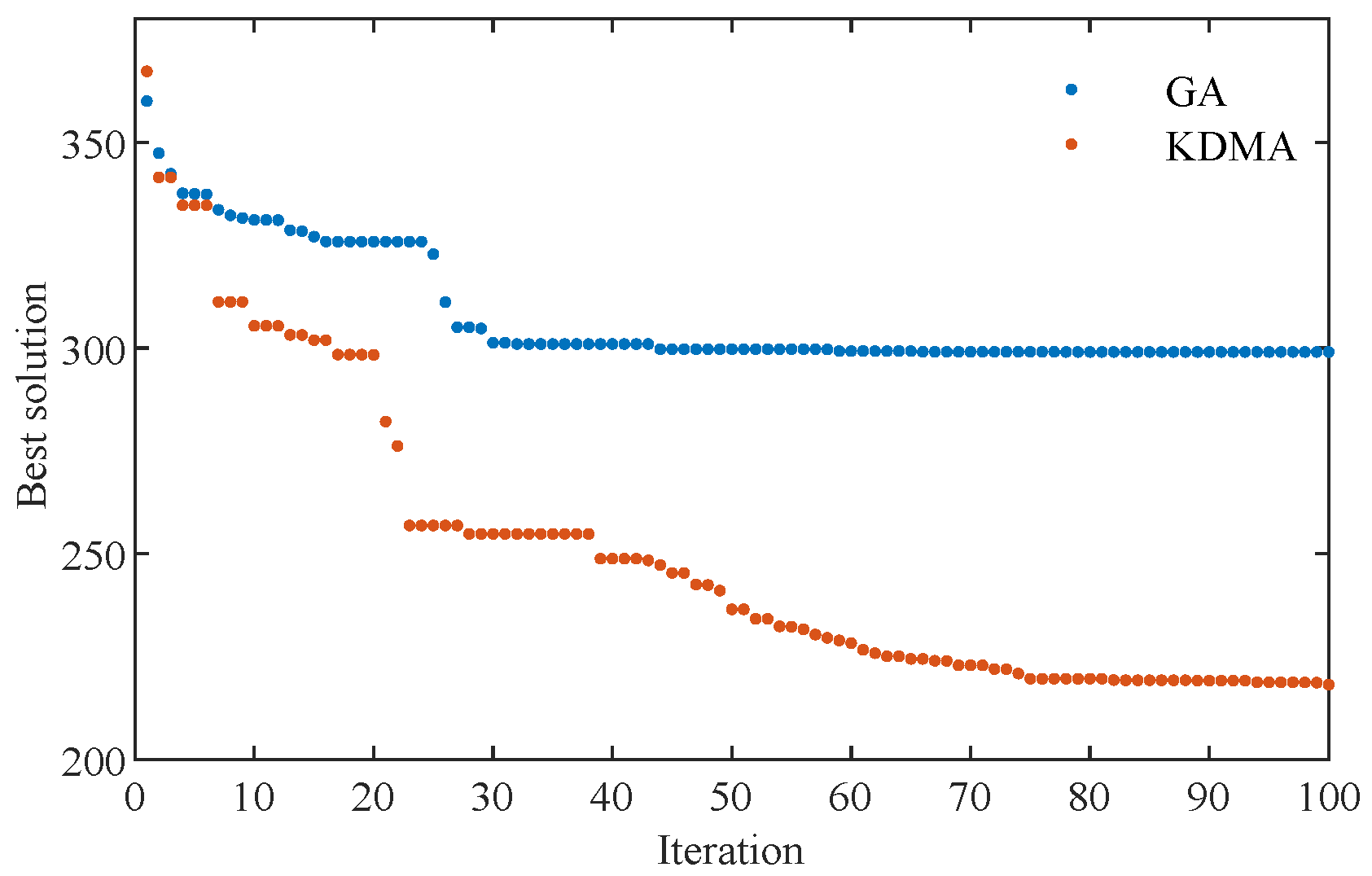
To further validate the effectiveness of the proposed KDMA, the genetic algorithm (GA) was used to solve the bulk cargo terminal loading scheduling optimization problem. For the scheduling of 30 vessels, the convergence effects of the algorithms are compared as shown in
Figure 7. Although the GA converges after only 42 iterations, its optimal solution of 299.05 h is significantly worse than the KDMA’s optimal solution of 218.20 h. Additionally, the GA’s computation time of 416.52 s is notably longer than the KDMA’s 244.6 s.
As shown in
Table 5, extensive experiments with scheduling tasks ranging from 5 to 60 vessels clearly demonstrate the consistent advantages of the KDMA, achieving an average reduction in optimal loading time of 20.3% and a reduction in computation time of 45.84%.
ANOVA (two-way analysis of variance) was conducted to evaluate the impact of two factors:
(depth of local intensification) and
(population size) on the best solution in the proposed KDMA. Five different settings of
were selected: 60, 80, 100, 120, and 140. Similarly, five different settings for
were chosen: 30, 40, 50, 60, and 70. Each combination of factors was repeated 50 times to ensure data reliability and stability. The ANOVA results are presented in
Table 6.
The p-values for both and , and their interaction, are all greater than 0.05, indicating that neither the single factors nor their interaction significantly influence the best solution, thereby demonstrating the robustness of the proposed KDMA.
Overall, by formulating the RLS problem to incorporate parallel reclaiming, collaborative loading, and operational conflicts, we have significantly enhanced loading efficiency. Additionally, the proposed KDMA not only delivers superior solutions but also requires less computation time compared to the traditional GA. The robustness of the parameters within this algorithm has also been effectively demonstrated. Notably, this approach is adaptable beyond the specific port setup described in this study, making it suitable for a wide range of bulk cargo terminal layouts and operational requirements.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}