1. Introduction
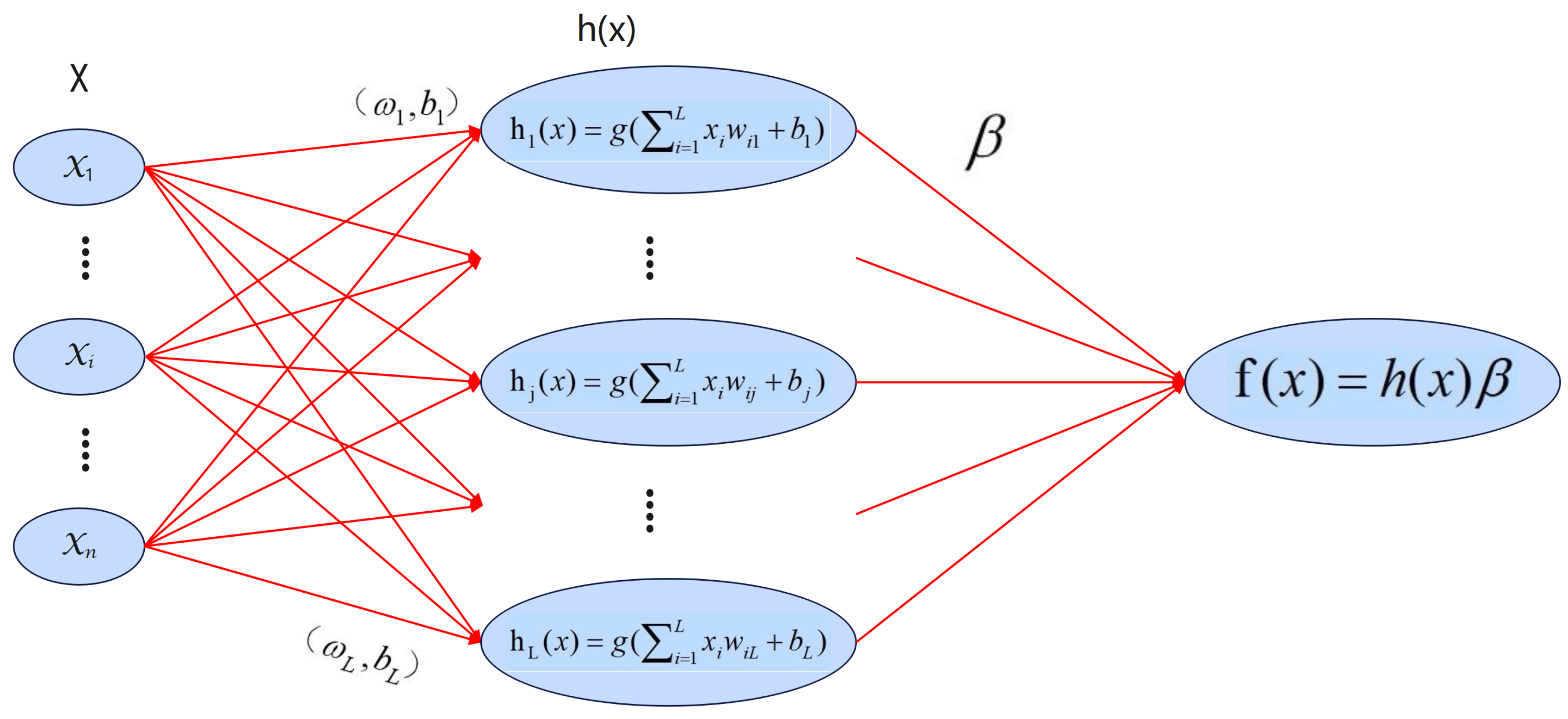
Extreme learning machine (ELM) [
1,
2] was proposed by Huang et al. on a single hidden layer feedforward network. Compared with traditional training methods, ELM has advantages in learning speed and generalization performance. This is because ELM differs from traditional methods, that is, the input consists of randomly generated weights and bias values of the hidden layer nodes, allowing for the quick and effective determination of output weights. Additionally, The ultimate aim of ELM is to reduce the training error and the norm of the weights, which enhances ELM’s generalization performance in feedforward neural networks. Nowadays, ELM is widely used in ship detection [
3], online visual tracking [
4], image quality assessment [
5], and other fields.
In recent years, many excellent scholars have proposed different algorithms based on ELM and achieved good performance. However, most of the ELM-based algorithms are more sensitive to outliers and affect the performance of the model. In recent years, the robust learning algorithm has become a new direction of machine learning. In order to overcome the influence of outliers on ELM, researchers have proposed some robust algorithms based on ELM from different perspectives [
6,
7,
8,
9,
10,
11,
12]. From the perspective of loss function and based on expected penalty and correntropy, Wu et al. [
7] proposed an asymmetric non-convex bounded loss function (AC-loss) and obtained a robust ELM learning framework of
-norm robust regularized extreme learning machine with asymmetric AC-loss (
-ACELM). Ren and Yang [
11] proposed a new hybrid loss function using pinball loss and least squares loss. Then, based on the hybrid loss function, a robust ELM framework with a hybrid loss function was proposed. Luo et al. [
12] proposed that the correntropy loss function induced by the p-order Laplace kernel can be used to replace the
loss function to reduce the influence of outliers during learning.
In recent years, the
-norm, called the sparse rule operator, has been given attention and applied in more and more fields, and it is considered to be robust to outliers [
13]. Zhang and Luo et al. [
14] took advantage of the robustness of
-norm to introduce the
loss function into ELM to solve the outlier problem. Although
-norm performs well in improving the robustness of the algorithm, most existing algorithms based on
-norm may not obtain a satisfactory result when the outliers are large. Therefore, more and more scholars have tried to use the capped
-norm to achieve some good results [
15,
16,
17,
18,
19]. Following is a brief review of some representative works, Wang et al. [
16] proposed a new capped
-norm twin SVM. Wang and Chen et al. [
17] proposed a capped
-norm sparse representation method (CSR) to remove outliers and ensure the quality of the graph. Li et al. [
18] proposed a new robust capped
-norm twin support vector machine (R-CTSVM+), which adopted the capped
regularization distance to ensure the robustness of the model.
In recent years, inspired by SVM and GEPSVM, Jayadeva et al. [
20] proposed twin SVM (TSVM). Compared with SVM, TWSVM shows great improvement in computational complexity and computational speed because it improves the speed of work by solving a large quadratic programming problem into a pair of small quadratic programming problems, which is theoretically four times faster than the traditional SVM [
20,
21]. Due to the excellent performance of TSVM, scholars have proposed many variants of TSVM. For example, Kumar et al. and Shao et al. proposed least squares TSVM (LSTSVM) [
22] and twin bounded SVM (TBSVM) [
23] based on TSVM. LSTSVM simplifies the solution of a pair of complex QPPs in TSVM to only solving two linear equations, which greatly improves the operation speed but loses the sparsity, and TBSVM considers the minimization of the structural risk of TSVM by introducing a regulaization term. These improvements make TSVM closer to perfection, while the recognition ability and adaptability are also strengthened. Wan et al. [
24] proposed twin extreme learning machine inspired by TWSVM. He combined twin support vector machine (TWSVM) with extreme learning machine (ELM), so TELM has the advantages of both TWSVM and ELM. At the same time, compared with ELM, TELM has faster learning speed.
Most researchers use the hard capped strategy to enhance the robustness of models by reducing the impact of noisy data, but it has inherent shortcomings, such as inadvertently ignoring key data and introducing non-differentiable regions. To address this, this paper proposes a soft capped loss function based on the -norm (SC-loss) and introduces SC-loss into TELM to construct the SCTELM model. SC-loss is a soft capped loss function that reaches the upper limit more smoothly than hard capped and can be applied to various machine learning problems, effectively reducing the impact of large outliers on the model. We also employ stochastic variance-reduced gradient (SVRG) to further improve the learning rate. A large number of experimental results show that SCTELM is more competitive in terms of accuracy and learning efficiency.
The main contributions of this paper are as follows:
This paper proposes an efficient and reliable learning framework based on TELM, namely robust twin extreme learning machine with the -norm loss function based on the soft capped strategy (SCTELM).
This paper proposes an -norm loss with soft capped, which can reach the upper bound more smoothly to reduce the impact of large outliers on the model.
Experimental results on various datasets show that our proposed SCTELM is competitive with other algorithms in terms of accuracy and learning efficiency.
The rest of this paper is organized as follows, and
Section 2 briefly reviews some properties of ELM, TWSVM and TELM. In
Section 3, some details of our proposed SC-loss and SCTELM are described and the related theoretical analysis is given. Experimental results on multiple datasets are presented in
Section 4.
Section 5 concludes the paper.
3. Main Contributions
In this section, we introduce a capped -norm loss into TELM, thereby establishing the proposed SCTELM in this paper. We optimize it using the SVRG algorithm and further conduct a convergence analysis of the model to investigate its stability.
3.1. Capped SC-Loss Function
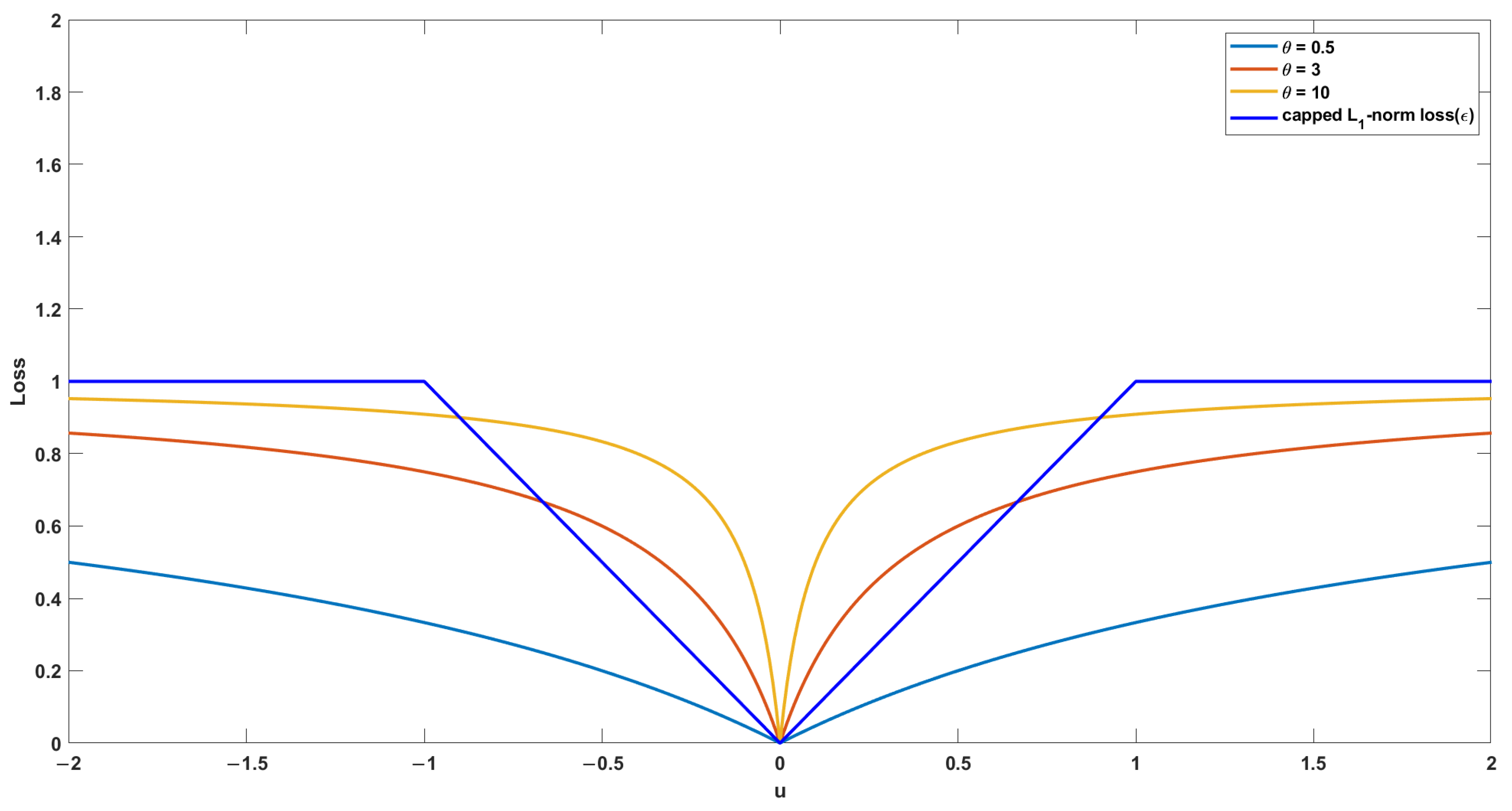
To alleviate the non-differentiable region that may be introduced by hard capped, we propose the soft-truncated SC-loss function as follows:
Definition 1. Given a vector u, the function is defined aswhere is the adaptive parameter of the loss function. For example, as shown in Figure 2, the capped -norm () loss is non-differentiable at , and our proposed -loss can avoid this problem, thus making it more convenient for us when dealing with it. The following are some properties of the :
Theorem 1. is a symmetric function.
Theorem 2. is a non-negative function.
Theorem 3. is a bounded function.
Remark 1. Here, 1 is the maximum value of , which determines the last term of the loss function and is therefore robust.
3.2. Linear SCTELM
Based on (
11), (
12) and our proposed
-loss function, we can obtain the formula for SCTELM, expressed as follows:
for SCTELM1, substituting into gives
Let
; there is
Substituting
into
gives
Let
; there is
Thus, (
20) can be expressed as
For a given sample
, its objective function is denoted by
If
, there is
Let
, there is
and the gradient of
with respect to
can be represented by
If
, we then have
and the gradient of
with respect to
can be represented by
Combining (
30) and (
32), the gradient of
with respect to
can be represented by
Then, the average gradient over
l samples can be computed as
The same can be said for the following:
where
,
. From the above equation, we can obtain
; when we obtain a new sample vector
x, we can make predictions according to the following decision function:
3.3. Nonlinear SCTELM
Sometimes, we will encounter datasets that are not linearly separable. In such a case, we can extend SCTELM to the nonlinear case by considering the surfaces generated by the following two kernels:
where
, and
is the kernel function of ELM, which can be expressed as
. From this, the original problem of TELM can be expressed as follows:
From the KKT condition, we can obtain and , where and , and are Lagrange multipliers. The original problem for SCTELM then becomes the following:
Following the way linear SCTELM is computed, we can obtain the following, according to SCTELM1:
and according to SCTELM2:
where
In the same way, from the above equation, we can obtain
. When we obtain a new sample vector
x, we can make predictions according to the following decision function:
3.4. Convergence Analysis
Consider a fixed-stage n in Algorithm 1. Let
. Assume that m is sufficiently large and, therefore,
Then, we can determine that the expectation on SVRG has geometric convergence, as follows:
where
. For a detailed proof, see the work of Johnson and Zhang (2013) [
25].
| Algorithm 1 SVRG for SCTELM |
Input: Training data and ; Parameters , , update frequency m and learning rate .
Output: .
Initialize ;
FOR n = 1, 2, 3, ⋯, N; ; Calculate according to ( 34) and ( 36) for SCTELM and ( 44) and ( 46) for Nonlinear SCTELM; FOR t = 1, 2, 3, ⋯, T; Randomly pick ; Update weight according to ( 33) and ( 35) for SCTELM and ( 43) and ( 45) for Nonlinear SCTELM; END ;
END |
3.5. Computational Complexity Analysis
In this section, we briefly analyze the complexity of the proposed algorithm. Here, we only compute the linear SCTELM, and similarly, the nonlinear SCTELM, which is well known to be determined by the computational cost and the number of iterations. First, we analyze the former; the computational complexity of
and
in (
33) and (
35) is
, while the computational complexity of
and
is
, so the overall complexity of (
33) and (
35) is
. Similarly, the complexity of (
34) and (
36) is
. In Algorithm 1, the outer loop is executed N times and the inner loop is executed T times, so the total computational cost of the algorithm is
. While L is the number of neurons, there is usually
, so the complexity of Algorithm 1 is
. It can be seen that the complexity of the SCTELM algorithm is mainly affected by the number of samples, and the convergence speed of the SVRG algorithm is faster than that of other algorithms, so the convergence speed of the SCTELM algorithm is faster than that of other algorithms.
SVRG reduces the variance of the stochastic gradient by introducing an estimate of the global gradient, thus improving the convergence speed. This means that in each iteration, SVRG can use fewer samples (mini-batch) to achieve the same accuracy as traditional SGD. This variance reduction property makes the algorithm more efficient when dealing with large-scale data, thus improving the scalability. Each iteration of SVRG needs to calculate the global gradient, which increases a certain computational overhead compared with only calculating the gradient of local samples. However, due to its faster convergence speed, the same performance can usually be achieved in a smaller number of iterations, thus reducing the overall computation time on large-scale datasets.
4. Numerical Experiments
In this section, to evaluate the robustness of SCTELM, we systematically compare it with other advanced algorithms in multiple datasets, including ELM [
2], LELM [
26], CTSVM [
18],CHELM [
27], TELM [
24], and FRTELM [
28]. For ease of observation, the bold font in the table below indicates the optimum. After dataset testing, we also performed classification visualization to further embody the performance of our proposed model. All experiments were performed using the Windows operating system with a 12th generation Intel (R) core (TM), i7-6700HQ @ 2.10 GHz, and 8.00 GB RAM, and the environment was implemented on a PC running a 64-bit XP operating system. All codes were run by MATLAB R2021b.
4.1. Experimental Setup
We can evaluate the performance of an algorithm based on different metrics, but here, we will use accuracy (ACC), which measures the proportion of instances that the model correctly predicted. ACC is defined as follows:
where TP and TN represent true positive and true negative, respectively, which represent the correct prediction of positive and negative samples; FP and FN represent false positive and false negative, respectively, which represent the incorrect prediction of positive and negative samples. Among them, a higher ACC value represents a more accurate classification and a better model performance.
In our experiment design, the training and testing samples were randomly selected from the dataset, and we added outliers of 0%, 10%, 20%, and 30% to the training set, respectively, and used these contaminated training samples to verify the robustness of the model. In this experiment, due to the large number of parameters, we used the random search method to find the best parameters. The parameters selected for the proposed model are as follows: parameter is selected from the set , and parameter is selected from the set .
4.2. Description of the Datasets
To verify the performance of our proposed SCTELM, we will numerically simulate it using various datasets, including eight benchmark datasets from UCI and two artificial datasets.
Among them, the UCI dataset includes the following: Australian (Australian Credit Approval), Ionosphere, German, Pima, Vote (Congressional Voting Records), WDBC (Breast Cancer Wisconsin), Spect (SPECTF Heart) and QSAR (QSAR biodegradation). We will use these UCI datasets to compare the performance of our proposed algorithm with other algorithms. See
Table 1 for relevant information on these datasets.
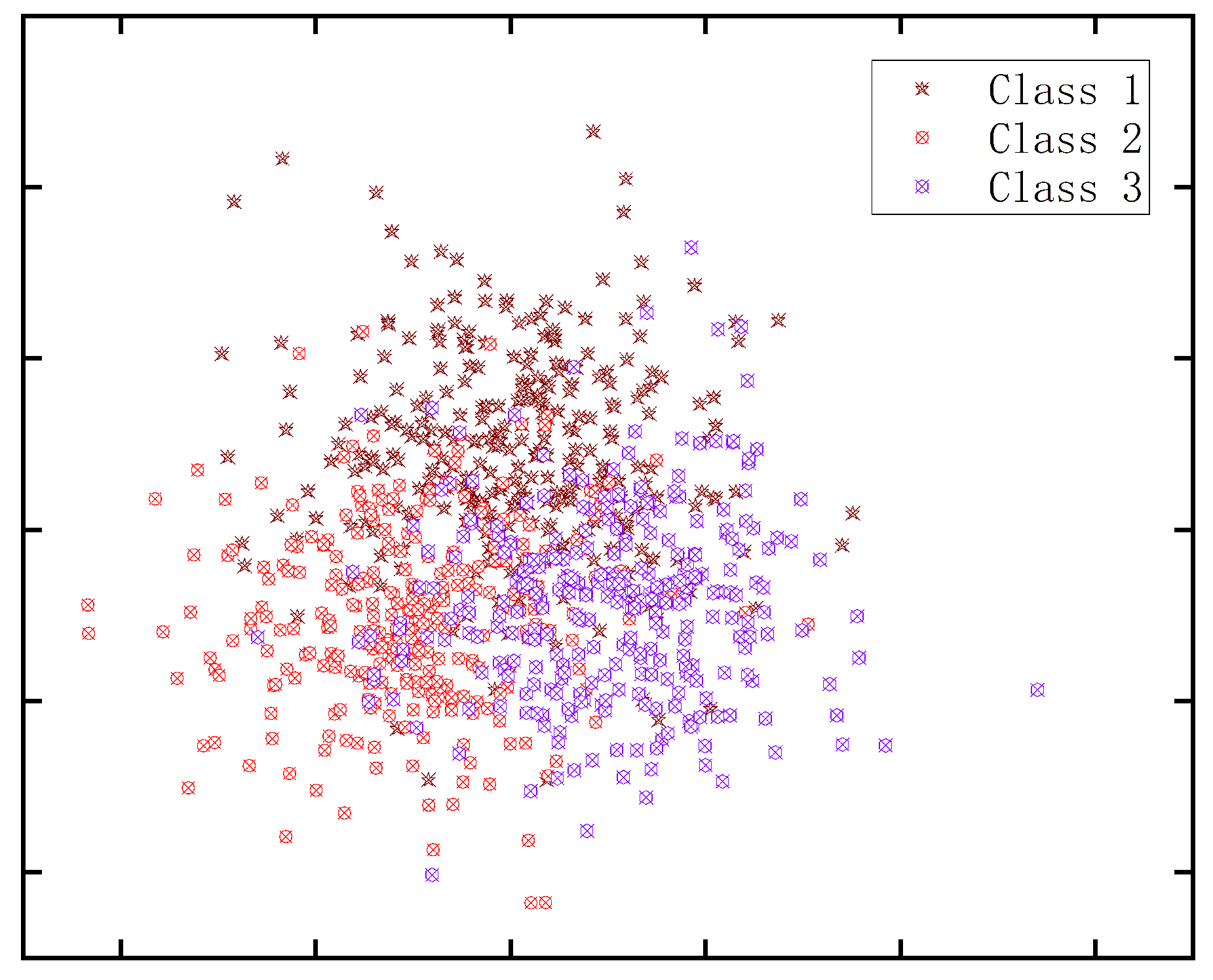
In terms of artificial datasets, we generated a two moons dataset containing two categories, 1000 positive and 1000 negative, and a dataset containing three categories. See
Figure 3 for the detailed dataset, where the positive and negative classes are represented by green and orange spheres. And the three-classification dataset contains 900 samples, and each class has 300 samples. See
Figure 4 for details.
We performed a 10-fold cross-validation on the selected datasets, which means that we randomly split one of the datasets into ten parts, nine of which were used as the training set and the remaining one as the test set. This process was repeated ten times, and the average of the ten results was taken as the final performance metric to reduce the risk of overfitting and underfitting. At the same time, to obtain more objective experimental results, we normalized all the datasets to make the data in the interval [0, 1]. Considering that we want to verify the robust performance of the model, we will successively increase the noise ratio for each dataset. If the accuracy of classification does not change much with the increase in noise, it indicates that the algorithm has good robust performance.
4.3. Experimental Results on Artificial Datasets
In order to verify the advantages of the proposed model over other original models, only ELM and TELM will be compared in this section. Observing
Table 2, it can be found that when the noise ratio is zero, the accuracy of SCTELM is higher than that of TELM and ELM, which indicates that SCTELM performs better than TELM and ELM. When the noise ratio is 0.1, the accuracy of the model is all reduced, which indicates that noise does affect the performance of the model. When the noise ratio is 0.2, the accuracy of all the models slightly decreases, but the accuracy of SCTELM is higher than that of TELM and ELM. When the noise ratio is 0.3, the accuracy of SCTELM decreases slightly, while the accuracy of ELM and TELM decreases more, which clearly illustrates the robustness of SCTELM.
To make a more intuitive comparison, the line chart of the proposed model and other models under different noises is drawn in
Figure 5. It can be seen from
Figure 5 that the corresponding line of SCTELM is always higher than that of the other models, which indicates that the performance of SCTELM is better than that of the other two models. When the noise gradually increases, the accuracy of all the models shows a decreasing trend, which indicates that noise does have a large impact on the performance of the model. It can be seen from the figure that when the noise rises from 0.2 to 0.3, the accuracy decline rate of ELM and TELM is faster than that of SCTELM, which also precisely demonstrates the superior robustness of the proposed model.
To extend SCRELM to the multi-class case, we adopted an artificial dataset with three classes. Generally speaking, either one-to-one or one-to-many strategy is used when using models such as ELM or TELM for multi-classification. Here, we use the more commonly used one-to-one strategy for classification. The strategy decomposes a three-class classification problem into three two-class classification problems, each of which is responsible for solving a pair of classes. The final classification results are determined by voting technology. The final results of classification are given in
Table 3. As expected, SCTELM shows its amazing ability and outperforms ELM and TELM in the final classification accuracy.
4.4. Experimental Results on UCI Datasets
In this section, to validate the classification performance algorithms, we ran them on eight datasets. We preliminarily verified the robustness of the SCTELM algorithm on the previous artificial datasets. Here, to further verify its robustness, we will add 20% and 30% Gaussian noise to all datasets. See
Table 4,
Table 5 and
Table 6 for details. However, the choice to set 20% or 30% noise in the SCTELM algorithm experiment can, on the one hand, simulate a data bias that may exist in the real environment to evaluate the performance of the model in the face of noisy data. A clearer understanding of the anti-noise performance of the SCTELM algorithm can be obtained by comparing the experimental results under different noise levels. For example, if the model performs well under 30% noise, it is robust to noise. On the other hand, the increase in noise level will increase the complexity and randomness of the data, making the distribution difference between the training data and the test data larger. Whether the SCTELM model can maintain good generalization performance when the noise is high reflects its ability to adapt to unseen data. All in all, this setting is useful for assessing how well the model generalizes on test sets or real-world application data.
4.4.1. Experimental Results on UCI Datasets Without Outliers
From
Table 4, we can clearly find that the classification performance of our proposed SCTELM is better than the other five algorithms on all datasets. In addition, we also find that TELM and CTSVM are faster than the other algorithms on most datasets, this is because they solve one large QPPs instead of two small QPPs. Our proposed algorithm also inherits this advantage. It can be clearly seen in
Table 4 that the learning efficiency of SCTELM is ahead of other algorithms in most datasets.
4.4.2. Experimental Results on UCI Datasets with Outliers
We verified the superiority of SCTELM in the previous experiments. To further verify the robustness of SCTELM, we added a certain proportion of outliers in each dataset and conduct new experiments. In this experiment, we chose to add 20% and 30% Gaussian noise, respectively, to test the robustness of the model.
Table 5 and
Table 6 present the experimental results of the six models with 20% and 30% noise introduced, respectively. From
Table 5 and
Table 6, we can intuitively find that the accuracy of each model decreases after the introduction of noise, which indicates that noise pollution indeed has a great impact on model classification. At the same time, we can also find that the accuracy of the SCTELM model still maintains its superiority, and it can be concluded that the robustness of our proposed SCTELM model is significantly better than the robustness of other models.
In order to improve our intuition, we drew
Figure 6,
Figure 7,
Figure 8 and
Figure 9 according to the noise ratio and accuracy. From the figure, we can clearly see that the accuracy decreases when the noise increases, and we can also intuitively see that the “slope” of SCTELM is small. It further shows that SCTELM has strong robustness.
4.5. Statistical Analysis
In this section, to analyze the significant differences in the six presented algorithms on these eight UCI datasets, we conducted the Friedman test [
29], which is considered as a non-parametric test with low data distribution requirements, strong processing power, and easy interpretation of the results. In this test, the null hypothesis
is as follows: there is no significant difference between the six algorithms; and if the null hypothesis is rejected, then the Nemeny test will be performed [
29]. The average ranking and average accuracy of these six algorithms on the eight datasets are shown in
Table 4,
Table 5 and
Table 6.
First, we can make a statistical comparison according to the noise-free case, and according to the Friedman statistic formula, it can be obtained as follows:
where
N is the number of datasets, k is the number of algorithms, and
is the average ranking of the
jth algorithm over all datasets. In this paper,
k = 7 and
N = 8.
Second, we can obtain the
-distribution with
degrees of freedom, as follows:
Similarly, we can obtain that the values of noise 0.2 and 0.3 are 32.41 and 40.07, respectively, and the values are 9.12 and 20.48, respectively. For , we can obtain . Clearly, all has . Therefore, it can be said that there are significant differences between the six algorithms.
In the following, to further compare the six algorithms, the Nemenyi post hoc test will be performed. Referring to the table, we obtain
, which gives us the critical difference (CD):
If the difference between the rankings of the two algorithms calculated is larger than the critical value, it represents a significant difference between the two algorithms. From
Table 4, we can obtain the difference between SCTELM and the other five algorithms when there is no noise, and the calculation results are as follows:
The notation D (A-B) represents the difference in average rankings between the two algorithms. We can conclude that SCTELM significantly outperforms ELM, LELM, CTSVM and CHELM on the noise-free dataset, while showing no significant difference compared to TELM and FRTELM. According to
Table 4 and
Table 5, it is clear that in datasets with 20% and 30% Gaussian noise, SCTELM shows a significant difference compared to ELM, TELM and LELM, but there is little difference compared to CTSVM and CHELM. To make the conclusions clear, the post hoc detection is visualized below in
Figure 10.
In
Figure 10, the abscissa represents the average ranking of each algorithm, and the ordinate represents the algorithms to be compared. If two algorithms overlap with respect to the abscissa, then there is no significant difference between them. From
Figure 10, we can easily draw this conclusion.
4.6. Parameter Analysis
To make it more convenient for other researchers to use SCTELM, the performance of SCTELM under different parameters will be further studied from the perspective of parameters, so we chose four representative datasets Australian, German, Spect and Ionosphere). Starting from the parameters C1, C2 and
, the sensitivity of the proposed algorithm to these parameters is analyzed. At the same time, the other parameters are fixed for experiments. The experimental results are shown in
Figure 11 and
Figure 12.
For the parameters C1 and C2, we observe that on these datasets, the ACC values show large fluctuations as the parameters change, and the fluctuations are particularly significant on some datasets. For example, on the German dataset, when C1 and C2 are changed, the fluctuation amplitude of ACC values is close to 60%, which indicates that this dataset is very sensitive to parameter changes. In contrast, the fluctuations of datasets like Australian are relatively small, about 30%. Through further analysis, it is found that the ACC value rises significantly as the parameter C1 decreases and reaches its maximum value at the value of C1 equal to , indicating that a smaller C1 is more beneficial to improve the classification accuracy. Therefore, parameter C1 is suitable for selecting a smaller value to optimize the algorithm performance. On the other hand, the effect of changing the parameter C2 on the results shows a linear trend. As the value of C2 increases, the ACC value also gradually rises, and the best classification effect is achieved when the value of C2 is . This indicates that appropriately increasing C2 is helpful to further improve the classification performance of the algorithm.
Compared with parameters C1 and C2, parameter shows relatively stable characteristics in the experiment, especially on the Australian dataset; its maximum fluctuation range is less than 2%, showing extremely strong stability. However, on the Ionosphere dataset, the parameter fluctuates by nearly 10%, indicating that there is still some sensitivity of on some datasets. Further analysis of the experimental results shows that the influence of the parameter on the classification accuracy shows a nonlinear trend. Setting in , the algorithm performs best, indicating that the value in this range can effectively optimize the classification performance.
4.7. Convergence Analysis Experiments
To verify the convergence of the proposed SCTELM algorithm, experiments will be carried out on the Austrasta, German, Spect and Ionosphere datasets in this section. The experiments are similar to those carried out in
Section 4.4.2, while the relevant parameters are set to establish the optimal parameters. The experimental results are shown in
Figure 13.
In
Figure 13, it is easy to see that the convergence condition of SCTELM steadily decreases with the increase in the number of iterations, and it converges to a stable value after a finite number of iterations, so it can be seen that the proposed SCTELM algorithm can converge within a finite number of iterations.
5. Conclusions
This paper proposes a novel robust twin extreme learning machine that employs a newly designed soft capped -norm loss function, designated as SCTELM for brevity. In contrast to the conventional hard capped methodology, the proposed soft capped approach effectively circumvents the potential non-differentiability issues associated with hard capped, whilst retaining the beneficial aspects of the hard capped technique. The objective of this approach is to mitigate the impact of outliers on the model, thereby increasing its robustness. Furthermore, the SCTELM only requires the resolution of a pair of relatively small quadratic programming problems (QPPs), which significantly reduces the complexity associated with the resolution of large QPPs in the past. Consequently, this enhances the learning efficiency of the model. The proposed model demonstrates enhanced stability and increased computational efficiency in the presence of data anomalies. The experimental results on noise-free and noisy datasets indicate that the SCTELM model exhibits heightened robustness compared to traditional methods. This is particularly evident in datasets containing outliers, where the “slope” of the SCTELM model exhibits a more gradual incline, and the learning efficiency is superior to other methods.
Our research is of considerable importance within the academic field. This paper introduces a novel loss function based on soft capped, which enables the construction of a robust twin extreme learning machine. This provides a new perspective and methodology for the field of machine learning and has the potential to encourage subsequent researchers to pursue innovative avenues in the design of loss functions and learning algorithms, thereby promoting the further advancement of both theoretical and practical developments. Furthermore, in the context of real-world data, such as the credit card approval dataset from the University of California, Irvine (UCI), users can be classified into two distinct categories: those who are approved for credit and those who are not. It is evident that SCTELM has gained significant advantages in terms of robustness to outliers in comparison to alternative algorithms. To illustrate, WDBC represents the Diagnostic Wisconsin Breast Cancer Database, and the SCTELM approach has also yielded significant benefits. It follows, therefore, that our research has significant practical implications for the fields of finance and medical treatment. The model is capable of facilitating the provision of real-time analysis and decision support to end users. The enhancement of accuracy and stability in the model enables enterprises and healthcare facilities to effectively address decision-making challenges in intricate contexts. The model may be utilized in a multitude of domains, including, although not limited to, image processing, signal processing, and natural language processing. These fields often have to contend with data noise and uncertainty, which robust models can help to overcome, thereby improving the accuracy and reliability of results. In conclusion, our study offers a significant contribution to the field of machine learning, providing a valuable perspective on robustness research and its potential for practical applications, which will inform future research and developments.
It should be noted that the algorithm is not without its limitations. At the commencement of each cycle, the SVRG algorithm is required to calculate the full gradient of the entire dataset. Although this will facilitate convergence more rapidly than the conventional SGD algorithm, the associated computational cost may be considerable in the context of large-scale datasets, potentially leading to a reduction in the rate of algorithmic execution. In future work, it would be worthwhile to consider employing periodic random sampling in place of calculating the full gradient each time, or to investigate combining the SVRG algorithm with an adaptive learning rate optimization algorithm. This would allow the learning rate to be adaptively changed in accordance with the gradient.















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}