3.2. Semantic Patch Labeling Based on GGCM-E Features
In our previous study, semantic patches were labeled according to outlier ratios, assigning the centered inlier a semantic level, which is its quality with respect to feature correspondences. However, the outlier ratio-based semantic patches labeling cannot perceive high-level semantic information, such that the relevant semantic filter has low accuracy in segmenting within complex environments. Consequently, we conducted further research to analyze the semantic information in semantic patches. Our previous research demonstrates that the trajectory error in semantic filter-based vSLAM can be significantly reduced when filtering out dense texture-rich scenes, such as scenarios with trees. The reason we envisage is that in the region of dense, complex textures, the number of ORB feature points extracted is very high. However, because of the complex similarity of the texture, this will lead to a mismatch between the ORB feature points of consecutive frames, and this kind of mismatch cannot be entirely eliminated by just relying on the RANSAC algorithm. Then, it generates a localization error. In order to investigate how the feature correspondences in dense texture-rich scenes affect the accuracy in vSLAM systems, we propose a GGCM-E feature descriptor to classify semantic patches, which can be implemented to classify the texture complexity level of semantic image patches and then detect the regions of dense and complex textures, enabling us to predict low-level semantic scenes associated with deep learning networks.
The Gray-level Gradient Co-occurrence Matrix (GGCM) is a statistical method that focuses on the semantic information within images in terms of the grayscale and gradient. As we know, grayscale images can describe the semantic contexts for different visual tasks, and gradient images proved to be more discriminant and reliable when it comes to texture-less targets in complex scenes. Consequently, the GGCM feature can reveal the semantic information with respect to pixel levels, providing a comprehensive prediction in dense texture-rich scenes.
Firstly, semantic patches of inliers are divided into
l equal-sized
S-
,
, to process GGCM feature calculations. Then, the number of pixel pairs with coordinates
is accumulated to obtain
for the covariance matrix
H. Note that the notion
is defined as the entire pixel-pair number in terms of the
x-
pixel in the normalized grayscale image
(Equation (
1)) and the
y-
pixel in the normalized gradient image
(Equation (
2)). Finally, the normalization of the GGCM is conducted to obtain
. Equation (
1) defines the normalized grayscale image of the
S-
:
where
denotes the gray value of pixel
in the original image,
denotes the gray value of pixel
in the normalized grayscale image,
is the maximum gray value in the original image, and
is the maximum gray value after normalization, with
being set to
l.
After that, the normalized gradient image is calculated as in Equation (
2):
where
is the gradient value of pixel
in the original image,
is the gradient value of pixel
in the normalized grayscale image,
is the maximum gradient value in the original image, and
is the maximum gradient value after normalization, with
being set to
l. Note that,
is derived from the square sum of the Sobel’s operator in the horizontal and vertical directions, respectively, according to Equation (
3):
Count the pixel pairs with respect to
and
in the normalized grayscale image
and the normalized gradient image
.
Until now, the normalized GGCM
(x, y) can be derived, as follows:
According to the normalized GGCM, we define the energy of the statistical property as Equation (
9):
As demonstrated in
Figure 3, when the energy is less than a threshold
, the
S-
can be characterized by complex textures, such that a significant change within the gradient value and the gray value occurs, presenting the relevant GGCM-E feature with 1-
result
r. On the contrary, if the energy is larger than or equal to the preset threshold, the
S-
contains many backgrounds, indicating that the texture is sparse and that non-existed GGCM-E features change with respect to the gradient value and the gray value, thus presenting a 0-
result
r. We illustrated the
parameter in
Figure 3. We set this value to 0.25. The reason for this is that when the proportion of flat and texture-free area reaches 50% of the
S-
, the probability that its corresponding certain value in the gray-level gradient co-occurrence matrix is normalized is 0.5. Moreover, when calculating the energy characteristics of the whole matrix, the sum-of-squares operation will be performed, and the energy value corresponding to this region will be 0.25. So, when we calculate the energy value of the gray-level gradient covariance matrix to be less than 0.25, the flat untextured region is less than half of the area of this
S-
. Alternatively, it means that the area of the textured region is more than half of the area of the
S-
, and we default to the
S-
with a complex texture, GGCM -E feature number plus 1. Then, by calculating all
S-
, the sum of the number of GGCM-E features is derived, which is used as the basis for classifying the image complexity of different image semantic patches. When the sum of the number of GGCM-E features of a certain semantic patch is
l, this indicates that all the
S-
exhibit GGCM-E characteristics, i.e., each
S-
exhibits complex textures. Thus, the semantic patch is the one that has the most complex texture semantic patch, which is suitable to be divided into a individual class to study. After the
transformation and the energy calculation, GGCM-E features are obtained in terms of the
r result. The GGCM-E feature calculation is summarized in Algorithm 1. Ultimately, these semantic patches will be classified in accordance with the number of GGCM-E features, which serves to ascertain the level of texture complexity.
To the end, a sequence of semantic patches labeled according to the GGCM-E features is obtained as the training data before they are input into the YOLOv8 network.
| Algorithm 1 Compute GGCM_E feature values. |
Input: Semantic patches of Inliers
Output: GGCM_E feature values
- 1:
- 2:
for S in do - 3:
S←patch// Extract S from the patch. - 4:
Sobel gradients of S - 5:
// Compute Sobel gradient magnitude. - 6:
- 7:
// Normalize the gray level matrix. - 8:
- 9:
// Normalize the gradient matrix. - 10:
for pixel in S do - 11:
) - 12:
) - 13:
// Fill the gray-level gradient co-occurrence matrix. - 14:
end for - 15:
- 16:
// Compute energy of the normalized . - 17:
if < then - 18:
// Compute GGCM_E feature value. - 19:
end if - 20:
end for
|












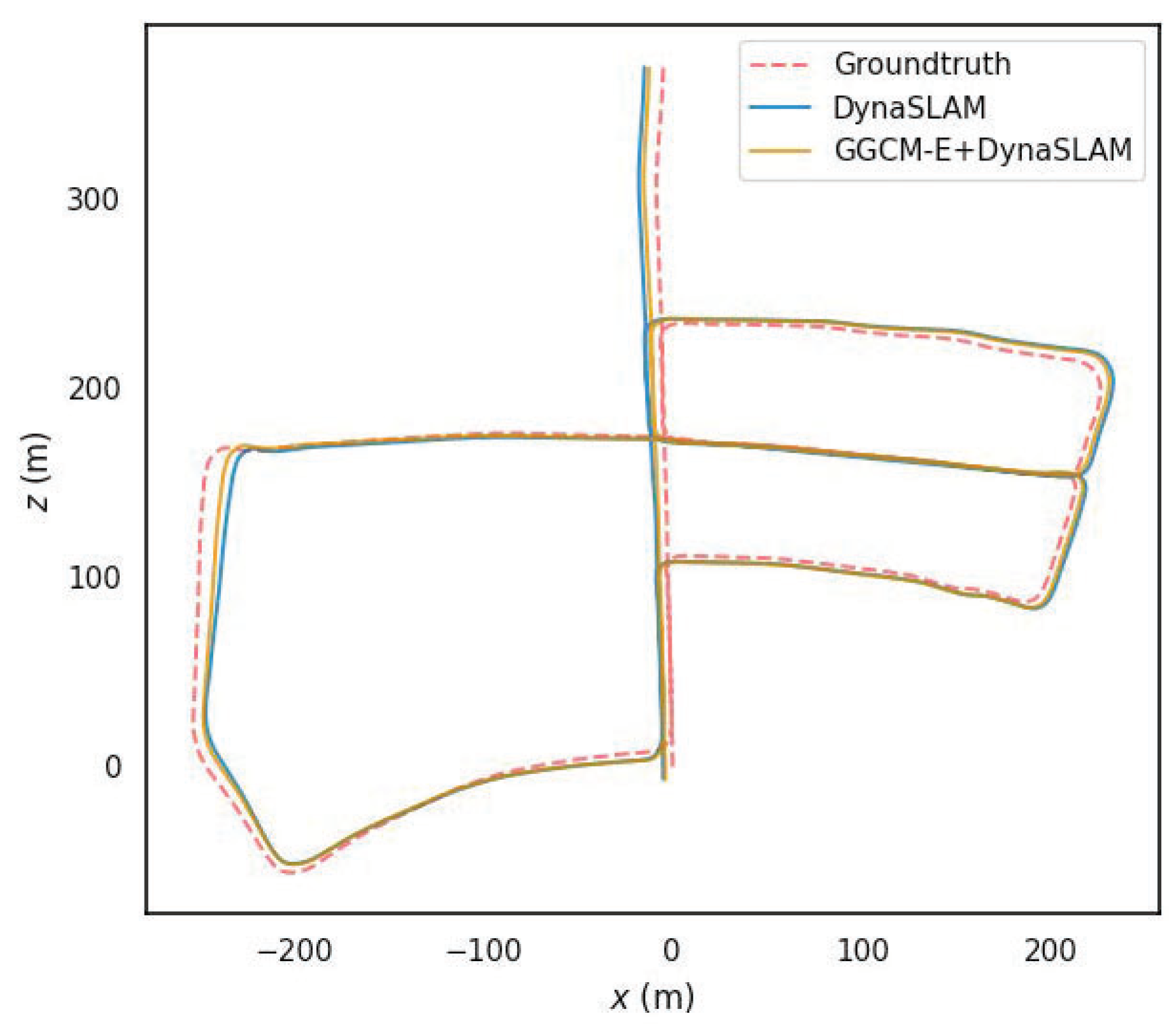
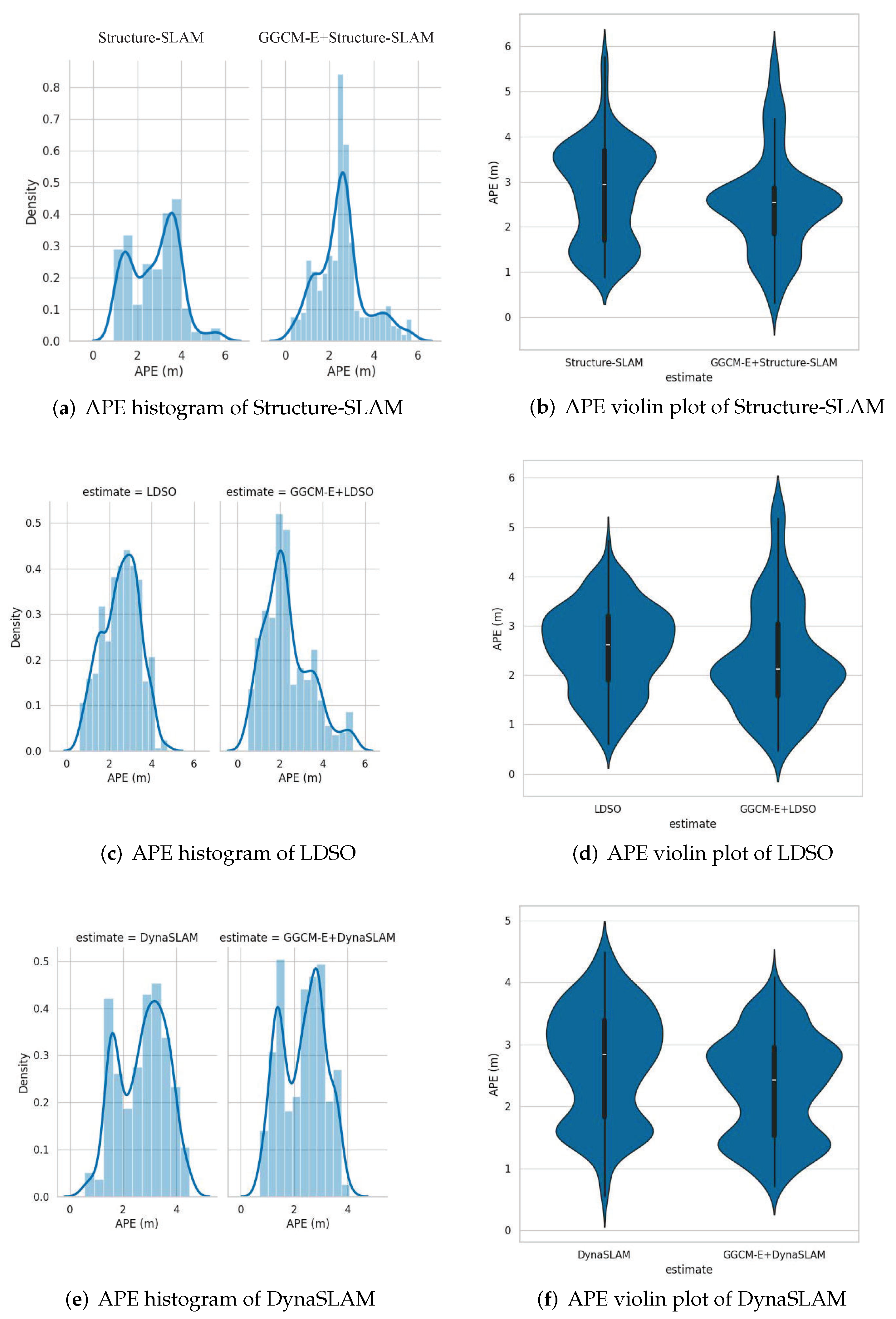

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}