1. Introduction
Distributed parameter systems (DPSs) are prevalent in the real world, such as flexible beams [
1], transport reaction processes [
2] and heat processes [
3]. Modeling these systems is crucial for the design, optimization, dynamic prediction and control. However, due to the complex system characters, such as time–space coupling, infinite dimension and so on, it is difficult to model these systems.
In the last several decades, many modeling methods of DPS have been proposed and these methods may be broadly classified into two distinct types. Grey/black box modeling with unknown partial differential equations [
4,
5,
6,
7] and first principles modeling with known partial differential equations (PDEs) [
8,
9,
10,
11,
12,
13] are the two types of modeling. Obtaining an accurate mathematical description of a system using partial differential equations is challenging due to imperfect understanding of physical and chemical processes. Compared with the first principles modeling method, the grey/black box modeling method is used more widely in practice. This study concentrates on the black box modeling method, which involves developing a model for a DPS without knowledge of the system’s partial differential equation structure or its parameters.
The black box modeling method drives a model for the DPSs in a data-driven style [
14]. To date, the most common data-driven modeling methods [
15,
16,
17,
18] of DPSs are based on KL decomposition, such as KL-MLP-LSTM [
19], in which the infinite dimensional spatiotemporal coupling data are reduced to finite dimensional by KL decomposition, and the space base function is extracted from it, then the time series model is constructed by MLP-LSTM and finally the DPS model is completed by spatiotemporal synthesis. In Ref. [
20], two neural network modeling methods are proposed. One is to use the control quantity and position information as the input and the output of the system is the system mathematical model obtained by training the neural network. The other is that singular value decomposition (SVD) is employed to separate the output data of the system in time and space, then a neural network is used to identify the relationship between the control variables and time coefficients and finally the finite low dimensional model of the system is generated via space–time reconstruction. Although the KL decomposition-based methods have been successfully employed in many applications, they neglect the influence of nonlinear space dynamics and depend on model reduction, which can lead to precision loss.
In recent years, a novel DPS modeling method has been developed: three-dimensional (3D) fuzzy modeling [
21,
22,
23]. The preceding and resulting components of a 3D fuzzy system are the temporal coefficient and space base function, respectively. This is a natural implementation of time–space separation and time–space reconstruction. The time–space separation is achieved through the computation of the preceding and resulting components, while the time–space reconstruction is achieved through the union of all activated 3D rules. The 3D fuzzy modeling method has two distinct advantages: linguistic interpretability and a lack of dependence on model reduction. A novel 3D fuzzy modeling framework without model reduction was proposed in Ref. [
24], where a 3D fuzzy model is established by employing the nearest neighbor clustering algorithm, the similarity analysis and multiple support vector regression. The method described in Reference [
25] employed spatial multiple output support vector regression (MSVR) to construct a comprehensive 3D fuzzy rule foundation. However, the above methods are offline modeling methods, i.e., historical data-driven models. As the internal or external parameters of a distributed parameters system change over time, the performance of the offline model will become worse and worse [
26].
Therefore, DPS online modeling has become a research hotspot recently. In Ref. [
27], Wang and Li proposed an online modeling method based on incremental spatiotemporal learning. The methods of incremental learning iteratively update the space base function and the accompanying temporal model. In reference [
28], Lu et al. introduced a nonlinear time-varying support vector machine model that depended on a spatiotemporal linear support vector machine. This model combined the adaptable space kernel functions with an online time factor model to reconstruct the DPS system. However, those online modeling methods have a complex modeling process and lack language interpretability.
Compared to the traditional learning methods, the reinforcement learning-based methods are naturally implemented in an incremental way based on immediate rewards obtained during the interaction, enabling online learning for different tasks. Reinforcement learning, as a very active algorithm in the field of machine learning, has been used in many disciplines like [
29], control [
30,
31], recognition [
32], batching [
33], scheduling [
34] and optimization [
35,
36]. Reinforcement learning algorithms learn the optimal policy directly from interactions with the environment, i.e., DPS in this paper. The fundamental components of reinforcement learning algorithms include policy, reward function, value function and environment.
Reinforcement learning algorithms may be categorized into two main types: value function-based reinforcement learning and direct policy search-based reinforcement learning, depending on the methodologies of policy updating and learning [
37]. For value function-based reinforcement learning algorithms, David Sliver proposed DQN (Deep Q-network) [
38] by combining deep neural network with reinforcement learning. There is also FQ-learning [
39] which combines a custom fuzzy system with Q-learning. As for direct policy search-based reinforcement learning, David Sliver et al. [
33] proposed DPG (deterministic policy gradient) and proved for the first time that a deterministic policy gradient exists. DPG uses a deterministic policy and outputs deterministic actions for each state, so it avoids expectation in the action space and greatly increases the sample utilization.
In recent years, the combination of reinforcement learning (RL) and fuzzy systems has become an important research direction in the field of intelligent control and decision-making systems. This combination aims to leverage the adaptive and self-optimizing capabilities of RL and the advantages of fuzzy systems in handling uncertainty and fuzzy information, thereby creating more intelligent and robust systems. The integration of RL and fuzzy systems, often referred to as fuzzy reinforcement learning (FRL), combines the learning abilities of RL with the rule-based reasoning of fuzzy systems to effectively solve decision-making problems in complex environments. Specifically, fuzzy systems can serve as approximators for RL’s policy functions or value functions, helping agents make smooth decisions in continuous spaces. Additionally, RL can automatically adjust the rules and parameters of fuzzy systems through online learning, thereby enhancing the adaptability and performance of the system. In Reference [
40], a fuzzy Q-learning method was proposed to achieve the online tuning of a PID controller. By introducing a fuzzy system, it addresses the issue that the traditional Q-learning algorithm cannot handle continuous state–action spaces. The paper proposed a fuzzy Q-learning multi-agent system algorithm, where three agents were used to control the three variables of the PID controller and experimental results demonstrate the effectiveness of this method. In Reference [
41], a method based on fuzzy actor–critic reinforcement learning was proposed to address the tracking problem. By using a fuzzy system, it enhanced the interpretability of network parameters, making the mapping structure easier to trace and understand. Compared with an artificial neural network, a fuzzy system is more explainable and it allowed the incorporation of necessary human knowledge to construct the inference rules. In Reference [
42], an Intelligent Traffic Control Decision-Making method based on Type-2 Fuzzy and Reinforcement Learning was proposed. In this method, the output action of the Type-2 fuzzy control system replaced the action of selecting the maximum output Q-value of the target network in the DQN algorithm, reducing the error caused by the max operation in the target network. In Reference [
43], a dynamic fuzzy Q-learning method was proposed, which enabled the automatic learning of the structure and parameters of the fuzzy system based on Q-learning. The effectiveness of the proposed method was validated through the wall-following task of mobile robots.
However, there is very little research on applying reinforcement learning and a fuzzy system to modeling distributed parameter systems. As far as we know, Wang Z. et al. [
44] introduced a modeling method for DPSs based on reinforcement learning algorithms. The fundamental concept is to represent the arrangement of measurement sensors in the DPS as a Markov Decision Process model and then use a reinforcement learning method based on a value function to ascertain the most advantageous sensor placement. However, this method employs an offline modeling method, meaning that once the sensor positions are determined, they remain fixed. When the dynamic characteristics of the distributed parameter system change, the initially optimal sensor placement may no longer be optimal, resulting in a substantial decrease in the accuracy of the model.
This study introduces a novel reinforcement learning-based method for online 3D fuzzy modeling. Based on the actor–critic framework, using the deterministic strategy gradient theory, two 3D fuzzy systems are used to represent the actor function and the critic function, respectively, and the critic function and actor function are updated alternately. The critic function uses TD (0) target and is updated by the semi-gradient method; the actor function changes via incorporating the chain derivation rule to the behavior value function. The actor function serves as the established DPS online model. Because DPS online modeling is a continuous problem, it has been in progress without termination. Thus, the average reward return is used and the actor can update itself for each data in real time, so as to realize online modeling.
The main contribution are as follows:
The actor–critic framework is combined with 3D fuzzy systems to construct a novel online 3D modeling method using the deterministic policy gradient reinforcement learning algorithm.
Three-dimensional fuzzy deterministic policy gradient algorithm with average reward set is proposed to solve the continuing modeling problem of DPS. The chosen reward set is the average rate of reward every time step, which defines the performance.
This online modeling method has the ability to build an online model adaptively from scratch without human knowledge.
The subsequent sections of this work are structured in the following manner.
Section 2 outlines the concept of the DPS modeling issue.
Section 3 provides a comprehensive description of the suggested method for modeling a 3D fuzzy system using reinforcement learning in an online setting. The suggested modeling technique is used in a rapid thermal chemical vapor deposition system and the outcome of the experiment is shown in
Section 4.
Section 5 provides the final conclusion.
2. Problem Formulation
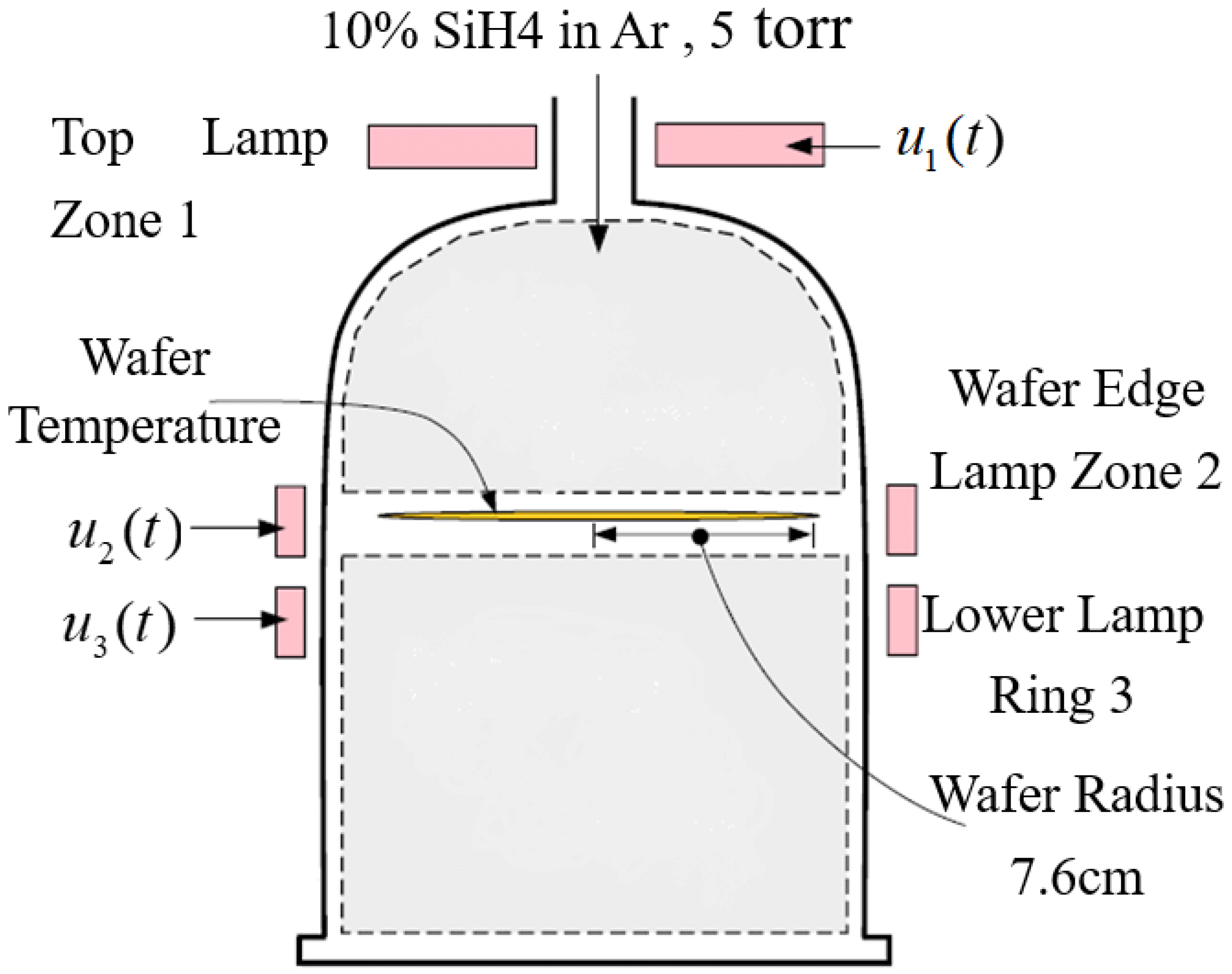
DPS commonly appears in industrial manufacturing processes. Taking the rapid thermal chemical vapor deposition (RTCVD) system in the semiconductor industry as an example, we introduce the characteristics and mathematical description of a DPS.
Figure 1 displays the schematic of an RTCVD system. A 6-inch silicon wafer is placed on a rotating platform inside the chamber of the system and exposed to heat from a heating apparatus. There are three lamp banks that make up the heating system. The first lamp bank warms the wafer’s surface evenly. The second lamp bank heats only the wafer’s edges and the third lamp bank warms the wafer evenly all over.
Figure 2 shows the heating lamps’ output incident radiation flux. The reactor is fed 10% concentration of silane gas (
). After breaking down, SiH4 yields silicon (
) and hydrogen gas (
). After about one minute, the wafer is covered with a 0.5
m thick layer of polysilicon that has been deposited at temperatures of at least 800K. The support is rotated to ensure that the temperature is distributed evenly in the azimuthal direction when the wafer is processing. Because the wafer is very thin, the temperature change in the
direction is ignored. Therefore, providing a uniform temperature distribution along the length of the wafer radius becomes the decisive factor for depositing a uniform layer of polysilicon on the wafer surface. The uniform distribution of the temperature can be controlled by adjusting the power of the heating lamp group in the three zones. This thermal dynamic characteristic can be described by a one-dimensional spatiotemporal coupled PDE model, as follows:
The above PDE is constrained by the following boundary conditions:
represents the dimensionless wafer temperature, expressed as
. Here,
represents the actual wafer temperature and
represents the ambient temperature. In this study,
= 300K.
represents the dimensionless time, expressed as
. Here,
t represents the actual time and
is 2.9s.
represents the dimensionless radius position, expressed as
. Here,
f represents the actual radius position and
is 7.6 cm.
,
and
represent the power of three heating lamp groups, respectively.
,
,
represent the radiation flow of the three zone heating lamp group incidents on the wafer, respectively. The parameters in Equations (
1) and (
2) are listed as follows:
where
is the thermal conductivity of the wafer,
is the emissivity of the quartz chamber,
is the is the emissivity of the wafer,
is the incident radiation flux at the edge of the wafer and
is the density of the wafer.
The RTCVD system is an infinite dimensional system with spatiotemporal coupling properties and is an infinite dimensional system.
can be spatiotemporally separated into an infinitely weighted summation of space base functions and time factors.
where
denotes a time coefficient and
denotes a space base function. In practice, this means that only a limited number of sensors at
may be used. Let
denote the space domain, i.e.,
.
denotes the spatial output.
Then,
may be essentially represented by Equation (
4).
In this process,
is simplified from Equation (
3) to Equation (
4), which is called dimension reduction. In the absence of the mechanism model delineated in Equations (
1) and (
2), the time coefficient in Equation (
4) may be determined using conventional methods. And the space base function in Equation (
4) can be estimated by the KL decomposition technique. In fact, most current DPS modeling methods utilize the dimension-reduction technique. However, it has a limit, ignoring dynamic aspects and ambiguities in the identified model because of the reduced dimensionality.
The 3D fuzzy modeling method is a novel modeling technique that has been established in the last few years. This method naturally integrates spatiotemporal separation and spatiotemporal reconstruction into 3D fuzzy rules without dimension reduction and has language interpretability. This paper incorporates reinforcement learning into 3D fuzzy modeling and presents a novel method for online 3D fuzzy modeling using reinforcement learning.
3. Reinforcement Learning-Based Online 3D Fuzzy Modeling
This section first introduces the Markov Decision Process (MDP) model as the basis of DPS modeling utilizing reinforcement learning. Then, the core content of this paper, 3D fuzzy deterministic policy gradient (3DFDPG) reinforcement learning, is described in detail, including the deterministic policy gradient algorithm, 3D fuzzy modeling and the fusion of them: 3DFDPG modeling method. Finally, under an actor–critic framework, it describes how to update the parameters of a 3D fuzzy system, including the update of actor function parameters and critic function parameters and the calculation process of the 3DFDPG modeling method.
3.1. MDP Model of the DPS Online Modeling Problem
Given the input and output data, we can derive the Markov Decision Process (MDP) model for the DPS, which is represented as a 5-tuple , where S and A, respectively, represent the sets of states and actions, R represents the reward function ( denotes the expected reward when taking action a in state s), T is the transition function ( denotes the probability of transitioning to state from s when taking action a and is the discount factor.
The output
of a DPS is determined by the past outputs
and input
, where
. For simplicity and without loss of generality, we consider the one-order case in this study, i.e.,
,
, where
depends on
and
. The DPS modeling problem can be expressed as an MDP. The state
is written as follows.
The action
is defined as
which is the predicted DPS output at time step
t + 1, i.e.,
The reward function
is given by Equation (
7).
The transition function is determined by the inherent dynamics of the DPS, which include its physical attributes and control inputs. is a fixed discounted factor.
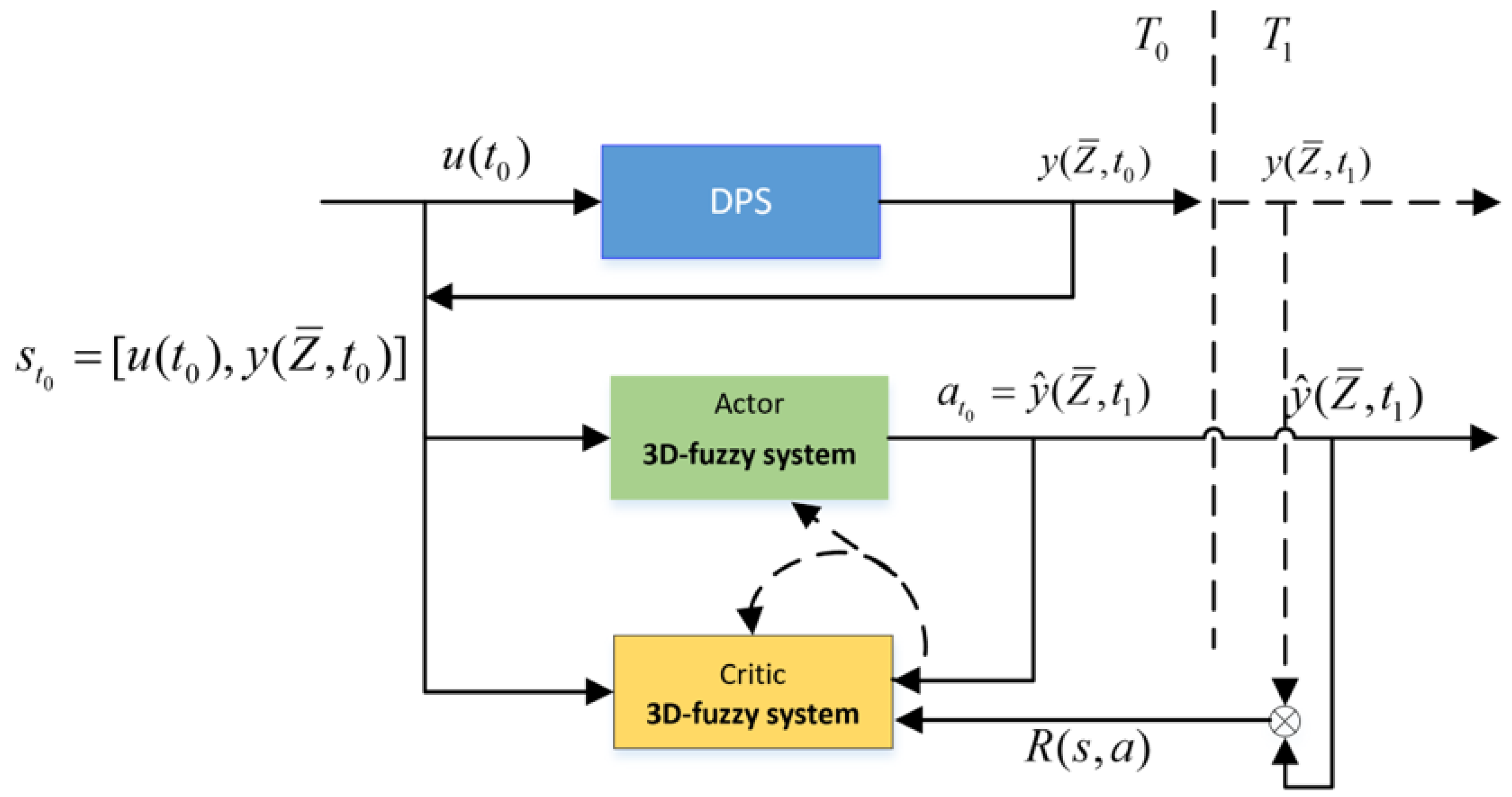
Figure 3 illustrates the architecture of the suggested online modeling method, where two 3D fuzzy systems are used. One is taken as the function of actor and the other is viewed as the role of a critic. The actor 3D fuzzy system serves as the DPS model, which takes
as input and exports the predicted value
as action at every time step
t, then the environment exports reward
R according to Equation (
7). The critic-3D fuzzy system takes the state
and the action
as input and exports the action value
. The main process of the proposed algorithm is interleaving evaluation and improvement of the actor’s policy. This work employs the temporal-difference method to assess the action value function
(also known as the critic function) and thereafter enhance the actor’s policy by adjusting the policy along the gradient of the function.
3.2. 3D Fuzzy Deterministic Policy Gradient Reinforcement Learning for DPS Online Modeling
Given the MDP model of the DPS modeling problem, the fusion of reinforcement learning and the 3D fuzzy system produces a novel 3D fuzzy reinforcement learning algorithm for DPS online modeling.
In order to describe the 3D fuzzy reinforcement learning algorithm well, we first introduce the principle of the deterministic policy gradient algorithm and 3D fuzzy modeling.
3.2.1. Deterministic Policy Gradient Algorithm
Deterministic policy gradient (DPG) is a specific type of policy gradient method that aims to optimize
. The fundamental concept underlying the DPG is to modify the policy parameters
in accordance with the gradient
of the performance measure. The DPG typically relies on the actor–critic architecture, as depicted in
Figure 4.
The deterministic policy gradient theorem examines a policy function
that is deterministic and has a parameter vector
for the policy. The term ’deterministic’ indicates that the action is chosen based on a deterministic policy
with parameter
, rather than a policy represented by a parametric probability distribution, which is known as SPG. The existence of the DPG is demonstrated in Reference [
45] and the DPG theorem is established.
Assuming that the MDP fulfills the conditions
,
,
and
, which are continuous in all parameters and variables
, it can be inferred that the conditions
and
also exist and consequently, the DPG exists. Then:
where
represents the action value function,
represents the discounted state distribution (analogous to the stochastic case) and
represents the performance objective. These variables are defined with regard to a deterministic policy
and parameter
. Empirical evidence shows that the DPG algorithm can achieve superior performance compared to stochastic algorithms when dealing with high-dimensional action spaces [
45]. Additionally, DPG is able to circumvent the challenges associated with integrating throughout the entire action space.
3.2.2. 3D Fuzzy Modeling
3D fuzzy modeling [
21] is an innovative intelligent modeling method designed for nonlinear DPSs in recent years. This method presents a novel fuzzy model equipped to handle and articulate time/space-coupled information. The 3D fuzzy model is distinct from conventional fuzzy models as it is based on the concept of 3D fuzzy sets [
21].
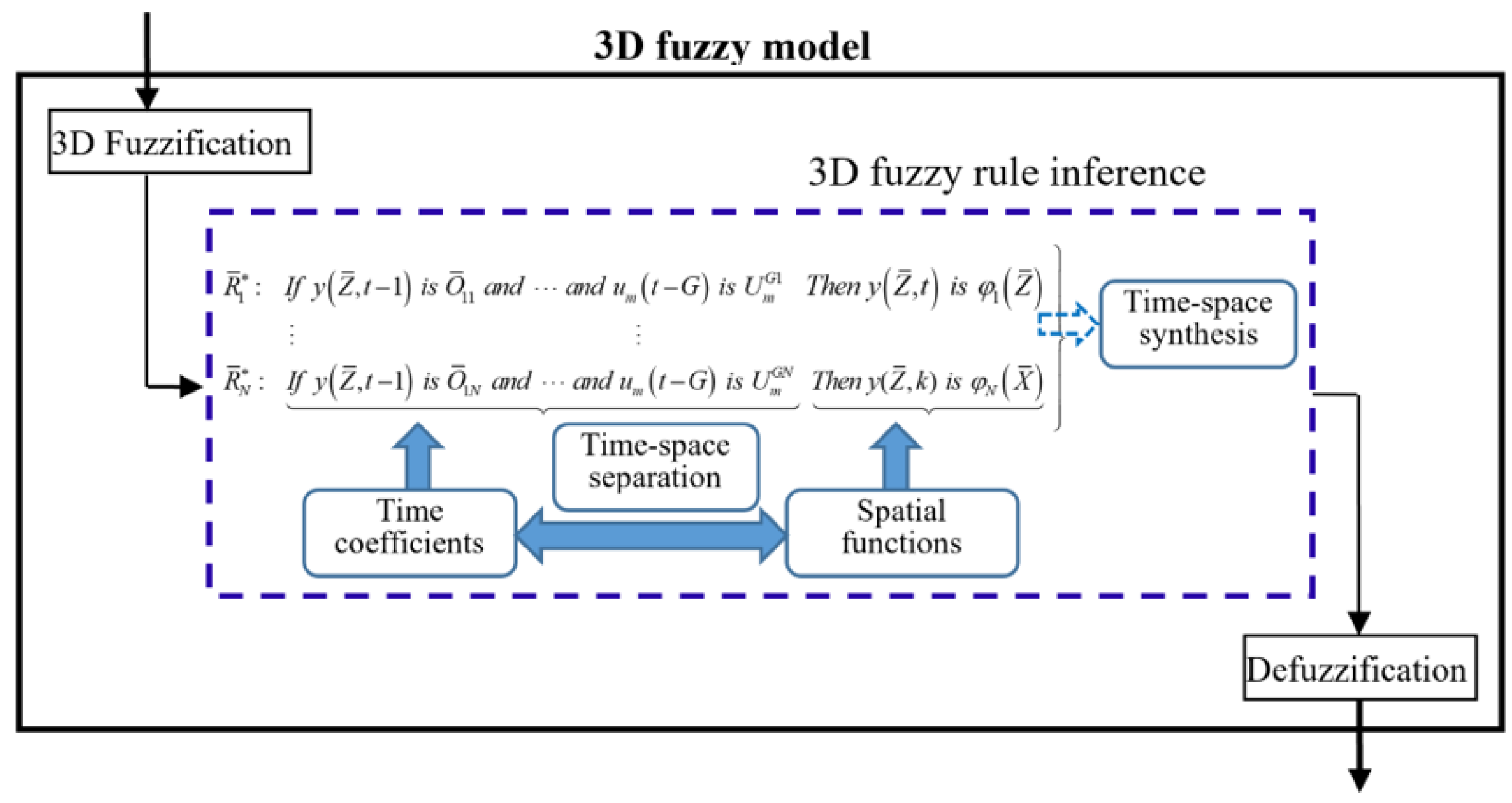
As demonstrated in
Figure 5, the 3D fuzzy model provides a cohesive structure for effectively combining time–space separation with time–space reconstruction. Therefore, it can be inferred that DPS modeling is achievable regardless of the necessity of model reduction within the context of the 3D fuzzy model.
The 3D fuzzy rule in
Figure 5 is rewritten as in Equation (
9).
where
denotes a space base function,
denotes a 3D fuzzy set,
denotes a conventional fuzzy set,
,
N indicates the quantity of fuzzy rules.
The preceding component in
is utilized to calculate temporal coefficients, while the resulting component in
is utilized to depict space functions. The rule
intrinsically accomplishes the role of separating time and space, similar to the traditional modeling of time and space in DPS. The process of time–space reconstruction is achieved by combining active 3D fuzzy rules. It has been shown that the 3D fuzzy model has the ability to approximate any function universally [
46].
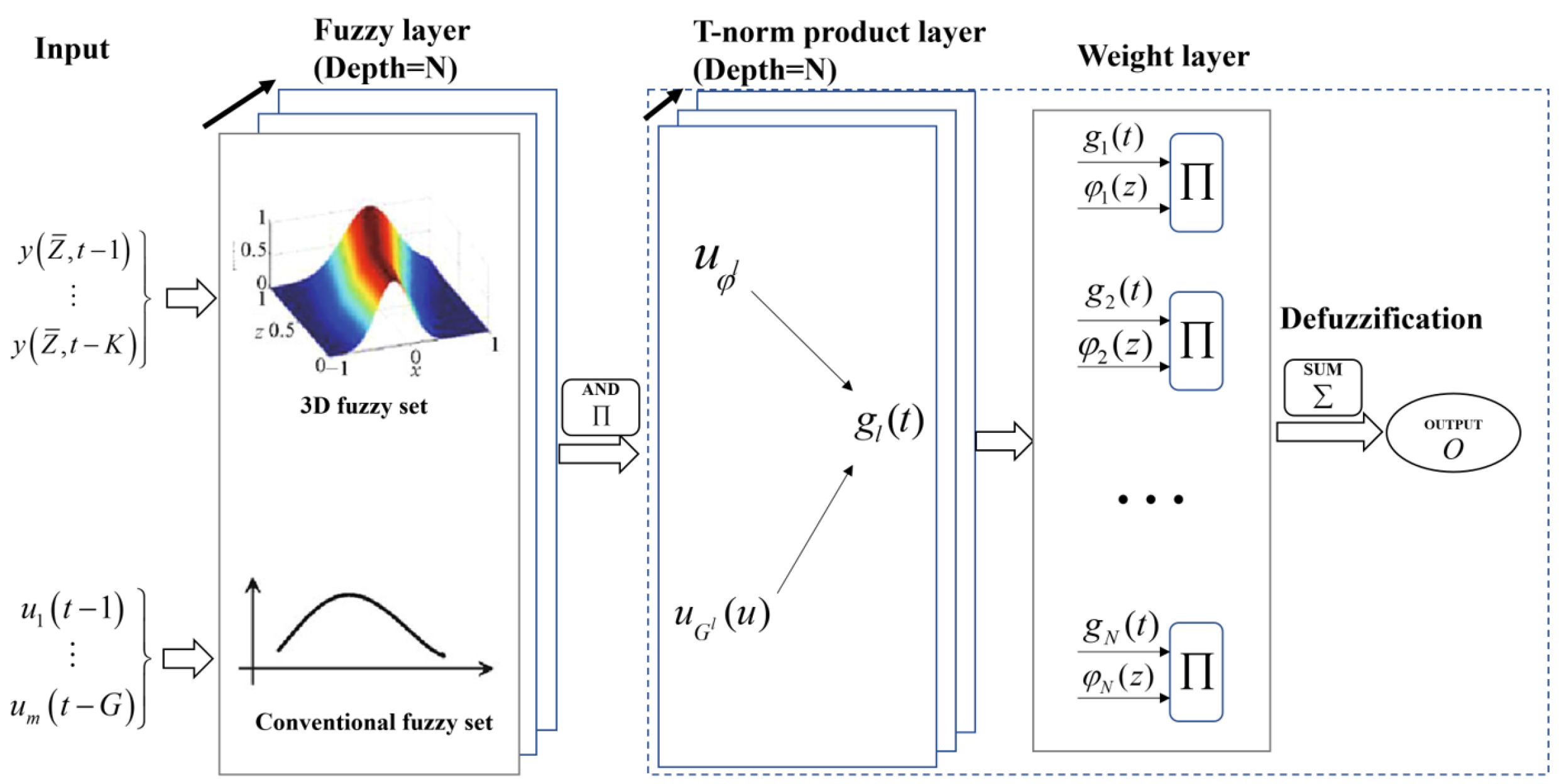
Like the neural network, the 3D fuzzy model also has the layer structure shown in
Figure 6.
The 3D fuzzy model is presumed to possess two distinct categories of inputs. One is the measured space–time coupled data
with
; the other is traditional data
. Within the fuzzy layer, there exist conventional fuzzy sets and 3D fuzzy sets that correspond to two distinct types of inputs. Suppose a Gaussian-type membership function is used. The “and” operation of multiple 3D fuzzy memberships and the “and” operation of multiple conventional memberships of the inputs are shown as Equations (
10) and (
11).
where
and
denote the centroid and spread of the Gaussian 3D fuzzy set
at the jth sensor position;
and
represent the centroid and spread of the conventional Gaussian fuzzy set
;
represents the weight of the
sensor position.
In the t-norm product layer, the active intensity of the rule is determined via combining the membership of each input in each rule, as in Equation (
12).
In the weight layer, the active rules are normalized and output is given as Equation (
13).
where
O represents the output generated by the 3D fuzzy model. Weight layer is known as the weight average defuzzification method. Up to now, 3D fuzzy modeling belongs to the offline category. In the next subsection, we will introduce the online 3D fuzzy modeling method based on reinforcement learning in detail.
3.2.3. 3DFDPG Modeling Method
The fusion of deterministic policy gradient algorithm and 3D fuzzy system generates 3D fuzzy deterministic policy gradient reinforcement (3DFDPG) learning. When it is used as DPS online modeling, we call it 3DFDPG modeling for short.
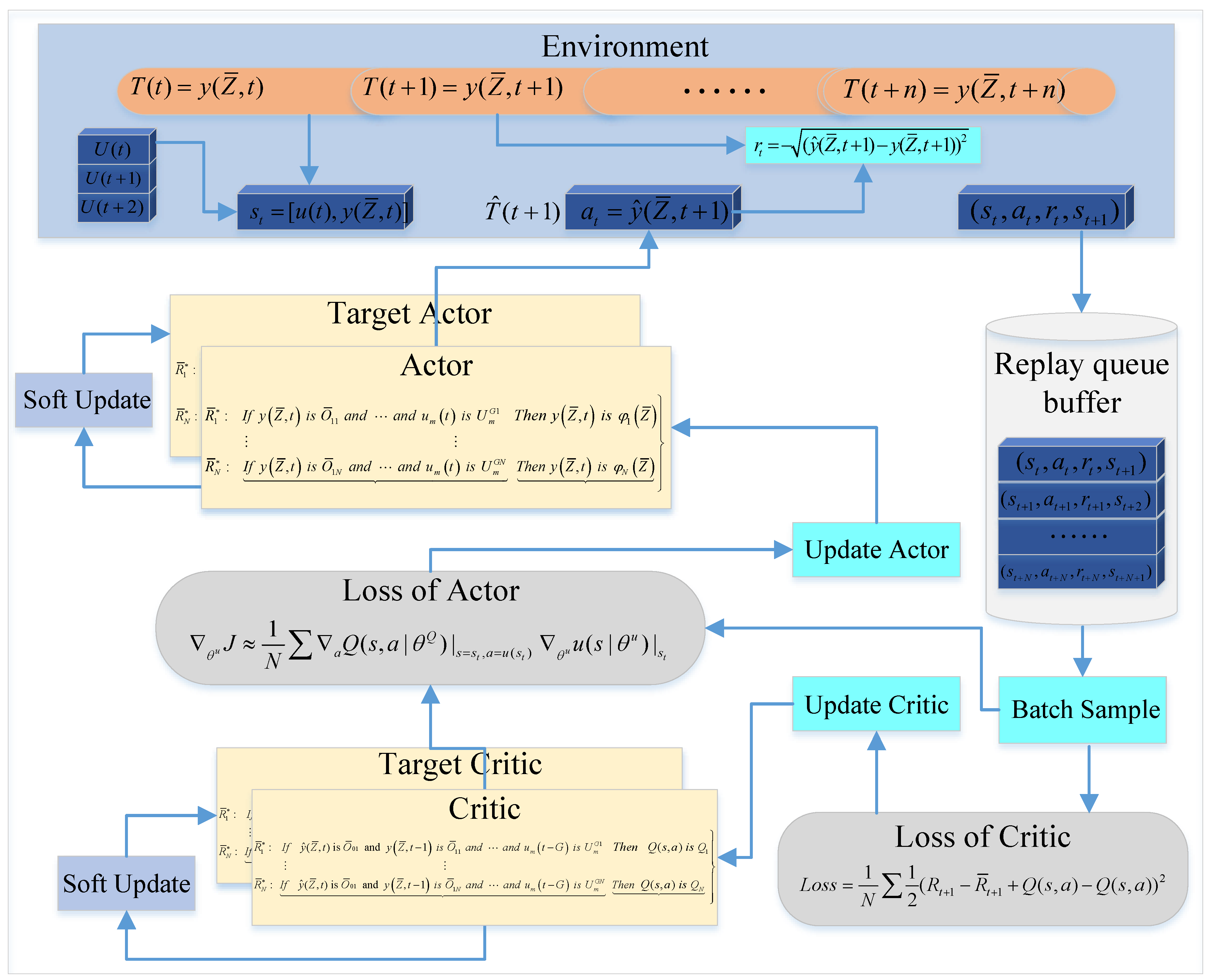
Figure 7 illustrates the detailed structural framework of 3DFDPG modeling.
As seen in
Figure 7, the environment is composed by a DPS.
is the DPS’s output at time step
t, i.e.,
.
is the DPS’s input. The state
, action
, reward
and next state
of the environment are set as
,
,
and
, respectively. The 3DFDPG algorithm utilizes an actor–critic structure as its foundation. The actor receives an environmental state as input and generates an action to be applied to the environment. The environment provides a subsequent state and a reward based on the action taken. The critic receives the actor’s action and the current state of the environment as input and produces an action value (also known as Q-value) for the specific state–action combination. The critic’s parameters are updated using the TD error. On the other hand, the actor’s parameters are updated by moving in the direction of the gradient of the action value function. Reinforcement learning may be prone to instability or be divergent when the action value function is represented by a nonlinear function approximator. To address this issue, the use of a replay buffer and target value method [
38] is recommended.
Online DPS modeling is a continuous problem where the ongoing interaction between the actor and the environment is perpetual, lacking any termination states; therefore, the average reward setting [
47] is needed. The average reward rate is defined as Equation (
14).
where
represents a stable distribution given the condition of
,
S is a set of states,
A is a set of actions,
is the state transition probability which implies the dynamics of the environment and
r is the reward at every time step. In the average reward setting, returns are defined in terms of differences between rewards and the average reward, as in Equation (
15).
where
is the long time return,
is the reward at time step
and
is the average reward under the policy
.
Then, the action value functions
for all
are defined as in Equation (
16).
The Bellman equation of the action value function
for all
is defined as Equation (
17).
Then, the TD error is defined as Equation (
18).
where
is an estimate at time
of the average reward
and
is an estimate at time
t of the action value function.
The average reward is updated by a soft style as in Equation (
19).
where
represents the update factor.
The mathematical description of the actor and critic is shown below. The actor function
’s structure is constructed as in Equation (
9), which is rewritten as Equation (
20)
If the Gaussian-type member function, singleton 3D fuzzification, average defuzzification and product t-norm are selected for a 3D fuzzy model, the following nonlinear mathematical statement is provided as Equation (
21).
where
,
,
.
is the Fourier base function, which can be given as Equation (
22).
The action value function
is constructed with the structure as expressed in Equation (
23).
where
represents a conventional fuzzy set,
represents a 3D fuzzy set,
represents a constant,
and
N indicates the quantity of fuzzy rules.
Similar to the actor function, Equation (
24) is provided for the mathematical expression of the action value function
.
where
,
,
,
.
3.3. Update Process of Parameters for 3D Fuzzy Systems
For a discrete state–action space with restricted options, the action value of each state may be enumerated, that is, tabular reinforcement learning. In the tabular reinforcement learning, the action value
is updated by the Bellman equation [
47]. Then, the policy optimization is completed by taking the maximum action
a corresponding to different states. As the action value function
is a continuous function, it is challenging to determine the utmost value when the state action space is continuous. Instead, a straightforward and computationally appealing alternative is to shift the policy in the direction of the gradient of
, rather than globally maximizing
.
The action value function is specified by the following Equation (
25):
Equation (
25) shows that
is the expected return after taking action
a and following strategy
from state
s. The goal of reinforcement learning is to find an optimal strategy to maximize
for each state action pair, which is equivalent to maximizing the total expected return
. Equation (
26) gives the return
as the sum of future rewards:
where
,
,
, ⋯ is the immediate reward for the future time step and
is the average reward under strategy
. Since
remains unchanged under the same strategy
, in order to maximize
, it is necessary to maximize every reward
in the future. According to Equation (
7), it is established that when the immediate reward
reaches its maximum value, the discrepancy between the predicted output of the online 3DFDPG model and the actual system output is zero. If the immediate reward
is not at its peak value, then a bigger
results in increased model accuracy, but a lower
leads to decreased accuracy. Therefore, the 3DFDPG algorithm maximizes the action value function
by updating the strategy
, which is equivalent to maximizing the expected return
by maximizing the immediate reward.
So the performance objective
is defined as in Equation (
27).
By the chain rule, the update of policy’s parameters is shown as Equation (
28).
where
is the parameters of the policy
,
N is the number of samples and
is the learning rate.
The critic function takes TD(0) as the target; the loss function is shown as Equation (
29).
where
is the
target defined as Equation (
30).
The update of the action value function’s parameters is shown as Equation (
31).
where
is the parameters of the action value function; the detail of the parameter’s updating is given in the following subsection.
In this paper, because of the instability that directly uses the 3D fuzzy system as the nonlinear approximators, the target critic and the target actor are adopted. Rather than updating the target parameters by directly copying the original 3D fuzzy model’s parameters, Equation (
32) is utilized to modify the parameters of the target 3D fuzzy model.
where
and
are the update factors.
3.3.1. The Parameter Updating of the Actor Function in Detail
The actor described in
Section 3.2.3 is updated by the performance objective as Equation (
27). Equation (
27) is subjected to the chain rule, resulting in the derivation of Equation (
33).
where
. Then, the partial derivative with respect to
a yields Equation (
34).
From Equation (
24), the term
and the term
can be determined by Equations (
36) and (
37).
Substituting Equations (
36) and (
37) into (
35), the gradient of
Q in relation to
a is given as in Equation (
38).
According to the same process as above, we can obtain
.
is the parameter vector of the actor function, described by Equation (
39).
Then, the partial derivative of the policy with respect to the parameter
is shown in Equation (
40).
where
and
denote the centroid and spread of the Gaussian 3D fuzzy set
at the
sensor position;
and
represent the centroid and spread of the conventional Gaussian fuzzy set
,
denote the coefficients of the base function in Fourier space.
From Equations (
21) and (
22), we can derive the partial derivative of the policy
,
,
,
,
,
,
,
, shown as Equations (
41)–(
48).
3.3.2. The Updating of the Parameters of the Critic Function in Detail
The critic function adopts the same structure as the actor function, as shown in
Figure 6. Different to the actor function’s performance objective, the loss function of the critic function is as in Equation (
18). To describe this clearly, here we write the equation again.
where,
is the parameter vector of the critic function.
N is the sample batch size.
is the learning rate.
is the
target defined as Equation (
30), and
is defined as Equation (
50).
Then the partial derivative of
with respect to
is shown in Equation (
51); the detailed formulas are shown in Equations (
52)–(
58).
3.3.3. The Process of the Proposed 3DFDPG
The proposed 3DFDPG is executed as follows.
Input: Batch size N, number of 3D fuzzy rules of policy and action value function , replay buffer size , actor’s learning rate and critic’s learning rate .
Step 1: Initialize critic and policy with parameters and randomly.
Step 2: Initialize target and with parameters and . The average reward .
Step 3: Initialize replay buffer .
Step 4: Loop forever:
Step 5: Perform action on the DPS and analyze the resulting reward and subsequent state of the DPS.
Step 6: Preserve the transition to .
Step 7: Randomly select a small quantity of transitions from .
Step 8: Set .
Step 9: Set .
Step 10: Minimize the loss function ∑ to update the critic.
Step 11: Utilize the policy gradient that was sampled to update the policy.
Step 12: If the estimate error is less than a threshold
, update the policy parameters and directly use the error via stochastic gradient descent.
Step 13: Update the target .
Step 14: Output the policy as the model of the DPS at every time step.
4. Applications
The typical distributed parameter system (RTCVD) depicted in
Section 2 is considered to assess the efficacy of the suggested algorithm 3DFDPG. To obtain sufficient dynamic knowledge about the system, the system manipulates the input variable
,
and
to add the interference signal whose amplitude is not more than 10%. Therefore, three input variables with interference signals can be given in the following ways.
where
,
and
are the steady-state input when the furnace temperature is 1000K,
,
and
are the disturbance amplitudes of
,
and
. In this study,
,
and
are 0.2028, 0.1008 and 0.2245, respectively;
,
and
are set to 10%. Eleven sensors are arranged equally along the radial direction. To replicate the effect of noise, eleven sets of separate random noise signals are then included into the data gathered by those eleven sensors. The sample period was set as
and the experiment lasted for 500 s. The data generated from the experiment are shown in Equation (
60).
where,
;
;
;
.
Unlike offline modeling algorithms, online modeling algorithms use data generated in real-time by the DPS simulation system. At a given time
t, the 3DFDPG model predicts the output at time
t based on the output and input of the DPS system at time
, as shown in Equation (
61).
The hyperparameters for the 3DFDPG are specified in
Table 1.
In this paper, we use Matlab2023b software to realize the simulation of RTCVD, the realization of 3D fuzzy modeling, and the comparison of different modeling methods.
4.1. Simulations
Ideally, an off-line model based on the historical data with sufficient information can show the dynamic characteristics of the actual system well. However, when the dynamic characteristics of the actual system change, such as equipment aging, local equipment damage and large changes in operating conditions, the off-line model cannot express the dynamic characteristics of the change. However, an online model makes up for this deficiency. In this study, two scenarios of the RTCVD system are investigated to simulate external or internal environmental changes, including change in the system’s radiation coefficient and change in wafer density .
(1) The parameters are changed
Parameters are reduced by 10% after 350 s to simulate the external change of the real system environment. To illustrate the modeling performance in response to changes in the DPS’s circumstances, we show the 400 data between 330 s and 370 ts.
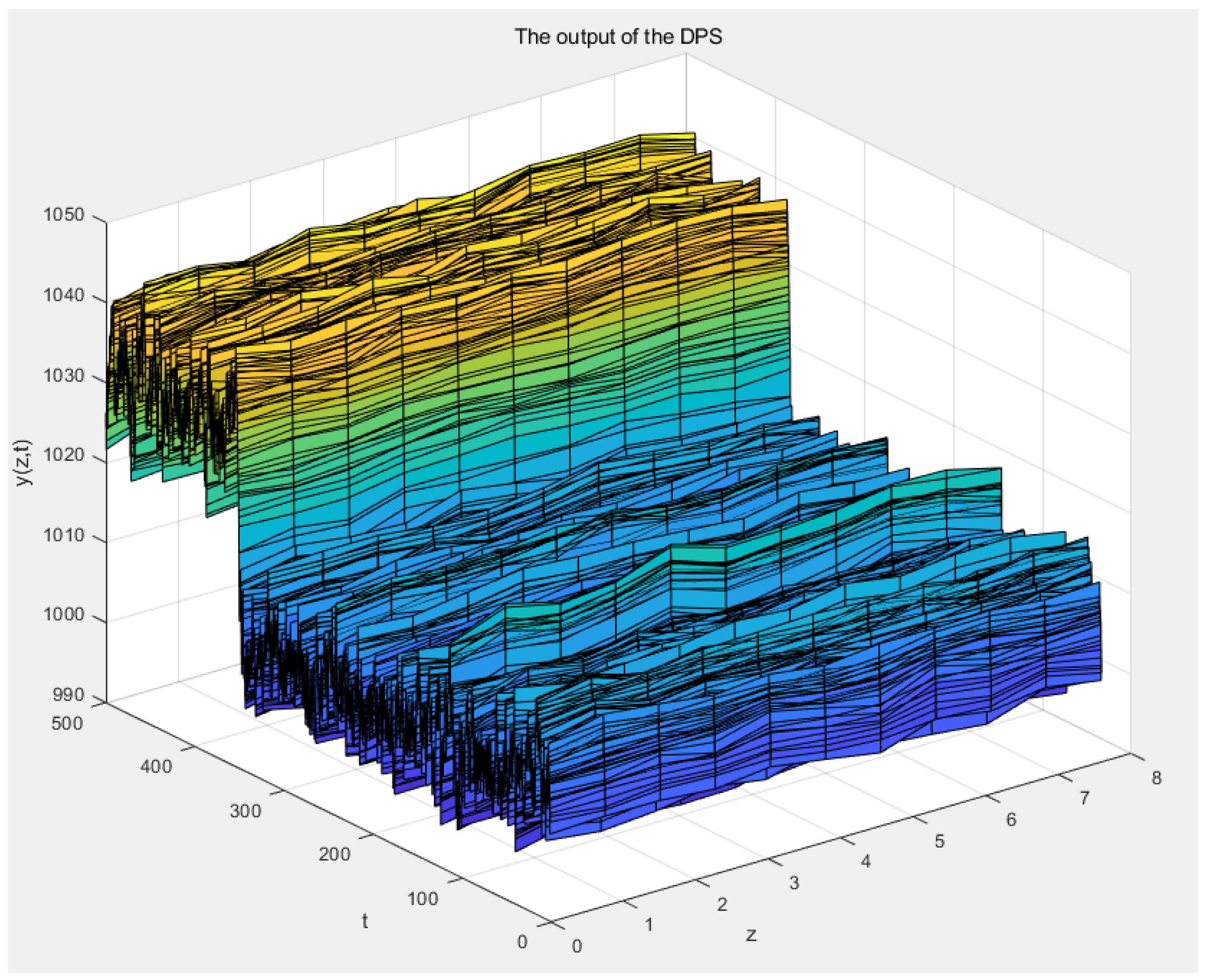
As shown in
Figure 8, when the system’s radiation coefficient
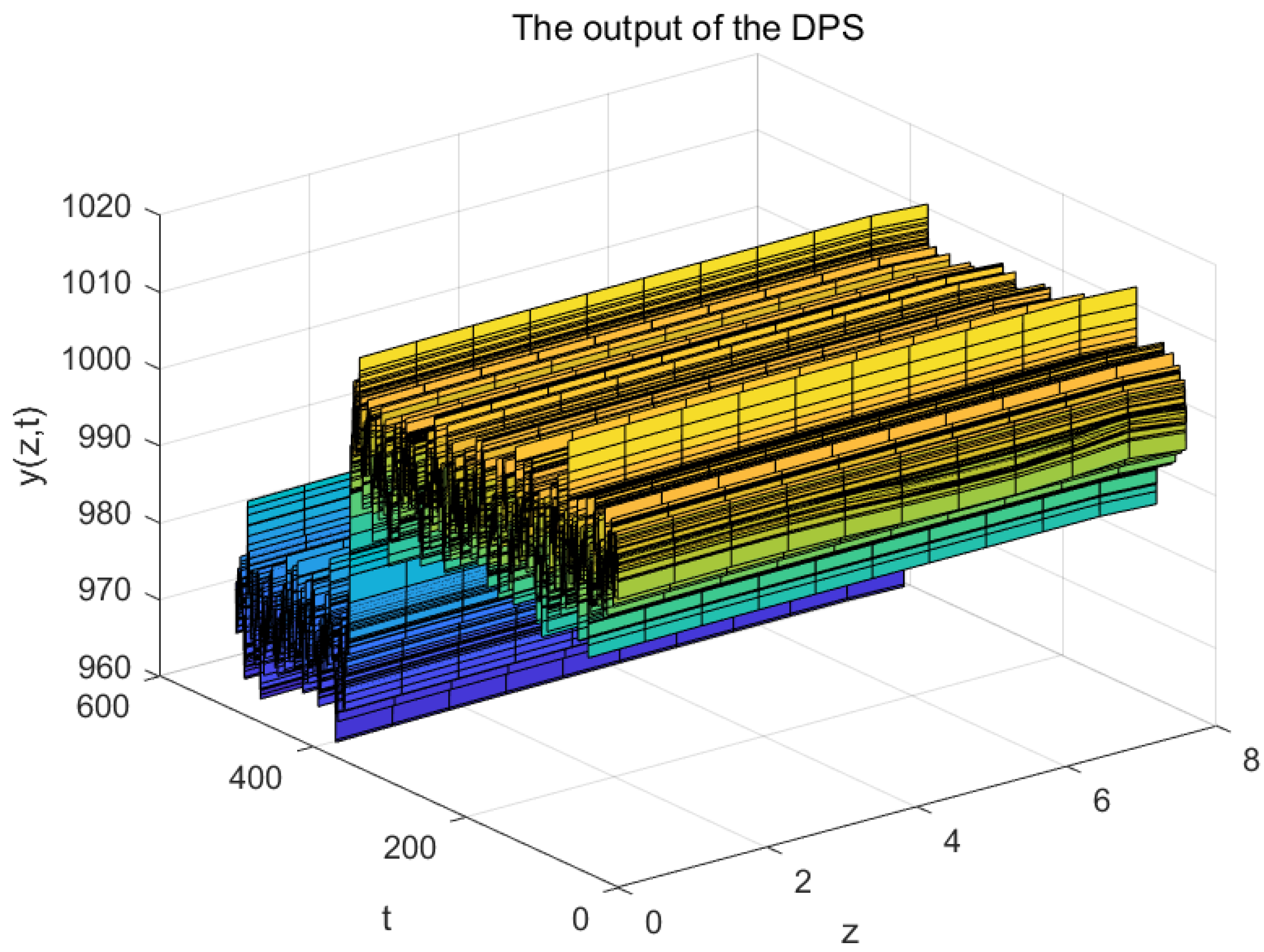
decreases, heat diffusion in the furnace slows down, causing a sudden temperature increase in the system, After a certain period, the system’s temperature stabilizes, that is the DPS’s actual output
. As the predicted output
illustrated in
Figure 9, the model established in this paper is able to follow this change in the system.
Figure 10 shows that the higher the immediate reward, the higher the model’s accuracy, with the peak reaching 0 at around 60 s, indicating that the proposed online modeling method has high modeling efficiency.
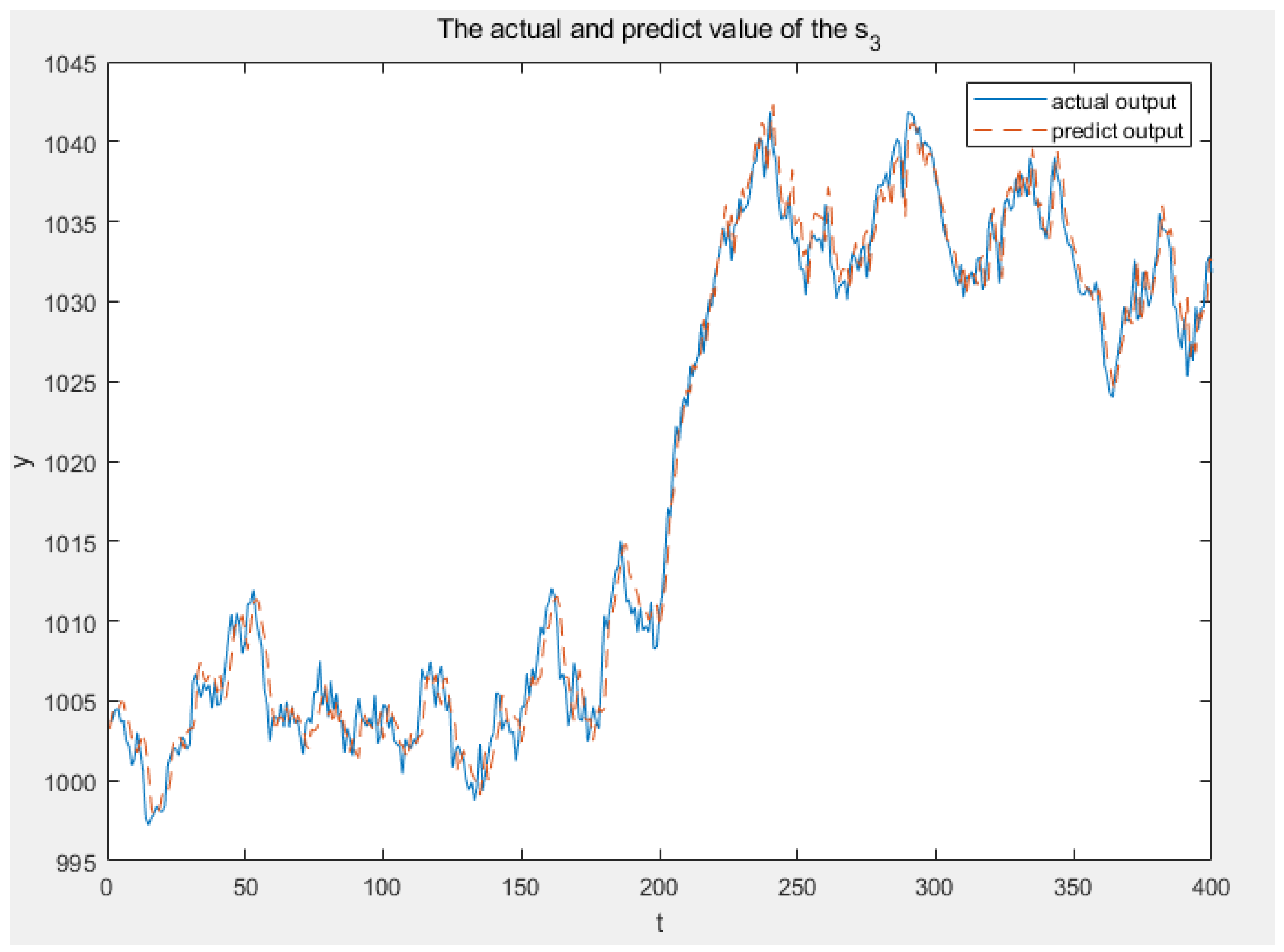
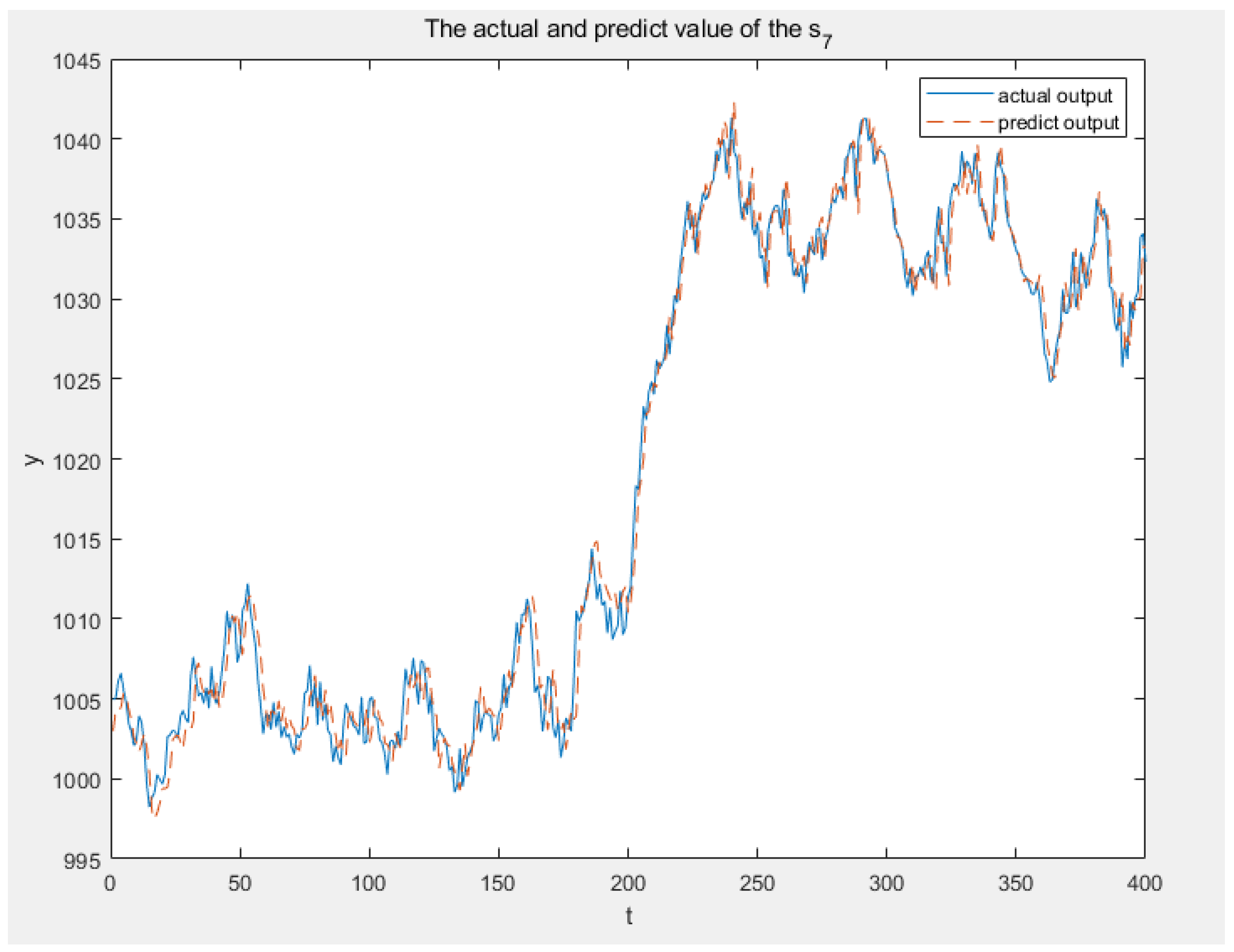
Figure 11,
Figure 12 and
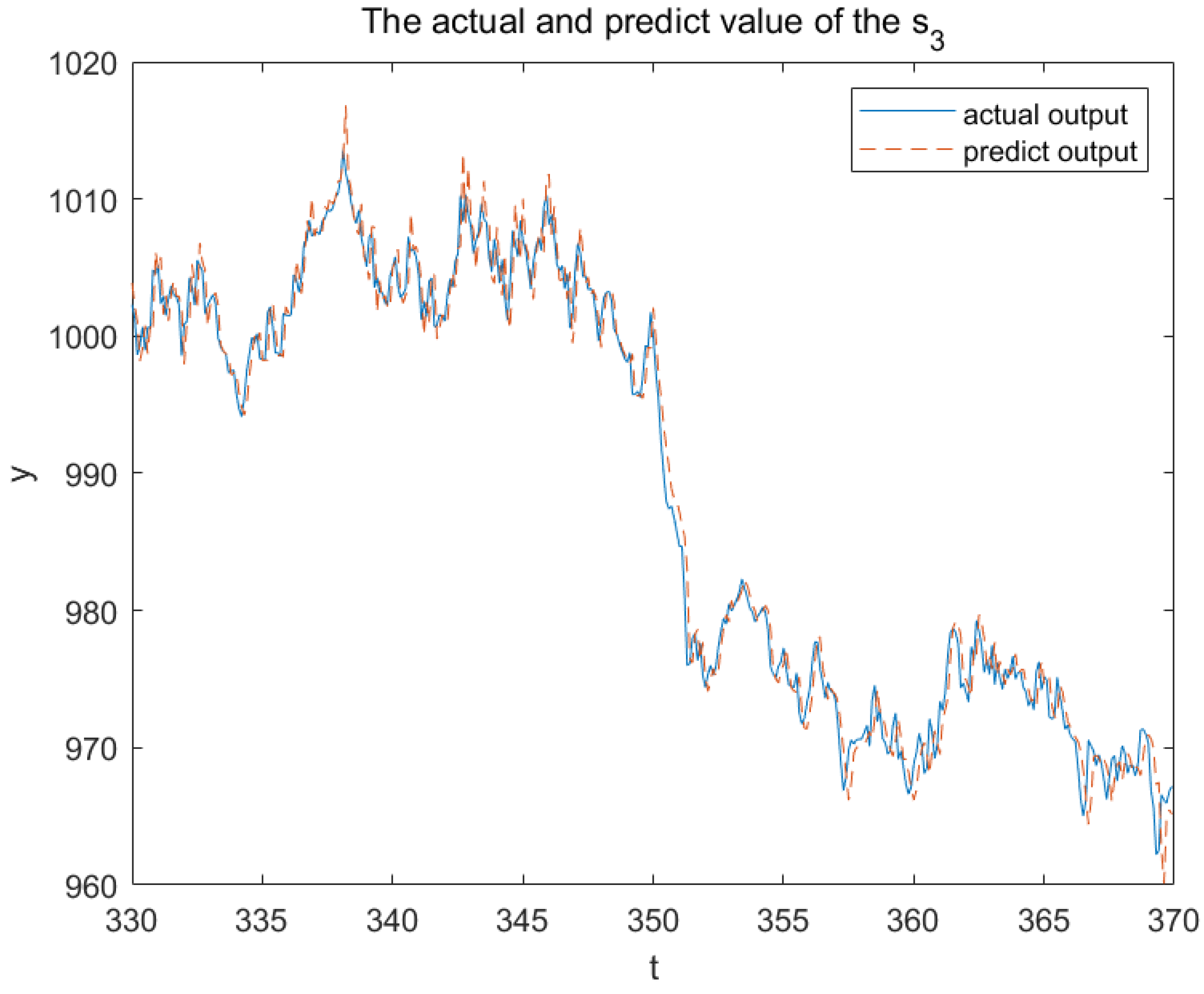
Figure 13 illustrate the real and anticipated values from sensors
,
and
, respectively, to elucidate the modeling accuracy of 3DFDPG under varying system conditions. It can be seen from the figures that the 3DFDPG model can promptly track changes in the system, proving the effectiveness of the proposed modeling method.
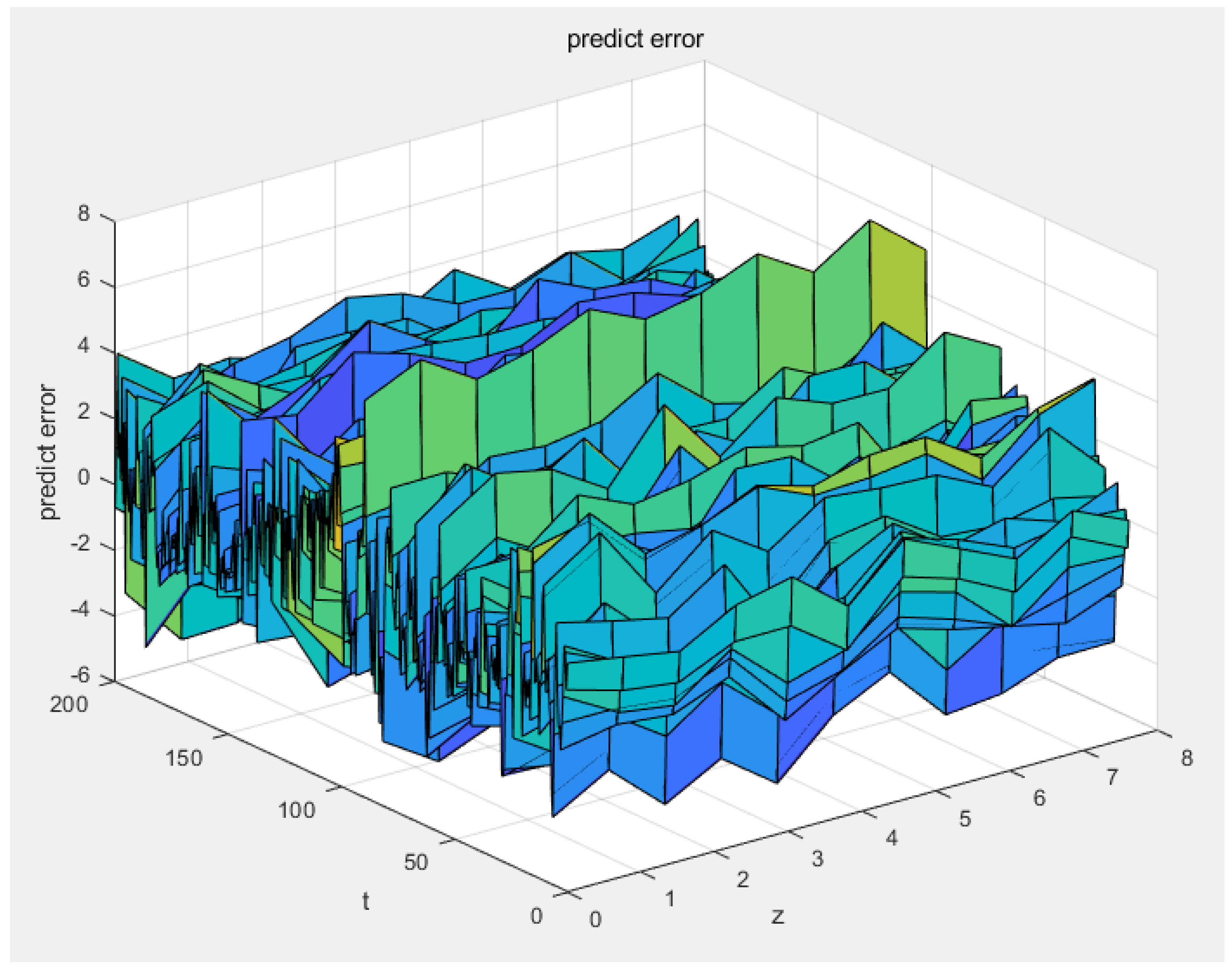
Figure 14 and
Figure 15 illustrate the prediction error and relative error of the 3DFDPG method, with the prediction error spanning from [−6, +6] and the relative error measuring 0.006. It indicates that the proposed online modeling method has good model accuracy.
(2) The parameters are changed
Parameters are reduced by 10% after 350s to simulate the internal change of the real system environment. To illustrate the modeling performance in response to changes in the DPS’s circumstances, we show the 400 data between 330s and 370s.
As shown in
Figure 16, when the wafer density
decreases, the wafer temperature drops, causing a sudden decrease in the system’s temperature, which then stabilizes after reaching a certain level. As illustrated in
Figure 17, the model established in this paper is able to follow this change in the system.
Figure 18 illustrates that an increase in immediate reward correlates with enhanced model accuracy, peaking at 0 around 60 s. This indicates that the proposed online modeling method has excellent modeling efficiency.
Figure 19,
Figure 20 and
Figure 21 correspondingly illustrate the actual and expected values from sensors
,
and
. These figures indicates that the 3DFDPG model can swiftly monitor system changes, hence validating the efficacy of the proposed modeling method.
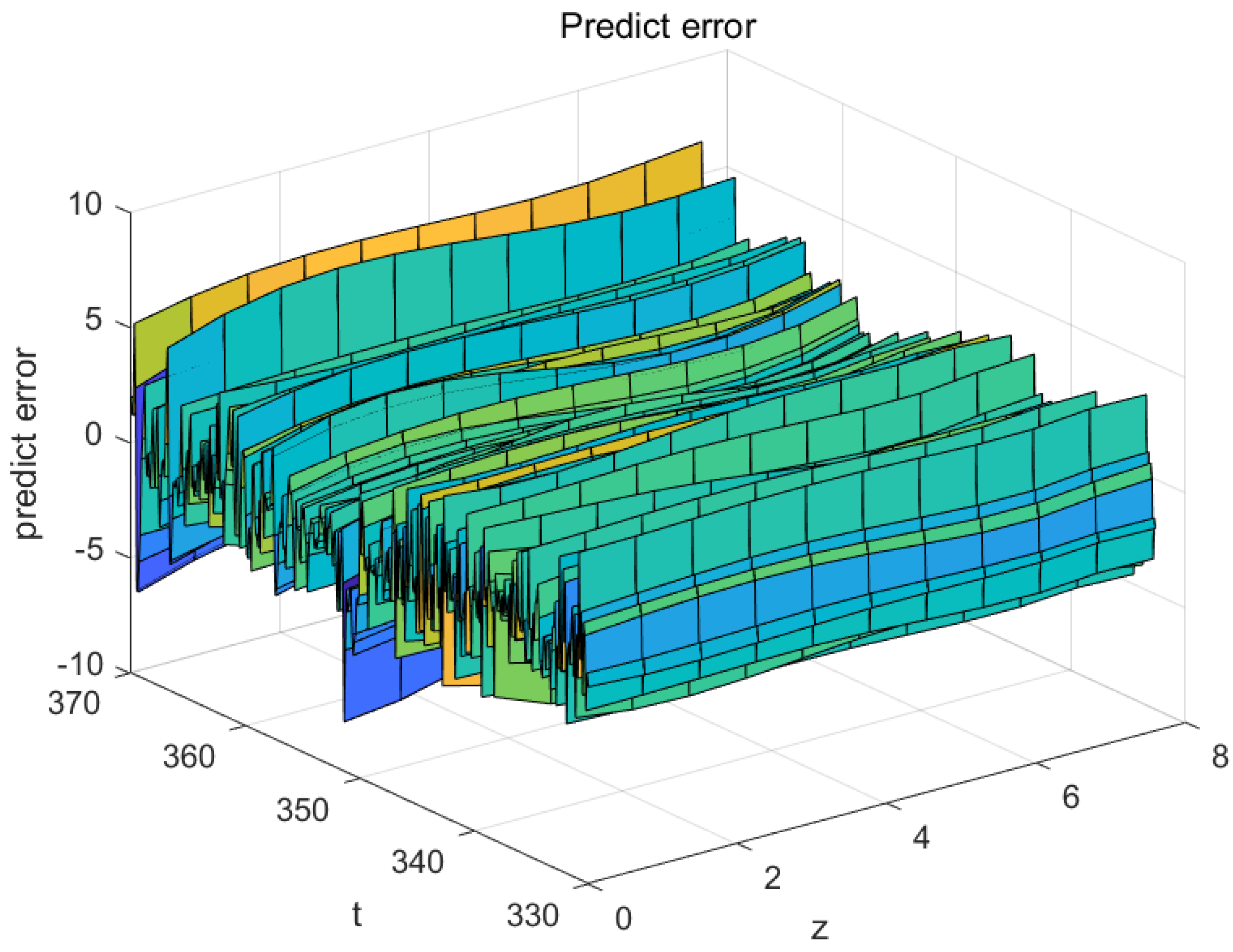
Figure 22 and
Figure 23 illustrate the prediction error and relative error of the 3DFDPG algorithm, with the prediction error spanning from [−6, +6] and the relative error at 0.006. This indicates that the proposed online modeling method maintains commendable model accuracy despite variations in wafer density
.
4.2. Comparison and Analysis
The accuracy of the model is measured by relative error, the time normalized absolute error (TNAE) and the relative L2 standard error (RLNE) as Equations (
62), (
63) and (
64), respectively.
Then, we compared the proposed 3DFDPG with KL-LS-SVM [
48] as a traditional offline DPS modeling method and online LS-SVM [
28] as a newly proposed online DPS modeling method.
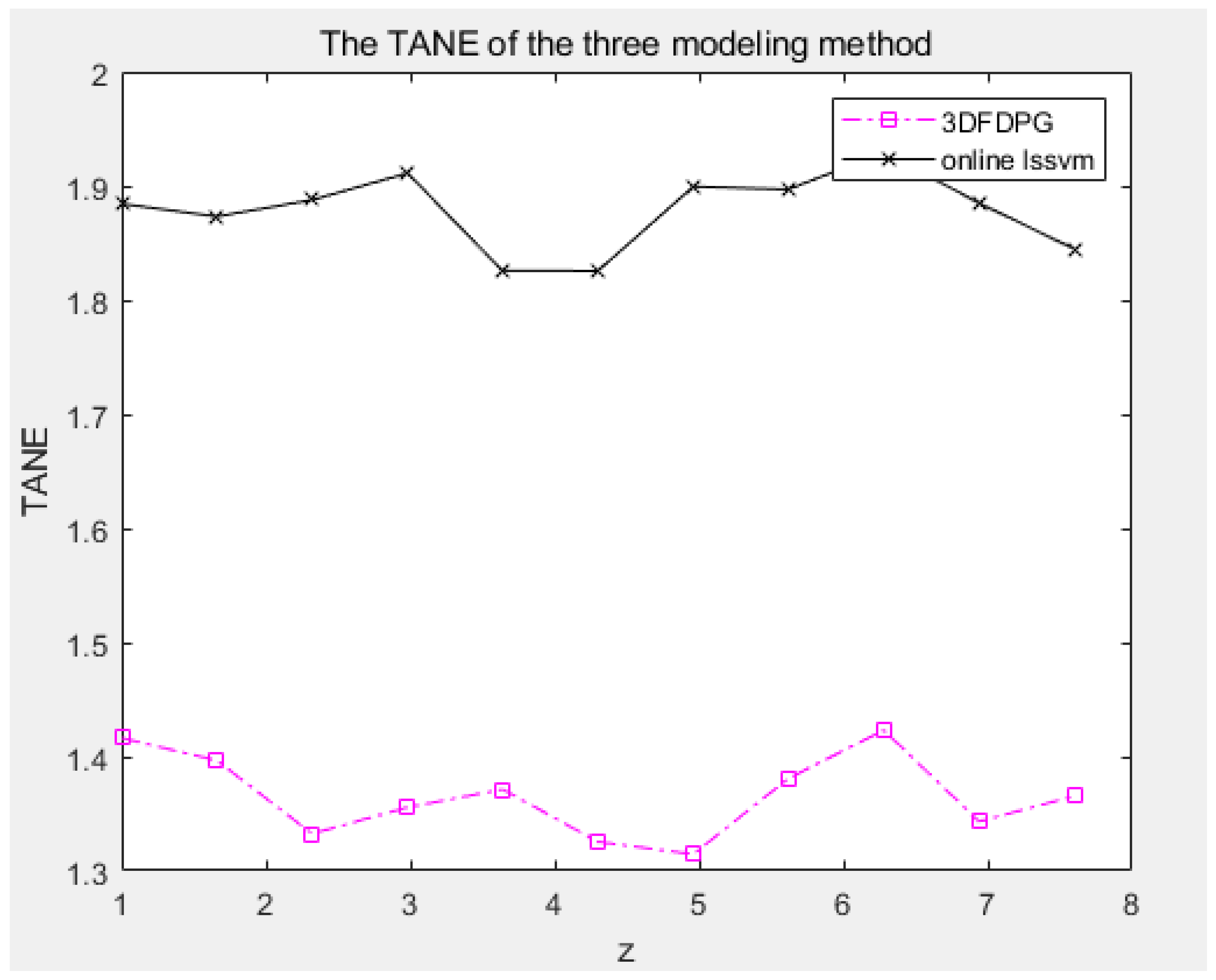
Figure 24 and
Figure 25 compare the TANE obtained from the two online modeling methods.
Figure 26 and
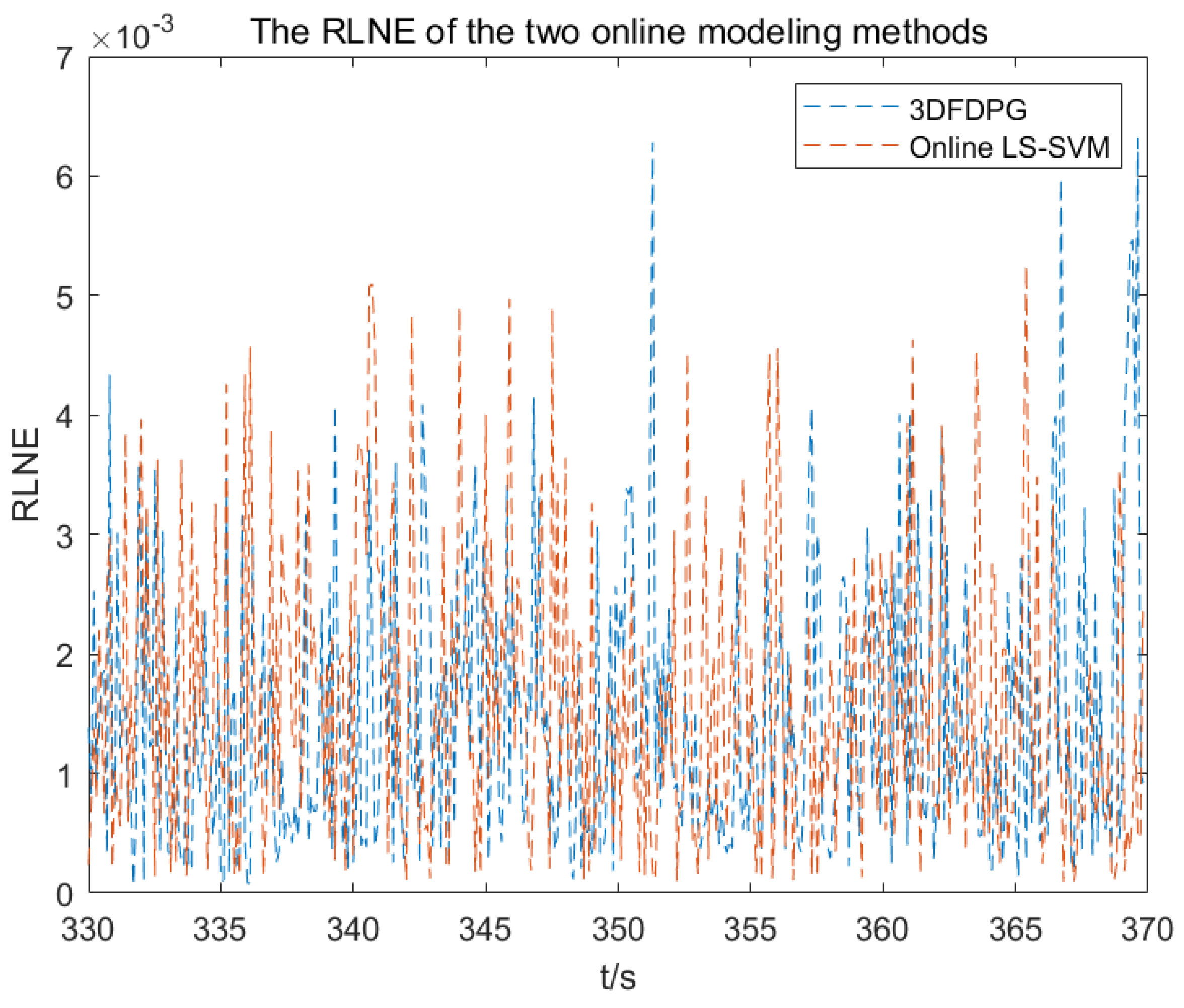
Figure 27 compare the RLNE obtained from the two modeling methods.
Table 2 presents the mean RMSE and the standard deviation of the three models by changing the random seed and conducting 10 trials. In both cases, the modeling error of the offline model (KL-LS-SVM) is much larger than that of the other two online models. The offline model is unable to cover the data in the new scenario when the DPS’s circumstances change. But since the online modeling method uses incremental learning, it can still appropriately assess the DPS in different scenarios. In addition, we conduct
t-test and
p-value analyses for the two online modeling methods. The T-test calculation equation for the two online models is as follows:
where
,
and
represent the mean of RMSE, the standard deviation of RMSE and the number of samples from the
ith online model, respectively,
represents the 3DFDPG model and
represents the online LS-SVM model. Substituting the data from
Table 2 into Equation (
65) yields the
T value. Then, we obtain the
p value by consulting the corresponding statistical distribution table, that is T = −35.27,
p < 0.01 with
changed and T = −13.47,
p < 0.01 with
changed. Since the
p value is less than 0.05, we reject the null hypothesis and conclude that there is a significant difference between the means of the two groups. This demonstrates that the proposed 3DFDPG model outperforms the Online LS-SVM model under the two application scenarios.
TNAE and RLNE represent the prediction errors of the 3DFDPG model and the online LS-SVM model in spatial and temporal dimensions, respectively. As shown in
Figure 24,
Figure 25,
Figure 26 and
Figure 27, in both cases, the errors of the 3DFDPG model are smaller than those of the online LS-SVM model. The reason is that the 3D fuzzy system naturally achieves temporal-spatial separation and temporal-spatial synthesis, allowing for the spatiotemporal modeling of DPS without the need for model reduction. Therefore, the 3DFDPG modeling method outperforms the online LS-SVM model. The online LS-SVM updates its model from an initial offline model. In contrast, the proposed 3DFDPG starts from scratch, relying on the interaction between the agent and the environment, with model parameters being updated adaptively.
5. Conclusions
In this paper, we proposed a 3DFDPG modeling method for online modeling of the DPSs. Reinforcement learning is learning from interactions between an environment and an agent; the 3D fuzzy system has the ability to deal with spatiotemporal data and has the universal approximation property. The reinforcement learning algorithm and the 3D fuzzy system were combined to realize the online learning. The average reward set was utilized to implement the online modeling of the DPS, so that the modeling process can run forever and have the ability to catch the situation change of the DPS. The simulation results confirmed the efficacy of the proposed 3DFDPG algorithm and its exceptional modeling performance is further emphasized by comparison with existing DPS modeling methods.
Due to practical constraints, this paper applied the proposed 3DFDPG modeling method to an RTCVD simulation system, aiming to simulate the real system as closely as possible by varying parameters and adding disturbances. When applied to the real system, the benefits are as follows:
It develops a very accurate model for the actual system to serve as a reference for system optimization, control and cost reduction.
This work proposes an online modeling technique capable of swiftly indicating internal or external component failures inside the system, hence furnishing engineers with accurate fault-localization data.
The proposed online modeling method can model the real system from scratch without human intervention, facilitating system modeling.
Although the proposed online modeling algorithm achieved good results, there are two limitations, which need to be solved in future work. Firstly, the 3D fuzzy system used in this paper has a fixed structure and lacks flexibility. In future work, a dynamic variable structure 3D fuzzy system will be investigated. Secondly, the reinforcement learning algorithm based on DPG used in this paper is somewhat insufficient in terms of action exploration and may become trapped in local optimal policies. In future work, the feasibility of using reinforcement learning algorithms based on stochastic policies will be explored. Finally, we plan to apply the proposed online modeling method to a real industrial system, for instance a rotary hearth furnace system.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}