1. Introduction
Artificial intelligence (AI) has rapidly become a transformative force across diverse sectors, significantly impacting areas such as code generation, image creation, and content development through its unparalleled ability to extract insights from vast datasets. Integrating AI knowledge and skills into educational curricula not only enhances students’ job market prospects but also fosters a culture of innovation and creativity, equipping them to tackle complex problems with advanced tools and knowledge. This integration is crucial in preparing a future workforce adept in AI and machine learning, ensuring global competitiveness.
Generative large language models (LLMs), specifically advanced chatbots (referred to as LLMs or GPTs in this paper), represent a groundbreaking innovation in AI. These models are profoundly transforming the educational landscape by providing intelligent, adaptive learning experiences and optimizing various administrative and educational tasks.
In a recent test, ChatGPT achieved an IQ score of 155, placing it above 99.98 percent of the human population [
1]. While human-like properties such as consciousness remain at a reasonably low level, significant progress has also been observed in this area [
2]. Furthermore, extensive “classical” Turing tests involving non-specialists demonstrated that humans were often unable to distinguish between the outputs generated by specialized LLMs and those produced by humans [
3].
In information and communication technology (ICT) education, programming presents significant challenges, as it demands a combination of technical skills, analytical thinking, and problem-solving abilities. LLMs have emerged as valuable tools in this space, offering personalized instruction and real-time support. By leveraging their natural language processing and programming capabilities, LLMs assist students in overcoming obstacles, reinforce key concepts, and deepen their understanding of programming fundamentals. One of the key advantages of LLMs in programming education is their ability to provide immediate assistance. They can swiftly identify errors, explain underlying issues, and suggest alternative solutions, thereby enhancing students’ problem-solving skills through timely feedback and encouraging the exploration of diverse approaches.
Not all the applications of LLMs have been successful. First, it is well known that LLMs fail at some simple tests, e.g., [
4]. Second, it is essential to provide proper prompts to obtain good results. For example, writing a good prompt equals providing program specifications in natural language; therefore, comparing humans with LLMs with perfect prompts might not be fair or comparing with LLMs with insufficient prompts.
This study aimed to fairly and consistently compare four distinct LLMs—ChatGPT (now GPT-4o), Bard (now Gemini), Copilot, and AutoGPT—in terms of their effectiveness in developing machine learning (ML) curricula tailored for high school students. The primary research aim was to investigate the efficacy of generative AI (GAI) in designing and preparing curricula suitable for high schools. The two main questions were
We prepared a series of tests for the LLMs, which included generating code from descriptions, generating descriptions from code, creating course text from descriptions, identifying errors and warnings in code, and optimizing code. Although the systems were evaluated on a wide range of tasks, this paper focuses on the most informative results. The conclusions drawn are broadly applicable to both the presented tests and the additional evaluations conducted within this framework.
The first hypothesis in this study was that GAI LLMs would perform comparably to human experts on several tasks designed as part of the international Valence project [
5]. That study aimed to identify which tasks would be successfully performed by each LLM and which tasks would present challenges. Although comparing response times is inherently problematic—since the project spanned three years while LLMs generate responses within seconds—significant time was invested in crafting appropriate prompts, often taking weeks, and the duration of each task’s study spanned several months. The second hypothesis anticipated notable differences in the performance of the tested LLMs across various tasks. The third hypothesis was that the timing of the tests would reveal temporal differences in the rankings and performance of the LLMs, indicating progression over time.
This paper is organized as follows:
Section 2 provides a review of the relevant scientific literature.
Section 3 outlines the benchmark teaching materials used for evaluating the performance of the LLMs and describes the experimental setup in detail.
Section 4 presents the key findings from the experiments. Finally,
Section 5 discusses the implications of these findings, draws conclusions, and suggests directions for future research.
2. Related Work
Recent advancements in LLMs have demonstrated their potential for addressing diverse educational needs, ranging from personalized tutoring to content creation, as shown by their successful application in numerous educational experiments and studies (e.g., [
6]). These studies underscore the growing acceptance and effectiveness of LLMs in enriching both teaching and learning experiences. In this paper, we explore the evolving roles of LLMs in the educational domain, drawing on insights from recent scholarly research.
A study [
6] highlights the challenges faced by the growing population of international students, particularly language barriers. The authors acknowledged the potential of LLMs in assisting these students, though they emphasized that LLMs are not replacements for faculty expertise in areas such as answering questions or creating material. Nonetheless, LLMs serve as valuable tools for students seeking assistance in subjects like machine learning.
Field experiments using LLMs to design cultural content in multiple languages are discussed in [
7]. In these experiments, LLMs functioned either as ICT-based tutors or as assistants to human tutors. Their user-driven interaction and welcoming language fostered an inviting, self-paced learning environment. The adaptability of LLMs in content creation not only enhanced tutor creativity and productivity but also significantly reduced their cognitive load in designing educational materials. This allowed educators to focus on more critical tasks. An evaluation through questionnaires revealed that students using LLMs to learn history outperformed those in a control group who did not have access to GPT assistance.
The widespread use of mobile phones in educational environments is discussed in [
8]. Rather than limiting phone usage, the study investigated the creation of a conversational assistant designed to support students who are new to computer programming. The results showed a positive reception among students and a strong willingness to utilize LLMs for learning. Moreover, devices such as smartphones, smartwatches, and smart wristbands were shown to further enhance the learning experience with LLMs [
9,
10]. However, our study did not focus on any specific hardware.
In [
11], the researchers developed a GPT to assist in teaching the Python programming language. This tool aids in program comprehension for novice programmers, lowering entry barriers to computer programming. The GPT is equipped with a ‘knowledge unit’ for processing user requests and a ‘message bank’ containing a database of predefined responses. The bot can discuss programming concepts, offer scheduling support for tutor meetings, or answer predefined questions. Surveys indicated that many students find computer programming courses challenging, underscoring the need for clear and accessible teaching methods. LLMs like this represent a step toward creating a more conducive learning environment.
The application of LLMs extends to assessing teamwork skills, as demonstrated in [
12]. In this study, a GPT was used to simulate human interactions in an online chatroom, unbeknownst to the users, to evaluate teamwork skills. The GPT interactions were analyzed using an algorithm to score users’ teamwork abilities. These scores were found to correlate strongly with the assessments conducted by human experts, suggesting that LLMs can effectively mimic human interactions and deliver reliable assessments, even in areas typically influenced by subjective factors.
A paper [
13] discusses the use of LLMs like Code Tutor, ProgBot, and Python-Bot to assist students in learning programming languages such as JAVA, C++, and Python. The LLMs provided coding suggestions, error corrections, and adapt quizzes based on student progress. A GPT utilizing IBM Watson service was used for non-technical students, emphasizing the need to help students learn programming logic. The study suggests redesigning GPT scripts to better support student learning based on the four-component instructional design (4C/ID) framework.
The adoption of GPT applications was studied in [
14] by integrating the technology acceptance model (TAM) and emotional intelligence (EI) theory. The study focused on international students using GPT applications in their university, employing machine learning methods to analyze the data. The results showed that classifiers like simple logistic, iterative classifier optimizer, and LMT had high accuracy in predicting users’ intention to use LLMs, suggesting the effectiveness of LLMs in enhancing educational activities.
ML algorithms are increasingly being used to automatically assess student learning outcomes, as illustrated by a recent work [
15], where image classification served as a key application. Significant progress has also been made in the field of ophthalmology, with researchers conducting various experimental evaluations to explore the role of AI in medical diagnostics [
16]. Moreover, an insightful study [
17] delved into content- and language-integrated learning, highlighting the potential of AI in educational contexts. Additionally, [
14] examined the integration of emotional intelligence within machine learning frameworks, further enhancing the adaptability and effectiveness of AI in diverse learning environments.
This study stands apart from the existing research by offering a comprehensive evaluation of the performance of four distinct LLMs over one year, with two separate assessments, each lasting several months. The primary focus of this investigation was the integration of ML education into high school curricula. In contrast to previous studies that broadly explored the application of generative pretrained transformers (GPTs) across diverse educational contexts, this research narrows its scope to specifically compare these LLMs to identify the most effective tools for ML instruction in high school courses.
4. Results
The Results Section consists of subsections corresponding to one specific experiment or test. Each test was conducted using the current LLM version most appropriate for the particular experimental conditions at the time of experiments.
4.1. Text-to-Text Experiment
To evaluate the text generation capabilities of the selected LLMs, the Valence ML definitions within the Jupyter notebooks were utilized. These materials had been thoroughly discussed and refined during the project, ensuring they were relevant and well suited for the experiment. The LLMs, therefore, competed both against each other and against human experts on tasks derived from material carefully tailored for high school education purposes. A total of 35 definitions, covering topics such as programming languages, basic statistics, mathematical concepts, and ML techniques, were extracted from the Valence material to serve as a benchmark.
In all experiments, the Valence material, developed by experts in AI and high school education, served as the ‘ground truth’. The LLMs were tasked with reconstructing the definitions from provided code and examples, with up to five attempts allowed per definition to produce the closest match. In each iteration, the LLMs were given consistent hints to guide their improvement, simulating the instructional feedback typically provided in high school settings. Given the inherent difficulty of achieving an exact replication, we employed a subjective evaluation method similar to a teacher’s assessment. This approach assessed whether the LLM-generated definitions effectively captured most or all critical elements outlined in the original Valence material.
In addition to assessing the readability of the generated content, the code-to-text experiment was expanded to include evaluations of the accuracy of the explanations and the appropriateness of the language style for high school education. Experts with a background in programming evaluated the correctness of the content, ensuring that the explanations accurately reflected the underlying code. Furthermore, the language style was analyzed to ensure clarity, conciseness, and suitability for high school students, with a focus on pedagogical clarity and avoiding overly technical language that could hinder student comprehension.
An illustrative comparison of one such definition is shown in
Figure 1. The evaluation results are subsequently presented in
Figure 2,
Figure 3 and
Figure 4, which compare each tested definition alongside the number of prompt attempts required to achieve a satisfactory outcome.
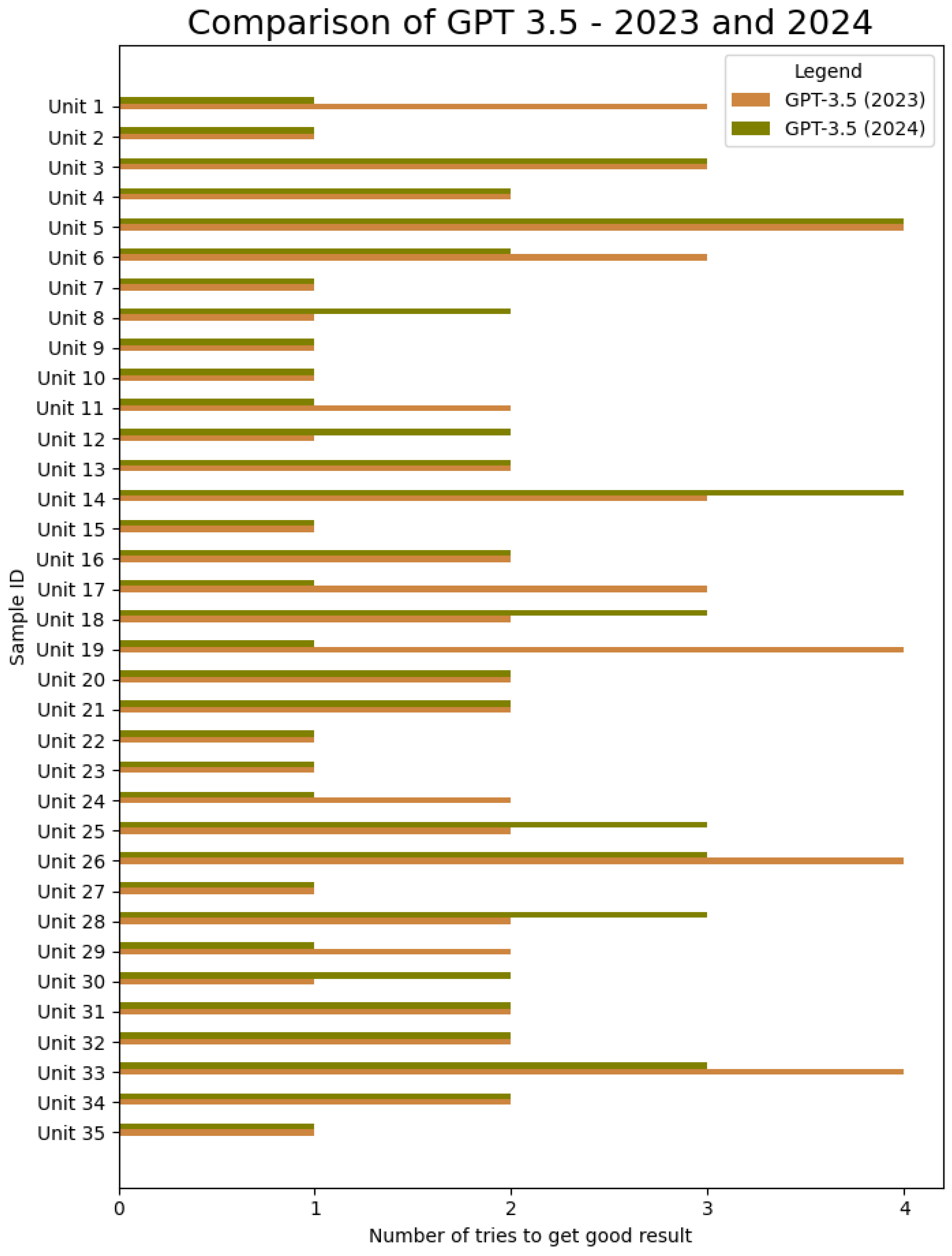
Figure 3 for GPT 3.5 (on average achieved 2.03 in 2023 and 1.86 in 2024) and
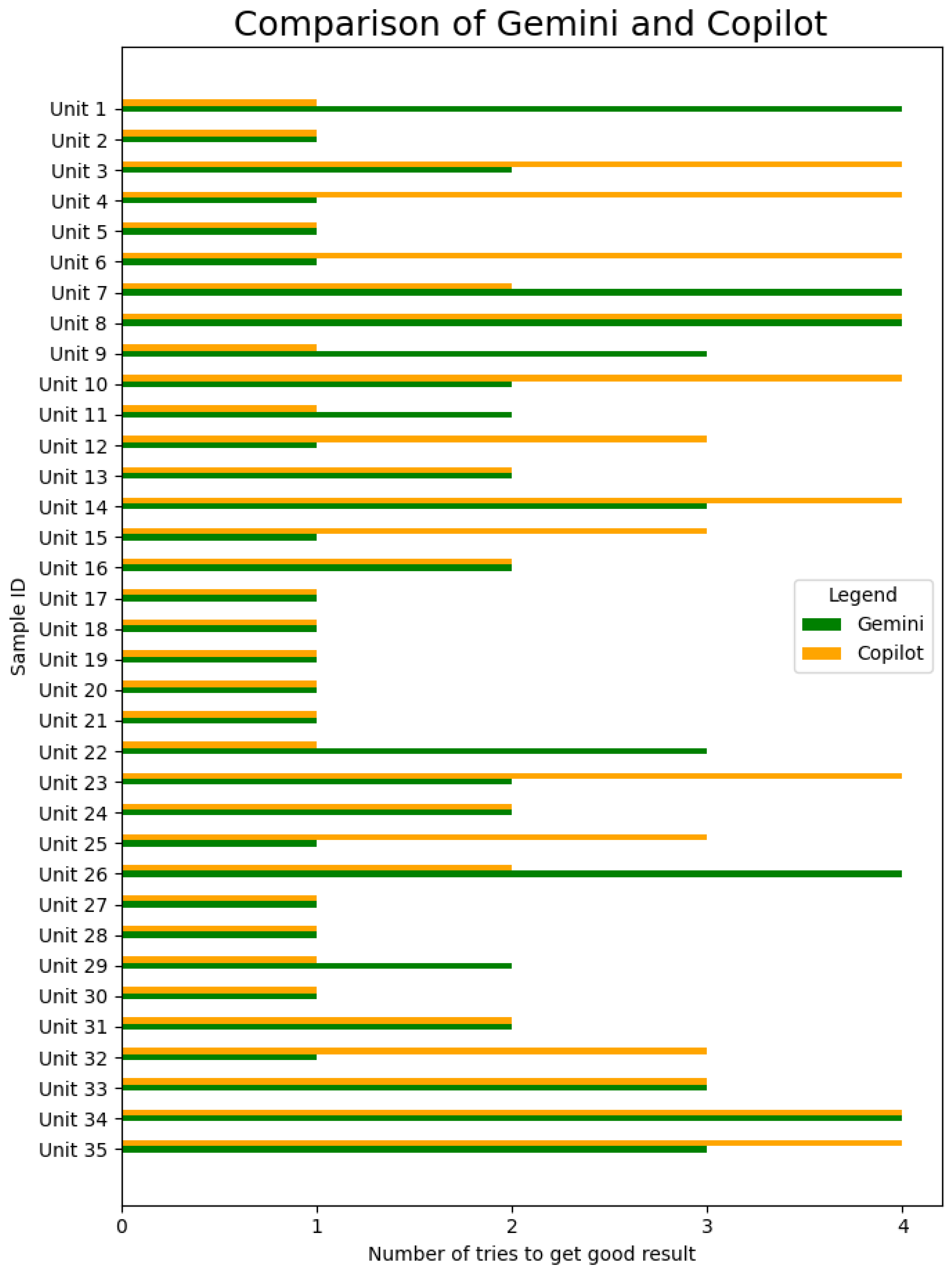
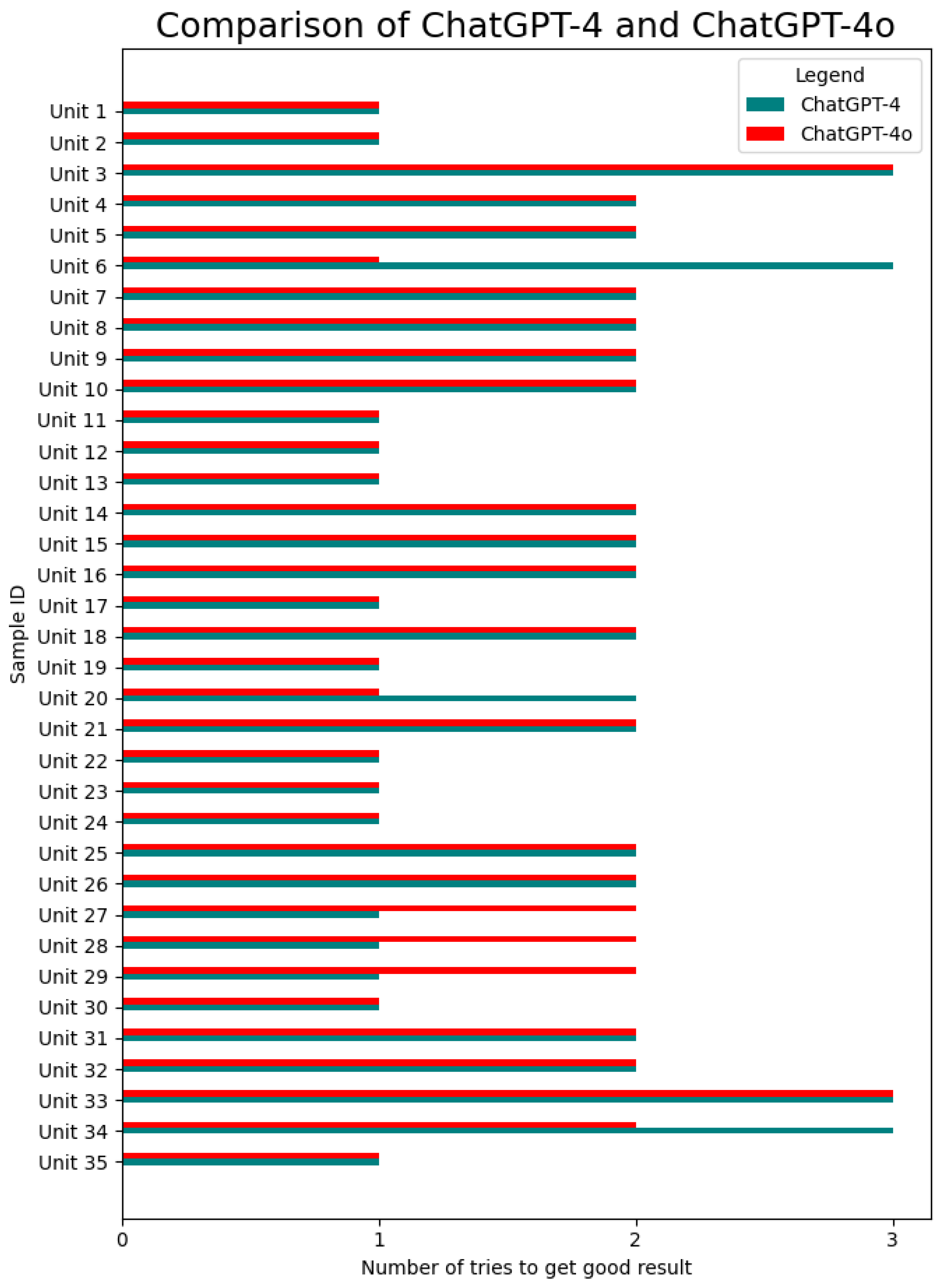
Figure 2 for Gemini (1.97) and Copilot (2.23; both 2024) show that these LLMs generally performed similarly. It might be that ChatGPT-4 in 2023 (1.69) and ChatGPT-4o in 2024 (1.69) required fewer prompts on average compared to the other LLMs, as presented in
Figure 4, but the differences were not significant.
The LLMs therefore, on average, performed nearly as well as humans, working on these items for a substantial period, while LLMs needed seconds to produce results after prompts were generated. This suggests a high level of efficiency by LLMs in generating technical definitions. The LLMs also properly prioritized key details.
At the same time, it was observed that the LLMs’ responses often lacked examples and tended to be verbose. To enhance the precision of the definitions generated, it is advisable to use detailed prompts, specifying aspects such as desired sentence count and response format. Such specificity in prompts can expedite the process of obtaining the required information.
Figure 4 shows that ChatGPT-4 typically required only one or two prompts to generate an accurate definition, although there were two instances where it failed. Excluding these failures, the average number of prompts needed by ChatGPT-4 to reach a satisfactory definition was 1.68, indicating that, in most cases, two prompts were sufficient to achieve the desired result. The other LLMs performed slightly worse in comparison.
ChatGPT-4o (1.69) performed similarly to ChatGPT-4 (1.69) in 2024, which was expected since the older version already performed so well that there was not much room for improvement. Also, the replies seemed a bit more human-like.
In summary, ChatGPT-4o performed slightly better in the text-to-text experiments, and all LLMs performed reasonably well. Please note that only the most interesting comparisons are presented in this paper, while summaries include overall observations.
4.2. Text-to-Code Experiment
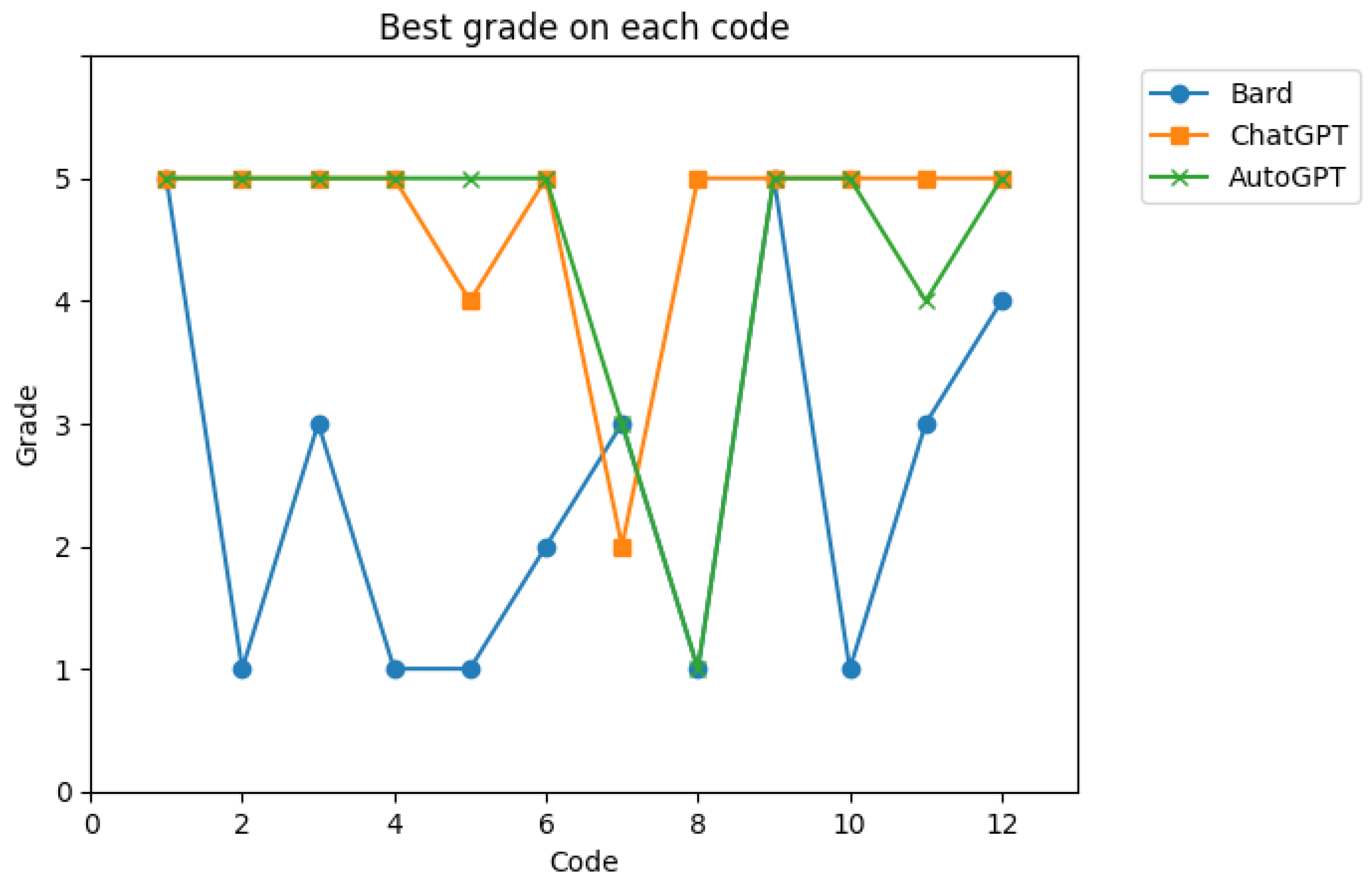
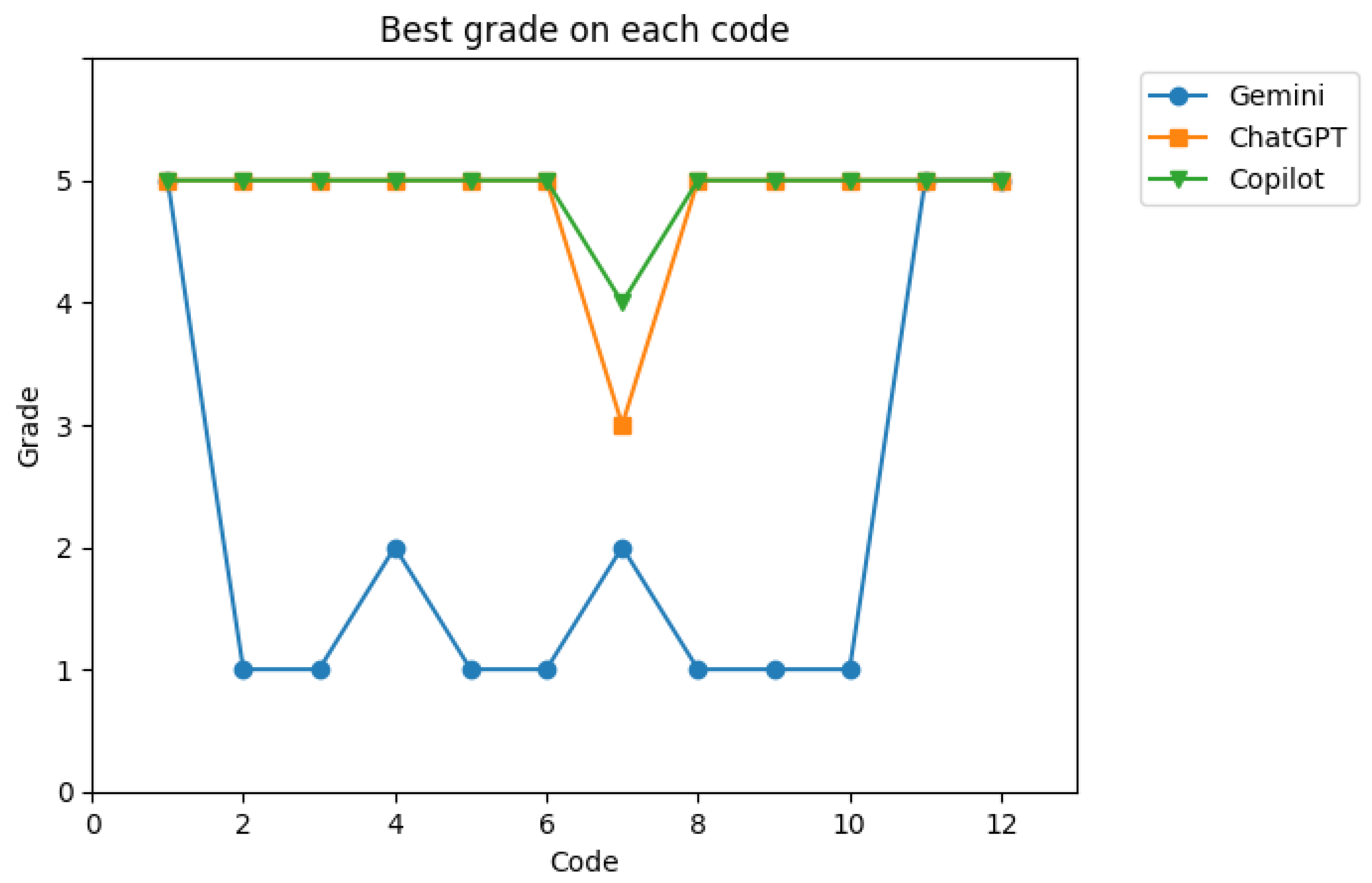
In this subsection, the LLMs’ capabilities in generating programming code from textual prompts are tested. Each LLM was given a maximum of five attempts to produce a functional code segment. This experiment involved all four LLMs: Bard (Gemini), AutoGPT, Copilot, and ChatGPT. If an LLM failed to generate a valid code segment after five attempts, the test was concluded as a failure for that segment. A total of 12 diverse code segments, representing various algorithms and methods, were selected for this purpose. This diversity was introduced to challenge the AI’s adaptability to different programming problems.
Table 1 presents an overview of the 12 code segments selected for this study, including the algorithm/method, category, and rationale for each. These code segments represent a diverse set of machine learning tasks, spanning supervised and unsupervised learning, as well as optimization and classification problems. The algorithms were chosen to challenge the adaptability of LLMs to various programming tasks commonly encountered in educational settings.
To ensure the consistency and quality of the results, each LLM was initially provided with a uniformly structured prompt describing the code segment. Follow-up prompts were tailored to address specific errors identified in the generated code. This approach simulated the experience of a novice programmer, who might rely on copying and pasting error messages without fully understanding the underlying issues. The goal was to replicate the educational process, where a teacher and student engage in an interactive, iterative dialogue aimed at improving understanding and performance.
While formalizing this process can be challenging, our method mirrored real-world scenarios of human feedback, in which helpful hints progressively guide the learner toward a more accurate solution. Unlike human interactions, which can be influenced by external factors such as a student’s appearance or demeanor, the interaction with LLMs remains purely objective, ensuring a more consistent and impartial feedback mechanism throughout the experiment.
The generated code from each prompt was assigned a score on a scale from 1 to 5, with criteria as follows:
1/5: Code causes a compilation error, rendering it unusable.
2/5: Code runs but produces an output significantly different from the requested one.
3/5: Code runs but produces an output that only partially aligns with the expected result.
4/5: Code nearly achieves the desired output, with minor discrepancies.
5/5: Code meets or exceeds the expected output requirements.
The performance scores (ranging from 5 for the best to 1 for the worst) are plotted for the four LLMs in
Figure 5 and
Figure 6 to compare the highest score achieved by each model across the different code segments. During the second evaluation, updated versions of the systems were introduced, bringing additional changes. AutoGPT was replaced with Copilot in the second comparison, and Bard was updated to its newer version, Gemini.
Comparisons enabled the testing of the significance of the similarities between the LLMs, helping to assess how closely their performance aligned across different tasks. The tests presented in
Table 4 indicate that, overall, the LLMs have improved over time.
While these scores indicate overall performance, they do not account for the efficiency in reaching these scores, measured by the number of prompt attempts. Therefore, a new metric was introduced: the efficiency score (
1). This score was calculated by dividing the LLM’s average score by the total number of prompt attempts, where the smaller the better.
The efficiency scores for each LLM are presented in
Table 5:
4.3. CodeBERT Score
To quantitatively evaluate the quality of the code segments generated by the LLMs, the CodeBERT score [
24] was employed as a key metric. The CodeBERT score measures semantic similarity by comparing the generated code to the original code from the Valence project. It utilizes contextual embeddings from large pretrained models, which have been shown to correlate strongly with human evaluative preferences. The calculation of the CodeBERT score incorporates four key metrics: precision, recall, F1 score, and F3 score. Each of these metrics contributes to a comprehensive assessment of the generated code’s quality:
Precision: measures the proportion of relevant instances among the retrieved instances.
Recall: assesses the proportion of relevant instances that have been retrieved over the total amount of relevant instances.
F1 score: provides a balance between precision and recall, calculated as the harmonic mean of these two metrics.
F3 score: Places more emphasis on recall compared to precision, suitable for scenarios where missing relevant instances (lower recall) are more critical than retrieving irrelevant ones (lower precision).
The integration of these metrics within the CodeBERT score framework alloeds for a nuanced analysis of the LLMs’ code generation capabilities, aligning with both technical accuracy and human judgment standards. The CodeBERT scores for each LLM are presented in
Table 6.
In summary, in the text-to-program experiments, ChatGPT, Copilot, and AutoGPT consistently performed well across all metrics, while Bard and Gemini did not exhibit similar performance on certain tests.
4.4. Code-to-Text Experiment
This subsection presents an evaluation of the LLMs’ ability to generate textual descriptions from provided code segments. To ensure consistency, an identical prompt was employed across all four LLMs (ChatGPT, Bard, Copilot, and Auto-GPT). A total of 11 distinct code segments were selected for this assessment. The uniform prompt issued to each LLM was “Generate a brief description of this code without using lists or bullet points”.
After the LLMs generated their descriptions, a binary rating system—‘good’ or ‘bad’—was applied. This system was chosen with the assumption that users without a computer science background, who are likely to use this feature, may lack the expertise to identify technical inaccuracies in the descriptions. Such users might also find it difficult to reformulate their queries for more precise explanations. To stay aligned with this user perspective, no additional prompts were issued after the initial description was generated.
This approach aimed to assess the LLMs’ effectiveness in providing clear and accurate descriptions that are easily understandable by nonexperts, reflecting real-world scenarios where laypersons seek to comprehend code without prior programming knowledge. Only Bard and Gemini produced 2 ‘bad’ descriptions according to our standards, while ChatGPT, AutoGPT, and Copilot achieved a perfect score of 11/11.
In conclusion, all LLMs performed well in the code-to-text experiment.
4.5. Error/Warning Detection and Optimization
This study further investigated the potential of the LLMs in assisting with code debugging and providing suggestions for improvement. Specifically, we evaluated the ability of the LLMs to identify errors and warnings within a set of selected code segments. Among these segments, two contained errors, one included a warning, while the remainder functioned correctly. The objective was to assess whether the LLMs could accurately detect and resolve these issues or if they would mistakenly flag nonexistent problems.
The methodology followed the approach used in the from-code-to-text experiment, utilizing a single prompt: ‘Tell me if this code has errors or warnings in it and try to improve it’. Auto-GPT was excluded from this test, as it was unable to interpret code segments and treated them as regular text, reflecting its primary design as a task automation assistant rather than a conversational agent. The results for Bard, ChatGPT, and Copilot are presented in
Table 7.
The results in
Table 7 indicate that while Bard did not identify any of the existing errors or warnings, it also did not create any false positives. ChatGPT-4, on the other hand, successfully detected two errors but failed to identify the warning and incorrectly reported an additional error. Copilot detected the warning but also incorrectly reported an additional warning/error. Both ChatGPT-4 and Copilot invented new errors/warnings, while Bard did not.
In addition to error detection, the LLMs’ capability to optimize code segments, particularly in terms of execution speed, was also examined. The following results were obtained after prompting the LLMs to enhance the code:
Both LLMs, on average, produced code that was slower than the original, indicating a lack of reliability in terms of code optimization. It is noteworthy that there was significant variability in the optimization results, with some instances showing substantial improvements, while others exhibited considerable slowdowns.
In conclusion, compared to human experts, all LLM-optimized code quite poorly. ChatGPT and Copilot provided reasonable error and warning detection, while Bard produced none.
4.6. Extending the Text-to-Code Experiment
To achieve a more comprehensive evaluation of LLM performance, we expanded the initial set of 12 code segments by generating variations and additional examples based on the original set. This expansion resulted in a total of 70 unique examples, after which new examples began to exhibit redundancy. Additionally, GPT was tasked with providing further examples, leading to a total of 103 examples (the dataset can be obtained by contacting the authors). These additional samples were designed to more reliably capture the diversity and complexity of various LLMs, enabling a more robust assessment across a wider range of scenarios. However, it is important to note that the additional samples were not part of the original Valence data.
The evaluation framework for the additional samples incorporates three distinct metrics to assess the comparative performance of the language models. These metrics are explained in
Table 8:
Strict comparison: This metric evaluates the outputs by assigning a score of 0 if the output qualities are closely comparable, if GPT’s performance is superior, and if the alternative LLM outperforms GPT. An overall performance review found that GPT performed better in 13% of the cases.
Soft similarity: This score is used when the outputs are generally similar, with a rating of 0, but marked if there are significant differences. This is intended to capture broader performance trends rather than focusing on minor discrepancies. GPT was found to have a 6% advantage using this approach.
CodeBERT metric: This metric is a more objective, data-driven measure of similarity between outputs, calculated using the CodeBERT model. CodeBERT focuses on semantic similarity, meaning it assesses how closely the generated outputs match the reference outputs in meaning. The results showed an 88% similarity, reflecting approximately a 10% difference between the outputs, demonstrating that both models performed highly similarly.
These results highlight the importance of using a range of metrics to compare different LLMs. Overall, the findings suggest that GPT-4 and Gemini performed quite similarly until precision-based metrics were applied. The results aligned with the original tests conducted on the 12 original samples, supporting the conclusion that metrics such as CodeBERT can reveal subtle performance differences.
4.7. Summary of Results
Table 9 presents a comparative analysis of the four LLMs (ChatGPT, Bard/Gemini, Copilot, and Auto-GPT) across various tasks such as text generation, code generation, error detection, and optimization. The table highlights key performance metrics including accuracy, average iterations required, success rates, and speed optimization performance.
Overall, the observed results suggested that while all tested LLMs exhibited strong capabilities in generating coherent and contextually appropriate text, there were notable differences in their accuracy and consistency. These differences highlight the importance of the continuous development and refinement of LLMs to meet specific educational needs effectively. The subset of all questions and some of the code is gathered in the
Appendix A.
5. Discussion and Conclusions
This paper presents a comparative analysis of four LLMs—ChatGPT, Bard (now known as Gemini), Copilot, and Auto-GPT—evaluated during the summer of 2023 and the spring of 2024. The primary objective was to assess their effectiveness in generating high school curricula focused on ML and AI topics. The performance of these LLMs was evaluated using various metrics in an educational context to provide insights into their suitability for specific tasks and educational levels.
An initial question was whether to integrate LLMs into educational tools. The findings revealed the exceptional performance of LLMs across multiple tasks. Their ability to produce expert-level results within seconds, compared to the weeks typically required by human contributors, is remarkable. Before the advent of LLMs and generative AI, no tool exhibited such a high degree of efficiency across diverse tasks. Consequently, the overall assessment is highly favorable, consistently highlighting the utility of LLMs in educational settings.
This observation aligns with the application of LLMs across various domains:
In the field of medicine, the highest-performing LLMs have demonstrated the ability to correctly answer 90 percent of questions on the United States Medical Licensing Examination (USMLE) and surpassed web-based consultations in both quality and empathy [
25].
During the initial phases of innovation, including ideation, exploration, and prototyping, LLMs provided significant support. Real-world examples of AI-assisted innovation highlight their role in accelerating progress and reducing costs across diverse projects [
26].
In genomics, researchers have developed an extensive QA database to evaluate GPT models, revealing their potential to revolutionize biomedical research. These models have been shown to substantially reduce AI-induced hallucinations and enhance the accuracy of genomics-related inquiries [
27].
While LLMs’ effectiveness is evident across various fields, their applicability varies significantly across educational tasks. Unlike standardized assessments such as the medical USMLE, which provide uniform evaluations, educational materials span a wide spectrum, making objective and consistent evaluation more challenging. This study suggests that some educational tasks align more closely with specific LLM capabilities than others. For tasks where LLMs have demonstrated effectiveness, delaying their integration into education seems unnecessary. However, it is crucial to recognize the risks of misuse when deploying these tools without careful consideration. Rigorous research and the thoughtful application of LLMs in educational contexts are essential to maximize their benefits while minimizing potential pitfalls. Future research should focus on identifying the most effective tools and contexts for specific educational tasks.
Consider, for example, code analysis, where the LLMs exhibited a reasonable capacity to detect errors and warnings in the provided code segments. However, due to the limited scope of the test samples, these findings should be interpreted particularly for short, similar programs, while further extensive testing is necessary to establish more definitive conclusions for other types of programs. Moreover, the effectiveness of this functionality varied, proving beneficial in some instances while being less effective in others. Other publications, such as [
28], have similarly noted the variability in LLM performance when applied to different types of code analysis tasks, highlighting the need for more robust benchmarking across diverse programming environments and task complexities. This underscores the importance of future studies focusing not only on broader testing scenarios but also on refining LLMs to improve consistency in code analysis, especially in more complex and longer programming contexts.
Regarding code optimization, particularly in improving execution speed, LLMs showed suboptimal performance. On average, the code modifications proposed by the LLMs resulted in slower execution times compared to the original code. Although LLMs generated results within seconds, human experts required significantly more time to produce optimized code. This implies that while LLMs offer rapid solutions, their optimization capabilities are more suited to novices than experts. These findings highlight a potential area for improvement in future LLM designs. While some studies, such as [
29], found LLMs to be competitive in code optimization, our comparison against human experts showed otherwise, likely due to the different nature of the tests used.
Regarding the different versions from 2023 and 2024, the newer versions generally showed improved performance. While it is understandable that high-performing systems may not experience significant upgrades, it is puzzling why some underperforming systems did not show substantial improvement over time, suggesting that certain problems may not be well suited to specific LLMs. However, there were other notable advancements, such as improvements in multimedia capabilities or faster response times compared to the spring version.
The results suggested that ChatGPT, Copilot, and Auto-GPT generally performed slightly better than Bard (later Gemini) on most of the tests, though the differences were not substantial. These three LLMs appeared to demonstrate greater proficiency on tasks related to curriculum creation and problem solving within the context of AI and ML. Bard’s somewhat lower performance on these tests may reflect differences in design and functionality, which are unique to each LLM. It is important to note that Bard (Gemini) has a different architecture than the other three models. Additionally, as Auto-GPT is a more specialized tool, ChatGPT-4 (also known as ChatGPT-4o) and Copilot emerged as particularly well suited for the tasks at hand.
Regarding the potential extension of the results to other educational levels, LLMs may encounter difficulties with tasks aimed at younger students, especially those requiring simpler, more creative approaches, analogies, or explanations tailored to a child-friendly level. The limited familiarity of these students with technical terminology could result in the need for more iterations to achieve satisfactory outcomes. Conversely, college students, who are likely to engage with more advanced topics like deep learning and reinforcement learning, may benefit from LLMs in addressing complex concepts. However, the models might face limitations when tackling tasks that demand deeper reasoning, abstract thinking, or specialized understanding of intricate algorithms. On the other hand, it is also possible that the LLMs could handle these variations in complexity without significant difficulty. Investigating how LLMs perform across different educational levels will be a key focus of future research.
Regarding the three outlined hypotheses,
The first hypothesis, which posited that LLMs could perform comparably to human experts in specific tasks, was confirmed. LLMs demonstrated performance on par with humans, particularly in text generation and error detection, and even matched expert performance in some cases.
The second hypothesis, suggesting significant performance differences between the LLMs, was partially validated. While most LLMs performed well on various tasks, they struggled qirh some tasks, e.g., with code optimization. Notably, ChatGPT and Copilot slightly outperformed Bard and Auto-GPT on several tasks, highlighting the variability in LLM capabilities.
The third hypothesis, which suggested that the timing of tests would reveal temporal differences in LLM performance (potentially fast progress), was not broadly supported. While we observed some improvements in LLM performance on specific experiments over a year and during the several-month testing period, their overall capabilities remained relatively stable, with no significant advancements on some tasks. Notably, there was no exponential growth in terms of performance. This underscores the need for continued development to further enhance LLM effectiveness, particularly for more complex educational tasks.
In addressing the primary questions posed in the Introduction, this study demonstrates that LLMs such as ChatGPT, Bard, Copilot, and Auto-GPT offer varying levels of utility across tasks related to the creation of high school ML curricula. LLMs were particularly effective in generating text-based content, providing accurate definitions, and identifying errors in code. However, their performance was less consistent on more complex tasks like code optimization and problem solving, where human expertise continued to hold an edge. The comparative analysis revealed notable differences among the LLMs, with ChatGPT and Copilot consistently, though only slightly, outperforming Bard and Auto-GPT on most tasks, especially in curriculum development and technical problem solving within the realm of AI and machine learning education.
The LLMs demonstrated certain limitations, particularly on tasks that required a deeper understanding of context, reasoning, and creative problem solving. Their responses often lacked illustrative examples and tended to be overly verbose. Numerous studies have already conducted extensive evaluations of these weaknesses across various domains, including cognitive tasks [
2]. Our study adopted a more focused approach, specifically assessing LLM performance within the context of high school machine learning curricula. In this domain, while the LLMs excelled at quickly generating relevant content, they often fell short when faced with advanced problem solving or tasks requiring creative solutions. For instance, for code generation and error detection tasks, the LLMs sometimes failed to fully grasp the context, leading to errors that human experts would typically avoid.
Although these models are not intended to replace human educators, especially in tasks that demand creativity and deep contextual understanding, they offer an unprecedented level of support in automating routine educational tasks and providing real-time assistance to students. Their ability to quickly generate relevant content and assist with immediate feedback makes them a valuable tool in the classroom. As LLMs continue to evolve, future advancements may address their current limitations, potentially allowing them to play an even more integral role in educational settings, complementing human educators in increasingly sophisticated ways.
These unique tests not only contribute to the understanding of LLM efficacy in educational settings but also shed light on pedagogical strategies that may optimize ML education for high school students.


 ,
, 


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}