
Multispectral Object Detection Based on Multilevel Feature Fusion and Dual Feature Modulation


Abstract
1. Introduction
- (1)
- We develop GMD-YOLO for light-infrared object detection, employing the Ghost module to optimize the dual-channel CSPDarknet53 network. This approach is appropriate for object detection tasks in low-light conditions and requires fewer parameters and less computation.
- (2)
- We propose a multilevel feature fusion module to integrate the different levels of visible-infrared information within the network. This module adopts a top-down, global-to-local approach, enhancing the representation of multiscale features through the construction of hierarchical residual connections.
- (3)
- We design a novel dual-feature modulation decoupling head, replacing the original coupled head. Generating feature encodings with specific semantic contexts resolves the conflict between classification and localization tasks, thereby increasing the accuracy of small object detection.
- (4)
- Experimental results demonstrated that GMD-YOLO surpasses existing advanced methods and exhibits strong robustness. On the KAIST dataset, the FPS value reached 61.7, surpassing other methods.
2. Related Work
2.1. Traditional Object Detection Algorithms
2.2. Multispectral Object Detection Algorithm
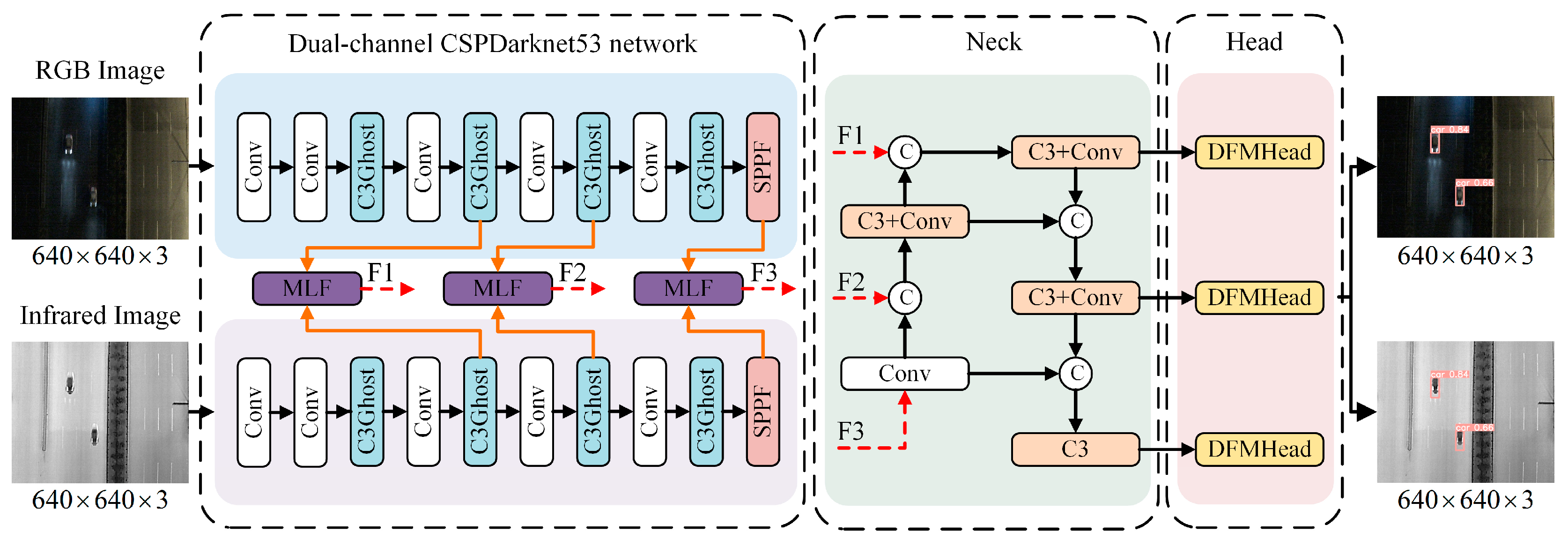
3. Methods
3.1. Dual-Channel CSPDarknet53 Network
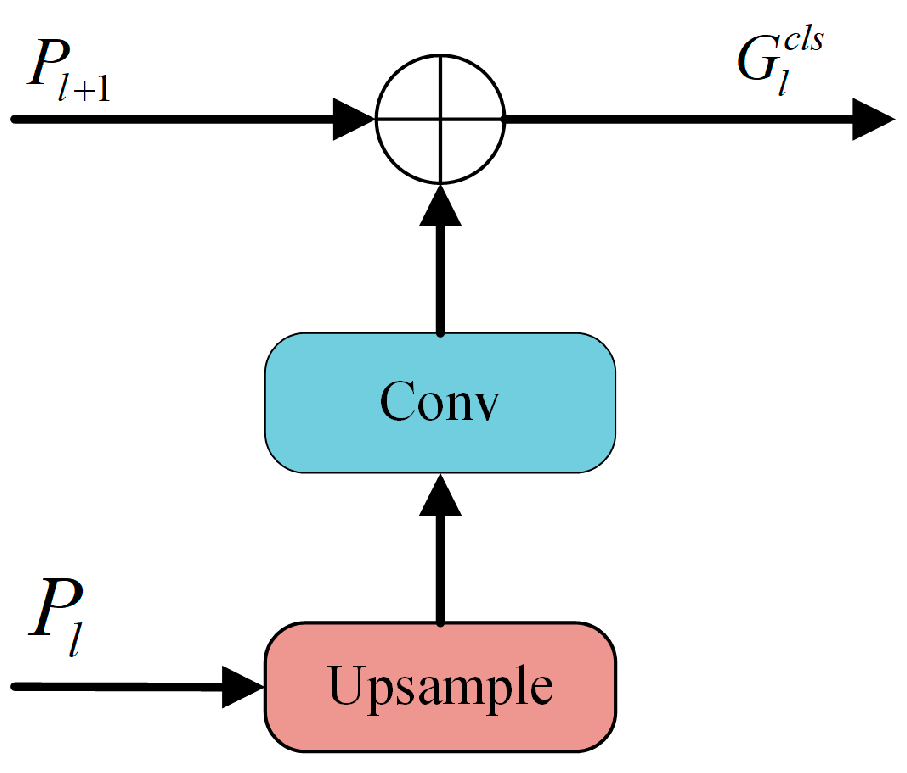
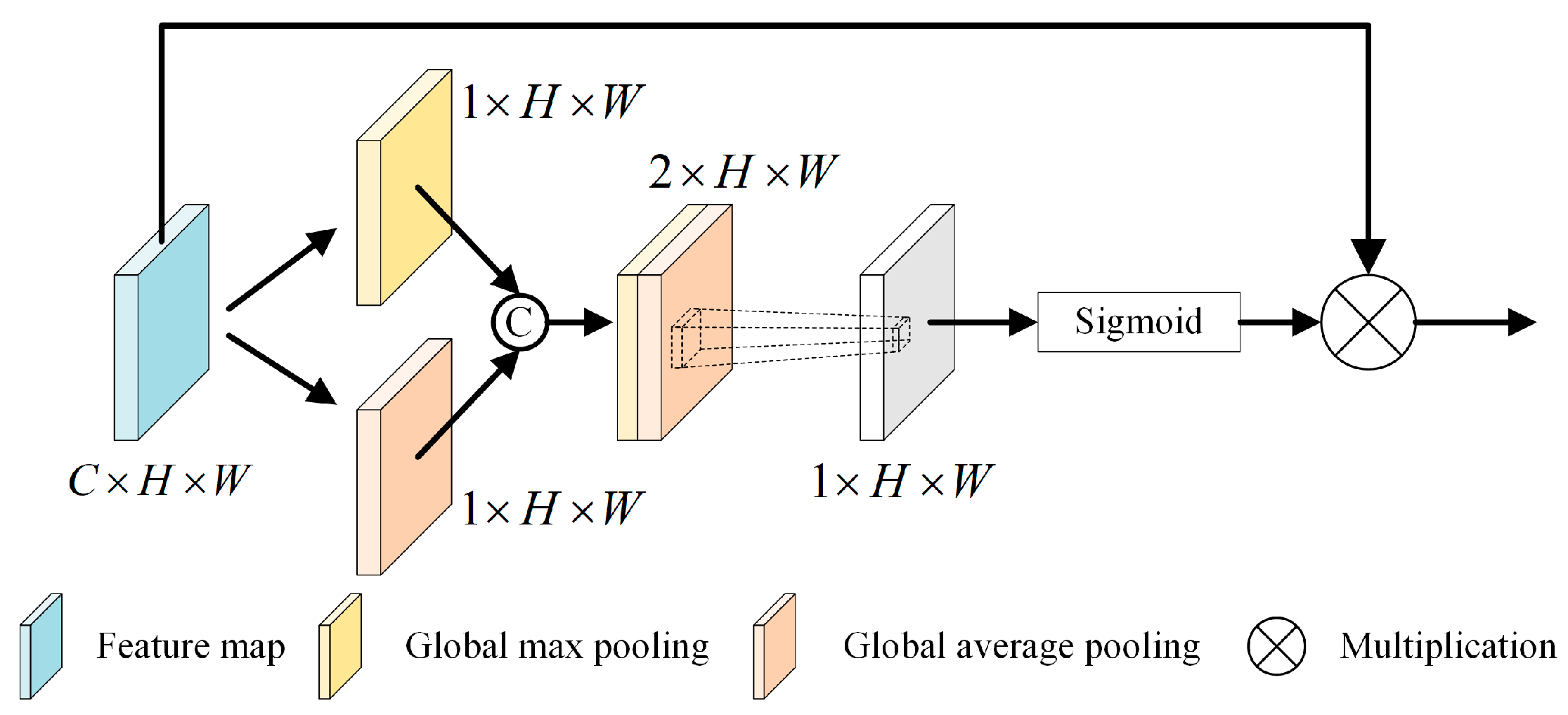
3.2. Multilevel Feature Fusion Module
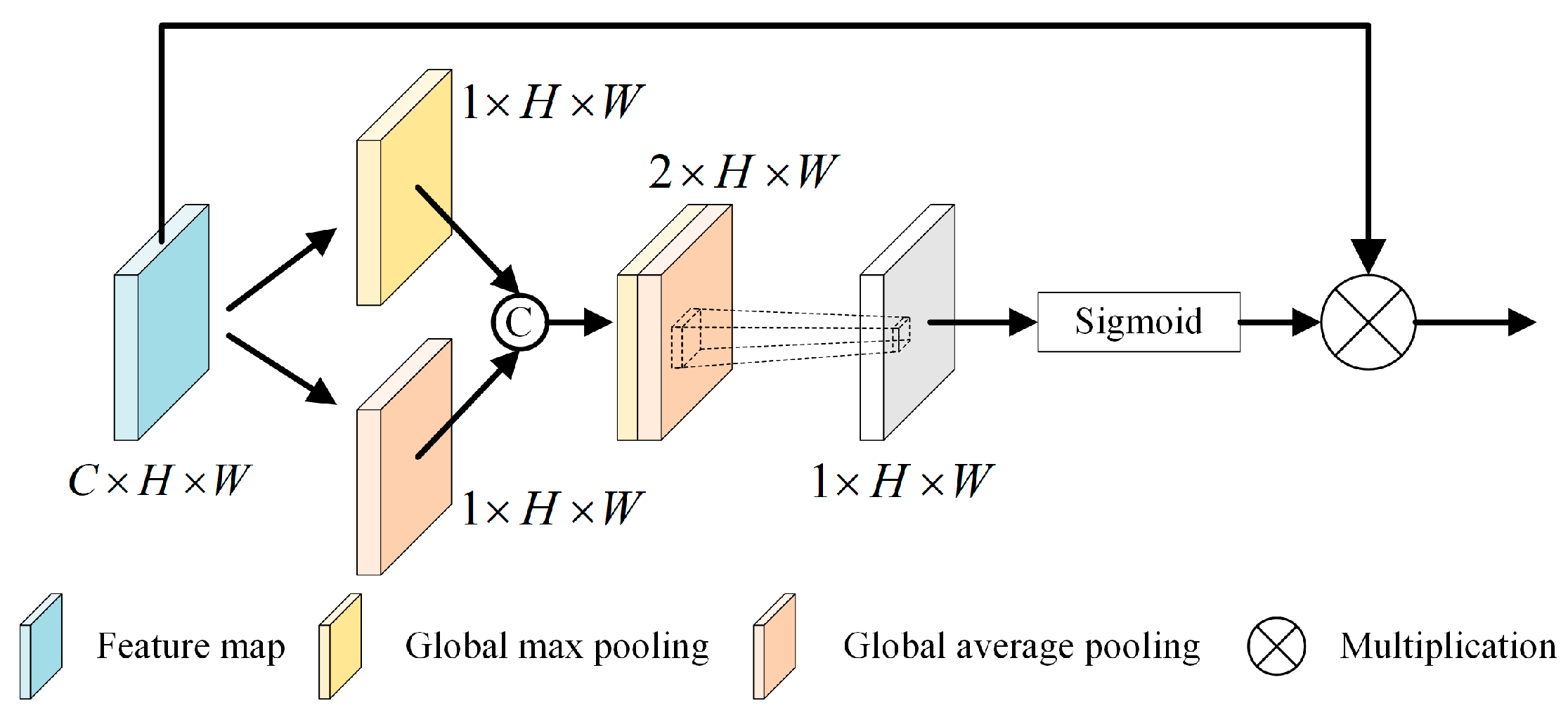
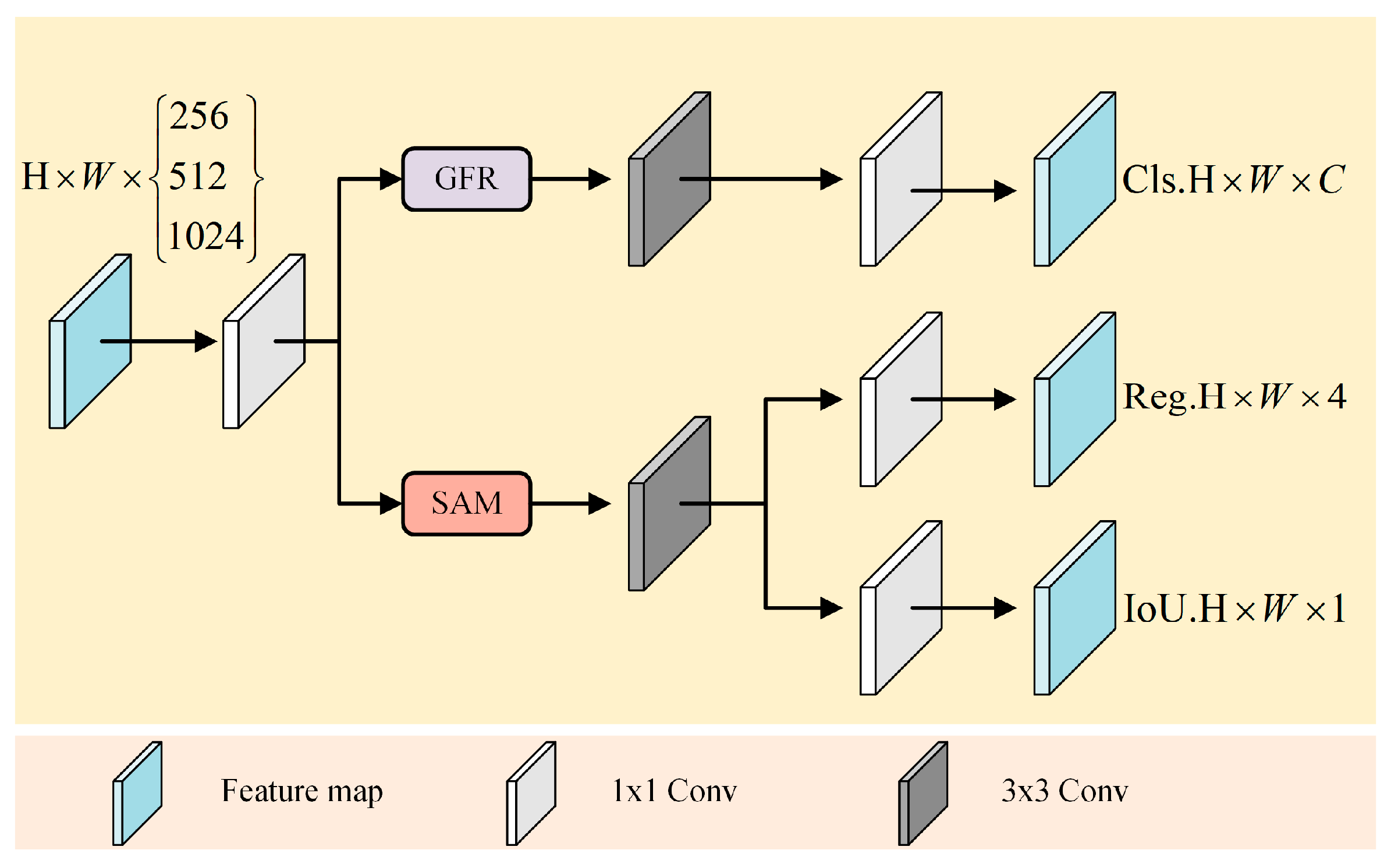
3.3. Dual Feature Modulation Decoupling Head
4. Experiments
4.1. Experimental Environment
4.2. Datasets and Evaluation Metrics
4.3. Ablation Experiments
4.3.1. Impact of the Multilevel Feature Fusion Module
4.3.2. Impact of Improved Detection Head
4.3.3. Impact of Different Modules
4.4. Comparison Experiment
4.4.1. Experiments on the DroneVehicle Dataset
4.4.2. Experiments on the KAIST Dataset
4.4.3. Experiments on the LLVIP Dataset
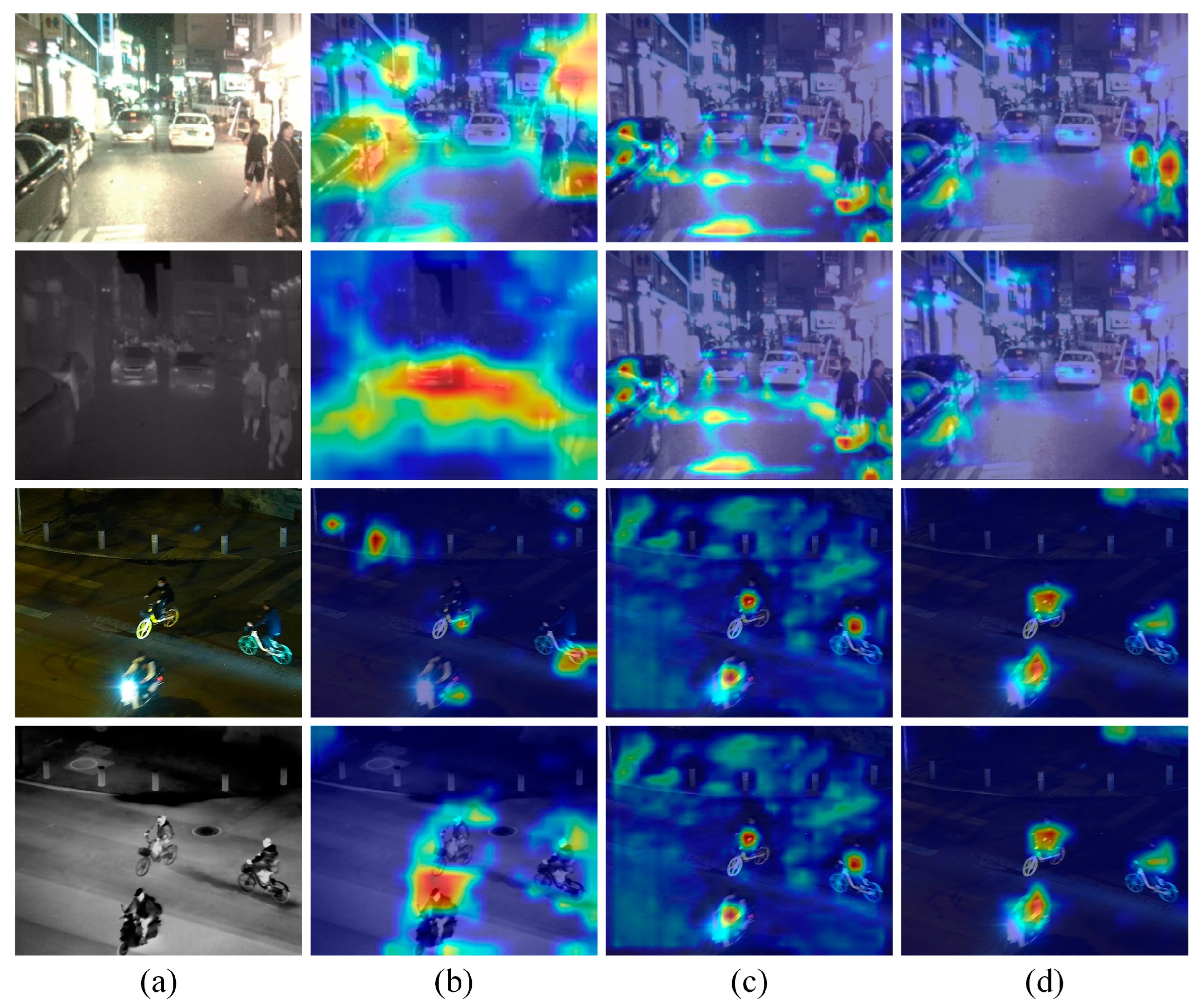
4.5. Qualitative Analysis
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Zhao, Z.; Zheng, P.; Xu, S.; Wu, X. Object detection with deep learning: A review. IEEE Trans. Neural Netw. Learn. Syst. 2019, 30, 3212–3232. [Google Scholar] [CrossRef] [PubMed]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single shot multibox detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; pp. 21–37. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You Only Look Once: Unified, Real-Time Object Detection. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 779–788. [Google Scholar]
- Singh, A.; Bhambhu, Y.; Buckchash, H.; Gupta, D.K.; Prasad, D.K. Latent Graph Attention for Enhanced Spatial Context. arXiv 2023, arXiv:2307.04149. [Google Scholar]
- Biswas, M.; Buckchash, H.; Prasad, D.K. pNNCLR: Stochastic Pseudo Neighborhoods for Contrastive Learning based Unsupervised Representation Learning Problems. arXiv 2023, arXiv:2308.06983. [Google Scholar]
- Gu, J.; Su, T.; Wang, Q.; Du, X.; Guizani, M. Multiple Moving Targets Surveillance Based on a Cooperative Network for Multi-UAV. IEEE Commun. Mag. 2018, 56, 82–89. [Google Scholar] [CrossRef]
- Kim, J.H.; Batchuluun, G.; Park, K.R. Pedestrian detection based on faster R-CNN in nighttime by fusing deep convolutional features of successive images. Expert Syst. Appl. 2018, 114, 15–33. [Google Scholar] [CrossRef]
- Zou, T.; Yang, S.; Zhang, Y.; Ye, M. Attention guided neural network models for occluded pedestrian detection. Pattern Recognit. Lett. 2020, 131, 91–97. [Google Scholar] [CrossRef]
- He, X.; Chen, Z.; Dai, L.; Liang, L.; Wu, J.; Sheng, B. Global-and-local aware network for low-light image enhancement. Eng. Appl. Artif. Intell. 2023, 126, 106969. [Google Scholar] [CrossRef]
- Zheng, A.; Ye, N.; Li, C.; Wang, X.; Tang, J. Multi-modal foreground detection via inter-and intra-modality-consistent low-rank separation. Neurocomputing 2020, 371, 27–38. [Google Scholar] [CrossRef]
- Zhang, X.; Zhang, Y.; Guo, Z.; Zhao, J.; Tong, X. Advances and perspective on motion detection fusion in visual and thermal framework. J. Infrared Millim. Waves 2011, 30, 354–359. [Google Scholar] [CrossRef]
- Yu, Z.; Yu, J.; Cui, Y.; Tao, D.; Tian, Q. Deep modular co-attention networks for visual question answering. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 6281–6290. [Google Scholar]
- Wanchaitanawong, N.; Tanaka, M.; Shibata, T.; Okutomi, M. Multi-Modal Pedestrian Detection with Large Misalignment Based on Modal-Wise Regression and Multi-Modal IoU. In Proceedings of the 2021 17th International Conference on Machine Vision and Applications (MVA), Virtual, 25–27 July 2021; pp. 1–6. [Google Scholar]
- Hwang, S.; Park, J.; Kim, N.; Choi, Y.; So Kweon, I. Multispectral pedestrian detection: Benchmark dataset and baseline. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Boston, MA, USA, 7–12 June 2015; pp. 1037–1045. [Google Scholar]
- Feichtenhofer, C.; Pinz, A.; Zisserman, A. Convolutional two-stream network fusion for video action recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Las Vegas, NV, USA, 27–30 June 2016; pp. 1933–1941. [Google Scholar]
- Wagner, J.; Fischer, V.; Herman, M.; Behnke, S. Multispectral Pedestrian Detection using Deep Fusion Convolutional Neural Networks. In Proceedings of the 24th European Symposium on Artificial Neural Networks, Computational Intelligence and Machine Learning, Bruges, Belgium, 5–7 October 2016; pp. 509–514. [Google Scholar]
- Konig, D.; Adam, M.; Jarvers, C.; Layher, G.; Neumann, H.; Teutsch, M. Fully convolutional region proposal networks for multispectral person detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition Workshops, Honolulu, HI, USA, 21–26 July 2017; pp. 49–56. [Google Scholar]
- Park, K.; Kim, S.; Sohn, K. Unified multi-spectral pedestrian detection based on probabilistic fusion networks. Pattern Recognit. 2018, 80, 143–155. [Google Scholar] [CrossRef]
- Sharma, M.; Dhanaraj, M.; Karnam, S.; Chachlakis, D.G.; Ptucha, R.; Markopoulos, P.P.; Saber, E. YOLOrs: Object detection in multimodal remote sensing imagery. IEEE J. Sel. Top. Appl. Earth Observ. Remote Sens. 2020, 14, 1497–1508. [Google Scholar] [CrossRef]
- Fang, Q.; Wang, Z. Cross-modality attentive feature fusion for object detection in multispectral remote sensing imagery. Pattern Recognit. 2022, 130, 108786. [Google Scholar] [CrossRef]
- Xue, Y.; Ju, Z.; Li, Y.; Zhang, W. MAF-YOLO: Multi-modal attention fusion based YOLO for pedestrian detection. Infrared Phys. Technol. 2021, 118, 103906. [Google Scholar] [CrossRef]
- Zhou, K.; Chen, L.; Cao, X. Improving multispectral pedestrian detection by addressing modality imbalance problems. In Proceedings of the Computer Vision–ECCV 2020: 16th European Conference, Glasgow, UK, 23–28 August 2020; pp. 787–803. [Google Scholar]
- Liu, T.; Lam, K.; Zhao, R.; Qiu, G. Deep cross-modal representation learning and distillation for illumination-invariant pedestrian detection. IEEE Trans. Circuits Syst. Video Technol. 2021, 32, 315–329. [Google Scholar] [CrossRef]
- Fang, Q.; Han, D.; Wang, Z. Cross-modality fusion transformer for multispectral object detection. arXiv 2021, arXiv:2111.00273. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich Feature Hierarchies for Accurate Object Detection and Semantic Segmentation. In Proceedings of the 2014 IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast R-CNN. In Proceedings of the 2015 IEEE International Conference on Computer Vision (ICCV), Santiago, Chile, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. Adv. Neural Inf. Process. Syst. 2015, 28. [Google Scholar] [CrossRef]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.; Liao, H.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, J.; Zhang, S.; Wang, S.; Metaxas, D.N. Multispectral deep neural networks for pedestrian detection. arXiv 2016, arXiv:1611.02644. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Multispectral pedestrian detection via simultaneous detection and segmentation. arXiv 2018, arXiv:1808.04818. [Google Scholar]
- Li, C.; Song, D.; Tong, R.; Tang, M. Illumination-aware faster R-CNN for robust multispectral pedestrian detection. Pattern Recognit. 2019, 85, 161–171. [Google Scholar] [CrossRef]
- Zhang, L.; Liu, Z.; Zhang, S.; Yang, X.; Qiao, H.; Huang, K.; Hussain, A. Cross-modality interactive attention network for multispectral pedestrian detection. Inf. Fusion 2019, 50, 20–29. [Google Scholar] [CrossRef]
- Zheng, Y.; Izzat, I.H.; Ziaee, S. GFD-SSD: Gated fusion double SSD for multispectral pedestrian detection. arXiv 2019, arXiv:1903.06999. [Google Scholar]
- Zhang, H.; Fromont, E.; Lefevre, S.; Avignon, B. Multispectral fusion for object detection with cyclic fuse-and-refine blocks. In Proceedings of the 2020 IEEE International Conference on Image Processing (ICIP), Abu Dhabi, United Arab Emirates, 25–28 October 2020; pp. 276–280. [Google Scholar]
- An, Z.; Liu, C.; Han, Y. Effectiveness Guided Cross-Modal Information Sharing for Aligned RGB-T Object Detection. IEEE Signal Process. Lett. 2022, 29, 2562–2566. [Google Scholar] [CrossRef]
- Sun, Y.; Cao, B.; Zhu, P.; Hu, Q. Drone-based RGB-infrared cross-modality vehicle detection via uncertainty-aware learning. IEEE Trans. Circuits Syst. Video Technol. 2022, 32, 6700–6713. [Google Scholar] [CrossRef]
- Yuan, M.; Wang, Y.; Wei, X. Translation, Scale and Rotation: Cross-Modal Alignment Meets RGB-Infrared Vehicle Detection. In Proceedings of the European Conference on Computer Vision, Tel Aviv, Israel, 23–27 October 2022; pp. 509–525. [Google Scholar]
- Zhang, J.; Lei, J.; Xie, W.; Fang, Z.; Li, Y.; Du, Q. SuperYOLO: Super resolution assisted object detection in multimodal remote sensing imagery. IEEE Trans. Geosci. Remote Sens. 2023, 61, 5605415. [Google Scholar] [CrossRef]
- Wang, Q.; Chi, Y.; Shen, T.; Song, J.; Zhang, Z.; Zhu, Y. Improving RGB-infrared object detection by reducing cross-modality redundancy. Remote Sens. 2022, 14, 2020. [Google Scholar] [CrossRef]
- Bao, C.; Cao, J.; Hao, Q.; Cheng, Y.; Ning, Y.; Zhao, T. Dual-YOLO Architecture from Infrared and Visible Images for Object Detection. Sensors 2023, 23, 2934. [Google Scholar] [CrossRef]
- Fu, H.; Wang, S.; Duan, P.; Xiao, C.; Dian, R.; Li, S.; Li, Z. LRAF-Net: Long-Range Attention Fusion Network for Visible–Infrared Object Detection. IEEE Trans. Neural Netw. Learn. Syst. 2023, 1–14. [Google Scholar] [CrossRef]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- You, S.; Xie, X.; Feng, Y.; Mei, C.; Ji, Y. Multi-Scale Aggregation Transformers for Multispectral Object Detection. IEEE Signal Process. Lett. 2023, 30, 1172–1176. [Google Scholar] [CrossRef]
- Chen, Z.; Yang, C.; Li, Q.; Zhao, F.; Zha, Z.; Wu, F. Disentangle your dense object detector. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual, 20–24 October 2021; pp. 4939–4948. [Google Scholar]
- Dai, J.; Li, Y.; He, K.; Sun, J. R-fcn: Object detection via region-based fully convolutional networks. Adv. Neural Inf. Process. Syst. 2016, 29. [Google Scholar]
- Woo, S.; Park, J.; Lee, J.; Kweon, I.S. CBAM: Convolutional block attention module. In Proceedings of the European Conference on Computer Vision (ECCV), Munich, Germany, 8–14 September 2018; pp. 3–19. [Google Scholar]
- Choi, Y.; Kim, N.; Hwang, S.; Park, K.; Yoon, J.S.; An, K.; Kweon, I.S. KAIST multi-spectral day/night data set for autonomous and assisted driving. IEEE Trans. Intell. Transp. Syst. 2018, 19, 934–948. [Google Scholar] [CrossRef]
- Jia, X.; Zhu, C.; Li, M.; Tang, W.; Zhou, W. LLVIP: A visible-infrared paired dataset for low-light vision. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021; pp. 3496–3504. [Google Scholar]
- Liu, Y.; Shao, Z.; Hoffmann, N. Global attention mechanism: Retain information to enhance channel-spatial interactions. arXiv 2021, arXiv:2112.05561. [Google Scholar]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 13713–13722. [Google Scholar]
- Wang, Q.; Wu, B.; Zhu, P.; Li, P.; Zuo, W.; Hu, Q. ECA-Net: Efficient channel attention for deep convolutional neural networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 11534–11542. [Google Scholar]
- Zhang, L.; Zhu, X.; Chen, X.; Yang, X.; Lei, Z.; Liu, Z. Weakly aligned cross-modal learning for multispectral pedestrian detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Long Beach, CA, USA, 16–19 June 2019; pp. 5127–5137. [Google Scholar]









{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Method | Modal | Precision (%) | mAP@0.5 (%) |
|---|---|---|---|
| Baseline-RGB | RGB | 90.2 | 90.0 |
| Baseline-Thermal | IR | 92.3 | 94.9 |
| Baseline | RGB + IR | 92.9 | 93.6 |
| Baseline + MLF | RGB + IR | 93.2 | 94.0 |
| Method | GFLOPs | Precision (%) | mAP@0.5 (%) |
|---|---|---|---|
| SAM | 46.0 | 94.0 | 95.5 |
| CBAM [47] | 46.2 | 93.1 | 95.3 |
| GAM [50] | 50.2 | 93.5 | 96.2 |
| CA [51] | 46.1 | 92.8 | 95.1 |
| ECA [52] | 46.0 | 93.2 | 95.0 |
| Method | Ghost | MLF | DFMHead | GFLOPs | Precision (%) | mAP@0.5 (%) |
|---|---|---|---|---|---|---|
| Baseline | 32.3 | 92.9 | 93.6 | |||
| 1 | √ | 26.4 | 92.4 | 92.9 | ||
| 2 | √ | 29.7 | 93.2 | 94.0 | ||
| 3 | √ | 46.0 | 94.0 | 95.5 | ||
| 4 | √ | √ | 22.9 | 93.4 | 95.9 | |
| 5 | √ | √ | 39.2 | 94.2 | 96.8 | |
| 6 | √ | √ | 42.5 | 95.2 | 96.7 | |
| 7 | √ | √ | √ | 35.7 | 96.0 | 98.0 |
| Method | Modal | Backbone | Precision (%) | mAP@0.5 (%) |
|---|---|---|---|---|
| YOLOv5 | RGB | CSPDarknet53 | 59.5 | 64.8 |
| YOLOv5 | IR | CSPDarknet53 | 70.1 | 75.9 |
| YOLOv5 | RGB + IR | CSPDarknet53 | 74.1 | 74.4 |
| CFR [35] | RGB + IR | ResNet | - | 73.9 |
| UA-CMDet [37] | RGB + IR | YOLO | - | 64.0 |
| ECISNet [36] | RGB + IR | ResNet | - | 76.0 |
| TSFADet [38] | RGB + IR | ResNet | - | 73.0 |
| GMD-YOLO | RGB + IR | YOLO | 80.3 | 78.0 |
| Method | MR (%) | FPS (Hz) | Platform |
|---|---|---|---|
| ACF + T + THOG [14] | 56.17 | - | - |
| Halfway Fusion [30] | 26.67 | 2.33 | TITAN X |
| Fusion RPN + BN [17] | 16.27 | - | - |
| MSDS-RCNN [31] | 13.73 | 4.55 | GTX 1080Ti |
| IAF-RCNN [32] | 16.70 | 4.76 | TITAN X |
| CIAN [33] | 11.13 | 16.67 | GTX 1080Ti |
| AR-CNN [53] | 9.02 | 8.33 | TITAN X |
| MBNet [22] | 7.86 | 14.29 | GTX 1080Ti |
| GMD-YOLO | 7.73 | 61.7 | GTX 3070 |
| Method | Modal | Backbone | Precision (%) | mAP@0.5 (%) |
|---|---|---|---|---|
| YOLOv3 | RGB | Darknet53 | 90.7 | 81.2 |
| YOLOv3 | IR | Darknet53 | 91.4 | 88.8 |
| YOLOv5 | RGB | CSPDarknet53 | 90.2 | 90.0 |
| YOLOv5 | IR | CSPDarknet53 | 92.3 | 94.9 |
| YOLOv5 | RGB + IR | CSPDarknet53 | 92.9 | 93.6 |
| CFT [24] | RGB + IR | CFB | - | 97.5 |
| SuperYOLO [39] | RGB + IR | YOLO | - | 96.7 |
| GMD-YOLO | RGB + IR | YOLO | 96.0 | 98.0 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Sun, J.; Yin, M.; Wang, Z.; Xie, T.; Bei, S. Multispectral Object Detection Based on Multilevel Feature Fusion and Dual Feature Modulation. Electronics 2024, 13, 443. https://doi.org/10.3390/electronics13020443
Sun J, Yin M, Wang Z, Xie T, Bei S. Multispectral Object Detection Based on Multilevel Feature Fusion and Dual Feature Modulation. Electronics. 2024; 13(2):443. https://doi.org/10.3390/electronics13020443
Chicago/Turabian StyleSun, Jin, Mingfeng Yin, Zhiwei Wang, Tao Xie, and Shaoyi Bei. 2024. "Multispectral Object Detection Based on Multilevel Feature Fusion and Dual Feature Modulation" Electronics 13, no. 2: 443. https://doi.org/10.3390/electronics13020443
APA StyleSun, J., Yin, M., Wang, Z., Xie, T., & Bei, S. (2024). Multispectral Object Detection Based on Multilevel Feature Fusion and Dual Feature Modulation. Electronics, 13(2), 443. https://doi.org/10.3390/electronics13020443