

PatchRLNet: A Framework Combining a Vision Transformer and Reinforcement Learning for The Separation of a PTFE Emulsion and Paraffin

 ,
,
Abstract
1. Introduction
2. Related Work
3. Materials and Methods
3.1. Research Queue and Data Augmentation
3.2. Method
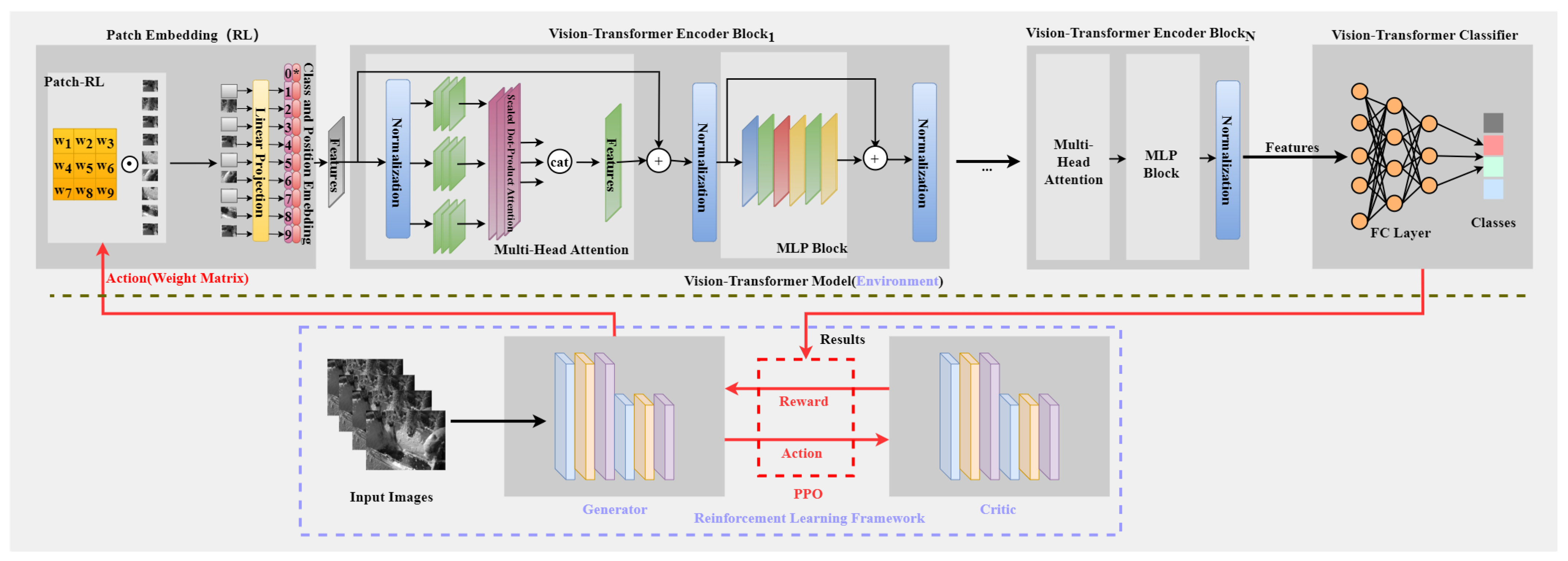
3.2.1. Reinforcement Learning for Enhancing Key Patch Features
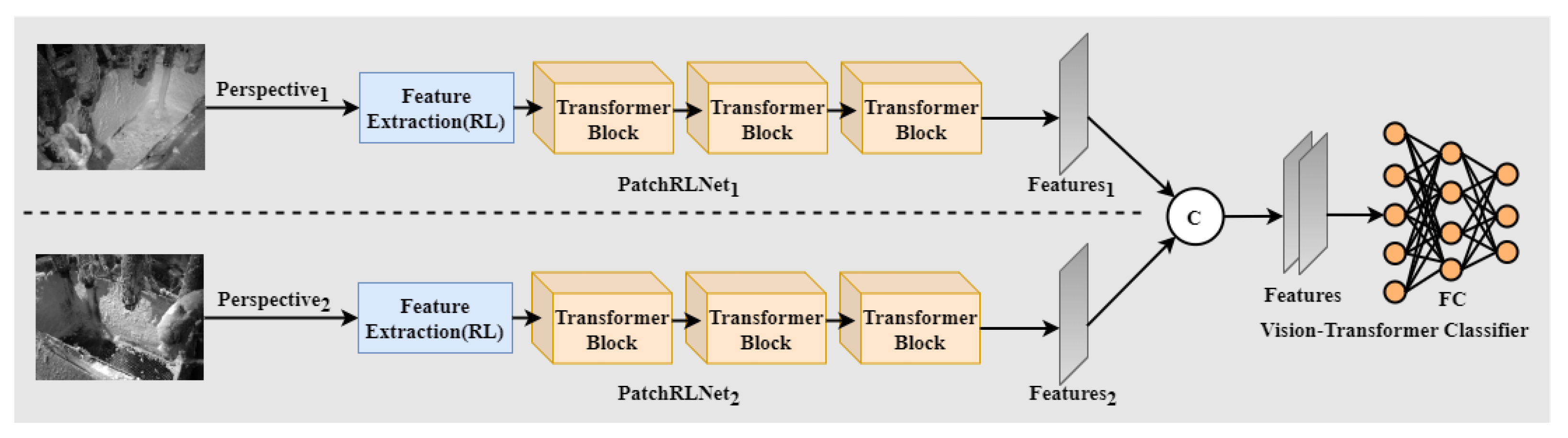
3.2.2. PatchRLNet for the Separation of PTFE Emulsion and Paraffin
3.3. Detection for PTFE Emulsion–Paraffin Separation Based on Multimodality
3.3.1. Multimodality
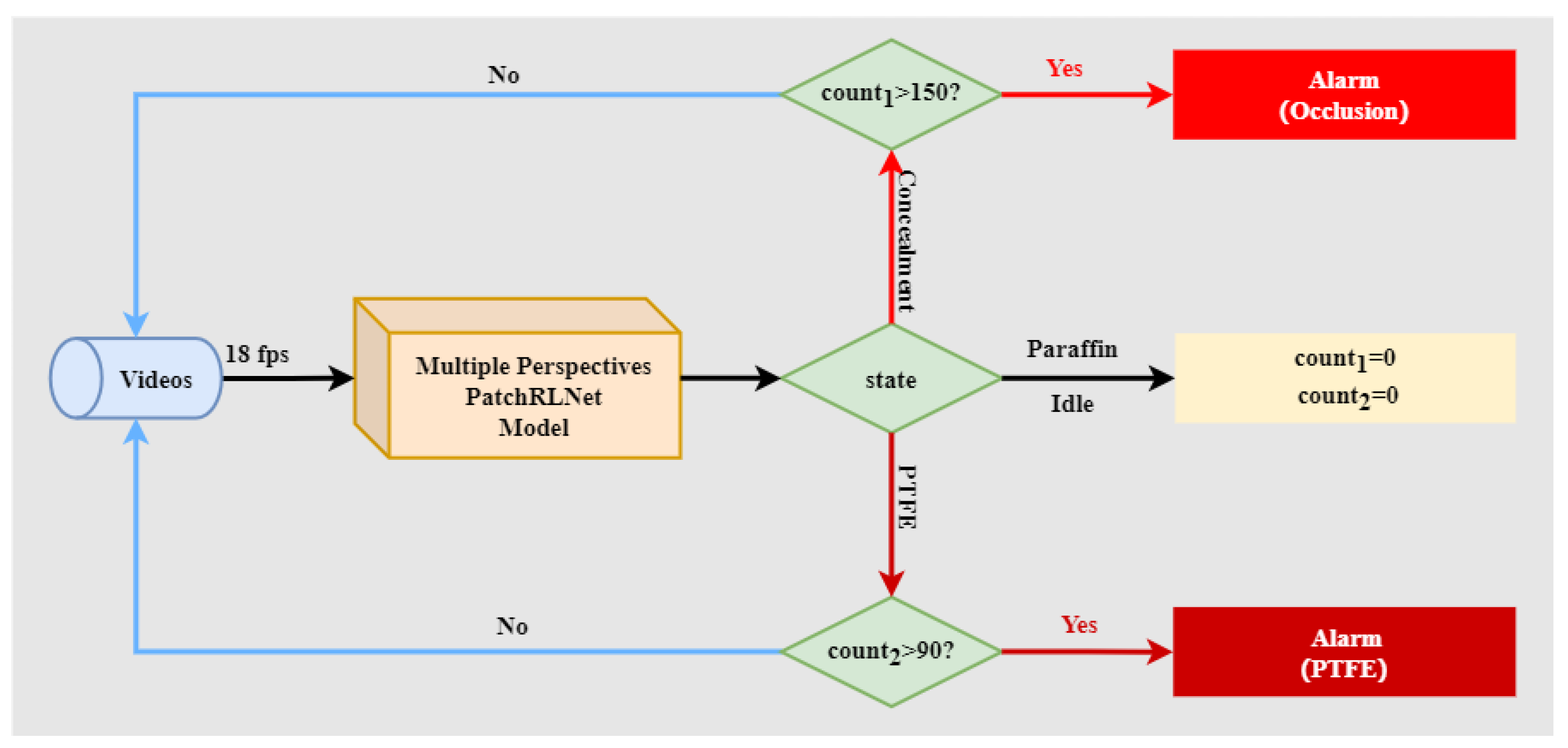
3.3.2. Engineering Control of Paraffin Separation from PTFE Emulsion
4. Results
4.1. Performance Evaluation Method
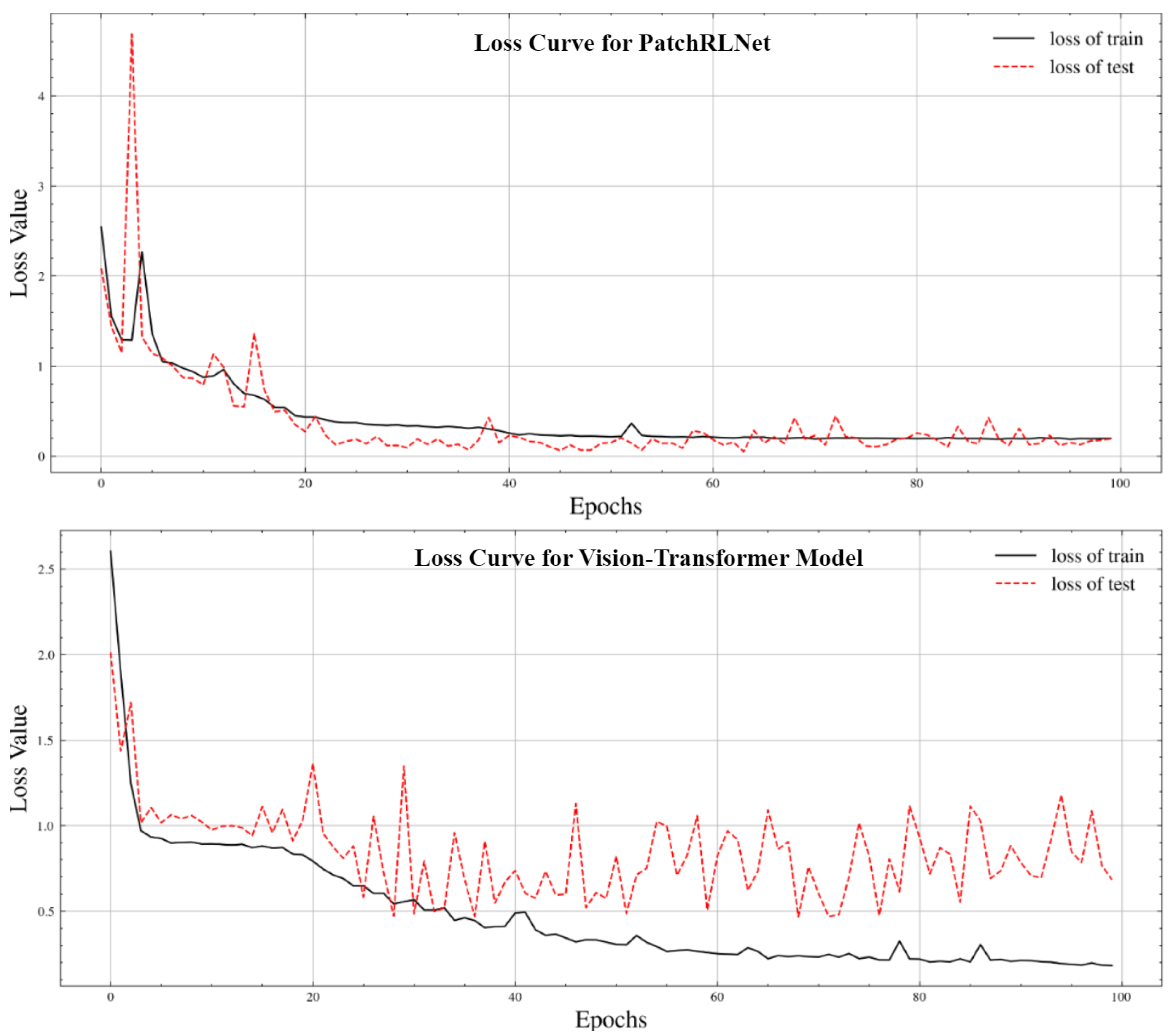
4.2. Performance Evaluation of the Vision Transformer
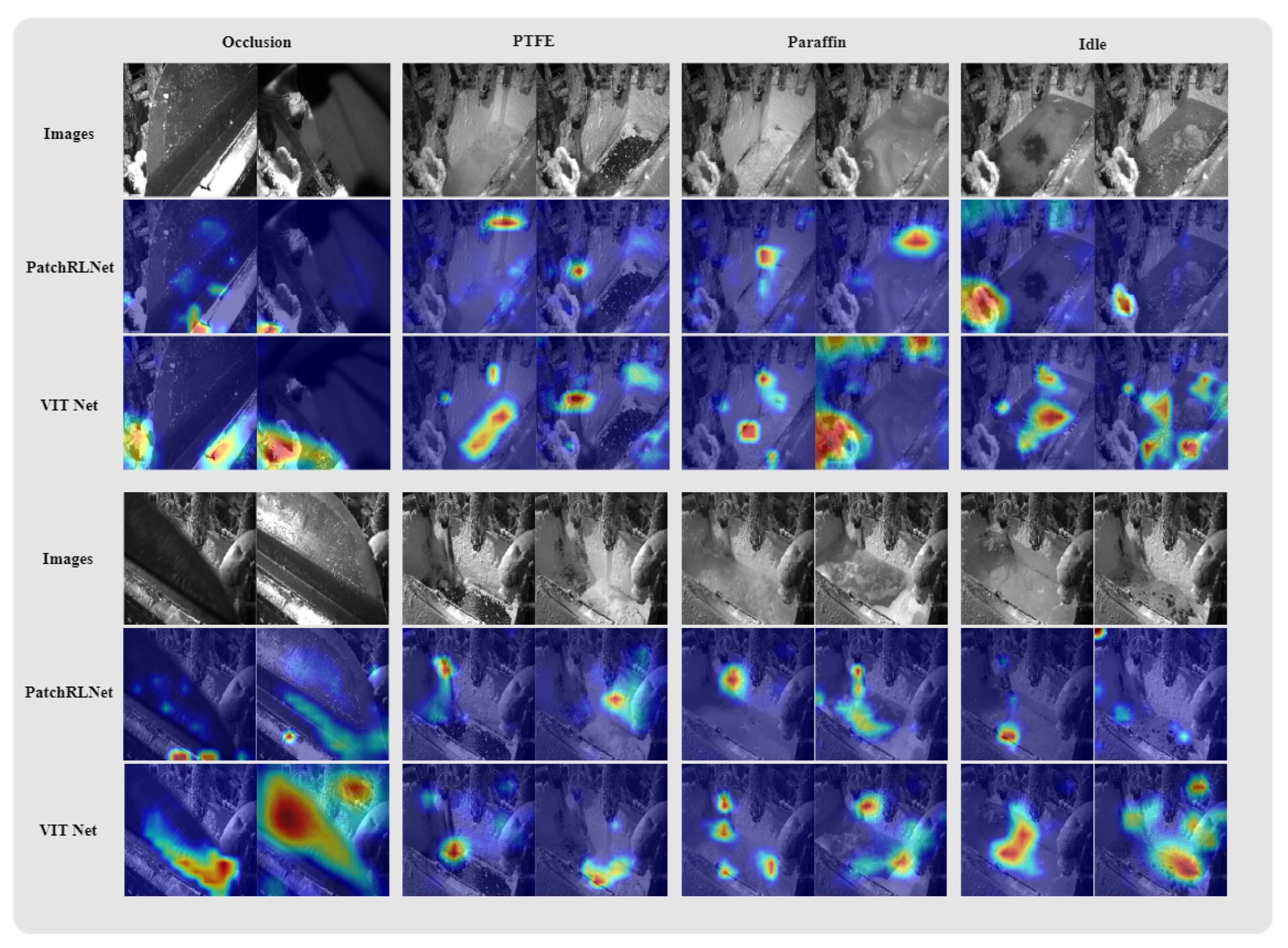
4.3. Performance Evaluation of PatchRLNet
4.4. Performance Evaluation of PTFE Emulsion–Paraffin Separation
5. Conclusions
Author Contributions
Funding
Institutional Review Board Statement
Informed Consent Statement
Data Availability Statement
Conflicts of Interest
Abbreviations
| PTFE | PolyTetraFluoroEthylene |
| VIT | Vision Transformer |
| CNN | Convolutional Neural Networks |
| AI | Artificial intelligence |
| FCN | Fully Convolutional Network |
| CAM | Class Activation Mapping |
References
- Dhanumalayan, E.; Joshi, G.M. Performance properties and applications of polytetrafluoroethylene (PTFE)—A review. Adv. Compos. Hybrid Mater. 2018, 1, 247–268. [Google Scholar] [CrossRef]
- Li, Y.; Liu, G.; Hou, J.; Sun, Y.; Yuan, Y. Application of artificial intelligence in computer network technology. In Application of Intelligent Systems in Multi-Modal Information Analytics, Proceedings of the 2021 International Conference on Multi-Modal Information Analytics (MMIA 2021), Huhehaote, China, 23–24 April 2021; Springer: Cham, Switzerland, 2021; Volume 1, pp. 523–528. [Google Scholar]
- Kaur, D.; Uslu, S.; Rittichier, K.J.; Durresi, A. Trustworthy artificial intelligence: A review. ACM Comput. Surv. (CSUR) 2022, 55, 1–38. [Google Scholar] [CrossRef]
- Liu, M.; Deng, J.; Yang, M.; Cheng, X.; Liu, N.; Liu, M.; Wang, X. Cost Ensemble with Gradient Selecting for GANs. In Proceedings of the Thirty-First International Joint Conference on Artificial Intelligence, IJCAI 2022, Vienna, Austria, 23–29 July 2022; pp. 1194–1200. [Google Scholar] [CrossRef]
- Lu, H.; Cheng, X.; Xia, W.; Deng, P.; Liu, M.; Xie, T.; Wang, X.; Liu, M. CyclicShift: A Data Augmentation Method For Enriching Data Patterns. In Proceedings of the MM ’22: The 30th ACM International Conference on Multimedia, Lisboa, Portugal, 10–14 October 2022; ACM: New York, NY, USA, 2022; pp. 4921–4929. [Google Scholar]
- Wang, K. An Overview of Deep Learning Based Small Sample Medical Imaging Classification. In Proceedings of the 2021 International Conference on Signal Processing and Machine Learning (CONF-SPML), Stanford, CA, USA, 14 November 2021; pp. 278–281. [Google Scholar]
- Deshmukh, V.M.; Rajalakshmi, B.; Krishna, G.B.; Rudrawar, G. An overview of deep learning techniques for autonomous driving vehicles. In Proceedings of the 2022 4th International Conference on Smart Systems and Inventive Technology (ICSSIT), Tirunelveli, India, 20–22 January 2022; pp. 979–983. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An image is worth 16 × 16 words: Transformers for image recognition at scale. arXiv 2020, arXiv:2010.11929. [Google Scholar]
- Han, K.; Wang, Y.; Chen, H.; Chen, X.; Guo, J.; Liu, Z.; Tang, Y.; Xiao, A.; Xu, C.; Xu, Y.; et al. A survey on vision transformer. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 87–110. [Google Scholar] [CrossRef] [PubMed]
- Molchanov, P.; Tyree, S.; Karras, T.; Aila, T.; Kautz, J. Pruning convolutional neural networks for resource efficient inference. arXiv 2016, arXiv:1611.06440. [Google Scholar]
- Khan, M.A.; Alqahtani, A.; Khan, A.; Alsubai, S.; Binbusayyis, A.; Ch, M.M.I.; Yong, H.S.; Cha, J. Cucumber leaf diseases recognition using multi level deep entropy-ELM feature selection. Appl. Sci. 2022, 12, 593. [Google Scholar] [CrossRef]
- Li, Y.; Gu, S.; Gool, L.V.; Timofte, R. Learning filter basis for convolutional neural network compression. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 5623–5632. [Google Scholar]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing atari with deep reinforcement learning. arXiv 2013, arXiv:1312.5602. [Google Scholar]
- Lyu, L.; Shen, Y.; Zhang, S. The Advance of reinforcement learning and deep reinforcement learning. In Proceedings of the 2022 IEEE International Conference on Electrical Engineering, Big Data and Algorithms (EEBDA), Changchun, China, 25–27 February 2022; pp. 644–648. [Google Scholar]
- Shi, J.C.; Yu, Y.; Da, Q.; Chen, S.Y.; Zeng, A.X. Virtual-taobao: Virtualizing real-world online retail environment for reinforcement learning. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 29–31 January 2019; Volume 33, pp. 4902–4909. [Google Scholar]
- Alrebdi, N.; Alrumiah, S.; Almansour, A.; Rassam, M. Reinforcement Learning in Image Classification: A Review. In Proceedings of the 2022 2nd International Conference on Computing and Information Technology (ICCIT), Tabuk, Saudi Arabia, 25–27 January 2022; pp. 79–86. [Google Scholar]
- Balamurugan, N.M.; Adimoolam, M.; Alsharif, M.H.; Uthansakul, P. A novel method for improved network traffic prediction using enhanced deep reinforcement learning algorithm. Sensors 2022, 22, 5006. [Google Scholar] [CrossRef] [PubMed]
- Ngiam, J.; Khosla, A.; Kim, M.; Nam, J.; Lee, H.; Ng, A.Y. Multimodal deep learning. In Proceedings of the 28th International Conference on Machine Learning (ICML-11), Bellevue, WA, USA, 28 June–2 July 2011; pp. 689–696. [Google Scholar]
- Baltrušaitis, T.; Ahuja, C.; Morency, L.P. Multimodal machine learning: A survey and taxonomy. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 423–443. [Google Scholar] [CrossRef] [PubMed]
- Neuendorf, L.; Müller, P.; Lammers, K.; Kockmann, N. Convolutional Neural Network (CNN)-Based Measurement of Properties in Liquid–Liquid Systems. Processes 2023, 11, 1521. [Google Scholar] [CrossRef]
- Chen, H.; Dang, Z.; Park, S.S.; Hugo, R. Robust CNN-based flow pattern identification for horizontal gas-liquid pipe flow using flow-induced vibration. Exp. Therm. Fluid Sci. 2023, 148, 110979. [Google Scholar] [CrossRef]
- Liu, D.; Liu, J.; Yuan, P.; Yu, F. A Lightweight Dangerous Liquid Detection Method Based on Depthwise Separable Convolution for X-Ray Security Inspection. Comput. Intell. Neurosci. 2022, 2022, 5371350. [Google Scholar] [CrossRef] [PubMed]
- Liu, N.; Yue, S.; Wang, Y. Flow Velocity computation in solid-liquid two-phase flow by convolutional neural network. In Proceedings of the 2023 IEEE International Instrumentation and Measurement Technology Conference (I2MTC), Kuala Lumpur, Malaysia, 22–25 May 2023; pp. 1–6. [Google Scholar]
- Zhao, Z.; Wu, X.; Liu, H. Vision transformer for quality identification of sesame oil with stereoscopic fluorescence spectrum image. LWT 2022, 158, 113173. [Google Scholar] [CrossRef]
- Li, H.; Kim, J.T.; Kim, J.S.; Choi, D.Y.; Lee, S.S. Metasurface-Incorporated Optofluidic Refractive Index Sensing for Identification of Liquid Chemicals through Vision Intelligence. ACS Photonics 2023, 10, 780–789. [Google Scholar] [CrossRef]
- Wu, Y.; Ye, H.; Yang, Y.; Wang, Z.; Li, S. Liquid content detection in transparent containers: A benchmark. Sensors 2023, 23, 6656. [Google Scholar] [CrossRef] [PubMed]
- Khan, S.; Naseer, M.; Hayat, M.; Zamir, S.W.; Khan, F.S.; Shah, M. Transformers in vision: A survey. ACM Comput. Surv. (CSUR) 2022, 54, 1–41. [Google Scholar] [CrossRef]
- Chen, Z.; Duan, Y.; Wang, W.; He, J.; Lu, T.; Dai, J.; Qiao, Y. Vision transformer adapter for dense predictions. arXiv 2022, arXiv:2205.08534. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep residual learning for image recognition. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016; pp. 770–778. [Google Scholar]
- Huang, G.; Liu, Z.; Van Der Maaten, L.; Weinberger, K.Q. Densely connected convolutional networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 4700–4708. [Google Scholar]
- Chen, Y.; Li, J.; Xiao, H.; Jin, X.; Yan, S.; Feng, J. Dual path networks. In Proceedings of the Advances in Neural Information Processing Systems 30: Annual Conference on Neural Information Processing Systems 2017, Long Beach, CA, USA, 4–9 December 2017. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–26 June 2018; pp. 7132–7141. [Google Scholar]
- Zhou, B.; Khosla, A.; Lapedriza, A.; Oliva, A.; Torralba, A. Learning Deep Features for Discriminative Localization. In Proceedings of the CVPR, Las Vegas, NV, USA, 27–30 July 2016. [Google Scholar]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Models | Params | GFlops | Average Accuracy | Accuracy | F1 Score |
|---|---|---|---|---|---|
| ResNet152 [29] | 5.81 M | 11.60 | 78.77 ± 3.90 | 79.85 ± 4.04 | 79.42 ± 5.02 |
| DenseNet201 [30] | 18.10 M | 4.39 | 80.92 ± 3.84 | 80.40 ± 3.83 | 79.78 ± 4.37 |
| DPN131 [31] | 76.58 M | 16.17 | 79.41 ± 3.58 | 80.56 ± 3.72 | 79.19 ± 4.49 |
| SE_ResNet152 [32] | 64.78 M | 11.39 | 80.41 ± 3.15 | 82.50 ± 3.67 | 79.13 ± 3.95 |
| VIT-L-16 [8] | 303.31 M | 59.73 | 82.34 ± 3.98 | 84.17 ± 4.43 | 81.50 ± 3.51 |
| VIT-B-16 | 85.80 M | 16.88 | 85.47 ± 4.09 | 87.31 ± 5.73 | 85.65 ± 3.34 |
| Models | Params | GFlops | Average Accuracy | Accuracy | F1 Score |
|---|---|---|---|---|---|
| ResNet152 | 5.81 M | 11.60 | 73.41 ± 3.42 | 73.28 ± 4.05 | 73.59 ± 3.84 |
| DenseNet201 | 18.10 M | 4.39 | 74.12 ± 3.25 | 74.11 ± 3.66 | 74.83 ± 3.97 |
| DPN131 | 76.58 M | 16.17 | 74.39 ± 4.18 | 75.52 ± 3.98 | 74.96 ± 3.70 |
| SE_ResNet152 | 64.78 M | 11.39 | 76.37 ± 4.23 | 78.93 ± 4.58 | 77.12 ± 4.25 |
| VIT-L-16 | 303.31 M | 59.73 | 78.81 ± 4.52 | 82.03 ± 5.01 | 80.61 ± 4.54 |
| VIT-B-16 | 85.80 M | 16.88 | 82.15 ± 5.76 | 83.95 ± 5.22 | 81.03 ± 4.45 |
| Models | Params | GFlops | Average Accuracy | Accuracy | F1 Score |
|---|---|---|---|---|---|
| VIT-B-16 | 85.80 M | 16.88 | 85.47 ± 4.09 | 87.31 ± 5.73 | 85.65 ± 3.34 |
| PatchRLNet | 85.80 M | 16.88 | 98.00 ± 1.04 | 98.69 ± 1.06 | 98.71 ± 1.12 |
| Models | Params | GFlops | Average Accuracy | Accuracy | F1 Score |
|---|---|---|---|---|---|
| VIT-B-16 | 85.80 M | 16.88 | 82.15 ± 5.76 | 83.95 ± 5.22 | 81.03 ± 4.45 |
| PatchRLNet | 85.80 M | 16.88 | 95.02 ± 2.88 | 96.73 ± 2.40 | 96.14 ± 2.08 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Wang, X.; Wu, L.; Hu, B.; Yang, X.; Fan, X.; Liu, M.; Cheng, K.; Wang, S.; Miao, J.; Gong, H. PatchRLNet: A Framework Combining a Vision Transformer and Reinforcement Learning for The Separation of a PTFE Emulsion and Paraffin. Electronics 2024, 13, 339. https://doi.org/10.3390/electronics13020339
Wang X, Wu L, Hu B, Yang X, Fan X, Liu M, Cheng K, Wang S, Miao J, Gong H. PatchRLNet: A Framework Combining a Vision Transformer and Reinforcement Learning for The Separation of a PTFE Emulsion and Paraffin. Electronics. 2024; 13(2):339. https://doi.org/10.3390/electronics13020339
Chicago/Turabian StyleWang, Xinxin, Lei Wu, Bingyu Hu, Xinduoji Yang, Xianghui Fan, Meng Liu, Kai Cheng, Song Wang, Jianqiang Miao, and Haigang Gong. 2024. "PatchRLNet: A Framework Combining a Vision Transformer and Reinforcement Learning for The Separation of a PTFE Emulsion and Paraffin" Electronics 13, no. 2: 339. https://doi.org/10.3390/electronics13020339
APA StyleWang, X., Wu, L., Hu, B., Yang, X., Fan, X., Liu, M., Cheng, K., Wang, S., Miao, J., & Gong, H. (2024). PatchRLNet: A Framework Combining a Vision Transformer and Reinforcement Learning for The Separation of a PTFE Emulsion and Paraffin. Electronics, 13(2), 339. https://doi.org/10.3390/electronics13020339