
Grapher: A Reconfigurable Graph Computing Accelerator with Optimized Processing Elements

Abstract
1. Introduction
2. Preparation for Grapher
2.1. Graph Algorithms
2.2. Formats of Graph Data
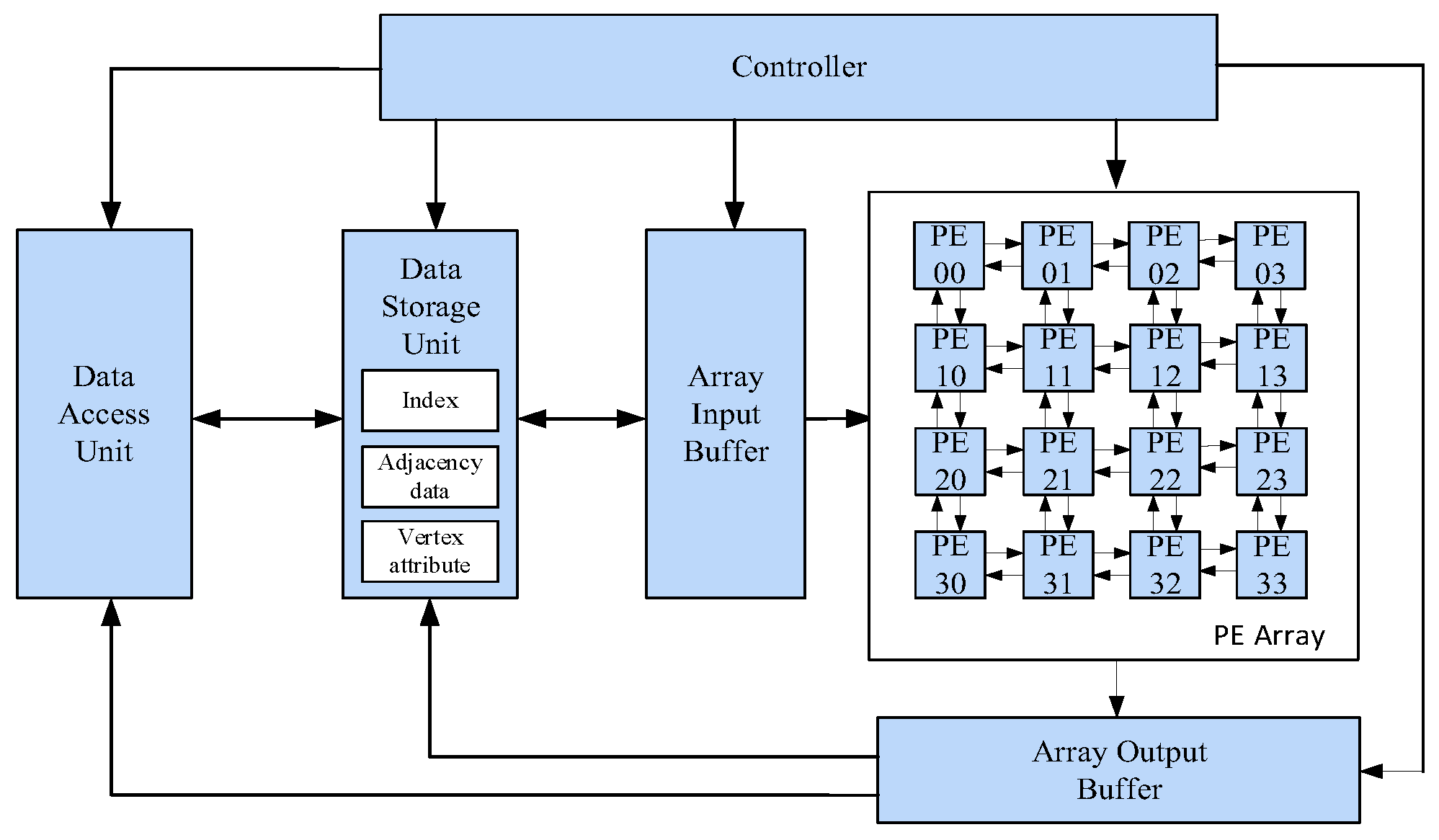
2.3. Architecture of Grapher
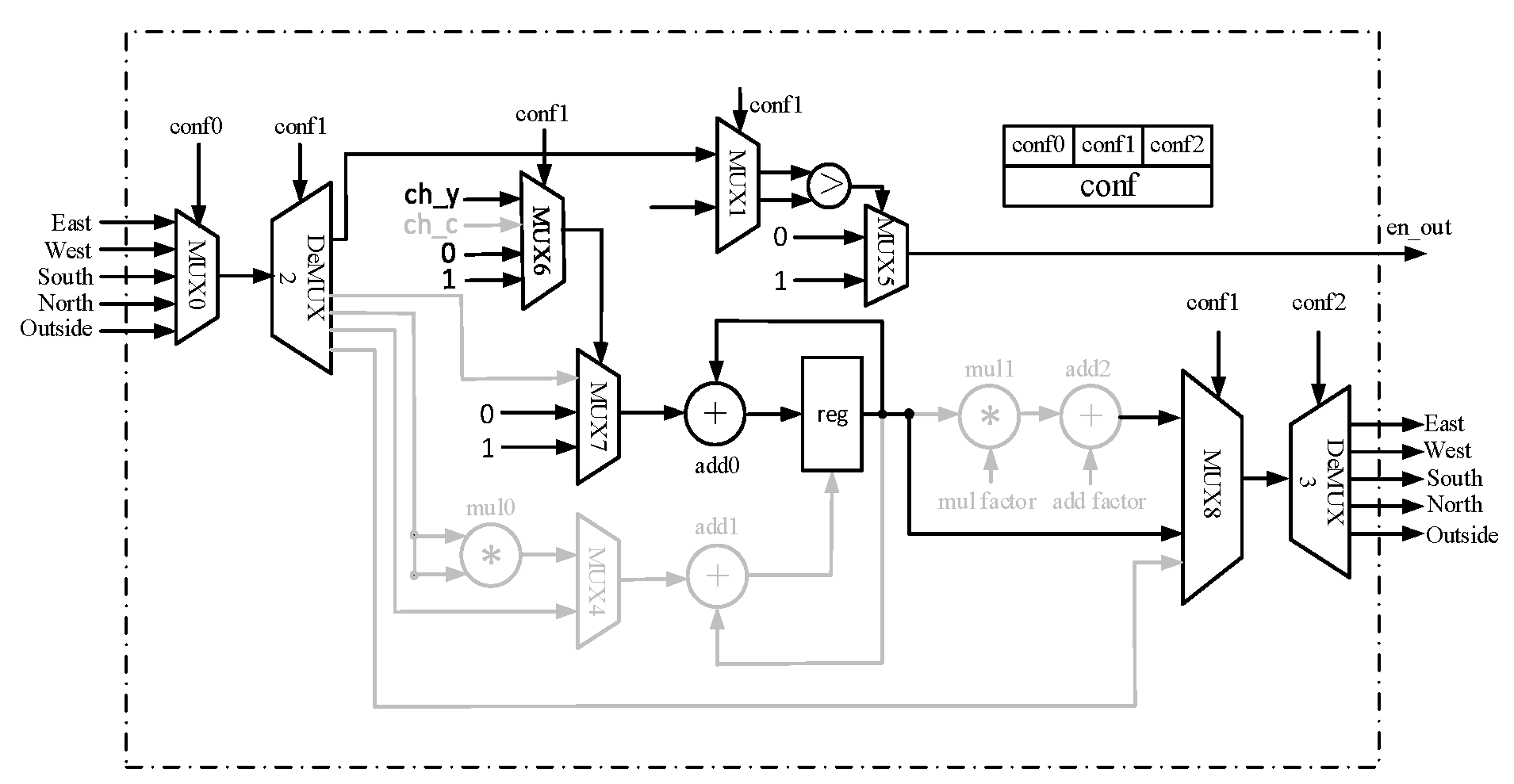
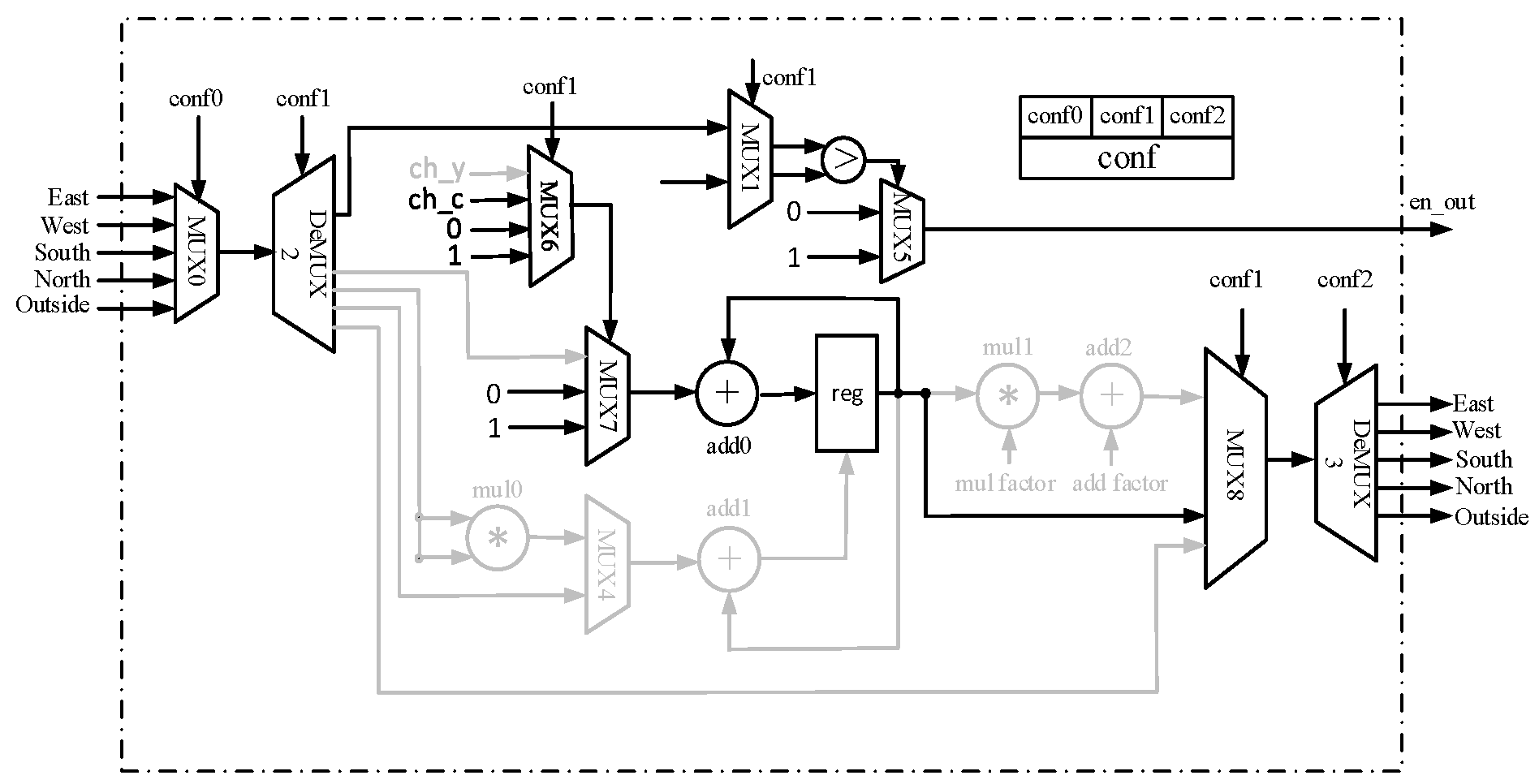
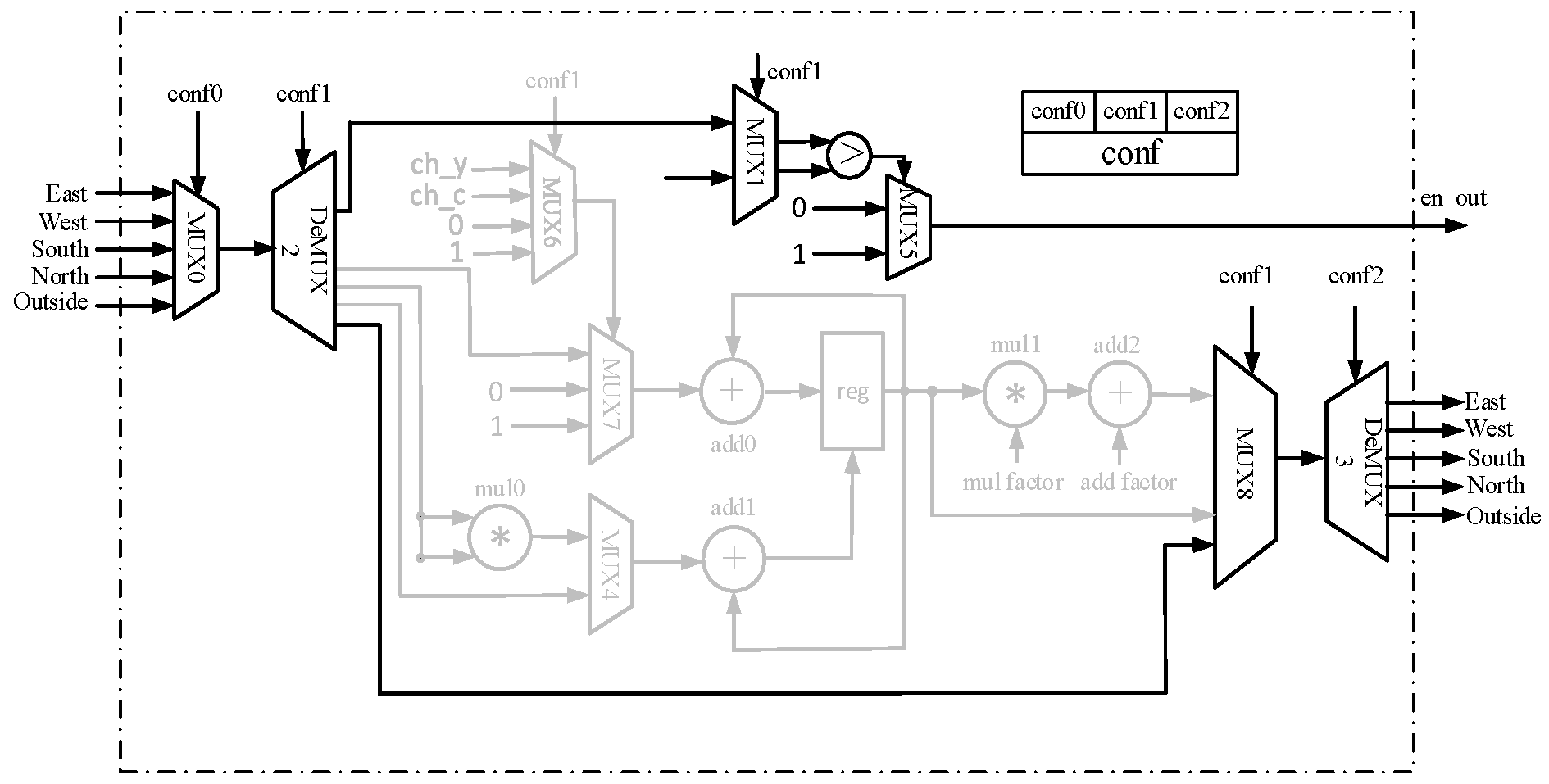
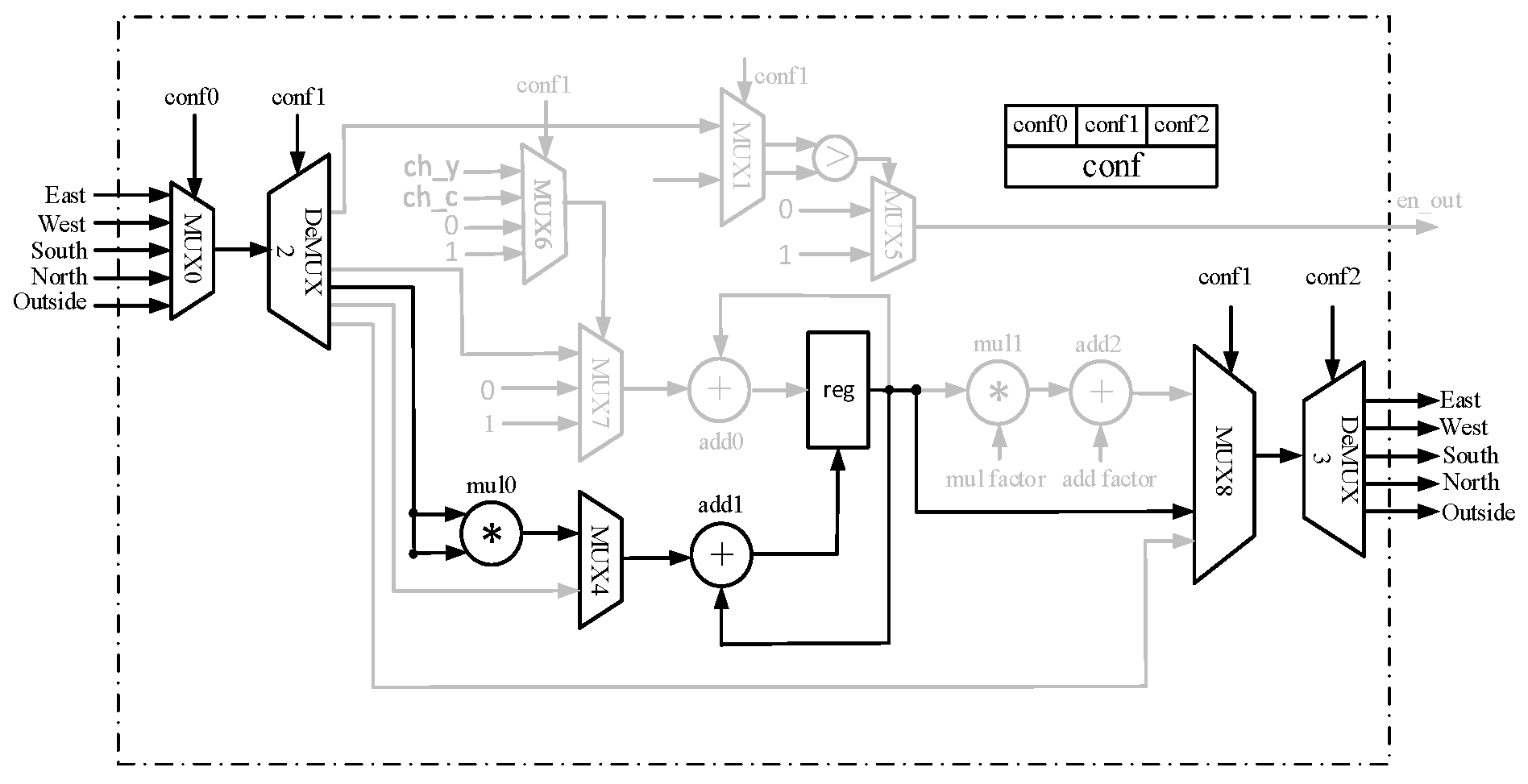
3. Design of Reconfigurable PE
4. Datapath Configuration
4.1. Datapath of BFS Algorithm
4.2. Datapath of CC Algorithm
4.3. Datapath of PR Algorithm
5. Results
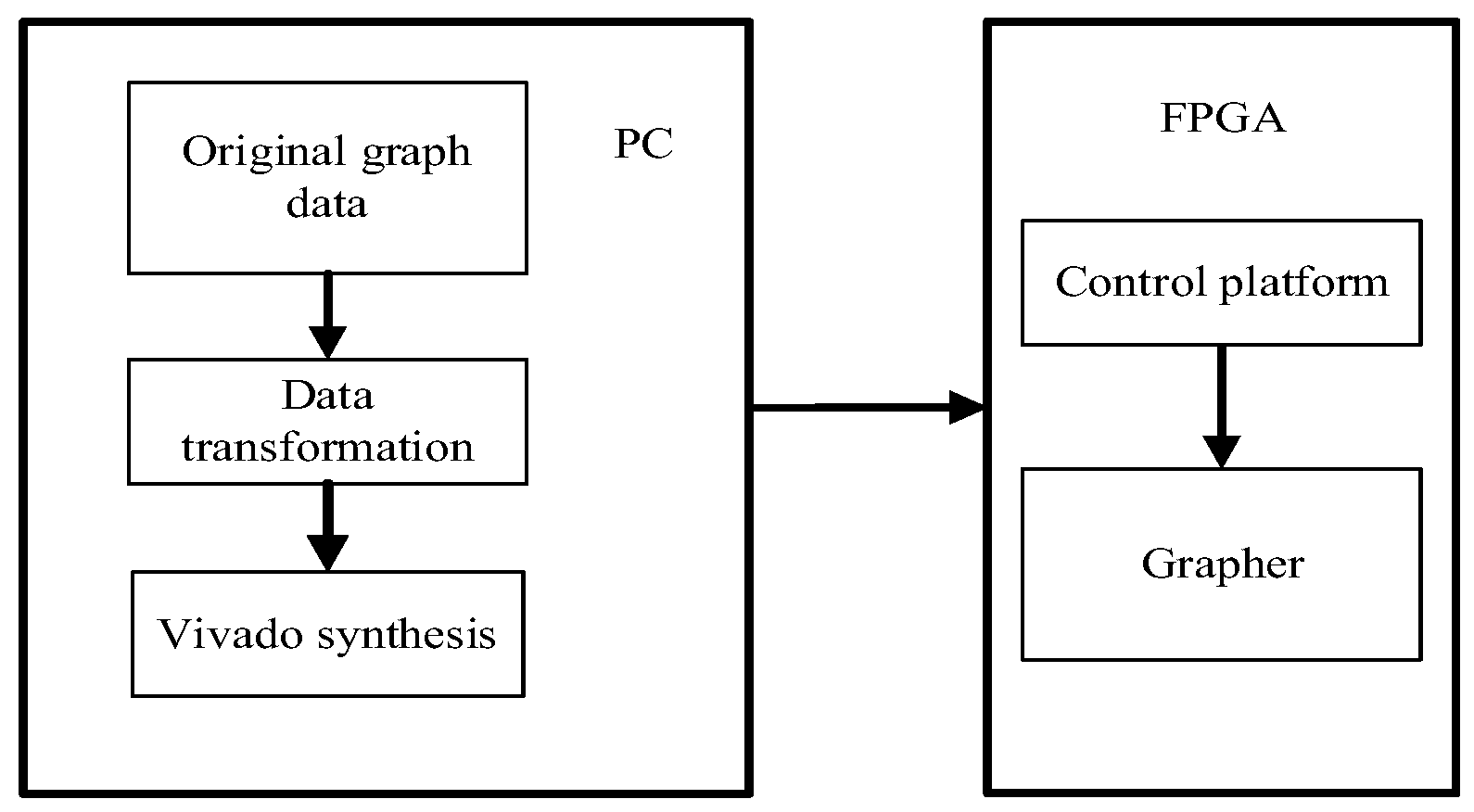
5.1. Grapher Testbench
5.2. Graph Data Selection
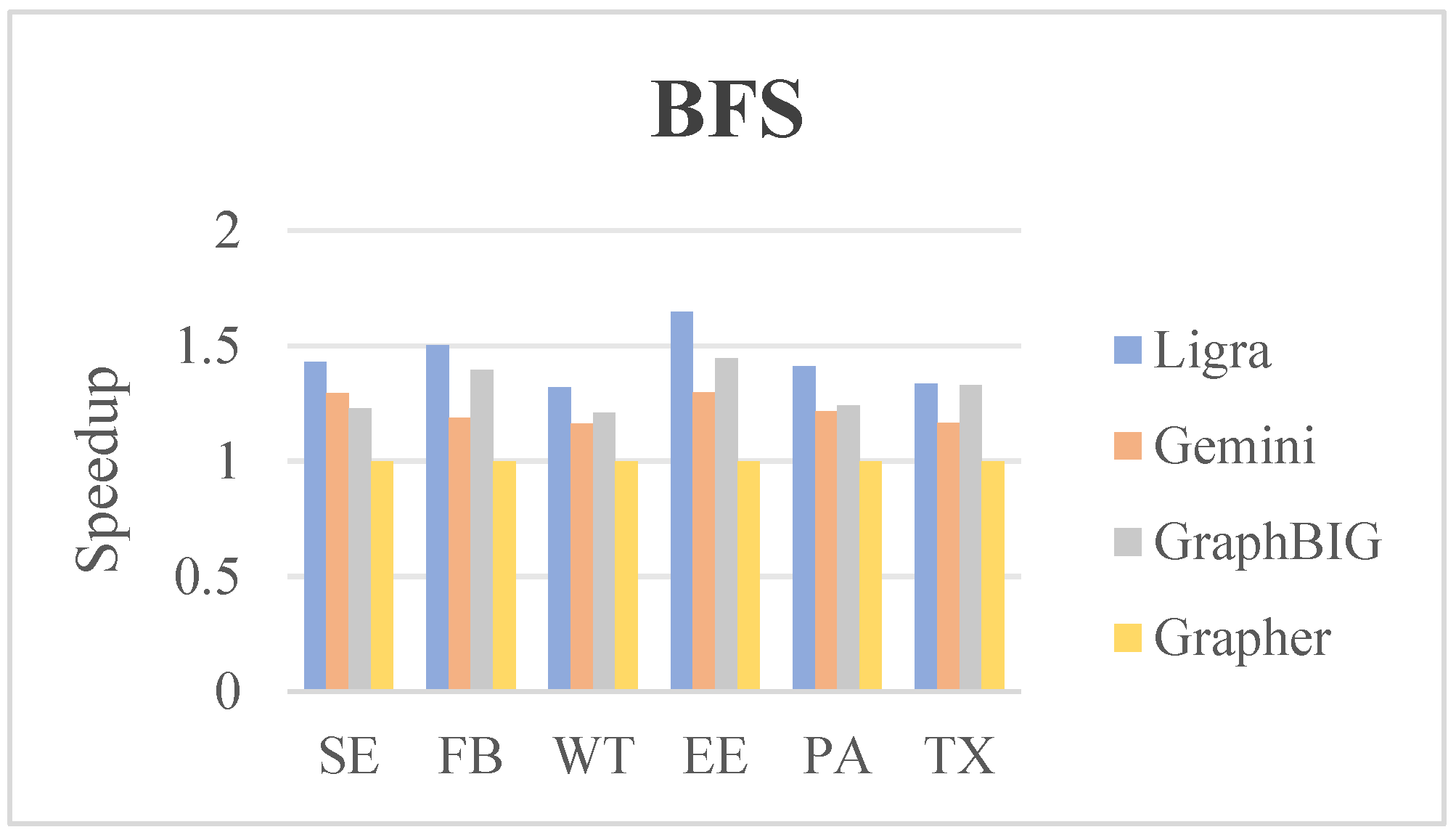
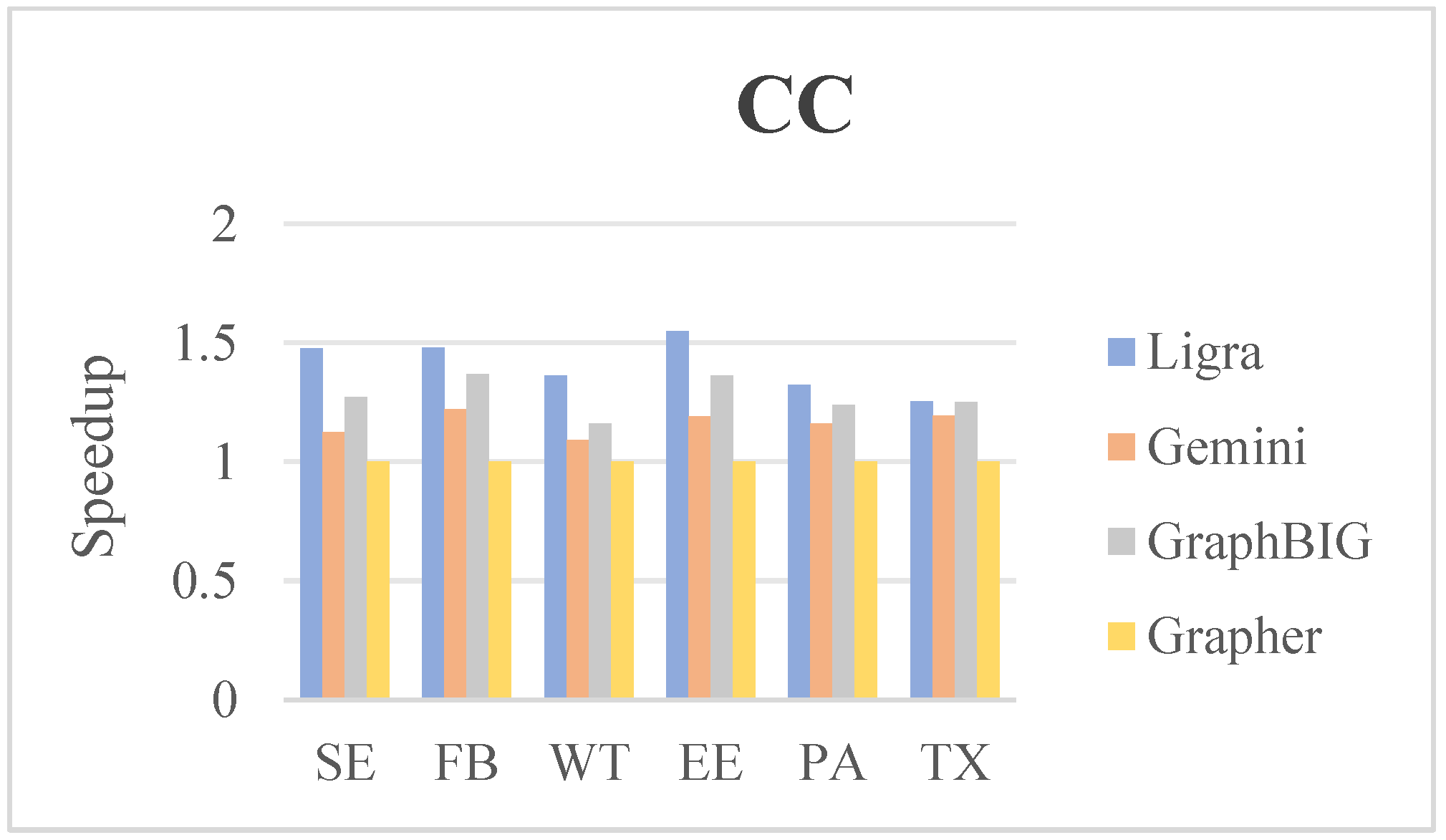
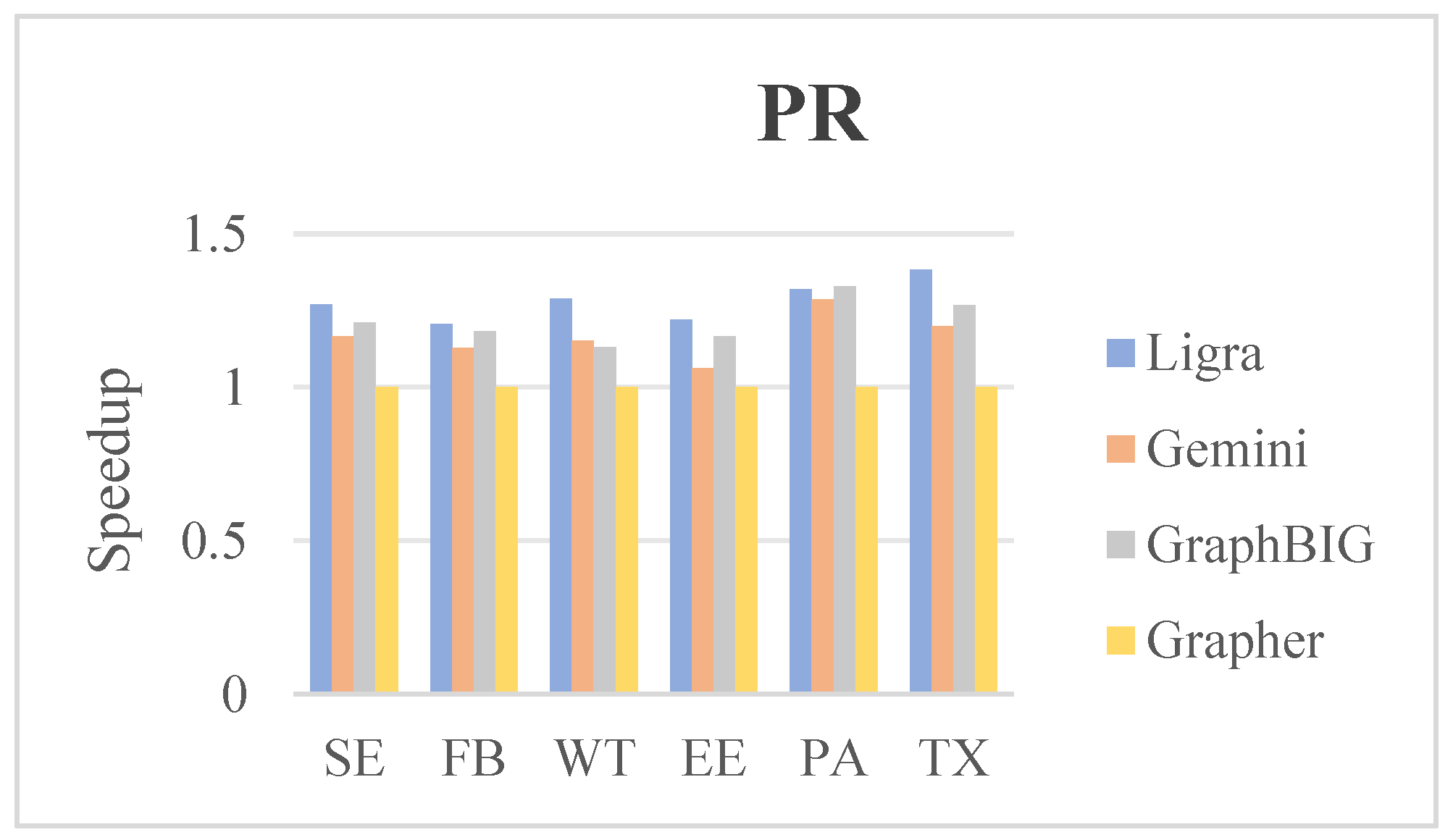
5.3. Comparison of Runtime
5.4. Comparison of Resource Utilization and Performance
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Sakr, S.; Bonifati, A.; Voigt, H. The future is big graphs: A community view on graph processing systems. Commun. ACM 2021, 64, 62–71. [Google Scholar] [CrossRef]
- Shun, J.; Blelloch, G.E. Ligra: A lightweight graph processing framework for shared memory. In Proceedings of the 18th ACM SIGPLAN Symposium on Principles and Practice of Parallel Programming, Shenzhen, China, 23 February 2013; pp. 135–146. [Google Scholar]
- Zhu, X.; Chen, W.; Zheng, W. Gemini: A {Computation-Centric} distributed graph processing system. In Proceedings of the 12th USENIX Symposium on Operating Systems Design and Implementation (OSDI 16), Savannah, GA, USA, 2–4 November 2016; pp. 301–316. [Google Scholar]
- Nai, L.; Xia, Y.; Tanase, I.G.; Kim, H.; Lin, C. GraphBIG: Understanding graph computing in the context of industrial solutions. In Proceedings of the International Conference for High Performance Computing, Networking, Storage and Analysis, Austin, TX, USA, 15 November 2015; pp. 1–12. [Google Scholar]
- Ching, A.; Edunov, S.; Kabiljo, M.; Logothetis, D.; Munthuktishnan, S. One trillion edges: Graph processing at facebook-scale. PVLDB 2015, 8, 1804–1815. [Google Scholar] [CrossRef]
- Jo, Y.Y.; Jang, M.H.; Kim, S.W.; Park, S. Realgraph: A graph engine leveraging the power-law distribution of real-world graphs. In Proceedings of the World Wide Web Conference, New York, NY, USA, 13 May 2019; pp. 807–817. [Google Scholar]
- Segura, A.; Arnau, J.M.; González, A. SCU: A GPU stream compaction unit for graph processing. In Proceedings of the 2019 ACM/IEEE 46th Annual International Symposium on Computer Architecture (ISCA), Phoenix, AZ, USA, 22 June 2019; pp. 424–435. [Google Scholar]
- Deng, J.; Wu, Q.; Wu, X.; Song, S.; Dean, J.; John, L.K. Demystifying graph processing frameworks and benchmarks. Sci. China Inf. Sci. 2022, 63, 229101. [Google Scholar] [CrossRef]
- Brahmakshatriya, A.; Zhang, Y.; Hong, C.; Kamil, S.; Shun, J.; Amarasinghe, S. Compiling graph applications for GPU s with GraphIt. In Proceedings of the 2021 IEEE/ACM International Symposium on Code Generation and Optimization (CGO), Seoul, Republic of Korea, 27 February 2021; pp. 248–261. [Google Scholar]
- He, L.; Liu, C.; Wang, Y.; Liang, S.; Li, H.; Li, X. Gcim: A near-data processing accelerator for graph construction. In Proceedings of the 2021 58th ACM/IEEE Design Automation Conference (DAC), San Francisco, CA, USA, 5–9 December 2021; pp. 205–210. [Google Scholar]
- Rahman, S.; Abu-Ghazaleh, N.; Gupta, R. Graphpulse: An event-driven hardware accelerator for asynchronous graph processing. In Proceedings of the 2020 53rd Annual IEEE/ACM International Symposium on Microarchitecture (MICRO), Athens, Greece, 17–21 October 2020; pp. 908–921. [Google Scholar]
- Dadu, V.; Liu, S.; Nowatzki, T. Polygraph: Exposing the value of flexibility for graph processing accelerators. In Proceedings of the 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; pp. 595–608. [Google Scholar]
- Dann, J.; Ritter, D.; Fröning, H. GraphScale: Scalable processing on FPGAs for HBM and large graphs. Proc. ACM Trans. Reconfigurable Technol. Syst. 2024, 17, 1–23. [Google Scholar] [CrossRef]
- Hu, Y.; Du, Y.; Ustun, E.; Zhang, Z. GraphLily: Accelerating graph linear algebra on HBM-Equipped FPGAs. In Proceedings of the 2021 IEEE/ACM International Conference on Computer Aided Design (ICCAD), Munich, Germany, 1–4 November 2021; pp. 1–9. [Google Scholar]
- Zhou, J.; Liu, S.; Guo, Q.; Zhou, X.; Zhi, T.; Liu, D.; Wang, C.; Zhou, X.; Chen, Y.; Chen, T. Tunao: A high-performance and energy-efficient reconfigurable accelerator for graph processing. In Proceedings of the 2017 17th IEEE/ACM International Symposium on Cluster, Cloud and Grid Computing (CCGRID), Madrid, Spain, 14–17 May 2017; pp. 731–734. [Google Scholar]
- Yang, C.; Huo, K.B.; Geng, L.F. DRGN: A dynamically reconfigurable accelerator for graph neural networks. J. AMB Intel. Hum. Comp. 2023, 14, 8985–9000. [Google Scholar] [CrossRef]
- Asiatici, M.; Ienne, P. Large-scale graph processing on FPGAs with caches for thousands of simultaneous misses. In Proceedings of the 2021 ACM/IEEE 48th Annual International Symposium on Computer Architecture (ISCA), Valencia, Spain, 14–18 June 2021; pp. 609–622. [Google Scholar]
- Zhou, S.; Kannan, R.; Prasanna, V.K.; Seetharaman, G.; Wu, Q. Hitgraph: High-throughput graph processing framework on fpga. IEEE TPDS 2019, 30, 2249–2264. [Google Scholar] [CrossRef]
- Liang, S.; Wang, Y.; Liu, C.; He, L.; Li, H.; Xu, D.; Li, X. Engn: A high-throughput and energy-efficient accelerator for large graph neural networks. IEEE Trans. Comput. 2020, 70, 1511–1525. [Google Scholar] [CrossRef]
- Gepner, P.; Kocot, B.; Paprzycki, M.; Ganzha, M.; Moroz, L.; Olas, T. Performance Evaluation of Parallel Graphs Algorithms Utilizing Graphcore IPU. Electronics 2024, 13, 2011. [Google Scholar] [CrossRef]
- Bundy, A.; Wallen, L. Breadth-first search. In Catalogue of Artificial Intelligence Tools; Springer: Berlin/Heidelberg, Germany, 1984; p. 13. [Google Scholar] [CrossRef]
- Ma, N.; Guan, J.; Zhao, Y. Bringing PageRank to the citation analysis. Inf. Process. Manag. 2008, 44, 800–810. [Google Scholar] [CrossRef]
- Di Stefano, L.; Bulgarelli, A. A simple and efficient connected components labeling algorithm. In Proceedings of the 10th International Conference on Image Analysis and Processing, Venice, Italy, 27–29 September 1999; pp. 322–327. [Google Scholar]
- Deng, J.; John, L.K.; Song, S. A Graph Data Compression Method for Graph Computing Accelerator and Graph Computing. Chinese Patent CN201910107925.9, 21 June 2019. (In Chinese). [Google Scholar]
- Deng, J.; John, L.K.; Song, S. A Parallel Graph Computing Accelerator Structure. Chinese Patent CN201910107937.1, 28 June 2019. (In Chinese). [Google Scholar]
- Ren, H.; Deng, J. Characterization analysis of the impact of graph data compression format on breadth-first search algorithm. J. Zhengzhou Univ. (Nat. Sci. Ed.) 2021, 53, 26–33. (In Chinese) [Google Scholar]
- Leskovec, J.; Sosič, R. Stanford network analysis platform. ACM TIST 2016, 8, 1–20. [Google Scholar]
- Chen, X.; Cheng, F.; Tan, H.; Chen, Y.; He, B.; Wong, W.; Chen, D. ThunderGP: Resource-efficient graph processing framework on FPGAs with hls. ACM Trans. Reconfig. Technol. Syst. 2022, 15, 1–31. [Google Scholar] [CrossRef]
- Dai, G.; Huang, T.; Chi, Y.; Xu, N.; Wang, Y.; Yang, H. ForeGraph: Exploring large-scale graph processing on multi-FPGA architecture. In Proceedings of the 2017 ACM/SIGDA International Symposium on Field-Programmable Gate Arrays, Monterey, CA, USA, 22 February 2017; pp. 217–226. [Google Scholar]
- O’Brien, F.; Agostini, M.; Abdelrahman, T.S. A streaming accelerator for heterogeneous CPU-FPGA processing of graph applications. In Proceedings of the 2021 IEEE International Parallel and Distributed Processing Symposium Workshops (IPDPSW), Portland, OR, USA, 11 February 2021; pp. 26–35. [Google Scholar]



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Graph Data Type | Datasets | Number of Vertices | Number of Edges |
|---|---|---|---|
| Social networks | Soc-Epinions1 (SE) | 75,879 | 508,837 |
| ego-Facebook (FB) | 4039 | 88,234 | |
| Communication networks | wiki-Talk (WT) | 2,394,385 | 5,021,410 |
| email-Enron (EE) | 36,692 | 420,045 | |
| Road networks | roadNet-PA (PA) | 1,088,092 | 1,541,898 |
| roadNet-TX (TX) | 1,379,917 | 1,921,660 |
| Logic Device | Resource Consumption | Resources Available | Resource Utilization |
|---|---|---|---|
| LUT | 42,191 | 1,182,240 | 3.57% |
| FF | 21,316 | 2,364,480 | 0.90% |
| BRAM | 1546 | 2160 | 71.6% |
| Logic Device | FPGA | Resource Consumption | Clock Frequency (MHz) | Power (W) | Throughput (MTEPS) | Energy Efficiency (MTEPS/W) | |
|---|---|---|---|---|---|---|---|
| Grapher | LUT | XCVU9P | 3.57% | 150 | 3.988 | 2265 | 568.0 |
| FF | 0.90% | ||||||
| BRAM | 71.6% | ||||||
| Hitgraph | LUT | XCVU5P | 68.1% | 200 | 10.7 | 3410 | 318.7 |
| FF | 26.1% | ||||||
| BRAM | 9.2% | ||||||
| ThunderGP | LUT | XCVU9P | 84.0% | 241 | 46 | 5510 | 119.8 |
| FF | - | ||||||
| BRAM | 66.0% | ||||||
| ForeGraph | LUT | XCVU9P | 31.2% | 200 | - | 1846 | - |
| FF | - | ||||||
| BRAM | 89.4% | ||||||
| [17] | LUT | UltraScale+ | 75.0% | 227 | 23 | 1800 | 78.3 |
| FF | 42.0% | ||||||
| BRAM | 39.0% | ||||||
| GraphScale | LUT | PAC D5005 | 19.0% | 192 | - | 1510 | - |
| FF | - | ||||||
| BRAM | 40.0% | ||||||
| [30] | LUT | Arria 10 GX1150 | - | 291 | - | 1492 | - |
| FF | - | ||||||
| BRAM | - | ||||||
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Deng, J.; Lu, S.; Zhang, B.; Jia, Y. Grapher: A Reconfigurable Graph Computing Accelerator with Optimized Processing Elements. Electronics 2024, 13, 3464. https://doi.org/10.3390/electronics13173464
Deng J, Lu S, Zhang B, Jia Y. Grapher: A Reconfigurable Graph Computing Accelerator with Optimized Processing Elements. Electronics. 2024; 13(17):3464. https://doi.org/10.3390/electronics13173464
Chicago/Turabian StyleDeng, Junyong, Songtao Lu, Baoxiang Zhang, and Yanting Jia. 2024. "Grapher: A Reconfigurable Graph Computing Accelerator with Optimized Processing Elements" Electronics 13, no. 17: 3464. https://doi.org/10.3390/electronics13173464
APA StyleDeng, J., Lu, S., Zhang, B., & Jia, Y. (2024). Grapher: A Reconfigurable Graph Computing Accelerator with Optimized Processing Elements. Electronics, 13(17), 3464. https://doi.org/10.3390/electronics13173464