


Swin-Fake: A Consistency Learning Transformer-Based Deepfake Video Detector




Abstract
1. Introduction
2. Related Work
2.1. Deepfake Detection
2.2. Swin Transformer
2.3. Data Augmentation
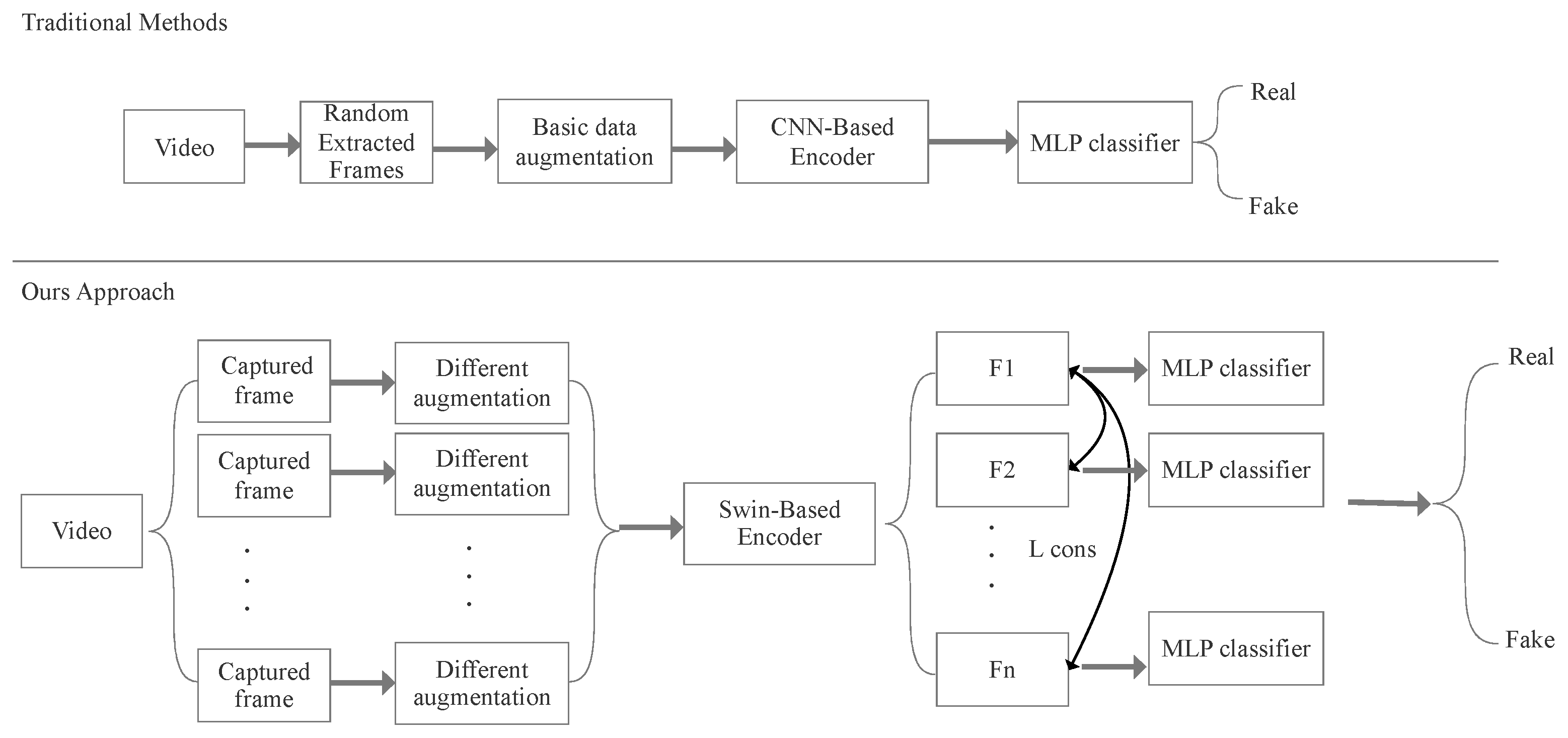
3. Proposed Methods
| Algorithm 1 The workflow of Swin-Fake |
|
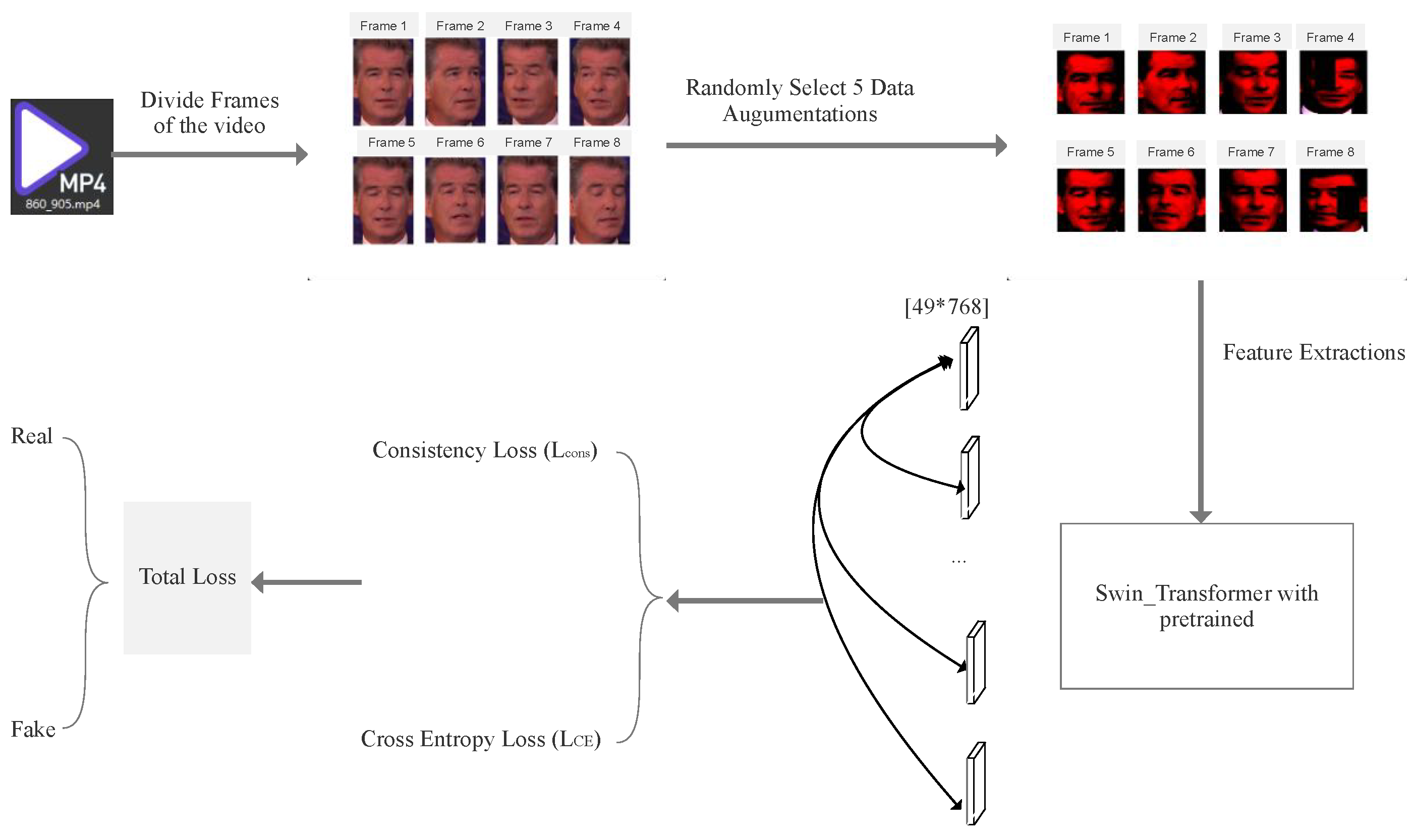
3.1. Pre-Processing Work
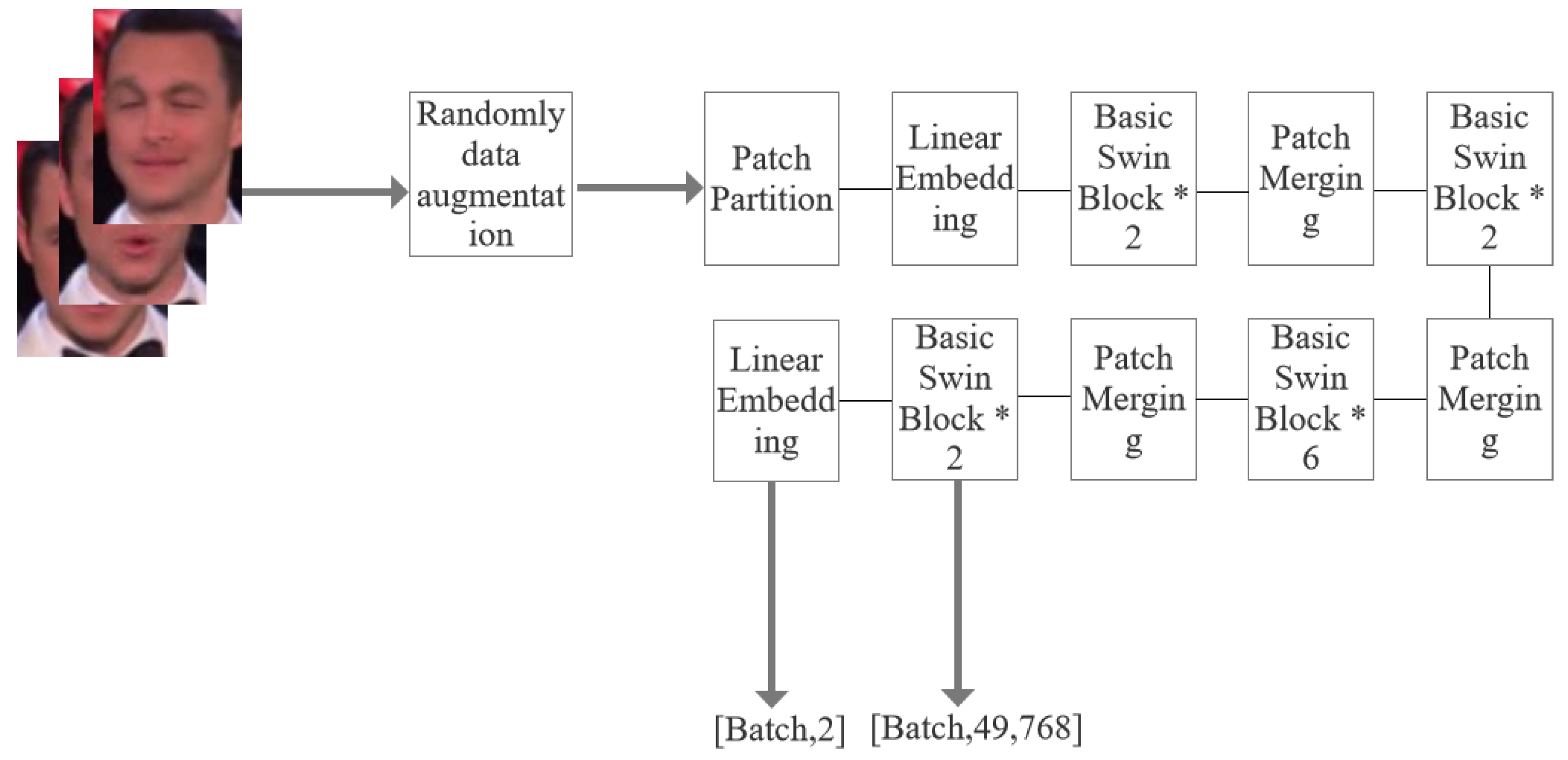
3.2. Encoder Network
3.3. Loss Functions
4. Experiments
4.1. Datasets
4.2. Implementation Details
4.3. In-Dataset Study
4.4. Ablation Test Results
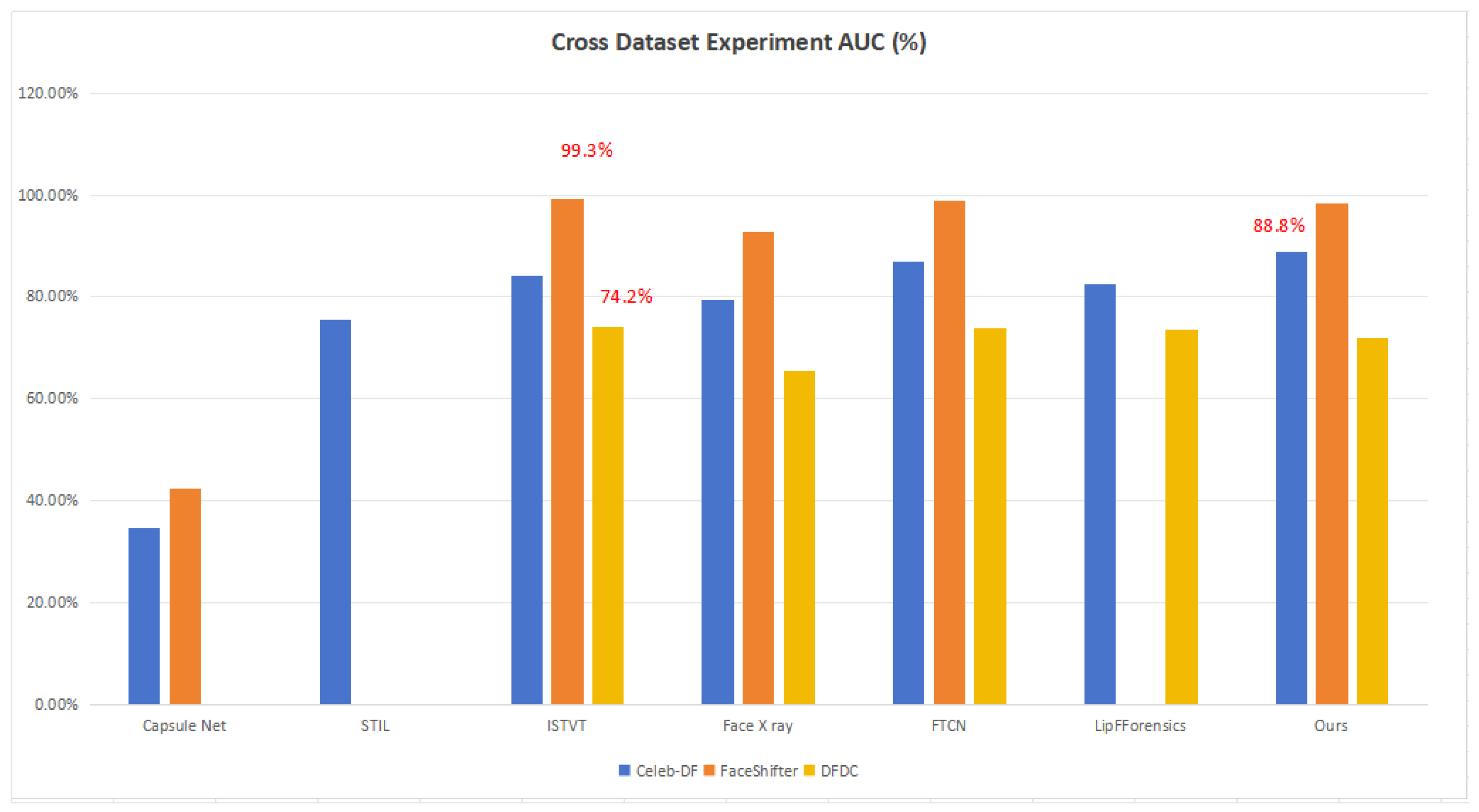
4.5. Cross-Dataset Study
5. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Goodfellow, I.; Pouget-Abadie, J.; Mirza, M.; Xu, B.; Wared-Farley, D.; Ozair, S.; Courville, A.; Bengio, Y. Generative Adversarial Network. Commun. Acm 2018, 63, 139–144. [Google Scholar] [CrossRef]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019. [Google Scholar]
- Ho, J.; Jain, A.; Abbeel, P. Denoising Diffusion Probabilistic Models. In Proceedings of the 34th International Conference on Neural Information Processing System, Red Hook, NY, USA, 6–12 December 2020; pp. 6840–6851. [Google Scholar]
- Nguyen, H.H.; Yamagishi, J.; Echizen, I. Use of a Capsule Network to Detect Fake Images and Videos. In Proceedings of the Computer Vision and Pattern Recognition, Long Beach, CA, USA, 16–20 June 2019. [Google Scholar]
- Das, S.; Seferbekov, S.; Datta, A.; Islam, M.S.; Amin, M.R. Towards solving the deepfake problem: An analysis on improving deepfake detection using dynamic face augmentation. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Zhao, T.; Xu, X.; Xu, M.; Ding, H.; Xiong, Y.; Xia, W. Learning Self-Consistency for Deepfake Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021. [Google Scholar]
- Dosovitskiy, A.; Beyer, L.; Kolesnikov, A.; Weissenborn, D.; Zhai, X.; Unterthiner, T.; Dehghani, M.; Minderer, M.; Heigold, G.; Gelly, S.; et al. An Image is Worth 16 × 16 Words: Transformers for Image Recognition at Scale. In Proceedings of the International Conference on Learning Representations, Virtual, 26 April–1 May 2020. [Google Scholar]
- Khan, S.A.; Dai, H. Video Transformer for Deepfake Detection with Incremental Learning. In Proceedings of the 29th ACM International Conference on Multimedia, Virtual Event, 20–24 October 2021; pp. 1821–1828. [Google Scholar]
- Khormali, A.; Yuan, J. DFDT: An End-to-End DeepFake Detection Framework Using Vision Transformer. Appl. Sci. 2022, 12, 2953. [Google Scholar] [CrossRef]
- Zhao, C.; Wang, C.; Hu, G.; Chen, H.; Liu, C.; Tang, J. ISTVT: Interpretable Spatial-Temporal Video Transformer for Deepfake Detection. IEEE Trans. Inf. Forensics Secur. 2023, 18, 1335–1348. [Google Scholar] [CrossRef]
- Liu, Z.; Lin, Y.; Cao, Y.; Hu, H.; Wei, Y.; Zhang, Z.; Lin, S.; Guo, B. Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, BC, Canada, 11–17 October 2021. [Google Scholar]
- Zhong, Z.; Zheng, L.; Kang, G.; Li, S.; Yang, Y. Random Erasing Data Augmentation. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020. [Google Scholar]
- DFDC Selim. Available online: https://github.com/selimsef/dfdc_deepfake_challenge (accessed on 15 May 2024).
- Chollet, F. Xception: Deep learning with depthwise separable convolutions. In Proceedings of the Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017. [Google Scholar]
- He, K.; Zhang, X.; Ren, S.; Sun, J. Deep Residual Learning for Image Recognition. In Proceedings of the 2016 IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 27–30 June 2016. [Google Scholar]
- Ni, Y.; Meng, D.; Yu, C.; Quan, C.B.; Ren, D.; Zhao, Y. CORE: Consistent Representation Learning for Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, New Orleans, LA, USA, 18–24 June 2022. [Google Scholar]
- Sun, K.; Yao, T.; Chen, S.; Ding, S.; Li, J.; Ji, R. Dual Contrastive Learning for General Face Forgery Detection. AAAI Conf. Artif. Intell. 2022, 36, 2316–2324. [Google Scholar] [CrossRef]
- Zhang, J.; Cheng, K.; Sovernigo, G.; Lin, X. A Heterogeneous Feature Ensemble Learning based Deepfake Detection Method. In Proceedings of the ICC 2022—IEEE International Conference on Communications, Seoul, Republic of Korea, 16–20 May 2022; pp. 2084–2089. [Google Scholar]
- Rana, M.S.; Sung, A.H. DeepfakeStack: A Deep Ensemble-based Learning Technique for Deepfake Detection. In Proceedings of the 2020 7th IEEE International Conference on Cyber Security and Cloud Computing (CSCloud)/2020 6th IEEE International Conference on Edge Computing and Scalable Cloud (EdgeCom), New York, NY, USA, 1–3 August 2020; pp. 70–75. [Google Scholar]
- Ilyas, H.; Javed, A.; Malik, K.M. AVFakeNet: A unified end-to-end Dense Swin Transformer deep learning model for audio–visual deepfakes detection. Appl. Soft Comput. 2023, 136, 110124. [Google Scholar] [CrossRef]
- Khalid, F.; Akbar, M.H.; Gul, S. SWYNT: Swin Y-Net Transformers for Deepfake Detection. In Proceedings of the 2023 International Conference on Robotics and Automation in Industry (ICRAI), Peshawar, Pakistan, 3–5 March 2023; pp. 1–6. [Google Scholar]
- Guo, J.; Deng, J.; Lattas, A.; Zafeiriou, S. Sample and Computation Redistribution for Efficient Face Detection. In Proceedings of the International Conference on Learning Representation, Virtual Event, 3–7 May 2021. [Google Scholar]
- Zhou, T.F.; Wang, W.G.; Liang, Z.Y.; Shen, J.B. Face Forensics in the Wild. In Proceedings of the Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021. [Google Scholar]
- Kaggle. Available online: https://www.kaggle.com/c/deepfake-detection-challenge/overview (accessed on 12 December 2023).
- Li, Y.Z.; Yang, X.; Sun, P.; Qi, H.G.; Lyu, S. Celeb-DF: A Large-scale Challenging Dataset for DeepFake Forensics. In Proceedings of the Computer Vision and Pattern Recognition, Seattle, WA, USA, 14–19 June 2020. [Google Scholar]
- Li, L.; Bao, J.; Yang, H.; Chen, D.; Wen, F. FaceShifter: Towards High Fidelity And Occlusion Aware Face Swapping. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Loshchilov, I.; Hutter, F. Decoupled weight decay Regularization. In Proceedings of the International Conference on Learning Representations, New Orleans, LA, USA, 6–9 May 2019. [Google Scholar]
- Gu, Z.; Chen, Y.; Yao, T.; Ding, S.; Li, J.; Huang, F.; Ma, L. Spatiotemporal Inconsistency Learning for Deepfake Video Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021. [Google Scholar]
- Li, L.; Bao, J.; Zhang, T.; Yang, H.; Chen, D.; Wen, F.; Guo, B. Face X-ray for More General Face Forgery Detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020. [Google Scholar]
- Zheng, Y.; Bao, J.; Chen, D.; Zeng, M.; Wen, F. Exploring temporal coherence for more general video face forgery detection. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Montreal, QC, Canada, 10–17 October 2021; pp. 15044–15054. [Google Scholar]
- Haliassos, A.; Vougioukas, K.; Petridis, S.; Pantic, M. Lips don’t lie: A generalisable and robust approach to face forgery detection. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Virtual, 19–25 June 2021; pp. 5039–5049. [Google Scholar]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Methods | FF++ | DFDC | |||
|---|---|---|---|---|---|
| DF | F2F | FS | NT | ||
| Capsule Net | 98.5% | 96.7% | 94.5% | 91.8% | - |
| STIL | 99.6% | 99.3% | 97.1% | 95.4% | 89.8% |
| ISTVT | 99.6% | 99.6% | 100% | 96.8% | 92.1% |
| Our approach | 99.9% | 99.6% | 100% | 98.8% | 93.7% |
| Methods | FF++(Binary Test) | DFDC |
|---|---|---|
| Swin Transformer | 89.4% | 91.4% |
| Our approach | 94.3% | 93.7% |
| 0.4 | 0.5 | 0.6 | 0.7 | 0.8 | |
|---|---|---|---|---|---|
| Accuracy | 92.6% | 93.9% | 94.1% | 94.3% | 93.7% |
| Models | Celeb-DF | FaceShifter | DFDC | Average |
|---|---|---|---|---|
| Capsule Net | 34.5% | 42.4% | - | 38.5% |
| STIL | 75.6% | - | - | 75.6% |
| ISTVT | 84.1% | 99.3% | 74.2% | 85.9% |
| Face X-ray | 79.5% | 92.8% | 65.6% | 79.3% |
| FTCN | 86.9% | 98.8% | 74.0% | 86.6% |
| LipForensics | 82.4% | 97.1% | 73.5% | 84.3% |
| Our approach | 88.8% | 98.3% | 71.8% | 86.3% |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Gong, L.Y.; Li, X.J.; Chong, P.H.J. Swin-Fake: A Consistency Learning Transformer-Based Deepfake Video Detector. Electronics 2024, 13, 3045. https://doi.org/10.3390/electronics13153045
Gong LY, Li XJ, Chong PHJ. Swin-Fake: A Consistency Learning Transformer-Based Deepfake Video Detector. Electronics. 2024; 13(15):3045. https://doi.org/10.3390/electronics13153045
Chicago/Turabian StyleGong, Liang Yu, Xue Jun Li, and Peter Han Joo Chong. 2024. "Swin-Fake: A Consistency Learning Transformer-Based Deepfake Video Detector" Electronics 13, no. 15: 3045. https://doi.org/10.3390/electronics13153045
APA StyleGong, L. Y., Li, X. J., & Chong, P. H. J. (2024). Swin-Fake: A Consistency Learning Transformer-Based Deepfake Video Detector. Electronics, 13(15), 3045. https://doi.org/10.3390/electronics13153045