


Enhanced Text Classification with Label-Aware Graph Convolutional Networks


Abstract
1. Introduction
- Introduction of label-aware nodes. We introduce label-aware nodes in the graph convolutional network to explicitly incorporate class information into the model, thereby enhancing the accuracy of text classification.
- Enhanced graph convolution process. We refine the graph convolution process by capturing document–word, word–word, and word–class correlations through the integration of label-aware nodes.
- Comprehensive evaluation. We conduct extensive experiments on public datasets (Ohsumed, Movie Review, 20 Newsgroups, and R8) to demonstrate the superiority of LaGCN over existing state-of-the-art models like HDGCN and BERT. Our results show significant accuracy improvements of 19.47%, 10%, 4.67%, and 0.4%, respectively.
- Setting a new benchmark. Our study highlights the importance of integrating class information into graph neural networks, establishing a new benchmark for text classification tasks.
2. Related Work
3. Proposed Model
3.1. Text-to-Graph
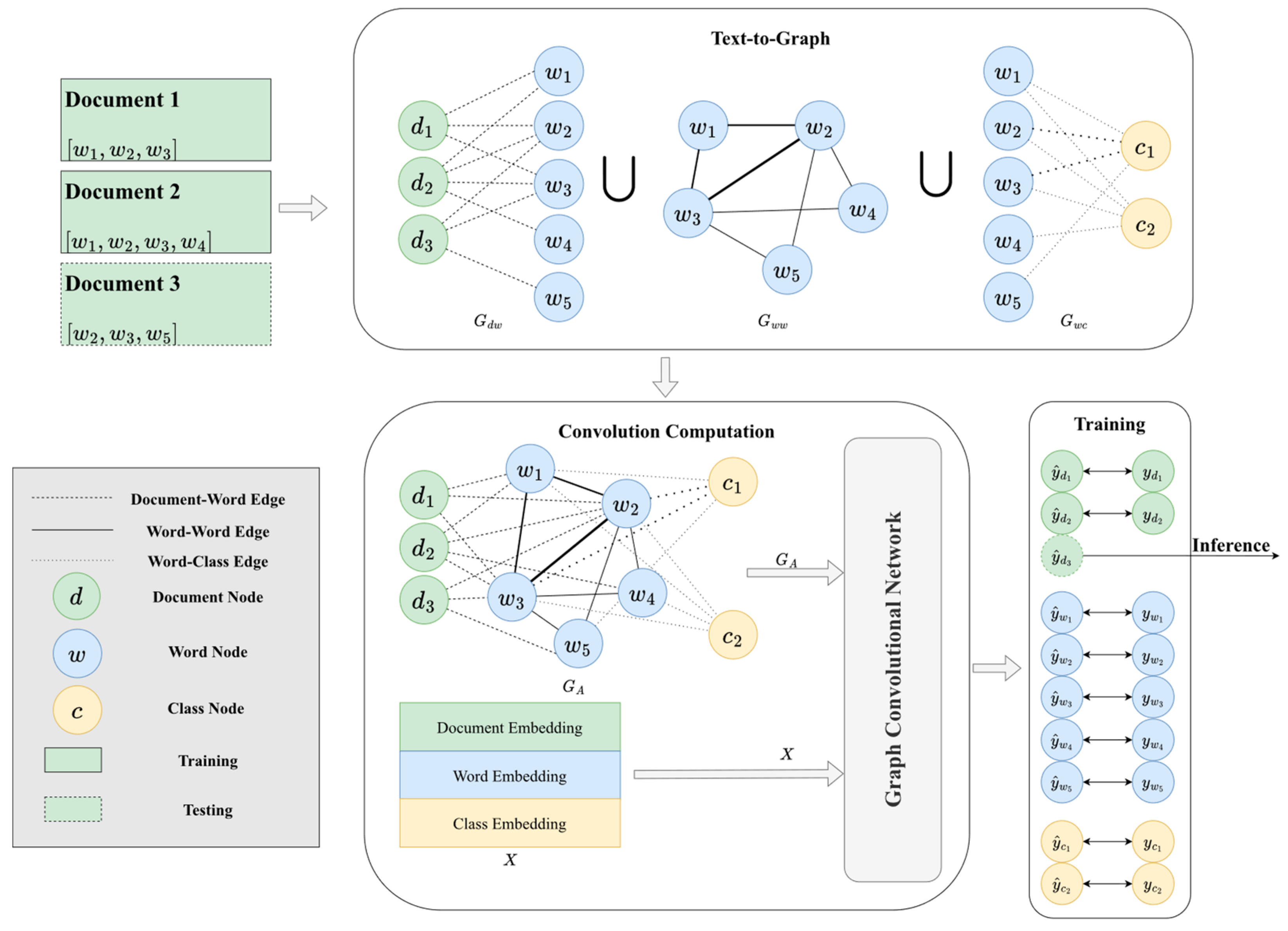
3.2. Convolution Computation
3.3. Loss Function and Training
4. Experiments
4.1. Experimental Datasets
- Movie Review (MR): This dataset comprises user movie reviews, each limited to a single sentence. The objective is to classify these reviews into either positive or negative sentiment classes. It includes 5331 positive and 5331 negative reviews.
- Reuters-21758 (R8 and R52): This dataset consists of various news articles. We focus on R8 and R52, which are subsets of Reuters-21758. R8 includes eight classes with 5485 training and 2189 testing news articles, while R52 encompasses fifty-two classes with 6532 training and 2568 testing news articles.
- 20NewsGroup (20NG): This dataset contains over 20,000 news articles across 20 different classes, with 11,314 articles for training and 7532 for testing.
- Ohsumed: Originating from the MEDLINE biomedical database, this dataset initially comprises over 10,000 abstracts related to various cardiovascular diseases. For single-label text classification, each article is classified into one of twenty-three cardiovascular disease types. The dataset includes 3357 training and 4043 testing samples.
4.2. Baseline Models
- PTE [21]: It performs word embedding pre-training through a heterogeneous graph and then averages the word vectors as text vectors.
- TextGCN [6]: A model that uses a heterogeneous graph with article and word nodes. Edge weights between articles and words are calculated using TF-IDF, while edge weights between word nodes are calculated using PMI.
- TextING [8]: A method that treats each article as an independent graph. A Gated Graph Neural Network (GGNN) simulates word distance relationships in articles, and a soft attention mechanism calculates the attention levels of all words in the articles.
- TensorGCN [9]: An extension of TextGCN that incorporates additional node edge weights for semantic, syntactic, and sequential relationships. It integrates information from article nodes.
- HyperGAT [22]: It constructs hyper-edges and iteratively updates node and edge features in graph convolution, in the subsequent layer of the graph convolutional network.
- T-VGAE [23]: It utilizes graph convolutional networks to transform node features into a lower-dimensional space, adds random noise, and reconstructs the graph structure through deconvolution operations. It uses the representations of document nodes for text classification.
- TextSSL [24]: It creates individual graphs for each sentence within a document, and employs Gumbel-Softmax during the convolutional operation to decide whether connections between sentences should be established.
- GCA2TC [25]: It employs data augmentation contrastive learning to simulate two distinct graph structures for comparison.
- TextFCG [26]: It integrates semantic information and co-occurrence details from the text’s historical context to enhance textual representations. It also extracts document representations through the utilization of attention mechanisms.
- HDGCN [10]: It attempts to address over-smoothing issues caused by multiple convolution layers using the Chebyshev approximation algorithm.
4.3. Experimental Results
4.3.1. Comparisons of Classification Accuracy
4.3.2. Parameter Sensitivity
4.3.3. Ablation Study
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Kim, Y. Convolutional neural networks for sentence classification. arXiv 2014. [Google Scholar] [CrossRef]
- Vaswani, A.; Shazeer, N.; Parmar, N.; Uszkoreit, J.; Jones, L.; Gomez, A.N.; Kaiser, Ł.; Polosukhin, I. Attention is all you need. Adv. Neural Inf. Process. Syst. 2017. [Google Scholar] [CrossRef]
- Gu, Y.; Wang, Y.; Zhang, H.-R.; Wu, J.; Gu, X. Enhancing Text Classification by Graph Neural Networks with Multi-Granular Topic-Aware Graph. IEEE Access 2023, 11, 20169–20183. [Google Scholar] [CrossRef]
- Li, X.; Wu, X.; Luo, Z.; Du, Z.; Wang, Z.; Gao, C. Integration of global and local information for text classification. Neural Comput. Appl. 2023, 35, 2471–2486. [Google Scholar] [CrossRef]
- Wang, K.; Ding, Y.; Han, S.C. Graph neural networks for text classification: A survey. Artif. Intell. Rev. 2024, 57, 190. [Google Scholar] [CrossRef]
- Yao, L.; Mao, C.; Luo, Y. Graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Honolulu, HI, USA, 27 January–1 February2019; Volume 33, pp. 7370–7377. [Google Scholar]
- Huang, L.; Ma, D.; Li, S.; Zhang, X.; Wang, H. Text Level Graph Neural Network for Text Classification. In Proceedings of the 2019 Conference on Empirical Methods in Natural Language Processing and the 9th International Joint Conference on Natural Language Processing (EMNLP-IJCNLP), Hong Kong, China, 3–7 November 2019; Association for Computational Linguistics: Kerrville, TX, USA, 2019; pp. 3444–3450. [Google Scholar] [CrossRef]
- Zhang, Y.; Yu, X.; Cui, Z.; Wu, S.; Wen, Z.; Wang, L. Every Document Owns Its Structure: Inductive Text Classification via Graph Neural Networks. In Proceedings of the 58th Annual Meeting of the Association for Computational Linguistics, Online, 6–8 July 2020; Association for Computational Linguistics: Kerrville, TX, USA, 2020; pp. 334–339. [Google Scholar] [CrossRef]
- Liu, X.; You, X.; Zhang, X.; Wu, J.; Lv, P. Tensor graph convolutional networks for text classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Philadelphia, PA, USA, 7–12 February 2020; Volume 34, pp. 8409–8416. [Google Scholar]
- Jiang, S.; Chen, Q.; Liu, X.; Hu, B.; Zhang, L. Multi-hop Graph Convolutional Network with High-order Chebyshev Approximation for Text Reasoning. In Proceedings of the 59th Annual Meeting of the Association for Computational Linguistics and the 11th International Joint Conference on Natural Language Processing, Online, 6 August 2021; Association for Computational Linguistics: Kerrville, TX, USA, 2021; Volume 1, pp. 6563–6573. [Google Scholar] [CrossRef]
- Bojanowski, P.; Grave, E.; Joulin, A.; Mikolov, T. Enriching Word Vectors with Subword Information. Trans. Assoc. Comput. Linguist. 2017, 5, 135–146. [Google Scholar] [CrossRef]
- Mikolov, T.; Chen, K.; Corrado, G.; Dean, J. Efficient estimation of word representations in vector space. arXiv 2013. [Google Scholar] [CrossRef]
- Pennington, J.; Socher, R.; Manning, C. GloVe: Global Vectors for Word Representation. In Proceedings of the 2014 Conference on Empirical Methods in Natural Language Processing (EMNLP), Doha, Qatar, 25–29 October 2014; Association for Computational Linguistics: Kerrville, TX, USA, 2014; pp. 1532–1543. [Google Scholar] [CrossRef]
- Shen, D.; Wang, G.; Wang, W.; Min, M.R.; Su, Q.; Zhang, Y.; Li, C.; Henao, R.; Carin, L. Baseline Needs More Love: On Simple Word-Embedding-Based Models and Associated Pooling Mechanisms. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Kerrville, TX, USA, 2018; pp. 440–450. [Google Scholar] [CrossRef]
- Dai, Y.; Shou, L.; Gong, M.; Xia, X.; Kang, Z.; Xu, Z.; Jiang, D. Graph fusion network for text classification. Knowl.-Based Syst. 2022, 236, 107659. [Google Scholar] [CrossRef]
- Kipf, T.N.; Welling, M. Semi-supervised classification with graph convolutional networks. arXiv 2016. [Google Scholar] [CrossRef]
- Ragesh, R.; Sellamanickam, S.; Iyer, A.; Bairi, R.; Lingam, V. Hetegcn: Heterogeneous graph convolutional networks for text classification. In Proceedings of the 14th ACM International Conference on Web Search and Data Mining, Jerusalem, Israel, 8–12 March 2021; pp. 860–868. [Google Scholar]
- Wang, G.; Li, C.; Wang, W.; Zhang, Y.; Shen, D.; Zhang, X.; Henao, R.; Carin, L. Joint Embedding of Words and Labels for Text Classification. In Proceedings of the 56th Annual Meeting of the Association for Computational Linguistics (Volume 1: Long Papers), Melbourne, Australia, 15–20 July 2018; Association for Computational Linguistics: Kerrville, TX, USA, 2018; pp. 2321–2331. [Google Scholar] [CrossRef]
- Ying, R.; He, R.; Chen, K.; Eksombatchai, P.; Hamilton, W.L.; Leskovec, J. Graph Convolutional Neural Networks for Web-Scale Recommender Systems. In Proceedings of the 24th ACM SIGKDD International Conference on Knowledge Discovery & Data Mining, London, UK, 19–23 August 2018; Association for Computing Machinery: New York, NY, USA, 2018; pp. 974–983. [Google Scholar] [CrossRef]
- Joulin, A.; Grave, E.; Bojanowski, P.; Mikolov, T. Bag of Tricks for Efficient Text Classification. In Proceedings of the 15th Conference of the European Chapter of the Association for Computational Linguistics, Valencia, Spain, 3–7 April 2017; Association for Computational Linguistics: Kerrville, TX, USA, 2017; Volume 2, pp. 427–431. Available online: https://aclanthology.org/E17-2068 (accessed on 12 June 2023).
- Tang, J.; Qu, M.; Mei, Q. Pte: Predictive text embedding through large-scale heterogeneous text networks. In Proceedings of the 21st ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, Sydney, NSW, Australia, 10–13 August 2015; pp. 1165–1174. [Google Scholar]
- Ding, K.; Wang, J.; Li, J.; Li, D.; Liu, H. Be More with Less: Hypergraph Attention Networks for Inductive Text Classification. In Proceedings of the 2020 Conference on Empirical Methods in Natural Language Processing (EMNLP), Online, 8–10 November 2020; Association for Computational Linguistics: Kerrville, TX, USA, 2020; pp. 4927–4936. [Google Scholar] [CrossRef]
- Xie, Q.; Huang, J.; Du, P.; Peng, M.; Nie, J.-Y. Inductive topic variational graph auto-encoder for text classification. In Proceedings of the 2021 Conference of the North American Chapter of the Association for Computational Linguistics: Human Language Technologies, Online, 6–11 June 2021; pp. 4218–4227. [Google Scholar]
- Piao, Y.; Lee, S.; Lee, D.; Kim, S. Sparse structure learning via graph neural networks for inductive document classification. In Proceedings of the AAAI Conference on Artificial Intelligence, Pennsylvania, PA, USA, 22 February–1 March 2022; Volume 36, pp. 11165–11173. [Google Scholar]
- Yang, Y.; Miao, R.; Wang, Y.; Wang, X. Contrastive graph convolutional networks with adaptive augmentation for text classification. Inf. Process. Manag. 2022, 59, 102946. [Google Scholar] [CrossRef]
- Wang, Y.; Wang, C.; Zhan, J.; Ma, W.; Jiang, Y. Text FCG: Fusing contextual information via graph learning for text classification. Expert Syst. Appl. 2023, 219, 119658. [Google Scholar] [CrossRef]






{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Study | Key Features | Limitations |
|---|---|---|
| TextGCN [6] | Heterogeneous graph with document and word nodes, TF-IDF and PPMI edge weights. | Scalability issues with large datasets and complex graphs. |
| Text Level GNN [7] | Local and global graphs for document classification, references external text sources. | Increased computational complexity and resource requirements. |
| TextING [8] | Distinct graph for each document, attention mechanism prioritizes key information. | Computationally intensive, poor scalability with large datasets. |
| TensorGCN [9] | Network with varied edge relationships (semantic, syntactic, contextual). | High computational demands and model optimization challenges. |
| HDGCN [10] | Controls information propagation to address over-smoothing. | Adds complexity and potential computational overhead. |
| Dataset | #Doc | #Train | #Test | #Word | #Node | #Class | AVG.LEN |
|---|---|---|---|---|---|---|---|
| 20NG | 18,846 | 11,314 | 7532 | 42,757 | 61,603 | 20 | 221.26 |
| R8 | 7674 | 5485 | 2189 | 7688 | 15,362 | 8 | 65.72 |
| R52 | 9100 | 6532 | 2568 | 8892 | 17,992 | 52 | 69.82 |
| Ohsumed | 7400 | 3357 | 4043 | 14,157 | 21,557 | 23 | 135.82 |
| MR | 10,662 | 7108 | 3554 | 18,764 | 29,426 | 2 | 20.39 |
| Model | MR | R8 | R52 | Ohsumed | 20NG |
|---|---|---|---|---|---|
| PTE | 70.23 | 96.69 | 90.71 | 53.58 | 76.74 |
| TextGCN | 76.74 | 97.07 | 93.56 | 68.36 | 86.34 |
| TextING | 79.82 | 98.04 | 95.48 | 70.42 | NA |
| TensorGCN | 77.91 | 98.04 | 95.05 | 70.11 | 87.74 |
| HyperGAT | 78.32 | 97.97 | 94.98 | 69.90 | 86.62 |
| T-VGAE | 78.03 | 97.68 | 95.05 | 78.05 | 88.08 |
| TextSSL | 79.74 | 97.81 | 95.48 | 70.59 | 85.26 |
| GCA2TC | 77.80 | 97.76 | 94.47 | 70.62 | NA |
| TextFCG | 80.78 | 98.22 | 96.23 | 71.65 | 85.18 |
| HDGCN | 86.50 | 98.45 | 96.57 | 73.97 | NA |
| LaGCN | 90.54 | 98.85 | 96.18 | 88.35 | 94.98 |
| Improvement | 4.67% | 0.4% | −0.05% | 13.1% | 7.8% |
| Model | MR | R8 | R52 | Ohsumed | 20NG |
|---|---|---|---|---|---|
| LaGCN w/o C | 90.79 | 98.58 | 93.10 | 85.01 | 94.64 |
| LaGCN w/o | 88.18 | 95.84 | 90.30 | 86.00 | 93.25 |
| LaGCN w/o | 80.02 | 97.98 | 96.37 | 74.42 | 88.27 |
| LaGCN w/o | 90.60 | 98.53 | 93.61 | 86.47 | 94.74 |
| LaGCN | 90.54 | 98.85 | 96.18 | 88.35 | 94.98 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Lin, M.-Y.; Liu, H.-C.; Hsush, S.-C. Enhanced Text Classification with Label-Aware Graph Convolutional Networks. Electronics 2024, 13, 2944. https://doi.org/10.3390/electronics13152944
Lin M-Y, Liu H-C, Hsush S-C. Enhanced Text Classification with Label-Aware Graph Convolutional Networks. Electronics. 2024; 13(15):2944. https://doi.org/10.3390/electronics13152944
Chicago/Turabian StyleLin, Ming-Yen, Hsuan-Chun Liu, and Sue-Chen Hsush. 2024. "Enhanced Text Classification with Label-Aware Graph Convolutional Networks" Electronics 13, no. 15: 2944. https://doi.org/10.3390/electronics13152944
APA StyleLin, M.-Y., Liu, H.-C., & Hsush, S.-C. (2024). Enhanced Text Classification with Label-Aware Graph Convolutional Networks. Electronics, 13(15), 2944. https://doi.org/10.3390/electronics13152944