

Expert System for Extracting Hidden Information from Electronic Documents during Outgoing Control


Abstract
1. Introduction
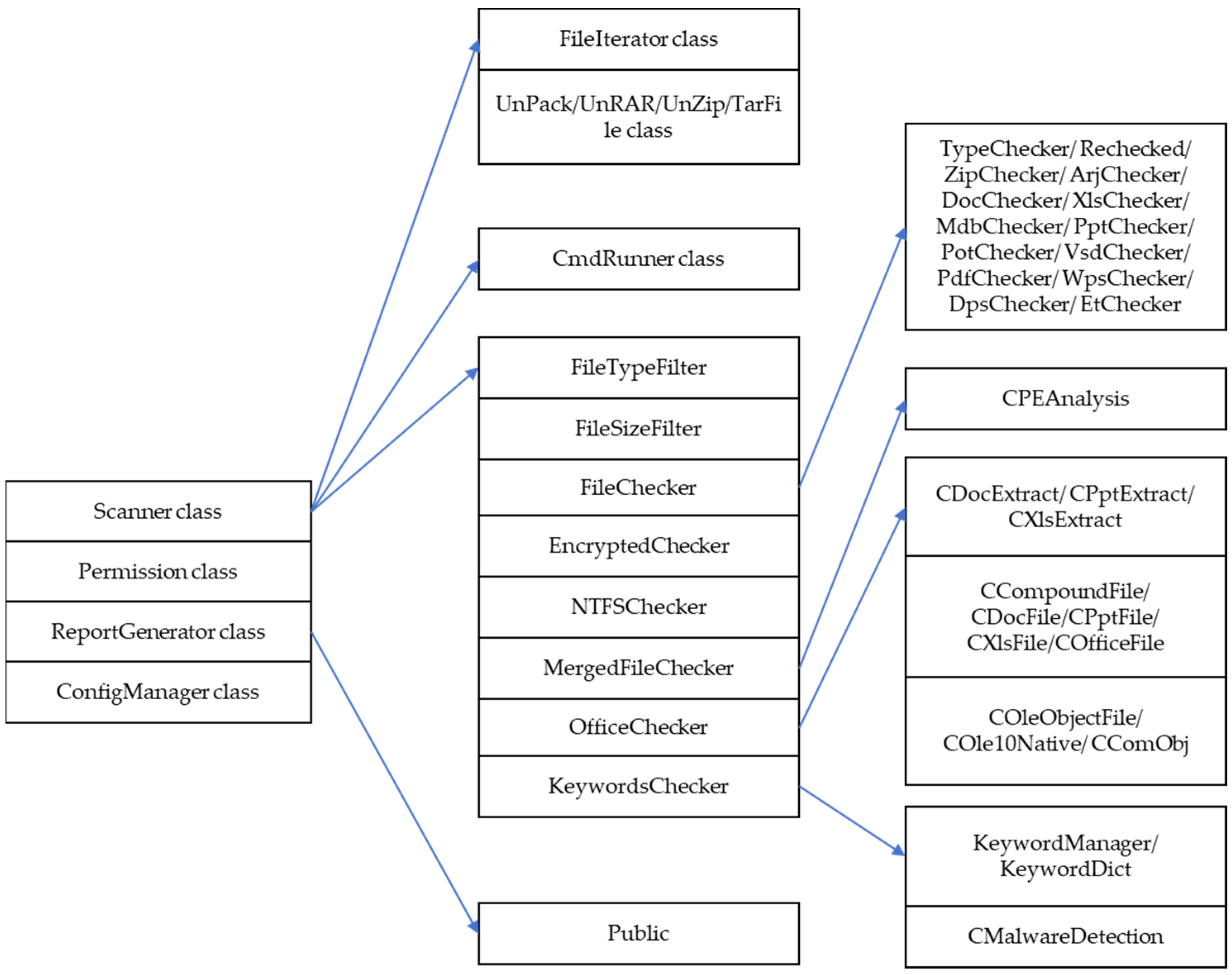
2. Structure Design of the Expert System
3. Knowledge Base Design of the Expert System
- Class 1: Scanner class
- Class 2: Permission class
- Class 3: ReportGenerator class
- Class 4: ConfigManager class
- Class 5: FileIterator class
- Class 6: UnPack/UnRAR/UnZip/TarFile class
- Class 7: CmdRunner class
- Class 8: FileTypeFilter class
- Class 9: FileSizeFilter class
- Class 10: FileChecker class
- Class 11: EncryptedChecker class
- Class 12: NTFSChecker class
- Class 13: MergedFileChecker class
- Class 14: OfficeChecker class
- Class 15: KeywordsChecker class
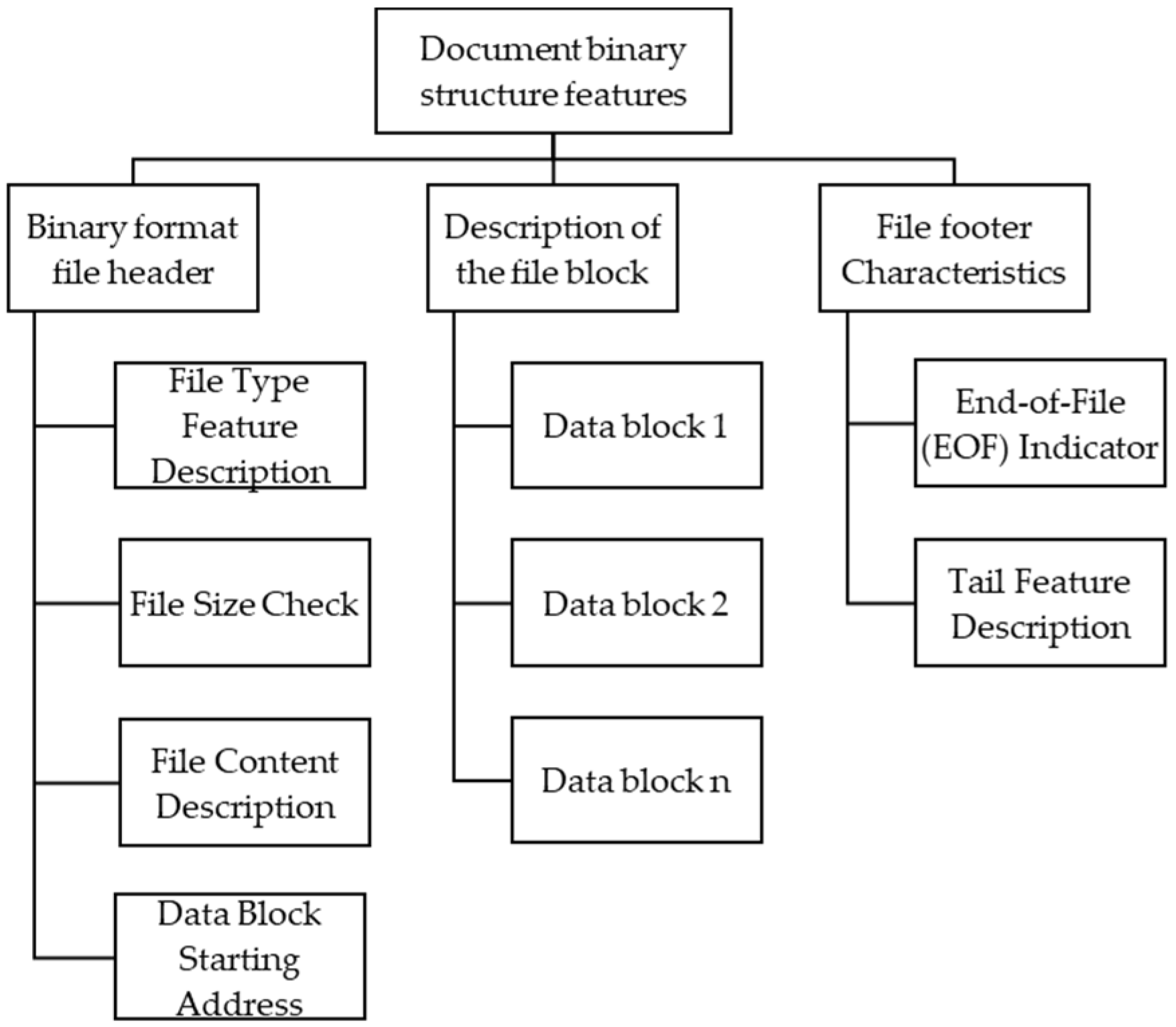
3.1. Feature Information Base
- (1)
- Feature information on file type
- (2)
- Feature information on document structure
- (a)
- The header information in binary format typically includes the file type, feature description, file length verification information, file content description, and the start address of the data block.
- (b)
- The file data block provides information about each individual data block within a file.
- (c)
- The tail feature of a file includes the end identifier of the file and a description of the tail feature.
- (3)
- Feature information on document content
- (4)
- Feature information on document permissions
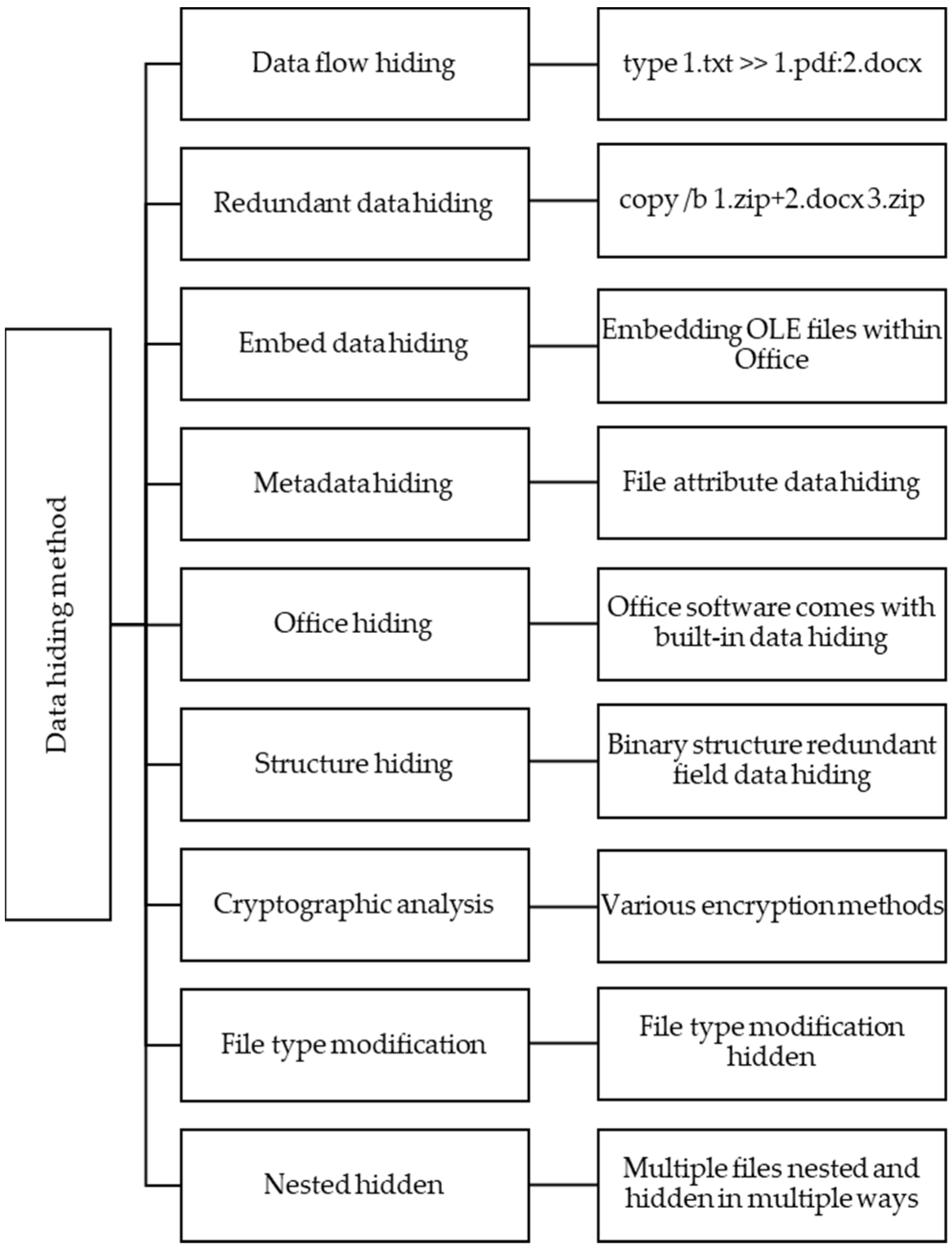
3.2. Rule Base for Mining Hidden Information
- (1)
- The expression of the file format filtering rule realized by the FileTypeFilter class is:
- (a)
- Office documents: .doc, .docx, .xls, .xlsx, .ppt, and .pptx.
- (b)
- Image files: .jpg, .JPEG, .bmp, .png, .tif, and .gif.
- (c)
- Compressed packages: .zip, .rar, .7z, .tar, and .gz.
- (d)
- Other types: .pdf, .txt, .chm, .cpp, .csv, .java, .apk, .mf, .sf, .rsa, .arsc, .exe, and .dll.
- (2)
- The expression of the file size filtering rule realized by FileSizeFilter class is:
- (3)
- The files’ format check rule realized by the FileChecker class means:
- (a)
- Develop validation rules for nested files, including but not limited to: drag and drop embedding, creating from a file, a new embedded file, etc.
- (b)
- Develop a multi-layer document hiding system with nested detection rules. For ZIP and RAR packages, the system will decompress all files and conduct a comprehensive security scan. If the decompressed file still contains a compressed package, it will continue to decompress layer by layer until all subfiles in all compressed packages have been scanned to ensure that no files are overlooked.
- (c)
- Design guidelines for verifying the endpoints of files, such as docx, xlsx, pptx, and other file formats, to determine whether there are any redundant Office documents at the end of the file.
- (d)
- Develop inspection rules for Object Linking and Embedding (OLE) embedded objects [30], analyze the binary stream file of Office documents, implement analysis and inspection of OLE embedded objects, and extract information from embedded objects.
- (e)
- Design NTFS data flow detection rules. The NTFS data stream is a feature of the NTFS disk format commonly utilized for concealing data and serving as a highly covert method of hiding information. Files containing NTFS data streams can be read, written, or copied, and even viewing the file properties will not raise any exceptions. These rules aim to identify and extract NTFS data streams into separate files.
- (f)
- Develop check rules for metadata entrainment [31]. Verify the metadata entrainment behavior of common office documents such as doc, ppt, docx, xlsx, and pptx. This is necessary because files with modifiable metadata in their properties can be utilized to conceal data.
- (g)
- Develop the guidelines for checking file splicing, identifying header and tail splicing across different files, detecting files merged using the Windows command copy, and removing redundant data from the file tail.
- (h)
- Develop rules for file encryption recognition to determine whether a document is encrypted. Office documents, RAR and ZIP packages, and PDF documents all support the use of document passwords, which may indicate an intentional effort to conceal content.
3.3. Rights Management Rules
4. Document Classification Based on Keywords
4.1. Algorithm of Document Sensitivity Classification
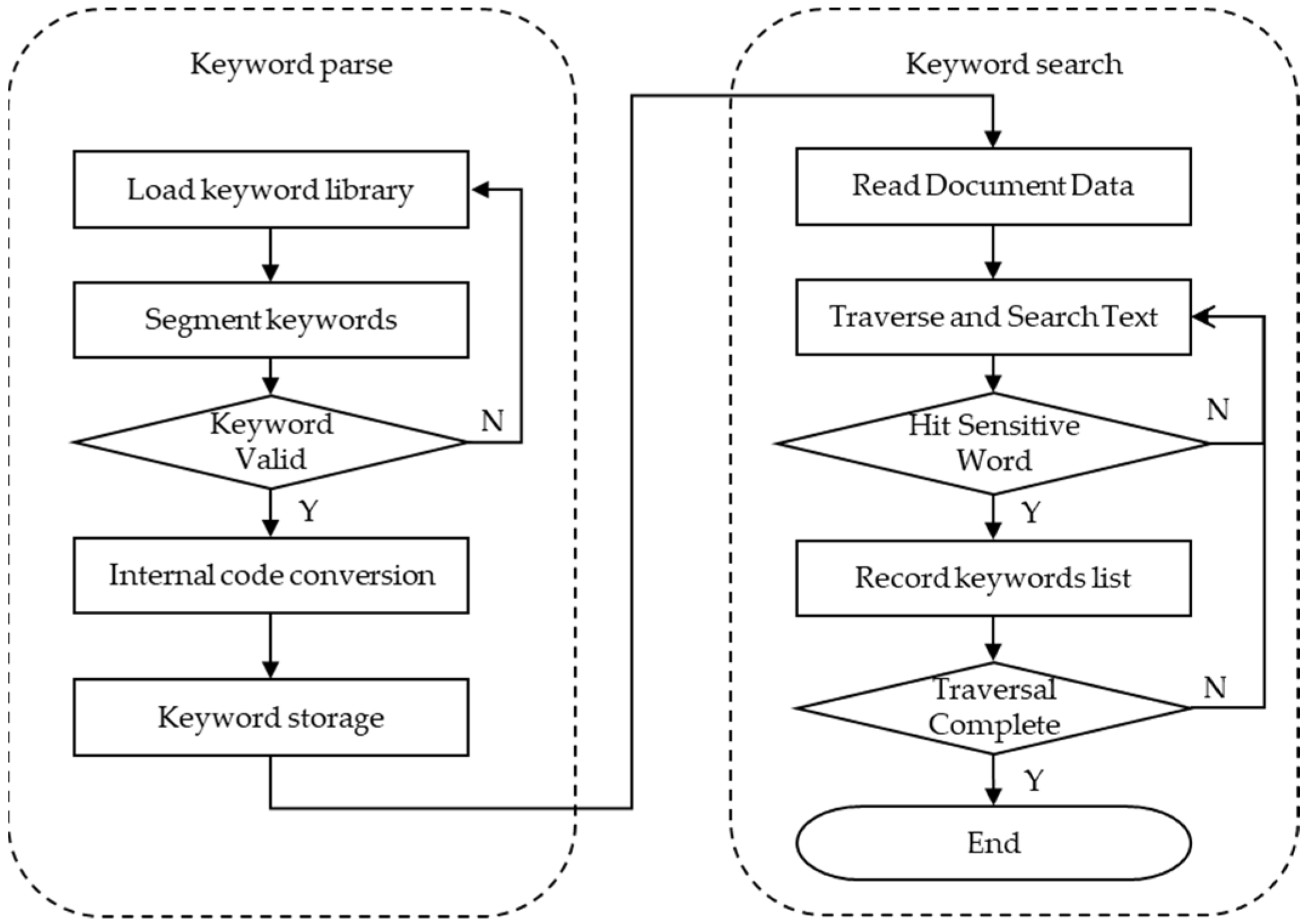
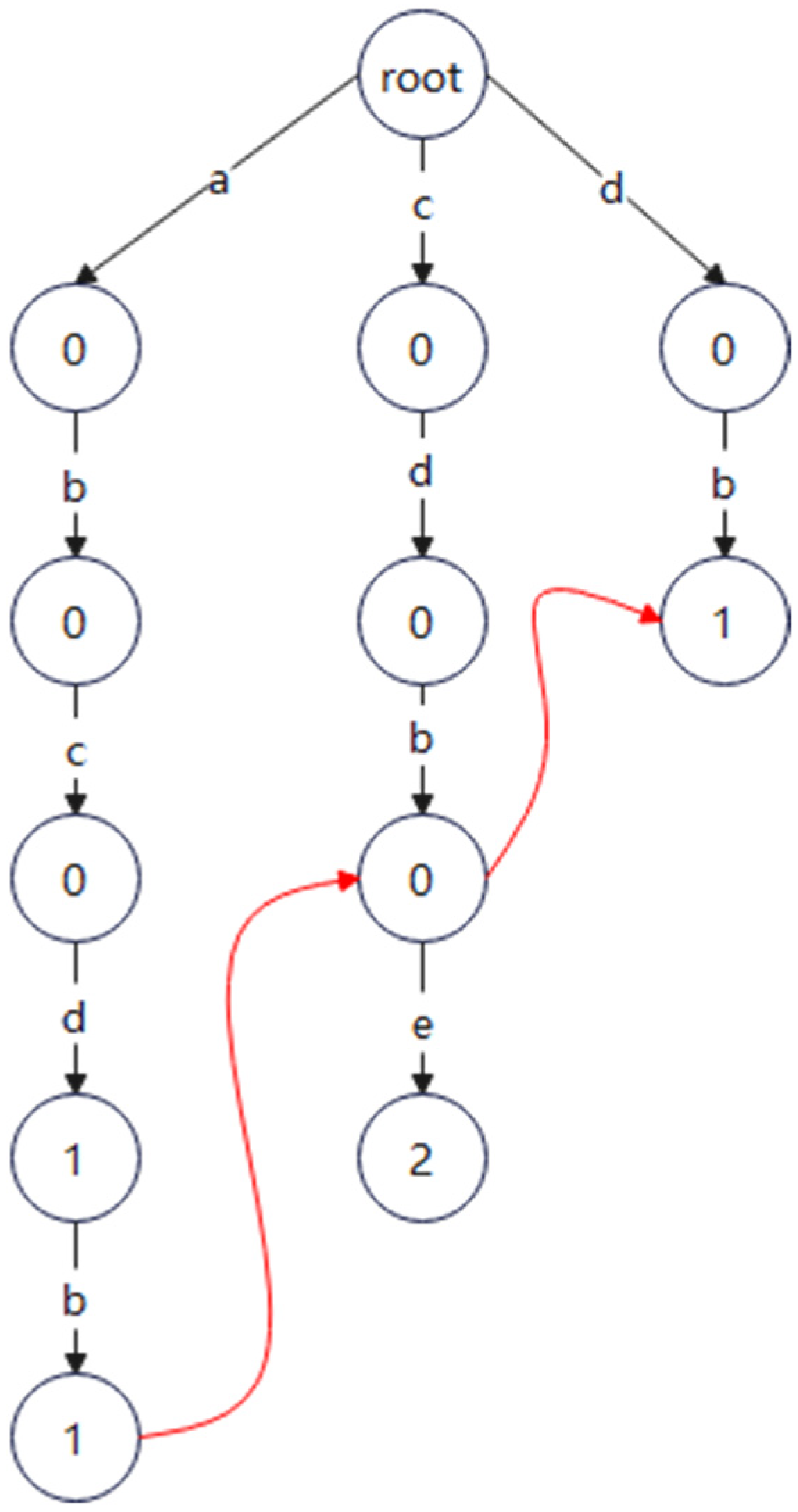
4.2. Sensitive Word Matching Algorithm Based on the AC Automaton
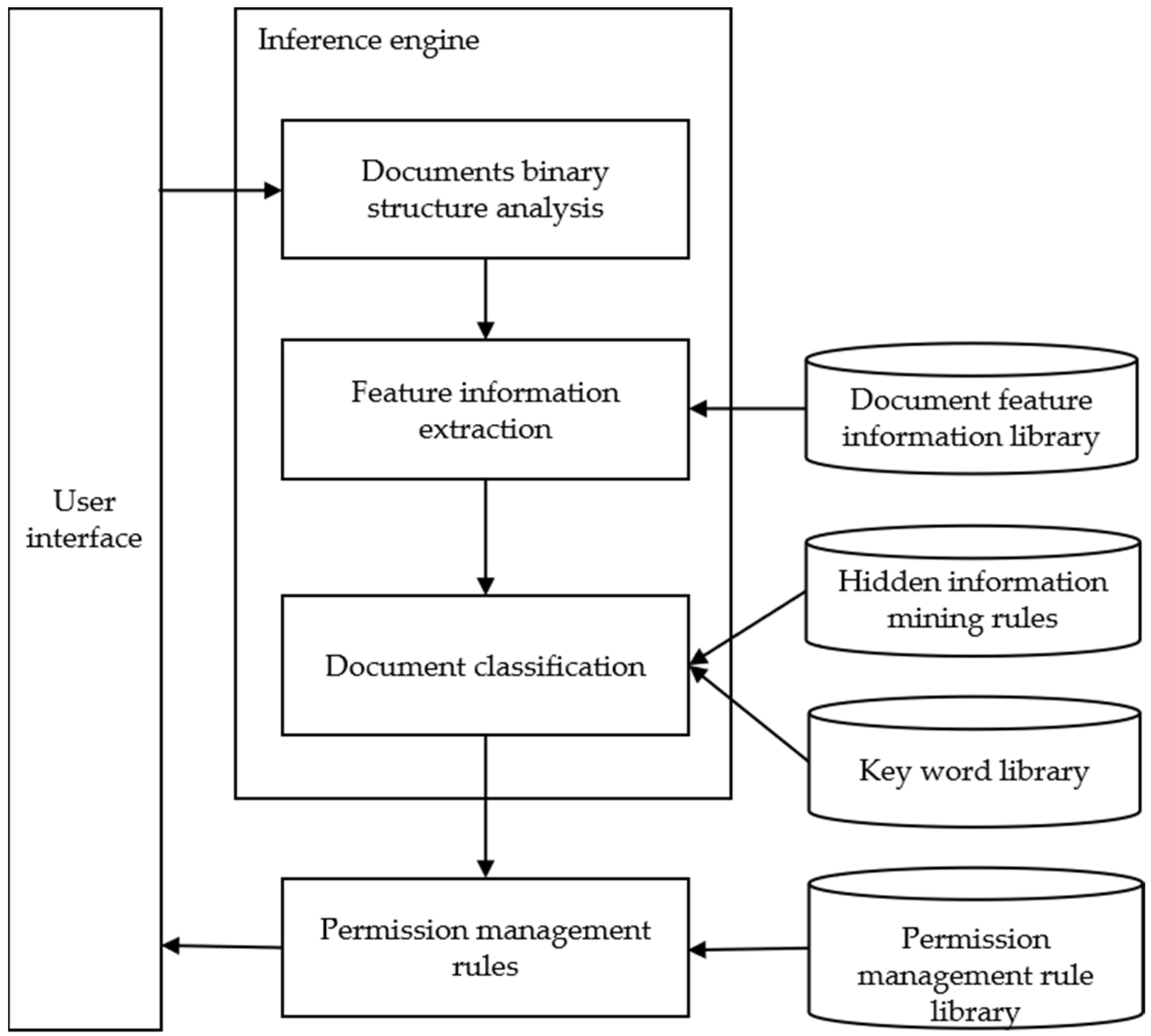
5. Inference Engine for Concealed Information
- (1)
- Firstly, the expert system for mining hidden information in electronic documents is capable of identifying the target file.
- (2)
- The file type is filtered, allowing only those file types that match the whitelist to pass through. File type verification involves identifying whether the content of a specified file conforms to the format declared by its suffix name, with unrecognized file types being reported as suspicious. The file encryption check entails scanning for supported encryption in order to identify and report encrypted files as suspicious. The NTFS data flow check involves examining whether a file has additional NTFS data flow and reporting such files as suspicious. The tail data check aims to prevent sensitive data from being written to the tail of normal files, reporting any files containing tail data as suspicious. If a file is not deemed acceptable, it will proceed to the next check.
- (3)
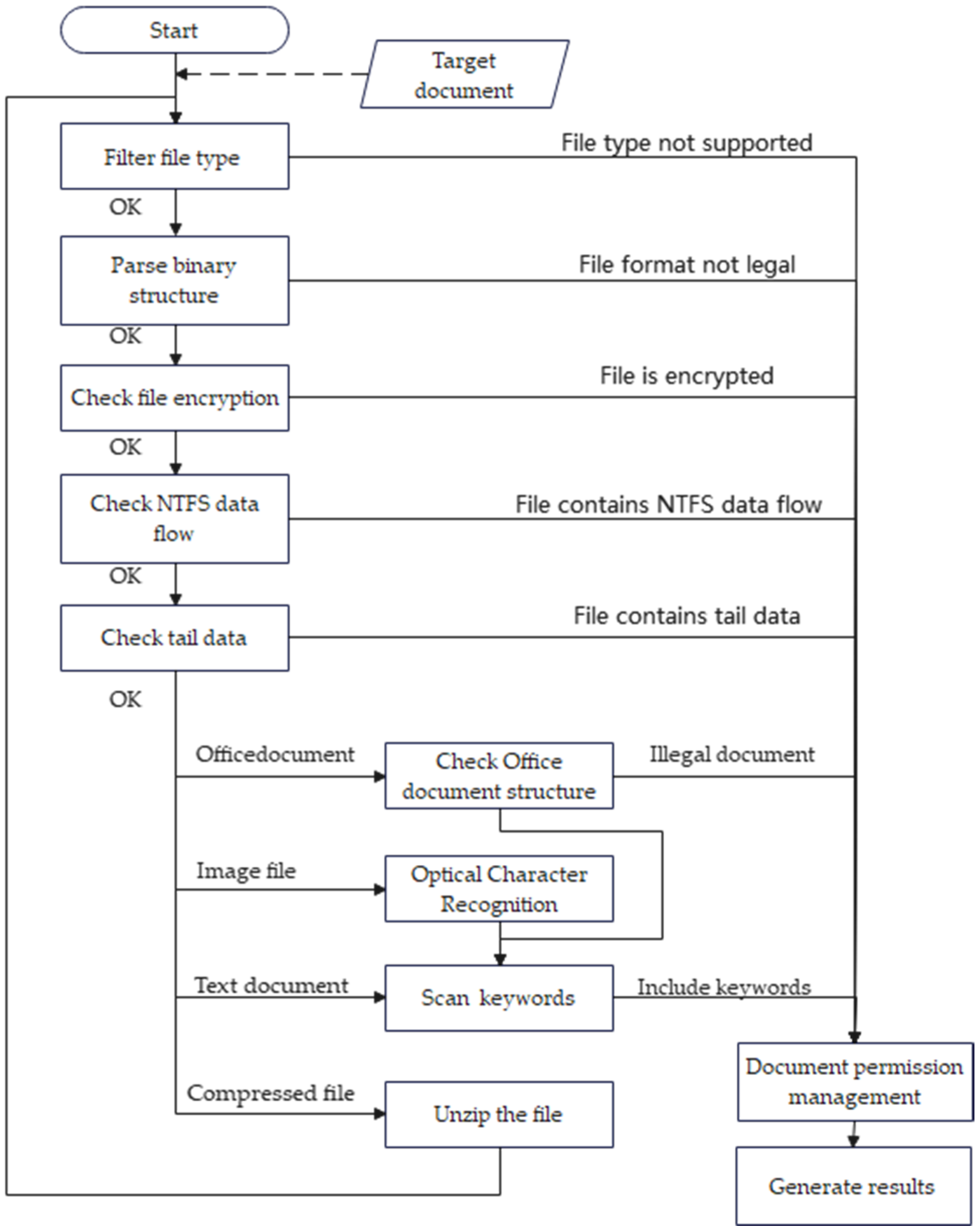
- A structure check on Office documents is performed followed by successively scanning for keywords in the text. The structure check involves examining the file structure of Office documents to identify any hidden data, as shown in Figure 6, and identifying files containing hidden data. Text keyword scanning entails searching for user-defined keywords by scanning every byte of the file in binary mode according to a specified keyword table. If hidden data or user-defined keywords are found, the file will be flagged as suspicious. Otherwise, if the test result is normal, it will proceed to the next test.
- (4)
- For image files, OCR is performed to read images in various formats of text in various languages. The words within the images are then converted into text, and keywords within the text are scanned.
- (5)
- For the compressed package, the files are first decompressed, then the file type filtering step takes place, and finally, all files are scanned within the compressed package.
- (6)
- When the file scan is completed, the report generator gathers all detection results, organizes them into mining result display files based on HTML and XML result display templates, and saves them to the specified path. At this stage, the task execution is considered complete. Figure 7 shows the flow chart of mining hidden information by the inference engine.
6. System Implementation and Testing
6.1. Experimental Environment and Test File Preparation
- (1)
- Development language: C++.
- (2)
- Development tool: Visual Studio 2022.
- (3)
- Basic software operating environment: Windows 11 Professional Edition operating system, 11th Gen Intel® CoreTM i9-11950H @ 2.60 GHz processor.
- Collect a total of 10 compressed package files in 5 different formats, along with 20 image files in 6 formats, and 40 Office documents in 6 formats as well as 30 files in more than 10 other formats, bringing the total number of files to 100, which constitutes the fundamental dataset.
- Include sensitive words of varying degrees in the compressed package, image, and the title, body, header, footer, comments, and hidden fonts of the document within the fundamental dataset. After these operations, build another 100 test cases on the basis of the fundamental dataset.
- Modify the file suffix of each item in the fundamental dataset to a different format to construct another 100 test cases.
- Utilize commands such as type and copy to conceal the data flow associated with each file within the fundamental dataset and combine the other additional files, which constructs another 100 test cases.
- Insert attachment files and objects in office documents within the fundamental dataset to construct 80 test cases.
- Encrypt the compressed package files and office files within the fundamental dataset to construct 10 test cases.
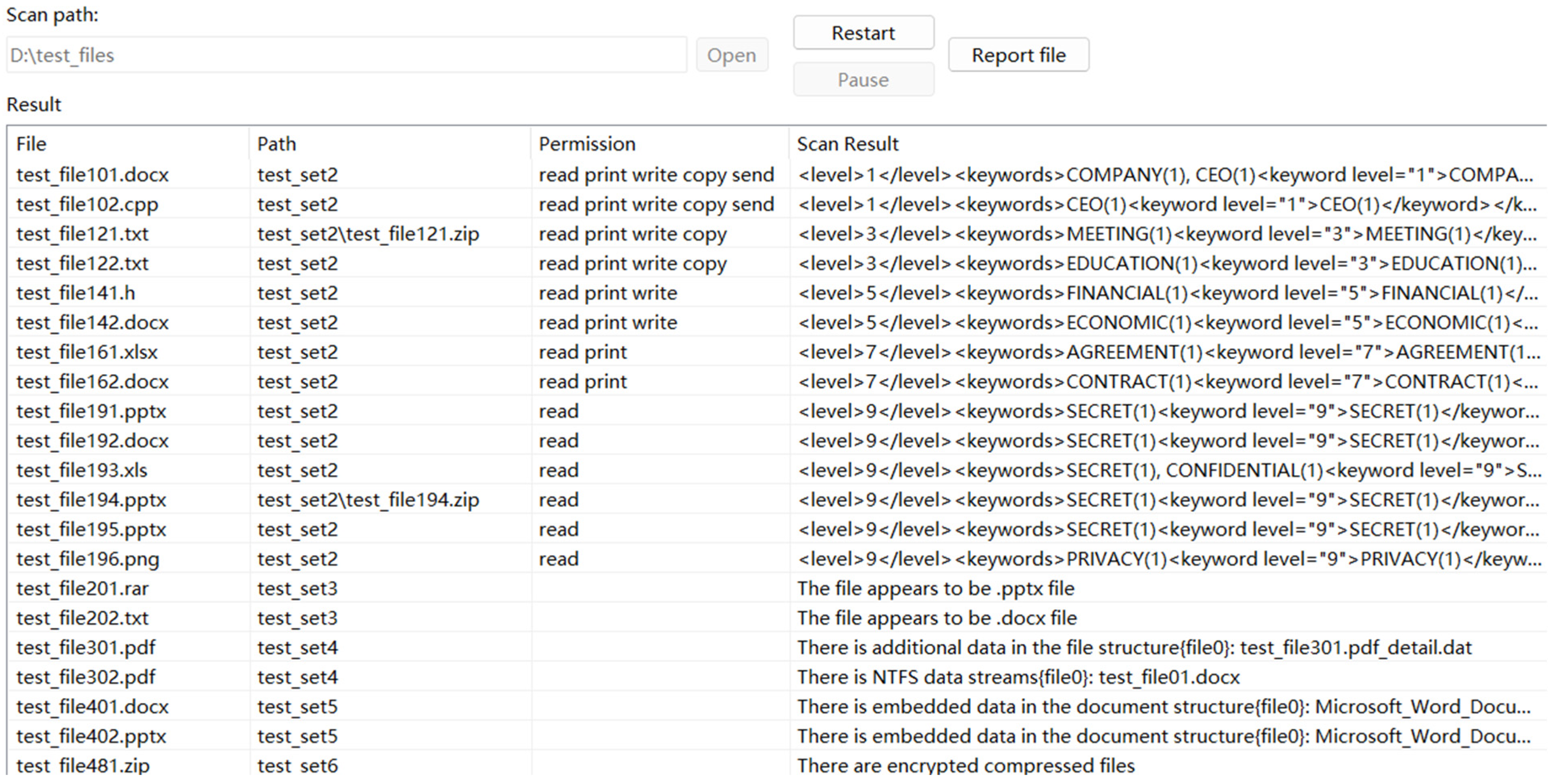
6.2. Test Result
7. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Gao, J.; Jiang, Y.; Liu, Z.; Yang, X.; Wang, C.; Jiao, X.; Yang, Z.; Sun, J. Semantic Learning and Emulation Based Cross-platform Binary Vulnerability Seeker. IEEE Trans. Softw. Eng. 2019, 47, 2575–2589. [Google Scholar] [CrossRef]
- Jegorova, M.; Kaul, C.; Mayor, C.; O’Neil, A.Q.; Weir, A.; Murray-Smith, R.; Tsaftaris, S.A. Survey: Leakage and Privacy at Inference Time. arXiv 2021, arXiv:2107.01614. [Google Scholar] [CrossRef] [PubMed]
- Kleij, R.V.D.; Wijn, R.; Hof, T. An application and empirical test of the Capability Opportunity Motivation-Behaviour model to data leakage prevention in financial organizations. Comput. Secur. 2020, 97, 101970. [Google Scholar] [CrossRef]
- Liang, Z.; Guo, J.; Qiu, W.; Huang, Z.; Li, S. When graph convolution meets double attention: Online privacy disclosure detection with multi-label text classification. Data Min. Knowl. Discov. 2024, 38, 1171–1192. [Google Scholar] [CrossRef]
- Akyildiz, T.A.; Guzgeren, C.B.; Yilmaz, C.; Savas, E. MeltdownDetector: A Runtime Approach for Detecting Meltdown Attacks. Future Gener. Comput. Syst. 2020, 112, 136–147. [Google Scholar] [CrossRef]
- Suma, M.; Madhumathy, P. Brakerski-Gentry-Vaikuntanathan fully homomorphic encryption cryptography for privacy preserved data access in cloud assisted Internet of Things services using glow-worm swarm optimization. Trans. Emerg. Telecommun. Technol. 2022, 33, e4641. [Google Scholar] [CrossRef]
- Kunhu, A.; Al-Ahmad, H.; Mansoori, S.A. A Reversible Watermarking Scheme for Ownership Protection and Authentication of Medical Images; Applications Development and Analysis Section, Mohammed bin Rashid Space Centre, College of Engineering and IT, University of Dubai: Dubai, United Arab Emirates, 2024. [Google Scholar] [CrossRef]
- Deshpande, P.M.; Joshi Sand Dewan, P.; Murthy, K.; Mohania, M.; Agrawal, S. The Mask of ZoRRo: Preventing information leakage from documents. Knowl. Inf. Syst. 2015, 45, 705–730. [Google Scholar] [CrossRef]
- Akshaya, S.; Viji, A. Image steganography using deep reinforcement learning. J. Instrum. Soc. India Proc. Natl. Symp. Instrum. 2021, 8, 2058–2064. [Google Scholar]
- Tong, Y.; Liu, Y.; Wang, J.; Xin, G. Text steganography on RNN-generated lyrics. Math. Biosciences Eng. 2019, 16, 5451–5463. [Google Scholar] [CrossRef] [PubMed]
- Peng, W.; Wang, T.; Qian, Z.; Li, S.; Zhang, X. Cross-modal text steganography against synonym substitution-based text attack. IEEE Signal Process. Lett. 2023, 30, 299–303. [Google Scholar] [CrossRef]
- Chang, C.Y.; Clark, S. Practical Linguistic Steganography using Contextual Synonym Substitution and a Novel Vertex Coding Method. Comput. Linguist. 2014, 40, 403–448. [Google Scholar] [CrossRef]
- Shirali-Shahreza, M. Text Steganography by Changing Words Spelling. In Proceedings of the ICACT 2008, 10th International Conference on Advanced Communication Technology, Gangwon, Republic of Korea, 17–20 February 2008. [Google Scholar] [CrossRef]
- Ding, C.; Fu, Z.; Yu, Q.; Wang, F.; Chen, X. Joint Linguistic Steganography With BERT Masked Language Model and Graph Attention Network. IEEE Trans. Cogn. Dev. Syst. 2023, 16, 772–781. [Google Scholar] [CrossRef]
- Yu, L.; Lu, Y.; Yan, X.; Yu, Y. MTS-Stega: Linguistic Steganography Based on Multi-Time-Step. Entropy 2022, 24, 585. [Google Scholar] [CrossRef] [PubMed]
- Liu, G.; Huang, F.; Li, Z. Designing adaptive JPEG steganography based on the statistical properties in spatial domain. Multimed Tools Appl. 2019, 78, 8655–8665. [Google Scholar] [CrossRef]
- Sultan, B.; ArifWani, M. A new framework for analyzing color models with generative adversarial networks for improved steganography. Multimed Tools Appl. 2023, 82, 19577–19590. [Google Scholar] [CrossRef]
- Dai, H.; Wang, R.; Xu, D.; He, S.; Yang, L. HEVC Video Steganalysis Based on PU Maps and Multi-Scale Convolutional Residual Network. IEEE Trans. Circuits Syst. Video Technol. 2024, 34, 2663–2676. [Google Scholar] [CrossRef]
- Miranda, J.D.; Parada, D.J. LSB steganography detection in monochromatic still images using artificial neural networks. Multimed Tools Appl. 2022, 81, 785–805. [Google Scholar] [CrossRef]
- Yang, Z.; Huang, Y.; Zhang, Y.J. TS-CSW: Text steganalysis and hidden capacity estimation based on convolutional sliding windows. Multimed Tools Appl. 2020, 79, 18293–18316. [Google Scholar] [CrossRef]
- Wang, H.; Yang, Z.; Yang, J.; Chen, C.; Huang, Y. Linguistic Steganalysis in Few-Shot Scenario. IEEE Trans. Inf. Forensics Secur. 2023, 18, 4870–4882. [Google Scholar] [CrossRef]
- Xue, Y.; Kong, L.; Peng, W.; Zhong, P.; Wen, J. An effective linguistic steganalysis framework based on hierarchical mutual learning. Inf. Sci. 2022, 586, 140–154. [Google Scholar] [CrossRef]
- Li, M.; Liu, Q. Steganalysis of SS Steganography: Hidden Data Identification and Extraction. Circuits Syst. Signal Process. 2015, 34, 3305–3324. [Google Scholar] [CrossRef]
- Mendoza, V.N.; Ledeneva, Y.; García-Hernández, R.A. Unsupervised extractive multi-document text summarization using a genetic algorithm. J. Intell. Fuzzy Syst. 2020, 39, 2397–2408. [Google Scholar] [CrossRef]
- Qian, Y.; Liang, J.; Dang, C. Knowledge structure, knowledge granulation and knowledge distance in a knowledge base. Int. J. Approx. Reason. 2009, 50, 174–188. [Google Scholar] [CrossRef]
- Karresand, M.; Axelsson, S.; Dyrkolbotn, G.O. Disk Cluster Allocation Behavior in Windows and NTFS. Mobile Netw. Appl. 2020, 25, 248–258. [Google Scholar] [CrossRef]
- Hakak, S.; Kamsin, A.; Shivakumara, P.; Idris, M.Y.I. Partition-based pattern matching approach for efficient retrieval of arabic text. Malays. J. Comput. Sci. 2018, 31, 200–209. [Google Scholar] [CrossRef]
- Bipin Nair, B.J.; Shobha Rani, N.; Khan, M. Deteriorated Image Classification Model for Malayalam Palm Leaf Manuscripts. J. Intell. Fuzzy Syst. 2023, 45, 4031–4049. [Google Scholar] [CrossRef]
- Mahajan, P.; Kandwal, R.; Vijay, R. Rough set-based approach for automated discovery of censored production rules. J. Exp. Theor. Artif. Intell. 2014, 26, 151–166. [Google Scholar] [CrossRef]
- Yang, F.; Zhang C, L. A New Approach of Expanding Data Processing Ability for Configuration Monitoring Software MCGS Based on OLE. Appl. Mech. Mater. 2011, 65, 295–298. [Google Scholar] [CrossRef]
- Cabarrão, V.; Batista, F.; Moniz, H.; Trancoso, I.; Mata, A.I. Acoustic-prosodic Entrainment in Structural Metadata Events. In Proceedings of the Interspeech 2018, Hyderabad, India, 2–6 September 2018; pp. 2176–2180. [Google Scholar] [CrossRef]
- Hendrian, D.; Inenaga, S.; Yoshinaka, R.; Shinohara, A. Efficient Dynamic Dictionary Matching with DAWGs and AC-automata. Theor. Comput. Sci. 2019, 792, 161–172. [Google Scholar] [CrossRef]

{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Name | Explanation | |
|---|---|---|
| 1 | Features | Characteristic information |
| 2 | SupportFilesType | File types supported by this feature |
| 3 | PreProcess | File binary data preprocessing |
| 4 | FeaturesExtract | Feature extraction method |
| 5 | HtmlXmlReturn | Result saving mode |
| 6 | setOptions | Functional setting |
| 7 | Check | Feature detection mode |
| Number | Filename | Extension | File Header | Skew | End-of-File |
|---|---|---|---|---|---|
| 1 | MS Office/OLE2 | doc; xls; ppt; ppa; pps; pot; dot; db | 0XD0CF11E0A1B11AE1 | 0 | 0X0100FEF03 |
| 2 | Rich Text Format | rtf | 0x7B5C7X7466434452 | 0 | |
| 3 | XML | xml | 0x3C3F786D6C7B5C72 | 0 | |
| 4 | HTML | html; htm; php; php3; php4; phtml; shtml | 0x68746D6C | 0 | |
| 5 | MS Access | mdb; mda; mde; mdt; fdb | 0x5374616E64617264 | 4 | |
| 6 | Adobe Acrobat | 0x255044462D | 0 | ||
| 7 | Quicken | qdf | 0XAC9eBD8F | 0 | |
| 8 | Windows Registry | registry | 0x72656766 | 0 | |
| 9 | ZIP Archive | zip; jar | 0x504B0304 | 0 | |
| 10 | RAR Archive | rar | 0x52617221 | 0 | |
| 11 | 7-ZIP Archive | 7z | 0x377A | 0 | |
| 12 | Compiled HTML | chm | 0x4954534603000000 | 0 |
| Secrete Grade | Ordinary User | Intermediate User | Advanced User |
|---|---|---|---|
| Top secret | read | read, print | read, print, write, copy |
| confidential | read, print | read, print, write | read, print, write, copy, send |
| secret | read, print, write | read, print, write, copy | read, print, write, copy, send |
| normal | read, print, write, copy | read, print, write, copy, send | read, print, write, copy, send |
| Test Folder | Problem | Sensitive Word Levels | Expected Permissions |
|---|---|---|---|
| test_file001~100 | Normal Files with no problem | / | read print write copy send |
| test_file101~120 | Include sensitive word | level 1 | read print write copy send |
| test_file121~140 | Include sensitive word | level 3 | read print write copy |
| test_file141~160 | Include sensitive word | level 5 | read print write |
| test_file161~180 | Include sensitive word | level 7 | read print |
| test_file181~200 | Include sensitive word | level 9 | read |
| test_file201~300 | Modify the file suffix to a different file type | Waring, No permissions | |
| test_file301~350 | Use type command to hide data | Waring, No permissions | |
| test_file351~400 | Use copy command to merge data | Waring, No permissions | |
| test_file401~440 | Office Insert File | Waring, No permissions | |
| test_file441~480 | Office Insert Object | Waring, No permissions | |
| test_file481~490 | Compressed file encryption | Waring, No permissions |
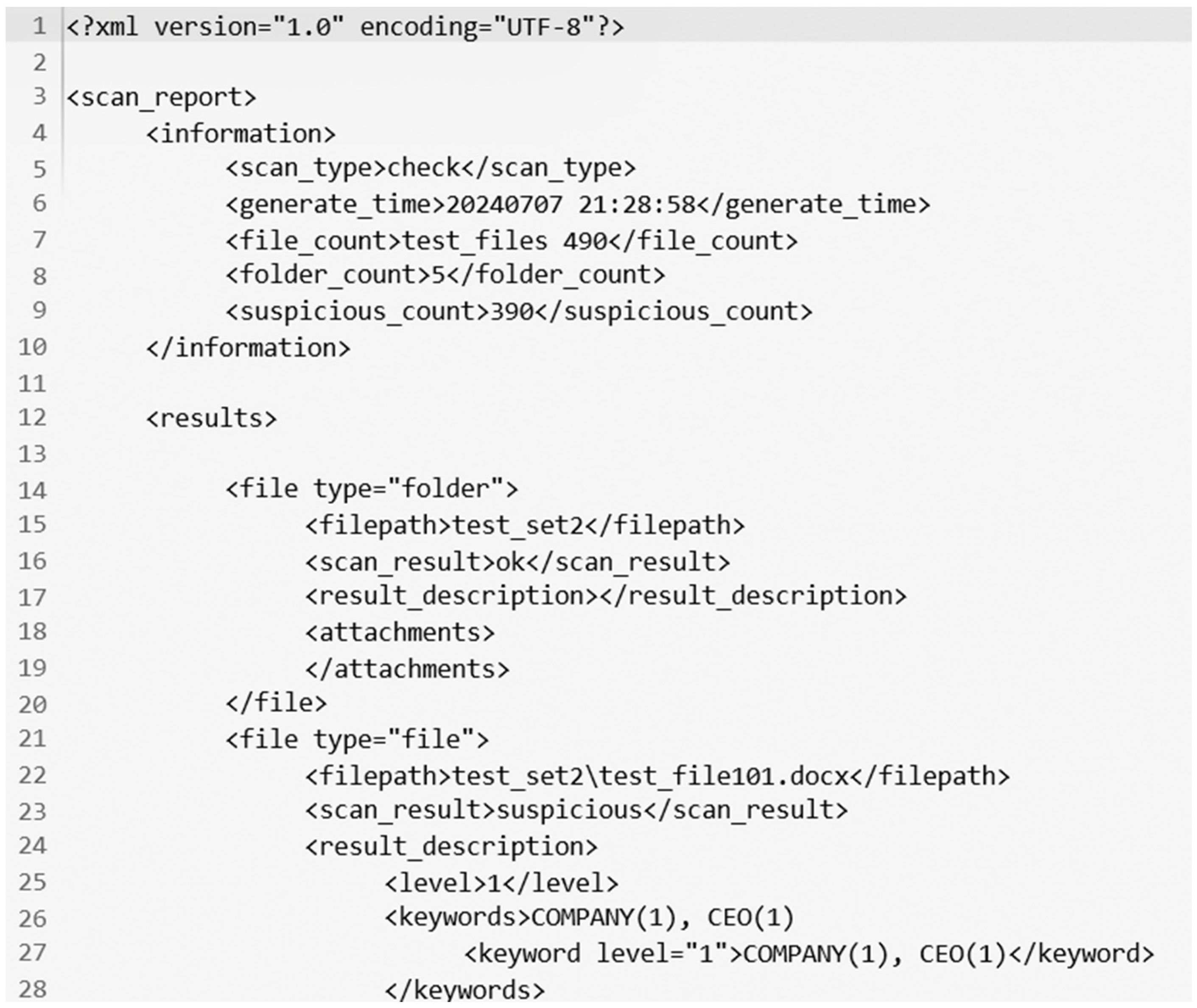
| Keyword in XML Format Report | Implication |
|---|---|
| scan_report | test report |
| information | summary information |
| scan_type | check whether completion |
| generate_time | check completion time of report |
| file_count | number of files |
| folder_count | number of folders |
| suspicious_count | number of suspicious files |
| results | specific document report |
| file type | type of file |
| filepath | file path/name |
| scan_result | scan result |
| result_description | result description |
| attachments | attachments |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Tan, L.; Yi, J. Expert System for Extracting Hidden Information from Electronic Documents during Outgoing Control. Electronics 2024, 13, 2924. https://doi.org/10.3390/electronics13152924
Tan L, Yi J. Expert System for Extracting Hidden Information from Electronic Documents during Outgoing Control. Electronics. 2024; 13(15):2924. https://doi.org/10.3390/electronics13152924
Chicago/Turabian StyleTan, Lingling, and Junkai Yi. 2024. "Expert System for Extracting Hidden Information from Electronic Documents during Outgoing Control" Electronics 13, no. 15: 2924. https://doi.org/10.3390/electronics13152924
APA StyleTan, L., & Yi, J. (2024). Expert System for Extracting Hidden Information from Electronic Documents during Outgoing Control. Electronics, 13(15), 2924. https://doi.org/10.3390/electronics13152924