


Automated Conversion of CVE Records into an Expert System, Dedicated to Information Security Risk Analysis, Knowledge-Base Rules




Abstract
1. Introduction
2. Background and Related Works
2.1. The Design of the Expert System
- ES-Builder [11]—a robust solution offering some benefits as it is created specifically for educational purposes. The limitations include the inability to be installed and used locally. The shell is built using AJAX framework, and knowledge base facts and rules are stored in MySQL database.
- Pyke v. 1.1 (Python Knowledge Engine) [12]—it uses logic programming that is inspired by the Prolog programming language, but the shell itself is written in Python. Python functions, Pyke rules, and Pyke template variables and graph plans are key features of the Pyke knowledge base. Pyke has an inference engine that applies rules to facts to determine additional facts, forward chaining, and backward chaining. The limitations are that it is rather heavy on resources.
- Drools v. 8.44.0 [13]—is an open-source tool that has a large support community. This shell is based on the Java Rules Engine API (Java Specification Request 94) standard and uses an improved version of the RETE algorithm called ReteOO. Drools is a widely applicable and modern tool for ES development, which makes this shell one of the most popular tools for ES development. The limitations are the heaviness of the resources as well as the slightly outdated technology stack.
- CLIPS v. 6.4.1 (C Language Integrated Production System) [14]—developed in 1985 at NASA’s Johnson Space Center and was originally called NAIL (NASA’s Artificial Intelligence Language). The syntax of CLIPS is similar to the Lisp programming language. This shell is written in the C programming language, so program extensions can be written in C, and CLIPS itself can be called from other C programs. This led to the popularity of this tool, and since 2005 CLIPS has been one of the most widely used ES development tools. A pretty lightweight solution, though the limitations come when dealing with the easiness to use and the slightly outdated technology stack.
- Jess v. 7.1 (Java Expert System Shell) [15]—widely used to create rule-based ESs. This shell was created in 1995 based on CLIPS, and Jess has all the features that CLIPS has, but unlike CLIPS, Jess is not open source, but it is free for educational purposes. Jess has an ES development environment integrated with the Eclipse platform, which is one of the strongest points for this ESS. It also provides cross-platform functionality. The shortcoming is its heaviness on resources.
2.2. Automated Methods of Forming the Knowledge Base of Expert Systems
- DAMLJessKB software [25] transforms DAML (DARPA Agent Markup Language) ontologies into Jess expert system rules. This method only uses specific DAML ontologies for conversion, which are converted to Jess expert system rules, being the major drawback of this method.
- DLEJena software [26] is able to convert a pD semantics-compatible OWL 2 RL profile into a Jena expert system knowledge base. Although the developed program does not use the full OWL 2 RL profile, it is able to successfully convert most of the OWL 2 RL ontologies. One of the shortcomings of this method is that this method is limited to the specific Jena expert system.
- The method proposed by [27]. The main idea of this method is to use the existing information security ontologies, converting them into a set of rules of expert systems through the universal RIF (Rule Interchange Format) format, from which it is easy to convert to the format of the set of rules supported by the selected expert system. This method can be widely applied because it solves the shortcomings of the previously described ontology conversion methods, where the rules are converted from a specific ontology language to a specific ES knowledge base.
2.3. Existing Data Transformation Models for CVE Data
3. The CVE Data
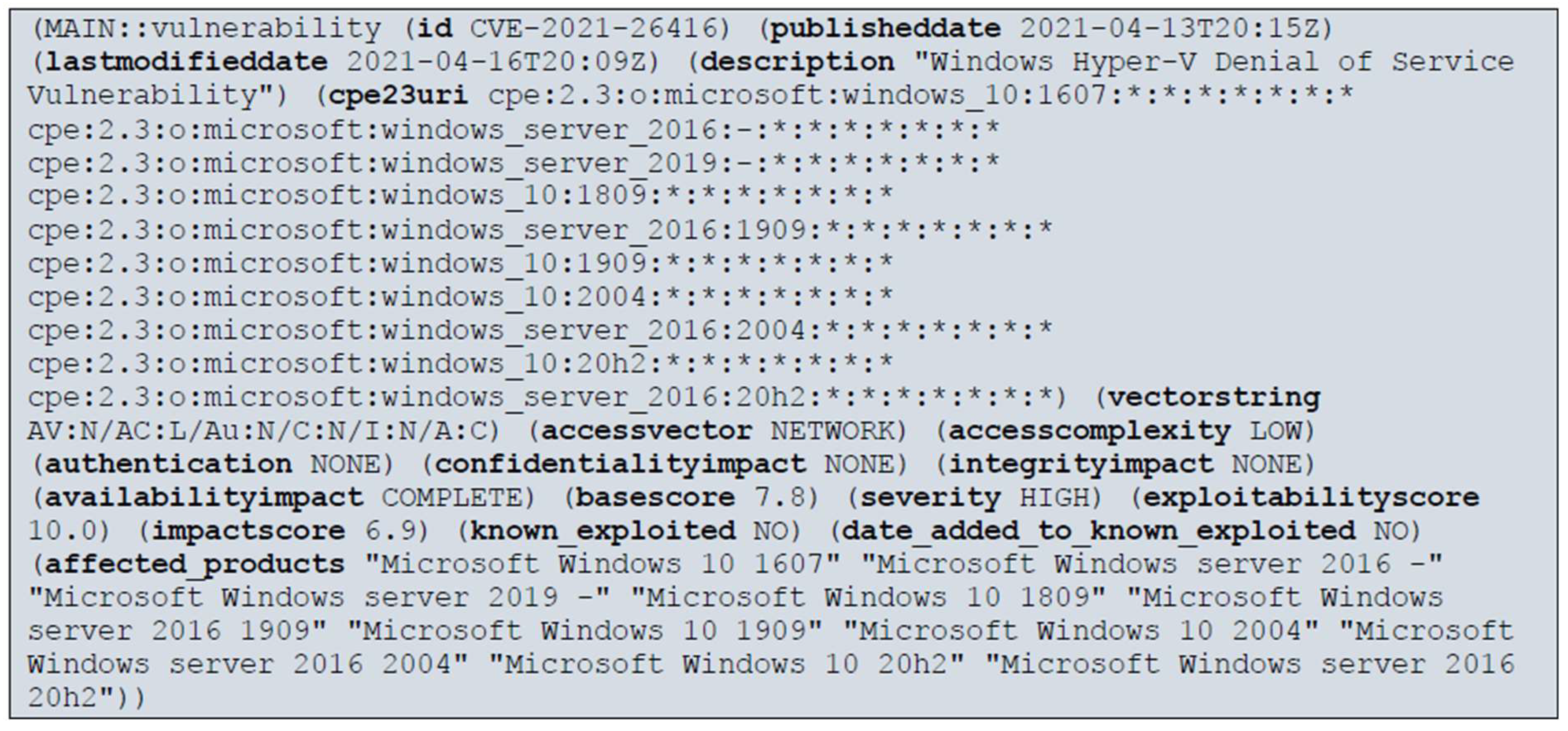
3.1. CVE Basic Data
3.2. The CVSS Data
3.3. CISA Known Exploited Vulnerabilities Catalog
- The vulnerability has a CVE ID assigned to it.
- There is solid evidence that the vulnerability has been actively exploited in the public domain.
- There is an obvious remedy for the vulnerability, such as a software update from the manufacturer.
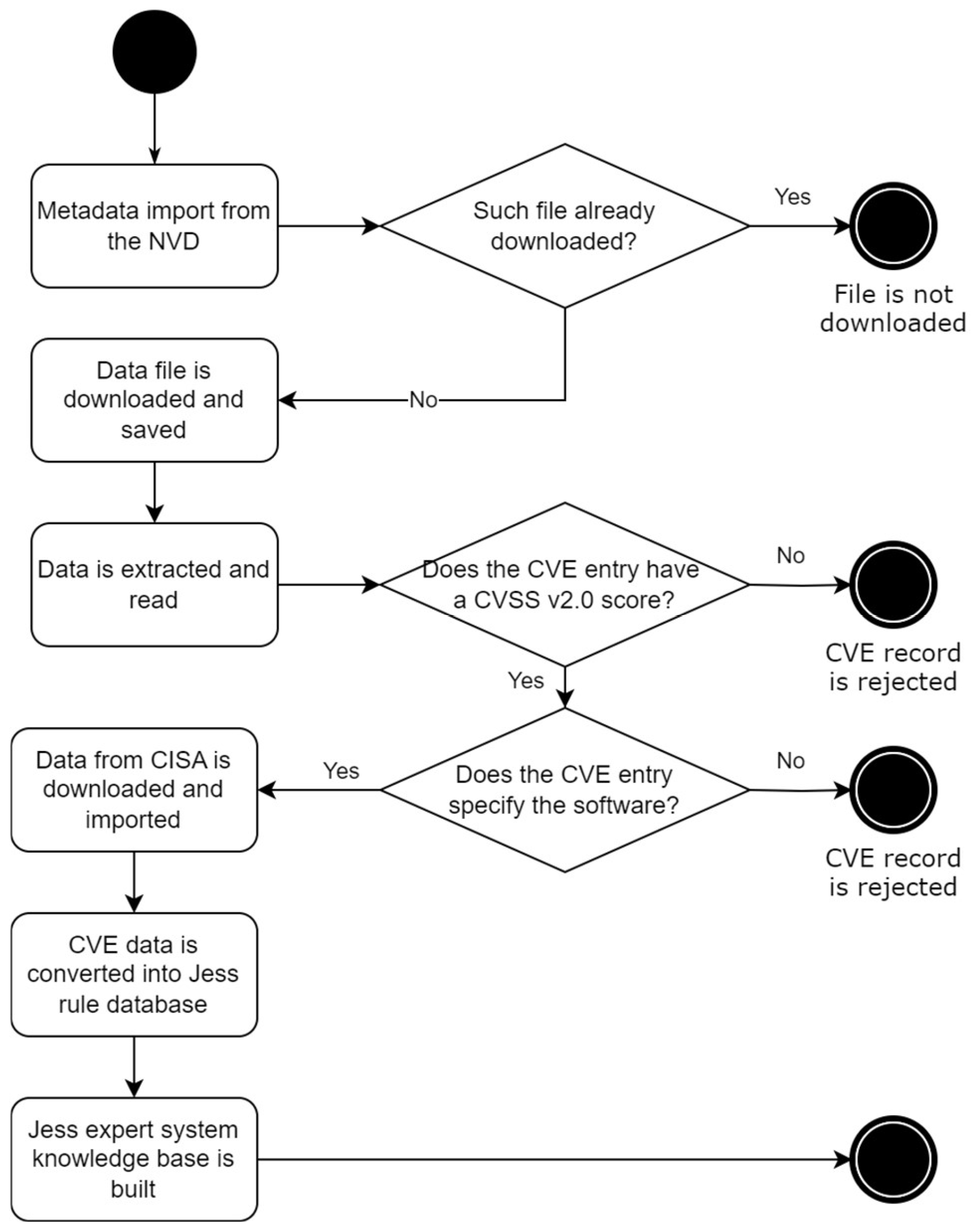
4. The Proposed Method
- Metadata are imported from the NVD. Since NVD provides data metadata (SHA256 hash sums), these data are downloaded and saved to compare with already downloaded data and to avoid re-sending the same data files.
- Is such file already downloaded? Before starting the CVE data download, the metadata from the previously downloaded CVE data are checked against the newly downloaded metadata from the NVD. If the metadata matches—the CVE data file is not sent, and if the metadata does not match—the process of downloading CVE data is initiated. In this way, data download time is saved.
- Data file is downloaded and saved. There are two ways to download vulnerability data from NVD: by downloading archives (in GZ or ZIP formats) containing CVE data in JSON format or by using the application programming interface (API). Both methods have advantages and disadvantages. It was decided to use a standard data download from NVD, which sends archives containing files in JSON format. This way, all CVE data are downloaded faster, and local requests are not tracked.
- Data are extracted and read. In this process, the downloaded archives are extracted, and the CVE data are obtained.
- Does the CVE entry have a CVSS V2.0 score? This process picks only those CVE records that contain available CVSS version 2.0 scores. If the record does not have it, it is not included in the forming ES knowledge base.
- Does the CVE specify the software? Only those CVE records that contain software specifications are included.
- Data from CISA are downloaded and imported. To mark in the conversion process those records that are included in the CISA Known Exploited Vulnerabilities Catalog, this directory is downloaded from the CISA website in CSV format, and the data in it are loaded.
- CVE data are converted into Jess rule database. This process converts CVE data with CVSS version 2 estimate data into Jess rules. This process also marks those CVE records that are included in the CISA Known Exploited Vulnerabilities Catalog and additionally extracts vulnerable software information from the CPE data contained in CVEs: manufacturer, name, and version.
- Unsorted facts—they are like rows in a relational database table, where table columns correspond to named data fields, which are called slots. When writing an unsorted fact, slots can be specified in any order. Unsorted facts are the most used type of facts and a good choice in most situations.
- Sorted facts—they do not have the structure of named fields, they are just a short, flat list. Such facts are convenient for simple pieces of information that do not require structure.
- Shadow facts—they are unsorted facts that are associated with Java objects in the real world—they provide the ability to reason about events that are occurring outside Jess ES.
- Jess expert system knowledge base is being built. This process creates and saves the end result, a file containing the CVE data facts that make up the Jess ES knowledge base.
4.1. Program Prototype of the Method Converting CVE Data into the ES Knowledge Base
4.2. Prototype Performance Evaluation
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Kühn, P.; Relke, D.N.; Reuter, C. Common vulnerability scoring system prediction based on open source intelligence information sources. Comput. Secur. 2023, 131, 103286. [Google Scholar] [CrossRef]
- Dawson, M.; Bacius, R.; Gouveia, L.B.; Vassilakos, A. Understanding the challenge of cybersecurity in critical infrastructure sectors. Land Forces Acad. Rev. 2021, 26, 69–75. [Google Scholar] [CrossRef]
- Hernandez, Z.; Hernandez, T.H.; Velasco-Bermeo, N.; Monroy, B. An expert system to detect risk levels in small and medium enterprises (SMEs). In Proceedings of the Fourteenth Mexican International Conference on Artificial Intelligence (MICAI), Cuernavaca, Mexico, 25–31 October 2015. [Google Scholar]
- Lee, Y.; Woo, S.; Song, Y.; Lee, J.; Lee, D.H. Practical vulnerability-information-sharing architecture for automotive security-risk analysis. IEEE Access 2020, 8, 120009–120018. [Google Scholar] [CrossRef]
- Azzazi, A.; Shkoukani, M. A Knowledge-based Expert System for Supporting Security in Software Engineering Projects. Int. J. Adv. Comput. Sci. Appl. 2022, 13, 395–400. [Google Scholar] [CrossRef]
- Atymtayeva, L.; Kozhakhmet, K.; Bortsova, G. Building a knowledge base for expert system in information security. Adv. Intel. Syst. Comput. 2014, 270, 57–76. [Google Scholar] [CrossRef]
- Tripathi, K.P. A review on knowledge-based expert system: Concept and architecture. IJCA Spec. Issue Artif. Intell. Tech. -Nov. Approaches Pract. Appl. 2011, 4, 19–23. [Google Scholar]
- Colson, A.R.; Cooke, R.M. Expert elicitation: Using the classical model to validate experts’ judgments. Rev. Environ. Econ. Policy 2018, 12, 113–132. [Google Scholar] [CrossRef]
- Tecuci, G.; Marcu, D.; Boicu, M.; Schum, D.A. Knowledge Engineering: Building Cognitive Assistants for Evidence-Based Reasoning; Cambridge University Press: Cambridge, UK, 2016. [Google Scholar]
- Ogu, E.C.; Adekunle, Y.A. Basic Concepts of Expert System Shells and an Efficient Model for Knowledge Acquisition. Int. J. Sci. Res. 2013, 2, 554–559. [Google Scholar]
- McGoo Software. ES-Builder Web Expert System Shell. Available online: http://www.mcgoo.com.au (accessed on 15 January 2024).
- Frederiksen, B. Applying Expert System Technology to Code Reuse with Pyke. In Proceedings of the PyCon, Birmingham, UK, 12–14 September 2008. [Google Scholar]
- Wen, Q. Drools Rules Engine Used in Management Accounting System Design Research. In Proceedings of the 4th International Conference on Management Science and Engineering Management (ICMSEM 2023), Nanchang, China, 2–4 June 2023. [Google Scholar]
- Riley, G. Adventures in Rule-Based Programming: A CLIPS Tutorial; Secret Society Software, LLC: AZ, USA, 2022. [Google Scholar]
- Yurin, A.Y.; Dorodnykh, N.O. Personal knowledge base designer: Software for expert systems prototyping. SoftwareX 2020, 11, 100411. [Google Scholar] [CrossRef]
- Orbst, L.; Chase, P.; Markeloff, R. Developing an Ontology of the Cyber Security Domain. In Proceedings of the Seventh International Conference on Semantic Technologies for Intelligence, Defense, and Security, Fairfax, VA, USA, 23–26 October 2012; pp. 49–56. [Google Scholar]
- Sicilia, M.A.; Garcia-Barriocanal, E.; Bermejo-Higuera, J.; Sanchez-Alonso, S. What are information security ontologies useful for? Commun. Comput. Inf. Sci. 2015, 544, 51–61. [Google Scholar]
- Fenz, S.; Plieschnegger, S.; Hobel, H. Mapping information security standard ISO 27002 to an ontological structure. Inf. Comput. Secur. 2016, 24, 452–473. [Google Scholar] [CrossRef]
- Ramanauskaite, S.; Olifer, D.; Goranin, N.; Čenys, A. Security ontology for adaptive mapping of security standards. Int. J. Comput. Commun. Control 2013, 8, 878. [Google Scholar] [CrossRef]
- Vitkus, D.; Salter, J.; Goranin, N.; Čeponis, D. Method for attack tree data transformation and import into risk analysis expert systems. Appl. Sci. 2020, 10, 8423. [Google Scholar] [CrossRef]
- ISO/IEC 27001:2005; Information Technology—Security Techniques—Information Security Management Systems—Requirements. International Organization for Standardization: Geneva, Switzerland, 2005.
- PCI DSS 3.2.1; Payment Card Industry Data Security Standard. PCI Security Standards Council: Wakefield, MA, USA, 2018.
- ISSA 5173; The Security Standard for SMEs. 2|SEC: London, UK, 2012.
- NISTIR 7621; Small Business Information Security. The National Institute of Standards and Technology: Gaithersburg, MD, USA, 2016.
- Kopena, J.; Regli, W.C. DAMLJessKB: A Tool for Reasoning with the Semantic Web. IEEE Intell. Syst. 2003, 18, 74–77. [Google Scholar] [CrossRef]
- Meditskos, G.; Bassiliades, N. DLEJena: A practical forward-chaining OWL 2 RL reasoner combining Jena and Pellet. J. Web Semant. 2010, 8, 89–94. [Google Scholar] [CrossRef]
- Vitkus, D.; Steckevičius, Ž.; Goranin, N.; Kalibatienė, D.; Čenys, A. Automated expert system knowledge base development method for information security risk analysis. Int. J. Comput. Commun. Control 2019, 14, 743–758. [Google Scholar] [CrossRef]
- Grigorescu, O.; Nica, A.; Dascalu, M.; Rughinis, R. CVE2ATT&CK: BERT-Based Mapping of CVEs to MITRE ATT&CK Techniques. Algorithms 2022, 15, 314. [Google Scholar] [CrossRef]
- Manjunatha, A.; Kota, K.; Babu, A.S. CVE Severity Prediction From Vulnerability Description—A Deep Learning Approach. Procedia Comput. Sci. 2024, 235, 3105–3117. [Google Scholar] [CrossRef]
- Dodiya, B.; Singh, U.K.; Gupta, V. Trend analysis of the CVE classes across CVSS metrics. Int. J. Comput. Appl. 2021, 183, 23–30. [Google Scholar] [CrossRef]
- Czarnowski, I. A framework for the clustering and categorization of CISA reports. Procedia Comput. Sci. 2022, 207, 4369–4377. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Selected Data | Data Type | Description of the Option | Obligation |
|---|---|---|---|
| id | String | This field specifies the unique identification number of the CVE. | Yes |
| publishedDate | String | The date of publication of the vulnerability is indicated, and this information is relevant to assess the date from which the risk posed by the vulnerability is relevant. It also helps to assess whether it is a new or long-known vulnerability that could have already caused one or another damage. | No |
| lastModifiedDate | String | This field indicates the date the vulnerability information was updated. This is relevant when monitoring the change in vulnerability information; based on the changed date, it is possible to initiate the update of vulnerability information in the ES knowledge base. | No |
| vulnerable | Boolean | This field indicates whether the specified PU version is vulnerable. Possible values: false or true. This field can be used to include only those versions of the PI that are vulnerable to the ES knowledge base. | Yes |
| cpe23Uri | String | This field indicates the firmware version using the CPE scheme. CPE is a structured naming scheme for information technology systems, software, and packages. According to CPE, the expert system will be able to determine whether the used PI has known vulnerabilities. | Yes |
| description_data. value | String | This field describes vulnerability itself. This information is useful for obtaining more information about the vulnerability. | No |
| Test No. 1 | Test No. 2 | Test No. 3 | |
|---|---|---|---|
| The actual number of CVE entries | 186,741 | 186,851 | 187,614 |
| The number of CVE entries read by the prototype | 186,741 | 186,851 | 187,614 |
| Reading data as a percentage | 100% | 100% | 100% |
| Target number of converted posts | 175,255 | 175,378 | 176,362 |
| Number of CVE records converted | 175,255 | 175,378 | 176,362 |
| Conversion of data into percentages | 100% | 100% | 100% |
| Number of rejected CVE entries | 11,486 | 11,473 | 11,252 |
| Conversion time with download from NVD | 6 min 36 s. | 6 min 42 s. | 6 min 58 s. |
| Test No. 1 | Test No. 2 | Test No. 3 | |
|---|---|---|---|
| Number of CVE entries converted by prototype | 175,255 | 175,255 | 175,378 |
| Number of facts successfully imported into Jess ES | 175,255 | 175,255 | 175,378 |
| Import as a percentage | 100% | 100% | 100% |
| Time to import data into Jess ES | 19 s | 20 s | 20 s |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Benetis, D.; Vitkus, D.; Janulevičius, J.; Čenys, A.; Goranin, N. Automated Conversion of CVE Records into an Expert System, Dedicated to Information Security Risk Analysis, Knowledge-Base Rules. Electronics 2024, 13, 2642. https://doi.org/10.3390/electronics13132642
Benetis D, Vitkus D, Janulevičius J, Čenys A, Goranin N. Automated Conversion of CVE Records into an Expert System, Dedicated to Information Security Risk Analysis, Knowledge-Base Rules. Electronics. 2024; 13(13):2642. https://doi.org/10.3390/electronics13132642
Chicago/Turabian StyleBenetis, Dovydas, Donatas Vitkus, Justinas Janulevičius, Antanas Čenys, and Nikolaj Goranin. 2024. "Automated Conversion of CVE Records into an Expert System, Dedicated to Information Security Risk Analysis, Knowledge-Base Rules" Electronics 13, no. 13: 2642. https://doi.org/10.3390/electronics13132642
APA StyleBenetis, D., Vitkus, D., Janulevičius, J., Čenys, A., & Goranin, N. (2024). Automated Conversion of CVE Records into an Expert System, Dedicated to Information Security Risk Analysis, Knowledge-Base Rules. Electronics, 13(13), 2642. https://doi.org/10.3390/electronics13132642