1. Introduction
In the digital age, network protocols serve as the foundation for information exchange, not only establishing rules and formats for data transfer but also ensuring the accuracy and efficiency of network information [
1]. Although these protocols are crucial for the advancement of modern informatization and intelligentization, their complexity and diversity elevate security risks. Moreover, potential oversights or errors during the protocol development often lead to vulnerabilities. This leaves plenty of room for hackers to target network applications [
2]. Therefore, effectively identifying and rectifying these implementation vulnerabilities is vital for maintaining the security and stability of cyberspace.
Fuzzing is an efficient software testing method that is widely used across various software applications. It was proven to be highly effective and powerful in discovering critical vulnerabilities [
3,
4]. Due to its automation and efficiency, fuzzing has become one of the popular methods for detecting security vulnerabilities in network protocols. This method involves sending large volumes of random or semi-random data to protocol implementations to trigger abnormal behavior, thereby uncovering potential vulnerabilities.
Compared with other fuzzing, network protocol fuzzing faces greater challenges in generating high-quality test cases, primarily due to the highly structured nature of its inputs. Specifically, the input consists of a series of request messages, with each divided into fields defined by strict syntactic rules with precise value constraints. If the input messages do not adhere to basic syntax requirements, the server discards them during the initial stage of processing. This strict requirement for input syntax significantly affects the quality of test cases.
In recent years, previous studies focused on acquiring the syntactic knowledge of protocol messages to generate high-quality test cases. These methods fall into four main categories: protocol specification extraction [
5,
6,
7,
8,
9,
10], network traffic analysis [
11,
12,
13,
14,
15], program behavior analysis [
16,
17,
18,
19], and machine learning analysis [
20,
21]. Protocol specification extraction methods primarily derive message syntax formats from protocol RFC specification documents. Network traffic analysis methods learn about keywords and field boundaries within messages by collecting and analyzing network traffic. Program behavior analysis methods obtain protocol format information by analyzing how programs behave when processing message data. Machine learning analysis methods leverage natural-language-processing techniques to learn protocol syntax. Although these methods can acquire the partial knowledge of protocol syntax, they still face three key challenges in generating high-quality test cases:
Challenge 1: inadequate input knowledge. Current protocol fuzzers [
5,
11,
16,
20] lack an effective and detailed understanding of message syntax. These tools typically reveal only the basic syntactic structure or syntactic constraints of specific fields, failing to fully grasp the comprehensive syntactic knowledge of the message. This partial comprehension of message syntax limits the ability to generate high-quality inputs, thereby impacting the overall effectiveness of fuzzing.
Challenge 2: insufficient seed diversity. The effectiveness of test cases in mutation-based fuzzing largely depends on the quality of the initial seed corpus. However, the most widely used network protocol fuzzing benchmark, ProFuzzBench [
22], often displays a lack of seed diversity. If the initial seeds are not comprehensive and solely rely on simplistic mutations, fuzzing may fail to adequately explore protocol implementations. This constraint limits the detection of a wider range of vulnerabilities.
Challenge 3: inefficient mutation strategies. Mutation strategies usually determine the quality of test cases when fuzzing. Most current protocol fuzzers [
23,
24,
25] rely on random mutation methods that do not employ targeted or strategic approaches. These approaches fail to produce diverse and high-quality test cases that can effectively assess the robustness of protocol implementations. Such deficiencies in mutation strategies restrict the depth and breadth of fuzzing coverage, thereby significantly reducing the overall effectiveness of fuzzing.
To overcome the above challenges, in this paper, we propose MSFuzz, which is a protocol-fuzzing method with message syntax comprehension. By comparing the message syntax extracted from existing research with that from the source code, we found that the source code contained more detailed and effective message syntax knowledge. To overcome challenge 1, we present a method for leveraging large language models (LLMs) to extract the message syntax from source code to construct message syntax trees for protocol implementations. For challenge 2, we used LLMs in conjunction with the constructed message syntax trees to expand the initial seed corpus of the protocol implementation. To address challenge 3, we designed a novel syntax-aware mutation strategy that guides fuzzing mutations through the constructed message syntax trees, thereby generating high-quality test cases that satisfy syntactic constraints.
Specifically, we first filtered out code files related to message parsing from a large volume of protocol implementation source code. Then, utilizing the code comprehension abilities of LLMs, we incrementally extracted message types, and requested line parameters and their value constraints, as well as header fields and their value constraints, from the filtered source code. This process enabled us to construct the message syntax tree of the protocol implementation. Based on the constructed message syntax tree and configuration files of the protocol implementation, we expanded the initial seed corpus, generating a diverse and comprehensive set of seeds. Finally, we used the constructed message syntax tree to guide the mutation strategy. By parsing the messages to be mutated and matching them with the syntax tree, we determined the syntactic constraints of message fields and generated high-quality test cases based on these constraints. So far, we have implemented a prototype of MSFuzz.
We evaluated the performance of MSFuzz on three widely used network protocols: RTSP, FTP, and DAAP. We compared MSFuzz with two SOTA protocol fuzzers: AFLNET and CHATAFL. The experimental results showed that within 24 h, MSFuzz improved the number of states by averages of 22.53% and 10.04%, and the number of state transitions by averages of 60.62% and 19.52%, respectively, when compared with AFLNET and CHATAFL. Additionally, MSFuzz effectively explored the code space, achieving average branch coverage improvements of 29.30% and 23.13% over SOTA protocol fuzzers. In the ablation study, we found that the two key components, seed expansion, and syntax-aware mutation, significantly enhanced the fuzzing performance. Additionally, MSFuzz discovered more vulnerabilities than the SOTA fuzzers.
The main contributions of this paper are summarized as follows:
To address the problem of generating high-quality test cases, we propose MSFuzz, which is a novel protocol-fuzzing technique. MSFuzz is built upon three core components: message syntax tree construction, seed expansion, and syntax-aware mutation.
By employing a novel abstraction of message syntax structures, MSFuzz leverages the code-understanding capabilities of LLMs to effectively extract message syntax from the source code of protocol implementations, thereby constructing uniformly structured message syntax trees.
MSFuzz utilizes the constructed protocol syntax trees to expand the initial seed corpus and applies syntax-aware mutation strategies to generate high-quality test cases that adhere to specified constraints.
We evaluated MSFuzz on widely used protocol implementations. The results demonstrate that MSFuzz outperformed the SOTA protocol fuzzers in state coverage, code coverage, and vulnerability discovery.
2. Background and Motivation
In this section, we introduce protocol fuzzing, large language models, and a motivating example. First, we provide a brief overview of protocol fuzzing. Next, we offer background information on large language models and their recent advancements in vulnerability discovery. Finally, we illustrate the limitations of existing methods through a motivating example.
2.1. Protocol Fuzzing
As one of the most effective and efficient methods for discovering vulnerabilities, fuzzing has been applied in the field of network protocols. The inception of PROTOS [
26], the pioneering protocol-focused fuzzing tool, marked the beginning of protocol fuzzing. Subsequently, this field has garnered extensive attention, resulting in numerous research achievements and establishing itself as a focal point in network security.
Protocol fuzzers primarily target server-side implementations by simulating client behavior. These tools continuously create and dispatch client messages to the servers. Depending on the method of message generation, protocol fuzzers can be broadly categorized into two types: generation based and mutation based.
Generation-based protocol fuzzers rely on prior knowledge of protocol formats to generate test cases [
26,
27,
28,
29,
30]. PROTOS [
26] generates erroneous inputs based on protocol specifications to trigger specific vulnerabilities. SPIKE [
27] employs a block-based modeling approach, breaking down the protocol into different blocks and automatically generating valid data blocks for protocol messages based on predefined generation rules. Peach [
31] defines data models of protocols by manually constructing Pit files, which are then used to generate test cases. SNOOZE [
6] requires testers to manually extract protocol specifications from request for comments (RFC) documents, including protocol field characteristics, information exchange syntax, and state machines. Testers then send specific sequences of messages to reach the desired state and generate numerous random test cases based on the protocol specifications.
Mutation-based protocol fuzzers generate new test cases by mutating seeds, which consist of a set of request messages [
19,
24,
32,
33,
34]. These mutation operators include altering field values within messages, inserting, deleting, or replacing specific sections of messages, as well as recombining or reordering messages. AFLNET [
24] employs byte-level and region-level mutation strategies, capturing traffic during client-server communication as initial seeds and generating test cases during the fuzzing process. Meanwhile, SGPFuzzer [
32] introduces various mutation operators to mutate selected seed files in a simple and structured manner, including sequence mutation, message mutation, binary field mutation, and variable string mutation.
Compared with other fuzzing, network protocol fuzzing faces more challenges, one of which is the highly structured nature of its input. Network protocol messages typically adhere to strict syntactic constraints, encompassing various types of messages, as well as syntactic constraints within internal fields. Deviations from these constraints may result in servers discarding received messages, thereby limiting the effectiveness and efficiency of fuzzing.
2.2. Large Language Models
Large language models (LLMs), as a form of deep learning-driven artificial intelligence technology, demonstrate powerful natural-language-processing capabilities. These models undergo extensive pre-training on large datasets, equipping them with the ability to deeply understand and generate natural language text. They possess a profound and rich understanding of linguistic knowledge, and their comprehension of context is remarkably thorough.
In recent studies, LLMs have shown great potential in the field of vulnerability detection. GPTScan [
35] combines GPT with static analysis techniques for intelligent contract logic bug detection. CHATAFL [
10] employs LLMs to guide protocol fuzzing, constructing protocol grammars, expanding initial seeds, and generating test cases capable of triggering state transitions through interactions with LLMs. Fuzz4All [
36] utilizes LLMs as an input generation and mutation engine for fuzzing across multiple input languages and features. ChatFuzz [
37] employs LLMs for seed mutation. TitanFuzz [
38] utilizes LLMs for fuzzing deep learning libraries. These studies provide rich practical experience in the application of large language models for vulnerability detection, showcasing their potential and value in enhancing vulnerability detection capabilities.
Although applying LLMs to network protocol fuzzing has great potential, it faces several challenges. When using LLMs to analyze source code, directly inputting the entire source code often fails due to input size limitations. Therefore, it is essential to filter the source code and extract key snippets when using LLMs.
2.3. Motivating Example
As one of the SOTA network protocol fuzzers, CHATAFL [
10] extracts message syntax structures from protocol specifications. Although protocol implementations generally adhere to RFC documents, variations exist between different implementations, and actual message syntactic constraints are often more detailed than the specifications. For example,
Figure 1 illustrates the
PLAY message syntax structure that CHATAFL extracts from the RTSP specification. Although the basic syntax of the message is determined, the specific values of key fields, like
Range, remain unknown.
Listing 1 shows a code snippet from the Live555 server based on the RTSP protocol, demonstrating the parsing process of the field. The code identifies six types of value constraints for the Range field: npt = %lf - %lf, npt = %n%lf -, npt = now - %lf, npt = now - %n, clock = %n, and smpte = %n. Live555 attempts six corresponding matches to determine the values of rangeStart and rangeEnd. If the Range value of the message does not adhere to any of these constraints, the function returns False, indicating a parsing failure.
| Listing 1. Simplified code snippet from Live555. |
Boolean parseRangeParam() {
...
if (sscanf(paramStr, "npt = %lf - %lf", &start, &end) == 2) {
rangeStart = start;
rangeEnd = end;
} else if (sscanf(paramStr, "npt = %n%lf -", &numCharsMatched1, &start) == 1) {
if (paramStr[numCharsMatched1] == '-') {
rangeStart = 0.0; startTimeIsNow = True;
rangeEnd = -start;
} else {
rangeStart = start;
rangeEnd = 0.0;
}
} else if (sscanf(paramStr, "npt = now - %lf", &end) == 1) {
rangeStart = 0.0; startTimeIsNow = True;
rangeEnd = end;
} else if (sscanf(paramStr, "npt = now -%n", &numCharsMatched2) == 0 &&
↪ numCharsMatched2 > 0) {
rangeStart = 0.0; startTimeIsNow = True;
rangeEnd = 0.0;
} else if (sscanf(paramStr, "clock = %n", &numCharsMatched3) == 0 &&
↪ numCharsMatched3 > 0) {
...
} else if (sscanf(paramStr, "smtpe = %n", &numCharsMatched4) == 0 &&
↪ numCharsMatched4 > 0) {
} else {
return False;
}
return True;
}
|
When CHATAFL mutates the
Range field in Live555 based on the message syntax shown in
Figure 1, it only identifies the position of the field value without understanding the value constraints listed in Listing 1, continuing to use a random mutation strategy. The test cases generated from this coarse-grained message syntax, although adhering to the basic syntax structure, are likely to fail because the field values do not adhere to the syntactic constraints.
Therefore, obtaining the message syntax structure solely from protocol specifications is insufficient. The source code of the protocol implementation contains finer-grained client message syntax. It is necessary to analyze this source code to achieve a more comprehensive and detailed understanding of the message syntax to improve the generation of high-quality test cases. Generating high-quality test cases that adhere to protocol syntax constraints can significantly enhance the coverage of fuzzing, thereby exploring deeper code space and increasing the likelihood of discovering complex vulnerabilities.
3. Methodology
3.1. Overview
Figure 2 shows the overview of MSFuzz, which consists of four components: preprocessing, message syntax tree construction, seed expansion, and fuzzing with syntax-aware mutation. Its primary objective is to address the challenges associated with generating high-quality test cases in protocol fuzzing, thereby improving the efficiency and effectiveness of the fuzzing process.
Preprocessing. Before extracting the message syntax from the source code, it is essential to pre-filter the source code files, as not all code is related to message parsing. By performing a preliminary analysis and filtering out irrelevant code, the search and analysis scope of LLMs during syntax tree construction is narrowed, thereby enhancing the efficiency of the LLMs.
Message Syntax Tree Construction. We investigated the structure of text-based protocol client messages and abstracted a general message syntax template. Based on the abstracted message syntax structure and heuristic rules derived from observing the source code, we designed a method to extract the message syntax from the protocol implementation source code using LLMs. This approach enables the construction of message syntax trees for the protocol implementation.
Seed Expansion. Given the critical role of initial seed diversity and quality in fuzzing, we focused on enhancing these aspects. We used the constructed message syntax tree and protocol implementation configuration files to guide the LLMs. This approach helped in expanding the initial seed corpus, thereby enhancing the seed diversity and quality.
Fuzzing with Syntax-Aware Mutation. In the fuzzing loop, we used the expanded seeds as input. For the seed mutation, MSFuzz leverages the message syntax tree to guide the mutation of the message. This ensures that the generated test cases adhered to the syntax structure and value constraints of the protocol, thereby improving the efficiency of the fuzzing. In order to ensure that MSFuzz possessed the capability to explore extreme scenarios, we also employed a random mutation strategy with a certain probability.
In the following, we present a detailed description of the core designs of MSFuzz, including message syntax tree construction, seed expansion, and fuzzing with syntax-aware mutation.
3.2. Message Syntax Tree Construction
MSFuzz leverages the code-understanding capabilities of LLMs to extract message syntax from preprocessed source code files. To facilitate the construction of syntax trees with a consistent structure, we first analyzed multiple text-based protocols and abstracted a general message syntax template. Then, based on this template and several heuristic rules derived from observing the source code, we designed a method for using LLMs to extract the syntax from the source code, thereby constructing the message syntax tree for the protocol implementation.
3.2.1. Message Syntax Structure
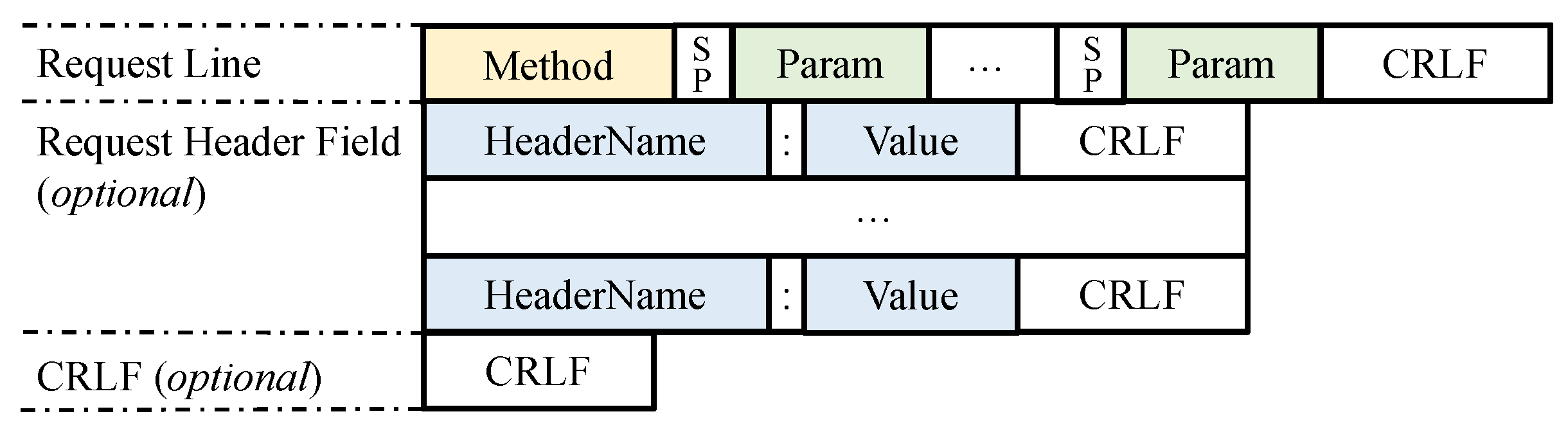
Defining a general message syntax structure is essential prior to employing LLMs for constructing message syntax trees. By analyzing multiple text-based protocols, we abstracted a general message syntax structure. This provided a standardized structure for interpreting and processing different protocol implementations. This ensured that the syntax trees generated by the LLMs were consistent and uniform.
We analyzed various text-based protocols and discovered that their client message structures could be abstracted into the general form shown in
Figure 3. This general message syntax structure consisted of three parts: the request line, the request header field, and the carriage return and line feed (CRLF) characters. Not all protocols include request header fields and the ending CRLF in their client messages.
Specifically, the request line contains the method name and multiple parameters, which are separated by space characters (SPs) and end with a CRLF. The request header field consists of key–value pairs in the format HeaderName: Value and also ends with a CRLF. The entire message typically concludes with a CRLF.
3.2.2. Extracting Syntax via LLMs
Based on the general syntax structure from
Section 3.2.1, we utilized LLMs to extract the message syntax from preprocessed source code files, focusing on the request line and request header fields of the general syntax structure. Specifically, we extracted the method name (message type), parameter types, and parameter value constraints from the request line. If the request header fields exist, we extracted the header names and their value constraints. Finally, we constructed a message syntax tree for the protocol implementation based on the extracted message syntax.
Although we filtered out irrelevant files from the protocol implementation, providing all the filtered code files to LLMs often exceeds its input limit. Additionally, some irrelevant content may still remain, potentially affecting the output of LLMs. Therefore, we needed to further refine the code selection, extracting only the snippets closely related to the task at hand. Based on our analysis of network protocol implementations, we employed the following heuristic rules to extract key code snippets. This ensures that LLMs can effectively learn and extract the message syntax.
In the source code of the protocol implementation, different types of messages or header fields have independent parsing functions. Therefore, when parsing a specific type of message or header field, LLMs can analyze only its corresponding parsing function to narrow the scope.
Function names often follow clear naming conventions and clearly express their basic functions in the source code. Thus, providing only the function names to LLMs allows it to infer the purposes of the functions, enabling more accurate identification of the target parsing functions.
Based on the heuristic rules mentioned above, we propose an automated framework that uses LLMs to construct message syntax trees for target protocol implementations. This method employs a hierarchical, step-by-step strategy. It inputs key parsing code extracted from source code files into LLMs. From this, the framework extracts message types, request line parameters, header field types, and their value constraints, gradually constructing the message syntax tree. This method employs a hierarchical extraction strategy aligned with the syntactic structure illustrated in
Figure 3. Initially, the framework identifies the message type. Subsequently, it extracts the types of request line parameters and header fields (if any). Finally, it determines the value constraints for the request line parameters and header fields. This process incrementally constructs the message syntax tree, ensuring a comprehensive representation of the protocol’s message structure.
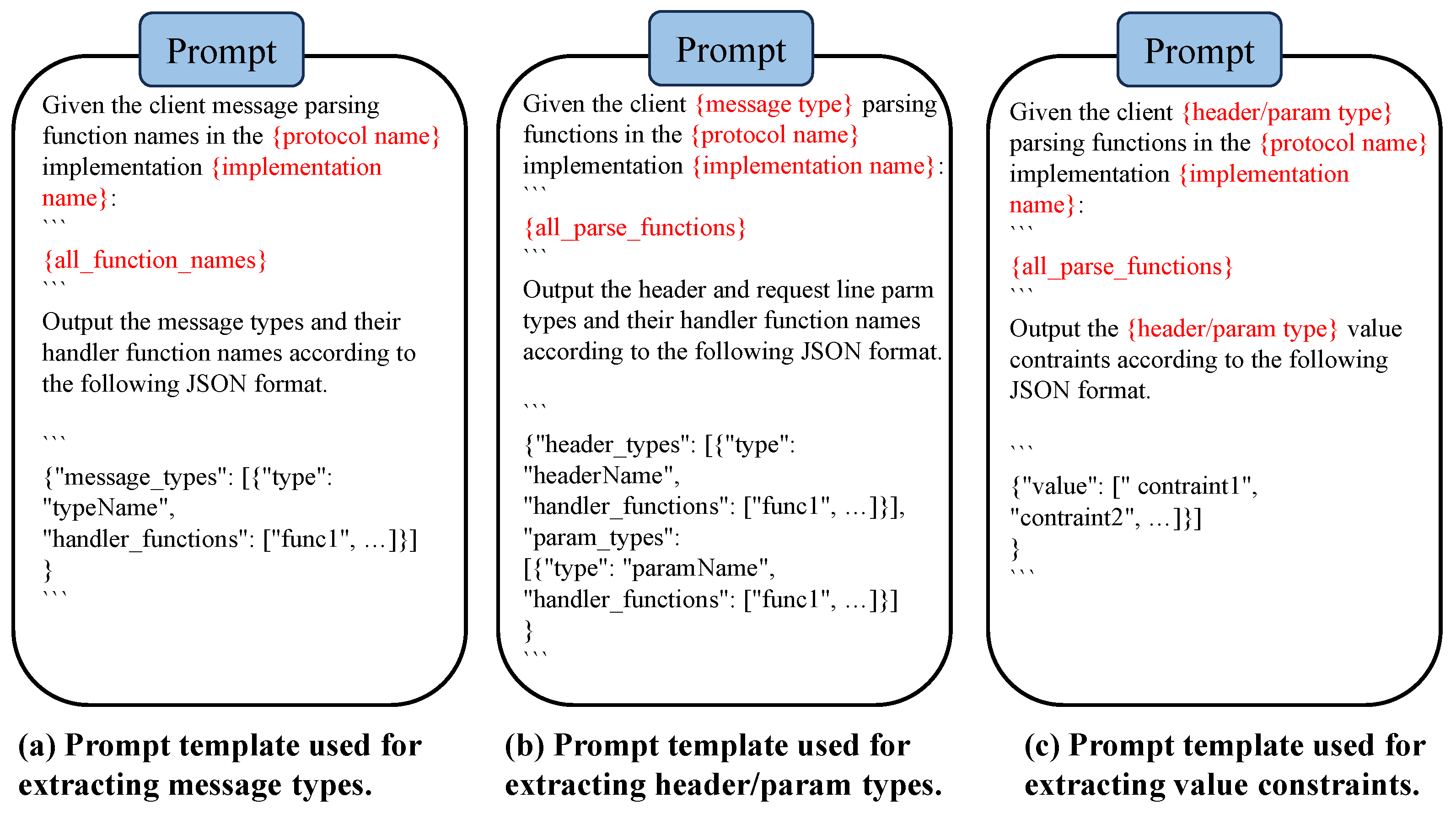
Message type extraction. MSFuzz extracts all function names from the filtered source code using the
Code Extraction module in
Figure 2. This module parses the source code to identify relevant function names, which are then utilized in prompt engineering to enable the LLM to identify message types in the target protocol implementation. The prompt includes all filtered function names and aims to identify all message types that the target protocol implementation can handle and map them to their corresponding handler functions, as shown in
Figure 4a.
Header/parameter type extraction. For each message type, MSFuzz uses the
Code Extraction module to locate and extract the corresponding function code from the source code based on the handler function names identified in the previous stage.
Figure 4b illustrates the prompt used by MSFuzz to leverage the LLM for extracting message request line parameters and header fields (if any). This prompt includes the parsing function code for the message and aims to establish a mapping between the message and its request line parameters and header fields.
Value constraints extraction. To parse the values of header fields or request line parameters, MSFuzz uses the
Code Extraction module to locate and extract the relevant function code from the source files based on the function names identified in the previous stage.
Figure 4c illustrates the prompt used by MSFuzz to extract value constraints using the LLM. In this prompt, MSFuzz provides the parsing function code for the parameters or header fields, with the aim to establish a mapping between them and their corresponding value constraints.
To illustrate the construction of a message syntax tree, we utilized the MSFuzz approach in the motivating example (
Figure 1) and present the results in
Figure 5.
Figure 5 displays only the syntactic constraints of the
Range header field in the
PLAY message of Live555.
3.3. Seed Expansion
To enhance the diversity and quality of the initial seed corpus, we employed LLMs to expand it. Although LLMs can generate new seeds for the target protocol implementation, three key problems need to be addressed: (1) How to comprehensively cover message syntactic constraints? (2) How to generate seeds specific to the target protocol implementation? (3) How to produce machine-readable seeds?
Regarding problem (1), MSFuzz constructs a message syntax tree for the target protocol implementation, as detailed in
Section 3.2. This tree extensively covers messages, request line parameters, and their value constraints, as well as header field types and their value constraints. By integrating this syntax tree into our prompts, MSFuzz enables LLMs to generate more comprehensive seeds.
Regarding problem (2), configuration files for protocol implementations typically contain crucial server information, such as usernames, passwords, and network addresses. Integrating these configuration files into the LLM’s prompts allows for the generation of more precise seeds that reflect the operational environment.
Regarding problem (3), an LLM demonstrates proficiency in learning from provided data and producing standardized outputs. By inputting initial seeds from the protocol implementation into the prompts and defining their format, this facilitates the production of machine-readable seeds that are immediately applicable for fuzzing.
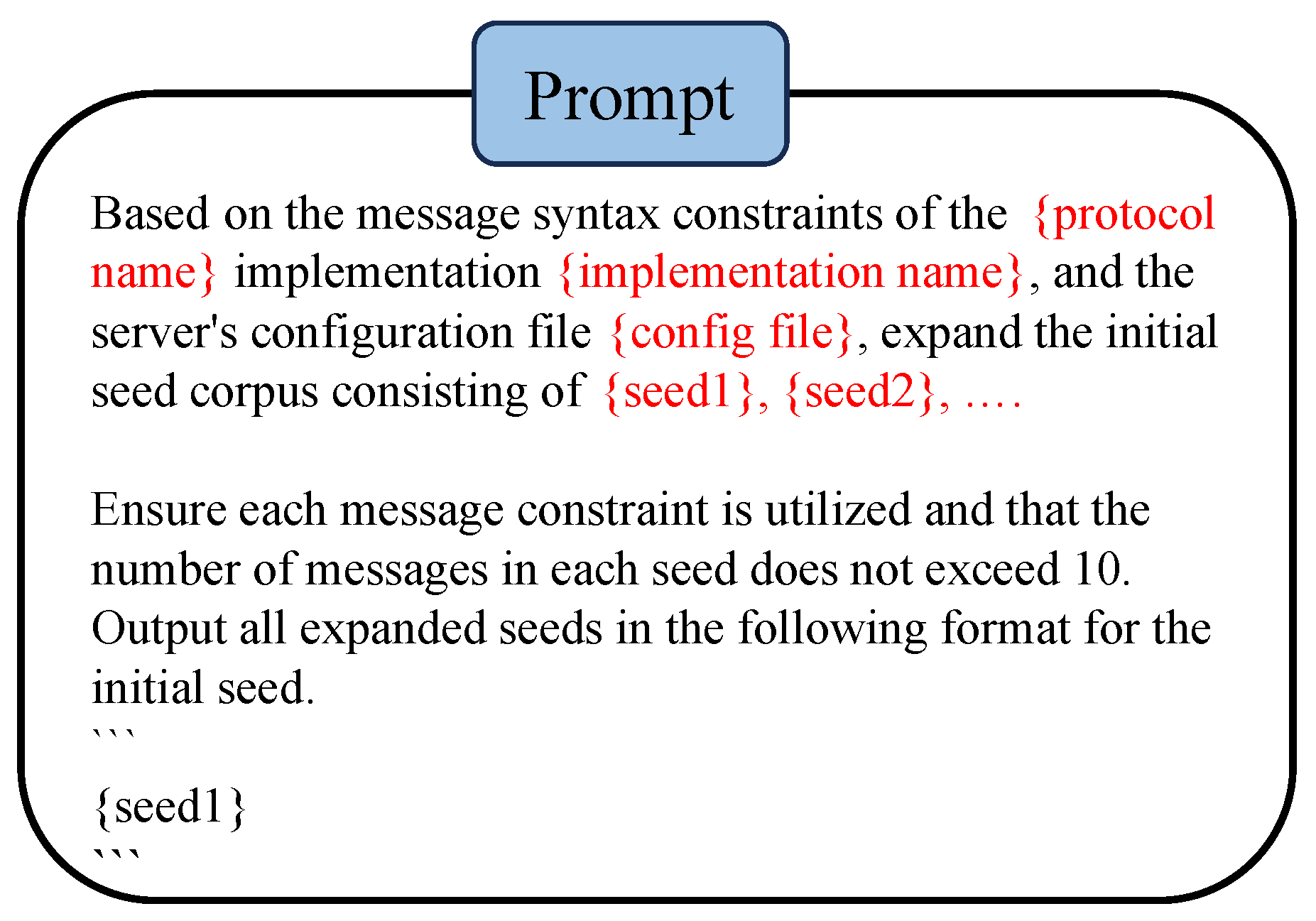
Figure 6 illustrates the prompt used by MSFuzz to expand the seed corpus using LLMs. The prompts displayed in
Figure 6 include the message syntax tree of the target protocol implementation, the configuration file, and the initial seed corpus, explicitly directing the LLM to generate outputs that adhere to the format of the initial seed corpus.
3.4. Fuzzing with Syntax-Aware Mutation
Although MSFuzz constructs a message syntax tree of the protocol implementation, it encounters two major problems when utilizing this syntax tree for message mutation: (1) How to select mutation locations to preserve the basic syntax structure of the message? (2) How to use the message syntax tree to precisely guide mutations? To address these problems, we designed a syntax-aware fuzzing approach, which is detailed in Algorithm 1. Specifically, MSFuzz first attempts to parse the message to obtain its basic syntax structure (line 7). After verifying the message against the syntax tree (line 9), MSFuzz randomly selects a field for mutation (line 11). Then, according to the value constraints of the field in the syntax tree, mutations are performed (lines 12–13).
Message parsing. Before mutating the messages, it is crucial to accurately identify suitable mutation locations. Randomly selecting mutation locations can disrupt the fundamental structure of the message, rendering it ineffective. Therefore, based on the general message syntax structure shown in
Figure 3, MSFuzz parses the message designated for mutation. Initially, MSFuzz analyzes the request line to determine the message type and request line parameter fields and records the offsets of these fields. Subsequently, MSFuzz parses the names and values of the header fields, also noting their offsets. During mutation, MSFuzz selects positions within the request line parameter fields or header fields to preserve the integrity of the basic syntactic structure of the message.
Syntax-guided mutation. To guide message mutation using the syntax tree, it is first necessary to determine whether the message type exists within the syntax tree. If the message type does not exist, a random mutation strategy is applied. If the message type is found in the syntax tree, a request line parameter field or a header field is randomly selected as the mutation target. Next, the constraints for the selected field are identified from the syntax tree. One of these constraints is randomly chosen, and a value that adheres to this constraint is generated to replace the original field value. If the newly generated field value differs in length from the original field value, the offsets of subsequent fields are adjusted to ensure that each field in the mutated message retains its correct offset. In order to ensure that MSFuzz possesses the capability to explore extreme scenarios, we also employed a random mutation strategy with a certain probability.
For instance, consider a
PLAY message that adheres to the syntax structure in
Figure 1 and is guided to mutate by the message syntax tree in
Figure 5. First, it is verified whether the
PLAY message type exists in the Live555 syntax tree. As shown in
Figure 5, this type of message syntax structure does exist. Next, a field in the
PLAY message is randomly selected, such as the
Range field. The value constraints of
Range header field in the message syntax tree are looked up and one is randomly selected, such as
npt = %lf - %lf. This value constraint specifies the playback range in seconds, where
%lf represents a floating point number indicating the start and end times. MSFuzz then identifies the data type of the placeholders in the field, which, in this case, are floating point numbers. To generate a random value that matches this type, MSFuzz uses a floating point number generation function. For example, it might generate 10.5 and 20.0 for the start and end times, respectively, formatting them as
npt = 10.5 - 20.0. Finally, MSFuzz replaces the original value in the
Range field with the newly generated value, ensuring that the modified message adheres to the syntactic constraints specified in the message syntax tree. After replacing the value, MSFuzz adjusts the offset of each field within the message. This adjustment is crucial to maintain the structural integrity of the message, as altering the length of one field can affect the positions of subsequent fields. By following this process, MSFuzz can produce test cases that adhere to the syntactic constraints, thereby ensuring the validity of the generated messages.
| Algorithm 1: Fuzzing with syntax-aware mutation |
- Input:
P: protocol implementation - Input:
E: expanded seeds - Input:
T: message syntax tree - Output:
: crash reports - 1:
struct Field { type;values } - 2:
struct Message { type;params;headers } - 3:
StateMachine - 4:
repeat - 5:
Seed - 6:
- 7:
Message - 8:
for to do - 9:
if then - 10:
Field - 11:
- 12:
if and then - 13:
- 14:
- 15:
else - 16:
- 17:
- 18:
end if - 19:
else - 20:
- 21:
- 22:
end if - 23:
Response - 24:
if then - 25:
- 26:
end if - 27:
if then - 28:
- 29:
- 30:
end if - 31:
end for - 32:
until timeout reached or abort-signal
|
4. Evaluation
In this section, we evaluate the performance of MSFuzz and compare it with the SOTA protocol fuzzers. We aim to answer the following research questions by evaluating MSFuzz.
RQ1. State coverage: Could MSFuzz achieve a higher state space coverage than the SOTA fuzzers?
RQ2. Code coverage: Could MSFuzz achieve a higher code space coverage than the SOTA fuzzers?
RQ3. Ablation study: What was the impact of the two key components on the performance of MSFuzz?
RQ4. Vulnerability discovery: Could MSFuzz discover more vulnerabilities than the SOTA fuzzers?
4.1. Experimental Setup
Implementation. Building upon the widely used protocol fuzzing framework AFLNET, we developed MSFuzz. The implementation of MSFuzz consisted of approximately 1.2k lines of C/C++ code and 800 lines of Python code. Specifically, we developed a Python script to interface with the LLM to acquire the message syntax of network protocol implementations and construct message syntax trees. To mitigate potential issues of incompleteness and inconsistency in the syntax extracted by the LLM, we performed three iterations and used the union of the results to construct the message syntax tree. Subsequently, leveraging the initial seed corpus and the message syntax tree, we expanded the seed corpus using the LLM. The syntax-aware mutation was predominantly implemented in C during the mutation phase of the fuzzing loop based on the constructed message syntax tree. The method of enhancing protocol fuzzing in MSFuzz does not rely on a specific LLM, and several popular LLMs on the market can be used. We selected Qwen-plus as the LLM for syntax extraction and seed expansion because it is one of the most advanced pretrained LLMs currently available. This model boasts parameters in the trillion range and was trained on a vast and diverse dataset, including software code and technical documentation. This extensive training endows the model with deep language understanding and generation capabilities, enabling it to comprehend the logical structure and semantics of source code. Additionally, it provides a substantial number of free tokens, facilitating more extensive experimentation and application. For the configuration of input parameters in the LLM, we used the default settings, such as max_token = 2000 and top_p = 0.8.
Benchmark. Table 1 provides detailed information on the benchmark network protocol implementations used in our evaluation. Our benchmark includes five network protocol implementations, encompassing three widely used protocols: RTSP, FTP, and DAAP. These protocols employ textual formats for communication and are part of the widely recognized protocol fuzzing benchmark ProFuzzBench [
22]. Given their widespread usage, we consider these five target programs representative of real-world applications.
Baselines. We conducted an in-depth comparison between MSFuzz and the SOTA network protocol fuzzers (AFLNET and CHATAFL). AFLNET, the first grey-box fuzzer designed for network protocol implementations, primarily relies on mutation-based generation methods. CHATAFL, as one of the SOTA grey-box fuzzers, leverages LLMs to expand seeds, extracts message structures, and utilizes them to guide mutation.
Environment. All experiments were run on a server equipped with 64-bit Ubuntu 20.04, featuring dual Intel(R) Xeon(R) E5-2690 @ 2.90 GHz CPUs and 128 GB of RAM. Each selected protocol implementation and each fuzzer were individually set up in separate Docker containers, utilizing identical computational resources for experimental evaluation. To ensure the fairness of the experimental results, each fuzzer was subjected to 24 h of fuzzing on each protocol implementation, with the experiments repeated five times.
4.2. State Coverage
State coverage is a crucial evaluation metric in network protocol fuzzing, as it reflects the depth of coverage within the protocol state machine and the extent to which the internal logic of the protocol implementation has been explored. By measuring the number of states reached and the number of state transitions during fuzzing, it is possible to effectively assess whether the fuzzer has thoroughly explored the various states of the protocol implementation and their transitions.
Table 2 presents the average number of states and state transitions covered by different fuzzers during five times of 24 h fuzzing. To evaluate the performance of MSFuzz, we report the percentage improvement in state and state transition coverage within 24 h (
Improv) The results indicate that compared with AFLNET and CHATAFL, MSFuzz exhibited significant advantages in discovering new states and state transitions. Specifically, MSFuzz achieved average improvements of 22.53% and 10.04% in the number of states compared with AFLNET and CHATAFL, respectively. Additionally, there were improvements of 60.62% and 19.52% in the state transitions. Compared with other protocol implementations, the state coverage improvement for LightFTP was the least significant. This was because LightFTP is a lightweight FTP protocol implementation with a simple functionality and minimal codebase. It lacks complex and deep state transitions, resulting in relatively minor improvements in the state coverage.
In summary, MSFuzz could achieve higher state coverage than the SOTA fuzzers. MSFuzz not only discovered more new states but also generated more state transitions, thereby enhancing the effectiveness and comprehensiveness of the fuzzing. By exploring the state space more deeply, MSFuzz demonstrated significant advantages in the field of protocol fuzzing.
4.3. Code Coverage
Code coverage has consistently served as the standard metric for evaluating fuzzers, reflecting the amount of code executed within the protocol implementation throughout the entire fuzzing. Code coverage, as an evaluation metric, provides an effective means of assessing the performance of fuzzers.
To assess the performance of MSFuzz, we report the percentage improvement in the code branch coverage within 24 h (
Improv) and analyzed the probability that MSFuzz outperformed baseline activities (
) through random activities using the Vargha–Delaney statistic.
Table 3 shows the average code branch coverage achieved by each fuzzer during five times of 24 h fuzzing.
The results demonstrate that MSFuzz achieved a higher code branch coverage than both AFLNET and CHATAFL across all five protocol implementations, validating the effectiveness of our proposed method in enhancing the code coverage. Specifically, compared with AFLNET, MSFuzz showed an average improvement of 29.30% in code branch coverage, and compared with CHATAFL, an average improvement of 23.13%. For all protocol implementations, the Vargha–Delaney effect size () indicates a significant advantage of MSFuzz in exploring the code branch coverage over baseline fuzzers.
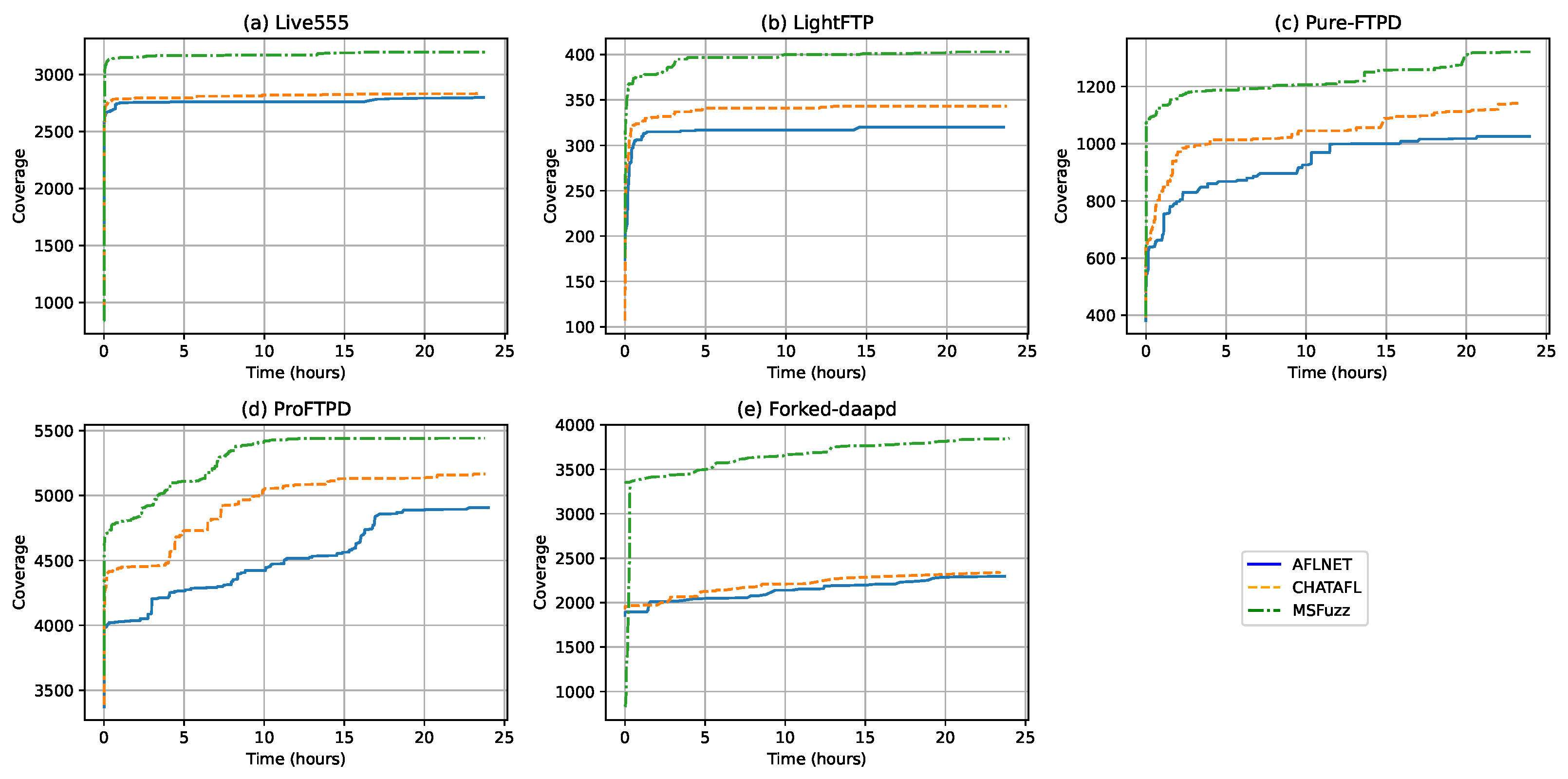
To further demonstrate the effectiveness of MSFuzz, we analyzed the average number of code branches explored by different fuzzers during five runs of 24 h and present the results in
Figure 7. As illustrated in the figure, MSFuzz not only achieved the highest code coverage compared with the other fuzzers but also exhibited the fastest exploration speed. Notably, the improvements were most significant for Pure-FTPD and Forked-daapd.
4.4. Ablation Study
MSFuzz employs an LLM to extract message syntax from the source code of protocol implementations, thereby constructing message syntax trees. Using these syntax trees, two strategies were employed to generate high-quality test cases that adhered to syntactic constraints, enhancing the performance of fuzzing. The first strategy involved using LLMs in conjunction with the extracted message syntax tree to expand the initial seed corpus of the protocol implementation, thereby improving the diversity and comprehensiveness of the seeds. The second strategy introduced a novel syntax-aware mutation strategy, which leveraged the constructed message syntax trees to guide the mutation process during fuzzing.
To quantitatively assess the contribution of each strategy to the overall performance of MSFuzz, we conducted an ablation study. In this study, we evaluated three tools: AFLNET (with all strategies disabled), STFuzz-E (with only the seed expansion enabled), and MSFuzz (with both the seed expansion and syntax-aware mutation strategies enabled). The experimental results are shown in
Table 4. We evaluated the performance of three tools during five times of 24-h fuzzing, specifically measuring the average improvement of states, state transitions, and the percentage improvement in the code branch coverage achieved by each fuzzer. The results indicate that both strategies implemented by MSFuzz enhanced the number of states, state transitions, and code branch coverage to varying extents without negatively impacting any of these metrics.
The experimental results of AFLNET and MSFuzz-E indicate that employing the seed expansion strategy increased the number of states by 19.31%, state transitions by 45.09%, and code branch coverage by 25.19%. This demonstrated the effectiveness of the seed expansion strategy, which enhanced the quality and diversity of the seeds. By ensuring that the expanded seeds comprehensively covered the message syntax of the protocol implementation, this strategy significantly improved the fuzzing exploration of the state space and code space.
Incorporating the syntax-aware mutation strategy alongside the seed expansion strategy, as demonstrated by the results of MSFuzz-E and MSFuzz, further enhanced the three evaluation metrics. The improvement in the number of states rose from 19.31% to 22.53%, the improvement in the state transitions rose from 45.09% to 60.62%, and the improvement in the code branch coverage rose from 25.19% to 29.30%. This demonstrated the effectiveness of the syntax-aware mutation strategy, which ensured that the test cases generated after mutation adhered to the protocol syntactic constraints. This strategy prevented the server from discarding them during the initial syntax-checking phase, thereby increasing the opportunity to explore the protocol implementation.
The analysis of the time overhead and resource consumption associated with the seed expansion and syntax-aware mutation strategies demonstrated that these strategies neither slowed down the execution nor introduced significant resource consumption. The construction of message syntax trees and the expansion of the seed corpus were conducted during the preparation phase and executed only once, thus not contributing to the time overhead and resource consumption of the protocol fuzzing. Although syntax-aware mutation was performed during the fuzzing process, it could generate test cases that adhered to the protocol constraints, thereby avoiding the substantial time and inefficiency associated with traditional random mutations. This resulted in a significant improvement in the overall testing efficiency. As shown in
Table 4, the experimental data for MSFuzz-E and MSFuzz substantiate this conclusion.
4.5. Vulnerability Discovery
To evaluate the vulnerability discovery performance of MSFuzz, we compared the number of unique crashes triggered by MSFuzz and the SOTA fuzzers. From the five times of 24 h fuzzing, neither AFLNET nor CHATAFL triggered any crashes across the five target protocol implementations. However, MSFuzz discovered crashes in two protocol implementations. Specifically, in LightFTP, MSFuzz detected 91 unique crashes, while in Forked-daapd, MSFuzz found 27 unique crashes. Notably, we have conducted a detailed analysis of 16 of these crashes so far, identifying two new vulnerabilities that have been reported to the Common Vulnerabilities and Exposures (CVE) database.
These experimental results validated the superior performance of MSFuzz in detecting and discovering software vulnerabilities. The differences in crash discovery capabilities among various fuzzers within the same time frame further highlight the significant advantages of MSFuzz in enhancing the fuzzing efficiency and vulnerability discovery.
5. Discussion
Although MSFuzz achieved a good performance in state coverage, code coverage, and vulnerability discovery compared with the SOTA fuzzers, it still has certain limitations.
Difficulty in applying to binary-based protocol implementations. Binary protocols have very compact data representations, with field boundaries often not clearly defined. These protocols lack explicit tags or markers to indicate the start and end of each field, which makes it challenging to discern the specific meaning and position of each field when parsing the code. This ambiguity in field delineation complicates the process of extracting and interpreting protocol messages, making it difficult to accurately construct message syntax trees. Furthermore, the variability in binary protocol structures requires a more sophisticated approach to handle the nuances of different implementations, thus posing a significant challenge for protocol-fuzzing tools like MSFuzz that rely on clear syntax demarcations.
Input capacity limitations of LLMs. Although MSFuzz provides LLMs with filtered key code functions to enhance its understanding of message syntax, the size of the function code may still exceed LLMs’ input limitations in some cases. This can lead to challenges in processing large volumes of code, as LLMs may struggle to maintain context and accuracy when handling excessive input data. The limitations in input capacity can result in incomplete analysis and the potential loss of critical information needed for effective fuzzing. Consequently, the efficiency and effectiveness of MSFuzz can be compromised, as LLMs might not fully capture the nuances of the protocol implementation. Therefore, we plan to prioritize the refinement of code by removing syntax-irrelevant content within functions as a focus of our future work to optimize the processing efficiency of LLMs.



 ,
, 



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}