1. Introduction
The accurate detection of objects within complex natural environments is critical for a variety of applications, including environmental monitoring and wildlife conservation. However, the task is challenging due to the intricacies of the natural world, such as varying weather conditions, dense foliage, and the presence of camouflage. Additionally, the detection of small or tiny objects within these environments requires sophisticated technology and algorithms, as well as significant computational resources. Despite advancements in automated systems, the reliable detection of objects in complex natural settings remains an open research problem. The emergence of deep neural networks such as R-CNN [
1], YOLO [
2] and VIT [
3] has provided solutions for reconnaissance purposes. The new end-to-end detection algorithms eliminate the need for feature extraction, making real-time detection faster in complex environments. However, the effectiveness of these algorithms in actual natural environments, which are significantly different from controlled experimental environments, remains a challenge. The following challenges remain when it comes to detecting in complex natural environments:
(1) In complex environments, the target’s color blends with the background, making it difficult for the algorithm to extract significant color features. As a result, the final image may appear blurry. (2) Poor lighting conditions and environmental factors such as haze and shadows further complicate the imaging process, creating a complex background. (3) The occlusion of the target by natural elements such as woods, mountains, and buildings also impacts the algorithm’s ability to extract the target’s edge features, causing it to be obscured. (4) It is worth noting that in real situations targets in complex environments tend to be small and difficult to obtain, resulting in fewer available samples for analysis.
Nowadays, different improvements are proposed in different complex environments. Utilizing YOLO, Mate et al. [
4] employed thermal image to improve object detection performance in challenging conditions such as bad weather, nighttime, and densely packed areas. However, it is difficult to collect stable and usable thermal images in most complex environments, especially when shooting conditions are limited. Another approach to reduce the impact of weather-specific information is to build complex image restoration networks: Liu et al. [
5] proposed a Differentiable Image Processing (DIP) module to target adverse weather conditions and predict the parameters of the DIP module through a small Convolutional neural network model (CNN-PP); Hnewa et al. [
6] proposed a domain-adaptive training framework to face the detection problems in foggy and snow scenarios; Huang et al. [
7] similarly introduced a Dual Subnet (DSNet) to solve the problems of target detection in foggy environments.
However, the pipeline used is different in low-light situations, so it is difficult to handle more complex scenes. For low-light situations, a number of approaches have been proposed: Sasagawa et al. [
8] proposed a detection method in low light conditions using a transfer learning approach that allows target detection in light conditions below 1 lux. However, prior domain knowledge is required, and the repeatability in different scenarios is not strong. Yuxuan et al. [
9], inspired by Receptive Fields (RFs), solved the problem of detecting targets with unclear features to some extent by preserving the low-dimensional spatial features, but the requirement of computational power is higher. Peng et al. [
10] proposed an NLE-YOLO model, which improves the model feature extraction capability and receptive field after modularization improvements based on YOLOV5 and performs well in the low-light detection problem. But these methods are not applicable in all scenarios. Zhao et al. [
11] proposed DIOU, which solves the problem of face occlusion detection. Eran et al. [
12] proposed a Soft-IOU layer that can achieve better performance in extremely dense artificial scenes, and Chen et al. [
13] proposed bounding boxes with rotation parameters, which can better detect selective and dense objects. At the same time, Pixels-IOU [
13] is introduced to improve the detection effect of tilted objects. Chi et al. [
14] designed a mask-guided module to leverage the head information to enhance the ability to detect occluded pedestrians. Li et al. [
15] used an occlusion-guided multi-task network (OGMN) that addresses the feature obfuscation problem for occluded targets. Cheng et al. [
16] proposed a joint network with a image enhancement subnet to solve the occlusion problem and a detection subnet to detect marine objects.
However, the detection of naturally occluded scenes is still a very cutting-edge challenge. Qi et al. [
17] devised a contrast training strategy and a multi-association detector, with the result that the model can be trained with fewer shots and can detect unlabeled categories; Zhu et al. [
18] combined semantic relations with visual information for better results with few-shot object detections; Ren et al. [
19] built a two-stage meta-learning model based on YOLO to avoid the detection error situation of a single YOLO model in few-shot detection. However, the generalization of the above models to different scenarios is not yet complete.
Despite the numerous proposals aimed at addressing the challenges of poor texture features, low illumination, occlusion, and lack of samples in complex situations, there is still a paucity of natural scene models that can perform robustly in all complex situations. It is more noteworthy that deploying target detection algorithms in border-complex environments and hardware conditions are also difficult to meet higher requirements. Therefore, we have to choose the model with the best generalization ability, i.e., propose adaptive improvements, with low arithmetic requirements. Therefore, we first aim at One-stage object detection. As such, we endeavor to enhance the YOLO model, which ranks among the most sought-after and easiest-to-improve models for tackling these practical problems.
In the YOLO series, YOLOV5 has distinguished itself as an efficient model in real-time scenes in the wild and other scenes [
20,
21,
22]. Then the welcomed YOLOV8 shows great performance [
23]. (The YOLOV6 and YOLOV7 models are not considered here, because they were not proposed by the same team as YOLOV8). However, after examining the model framework of YOLOV8 in detail, it is found that the improvement of YOLOV8 is not fully applicable to the practical application scenarios of weak target detection in complex scenes with limited arithmetic power and high real-time requirements. For example, although the anchor-free design does not rely on predefined anchors, it also means that the model will confront a larger solution space, which is easy to get too many false positives. The precision and detection speed will be reduced as a result. Moreover, replacing the C3 module with the deeper C2f module in YOLO V8 and using the Task-Aligned Assigner’s positive and negative sample allocation strategy will lead to the consumption of computational resources and reduce the inference speed. And it has been proved that YOLOV8’s generalization performance on some wild scenarios is not as impressive as YOLOV5 [
24,
25,
26]. However, it is worth noting that the differences in the mAP, Precision, and other norms between the versions was relatively small, indicating that both versions can achieve high levels of object detection accuracy in different challenging environments.
In summary, the latest YOLOV8 model is now only a different improvement strategy from its predecessor, the YOLOV5 model, in several aspects; YOLOV8 proves better performance on public datasets, but does not prove that it improves generalization performance on arbitrary custom data. More importantly, the two are on the order of n and s. The model of v5 has only two-thirds of the number of parameters of the v8 model and one-half of the model complexity; thus, YOLOV5 better meet the requirements of our edge deployment in complex scenarios. And the YOLO framework is known for its easy improvement, so we also decided to make adaptive improvements on the YOLOV5 framework to meet weak object detection in complex real-world scenarios.
For adaptive improvement, the attention mechanism is the first that springs to mind, as it has been widely demonstrated and applied for improvements using various types of scenarios. In common detectors, there are usually three network structures that can be used for improvement: the head, the neck, and the backbone. The head and the neck, in turn, often act as a whole. To avoid confusion, these parts of the structure are in the following collectively referred to as the backbone network. Therefore our improvement is also carried out in both directions: the head and backbone. Adaptive improvements in these areas help to improve the model’s detection ability under conditions such as weak features, an ambiguous background, and weak targets. To surmount the problem of inadequate data, we utilize a combination of copy–paste enhancement and image enhancement techniques. And copy–paste enhancement has been proven accuracy and efficiency with translation, scaling, and rotation in similar scenarios [
27,
28,
29]. We have also created a dataset of people in natural scenes, including mountains, mountain forests, and plains scenes.
All of the improvements currently proposed in the community claim that they reduce the arithmetic requirements while increasing the detection accuracy. Therefore, it is incomplete for us to analyse the advantages and disadvantages of these improvements only through subjective analysis. Experiments must be conducted based on real-scenario environments, and the results must be compared with the impacts of different improvements on the model in order to explore the usefulness of these improvements for real scenarios. Objectively speaking, although this will make some improvements, they are not advantageous or even show disadvantages. However, we still need to start by giving explanations for the more inferior strategies to provide ideas for researchers in more complex scenarios. The novelty of our work lies in questioning the current hot improvement methods and giving more realistic adaptive improvements. Perhaps the improvements we provide do not satisfy the task in all complex scenarios, but for similar scenarios, our work has some value and relevance.
Our contribution can be distilled into the following points:
A natural scene dataset, featuring people in mountain, mountain forest, and plains scenes, has been contributed through the combination of copy–paste and image enhancement techniques.
A framework is proposed for enhancing the capability of detectors in extracting weak objects in complex environment, which can be adapted to integrate with popular detectors.
Nine improved methods based on YOLOV5 are employed to compare and analyze the advantages and disadvantages of these strategies for weak target detection in complex environment, thereby guiding researchers in similar work.
2. Methods
Our research aims to improve the accuracy of human detection in complex environments and investigate whether the most popular improvements have a sufficient generalization performance in complex natural environment. To face challenges, we started by expanding our datasets through the use of copy–paste and image enhancement methods, resulting in a more diverse and comprehensive datasets. Firstly, we collected and annotated only 1100 images, and some of them contained only single human objects. Thus, we applied the copy–paste enhancement so that images that contain only a single target contain at least three targets. And the images that contain only one target are retained so that we end up with 1825 images, which not only expands the datasets but also improves the coverage of the datasets. Secondly, we randomly selected and combined each image according to probability among twenty enhancement methods. Then, the datasets amounts to 3650 images. Thirdly, we extracted 1000 images from the open-source datasets Visdrone and OA to further expand our dataset’s size and diversity. Finally, we contributed a natural scene human-detection datasets in mountain, mountain forest, and plains scenes with 5650 images.
Then, we chose YOLOV5s as the baseline model for our research due to its adaptability and low computational consumption. As the hottest one-stage detector, these three improvements to the YOLOV5 are widely proposed and used: adding an attention mechanism, improving the head network, and improving the backbone network. In an effort to make the detector perform better in complex environments and explore whether these improvements “actually” work, we proposed improvements in the following three directions: adding an attention mechanism, replacing the head network, and replacing the backbone network. It is worth noting that we used both YOLOV8s for comparison during the baseline experiments and later compared and discussed them with the YoloV5s model.
We proposed adding an attention mechanism to our model, which extracts local information for efficient feature extraction. This helps to improve the accuracy of detection, with fewer parameters introduced. We also tried to replace the head network to fully extract target features, especially for weak and tiny targets. Finally, we tried to replace the backbone network’s ability to extract target features, making the detector more effective in sparse textures and blurred backgrounds. By comparing the different options in the improvement strategy, we discuss and analyze which improvements are worth using on the YOLOV5s framework and which ones make the model redundant. The following
Figure 1 illustrates the framework of ideas in this paper:
2.1. Review of YOLOV5
YOLOV5 follows the grid concept of previous models, where the architecture images are divided into grids, and each grid is allowed to predict one or more objects. In the process of training, the anchor frame will move closer or farther toward the grid where the real values exist, the difference between the direct width and height of the anchor frame and the real frame and the difference in the coordinates are regarded as the loss function, and the binary cross entropy is taken as the loss of confidence; then the target detection problem will be greatly simplified into a simple regression prediction and classification problem.
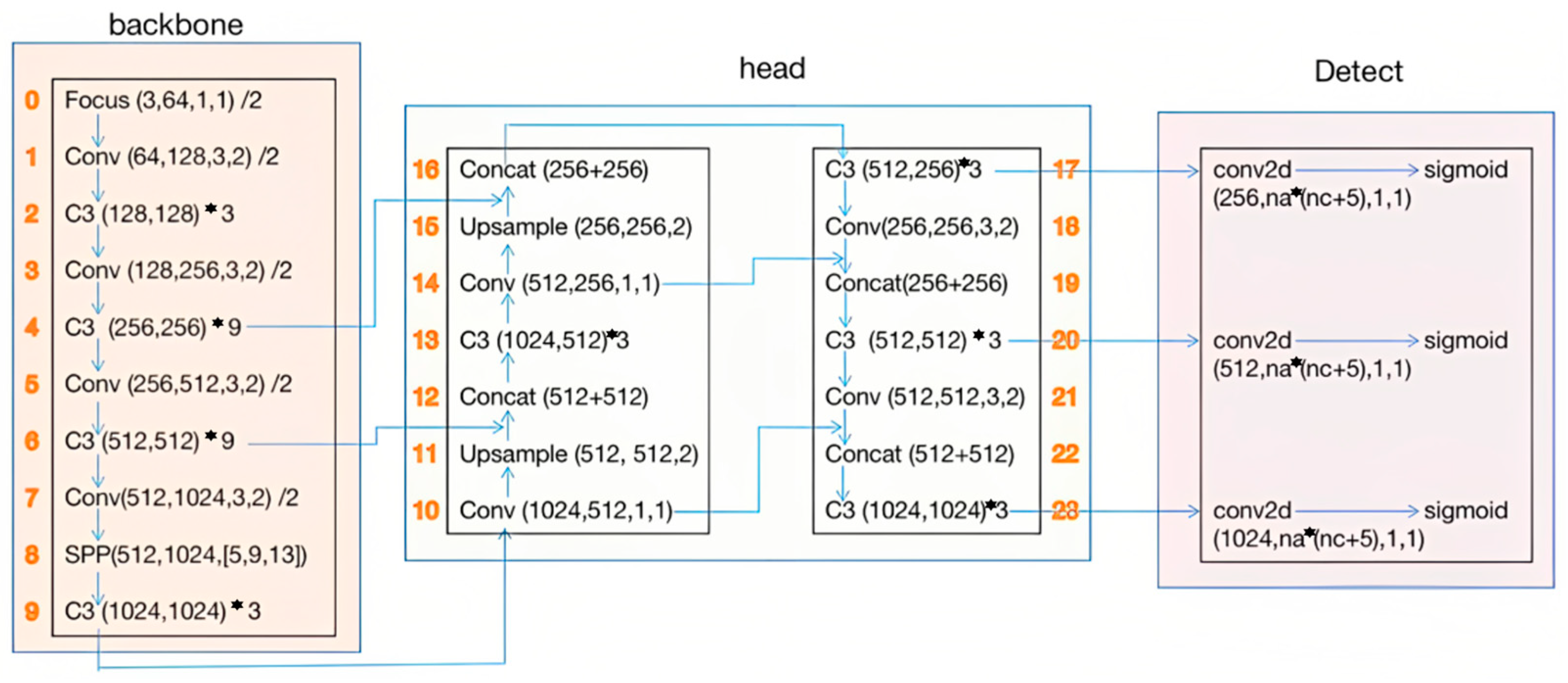
Currently, the sixth generation of YOLOV5 proposes a total of five network junctions: YOLOV5n, YOLOV5s, YOLOV5m, YOLOV5l, and YOLOV5x. YOLOV5n is a variant in the series, which has been deployed in large numbers on embedded platforms for real-time detection tasks. YOLOV5s is the smallest model in the series and can demonstrate the fastest detection speed on devices with limited computational resources. The network structure of YOLOV5s is shown in
Figure 2.
As the depth of the network increases, the AP accuracy also increases, requiring more computational resources. The YOLOV5s model is described here.
YOLOV5, which has a wide range of applications in surveillance recognition, vehicle driving, etc., still needs different degrees of improvement to obtain a more accurate detection capability for small and weak targets in real, complex natural environments. In this chapter, we first take YOLOV5s as the basis and analyze the more advanced network modules; then, we propose the improvement scheme in three parts: the attention mechanism, head network, and backbone network.
2.2. Improved Detection Methods Based on the Attention Mechanism
SENet is a network structure proposed by Hu et al. [
30], inserted in popular detection networks such as ResNet and VGG16 that have achieved improved results. YOLOV5 uses CSPDarknet53 as the backbone network to transform the original input image into a multilayer feature map. Adding SE structure into the backbone network can eliminate the invalid channel information, reduce the false judgment rate, and improve the detection accuracy. The SE mechanism consists of two main parts: Squeeze and Excitation. Squeeze refers to the compression of global information into a single-channel descriptor, i.e., using global average pooling of channels to compress a
W × H × C feature map containing global information into a 1
× 1
× C feature vector
z. The Squeeze calculation is defined as follows:
where
c in
stands for its ordinal number in
z.
The Excitation module, in order to utilize the information aggregated after Squeeze, enables the module to obtain multi-channel information through two fully connected layers. The first fully connected layer compresses the C channels and then performs the RELU computation; the second fully connected layer restores the number of channels to
C and then obtains the weight
s use Sigmoid computation, which is used to inscribe the weights in the feature map. Excitation calculation is defined as follow:
Finally, the Scale operation multiplies the resulting attention weights with the corresponding channel feature weighting:
where
X is the output of the SE, i.e., the channel characteristics with mutual dependencies.
And the initial network layer learning function in the network is not affluent. In order to obtain good results, we propose to produce a new backbone network structure after adding two SE modules to layers 6 and 9 of the original backbone network. The network structure is showed in
Figure 3:
CBAM [
31] is a network module that can infer attention through both channel and spatial dimensions. Compared to SENet, which focuses only on the channel attention mechanism, the CBAM module achieves better results. In YOLOV5, C3 module is used to extract image features. And C3 stands for Cross-Stage Partial Connection with 3 branches, which enhances feature transfer and reuse by partitioning the feature map into multiple branches and cross-connecting them between different layers.
Figure 4 illustrates the improvement strategy proposed in this paper:
In CBAM, the channel attention expression is given as follows:
where
F stands for feature,
MLP stands for multilayer perceptron, and
stands for sigmoid function.
Spatial attention takes the feature map’s output from channel attention as input and performs mean pooling and maximum pooling in the channel dimension, separately. The calculation is as follows:
where 7 × 7 stands for the size of the convolution kernel, which has been proven to have a better performance than the 3 × 3 kernel.
As a plug-and-play attention module, after we add the CBAM module into C3, we perform an attention mechanism compensation each time, which weights the attention on the targets on the feature graph in different dimensions and attenuates the attention on other irrelevant features.
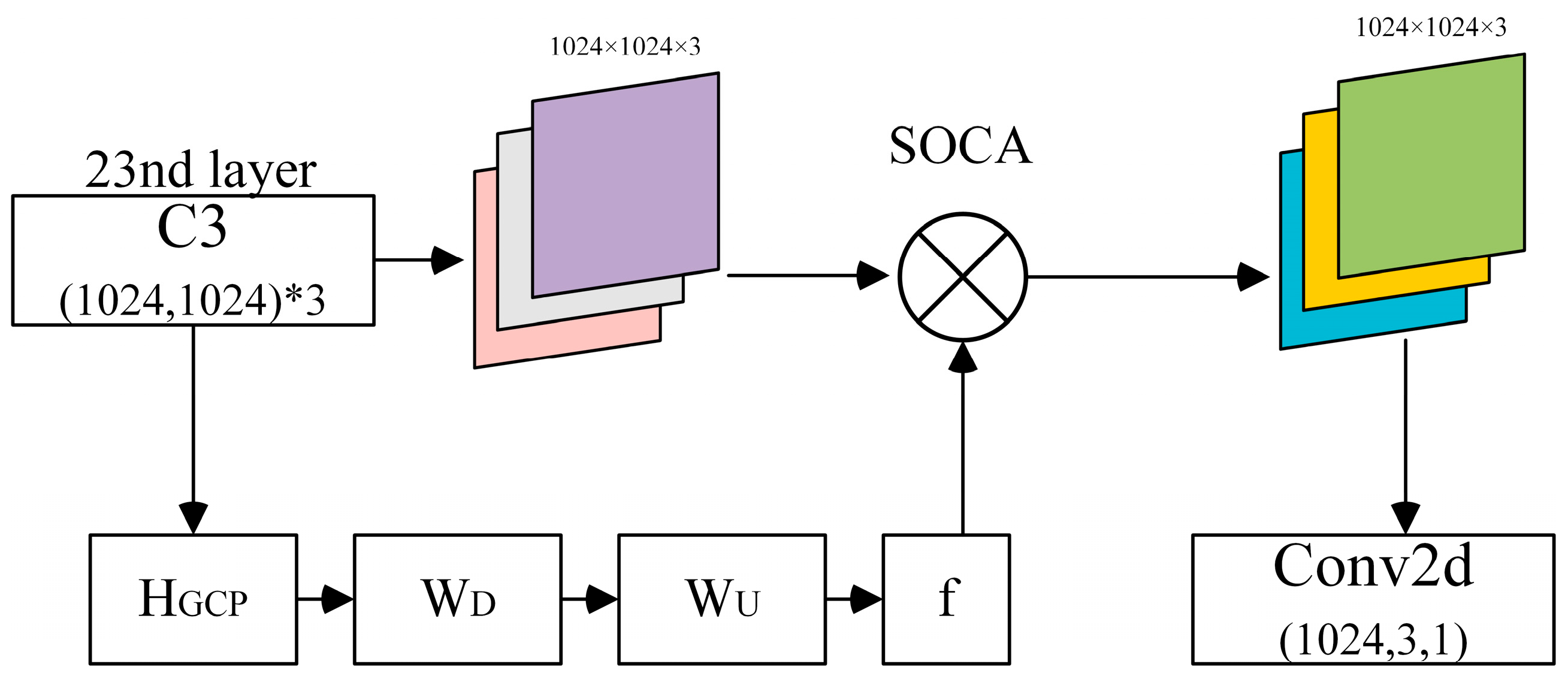
SOCA [
32] is a mechanism used to consider the correlation between high-level features for deeper networks. SOCA consists of two parts: covariance normalization and channel attention mechanism. The SOCA mechanism enables the network to be more focused on locally beneficial information, i.e., it has the capability of super-resolution images. A covariance matrix is used in SOCA to describe the correlation between the C channels:
where
N stands for the number of channels,
X stands for the feature map,
V stands for the matrix of feature, and
D stands for the diagonal matrix with eigenvalues. By means of the above equation, the feature map is decomposed. And the calculation of weighted feature map is given as follows:
where
stands for the multiply symbol.
However, since SOCA is not capable of extracting features in shallow networks, this paper adds the SOCA module to the 23nd layer of the HEAD network. The specific structure is shown in
Figure 5:
2.3. Improved Detection Methods Based on the Head Network
In YOLOX [
33], a dual head structure (decoupled head) had been designed. Classification and localization tasks in object detection, the decoupled head network is able to make predictions for classification and localization, respectively, the classification task is more concerned with which target class the features in the network are more similar to, and the classification and localization task is more concerned with the coordinates of the location where the target is actually located. While in the YOLO series of algorithms, the detection head is always coupled. By introducing a branching operation network in the detection head, two-channel prediction of target frames and categories is performed, which greatly improves the detection speed. The calculation of the classification head is based on the following formula:
where
stands for the logits of the output, and
C stands for the number of categories.
The regression header is used to predict the position of the bounding box for each anchor. The bounding box is defined by the center coordinates (
x,
y)(
x,
y), the width w, and the height h. The regression objective is to predict the offset of these values relative to the anchor point (
dx,
dy,
dw,
dh). Corresponding equation goes here:
On the basis of the double-decoupled detection head, considering that the fully connected layer is more suitable for the classification task and the conv layer is more suitable for the localization task, this paper proposes a more concise and efficient detection head. The design structure is shown in
Figure 6:
Adaptive Spatial Feature Fusion [
34] is a pyramid feature fusion strategy that solves the problem of inconsistency of different scale features inside the feature pyramid by adaptively learning the fusion weights of each different feature map. For each pair of neighboring layers, the fusion feature map is computed by ASFF:
where
w can be computed by weighted network:
where
G stands for the weighted network, and
stands for sigmoid.
This strategy can be used by any single-stage detector, so the improved model of the head structure proposed in this paper is shown in
Figure 7:
BIFPN [
35] is a repetitively weighted, bi-directional feature pyramid network that uses residual links to enhance the characterization of features. Unlike ASFF, the feature map will be processed through a bottleneck structure, which will contain several convolutional layers with the aim of reducing the dimensionality of the feature map. Subsequently, the upper feature maps are fused with the bottom level feature maps that have been processed by the bottleneck structure. The calculation is given as follows:
where
Conv stands for convolution,
stands for upper feature maps, and
stands for fusion weight.
The number of BIFPN feature fusion strategies to use is not set artificially and was obtained in the original paper using a parametric grid search. In this paper, only one BIFPN network is added to replace the PANET strategy in the original model. The specific structure is shown in
Figure 8:
2.4. Improved Detection Methods Based on the Backbone Network
A YOLOV5 backbone network based on DarkNet can achieve excellent performance under normal circumstances, but it does not fully satisfy the real needs. ConvNext [
36] is based on ResNet50, modeled after Swin Transformer structural modification to obtain a network composed entirely of convolutional structures, and its accuracy and scalability have the ability to be able to compete with the Transformer. The biggest innovation in its backbone network is the use of Depth-wise Convolution (i.e., the number of convolutional kernels is equal to the number of input channels) and increasing the size of each convolutional kernel. This architecture allows each convolution kernel to process its respective channel independently, mirroring the self-attention mechanism’s ability to focus dynamically on different parts of the input data. In depth-wise convolution, each kernel acts independently across its channel, extracting features specifically relevant to that channel and mimicking the selective, dynamic focusing that characterizes self-attention mechanisms. This capability enables the model to perform efficient and precise feature extraction by focusing on local spatial details within each channel, similar to how self-attention mechanisms weigh the importance of different input parts to enhance model understanding and performance. The calculation is given as follows:
where
stands for the channel number of the input feature map,
stands for the convolution kernel for this channel, and
stands for the position of feature map.
Drawing on the ConvNext-T model, the YOLOV5 backbone network is replaced with four ConvNext structural blocks. Among them, the LN layer is a normalization layer, which is not limited by the number of samples compared to the BN normalization and can be normalized for different features of a single sample. The Layer Scale layer is used for scaling and panning the input. Referring to the above network construction, our proposed improved structure is specifically shown in
Figure 9:
MobileNet [
37] is a lightweight deep learning neural network that uses depth-wise separable convolution instead of standard convolution, which dramatically reduces the computational effort and model parameters. Combined with the network structure proposed in the original MobileNet article, ordinary convolution and depth-wise separable convolution are combined to form a convolution block.
Unlike Depth-wise Convolution, after depth-wise convolution, a point-wise convolution (i.e., a 1 × 1 convolution kernel) is usually used with the purpose of combining the C feature maps generated in the previous step into a new feature map, so that the corresponding equation goes here:
where
stands for the set of feature maps obtained after applying depth-wise convolution independently for each channel. And it is precisely because point-wise convolution can contribute weights and therefore reduce the number of parameters.
In this paper, the MobileNet Block is stacked three times in the backbone network, and the output results are sent to the feature pyramid processing, the structure of which is shown in
Figure 10:
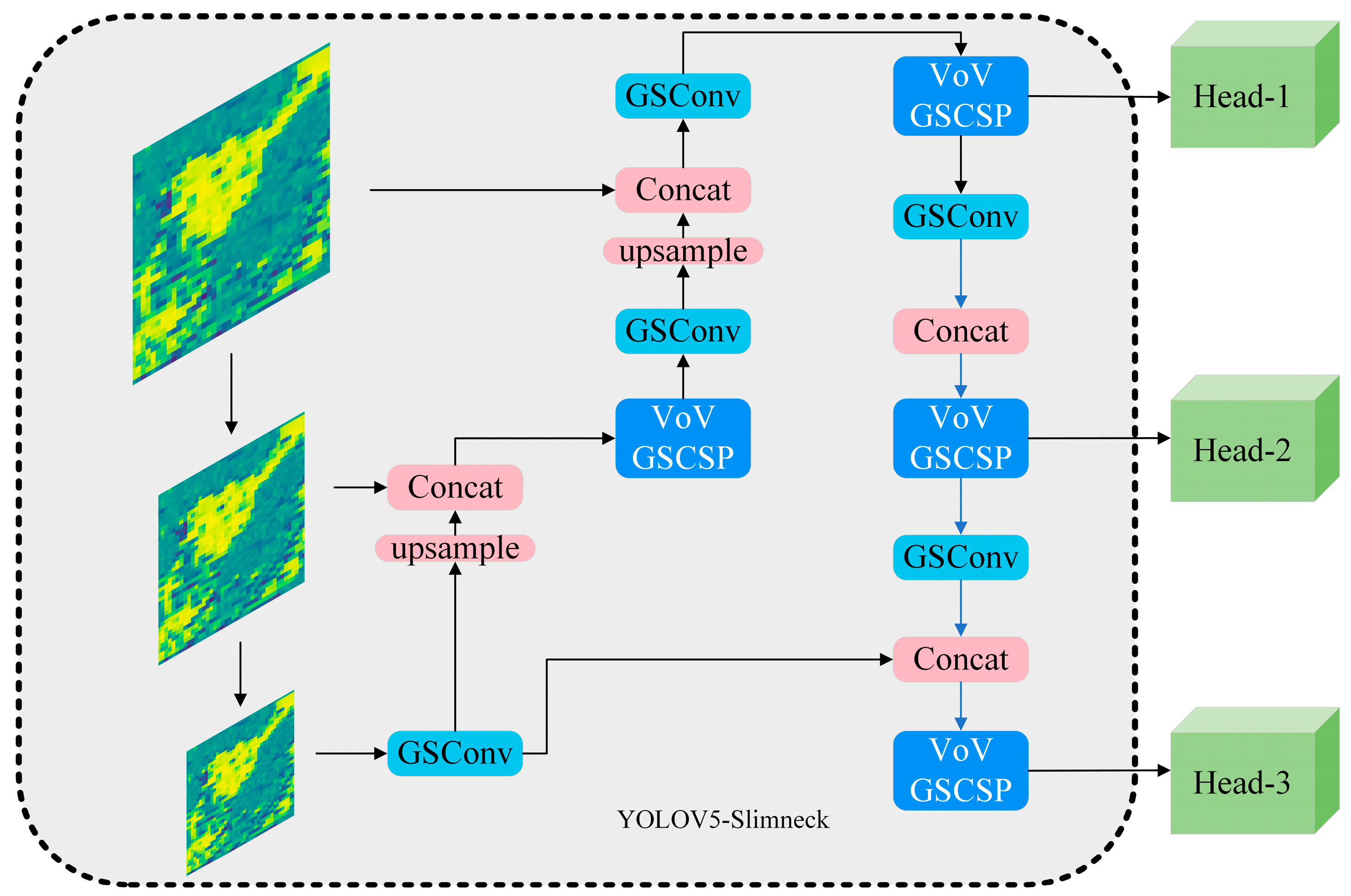
Slimneck [
38] proposed that Depth-wise separable Convolution reduces the computational effort, but its feature extraction and fusion capabilities are much lower than standard convolution, so a new method, GSConv, was introduced to make the output of DSC as close as possible to the standard convolution by disrupting the features in the standard convolution and mixing them into the output of DSC. GSConv enhances the feature representation by integrating the self-attention module into the convolution operation. The calcuation of GSConv can be represented as:
where
Q,
K, and
V individually stand for the Query, Key, and Value.
stands for the dimension of key, which is used to scale the dot product for a more stable gradient when performing softmax.
However, if it is used at every stage in the network structure, it increases the number of model parameters and reduces the inference speed. The original article similarly mentions adding this structure to the neck network. This part of the improvement is classified here in the backbone network for the sake of uniform analysis. The structure proposed in this paper is shown in
Figure 11:
3. Experiments and Results
Before validating the improved models, Validation of the scientific validity of the custom datasets is needed. Similarly, we need to test the baseline model on our custom datasets to ensure the viability of the baseline model on the dataset.
3.1. Datasets
Our task is to detect human targets in real scenarios. These scenes cover mountains, snow, and mountain forests. Human eye recognition is difficult due to restricted conditions such as low data collection, fog jams, and fuzzy targets. Therefore, the priority is to enhance the data and expand the datasets.
The realities of scarcity of target images, limited acquisition conditions, and poor imaging quality exist in complex environments. Therefore, images must be processed and enhanced.
We have collected about 1100 human target images, but the number of positive samples is relatively limited, which makes it difficult to meet the model training requirements. Kisantal [
39] et al. proposed to increase the number of weak targets in each image by using a “copy and paste” method and applying a stochastic transformation enhancement method to the targets before they are pasted to a new location to produce appropriate variations in the target size and rotation angle. Before we pasted, we need to extract the targets based on the annotations. Then, we randomly take out 1 or 2 targets, add them to the images with less than three targets, and keep the images with less than three targets. Finally, we get 1825 images. When pasting the targets, a judgment is made as to whether their new positions will be with the original image targets in order to avoid target cross-obscuration. By using this method, there are three more weak targets on the newly generated image than on the original image. The rendering is shown in
Figure 12.
Then, we deployed mosaic data enhancement, random affine transformation, hybrid data enhancement, and HSV random image enhancement. Here, we used the Albumentations library in python, employing twenty of these augmentations and selecting them at random. With these methods, the amount of images can be further extended to 3650. The enhanced images are shown in
Figure 13.
The single use of custom datasets not only reduces the generalization ability of the model, but also leads to overfitting of the model during the training process, so it is necessary to add some target detection datasets similar to those in complex scenarios. The final custom dataset consists of the following parts:
3.2. Baseline and Evaluation Methods
The experiments in this paper on custom datasets are conducted by using YOLOV5s as the experimental baseline. The results of each metric in the training and validation process are shown as
Figure 14:
The YOLOV5s pre-trained model is used for migration learning, and the loss function is optimized by stochastic descent algorithm. The initial learning rate is 0.01, and the learning rate will gradually decrease with the training process, while the learning momentum is 0.9. The original YOLOV5s model is being trained.
The prediction training loss continues to decrease, and the category training loss stabilizes, mainly due to single-category detection. The confidence loss obj_loss shows a slight increase after 50 generations, indicating that the model’s prediction ability improves in correctly predicted scenarios, while its performance decreases in incorrectly predicted scenarios. All other metrics are normal and stabilized, proving that YOLOV5s can be used as a benchmark model for this experiment.
In this study, the evaluation metrics include the parameters mAP_0.5, mAP_0.5:0.95, precision, recall, fps, and FLOPs. The parameter denotes the model size, fps denotes the number of frames per second processed by the model (higher is better), and FLOPs denotes the computational resources needed to run the model. Other metrics were calculated as follows:
where
TP (True Positives) stands for the number of correctly detected targets;
FP (False Positives) stands for the number of incorrectly detected background or other objects as targets;
FN (False Negatives) stands for the actual number of targets that the model failed to detect;
n stands for the number of the type of object (here, n takes 1); 0.5 stands for threshold setting at 0.5, and 0.5:0.95 stands for an IoU setting range of 0.5 to 0.95. And IoU is a metric that measures the extent to which the predicted bounding box overlaps the true bounding box.
On the basis of the experiments with the baseline model, we also fine-tuned and tested it with YOLOV8s to facilitate the subsequent discussion with the same hyperparameters.
As can be seen in
Table 1, YOLOV8s do show a better performance. However, as discussed before, YOLOV8s does not show a dominating performance. While the larger model parameters give stronger feature extraction and, thus, improved mAP and Precision, the optimised inference speed and smaller parameter count of the YOLOV5s is still the preferred choice for edge-computing devices. It is not possible to conclude which model is better here, and in case of sufficient arithmetic power, the choice of YOLOV8s is unquestionable. And the purpose of our study is not to compare the two models, but to find suitable improvement strategies for models like YOLOV5 that are more suitable for deploying inference. Through the experimental results of the model that is considered the most SOTA by the community, the next improvement strategies can be better judged.
3.3. Experimental Results and Analysis
3.3.1. Experiments Based on the Attention Mechanism
After testing the standard model, we experimented with the improved model presented in 2.2. The training results are shown in the table following.
As can be seen in
Table 2, the model with the added SE mechanism, mAP_0.5, improves by 0.8% for the baseline, mAP_0.5:0.95 improves by 1.9%, and accuracy improves by 0.8%, which is the most metrics-enhancing model of the other three models. Although the model with the addition of the SE mechanism has more parameters than the original model, the presence of the SE mechanism makes the model more parallel and therefore reduces the complexity of the model. The improvement of mAP at different IoU thresholds indicates that the improved model predicts the target location more accurately. However, at the same time, the overall value of mAP_0.5:0.9 is low. When the IoU threshold is set too high, the position of the target detection frame is also too demanding. Since it is not possible to demonstrate the poor accuracy of YOLOV5s at high IoU threshold settings with the addition of a publicly available dataset, it is not possible to demonstrate the poor accuracy of YOLOV5s at high IoU threshold settings. The model with the addition of the CBAM mechanism is greater than the other models in terms of the parameters and model complexity, but it also requires more computational resources and has a higher computational complexity, which leads to a decrease in the performance of the model. And even though the CBAM module is able to improve the detection ability in complex backgrounds, the decrease from the mAP and recall shows that it is more difficult for CBAM to show the ability to detect object, especially when complex background images dominate the dataset. The model with the addition of the SOCA mechanism improves the detection speed by 2.5%, but the accuracy rate decreases, indicating that the SOCA mechanism outperforms the other models in terms of complexity, but its super-resolution capability performs poorly for the low-resolution data in this experimental dataset. This makes it difficult for the SOCA mechanism to detect correlations between features when the target is not sufficiently salient.
The following
Figure 15 shows the true value of surveillance video data in a centralized urban environment, where the green box represents the data labeling box. And it can be seen that there is an obvious omission of labeling, and only five targets are labeled in the figure.
The images are detected with the benchmark model and the improved model, and the results are shown in
Figure 16. The baseline model and the model adding the CBAM and SOCA mechanisms are equipped with certain generalization ability, which can detect human targets other than the labeled targets, and the model adding the attention mechanism has a higher prediction confidence and more accurate localization. This happens mainly because the model does not obtain enough generalization ability due to the insufficient number of datasets in this scenario, and the omitted labeled data has a great impact on the model, which may lead to serious model leakage detection.
3.3.2. Improved Experiments Based on the Head Network
In this section, experiments are conducted on the model presented in
Section 2.3.
Table 3 shows each parameter of the training process:
From the following table, it can be seen that the improved model using the ASFF head network shows varying degrees of degradation in all the metrics, which is due to the complex structure of the ASFF head network and its applicability in target tasks with varying scales. Therefore, the potential of pyramidal feature representation on the dataset presented in this paper cannot be fully utilized. In tiny target detection tasks, multiscale feature fusion requires finer feature capture details, and multiscale features do not match weak target representations well enough, leading to increased interference from background noise. The models using BIFPN and decoupled head networks show improvements in all metrics, with the decoupled improved model showing an improvement of 23.68% and 31.8% in the most important metrics, mAP_0.5 and mAP_0.5:0.95, respectively. More notably, similar to the inclusion of decoupled head in YOLOV8, its improvement on YOLOV5s reaches 0.872, 0.538, and 87.5% in the metrics of mAP_0.5, mAP_0.5:0.95, and accuracy, respectively, achieving similar improvements as BIFPN. And it shows better performance with less number of parameters.
The previous section doesn’t show the performance improvements from the attention mechanism due to insignificant differences in real dataset results.
Figure 17 presents a more challenging graph:
The above data show data from a real blurred scene with 8 targets. It can be seen that the scene is very fuzzy, especially the targets that are obscured by each other. Compared to the real picture shown in the first experiment, the picture is more blurred, with more background texture features and background interference behind the targets, which makes it more difficult to detect. The results are shown in
Figure 18:
The figure above shows the detection of the baseline and the improved model with the data. 7 targets were successfully detected by the baseline, but one target missed detection, which indicates that the conf-thres and IoU-thres parameters of the baseline need to be adjusted. Increasing the confidence intervals and decreasing the IoU values between the prediction frames from the default values of 0.25 and 0.45 can better handle the recognition task in such scenarios. The models using BIFPN head showed misclassification to some extent, proving that some of the features are similar to the target features in the current scene and the feature detection module used did not improve the detection. Whereas the models using ASFF showed a missing detection due to the multi-scale features of ASFF are difficult to match with small targets, and the resulting background noise can easily produce a false judgment situation. Similarly, BIFPN uses bidirectional feature fusion, and the noise in the complex background leads to the fusion of features that may incorrectly mix the features of these interferences with the target features, resulting in misjudgments. The improved network using Decoupled detection header on the other hand is able to detect the eight targets in the figure well and has better performance than the baseline.
3.3.3. Improved Experiments Based on the Backbone Network
In the previous section, we proposed improved models based on backbone network, and
Table 4 shows the improved model training parameters:
As can be seen from the table, the final results appear to be very different due to the different structure of each improved backbone network. The improved model using the ConvNext backbone network is far more structured than the baseline model due to the inclusion of four layers of backbone blocks, each with a parameter count of more than 27.8M, resulting in a network structure that far exceeds that of the baseline model. Therefore, this improvement does not match well enough with the lightweight design of YOLOV5s, leading to the extraction of overly complex features that are difficult to process. The model using the MobileNet backbone network, which is typically used in the lightweighting of large models, showed a 10.2% improvement in the mAP_0.5 metric and a 64.3% improvement in detection speed in this experiment, illustrating the superiority of the MobileNet model in accelerating the model and improving the quality of the detection. However, at the same time, the insufficient feature extraction capability causes this improvement to be ineffective in enhancing the detection performance, and the rest of the metrics are degraded to some extent. The model using the Slimneck backbone network improved 20.4%, 18.2%, 7.4%, and 33.3% in the four metrics of mAP_0.5, mAP_0.5:0.95, detection accuracy, and recall, respectively, compared to the original model, which illustrates that the use of the Slimneck backbone network greatly improves the model’s weak target detection. We also note that with a similar number of model parameters as YOLOV8s, the Slimneck-based improvement is superior in all performance metrics.
Figure 19 shows the detection results of each model in the above real scenario:
The above figure shows the detection results of the improved models. The improved models with ConvNext and Mobilenet have misidentification. It also indicates that these two popular improvement methods are not applicable to YOLOV5s, and the feature capability extraction and feature recognition capabilities do not match. From a certain point of view the misjudged target is very similar to the correct target features, and the amount of data in such scenarios needs to be increased to improve the recognition ability of the model. In contrast, the model using Slimneck backbone network did not experience misclassification, and the eighth target was detected, such results have produced a large improvement over the baseline model.
4. Conclusions
The research presented in this paper has proposed the way to face the challenge of object detection in complex natura environments, a critical issue in security and surveillance. We first aimed at single-stage algorithms, because they are good enough for demanding hardware and real-time requirements. Secondly, we chose the YOLO framework, because it is the most popular in the industry and easy to deploy. Finally, for the model, we chose YOLOV5s because of its lightweight design and greater room for improvement. By employing an enhanced version of the YOLOv5 algorithm, this study has not only demonstrated a significant improvement based on decoupled head and Slimneck within diverse and challenging setting, but also revealed the drawbacks that arise from blindly making improvements to the model. In fact, YOLOV5s is lighter while having some improved strategies that do not drastically increase the number of model parameters, and its detection performance even exceeds that of YOLOV8s.
One of the pivotal contributions of this work is the innovative approach to dataset augmentation. By combining image enhancement techniques with copy–paste methods, we have not only enriched our dataset but also expanded it to include other scenarios, thereby creating a robust and diverse dataset of human targets. This comprehensive dataset has been instrumental in training the YOLOv5 model to better detect and respond to the intricacies of natural environments.
Furthermore, multiple adaptive improvement strategies into the YOLOv5 algorithm has yielded remarkable results. Our modifications, tailored to the specific demands of detection tasks, improvements based on BIFPN, decoupled head, and Slimneck, have significantly enhanced the model’s performance in various indicators. The rigorous testing conducted on our expanded dataset has validated the effectiveness of these improvements, leading to a model that is not only accurate but also highly adaptable to requirements for deployment and real-time. Meanwhile, some of the other hottest improvements through the results proved not to be suitable on our task.
We discuss whether the hottest improvement options in the current community work in real complex scenarios through experimental comparisons. The addition of attention mechanisms such as CBAM and SOCA does not improve YOLOV5s much. And improvements based on the head network, such as ASFF, despite having stronger feature fusion capabilities, do not match the feature extraction capabilities of the backbone network of YOLO5s, resulting in performance degradation and misclassification during recognition. The settings of backbone networks such as ConvNexT and MobileNet are experimentally proved to not be blindly replaced into the YOLO framework, which will not only lead to an increase in the arithmetic demand, but also a decrease in the detection performance.
In conclusion, this paper has made strides in addressing the detection of tiny objects in complex environments, providing valuable insights for further research. However, it is important to note the existing limitations: Firstly, the model’s training parameters and hyperparameters may not be optimal and require extensive experimentation to find the best settings. Secondly, the learning strategy used is conventional and does not specifically cater to the challenges of few samples. Exploring alternative strategies, such as active learning and supervised deep correlation tracking, could help address data scarcity issues. Lastly, the dataset augmentation technique, which involves copying and pasting objects, does not consider the context between the target and the new background, resulting in unrealistic synthetic images. Incorporating context and using seamless cloning techniques such as poisson blending could improve the naturalness of the augmented data. By addressing these areas, future research can aim to achieve more robust and natural results in the challenging domain of target detection.


















{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}