1. Introduction
Adding colors to grayscale or black-and-white images is known as image colorization. This technology holds considerable importance across multiple fields, such as the digital restoration of old photographs, entertainment and media sectors, historical preservation, and augmentation of visual communication. Incorporating color into images can enhance their realism and visual appeal by accurately representing the depicted scene or object.
Despite its significance, image colorization poses numerous challenges. One of the foremost challenges is the precise selection of suitable colors for individual pixels within an image, particularly when color data are unavailable. Accurately predicting the appropriate colors involves understanding the context and semantics of the image, which can be especially challenging for complex scenes with multiple objects and varying textures. The difficulty level of this task escalates when confronted with complex visuals or uncertain grayscale variations. Throughout the years, researchers have proposed various methodologies to address the issue of image colorization. Historically, conventional techniques have frequently required human involvement, whereby skilled artists or experts have meticulously incorporated hues into monochromatic images. Although these methods produced adequate outcomes, they were time-intensive and required knowledge of color theory and image manipulation. Furthermore, the manual process was not scalable and could not meet the growing demand for colorized images in various industries, including entertainment, restoration, and digital art.
Automated image colorization techniques have attracted significant attention recently, owing to the progress made in deep learning and computer vision. These methodologies utilize extensive datasets, convolutional neural networks (CNNs), and generative models [
1] to learn the correlation between grayscale and color images. In this study, we aim to develop an automated system for predicting and assigning appropriate colors to grayscale pixels, thereby significantly reducing the need for manual intervention.
Although current methods leverage CNNs or transformer architectures, they face challenges, such as color bleeding, desaturation, and limitations in effectively capturing local and global features. The trickier part of colorization is determining the right balance between paying attention to small details, such as textures, and comprehending a broader context. These challenges make it difficult for automated methods to consistently produce accurate and visually pleasing colorizations. Striking a delicate balance between preserving fine details and comprehending a broader context is crucial for achieving natural and realistic results. Overcoming these challenges is essential for advancing state-of-the-art image colorization and ensuring that automated techniques seamlessly capture fine details for colorization.
This paper presents a new method for image colorization that overcomes certain limitations of current methodologies. The proposed method utilizes a color encoder [
2], a color transformer, and a encoder–decoder-based generative adversarial network (GAN) [
1] architecture to achieve precise and effective colorization. The objective of incorporating a color transformer and encoder into the generator architecture is to improve the colorization procedure by providing color assignments that are more contextually relevant and coherent. By adding these components, our method aims to leverage the strengths of both transformer networks and GANs to produce visually pleasing colorized images.
The subsequent sections of this paper are organized as follows.
Section 2 gives a detailed review of existing works, providing insight into existing methodologies and their limitations. Following this,
Section 3 elaborates on our proposed method, detailing its theoretical basis and practical implementation. Subsequently,
Section 4 presents the results of our experimental evaluation, which includes comparisons with other state-of-the-art techniques. Finally,
Section 5 concludes the paper, summarizing key findings and out-lining directions for future research.
2. Related Works
This section provides a comprehensive overview of current image colorization methodologies, including conventional and deep learning-based techniques. The strengths, limitations, and areas for improvement of the subject are analyzed, and this section also highlights the specific gaps in existing research that our proposed method addresses.
Historically, conventional methods of colorizing images have relied heavily on the involvement of skilled artists and professionals. The aforementioned techniques entail a rigorous procedure for incorporating hues into monochromatic images based on color theory and artistic proficiency. An example of such a methodology is the research conducted by Levin et al., who presented a colorization technique based on scribbles [
3]. Although manual techniques can produce acceptable outcomes, they are time-consuming and labor-intensive, and they require proficient human operators. Traditional example-based methods were crucial in early attempts at image colorization. Approaches such as optimization techniques using graph cuts, energy minimization [
4], texture-based methods involving texture synthesis, and patch-based techniques [
5] have been explored. These methods often rely on transferring color information from reference or exemplar images to grayscale targets, although they can face challenges in handling complex scenes and may introduce artifacts, such as color bleeding. The manual selection of reference images is also time-consuming.
Automated image colorization techniques have emerged as a promising approach owing to advancements in deep learning and computer vision. Deep learning techniques utilize extensive datasets and convolutional neural networks (CNNs) to comprehensively understand the complex associations between grayscale and color images. One noteworthy technique employs a deep learning-based strategy that incorporates both classification and colorization networks [
6].
GANs have recently gained considerable attention. Using generative models enables multimodal colorization. In a recent study [
1], a conditional GAN-based image-to-image translation model was proposed utilizing a generator based on the UNet architecture. The results of this approach demonstrate improved image colorization, which can be attributed to the use of adversarial training. In [
7], the model was extended to include high-resolution images. The generative priors for colorization were further investigated in [
8], given that the spatial structures of the image had already been produced. SCGAN [
9] is a GAN-based image colorization method that uses saliency maps to guide colorization. SCGAN can first focus on the most significant portions of an image by employing saliency maps, resulting in more accurate and realistic colorization results. The double-channel-guided GAN (DCGAN) [
10] is another GAN-based image colorization approach and guides the colorization process using two channels, where the first channel contains a grayscale image, and the second includes a color palette. DCGAN learns the structure of an image using grayscale images, whereas the color palette learns the color distribution using color palettes. Vivid and diverse image colorization with a generative color prior (GCPrior) [
11] is an image colorization method that learns color priors using a generative model. The color prior is the distribution of probable colors for each pixel in the image. The color prior is used by GCPrior to guide the colorization process, resulting in more vivid and diverse colorizations. DDColor [
12] is an image colorization approach that uses dual decoders. The pixel decoder reconstructs the spatial resolution of an image, whereas the query-based color decoder learns semantically aware color representations from multiscale visual data. The two decoders were merged using cross-attention to establish correlations between color and semantic information, substantially relieving the color-bleeding effect.
Transformers [
13] have attracted significant interest in computer vision. Vaswani et al. [
13] initially presented the transformer architecture. Subsequently, a novel approach to image classification was introduced, denoted as vision transformers (ViTs) [
14]. ViTs adapt the transformer architecture for image data, enabling the model to efficiently capture long-range dependencies and hierarchical representations. In addition to image classification, transformers have been utilized in various other image-processing tasks, including object detection, segmentation, image super-resolution, denoising, and colorization. The transformer’s ability to process entire images as sequences of patches has enabled more comprehensive feature extraction and representation. In addition, transformers, exemplified by ColTran [
15], have exhibited encouraging outcomes in the image colorization task, thereby attesting to their efficacy in this domain. CT2 [
16] is another example of image colorization that uses an end-to-end transformer framework. Grayscale features were extracted and encoded, and discrete color tokens representing quantized
ab spaces were introduced. A dedicated color transformer fuses the image and color information guided by luminance selection and color attention modules.
Despite the notable performance improvement, existing colorization networks that rely on CNNs or transformers encounter notable limitations, including color bleeding, desaturation, and difficulties in capturing local and global features. We introduce a novel image colorization method to overcome these challenges that strategically integrates transformers and CNNs into the generator architecture. This approach aims to effectively address the challenges of existing methods by leveraging the strengths of architectures and adversarial training. Moreover, we introduce two key components in the generator, the color encoder and the color transformer, to further augment the colorization process. The color encoder focuses on capturing intricate color features, whereas the color transformer enhances the integration of local and global information using a transformer architecture. These modules form a comprehensive and robust image colorization framework, mitigating the shortcomings observed in the current state-of-the-art approaches.
3. Proposed Method
The proposed colorization method in this paper uses an encoder–decoder architecture with a color transformer at the bottleneck and a color encoder block in the generator. In this section, we describe the overall architecture of the proposed method. We then provide the details of the proposed generator architecture, which includes the color encoder, color transformer, and proposed objective function.
3.1. Overall Architecture
Figure 1 shows the overall architecture of the proposed image colorization network. The proposed method introduces a comprehensive architectural design that integrates several key components. Specifically, we employ VGG-based global feature extraction, a color encoder, a color transformer, and GAN architecture to enhance the visual quality. Initially, the RGB color space is converted into the CIELAB color space (Lab) [
17]. The Lab color space separates luminance from chromaticity, thus providing a perceptually uniform space.
L represents the luminance channel of an image, and
ab represents the chrominance channels of the image. This separation helps the colorization model to capture chromatic details independent of luminance, thereby improving the overall accuracy and perceptual quality. The luminance channel image input undergoes initial processing via a pretrained VGG network and encoder, extracting high-level global features that capture semantic information. The global features from the VGG network are combined with the encoder layers, as shown in
Figure 1. This integration of pretrained VGG features at different encoder levels is designed to enrich the understanding of the input image in the encoder, providing a more enhanced representation that facilitates improved colorization performance. Concurrently, a color encoder uses convolutional layers to produce color features from a normal distribution, as described in reference [
2]. The integration of global and color-specific information is facilitated by fusing the color-encoded features at the bottleneck in the color transformer block and the global features in the encoder layers, as shown in
Figure 1. The fused features are then fed into a Swin Transformer [
18] block that captures the long-range dependencies and spatial relationships in the image. Two transformer blocks are used to effectively capture the global information. The decoder network employs a gradual upsampling process to reconstruct the
ab channels of the Lab color space while preserving fine-grained details using skip connections.
GAN architecture, which consists of a generator that includes an encoder, color transformer, color encoder, decoder, and discriminator, is utilized to improve visual fidelity. The generator tries to produce convincingly realistic colorizations, thereby deceiving the discriminator. In contrast, the discriminator’s role is to differentiate between the colorized outputs and the actual color images that serve as the ground truth (GT). The training process is guided by various loss functions, such as perceptual loss, adversarial loss, and color loss, which collectively contribute to precise colorization. In our proposed architecture, we utilize a Patch-GAN-based discriminator [
1] for image colorization. The Patch-GAN discriminator assesses local image patches instead of the entire image, allowing for a more detailed evaluation of textures and features. By concentrating on smaller regions, our method significantly enhances the synthesis of colorized images, achieving improved local coherence and a realistic distribution of textures, which contributes to the enhanced overall quality of the generated results.
3.2. Color Encoder
The color encoder plays a crucial role in the proposed image colorization by generating color features from a Gaussian normal distribution. This part utilizes a CNN to convert randomly sampled normal features into significant color-encoded features. Normal features are fed into the color encoder and subjected to multiple convolutional layers. These layers learn to extract spatially relevant information from the normal features, resulting in color-coded features that capture color-specific information.
To train the color encoder, the output of the VGG network is compared with the generated color-encoded features. The VGG network receives a color image input that comprises the L channel input image and the GT image ab channels. A VGG network can extract global features from a given color image, capturing high-level semantic information. The color-encoded features generated by the color encoder are compared with the global features extracted by the VGG network using loss. A color encoder is crucial for generating colorful and visually appealing colorization results.
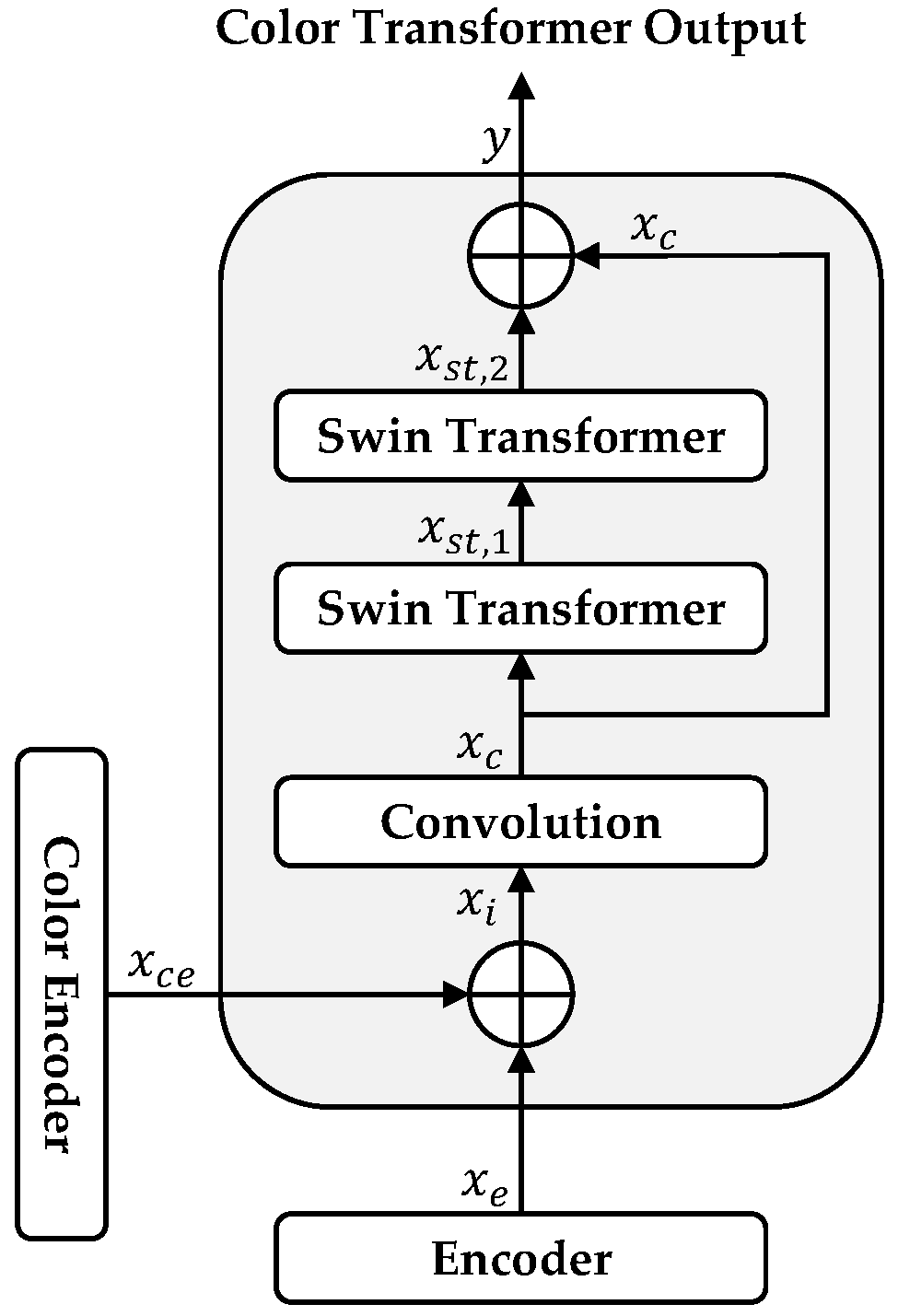
3.3. Color Transformer
A color transformer module is designed to improve the image colorization process. This is achieved by integrating color features with grayscale image features and subsequently passing them through two Swin Transformer [
18] layers, as shown in
Figure 2. The fusion process generates a comprehensive representation by integrating global and color-specific information. Swin Transformer layers can capture global dependencies and spatial relationships, which facilitate the model’s understanding of long-range dependencies and complex relationships present within the image. The incorporation of global information from a color transformer enhances the precision and visual quality of colorized outputs. A residual connection is used to compensate for missing information and improve the gradient flow. This process can be described by (1)–(5). First, the outputs of the encoder and color encoder
and
are concatenated, and single tensor
is obtained as (1), setting the foundation for integrated feature processing.
Let
denote a convolution operation that transforms
by extracting spatial relationships. We use a standard 3 × 3 convolutional kernel for this operation, which effectively captures local features while maintaining computational efficiency. Then
is obtained by (2).
Subsequently,
is passed through two Swin Transformer blocks represented as
and
. The two Swin Transformer blocks are constructed following the architecture described for the original Swin Transformer [
18]. Each block consists of a shifted window-based multi-head self-attention (W-MSA) module and a multi-layer perceptron (MLP) with a GELU activation function. Layer normalization (LN) is applied before both W-MSA and MLP, and a residual connection is employed after each module. The Swin Transformer blocks enable the extraction and enhancement of long-range dependencies within the data.
Finally, the obtained output
is added elementwise to
and represented as (5).
where
represents the output of color transformer module as in (5). This addition of the initial convolutional features with the advanced features processed by the Swin Transformer blocks creates a residual connection that enhances the flow of gradients and compensates for any potential loss of information.
The color transformer ensures the seamless integration of grayscale and color features, facilitating a comprehensive understanding of the image content within the color transformer module. Incorporating Swin Transformers and the residual connection collectively enhances the capability of the model to produce accurate and visually compelling colorizations.
3.4. Objective Function
The objective function in the proposed method is defined as (6).
where
represents the total loss, and
denotes the adversarial Wasserstein (WGAN) loss [
19] and is used to avoid the vanishing gradient problem and achieve stable training for the GAN. The purpose of the objective function is to optimize the colorization process by balancing different aspects of the loss. The adversarial loss
encourages the generator to produce images that are indistinguishable from real images, thereby improving the realism of the generated images.
The perceptual loss
is obtained by comparing the high-level feature representations of the generated and GT images using a pretrained VGG network. Specifically, the
distance between the feature maps of the generated image
and the GT image
at different layers
of the VGG network is computed as follows:
where
represents the feature extractor function of the pretrained VGG network. Mathematically,
denotes the feature map extracted from the input image
at the
-th layer of the VGG network. Each
can be considered as a mapping function
, where
, and
are the height, width, and number of channels of the input image;
and
are the dimensions of the feature map at layer
; and
and
represent the GT and output image, respectively. In our implementation, we use the VGG16 model pretrained on ImageNet, and we divide it into several blocks corresponding to different layers. Specifically, we utilize the feature maps from the conv1_2, conv2_2, conv3_3, and conv4_3 layers of the VGG16 model. These layers are selected to capture both low-level and high-level features, which are crucial for ensuring high-quality perceptual similarity between the generated and GT images. The perceptual loss
helps to preserve high-level features and details by ensuring that the generated images are perceptually similar to the GT images as perceived by the VGG network.
The
loss is the conventional
loss, which is obtained by computing the absolute differences between the pixel values of the generated image
and the GT image
. This can be mathematically expressed as (8).
where
denotes the
norm, which sums up the absolute differences between the corresponding pixels of the two images. The
loss ensures pixel-wise accuracy by minimizing these differences, which helps in maintaining the overall structure and color integrity.
is the color loss, which is the comparison of the random normal distribution feature map from the color encoder and GT image feature map and is defined as (9).
where
represents the expectation operator, which averages the loss over the distribution of the training data. This means that the color loss
is computed as the expected value of the
norm of the differences between the generated features and the VGG features of the GT images over all samples in the training set. Furthermore,
is the random normal distribution with mean
and standard deviation
.
represents the function of the color encoder, and
is the GT image. The color loss
ensures that the generated color features are consistent with those of the GT image, thereby enhancing the color accuracy and vividness of the final output.
values are fixed and empirically set to {
, respectively.












{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}