
Efficient and Lightweight Neural Network for Hard Hat Detection

Abstract
1. Introduction
2. Related Work
3. Method
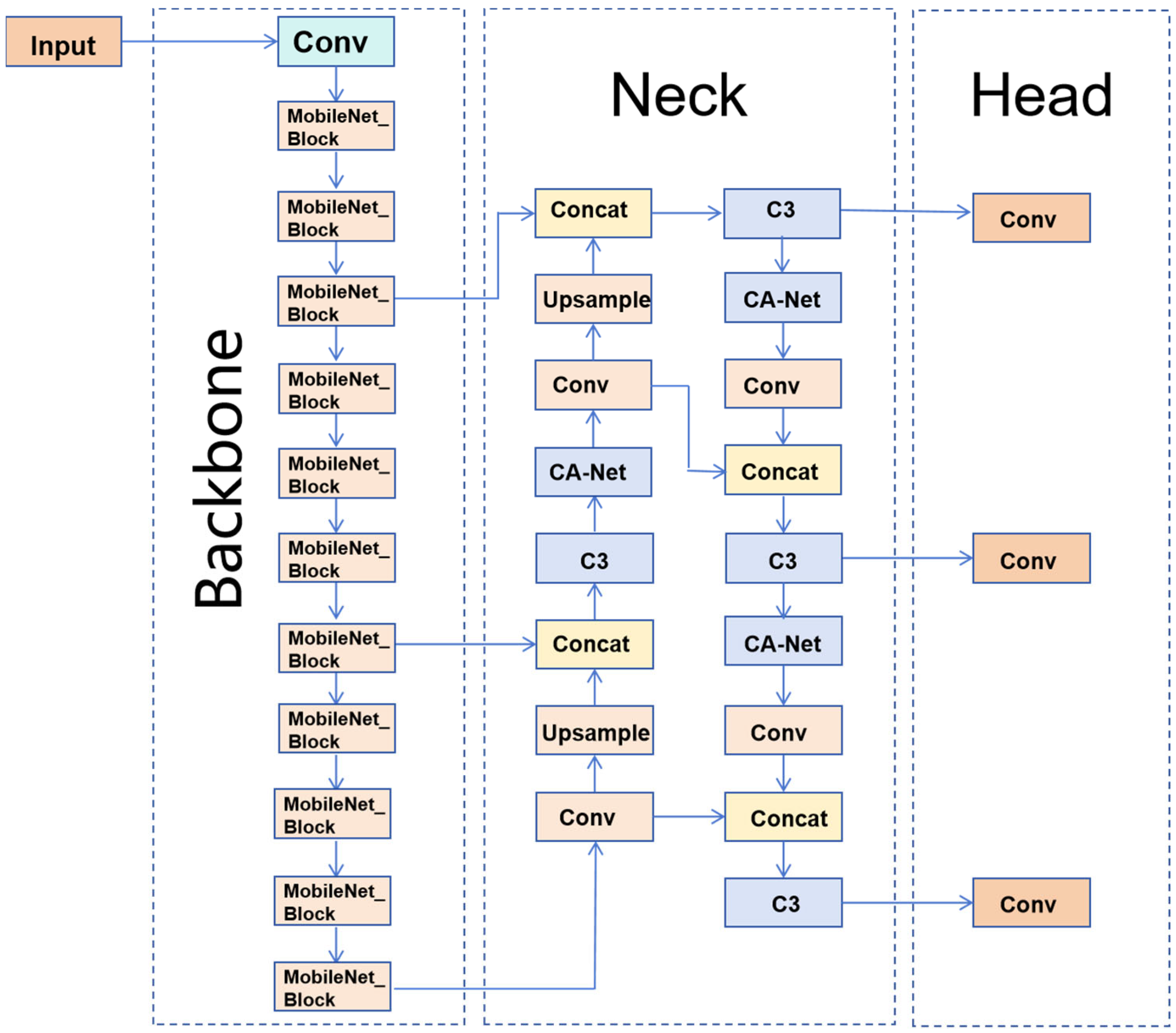
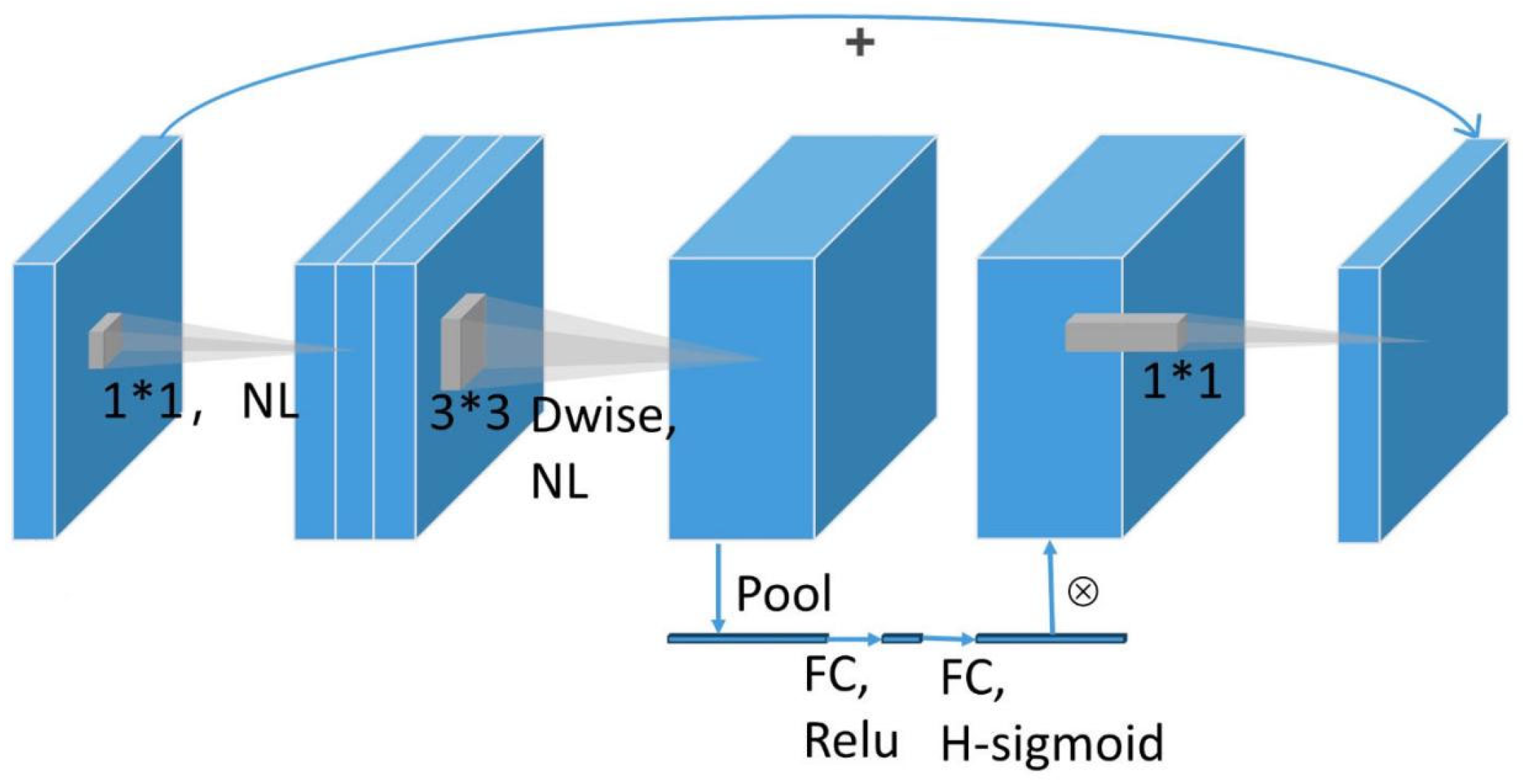
3.1. YOLO-M3C
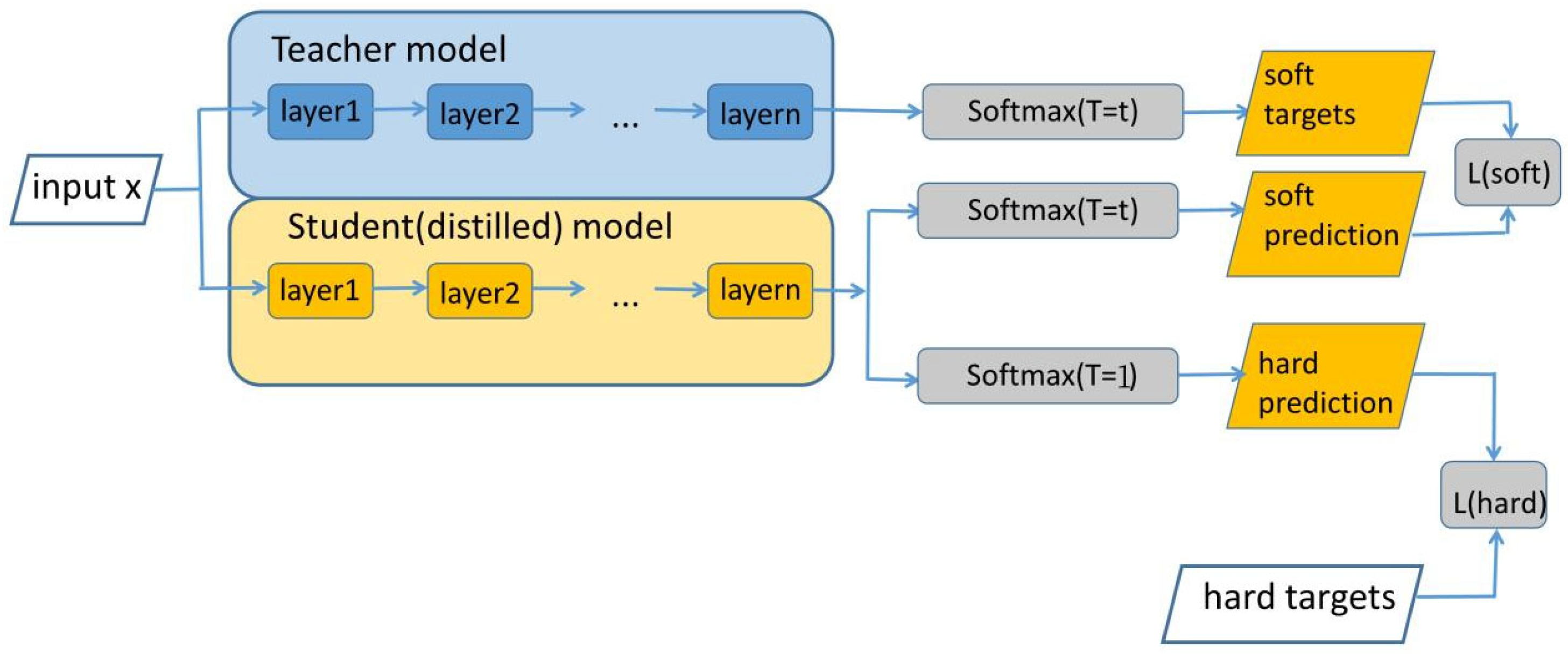
3.2. YOLO’s Multi-Scale Output Feature Distillation Design
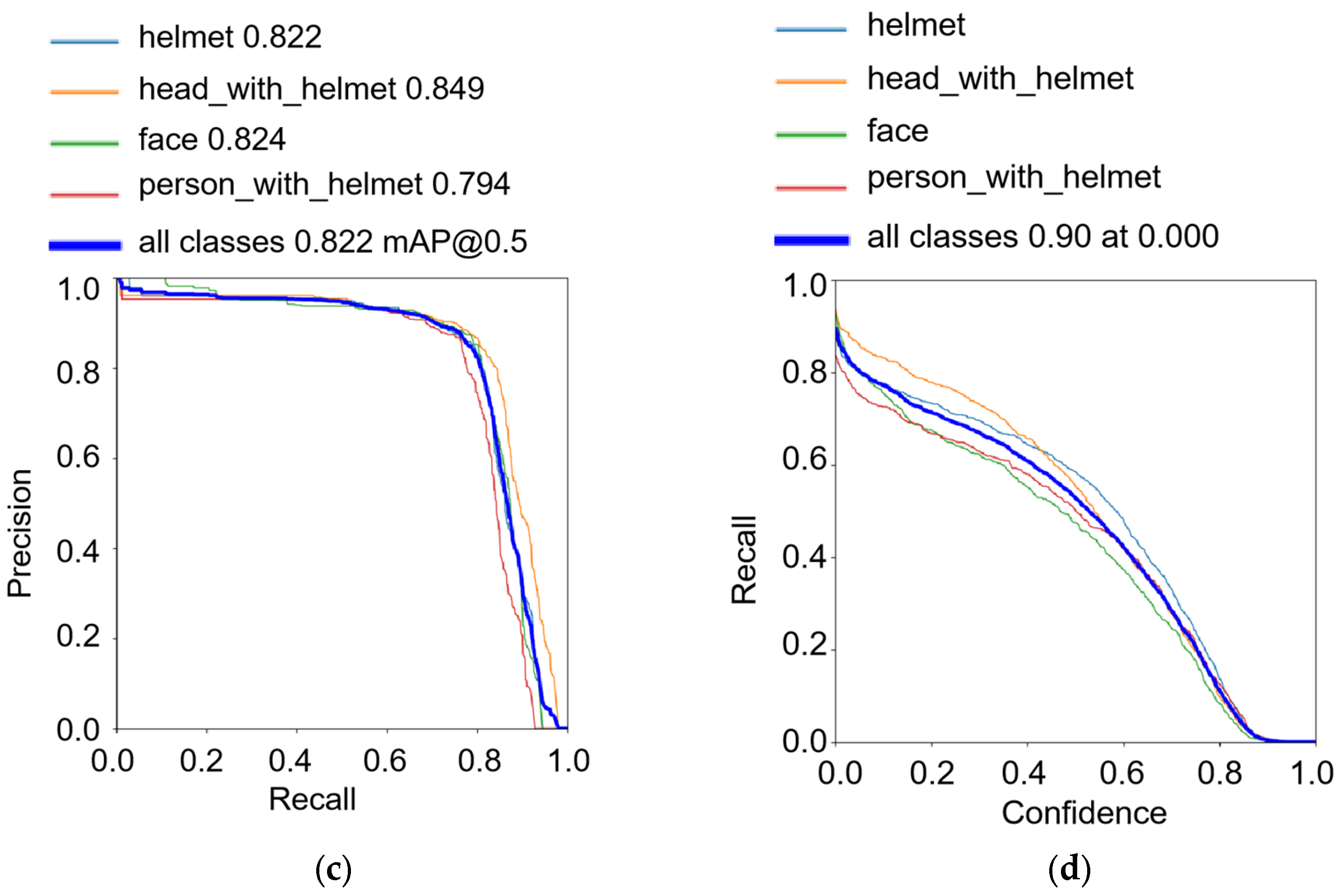
4. Experimental Results and Comparative Analysis
4.1. Experiment Settings
4.2. Evaluation Index
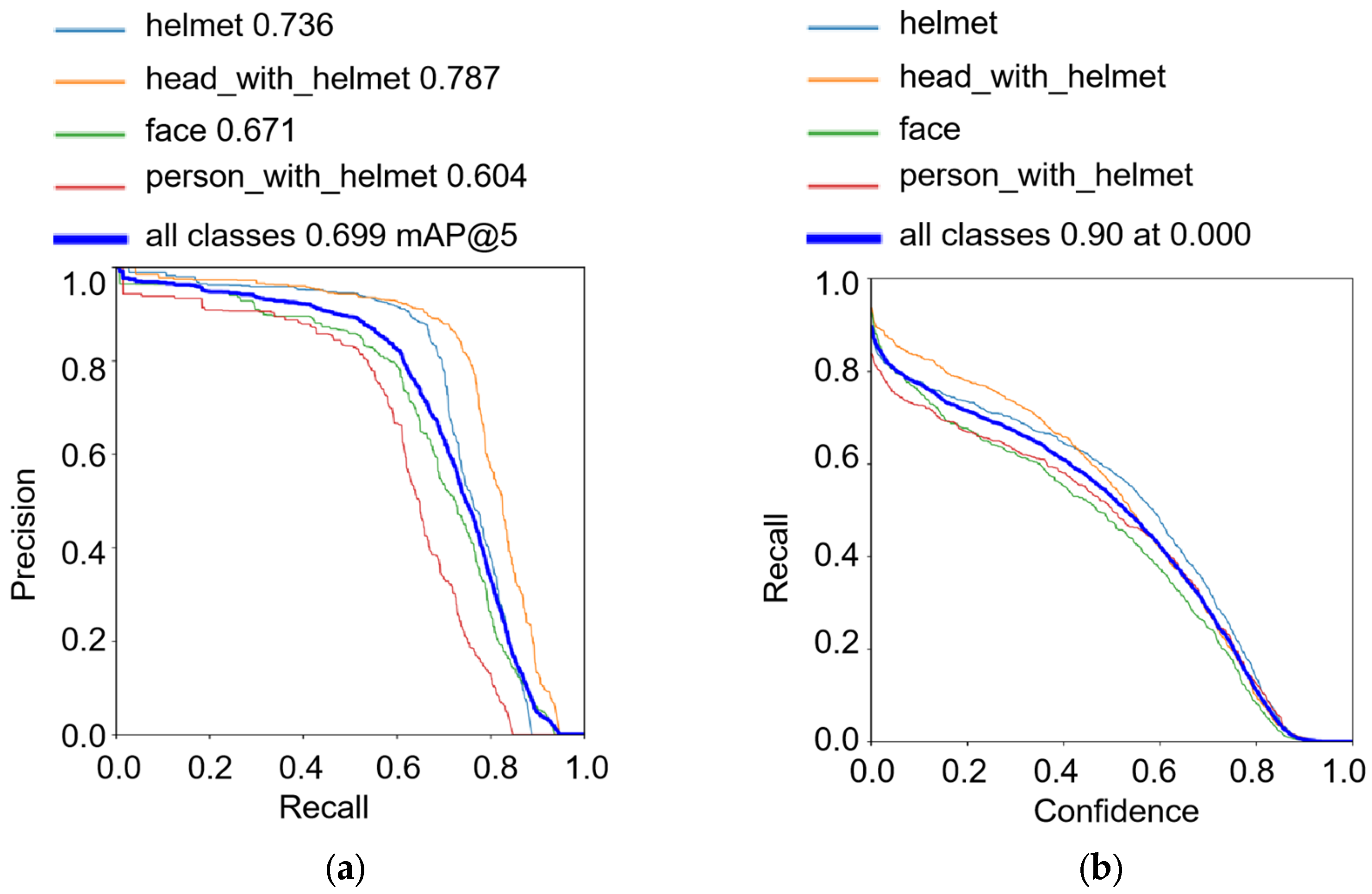
4.3. Ablation Study
4.4. Comparison of YOLO-M3C with Other Algorithms
5. Conclusions
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Li, K.; Zhao, X.; Bian, J.; Tan, M. Automatic Safety Helmet wearing detection. In Proceedings of the 2017 IEEE 7th Annual International Conference on CYBER Technology in Automation, Control, and Intelligent Systems (CYBER), Honolulu, HI, USA, 31 July–4 August 2017. [Google Scholar] [CrossRef]
- Wu, F.; Jin, G.; Gao, M.; He, Z.; Yang, Y. Helmet detection based on improved Yolo V3 Deep Model. In Proceedings of the 2019 IEEE 16th International Conference on Networking, Sensing and Control (ICNSC), Banff, AB, Canada, 9–11 May 2019. [Google Scholar] [CrossRef]
- Long, X.; Cui, W.; Zheng, Z. Safety helmet wearing detection based on Deep Learning. In Proceedings of the 2019 IEEE 3rd Information Technology, Networking, Electronic and Automation Control Conference (ITNEC), Chengdu, China, 15–17 March 2019. [Google Scholar] [CrossRef]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.; Berg, A.C. SSD: Single Shot MultiBox Detector. In Computer Vision–ECCV 2016, Proceedings of the 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Lecture Notes in Computer Science; Springer: Cham, Switzerland, 2016; pp. 21–37. [Google Scholar] [CrossRef]
- Chen, S.; Tang, W.; Ji, T.; Zhu, H.; Ouyang, Y.; Wang, W. Detection of safety helmet wearing based on improved faster R-CNN. In Proceedings of the 2020 International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020. [Google Scholar] [CrossRef]
- Park, M.; Elsafty, N.; Zhu, Z. Hardhat-Wearing detection for enhancing On-Site safety of construction workers. J. Constr. Eng. Manag. 2015, 141, 04015024. [Google Scholar] [CrossRef]
- Mneymneh, B.E.; Abbas, M.; Khoury, H. Automated hardhat detection for construction safety applications. Procedia Eng. 2017, 196, 895–902. [Google Scholar] [CrossRef]
- Merlin, P.M.; Farber, D. A parallel mechanism for detecting curves in pictures. IEEE Trans. Comput. 1975, C-24, 96–98. [Google Scholar] [CrossRef]
- Lee, D. Effective Gaussian mixture learning for video background subtraction. IEEE Trans. Pattern Anal. Mach. Intell. 2005, 27, 827–832. [Google Scholar] [CrossRef] [PubMed]
- Felzenszwalb, P.F.; Girshick, R.; McAllester, D.; Ramanan, D. Object Detection with Discriminatively Trained Part-Based Models. IEEE Trans. Pattern Anal. Mach. Intell. 2010, 32, 1627–1645. [Google Scholar] [CrossRef] [PubMed]
- Viola, P.; Jones, M. Rapid object detection using a boosted cascade of Simple features. In Proceedings of the 2001 IEEE Computer Society Conference on Computer Vision and Pattern Recognition. CVPR 2001, Kauai, HI, USA, 8–14 December 2001. [Google Scholar] [CrossRef]
- Wang, X.; Han, T.X.; Yan, S. An hog-LBP human detector with partial occlusion handling. In Proceedings of the 2009 IEEE 12th International Conference on Computer Vision, Kyoto, Japan, 29 September–2 October 2009. [Google Scholar] [CrossRef]
- Cao, X.; Wu, C.; Yan, P.; Li, X. Linear SVM classification using boosting hog features for vehicle detection in low-altitude airborne videos. In Proceedings of the 2011 18th IEEE International Conference on Image Processing, Brussels, Belgium, 11–14 September 2011. [Google Scholar] [CrossRef]
- Wu, S.; Nagahashi, H. Parameterized AdaBoost: Introducing a parameter to speed up the training of real AdaBoost. IEEE Signal Process. Lett. 2014, 21, 687–691. [Google Scholar] [CrossRef]
- Kazemi, F.M.; Samadi, S.; Poorreza, H.R.; Akbarzadeh-T, M.-R. Vehicle recognition using curvelet transform and SVM. In Proceedings of the Fourth International Conference on Information Technology (ITNG’07), Las Vegas, NV, USA, 2–4 April 2007. [Google Scholar] [CrossRef]
- Waranusast, R.; Bundon, N.; Timtong, V.; Tangnoi, C.; Pattanathaburt, P. Machine vision techniques for motorcycle safety helmet detection. In Proceedings of the 2013 28th International Conference on Image and Vision Computing New Zealand (IVCNZ 2013), Wellington, New Zealand, 27–29 November 2013. [Google Scholar] [CrossRef]
- Li, J.; Liu, H.; Wang, T.; Jiang, M.; Wang, S.; Li, K.; Zhao, X. Safety helmet wearing detection based on image processing and machine learning. In Proceedings of the 2017 Ninth International Conference on Advanced Computational Intelligence (ICACI), Doha, Qatar, 4–6 February 2017. [Google Scholar] [CrossRef]
- Filatov, N.; Maltseva, N.; Bakhshiev, A. Development of hard hat wearing monitoring system using deep neural networks with high inference speed. In Proceedings of the 2020 International Russian Automation Conference (RusAutoCon), Sochi, Russia, 6–12 September 2020. [Google Scholar] [CrossRef]
- Li, Z.; Xie, W.; Zhang, L.; Lu, S.; Xie, L.; Su, H.; Du, W.; Hou, W. Toward efficient safety helmet detection based on Yolov5 with hierarchical positive sample selection and box density filtering. IEEE Trans. Instrum. Meas. 2022, 71, 1–14. [Google Scholar] [CrossRef]
- Han, K.; Zeng, X. Deep learning-based workers safety helmet wearing detection on construction sites using multi-scale features. IEEE Access 2022, 10, 718–729. [Google Scholar] [CrossRef]
- Zhao, Y.; Cheng, J.; Zhou, W.; Zhang, C.; Pan, X. Infrared pedestrian detection with converted temperature map. In Proceedings of the 2019 Asia-Pacific Signal and Information Processing Association Annual Summit and Conference (APSIPA ASC), Lanzhou, China, 18–21 November 2019. [Google Scholar] [CrossRef]
- Wang, C.-Y.; Liao, H.-Y.M.; Wu, Y.-H.; Chen, P.-Y.; Hsieh, J.-W.; Yeh, I.-H. CSPNet: A new backbone that can enhance learning capability of CNN. In Proceedings of the 2020 IEEE/CVF Conference on Computer Vision and Pattern Recognition Workshops (CVPRW), Seattle, WA, USA, 14–19 June 2020. [Google Scholar] [CrossRef]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature Pyramid Networks for Object Detection. In Proceedings of the 2017 IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017. [Google Scholar] [CrossRef]
- Wang, C.; Xu, C.; Wang, C.; Tao, D. Perceptual adversarial networks for image-to-image transformation. IEEE Trans. Image Process. 2018, 27, 4066–4079. [Google Scholar] [CrossRef] [PubMed]
- Yu, K.; Tang, G.; Chen, W.; Hu, S.; Li, Y.; Gong, H. MobileNet-YOLO v5s: An Improved Lightweight Method for Real-Time Detection of Sugarcane Stem Nodes in Complex Natural Environments. IEEE Access 2023, 11, 104070–104083. [Google Scholar] [CrossRef]
- Sandler, M.; Howard, A.; Zhu, M.; Zhmoginov, A.; Chen, L.C. Mobilenetv2: Inverted residuals and linear bottlenecks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 4510–4520. [Google Scholar] [CrossRef]
- Liu, L.; Ke, C.; Lin, H.; Xu, H. Research on pedestrian Detection algorithm based on MobileNet-YOLO. Comput. Intell. Neurosci. 2022, 2022, 8924027. [Google Scholar] [CrossRef]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar] [CrossRef]
- Howard, A.G.; Zhu, M.; Chen, B.; Kalenichenko, D.; Wang, W.; Weyand, T.; Andreetto, M.; Adam, H. Mobilenets: Efficient convolutional neural networks for mobile vision applications. arXiv 2017, arXiv:1704.04861. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the 2021 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Nashville, TN, USA, 20–25 June 2021. [Google Scholar] [CrossRef]
- Hinton, G.E.; Vinyals, O.; Dean, J.M. Distilling the Knowledge in a Neural Network. arXiv 2015, arXiv:1503.02531. [Google Scholar] [CrossRef]
- Yang, Q.; Li, F.; Tian, H.; Li, H.; Xu, S.; Fei, J.; Wu, Z.; Feng, Q.; Lu, C. A new knowledge-distillation-based method for detecting conveyor belt defects. Appl. Sci. 2022, 12, 10051. [Google Scholar] [CrossRef]
- Aubard, M.; Antal, L.; Madureira, A.; Ábrahám, E. Knowledge Distillation in YOLOX-ViT for Side-Scan Sonar Object Detection. arXiv 2024, arXiv:2403.09313. [Google Scholar] [CrossRef]
- Gochoo, M. Safety Helmet Wearing Dataset. Mendeley Data, V1. 2021. Available online: https://data.mendeley.com/datasets/9rcv8mm682/1 (accessed on 19 June 2024). [CrossRef]
- Peng, D.; Sun, Z.; Chen, Z.; Cai, Z.; Xie, L.; Jin, L. Detecting heads using feature refine net and cascaded multi-scale architecture. In Proceedings of the 2018 24th International Conference on Pattern Recognition (ICPR), Beijing, China, 20–24 August 2018; pp. 2528–2533. [Google Scholar] [CrossRef]




{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Network | Recall | mAP | Detection Speed (Frames/s) | Params/106 |
|---|---|---|---|---|
| YOLOv5s | 0.90 | 0.699 | 42.0 | 7.0 |
| YOLOv5s+ MobileNetv2 | 0.84 | 0.634 | 62.5 | 5.5 |
| YOLOv5s+ MObileNetv3 | 0.88 | 0.678 | 55.6 | 5.3 |
| Network | Recall | mAP | Params/106 | FLOPs/109 | Model Size/MB |
|---|---|---|---|---|---|
| YOLOv5s | 0.90 | 0.699 | 7.0 | 16.0 | 13.7 |
| YOLOv5s+ MobileNetv3 | 0.88 | 0.678 | 5.3 | 10.0 | 10.2 |
| YOLOv5s+ MObileNetv3+CA | 0.89 | 0.762 | 4.2 | 9.6 | 8.4 |
| YOLOv5s-M3C (ours) | 0.90 | 0.822 | 4.2 | 9.6 | 8.4 |
| Network | mAP | Params/106 | Model Size/MB |
|---|---|---|---|
| YOLO-M3C (ours) | 0.822 | 4.2 | 8.4 |
| ShuffleNetV2-YOLOv5s | 0.635 | 1.4 | 2.8 |
| GhostNet-YOLOv5s | 0.795 | 3.6 | 7.3 |
| YOLOv3 | 0.816 | 62.0 | 236.0 |
| Network | mAP | Params/106 | Model Size/MB |
|---|---|---|---|
| YOLO-M3C (ours) | 0.806 | 4.2 | 8.4 |
| Fast R-CNN | 0.615 | 18.6 | 182 |
| SSD | 0.73 | 25.0 | 188 |
| SSD-Lite | 0.78 | 3.4 | 25 |
| MobilNetV2 SSD-Lite | 0.412 | 3.0 | 23.7 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
He, C.; Tan, S.; Zhao, J.; Ergu, D.; Liu, F.; Ma, B.; Li, J. Efficient and Lightweight Neural Network for Hard Hat Detection. Electronics 2024, 13, 2507. https://doi.org/10.3390/electronics13132507
He C, Tan S, Zhao J, Ergu D, Liu F, Ma B, Li J. Efficient and Lightweight Neural Network for Hard Hat Detection. Electronics. 2024; 13(13):2507. https://doi.org/10.3390/electronics13132507
Chicago/Turabian StyleHe, Chenxi, Shengbo Tan, Jing Zhao, Daji Ergu, Fangyao Liu, Bo Ma, and Jianjun Li. 2024. "Efficient and Lightweight Neural Network for Hard Hat Detection" Electronics 13, no. 13: 2507. https://doi.org/10.3390/electronics13132507
APA StyleHe, C., Tan, S., Zhao, J., Ergu, D., Liu, F., Ma, B., & Li, J. (2024). Efficient and Lightweight Neural Network for Hard Hat Detection. Electronics, 13(13), 2507. https://doi.org/10.3390/electronics13132507