1. Introduction
Beamforming is a spatial filtering technique used to enhance signals in a specific direction while suppressing signals from other directions [
1,
2,
3]. Based on the bandwidth of the processed signal, they can be categorized into two groups, namely narrowband beamforming and wideband beamforming [
4,
5,
6]. Traditional beamforming studies mainly focus on the narrowband field. As the signal propagation environment becomes more and more complex, adaptive wideband digital beamforming (AWDBF) has been broadly utilized in many fields such as radio communications, radar, sonar, microphone arrays, seismology, astronomy and medical imaging [
7,
8,
9].
Based on the processing domain of the received signal, the adaptive wideband beamforming algorithms can be categorized into spatial-temporal and spatial-frequency beamforming, respectively [
10,
11,
12]. Frost beamformer (FB) is a well-known wideband space-time beamformer that employs a series of tapped delay lines (TDLs) for frequency-dependent weighting [
13]. The FB utilizes the linearly constrained minimum variance (LCMV) criterion and can effectively achieve real-time wideband beamforming. To achieve accurate beam pointing and undistorted response to the signals of interest (SOIs), the pre-steering delay structures are utilized to correct the misalignment between SOI orientation and array geometry. However, this structure often has time-delay errors in practical applications, resulting in serious deterioration in performance [
6,
14]. Therefore, convolution constraints are introduced to remove the pre-steering delay structures [
15], while this algorithm adds additional computational complexity. Then, the frequency constraint matrix is introduced to eliminate the pre-steering delay structures, namely frequency-constrained FB (FCFB) [
16]. This method eliminates the pre-steering delay structures without increasing computational complexity and demonstrates good performance. Nonetheless, the FCFB still requires multiple adaptive weights to achieve a satisfactory output signal-to-interference-plus-noise ratio (SINR), resulting in poor performance in real-time calculations. Moreover, the traditional AWDBF algorithm cannot effectively generate a gain for the SOI and suppress the jamming sources when there are insufficient signal snapshots, leading to significant performance degradation.
Deep learning (DL) has experienced rapid development in recent years, finding widespread applications across various domains, such as target recognition and image classification [
17,
18,
19]. Among the crucial models within DL, the convolutional neural network (CNN) stands out. It boasts essential features such as local connections, weight sharing, and multi-level feature learning. This network model significantly reduces the number of parameters, rendering it a potent instrument for tackling numerous intricate problems. CNNs have been utilized in the field of beamforming to obtain better beamforming performance. In [
20], a radial basis function (RBF) based method using a two-stage CNN is proposed, which can perform beamforming without requiring model parameters, and has good accuracy and robust performance. A novel robust adaptive beamforming approach is proposed [
21], where the signal covariance matrix is utilized as training data, and it achieves the purpose of calculating the beamforming weights directly from the signal covariance matrix. However, the process of solving the signal covariance matrix still has some complexity when compared with directly obtaining information from the received array signal. In [
22], the CNN is utilized to the transmitter and trained in a supervised manner considering both uplink and downlink transmissions. However, the above-mentioned methods of applying neural networks to the field of beamforming to improve the performance of traditional beamformers focus on the narrowband beamforming. The model establishment in the field of wideband beamforming is more complex, and the number of parameters is larger. Applying deep learning to wideband beamforming to reduce complexity is meaningful. A frequency constraint wideband beamforming prediction network (WBPNet) based on the CNN is proposed in [
23], which maintains good beam pointing under low-signal snapshots. However, the proposed method just preliminarily explores the possibility of a wideband beamforming algorithm based on deep learning. The network structure utilized is just a simple stack of three convolutional layers, and the large fully connected layer leads to the network difficult to train. A neural network-based wideband beamformer using progressive learning to train the network is proposed [
24]. Although the training time is reduced, it still takes about one hour.
Pooling layers (PLs) [
25,
26,
27,
28] can significantly reduce the spatial dimension of the input and prevent overfitting of the network, thus reducing computational costs and improving network performance [
29]. Moreover, the pooling technology can significantly and effectively reduce model training time, making beamforming more economical [
26].
Based on the WBPNet, a new network structure for wideband beamforming weights generation is explored, named improved WBPNet (IWBPNet). The strong points of the proposed method are as follows. Firstly, to solve the problem of insufficient feature extraction capability of WBPNet, the network layer is added to improve the network’s ability to extract the features of array signals. Moreover, to solve the problem that the parameters of WBPNet are too large, resulting in the network training time is long, and the generalization ability is insufficient, PL is introduced into the IWBPNet to reduce the number of parameters that need to be trained, which makes the network easier to train and improves the generalization ability of the network. Through the above methods, the proposed IWBPNet shows superior performance compared with the WBPNet. In terms of network training speed, the training time of IWBPNet is
h, which is only
of WBPNet training time. In terms of beamforming performance, while maintaining good beam pattern performance, the output SINRs of IWBPNet have a small improvement. Compared with the method in [
24], the proposed IWBPNet saves
of training time while ensuring beamforming performance.
The rest of the paper is organized as follows:
Section 2 introduces the conventional wideband beamforming method, FB and FCFB. In
Section 3, a more economical network structure for the adaptive spatial-temporal wideband beamforming is presented, which greatly improves the problem of long network training time. In
Section 4, the simulation results and analyses are given to show the correctness and effectiveness of the proposed algorithm. Finally, the brief conclusions can be found in
Section 5.
3. The Improved Adaptive Wideband Beamforming Method Based on Machine Learning
The beamforming weights of traditional algorithms require the covariance matrix of interference plus noise. In actual situations, the covariance matrix can only be estimated based on a finite number of signal snapshots, and the accuracy of the estimated covariance matrix is closely related to the number of snapshots. When the number of snapshots is insufficient, the performance of traditional wideband beamforming will deteriorate severely. To solve this problem, the neural network-based wideband beamformer has emerged. However, the wideband beamforming algorithm cannot be regarded as a simple superposition of the narrowband beamforming algorithm. It usually introduces a new dimension for frequency correlation of the wideband signal, which is a complex process. The wideband beamforming algorithm based on neural networks is in the early stages of research, and has problems such as unstable network training and long network training time. In this section, an improved neural network-based wideband beamforming algorithm is introduced to solve the problem of long training time.
3.1. The Structure of the Improved Neural Network
CNNs possess unique attributes that enhance their efficiency and effectiveness in various tasks. One of the key strengths is local awareness, which allows them to concentrate on specific local regions within the input, thus reducing computational complexity. Furthermore, CNNs utilize parameter sharing, which allows the same set of weights to process different regions of the input. This feature reduces the number of parameters in the network and mitigates overfitting.
Neural networks constructed with multiple convolutional layers exhibit a hierarchical learning capability. Each layer is capable of learning features at different levels of abstraction. This hierarchical learning empowers the network to automatically extract features ranging from low-level details to high-level patterns, thereby enhancing its overall performance.
In this section, an improved neural network-based wideband beamforming method is proposed to solve the problems of long training time in existing neural network-based methods caused by too many network parameters. The improved neural network structure is depicted in
Figure 2.
The input feature map has a size of 16 by 400 with 2 channels. Thereinto, the values 16 and 400 correspond to the width and height of the feature map, while 2 signifies the number of channels. In array signal processing, the received data and weights for beamforming are usually in complex form. Therefore, dual channels are used for data transmission, where one channel transmits the real part and the other transmits the imaginary part of the complex-valued data.
Then, the data enters the convolutional layer, which processes the information of each small area, reducing the amount of parameters while maintaining the continuity of the information. The process can be expressed as
where
and
denote the input data and the weight of the convolutional kernel, respectively.
b is the bias term.
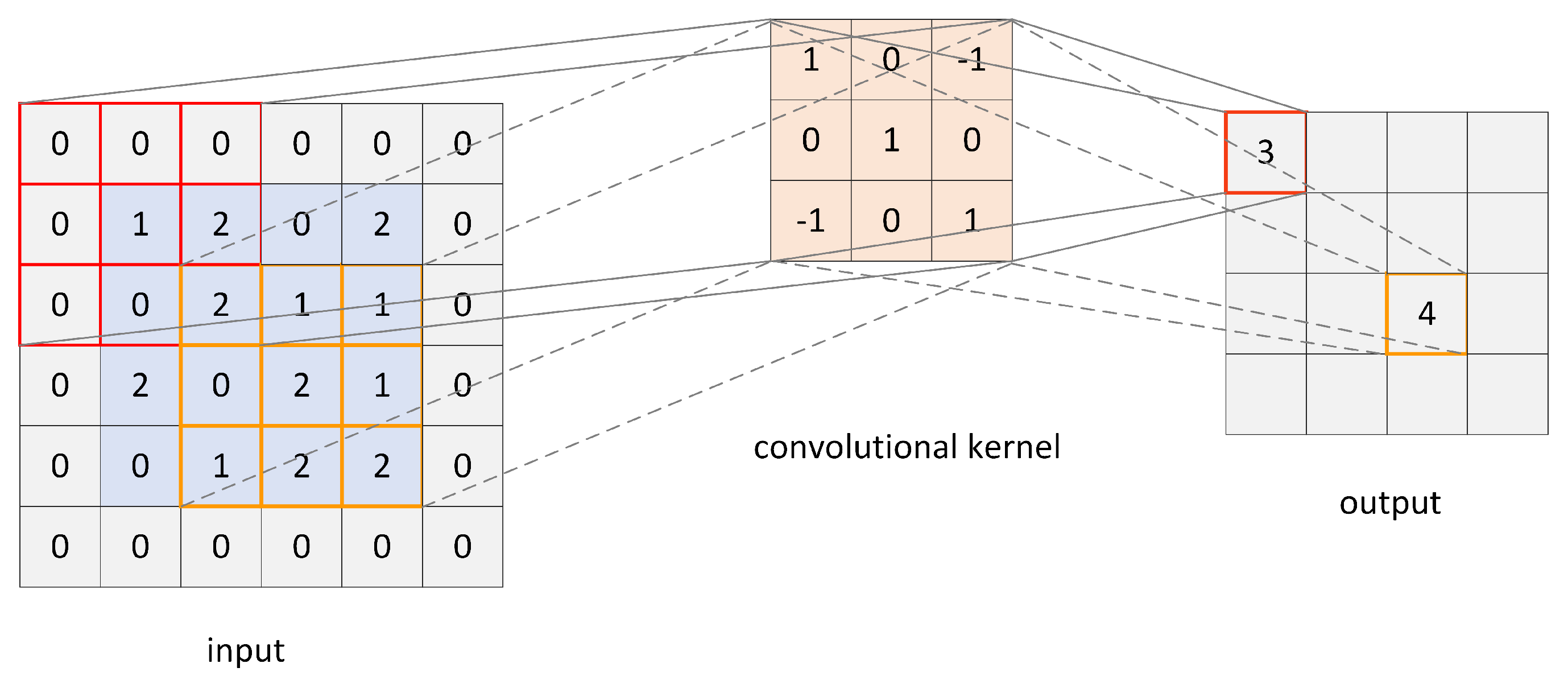
Figure 3 illustrates a simple schematic diagram of the convolutional process. All of the information in the diagram is hypothetical and intended to illustrate the convolution process, and the bias is set as zero.
As can be seen from the diagram, when the input is convolved according to Equation (
15), the convolution kernel remains consistent. This feature reduces the number of parameters that need to be updated during network training process. In this paper, the size of the convolution kernel is set as
, and the padding and stride are both set as 1.
Then, the batch normalization [
30] layers are utilized, which can accelerate the convergence speed during model training, enhance the stability of the training process, prevent issues such as gradient explosions or vanishing, and introduce a beneficial regularization effect. Subsequently, max pooling operations are used in the first three layers of the network to reduce feature dimensions, model complexity, and mitigate the risk of overfitting. The schematic diagram of the max pooling operation is shown in
Figure 4.
The Leaky Rectified Linear Unit (LeakyReLU) [
31] is utilized as the activation function, and can be expressed as
where
is a coefficient, typically assigned a value of
.
Finally, the data are flattened and then passes through the FC layer to achieve classification output of the data.
3.2. Training Process of the Improved Network
First, in the case of low snapshots, 500 sets of training data and 10 sets of test data are generated for neural network training. The data set consists of array received signals directly. Then, under the high snapshot scenarios, according to Equation (
13), the analytical solution of optimal weights for the traditional wideband beamforming method, FCFB, is utilized to generate the weights
required for wideband beamforming. The weights also serve as the target labels that the neural network aims to fit during the training process.
Moreover, the Adam algorithm [
32] is utilized to adaptively adjust the learning rate. This aids in achieving faster convergence during the early stages of training and ensures that the learning rate decreases as the optimal solution is approached, thus preventing the possibility of skipping the optimal solution. The initial learning rate used in training is
, the adaptive attenuation factor is
, and the attenuation step is 20. The batch size is set as 16. The signal with low snapshots and the beamforming weights obtained with high snapshots are used as the input and label of the network, respectively, to achieve the mapping between the low-snapshot signal and the wideband beamforming weights. The loss function during network training is expressed as follows:
where
M is the number of outputs.
and
y denote the label and output of the network, the goal of training is to minimize the loss function
.
After successful training, the network can map input signals to corresponding wideband beamforming weights at low snapshots. This means that we only need to feed low-snapshot signals into the network to quickly obtain the corresponding weights, significantly reducing the waiting time during system sampling.
4. Simulation Results
In this section, we compare the IWBPNet with the WBPNet and traditional FCFB in terms of beam pattern performance and output SINRs. Moreover, the proposed method is compared with the method in [
24], the broadband beamforming weight generation network (BWGN). All simulations in this article are conducted under the PyTorch framework, the version is
, and the Python version is
. A total of 40 Monte Carlo simulations are carried out for all results.
The simulation is carried out under the following conditions. The number of ULA antennas J and delay structures after each antenna element K are 16 and 18, respectively. The number of sub-bands I, is set as 10. Assume that a wideband desired signal comes from , and the interference plus noise signals come from the range , i.e., .
For simplicity and clarity of description, we define some abbreviations. The traditional beamforming method, FCFB, under sufficient signal snapshots, is defined as FCFB-SS. While that under insufficient signal snapshots is defined as FCFB-IS. The WBPNet under insufficient signal snapshots, is defined as WBPNet-IS. Similarly, the improved CNN structure for AWDBF under insufficient snapshot scenarios is defined as IWBPNet-IS, and the BWGN with insufficient snapshots is defined as BWGN-IS. The number of sufficient snapshots and insufficient snapshots are set as 4000 and 400, respectively. In addition, and are set as GHz and GHz, respectively. Gaussian white noise with a mean of 0 and a variance of 1 is added to simulate the environment. The interference-to-noise ratio (INR) and signal-to-noise ratio (SNR) are assumed as 40 dB and 0 dB.
Without loss of generality, the following three interference angles are randomly selected to evaluate the performance of the beam pattern, that is:
,
,
, at
,
,
, respectively.
Figure 5 shows the beam patterns of FCFB-SS and FCFB-IS for the desired and interference signals from the following directions: (
), (
) and (
); and (
) represents the desired signal comes from
and the interference signal comes from
. The beam patterns of WBPNet-IS, BWGN-IS and IWBPNet-IS are illustrated in
Figure 6.
The beam patterns presented in
Figure 5 show that the traditional beamformer, FCFB, has good performance under high snapshots, but when the snapshots are insufficient, the performance deteriorates seriously. In contrast, from
Figure 6, the WBPNet, BWGN and IWBPNet all have a high gain in the SOI direction and a deep null in the interference direction, although the number of signal snapshots is insufficient. This is due to the powerful nonlinear fitting ability of neural networks, which can fully learn the intrinsic relationship between the input data and output weights used for wideband beamforming with limited snapshots. After the network is successfully trained, we only need to provide the network with insufficient snapshot data, and the network can quickly generate good weights required for wideband beamforming, which significantly reduces the sampling time.
However, due to the large number of fully connected layers in WBPNet and the lack of necessary network optimization, which is just a stack of three convolutional networks, WBPNet takes a long time to train and is unstable. Due to the two-dimensional complex network structure in BWGN, the network training process is relatively complicated, which affects the network training speed. The WBPNet, BWGN and IWBPNet are all trained under the same parameters for 300 epochs. The training process of the WBPNet takes h, the training process of the BWGN takes h, while the IWBPNet just spends h to train, saving of the time compared with WBPNet and compared with BWGN, which is a huge improvement. The results show that while maintaining good wideband beamforming performance, the training time of IWBPNet is significantly reduced compared to the other two networks. Considering the application of neural network-based wideband beamformers are needed online training in real-time systems, less network training time is of great significance while maintaining good performance. Reducing the network training time while maintaining good beamforming performance is also the core of this research.
Furthermore, the output SINRs of FCFB with 400 and 4000 signal snapshots, and output SINRs of WBPNet, BWGN and IWBPNet with 400 signal snapshots at different interference angles are shown in
Table 1. The results show that FCFB has good SINR performance when the signal snapshots are sufficient, because the covariance matrix of the array received signals is estimated approximately accurately. However, when the number of signal snapshots is insufficient, the estimated covariance matrix will be wrong, resulting in severe degradation of SINR performance. In contrast, the SINRs of WBPNet-IS, BWGN-IS and IWBPNet-IS demonstrate that the neural network-based wideband beamformers have good SINR performance despite the number of signal snapshots is insufficient. This is because the neural network has a strong fitting ability and can extract the characteristics of the array signals from a limited number of snapshots, resulting in good performance. Compared with the WBPNet, the IWBPNet demonstrates better SINR performance with insufficient snapshots. This is attributed to the IWBPNet having a deeper network structure, which increases the network’s ability to extract signal features. In addition, the PLs reduce the risk of network overfitting and greatly improve the generalization ability of the network. Compared with BWGN, the SINR performance of IWBPNet is also slightly improved due to the stronger generalization ability of IWBPNet. And the network training time of IWBPNet is only
of training BWGN, demonstrating great time advantage of the proposed method. The simulation results of beam patterns, training time and SINRs for FCFB, WBPNet, BWGN and IWBPNet manifest the effectiveness and superiority of the proposed IWBPNet compared with the traditional wideband beamformer and the existing neural network-based wideband beamformers.
5. Conclusions
In this paper, for the neural network-based wideband beamformers, we start from the perspective that real-time training is required in actual systems due to environmental changes, and are committed to reducing the network training time while maintaining the performance of wideband beamforming. An improved neural network-based wideband beamformer, IWBPNet, is proposed to address the problem of long network training time of the existing neural network-based wideband beamforming algorithms. The improved structure utilizes the neural network to express the nonlinear mapping between the input signal and the weights used for AWDBF, which increases the number of network layers compared with WBPNet, thereby improving the network’s ability to extract signal features. In addition, the pooling layers are added to reduce the dimension of data transmission in the network, thus increasing the generalization ability of the network and solving the problem of too large fully connected layer in WBPNet. The proposed algorithm has great advantages in training time. Simulation results demonstrate that the training time of the proposed algorithm is h, which saves of the time compared with WBPNet. Compared with BWGN, the proposed method saves of the time. Moreover, due to the better fitting and generalization capabilities of the improved network, the proposed algorithm has better SINR performance.








{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}