
Contrastive Learning Joint Regularization for Pathological Image Classification with Noisy Labels


Abstract
1. Introduction
- We propose a novel training framework for pathological images with noisy labels based on contrastive learning joint regularization. This framework does not rely on any priors, reducing limitations for future general pathological diagnostic assistance applications.
- We introduce a historical prediction penalty module to alleviate the model’s tendency to memorize noisy labels over time. This ensures that predictions made late in training are similar to those made early in training.
- We present an adaptive separation module to minimize the impact of noisy labels on the model’s performance. This employs an implicit sample selection strategy to maximize the use of clean samples for training, thereby enhancing the model’s generalization ability.
- We conducted extensive experiments on a synthetic pathological image noise dataset and validate our method on a real-world pathological image noise dataset. The comprehensive experimental results demonstrate that our proposed method achieves state-of-the-art classification performance under various types of noise at different noise levels.
2. Related Work
2.1. Learning with Noisy Labels
2.2. Learning with Noisy Labels in Medical Images
2.3. Contrastive Learning
3. Method
3.1. Problem Setting
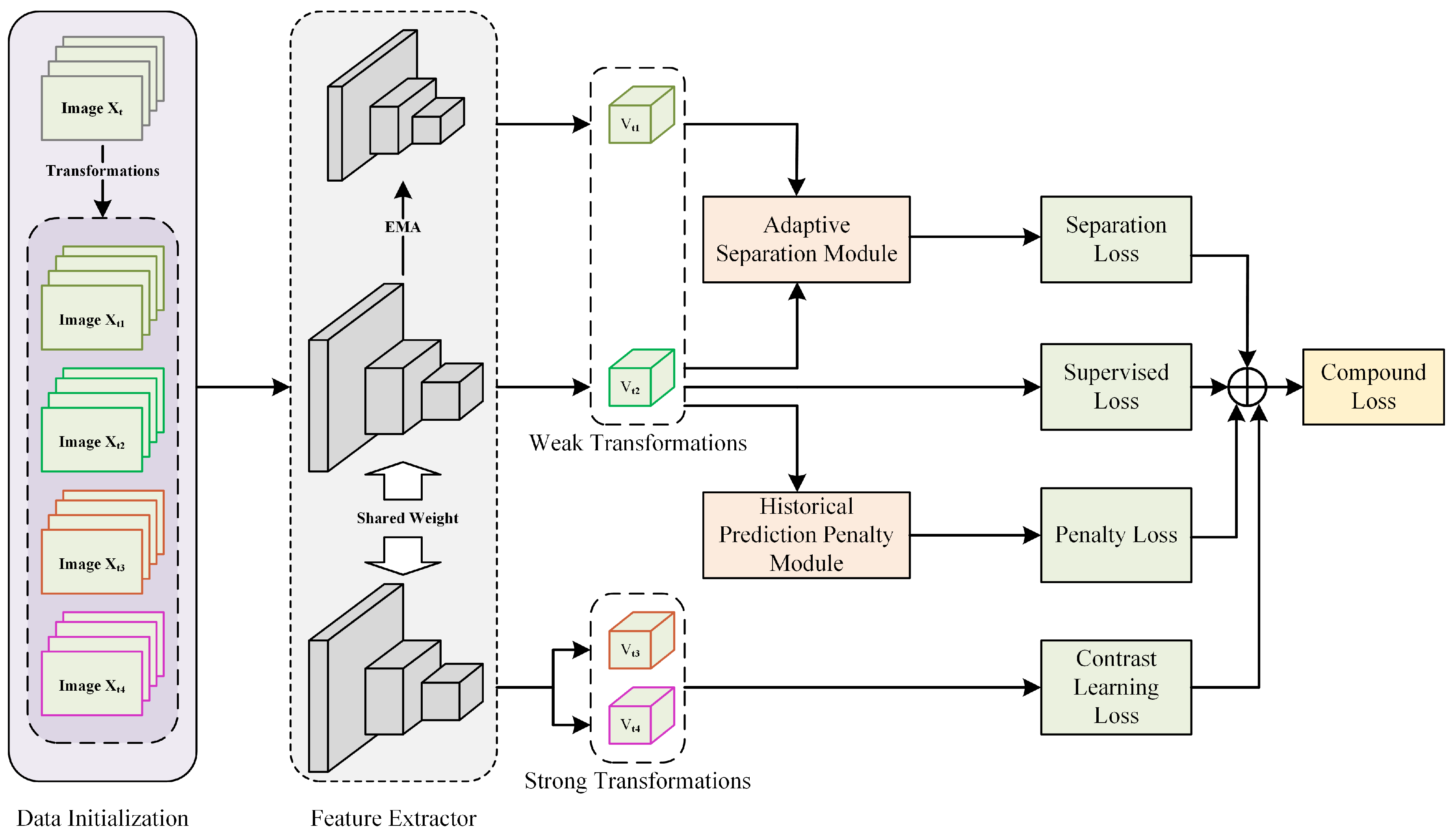
3.2. Method Framework
3.3. Data Initialization
3.4. Contrastive Learning Feature Extractor
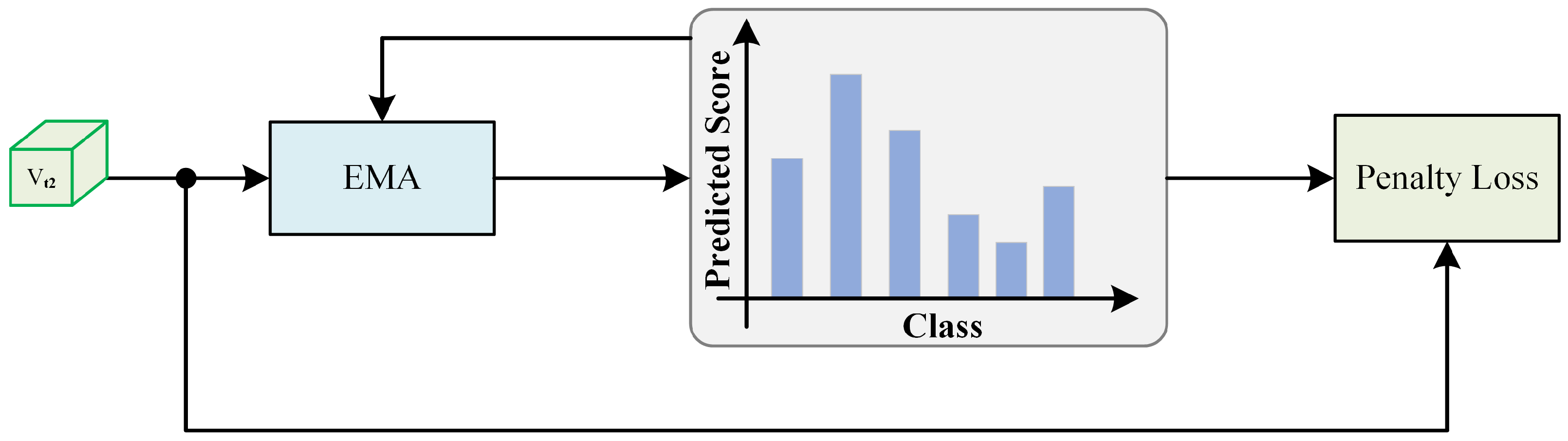
3.5. Historical Prediction Penalty Module
3.6. Adaptive Separation Module
3.7. Overall Loss Functions
4. Experiment Design
4.1. Dataset Accumulation and Transformation
4.1.1. Dataset Description
4.1.2. Noise Injection
4.2. Evaluation Metrics
4.3. Compared Methods
- (1)
- Standard: This baseline involves training a common convolutional neural network (CNN) without noise-handling techniques.
- (2)
- Joint [22]: This method proposes a simultaneous update of network parameters and data labels to tackle the issue of noisy labels.
- (3)
- Co-teaching [5]: Introduces a dual-network architecture where each network selects samples with smaller loss for the other network’s training and parameter updating.
- (4)
- DivideMix [11]: This method proposes a novel framework for learning with noisy labels using semi-supervised learning techniques.To achieve noise robustness, it trains two networks concurrently through dataset co-partitioning, label co-refinement, and co-guessing.
- (5)
- Co-Correcting [46]: This offers a noise-resistant medical image classification framework which enhances accuracy through dual-network mutual learning, label probability estimation, and curricular label correction.
- (6)
- HSA_NRL [40]: This method uses the training prediction history to distinguish between hard and noisy samples. This robust learning method for histopathological image classification aims to preserve more clean samples and improve model performance.
4.4. Implementation Details
5. Results and Discussion
5.1. Classification Experiment Results for Synthetic Noisy Medical Data
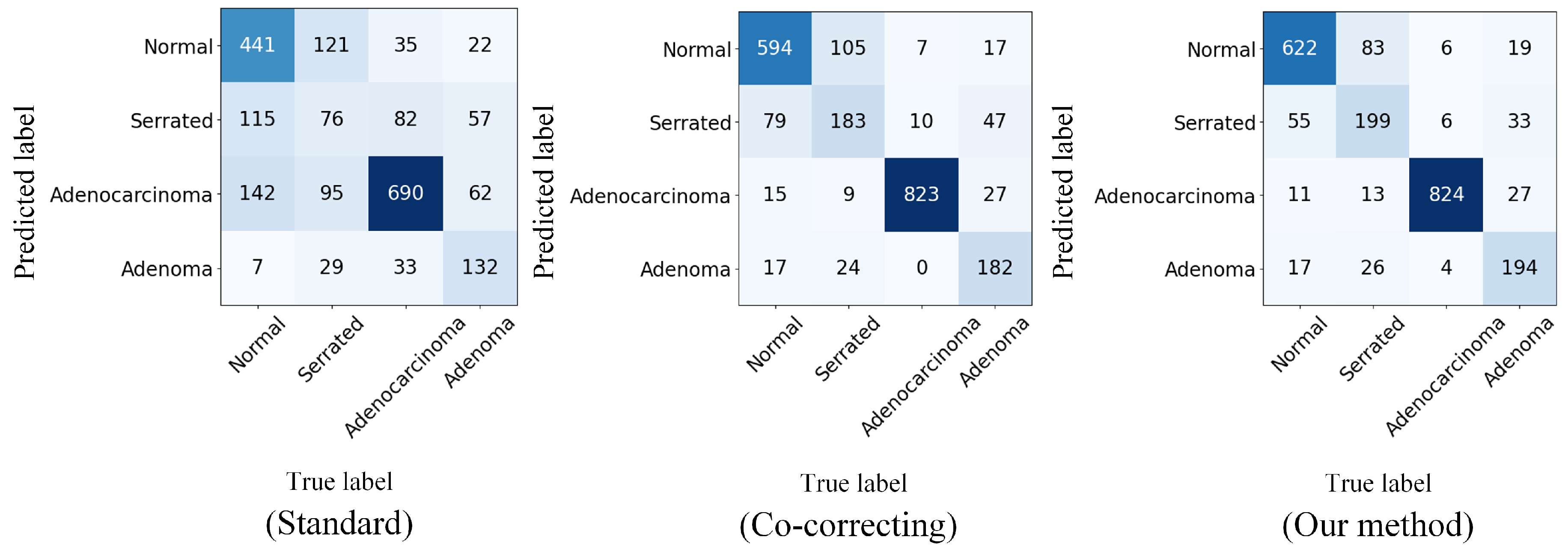
5.2. Classification Experiment Results for Real-World Noisy Medical Data
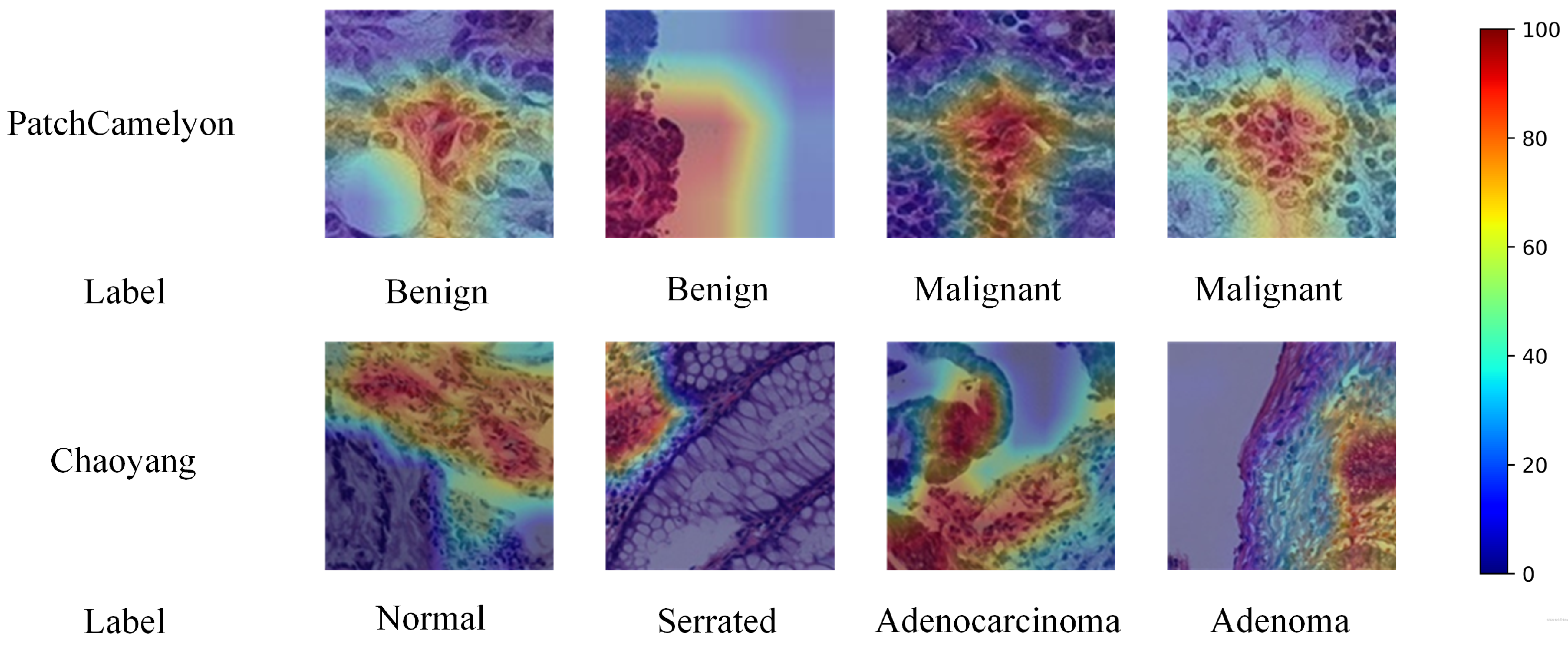
5.3. Grad-CAM Visualization
5.4. Backbone Ablation Study
5.5. Module Ablation Study
5.6. Hyperparameter Experiment
6. Conclusions
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- Zhang, C.; Bengio, S.; Hardt, M.; Recht, B.; Vinyals, O. Understanding deep learning (still) requires rethinking generalization. Commun. ACM 2021, 64, 107–115. [Google Scholar] [CrossRef]
- Cheng, H.; Zhu, Z.; Sun, X.; Liu, Y. Mitigating Memorization of Noisy Labels via Regularization between Representations. In Proceedings of the International Conference on Learning Representations (ICLR), Kigali, Rwanda, 1–5 May 2023; pp. 1–27. [Google Scholar]
- Arplt, D.; Jastrzbskl, S.; Bailas, N.; Krueger, D.; Bengio, E.; Kanwal, M.S.; Maharaj, T.; Fischer, A.; Courville, A.; Benglo, Y.; et al. A closer look at memorization in deep networks. In Proceedings of the International Conference on Machine Learning (ICML), Sydney, Australia, 6–11 August 2017; Volume 1, pp. 350–359. [Google Scholar]
- Huang, C.; Wang, W.; Zhang, X.; Wang, S.H.; Zhang, Y.D. Tuberculosis Diagnosis Using Deep Transferred EfficientNet. IEEE/ACM Trans. Comput. Biol. Bioinform. 2023, 20, 2639–2646. [Google Scholar] [CrossRef] [PubMed]
- Han, B.; Yao, Q.; Yu, X.; Niu, G.; Xu, M.; Hu, W.; Tsang, I.; Sugiyama, M. Co-teaching: Robust training of deep neural networks with extremely noisy labels. In Proceedings of the 32nd International Confonference on Neural Information Processing Systems (NIPS), Montreal, QC, Canada, 3–8 December 2018; Volume 31, pp. 1–11. [Google Scholar]
- Yu, X.; Han, B.; Yao, J.; Niu, G.; Tsang, I.W.; Sugiyama, M. How does disagreement help generalization against label corruption? In Proceedings of the International Conference on Machine Learning (ICML), Long Beach, CA, USA, 10–15 June 2019; pp. 12407–12417. [Google Scholar]
- Nguyen, D.T.; Mummadi, C.K.; Nhung Ngo, T.P.; Phuong Nguyen, T.H.; Beggel, L.; Brox, T. Self: Learning to Filter Noisy Labels with Self-Ensembling. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–16. [Google Scholar]
- Wei, H.; Feng, L.; Chen, X.; An, B. Combating Noisy Labels by Agreement: A Joint Training Method with Co-Regularization. In Proceedings of the Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 18–24 June 2020; pp. 13723–13732. [Google Scholar]
- Han, G.; Guo, W.; Zhang, H.; Jin, J.; Gan, X.; Zhao, X. Sample self-selection using dual teacher networks for pathological image classification with noisy labels. Comput. Biol. Med. 2024, 174, 108489–108501. [Google Scholar] [CrossRef] [PubMed]
- Fan, H.; Zhang, X.; Xu, Y.; Fang, J.; Zhang, S.; Zhao, X.; Yu, J. Transformer-based multimodal feature enhancement networks for multimodal depression detection integrating video, audio and remote photoplethysmograph signals. Inf. Fusion 2024, 104, 102161. [Google Scholar] [CrossRef]
- Li, J.; Socher, R.; Hoi, S.C. Dividemix: Learning with Noisy Labels as Semi-Supervised Learning. In Proceedings of the International Conference on Learning Representations (ICLR), Addis Ababa, Ethiopia, 26–30 April 2020; pp. 1–11. [Google Scholar]
- Pulido, J.V.; Guleria, S.; Ehsan, L.; Fasullo, M.; Lippman, R.; Mutha, P.; Shah, T.; Syed, S.; Brown, D.E. Semi-Supervised Classification of Noisy, Gigapixel Histology Images. In Proceedings of the 20th IEEE International Conference on Bioinformatics and Bioengineering (BIBE), Cincinnati, OH, USA, 26–28 October 2020; pp. 563–568. [Google Scholar]
- Bdair, T.; Navab, N.; Albarqouni, S. FedPerl: Semi-Supervised Peer Learning for Skin Lesion Classification. In Proceedings of the Medical Image Computing and Computer Assisted Intervention (MICCAI), Strasbourg, France, 27 September–1 October 2021; Volume 12903 LNCS, pp. 336–346. [Google Scholar]
- Wang, Z.; Jiang, J.; Han, B.; Feng, L.; An, B.; Niu, G.; Long, G. SemiNLL: A Framework of Noisy-Label Learning by Semi-Supervised Learning. arXiv 2022, arXiv:2012.00925. [Google Scholar]
- Zhang, S.; Yang, Y.; Chen, C.; Zhang, X.; Leng, Q.; Zhao, X. Deep learning-based multimodal emotion recognition from audio, visual, and text modalities: A systematic review of recent advancements and future prospects. Expert Syst. Appl. 2024, 237, 121692. [Google Scholar] [CrossRef]
- Ren, Z.; Kong, X.; Zhang, Y.; Wang, S. UKSSL: Underlying knowledge based semi-supervised learning for medical image classification. IEEE Open J. Eng. Med. Biol. 2023, 5, 459–466. [Google Scholar] [CrossRef] [PubMed]
- Zhang, S.; Zhang, X.; Zhao, X.; Fang, J.; Niu, M.; Zhao, Z.; Yu, J.; Tian, Q. MTDAN: A Lightweight Multi-Scale Temporal Difference Attention Networks for Automated Video Depression Detection. IEEE Trans. Affective Comput. 2023; early access. [Google Scholar]
- Dgani, Y.; Greenspan, H.; Goldberger, J. Training a neural network based on unreliable human annotation of medical images. In Proceedings of the IEEE 15th International Symposium on Biomedical Imaging (ISBI), Washington, DC, USA, 4–7 April 2018; pp. 39–42. [Google Scholar]
- Chen, X.; He, K. Exploring simple Siamese representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 19–25 June 2021; pp. 15745–15753. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.E.; McGuinness, K. Unsupervised label noise modeling and loss correction. In Proceedings of the 36th International Conference on Machine Learning (ICML), Long Beach, CA, USA, 9–15 June 2019; Volume 2019, pp. 465–474. [Google Scholar]
- Miyato, T.; Maeda, S.i.; Koyama, M.; Ishii, S. Virtual adversarial training: A regularization method for supervised and semi-supervised learning. IEEE Trans. Pattern Anal. Mach. Intell. 2018, 41, 1979–1993. [Google Scholar] [CrossRef]
- Tanaka, D.; Ikami, D.; Yamasaki, T.; Aizawa, K. Joint Optimization Framework for Learning with Noisy Labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 5552–5560. [Google Scholar]
- Patrini, G.; Rozza, A.; Menon, A.K.; Nock, R.; Qu, L. Making deep neural networks robust to label noise: A loss correction approach. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Honolulu, HI, USA, 21–26 July 2017; Volume 2017, pp. 2233–2241. [Google Scholar]
- Jiang, H.; Gao, M.; Hu, Y.; Ren, Q.; Xie, Z.; Liu, J. Label-noise-tolerant medical image classification via self-attention and self-supervised learning. arXiv 2023, arXiv:2306.09718. [Google Scholar]
- Tu, Y.; Zhang, B.; Li, Y.; Liu, L.; Li, J.; Zhang, J.; Wang, Y.; Wang, C.; Zhao, C.R. Learning with Noisy Labels via Self-Supervised Adversarial Noisy Masking. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 19–22 June 2023; Volume 2023, pp. 16186–16195. [Google Scholar]
- Tu, Y.; Zhang, B.; Li, Y.; Liu, L.; Li, J.; Wang, Y.; Wang, C.; Zhao, C.R. Learning from Noisy Labels with Decoupled Meta Label Purifier. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 19–22 June 2023; Volume 2023, pp. 19934–19943. [Google Scholar]
- Zheltonozhskii, E.; Baskin, C.; Mendelson, A.; Bronstein, A.M.; Litany, O. Contrast to Divide: Self-Supervised Pre-Training for Learning with Noisy Labels. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Waikoloa, HI, USA, 4–8 January 2022; pp. 387–397. [Google Scholar]
- Zhang, J.; Song, B.; Wang, H.; Han, B.; Liu, T.; Liu, L.; Sugiyama, M. BadLabel: A Robust Perspective on Evaluating and Enhancing Label-Noise Learning. IEEE Trans. Pattern Anal. Mach. Intell. 2024, 46, 4398–4409. [Google Scholar] [CrossRef] [PubMed]
- Karim, N.; Rizve, M.N.; Rahnavard, N.; Mian, A.; Shah, M. UNICON: Combating Label Noise Through Uniform Selection and Contrastive Learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleands, LA, USA, 19–24 June 2022; Volume 2022, pp. 9666–9676. [Google Scholar]
- Goldberger, J.; Ben-Reuven, E. Training deep neural-networks using a noise adaptation layer. In Proceedings of the International Conference on Learning Representations (ICLR), Toulon, France, 24–26 April 2017; pp. 1–9. [Google Scholar]
- Tanno, R.; Saeedi, A.; Sankaranarayanan, S.; Alexander, D.C.; Silberman, N. Learning from noisy labels by regularized estimation of annotator confusion. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Long Beach, CA, USA, 16–20 June 2019; Volume 2019, pp. 11236–11245. [Google Scholar]
- Xia, X.; Liu, T.; Wang, N.; Han, B.; Gong, C.; Niu, G.; Sugiyama, M. Are anchor points really indispensable in label-noise learning? In Proceedings of the 33rd International Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 8–14 December 2019; Volume 32, pp. 1–12. [Google Scholar]
- Li, S.; Xia, X.; Zhang, H.; Zhan, Y.; Ge, S.; Liu, T. Estimating Noise Transition Matrix with Label Correlations for Noisy Multi-Label Learning. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS), New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 24184–24198. [Google Scholar]
- Cheng, D.; Ning, Y.; Wang, N.; Gao, X.; Yang, H.; Du, Y.; Han, B.; Liu, T. Class-dependent label-noise learning with cycle-consistency regularization. In Proceedings of the 36th International Conference on Neural Information Processing Systems (NIPS), New Orleans, LA, USA, 28 November–9 December 2022; Volume 35, pp. 11104–11116. [Google Scholar]
- Ren, M.; Zeng, W.; Yang, B.; Urtasun, R. Learning to reweight examples for robust deep learning. In Proceedings of the 35th International Conference on Machine Learning (ICML), Stockholm, Sweden, 10–15 July 2018; Volume 10, pp. 6900–6909. [Google Scholar]
- Liang, X.; Yao, L.; Liu, X.; Zhou, Y. Tripartite: Tackle Noisy Labels by a More Precise Partition. arXiv 2022, arXiv:2202.09579. [Google Scholar]
- Xiao, R.; Dong, Y.; Wang, H.; Feng, L.; Wu, R.; Chen, G.; Zhao, J. ProMix: Combating Label Noise via Maximizing Clean Sample Utility. In Proceedings of the International Joint Conference on Artificial Intelligence (IJCAI), Macau, China, 19–25 August 2023; Volume 2023, pp. 4442–4450. [Google Scholar]
- Arazo, E.; Ortego, D.; Albert, P.; O’Connor, N.E.; McGuinness, K. Pseudo-labeling and confirmation bias in deep semi-supervised learning. In Proceedings of the International Joint Conference on Neural Networks (IJCNN), Glasgow, UK, 19–24 July 2020; pp. 1–8. [Google Scholar]
- Liao, Z.; Xie, Y.; Hu, S.; Xia, Y. Learning from Ambiguous Labels for Lung Nodule Malignancy Prediction. IEEE Trans. Med. Imaging 2022, 41, 1874–1884. [Google Scholar] [CrossRef] [PubMed]
- Zhu, C.; Chen, W.; Peng, T.; Wang, Y.; Jin, M. Hard Sample Aware Noise Robust Learning for Histopathology Image Classification. IEEE Trans. Med. Imaging 2022, 41, 881–894. [Google Scholar] [CrossRef] [PubMed]
- Wang, Z.; Jin, S.; Li, L.; Dong, Y.; Hu, Q. Meta-Probability Weighting for Improving Reliability of DNNs to Label Noise. IEEE J. Biomed. Health Inform. 2023, 27, 1726–1734. [Google Scholar] [CrossRef] [PubMed]
- Xue, C.; Dou, Q.; Shi, X.; Chen, H.; Heng, P.A. Robust learning at noisy labeled medical images: Applied to skin lesion classification. In Proceedings of the IEEE 16th International Symposium on Biomedical Imaging (ISBI), Venice, Italy, 8–11 April 2019; pp. 1280–1283. [Google Scholar]
- Wang, Y.; Liu, W.; Ma, X.; Bailey, J.; Zha, H.; Song, L.; Xia, S.T. Iterative Learning with Open-Set Noisy Labels. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition (CVPR), Salt Lake City, UT, USA, 18–22 June 2018; pp. 8688–8696. [Google Scholar]
- Gong, C.; Ding, Y.; Han, B.; Niu, G.; Yang, J.; You, J.; Tao, D.; Sugiyama, M. Class-wise denoising for robust learning under label noise. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 2835–2848. [Google Scholar] [CrossRef]
- Ding, Y.; Wang, L.; Fan, D.; Gong, B. A Semi-Supervised Two-Stage Approach to Learning from Noisy Labels. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision (WACV), Lake Tahoe, NV, USA, 12–15 March 2018; Volume 2018, pp. 1215–1224. [Google Scholar]
- Liu, J.; Li, R.; Sun, C. Co-Correcting: Noise-Tolerant Medical Image Classification via Mutual Label Correction. IEEE Trans. Med. Imaging 2021, 40, 3580–3592. [Google Scholar] [CrossRef]
- Zou, H.; Gong, X.; Luo, J.; Li, T. A Robust Breast ultrasound segmentation method under noisy annotations. Comput. Methods Programs Biomed. 2021, 209, 106327. [Google Scholar] [CrossRef]
- Yang, M.; Li, Y.; Hu, P.; Bai, J.; Lv, J.; Peng, X. Robust multi-view clustering with incomplete information. IEEE Trans. Pattern Anal. Mach. Intell. 2022, 45, 1055–1069. [Google Scholar] [CrossRef]
- Pratap, T.; Kokil, P. Efficient network selection for computer-aided cataract diagnosis under noisy environment. Comput. Methods Programs Biomed. 2021, 200, 105927. [Google Scholar] [CrossRef]
- Fatayer, A.; Gao, W.; Fu, Y. SEMG-Based Gesture Recognition Using Deep Learning from Noisy Labels. IEEE J. Biomed. Health Inform. 2022, 26, 4462–4473. [Google Scholar] [CrossRef]
- Guo, W.; Xu, Z.; Zhang, H. Interstitial lung disease classification using improved DenseNet. Multimedia Tools Appl. 2019, 78, 30615–30626. [Google Scholar] [CrossRef]
- Jing, L.; Tian, Y. Self-supervised visual feature learning with deep neural networks: A survey. IEEE Trans. Pattern Anal. Mach. Intell. 2020, 43, 4037–4058. [Google Scholar] [CrossRef] [PubMed]
- Zhang, H.; Guo, W.; Zhang, S.; Lu, H.; Zhao, X. Unsupervised Deep Anomaly Detection for Medical Images Using an Improved Adversarial Autoencoder. J. Digit. Imaging 2022, 35, 153–161. [Google Scholar] [CrossRef] [PubMed]
- He, K.; Fan, H.; Wu, Y.; Xie, S.; Girshick, R. Momentum contrast for unsupervised visual representation learning. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Virtual, 13–19 June 2020; pp. 9729–9738. [Google Scholar]
- Chen, T.; Kornblith, S.; Norouzi, M.; Hinton, G. A simple framework for contrastive learning of visual representations. In Proceedings of the 37th International Conference on Machine Learning (ICML), Virtual, 13–18 July 2020; pp. 1597–1607. [Google Scholar]
- Grill, J.B.; Strub, F.; Altché, F.; Tallec, C.; Richemond, P.; Buchatskaya, E.; Doersch, C.; Avila Pires, B.; Guo, Z.; Gheshlaghi Azar, M. Bootstrap your own latent—A new approach to self-supervised learning. In Proceedings of the 34th Conference on Neural Information Processing Systems (NIPS), Vancouver, BC, Canada, 6–12 December 2020; Volume 33, pp. 21271–21284. [Google Scholar]
- Li, S.; Xia, X.; Ge, S.; Liu, T. Selective-supervised contrastive learning with noisy labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), New Orleans, LA, USA, 19–24 June 2022; pp. 316–325. [Google Scholar]
- Huang, Z.; Zhang, J.; Shan, H. Twin Contrastive Learning with Noisy Labels. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR), Vancouver, BC, Canada, 18–22 June 2023; Volume 2023, pp. 11661–11670. [Google Scholar]
- Bejnordi, B.E.; Veta, M.; Van Diest, P.J.; Van Ginneken, B.; Karssemeijer, N.; Litjens, G.; Van Der Laak, J.A.; Hermsen, M.; Manson, Q.F.; Balkenhol, M. Diagnostic assessment of deep learning algorithms for detection of lymph node metastases in women with breast cancer. JAMA 2017, 318, 2199–2210. [Google Scholar] [CrossRef]
- Selvaraju, R.R.; Cogswell, M.; Das, A.; Vedantam, R.; Parikh, D.; Batra, D. Grad-CAM: Visual Explanations from Deep Networks via Gradient-Based Localization. Int. J. Comput. Vis. 2020, 128, 336–359. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Dataset | Pre-Training Epoch | Batch Size | Optimizer | ||
|---|---|---|---|---|---|
| Chaoyang | 30 | 64 | SGD | 0.1 | 2 |
| PatchCamelyon | 50 | 128 | SGD | 0.1 | 2 |
| Noise Ratio | Clean | 0.05 | 0.10 | 0.20 | 0.30 | 0.40 |
|---|---|---|---|---|---|---|
| Standard | 86.64 | 84.44 | 81.69 | 74.24 | 67.10 | 58.46 |
| Joint Optim | 36.18 | 45.07 | 38.37 | 39.95 | 38.74 | 36.44 |
| Co-Teaching | 74.85 | 74.54 | 74.40 | 73.40 | 76.84 | 67.97 |
| DivideMix | 84.85 | 83.84 | 83.43 | 80.11 | 62.40 | 42.49 |
| Co-Correcting | 86.98 | 85.66 | 87.25 | 87.14 | 87.10 | 84.95 |
| HSA-NRL | 93.83 | 92.09 | 93.13 | 87.33 | 85.99 | 82.94 |
| Ours | 94.69 | 94.35 | 93.41 | 91.27 | 88.46 | 85.07 |
| Methods | ACC | Precision | Recall | F1 Score |
|---|---|---|---|---|
| Standard | 62.60 | 57.42 | 55.76 | 54.18 |
| Joint Optim | 75.99 | 70.97 | 67.91 | 67.72 |
| Co-teaching | 79.39 | 74.57 | 70.77 | 71.97 |
| DivideMix | 77.25 | 70.68 | 69.11 | 69.78 |
| Co-Correcting | 83.31 | 76.48 | 78.87 | 77.61 |
| HSA-NRL | 83.40 | 78.33 | 75.45 | 76.54 |
| Ours | 85.97 | 79.84 | 81.95 | 80.88 |
| Noise Ratio | Clean | 0.05 | 0.10 | 0.20 | 0.30 | 0.40 |
|---|---|---|---|---|---|---|
| ResNet18 | 94.14 | 92.80 | 91.85 | 88.37 | 85.65 | 81.44 |
| ResNet34 | 94.72 | 93.56 | 92.77 | 92.00 | 86.90 | 85.53 |
| ResNet50 | 94.17 | 93.59 | 92.74 | 88.64 | 86.78 | 81.93 |
| DenseNet121 | 94.69 | 94.35 | 93.41 | 91.27 | 88.46 | 85.07 |
| DenseNet161 | 95.27 | 94.35 | 93.40 | 91.27 | 87.30 | 82.72 |
| HPPM | ASM | CLM | Clean | 0.05 | 0.10 | 0.20 | 0.30 | 0.40 | Real World |
|---|---|---|---|---|---|---|---|---|---|
| × | × | × | 86.64 | 84.44 | 81.69 | 74.24 | 67.10 | 58.46 | 62.60 |
| ✓ | × | × | 93.44 | 91.03 | 90.23 | 88.61 | 85.50 | 81.56 | 85.51 |
| × | ✓ | × | 94.84 | 93.96 | 93.22 | 90.63 | 87.09 | 83.46 | 85.32 |
| ✓ | ✓ | × | 95.09 | 93.93 | 93.35 | 90.60 | 87.64 | 83.27 | 85.56 |
| ✓ | × | ✓ | 92.92 | 92.00 | 91.23 | 87.70 | 84.92 | 81.53 | 85.46 |
| × | ✓ | ✓ | 94.68 | 93.96 | 93.19 | 91.45 | 87.36 | 81.84 | 85.74 |
| ✓ | ✓ | ✓ | 94.69 | 94.35 | 93.41 | 91.27 | 88.46 | 85.07 | 85.97 |
| Clean | 0.05 | 0.10 | 0.20 | 0.30 | 0.40 | Real World | |
|---|---|---|---|---|---|---|---|
| 0.1 | 93.83 | 92.46 | 90.93 | 88.98 | 86.14 | 81.62 | 85.83 |
| 1 | 94.51 | 93.71 | 92.16 | 90.57 | 87.42 | 84.86 | 85.60 |
| 2 | 94.69 | 94.35 | 93.41 | 91.27 | 88.46 | 85.07 | 85.97 |
| 5 | 95.36 | 94.20 | 93.25 | 91.03 | 87.55 | 81.62 | 85.41 |
| 10 | 95.24 | 93.71 | 93.32 | 92.31 | 88.13 | 80.65 | 85.27 |
| 100 | 93.07 | 93.16 | 92.64 | 91.39 | 87.52 | 80.80 | 84.67 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Guo, W.; Han, G.; Mo, Y.; Zhang, H.; Fang, J.; Zhao, X. Contrastive Learning Joint Regularization for Pathological Image Classification with Noisy Labels. Electronics 2024, 13, 2456. https://doi.org/10.3390/electronics13132456
Guo W, Han G, Mo Y, Zhang H, Fang J, Zhao X. Contrastive Learning Joint Regularization for Pathological Image Classification with Noisy Labels. Electronics. 2024; 13(13):2456. https://doi.org/10.3390/electronics13132456
Chicago/Turabian StyleGuo, Wenping, Gang Han, Yaling Mo, Haibo Zhang, Jiangxiong Fang, and Xiaoming Zhao. 2024. "Contrastive Learning Joint Regularization for Pathological Image Classification with Noisy Labels" Electronics 13, no. 13: 2456. https://doi.org/10.3390/electronics13132456
APA StyleGuo, W., Han, G., Mo, Y., Zhang, H., Fang, J., & Zhao, X. (2024). Contrastive Learning Joint Regularization for Pathological Image Classification with Noisy Labels. Electronics, 13(13), 2456. https://doi.org/10.3390/electronics13132456