
An Approach to Deepfake Video Detection Based on ACO-PSO Features and Deep Learning



Abstract
1. Introduction
1.1. Motivations
1.2. Main Contributions
- The integration of ACO-PSO features and deep learning for improved deepfake video detection.
- The utilization of transfer learning with pre-trained ACO-PSO models to address the limitations of the available training data.
- An emphasis on optical flow features to analyze temporal dynamics and enhance detection accuracy.
- A comprehensive analysis encompassing both the spatial and temporal dimensions of video data to strengthen deepfake detection capabilities.
2. Related Works
2.1. Leveraging Artificial Intelligence for Enhanced Deepfake Detection
2.1.1. Deep Learning in Deepfake Detection
- Deep learning, a subset of AI, has emerged as a cornerstone in the battle against deepfake manipulation [27,28]. By harnessing neural networks with intricate layers, deep learning models autonomously glean complex patterns and features from extensive datasets [29,30]. In the realm of deepfake detection, deep learning techniques offer several advantages.
- Feature representation: deep neural networks excel in automatically extracting hierarchical representations from raw data, facilitating the capture of nuanced cues indicative of deepfake alterations [31].
- End-to-end learning: these models can undergo end-to-end training, seamlessly integrating feature extraction and classification stages to streamline the detection process [32].
2.1.2. Convolutional Neural Networks for Facial Analysis
- Facial feature extraction: CNN architectures adeptly extract discriminative facial features, such as textures, shapes, and expressions, facilitating precise discrimination between authentic and manipulated faces [36].
- Transfer learning: transfer learning, wherein pre-trained CNN models are fine-tuned on domain-specific datasets, proves instrumental in enhancing detection performance, particularly in scenarios with limited training data [38].
2.1.3. Ensemble Learning and Metaheuristic Optimization
2.1.4. Integration of Artificial Intelligence (AI) Techniques for Comprehensive Detection
2.2. Comparison between Deep Learning and AI Approaches
2.2.1. Deep-Learning-Based Detection
2.2.2. Artificial-Intelligence-Based Detection
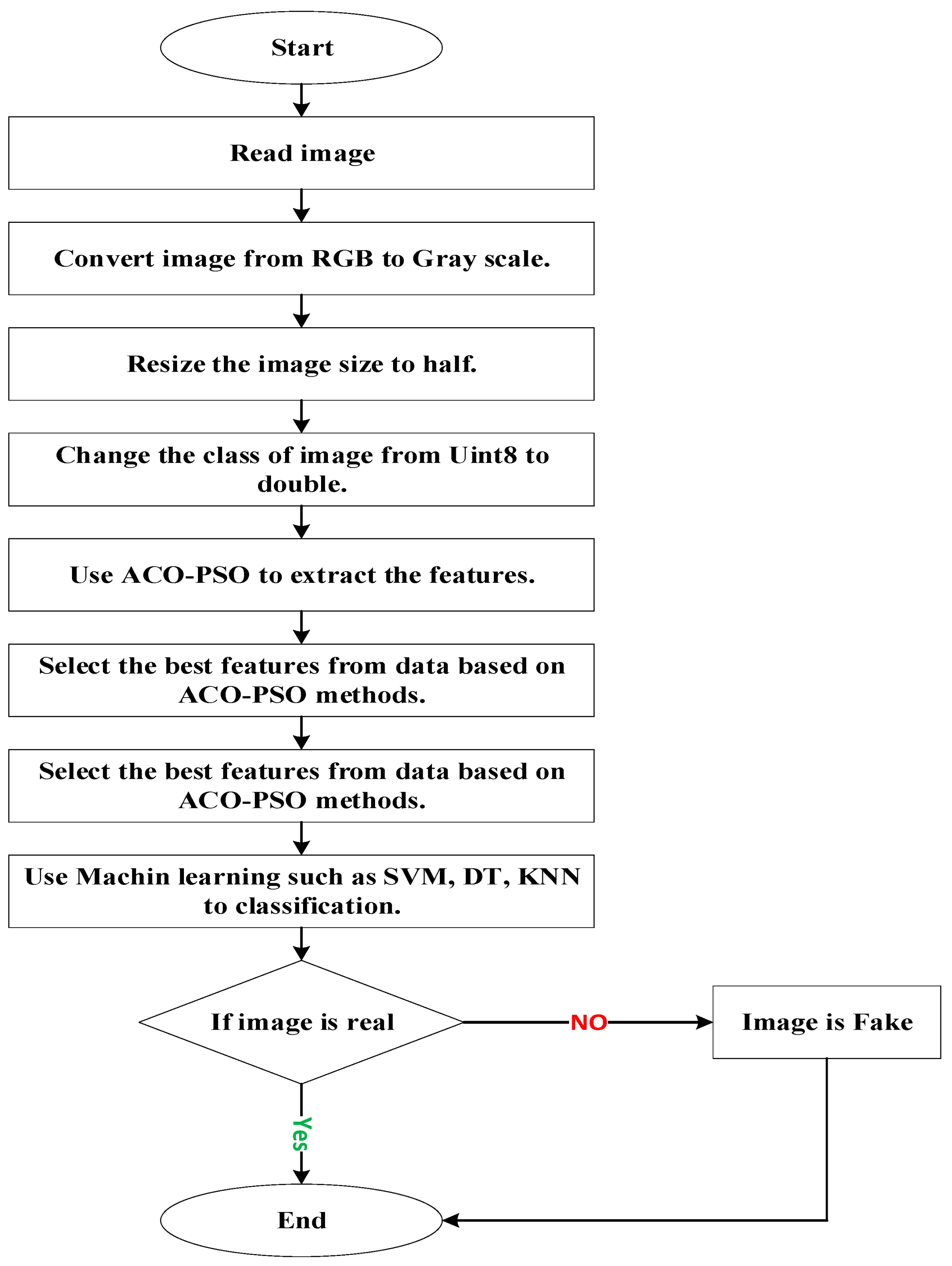
3. Material and Methods
- Initialization:
- 2.
- Construct Ant Solutions:
- 3.
- Update Pheromones:
- 1.
- Initialization:
- 2.
- Update Velocities:
- 3.
- Update Positions:
- 4.
- Update Personal and Global Bests:
- 1.
- Initialization:
- 2.
- PSO Update:
- 3.
- ACO Update:
- 4.
- Information Sharing:
- 5.
- Iteration:
4. Innovative Solutions for Overcoming Contemporary Challenges in Facial Forgery Detection
- A.
- Challenges facing contemporary facial forgery detection systems
- Adapting to varied manipulation techniques: existing systems struggle with the ever-evolving manipulation techniques seen in deepfake creation, ranging from basic facial swaps to intricate alterations of expressions, lighting, and occlusions.
- Limited training data: obtaining labeled data for training is hindered by privacy concerns and the expertise needed to label deepfake videos, impacting the system’s ability to be generalized to new manipulation techniques.
- Real-time processing: handling high-resolution video streams in real time, especially on platforms such as social media or video-streaming services, poses significant computational hurdles.
- Robustness to compression and quality loss: deepfake videos undergo compression and quality degradation when shared online, challenging detection systems to maintain accuracy across various platforms and viewing conditions.
- Ethical considerations: deploying these systems raises ethical concerns regarding privacy, consent, and potential misuse, necessitating the careful consideration of user consent, false positives, and privacy implications.
- B.
- How our method addresses these challenges
- Feature integration using ACO-PSO and deep learning: our approach combined the features of ACO-PSO and deep learning to enhance detection accuracy and robustness.
- Transfer learning with ACO-PSO: we employed transfer learning with pre-trained ACO-PSO models to leverage knowledge from large datasets, reducing the need for extensive training data.
- Focus on facial regions: by concentrating on facial features using the Viola–Jones face detection method, we streamlined detection and reduced computational overhead.
- Evaluation of benchmark datasets: extensive experiments on benchmark datasets allowed us to assess our method’s effectiveness in terms of detection accuracy, robustness, and generalization to new data.
- Computational efficiency: we analyzed the computational efficiency of our approach, ensuring practical feasibility for real-time applications while maintaining accuracy.
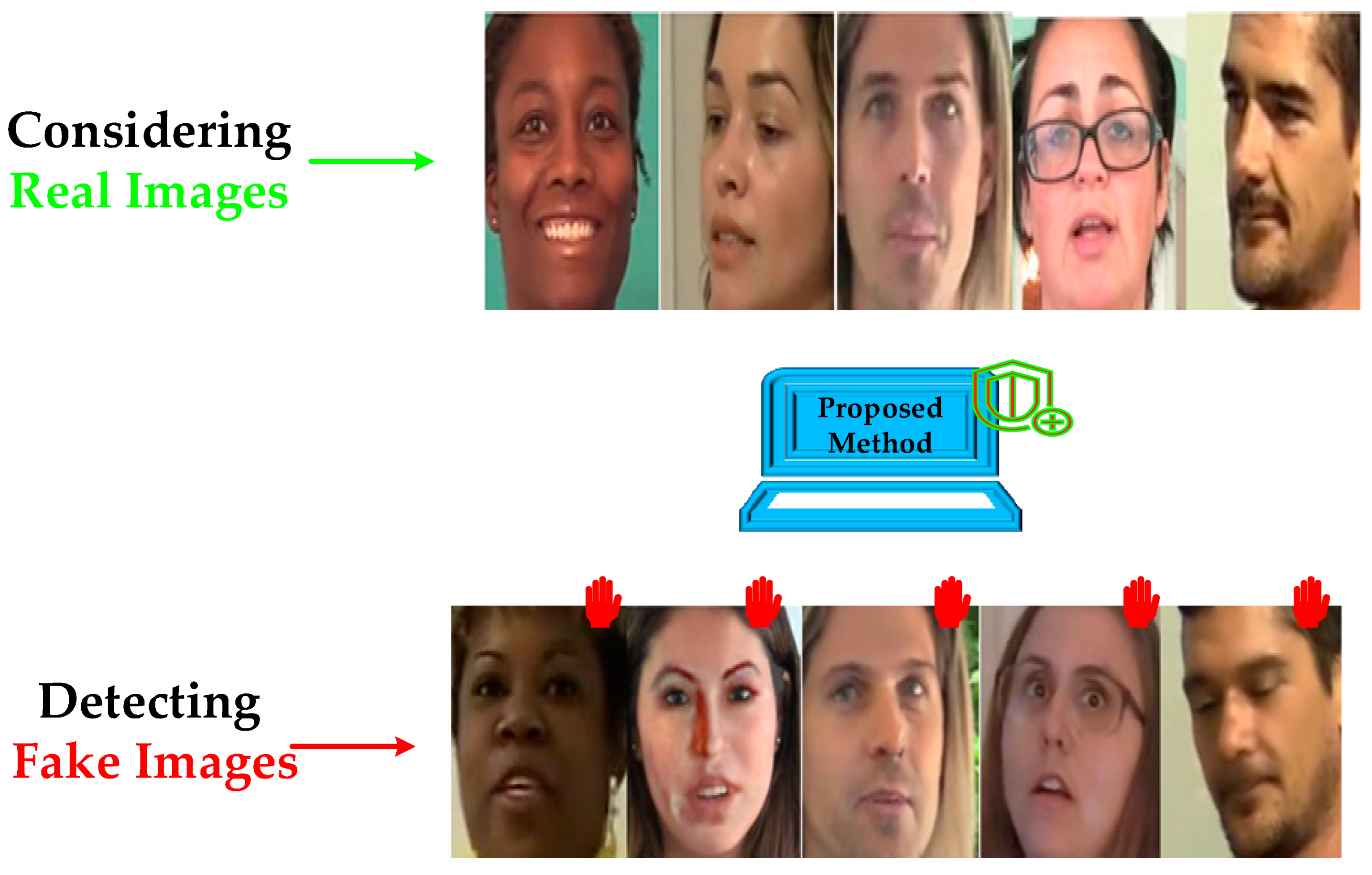
5. Dataset Description and Features
Dataset Features
- (1)
- Diverse video content: this dataset spans a wide gamut of video content, ranging from everyday scenarios to orchestrated performances, ensuring a comprehensive representation of real-world contexts.
- (2)
- Manipulation techniques: videos within the dataset exhibit a plethora of manipulation techniques characteristic of deepfake creation, including facial swaps, expression alterations, lighting modifications, and occlusion effects. This diversity fosters the thorough training and evaluation of detection algorithms across various manipulation scenarios.
- (3)
- Variation in resolution and quality: reflecting real-world conditions encountered across diverse platforms and recording devices, videos in the dataset exhibit variations in resolution and quality. This diversity fortifies the robustness of detection algorithms against discrepancies in video resolution and quality, which is vital for real-world deployment.
- (4)
- Temporal dynamics: capturing the intrinsic temporal dynamics of video sequences, the dataset encapsulates motion patterns, temporal irregularities, and frame-level alterations. This temporal dimension enriches the training data, empowering algorithms to discern subtle temporal cues indicative of deepfake manipulation.
- (5)
- Focus on facial regions: Considering the predominant focus on deepfake manipulation of facial features, the dataset emphasizes facial regions within videos. Leveraging the Viola–Jones face detection method, the dataset streamlines the extraction of facial frames, optimizing the detection process and enhancing computational efficiency.
- (6)
- Annotation and labeling: Each video in the dataset undergoes meticulous annotation and labeling, indicating its authenticity status—whether it is real or a deepfake. These annotations serve as ground truth labels, ensuring the accuracy and reliability of performance metrics during algorithm training and evaluation.
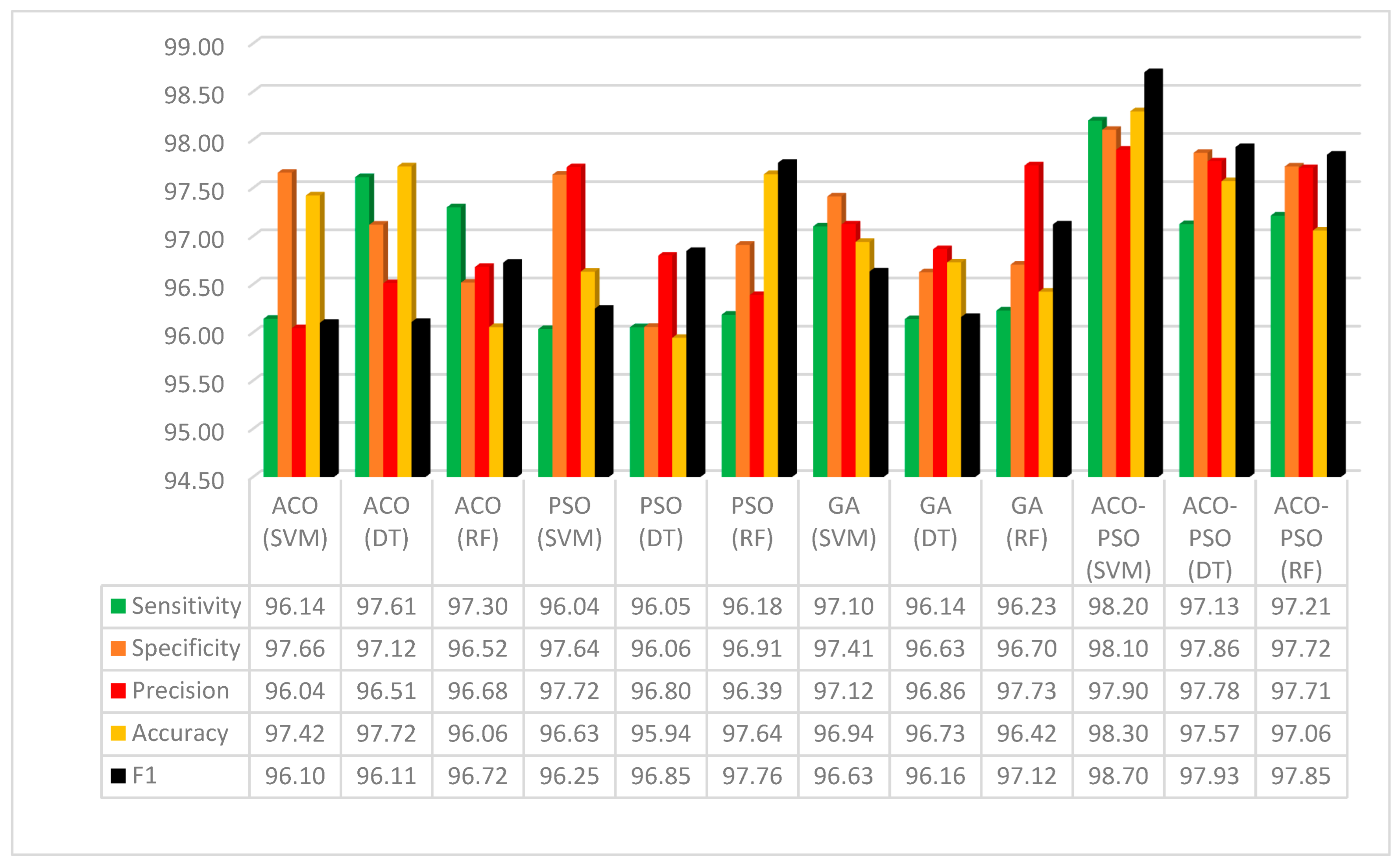
6. Results and Discussion
7. Limitations of the Proposed Method
- Dataset size: Acknowledging the influence of dataset size on method effectiveness is crucial. While the ACO-PSO model exhibited proficiency with the current dataset, it is important to recognize that outcomes may differ with larger datasets. This constraint could impact the adaptability of the approach across diverse contexts with varying dataset sizes.
- Computational complexity: The integration of deep learning techniques with optimization algorithms such as ACO-PSO can lead to computational intensiveness. This complexity may pose challenges for real-time applications, especially on platforms with limited computational resources.
- Robustness to new manipulation techniques: The dynamic nature of deepfake creation constantly introduces novel manipulation techniques. Ensuring the method’s resilience to these evolving techniques necessitates ongoing adaptation and updates, presenting a hurdle in terms of maintaining detection accuracy over time.
- Ethical considerations: Deploying deepfake detection systems raises ethical concerns surrounding privacy, consent, and potential misuse. Addressing these ethical implications requires the development of comprehensive mechanisms to safeguard against misuse and ensure ethical usage.
Potential Solutions
- Dataset expansion: expanding the dataset to include a wider array of manipulation techniques, resolutions, and quality levels can enhance method generalizability and facilitate a more thorough performance evaluation.
- Model optimization: Exploring techniques to enhance the computational efficiency of the model without compromising detection accuracy is essential. This may involve strategies such as model compression, pruning, or the development of lightweight architectures tailored for real-time deployment.
- Adaptability mechanisms: Developing mechanisms to dynamically monitor and adapt the detection system to emerging manipulation techniques in real time is critical. Continuous model retraining using incoming data streams or integrating anomaly detection algorithms can aid in identifying and addressing suspicious content.
- Ethical framework development: Collaborating with ethicists, policymakers, and stakeholders to formulate comprehensive ethical frameworks is imperative. These frameworks should address issues of consent, user privacy, and potential societal impacts, ensuring responsible deployment and minimizing harm.
8. Conclusions
9. Future Work
- Enhanced ensemble methods: Delve into the untapped potential of refining ensemble learning techniques by integrating a broader spectrum of machine learning algorithms and architectures. Explore innovative combinations to fine-tune deepfake detection accuracy and resilience.
- Dynamic feature selection: Investigate dynamic feature selection methods aimed at intelligently adapting to select the most pertinent features for deepfake detection. This approach has the potential to bolster efficiency and efficacy, particularly in real-time applications
- Adversarial defense mechanisms: Forge robust adversarial defense mechanisms to counter the impact of adversarial attacks on deepfake detection systems. Explore advanced techniques, such as adversarial training and GANs, to fortify model resilience.
- Continual learning strategies: Explore continual learning strategies to empower deepfake detection models to evolve and improve over time. This is especially crucial in the face of evolving manipulation techniques and emerging variants of deepfake technology.
- Ethical and legal implications: Scrutinize the ethical and legal dimensions of deploying deepfake detection systems, delving into issues surrounding privacy, consent, and potential misuse. Develop comprehensive guidelines and frameworks to ensure the responsible deployment and ethical usage of deepfake detection technology.
- User education and awareness: Place a spotlight on educating users about the existence and potential risks associated with deepfake technology. Empower users to critically assess media content and equip them with the necessary tools to safeguard against misinformation and manipulation.
- Real-world deployment and integration: Initiate pilot studies and forge collaborations with pertinent stakeholders to seamlessly deploy deepfake detection systems and integrate them into real-world scenarios. This includes integration into platforms such as social media, video-streaming services, and forensic analysis tools.
- Multi-modal fusion: Explore the fusion of diverse modalities, such as audio, text, and contextual information, with visual data to create a more comprehensive deepfake detection framework. Uncover synergies between various modalities to amplify detection accuracy and robustness.
- Benchmarking and evaluation: Establish standardized benchmarks and evaluation protocols for deepfake detection systems to facilitate fair comparison and reproducibility across various research endeavors. Continuously update benchmarks to reflect evolving challenges and advancements in deepfake technology.
Author Contributions
Funding
Data Availability Statement
Conflicts of Interest
References
- Afchar, D.; Nozick, V.; Yamagishi, J.; Echizen, I. Mesonet: A compact facial video forgery detection network. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Agarwal, S.; Farid, H.; Gu, Y.; He, M.; Nagano, K.; Li, H. Protecting World Leaders Against Deep Fakes. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR) Workshops, Long Beach, CA, USA, 15–20 June 2019; p. 38. [Google Scholar]
- Güera, D.; Delp, E.J. Deepfake video detection using recurrent neural networks. In Proceedings of the 2018 15th IEEE International Conference on Advanced Video and Signal Based Surveillance (AVSS), Auckland, New Zealand, 27–30 November 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–6. [Google Scholar]
- Karras, T.; Aila, T.; Laine, S.; Lehtinen, J. Progressive growing of gans for improved quality, stability, and variation. arXiv 2017, arXiv:1710.10196. [Google Scholar]
- Karras, T.; Laine, S.; Aila, T. A style-based generator architecture for generative adversarial networks. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 4401–4410. [Google Scholar]
- Li, Y.; Chang, M.-C.; Lyu, S. In ictu oculi: Exposing ai created fake videos by detecting eye blinking. In Proceedings of the 2018 IEEE International Workshop on Information Forensics and Security (WIFS), Hong Kong, China, 11–13 December 2018; IEEE: Piscataway, NJ, USA, 2018; pp. 1–7. [Google Scholar]
- Hussain, S.; Neekhara, P.; Jere, M.; Koushanfar, F.; McAuley, J. Adversarial deepfakes: Evaluating vulnerability of deepfake detectors to adversarial examples. In Proceedings of the IEEE/CVF Winter Conference on Applications of Computer Vision, Virtual, 5–9 January 2021; pp. 3348–3357. [Google Scholar]
- Nirkin, Y.; Keller, Y.; Hassner, T. Fsgan: Subject agnostic face swapping and reenactment. In Proceedings of the IEEE/CVF International Conference on Computer Vision, Seoul, Republic of Korea, 27 October–2 November 2019; pp. 7184–7193. [Google Scholar]
- Siarohin, A.; Lathuilière, S.; Tulyakov, S.; Ricci, E.; Sebe, N. First order motion model for image animation. In Proceedings of the 33rd Conference on Neural Information Processing Systems (NeurIPS 2019), Vancouver, Canada, 8–14 December 2019. [Google Scholar]
- Thies, J.; Elgharib, M.; Tewari, A.; Theobalt, C.; Nießner, M. Neural voice puppetry: Audio-driven facial reenactment. In European Conference on Computer Vision; Springer: Berlin/Heidelberg, Germany, 2020; pp. 716–731. [Google Scholar]
- Vougioukas, K.; Petridis, S.; Pantic, M. Realistic speech-driven facial animation with gans. Int. J. Comput. Vis. 2020, 128, 1398–1413. [Google Scholar] [CrossRef]
- Yang, X.; Li, Y.; Lyu, S. Exposing deep fakes using inconsistent head poses. In Proceedings of the ICASSP 2019-2019 IEEE International Conference on Acoustics, Speech and Signal Processing (ICASSP), Brighton, UK, 12–17 May 2019; IEEE: Piscataway, NJ, USA, 2019; pp. 8261–8265. [Google Scholar]
- Yi, R.; Ye, Z.; Zhang, J.; Bao, H.; Liu, Y.-J. Audio-driven talking face video generation with learning-based personalized head pose. arXiv 2020, arXiv:2002.10137. [Google Scholar]
- Kong, C.; Chen, B.; Li, H.; Wang, S.; Rocha, A.; Kwong, S. Detect and locate: Exposing face manipulation by semantic-and noise-level telltales. IEEE Trans. Inf. Forensics Secur. 2022, 17, 1741–1756. [Google Scholar] [CrossRef]
- Luo, A.; Kong, C.; Huang, J.; Hu, Y.; Kang, X.; Kot, A.C. Beyond the prior forgery knowledge: Mining critical clues for general face forgery detection. IEEE Trans. Inf. Forensics Secur. 2023, 19, 1168–1182. [Google Scholar] [CrossRef]
- Mohamed, M.H.; Khafagy, M.H.; Elbeh, H.; Abdalla, A.M. Sparsity and cold start recommendation system challenges solved by hybrid feedback. Int. J. Eng. Res. Technol. 2019, 12, 2734–2741. [Google Scholar]
- Mohamed, M.H.; Ibrahim, L.F.; Elmenshawy, K.; Fadlallah, H.R. Adaptive learning systems based on ILOs of courses. WSEAS Trans. Syst. Control 2023, 18, 1–17. [Google Scholar] [CrossRef]
- Mohamed, M.H.; Khafagy, M.H. Hash semi cascade join for joining multi-way map reduce. In Proceedings of the 2015 SAI Intelligent Systems Conference (IntelliSys), London, UK, 10–11 November 2015; IEEE: Piscataway, NJ, USA, 2015; pp. 355–361. [Google Scholar]
- Mohamed, M.H.; Khafagy, M.H.; Hasan, M. Music Recommendation System Used Emotions to Track and Change Negative Users’ mood. J. Theor. Appl. Inf. Technol. 2021, 99, 4358–4376. [Google Scholar]
- Sayed, A.R.; Khafagy, M.H.; Ali, M.; Mohamed, M.H. Predict student learning styles and suitable assessment methods using click stream. Egypt. Inform. J. 2024, 26, 100469. [Google Scholar] [CrossRef]
- Shan, Y.; Hu, D.; Wang, Z. A Novel Truncated Norm Regularization Method for Multi-channel Color Image Denoising. IEEE Trans. Circuits Syst. Video Technol. 2024. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Tan, J.; Li, Y. Multi-purpose oriented single nighttime image haze removal based on unified variational retinex model. IEEE Trans. Circuits Syst. Video Technol. 2022, 33, 1643–1657. [Google Scholar] [CrossRef]
- Liu, Y.; Yan, Z.; Chen, S.; Ye, T.; Ren, W.; Chen, E. Nighthazeformer: Single nighttime haze removal using prior query transformer. In Proceedings of the 31st ACM International Conference on Multimedia, Ottawa, ON, Canada, 29 October–3 November 2023; pp. 4119–4128. [Google Scholar]
- Li, C.; Hu, E.; Zhang, X.; Zhou, H.; Xiong, H.; Liu, Y. Visibility restoration for real-world hazy images via improved physical model and Gaussian total variation. Front. Comput. Sci. 2024, 18, 1–3. [Google Scholar] [CrossRef]
- Xiao, J.; Zhou, J.; Lei, J.; Xu, C.; Sui, H. Image hazing algorithm based on generative adversarial networks. IEEE Access 2019, 8, 15883–15894. [Google Scholar] [CrossRef]
- Mustak, M.; Salminen, J.; Mäntymäki, M.; Rahman, A.; Dwivedi, Y.K. Deepfakes: Deceptions, mitigations, and opportunities. J. Bus. Res. 2023, 154, 113368. [Google Scholar] [CrossRef]
- Traboulsi, N. Deepfakes: Analysis of Threats and Countermeasures; California State University: Fullerton, CA, USA, 2020. [Google Scholar]
- Don, L. Advanced Cybersecurity Strategies: Leveraging Machine Learning for Deepfake and Malware Defense. Cameroon. 2024. Available online: https://easychair.org/publications/preprint/pN7Q (accessed on 16 April 2024).
- Owaid, M.A.; Hammoodi, A.S. Evaluating Machine Learning and Deep Learning Models for Enhanced DDoS Attack Detection. Math. Model. Eng. Probl. 2024, 11, 493–499. [Google Scholar] [CrossRef]
- Wazirali, R.; Yaghoubi, E.; Abujazar, M.S.S.; Ahmad, R.; Vakili, A.H. State-of-the-art review on energy and load forecasting in microgrids using artificial neural networks, machine learning, and deep learning techniques. Electr. Power Syst. Res. 2023, 225, 109792. [Google Scholar] [CrossRef]
- Thippanna, D.G.; Priya, M.D.; Srinivas, T.A.S. An Effective Analysis of Image Processing with Deep Learning Algorithms. Int. J. Comput. Appl. 2023, 975, 8887. [Google Scholar] [CrossRef]
- Hassini, K.; Khalis, S.; Habibi, O.; Chemmakha, M.; Lazaar, M. An end-to-end learning approach for enhancing intrusion detection in Industrial-Internet of Things. Knowl. Based Syst. 2024, 294, 111785. [Google Scholar] [CrossRef]
- George, A.S.; George, A.S.H. Deepfakes: The Evolution of Hyper realistic Media Manipulation. Partn. Univers. Innov. Res. Publ. 2023, 1, 58–74. [Google Scholar]
- Masood, M.; Nawaz, M.; Malik, K.M.; Javed, A.; Irtaza, A.; Malik, H. Deepfakes generation and detection: State-of-the-art, open challenges, countermeasures, and way forward. Appl. Intell. 2023, 53, 3974–4026. [Google Scholar] [CrossRef]
- Namazli, P. Face Spoof Detection Using Convolutional Neural Networks. Probl. Inf. Soc. 2023, 14, 40–46. [Google Scholar]
- Alkishri, W.; Widyarto, S.; Yousif, J.H.; Al-Bahri, M. Fake Face Detection Based on Colour Textual Analysis Using Deep Convolutional Neural Network. J. Internet Serv. Inf. Secur. 2023, 13, 143–155. [Google Scholar] [CrossRef]
- Gupta, A.; Pandey, D. Unmasking the Illusion: Deepfake Detection through MesoNet. In Proceedings of the 2024 IEEE International Conference on Computing, Power and Communication Technologies (IC2PCT), Greater Noida, India, 9–10 February 2024; IEEE: Piscataway, NJ, USA, 2024; pp. 1934–1938. [Google Scholar]
- Sajith, S.; Pooja, A.; Ramesh, T.; Rajpal, P.; Roshna, A.R.; Ahammad, J. Anemia Identification from Blood Smear Images Using Deep Learning: An XAI Approach. In Proceedings of the 2023 International Conference on Recent Advances in Information Technology for Sustainable Development (ICRAIS), Manipal, India, 6–7 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 147–152. [Google Scholar]
- Zhang, C.; Costa-Perez, X.; Patras, P. Adversarial attacks against deep learning-based network intrusion detection systems and defense mechanisms. IEEE/ACM Trans. Netw. 2022, 30, 1294–1311. [Google Scholar] [CrossRef]
- Mohammed, A.; Kora, R. A comprehensive review on ensemble deep learning: Opportunities and challenges. J. King Saud Univ.-Comput. Inf. Sci. 2023, 35, 757–774. [Google Scholar] [CrossRef]
- Khaleel, M.; Yaghoubi, E.; Yaghoubi, E.; Jahromi, M.Z. The role of mechanical energy storage systems based on artificial intelligence techniques in future sustainable energy systems. Int. J. Electr. Eng. Sustain. (IJEES) 2023, 1, 1–31. [Google Scholar]
- Zhang, L.; Zhao, D.; Lim, C.P.; Asadi, H.; Huang, H.; Yu, Y.; Gao, R. Video Deepfake Classification Using Particle Swarm Optimization-based Evolving Ensemble Models. Knowl. Based Syst. 2024, 289, 111461. [Google Scholar] [CrossRef]
- Nailwal, S.; Singhal, S.; Singh, N.T.; Raza, A. Deepfake Detection: A Multi-Algorithmic and Multi-Modal Approach for Robust Detection and Analysis. In Proceedings of the 2023 International Conference on Research Methodologies in Knowledge Management, Artificial Intelligence and Telecommunication Engineering (RMKMATE), Chennai, India, 1–2 November 2023; IEEE: Piscataway, NJ, USA, 2023; pp. 1–8. [Google Scholar]
- Taji, K.; Sohail, A.; Shahzad, T.; Khan, B.S.; Khan, M.A.; Ouahada, K. An Ensemble Hybrid Framework: A Comparative Analysis of Metaheuristic Algorithms for Ensemble Hybrid CNN features for Plants Disease Classification. IEEE Access 2024, 12, 61886–61906. [Google Scholar] [CrossRef]
- Passos, L.A.; Jodas, D.; Costa, K.A.P.; Júnior, L.A.S.; Rodrigues, D.; Del Ser, J.; Camacho, D.; Papa, J.P. A review of deep learning-based approaches for deepfake content detection. Expert Syst. 2022. [Google Scholar] [CrossRef]
- Bappy, J.H.; Roy-Chowdhury, A.K.; Bunk, J.; Nataraj, L.; Manjunath, B.S. Exploiting spatial structure for localizing manipulated image regions. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 4970–4979. [Google Scholar]
- Zhang, W.; Gu, X.; Tang, L.; Yin, Y.; Liu, D.; Zhang, Y. Application of machine learning, deep learning and optimization algorithms in geoengineering and geoscience: Comprehensive review and future challenge. Gondwana Res. 2022, 109, 1–17. [Google Scholar] [CrossRef]
- Dolhansky, B.; Bitton, J.; Pflaum, B.; Lu, J.; Howes, R.; Wang, M.; Ferrer, C.C. The deepfake detection challenge (dfdc) dataset. arXiv 2020, arXiv:2006.07397. [Google Scholar]
- Zi, B.; Chang, M.; Chen, J.; Ma, X.; Jiang, Y.G. Wilddeepfake: A challenging real-world dataset for deepfake detection. In Proceedings of the 28th ACM International Conference on Multimedia, Seattle, WA, USA, 12–16 October 2020. [Google Scholar]
- Al Shalchi, N.F.A.; Rahebi, J. Human retinal optic disc detection with grasshopper optimization algorithm. Multimed. Tools Appl. 2022, 81, 24937–24955. [Google Scholar] [CrossRef]
- Al-Safi, H.; Munilla, J.; Rahebi, J. Patient privacy in smart cities by blockchain technology and feature selection with Harris Hawks Optimization (HHO) algorithm and machine learning. Multimed. Tools Appl. 2022, 81, 8719–8743. [Google Scholar] [CrossRef]
- Al-Safi, H.; Munilla, J.; Rahebi, J. Harris Hawks Optimization (HHO) Algorithm based on Artificial Neural Network for Heart Disease Diagnosis. In Proceedings of the 2021 IEEE International Conference on Mobile Networks and Wireless Communications (ICMNWC), Tumkur, India, 3–4 December 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1–5. [Google Scholar]
- Al-Rahlawee, A.T.H.; Rahebi, J. Multilevel thresholding of images with improved Otsu thresholding by black widow optimization algorithm. Multimed. Tools Appl. 2021, 80, 28217–28243. [Google Scholar] [CrossRef]


{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Ref. | Method | Advantage | Disadvantage | Accuracy of Detection % |
|---|---|---|---|---|
| [1] | Two network architectures, one convolutional neural network (CNN) and one inception-based. | Provides lossless compressed videos. | Processing time is high. | 98 (%) |
| [2] | A method used in forensics to simulate the facial expressions and body language that characterize a speaker. | High recognition rate. | A huge number of features. | 99 (%) |
| [3] | CNN extracts frame-level information, which is subsequently used to train recurrent neural networks (RNNs) that can determine whether a video has been altered. | The number of features used is low. | Using both a CNN and RNN increases the process time. | 97.1 (%) |
| [4] | They provide a fresh metric for assessing GAN outcomes. | As training advances, new layers that simulate ever-finer aspects are added. | Requires a high-resolution video stream. | 8.80 (record inception score) |
| [5] | They suggested two new automated techniques that may be used with any generator design to measure interpolation quality and disentanglement. | Time training convergence is fast. | Requires high-resolution images and a style-based approach. | Not calculated |
| [6] | Because it is a physiological signal that is poorly represented in fake videos, they employed the artificial neural network (ANN) model to detect eye blinking in the videos. | Good results for identifying films created using deepfake. | Focus on specific aspects of videos, such as blinking patterns. | 99.00 (%) |
| [7] | Using deepfake detectors based on DNNs, real videos are classified as fakes. | By adversarial altering fake movies created using deepfake’s existing generation techniques, they showed that it is possible to evade such detectors. | Requires a high level of mathematical complexity and increases processing time. | 97.49 (%) |
| [8] | It provides a revolutionary face recreation method based on recurrent neural networks (RNNs) that account for differences in position and expression. | Utilizes a brand-new Poisson blending loss that fuses perceptual loss and Poisson optimization. | Requires combining many methods. | Structural similarity index (0.54) |
| [9] | Using a self-supervised formulation to separate the information about appearance and motion. | This framework performs best over a wide range of benchmarks and object classifications. | Occlusions that occur as a result of target motion and poor precision are modeled by a generator network. | 80.6 (%) |
| [10] | They provide a photo-realistic output video of a target subject synchronized with the source input’s audio. A deep neural network uses a latent 3D face model space to power this audio-driven facial recreation. | A set of audio- and text-based puppetry demonstrations demonstrate the method’s capabilities. | This approach fails when there are numerous voices in the audio stream. | 65 (%) |
| [11] | An end-to-end system that creates talking head films utilizing a person’s still image and a speech-containing audio clip without the use of manually created intermediary features. | They shed light on the model’s latent representation. | The recognition rate is low. | 80 (%) |
| [12] | This approach is founded on the observation that deepfakes are produced by splicing a synthetic face region into the original image, creating faults in the process that may be seen when 3D head postures are calculated from the face photos. | Machine learning algorithm used for classification, which reduces the process time. | Low recognition rate and high training process time. | 89 (%) |
| [13] | They are creating a deep neural network model that, given the inputs of a very brief video, V, of the target and an audio signal, A, from the source person, creates a talking-face video with a customized head position. Additionally, a novel memory-augmented GAN module is used. | A powerful technique that requires a minimal number of frames. | The recognition rate is low, and process time is high. | 83.67 (%) |
| Resource Title | Description |
|---|---|
| Recognition and Localization | This resource focuses on recognizing and pinpointing deepfake manipulation by analyzing semantic markers and noise levels in facial images. By identifying specific features indicative of manipulation, it aims to elevate the accuracy and precision of deepfake detection and localization. |
| Dual Adversarial Learning | Employing dual adversarial learning techniques, this resource is intended to construct a robust face forgery detection framework capable of identifying a wide spectrum of facial alterations. Training two adversarial networks simultaneously enhances the model’s ability to distinguish between authentic and doctored facial images. |
| Facial X-Ray | This resource proposes a methodical examination of subtle but pivotal clues within facial imagery by likening deepfake detection to an X-ray of the face. By scrutinizing these cues, it aims to achieve the more comprehensive detection of facial forgery, encompassing various deepfake manipulation techniques. |
| Beyond Conventional Wisdom | Breaking free from traditional approaches that rely solely on prior knowledge, this resource advocates for the extraction of crucial cues embedded within facial images to enhance forgery detection efficacy. By harnessing and leveraging these cues, it seeks to augment deepfake detection systems’ ability to discern a broader array of manipulation techniques. |
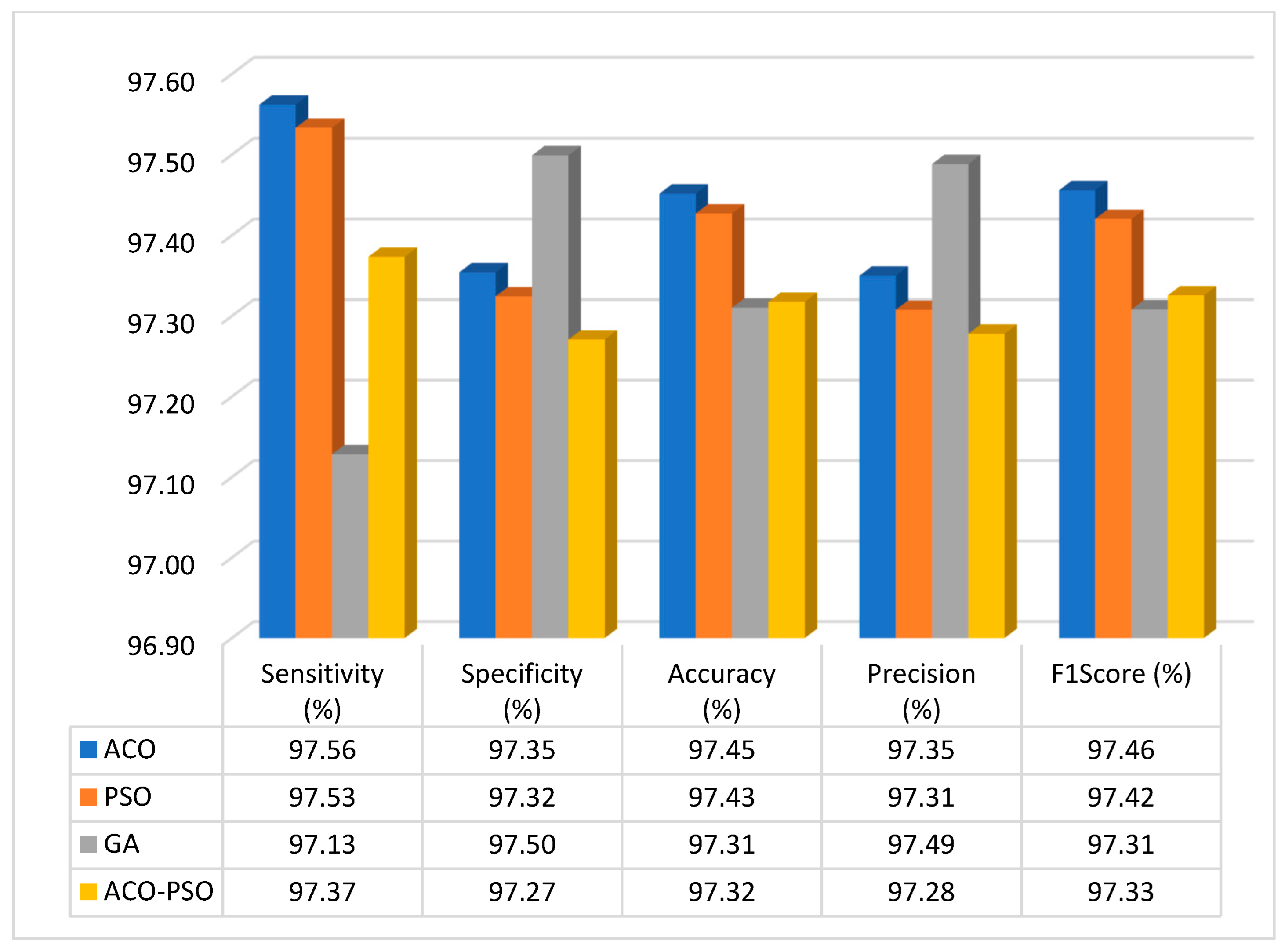
| Method | Sensitivity | Specificity | Accuracy | F1 Score |
|---|---|---|---|---|
| ACO | 97.56 | 97.35 | 97.45 | 97.35 |
| PSO | 97.53 | 97.32 | 97.43 | 97.31 |
| GA | 97.13 | 97.50 | 97.31 | 97.49 |
| ACO-PSO | 97.37 | 97.27 | 97.32 | 97.28 |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Alhaji, H.S.; Celik, Y.; Goel, S. An Approach to Deepfake Video Detection Based on ACO-PSO Features and Deep Learning. Electronics 2024, 13, 2398. https://doi.org/10.3390/electronics13122398
Alhaji HS, Celik Y, Goel S. An Approach to Deepfake Video Detection Based on ACO-PSO Features and Deep Learning. Electronics. 2024; 13(12):2398. https://doi.org/10.3390/electronics13122398
Chicago/Turabian StyleAlhaji, Hanan Saleh, Yuksel Celik, and Sanjay Goel. 2024. "An Approach to Deepfake Video Detection Based on ACO-PSO Features and Deep Learning" Electronics 13, no. 12: 2398. https://doi.org/10.3390/electronics13122398
APA StyleAlhaji, H. S., Celik, Y., & Goel, S. (2024). An Approach to Deepfake Video Detection Based on ACO-PSO Features and Deep Learning. Electronics, 13(12), 2398. https://doi.org/10.3390/electronics13122398