1. Introduction
Spam emails and phishing attacks are prevalent threats in the digital realm, posing serious risks to the integrity and security of global email communication [
1]. Spam, often recognized as unsolicited bulk emails, floods inboxes with advertisements, fraudulent offers, or irrelevant content, causing inconvenience and potential harm to recipients. These messages, sent indiscriminately to a large audience, aim to promote products, services, or spread malware. In contrast, phishing attacks are sophisticated cybercrimes designed to deceive individuals into revealing sensitive information such as login credentials, financial data, or personal details [
2]. Phishing emails disguise themselves as authentic communications from trusted sources like banks, government agencies, or reputable organizations, enticing recipients to click on malicious links, download harmful attachments, or disclose confidential information. Both spam and phishing present significant challenges for email users, requiring advanced techniques and vigilant strategies for detection, mitigation, and prevention.
The widespread occurrence of spam emails and phishing attacks emphasizes the urgent need for robust email security measures to protect individuals, businesses, and organizations from cyber threats. Spam, characterized by its unsolicited nature and widespread distribution, not only inundates email inboxes but also poses various risks, including malware distribution and phishing attempts [
3]. Conversely, phishing attacks utilize deceptive tactics and social engineering techniques to exploit human vulnerabilities, infiltrating systems and compromising sensitive information [
4]. As these threats continue to evolve in sophistication, traditional spam filtering methods have proven insufficient in effectively identifying and mitigating such malicious activities. Therefore, there is a critical imperative to explore innovative approaches and technologies to strengthen email security, mitigate risks, and uphold the integrity of digital communication channels.
In this context, leveraging advanced Natural Language Processing (NLP) techniques and state-of-the-art Large Language Models (LLMs) offers a promising avenue for enhancing spam filtering and phishing detection capabilities. This paper aims to address this pressing need by proposing a novel methodology that harnesses the power of pre-trained language models, specifically GPT-4 LLM, BERT, and RoBERTa NLPs, tailored for email spam classification tasks. We aim to evaluate their effectiveness in comparison to traditional spam detection methods like Convolutional Neural Networks (CNNs). By integrating cutting-edge NLP and LLM models into spam filtering mechanisms and fine-tuning them with few-shot learning for this specific task, our research endeavors to contribute to the advancement of email security frameworks and mitigate the evolving threats posed by spam and phishing attacks.
The main objective of this research is twofold: firstly, to evaluate and compare the effectiveness of the models for spam detection tasks, and secondly, to address specific research inquiries that previous studies have not adequately covered.
Q1: Which of the fine-tuned models—GPT-4, BERT, RoBERTa, or CNN—exhibits the most effective predictive abilities in email spam detection?
Q2: Why is fine-tuning LLMs and NLP models essential for tasks specific to particular domains?
Q3: Which of the fine-tuned models exhibits superior generalization abilities following cross-dataset evaluation?
Q4: What is the significance of prior-training data analysis, and how can plots provide valuable insights into the effectiveness of models’ predictions?
Q5: Are LLMs, specifically the GPT-4 model, efficient tools for spam detection, and how can they be used to enhance existing spam filter technologies?
To achieve our study’s objectives, we conduct a comprehensive literature review on spam filtering in
Section 2.
Section 3 outlines the materials and methodology employed in this study, while
Section 4 presents the prediction results for the models and their efficacy during cross-dataset evaluation.
Section 5 delves into the discussion of the results, extracting valuable insights based on the research findings.
2. Literature Review
The rise of digital communication has brought about unprecedented global connectivity, but it has also triggered a surge of unwanted and malicious emails, commonly referred to as spam. In today’s era of cyber threats, effective spam filtering serves as a crucial component of email security, acting as the primary defense against undesirable and potentially harmful messages [
5]. Spam, often intertwined with complex phishing schemes, presents a myriad of challenges to individuals, businesses, and organizations worldwide. These challenges range from mere annoyance and decreased productivity to severe security breaches and financial fraud. As the frequency and sophistication of spam and phishing attacks continue to increase, conventional filtering methods have struggled to keep pace. This underscores the urgent necessity for advanced techniques and technologies to effectively counteract these evolving threats.
2.1. Traditional Approaches to Spam Filtering
Traditional spam detection methods utilize rule-based filtering, Bayesian filtering, and content-based filtering techniques. Rule-based filtering involves predefined rules or patterns to flag spam based on specific criteria like keywords, sender information, or email structure [
6,
7]. While effective at identifying obvious spam, rule-based filters struggle to adapt to evolving spam tactics, leading to both false positives and false negatives due to their inflexibility.
Bayesian filtering, on the other hand, employs statistical algorithms to assess the probability of an email being spam or legitimate based on certain words or features within the message [
8]. Although more adaptable than rule-based methods, Bayesian filtering still faces challenges in accurately distinguishing between spam and legitimate emails, especially with sophisticated spam campaigns that mimic authentic communication.
Content-based filtering analyzes the content of emails, including language, syntax, and structure, to determine their likelihood of being spam [
6]. While effective to some extent, content-based approaches are susceptible to evasion tactics like obfuscation and content manipulation employed by spammers to avoid detection.
Despite their utility in certain scenarios, traditional spam detection methods have limitations. These include vulnerability to evasion tactics, difficulty in accurately discerning spam from legitimate emails, and the potential for high false positive rates [
9]. With spamming techniques becoming increasingly sophisticated, there is a critical need for advanced techniques such as machine learning and NLP to complement traditional methods and bolster email security.
2.2. Evolution of Machine Learning in Spam Filtering
The advancement of machine learning techniques in spam filtering has been pivotal in addressing the persistent challenge posed by unsolicited emails. Early spam filtering methods relied heavily on heuristic and rule-based systems, employing features such as email header details, lexical analysis of content, and statistical analysis [
7].
However, the emergence of advanced machine learning algorithms, such as support vector machines (SVMs), neural networks, and deep learning models, revolutionized spam filtering [
10,
11]. These algorithms enabled the automatic extraction of pertinent features directly from raw email data, learning intricate patterns and relationships within emails. This led to significant enhancements in the accuracy and robustness of spam detection systems.
In summary, the evolution of machine learning techniques in spam filtering represents a shift from heuristic-based approaches to more data-driven and adaptable methodologies. By harnessing advanced algorithms and learning from extensive email data, modern spam filters are better equipped to combat the evolving tactics of spammers, offering users improved protection against unwanted and potentially harmful emails.
2.3. Previous Studies
Spam emails pose a persistent challenge in modern communication networks, necessitating continuous innovation in detection methodologies. This literature review synthesizes recent research efforts addressing the evolving landscape of spam detection across various communication channels, including email and SMS. The reviewed studies underscore the significance of leveraging diverse techniques, ranging from traditional machine learning algorithms to cutting-edge deep learning models, to combat the proliferation of spam and associated security threats effectively. To facilitate comprehensive understanding, the reviewed studies are categorized into eight distinct groups, ensuring optimal readability and comprehension.
2.3.1. Traditional Techniques in Spam Detection
Şahin et al. [
12] investigate the effect of the k value in the K-Nearest Neighbor (KNN) algorithm on spam filtering performance. Through extensive experimentation on different datasets, the study concludes that optimal performance is achieved when k equals 1, showcasing the significance of parameter tuning in machine learning-based spam detection systems.
Manita et al. [
13] propose an efficient spam filtering approach, OAOS-LR, which combines the Logistic Regression model with an improved Atomic Orbital Search (AOS) algorithm. The integration of OAOS enhances the LR model’s detection capabilities, resulting in superior performance compared to traditional machine learning methods. Experimental results demonstrate OAOS-LR’s effectiveness in achieving high F1-score success rates across various datasets.
Chandan et al. [
14] focus on mobile spam messages, highlighting the increasing threat posed by spammers who disguise messages as legitimate communication from banks. They compare BERT with traditional machine learning algorithms using a Kaggle dataset containing labeled spam and non-spam messages. Their results indicate that BERT achieves the highest testing accuracy of 98%, outperforming Logistic Regression, multinomial Naïve Bayes, SVM, and Random Forest algorithms.
2.3.2. Novel Techniques in Spam Detection
Gaurav et al. [
15] address the challenge of spam detection in emails, highlighting the inefficiency of traditional rule-based methods due to limitations in datasets and informal text structures. They propose a novel spam mail detection method based on document labeling, utilizing algorithms such as Naïve Bayes, Decision Tree, and Random Forest (RF). Experimental results demonstrate the superior accuracy of RF in classifying emails as spam or ham, thereby offering an automated solution to mitigate spam-related concerns.
Mehrotra et al. [
16] explore spam detection techniques from diverse perspectives, emphasizing parameter tuning, dataset division, and algorithm comparison. By preprocessing and feature extraction, they enhance the efficiency of spam detection, thereby safeguarding users from malicious emails. Their study underscores the significance of effective categorization based on various parameters to mitigate security risks associated with spam emails.
Rapacz et al. [
17] introduce a meta-algorithm for the fast selection of machine learning classifiers in spam filtering, emphasizing the importance of text analysis in classification processes. Through a comparative analysis of classifiers such as k-nearest neighbors (k-NNs), Support Vector Machines (SVM), and Naïve Bayes (NB), they demonstrate the efficacy of NB in combating spam. Their research underscores the significance of classifier selection in enhancing spam filtering efficiency, particularly in handling large datasets.
Kuchipudi et al. [
18] investigate the vulnerability of machine learning-based spam filters to adversarial attacks. The authors demonstrate the effectiveness of various adversarial techniques, such as synonym replacement and word spacing manipulation, in deceiving spam filters. Their findings underscore the pressing need for robust defenses against adversarial manipulation in machine learning-based security mechanisms.
Gomaa [
11] explores the impact of deep learning techniques on SMS spam filtering, emphasizing the persistence of SMS as a marketing tool and the consequent proliferation of spam. By comparing various deep neural network architectures and classical machine learning classifiers, the study achieves remarkable accuracy in spam detection, highlighting the efficacy of deep learning in combating evolving spam threats.
2.3.3. NLP Frameworks and Security Challenges
Garg et al. [
3] delve into the realm of spam filtering using NLP frameworks, recognizing spam as a significant impediment to email services. Leveraging NLP techniques such as tokenizing, stemming, POS-tagging, and chunking, they propose methodologies to identify and eliminate spam content effectively. By harnessing the power of AI-driven NLP, their approach offers a promising avenue for combating spam-related challenges.
Zhang et al. [
19] investigate label flipping attacks against the Naïve Bayes (NB) algorithm in spam filtering systems, aiming to evaluate the robustness of NB under label noise. By proposing novel label flipping attacks and conducting evaluations on multiple datasets, they reveal vulnerabilities in NB’s classification performance under label noise. Furthermore, they compare the effectiveness of various machine learning algorithms and deep learning models in mitigating label flipping attacks, providing insights into improving spam filtering resilience.
Zhaoquan et al. [
20] investigate the vulnerability of spam filters to adversarial attacks, particularly marginal attacks aimed at undermining Naïve Bayesian classifiers. By systematically generating adversarial examples through the insertion of sensitive words, the authors demonstrate significant reductions in filter accuracy. Moreover, the transferability of these adversarial examples across different filtering algorithms highlights the broader implications of such attacks in compromising spam detection systems.
Cao et al. [
21] tackle the challenge of detecting bilingual multi-type spam by introducing a novel model based on M-BERT. Leveraging a bilingual multi-type spam dataset and incorporating OCR for image-based spam, their approach achieves a remarkable accuracy of 0.9648. Furthermore, the model’s low time overhead of 0.3168 s per training step makes it a viable solution for efficient spam detection.
2.3.4. Advanced Techniques in Spam Filtering
Baaqeel et al. [
22] address the proliferation of SMS spam, proposing a hybrid spam filtering system using supervised and unsupervised machine learning techniques. By leveraging the strengths of both approaches, their hybrid system aims to enhance spam filtration accuracy and F-measures, thereby providing a robust solution to combat spam SMS threats. Their research highlights the adaptability of machine learning algorithms in addressing diverse spam filtering challenges across different communication channels.
Magdy et al. [
10] introduce a deep learning model designed to combat both spam and phishing emails, addressing the multifaceted threats posed by malicious communications. By leveraging content-based features and prioritizing validation accuracy and computational efficiency, the proposed classifier demonstrates superior performance compared to existing methodologies. This research highlights the potential of deep learning approaches in enhancing the efficacy of email filtering systems.
Bhattacharya et al. [
23] introduce a genetic algorithm-based approach for spam detection, emphasizing adaptability and effectiveness with limited datasets. By incorporating probabilistic weights and word counts, the method achieves accurate classification by considering the content of emails. Singh underscores the necessity for adaptive schemes in real-world applications to counter spam effectively.
Hnini et al. [
24] propose a spam filtering system based on Nearest Neighbor (NN) algorithms, namely K-NN, WKNN, and K-d tree. By employing preprocessing techniques such as NLP and feature extraction methods like Bag-of-words and TF-IDF, the study demonstrates the efficacy of K-NN in achieving high performance across Enron and LingSpam datasets.
2.3.5. Advanced Models and Approaches
Kihal et al. [
25] present a robust multimedia spam filtering system, VTA-CNN-RF, capable of detecting spam across text, image, audio, and video modalities. Leveraging Convolutional Neural Networks (CNNs) for feature extraction and Random Forest (RF) for classification, the proposed model outperforms existing methods in spam identification. The study underscores the importance of multimodal fusion in enhancing spam detection accuracy and highlights VTA-CNN-RF’s superior performance across diverse multimedia datasets.
Shaik et al. [
26] address the escalating challenge posed by email spam through a comparative analysis of machine learning (ML) and deep learning algorithms. By exploring techniques such as Naïve Bayes Classifier, Random Forest, Artificial Neural Network, Support Vector Machine, Long Short-Term Memory (LSTM), and Bidirectional-Long Short-Term Memory (Bi-LSTM), the study seeks to identify the most effective model for classifying emails as spam or legitimate (ham). This research underscores the need for adaptive strategies in response to evolving spamming tactics.
Ghiassi et al. [
27] present an innovative approach to text classification, leveraging the Yet Another Clustering Algorithm (YAC2) alongside domain-transferrable feature engineering. By applying this integrated solution to sentiment analysis on Twitter and spam filtering of YouTube comments, the study demonstrates superior performance compared to traditional clustering methods. Notably, their approach offers simplicity, transferability across domains, and reduced computational overhead, marking a significant advancement in text classification methodologies.
Wang et al. [
28] propose a manifold learning-based approach to spam filtering, aiming to mitigate the time complexity associated with Support Vector Machine (SVM) classifiers. By employing the Laplace feature map algorithm to extract decisive features from email text datasets, the study enhances the efficiency of spam detection while maintaining high accuracy. This research underscores the importance of leveraging geometric information in text data to improve the efficacy of spam filtering mechanisms.
2.3.6. Comparative Analysis and Performance Enhancement
Kontsewaya et al. [
29] evaluate the effectiveness of various machine learning algorithms in spam detection, emphasizing the importance of robust filtering systems in safeguarding users against spam threats. Through a comparative analysis of algorithms such as Naïve Bayes, K-Nearest Neighbors, SVM, Logistic Regression, Decision Trees, and Random Forests, the study underscores the efficacy of NLP approaches. Logistic regression and Naïve Bayes emerge as top performers, offering accuracy levels of up to 99% and laying the groundwork for future advancements in intelligent spam detection systems.
Ahmed et al. [
30] provide an overview of machine learning techniques utilized for spam filtering in email and IoT environments. They categorize these techniques into suitable classes and conduct a comprehensive comparison based on metrics like accuracy, precision, and recall. While acknowledging the importance of filtering email, the study emphasizes the escalating ratio of spam emails and the pressing need for efficient detection methods.
Xia [
7] addresses the challenge of throughput in rule-based spam detection systems (RBS) caused by the rapid expansion of obfuscated words. To mitigate this issue, Xia proposes a novel constant time complexity algorithm leveraging a specialized data structure called Hash Forest. This algorithm ensures a consistent processing speed independent of rule and vocabulary size, thus enhancing the filtering throughput of RBS.
Shobana et al. [
8] propose a Naïve Bayesian classifier-based model for spam identification, emphasizing the escalating prevalence and detrimental effects of spam emails. Through an analysis of various spam filtering technologies, the authors advocate for the adoption of machine learning-based approaches. The presented model demonstrates effectiveness in distinguishing spam from legitimate emails, contributing to the mitigation of spam-related nuisances and security threats.
2.3.7. Transfer Learning and Fine-Tuning
Kim et al. [
6] address privacy concerns associated with traditional spam filtering methods by proposing the Privacy-Preserving Content-based Spam Filter (PCSF). Their system ensures email content and detection rules remain private, mitigating risks associated with exposure to third parties or decryption attacks. Furthermore, PCSF provides pre-validation, enhancing security by filtering spam before it reaches the recipient’s terminal.
Bhopale et al. [
31] address the pressing need for robust spam email filtering systems by proposing a transfer learning approach that fine-tunes a pre-trained BERT model on spam email datasets. Their experiments, conducted on the Enron spam dataset and Kaggle’s SMS Spam Collection dataset, demonstrate significant improvements in classification performance compared to traditional techniques such as Logistic Regression, SVM, Naïve Bayes, Random Forest, and LSTM.
2.3.8. Unique Challenges and Solutions
Ojugo et al. [
32] address the unique challenges posed by spam filtering in the context of short messaging services (SMS). By employing a hybrid Genetic Algorithm (GA)-trained Bayesian Network model, the study aims to normalize noisy features and enhance classification accuracy through semantic analysis. This approach emphasizes the necessity of adapting filtering techniques to accommodate the constraints of SMS communication, including character limitations and linguistic idiosyncrasies.
Nam et al. [
33] introduce a novel approach that integrates visual and textual information to enhance spam filtering performance. Recognizing the limitations of traditional text-based spam detection methods against image-based spam attacks, the authors propose a hybrid feature extraction model. By combining topic-, word-, and image-embedding-based features extracted from spam images using optical character recognition (OCR), latent Dirichlet allocation (LDA), and word2Vec techniques, respectively, the model achieves significant improvements in classification accuracy (accuracy: 0.9814, Macro-F1: 0.9813). However, challenges such as OCR evasion techniques highlight the need for ongoing refinement of image-based spam detection strategies.
Ji et al. [
34] address the escalating need for efficient spam filtering in email communication. Leveraging the scalability and parallel processing capabilities of Hadoop MapReduce, the authors implement a Naïve Bayes classifier for malicious email detection. A comparative analysis with traditional Python-based approaches demonstrates superior performance in terms of accuracy and prediction error rates. The Hadoop MapReduce Naïve Bayes method outperforms its non-Hadoop counterpart by 1.11 times in accuracy and reduces prediction error rates by 14.13 times, underscoring the efficacy of distributed computing paradigms in large-scale spam filtering applications.
Rifat et al. [
35] tackle social engineering attacks through SMS phishing, leveraging machine learning algorithms for real-time spam detection. They propose a universal spam detection model using pre-trained BERT, achieving an overall accuracy of 99% with an F1 score of 0.97. Their findings affirm the effectiveness of distilled BERT in combating spam messages.
2.4. Large Language Models in NLP
The rise of LLMs has transformed the landscape of NLP, offering unparalleled abilities in comprehending and producing human-like text. Two groundbreaking models leading this charge are the GPT (Generative Pre-trained Transformer) series and BERT (Bidirectional Encoder Representations from Transformers), each making significant strides in the field [
36].
The GPT series, developed by OpenAI, includes iterations like GPT-2, GPT-3, and GPT-4, leveraging the Transformer architecture for efficient sequential data processing with long-range dependencies [
37]. Trained on extensive internet text data, GPT models grasp intricate language representations through unsupervised learning. This enables them to understand syntax, semantics, and context, leading to coherent and contextually relevant text generation [
38]. Notably, GPT-3’s massive scale of 175 billion parameters has showcased exceptional performance across various NLP tasks such as text completion, summarization, and question answering.
BERT, pioneered by Google, stands as another landmark in NLP research. Introducing bidirectional context modeling, BERT considers both preceding and succeeding context when predicting a word, allowing for a deeper grasp of semantic nuances [
39]. Through pre-training on vast text corpora and fine-tuning on task-specific data, BERT achieves state-of-the-art results in tasks like sentence classification, named entity recognition, and sentiment analysis [
35]. BERT’s success has paved the way for refined bidirectional context models like RoBERTa and ALBERT [
40].
Both the GPT series and BERT have significantly elevated the capabilities of LLMs in NLP, surpassing previous benchmarks and setting new standards. Their prowess extends beyond research, finding practical applications in virtual assistants, content creation, and language translation. As LLMs evolve further, they hold immense promise for enhancing human interactions and the understanding of natural language.
3. Materials and Methods
In the literature review section, previous research on spam filtering was thoroughly examined, highlighting the consensus regarding the efficacy of advanced machine learning algorithms in spam detection. These studies have delved into a spectrum of algorithms, from simple to advanced, as well as hybrid approaches to enhance spam detection and filtering.
This study will initially focus on utilizing the groundbreaking GPT-4 LLM, BERT, and RoBERTa NLPs, alongside a parallel comparison with CNNs. Both LLM and NLPs have demonstrated proficiency in understanding human text. In the proposed approach, the models will undergo fine-tuning on two different datasets using few-shot learning, with their spam detection capabilities assessed through direct pre- and post-fine-tuning comparisons.
In the initial stages of our research, we rigorously assess GPT-4’s proficiency in accurately identifying spam emails. This involves conducting an exhaustive performance evaluation comparing the base GPT-4 model with its fine-tuned version. Subsequently, we proceed to fine-tune the BERT and RoBERTa models for spam detection. Both the fine-tuned LLM and NLP models will be compared, demonstrating how the fine-tuning process bolsters their ability to adeptly address the multifaceted challenges posed by spam emails with enhanced precision. Additionally, their effectiveness will be directly compared with a trained CNN on the same datasets.
Our research findings affirm that both LLM and NLPs achieve nearly 100% accuracy in their predictions, with the fine-tuned GPT demonstrating a slightly higher performance compared to its base version and the RoBERTa model. It was interesting, though, to find that the BERT model surpassed the fine-tuned GPT-4 model slightly, with the CNN-trained model achieving far less accurate results than LLM and NLPs. The entirety of the code utilized in this research, including methods for data cleansing, fine-tuning methodologies, and the datasets themselves, is accessible in a GitHub repository licensed under the open-source MIT license [
41].
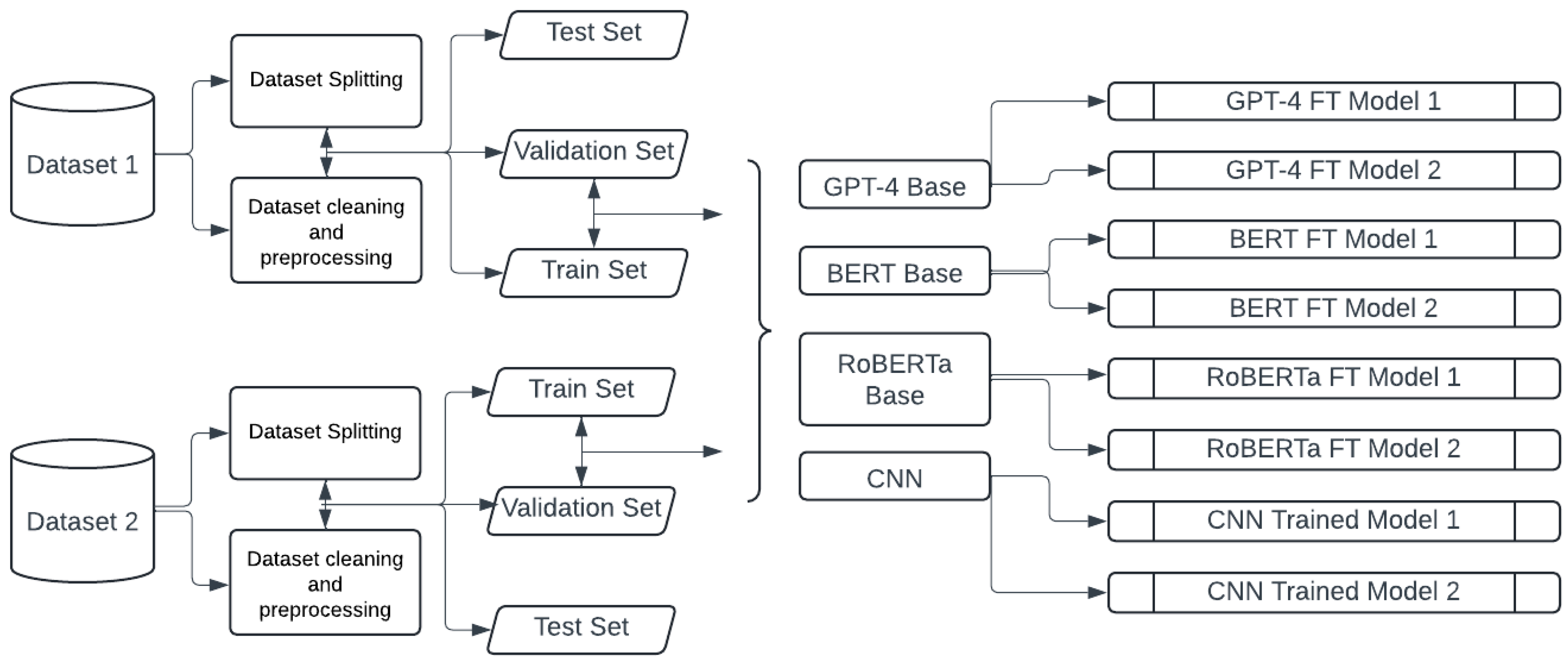
To achieve the objectives outlined in this paper, it was crucial to adopt a specific research methodology due to the extensive and intricate processes involved. This methodology has been carefully selected to support not only the implementation of data cleaning techniques and prompting engineering but also the following deployment and refinement of the models. The detailed structure for these processes is explained in the subsequent subsections, furnishing an exhaustive and cohesive approach for the investigation. To enhance comprehension, the procedure is visually represented through two flow charts
Figure 1 and
Figure 2 crafted with the Lucidchart software (
https://www.lucidchart.com).
3.1. Dataset Splitting, Cleaning, and Preprocessing
For our research, we utilized two different datasets: the “NLP—SPAM/HAM Email Classification” by YASHPAL [
42] and the “Spam Emails” by ABDALLAH WAGIH IBRAHIM [
43]:
The “NLP—SPAM/HAM Email Classification” dataset is available on Kaggle [
42]. With a usability rating of 8.82 on Kaggle, this dataset provides well-balanced data conducive to our spam detection efforts. The dataset is 3 MB in size, containing 5728 rows with two columns: Text and Spam labels. The original dataset consists of 76.12% ham emails and 23.88% spam emails. The maximum Text row length is 41,271 characters, and the average length is 1349 characters.
The “Spam Emails” dataset is also available on Kaggle [
43]. The dataset has a usability rating of 10, making it ideal for our spam classification task. The dataset is 212 kb, containing 5572 unique rows with two columns: Message and Category labels. The original dataset consists of 86.59% ham emails and 13.41% spam emails. The maximum Message row length is 888 characters, and the average length is 75. To better handle the data in our fine-tuning procedure, the two datasets were homogenized by renaming the columns of the second dataset. The columns were renamed from Message and Category to Text and Spam. For the Spam column, all the string labels were changed to binary, with “spam” labels changed to 1 and “ham” labels changed to 0.
Both the datasets hold significant promise for providing insights into spam emails and improving spam filtering techniques.
3.1.1. Dataset Limitations
Both datasets used in this study include two columns: one for the text and one for the label. The first dataset explicitly includes the word “Subject” before the text, indicating that the text column contains email subjects.
The second dataset, however, has a column named “Message” without explicitly stating whether it contains email bodies or subjects. From manual inspection, we found that some entries in the “Message” column appear to be subjects, while others seem to be email bodies.
For the first dataset, it is unclear how an email subject could contain 41,271 characters, which is the maximum length for a text row, with an average length of 1349 characters. According to Gmail’s limits documentation, the maximum subject length in emails is 998 characters [
44]. Any subject line longer than this would likely be truncated or cause the email to be blocked due to exceeding the header limit. Therefore, we assume that some of the entries in this dataset are subjects, while the longer ones are email bodies.
It is important to clarify that the data fed into our evaluation window consist solely of the text content from the datasets, without including any email headers. Headers can easily consume over 100 characters in modern emails, especially with schemes like DMARC/DKIM. In real-life email bodies, HTML preambles and MIME encodings can further complicate and fill the data before the actual message content is used. This treatment could lead to shortcomings, as the full context of the email is not considered.
For this study, the datasets used do not include headers or HTML/MIME-encoded bodies, but rather preprocessed plain text. This means the models are trained on simplified data that do not fully represent real-world emails, which typically contain both header and body information. Consequently, our current approach may not directly apply to practical environments without significant preprocessing of real emails to extract only the relevant text content.
This study is primarily a “bench-top” validation. The main objective is to fine-tune three types of models—LLMs, NLPs, and CNNs—using few-shot learning, by providing them with a minimal number of labeled data and prompting them to predict whether the subjects/bodies are ham or spam. Due to the advanced natural language capabilities of LLMs and NLPs, the outcome could be consistent whether specific words or combinations of words appear, or from the context of the text, regardless of whether we are dealing with subjects or email bodies.
For practical applications, an AI team would need to preprocess emails to extract only the text before prompting the models to make predictions. Alternatively, a more advanced solution could be to train these models from scratch using entire emails, including both headers and HTML bodies, contained in exported EML files.
3.1.2. Dataset Preprocessing
To ensure our predictive modeling and fine-tuning procedures are of high quality and effectiveness, we meticulously prepared the dataset. This involved a systematic approach with several essential steps, each aimed at improving the data’s suitability for the classification task.
Firstly, we utilized a function to identify the distinct labels within a specific column (Spam), enabling us to gain insights into our dataset. Through this process, we discovered emails categorized into two different labels: 0 for “ham” and 1 for “spam”.
Following that, we delved into data preprocessing, a crucial stage in enriching the quality of the dataset. During this stage, we addressed various aspects of the text data to ensure its suitability for modeling objectives. An essential aspect of data preprocessing involved eliminating special characters, redundant white spaces, and empty rows, crucial for maintaining the integrity and consistency of the data. Unaddressed special characters might introduce unwanted noise into the dataset, which could potentially hinder the efficacy of NLP models.
In addition, text normalization played a crucial role in ensuring the uniformity and standardization of the text data. As a component of this process, we executed tasks like transforming accented characters into their base forms. This was particularly important for languages employing diacritics, guaranteeing uniform handling of words with accentual differences. Furthermore, to achieve case-insensitivity in the text data, we systematically converted all text to lowercase.
In the field of NLP tasks, dividing a dataset into parts is essential for effectively creating, improving, and assessing models. This practice is crucial for building robust and dependable models that can effectively generalize to unfamiliar data in diverse linguistic environments. In our methodology, we divided the dataset into training, validation, and test sets. The partitioning process unfolded in two stages: first, dividing the data into test and training sets, then subdividing the training set into validation and additional training subsets. To elaborate, we employed the train_test_split method, initially splitting the original dataset into 20% test data and 80% train data. Subsequently, we further partitioned the train data into 20% validation data and 80% additional training data. During the fine-tuning stage, the training set was pivotal in enabling the model to grasp patterns, connections, and representations within the input data, thus facilitating its ability to make predictions or execute specific tasks. The validation set played a crucial role in refining the model by fine-tuning hyperparameters and configurations. Assessing the model’s performance on the validation set directed adjustments that improved generalization and mitigated overfitting. Subsequently, the fine-tuned models employed the test set for predictions, concluding the thorough process of refining and evaluating the model. To ensure that the training process did not encounter unseen data, we employed the stratify parameter in the train_test_split function, ensuring that values in the Spam column were represented in all sets: training, validation, and test.
After the splitting process, three distinct CSV files were generated for each dataset.
For the “NLP—SPAM/HAM Email Classification” dataset:
test_set.csv: Comprising 1146 samples, with the longest row in the Text column containing 41,271 characters at maximum, and an average of 1355 characters. In the Spam column, 76.09% are classified as ham labels and 23.91% as spam labels.
train_set.csv: Encompassing 3665 samples, with the longest row in the Text column reaching 27,601 characters at maximum, and an average of 1348 characters. In the Spam column, 76.13% are designated as ham labels and 23.87% as spam labels.
validation_set.csv: Consisting of 917 samples, with the longest row in the Text column extending to 40,780 characters at maximum, and an average of 1346 characters. In the Spam column, 76.12% are labeled as ham and 23.88% as spam.
For the “Spam Emails” dataset:
test_set.csv: Comprising 1114 samples, with the longest row in the Text column containing 756 characters at maximum, and an average of 78 characters. In the Spam column, 86.62% are categorized as ham labels and 13.38% as spam labels.
train_set.csv: Including 3565 samples, with the longest row in the Text column reaching 519 characters at maximum, and an average of 74 characters. In the Spam column, 86.59% are labeled as ham and 13.41% as spam.
validation_set.csv: Holding 891 samples, with the longest row in the Text column extending to 888 characters at maximum, and an average of 76 characters. In the Spam column, 86.53% are classified as ham and 13.47% as spam.
3.2. LLM Prompt Engineering
Our objective was to create a prompt that smoothly integrates with different LLM models, improving the accessibility of their outputs via our code. We focused not only on the prompt’s substance but also on its output presentation.
In order to develop a prompt compatible with all LLMs, we required a thorough comprehension of the distinct models at our disposal, including GPT-3, GPT-4, and LLaMA-2, each possessing its individual attributes and constraints. Designing a prompt capable of eliciting coherent responses from these models, while ensuring ease of use, presented a notable obstacle. To tackle this, we utilized two established engineering methodologies for prompting, taking into account the specific characteristics of each LLM [
19].
Model-agnostic content: We designed a prompt devoid of reliance on any particular architecture or familiarity with a specific LLM. This versatility enables our prompt to be easily adjusted and utilized across diverse models. Our emphasis was on formulating a prompt that effectively conveys the task, furnishing pertinent context and information understandable to any LLM.
Accessibility through output formatting: Recognizing the importance of formatting the output for ease of use, we emphasized designing an output format conducive to coding and accessibility. This entailed structuring the responses logically and intuitively, with a specific requirement for outputs to conform to the JSON format.
Following multiple rounds of iterations and experimentation involving various LLMs, we settled on a prompt that consistently yielded responses in the intended output format, understandable by both models, as depicted in Listing 1.
| Listing 1. Model-agnostic prompt. |
conversation.append({'role': 'system', 'content': "You are a spam filter."})
conversation.append({'role': 'user', 'content': 'Please parse the text and classify it. Return your response in JSON format as either spam {"Spam":1} or non-spam {"Spam":0}. Text:\n' + input['Text'] + ''}) |
3.3. Model Deployment, Fine-Tuning, and Predictive Evaluation
In this study, we address the critical task of spam detection and classification by employing four distinct models: GPT-4, BERT, RoBERTa, and CNN. While previous research has explored various algorithms for spam detection, there is a noticeable gap in leveraging LLMs for this purpose. Our approach involves subjecting these models to rigorous stress testing both before and after fine-tuning.
To begin, we curated two datasets from the Kaggle repository, detailed in
Section 3.1, and preprocessed them to facilitate easy adoption for training, validation, and testing. Subsequently, each model underwent fine-tuning on the respective datasets, followed by validation processes using dedicated validation sets. The trained models then made predictions on the test sets to classify email messages into spam or non-spam labels, with the results recorded in corresponding CSV files for later evaluation.
We further explored the generalization ability of these models across datasets through cross-dataset testing. This methodology involved the following steps:
Training and validation on Dataset 1: Each model was fine-tuned using the training and validation sets of the first dataset. This step allowed us to optimize model parameters and hyperparameters tailored to the specific characteristics of Dataset 1.
Testing on Dataset 1: Following training, we assessed the models’ performance on the test set of Dataset 1, gauging their ability to generalize to unseen data from the same distribution as the training data.
Testing on Dataset 2: Subsequently, the models’ performance was evaluated on the test set of Dataset 2, enabling us to measure their adaptability to data from a different distribution than what they were initially trained on.
To ensure fairness in our comparative analysis, we standardized certain hyperparameters across all models. This entailed setting a learning rate of 2 × 10−5, a batch size of 6, and conducting training for 3 epochs, alongside utilizing the Adam optimizer during the fine-tuning stage. Additionally, the CNN and GPT-4 models were trained with a maximum length of 4096 tokens, while the RoBERTa and BERT models were fine-tuned with a maximum length of 512 tokens.
Both the BERT and RoBERTa models are designed to accommodate up to 512 tokens during both fine-tuning and prediction phases, which roughly corresponds to about 2560 characters. If an email’s length exceeds this limit, the text is truncated to meet the specified length. While techniques like chunking or hierarchical processing can manage longer texts, they may introduce complexities and drawbacks. Similarly, the GPT model faces a token limit of approximately 4096 tokens, requiring truncation for longer texts during prediction.
The deployment of each model is outlined below, illustrating our unique approach to utilizing them for the task of spam detection and classification.
3.3.1. GPT Model Deployment and Fine-Tuning
In this phase, we initially employed the GPT-4 Turbo base model, also known as
gpt-4-0125-preview, to undertake the classification of spam and non-spam emails within the test set [
45]. Utilizing a particular prompt outlined in
Figure 1, we tapped into the extensive pre-training of LLMs, enabling them to adeptly discern nuanced cues within the provided texts, including email bodies and subjects, facilitating various classification tasks. Our approach entailed furnishing the LLM with the textual content extracted from emails, allowing it to comprehend the intricacies and core themes of spam embedded within the email bodies and subjects. Utilizing the official OpenAI API, we executed predictions and conducted fine-tuning on the
gpt-4-0125-preview base model. Furthermore, drawing from insights shared by Azure CTO Mark Russinovich, Azure incorporates innovative techniques such as Low-Rank Adaptation (LoRA) and Parameter-Efficient Fine-Tuning (PEFT) alongside DeepSpeed methodologies to optimize GPU utilization and improve memory efficiency during the fine-tuning process of the GPT-3 model [
46].
The predicted labels generated by GPT-4 underwent thorough scrutiny against the original labels within the datasets. This meticulous comparison facilitated a comprehensive analysis, enabling us to assess the base model’s efficacy in capturing the essence of emails and making classifications that closely match human assessments.
Throughout the fine-tuning process, the gpt-4-0125-preview model was immersed in vast amounts of data and adjustments to comprehend precise nuances and patterns within the training set. Employing a multi-epoch training strategy, the model iteratively refined its comprehension and abilities, gradually enhancing its performance on specific tasks. This iterative process ensured its preparedness for precise predictions and valuable insights during subsequent evaluations.
Two fine-tuning procedures were carried out, marked by the Job ID ft:gpt-4-turbo-0125:personal::9785aYKI and ft:gpt-4-turbo-0125:personal::9JlzpxAO. The first fine-tuning process involved training over 3,909,594 tokens, with the initial training loss starting at 0.3207 and gradually minimizing to near 0.0000. In comparison, the validation loss began at 0.1989 and decreased to below 0.0001 across three epochs. The second fine-tuning process involved training over 840,474 tokens, with the initial validation loss starting at 0.1007 and gradually minimizing to nearly 0.0000. In comparison, the validation loss began at 0.0125 and decreased to below 0.0076 across three epochs. These metrics underscore the remarkable effectiveness of the models for this particular task and their capacity for generalization during the fine-tuning process.
Upon the conclusion of the fine-tuning stage, the fine-tuned models were tasked with spam filtering, predicting the classification of emails within the corresponding test sets. The resulting outcomes were subsequently integrated into the same test_set.csv files, streamlining subsequent comparative analyses.
In order to streamline the fine-tuning process of the LLMs, four JSONL files were generated, containing pairs of prompts and completions, as depicted in Listing 2.
| Listing 2. JSONL files containing prompt and corresponding label pairs for fine-tuning in both training and validation datasets. |
{"messages": [{"role": "system", "content": "You are a spam filter."},
{"role": "user", "content": "Please parse the text and classify it. Return your response in JSON format as either spam {\"Spam\":1} or non-spam {\"Spam\":0}. Text:\n ..."},
{"role": "assistant", "content": "{\"Spam\":0}"}]} |
3.3.2. BERT and RoBERTa Models Deployment and Fine-Tuning
In this phase, we harnessed the power of both the bert-base-uncased and the
RoBERTa-base model for the spam email classification task [
47,
48]. Our decision to incorporate both models stemmed from a gap we identified in the existing literature, where RoBERTa had not been previously utilized for this specific task.
To achieve this, we utilized the
BertForSequenceClassification model from the transformers library. The foundational BERT model produces contextualized representations of input tokens through its transformer layers.
BertForSequenceClassification, a specialized version of BERT, includes an additional classification head tailored for sequence classification tasks. Typically, this classification head comprises a fully connected layer that converts BERT’s output into class probabilities. The
bert-base-uncased model, a variant of BERT, converts all input text to lowercase during training. Like the broader BERT architecture, this variant is transformer-based, with multiple layers and hidden units. The
bert-base-uncased model is characterized by 12 layers, 768 hidden units, 12 heads, and 110 million parameters [
49]. The self-attention mechanisms incorporated into BERT help capture contextual dependencies within input sequences.
RoBERTa, akin to
BERT-base, utilizes numerous layers of self-attention mechanisms to capture contextual connections within input sequences. RoBERTa is structured with a 12-layer transformer-based neural network featuring 768 hidden units, 12 attention heads, and a sum of 125 million parameters [
49]. Each layer in this design integrates self-attention mechanisms and feedforward neural networks, collectively improving the model’s capacity to grasp and depict complex relationships within sequential data.
For the prediction stage, we utilized the
BertForSequenceClassification and
RobertaForSequenceClassification models from the
transformers library, which involves loading the pre-trained model using the pre-trained method [
50].
During the fine-tuning phase, both the models were prompted to perform the email spam filtering classification task using the training sets composed of emails and their respective spam labels. This fine-tuning and prediction process took place on Google Colab, harnessing the computational power of a Tesla V100-SXM2-16 GB GPU. The datasets, sourced from a CSV file stored in Google Drive, underwent preprocessing, which involved tokenization utilizing the BERT and RoBERTa tokenizers. The fine-tuning process involved the meticulous specification of hyperparameters, including a learning rate of 2 × 10
−5, a batch size of 6, and the use of the Adaptive Moment Estimation (Adam) optimizer. Training spanned three epochs, with progress monitored using the
tqdm library. Backpropagation and optimization were conducted within the training loop, while validation utilized the same datasets as employed by the GPT-4 model. GPU availability was verified within the code to expedite computation. Following training, the fine-tuned model and tokenizer were saved to a directory in Google Drive for future use and predictions. Our code embodies a careful and thorough fine-tuning approach, ensuring alignment with the specific requirements of the email spam classification task and readiness for deployment. Post-fine-tuning, the models proceeded to generate predictions for the same test sets utilized by the GPT-4 model. The corresponding code along with training and validation losses and validation accuracy metrics are accessible within an
ipynb Jupyter file hosted on GitHub [
41].
3.3.3. Convolutional Neural Network (CNN) Deployment and Fine-Tuning
In this phase, a CNN was trained for email spam classification using TensorFlow 2.16.1 and Keras 3.3.3. The process began with importing the necessary libraries including Pandas for data manipulation and TensorFlow for building and training the neural network. Data preprocessing involved tokenizing text using the Tokenizer module and padding sequences to a fixed length using the pad_sequences method. The CNN architecture consisted of an Embedding layer, a Conv1D layer with ReLU activation, a GlobalMaxPooling1D layer, and two Dense layers with ReLU and sigmoid activations, respectively. The model was compiled using the Adam optimizer with binary crossentropy loss. Training was conducted over three epochs with a batch size of six. Training and validation datasets were loaded, preprocessed, and fed into the model. The trained model was then saved for future use. Finally, training loss, validation loss, validation accuracy, and training time were recorded.
The prediction phase involved loading the test dataset and extracting text data from the Text feature column. The text data is then tokenized using a Tokenizer object initialized and fitted on the test text data. Subsequently, the text sequences are padded to match the maximum length specified during training. The trained CNN model is loaded from the specified path, and predictions are made on the test sets using the loaded model. These predictions are then converted to binary labels based on a predefined threshold, typically 0.5, and added as a new column to the test data frames. Finally, the predicted labels are saved back to the CSV files for further analysis. This process ensures efficient utilization of the trained model for real-world predictions on unseen data.
4. Results
In
Section 3, we explore the methodological framework used to evaluate the predictive abilities of the GPT-4 LLM, BERT, and RoBERTa NLP models, as well as the CNN model, within the realm of email filtering and classification, aiming to comprehend their intricacies. This section unveils the outcomes of the comparative analysis conducted between the two models at the different phases of our study.
4.1. Fine-Tuning Metrics across Model Architectures
Throughout the fine-tuning phase, we capture essential metrics for each model such as Training Loss, Validation Loss, and Training Time, which are detailed in
Table 1.
It is crucial, however, to mention that directly comparing validation and training losses between fine-tuned NLP models, LLMs, and CNNs might not be straightforward due to several factors:
Model architecture: The aforementioned models have different architectures, although they are trained for classification tasks. BERT and RoBERTa are transformer-based models primarily used for tasks like text classification, while GPT-4, although it is transformer-based, is a language model designed for generating human-like text and can be adapted for classification tasks as well. CNNs, on the other hand, have a different architecture optimized for tasks like image recognition, but they are also widely used in text classification tasks. While transformers capture long-range dependencies in sequences, CNNs excel at capturing local patterns in data. This architectural distinction influences how information is processed and encoded, thus affecting loss calculation and interpretation.
Training process: The fine-tuning process for NLPs typically involves training on a specific downstream classification task with a labeled dataset. Similarly, LLMs can be fine-tuned for classification tasks by training them on labeled data. In contrast, CNNs are trained using labeled datasets for tasks such as image classification or text classification. Despite differences in input data type and model architecture, all three types of models undergo a supervised learning process with labeled data, though the specific training procedures may vary.
Loss metric interpretation: Even if these models provide validation and training losses, interpreting these losses can be different. In classification tasks, the loss typically represents how well the model is predicting the correct class labels. For BERT and similar NLP models, the loss reflects the model’s ability to classify text accurately. In contrast, for GPT-4 and other LLMs, the loss may indicate how well the model generates text consistent with the labeled class. For CNNs, the loss is associated with the model’s ability to discriminate between different classes based on input features. The interpretation of loss thus varies based on the nature of the task and the model architecture.
Loss magnitude: The absolute values of loss may not be directly comparable between models due to differences in scale, loss calculation methods, and optimization algorithms. Additionally, factors such as the complexity of the classification task, the size and diversity of the training dataset, and the model architecture can all influence the magnitude of loss. These factors highlight the importance of considering contextual factors when interpreting loss metrics in classification tasks across different model types.
4.2. Model Evaluation Phase
Prior to sharing our results, it is imperative to underscore the significance of model evaluation. In the domains of machine learning and NLP, assessing models holds pivotal importance, offering invaluable insights into the performance and efficacy of our fine-tuned models. Model evaluation serves as a guiding beacon, facilitating informed decisions regarding their applicability and simultaneously propelling us towards continuous improvements in fine-tuning and optimization tailored to particular applications.
Table 2 and
Table 3 encapsulate a comprehensive array of evaluations for each model and dataset, incorporating a suite of crucial evaluation metrics. Additionally, these tables capture the performance of trained models in cross-dataset evaluation.
4.3. GPT Base Model Evaluation Phase
In the early stages of our research, we deployed the GPT-4 LLM base model, denoted as gpt-4-0125-preview, to address the task of email spam filtering across two distinct test sets comprising 1146 and 1114 email samples. Our primary objective revolved around assessing the model’s accuracy in distinguishing between spam and non-spam emails.
Upon meticulous examination of the model’s responses and subsequent comparison with the original user-provided labels, we noted some significant observations. The gpt-4-0125-preview model demonstrated a commendable level of accuracy, accurately predicting 98.25% and 93.80% of the relevant class instances within the first and second test sets, respectively. This equates to successful classifications for 1126 and 1045 out of the 1146 and 1114 emails comprising our test sets. These findings indicate that even the base model, without any specific fine-tuning, possesses a notable ability to discern spam content based on contextual cues.
It is crucial to underscore that attaining a 98.25% accuracy rate in predictive modeling is exceptionally high, suggesting that the model can be confidently utilized for spam filtering and classification tasks.
Nevertheless, the efficacy of the models can be improved by fine-tuning them to suit the particular task at hand. The fine-tuning process can improve their ability to grasp and interpret complex patterns and relationships within the data.
4.4. Fine-Tuned Models Evaluation Phase
In the next stage of our investigation, we delved into the fine-tuning process, focusing on enhancing the performance of the GPT-4 model. Concurrently, we subjected the BERT, RoBERTa, and CNN models to identical fine-tuning procedures. This involved utilizing two training sets comprising 3665 and 3565 email samples, respectively. Our overarching objective was to refine the models’ performance and enhance their adaptation specifically for the spam filtering task.
Following the fine-tuning process, we evaluated the performance of the fine-tuned models by testing their ability to predict spam labels in their respective test sets.
The outcomes of this phase yielded highly promising results. Post-fine-tuning, the GPT-4 models exhibited a significant enhancement in predictive capabilities, achieving a remarkable 99.3% accuracy for the first test set and 98.29% for the second. Similarly, the fine-tuned BERT models demonstrated impressive improvements, achieving accuracies of 99.39% and 99.01%, respectively, while the RoBERTa models achieved accuracies of 99.04% and 98.38%. In contrast, the CNN model exhibited accuracies of 76.09% and 86.62%, indicating a comparatively lower performance following fine-tuning.
4.5. Assessing Models’ Performance and Proximity with Original Labels
To gain insights into both the base and fine-tuned models’ performance and assess the alignment between their predictions and the original spam labels provided by users, we utilized the mean_absolute_error class from the sklearn library. The Mean Absolute Error (MAE) quantified the disparity between the models’ predictions and the original ratings provided by users. These MAE values provided crucial insights into the accuracy of different NLP models across various fine-tuning configurations. A lower MAE indicates that, on average, the model’s predictions are closer to the true values, reflecting superior accuracy, predictive capabilities, and overall performance.
For instance, the base gpt-4-0125-preview model demonstrates an MAE of 0.01745 for the first test set and 0.06193 for the second, reflecting the average absolute differences between its predictions and the true values. Following fine-tuning on the training sets, GPT-4 showcases MAEs of 0.006980 and 0.0170, RoBERTa exhibits 0.00959 and 0.0161, BERT records 0.0061 and 0.0098, while CNN presents 0.2390 and 0.1337.
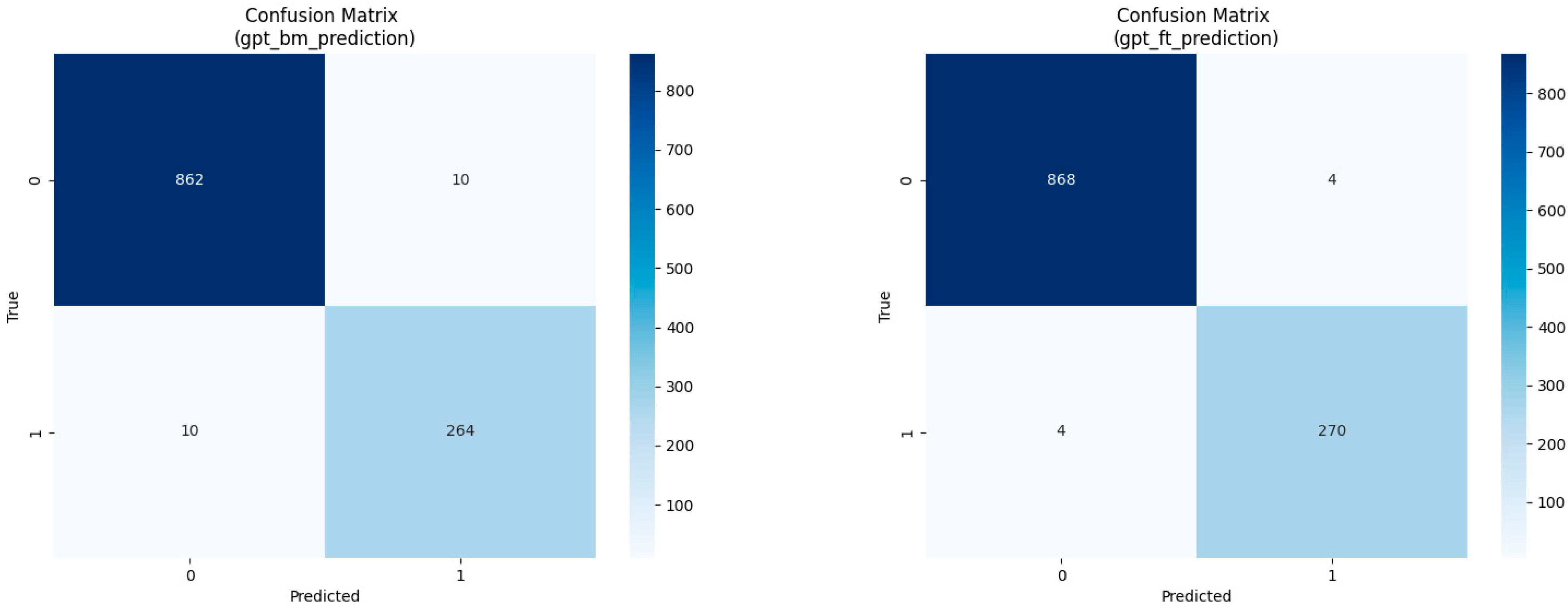
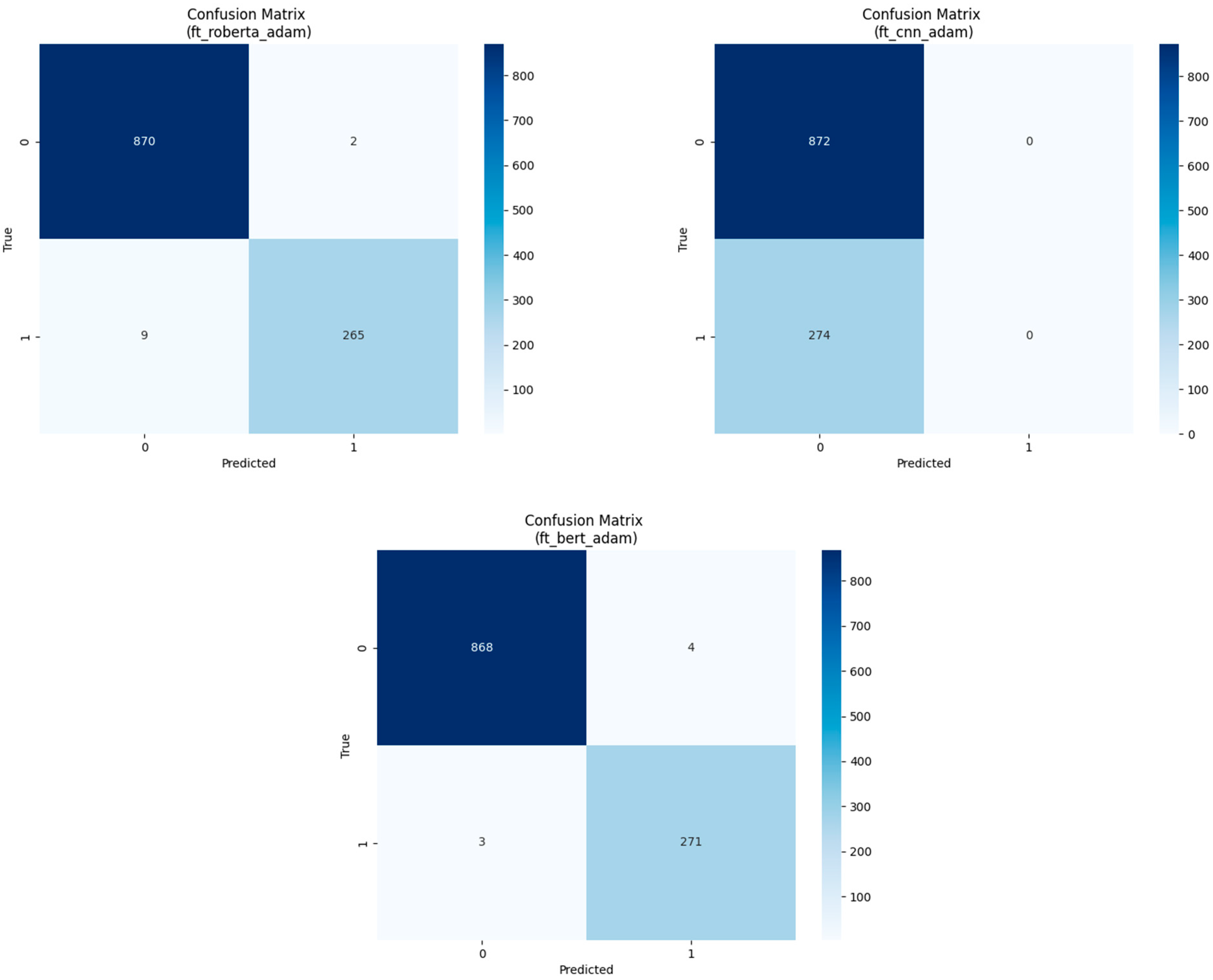
While initially intending to employ scatterplots to visualize the distribution of predicted values in contrast to the original ones, we encountered a challenge. The exceptionally high accuracy percentage resulted in nearly identical plots, rendering them insufficient for meaningful interpretation. Consequently, in
Figure 3 and
Figure 4, we opted to present confusion matrices instead. This decision offers readers a more representative depiction of the prediction distribution, facilitating a deeper understanding of the models’ performance. To maintain brevity, we focused on presenting the models’ matrices for the first dataset.
5. Research Findings and Discussion
In the previous sections, we delved into the methodology and outcomes of assessing the predictive capabilities of the GPT-4 model in email spam detection, both before and after fine-tuning. We applied a similar fine-tuning approach to BERT, RoBERTa, and CNN models across two distinct datasets.
Section 4 provides a comprehensive analysis of our evaluation results, covering the performance of these models across the datasets and their efficacy in a cross-dataset evaluation setting. This section reveals the research findings and insights obtained by the authors regarding the effectiveness of LLMs and NLPs as valuable tools for spam filtering, while also addressing relevant research inquiries.
5.1. Fine-Tuned Model Comparison
Research Question 1: Which of the fine-tuned models—GPT-4, BERT, RoBERTa, or CNN—exhibits the most effective predictive abilities in email spam detection?
Research Statement 1: Each fine-tuned model exhibited high accuracy in filtering spam emails. Specifically, the GPT-4 model achieved a remarkable accuracy of 99.3%, slightly edging out the RoBERTa model by approximately 0.17%. Conversely, the BERT model outperformed the GPT-4 model by 0.09%, while the CNN model lagged behind with a prediction accuracy of 76.09%.
In
Section 4.4, we presented the results of our examination into the effectiveness of fine-tuned GPT-4, BERT, RoBERTa, and CNN models in spam detection. These models were trained on two distinct training sets and tasked with predicting labels for two separate test sets.
For the first test set, the BERT model demonstrated superior predictive capabilities, correctly predicting 99.39% of the labels, followed closely by the GPT-4 model at 99.4%, then the RoBERTa model at 99.04%, and finally the CNN model at 76.09%.
In the case of the second test set, the BERT model once again led with a prediction accuracy of 99.01%, followed by the RoBERTa model at 98.38%, the GPT-4 model at 98.29%, and the CNN model at 86.62%.
This slight variation could be attributed to differences in their respective pre-training phases. While the GPT-4 model has been exposed to a wider and more diverse range of public datasets, it achieved slightly less accurate predictions compared to the NLP models.
Conversely, the CNN model, as a traditional method for detecting spam emails, exhibited a significantly lower accuracy compared to the NLP models and the GPT-4.
It is worth noting our observations from the confusion matrix (
Figure 4). While the GPT-4 and NLP models excelled in predicting both 0 and 1 labels, the CNN model struggled particularly with the 1 label (spam), evident in the bottom-right cell. Several factors could contribute to this, including less effective hyperparameters chosen for training all models. However, the most significant factor appears to be the imbalance in the data, as discussed in
Section 3.1. Despite efforts to address data imbalance in the other models, the CNN model appears more vulnerable to its effects.
It is also essential to grasp how various fine-tuning strategies can affect model performance. As detailed in
Section 3.3 of this research, we opted to fine-tune our models on an equal basis to ensure fairness in our comparative analysis. We utilized specific hyperparameters consistently across all models, such as a learning rate of 2 × 10
−5, a batch size of 6, and three epochs of training, employing the Adam optimizer throughout the fine-tuning process. Moreover, the CNN and GPT-4 models underwent training with a maximum token length of 4096, while the BERT and RoBERTa models were fine-tuned with a maximum token length of 512.
While our methodology offers clear insights into model comparisons, it is crucial to note that each model possesses its own intricacies, and experimenting with different hyperparameters may yield more effective results than those presented in this study.
5.2. Base versus Fine-Tuned GPT Model Comparison
Research Question 2: Why is fine-tuning LLMs and NLP models essential for tasks specific to particular domains?
Research Statement 2: Fine-tuning empowers the model to tailor its existing knowledge to the unique characteristics of the target task and dataset. In our case study, the observed improvement after fine-tuning was 1.05% for the first dataset and 4.48% for the second dataset post-fine-tuning. However, this margin has the potential to expand further with the utilization of a larger dataset.
Customizing LLMs and NLP models through fine-tuning for domain-specific tasks is crucial for maximizing their utility in real-world scenarios. Models such as OpenAI’s GPT-4, BERT, and RoBERTa are initially trained on extensive text datasets from various sources, enabling them to comprehend and generate human-like text across diverse domains. However, fine-tuning these models for specific tasks, such as spam filtering, enhances their performance and applicability in specialized contexts.
For instance, the gpt-4-0125-preview base model achieved 98.25% accuracy in spam classification. However, after fine-tuning on the first dataset, its accuracy surged to 99.3%, marking a significant 1.05% enhancement, and an even more notable 4.48% improvement for the second dataset. This improvement underscores the importance of fine-tuning LLMs like GPT-4 for domain-specific tasks. By fine-tuning the model on a larger and more representative dataset, it gains a deeper understanding of the intricacies and patterns unique to spam detection, resulting in more precise predictions.
Fine-tuning enables the model to adapt its existing knowledge to the specific characteristics of the target task and dataset. In spam classification, this adaptation might involve learning to identify spam-related words, comprehend context, and extract pertinent features from text inputs. Through iterative adjustments during the fine-tuning process, utilizing both the training and validation sets, the model becomes increasingly adept at capturing these domain-specific nuances, leading to improved performance metrics such as accuracy.
5.3. Cross-Dataset Evaluation of Model Performances
Research Question 3: Which of the fine-tuned models exhibits superior generalization abilities following cross-dataset evaluation?
Research Statement 3: The GPT-4 fine-tuned model attained an accuracy of 94.33% on the opposite dataset, indicating its superior generalization compared to the BERT and RoBERTa models.
In
Section 3.3, we outlined our focus on assessing the models’ generalization capabilities using the cross-dataset evaluation approach. During this phase, we tasked the trained models with making predictions on the test sets of both datasets, each trained on the opposite dataset. The results of this cross-dataset evaluation are detailed in
Table 2 and
Table 3.
Upon examining the outcomes for the first dataset, we noted that the GPT-4 model, trained on the second dataset, achieved an impressive 94.33% accuracy on predictions for the test set of the first dataset. In contrast, the BERT and RoBERTa models demonstrated significantly lower accuracies, reaching only 58.46% and 61.61%, respectively. Conversely, the CNN model achieved an accuracy of 76.09%.
Similarly, for the second dataset, we observed that the GPT-4 model, trained on the first dataset, attained a noteworthy 90.13% accuracy on predictions for the test set of the second dataset. In comparison, the BERT and RoBERTa models exhibited lower accuracies, recording only 59.16% and 62.57%, respectively. Conversely, the CNN model achieved a relatively high accuracy of 86.62%.
These findings indicate that the GPT-4 model effectively retained the knowledge acquired during training, showcasing superior generalization abilities across different datasets compared to the RoBERTa and BERT models.
5.4. Exploring the Significance of Prior-Training Data Analysis and Plots Post-Fine-Tuning
Research Question 4: What is the significance of prior-training data analysis, and how can plots provide valuable insights into the effectiveness of models’ predictions?
Research Statement 4: Both prior-training data analysis and post-fine-tuning plots play pivotal roles in shaping the quality of training and the accuracy of models’ predictions.
Exploring the significance of prior-training data analysis and plots post-fine-tuning underscores the crucial role of understanding and adapting to pre-existing knowledge in machine learning models. Prior-training data analysis provides essential insights into dataset characteristics, guiding fine-tuning strategies, while post-fine-tuning plots offer visual narratives of model performance, aiding in diagnostics, interpretability, and the identification of overfitting or underfitting tendencies. This iterative process not only optimizes model performance but also fosters transparency, accountability, and trust in AI systems, ultimately driving transformative advancements in AI-driven solutions.
Examining the confusion matrix plots from
Section 4.3 provides valuable insights into the behavior of models after fine-tuning. In
Figure 3, both the base and fine-tuned GPT-4 models exhibit a balanced distribution of false positives and false negatives, indicating comparable error rates across labels. However, in
Figure 4, focusing on the RoBERTa fine-tuned model, we observe a distinct pattern: false predictions are primarily directed towards the 0 label, suggesting that the RoBERTa model struggles to discern the 0 label within the context of spam emails. Armed with these insights, further optimizations can be pursued through adjustments to enhance overall models’ performance.
Conducting a comprehensive data analysis on the dataset before fine-tuning is essential for understanding potential errors prior to introducing false data to the model. This prior-training data analysis enables us to identify the labels within our dataset and ascertain its distribution, a critical factor influencing the training process and subsequent predictions. Instances where labels are unevenly distributed can significantly impact both training and predictive accuracy. Additionally, it is imperative to emphasize the importance of employing proper cleaning techniques before fine-tuning. Addressing issues such as noise, extra spaces, capitalization, and symbols within the data is crucial, as these factors can adversely affect both the training process and the accuracy of predictions.
5.5. The Role of LLMs and Their Potential to Enhance Existing Spam Filter Technologies
Research Question 5: Are LLMs, specifically the GPT-4 model, efficient tools for spam detection, and how can they be used to enhance existing spam filter technologies?
Research Statement 5: The GPT-4 model, with its advanced natural language processing capabilities, presents a formidable opportunity to revolutionize spam detection, adeptly discerning intricate text patterns and subtle linguistic indicators to effectively differentiate between legitimate messages and spam, thus fortifying existing filters, adapting to evolving spam tactics, and promising more efficient filtering, thereby bolstering cybersecurity measures significantly.
LLMs, especially the GPT-4 model, present exciting opportunities to bolster spam detection thanks to their advanced NLP capabilities. Through thorough comprehension of language nuances, GPT-4 can detect intricate text patterns, significantly improving the differentiation between legitimate messages and spam. Its ability to extract features and classify content further enhances existing spam filters by pinpointing subtle linguistic indicators of spam, like repetitive phrases, deceptive language, or irregular syntax. What is more, GPT-4 continuously adapts to evolving spam tactics by learning from new data, thus fortifying spam filters against emerging threats. Integrating GPT-4 into existing spam detection systems promises more efficient filtering, curbing the prevalence of unwanted messages and fortifying overall cybersecurity measures. Additionally, the adaptability of LLMs like GPT-4 to specific domain fine-tuning is a pivotal advantage in spam detection. By fine-tuning the model with data from various industries—such as finance, healthcare, or technology—it gains a deeper understanding of the unique language patterns and contexts within these sectors. This tailored approach facilitates more precise identification of industry-specific spam messages, which may contain specialized jargon or themes. The model’s capacity for continuous updating and refinement ensures it remains abreast of new spam tactics and trends within these domains, rendering it a dynamic and effective tool for improving existing spam filter technologies. Our research underscores the exceptional pattern discernment capabilities of the GPT-4 model, particularly after fine-tuning, highlighting its significant potential in combating spam emails.
Addressing the practical applications of advanced, fine-tuned language models against sophisticated spam attacks is crucial. In a world where time and cost are primary concerns for busy organizations, leveraging LLMs and NLPs presents an instant and cost-effective solution to combat spam. With the assistance of an artificial intelligence team and by utilizing our openly available reusable classes on GitHub, companies can easily fine-tune the models on their specialized datasets at minimal expense. NLPs can be fine-tuned on the cloud, and the GPT-4 model can be fine-tuned through the official API with a small fee. Once the models are trained, companies can adopt a continuous fine-tuning process by monitoring the actions of individuals within the organization, enabling the models to adapt to new threats effortlessly.
The fine-tuned models can operate in the background as intermediaries between users and email servers, classifying emails within milliseconds. In terms of cost, although the GPT-4 model can only be run and fine-tuned through the official API, it proves to be a more robust solution without requiring an entire team to update the code base and maintain servers.
6. Conclusions
In conclusion, this paper has proposed novel approaches to combat the persistent challenges posed by spam emails and phishing attacks, which continue to threaten email users worldwide. By harnessing the capabilities of cutting-edge technologies such as the GPT-4 LLM and the BERT and RoBERTa NLPs, fine-tuned with few-shot learning specifically for spam classification tasks, we have introduced next-generation spam filtering solutions. Through our research, which involved a comprehensive literature review, experimentation, an exhaustive evaluation with cross-dataset assessment, and comparative model analyses, we have demonstrated the effectiveness of fine-tuned LLMs and NLPs in direct comparison with traditional methods such as CNNs.
Spammers continuously evolve their strategies; the same should be true for spam detection systems. Future works could examine and enhance models’ robustness against adversarial attacks, providing more accurate predictions against more sophisticated threats and strengthening the protection provided by the systems. This research significantly contributes to the advancement of spam filtering techniques and lays a solid foundation for the development of robust email security systems based on LLMs, capable of mitigating increasingly sophisticated threats in the digital landscape.









{kind=link}
{kind=link}
{kind=link}
{kind=link}