
Deep-Reinforcement-Learning-Based Collision Avoidance of Autonomous Driving System for Vulnerable Road User Safety




Abstract
1. Introduction
2. Methodology
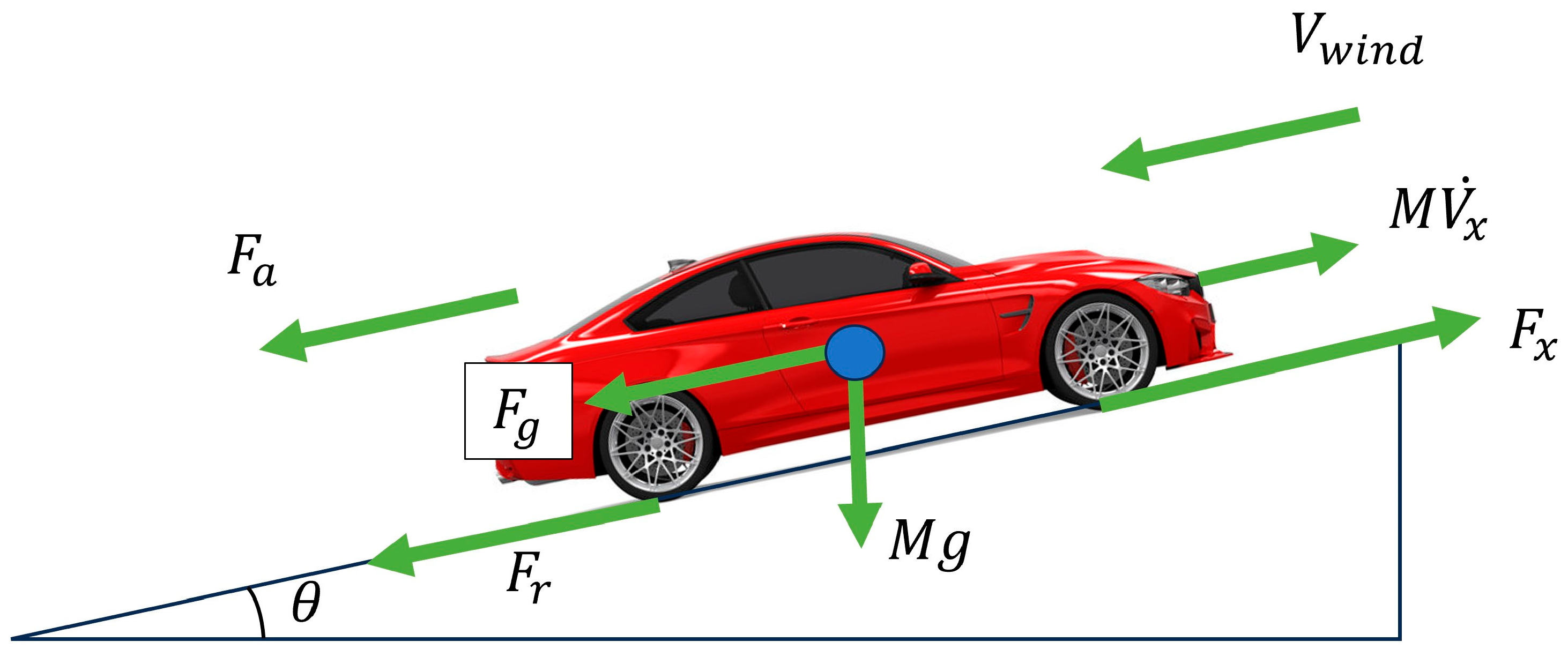
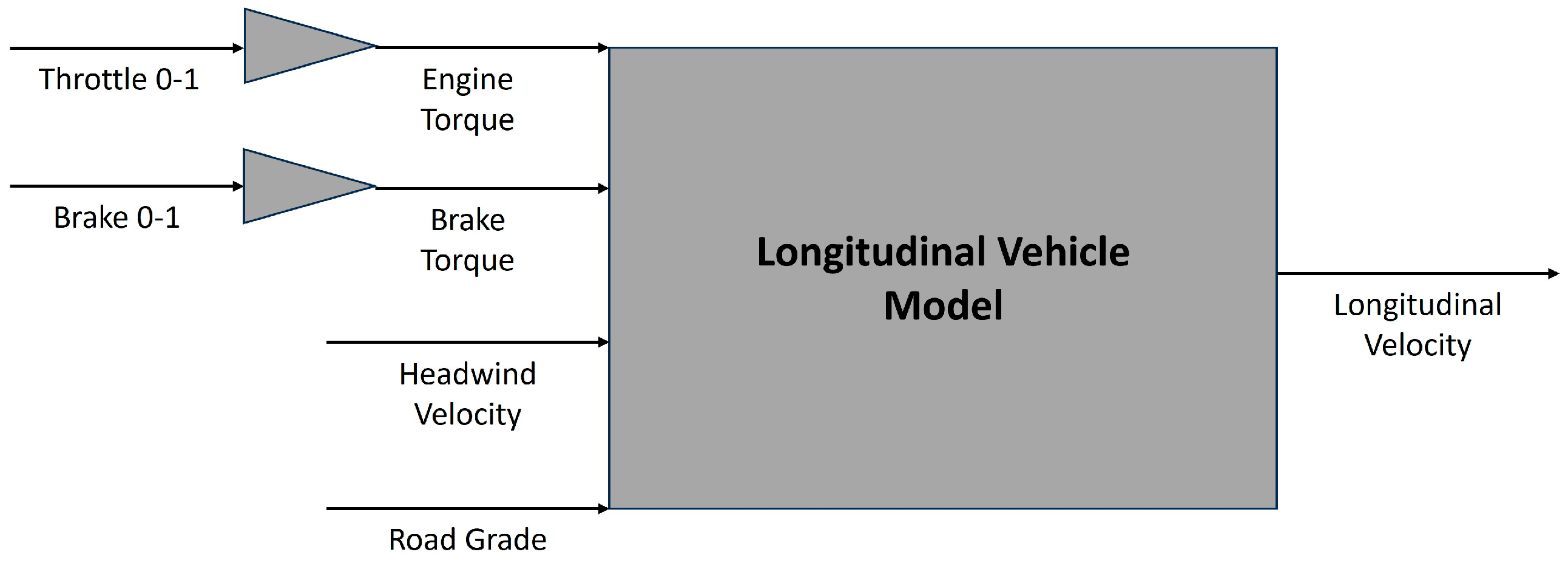
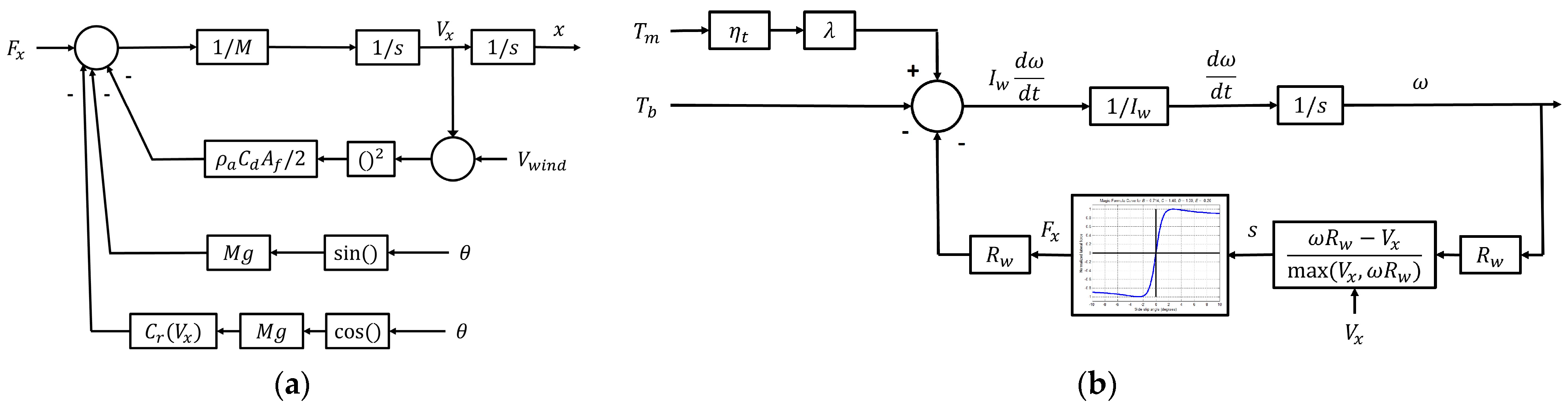
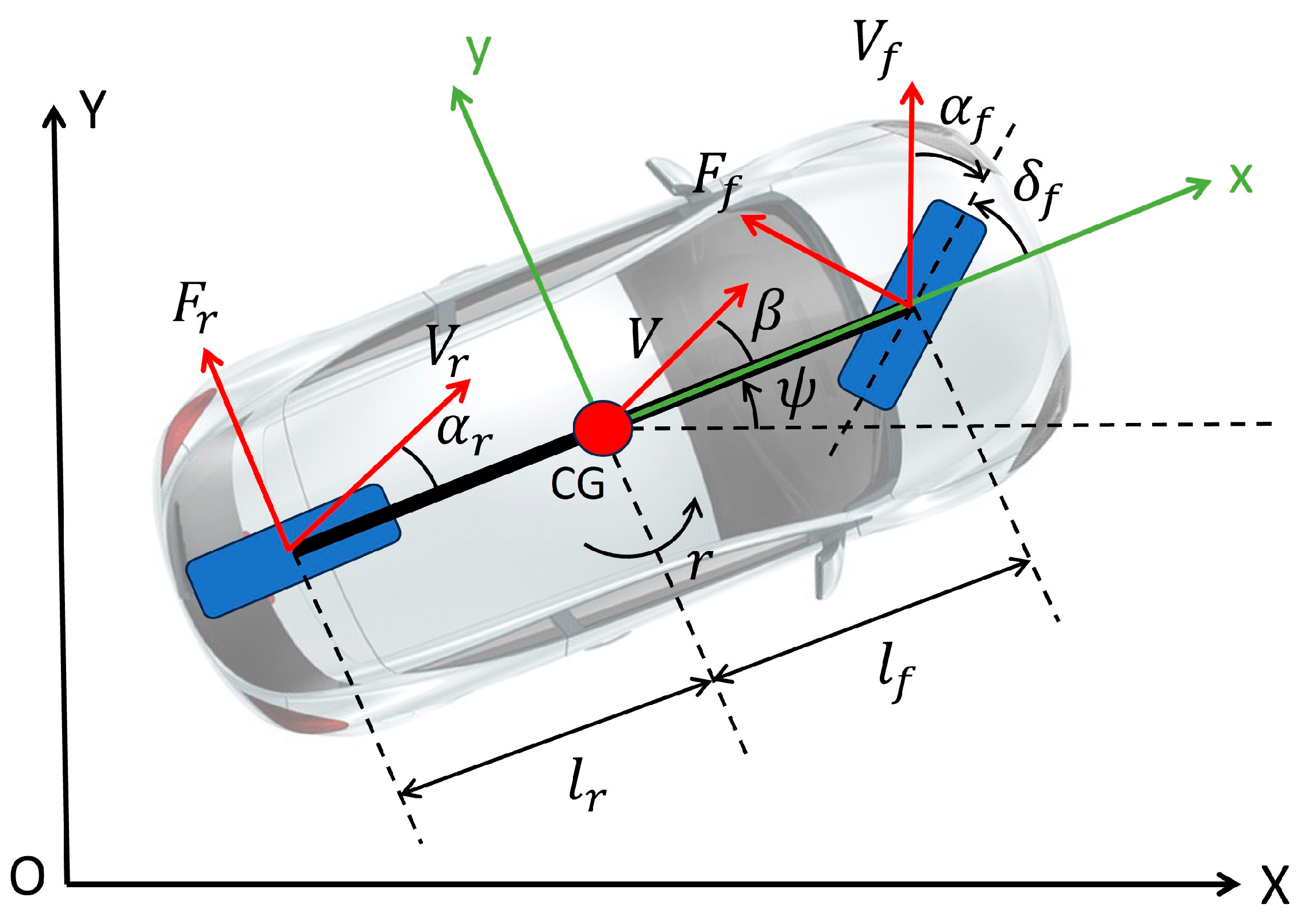
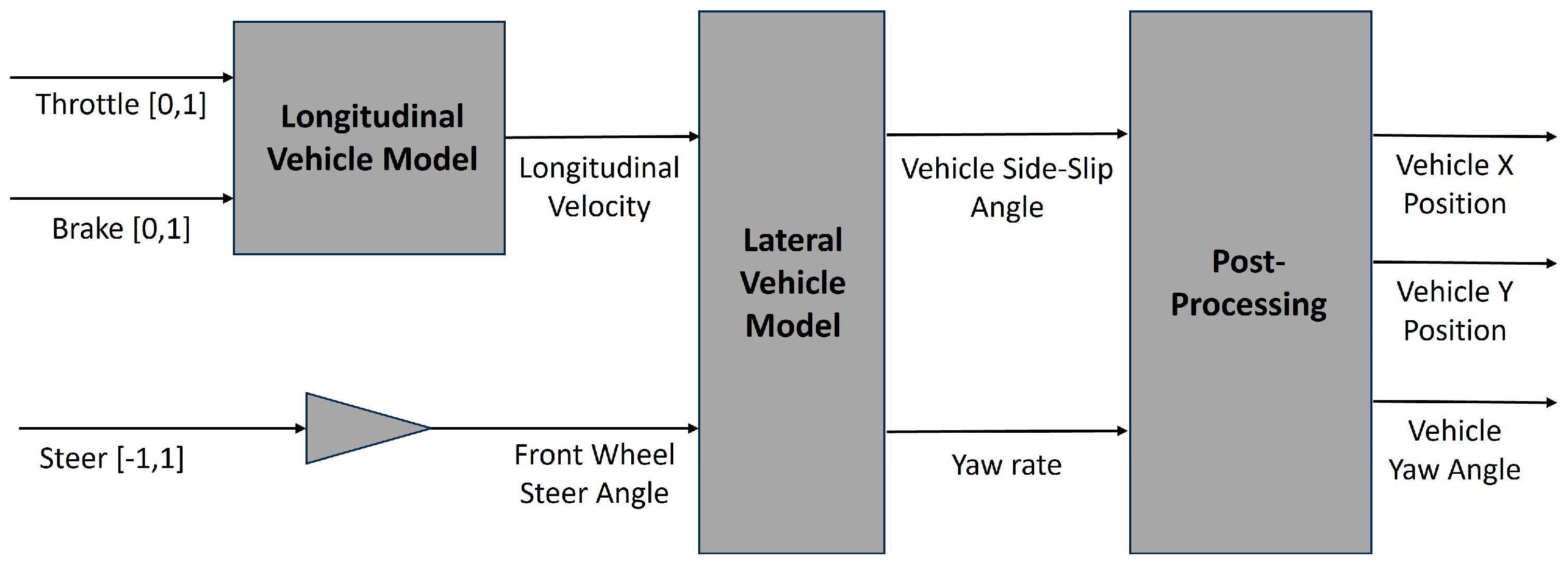
2.1. Vehicle Model
2.2. Autonomous Driving System Design
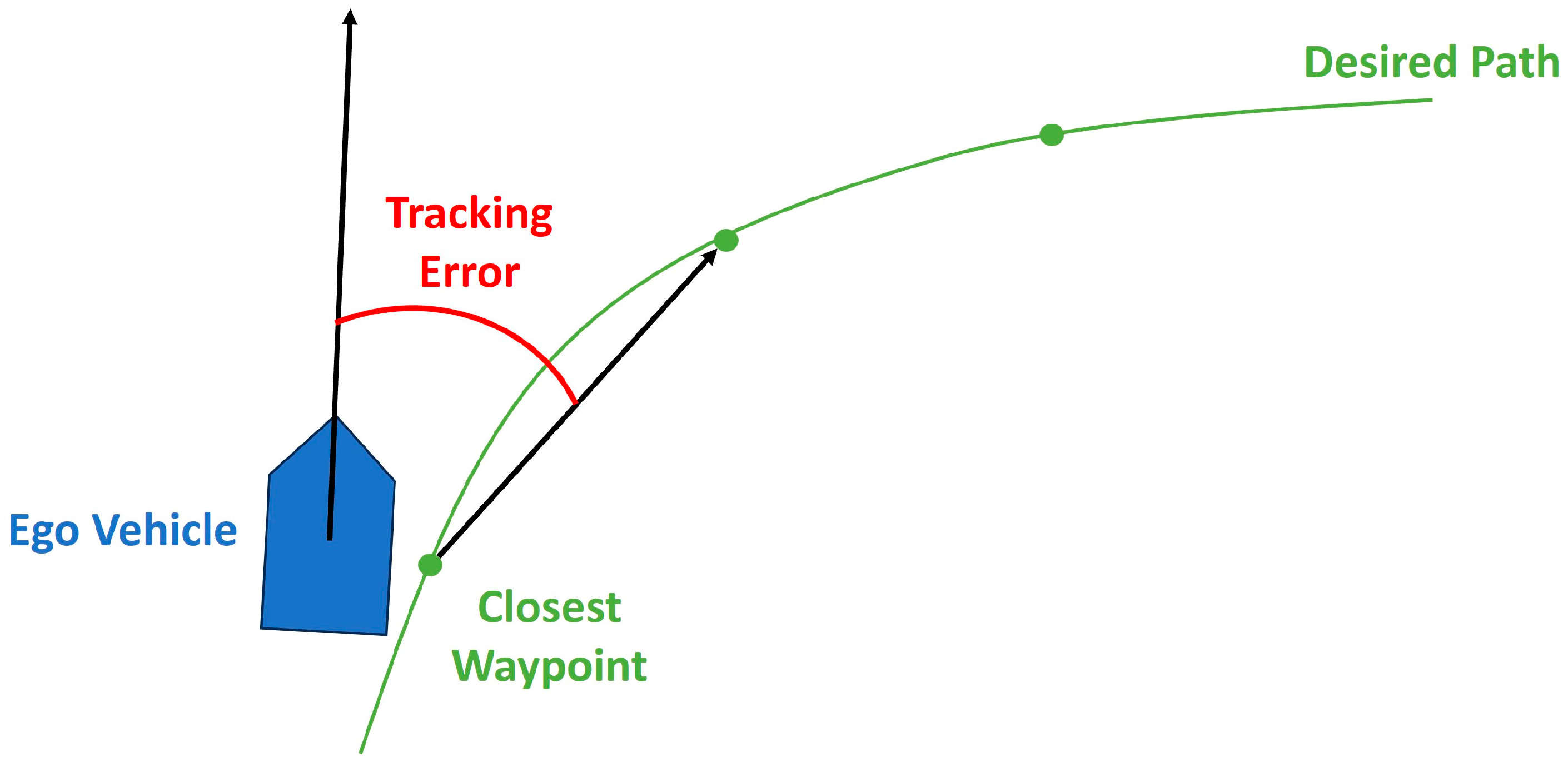
2.2.1. PID Pure Pursuit Controller Design
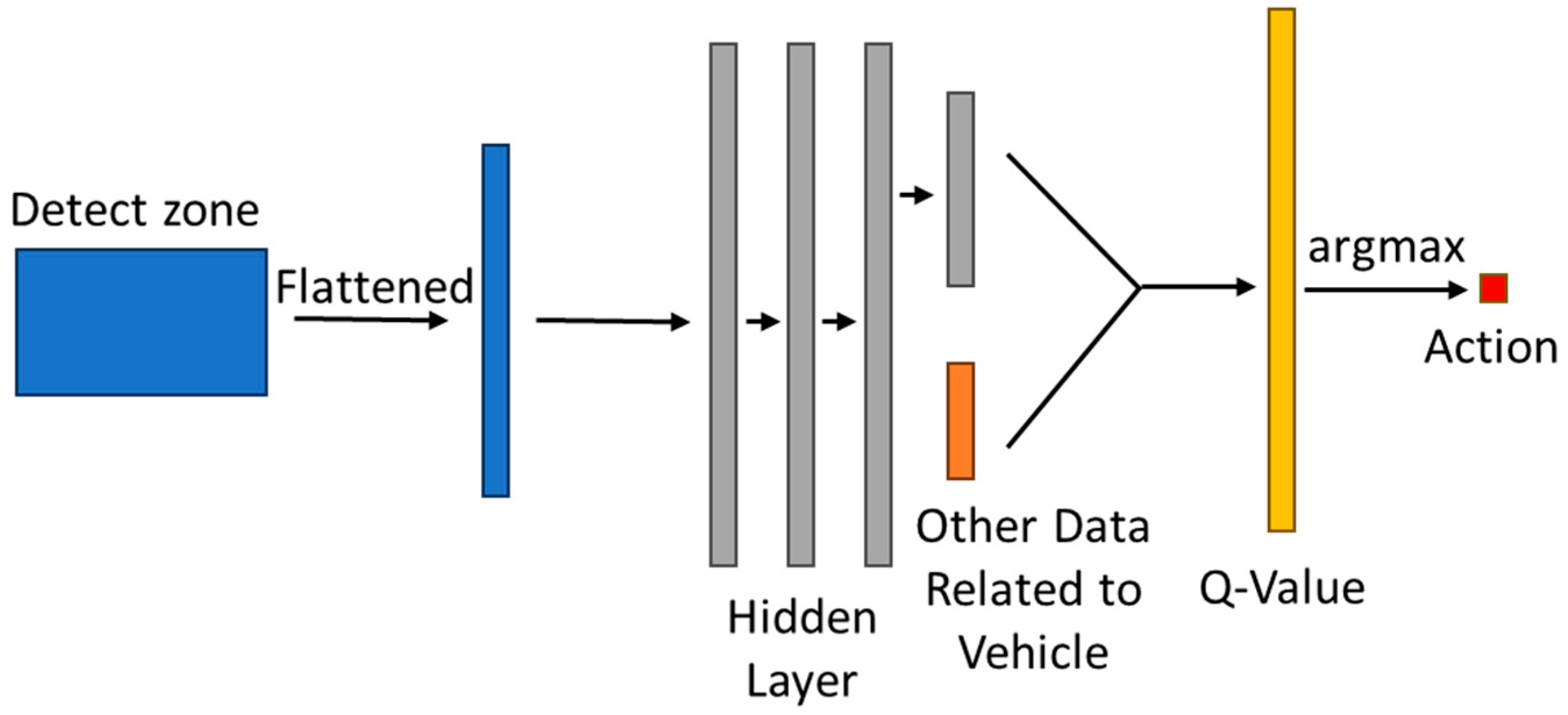
2.2.2. Markov Decision Process and Deep Reinforcement Learning
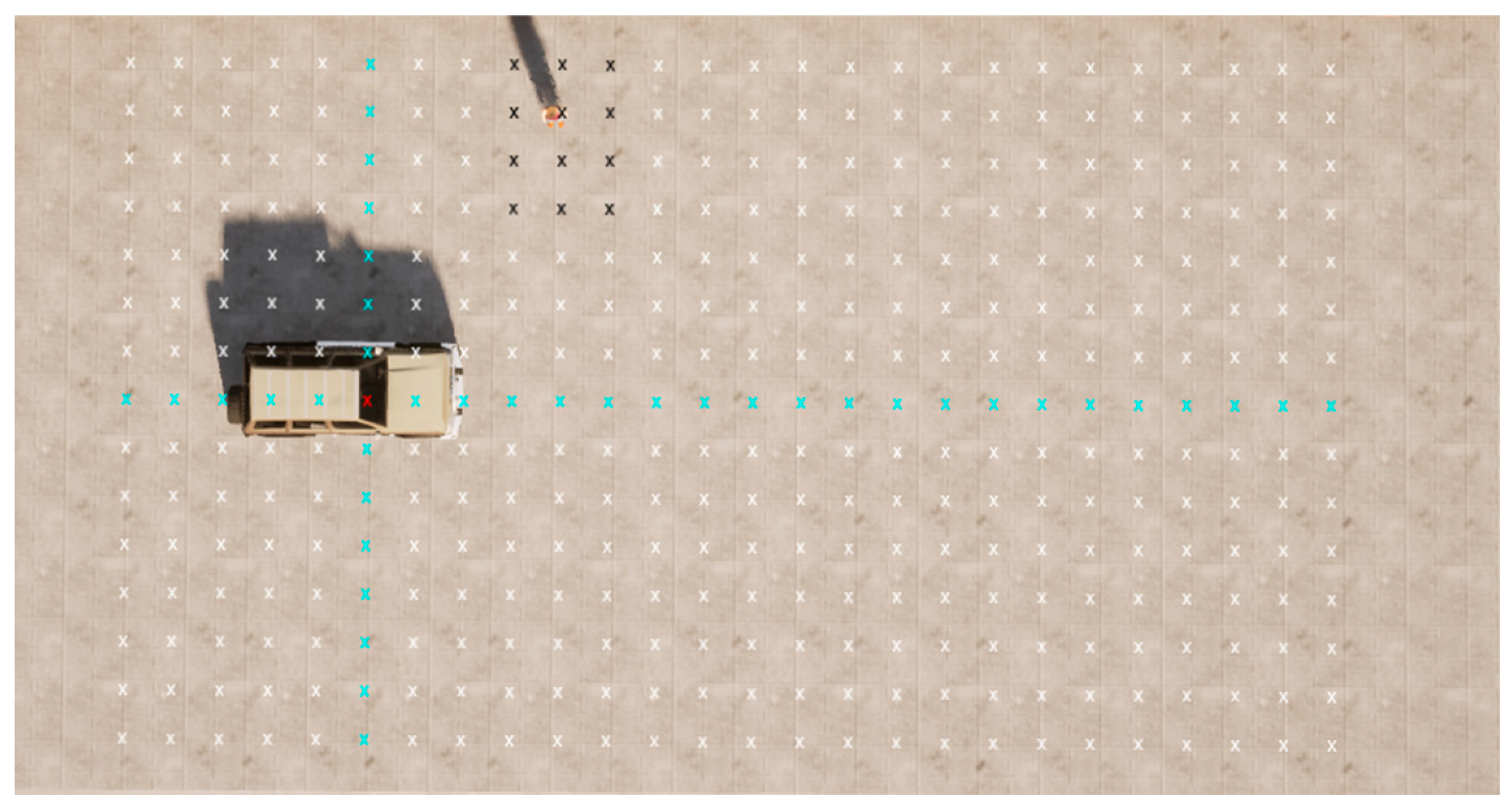
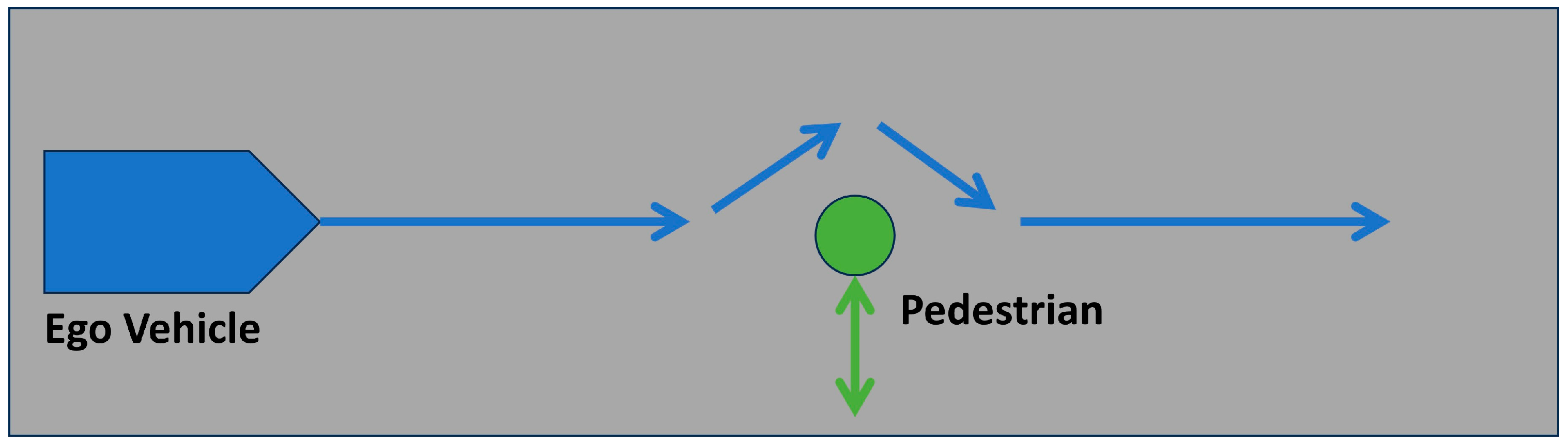
- State space (S): The state space contains a collection of states that represent the current traffic environment’s information. Each state within the state space consists of four essential components. Firstly, an occupancy grid represented by a 2D array is utilized to map the surrounding obstacles relative to the vehicle. The occupancy grid can identify other road users as obstacles within a specified range and assign a weight to each grid based on the importance of nearby road users. A relatively higher weight will be assigned to vulnerable road users (VRUs). In this paper, the detection ranges are defined as 20 m forward, 5 m backward, and 7 m to the sides. Figure 7 and Figure 8 demonstrate the occupancy grid for a vehicle with zero yaw angle orientation and non-zero yaw angle orientation, respectively. In the figure, the cross symbols are used to indicate the proposed occupancy grid: white crosses for collision-free areas, black for potential collisions with the pedestrian, red for the vehicle’s geometric center, and blue for the vehicle’s vertical and horizontal coordinates. In practical implementations, the occupancy grid is typically derived through the fusion of data from multiple sensors, such as the lidar, camera, and radar. However, the purpose of this study is to validate the proposed hybrid controller. Thus, to simplify the data collection procedure, the occupancy grid array data are extracted and processed from the simulation environment through frame transformation techniques, enabling precise collision detection for each array point with obstacles. The second component contains the ego-vehicle’s data, such as its location, orientation, and velocity. The third component contains information regarding the pre-calculated path, including target-tracking waypoints. Lastly, the fourth component contains obstacle information, including the vehicle time-to-collision-zone (TTZ_v), the pedestrian time-to-collision-zone (TTZ_p), and the difference between vehicle and pedestrian time-to-collision-zones (TTZ_diff).
- Action space (A): The action space contains a collection of discrete actions available to the ego-vehicle in response to varying traffic scenarios. The action is defined as a control command tuple consisting of steering, throttle, and brake commands. The configuration of the action space is designed according to the specific requirements of different test cases.
- Transition model (P): The transition model is the key component of traffic simulation designed to simulate next states based on the execution of a given action at the current state and the transition probability. This paper divides the transition model into two major parts. Firstly, a SIMULINK vehicle model simulates the motion of the ego-vehicle. At the same time, the CARLA simulator is used to simulate the traffic environment and the motion of other road users. The details of the vehicle model have been discussed in previous sections, while the details of the traffic simulator are elaborated within the case study section.
- Reward (r): A reward function is used to calculate the immediate reward for each step based on the transition from the current state to next state after executing specific actions. The details of the reward function’s design are elaborated within the case study section.

| Algorithm 1. DDQN |
| 1: Initialize replay memory |
| 2: Initialize target network and Online Network with random weights |
| 3: for each episode do |
| 4: Initialize traffic environment |
| 5: for t = 1 to T do |
| 6: With probability select a random action |
| 7: Otherwise select |
| 8: Execute in CARLA and extract reward and next state |
| 9: Store transition ( |
| 10: if t mod training frequency == 0 then |
| 11: Sample random minibatch of transitions ()) from D |
| 12: Set |
| 13: for non-terminal |
| 14: or for terminal |
| 15: Perform a gradient descent step to update |
| 16: Every N steps reset |
| 17: end if |
| 18: Set |
| 19: end for |
| 20: end for |
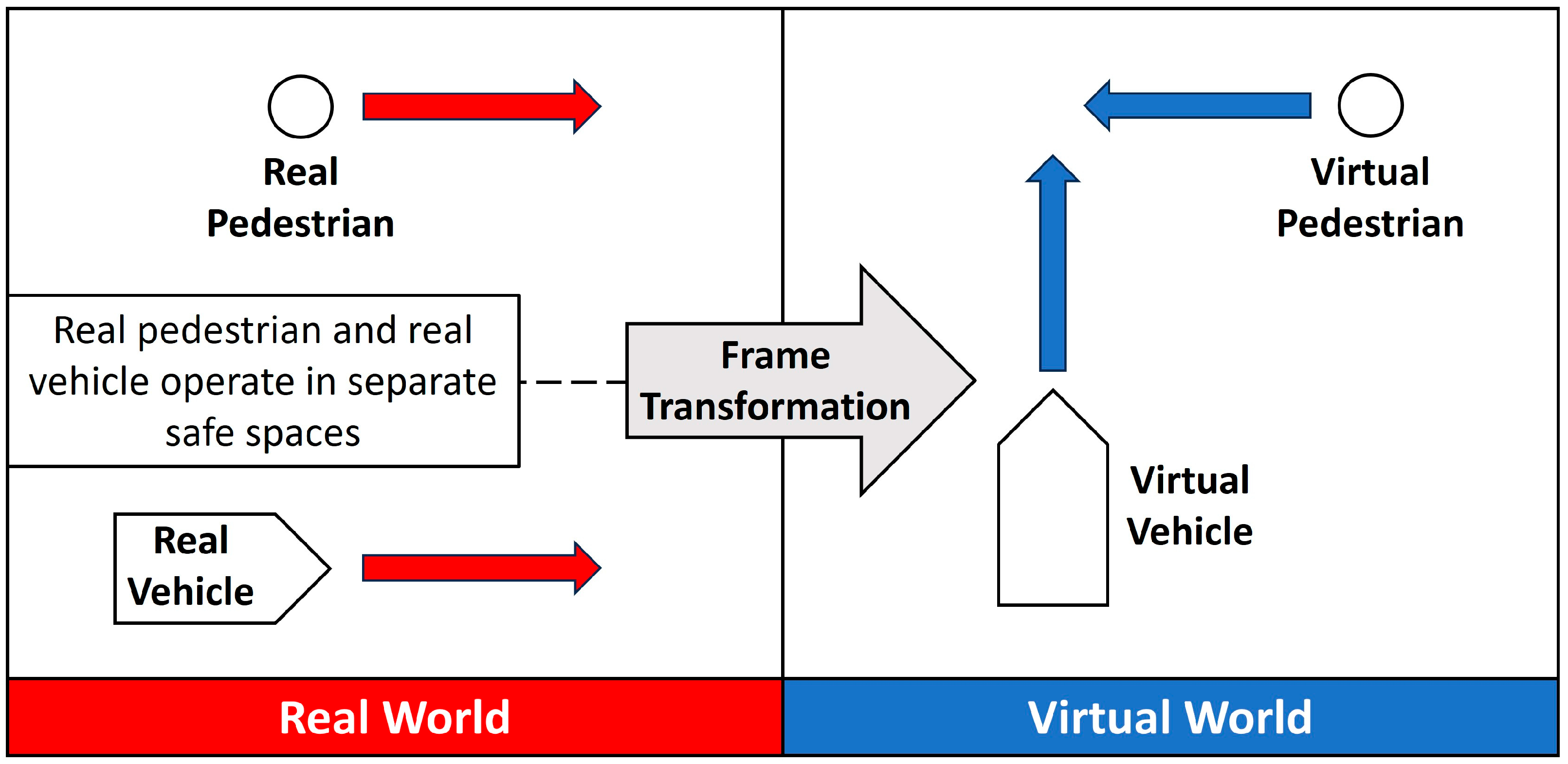
2.3. Vehicle-in-Virtual-Environment (VVE)
3. Case Study
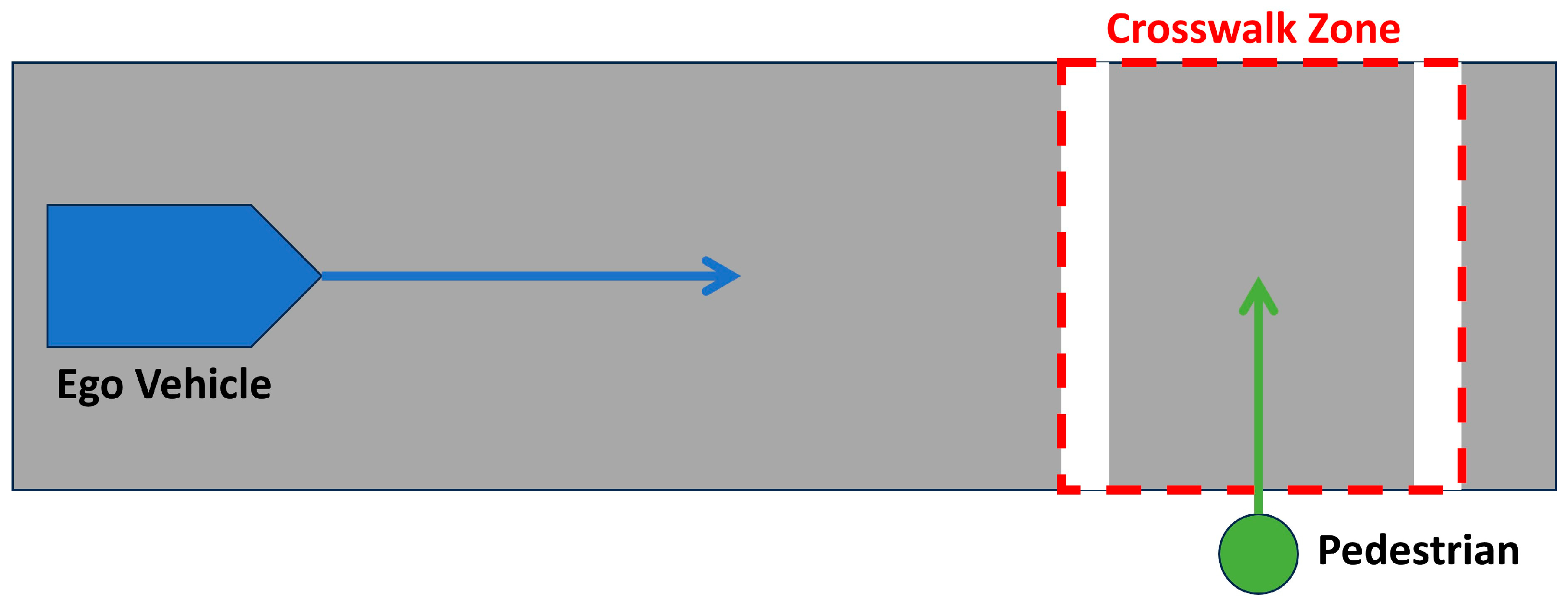
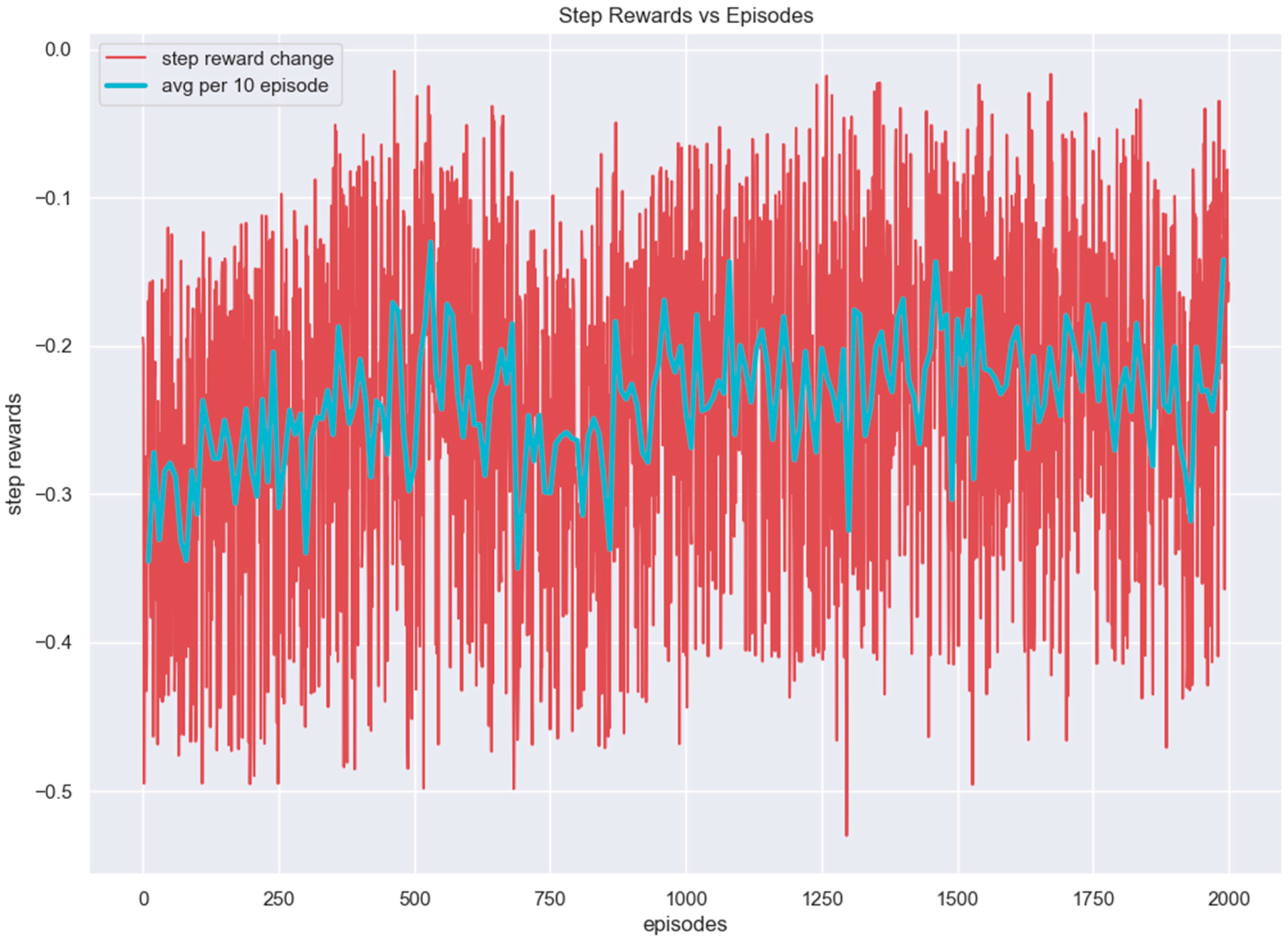
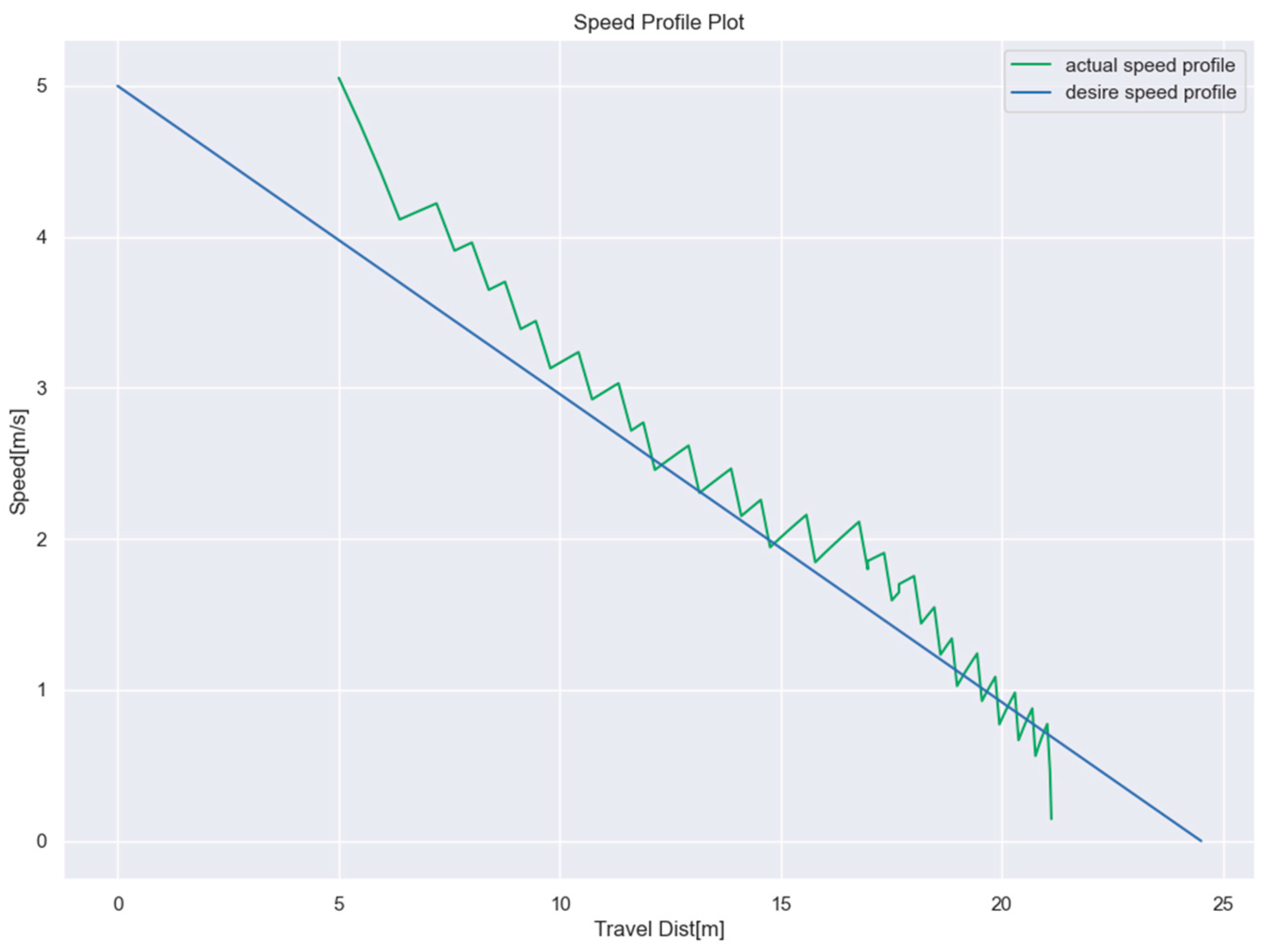
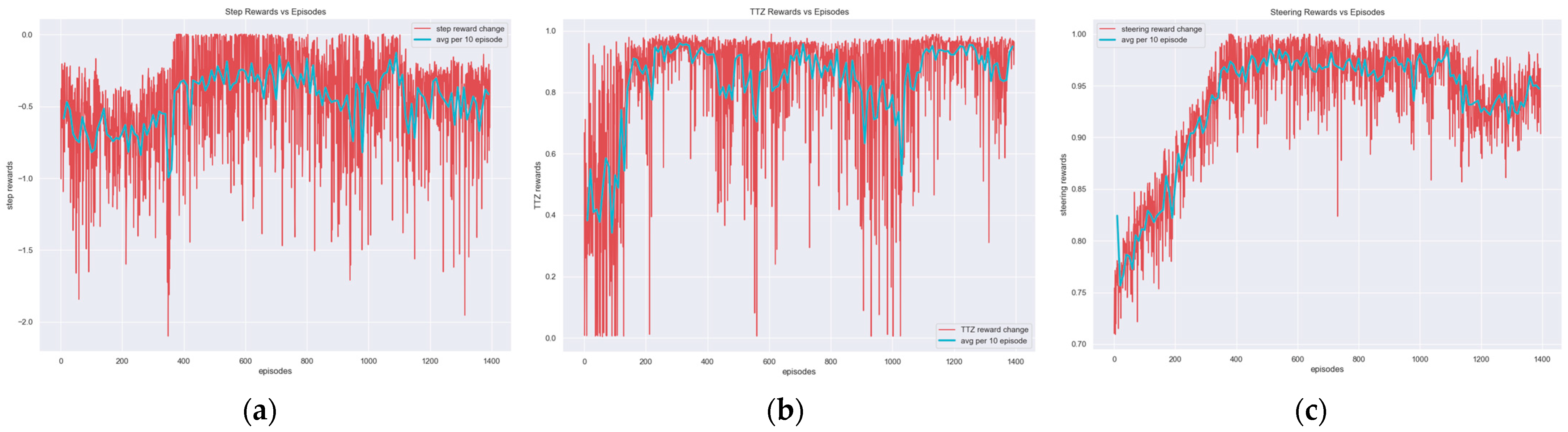
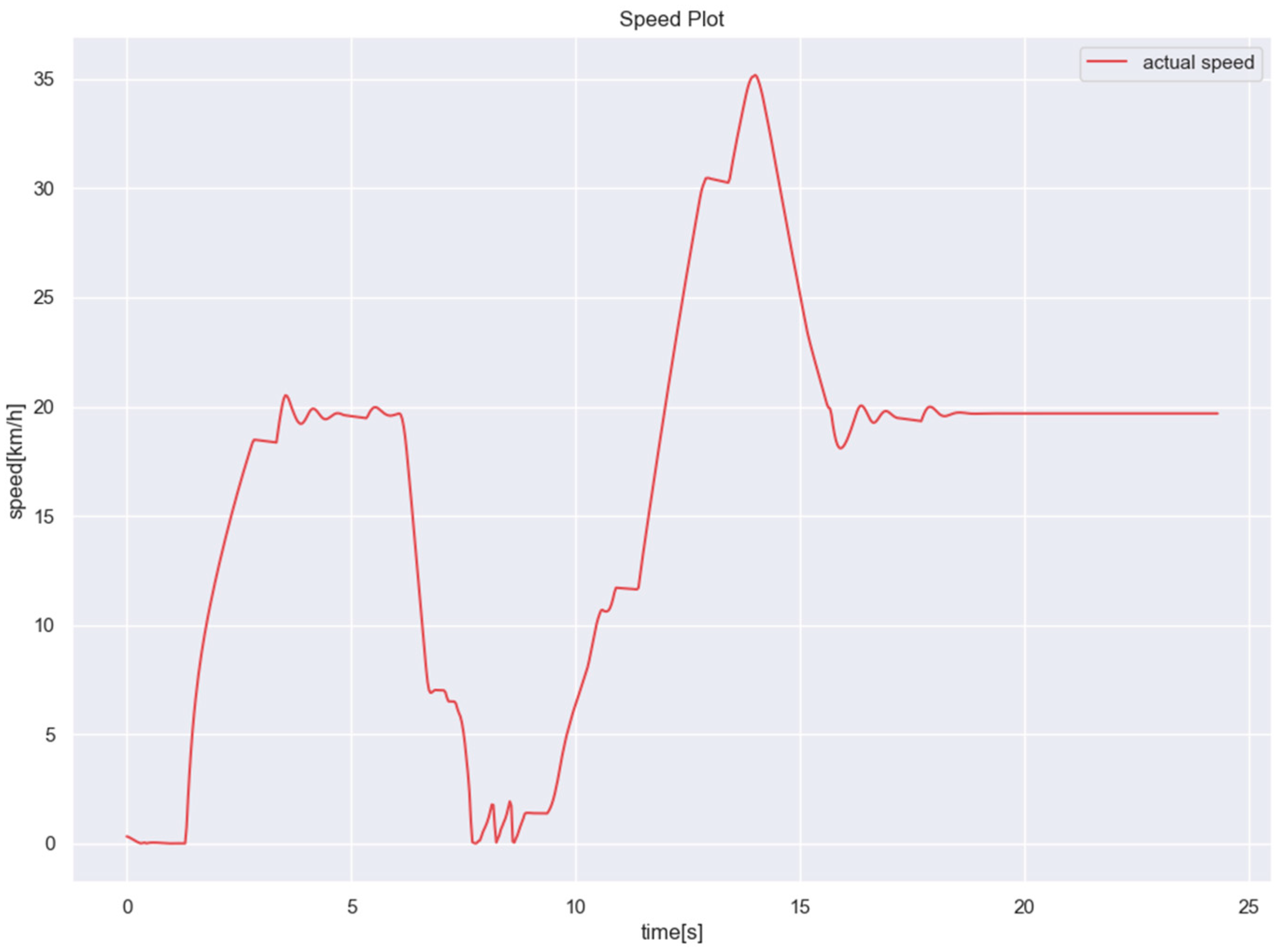
3.1. Scenario 1
3.2. Scenario 2
4. Conclusions and Future Work
Author Contributions
Funding
Data Availability Statement
Acknowledgments
Conflicts of Interest
References
- World Health Organization. Global Status Report on Road Safety 2015; World Health Organization: Geneva, Switzerland, 2015; Available online: https://iris.who.int/handle/10665/189242 (accessed on 24 October 2023).
- Medina, A.; Lee, S.; Wierwille, W.; Hanowski, R. Relationship between Infrastructure, Driver Error, and Critical Incidents. Proc. Hum. Factors Ergon. Soc. Annu. Meet. 2004, 48, 2075–2079. [Google Scholar] [CrossRef]
- J3016_202104: Taxonomy and Definitions for Terms Related to Driving Automation Systems for On-Road Motor Vehicles—SAE International. Available online: https://www.sae.org/standards/content/j3016_202104/ (accessed on 24 October 2023).
- Ye, F.; Zhang, S.; Wang, P.; Chan, C.-Y. A Survey of Deep Reinforcement Learning Algorithms for Motion Planning and Control of Autonomous Vehicles. In Proceedings of the 2021 IEEE Intelligent Vehicles Symposium (IV), Nagoya, Japan, 11–17 July 2021; pp. 1073–1080. [Google Scholar] [CrossRef]
- Kiran, B.R.; Sobh, I.; Talpaert, V.; Mannion, P.; Al Sallab, A.A.; Yogamani, S.; Pérez, P. Deep Reinforcement Learning for Autonomous Driving: A Survey. IEEE Trans. Intell. Transp. Syst. 2022, 23, 4909–4926. [Google Scholar] [CrossRef]
- Zhu, Z.; Zhao, H. A Survey of Deep RL and IL for Autonomous Driving Policy Learning. IEEE Trans. Intell. Transp. Syst. 2022, 23, 14043–14065. [Google Scholar] [CrossRef]
- Zha, Y.; Deng, J.; Qiu, Y.; Zhang, K.; Wang, Y. A Survey of Intelligent Driving Vehicle Trajectory Tracking Based on Vehicle Dynamics. SAE Int. J. Veh. Dyn. Stab. NVH 2023, 7, 221–248. [Google Scholar] [CrossRef]
- Autonomous Road Vehicle Path Planning and Tracking Control|IEEE eBooks|IEEE Xplore. Available online: https://ieeexplore.ieee.org/book/9645932 (accessed on 24 October 2023).
- Wang, H.; Tota, A.; Aksun-Guvenc, B.; Guvenc, L. Real time implementation of socially acceptable collision avoidance of a low speed autonomous shuttle using the elastic band method. Mechatronics 2018, 50, 341–355. [Google Scholar] [CrossRef]
- Morsali, M.; Frisk, E.; Åslund, J. Spatio-Temporal Planning in Multi-Vehicle Scenarios for Autonomous Vehicle Using Support Vector Machines. IEEE Trans. Intell. Veh. 2021, 6, 611–621. [Google Scholar] [CrossRef]
- Zhu, S. Path Planning and Robust Control of Autonomous Vehicles. Ph.D. Thesis, The Ohio State University, Columbus, OH, USA, 2020. Available online: https://www.proquest.com/docview/2612075055/abstract/73982D6BAE3D419APQ/1 (accessed on 24 October 2023).
- Chen, G.; Yao, J.; Gao, Z.; Gao, Z.; Zhao, X.; Xu, N.; Hua, M. Emergency Obstacle Avoidance Trajectory Planning Method of Intelligent Vehicles Based on Improved Hybrid A*. SAE Int. J. Veh. Dyn. Stab. NVH 2023, 8, 3–19. [Google Scholar] [CrossRef]
- Ararat, Ö.; Güvenç, B.A. Development of a Collision Avoidance Algorithm Using Elastic Band Theory. IFAC Proc. Vol. 2008, 41, 8520–8525. [Google Scholar] [CrossRef]
- Emirler, M.T.; Wang, H.; Güvenç, B. Socially Acceptable Collision Avoidance System for Vulnerable Road Users. IFAC Pap. 2016, 49, 436–441. [Google Scholar] [CrossRef]
- Gelbal, S.Y.; Guvenc, B.A.; Guvenc, L. SmartShuttle: A Unified, Scalable and Replicable Approach to Connected and Automated Driving in A Smart City. In Proceedings of the 2nd International Workshop on Science of Smart City Operations and Platforms Engineering; In SCOPE ’17; Association for Computing Machinery: New York, NY, USA, 2017; pp. 57–62. [Google Scholar] [CrossRef]
- Guvenc, L.; Guvenc, B.A.; Emirler, M.T. Connected and Autonomous Vehicles. In Internet of Things and Data Analytics Handbook; John Wiley & Sons, Ltd.: Hoboken, NJ, USA, 2017; pp. 581–595. [Google Scholar] [CrossRef]
- Wang, Z.; Delahaye, D.; Farges, J.L.; Alam, S.S. A quasi-dynamic air traffic assignment model for mitigating air traffic complexity and congestion for high-density UAM operations. Transp. Res. Part C Emerg. Technol. 2023, 154, 104279. [Google Scholar] [CrossRef]
- Maruyama, R.; Seo, T.T. Integrated public transportation system with shared autonomous vehicles and fixed-route transits: Dynamic traffic assignment-based model with multi-objective optimization. Int. J. Intell. Transp. Syst. Res. 2023, 21, 99–114. [Google Scholar] [CrossRef]
- Kendall, A.; Kendall, A.; Hawke, J.; Janz, D.; Mazur, P.; Reda, D.; Allen, J.M.; Lam, V.-D.; Bewley, A.; Shah, A. Learning to Drive in a Day. In Proceedings of the 2019 International Conference on Robotics and Automation (ICRA), Montreal, QC, Canada, 20–24 May 2019; pp. 8248–8254. [Google Scholar] [CrossRef]
- Yurtsever, E.; Capito, L.; Redmill, K.; Ozgune, U. Integrating Deep Reinforcement Learning with Model-based Path Planners for Automated Driving. In Proceedings of the 2020 IEEE Intelligent Vehicles Symposium (IV), Las Vegas, NV, USA, 19 October–13 November 2020; pp. 1311–1316. [Google Scholar] [CrossRef]
- Peng, B.; Sun, Q.; Li, S.E.; Kum, D.; Yin, Y.; Wei, J.; Gu, T. End-to-End Autonomous Driving Through Dueling Double Deep Q-Network. Automot. Innov. 2021, 4, 328–337. [Google Scholar] [CrossRef]
- Jaritz, M.; de Charette, R.; Toromanoff, M.; Perot, E.; Nashashibi, F. End-to-End Race Driving with Deep Reinforcement Learning. In Proceedings of the 2018 IEEE International Conference on Robotics and Automation (ICRA), Brisbane, QLD, Australia, 21–25 May 2018. [Google Scholar] [CrossRef]
- Merola, F.; Falchi, F.; Gennaro, C.; Di Benedetto, M. Reinforced Damage Minimization in Critical Events for Self-driving Vehicles. In Proceedings of the 17th International Joint Conference on Computer Vision, Imaging and Computer Graphics Theory and Applications; Online Streaming, —Select a Country—: SCITEPRESS—Science and Technology Publications; SciTePress: Setúbal, Portugal, 2022; pp. 258–266. [Google Scholar] [CrossRef]
- Cao, Z.; Bıyık, E.; Wang, W.Z.; Raventos, A.; Gaidon, A.; Rosman, G.; Sadigh, D. Reinforcement Learning based Control of Imitative Policies for Near-Accident Driving. arXiv 2020, arXiv:2007.00178. [Google Scholar] [CrossRef]
- Nageshrao, S.; Tseng, H.E.; Filev, D. Autonomous Highway Driving using Deep Reinforcement Learning. In Proceedings of the 2019 IEEE International Conference on Systems, Man and Cybernetics (SMC), Bari, Italy, 6–9 October 2019; pp. 2326–2331. [Google Scholar] [CrossRef]
- Deep Reinforcement-Learning-Based Driving Policy for Autonomous Road Vehicles—Makantasis—2020—IET Intelligent Transport Systems—Wiley Online Library. Available online: https://ietresearch.onlinelibrary.wiley.com/doi/full/10.1049/iet-its.2019.0249 (accessed on 24 October 2023).
- Aksjonov, A.; Kyrki, V. A Safety-Critical Decision-Making and Control Framework Combining Machine-Learning-Based and Rule-Based Algorithms. SAE Int. J. Veh. Dyn. Stab. NVH 2023, 7, 287–299. [Google Scholar] [CrossRef]
- Knox, W.B.; Allievi, A.; Banzhaf, H.; Schmitt, F.; Stone, P. Reward (Mis)design for autonomous driving. Artif. Intell. 2023, 316, 103829. [Google Scholar] [CrossRef]
- Wang, Y.; Wei, H.; Yang, L.; Hu, B.; Lv, C. A Review of Dynamic State Estimation for the Neighborhood System of Connected Vehicles. SAE Int. J. Veh. Dyn. Stab. NVH 2023, 7, 367–385. [Google Scholar] [CrossRef]
- Lu, S.; Xu, R.; Li, Z.; Wang, B.; Zhao, Z. Lunar Rover Collaborated Path Planning with Artificial Potential Field-Based Heuristic on Deep Reinforcement Learning. Aerospace 2024, 11, 253. [Google Scholar] [CrossRef]
- Xi, Z.; Han, H.; Cheng, J.; Lv, M. Reducing Oscillations for Obstacle Avoidance in a Dense Environment Using Deep Reinforcement Learning and Time-Derivative of an Artificial Potential Field. Drones 2024, 8, 85. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Graves, A.; Antonoglou, I.; Wierstra, D.; Riedmiller, M. Playing Atari with Deep Reinforcement Learning. arXiv 2013, arXiv:1312.5602. [Google Scholar] [CrossRef]
- Mnih, V.; Kavukcuoglu, K.; Silver, D.; Rusu, A.A.; Veness, J.; Bellemare, M.G.; Graves, A.; Riedmiller, M.; Fidjeland, A.K.; Ostrovski, G.; et al. Human-level control through deep reinforcement learning. Nature 2015, 518, 7540. [Google Scholar] [CrossRef]
- van Hasselt, H.; Guez, A.; Silver, D. Deep Reinforcement Learning with Double Q-Learning. Proc. AAAI Conf. Artif. Intell. 2016, 30, 1. [Google Scholar] [CrossRef]
- Zhang, X.; Liniger, A.; Borrelli, F. Optimization-Based Collision Avoidance. IEEE Trans. Control Syst. Technol. 2021, 29, 972–983. [Google Scholar] [CrossRef]
- Mu, C.; Liu, S.; Lu, M.; Liu, Z.; Cui, L.; Wang, K. Autonomous spacecraft collision avoidance with a variable number of space debris based on safe reinforcement learning. Aerosp. Sci. Technol. 2024, 149, 109131. [Google Scholar] [CrossRef]
- Feng, S.; Sebastian, B.; Ben-Tzvi, P. A Collision Avoidance Method Based on Deep Reinforcement Learning. Robotics 2021, 10, 73. [Google Scholar] [CrossRef]
- Wang, C.; Zhang, X.; Yang, Z.; Bashir, M.; Lee, K. Collision avoidance for autonomous ship using deep reinforcement learning and prior-knowledge-based approximate representation. Front. Mar. Sci. 2023, 9, 1084763. [Google Scholar] [CrossRef]
- Sun, Z.; Fan, Y.; Wang, G. An Intelligent Algorithm for USVs Collision Avoidance Based on Deep Reinforcement Learning Approach with Navigation Characteristics. J. Mar. Sci. Eng. 2023, 11, 812. [Google Scholar] [CrossRef]
- de Curtò, J.; de Zarzà, I. Analysis of Transportation Systems for Colonies on Mars. Sustainability 2024, 16, 3041. [Google Scholar] [CrossRef]
- Cao, X.; Chen, H.; Gelbal, S.Y.; Guvenc, B.A.; Guvenc, L. Vehicle-in-Virtual-Environment Method for ADAS and Connected and Automated Driving Function Development, Demonstration and Evaluation; SAE Technical Paper 2024-01–1967; SAE International: Warrendale, PA, USA, 2024; Available online: https://www.sae.org/publications/technical-papers/content/2024-01-1967/ (accessed on 7 March 2024).



{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
| Symbol | Parameter |
|---|---|
| Longitudinal tire force | |
| M | Vehicle mass |
| Vehicle longitudinal velocity | |
| X | Vehicle longitudinal position |
| Air density | |
| Air drag coefficient | |
| Vehicle cross-sectional area | |
| Headwind velocity | |
| Road grade | |
| Rolling resistance coefficient | |
| Motor torque | |
| Brake torque | |
| Transmission efficiency | |
| Gear ratio | |
| Wheel moment of inertia | |
| Wheel angular velocity | |
| Wheel radius | |
| Longitudinal tire slip |
| Symbol | Parameter |
|---|---|
| Earth-fixed frame coordinate | |
| Vehicle-fixed frame coordinate | |
| Vehicle center-of-gravity (CG) velocity | |
| M | Vehicle mass |
| Vehicle yaw moment of inertia | |
| Vehicle side-slip angle | |
| Vehicle yaw angle | |
| r | Vehicle yaw rate |
| Yaw disturbance moment | |
| Front and rear wheel steer angle | |
| Front and rear lateral tire force | |
| Front and rear axle velocity | |
| Front and rear tire slip angle | |
| Distance between vehicle CG and front and rear axle | |
| Front and rear tire cornering stiffness |
| Approaches | Pros | Cons |
|---|---|---|
| Elastic Band [9] | 1. Easy to implement. 2. Can avoid getting stuck at local minimum. 3. Flexibility in local path modification. | 1. Path shape may be irregular, especially in complex environment. 2. Computational complexity may increase with number of obstacles. 3. Path may be control-infeasible. |
| Potential-Field-related | 1. Easy to implement. 2. Can achieve real-time performance. 3. Path easy to visualize and understand. | 1. Sometimes stuck at local minimum, especially in complex environment. 2. Oscillations may occur around obstacles. 3. Path may be control-infeasible. |
| SVM-based optimization [10] | 1. Path planning in spatial–temporal region. 2. Can find optimal, efficient, and control-feasible path. | 1. Sometimes stuck at local minimum, especially in complex environment. 2. Oscillations may occur around obstacles. 3. Path may be control-infeasible. |
| Other optimization-based method [11,35] | 1. Can generate control-feasible and optimal (either time- or fuel-efficient) path. 2. Can adapt to different traffic scenarios. | 1. Computationally inefficient and may not achieve real-time performance. 2. Performance of the optimization might be sensitive to the tuning of parameters. |
| Proposed DDQN-based ADS | 1. Learning ability. 2. Model can achieve real-time performance. 3. Can adapt to different traffic scenarios. | 1. Training requires good computational resources. 2. Performance of the model depends on training data quality. |
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).
Share and Cite
Chen, H.; Cao, X.; Guvenc, L.; Aksun-Guvenc, B. Deep-Reinforcement-Learning-Based Collision Avoidance of Autonomous Driving System for Vulnerable Road User Safety. Electronics 2024, 13, 1952. https://doi.org/10.3390/electronics13101952
Chen H, Cao X, Guvenc L, Aksun-Guvenc B. Deep-Reinforcement-Learning-Based Collision Avoidance of Autonomous Driving System for Vulnerable Road User Safety. Electronics. 2024; 13(10):1952. https://doi.org/10.3390/electronics13101952
Chicago/Turabian StyleChen, Haochong, Xincheng Cao, Levent Guvenc, and Bilin Aksun-Guvenc. 2024. "Deep-Reinforcement-Learning-Based Collision Avoidance of Autonomous Driving System for Vulnerable Road User Safety" Electronics 13, no. 10: 1952. https://doi.org/10.3390/electronics13101952
APA StyleChen, H., Cao, X., Guvenc, L., & Aksun-Guvenc, B. (2024). Deep-Reinforcement-Learning-Based Collision Avoidance of Autonomous Driving System for Vulnerable Road User Safety. Electronics, 13(10), 1952. https://doi.org/10.3390/electronics13101952