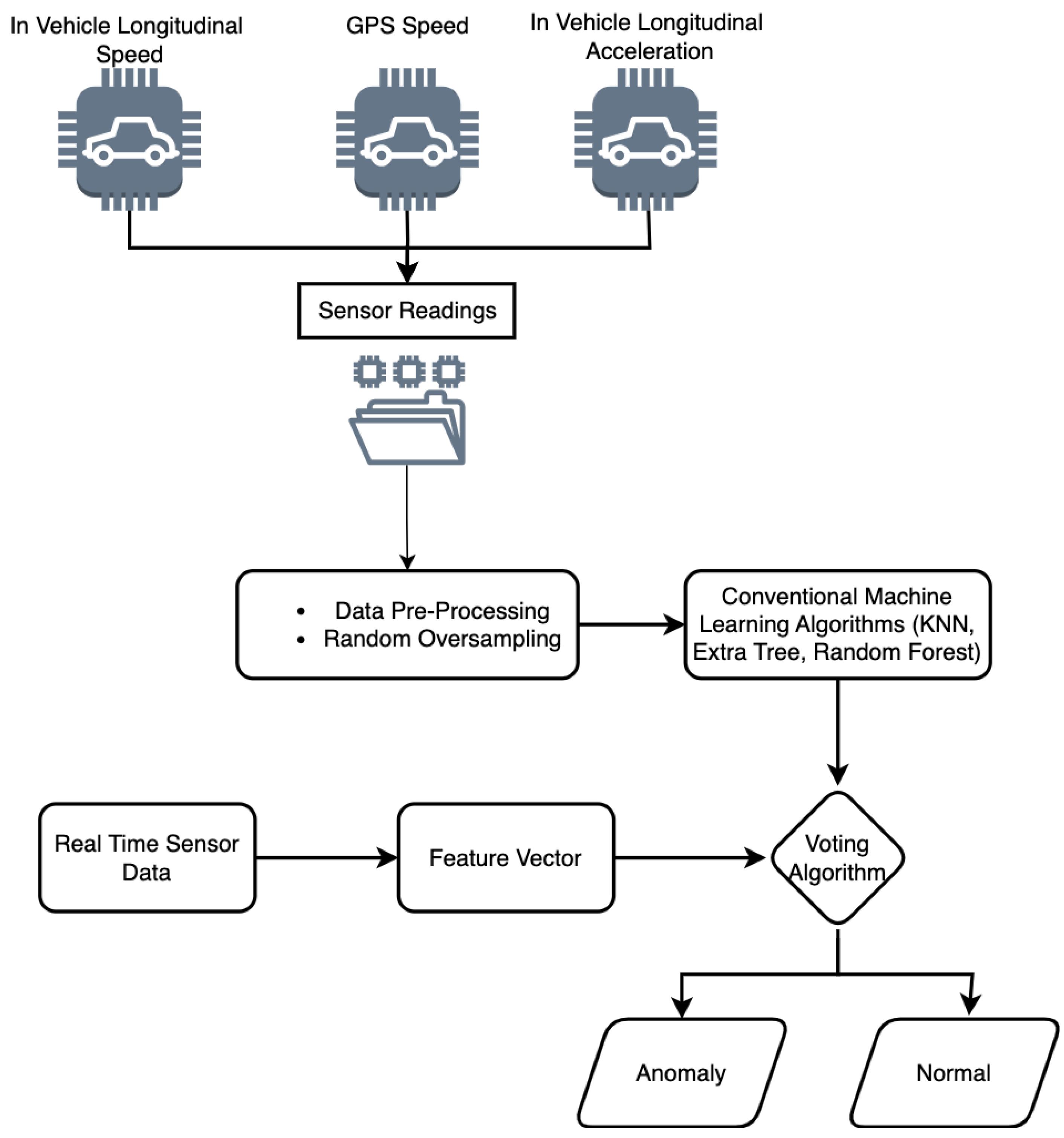
This section provides the experimental setup, analysis, and results of the proposed approach. We first present the results of all detection algorithms and provide a comparison. Next, we compare the results with state-of-the-art methods KF-CNN [
14], MSALSTM-CNN and WAVED [
5]. We evaluate our approach on two important factors: detection performance and time complexity. For the performance analysis, we select standard evaluation measures such as the accuracy, precision, recall, F1-Score and Area Under Curve (AUC).
4.1. Single Anomaly Types
This section elucidates the results of single anomaly types detected during the classification: instant, constant, gradual drift, and bias.
(1) Instant:
Table 2 presents the detection performance of instant anomaly detection using
FT-HV. The first row represents the results of instant anomaly detection when the magnitude is low. In all the next rows, the magnitude of the anomaly increases. There is less danger when the magnitude is low, and there is a higher chance of danger when the magnitude is higher. For a magnitude of “25 × N(0, 0.01)”, the model achieves an accuracy of 99.27, a recall of 99.27, a precision of 99.28, an F1-Score of 99.27, and an AUC of 99.26. The training time (second(s)) is reported as
, the prediction time is
, and the overall time is
. The table shows that as the number of anomalies increases, the accuracy, recall, precision, F1-Score, and AUC of the model decrease slightly. However, the decrease in performance is relatively small, indicating that the model can still accurately predict the labels even when the number of anomalies is high. We can also see that as the number of anomalies increases, the model’s training time and prediction time increase, which is expected as the model processes more data.
(2) Constant: From
Table 3, we can see that as the duration of the anomaly increases, the accuracy, recall, precision, F1-Score, and AUC of the model decrease. This indicates that the model has a harder time detecting longer anomalies. Additionally, we can see that as the range of the uniform distribution decreases, the accuracy, recall, precision, F1-Score, and AUC of the model decrease. This indicates that anomalies with a smaller range are harder to detect. Finally, we can see that the model’s training time and prediction time remain relatively constant across different instances of constant anomalies.
(3) Gradual Drift:
Table 4 shows the performance of the proposed approach for gradual drift anomaly detection. The first two rows of the table indicate that the algorithm performs well when the drift anomaly has a small duration (either 10 or 20) and a low drift intensity (between 0 and 2). The algorithm achieved an accuracy of 81.63% and 64.00%, respectively. The recall and AUC values are also high, indicating that the algorithm can effectively identify anomalies. The third row shows the results for a drift anomaly with a higher intensity of up to four. In this case, the algorithm achieved an accuracy of 81.51%, slightly lower than the first row but still acceptable. However, the recall is relatively low at 51.51%, which suggests that the algorithm had some difficulty detecting the anomaly in this case. The fourth row shows the results for a longer-duration drift anomaly with a low intensity of up to four. In this case, the algorithm achieved an accuracy of 63.88%, which is lower than the other rows. The recall, precision, and F1-Score values are also low, indicating that the algorithm had significant difficulty detecting the anomaly in this case.
(4) Bias: From
Table 5, we can see that for the first three samples of bias, the accuracy, recall, precision, and F1-Score of the model are low. However, for the next two levels of bias anomalies, the model’s performance is still relatively high compared to the other levels of bias anomaly. The training time, prediction time, and total time are relatively consistent across different levels of bias anomaly. Moreover, the 0_5_dur_3 level of bias anomaly is slightly longer than the others. Finally, we can see that the AUC is highest for the 0_5_dur_5 level and lowest (at 81.67%) for the 0_3_dur_10 level.
4.2. Mixed Anomaly Types
This section elucidates the results of mixed anomaly types. As shown in
Table 6, for the “Instant Anomaly” type, the
FT-HV achieved a high accuracy, precision, recall, and F1-Score across all sensors, indicating that it could detect instant anomalies with a very high accuracy. The training time and prediction time were also reasonable. The AUC value was close to 1, indicating that the classifier performed well in distinguishing between normal and anomalous data points. The
FT-HV also performed well for the “Constant Anomaly” type, achieving a high accuracy, precision, recall, and F1-Score. The training time and prediction time were reasonable as well. However, the AUC values were slightly lower than for the “Instant Anomaly” type, indicating that the classifier’s performance distinguishing between normal and anomalous data points was slightly worse. For the “Gradual Drift Anomaly” type, the
FT-HV did not perform as well as the other types of anomalies, achieving a lower accuracy, precision, recall, and F1-Score across all sensors. The training and prediction time was reasonable, and the AUC value was also lower, indicating that the classifier’s performance in distinguishing between normal and anomalous data points was poor. For the “Bias Anomaly” type,
FT-HV achieved a high accuracy, precision, recall, and F1-Score across all sensors, indicating that it could detect bias anomalies with a high accuracy. The training and prediction times were reasonable, and the AUC value was close to 1, indicating that the classifier performed well in distinguishing between normal and anomalous data points. Overall, the
FT-HV classifier performed well for instant and bias anomalies but struggled with gradual drift anomalies. The results also suggest that the classifier’s performance varies depending on the type of anomaly and the sensor used.
Figure 2,
Figure 3,
Figure 4 and
Figure 5 provide the overall comparison of three models,
FT-KNN,
FT-ERT, and
FT-RF, and
FT-HV (a combination of the previous three models). All the algorithms perform well in detecting instant anomalies, with F1-Scores ranging from 98.29% to 99.27%.
Figure 2 compares the F1-Scores and total time (in seconds) for different anomaly detection models applied to datasets with varying numbers of instant anomalies.
FT-RF and
FT-HV algorithms show the highest F1-Scores for all the magnitudes of instant anomalies, followed closely by
FT-ERT. The time the algorithms take to detect instant anomalies increases with the magnitude of the anomalies.
FT-KNN is the fastest algorithm for detecting anomalies for all magnitudes, taking less than 4 s for all cases.
FT-ERT and
FT-HV algorithms take around 4 to 25 s, while
FT-RF takes the longest time, ranging from 13 to 41.5 s. In most cases, the
FT-HV model has the highest F1-Score, followed closely by the
FT-RF model. The
FT-KNN model has the lowest F1-Score across all datasets. The
FT-KNN model has the lowest run time, while the others take longer to train. However, the difference in run time between the models needs to be larger to significantly impact the choice of model, considering the high F1-Scores achieved by all models.
Figure 3 compares all classifiers and the time consumption. Among the algorithms,
FT-HV performs better than
FT-KNN and others, as indicated by the higher F1-Scores across different dataset settings. The
FT-KNN model has the lowest F1-Score across all datasets. The
FT-KNN model has the lowest run time, while the others take longer to train.
Figure 4 shows that the
FT-RF model performs consistently well across all drift anomalies and durations, with the highest F1-Score in most cases. The
FT-ERT model performs well, with high F1-Scores and relatively short total times.
FT-HV, which combines the predictions of multiple models, performs similarly to individual models in most cases. The
FT-KNN model has lower F1-Scores and shorter total times than the other models.
Figure 5 shows that the
FT-HV algorithm performs well for most anomaly types and durations, while the
FT-ERT algorithm is particularly effective at detecting bias anomalies with short durations. The
FT-KNN model has lower F1-Scores and shorter total times than the other models.
Figure 6,
Figure 7,
Figure 8 and
Figure 9 show the results of our approach alongside the baseline results.
Figure 6 shows that our
FT-ERT model achieves better results in most instant anomaly detection cases. Furthermore,
Figure 7 depicts that our
FT-HV model achieves better results when the anomaly magnitude is low and obtained poorer results in the rest of the cases for instant anomaly detection. In
Figure 8, it can be noted that our
FT-RF model achieves poorer results in the rest of the cases for instant anomaly detection. Finally,
Figure 9 depicts that our
FT-HV model achieves better results when the anomaly magnitude is low and obtains poorer results for instant anomaly detection in the rest of the cases.
Table 7 shows that the proposed approach outperforms the other two methods regarding the accuracy and F1-Score for all types of anomalies and all sensors. We provide a comparison only with studies that used all sensor anomalies, single anomalies, and mixed sensor anomalies. Specifically, the proposed approach achieves an accuracy and F1-Score close to 100% for most cases, while the other two achieve an accuracy and F1-Score around 90% or lower. It is also worth noting that the performance of all methods is affected by the type of anomaly and the sensor used. For example, the proposed approach achieves a lower F1-Score for the gradient anomaly type than other types. In contrast, the other two methods achieve a higher accuracy and F1-Score for the constant anomaly type compared to other types. Overall, this table suggests that the proposed approach is promising for detecting various types of anomalies in sensor data.
Overall, the proposed FT-RF approach performed well in the case of a single anomaly type, and FT-HV performed well in mixed anomaly detection compared to other classifiers and state-of-the-art studies. Further, it is noted that there is a trade-off between speed and accuracy. FT-KNN and FT-RF are seen to be the fastest algorithms, but in some cases, they did not perform well. Meanwhile, FT-HV takes a lot of time but performs well on mixed anomaly types. Further, it is noted that since the datasets have few features and deep learning needs high feature dimensions and a large dataset, this is the reasoning behind the superior working of our approach.













{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}