Abstract
Cybersecurity is one of the important considerations when adopting IoT devices in smart applications. Even though a huge volume of data is available, data related to attacks are generally in a significantly smaller proportion. Although machine learning models have been successfully applied for detecting security attacks on smart applications, their performance is affected by the problem of such data imbalance. In this case, the prediction model is preferable to the majority class, while the performance for predicting the minority class is poor. To address such problems, we apply two oversampling techniques and two undersampling techniques to balance the data in different categories. To verify their performance, five machine learning models, namely the decision tree, multi-layer perception, random forest, XGBoost, and CatBoost, are used in the experiments based on the grid search with 10-fold cross-validation for parameter tuning. The results show that both the oversampling and undersampling techniques can improve the performance of the prediction models used. Based on the results, the XGBoost model based on the SMOTE has the best performance in terms of accuracy at 75%, weighted average precision at 82%, weighted average recall at 75%, weighted average F1 score at 78%, and Matthews correlation coefficient at 72%. This indicates that this oversampling technique is effective for multi-attack prediction under a data imbalance scenario.
1. Introduction
The Internet of Things (IoT) is used in a huge number of smart applications that exchange data and perform tasks autonomously like smart agriculture, smart homes, and smart cities [1]. IoT devices produce a huge volume of data that is utilized by smart applications. Due to their large number, distributed nature, and diverse functionalities, IoT networks always face a huge number of cyberattacks [2]. Therefore, securing IoT networks from attackers is critical to ensure the safe and reliable use of these devices and applications. The heterogeneity of the devices and protocols, and the limited processing power, memory, and energy of many IoT devices, are some of the major challenges in choosing security measures [3].
Recently machine learning has been used to detect cyberattacks on smart applications. These machine learning algorithms create security models for detecting attacks based on the training data that consists of data regarding normal and malicious traffic [4]. In most of the datasets used by these algorithms, the proportion of data related to normal and attack classes may be imbalanced. The imbalanced dataset is a big obstacle in detecting attacks accurately, especially for minority classes [5].
In machine learning, it is common to encounter datasets that are imbalanced, where one class has significantly more or fewer instances than other classes. An imbalanced dataset can play a role in creating a biased model favoring the majority classes and performing poorly on the minority classes [6]. Common approaches that have been used to overcome this challenge are using oversampling and undersampling techniques. By randomly duplicating records in smaller or minority classes, oversampling tries to match the number of records to the bigger or majority classes. This can also be accomplished by artificially creating new records or instances. Some of the oversampling approaches include synthetic minority oversampling technique (SMOTE) [7], distributed random oversampling [8], BorderlineSMOTE [9], borderline oversampling with support vector machine (SVM) [10], adaptive synthetic sampling (ADASYN) [11], etc.
On the other hand, undersampling is based on the idea that the number of records in majority classes is to be reduced in order to keep them the same in number as the instances in minority classes. This can be achieved by randomly removing instances from the majority class or selecting a representative subset of instances based on certain criteria. Some of the undersampling approaches are condensed nearest-neighbor undersampling [12], Tomek Links method [13], edited nearest neighbors [14], one-sided selection [15], and instance hardness threshold [16].
Both oversampling and undersampling techniques have their advantages and disadvantages [17,18]. Oversampling can be effective in increasing the number of instances in the minority class and reducing the bias toward the majority class. By providing more instances in the minority class, oversampling can help the model learn the patterns and characteristics of the minority class and improve its ability to generalize to new instances. However, it can also lead to overfitting and generate synthetic instances that do not accurately represent the minority class. Undersampling can be effective in reducing the number of instances in the majority class and focusing on the most informative instances. Undersampling can help to focus on the most informative instances and reduce the noise and redundancy in the dataset as well. However, it can also lead to information loss and remove instances that are important for the model’s performance.
It is important to point out that oversampling and undersampling techniques should be used with caution and in conjunction with different preprocessing techniques, such as feature selection and normalization [18]. Furthermore, the choice of oversampling or undersampling technique should be based on the specific characteristics of the dataset and the goals of the machine learning task [19]. In this paper, we focus on exploring the effect of multiple oversampling and undersampling approaches for attack detection for different machine learning algorithms. The IoT dataset we chose shows very poor detection performance for most of the minority classes if no oversampling or undersampling approach is used. The main contributions of the paper are as follows:
- We identify that the traditional machine learning algorithms may not detect minority attack classes when no sampling technique is used. Therefore, in reality, for network attack detection systems, such a limitation may result in failure to detect some of the attacks completely, which emphasizes the importance of using sampling techniques for imbalanced datasets.
- We thoroughly investigate the effect of different oversampling and undersampling techniques on the performance of multiple traditional and ensemble machine learning algorithms.
- We identify the best sampling approach for network attack detection using one of the latest IoT datasets.
Section 2 provides a discussion and analysis of the relevant literature in two areas: machine learning models and relevant research using the IOTID20 dataset. Section 3 provides the details of machine learning models and sampling techniques. Section 4 provides an in-depth analysis of the collected results for the intrusion detection system. A summary of the paper and some options about the possible future work are provided in Section 5.
2. Related Work
In this section, we provide an overview of the machine learning approaches used in the domain of cybersecurity. We also present recent efforts on the use of oversampling and undersampling approaches to improve attack detection for imbalanced datasets. It is important to mention here that oversampling and undersampling approaches are used effectively in improving overall attack detection; however, most of the literature does not specify the detection accuracy for the minority classes. Due to a small proportion of records for the minority classes, the overall detection accuracy can be very high even when the system fails to detect smaller classes completely.
A random forest-based attack detection approach is proposed that uses smart feature selection to improve attack prediction performance [20]. The use of oversampling and some feature selection approaches is explored for imbalanced datasets in the area of cybersecurity, specifically intrusion detection. Decision trees were used for different binary and muti-class attack detection models, and the models performed reasonably [21]. The multilayer perceptron network showed very good anomaly detection abilities with a small number of features for multi-class problems [22]. A combination of random forest and optimization approaches produced very good results for classifying cyberattacks and reducing false alarm rates [23].
The overall accuracy of these proposed approaches was good, but the prediction accuracy for all minority classes was not investigated. Hence, the performance for all attack types cannot be analyzed and compared to this work. With a very small sample size for most minority classes, the overall attack detection accuracy can be very high, but the detection for some of the minority classes may be very low or even zero. This results in completely missing some cyberattacks, which may have a catastrophic effect on the security systems.
An intrusion detection system using an artificial neural network provides very high attack detection when the hyperparameters of the neural network are tuned [24]. Another artificial neural network-based intrusion detection system for binary classification showed promising results for a simulated IoT network [25]. An artificial neural network-based approach for three different levels of classification of attacks is proposed while tuning the hyperparameters for optimal performance [26]. With the proper tuning of hyperparameters, the neural network model showed very high accuracy for most of the cases.
The ANN approach provides a good option for intrusion detection systems and has high performance but faces the challenges of being complex, computationally expensive, and requiring the selection of hyperparameters. Also, the low detection rate for minority classes still exists in the above-mentioned ANN-based approaches, so the above-mentioned works did not consider that specifically.
Ensemble classifiers provide an excellent option for gaining the combined benefits of two different algorithms. Jabbar et al. [27] used an ensemble classifier for the binary detection problem of cyberattacks and combined random forest with another approach. The same research group also proposed ADTree and KNN ensemble classifiers for detecting cyberattacks [28]. To reduce the time of model building and training, a tree-based approach was combined with a bagging method for the classification of attacks [29]. Most of the above-mentioned approaches provide high accuracy for overall attack detection; however, when it comes to multi-class attack detection, the detection rate of smaller or minority attack classes is a great challenge.
Karthik and Krishnan [30] proposed a novel approach to detect IoT attacks using a combination of random forest techniques with a novel oversampling approach. The proposed method was evaluated on different datasets and compared with several approaches; it showed good results in terms of accuracy, precision, recall, and F1 score. Bej et al. [31] proposed a new oversampling technique for imbalanced datasets. The minority samples were scaled and stretched to create new samples for smaller classes. With extensive experiments and testing on numerous imbalanced datasets, the proposed approach showed very promising results.
We used the IOTID20 dataset for testing our approach. Qaddoura et al. [32] addressed the class imbalance issue in the IoTID20 dataset by considering clustering and oversampling techniques. Support vector machine (SVM) with an oversampling technique was investigated for classification and achieved good performance for attack detection at the binary level, where only attacks and normal classes were detected. Farah [33] compared the performance of multiple techniques to detect attacks in the IOTID20 dataset and detected some classes of attacks. However, subcategory attacks that were of minority classes were not detected. Krishnan. Nawaz and Lin [34] compared the attack detection considering random forest, XGBoost, and SVC approaches for detecting normal and attack classes only and achieved very high accuracy. However, the minority class detection was not targeted, as subcategory-based attack detection was not considered.
The main motivation of this work is to detect cyberattacks belonging to minority classes when imbalanced datasets are considered for attack detection, which is a significant concern in almost all datasets in this domain, as previously discussed. In the Section 4, we provide detection accuracy, precision, recall, and F1 score for all attack classes, including minority classes that have very few samples, to show that our approach significantly improves the detection of these small attack classes. In Table 1, we compare our work with other existing studies that use the same dataset to show that we succeeded in detecting minority classes, which were not considered by the other studies due to the small sample sizes for these classes.

Table 1.
Comparison with existing approaches.
Undersampling is one efficient method to handle imbalanced datasets as it focuses on reducing the number of samples from the majority classes. An undersampling approach based on the theory of evidence is proposed in evidential undersampling [35]. This approach considers a very important factor, which is to avoid removing meaningful samples. The samples in the majority classes are assigned a soft evidential label after removing unclear samples. When tested with different ML algorithms, this approach outperformed some basic undersampling approaches. An undersampling approach based on consensus clustering is proposed to handle imbalanced learning [36]. The consensus clustering-based scheme used a different combination of clustering algorithms for the undersampling purpose. The results obtained with different ML algorithms showed that different combinations can produce very different results. A novel two-step undersampling approach is proposed [37]. Firstly, the majority class is considered for similar instances, which are grouped together into subclasses. Then, from those subclasses, unrepresentative data samples are removed. The proposed approach performed significantly better than other undersampling approaches.
3. Methods
In this section, we first introduce the machine learning algorithms. Next, we describe the oversampling techniques, followed by the undersampling techniques. Finally, we present the flowchart of the prediction model for the intrusion detection prediction. For researchers to duplicate the outcomes, we have shared our code with the GitHub repository [38]. All undersampling and oversampling approaches that we used are from imblearn library [39]. A snapshot of example source code is shown in Figure 1. All undersampling and oversampling source codes are provided in our GitHub repository [38]. Beside the ReadMe file, five Python Notebook files uploaded to the Github repository, which are ADASYN-sent to github.ipynb, Baseline.ipynb, InstaceHardnessThresholdsent to github.ipynb, RandomUnderSampler-sent to github.ipynb, and SMOTE-sent to github.ipynb.
Figure 1.
A snapshot of the code for InstanceHardnessThreshold undersampling method.
3.1. Machine Learning Algorithms
In this section, five frequently utilized machine learning algorithms are briefly explained, including the decision tree (DT), multilayer perceptron (MLP), random forest (RF), extreme gradient boosting (XGBoost), and category boosting (CatBoost).
3.1.1. DT
The DT [40] is a tree-based supervised algorithm that can be used for classification tasks. A DT algorithm is constructed by three types of nodes, which are the decision node, change node, and end node. Each type of node has its task. More specifically, the decision node indicates a choice that needs to be determined. Consequently, the chance node analyzes the probabilities of the results. The end node presents the ultimate result of a decision pathway. By calculating the value of each option in the tree, the DT is able to achieve promising results by minimizing the risk and maximizing the likelihood.
The primary purpose of the DT algorithm is to obtain the measure of information gain. Specifically, the DT model first evaluates the entropy, as given in Equation (1). After that, the conditional entropy is calculated using Equation (2). Finally, the information gain is obtained using Equation (3).
where D is a given dataset, K represents the count of categories, n stands for the number of features, denotes the probability rate of the kth category, and signifies the probability of the feature A in the ith subset.
3.1.2. MLP
The MLP is composed of three types of layers, which are the input layer, the hidden layer, and the output layer [41]. Every layer is linked to its neighboring layers. Similarly, every neuron within the hidden and output layers is connected to all neurons in the preceding layer via a weight vector. Each layer proceeds its own computation. The output of each layer is generated by passing the weighted sum of inputs and bias terms through a non-linear activation function, which then becomes the input for the subsequent layer. In the input layer, the number of neurons corresponds to the number of input features, while the output layer represents the model’s output. For a binary classification, a single neuron will be generated as the result. The hidden layer neurons reside between the input and output layers, forming connections with both. These interconnected neurons enable communication and information exchange among themselves. Through adjusting weights in the connections between neurons, the MLP can mimic the information analysis and processes like a human brain.
For a binary classification problem, the MLP generates one single neuron in the output layer where its value can be obtained using Equation (4).
where represents the weights, and denotes a bias term in the transition from the input layer to the neighboring hidden layer. Likewise, represents the weights, and denotes a bias term when passing from the hidden layer to the output layer. signifies an activation function.
3.1.3. RF
The RF is an ensemble algorithm that leverages multiple decision trees [42]. By constructing numerous decision trees using bootstrap samples, the RF algorithm enhances prediction accuracy and stability. It effectively addresses overfitting issues by utilizing resampling and feature selection techniques. During the training process, the RF generates multiple sub-datasets, each containing the same number of samples as the original training set, through resampling. For each sub-dataset, individual decision trees are trained using a recursive partitioning approach. This involves searching for the best feature splits within the selected features. Ultimately, the RF algorithm combines the predictions from all decision trees by taking their average as the final output.
3.1.4. XGBoost
XGBoost is also an ensemble algorithm [43]. To achieve the final result, this algorithm employs gradient boosting to aggregate multiple outcomes from the decision tree-based algorithms. To scale down the impact of overfitting, this algorithm uses shrinkage and feature subsampling techniques. The XGBoost method is tailored to real-world applications that require high computation time and storage memory. Therefore, it is well suited for applications that necessitate parallelization, distributed computing, out-of-core computing, and cache optimization. Additionally, this ensemble algorithm enables parallel tree boosting, alternately referred to as gradient-boosted decision tree and gradient boosting machine.
Gradient boosting aims to discover the function that most effectively approximates the data by optimizing Equation (5).
where L represents a convex loss function that quantifies the dissimilarity between the target value and the predicted value . The weight vector is denoted by , refers to the function, T signifies the number of leaves in the tree, and penalizes model complexity, while and impose constant penalties for each additional tree leaf and extreme weights, respectively.
3.1.5. CatBoost
CatBoost, based on categorical boosting, is an ensemble model that is effective for prediction tasks involving categorical features [44]. Distinguished from the other gradient boosting algorithms, an ordered boosting technique is employed to mitigate the issue of target leakage. Furthermore, it effectively resolves the issues with categorical features by replacing the original features with one or more numerical values. Constructed on the foundation of the traditional gradient boosting-based algorithms that can lead to the overfitting problem, CatBoost addresses this issue by utilizing random permutation for leaf value estimation to minimize the issue of overfitting. It can rapidly construct a model for big data projects with a high level of generalization. By combining many base estimators, this algorithm is able to build a strong competitive prediction model that achieves better performance than random selection.
3.2. Oversampling Techniques
One or more classes that are characterized with few examples are referred to as minority classes, while one or more classes with a significant number of examples are known as majority classes. When minority classes and majority classes are in the same dataset, they cause an imbalanced class distribution. As a common practice in dealing with a binary (two-class) classification problem, class 0 is recognized as the majority class, and class 1 signifies the minority class.
3.2.1. SMOTE
One of the most significant obstacles in classification problems is that there are far more majority classes than minority ones. To overcome this, an oversampling technique was adopted to balance the data before the prediction models were trained. The synthetic minority oversampling technique (SMOTE) was applied to oversample the data, and it was found that it effectively mitigates the overfitting problem of the prediction model to the majority class [7]. The SMOTE is an oversampling technique that generates synthetic samples for minority classes. To mitigate the overfitting problems, this algorithm generates new instances by utilizing the interpolation between the positive instances that are in proximity, with a focus on the feature space.
The SMOTE first randomly selects a minority class instance a. Then, the algorithm searches for its k nearest neighbors which are also minority classes. Consequently, one of the k nearest neighbors b is identified by chance. Connecting a and b to form a line segment in the feature space creates synthetic instances. As a result, the synthetic instances are created as a convex combination of the two chosen neighboring instances a and b.
3.2.2. ADASYN
ADASYN represents a generalized version of SMOTE. This algorithm also creates synthetic instances to oversample the minority classes. However, it considers the density distribution that determines the number of synthetic instances to be generated for samples, which is difficult to learn [11]. By doing so, this algorithm dynamically adjusts the decision boundaries based on the samples difficult to learn. This is where the fundamental distinction exists between ADASYN and SMOTE.
3.3. Undersampling Techniques
Undersampling techniques are tailored to address the issues of skewed distribution in classification datasets.
3.3.1. RandomUnderSampler
Random undersampling, also termed RandomUnderSampler, arbitrarily selects samples from the majority class and then deletes them from the training dataset [45]. This approach is regarded as the simplest undersampling technique. Although it is simple, it is effective. However, this algorithm is not without limitations. A drawback of this technique is that samples are eliminated without considering their potential usefulness or importance in determining the decision boundary between the classes. In random undersampling models, the instances in the majority class are deleted randomly to reach a balanced distribution. This potentially results in the removal of valuable information.
3.3.2. InstanceHardnessThreshold
Instance hardness threshold (InstanceHardnessThreshold) is an undersampling method that can be used to alleviate class imbalance by removing samples with the aim of balancing the dataset [16]. In other words, the samples classified with a low probability will be removed from the dataset. Consequently, the prediction model can be trained based on the simplified dataset. The probability of misclassification for each sample is defined by the hardness threshold, which is considered the core difference between the instance hardness threshold and other undersampling techniques.
3.4. Flowchart of a Prediction Model for the Intrusion Detection Prediction
A flowchart for intrusion detection prediction using the machine learning models, namely the DT, MLP, RF, XGBoost, and CatBoost, is presented in Figure 2. As illustrated in the figure, parameter tuning incorporated a grid search with 10-fold cross-validation. Specifically, the given dataset was preprocessed. After that, the grid search with 10-fold cross-validation tuned the model parameters with the use of different sampling techniques, including the oversampling techniques (SMOTE and ADASYN) and the undersampling techniques (RandomUnderSampler and InstanceHardnessThreshold). The dataset was divided into ten subsets, with each subset used once as the validation data while the model was trained on the remaining nine subsets. This process was repeated 10 times, with each subset serving as the validation data exactly once. The average performance across all folds was then computed to evaluate the model’s performance under different hyperparameter configurations. Finally, with the best parameters obtained, the prediction model was trained and evaluated.
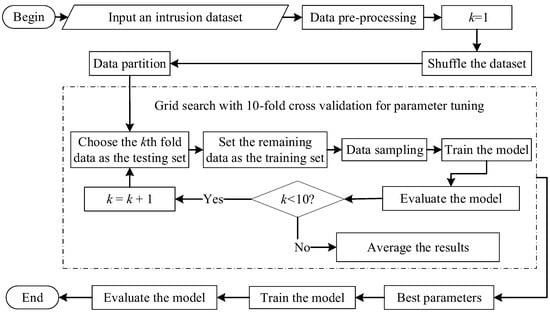
Figure 2.
A flowchart showing the prediction procedure for the intrusion detection prediction.
4. Experimental Setup and Results
The main motivation behind this work is to evaluate the efficacy of undersampling and oversampling approaches to improve minority class detection for imbalanced datasets using different machine learning approaches. With extensive experimentation, we compared the detection accuracy of IoT attacks belonging to minority classes using matching learning models outlined in Section 3.
4.1. System Setup
The experiments were conducted and assessed using the Python programming language within Jupyter Notebook from the Anaconda distribution. We utilized the sklearn library in our implementation. Furthermore, the experiments were executed on a computer system featuring an i7-12700H CPU operating at 2.30 GHz and 64.0 GB of RAM.
4.2. Data Description
Datasets are required to train machine learning models for attack detection. Without a dataset, no training/testing of models can be carried out. In recent years, several datasets have been developed and made available by researchers, including UNSW-NB15 [46] and Bot-IoT [47]. Specifically, the IoTID20 dataset [48] was chosen for this research as this is one of the most recent datasets established in the IoT scenario for depicting realistic and up-to-date network traffic features [26]. A number of studies have been conducted based on this dataset for experimentation. Ullah and Mahmoud [48] used this dataset. Anomalous activities in attack detection were divided into binary, category, and subcategory levels. Five machine learning models (i.e., DT, MLP, RF, XGBoost, and CatBoost) were applied to detect IoT attacks. As minority attack classes are important in cybersecurity, we focused on the detection of subcategory attacks (nine-class classification). The IoTID20 dataset, developed by Ullah and Mahmoud [48], contains 86 attributes, including 3 categorical attributes. The categorical attribute is Sub_Cat. The data types in Sub_Cat data column are Mirai-Ackflooding, Mirai-Hostbruterforceg, Mirai-HTTP Flooding, Mirai-UDF Flooding, MITM ARP Spoofing, DoS-Synflooding, Scan Hostport, Scan Port OS, and Normal. The distributions of nine data types of Sub_Cat are presented in Figure 3.
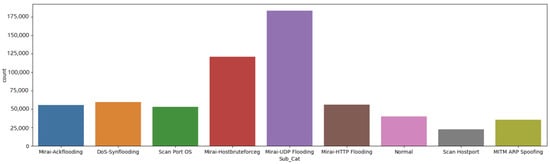
Figure 3.
IoTID20 data distribution based on Sub_Cat.
4.3. Experimental Settings
Machine learning models are sensitive to the setting of hyperparameters; hence, we applied the grid search approach to select the best hyperparameters. For a given model, the grid search approach exhaustively generates several candidate values from a list of hyperparameter values to determine the optimal hyperparameters. In this paper, the grid search was used with 10-fold cross-validation in the machine learning models for parameter tuning. To be specific, for the DT, candidate values of [3, 4, 5] were considered for the maximum tree depth [49]. For the MLP, candidate values of [100, 200, 300] for the neuron number in the hidden layer and [100, 200, 300] for the maximum iterations were considered. For the ensemble models (RF, XGBoost, and CatBoost), candidate values of [10, 100, 200] for the number of estimators and [3, 4, 5] for the maximum tree depth in each estimator were considered [50]. The final results were obtained based on the models trained using the optimal hyperparameters. Take the RF as an example; nine pairs of hyperparameters ([10, 3], [10, 4], [10, 5], [100, 3], [100, 4], [100, 5], [200, 3], [200, 3], [200, 4], and [200, 5]) were used to trained and evaluate the model. The pair with the best results were utilized as the optimal hyperparameters for the final evaluation.
For the evaluation of different sampling-based machine learning models, macroaccuracy was used to calculate the accuracy for each class independently and then determine the unweighted average. It treats all classes equally regardless of their imbalance. Similar to macro-accuracy, these metrics account for class imbalance by considering precision, recall, and F1 score for each class and then taking the macro-average. Moreover, weighted accuracy was utilized to take the class imbalance by assigning higher weights to minority classes during calculation. It was calculated as the average accuracy of each class weighted by the number of instances in each class. Similar to weighted accuracy, these metrics account for class imbalance by considering precision, recall, and F1 score for each class and then taking the weighted average. Further, we introduced the Matthews correlation coefficient (MCC) [51] to evaluate the model performance.
4.4. Multi-Class Classification Based on Oversampling
In this section, we compare the results obtained from the oversampling-based machine learning models, namely the DT, MLP, RF, XGBoost, and CatBoost, as shown in Table 2, Table 3, Table 4, Table 5 and Table 6, based on SMOTE and ADASYN. As we can see from Table 2, without the use of oversampling techniques, some results of the DT have zero values for precision, recall, and F1 score. This is because the number of MITM ARP Spoofing (35,377), Mirai-Ackflooding (55,124), and Scan Hostport (22,192) is far less than that of Mirai-UDP Flooding (183,189), making the DT overfit to the majority class, while with the use of SMOTE and ADASYN, this problem can be alleviated. Specifically, MITM ARP Spoofing can be detected with the use of SMOTE, while MITM ARP Spoofing and Mirai-Ackflooding can be detected with the use of ADASYN. Among all the results, the baseline DT has the best MCC.
Table 2.
Oversampling for multi-class classification using the DT.
Table 3.
Oversampling for multi-class classification using the MLP.
Table 4.
Oversampling for multi-class classification using the RF.
Table 5.
Oversampling for multi-class classification using the XGBoost.
Table 6.
Oversampling for multi-class classification using the CatBoost.
Oversampling for multi-class classification using the MLP can be found in Table 3. As we can see from the table, similar to the results in Table 2, some results of the MLP have low values for precision, recall, and F1 score (e.g., Mirai-Ackflooding) without the use of oversampling techniques. However, with the use of SMOTE and ADASYN, the performance of the minority attack precision can be improved. For example, the F1 score of Mirai-Ackflooding attack is improved from 28% to 38% and 42% with the use of SMOTE and ADASYN, respectively. The F1 score of the Scan Hostport attack is improved from 11% to 34% and 33% with the use of SMOTE and ADASYN, respectively. In addition, with the use of the ADASYN technique, the performance of MLP can be improved from 63% macro-average accuracy to 68% and from 70% weighted average F1 score to 73%. However, the ADASYN-based MLP sacrifices the performance of accuracy and MCC.
Oversampling for multi-class classification using the RF can be found in Table 4. As we can see from the table, the F1 score results from the baseline are low, while the results from SMOTE and ADASYN are greatly improved. For example, for [Mirai-Ackflooding, Mirai-HTTP Flooding, Scan Hostport], their results are improved from [1%, 8%, 0%] to [44%, 41%, 16%] and [29%, 39%, 16%] using SMOTE and ADASYN, respectively. This is very important in real-world intrusion detection applications when the intrusion will severely affect user information security. According to the results, the SMOTE-based RF has the best performance in terms of macro-average F1 score, weighted average F1 score, and MCC.
Oversampling for multi-class classification using the XGBoost can be found in Table 5. As we can see from the table, XGBoost has no zero results. The reason could be that it is an ensemble model that integrates multiple estimators for the final prediction. Although the baseline of XGBoost outperforms the DT, MLP, and RF in Table 2, Table 3 and Table 4, with the use of SMOTE and ADASYN, the performance of the XGBoost model can be further improved, from 76% weighted average precision to 82% and 80%, respectively. According to the results, the SMOTE-based XGBoost has the best weighted average F1 score and MCC.
Oversampling for multi-class classification using the CatBoost can be found in Table 6. As we can see from the table, similar to the results in Table 5, the CatBoost model has no zero results. The reason could be that CatBoost is also an ensemble model that can reduce the effect of the imbalance problem. Although the baseline of CatBoost outperforms the DT, MLP, and RF in Table 2, Table 3 and Table 4, its performance is slightly worse than the XGBoost model in Table 5. However, with the use of SMOTE, its performance can be further improved, from 75% weighted average F1 score to 77%. According to the results, the SMOTE-based model has the best performance for accuracy, precision, recall, F1 score, and MCC.
4.5. Multi-Class Classification Based on Undersampling
Although the oversampling techniques are able to improve machine learning models’ performance in the dataset of imbalanced scenarios, in this study, we conducted experiments using undersampling techniques to see if the machine learning models could still be improved. We compare the results obtained from the undersampling-based machine learning models, namely the DT, MLP, RF, XGBoost, and CatBoost, as shown in Table 7, Table 8, Table 9, Table 10 and Table 11, based on the RandomUnderSampler and InstanceHardnessThreshold. It is worth noting that, with the use of undersampling techniques, fewer samples are used for training, which can improve the training efficiency. This is more practical in real-world applications, especially in big data scenarios. As we can see from Table 7, with the use of RandomUnderSampler and InstanceHardnessThreshold, the performance of DT can be improved. This is because the RandomUnderSampler is utilized to randomly remove the samples, which will remove some important information. However, with the use of InstanceHardnessThreshold, the performance of DT can be improved from [62%, 42%, 53%, 0.55] to [66%, 58%, 66%, 0.61] in terms of accuracy, macro-average F1 score, weighted average, and MCC, respectively.
Table 7.
Undersampling for multi-class classification using DT.
Table 8.
Undersampling for multi-class classification using MLP.
Table 9.
Undersampling for multi-class classification using RF.
Table 10.
Undersampling for multi-class classification using XGBoost.
Table 11.
Undersampling for multi-class classification using CatBoost.
Undersampling for multi-class classification using the MLP model can be found in Table 8. As shown in the table, unlike the results in Table 2, although with fewer samples obtained using the InstanceHardnessThreshold model, the undersampling-based MLP can greatly outperform its baseline. Without the use of undersampling techniques, sample results have low values, while with the use of RandomUnderSampler and InstanceHardnessThreshold, this problem can be improved. In addition, comparing the two undersampling techniques, the performance of InstanceHardnessThreshold-based MLP outperforms RandomUnderSampler-based MLP. The macro-average F1 score of the baseline is 63%, while the macro-average F1 score of InstanceHardnessThreshold-based MLP is 66%; the weighted average F1 score of the baseline is 70%, while the weighted average F1 score of InstanceHardnessThreshold-based MLP is 72%. According to the results, the MLP has the best performance for MCC.
Undersampling for multi-class classification using the RF can be found in Table 9. As we can see from the table, with the use of undersampling techniques, the performance of RF is improved. For the macro average F1 score and weighted average F1 score of RF, their results are improved from [43%, 54%] to [54%, 60%] and [45%, 57%] with the use of RandomUnderSampler and InstanceHardnessThreshold, respectively. According to all the results, the RF and RandomUnderSampler-based RF have the same MCC.
Undersampling for multi-class classification using the XGBoost can be found in Table 10. As shown in the table, similar to the results of RF in Table 9, with the use of undersampling techniques, the performance of baseline has similar results compared to the RandomUnderSampler-based XGBoost. The reason could be that although the RandomUnderSampler removes samples, the XGBoost model can still maintain its high performance by integrating multiple estimators for the final prediction. Although the baseline of XGBoost outperforms the DT, MLP and RF in Table 7, Table 8 and Table 9, with the use of RandomUnderSampler, the performance of the XGBoost model can be further improved, from 76% weighted average F1 score to 78%. From the results, it is evident that in terms of the macroaverage F1 score, weighted average F1 score, and MCC, RandomUnderSampler-based XGBoost has the best performance.
Undersampling for multi-class classification using the CatBoost can be found in Table 11. As we can see from the table, although the baseline of CatBoost outperforms the DT, MLP and RF in Table 7, Table 8 and Table 9, its performance is slightly worse than the XGBoost model in Table 10. Based on all the results, RandomUnderSampler-based model has the best performance in terms of macro-average F1 score, weighted average F1 score, and MCC.
4.6. Comparison of Machine Learning Using Different Sampling Techniques for Multi-Class Classification
Based on the results of oversampling techniques in Table 2, Table 3, Table 4, Table 5 and Table 6, the ensemble models (XGBoost, and CatBoost) have better performance than the single models (DT and MLP). This is reasonable because the ensemble model is able to reduce the overfitting problem by aggregating multiple estimators for final prediction. In addition, with the use of SMOTE, all machine learning models used can be further improved. Based on all the results, the SMOTE-based XGBoost has the best performance for this multi-class classification task. Based on the results of undersampling techniques in Table 7, Table 8, Table 9, Table 10 and Table 11, the ensemble models (XGBoost and CatBoost) have better performance than the single models (DT and MLP).
We can also see from Table 12 that XGBoost and CatBoost have high performance with the use of oversampling or undersampling techniques. It is surprising to see that with the use of undersampling techniques, the performance of machine learning models is similar to the oversampling-based machine learning models. The reasons could be that (1) undersampling reduces the size of the majority class, which can simplify the learning task for the model; (2) oversampling techniques may introduce synthetic instances into the minority class, which could potentially add noise to the dataset; (3) undersampling ensures that the model focuses on the most relevant instances in the dataset by reducing the dominance of the majority class, which could lead to better discrimination between classes and improved model performance; and (4) oversampling techniques may generate synthetic instances that are outliers in feature space, potentially affecting the model’s performance. However, the choice between undersampling and oversampling should focus on the specific problems. According to all the results, the SMOTE-based XGBoost and CatBoost have the best performance for this multi-class classification task, with an accuracy of 75%, a weighted average precision of 82%, a weighted average recall of 75%, and a weighted average F1 score of 77%, while the RandomUnderSampler-based CatBoost has similar performance with their results of [75%, 81%, 75%, 77%] for [accuracy, weighted average precision, weighted average recall, weighted average F1 score].
Table 12.
Comparison of machine learning using different sampling techniques for multi-class classification.
5. Conclusions and Future Work
In the context of a smart home environment, one of the major challenges is the users’ inability to understand and take the necessary security precautions. However, the data of attacks are imbalanced, making it difficult to accurately predict the right category. In this paper, five machine learning models were used for security attack detection on smart applications. In addition, oversampling and undersampling techniques were introduced to solve the imbalanced problem. The results show that the SMOTE-based XGBoost has the best performance with the best accuracy, weighted average precision, weighted average recall, weighted average F1 score, and MCC, with values of 75%, 82%, 75%, 77%, and 72%, respectively. This indicates that these sampling techniques are effective for multi-attack prediction. Further, without the use of sampling techniques, the traditional machine learning models could not detect minority attack classes in some cases, while the model with the sampling techniques used was able to address this problem. This indicates that this sampling-based model is effective for intrusion detection.
However, deploying machine learning models in the real-world IoT environment presents several challenges. The implementation of these models in IoT devices, which often have limited resources, introduces several considerations that can impact their effectiveness and feasibility. In addition, the computational requirements of the models directly impact their deployment on IoT devices. For model training, the computation time ranged from 295 s to 56,777 s depending on which machine learning model and sampling technique was used.
5.1. Threats to Validity
In terms of threats to validity, the first is data quality. The data used to train models or inform research should be accurate and reliable. This means ensuring that data collection methods are valid and that the data are free from errors or biases. In addition, given the class imbalance problem discussed in this paper, sampling techniques (oversampling or undersampling) should be applied to alleviate this problem. In addition, the security of the system is also important. The system should be designed to resist tampering and ensure that it operates as intended without being compromised. Finally, cognitive understanding of system results is crucial for allowing users to understand how decisions are made. By doing so, users can trust the system and understand its limitations.
5.2. Future Work
For future work, considering that the undersampling-based XGBoost model showed the best performance, we will investigate more of the RandomUnderSampler technique to further address the imbalanced problem. In addition, as the deep learning approaches have feature learning capabilities, we will investigate how to integrate feature generation into the ensemble models to further improve detection accuracy. Finally, considering the sampling techniques that can be used to improve the prediction performance for imbalanced data, more advanced techniques (e.g., generative adversarial networks [52,53,54,55]) will be investigated to generate synthetic data and handle imbalance problems.
Author Contributions
Conceptualization, S.S., F.S., X.G. and Z.F.; methodology, Z.F.; validation, Z.F., X.G., F.S. and S.S.; formal analysis, X.G., S.S., Z.F. and F.S.; investigation, X.G., S.S., Z.F. and F.S.; resources, F.S., X.G., S.S. and Z.F.; data curation, X.G., S.S., Z.F. and F.S.; writing—original draft preparation, Z.F.; writing—review and editing, S.S., F.S., Z.F. and X.G.; visualization, Z.F. and X.G.; supervision, X.G., S.S., Z.F. and F.S.; project administration, Z.F. All authors have read and agreed to the published version of the manuscript.
Funding
This study was conducted without external funding or financial support.
Data Availability Statement
The data analyzed during this study are available via public bibliographic databases and can be found on Github at: https://github.com/Zongwen-Fan/SamplingML (accessed on 7 March 2024).
Conflicts of Interest
The authors declare no conflicts of interest.
Abbreviations
The following abbreviations are used in this manuscript:
| IoT | Internet of Things |
| SMOTE | Synthetic minority oversampling technique |
| SVM | Support vector machine |
| ADASYN | Adaptive synthetic sampling |
| DT | Decision tree |
| MLP | Multilayer perceptron |
| RF | Random forest |
| XGBoost | Extreme gradient boosting |
| CatBoost | Category boosting |
References
- Perwej, Y.; Haq, K.; Parwej, F.; Mumdouh, M.; Hassan, M. The internet of things (IoT) and its application domains. Int. J. Comput. Appl. 2019, 975, 182. [Google Scholar] [CrossRef]
- Hafeez, I.; Antikainen, M.; Ding, A.Y.; Tarkoma, S. IoT-KEEPER: Detecting malicious IoT network activity using online traffic analysis at the edge. IEEE Trans. Netw. Serv. Manag. 2020, 17, 45–59. [Google Scholar] [CrossRef]
- Farooq, U.; Tariq, N.; Asim, M.; Baker, T.; Al-Shamma’a, A. Machine learning and the Internet of Things security: Solutions and open challenges. J. Parallel Distrib. Comput. 2022, 162, 89–104. [Google Scholar] [CrossRef]
- Shafiq, M.; Tian, Z.; Sun, Y.; Du, X.; Guizani, M. Selection of effective machine learning algorithm and Bot-IoT attacks traffic identification for internet of things in smart city. Future Gener. Comput. Syst. 2020, 107, 433–442. [Google Scholar] [CrossRef]
- Rani, M. Effective network intrusion detection by addressing class imbalance with deep neural networks multimedia tools and applications. Multimed. Tools Appl. 2022, 81, 8499–8518. [Google Scholar] [CrossRef]
- Pirizadeh, M.; Alemohammad, N.; Manthouri, M.; Pirizadeh, M. A new machine learning ensemble model for class imbalance problem of screening enhanced oil recovery methods. J. Pet. Sci. Eng. 2021, 198, 108214. [Google Scholar] [CrossRef]
- Chawla, N.V.; Bowyer, K.W.; Hall, L.O.; Kegelmeyer, W.P. SMOTE: Synthetic minority over-sampling technique. J. Artif. Intell. Res. 2002, 16, 321–357. [Google Scholar] [CrossRef]
- Moreo, A.; Esuli, A.; Sebastiani, F. Distributional random oversampling for imbalanced text classification. In Proceedings of the 39th International ACM SIGIR Conference on Research and Development in Information Retrieval, Pisa, Italy, 17–21 July 2016; pp. 805–808. [Google Scholar]
- Han, H.; Wang, W.Y.; Mao, B.H. Borderline-SMOTE: A new over-sampling method in imbalanced datasets learning. In Advances in Intelligent Computing, Proceedings of the International Conference on Intelligent Computing, ICIC 2005, Hefei, China, 23–26 August 2005; Springer: Berlin/Heidelberg, Germany, 2005; Part I; pp. 878–887. [Google Scholar]
- Nguyen, H.M.; Cooper, E.W.; Kamei, K. Borderline over-sampling for imbalanced data classification. Int. J. Knowl. Eng. Soft Data Paradig. 2011, 3, 4–21. [Google Scholar] [CrossRef]
- He, H.; Bai, Y.; Garcia, E.A.; Li, S. ADASYN: Adaptive synthetic sampling approach for imbalanced learning. In Proceedings of the 2008 IEEE International Joint Conference on Neural Networks (IEEE World Congress on Computational Intelligence), Hong Kong, China, 1–8 June 2008; pp. 1322–1328. [Google Scholar]
- Siddappa, N.G.; Kampalappa, T. Adaptive condensed nearest neighbor for imbalance data classification. Int. J. Intell. Eng. Syst. 2019, 12, 104–113. [Google Scholar] [CrossRef]
- Elhassan, T.; Aljurf, M. Classification of imbalance data using tomek link (T-Link) combined with random under-sampling (RUS) as a data reduction method. Glob. J. Technol. Optim S 2016, 1, 1–11. [Google Scholar]
- Putrada, A.G.; Abdurohman, M.; Perdana, D.; Nuha, H.H. Shuffle Split-Edited Nearest Neighbor: A Novel Intelligent Control Model Compression for Smart Lighting in Edge Computing Environment. In Information Systems for Intelligent Systems, Proceedings of the ISBM 2022; Springer: Singapore, 2023; pp. 219–227. [Google Scholar]
- Kubat, M.; Matwin, S. Addressing the curse of imbalanced training sets: One-sided selection. In Proceedings of the 14th International Conference on Machine Learning, San Francisco, CA, USA, 8–12 July 1997; Volume 97, p. 179. [Google Scholar]
- Smith, M.R.; Martinez, T.; Giraud-Carrier, C. An instance level analysis of data complexity. Mach. Learn. 2014, 95, 225–256. [Google Scholar] [CrossRef]
- Shelke, M.S.; Deshmukh, P.R.; Shandilya, V.K. A review on imbalanced data handling using undersampling and oversampling technique. Int. J. Recent Trends Eng. Res 2017, 3, 444–449. [Google Scholar]
- Wongvorachan, T.; He, S.; Bulut, O. A Comparison of Undersampling, Oversampling, and SMOTE Methods for Dealing with Imbalanced Classification in Educational Data Mining. Information 2023, 14, 54. [Google Scholar] [CrossRef]
- Liu, A.Y.c. The Effect of Oversampling and Undersampling on Classifying Imbalanced Text Datasets. Ph.D. Thesis, The University of Texas at Austin, Austin, TX, USA, 16 August 2004. [Google Scholar]
- Negandhi, P.; Trivedi, Y.; Mangrulkar, R. Intrusion detection system using random forest on the NSL-KDD dataset. In Emerging Research in Computing, Information, Communication and Applications, Proceedings of the ERCICA 2018; Springer: Singapore, 2019; Volume 2, pp. 519–531. [Google Scholar]
- Panigrahi, R.; Borah, S.; Bhoi, A.K.; Ijaz, M.F.; Pramanik, M.; Kumar, Y.; Jhaveri, R.H. A consolidated decision tree-based intrusion detection system for binary and multiclass imbalanced datasets. Mathematics 2021, 9, 751. [Google Scholar] [CrossRef]
- Yin, Y.; Jang-Jaccard, J.; Xu, W.; Singh, A.; Zhu, J.; Sabrina, F.; Kwak, J. IGRF-RFE: A hybrid feature selection method for MLP-based network intrusion detection on UNSW-NB15 Dataset. J. Big Data 2023, 10, 15. [Google Scholar] [CrossRef]
- Chaithanya, P.; Gauthama Raman, M.; Nivethitha, S.; Seshan, K.; Sriram, V.S. An efficient intrusion detection approach using enhanced random forest and moth-flame optimization technique. In Computational Intelligence in Pattern Recognition, Proceedings of the CIPR 2019; Springer: Singapore, 2020; pp. 877–884. [Google Scholar]
- Choraś, M.; Pawlicki, M. Intrusion detection approach based on optimised artificial neural network. Neurocomputing 2021, 452, 705–715. [Google Scholar] [CrossRef]
- Hodo, E.; Bellekens, X.; Hamilton, A.; Dubouilh, P.L.; Iorkyase, E.; Tachtatzis, C.; Atkinson, R. Threat analysis of IoT networks using artificial neural network intrusion detection system. In Proceedings of the 2016 International Symposium on Networks, Computers and Communications (ISNCC), Yasmine Hammamet, Tunisia, 11–13 May 2016; pp. 1–6. [Google Scholar] [CrossRef]
- Sohail, S.; Fan, Z.; Gu, X.; Sabrina, F. Multi-tiered Artificial Neural Networks model for intrusion detection in smart homes. Intell. Syst. Appl. 2022, 16, 200152. [Google Scholar] [CrossRef]
- Jabbar, M.; Aluvalu, R.; Reddy, S.S.S. RFAODE: A novel ensemble intrusion detection system. Proc. Comput. Sci. 2017, 115, 226–234. [Google Scholar] [CrossRef]
- Jabbar, M.A.; Aluvalu, R.; Reddy, S.S.S. Cluster based ensemble classification for intrusion detection system. In Proceedings of the 9th International Conference on Machine Learning and Computing, Singapore, 24–26 February 2017; pp. 253–257. [Google Scholar]
- Gaikwad, D.; Thool, R.C. Intrusion detection system using bagging ensemble method of machine learning. In Proceedings of the 2015 International Conference on Computing Communication Control and Automation, Pune, India, 26–27 February 2015; pp. 291–295. [Google Scholar]
- Karthik, M.G.; Krishnan, M.M. Hybrid random forest and synthetic minority over sampling technique for detecting internet of things attacks. J. Ambient. Intell. Humaniz. Comput. 2021, 1–11. [Google Scholar] [CrossRef]
- Bej, S.; Davtyan, N.; Wolfien, M.; Nassar, M.; Wolkenhauer, O. LoRAS: An oversampling approach for imbalanced datasets. Mach. Learn. 2021, 110, 279–301. [Google Scholar] [CrossRef]
- Qaddoura, R.; Al-Zoubi, A.M.; Almomani, I.; Faris, H. A Multi-Stage Classification Approach for IoT Intrusion Detection Based on Clustering with Oversampling. Appl. Sci. 2021, 11, 3022. [Google Scholar] [CrossRef]
- Farah, A. Cross Dataset Evaluation for IoT Network Intrusion Detection. Ph.D. Thesis, University of Wisconsin Milwaukee, Milwaukee, WI, USA, December 2020. [Google Scholar]
- Krishnan, S.; Neyaz, A.; Liu, Q. IoT Network Attack Detection using Supervised Machine Learning. Int. J. Artif. Intell. Expert Syst. 2021, 10, 18–32. [Google Scholar]
- Grina, F.; Elouedi, Z.; Lefevre, E. Evidential undersampling approach for imbalanced datasets with class-overlapping and noise. In Modeling Decisions for Artificial Intelligence, Proceedings of the 18th International Conference, MDAI 2021, Umeå, Sweden, 27–30 September 2021; Springer: Cham, Switzerland, 2021; pp. 181–192. [Google Scholar]
- Onan, A. Consensus clustering-based undersampling approach to imbalanced learning. Sci. Program. 2019, 2019, 5901087. [Google Scholar] [CrossRef]
- Tsai, C.F.; Lin, W.C.; Hu, Y.H.; Yao, G.T. Under-sampling class imbalanced datasets by combining clustering analysis and instance selection. Inf. Sci. 2019, 477, 47–54. [Google Scholar] [CrossRef]
- Fan, Z.; Sohail, S.; Sabrina, F.; Gu, X. The Code of Sampling-Based Machine Learning Models for Intrusion Detecion. 2024. Available online: https://github.com/Zongwen-Fan/SamplingML (accessed on 8 April 2024).
- Imbalanced-Learn Documentation. Available online: https://imbalanced-learn.org/stable/ (accessed on 20 December 2023).
- Zhou, H.; Zhang, J.; Zhou, Y.; Guo, X.; Ma, Y. A feature selection algorithm of decision tree based on feature weight. Expert Syst. Appl. 2021, 164, 113842. [Google Scholar] [CrossRef]
- Rosenblatt, F. The perceptron: A probabilistic model for information storage and organization in the brain. Psychol. Rev. 1958, 65, 386–408. [Google Scholar] [CrossRef] [PubMed]
- Ho, T.K. Random decision forests. In Proceedings of the 3rd International Conference on Document Analysis and Recognition, Montreal, QC, Canada, 14–16 August 1995; Volume 1, pp. 278–282. [Google Scholar]
- Chen, T.; Guestrin, C. Xgboost: A scalable tree boosting system. In Proceedings of the 22nd ACM SIGKDD International Conference on Knowledge Discovery and Data Mining, San Francisco, CA, USA, 13–17 August 2016; pp. 785–794. [Google Scholar]
- Zhang, Y.; Zhao, Z.; Zheng, J. CatBoost: A new approach for estimating daily reference crop evapotranspiration in arid and semi-arid regions of Northern China. J. Hydrol. 2020, 588, 125087. [Google Scholar] [CrossRef]
- Batista, G.E.; Prati, R.C.; Monard, M.C. A study of the behavior of several methods for balancing machine learning training data. ACM SIGKDD Explor. Newsl. 2004, 6, 20–29. [Google Scholar] [CrossRef]
- Moustafa, N.; Slay, J. UNSW-NB15: A comprehensive dataset for network intrusion detection systems (UNSW-NB15 network dataset). In Proceedings of the 2015 Military Communications and Information Systems Conference (MilCIS), Canberra, ACT, Australia, 10–12 November 2015; pp. 1–6. [Google Scholar] [CrossRef]
- Koroniotis, N.; Moustafa, N.; Sitnikova, E.; Turnbull, B. Towards the development of realistic botnet dataset in the Internet of Things for network forensic analytics: Bot-IoT dataset. Future Gener. Comput. Syst. 2019, 100, 779–796. [Google Scholar] [CrossRef]
- Ullah, I.; Mahmoud, Q. A Scheme for Generating a Dataset for Anomalous Activity Detection in IoT Networks. In Advances in Artificial Intelligence, Proceedings of the Canadian Conference on AI, Ottawa, ON, Canada, 13–15 May 2020; Springer: Cham, Switzerland, 2020. [Google Scholar]
- Fan, Z.; Gou, J. Predicting body fat using a novel fuzzy-weighted approach optimized by the whale optimization algorithm. Expert Syst. Appl. 2023, 217, 119558. [Google Scholar] [CrossRef]
- Fan, Z.; Gou, J.; Weng, S. A Novel Fuzzy Feature Generation Approach for Happiness Prediction. IEEE Trans. Emerg. Top. Comput. Intell. 2024, 8, 1595–1608. [Google Scholar] [CrossRef]
- McDonnell, K.; Murphy, F.; Sheehan, B.; Masello, L.; Castignani, G. Deep learning in insurance: Accuracy and model interpretability using TabNet. Expert Syst. Appl. 2023, 217, 119543. [Google Scholar] [CrossRef]
- Lim, W.; Yong, K.S.C.; Lau, B.T.; Tan, C.C.L. Future of generative adversarial networks (GAN) for anomaly detection in network security: A review. Comput. Secur. 2024, 139, 103733. [Google Scholar] [CrossRef]
- Liu, L.; Wang, P.; Lin, J.; Liu, L. Intrusion detection of imbalanced network traffic based on machine learning and deep learning. IEEE Access 2020, 9, 7550–7563. [Google Scholar] [CrossRef]
- Pan, Z.; Niu, L.; Zhang, L. UniGAN: Reducing mode collapse in GANs using a uniform generator. Adv. Neural Inf. Process. Syst. 2022, 35, 37690–37703. [Google Scholar]
- Kim, J.; Jeong, K.; Choi, H.; Seo, K. GAN-based anomaly detection in imbalance problems. In Proceedings of the Computer Vision–ECCV 2020 Workshops: Glasgow, UK, 23–28 August 2020; Springer: Cham, Switzerland, 2020; Part VI; pp. 128–145. [Google Scholar]
Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2024 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).