The first part of this section will analyze the methods used for system-call grouping in the scope of applicability for malware detection. In addition, this part also reviews the ML and DL methods used for malware and intrusion detection. The second part evaluates datasets suitable for malware and intrusion-detection training.
2.1. Overview of Research on System-Call Grouping and Machine Learning Methods
System-call grouping is an important technique in computer science and intrusion-detection systems. System-call grouping refers to the categorization and organization of system calls based on their characteristics and relationships. This grouping allows the analysis and understanding of system-call patterns and dependencies, which can be useful in various domains such as malware detection [
22] and anomaly-based intrusion-detection systems [
23]. By grouping system calls together, researchers and practitioners can identify commonalities and differences among system-call behaviors, enabling them to develop more effective detection and classification algorithms [
22].
One example of system-call grouping is the study conducted by [
23], where they considered system calls such as read, readv, pread, and fread as the same system call. This approach of grouping similar system calls together enabled a more comprehensive analysis of their behavior and could improve the accuracy of anomaly-detection systems. Another relevant reference is the work by [
22], which discusses the utilization of temporal graphs of system-call group relations for malicious software detection and classification. By creating a system-call dependency graph and grouping related system calls, it demonstrates how the graph can be used to identify patterns and relationships among system calls, aiding in the detection and classification of malicious software. However, the research does not mention any experiments conducted with real data as the focus of the paper is on discussing the technological status of malware detection and classification and presenting the main components of the proposed model.
System-call grouping is not only used in malware detection, but also in the graphical representation of applications. The graphical representation of system calls is a valuable approach for understanding and analyzing the behavior of these calls in an operating system. Several studies have explored the use of clustering methods in conjunction with graphical representations of system calls. One study [
24] utilized the open-source tool Graphviz to generate graphical representations of Unix process system calls. This approach facilitated the comprehension of the behavior of these system calls, aiding in the learning of the Unix operating system. By visualizing the relationships between different system calls, clustering methods could be applied to identify patterns and group similar calls together. Another work proposed the collection of sequences of system functions from malware samples and map them to color heat maps [
11]. To represent such a heat map, the author defined a system function on one axis, a process that calls this function, and the number of calls on the other. The problem with this way of mapping is that it maps the system functions of several processes and does not map just one malware sample, but the system functions called by many applications and their processes. This issue does not allow the reuse of the mapping technique for system-call grouping properly for later analysis with ML methods.
Another way to represent the actions of a malware that researchers have proposed is mentioned in [
25]. The authors collected the dataset and visualized the functions’ actions using a tree map algorithm, which displays the information in defined rectangles for each group of records. With this mapping method, the more the malware calls a specific system function, the larger the rectangle for that call will be. In total, 120 different system functions were analyzed but, unfortunately, the authors did not specify how the image creation was performed [
25]. As with the aforementioned heat mapping approach, there was also a loss of sequences.
The authors of another research paper decided to group Windows API functions according to their level of maliciousness, from non-malicious to very malicious [
26]. For each level, the colors were indicated, and a bar was generated from the called system functions, in order to replace the entry of each function with a bar of a given, specified color. By generating bands of function sequences, the authors were able to preserve the order of the function sequences, unlike other representations of system functions discussed in other approaches. Knowing which function is followed by which function is essential, as it is likely that not only the called functions could be used to determine whether it is a malware, but also the order of the harmful functions. This is the most appropriate way to represent system-call sequences because, as mentioned before, the order is preserved, but there was a major problem with the representation: there was no indication of how the author had grouped or determined the riskiness of each function and its effectiveness. Also, when looking at the figures, it was difficult to determine whether the figure referred to a malware or a benign code, as the authors used too many different colors.
In summary, system-call grouping is a valuable technique that enables the categorization and analysis of system calls based on their characteristics and relationships. It has applications in various domains, including malware detection and anomaly-based detection systems. A comparison of reviewed methods is presented in
Table 1. By grouping system calls together, researchers and practitioners can gain insights into their behavior and patterns, leading to more effective detection and classification algorithms. More importantly, the analysis of work where graphical representation is described could help to improve host-based intrusion-detection systems, as they can provide valuable information on how to cluster system calls by similar properties.
Moreover, the use of sequential system calls and API call sequences, as demonstrated by [
27], enables the incremental detection of malware, addressing the need for continuous monitoring and detection in contemporary cybersecurity. These methods leverage the inherent characteristics of API calls and system calls to detect anomalies and malicious behaviors, aligning with the evolving threat landscape and the need for robust protection against malware, as discussed by [
28].
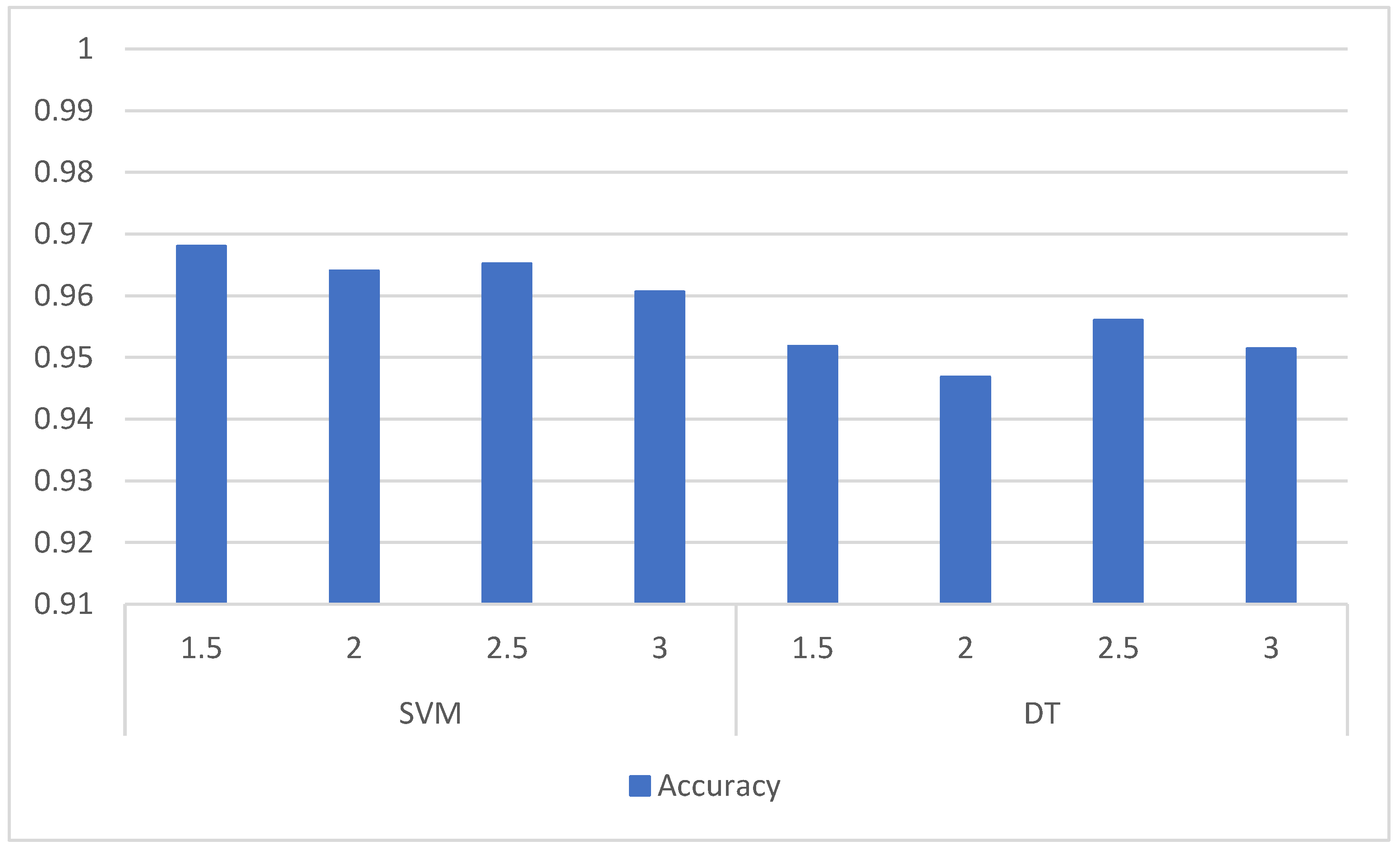
An extensive range of machine learning methods has been employed for anomaly detection in the domains of malware and intrusion detection. Some commonly used machine learning methods are: naive Bayes (NB), support vector machine (SVM), K-nearest neighbor (KNN), artificial neural networks (ANN), DT, random forest (RF), hidden Markov model (HMM). Research studies have indicated that SVM and DT are among the most promising methods for anomaly detection. SVM and DT algorithms have been widely used in HIDSs due to their effectiveness in detecting and classifying intrusions [
29,
30,
31]. In the context of HIDSs, SVM can learn the patterns and characteristics of known attacks and identify similar patterns in real-time system behavior, enabling the detection of unknown or novel attacks [
29]. The advantages of SVM in HIDSs include its ability to handle high-dimensional data, its robustness against overfitting, and its effectiveness in handling both linear and non-linear classification problems. The advantages of DT in HIDSs include their interpretability, ease of understanding, and the ability to generate rules that can be used for further analysis and investigation of detected intrusions [
29]. In our previous research, where different machine learning methods were evaluated, SVM showed promising intrusion-detection results in combination with the lowest training and classification times. The classification results were better than the DL LSTM model [
32]. The same idea supports DT—this ML method also produced comparable classification results [
33]. Additionally, DT showed the best results in classification time and comparable results in training-time experiments. The aforementioned results encouraged us to experiment with SVM and DT in the field of HIDSs, as they can provide better performance in terms of time used for the training and classification tasks.
2.2. Analysis of Applicable Datasets for Malware Intrusion Detection
For almost two decades, researchers working in the field of intrusion detection have been using a publicly available Linux-based KDD98 data set [
34,
35,
36]. However, that database is from 1998 and has lost its completeness and quality. Furthermore, the nature of the data collected in the KDD98 dataset was more geared toward NIDSs than towards HIDSs [
37]. To address those issues, another Linux dataset, ADFA-LD, was developed in 2014. ADFA-LD, was created by running selected malicious programs on the Ubuntu 11.03 Linux operating system, which also ran essential services such as web, database, secure shell (SSH) and FTP [
38]. As the Windows operating system is much more popular than Linux, subsequently, the need arose to develop the ADFA-WD. The ADFA-WD dataset was built on a Windows XP SP2 operating system running applications such as a web-server, a database server, an FTP server, a streaming media server, a PDF reader, etc. A total of 12 different vulnerabilities were tested using Metasploit software, and a complement to the dataset, ADFA-WD:SAA, was created by using three different secret Windows operating system stealth attacks [
38]. ADFA-WD:SAA is a stealth attack-oriented addition to the ADFA-WD suite [
39]. Unfortunately, the ADFA-WD dataset does not provide a way to identify exactly which method was called from the DLL files.
There are also other HIDS-related datasets worth mentioning, but they all have issues that made them unusable in our research which is oriented towards Windows system-call analysis. A table with those datasets and notes about the data it contains is provided below (
Table 2).
Slightly later, in 2018, a new dataset, AWSCTD, was created. This dataset provides a better training capability for HIDSs, as it not only provides more detailed malware system-call sequences, but also provides additional information on malware, such as modified files and other general information about actions [
47]. AWSCTD is probably one of the newest Windows system-call datasets that is generated from the publicly available, VirusShare malware database. As the samples in VirusShare are not necessarily malicious, therefore, for the dataset, only samples with 15 or more positive detections by different antiviruses were selected [
47]. The dataset contains over 10,276 samples. It should also be noted that the AWSCTD dataset has a significantly higher number of collected malware system function sequences than the older Windows dataset ADFA-IDS (
Table 3). It is therefore expected that, due to the novelty and the size of the dataset, it will be possible to generate malware graphically with higher accuracy.
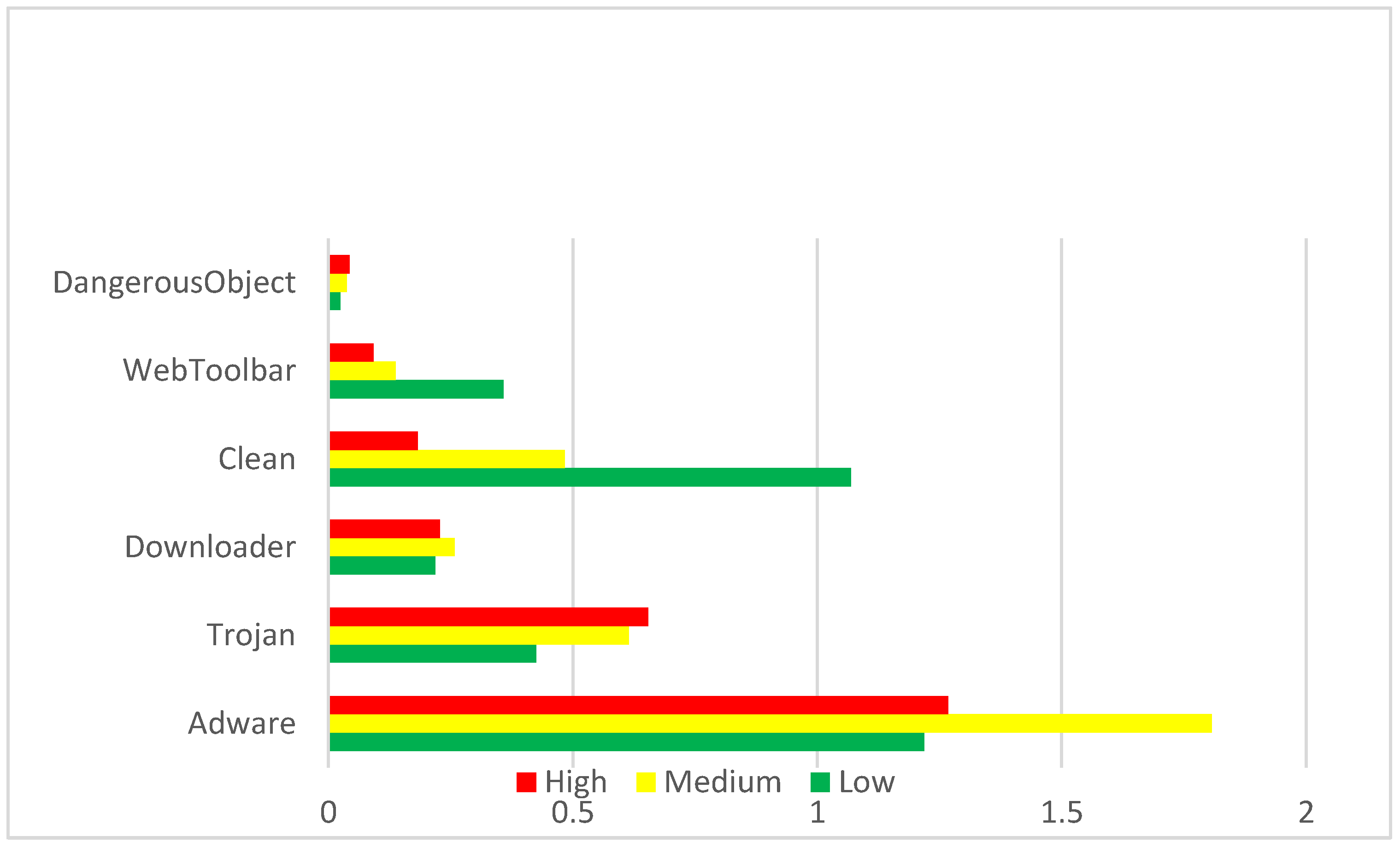
The AWSCTD dataset contains up to 540 unique system functions; it also contains 115 unique system functions that have never been called in clean code. Of these, up to 29 functions have been called more than 100 times by malicious code. There were 45 functions that were not called by the malware and only called by the clean code. Hence, as this dataset is newer and has a vast number of system-call records, it is more suitable for analyzing the sequences of different malware functions than the ADFA dataset. It is likely that the use of more recent data will lead to better results for this study, and for this reason the AWSCTD dataset will be used in this study, as it is intended to adapt the study to data that is more contemporary.
The unconverted AWSCTD was used in our previous experiments [
7,
32,
33]. The results obtained were really good for the resource requiring deep-learning methods (dual-flow deep LSTM-FCN and GRU-FCN, single-flow CNN) and the accuracy metric was equal to 98.9, 98.8 and 99.3 percent, respectively [
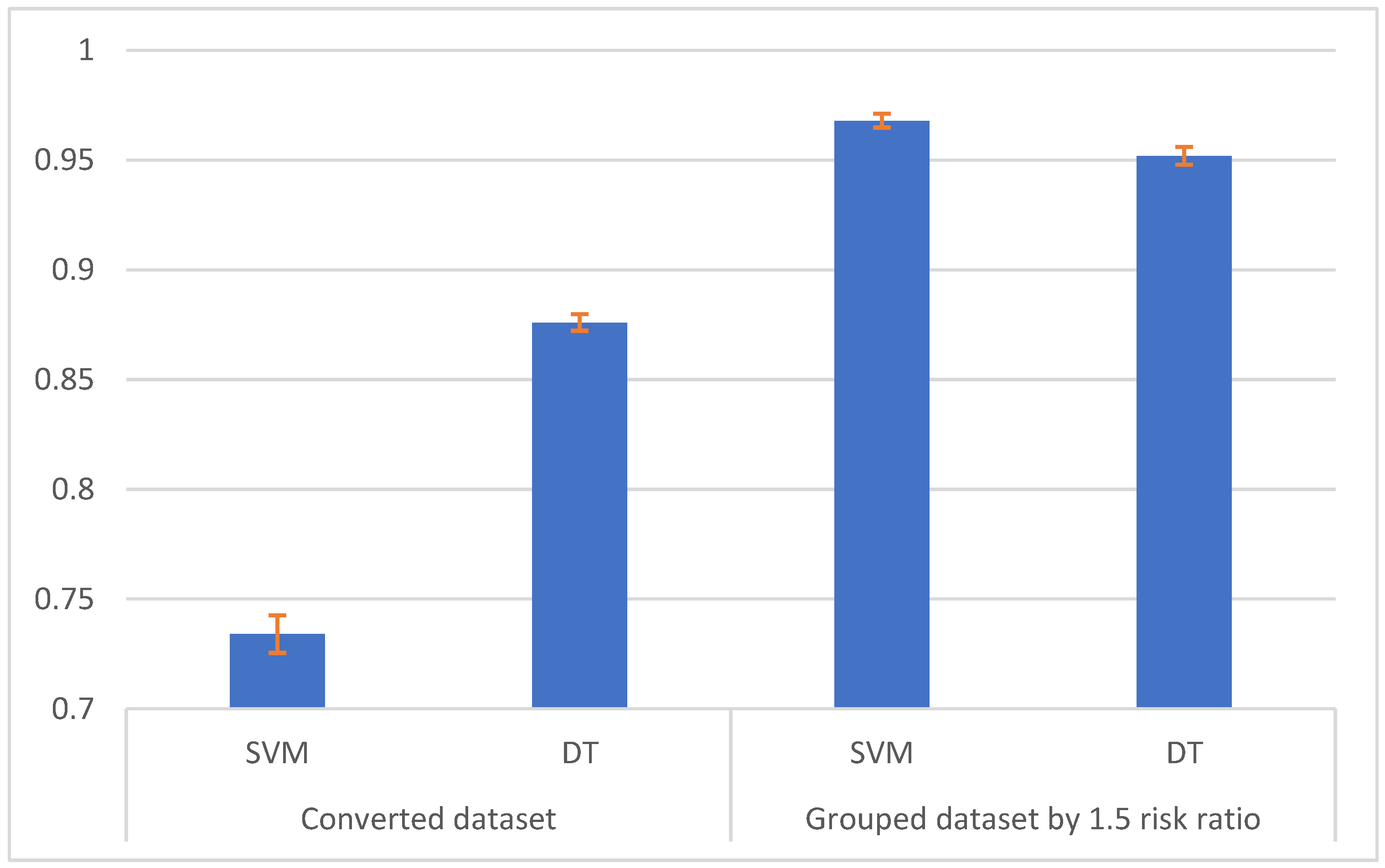
7]. The use of classical and relatively lightweight machine learning methods was not as good and the accuracy for SVM and DT was equal to TT and PP, respectively, [
32,
33] although it is worth mentioning that in the latter research no system-call grouping, or other optimization methods, were used.










{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}