Abstract
Targeting the issue that the traditional target detection method has a high missing rate of minor target defects in the lithium battery electrode defect detection, this paper proposes an improved and optimized battery electrode defect detection model based on YOLOv8. Firstly, the lightweight GhostCony is used to replace the standard convolution, and the GhostC2f module is designed to replace part of the C2f, which reduces model computation and improves feature expression performance. Then, the coordinate attention (CA) module is incorporated into the neck network, amplifying the feature extraction efficiency of the improved model. Finally, the EIoU loss function is employed to swap out the initial YOLOv8 loss function, which improves the regression performance of the network. The empirical findings demonstrate that the enhanced model exhibits increments in crucial performance metrics relative to the original model: the precision rate is elevated by 2.4%, the recall rate by 2.3%, and the mean average precision (mAP) by 1.4%. The enhanced model demonstrates a marked enhancement in the frames per second (FPS) detection rate, significantly outperforming other comparative models. This evidence indicates that the enhanced model aligns well with the requirements of industrial development, demonstrating substantial practical value in industrial applications.
1. Introduction
Lithium-ion batteries, as established energy storage devices, are extensively employed in various industrial and domestic applications. Consequently, the market’s demand for these batteries and stringent quality requirements continue escalating [1]. The manufacturing process for lithium battery electrode sheets is intricate, as it is vulnerable to various factors such as environmental conditions, equipment reliability, and human intervention. These factors often result in defects like metal leakage, holes, and scratches on the electrode sheet surface [2]. Since electrodes are crucial components of lithium batteries, surface defects can significantly impair the battery’s performance and longevity, potentially posing safety hazards [3]. Hence, detecting defects in lithium battery electrodes is imperative to ensure the reliability and safety of these batteries.
The defect detection technology of lithium battery electrodes is mainly divided into traditional and deep learning-based defect detection algorithms. In lithium battery electrode defect detection, the traditional defect detection algorithm makes it difficult to meet the defect detection task of the high-speed moving electrode in the industrial production environment. The faults on the lithium battery electrode are minor and complex, with many defects. Traditional defect detection algorithms rely on predefined feature extraction rules and may not be able to capture complex or subtle defect features. The traditional method is slow in complex defect detection tasks, and it is not easy to meet the requirement of real-time detection in industrial production. More and more scholars have applied deep learning-based defect detection technology to the surface defect detection of lithium batteries. Defect detection technology in the context of object detection algorithms is bifurcated into two primary categories: single-stage and two-stage object detection algorithms. Prominent among two-stage algorithms are R-CNN, Fast R-CNN, and Faster R-CNN, which are widely recognized for their precision [4,5,6]. On the other hand, standard single-stage methods like You Only Look Once (YOLO) and Single Shot MultiBox Detector (SSD) are notable for their speed [7,8]. While two-stage algorithms excel in detection accuracy, they are generally slower compared to their single-stage counterparts [9,10,11]. This makes single-stage algorithms particularly attractive for applications like lithium battery pole chip defect detection, where speed is crucial. The latest iteration in the YOLO series, the YOLOv8, emerges as a fitting solution for this application, balancing superior detection speed with enhanced accuracy, thus meeting the industrial demands for lithium battery pole chip defect detection.
To address the challenge posed by traditional target detection methods, particularly their inefficiency in detecting small targets within lithium battery electrode defect detection, this study introduces an innovative model: YOLOv8-GCE(Ghost-CA-EIoU), an enhancement based on the YOLOv8. The primary contributions of this algorithm are as follows:
- Firstly, the lightweight convolutional GhostConv (GhostNet Convolution) is used to replace the standard convolution, and the GhostC2f (GhostNet C2f) module is designed to replace part of the C2f (CSP Darknet53 to 2-Stage FPN), which reduces model computation and improves feature expression performance.
- Then, the CA module is incorporated into the neck network, amplifying the feature extraction efficiency of the improved model.
- Finally, the EIoU loss function is added to improve the regression performance of the network, resulting in faster convergence.
This paper is organized as follows: Section 2 provides an overview of the related work in the field. Section 3 delves into the YOLOv8 network model, detailing the strategies employed for its improvement. Section 4 initially describes the experimental setup, including the environment and parameter configurations. This section then proceeds to present a series of experiments: comparative, ablation, module position analysis, and algorithm visualization, all conducted on the dataset to validate the efficacy of the improved algorithm. Finally, Section 5 summarizes the study and outlines prospective directions for future research.
2. Related Work
The defect detection methodologies for lithium battery electrode plates predominantly fall into two categories: traditional defect detection algorithms and those based on deep learning. The latter is garnering increasing attention from scholars for its application in detecting surface defects of lithium batteries [12]. Presently, lithium battery electrode chip defect detection research primarily utilizes traditional detection algorithms and image segmentation technology. For instance, Xu et al. utilized standard image processing tools like contrast adjustment, the Canny operator, and logic operations to process images of lithium battery pole slices. By extracting texture features, edge features, and HOG (Histogram of Oriented Gradients) features of the defect area, their method achieved an average recognition rate of 98.3% on the test set [13]. Additionally, Liu et al. developed a rapid background compensation algorithm to counteract issues caused by uneven thickness in lithium battery pole slices and inconsistent lighting conditions during imaging [14]. They employed an adaptive threshold segmentation algorithm based on gray histogram reconstruction, demonstrating significant improvements in detection outcomes and operational speed compared to classical methods like Otsu’s algorithm. Nevertheless, as the new energy industry rapidly evolves, traditional algorithms are increasingly falling short of meeting the escalating demands for detection accuracy and real-time performance. Consequently, deep learning-based defect detection algorithms, with their robust characterization capabilities and superior adaptability, are progressively supplanting traditional methods and have emerged as a focal point in research on surface defect detection.
Initially introduced by Joseph et al. in 2016, the YOLO (You Only Look Once) algorithm marked a significant advancement in object detection. Following its introduction, subsequent researchers have continuously enhanced the original framework, leading to the development of YOLOv2 and YOLOv3. These iterations have seen a steady improvement in detection performance, garnering extensive attention and becoming a focal point of research within the industry [15,16]. Cao et al. improved the YOLOv3 network model to solve the problem of difficult detection of acceptable defects on the wafer surface, and mAP increased by 13 percentage points and improved the detection speed [17]. Lan et al. utilized YOLOv3 as a foundational model and introduced the integration of the batch normalization (BN) layer with the convolutional layer. This strategic combination shortened the model’s training duration and involved enhancements to the loss function, optimizing the overall performance [18]. In 2020, Alexey et al. innovatively integrated multiple practical modules based on traditional YOLO. They proposed the YOLOv4 algorithm with higher efficiency and a more accurate detection effect, which has been studied and improved by many experts and scholars [19]. Huang et al. focused on optimizing the PANet structure within the YOLOv4 framework. Their approach involved the expansion of novel shallow features, which were then integrated with the existing feature layers. This innovation reduced the model’s complexity and effectively enhanced the network’s performance in defect detection. As a result of these improvements, the modified model exhibited a 3.4% increase in mean average precision (mAP) and a notable 29% boost in detection speed [20]. Zhang et al. used a cross-stage local bottleneck module and a small target prediction head combined with YOLOv5 to detect panel defects and obtained good accuracy on multi-scale targets [21,22]. Dai et al. proposed a tripartite feature enhancement pyramid network and introduced a feature calibration module to calibrate the up-sampled features to achieve an accurate correspondence of feature fusion [23].
The YOLOv8 algorithm, building upon the successes of its predecessors, introduces a series of novel functions and enhancements. These advancements aim to augment the model’s structural flexibility and improve its detection accuracy. This evolution represents a significant stride in the ongoing development of the YOLO series, continually pushing the boundaries in object detection performance. In addressing the challenge of small target detection in memorable scenes, Lou et al. introduced an innovative downsampling technique and a feature fusion network tailored to the YOLOv8 framework. This approach uniquely assimilates shallow and deep information, concurrently preserving essential background feature details and facilitating a nuanced and effective detection strategy within complex visual environments [24]. Li et al. advanced the YOLOv8 framework by refining its lightweight backbone network and integrating the Bi-PAN-FPN (Bi-Directional Path Aggregation Network-Feature Pyramid Network) module into the neck network. This innovation effectively mitigated the loss of information during long-distance feature transmission, thereby enhancing the overall efficiency and accuracy of the model [25]. Previous research in target detection has yielded significant advancements in model recognition precision and efficiency. However, challenges persist, particularly in detecting small targets with variable morphology and low contrast. Addressing these issues, the algorithm proposed in this paper uses YOLOv8 as the foundational model and introduces several key enhancements. Initially, the model undergoes lightweight modifications in its neck structure, employing the GhostConv convolutional layer to replace standard convolutions and introducing the novel GhostC2f module instead of part of the C2f. This facilitates learning residual features and enriches the network with diverse gradient flow information. Subsequently, the CA module is integrated into the neck network, significantly bolstering its feature extraction capabilities [26]. Finally, the EIoU loss function is employed, superseding the original YOLOv8 loss function. This change accelerates convergence speed, enhances positioning accuracy, and aligns the model more closely with the practical demands of industrial applications, where detecting speed and accuracy are paramount.
3. YOLOv8 Algorithm Improvement Strategy
YOLOv8, representing the most recent iteration in the YOLO series, is versatile enough to be applied to object detection, image classification, and instance segmentation tasks. In the context of this paper, its application is focused on object detection tasks. The structure diagram of the YOLOv8 model is illustrated in Figure 1.
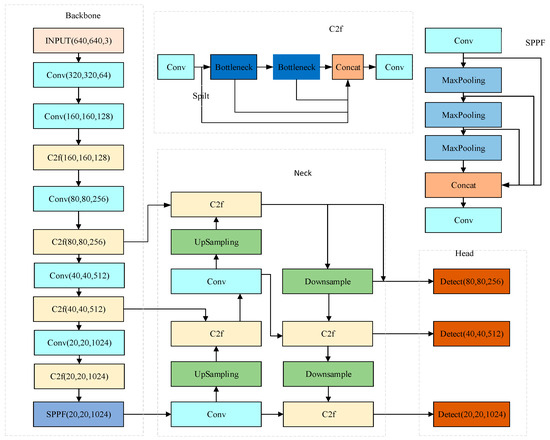
Figure 1.
YOLOv8 structure.
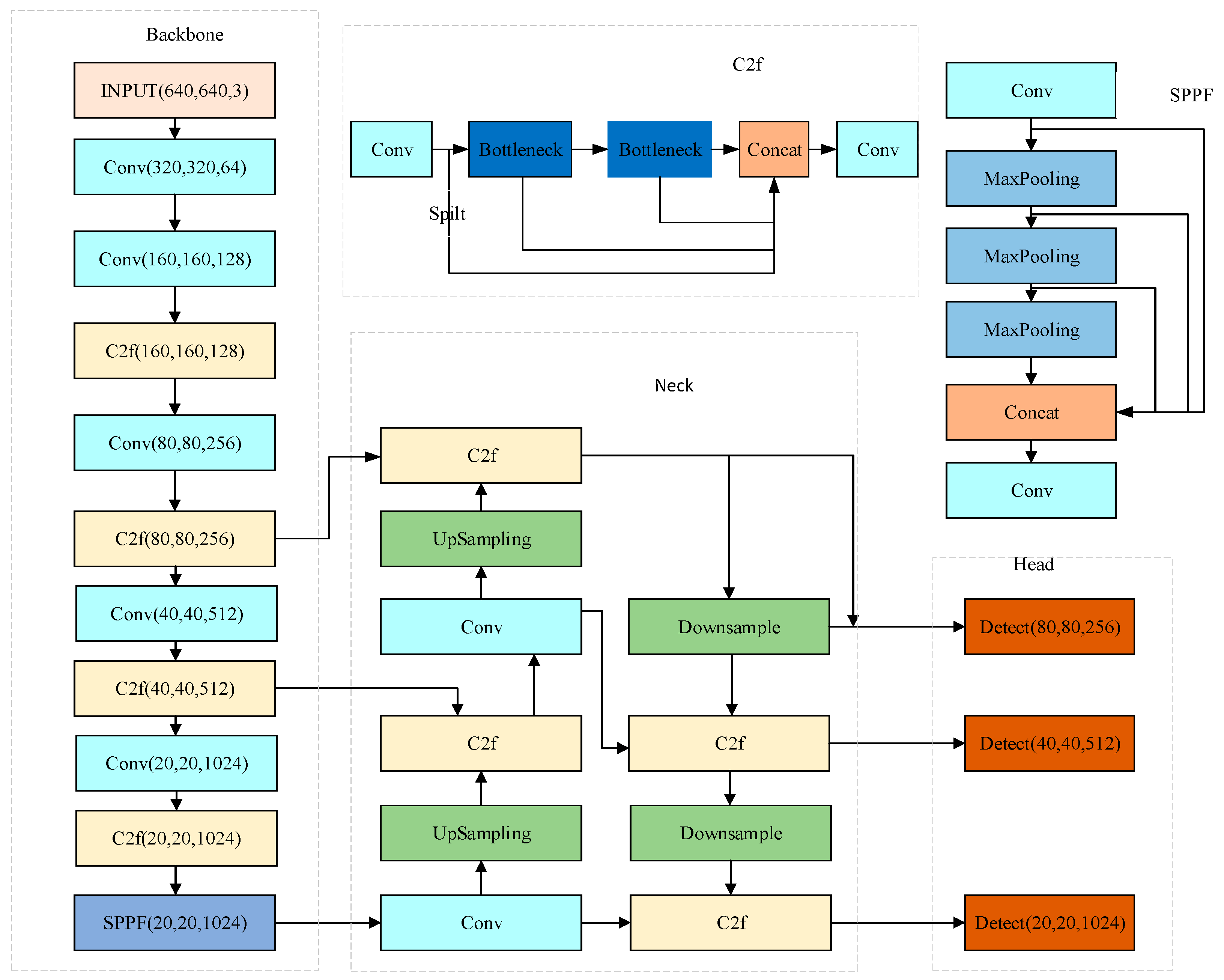
The YOLOv8 model, as depicted in Figure 1, comprises four key components: Input, Backbone, Neck, and Head. At the Input stage, YOLOv8 undertakes data preprocessing, employing four primary augmentation methods during training: Mosaic enhancement, Mix-up enhancement, Random Perspective enhancement, and HSV (Hue, Saturation, Value) augmentation. These methods enrich the detection background of images, thereby increasing the number of targets and enhancing the diversity of the image dataset [27]. The Anchor-Free thought is used to improve the prediction strategy to accelerate NMS (Non-Maximum Suppression) [28].
The backbone of the YOLOv8 model is primarily composed of convolution layers, C2f, and SPPF (Spatial Pyramid Pooling Fast), which collectively contribute to an enhanced feature expression capability. This is achieved through a dense residual structure, enabling the model to capture and process complex input data features effectively. The C2f module adds more branches to enrich tributaries of gradient backpasses. According to the scaling coefficient, splitting and splicing operations change the number of channels to reduce the computational complexity and model capacity. In the tail of the backbone, the rapid spatial pyramid pooling layer is employed to enhance the receptive field and capture feature information from multiple levels of the picture [29].
The neck, serving as an intermediary layer bridging the backbone and the detection head in the YOLOv8 model, is intricately structured. It comprises two up-sampling layers and multiple C2f modules, which are instrumental in further extracting multi-scale features. YOLOv8 continues to utilize the FPN-PAN architecture to construct its feature pyramid. This design choice ensures a comprehensive integration of the network’s information flow from upper and lower levels, thereby significantly augmenting the model’s detection efficiency [30,31].
As the terminal component responsible for predictions, the head of the YOLOv8 model employs an Anchor-Free approach to determine the location and classification of targets, drawing on the feature attributes processed by the neck. This method is particularly effective in identifying targets with atypical lengths and widths. In the output phase, the head employs a decoupled structure, distinctly segregating the detection and classification tasks. Furthermore, the model’s accuracy is refined by identifying positive and negative samples based on scores weighted by classification and regression metrics. This approach streamlines the prediction process and significantly enhances the model’s overall performance.
3.1. Introduce the GhostNet Module to Improve the Network Module
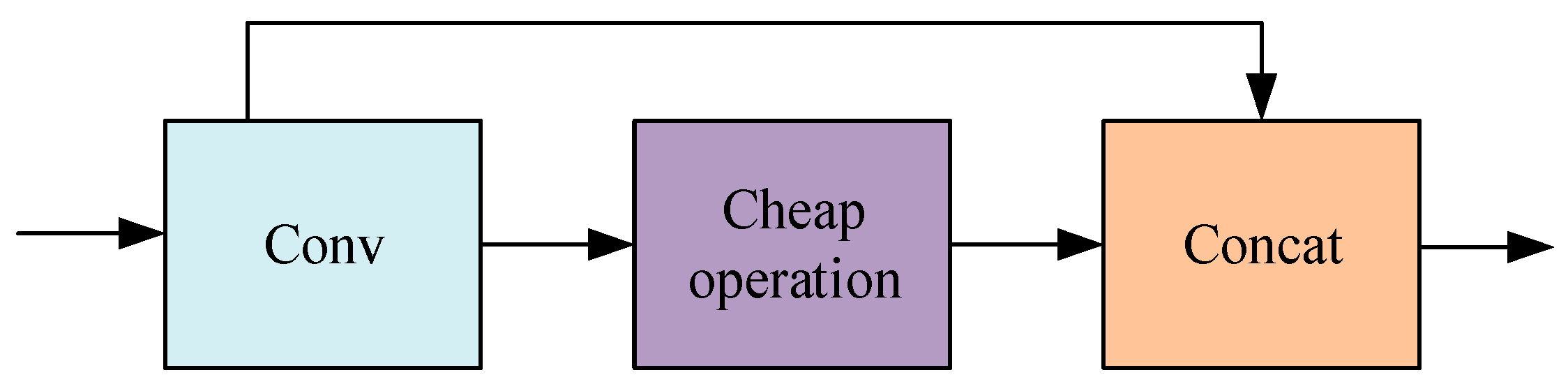
The Huawei team has proposed the lightweight CNN network known as the Ghostnet [32]. As shown in Figure 2, its core Ghost module is to generate feature maps through original convolution and cheap operation. Cheap operation can be a linear transformation of the remaining feature maps, or it can also be the result of the original convolution generate similar feature diagrams through depth-wise convolution. This article uses the GhostConv’s new convolutional method. The convolutional method uses uniformly mixed operations to penetrate the standard convolution information into the information generated by depth, which can be separated. Keep information interaction between channels, design the GhostC2f structure based on GhostConv, use GhostConv instead of ordinary convolution operations on the neck’s side, and swap out the initial C2f module with the GhostC2f module while maintaining the complexity of the model calculation and the accuracy of the reasoning time.
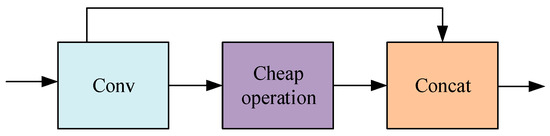
Figure 2.
GhostConv structure.
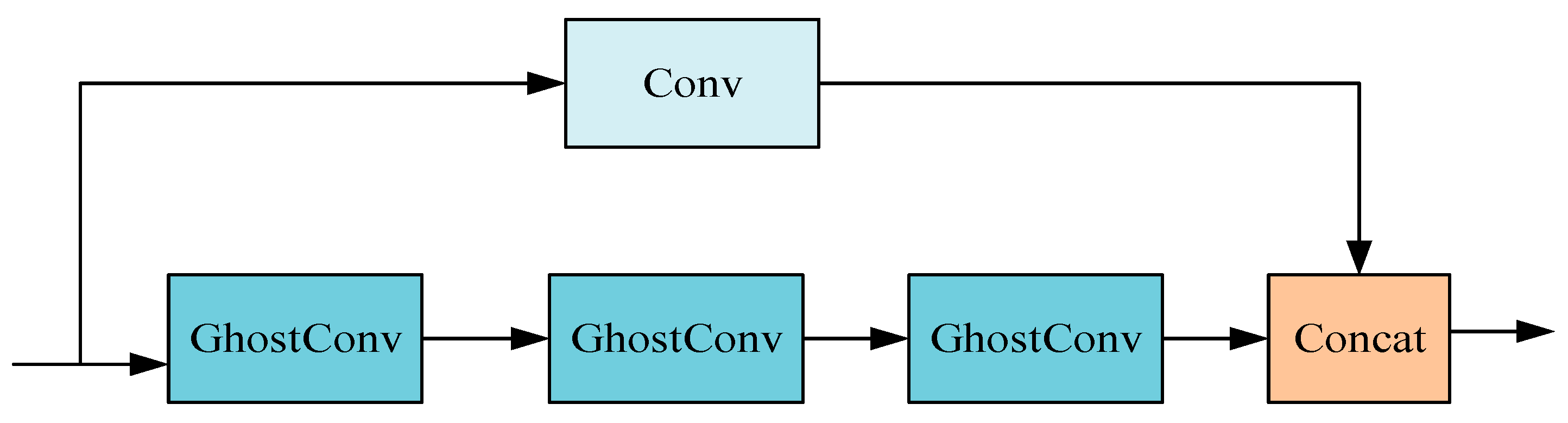
As depicted in Figure 3, the study introduces a novel double-layer bottleneck structure, GhostBottleneck (GhostNet Bottleneck), comprising one convolution layer coupled with multiple GhostConv layers. This innovative design synergizes the robust feature extraction capabilities of conventional convolution with the efficient computational performance of the GhostConv. The structure is adept at extracting rich features across various levels and scales, thereby enhancing the speed of processing redundant information. This functionality is particularly beneficial for detecting minor and complex multi-type defects on lithium battery electrodes, meeting the stringent requirements of precision and efficiency necessitated in such applications.
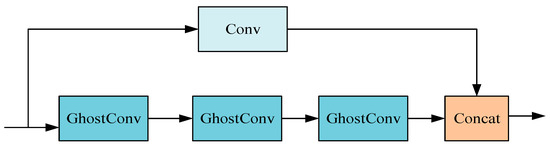
Figure 3.
GhostBottleneck structure.
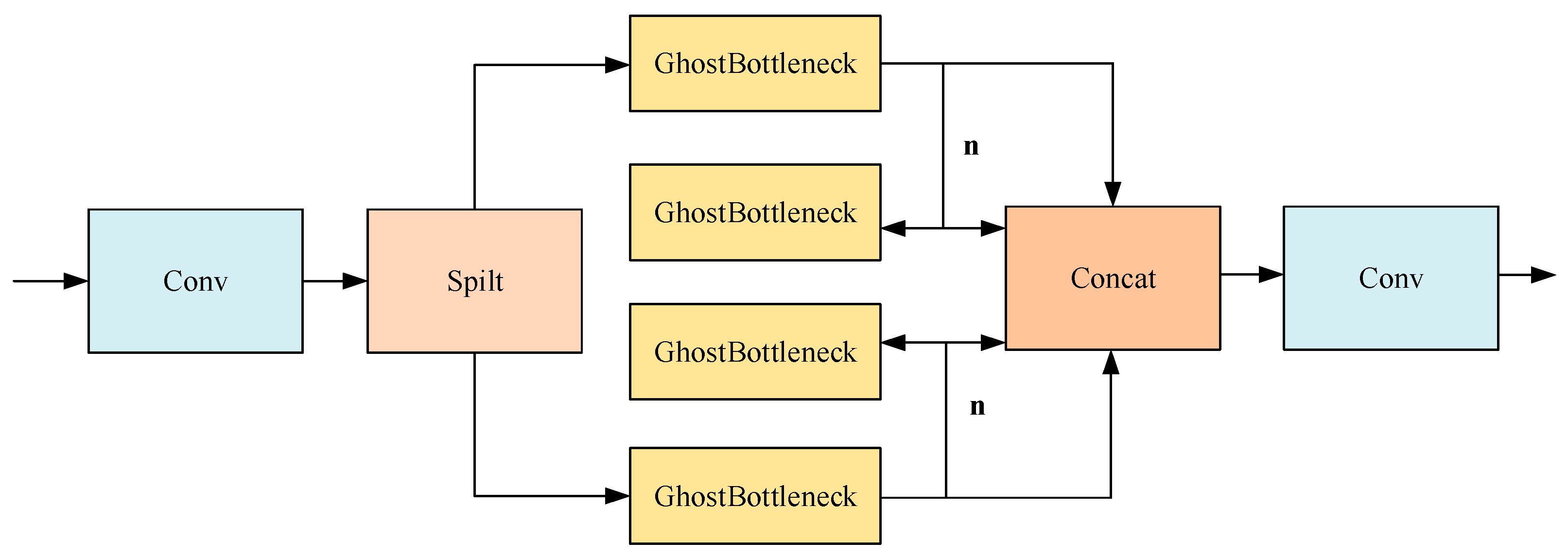
As illustrated in Figure 4, the GhostC2f module designed in this paper replaces all bottlenecks in the C2f module in the original network with the Ghostbottleneck. The redesigned GhostC2f module employs an interstage feature fusion strategy and truncated gradient flow technology, which are instrumental in amplifying the variation in learning characteristics across different network layers, effectively minimizing the impact of redundant gradient information and bolstering the network’s learning capacity. The integration of the GhostConv and GhostC2f modules significantly reduces the count of conventional 3 × 3 convolutions found in the original architecture, leading to substantial savings in computational resources and training time and markedly reducing the overall model size. Furthermore, the strategic combination of hierarchical design and residual connections facilitates improved gradient flow, enhancing the ability to train deeper network models effectively.
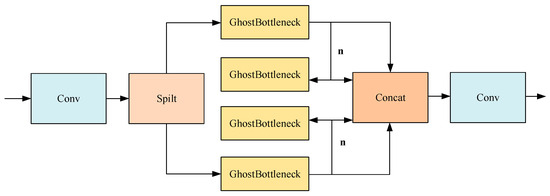
Figure 4.
GhostC2f structure.
3.2. CA Module
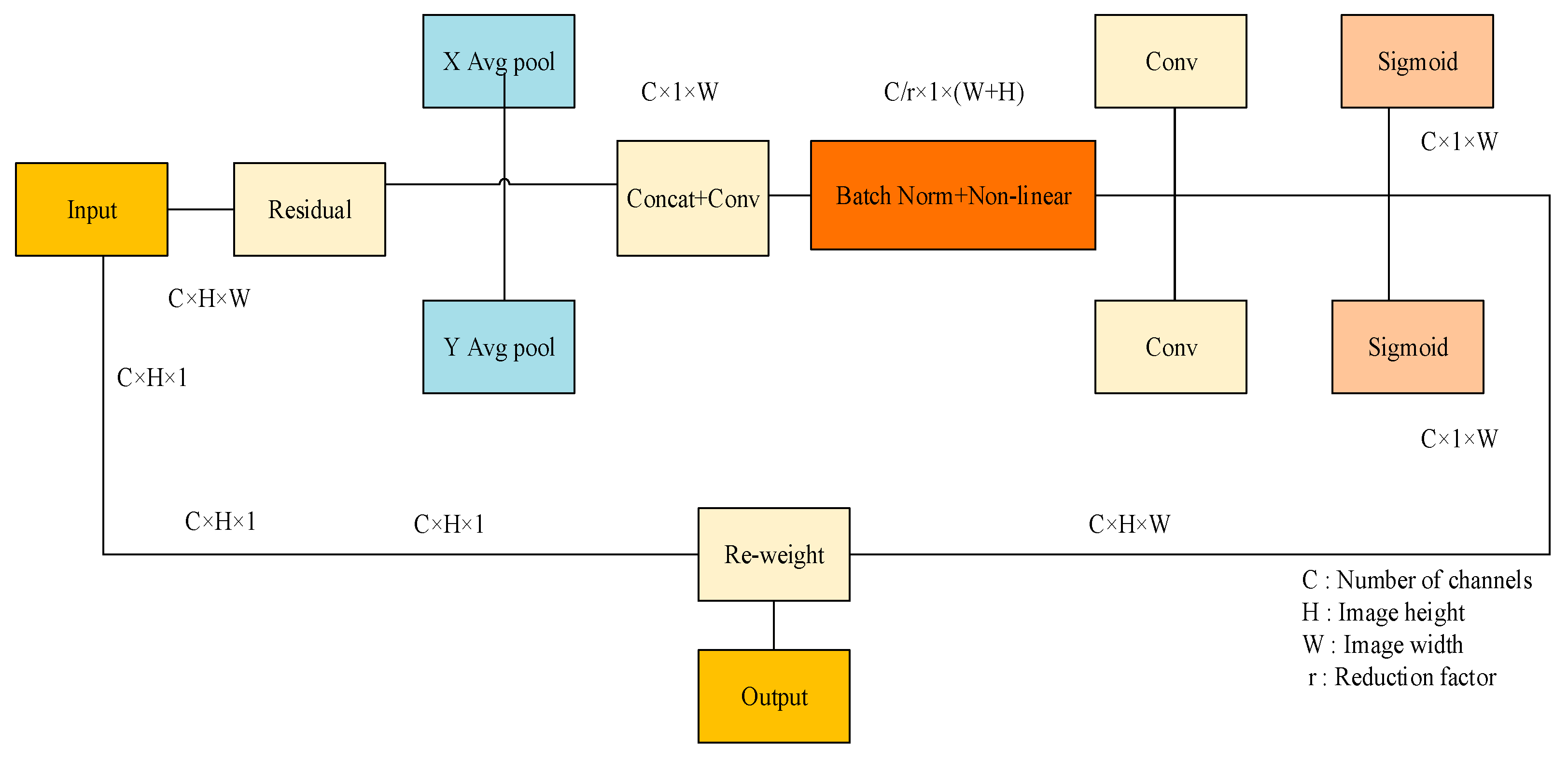
To enhance the model’s capacity for expressing features, the CA module was added to the YOLOv8 model for local feature enhancement so that the network model could ignore the interference of irrelevant information [33]. The CA module, as shown in Figure 5, is a new channel attention module that can be flexibly added to multiple positions in the existing model. The use of the GhostConv to maximize the hidden link between each channel at the front-end network can deepen the network layer of the model, which will exacerbate the resistance to the data flow. When these characteristic charts run to the neck part, the channel dimension has reached compared to the neck. To a large extent, the width dimension is small. Therefore, integrating the CA module after the neck module significantly enhances the model’s ability to learn regional features specific to surface defects on lithium battery electrodes. This strategic placement allows for a more focused extraction of defect features from the electrode plates, enabling more relevant feature data aggregation. Consequently, this enhances the precision of the algorithm’s detection capabilities.
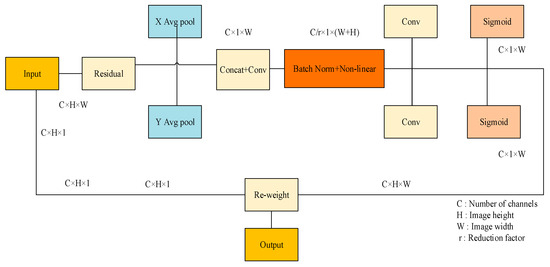
Figure 5.
CA structure.
First, the initial feature map is input, global average pooling is carried out so that the CA module can obtain attention weights in different directions, and the two-dimensional global pool is deconstructed to obtain feature maps in two directions, as shown in Formulas (1) and (2).
Subsequently, the two feature graphs of width and height that determine the direction of the global receptive field are combined. These feature graphs are then incorporated into the convolution module, which uses a 1 × 1 shared convolution kernel. The dimensions of the feature graphs F1 are returned to their original C/r after batch normalization. Ultimately, by feeding the Sigmoid activation function, a feature graph f in the form of 1 × (W + H) × C/r is produced, as indicated by Formula (3).
Next, concerning the initial dimensions, the feature graph f is processed using a 1 × 1 convolution kernel, producing feature graphs and , both maintaining an equal number of channels. The attention weights for these feature graphs, denoted as and for the height and width dimensions, respectively, are derived through the Sigmoid activation function. This process is further elaborated in Formulas (4) and (5) presented below.
Following the computation above, the attention weights and for the input feature map are determined, corresponding to the height and width dimensions, respectively. Subsequently, the initial feature graph undergoes a multiplication weighting operation, producing a new feature graph that incorporates the attention weights for width and height dimensions, as specified in the Formula (6).
3.3. Improved Loss Function
The loss function calculates the difference between the neural network’s prediction and actual frames [34,35]. The value of the loss function decreases as the two get closer. Improving the loss function can optimize the model performance and training effect. EIoU consists of IoU loss (, distance loss (, and orientation loss (). The IoU loss function is calculated as Formula (7).
In this context, A represents the size of the predicted bounding box, while B denotes the size of the actual bounding box. The term is used as a weight function representation, and v is utilized to calculate the comparability of the aspect ratio. Additionally, C is defined as the minimum area of overlap between the predicted and actual boxes. In this model, w and h denote the width and height of the predicted box, respectively, while and represent the width and height of the actual box. The formulas for and v are given in Formulas (8) and (9).
The EIoU loss function is calculated as Formula (10).
C is the minimum overlapping area between the predicted and actual boxes. wc and hc represent the smallest external rectangle’s width and height, respectively. In the model, the center points of the actual box and the predicted box are denoted by and , respectively.
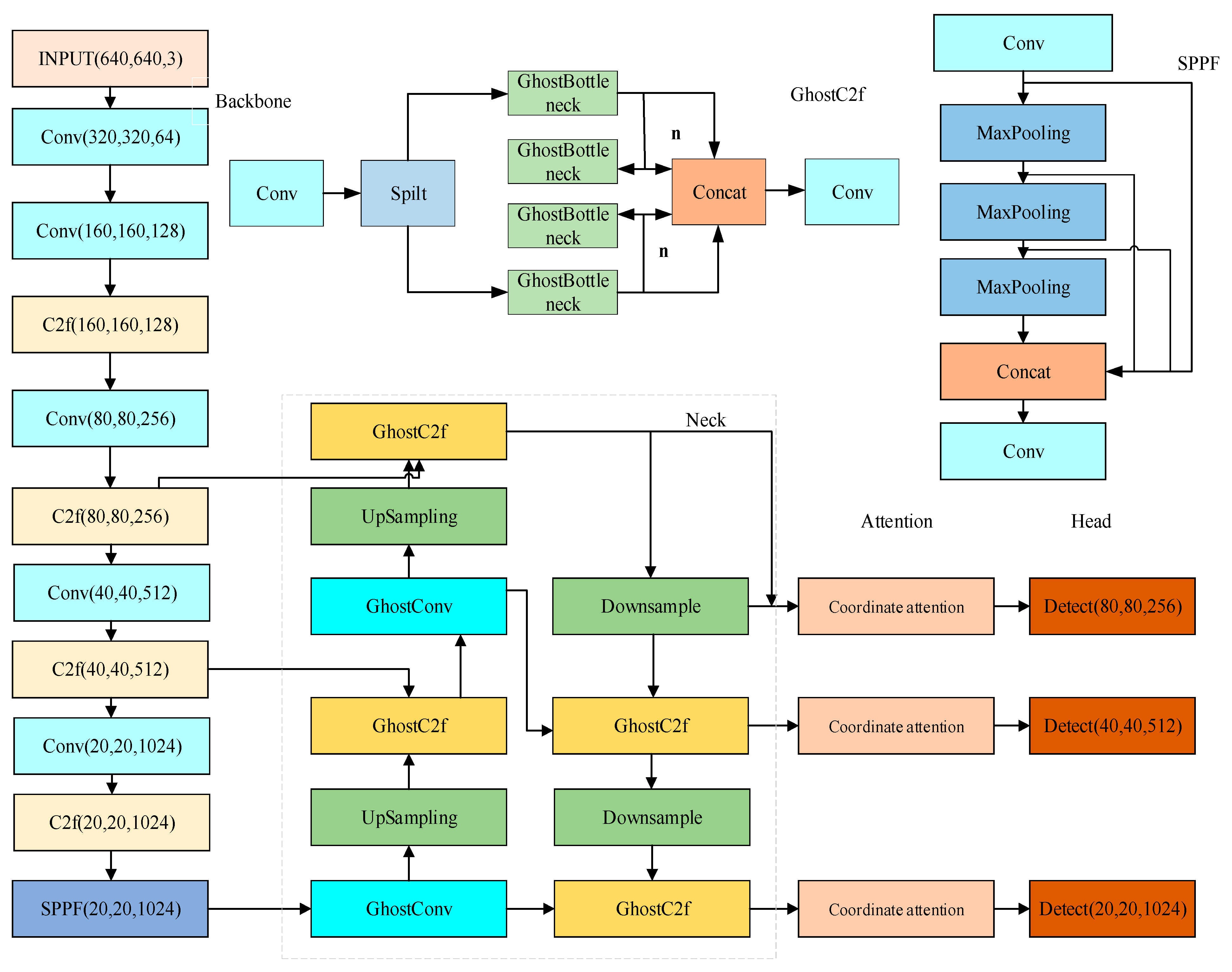
Given the problems that the current network model needs to improve the detection accuracy and speed of lithium battery electrodes, the number of model parameters and the size of the model are too large, the algorithm in this paper takes YOLOv8 as the base model framework, improves the network backbone network to be consistent with the backbone network of YOLOv8, and replaces all the C2f modules in the neck network with GhostC2f modules. All the standard convolutions in the neck network are replaced by the GhostConv, which can effectively reduce the complexity of the neck network. The CA module is incorporated into the neck network, amplifying the feature extraction efficiency of the improved model. The EIoU loss function is employed to swap out the initial YOLOv8 loss function, which improves the regression performance of the network. Integrating the aforementioned improved module with YOLOv8 has led to the proposal of a high-precision, real-time electrode defect detection method for lithium-ion batteries, termed YOLOv8-GCE, whose network structure is depicted in Figure 6.
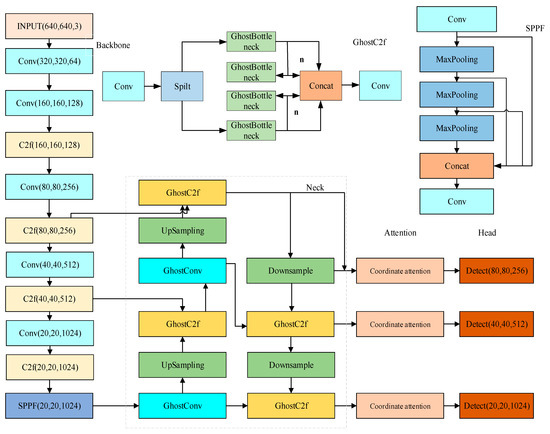
Figure 6.
YOLOv8-GCE structure.
4. Experiment
4.1. Experimental Environment and Parameter Configuration
This experiment utilized a self-constructed dataset of lithium battery pole slice images, encompassing various defect types such as holes, scratches, and metal leakage. Table 1 displays the configuration of the experimental environment.

Table 1.
Experimental environment configuration.
The data set prepared for this experiment was partitioned into training and test sets, following an 8:2 ratio. The specific parameter settings used in the experiment are detailed in Table 2.
Table 2.
Parameter setting.
4.2. Evaluation Index
The evaluation indexes chosen for model detection accuracy were mean average precision (mAP@0.5), recall rate (R), and precision rate (P). FPS is chosen as the real-time detection evaluation index based on model detection performance. FPS stands for frames detected per second, and the amount of this value depends on the hardware setup of the experimental apparatus as well as the algorithm’s weight. The precision rate is calculated as the proportion of accurately predicted positive samples (TP) to the total number of predicted positive samples (TP + FP), as delineated in Formula (11).
The recall rate is the ratio of correctly predicting TP to being TP + FN, as shown in Formula (12).
In the context of mean precision, ‘m’ denotes the average, and AP@0.5 refers to the average accuracy of samples when the IoU threshold in the confusion matrix is set at 0.5. The term mAP@0.5, representing the mean Average Precision for all test samples at this IoU threshold, illustrates the relationship between the model’s precision rate (P) and its recall rate (R). The model finds it easier to keep a high accuracy rate in a high recall rate when the value is higher, as shown in Formulas (13) and (14).
4.3. Experimental Results and Analysis
4.3.1. Contrast Experiment
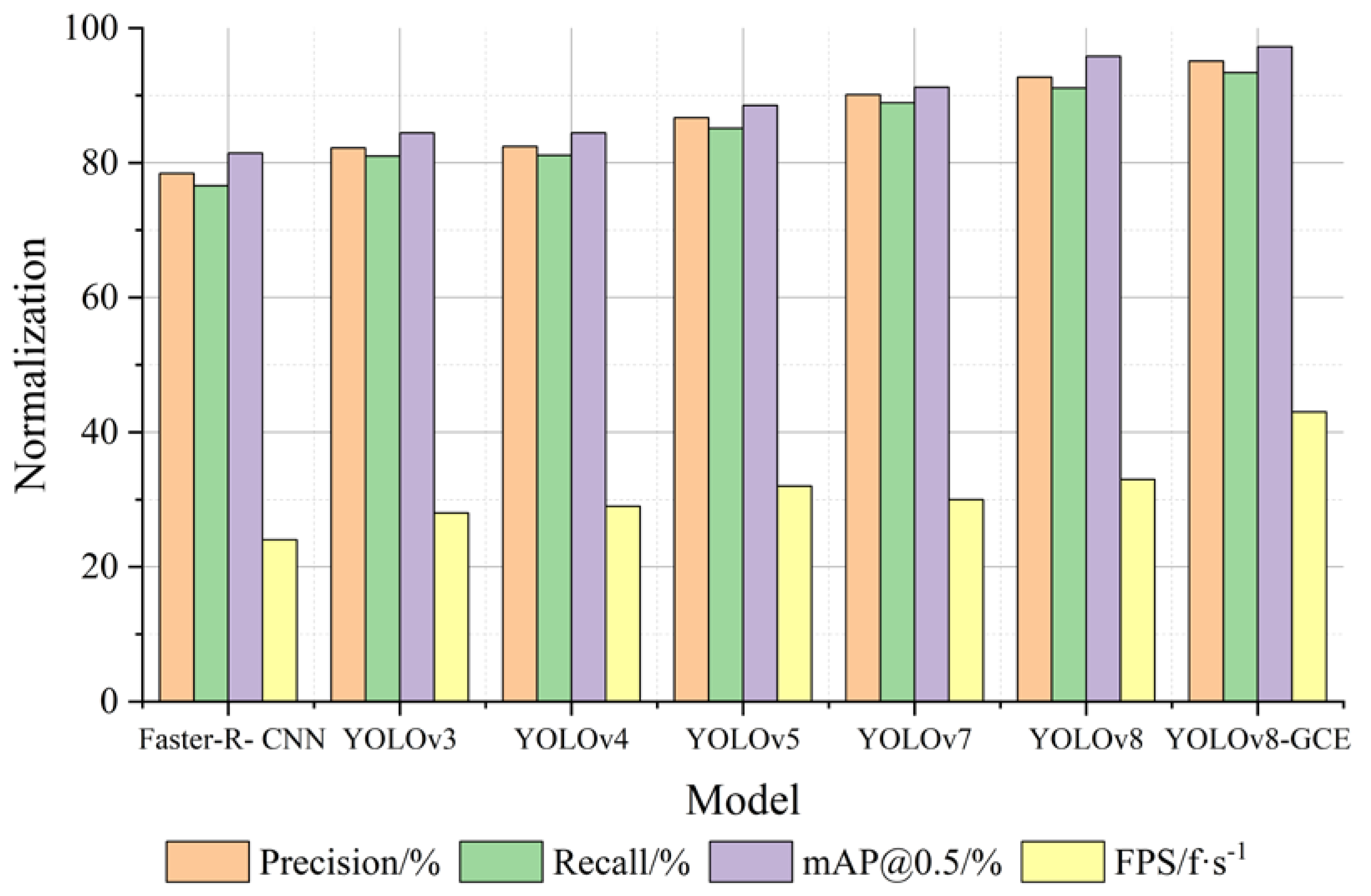
To test and verify the superiority of this algorithm, the algorithm in this paper and Faster-R-CNN, YOLOv3, YOLOv4, YOLOv5, YOLOv7, YOLOv8 under the identical experimental setting (unified configuration with the same data set) using experimental comparison. According to Table 3 and Figure 7, YOLOv8-GCE inaccurate rate, homing rate, mAP@0.5, and detection rate (FPS) on the comprehensive performance is superior to Faster-R-CNN, YOLOv3, YOLOv4, YOLOv5, YOLOv7, YOLOv8 algorithm.
Table 3.
Contrast experiment.
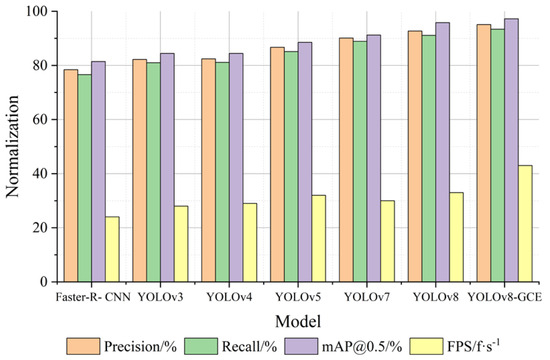
Figure 7.
Comparison of the normalization effect of experimental indicators (contrast experiment).
4.3.2. Ablation Experiment
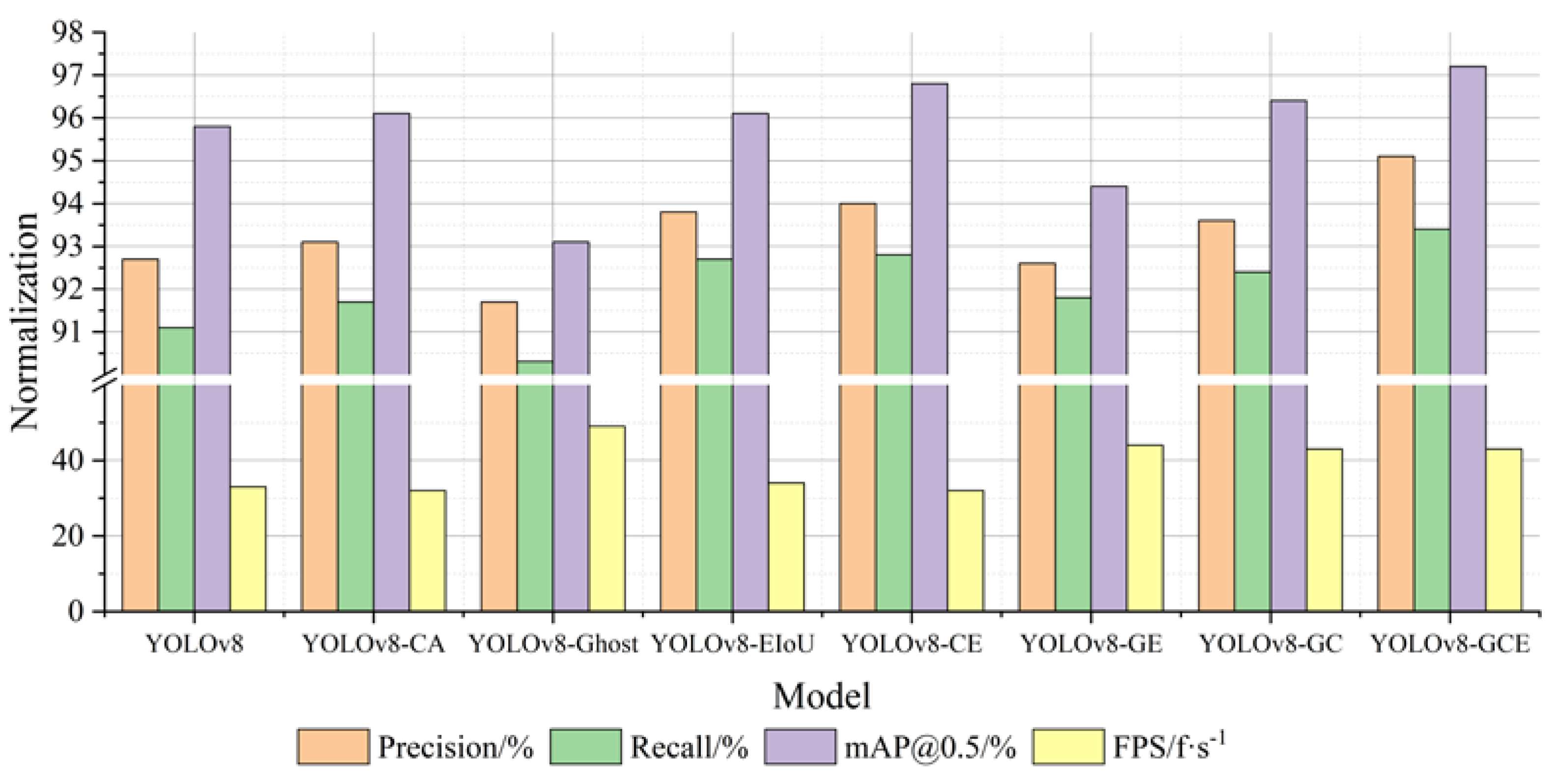
The ablation experiment was designed to confirm the efficacy of the modified portion of the YOLOv8-GCE network model. As indicated in Table 4 below, ablation experiments were carried out using various combinations of multiple improved modules, with the original model YOLOv8 serving as the baseline model. The checkmark indicates that the network model contains this module, and the cross mark indicates that the network model does not contain this module.
Table 4.
Ablation experiment.
As depicted in Figure 8, the YOLOv8-GCE model employs a more efficient network structure than the standard YOLOv8. Compared with the YOLOv8-CA model with the CA module and the YOLOv8-EIoU model with the EIoU, the improved algorithm adopts a more efficient network structure. However, the performance of the detection rate (FPS) is superior. It is evident that increasing the detection rate is significantly impacted by the addition of GhostNet to enhance the network. YOLOv8-CE, YOLOv8-GE, and YOLOv8-GC, which combine the three improvement strategies in two, have a good performance in accuracy and a significant improvement in FPS, indicating that the addition of the CA module and EIoU in the YOLOv8 model has a significant effect on enhancing detection accuracy. The expression of YOLOv8-GCE is the best. The accuracy, recall rate, and average accuracy are all improved by 2.4%, 2.3%, and 1.4%, respectively, in comparison to the YOLOv8 model, and the detection rate FPS is significantly improved, which demonstrates the enhanced algorithm’s efficacy as suggested in this paper.
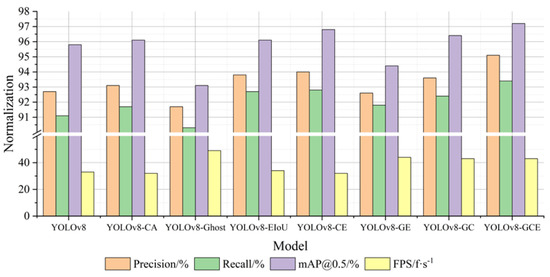
Figure 8.
Normalization effect diagram of overall indicators (ablation experiment).
4.3.3. CA Module Position Analysis
This paper includes the design of a position comparison test specifically to check into the influence of the CA module’s placement on the detection results. The CA module is placed in three different locations: behind the backbone’s SPPF, inside the neck’s GhostC2f, and behind the neck’s GhostC2f. Table 5 displays the comparison test results. When the CA module is added to the neck, the model achieves higher accuracy and recall rate than when the CA module is added to the backbone. This is because the backbone network mainly extracts the image’s underlying characteristics and cannot obtain global information on the defect features of the pole film well. The neck network uses the output of the backbone network to better extract and fuse features. Moreover, positioning the CA module within the neck’s GhostC2f module yields substantial improvements. Adding an attention mechanism to the C2f module post-network allows for more refined adjustments during feature fusion. Consequently, this enables the model to focus more intently on the target’s feature information, thereby significantly enhancing the precision of target detection.
Table 5.
CA module position analysis.
4.4. Algorithm Verification
Compared with YOLOv3 and YOLOv4, YOLOv5 is a more mature and complete YOLO series model. YOLOv8 is improved based on YOLOv5. The network structure of YOLOv7 is shallow. Therefore, YOLOv5, YOLOv8, and the improved YOLOv8-GCE algorithm were selected to contrast the findings of detection of lithium battery electrode plate defects. As shown in Figure 9, Group A contrasts the experimental effect of the single scratch defect, Group B contrasts the experimental effect of the single hole defect, Group C contrasts the experimental effect of the metal leakage defect, and Group D and Group E contrast the experimental effect of mixed defects.
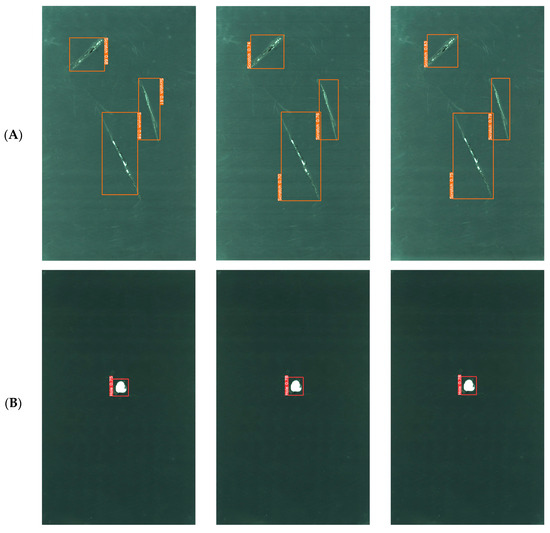

Figure 9.
Comparison of the detection effect of lithium battery pole slice for different algorithms. (A) Comparison of experimental effects for single scratch defect. (B) Comparison of experimental effects for single hole defect. (C) Comparison of experimental effects for metal leakage defect. (D,E) Comparison of experimental effects for mixed defects.
The comparative analysis of experimental results from Groups A, B, and C reveals distinct outcomes. In Group A, all three algorithms successfully detected the single scratch defect, while in Group B, they identified the single hole defect. The experimental results of Group C show that the three algorithms all detect the single metal leakage defect, proving that the YOLO algorithm has a high accuracy for detecting lithium battery pole chip defects. In this experiment, IoU is set to 0.5, and the detection confidence of the improved YOLOv8-GCE algorithm is significantly higher than that of the YOLOv5 and YOLOv8 algorithms.
According to the comparison of experimental results between Group D and Group E, it is evident that targets that other models are unable to identify can be found by the enhanced YOLOv8-GCE algorithm. In the experiments of Group D and Group E, the mixed defect images containing holes, metal leakage, and scratches were detected, and the performance of the YOLOv5 algorithm was poor; not only did it not detect scratch defects, but it also was inferior to the other two algorithms in the defect detection of holes and metal leakage. The YOLOv8 algorithm also failed to detect scratch defects in relatively complex mixed defect detection images, but its performance was better than the YOLOv5 algorithm. YOLOv8-GCE algorithm can detect all types of defects in mixed defect detection images and performs better in detecting scratch defects in mixed defect images. The YOLOv8-GCE algorithm presented in this paper can solve the issues with incorrect and missing detection of lithium battery electrode chip defects, demonstrating the algorithm’s dependability and ability to satisfy industrial development requirements in industrial applications.
5. Conclusions and Future Work
This essay suggests an enhanced and optimized YOLOv8-GCE battery electrode defect detection model based on YOLOv8. Firstly, the lightweight GhostCony is used to replace the standard convolution, and the GhostC2f module is designed to replace part of the C2f, which reduces model computation and improves feature expression performance. Then, the CA module is incorporated into the neck network, amplifying the feature extraction efficiency of the improved model. Finally, the EIoU loss function is employed to swap out the initial YOLOv8 loss function, which improves the regression performance of the network. According to the experimental findings, the mAP of the YOLOv8-GCE battery pole chip defect detection model in the self-built data set reaches 97.2%, and the FPS is maintained at 43f·s−1. In contrast to the current model, the method has higher detection accuracy and reduces the requirement for platform computing power. In the future, the focus of the research is to deploy the improved model to the automatic detection equipment of lithium batteries and improve the proposed algorithm in practical applications.
Author Contributions
Conceptualization, H.Z. and Y.Y.; methodology, H.Z., Y.Y. and Y.H.; software, H.Z.; validation, H.Z., Y.Y. and Y.H.; writing—original draft preparation, H.Z.; writing—review and editing, H.Z. and K.W.; funding acquisition, H.Z. All authors have read and agreed to the published version of the manuscript.
Funding
This work was funded by the Science and Technology Planning Project of Guangzhou City under Grant No. 2023A04J1691, Guangdong Province, China.
Data Availability Statement
Data are contained within the article.
Conflicts of Interest
The authors declare no conflicts of interest.
References
- Bockholt, H.; Indrikova, M.; Netz, A.; Golks, F.; Kwade, A. The interaction of consecutive process steps in the manufacturing of lithium-ion battery electrodes with regard to structural and electrochemical properties. J. Power Sources 2016, 325, 140–151. [Google Scholar] [CrossRef]
- Lai, X.; Jin, C.; Yi, W.; Han, X.; Feng, X.; Zheng, Y.; Ouyang, M. Mechanism, modeling, detection, and prevention of the internal short circuit in lithium-ion batteries: Recent advances and perspectives. Energy Storage Mater. 2021, 35, 470–499. [Google Scholar] [CrossRef]
- Xiong, R.; Sun, W.; Yu, Q.; Sun, F. Research progress, challenges and prospects of fault diagnosis on battery system of electric vehicles. Appl. Energy 2020, 279, 115855. [Google Scholar] [CrossRef]
- Girshick, R.; Donahue, J.; Darrell, T.; Malik, J. Rich feature hierarchies for accurate object detection and semantic segmentation. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Columbus, OH, USA, 23–28 June 2014; pp. 580–587. [Google Scholar]
- Girshick, R. Fast r-cnn. In Proceedings of the IEEE International Conference on Computer Vision, Washington, DC, USA, 7–13 December 2015; pp. 1440–1448. [Google Scholar]
- Ren, S.; He, K.; Girshick, R.; Sun, J. Faster R-CNN: Towards real-time object detection with region proposal networks. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 39, 1137–1149. [Google Scholar] [CrossRef] [PubMed]
- Redmon, J.; Farhadi, A. Yolov3: An incremental improvement. arXiv 2018, arXiv:1804.02767. [Google Scholar]
- Bochkovskiy, A.; Wang, C.Y.; Liao, H.Y.M. Yolov4: Optimal speed and accuracy of object detection. arXiv 2020, arXiv:2004.10934. [Google Scholar]
- Liu, W.; Anguelov, D.; Erhan, D.; Szegedy, C.; Reed, S.; Fu, C.Y.; Berg, A.C. Ssd: Single Shot Multibox Detector. In Proceedings of the Computer Vision–ECCV 2016: 14th European Conference, Amsterdam, The Netherlands, 11–14 October 2016; Proceedings, Part I 14. Springer: Berlin/Heidelberg, Germany, 2016; pp. 21–37. [Google Scholar]
- Fu, C.Y.; Liu, W.; Ranga, A.; Tyagi, A.; Berg, A.C. Dssd: Deconvolutional single shot detector. arXiv 2017, arXiv:1701.06659. [Google Scholar]
- Li, Z.; Zhou, F. FSSD: Feature fusion single shot multibox detector. arXiv 2017, arXiv:1712.00960 2017. [Google Scholar]
- Chang, M.; Chen, B.C.; Gabayno, J.L.; Chen, M.F. Development of an optical inspection platform for surface defect detection in touch panel glass. Int. J. Optomechatronics 2016, 10, 63–72. [Google Scholar] [CrossRef]
- Xu, C.; Li, L.; Li, J.; Wen, C. Surface defects detection and identification of lithium battery pole piece based on multi-feature fusion and PSO-SVM. IEEE Access 2021, 9, 85232–85239. [Google Scholar] [CrossRef]
- Liu, Y.; Chen, Y.; Xu, J. An Automatic Defects Detection Scheme for Lithium-Ion Battery Electrode Surface. In Proceedings of the 2020 International Symposium on Autonomous Systems (ISAS), Guangzhou, China, 6–8 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 94–99. [Google Scholar]
- Redmon, J.; Divvala, S.; Girshick, R.; Farhadi, A. You only look once: Unified, real-time object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Las Vegas, NV, USA, 26 June–1 July 2016; pp. 779–788. [Google Scholar]
- Redmon, J.; Farhadi, A. YOLO9000: Better, faster, stronger. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 7263–7271. [Google Scholar]
- Cao, X.; Zhang, F.; Yi, C.; Tang, K.; Bian, T.; Yang, M. Wafer Surface Defect Detection Based on Improved YOLOv3 Network. In Proceedings of the 2020 5th International Conference on Mechanical, Control and Computer Engineering (ICMCCE), Harbin, China, 25–27 December 2020; IEEE: Piscataway, NJ, USA, 2020; pp. 1475–1478. [Google Scholar]
- Lan, Z.; Hong, Y.; Li, Y. An Improved YOLOv3 Method for PCB Surface Defect Detection. In Proceedings of the 2021 IEEE International Conference on Power Electronics, Computer Applications (ICPECA), Shenyang, China, 22–24 January 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 1009–1015. [Google Scholar]
- Xie, H.; Li, Y.; Li, X.; He, L. A Method for Surface Defect Detection of Printed Circuit Board Based on Improved YOLOv4. In Proceedings of the 2021 IEEE 2nd International Conference on Big Data, Artificial Intelligence and Internet of Things Engineering (ICBAIE), Nanchang, China, 26–28 March 2021; IEEE: Piscataway, NJ, USA, 2021; pp. 851–857. [Google Scholar]
- Huang, H.; Tang, X.; Wen, F.; Jin, X. Small object detection method with shallow feature fusion network for chip surface defect detection. Sci. Rep. 2022, 12, 3914. [Google Scholar] [CrossRef] [PubMed]
- Li, L.; Wang, Z.; Zhang, T. Gbh-yolov5: Ghost convolution with bottleneckcsp and tiny target prediction head incorporating yolov5 for pv panel defect detection. Electronics 2023, 12, 561. [Google Scholar] [CrossRef]
- Liu, D.; Liang, J.; Geng, T.; Loui, A.; Zhou, T. Tripartite feature enhanced pyramid network for dense prediction. IEEE Trans. Image Process. 2023, 32, 2678–2692. [Google Scholar] [CrossRef] [PubMed]
- Dai, X.; Chen, Y.; Xiao, B.; Chen, D.; Liu, M.; Yuan, L.; Zhang, L. Dynamic head: Unifying object detection heads with attentions. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 7373–7382. [Google Scholar]
- Lou, H.; Duan, X.; Guo, J.; Liu, H.; Gu, J.; Bi, L.; Chen, H. DC-YOLOv8: Small-Size Object Detection Algorithm Based on Camera Sensor. Electronics 2023, 12, 2323. [Google Scholar] [CrossRef]
- Li, Y.; Fan, Q.; Huang, H.; Han, Z.; Gu, Q. A Modified YOLOv8 Detection Network for UAV Aerial Image Recognition. Drones 2023, 7, 304. [Google Scholar] [CrossRef]
- Hou, Q.; Zhou, D.; Feng, J. Coordinate attention for efficient mobile network design. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Nashville, TN, USA, 20–25 June 2021; pp. 13713–13722. [Google Scholar]
- Aboah, A.; Wang, B.; Bagci, U.; Adu-Gyamfi, Y. Real-time multi-class helmet violation detection using few-shot data sampling technique and yolov8. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Vancouver, BC, Canada, 18–22 June 2023; pp. 5349–5357. [Google Scholar]
- Bodla, N.; Singh, B.; Chellappa, R.; Davis, L.S. Soft-NMS–improving object detection with one line of code. In Proceedings of the IEEE International Conference on Computer Vision, Venice, Italy, 22–29 October 2017; pp. 5561–5569. [Google Scholar]
- Chen, L.C.; Papandreou, G.; Kokkinos, I.; Murphy, K.; Yuille, A.L. Deeplab: Semantic image segmentation with deep convolutional nets, atrous convolution, and fully connected crfs. IEEE Trans. Pattern Anal. Mach. Intell. 2017, 40, 834–848. [Google Scholar] [CrossRef] [PubMed]
- Lin, T.Y.; Dollár, P.; Girshick, R.; He, K.; Hariharan, B.; Belongie, S. Feature pyramid networks for object detection. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Honolulu, HI, USA, 21–26 July 2017; pp. 2117–2125. [Google Scholar]
- Liu, S.; Qi, L.; Qin, H.; Shi, J.; Jia, J. Path aggregation network for instance segmentation. In Proceedings of the IEEE conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 8759–8768. [Google Scholar]
- Han, K.; Wang, Y.; Tian, Q.; Guo, J.; Xu, C.; Xu, C. Ghostnet: More features from cheap operations. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Seattle, WA, USA, 13–19 June 2020; pp. 1580–1589. [Google Scholar]
- Hu, J.; Shen, L.; Sun, G. Squeeze-and-excitation networks. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, Salt Lake City, UT, USA, 18–23 June 2018; pp. 7132–7141. [Google Scholar]
- Rezatofighi, H.; Tsoi, N.; Gwak, J.; Sadeghian, A.; Reid, I.; Savarese, S. Generalized intersection over union: A metric and a loss for bounding box regression. In Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition, Long Beach, CA, USA, 15–20 June 2019; pp. 658–666. [Google Scholar]
- Zheng, Z.; Wang, P.; Liu, W.; Li, J.; Ye, R.; Ren, D. Distance-IoU loss: Faster and better learning for bounding box regression. In Proceedings of the AAAI Conference on Artificial Intelligence, New York, NY, USA, 7–12 February 2020; Volume 34, pp. 12993–13000. [Google Scholar]


Disclaimer/Publisher’s Note: The statements, opinions and data contained in all publications are solely those of the individual author(s) and contributor(s) and not of MDPI and/or the editor(s). MDPI and/or the editor(s) disclaim responsibility for any injury to people or property resulting from any ideas, methods, instructions or products referred to in the content. |
© 2023 by the authors. Licensee MDPI, Basel, Switzerland. This article is an open access article distributed under the terms and conditions of the Creative Commons Attribution (CC BY) license (https://creativecommons.org/licenses/by/4.0/).